


INTRODUCTION
As people learn to speak, they acquire the language and dialect spoken around them. The exact forms of every level of linguistic representation—from syntax to lexical choice to pronunciation—are all determined by the patterns of the ambient language. This is done with great ease by young language learners. It has been documented, however, that after a certain age, children are unable to fully acquire particularly complex phonological aspects of a second dialect (Payne Reference Payne and Labov1980, Chambers Reference Chambers1992). Trudgill (Reference Trudgill1986:58) argues that this is due to the fact that accommodation of sound structure in dialect contact is “phonetic rather than phonological” (emphasis in original).
Despite the purported difficulty in acquiring a new dialect, research on adults exposed to new dialects demonstrates that ways of speaking do indeed change. For example, Munro, Derwing, and Flege (Reference Munro, Derwing and Flege1999) found that accents of Canadians living in Alabama were perceived by listeners as sounding intermediate between those of Canadians living in Canada and native Alabamans. A series of studies have focused on longitudinal changes within the speech of a single speaker over a fifty-year span. Harrington (Reference Harrington2006, Reference Harrington, Cole and Hualde2007) and Harrington, Palethrope, and Watson (Reference Harrington, Palethrope and Watson2000a,b) have analyzed vowel changes in the speech of Queen Elizabeth II. The recordings under analysis were her yearly Christmas broadcasts from 1952 through 2002. After accounting for maturational changes in the vocal tract, this work has demonstrated that the Queen's vowels shifted in the direction of Southern British English, away from Received Pronunciation. Evans and Iverson (Reference Evans and Iverson2007) examined changes in both perception and production in new dialect exposure. College students from a northern English dialect (Sheffield) were interviewed at the commencement of university studies, three months after the beginning of studies, after one year of study, and after two years of study at a southern English university where Standard Southern British English (SSBE) was spoken. SSBE has /ʌ/ in bud and cud and /ɑ/ in bath. Northern varieties of English use the vowel /ʊ/ for bud and cud and /a/ for bath. The authors found that both bud and cud became more centralized. In the northern dialects, cud and could are homophonous, both having the vowel /ʊ/. Could has this vowel in the southern dialects, but cud has /ʌ/. After their time at the university, the participants began to centralize the vowel for could as well. Participants were also rated on a ten-point scale from ‘very northern’ to ‘very southern’. Overall, participants were rated as sounding more southern after their time at the university.
Delvaux and Soquet (Reference Delvaux and Soquet2007) provide evidence demonstrating that speakers can shift from one dialect to another after very brief periods of exposure. Female speakers of the Mons dialect of Belgian French were exposed to the voice of a female model talker from the Liège dialect of Belgian French. After auditory exposure to the model talker's voice, the Mons speakers modified their pronunciations of /o/ and /ɛ/ in a sentence production task.
Of course, dialect acquisition and dialect change are not the only ways in which an individual's speech fluctuates. Individuals regularly style-shift in language use; style-shifting is the process of changing ways of speaking according to social contexts (see Eckert & Rickford Reference Eckert and Rickford2001 or Coupland Reference Coupland2007 for deeper treatments of style). In a landmark study, Coupland (Reference Coupland1980) examined the speech patterns of a travel agent in Cardiff while she interacted with different participants (friends, clients, coworkers) about different topics and across different communication channels (in person or on the telephone). The frequency with which the travel agent used particular phonological variables was correlated with the contextual dynamic. Bell (Reference Bell1984) reports on similar data showing that four radio newsreaders in New Zealand varied their productions of intervocalic /t/ when reading on different radio stations. All newsreaders had higher incidence of flapping intervocalic /t/ on the community radio station, with lower flapping rates occurring on the national radio station. Bell's theory of audience design, which arose from his 1984 study, is a model that attempts to account for when stylistic shifting arises. In audience design, a speaker considers not only the addressee in the selection of a proper linguistic variable for an utterance, but also the individuals who are assuming the role of auditor, overhearer, and eavesdropper. Bell (Reference Bell, Eckert and Rickford2001) expands the theory of audience design by adding a notion of referee design as a mechanism parallel with audience design. Referee design is the change in a speaker's style that affiliates the speaker with a particular social group as prompted by the audience (Bell Reference Bell, Eckert and Rickford2001:163). Bell argues that a comprehensive theory of style-shifting must consider the two principal driving forces—audience and referee design—simultaneously. While a talker is crafting from a stylistic repertoire that heeds the needs of the audience, a speaker feels the pressure to maintain a level of faithfulness to their social network and larger social affiliations.
What determines a speaker's stylistic selection? This question is also addressed by Bell (Reference Bell1984:167), where he considers three possibilities: (i) speakers examine an addressee's personal traits and design their style accordingly; (ii) speakers gauge the general speech style of an addressee and design accordingly; or (iii) speakers listen for specific linguistic variables and select their stylistic variants to reflect their findings. Many of Bell's suggestions are both echoed in and echoes of communication accommodation theory (CAT; Giles Reference Giles1973, Giles & Coupland Reference Giles and Coupland1991, Giles, Coupland, & Coupland Reference Giles, Coupland, Coupland, Giles, Coupland and Coupland1991, Shepard, Giles, & LePoire Reference Shepard, Giles, LePoire, Robinson and Giles2001). In CAT, it is argued that linguistic choices made in interaction are a function of speakers creating and maintaining social distance. Linguistic accommodation or convergence lessens the social distance between interlocutors while divergence maximizes it. A speaker's speech style will shift in an interaction to modify the social distance between the speaker and the addressee, overhearers and eavesdroppers, and the referee. This connection between style-shifting and CAT is not novel. In fact, Giles (Reference Giles1973) claimed that, perhaps, all style-shifting in sociolinguistics interviews was the result of accommodation. Trudgill (Reference Trudgill, Hendrick, Masek and Miller1981), however, provided evidence from his interviews in Norwich to refute this claim. In his data, Trudgill found that he actually accommodated to the interviewees more than the other way around.
This research on dialect change and style-shifting demonstrates that speakers modify their speech patterns as a result of changes in social contexts and new cultural environments. In addition to these findings, several laboratory-based studies have found that individuals acquire the phonetic characteristics of model talkers in highly asocial speech production tasks. In what is known as a shadowing task or an auditory naming taskFootnote 1 where participants simply repeat single words after a model talker, Goldinger (Reference Goldinger1998) found that when participants repeat words, they acquire phonetic aspects of the model talker's voice. This general finding has been well replicated (Namy, Nygaard, & Sauerteig Reference Namy, Nygaard and Sauerteig2002, Goldinger & Azuma Reference Goldinger and Azuma2004). In the completion of a conversational map task, speakers were also found to converge phonetically on each other's productions; the direction of the convergence, however, was influenced by several social factors, namely gender and participant role (Pardo Reference Pardo2006). In Pardo's study, male dyads converged more than female dyads. As far as participant role, women were found to converge toward the speaker who was receiving instructions while men converged toward the speaker who was giving instructions. In the speech science literature, there has also been some investigation of what exactly can be imitated. Shockley, Sabadini, and Fowler (Reference Shockley, Sabadini and Fowler2004) and Nielsen (Reference Nielsen2008) find that speakers imitate the voice onset time of aspirated stops. Recently, Babel (Reference Babel2009) found that phonetic accommodation of vowel formants is selective. In that study, the American English vowels /i æ ɑ o u/ were examined for imitative behaviors; only /æ/ and /ɑ/ exhibited shifts toward the model talker in an auditory naming task.
Thus, there is ample evidence demonstrating that phonetic and phonological accommodation occurs in language behavior both in ecologically valid social interactions and in more sterile laboratory contexts. There is currently considerable debate as to why this happens. Psycholinguists who study the mechanisms of speech behavior have developed models to account for accommodative behaviors in language. The interactive alignment model is a popular model proposed by Pickering and Garrod (Reference Pickering and Garrod2004) to account for speech accommodation. In this model every level of linguistic representation—the situation model, semantics, syntax, the lexicon, phonology, and phonetics—is connected within an individual, and each level of representation between the listener and the talker is connected. An automatic priming process that percolates through the levels of representations of the interlocutors aligns speech. The use of a representation by a talker leads to the activation of that representation in the listener, and that activation leads to increased incidence of use.
Sociolinguists have also contributed to the how-and-why discussion of accommodation. Traditionally, research on dialect contact and acquisition has remained agnostic regarding the mechanisms for accommodation, while the motivation is considered one of belonging, group identity, and social-network membership. But, recently, Trudgill (Reference Trudgill2008:252) argues that “accommodation is not only a subconscious but also a deeply automatic process.” He reaches this conclusion after reviewing four cases of European languages forming new varieties as a result of dialect contact, and he discards the theory that new dialects arise as a result of the formation of new national identities:
if a common identity is promoted through language, then this happens as a consequence of accommodation; it is not its driving force. Identity is not a powerful enough driving force to account for the emergence of new, mixed dialects by accommodation. It is parasitic upon accommodation, and is chronologically subsequent to it. (Trudgill Reference Trudgill2008:251)
It is striking to see Trudgill eschewing social factors as a palpable force in language change. Trudgill's claim has been criticized extensively (Bauer Reference Bauer2008, Coupland Reference Coupland2008, Holmes & Kerswill Reference Holmes and Kerswill2008, Mufwene Reference Mufwene2008, Schneider Reference Schneider2008, Tuten Reference Tuten2008). Bauer, for example, points out there are instances where individuals have lived for a considerable amount of time in a new dialect area without displaying significant accommodation.
Trudgill's hypothesis makes a prediction that is testable: if linguistic accommodation is automatic, it should not only be demonstrable in a laboratory, but everyone should do it. One particular CAT study poses a clear challenge for the automatic accommodation model. Bourhis and Giles (Reference Bourhis, Giles and Giles1977) is the hallmark example of dialect divergence and served as inspiration for the study presented in this article. Bourhis and Giles examined accent convergence and divergence in two groups of Welsh-born adults. A group of Welsh adults who attended both Welsh language and Welsh culture classes were found to diverge from an out-group speaker of Received Pronunciation (RP) by adopting a Welsh-accented dialect. The RP interviewer had questioned the vitality and function of the Welsh language in modern times. The second group of Welsh adults participating in the experiment also attended Welsh language classes, but only on business time with the explicit goal of furthering their careers. These adults were found to converge with the RP interviewer. The perceived changes in the accents of the adults were measured on an eleven-point scale by two judges who were not linguistically trained and naive to the experiment. Crucially, however, the judgments of convergence and divergence came from instances of running speech. This means that the perceptual judgments could have been made based on lexical items, syntactic structure, or phonetic features. For example, one participant in the experiment who was judged to have diverged from the RP speaker was heard conjugating Welsh verbs. While this type of behavior is clearly divergent, it is distinct from a speaker using a slightly different pronunciation to socially distance themself.
The goal of this article is twofold. The first goal is to attempt a replication of Bourhis and Giles looking at phonetic convergence and divergence. When an individual wants to socially distance themself from another speaker, do they do it phonetically? To answer this question, an auditory naming task was designed using the voice of a male Australian as that of the model talker (like the RP speaker in the Bourhis and Giles study) and New Zealand participants.Footnote 2 Australian and New Zealand Englishes (AuE and NZE) share many basic dialect features (Bauer, Warren, Bardsley, Kennedy, & Major Reference Bauer, Warren, Bardsley, Kennedy and Major2007, Cox & Palethorpe Reference Cox and Palethorpe2007), but there are several key differences in the front vowel monophthongs (Watson, Harrington, & Evans Reference Watson, Harrington and Evans1998, Easton & Bauer Reference Easton and Bauer2000). Ongoing sound changes in NZE have made the front vowel space particularly distinct in the two dialects (Maclagan & Hay Reference Maclagan and Hay2007). In NZE, for instance, the DRESS and TRAP vowels are raising.Footnote 3 The KIT vowel in AuE is raising, while in NZE it is centralizing. Not all of these sound changes are considered salient differences within the NZ community. Bayard (Reference Bayard, Bell and Kuiper2000) states that KIT is the most salient difference between NZE and AuE. Hay, Nolan, and Drager (Reference Hay, Nolan and Drager2006) examined NZE listeners' sensitivity to the salient differences in KIT, TRAP, and DRESS in NZE and AuE; they found equally strong results for KIT and TRAP, but NZE listeners did not behave as though they were explicitly aware of the differences between the DRESS vowel in these two dialects. It is important to be aware of the salient differences across the two dialects as Trudgill (Reference Trudgill, Hendrick, Masek and Miller1981) argues that only socially salient variables are susceptible to accommodation. Following this, in interactions between NZE and AuE speakers, we predict that only TRAP and KIT would exhibit accommodation.
The second goal is to query the role of social factors in speech production and the role of social interaction in accommodation. The fact that speakers automatically accommodate in auditory naming tasks demonstrates that at least a small part of accommodation and style-shifting in social interactions may be unintentional and simply an automatic reflex of the language system. But, furthermore, demonstrating that social factors affect the degree of accommodation in asocial laboratory interactions would indicate that it is unlikely that language use lacks social conditioning and influence at any level.
METHODOLOGY
In the following paragraphs I describe the speech production task used to explore phonetic convergence and divergence in NZE. Next, I provide methodology for the Implicit Association Task that measured each NZ participants' inherent bias toward Australia. Participants' scores on this task were used in the statistical analysis described in the Analysis and results section.
Speech production task
Participants (females = 34, males = 8) from the Victoria University of Wellington community completed an auditory naming task. The task took approximately thirty minutes and participants were compensated with a $10 book voucher. The auditory stimuli were monosyllabic single-word productions from a male talker who was born and raised in Melbourne, Australia. Monophthongal stimuli were words taken from the lexical sets KIT, DRESS, TRAP, START, STRUT, and THOUGHT. In addition to the target monophthongs, participants were also presented with diphthongs involved in the NEAR/SQUARE merger in New Zealand English (Hay, Warren, & Drager Reference Hay, Warren and Drager2006). Only the results from the monophthongs are presented in this article. The full list of monophthongal words used in the task appears in the appendix.
Participants were seated at a PC laptop and the experiment was presented using E-Prime 2.0 Experimental Software (Schneider, Eschman, & Zuccolotto Reference Schneider, Eschman and Zuccolotto2007). Auditory stimuli were presented over AKG K271 headphones. Audio recording was done directly in E-prime using an M-Audio USB audio device with a head-mounted AKG C520 microphone positioned three inches from the participant's mouth.
The auditory naming task was designed as follows: Participants were randomly presented with hVd words (hid, had, head, etc.), which they were to read aloud. In the next block, participants were presented with the target word list, which they were asked to produce aloud. The words in the list were presented in a different random order for each participant; this is referred to as the pretask block. The purpose of the pretask block is to obtain a baseline production of how a participant produces each word. The following block was the shadowing block where participants were exposed to the target-word productions from the Australian model talker. Words were randomly presented twice through the course of the test block. Participants' instructions for this part of the task are to identify the word heard by saying it out loud. Finally, participants did a posttask reading of the wordlist; this block was identical to the pretask block, except that the words were presented in a different random order. Finally, participants reread the hVd words again. The methodology of this auditory naming task follows that of Goldinger Reference Goldinger1998 and Namy et al. Reference Namy, Nygaard and Sauerteig2002.
In comparing pretask and test-block productions, we can see how NZ participants modify productions as a result of exposure to the Australian model talker. In this task participants were assigned to one of two conditions, a Positive Condition and a Negative Condition. In the Positive Condition, participants were presented with the following text that was intended to make them view the talker and Australia as a whole in a positive light:Footnote 4
The Australian talker you are about to hear was actually born in Auckland. At a young age, however, he and his parents moved to Melbourne where he has lived since. His grandparents and the rest of his extended family still live in New Zealand, so he visits frequently. In fact, he is currently looking for employment in New Zealand so that his children may live closer to their great-grandparents.
Participants in the Positive Condition were expected to develop positive feelings toward the Australian talker. These positive feelings were predicted to create the desire to lessen the social distance, and thus following CAT, NZ participants were expected to converge toward the Australian model talker in this condition. The purpose of the Negative Condition was to inspire negative feelings toward the talker and Australia, which, according to CAT, would cause divergence:
The Australian talker you are about to hear was born in Sydney. Like many Australians, he has strong negative opinions of New Zealand. For one, he thinks that New Zealanders are rather stupid and that they lack culture. In addition, he finds the entire population backwards and naïve. In his mind, New Zealand is provincial and has a horrid cricket team. He never intends to visit New Zealand because of these views.
The texts associated with each condition were written in consultation with two Australians. In both conditions participants were exposed to a screen with the assigned text immediately before beginning the test-block. The Positive and Negative texts were presented under the guise that the purpose of the experiment was to examine how personal information about the model talker affected word recognition. After reading the Positive or Negative text, participants pressed a button that took them to the test-block. Male and female participants were evenly assigned to the two conditions.
Upon completion of the speech production task, all participants took an Implicit Association Task. This task is described in the next section.
Implicit Association Task
Traditionally in sociolinguistics, attitudes are elicited explicitly through surveys or questionnaires. One aspect of this project was to examine how implicit and subconscious attitudinal measures that participants may not admit forthright in an interview may predict speech behavior. To this end, an Implicit Association Task (IAT; Greenwald, McGhee, & Schwarz Reference Greenwald, McGhee and Schwartz1998) was used. While the IAT is not commonly used in sociolinguistics, it is a standard social psychology tool that uses reaction time in category classification to measure implicit biases.
There are five blocks in this task. Block 1 is target-concept discrimination. The targets AUSTRALIA and NEW ZEALAND are presented on opposite sides of the monitor. A combination of Australian or New Zealand concepts—famous individuals, maps, and images (flags, native scenery, sports emblems, etc.)—is then randomly presented (e.g. an image of a kangaroo or an image of a kiwi) in the middle of the screen. A participant's task is to categorize the concepts as AUSTRALIA or NEW ZEALAND as quickly as possible. Block 2 is associated attribute discrimination. Here, the attributes good and bad are presented on opposite sides of the computer screen, and the concepts AUSTRALIA and NEW ZEALAND are no longer present on the screen. Attribute words are presented randomly (e.g. rainbow or cancer) in the middle of the screen. Participants categorize the words as semantically good or bad words. Block 3 is a combined test block. Labels for the concept categories (AUSTRALIA vs. NEW ZEALAND) and word (good vs. bad) attributes are presented simultaneously at the top corners of the screen. In the center, either a concept (eliciting either an AUSTRALIA or NEW ZEALAND response) or a word (to be classified as good or bad) are randomly presented and must be categorized. Participants are instructed to ignore the target-concept when categorizing words and ignore the attributes when categorizing concepts. Concepts illustrated as words (eg. Kevin Rudd and Helen Clark) are presented in all capital letters and good/bad words are presented in all lowercase letters to facilitate the process. Block 4 is just like Block 1, except that the labels AUSTRALIA and NEW ZEALAND are presented on different sides of the screen (so, if AUSTRALIA is on the right-side of the screen in Block 1, it is on the left side in Block 4). Participants then categorize concepts as AUSTRALIA or NEW ZEALAND as they did in Block 1. Block 5 is the reversed combined task; the reversed order of the target-concepts (AUSTRALIA and NEW ZEALAND) match up with the original order of good and bad such that if AUSTRALIA is originally presented above good and NEW ZEALAND with bad, this pattern is reversed and AUSTRALIA is presented with bad and NEW ZEALAND with good. The experiment was counterbalanced so that half of the participants were initially exposed to AUSTRALIA paired with good and NEW ZEALAND paired with bad while the other half were first presented with AUSTRALIA paired with bad and NEW ZEALAND paired with good.
Participants logged responses using assigned buttons on a computer keyboard. Responses were collected automatically using E-prime. Participants' scores were calculated using the updated methods described in Greenwald, Nosek, & Banaji Reference Greenwald, Nosek and Banaji2003. After eliminating responses with latencies over 10,000 milliseconds, the mean reaction time was calculated for each participant based on correct responses for each block. One standard deviation was also calculated for each block. Then, each response error was replaced with the block mean and a 600 ms penalty, following the updated scoring algorithm described in Greenwald et al. Reference Greenwald, Nosek and Banaji2003. Means were then recalculated for each block and the difference between these two blocks was computed. Finally, to get the IAT score, the difference was divided by the standard deviation previously calculated. A negative IAT score is indicative of a pro-Australian bias and a positive IAT score indicates a pro-New Zealand bias. These values were used as predictors in the statistical model described below.
After completing the Implicit Association Task, participants were debriefed on the purposes of both the speech production task and the IAT. While most participants made no explicit comment about the task, a small number of participants assigned to the Negative Condition remarked that the text seemed a bit extreme.
ANALYSIS AND RESULTS
Analysis
Vowels from the participant productions were hand-marked. A Praat (Boersma & Weenink Reference Boersma and Weenink2005) script calculated the average first and second formants over the middle 50% of the vowel. Data points that fell beyond the general vowel categories were identified as outliers and hand-corrected. In order to minimize physiological differences between participants so that the analysis can focus on speech production differences in dialect and style, it is necessary to normalize the vowel formants. As per Adank, Smits, and van Hout (Reference Adank, Smits and van Hout2004), the Lobanov normalization method was used (Lobanov Reference Lobanov1971).
Euclidean distance is a way of measuring distance within a two-dimensional space; with vowels, the Euclidean distance calculates the distance between vowels by considering both the first and second formant. Using the normalized formant values, the Euclidean distance between each NZ word production and the same word from the Australian model talker was calculated. This means that for each word from each block for each participant there is a single distance measure. To understand how NZ participants' productions changed as a result of exposure to the model talker, the distance for each word from the test-block and posttask blocks were subtracted from the pretask block distances, creating a difference in distance metric. This difference-in-distance measure is indicative of how much a participant modified their vowel productions with respect to the speech of the model talker. A negative value indicates that the distance between the NZ participant and the Australian model has shrunk, which would indicate convergence. A positive value signals that the phonetic distance has grown; this would mean there was divergence.
Results from the shadowed productions
Analyses were conducted separately on the task and posttask productions. First, the results from the task productions are discussed. A stepwise hierarchical linear regression analysis using only the data from the task block of shadowed productions was run. With this type of analysis all potential main effects and interactions are evaluated against one another. The model automatically selects the predictor variables that account for larger proportions of variance in the data. The difference-in-distance metric was used as the dependent variable, while vowel category (DRESS, KIT, TRAP, START, STRUT, THOUGHT), participant gender (male or female), experimental condition (Positive or Negative), participant age, word frequency, and IAT score were entered as independent predictors. Word frequency was determined by logarithmic frequency counts in CELEX (Baayen, Piepenbrock, & van Rijn Reference Baayen, Piepenbrock and van Rijn1993). The variables that were selected by the model are shown in Table 1. The model selected vowel, participants' IAT score, word frequency, and the vowel by IAT interactions as predictors in the model [F (12, 2037) = 6.2, p < 0.001]. The negative intercept in Table 1 indicates that on average participants converged with the model talker; the difference-in-distance was less in the shadowed tokens than in the pretask tokens.
Table 1. Results of a stepwise hierarchical linear regression used to predict difference-in-distance values from the shadowed tokens.
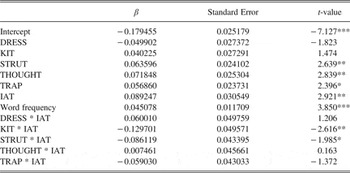
Symbols following the t-values indicate the associated p-value: ***p < 0.001, **p < 0.01, *p < 0.05.
Participants' IAT score and word frequency have positive β coefficients in Table 1. This means that the difference-in-distance value increased as these values increased; rather, there was less imitation as word frequency was higher and IAT score was higher (which equals a pro-New Zealand bias). For word frequency, this is in accordance with previous work; lower-frequency words exhibit more imitation than high-frequency words (Goldinger Reference Goldinger1998). In terms of the IAT score, the positive coefficient demonstrates that participants who scored as pro-Australian were more likely to accommodate toward the vowels of the Australian model talker. The condition to which participants were assigned did not show up in the regression model. In addition, posthoc analysis found no reliable effect of the Positive or Negative Conditions on difference-in-distance values. Figure 1 presents participants' IAT scores plotted against their average difference-in-distance value. Again, these results show that participants who scored as pro-Australian in the IAT were significantly more likely to spontaneously accommodate toward the vowels of the Australian talker [t(40) = 2.2, p < 0.05, Pearson's R = 0.32]. In Figure 1, each “positive” or “negative” data point represents one participant and indicates which Condition the participant was assigned to. This method of presenting the data also reveals the trend—albeit insignificant—that participants in the Negative Condition scored as more pro-New Zealand in the IAT than those participants randomly assigned to the Positive Condition.

Figure 1. Each participant's averaged difference-in-distance plotted against their IAT score. The difference-in-distance measure on the y-axis indicates the amount of phonetic accommodation. A negative value demonstrates phonetic convergence while a positive value demonstrates phonetic divergence. On the x-axis, a negative IAT score indicates a pro-Australian bias and a positive score a pro-New Zealand bias. The negatively skewed regression line in the figure demonstrates that a participant was more likely to phonetically accommodate to the Australian talker when they scored with a pro-Australian bias on the IAT.
While the overall pattern was that of convergence, participants did not accommodate toward all vowels to the same extent. Figure 2 presents difference-in-distance values for each vowel averaged across all participants in the task block. Any value below zero—denoted by the dashed line in the figure—indicates some degree of phonetic accommodation toward the vowels of the AuE talker. Negative difference-in-distance values for all vowels show that there was convergence toward the model talker and no patterns of divergence in the data set as a whole. Looking at Figure 2, it is also apparent that participants respond to vowels in a nonuniform manner. For example, it seems that DRESS elicited the most accommodation. Indeed, posthoc analyses found that the DRESS vowel was imitated more than STRUT (p < 0.05), THOUGHT (p < 0.001), and TRAP (p < 0.01). START was also imitated more than THOUGHT (p < 0.05).Footnote 5

Figure 2. Amount of phonetic accommodation to the vowels averaged across all participants in both the Positive and Negative Conditions. The difference-in-distance measure on the y-axis indicates the amount of phonetic accommodation. A negative value demonstrates phonetic convergence while a positive value demonstrates phonetic divergence. The dashed-line marks the cut-off point for accommodation; all data below the line is indicative of phonetic convergence. The error bars represent 95% confidence intervals.
Figures 3 and 4 plot the averaged normalized vowel formants for female and male participants, respectively. In both figures the words printed in the larger font represent the averaged vowel formants for the lexical sets from the Australian talker. The smaller words in black are averaged from participants' pretask productions. The smaller words in black italics are the shadowed productions and those in small gray italics are productions from the posttask block. These figures depict the direction of the accommodation. For female participants (Fig. 3), all vowels in the test block shifted in the direction of the Australian talker. Male participants (Fig. 4), however, display this same pattern of drift toward the Australian talker for DRESS, START, STRUT, and THOUGHT, but demonstrate divergence or maintenance for KIT and TRAP.
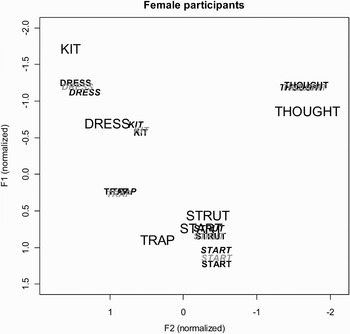
Figure 3. Formant plot displaying phonetic accommodation for the female participants. The Australian model talker's mean vowels are plotted in the larger black typeface. Female participants' pretask productions are in a small black font, shadowed productions are in black italics, and posttask productions are in gray italics. The shadowed productions move in the direction of the model talker's tokens and the posttask productions generally lie somewhere between the pretask and shadowed productions.
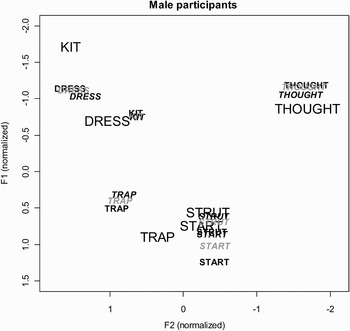
Figure 4. Formant plot displaying phonetic accommodation for the male participants. The Australian model talker's mean vowels are plotted in the larger black typeface. Male participants' pretask productions are in a small black font, shadowed productions are in black italics, and posttask productions are in gray italics. The shadowed productions move in the direction of the model talker's tokens and the posttask productions generally lie somewhere between the pretask and shadowed productions.
Results from the posttask productions
For the posttask productions, another stepwise hierarchical linear regression analysis was used. Again, the difference-in-distance metric was used as the dependent variable, while vowel category (DRESS, KIT, TRAP, START, STRUT, THOUGHT), participant gender (male or female), experimental condition (Positive or Negative), participant age, word frequency, and IAT score were entered as the predictor variables. The variables chosen by the model are summarized in Table 2. The model selected IAT scores, Experiment Condition (with Positive as the model's default reference variable), word frequency, and participant age [F(4, 1039) = 4.3, p < 0.05]. Like what was found for the shadowed productions, the negative intercept indicates that overall the difference-in-distance values in the posttask block were smaller than those in the pretask. After exposure to the Australian model talker ceased, NZ participants retained the more Australian-like vowels they had acquired during the shadowing block.
Table 2. Results of a stepwise hierarchical linear regression used to predict difference-in-distance values from the posttask tokens.

Symbols following the t-values indicate the associated p-value: ***p < 0.001, **p < 0.01, *p < 0.05.
Only the IAT score contributed significantly to this model. The positive β coefficient for IAT in Table 2 means that participants who scored as pro-Australian were more likely to continue their accommodative vowel behavior into the posttask reading. The correlation between a participant's average difference-in-distance and their IAT score was slightly stronger with the posttask productions than it had been with the task productions [t(40) = 2.5, p < 0.05, Pearson's R = 0.37]. While Positive Condition was used as a predictor in the regression model, its contribution was not significant. Moreover, posthoc analysis found no difference in the amount of accommodation across the Positive and Negative Conditions in the posttask productions. Again, like in the shadowed productions, lower-frequency words elicited more accommodation (Goldinger Reference Goldinger1998). Participant age was selected by the model, but it did not make a significant contribution in accounting for the variance in the data. Still, it is interesting that this predictor has a positive β coefficient. This indicates a trend that younger participants accommodated more than older participants. There were no differences in degree of imitation between vowels in the posttask productions. The general pattern of accommodative behavior can be seen in Figs. 3 and 4. The posttask productions (small gray italics) are intermediate between the pretask productions (small black regular font) and the shadowed productions (small black italics).
DISCUSSION AND CONCLUSION
In this study New Zealand participants completed an auditory word-naming speech production task where the model voice was a speaker of Australian English. In an attempt to replicate Bourhis & Giles Reference Bourhis, Giles and Giles1977, one group of NZ participants was insulted (the Negative Condition) and the other was flattered (the Positive Condition) through a short story about the beliefs of the AuE speaker. The first and second formants of monosyllabic words containing the vowels KIT, DRESS, TRAP, START, STRUT, and THOUGHT were acoustically analyzed for acoustic convergence and divergence. In addition to completing a speech production task, NZ participants took an IAT designed to explore implicit biases to Australia and New Zealand. Stepwise hierarchical linear regression models were used to analyze the tokens from the shadowed block and the posttask block. This type of model automatically selects predictors that best account for the data and ignores others. For the model using the shadowed task productions, each of the vowels were selected by the model along with word frequency and participants' IAT scores. The results were vowel-specific such that not all vowels were imitated to the same extent. In terms of word frequency, participants accommodated to lower-frequency words more than higher-frequency words (Goldinger Reference Goldinger1998). For IAT scores, participants who scored as pro-Australian on the task were more likely to accommodate to the AuE model talker than those who scored with a pro-New Zealand bias. Crucially, scores on this task were selected by the model as a predictor while assignment to the Positive or Negative Condition was not. For the posttask productions, IAT scores and word frequency had the similar effect as they did for the shadowed model. Only IAT scores contributed significantly to this second model; pro-Australian IAT scores resulted in more accommodation. In the posttask model, lower word frequency, younger participants, and assignment to the Positive Condition all tended toward more accommodation, but not significantly so.
Bourhis and Giles (Reference Bourhis, Giles and Giles1977) found convergence in a group of Welsh participants when they were meant to feel solidarity with a speaker of RP and divergence in a group who disagreed with a view expressed by the RP speaker. In general in this study, NZ participants converged on the spectral characteristics of an AuE speaker regardless of the feelings incited by the task design and their assignment to the Positive or Negative Conditions. Differences in accommodation were found, however, based on participants' preexisting sentiments toward Australia. The more positive participants' feelings were toward Australia, the more likely they were to converge on the model speaker's vowels. Following CAT, participants with a positive perspective of Australia can be interpreted as having decreased the social distance between themselves and the model talker by accommodating to a greater degree than those participants who viewed Australia negatively. In terms of referee design (Bell Reference Bell, Eckert and Rickford2001), participants with positive views of Australia would be interested in affiliating themselves with that group through convergent speech acts. As far as actual replication of Bourhis & Giles (Reference Bourhis, Giles and Giles1977) goes, if IAT scores are a means of participants self-organizing themselves into “positive” and “negative” groups (like those of Bourhis & Giles), the finding here is then similar. While positive feelings lead to greater likelihood to accommodate, a key result in this experiment is that all participants accommodated to some extent. What this potentially means is that the default behavior is for accommodation and convergence, and this may be due to psychological mechanisms stemming from the organization of language systems. Then, sociolinguistic factors such as social biases, the desire to create social distance, and positive affiliation may affect the degree of accommodation. Importantly, if implicit biases (eg. the IAT) mediate spoken language outside of socially meaningful interaction, it can only be expected that social biases would have an even greater effect in real-world language use.
An interesting difference revealed by the analysis of the task and posttask productions relates to the vowel effects. In the task productions, participants accommodated toward the vowels to different extents. Participants accommodated to the DRESS vowel considerably, but, for example, to the THOUGHT vowel much less so. In the posttask productions, there were no specific vowels effects, but simply a general tendency for the NZ participants to pronounce their vowels more like those of the Australian model talker. The carry-over effects into the posttask productions once exposure to the model talker has ceased indicates that there is some long-term change to the word-level representations such that they are more Australian-like; this effect influences all the vowels roughly to the same extent. In the task productions, the DRESS vowel was imitated to a greater extent than all other vowels used in the task. While this vowel is produced very differently in the two dialects (compare NZE [dɹ![]() s], AuE [dɹ
s], AuE [dɹ![]() s]), it is not considered a particularly salient difference. Hay and colleagues (2006) report that the largest vowel differences between NZE and AuE are for the KIT, DRESS, and TRAP vowels. They found that NZE speakers are not particularly sensitive to the difference between the DRESS vowels across the dialects, but they are aware of the dialect difference for the KIT and TRAP vowels. This awareness of the KIT and TRAP vowels may have prevented larger accommodation results for those vowels. For the DRESS vowel, however, with a large amount of phonetic space between the NZE and AuE categories, there is ample room for a New Zealander to accommodate, and the lack of salience for this category may facilitate the accommodation process.
s]), it is not considered a particularly salient difference. Hay and colleagues (2006) report that the largest vowel differences between NZE and AuE are for the KIT, DRESS, and TRAP vowels. They found that NZE speakers are not particularly sensitive to the difference between the DRESS vowels across the dialects, but they are aware of the dialect difference for the KIT and TRAP vowels. This awareness of the KIT and TRAP vowels may have prevented larger accommodation results for those vowels. For the DRESS vowel, however, with a large amount of phonetic space between the NZE and AuE categories, there is ample room for a New Zealander to accommodate, and the lack of salience for this category may facilitate the accommodation process.
In this study, the most salient dialect differences were not the most imitated; this finding is contra Trudgill Reference Trudgill, Hendrick, Masek and Miller1981. The vowel-specific results seem to contradict Trudgill Reference Trudgill2008 to some extent as well. Trudgill's recent work claims accommodation is automatic and that social identities play no role in whether it happens, but that social ties are fostered as a result of accommodation. In this study, it was found that vocalic convergence is automatic in the sense that participants are not aware they are doing it, but it is not automatic in the sense of being a process that happens at all times. Some vowels are targeted more than others (see also Babel Reference Babel2009). Moreover, with respect to social identities, implicit social biases about how a participant feels about a speaker strongly influence the extent of accommodation. These biases are automatic in that they are subconscious and not derived by explicit and strategic decision making (Djiksterhuis & Bargh Reference Dijksterhuis, Bargh and Zanna2001), but they, crucially, exist prior to the interaction that elicits convergent speech behavior. This result leads to a nuanced view reminiscent to that of Trudgill Reference Trudgill2008: speakers of language cannot help accommodating, but group-identity attitudes modulate this automatic process, much like what is predicted in both audience and referee design (Bell Reference Bell1984, Reference Bell, Eckert and Rickford2001) and CAT (Giles et al. Reference Giles, Coupland, Coupland, Giles, Coupland and Coupland1991). Additionally, these results demonstrate that social factors overlay even very basic and low-level aspects of speech production.
APPENDIX: WORD LIST FOR SPEECH PRODUCTION TASK







