


Introduction
Studies have shown that bilinguals (by which we mean speakers of more than one language) cannot suppress activation of their other languages while they read, comprehend or speak one of their languages (e.g., Colomé, Reference Colomé2001; Costa, Caramazza & Sebastían-Gallés, Reference Costa, Caramazza and Sebastián-Gallés2000). Many of these studies have used cognate words to make their point. In psycholinguistic terms, these are words that are almost identical between different languages, in form as well as in meaning (e.g., banjo has the same orthographic form and meaning in English, Dutch, French, and German). As these words are not only semantically but also orthographically and phonologically related across languages, they can reveal what kind of information (semantic, orthographic, phonological) is co-activated during multilingual language processing and production, and to what extent representations of the non-target language are activated.
Experiments investigating the production of cognate words in bilinguals who have learned their second language in early childhood (Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000) and bilinguals who have learned this language later (Hoshino & Kroll, Reference Hoshino and Kroll2008) have shown that cognate words are produced faster than matched control words (translation equivalents with unrelated word forms), in native language (L1) as well as non-native language (L2) production. Additionally, they are more resistant to tip-of-the-tongue states than control words (Gollan & Acenas, Reference Gollan and Acenas2004). There is also a cognate advantage in comprehension for words read in isolation (L2: Dijkstra, Grainger & Van Heuven, Reference Dijkstra, Grainger and Van Heuven1999; Lemhöfer, Dijkstra & Michel, Reference Lemhöfer, Dijkstra and Michel2004; L1: Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002) and words embedded in a sentence context (L2: Schwartz & Kroll, Reference Schwartz and Kroll2006; Van Hell & De Groot, Reference Van Hell and De Groot2008; L1: Van Assche, Duyck, Hartsuiker & Diependaele, Reference Van Assche, Duyck, Hartsuiker and Diependaele2009).
Several explanations have been put forward to account for the processing advantage for cognate words. Some researchers assume that the critical difference between cognates and non-cognates is that cognate words tend to be morphologically related across languages, while non-cognates are not (Kirsner, Lalor & Hird, Reference Kirsner, Lalor, Hird, Schreuder and Weltens1993; Sánchez-Casas & García-Albea, Reference Sánchez-Casas, García-Albea, Kroll and De Groot2005). This morphological relatedness enables cognates to have shared stem representations, which facilitates lexical access. Alternatively, cognate advantages could be due to the phonological and/or orthographic similarity between the word forms in the two languages (Costa, Santésteban & Caño, Reference Costa, Santésteban and Caño2005). According to this account, stimuli such as target pictures do not only activate their own conceptual, lexical, phonological and orthographic representations, but also those of their translation equivalents, through cascading activation. Faster picture-naming times for cognates occur because both the name of the target picture and its translation equivalent activate the same phonemes, which speeds up the selection of the relevant phonemes. Additionally, feedback from the phoneme/grapheme level to the lexical level might make it possible to select the correct lexical item more quickly for cognates than non-cognates.
In spoken language production, evidence for feedback from the phonological to the lexical level is found in the lexical bias effect: the observation that phonological substitution errors result more often in existing words (darn bore becomes barn door) than predicted by chance (see Hartsuiker, Reference Hartsuiker2006, for a review). Costa, Roelstraete and Hartsuiker (Reference Hartsuiker2006) showed that this effect does not only occur within a language, but also between the two languages of bilinguals: Spanish–Catalan bilinguals made more substitution errors in a Spanish error elicitation task if the error resulted in an existing Catalan word (nip tas → tip nas “full nose”) than if it did not (nil taf → til naf). Hence, Costa et al. concluded that, during speech production, the activation of phonological segments sends feedback to all lexical representations they are linked to, independently of the language to which they belong.
As we already mentioned, such feedback might add to the cognate advantage in bilingual speech. The production of cognate words is then facilitated not only because target pictures and their translation equivalents activate their common phonemes, which speeds up phoneme selection, but also because these common phonemes send feedback to the lexical level, which speeds up lexical selection. If the cognate advantage in speech production is at least partly caused by interactivity between the phonological and the lexical level of production, the effect should vary in strength together with the phonological overlap between the cognate word pairs: The larger the phonological overlap, the larger the amount of feedback to the lexical level and the quicker lexical selection can take place.
In order to investigate whether activation from the overlapping phonemes in cognate words feeds back to the lexical representations of these words, we need a task that is sensitive to the co-activation of non-target words in the other language during speech production. Whereas Costa et al. (Reference Costa, Roelstraete and Hartsuiker2006) elicited speech errors in order to show co-activation of phonologically related words, we use cross-linguistic syntactic priming, which is concerned with the tendency to repeat syntactic structure across languages. Several studies have made use of syntactic priming to investigate the representation and activation of lexical information (Cleland & Pickering, Reference Cleland and Pickering2003; Pickering & Branigan, Reference Pickering and Branigan1998; Salamoura & Williams, Reference Salamoura and Williams2007; Santésteban, Pickering & McLean, Reference Santésteban, Pickering and McLean2010; Schoonbaert, Hartsuiker & Pickering, Reference Schoonbaert, Hartsuiker and Pickering2007). By using this paradigm, we can investigate whether phonological feedback affects syntactic choice. In contrast to production errors, syntactic choices are made in every utterance, giving us a good chance to observe effects of phonological feedback. We investigate whether phonological feedback can influence the activation of lexical items and the selection of syntactic structures in bilingual sentence production by examining the effect of cognate words on the strength of between-language syntactic priming in bilinguals. Our bilingual population is quite different from the one studied in Costa et al. (Reference Costa, Roelstraete and Hartsuiker2006): While they studied early Spanish–Catalan bilinguals who use both of their languages on a daily basis, our study uses late Dutch–English bilinguals living in an L1-dominant environment. Hence, our study does not only enable us to investigate whether cross-linguistic phonological feedback influences syntactic choices, but it also gives us the opportunity to investigate whether Costa et al.'s (Reference Costa, Roelstraete and Hartsuiker2006) findings on cross-linguistic interactivity between the phonological and the lexical level generalize to a bilingual population with a lower level of L2-proficiency.
Syntactic priming as a tool to investigate the representation and activation of lexical and syntactic information
In production studies, it has been shown that speakers tend to repeat the syntactic structure of sentences that they have just encountered, even when the prime and target sentences are unrelated in meaning. If, for example, participants produce or comprehend a double object (DO) dative sentence such as The nun sells the sailor a book, they tend to re-use the syntactic structure of this sentence, and produce another double object dative such as The swimmer gives the cook a gun, rather than a prepositional object (PO) dative such as The swimmer gives a gun to the cook. This syntactic priming effect occurs in a wide variety of languages and syntactic structures (see Pickering & Ferreira, Reference Pickering and Ferreira2008, for a review). Effects of syntactic priming occur not only when the prime sentence immediately precedes the to-be-produced target: Studies have shown that the effects persist across as many as 10 intervening sentences (Bock & Griffin, Reference Bock and Griffin2000; Hartsuiker, Bernolet, Schoonbaert, Speybroeck & Vanderelst, Reference Hartsuiker, Bernolet, Schoonbaert, Speybroeck and Vanderelst2008). Furthermore, syntactic priming occurs not only within a given language but also between languages in late bilinguals living in an L2-dominant environment (e.g., Hartsuiker, Pickering & Veltkamp, Reference Hartsuiker, Pickering and Veltkamp2004; Loebell & Bock, Reference Loebell and Bock2003; Salamoura & Williams, Reference Salamoura and Williams2007) or an L1-dominant environment (Desmet & Declercq, Reference Desmet and Declercq2006; Schoonbaert et al., Reference Schoonbaert, Hartsuiker and Pickering2007). The occurrence of between-language syntactic priming indicates that representations of syntactic structures can, in some cases, be shared between the different languages of a bilingual and that these shared representations can be primed.
Several studies have used syntactic priming in order to investigate the representation and the activation of lexical information and the way this information interacts with syntactic information. Pickering and Branigan (Reference Pickering and Branigan1998) showed that syntactic priming effects for English datives (The nun sells a book to the sailor vs. The nun sells the sailor a book) were larger when the head verb was repeated across prime and target sentences (give–give) than when it was not (sell–give). The strength of syntactic priming, however, was unaffected by whether or not tense (was showing–showed), aspect (has shown–showed), or number (show–shows) of the verb was repeated. Pickering and Branigan (Reference Pickering and Branigan1998) used these results to argue that syntactic information must be connected to the lemmas of verbs, rather than their word-form representations (see Levelt, Roelofs & Meyer, Reference Levelt, Roelofs and Meyer1999).Footnote 1 They proposed a two-stage model of syntactic production in which syntactic information is represented within the lemma stratum in the form of combinatorial nodes that are connected to the lemmas of all words they can combine with. When a sentence is processed, the lemma node representing the main verb of the sentence (e.g., give) and the combinatorial node representing its syntactic structure (e.g., DO) are activated, as well as the link between them. Residual activation in the combinatorial node causes syntactic priming, while residual activation in the link between this node and a particular lemma node leads to a lexical boost to this effect when the same verb is used in prime and target sentences.
Cleland and Pickering (Reference Cleland and Pickering2003) discovered that a lexical boost to syntactic priming also occurred for nominal heads in noun–modifier constructions (the red sheep vs. the sheep that is red). Additionally, they showed a (smaller) boost to priming when the heads of prime and target constructions were semantically related (goat–sheep) than otherwise (knife–sheep). In a between-language priming study, Schoonbaert et al. (Reference Schoonbaert, Hartsuiker and Pickering2007) showed that, when priming from the first language (L1) to the second language (L2) of bilinguals, stronger syntactic priming between Dutch and English datives occurs when the heads of prime and target constructions were translation equivalents (geven–give) than when they were unrelated (verkopen–give). The results of this study thus indicate that the extent of priming between syntactic structures of different languages is influenced by the relationship between the lexical items that are used: Because target verbs of one language activate semantically related verbs of the other language through their shared meaning representation, translation equivalent prime verbs and the syntactic structures they were combined with get re-activated during target production. This leads to a stronger tendency to re-use the syntactic structure of the prime sentence when the heads of prime and target constructions were translation equivalents than when they were unrelated.Footnote 2
It is, however, not clear whether between-language syntactic priming can be influenced by the phonological overlap between cognate heads. Studies investigating the influence of phonological feedback on the selection of syntax have produced mixed results. Cleland and Pickering (Reference Cleland and Pickering2003) found no boost to noun phrase priming when the heads of prime and target constructions were phonologically related (ship–sheep) versus when they were unrelated (knife–sheep). They used these data to argue against feedback from activated phonemes to the lemma representations of the words in which they are used, because any such feedback should have enhanced syntactic priming. Using the same prime and target structures as Cleland and Pickering (Reference Cleland and Pickering2003), however, Santésteban et al. (Reference Santésteban, Pickering and McLean2010) recently observed a homophone boost of within-language syntactic priming: When describing a picture of a red bat (the flying mammal), participants tended to produce relative clauses such as the bat that's red more often after hearing the bat that's red (referring to a cricket bat) than after the pool that's red. As homophones have distinct conceptual and lemma representations (Caramazza, Costa, Miozzo & Bi, Reference Caramazza, Costa, Miozzo and Bi2001; Jescheniak & Levelt, Reference Jescheniak and Levelt1994), this boost to priming can only be explained as a result of the homophones’ shared phonological form. Santésteban et al. therefore assume that, during target production, the homophones’ shared word-form representation feeds its activation back to the lemma of the meaning of the homophone that was activated during the processing of the prime. Residual activation of the link between this lemma and the combinatorial node for the prime's syntactic structure causes the homophone boost (see Figure 1).
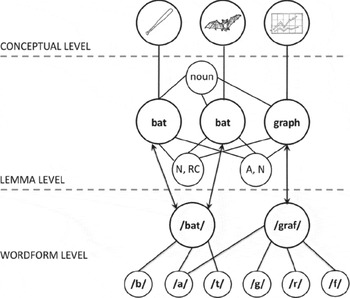
Figure 1. Santesteban et al.'s (Reference Santésteban, Pickering and McLean2010) adaptation of the model of sentence production proposed by Pickering and Branigan (Reference Pickering and Branigan1998) based on the lexical access model of Levelt et al. (Reference Levelt, Roelofs and Meyer1999). Note that this model has separate levels for lemma and word-form representations. Homophones like bat thus have a shared word form, but separate lemma nodes. We added arrows to the model in order to show that it assumes feedback from the word-form level to the lemma level, though not necessarily from activated phonemes to word forms and lemmas that contain these phonemes.
Although Santésteban et al. (Reference Santésteban, Pickering and McLean2010) proposed some interactivity (i.e., from word forms to lemma representations) in their version of Pickering and Branigan's (Reference Pickering and Branigan1998) sentence production model, they did not specify whether it allows feedback from phonemes to word forms. If this kind of interactivity occurs, as is assumed by interactive models of speech production (Dell, Reference Dell1986; Harley, Reference Harley1993; Rapp & Goldrick, Reference Rapp and Goldrick2000), their model would predict that a phonological boost to syntactic priming should also occur in the absence of full phonological overlap, that is for words that do not share a word-form representation. In fact, it would predict a phonological boost to syntactic priming that is larger when the degree of phonological overlap between the heads of the prime and target constructions is larger. Although the data obtained by Cleland and Pickering (Reference Cleland and Pickering2003) speak against such an interactive model, two studies have shown effects of phonological overlap on grammatical encoding. Bock (Reference Bock1987) found significant (though small) effects of primes that had close phonological relationships to the target (typically differing in only the final phoneme, as in beet for the target word bee, or mat for man), with participants tending to produce transitive sentences in which a word phonologically unrelated to the prime came first (The bee stings the man vs. The man is being stung by the bee). Additionally, Lee and Gibbons (Reference Lee and Gibbons2007) showed that the phonological preference for rhythmic alternation of stressed and unstressed syllables affected the tendency to include or omit the complementiser that (with participants tending to say Henry knew that Louise washed the dishes or Henry knew Lucy washed the dishes).
The present study uses between-language syntactic priming (Dutch–English) and cognate heads in order to investigate whether there is feedback from the phonological level of one language to the lexical and syntactic levels of another language. To test for such cross-linguistic feedback, we compared syntactic priming between prime-target pairs that were cognates (nest–nest) and non-cognate translation equivalents (emmer–bucket). Thus, there was always repetition of meaning between the head nouns in prime and target (which we expected to strengthen priming overall, see Schoonbaert et al., Reference Schoonbaert, Hartsuiker and Pickering2007), but degree of phonological overlap differed across conditions.
We primed the structure of English genitives in spoken dialogue using Dutch genitive primes. We primed from the participants’ L1 (Dutch) to their L2 (English), because Schoonbaert et al. (Reference Schoonbaert, Hartsuiker and Pickering2007) only obtained a translation equivalence boost in this priming direction. Both in Dutch and in English, a genitive noun phrase can be formed by placing the owner of the object before the object that is owned (resulting in a Saxon genitive or s-genitive, as in (1a)) or after the object that is owned (resulting in an of-genitive, as in (1b)).Footnote 3
- (1)
a. Het meisje haar appel is blauw. (s-genitive)
“The girl's apple is blue.”
b. De appel van het meisje is blauw. (of-genitive)
“The apple of the girl is blue.”
In our experiment, the possessed nouns in the prime and target constructions were always translation equivalents. For each of the translation equivalent word pairs, we computed the degree of phonological overlap, defined as the number of shared phonemes divided by the mean number of phonemes in the two words; and the degree of phonetic overlap, defined as the number of shared phones divided by the mean number of phones in the two words (see Appendix A for the item values in both coding schemes).Footnote 4 We divided the word pairs into two groups, based on their degree of phonological overlap: a group of cognate items with a high degree of form overlap (50–100% of the phonemes shared) and a group of non-cognate items that have unrelated word forms in the two languages (0–33% of the phonemes shared). As we do not know how much sound overlap is needed to produce an effect of phonological feedback, we do not only compare the priming effects for cognate and non-cognate items, but also look at the effect of sound overlap (for cognate and non-cognate items) as a continuous predictor.
We made use of the confederate scripting technique (Branigan, Pickering & Cleland, Reference Branigan, Pickering and Cleland2000), in which the participant and a confederate of the experimenter take turns to describe pictures and match pictures to these descriptions. Instead of spontaneous picture descriptions, the confederate produced scripted prime sentences. We used this kind of dialogue setting to investigate syntactic priming, because effects obtained with this technique are, at least numerically, larger than in the original paradigm used by Bock (Reference Bock1986), in which participants do not interact with a dialogue partner.
Method
Participants
Thirty undergraduate students from Ghent University (28 females and 2 males) took part. A further six participants were excluded because more than 25% of their responses were unusable. All participants were late, unbalanced Dutch–English bilinguals living in an L1-dominant environment (as in Bernolet, Hartsuiker & Pickering, Reference Bernolet, Hartsuiker and Pickering2007, Reference Bernolet, Hartsuiker and Pickering2009; Desmet & Declercq, Reference Desmet and Declercq2006; Schoonbaert et al., Reference Schoonbaert, Hartsuiker and Pickering2007). They reported at least five years of experience with English as their second language (mean of 11 years). A female undergraduate student with L1 Dutch and L2 English acted as confederate.
After the experiment, the participants were asked to rate their proficiency in writing, speaking, and reading, as well as their overall proficiency (general proficiency)5 in L1 (Dutch) and L2 (English) on seven-point scales, with 1 = “very bad” and 7 = “very good” (see Table 1 for the means of the self-ratings of L1 and L2 proficiency).
Table 1. Participants’ self-assessed ratings (seven-point scale) of L1 and L2 proficiency.

Standard deviations are indicated in parentheses; L1 = native language; L2 = non-native language
Materials and design
We selected 22 Dutch–English cognates that were defined as having a high degree of form overlap (50–100% of the phonemes shared) and 22 non-cognates that have unrelated word forms in both languages (0–33% of the phonemes shared). The Dutch word of each pair was used in two different prime structures: an s-genitive and an of-genitive. The selected word (e.g., appel) was always the possessed noun in these constructions and matched the possessed object on the corresponding target picture (apple). This way, we had a 2 (Prime Structure) × 2 (Cognate Status) design; Prime Structure (s-genitive vs. of-genitive) was manipulated within items, while Cognate Status (cognate vs. non-cognate heads of prime and target constructions) was manipulated between items (see (2a–d) and Appendix A for a complete list of prime sentences and corresponding target pictures).
- (2)
a. Het meisje haar appel is blauw.
“The girl's apple is blue.”
(s-genitive, cognate item)
b. De appel van het meisje is blauw.
“The apple of the girl is blue.”
(of-genitive, cognate item)
c. De jongen zijn eend is rood.
“The boy's duck is red.”
(s-genitive, non-cognate item)
d. De eend van de jongen is rood.
“The duck of the boy is red.”
(of-genitive, non-cognate item)
Two sets of 88 pictures were constructed for the participant: a verification set and a description set. All pictures in the experiment showed black-and-white line drawings of two figurines (chosen equally often from a boy, a girl, a nurse, a wizard, a pirate, a nun, a priest, and a witch) in frontal view. The participant's description set contained 44 description pictures and 44 filler pictures. On the description pictures (i.e., the pictures used to elicit genitive structures), both figurines were depicted with the same object. One object in the experimental pictures was always colored (in yellow, red, blue, or green); the rest of the picture was in black-and-white (see Figure 2). In the filler pictures, no objects were shown. Instead, one figure was completely colored (thus allowing descriptions such as “the nun is green”). Each of the four colors was used equally often for the different objects and the figures. The participant's verification set contained 44 pictures that were similar to the experimental pictures (i.e., two figurines depicted with the same object, one of which was colored) and 44 filler pictures (one colored figure and one figure in black-and-white).

Figure 2. Example of a target picture.
Half of the pictures in the participant's verification set matched the descriptions in the confederate's description set (50% “yes” responses), which contained 44 Dutch prime sentences (see Appendix B) and 44 filler sentences. On the critical trials, the head noun of the genitive prime (i.e., the possessed noun) always matched the object that was depicted in the corresponding target picture. Furthermore, the objects in the prime and target descriptions always had the same color; the owner of the object was always different in prime and target descriptions. The remaining 44 sentences in the confederate's description set were filler sentences that could be used to describe the filler items in the participant's description set.
We constructed two counterbalanced pseudo-random lists so that each target object was preceded by an s-genitive in one list and by an of-genitive in the other list. For both lists, the trials were presented in the same pseudo-random order. At the beginning of each list, four filler trials were presented; in the rest of the list critical trials were separated by between zero and six filler trials. Each participant was presented with one of these two lists.
Procedure
The experimenter treated the participant and the confederate in the same way (so that the confederate appeared to be a real participant). Both the participant and the confederate sat in front of a PC, and they were told that they would be playing a game in which they would have to describe pictures to each other and verify each other's descriptions. They sat opposite each other, with the PCs between them (see Figure 3). Neither of them could see what appeared on their partner's screen. First, they were familiarized with the materials in a study session, where all objects and all characters that appeared on the pictures in the experiment were presented together with their Dutch and English names. The participant and the confederate were instructed to look at the pictures and to memorize the corresponding names. After that, the participant's first verification picture was shown in order to explain how the objects were arranged on the screen and how the participants were supposed to respond (the use of either s-genitives or of-genitives was avoided). The experimenter then assigned a target language to the participant (English, L2) and the confederate (Dutch, L1), making it look as if these languages were randomly assigned. The participant and the confederate were informed that their speech would be recorded on minidisk. The program was set up so that the confederate always took the first turn, and ran simultaneously on the PCs used by the confederate and the participant.

Figure 3. Computerized version of the confederate scripting technique.
The sequence of events during the experiment was as follows:
1. A picture appeared on the screen of the participant's PC (Figure 1). This picture was necessary for the verification task.
2. The confederate read the (critical) prime description from the screen of her PC.
3. The participant responded to the prime description by pressing “1” if this description matched the picture on his/her screen or “2” if the description and the picture did not match. When either key was pressed, the verification picture changed into a description picture. At the same time, a beep notified the confederate that the participant had responded.
4. At the sound of the beep, the confederate pressed “3”, to change the prime sentence into a verification picture.
5. The participant produced a description for the situation depicted on the (critical) description picture.
6. The confederate responded to the participant's description by pressing “1” (match) or “2” (mismatch). By doing this, the picture was automatically replaced by the prime sentence for the next trial. At the same time, a beep notified the participant that the confederate had responded.
7. At the sound of the beep, the participant pressed “3”, in order to make the verification picture for the next trial appear on the screen.
Sessions lasted about 35 minutes.
Scoring
Responses were coded as s-genitives, of-genitives, or Other responses. A response was coded as an s-genitive when the owner of the object (possessor) preceded the object that is owned and the appropriate possessive morpheme was added to the possessor (e.g., “the boy's rose is green”). A response was coded as an of-genitive when the sentence began with the object that is owned, followed by the preposition of and the possessor (e.g., “the rose of the boy is green”). If a different preposition was used (e.g., “the rose from the boy is green”) or if the possessed noun was not named correctly, the response counted as an Other response, as did all other responses.
Results
Participants produced 950 of-genitives (72%), 267 s-genitives (20%), and 103 Others (8%). Table 2 represents the proportions of s-genitives in the different priming conditions, for cognate and non-cognate items.
Table 2. Proportions of s-genitives out of all s- and of-genitives in the two priming conditions.

The participants’ responses were fit using two different mixed logit models (see Jaeger, Reference Jaeger2008, for the use of mixed logit models for categorical data analysis) that predict the logit-transformed likelihood of an s-genitive response. In both models, we included random intercepts for participants and items (other random effects or interactions did not significantly improve the log-likelihood of the models). The fixed factor was Prime Type (of-genitive vs. s-genitive). In the first model, cognate status was added as a factor (cognate vs. non-cognate); in the second model, the phonological similarity of the head nouns in both languages was used as a continuous measure (this variable was centered to its mean). In the first model, the intercept thus represents the odds for an s-genitive response for non-cognates in the of-genitive condition; in the second model, the intercept represents the odds for an s-genitive in the of-genitive condition, for items at the centre of the phonological similarity variable. Analyses using the phonetic similarity of the heads as a continuous predictor yielded virtually identical results. The results of the first analysis are summarized in Table 3; the results of the second one in Table 4.
Table 3. Results of the analyses when the cognate status of the translation equivalent heads is included as a factor (cognate vs. non-cognate).

SE = standard error
Table 4. Results of the analyses when phonological similarity between the translation equivalent heads is included as a continuous predictor.

SE = standard error
In both models, the significant negative intercept indicates that there was an overall bias towards of-genitives: The probability of producing an s-genitive in the of-genitive condition was significantly below 50%. Participants produced 13.9% s-genitives in the of-genitive condition, and 30.6% in the s-genitive condition, yielding a significant effect of between-language priming. Responses in the of-genitive condition (i.e., the reference level) were unaffected by the cognate status of the head nouns or the phonological similarity between them (p > .2 in both models). When the cognate status of the head nouns in prime and target was coded as a factor (non-cognate vs. cognate), the model showed a significant interaction (p < .05) between the size of the priming effect and cognate status: The priming effect was larger for cognates (20.8%) than for non-cognates (12.5%). The same interaction was obtained when we used the sound overlap between the head nouns as a continuous predictor: The strength of priming increased together with the nouns’ phonological and phonetic similarity (see Figure 4).

Figure 4. Results of regression 2: Priming effects (in probabilities) as a function of the phonological similarity between the head nouns.
Discussion
Our results clearly indicate that between-language syntactic priming is modulated by the cognate status of the related heads: The syntactic priming effect was larger for cognate items than for non-cognates that are only semantically equivalent. The fact that this boost of between-language priming was also obtained when the sound overlap was added as a continuous predictor indicates that the stronger effect for cognate items is at least partly due to their sound overlap. Otherwise, the observed boost would not be a continuous effect that occurs for cognate (vork–fork) and non-cognate (pop–doll) items.
The results of this study suggest that feedback from the phonological level can, in some cases, influence the selection of syntax: The larger the proportion of phonemes that is shared between the heads of prime and target constructions, the stronger the effect of between-language priming. In order to be able to account for this effect, models of bilingual sentence production (e.g., Hartsuiker & Pickering, Reference Hartsuiker and Pickering2008) should allow activation of phonemes to feed back to the word-form and lemma representations in which they occur. In such an interactive model, a target noun (e.g., doll) does not only co-activate its translation equivalent via cascading activation going from the semantic level to the lemma level of production. When there is phonological overlap between translation equivalents, feedback going from the target's phonemes to the lexemes and the lemmas in which these phonemes occur also adds to the activation of the translation equivalent lemma. Consequently, syntactic priming for constructions with translation-equivalent heads can be boosted by the phonological overlap between these heads.
In Figure 5 we present a sentence production model, based on the bilingual production models of Bernolet et al. (Reference Bernolet, Hartsuiker and Pickering2007) and Hartsuiker et al. (Reference Hartsuiker, Pickering and Veltkamp2004). This model assumes shared representations for Dutch and English s- and of-genitives that are connected to the lemmas of all Dutch and English nouns they can be used with. The lemmas, in turn, are tagged for their language by being linked to a “Dutch” or “English” language node. The lemmas of translation-equivalent words in Dutch and English are linked to a shared semantic node, and all noun lemmas are linked to the same categorical node “noun”. In contrast to Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model, our model also has a word-form level, where word forms are stored together with the phonemes they consist of. When activated, these phonemes send activation to all word forms in which they occur. The word forms pass this activation on to their corresponding lemma representations and thus influence the selection of syntax.
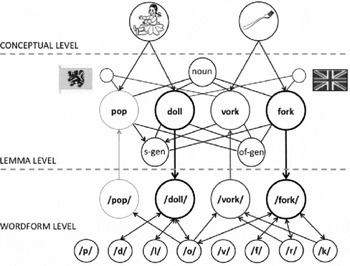
Figure 5. Model for the representation of genitive constructions in Dutch–English bilinguals (adapted from Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2007, and Hartsuiker et al., Reference Hartsuiker, Pickering and Veltkamp2004). In this integrated network (featuring a shared lexicon and shared lexical representations), the lemma representations of Dutch (pop–vork) and English (doll–fork) nouns are linked to one conceptual node at the conceptual level, to one category node (Noun), and to one language node (represented by a Flemish and a British flag). All lemma representations are connected with the combinatorial nodes for the s-genitive and the of-genitive. The flow of activation (when doll or pan is the head of the target construction) is indicated by arrows; the color and the thickness of the lines indicate the strength of activation.
Figure 5 shows what happens when a genitive construction has to be formed with the target words doll or fork. The target picture activates the conceptual representation of doll or fork. This conceptual representation does not only activate the corresponding lemma in the target language (English, L2), but also in the language in which the prime was presented (Dutch, L1), thereby re-activating the head of the prime construction (pop or vork) and the combinatorial node that was activated during the processing of the prime (s-genitive or of-genitive). At the same time, the target lemma (doll or fork) activates its corresponding word form (/dol/ or /fork/), which, in its turn, activates its constituent phonemes (/d/, /o/, /l/ or /f/, /o/, /r/, /k/). These phonemes send feedback to all the word forms and the lemmas in which they occur. Because fork shares a larger proportion of its phonemes with its Dutch translation equivalent than doll (75% vs. 33%), the tendency to re-use the syntactic structure of the prime is stronger when fork is the target word than when the target word is doll.
Although our version of Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) bilingual sentence production model has separate levels for lemma and word-form representations, it is not strictly necessary to assume such an architecture in order to explain our data. Interactive models that assume a single level of lexical representation (e.g., Caramazza, Reference Caramazza1997) can also account for our data, assuming that the entries at the lexical level are linked to syntactic representations that are shared between both languages of a bilingual. Feedback going from activated phonemes to all lexical items in which they occur can then influence syntactic choices. In fact, our data support a bilingual production model in which lexical-syntactic representations of the non-target language are activated via cascading activation from the semantic level as well as through feedback from the phonological level.
It is not yet clear how we can explain the discrepancy between our data and the data obtained by Cleland and Pickering (Reference Cleland and Pickering2003). It is possible that it is easier to observe a phonological boost of priming when priming is concurrently boosted by semantic overlap between the heads of prime and target constructions. On the other hand, the difference may be due to the fact that we investigated between-language syntactic priming instead of within-language priming, and the use of two different languages may induce a stronger activation of non-target words.
In any case, by investigating the effect of repeated cognates on the selection of syntax in bilinguals, we have shown that, in some cases, feedback from activated phonemes can influence the selection of lexical representations and the syntactic structures associated with them. More specifically, our results suggest that, during bilingual language production, the activation of phonological segments sends feedback to all word-form representations they are linked to, independently of the language to which they belong, in a way that influences the strength of between-language syntactic priming in bilinguals. Although there are no within-language priming data available yet to prove this claim (though Santésteban et al.'s (Reference Santésteban, Pickering and McLean2010) data can be seen as evidence for phonological effects on the selection of syntax in the case of complete phonological overlap), we believe that phonological feedback can influence the strength of within-language syntactic priming in the same way as it influences the strength of between-language syntactic priming. This means that Cleland and Pickering's (Reference Cleland and Pickering2003) claim that there is no feedback from activated phonemes to the lemmas in which they occur, is no longer tenable. Hence, our data argue for an adaptation of Cleland and Pickering's sentence production model and the models based on it.
Our data are also informative for studies investigating bilingual speech production at the word level. As we already mentioned, Costa et al. (Reference Costa, Roelstraete and Hartsuiker2006) showed that interactivity between the phonological and the lexical level extends across languages in bilingual speech production. Our data corroborate their findings and extend them to a different set of languages (Dutch and English instead of Spanish and Catalan) and to bilinguals with a lower level of L2-proficiency (late bilinguals living in an L2-dominant environment instead of balanced bilinguals living in a mixed language environment). Most importantly our results lend support to the idea that the cognate advantage in speech production is, at least partly, caused by interactivity between the phonological and the lexical level of production (Costa et al., Reference Costa, Santésteban and Caño2005).
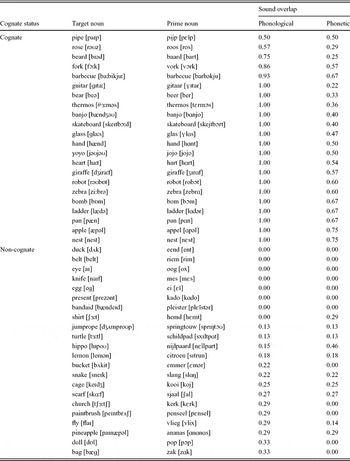
Appendix A. English and Dutch head nouns (with phonetic transcriptions) with the proportions of their phonological and phonetic overlap
Appendix B. Items used in the experiment
The first of each set of three lines includes a description of the target picture. The possessor of the colored object and the object that is owned are mentioned first, and the word referring to the person possessing the uncolored object is set in parentheses. In the following two lines, the s-genitive and the of-genitive primes are given in Dutch (a) together with their English translations (b).
1. wizard with a blue apple (witch)
1a. [Het meisje haar appel] – [De appel van het meisje] is blauw.
1b. [The girl's apple] – [The apple of the girl] is blue.
2. nurse with a blue bucket (wizard)
2a. [Het meisje haar emmer] – [De emmer van het meisje] is blauw.
2b. [The girl's bucket] – [The bucket of the girl] is blue.
3. nurse with a yellow banjo (nun)
3a. [De piraat zijn banjo] – [De banjo van de piraat] is geel.
3b. [The pirate's banjo] – [The banjo of the pirate] is yellow.
4. wizard with a red beard (pirate)
4a. [De jongen zijn baard] – [De baard van de jongen] is rood.
4b. [The boy's beard] – [The beard of the boy] is red.
5. witch with a red duck (wizard)
5a. [De jongen zijn eend] – [De eend van de jongen] is rood.
5b. [The boy's duck] – [The duck of the boy] is red.
6. witch with a blue bear (priest)
6a. [De non haar beer] – [De beer van de non] is blauw.
6b. [The nun's bear] – [The bear of the nun] is blue.
7. boy with a blue doll (priest)
7a. [De tovenaar zijn pop] – [De pop van de tovenaar] is blauw.
7b. [The wizard's doll] – [The doll of the wizard] is blue.
8. pirate with a green barbecue (nurse)
8a. [De heks haar barbecue] – [De barbecue van de heks] is groen.
8b. [The witch's barbecue] – [The barbecue of the witch] is green.
9. girl with a red pineapple (witch)
9a. [De verpleegster haar ananas] – [De ananas van de verpleegster] is rood.
9b. [The nurse's pineapple] – [The pineapple of the nurse] is red.
10. nurse with a red bomb (girl)
10a. [De tovenaar zijn bom] – [De bom van de tovenaar] is rood.
10b. [The wizard's bomb] – [The bomb of the wizard] is red.
11. nurse with a green belt (pirate)
11a. [De jongen zijn riem] – [De riem van de jongen] is groen.
11b. [The boy's belt] – [The belt of the boy] is green.
12. girl with a green fork (priest)
12a. [De verpleegster haar vork] – [De vork van de verpleegster] is groen.
12b. [The nurse's fork] – [The fork of the nurse] is green.
13. priest with a yellow scarf (nun)
13a. [De jongen zijn sjaal] – [De sjaal van de jongen] is geel.
13b. [The boy's scarf] – [The scarf of the boy] is yellow.
14. pirate with a red giraffe (wizard)
14a. [De priester zijn giraf] – [De giraf van de priester] is rood.
14b. [The priest's giraffe] – [The giraffe of the priest] is red.
15. boy with a yellow jump rope (pirate)
15a. [De priester zijn springtouw] – [Het springtouw van de priester] is geel.
15b. [The priest's jump rope] – [The jump rope of the priest] is yellow.
16. nurse with a blue glass (boy)
16a. [De heks haar glas] – [Het glas van de heks] is blauw.
16b. [The witch's glass] – [The glass of the witch] is blue.
17. nurse with a green bag (witch)
17a. [Het meisje haar zak] – [De zak van het meisje] is groen.
17b. [The girl's bag] – [The bag of the girl] is green.
18. wizard with a green guitar (priest)
18a. [De jongen zijn gitaar] – [De gitaar van de jongen] is groen.
18b. [The boy's guitar] – [The guitar of the boy] is green.
19. priest with a blue turtle (girl)
19a. [De heks haar schildpad] – [De schilpad van de heks] is blauw.
19b. [The witch's turtle] – [The turtle of the witch] is blue.
20. priest with a yellow hand (witch)
20a. [De tovenaar zijn hand] – [De hand van de tovenaar] is geel.
20b. [The wizard's hand] – [The hand of the wizard] is yellow.
21. witch with a green eye (nun)
21a. [Het meisje haar oog] – [Het oog van het meisje] is groen.
21b. [The girl's eye] – [The eye of the girl] is green.
22. girl with a blue heart (boy)
22a. [De non haar hart] – [Het hart van de non] is blauw.
22b. [The nun's heart] – [The heart of the nun] is blue.
23. pirate with a yellow church (girl)
23a. [De verpleegster haar kerk] – [De kerk van de verpleegster] is geel.
23b. [The nurse's church]- [The church of the nurse] is yellow.
24. girl with a green ladder (boy)
24a. [De priester zijn ladder] – [De ladder van de priester] is groen.
24b. [The priest's ladder] – [The ladder of the priest] is green.
25. boy with a blue lemon (nurse)
25a. [De non haar citroen] – [De citroen van de non] is blauw.
25b. [The nun's lemon] – [The lemon of the nun] is blue.
26. wizard with a red nest (nun)
26a. [De verpleegster haar nest] – [Het nest van de verpleegster] is rood.
26b. [The nurse's nest] – [The nest of the nurse] is red.
27. pirate with a red cage (girl)
27a. [De non haar kooi] – [De kooi van de non] is rood.
27b. [The nun's cage] – [The cage of the nun] is red.
28. pirate with a yellow pan (boy)
28a. [De heks haar pan] – [De pan van de heks] is geel.
28b. [The witch's pan] – [The pan of the witch] is yellow.
29. priest with a green knife (nurse)
29a. [De verpleegster haar mes] – [Het mes van de verpleegster] is groen.
29b. [The nurse's knife] – [The knife of the nurse] is green.
30. nurse with a red robot (nun)
30a. [De tovenaar zijn robot] – [De robot van de tovenaar] is rood.
30b. [The wizard's robot] – [The robot of the wizard] is red.
31. nurse with a yellow paintbrush (girl)
31a. [De heks haar penseel] – [Het penseel van de heks] is geel.
31b. [The witch's paintbrush] – [The paintbrush of the witch] is yellow.
32. priest with a blue rose (wizard)
32a. [De jongen zijn roos] – [De roos van de jongen] is blauw.
32b. [The boy's rose] – [The rose of the boy] is blue.
33. boy with a blue shirt (girl)
33a. [De piraat zijn hemd] – [Het hemd van de piraat] is blauw.
33b. [The pirate's shirt] – [The shirt of the pirate] is blue.
34. girl with a red fly (boy)
34a. [De non haar vlieg] – [De vlieg van de non] is rood.
34b. [The nun's fly] – [The fly of the nun] is red.
35. witch with a yellow egg (pirate)
35a. [De zuster haar ei] – [Het ei van de zuster] is geel.
35b. [The nurse's egg] – [The egg of the nurse] is yellow.
36. pirate with a blue skateboard (priest)
36a. [De non haar skateboard] – [Het skateboard van de non] is blauw.
36b. [The nun's skateboard] – [The skateboard of the nun] is blue.
37. boy with a yellow thermos (witch)
37a. [Het meisje haar thermos] – [De thermos van het meisje] is geel.
37b. [The girl's thermos] – [The thermos of the girl] is yellow.
38. nun with a blue gift (priest)
38a. [De tovenaar zijn cadeau] – [Het cadeau van de tovenaar] is blauw.
38b. [The wizard's present] – [The present of the wizard] is blue.
39. nun with a yellow yoyo (girl)
39a. [De piraat zijn jojo] – [De jojo van de piraat] is geel.
39b. [The pirate's yoyo] – [The yoyo of the pirate] is yellow.
40. boy with a red bandaid (wizard)
40a. [Het meisje haar pleister] – [De pleister van het meisje] is rood.
40b. [The girl's bandaid] – [The bandaid of the girl] is red.
41. pirate with a green zebra (nurse)
41a. [De tovenaar zijn zebra] – [De zebra van de tovenaar] is groen.
41b. [The wizard's zebra] – [The zebra of the wizard] is green.
42. witch with a green hippo (wizard)
42a. [De priester zijn nijlpaard] – [Het nijlpaard van de priester] is groen.
42b. [The priest's hippo] – [The hippo of the priest] is green.
43. boy with a red pipe (wizard)
43a. [De priester zijn pijp] – [De pijp van de priester] is rood.
43b. [The priest's pipe] – [The pipe of the priest] is red.
44. pirate with a yellow snake (priest)
44a. [De non haar slang] – [De slang van de non] is geel.
44b. [The nun's snake] – [The snake of the nun] is yellow.










