Introduction
Word learning in children is the focus of many research efforts in developmental science, but the mechanisms that underpin typical lexical development are not well understood, and those of slower learners even less so. Stokes and colleagues recently reported that the statistical characteristics of words in the ambient language play a significant role in lexical learning in toddlers (Stokes, Reference Stokes2010; Stokes, Kern & dos Santos, Reference Stokes, Kern and dos Santos2012; Stokes, Bleses, Basbøll & Lambertsen, 2012). This research has examined the distributions of word frequency (WF) and neighborhood density (ND) in emerging lexicons. The methods employed were similar to those of prior studies, such that only monosyllabic words from the language-relevant versions of the MacArthur-Bates Communicative Development Inventory (Fenson et al., Reference Fenson, Dale, Reznick, Thal, Bates, Hartung and Reilly1993) were included, and the ND and WF values of each of these words were derived from the relevant adult ambient language (e.g., Storkel, Reference Storkel2009). Average ND and WF values were calculated for each child. For English- (N=220), French- (N=208), and Danish- (N=894) speaking children respectively, the three reports showed that children's small expressive lexicons were comprised of words that had many phonologically related words (phonological neighbors) in the ambient language, while children with average or large expressive lexicons had significantly lower average ND values than the small lexicons. ND accounted for 47%, 53%, and 39% of the variance in total expressive vocabulary size for English- (Stokes, Reference Stokes2010), French- (Stokes et al., Reference Stokes, Kern and dos Santos2012b), and Danish- (Stokes et al., Reference Stokes, Bleses, Basbøll and Lambertsen2012a) speaking children respectively. WF accounted for 14%, 9%, and 3% of the variance in expressive lexicon size. Given the relatively weak findings for WF in these prior studies, the impact of WF is not discussed further in this article.
One conclusion from these findings is that ND may contribute to learning mechanisms that are harnessed to create an expressive lexicon. Words of high ND, those that come from phonologically dense portions of the adult language (dense words), place lower demands on children's working memory systems than words of lower ND, words that come from phonologically sparse portions of the adult language (sparse words). That is, dense words are comprised of phonological strings that are repeated across many words, as words of high ND, by definition, share onset (CV#, such as cat, cap), rhyme (#VC, such as cat, hat), or consonants (C#C, such as cat, cot). These repeated strings become more familiar than the less frequently repeated phoneme strings of sparse words, and are therefore less taxing on young children's working memory abilities. Children may establish lexical representations for dense words more easily than sparse words because the phonological forms of dense words are more readily held in working memory (Hoover, Storkel & Hogan, Reference Hoover, Storkel and Hogan2010). If the working memory abilities of late talkers (LTs) are not as well developed as that of their typically developing (TD) age-matched peers (Stokes & Klee, Reference Stokes and Klee2009a, Reference Stokes and Klee2009b) then late LTs may have greater difficulty forming representations for words from sparse portions of the ambient language (Stokes, Reference Stokes2010).
Late talkers
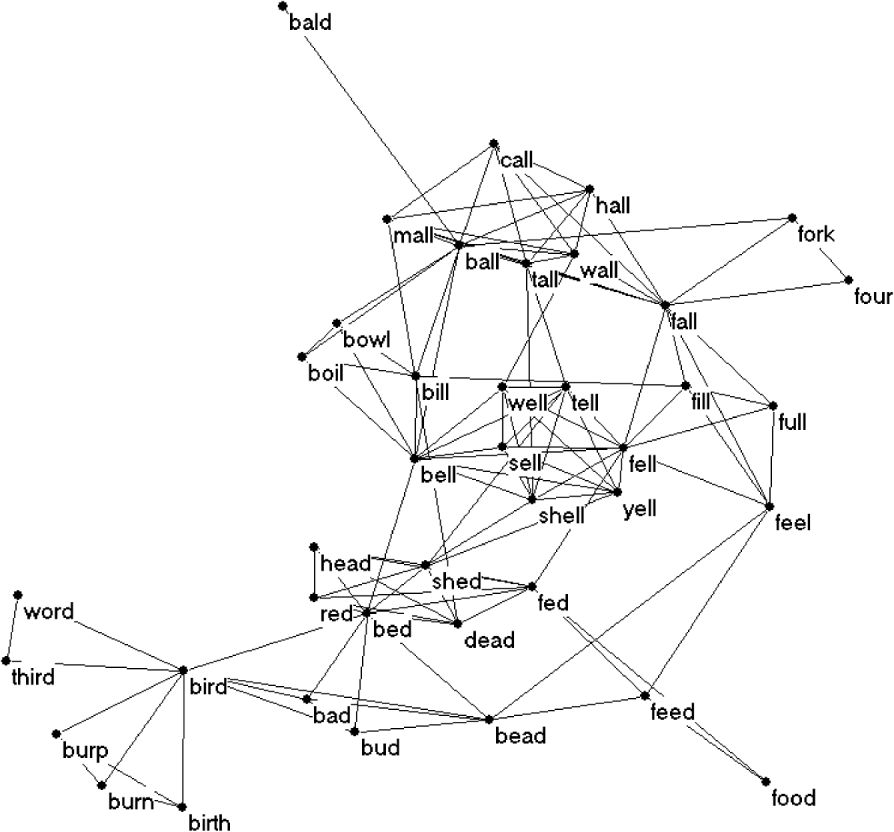
To explore the effects of statistical input cues on lexicon size, Stokes and colleagues (2010, Reference Stokes, Bleses, Basbøll and Lambertsen2012b) split their samples by the size of the expressive lexicons, at one standard deviation below the mean for age, to yield a group of children with small lexicons relative to those of their same-age peers (late talkers). Stokes and colleagues suggested that these children's expressive lexicons were small relative to those of their peers because they had difficulty abstracting sparse words from the ambient input, unlike their same-age peers, who, after learning more dense words than sparse words at the onset of lexical development, quickly begin to learn sparse words too. The authors' reasoning was as follows. Typically developing children used the cues provided from dense words to facilitate word learning in the early stages of building a lexicon, but rapidly shifted to process sparse words too. This occurs with increased experience of, and familiarity with, overlapping phonological neighborhoods. For example, the phonological neighborhood for the word bird includes heard, bud, birth, bad; the word birth includes the neighbors both, burn, worth; the word worth includes the neighbors whirl, with, word (see Figure 1 for an example of a phonological network). While bird has 31 neighbors, birth has 19, and worth has 16. As experience increases and the phonological network widens, the likelihood of learning sparse words increases. In contrast, late talkers were more reliant on the frequent, familiar strings of dense words, developing a learning mechanism that learned dense words, and failing to make the phase shift to abstracting sparse words from the input. The Extended Statistical Learning (ExSL) theory was proposed to account for these results. The ExSL account suggests that LTs continue to use dense word cues for word learning beyond the period when their more able peers had shifted to learning less dense words. Essentially, LTs continue to use one learning mechanism when another would be more productive.

Fig. 1. Representation of interconnecting phonological networks for the words bird, bed, and ball.
If the ExSL account is correct, the lexical statistical characteristics of LTs' expressive lexicons should resemble those of younger, typically developing children. This has not been directly tested. Further, if the source of the problem is difficulty with abstracting words from sparse portions of the input language, then we would expect that LTs' receptive lexicons, as well as their expressive lexicons, would be comprised of words from dense neighborhoods. However, reports of the effects of neighborhood density on adult word processing in word recognition tasks suggest that this view is problematic.
Neighborhood density effects on word processing
Word recognition
The results of word recognition studies suggest that adults are better able to recognize words from sparse neighborhoods than dense. For example, Vitevitch (Reference Vitevitch2002a) reported that adults responded faster to words with a sparse onset than words with a dense onset, in a word recognition task. This effect can be explained within a model of spreading activation (e.g., Dell, Reference Dell1986). When a dense word (the target) occurs in the input, all the stored words that fall within the target word's phonological neighborhood, and thus share phonological components of the target word, are also activated, by spreading activation. For example, activation of the onset /kæ/ will activate all words sharing that onset because activation of the phonological components spreads to activate the complete lexical representation for the target word and its neighbors, for example, cat, can, cap, and catch. Activation of the lexical representation creates a reverse activation back to the phonological components, and so dense words benefit from multiple activations during processing (e.g., Chen & Mirman, Reference Chen and Mirman2012). The resulting effect on word recognition is slower recognition of dense words than sparse words, as lexical competitors must be inhibited before word recognition occurs. Therefore, sparse words, with fewer phonological neighbors, are processed faster during input processing because of fewer competition effects.
Word production
The inhibitory effect of dense words is not seen in word production; rather, dense words are produced faster by adults and with fewer errors than sparse words (Goldrick, Folk & Rapp, Reference Goldrick, Folk and Rapp2010; Vitevitch, Reference Vitevitch2002b). Retrieval of a dense word for production activates multiple words that share the target word's phonological components, so activating the lexical representation for cat will also activate the onset of can, cap, catch, etc. Spreading activation may have an effect on the target by strengthening the phonological and lexical representation of dense, but not sparse, words, as a product of phonological–lexical interaction (Scarborough, Reference Scarborough2012; Yao, Reference Yao2011). The net effect would be facilitated activation of the target word form during word production.
Implications for emerging lexicons
Toddlers are remarkably good at recognizing the labels of newly encountered novel form–referent mappings in recognition tasks administered five minutes after exposure, and the effect is maintained several days later (e.g., Munroe, Baker, McGregor, Docking & Arculi, Reference Munroe, Baker, McGregor, Docking and Arculi2012). However, while toddlers can immediately imitate an experimenter's novel label for a novel referent, they are remarkably poor at naming novel referents even one minute after hearing the novel word form. Children can recognize a novel object–label mapping to which they have been exposed, but cannot produce that same label when asked to label the object. Munroe et al. (Reference Munroe, Baker, McGregor, Docking and Arculi2012) concluded that these children had encoded the necessary acoustic-phonetic representations to permit word recognition, but not word production.
We can assume then that children are able to form sufficient phonological and lexical representations for heard words from limited exposures. If so, we might expect that toddlers are able to do so for all words, not just words from dense portions of the input language. Sparse words can be recognized just from their onsets (McMurray, Samelson, Lee & Tomblin, Reference McMurrary, Samelson, Lee and Tomblin2010) because there are few lexical competitors, so toddlers' representations for sparse words need not be robust for input processing. Therefore, the difficulty for LTs is likely not with abstracting sparse word forms to establish lexical representations, but rather with activating the correct word form for sparse words for word production. The assumption here is that a sparse word form may be activated for receptive processing, but not expressive processing. This may occur because of weaker lexical representations for sparse words than dense words. Therefore, children's receptive lexicons should not show a preference for dense words over sparse words, but words from dense neighborhoods in the input may become part of the expressive lexicon earlier than sparse words. Words strings that were heard and produced more frequently by children would be accessed and produced more easily, placing fewer demands on working memory than low-density words, because of stronger lexical representations. Dense words in the memory store would be easily accessed for word production, because retrieving a dense word form would be easier than retrieving a sparse word form, given the working memory constraints mentioned previously. The impact would be that any word that is experienced, whether from dense or sparse portions of the input, could be understood by the child, but only dense words would be spoken by the child. Some words could be understood by the child, but not said (presumably sparser words), while others would be understood and said (presumably denser words). This potential difference in receptive and expressive lexicons had been overlooked by Stokes and colleagues. These authors studied the neighborhood density effects in children's expressive lexicons only.
active and passive lexicons
To explore the hypothesis that sparse words are part of the receptive lexicons (understood, but not said) while expressive lexicons are comprised of dense words, these lexicons need to be defined as separate entities. Presumably, words that speakers say are also words that they understand, but there are other words that are understood, but are not spoken. Researchers (mostly in the field of bilingualism) have coined the terms active lexicon and passive lexicon to represent the former and the latter respectively (e.g., Yuen & Murphy, Reference Yuen and Murphy2010). We see an implementation of this idea in the Oxford Communicative Development Inventory (OCDI; Hamilton, Plunkett & Schafer, Reference Hamilton, Plunkett and Schafer2000). The OCDI vocabulary checklist is a British communicative development inventory that was modeled on the MacArthur-Bates Communicative Development Inventory (Fenson et al., Reference Fenson, Dale, Reznick, Thal, Bates, Hartung and Reilly1993). The Oxford BabyLab website (http://babylab.psy.ox.ac.uk/research/oxford-cdi) describes the checklist as an instrument for gauging children's receptive and expressive vocabulary size using parent report. The 416 items are words that children aged 0;11 to 2;02 are likely to understand, or understand and say. Table 1 shows some items from the animal section of the checklist. As is shown, parents are required to indicate whether their child shows understanding of a given word only, or whether they understand and say it. A tally of these separate columns yields an estimation of a child's passive and active lexicons respectively.
Table 1. Examples of words in the animal section of the Oxford Communicative Development Inventory (Hamilton et al., Reference Hamilton, Plunkett and Schafer2000)

note: U indicates understands; U/S indicates understands and says.
It is important to understand that the passive lexicon is mutually exclusive of the active lexicon. The passive lexicon is comprised of words that the child understands, but the parent believes the child has not said. The active lexicon is comprised of words that are said and understood by the child. Checking off the items in Table 1 illustrates the principle. Words can only be checked off once, either as understood (passive lexicon), or understood and said (active lexicon). Thus each word can only be coded as either in the active or passive lexicon.
Hypotheses
Using this definition of active and passive lexicons, the following hypothesis is proposed. Words that children produce in the earliest stages of vocabulary learning come from dense portions of the adult lexicon for two reasons. First, the phonological composition of words from dense neighborhoods is recurring in the input (having many onset, rhyme, or consonant neighbors). Perceptual experience with these repeated strings may bias the learning mechanism, through spreading activation, to stimulate the formation of strong, well-formed phonological representations for dense words. Second, saying words repeatedly (i.e., many tokens of one type) increases the child's experience with the phonological form, which in turn generates stronger, or better-formed phonological representations. Subsequently, the child retrieves representations for dense words in word production more easily than representations for sparse words. Nonetheless, it may be that the infant or toddler does understand words from sparse portions of the adult lexicon. The first hypothesis then is that words in the passive lexicon come from sparser portions of the adult lexicon. This is proposed because once a dense word enters the passive lexicon, it should transition from a passive to an active status more quickly than sparse words. Dense words become available for production rapidly, and sparse words do not. To test this hypothesis, the density values in TD children's active and passive lexicons are compared. Further, if the use of density cues plays a role across the period of early word learning, then we should expect to find the same relationships in the lexicons of children at 1;6 and 2;0.
Next, we consider how the lexical statistical properties of active and passive lexicons may differ for LTs. The Extended Statistical Learning account (Stokes et al., Reference Stokes, Kern and dos Santos2012b) proposed that the problem is one of continuing to use an early successful statistical learning cue when a different mechanism is required for further lexical learning. If the ExSL theory is correct, then LTs' active lexicons will have higher mean ND values than the lexicons of their age-matched peers, but the mean ND values should be similar to those of their language-matched peers. This is a testable hypothesis that requires a comparison of the lexicons of LTs with those of their age-matched and language-matched peers. LTs are usually identified between 1;6 and 2;6, with the first indicators being late onset and slow growth of using words, and/or a late onset and slow growth of using two-word combinations (Thal, Reference Thal2000). Quantitative criteria for defining LTs vary. One metric is less than 50 words, and/or no two-word combinations at 2;0 (Thal, Reference Thal2000). A second metric is a vocabulary size at or below the 10th (Dale, Simonoff, Bishop & Plomin, Reference Dale, Simonoff, Bishop and Plomin1998), 16th (Bishop, Holt, Line, D. McDonald, S. McDonald & Watt, Reference Bishop, Holt, Line, McDonald, McDonald and Watt2012), or 20th (Jones & Smith, Reference Jones and Smith2005) percentile for age on the MacArthur-Bates Communicative Development Inventory. As there is no consensus for the cut point, the 16th percentile on the OCDI was used here, and these children will be referred to as LTs. The density values in the active and passive lexicons of LTs are compared with those of their language-matched (younger) peers to test the second hypothesis.
Methodological concerns
Before turning to the aims and research questions of the current study, three methodological issues are addressed. First, the current study seeks to provide evidence for or against the ExSL account that was founded on the finding that ND was a strong predictor of vocabulary size in prior studies. It may be tempting to explain these findings for ND as a mathematical inevitability, whereby small lexicons are comprised of dense words because there is more opportunity for dense words to occur. The causal direction from small lexicons to high ND versus from high ND to small lexicons is currently unresolved. If the former were true, then small passive, as well as small active, lexicons should show the same pattern. This premise was tested in the current research. The density values of large and small passive lexicons were compared.
Second, some readers may question the decision to use ND values generated from adult databases. This issue was addressed at some length in Stokes et al. (Reference Stokes, Kern and dos Santos2012b), and an elegant explanation for why adult databases are appropriate for these studies is found in Gierut and Dale (Reference Gierut and Dale2007). The theory under scrutiny in the current study warrants the use of adult density values. We are concerned with the words that children hear (some of which they come to say), that is, the words of the ambient language, making it is sensible to use calculations from adult lexicons to test the theory.
Third, it is important to point out that there is no absolute value attributed to dense versus sparse neighborhoods in this work. Each word in the ambient language has a density value, derived from adult corpora, and each child's word was coded for that density value. A mean ND value was then generated for each child's lexicon, for use in statistical analyses. Differences in mean density values for small and large lexicons were analyzed. Between-group differences are comparisons of the average ND values for groups.
Research aims and questions
The current research has three aims. The first aim is to explore the ND characteristics of the active and passive lexicons of children at 1;6 and 2;0. Finding that small active and passive lexicons both have high average densities would support the claim that children with small lexicons have difficulty abstracting sparse words from the input. Finding that active lexicons had significantly higher density scores than passive lexicons would provide support for the hypothesis that the strength of phonological representations of dense words may result in dense words becoming part of the active lexicon more readily than sparse words. Research question one is: ‘Is there a significant difference between mean ND values in toddlers’ active and passive lexicons?' Lexicons at 1;6 and 2;0 were examined.
The second aim is to determine if the ND characteristics in the active and passive lexicons of LTs differ from those of younger TD language-matched peers. If so, then this would provide evidence against the ExSL account and would suggest instead that LTs learn differently, not just later. If the language-matched groups do not differ on these properties, then this provides support for the ExSL account. Two research questions arise: Is there a significant difference between LTs and TD age-matched children in the ND values of their active and passive lexicons? Is there a significant difference between LTs and TD language-matched children in the ND values of their active and passive lexicons?
The third aim was to determine whether the effects for ND reported in prior work for expressive lexicons could have occurred as a mathematical inevitability. If yes, then the hypothesis is that small passive lexicons will have significantly higher mean ND values than large passive lexicons, as has been found for expressive lexicons. The current study also compared the mean ND values in active lexicons in children at 1;6 and 2;0 to extend previous findings to a younger age group.
Method
Participants
A database of vocabulary scores from 325 children was downloaded from the Oxford University Baby Lab Website (http://babylab.psy.ox.ac.uk/research/oxford-cdi). The children were from the Oxford region of the United Kingdom (Hamilton et al., Reference Hamilton, Plunkett and Schafer2000). Tallies were generated for active and passive lexicons for each child. An inclusion criterion was that the core (see below) active and passive lexicons of each child had to exceed 20 words. The cut point of 20 words was set because lexicons smaller than 21 words yield heteroscedastic, and thus meaningless, results in subsequent analyses. This inclusion criterion yielded a sample of 203 children, aged 1;02–2;03. In order to address all research questions two ages were selected for analysis, children at 1;06 (1;05–1;06) and 2;00 (1;11–2;0), yielding 68 children in the younger group and 52 children in the older group (total N=120). This decision made the data amenable to between-group comparisons, avoiding the linearity assumptions of regression, and ensured that any confound between age and rate of development was avoided.
Data coding
The OCDI checklist consists of 416 words in categories of animal sounds, animals, vehicles, toys, food and drink, body parts, clothes, furniture and rooms, outside, household items, people, games and routines, action words, descriptive words, question words, pronouns, prepositions, and quantifiers (Hamilton et al., Reference Hamilton, Plunkett and Schafer2000). Parents checked off the words their child understands (passive lexicon), or understands and says (active lexicon), and the database also provides tallies for the total combined lexicon. Related research has examined nouns only (Storkel, Reference Storkel2004; Zamuner Reference Zamuner2009) or nouns, verbs, and adjectives (Stokes, Reference Stokes2010). For the current research 210 monosyllabic nouns, verbs, and adjectives were included to center the analysis on words unlikely to be context based (‘people’) or function words, and to allow coding of each word with phonological ND values. This list is referred to as the set of core words. Selecting core words means that the following categories on the OCDI were not included: animal sounds, people, games and routines, question words, pronouns, prepositions, and quantifiers.
De Cara and Goswami's (Reference De Cara and Goswami2002; n.d.) calculations of ND for British English were used in this study. The reference database was 4,086 monosyllables derived from the 17·9 million words of the CELEX database (Baayen, Piepenbrock & Gulikers, Reference Baayen, Piepenbrock and Gulikers1995). Two definitions of ND were used by de Cara and Goswami (Reference De Cara and Goswami2002), but only one is used here, to align our findings with previous research. The chosen metric is the commonly used +/− one phoneme substitution, addition, or deletion (Ph+/−1 metric; e.g., Charles-Luce & Luce, Reference Charles-Luce and Luce1990), where hat and bat would be rhyme neighbors, but not hat and splat. ND values were entered for each child for each CDI word and an average ND value was generated for each child.
Results
Descriptive results
The mean, standard deviation, minimum, and maximum scores for OCDI expressive lexicon size, OCDI receptive lexicon size, and OCDI total lexicon size, as well as the descriptive statistics for the core lexicons (active and passive) size, ND values for core active and passive lexicons, and Age are presented in Tables 2 (at 1;6) and 3 (at 2;0). These tables include the results of Kolmogorov–Smirnov tests of normalcy for all variables.
Table 2. Descriptive statistics at 1;6
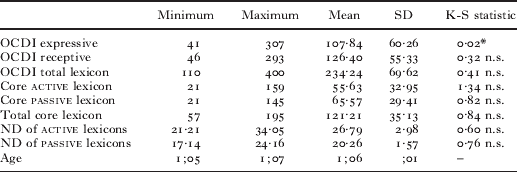
note: SD=standard deviation. OCDI – Oxford Communicative Development Inventory (Hamilton et al., Reference Hamilton, Plunkett and Schafer2000). ND=phonological neighborhood density. Total lexicon=combined total of active and passive lexicons. See text for definitions of core lexicon and ND. K-S test is the Kolmogorov–Smirnov test of a normal distribution. n.s. indicates a non-significant result.
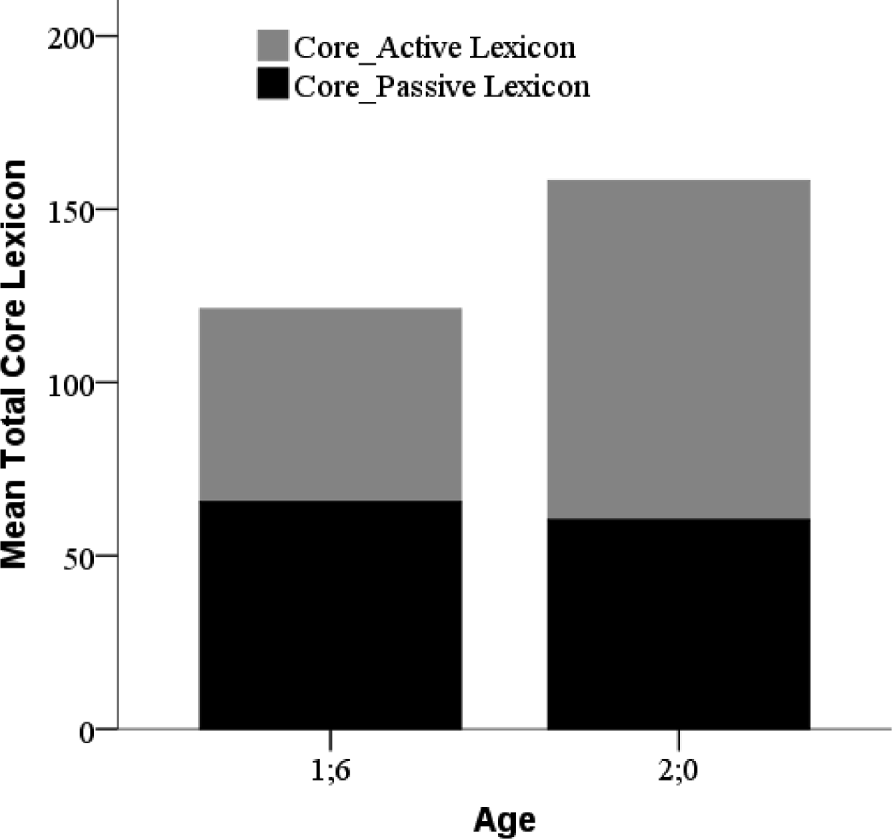
Figure 2 shows the relative contribution of core active and core passive lexicon size to total core lexicon size at 1;6 and 2;0. At 1;6, there was no significant difference between the size of the active and passive core lexicons (paired samples t-test: t(67)=1·59, p>·05, d=·32). The OCDI is a finite set of words, and at 1;6, children, on average, can say about half of the monosyllabic OCDI words that they know. At 2;0, the core active lexicon was larger than the passive lexicon (t(51)=4·29, p<·001, d=1·10). At 2;0, children, on average can say almost two-thirds of the OCDI monosyllabic words that they know.
Fig. 2. Contribution of passive and active lexicon size to total core lexicon size at 1;6 and 2;0.
To answer research questions 1 and 2, first a 2 (group)×2 (age)×2 (lexicon) MANOVA with repeated measures on the last variable was run. The children who scored at or below the 16th percentile for age on the OCDI expressive score (not the core scores) were coded as LTs, yielding 13 children at 1;6, and 9 children at 2;0. The lexicon variable was the mean ND values of the active and passive lexicons. Bonferroni corrections were applied to pairwise comparisons.
Question 1
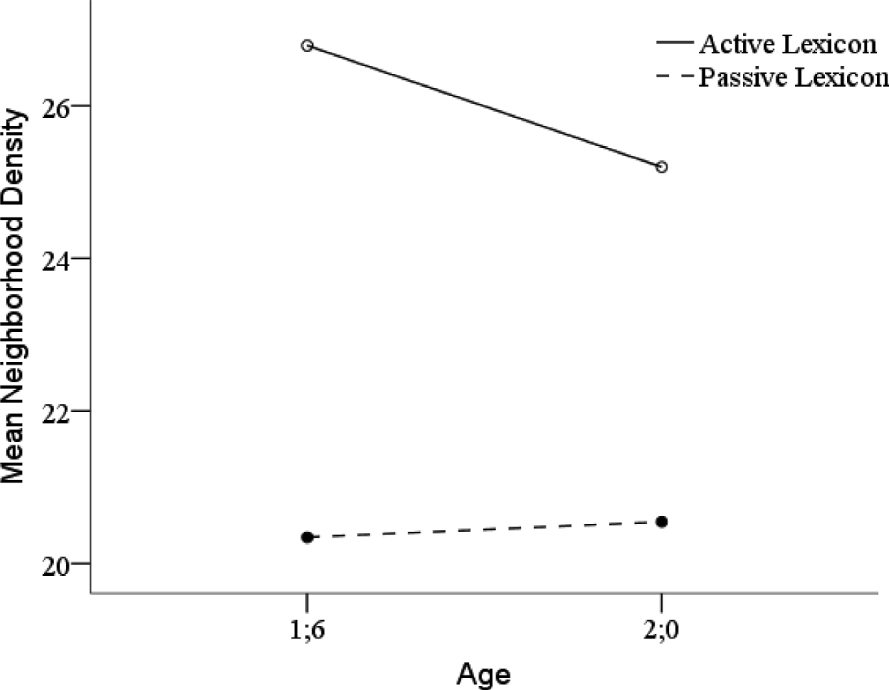
Is there a significant difference between mean ND values in toddlers' active and passive lexicons? There was a significant main effect for lexicon (F(1,116)=184·98, p<·001, partial η 2=·62), with higher ND scores in active (Mean=26·00, SE=·28, CI=25·44–26·55) than passive (Mean=20·45, SE=·20, CI=20·05–20·84) lexicons, with age (1;6 and 2;0) and group status (LT and TD) collapsed. The effect size was large. There was a significant main effect for age (F(1,116)=7·04, p=·009, partial η 2=·06), with higher ND values for younger (Mean=23·57, SE=·17, CI=23·23–23·90) than older children (Mean=22·87, SE=·20, CI=22·48–23·27). The effect size was small. There was no significant age×group interaction (F(1,116)=·01, p=·92).
There was a significant two-way interaction of lexicon by age (F(1,116)=4·84, p=·03, partial η 2=·04), indicating that the results for the younger and older children patterned differently for ND in active and passive lexicons. The difference between the ND values for the active and passive lexicons was larger at 1;6 than at 2;0 (Tables 2 and 3, Figure 3; mean difference=6·45 and 4·65 at 1;6 and 2;0, respectively).
Fig. 3. Mean neighborhood density values for active and passive lexicons at 1;6 and 2;0.
Table 3. Descriptive statistics at 2;0
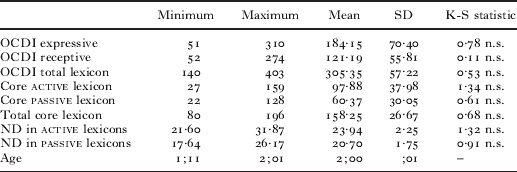
note: SD=standard deviation. OCDI – Oxford Communicative Development Inventory (Hamilton et al., Reference Hamilton, Plunkett and Schafer2000). ND=phonological neighborhood density. Total lexicon=combined total of active and passive lexicons. See text for definitions of core lexicon and ND. K-S test is the Kolmogorov–Smirnov test of a normal distribution. n.s. indicates a non-significant result.
Question 2
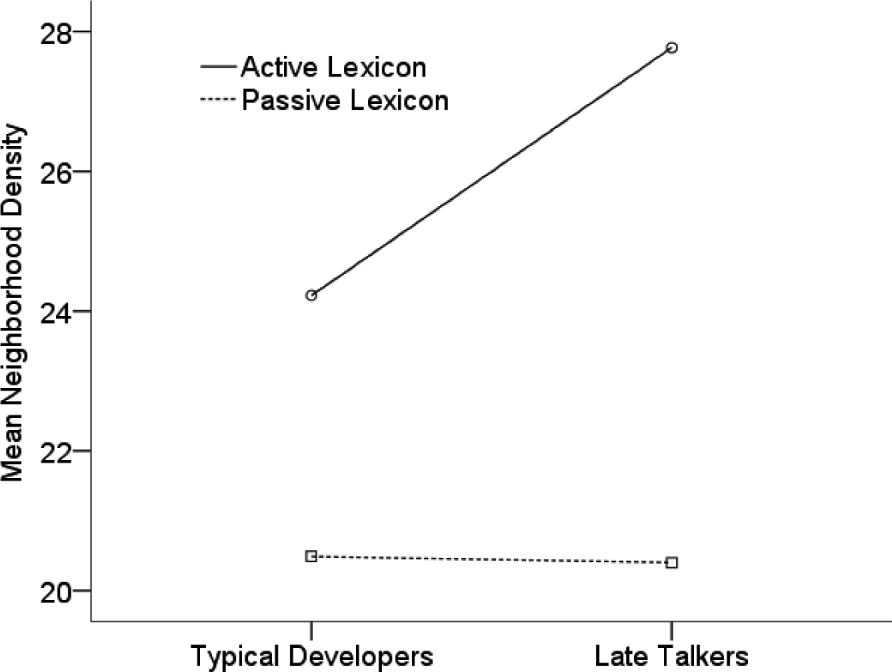
Is there a significant difference between LTs and TD age-matched children in the ND values of their active and passive lexicons? There was a significant main effect for group (F(1,116)=43·57, p<·001, partial η 2=·27), with higher ND values for the LTs (Mean=24·08, SE=·24, CI=23·62–24·55) than the TDs (Mean=22·35, SE=·11, CI=22·14–22·58) overall (collapsed for age). There was a significant two-way interaction between group and lexicon (F(1,116)=19·85, p<·001, partial η 2=·15; Figure 4). The LTs had a greater difference between the ND values of the active versus passive lexicons than the TDs (Figure 4; mean difference=7·37 and 3·73 for LTs and TDs, respectively).
Fig. 4. Mean neighborhood density values for active and passive lexicons for typical developers and late talkers.
There was no significant group by age by lexicon interaction (F(1,116)=·71, p=·40), indicating that at both 1;6 and 2;0 the differences between the LTs and the TDs patterned in the same way.
Question 3
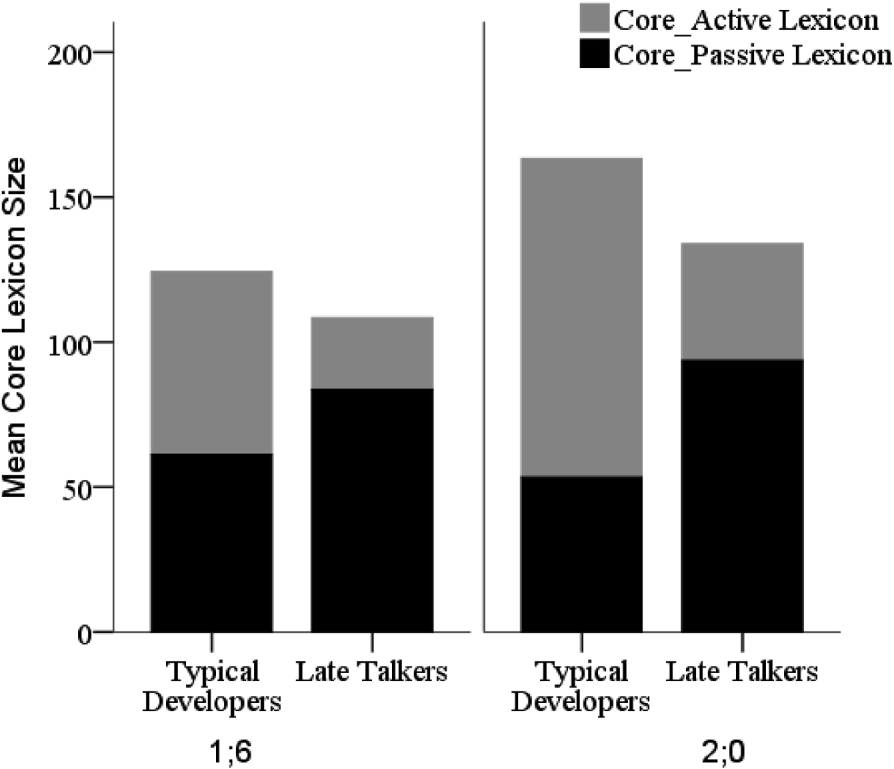
Is there a significant difference between LTs and TDs in the number of words that they say, of all words that they know? At 1;6 the LT total core lexicon size (active plus passive core lexicons) is not significantly different from that of their TD peers (independent samples t-test: t(66)=1·48, p=·15, d=·48; mean number of words for TDs and LTs is 124 and 108, respectively; Figure 5).
Fig. 5. Contribution of passive and active lexicon size to total CORE lexicon size for typical developers and late talkers at 1;6 and 2;0.
However, there was a significant difference between LTs and TD children in the percentage of the total core words attributed to the active lexicon. The TD children expressed 50% of the monosyllabic words that they knew, while the LTs only expressed 25% (independent samples t-test, equal variances not assumed: t(38·99)=8·30, p<0·001, d=1·74, mean difference=·25, CI=0·19–0·31). At 1;6, LTs did not differ from TD children in overall core lexicon size, but they had significantly fewer words in their active lexicons which were comprised of words from denser portions of the ambient language. This fits with the conventional way of categorizing LTs as those who say significantly fewer words than their age-matched peers.
Of all the monosyllabic core words that children know, at 1;6, on average, they can say about half of them, with this figure increasing to about two-thirds at 2;0. There was no significant difference between LTs and TD children in core monosyllabic lexicon size at 1;6. However, at 2;0, the total monosyllabic lexicon size of the TD children was larger than that of the LTs (t(50)=3·29, p=·002; d=1·06; mean number of words for TDs and LTs was 163 and 134, respectively; mean difference=29·46, CI=11·48–47·44). At 2;0, there was a significant difference between LTs and TD children in the percentage of the total core monosyllabic lexicons attributed to the active lexicon. The TD children expressed 67% of the monosyllabic words that they knew, while the LTs only expressed 32% (t(50)=7·10, p<·001, d=2·87). At 2;0, LTs had significantly smaller core lexicons than their TD age-matched peers, and significantly fewer words in their active lexicons, which were comprised of words from denser portions of the ambient language.
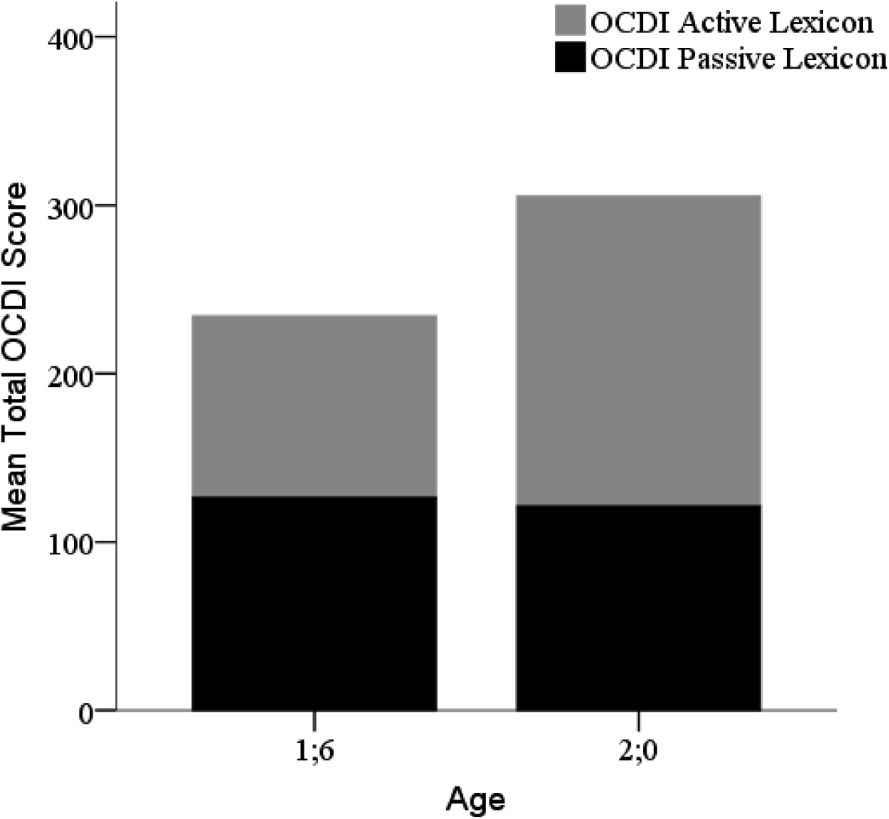
Given the surprising result that at 1;6 the total core lexicon size does not differ between TD and LTs, the analysis was repeated by including all of the words on the OCDI. The total OCDI scores (all words, including multisyllabic) were divided into active and passive lexicons. At 1;6, there was no significant difference in the size of the active and passive lexicons (t(67)=1·66, p>·05, d=·41), with means of 108 and 126 for active and passive lexicons respectively (Figure 6). At 2;0, the active lexicon was larger than the passive lexicon (t(51)=4·00, p<·001, d=1·21), with means of 184 and 121, respectively. Note that these checklists are of a finite size so it is inevitable that passive lexicons will become smaller than active lexicons with age.
Fig. 6. Contribution of passive and active lexicon size to total OCDI lexicon size at 1;6 and 2;0.
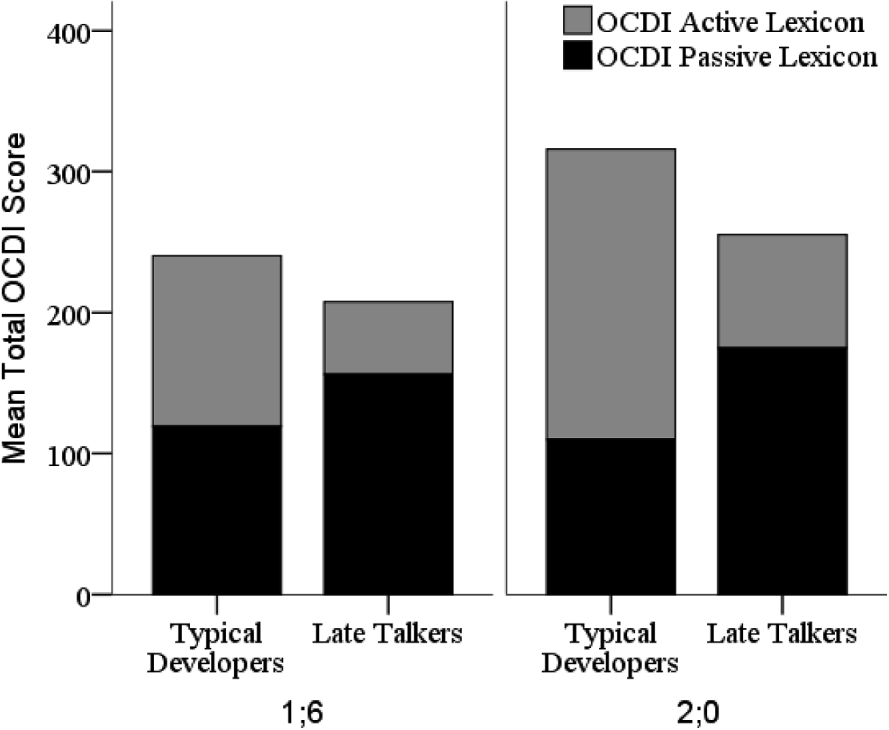
At 1;6, the TD children expressed 50% of the OCDI words that they knew, while the LTs only expressed 27% (Figure 7; independent samples t-test: t(66)=5·55, p<0·001, d=2·02, mean difference=·23, CI=0·17–0·29). At 2;0, the TD children expressed 65% of the OCDI words that they knew, while the LTs only expressed 33% (independent samples t-test: t(50)=6·77, p<0·001, d=2·63, mean difference=·32, CI=0·23–0·42). The findings from the monosyllabic samples reflect the distributions of the total OCDI scores.
Fig. 7. Contribution of passive and active lexicon size to total OCDI lexicon size for typical developers and late talkers at 1;6 and 2;0.
Question 4
Is there a significant difference between LTs and TD language-matched children in the ND values of their active and passive lexicons? The nine LT children at 2;0 were matched on active lexicon size with nine TD children aged 1;6 (six children's lexicons were exact matches, and the other three were within one point, e.g., 29 and 30 words). Active lexicon size was chosen as the matching metric because expressive vocabulary size is the variable usually used to categorize LT and TD children. There was no significant difference between LTs and TD children in the mean ND values in active (independent samples t-test: t(16)=1·40, p>·05, d=·66) or passive lexicons (equal variances not assumed: t(9·44)=·71, p>·05, d=·33).
Question 5
Do large passive lexicons differ from small passive lexicons in mean ND values? The median passive lexicon size was identified at 1;6 and 2;0. Lexicon sizes above the medians were categorized as large lexicons, and those below the median, small lexicons. At 1;6, there was no significant difference in mean ND values between large and small passive lexicons (independent samples t-test: t(66)=1·64, p>·05, d=·40). The mean ND values for small and large passive lexicons were 19·94 and 20·56, respectively. At 2;0, there was no significant difference in mean ND values between large and small passive lexicons (equal variances not assumed: t(42·16)=2·05, p>·05, d=·56). The mean ND values for small and large lexicons were 21·15 and 20·20, respectively.
Do large active lexicons differ from small active lexicons in mean ND values? The median active lexicon size was identified at 1;6 and 2;0. Lexicon sizes above the medians were categorized as large lexicons, and those below, small lexicons. At 1;6, there was a significant difference in mean ND values between large and small active lexicons (independent samples t-test, equal variance not assumed: t(51·34)=3·92, p<·001, d=1·09, mean difference=2·57, CI 1·25–3·88). At 2;0, there was a significant difference in mean ND values between large and small active lexicons (independent samples t-test, equal variance not assumed: t(28·54)=6·02, p<·001, d=2·25, mean difference=2·88, CI=1·90–3·86). Mean ND values for the small and large active lexicons were 27·08 and 24·51, respectively, at 1;6, and 25·38 and 22·49, at 2;0. The effect sizes were large.
Summary of the results
1. Mean ND values were significantly higher in the active than the passive lexicons at both 1;6 and 2;0.
2. Mean ND values were significantly higher in LTs' lexicons than TD age-matched children's lexicons for active, but not passive lexicons at both 1;6 and 2;0. At 1;6, LTs did not differ from TD children in overall core lexicon size, but they had significantly fewer words in their active lexicons (25% versus 50%), which were comprised of words from denser portions of the ambient language. At 2;0, LTs had significantly smaller core lexicons than their TD age-matched peers, and the proportion of words in their active lexicon was smaller (32% versus 67%), which were comprised of words from denser portions of the ambient language.
3. The LTs at 2;0 were language-matched with TD children at 1;6. There was no significant difference in mean ND values between LT lexicons and their language-matched TD peers' lexicons.
4. At both 1;6 and 2;0, small lexicons had significantly higher ND values than large lexicons, for the active, but not the passive lexicons.
Discussion
active, but not passive, lexicons are comprised of words from dense neighborhoods
The first hypothesis was that words in the passive lexicon come from sparser portions of the adult lexicon. The assumption was that at any given time, the passive lexicon must be comprised of dense and sparse words, but once dense words enter the passive lexicon, they should transition from a passive to an active status more quickly than sparse words; dense words become available for production rapidly, and sparse words do not. In this study, children's lexicons were split into two mutually exclusive categories of active lexicons (the words understood and said by the child) and passive lexicons (only those words understood by the child, but not said) to explore whether or not the mean neighborhood density values in children's active and passive lexicons were significantly different. Active lexicons had significantly higher mean ND values than passive lexicons. It is noteworthy that the minimum ND score of the active lexicon sits above the mean ND value of the passive lexicons (Tables 2 and 3), indicating marked differences between the active and passive lexicons, as reflected in the large effect sizes. Words that become available for production are predominantly dense, while sparse words remain in the passive lexicon presumably because phonological representations for sparse words are not robust enough to facilitate word retrieval for production. This explanation would account for why children's active lexicons are comprised of words from dense phonological neighborhoods. In this way, it is assumed that all words that a child understands have some degree of lexical representation, even if that representation is partial. Gating tasks show that listeners do not have to hear all of a phonological form to identify a word, as anticipatory mechanisms achieve recognition before the entire word is heard (McMurray et al., Reference McMurrary, Samelson, Lee and Tomblin2010) . However, the phonological representation must be completely retrieved for accurate word production. By this logic, words in an active lexicon must have complete, well-formed phonological representations for accurate word production, whereas words in a passive lexicon could be less well-formed. The strength of phonological representations of dense words may result in dense words becoming part of the active lexicon more readily than sparse words.
Words of high ND in the ambient language generate strong phonological representations for recurring syllable structures, because words of high ND by definition share onset (CV#, such as cat, cap), rhyme (#VC, such as cat, hat), or consonants (C#C, such as cat, cot) and the repeated processing of these combinations lays down strong and robust word form representations that are easily accessed in word production. These strong representations are presumably more easily accessed because they are more easily held in working memory (Hoover et al., Reference Hoover, Storkel and Hogan2010) and/or have a higher resting activation state than weaker phonological representations (Scarborough, Reference Scarborough2012). The phonological representations for sparse words may be fuzzy, making retrieval of word forms more difficult in production.
At 1;6, regardless of whether we consider monosyllabic lexicons or total lexicons, TD children's active and passive lexicons were of a similar size. At 2;0, the active lexicons were larger than the passive lexicons. This difference between 1;6 and 2;0 may reflect children's increasing ability to develop stronger phonological representations to facilitate word production as lexicon size increases. Note that this is a conjecture, as the current study was cross-sectional, not longitudinal. Further work using longitudinal datasets is required.
Late talkers and the Extended Statistical Learning account
The current findings do not support Stokes' (Reference Stokes2010) proposal that LTs have difficulty abstracting sparse words from the input language. Rather, children understand words from dense and sparse portions of the input lexicon. LTs' total lexicon size was similar to that of TD age-matched children, but the LTs had smaller active lexicons, and higher ND values in their active, but not passive lexicons. It seems that only the densest words were available for production in LTs. If so, this is the first finding that points directly to a possible reason for why LTs are slower to learn to talk. The TD children's active lexicons were 50% of the total lexicon at 1;6, and 67% of the total lexicon at 2;0. However, for LT children the difference in active lexicon size at 1;6 and 2;0 was minimal (25% and 32%). At 2;0, LTs had smaller total lexicons than their TD peers. This finding is consistent with the Extended Statistical Learning account that proposed that while TD children began to add words from sparse portions of the ambient language to their active lexicons, LT children did not.
When language-matched with their TD peers, LTs' mean ND values do not differ, for both active and passive lexicons. According to the ExSL account, LTs continue to use the cues from dense words when their TD peers have adopted learning mechanisms that enable them to produce sparse words (Stokes et al., Reference Stokes, Kern and dos Santos2012b). The implication is that the lexicons of LT children at 2;0 should resemble those of TD children at 1;6, and in the current analysis they do, providing support for the ExSL. It seems that LTs employ statistical cues in the same way as their younger TD peers.
Fact or artifact?
Finally, this research tested the claim that prior results for high ND values in small expressive lexicons were mathematically inevitable. If the claim were true, then small passive lexicons would also have higher mean ND values than large passive lexicons. This claim was not supported. Rather, when small and large lexicons were identified using a median split of lexicon size, small active lexicons had higher mean ND values than large active lexicons, but there was no difference in mean ND values between large and small passive lexicons.
Implications
This research has provided a clear way forward to test a set of hypotheses about children who are LTs. The first hypothesis, as Stokes (Reference Stokes2010) suggested, is that lexically targeted intervention for LTs could be effective. The words that are spoken by the child could form a base set from which phonological neighbors could be identified and targeted as branching words to increase the active lexicon size. For example, first the clinician would choose a high-density word that the child is known to say as a base word. Then, given that there is a greater proportion of rhyme neighbors (e.g., bat, cat) in English than lead or consonant neighbors (Zamuner, Reference Zamuner2009) several rhyme neighbors of the base word would be selected from those likely to be relevant to toddlers. These words would be introduced to the child via play, with the child imitating the clinician's production of the neighbors. Once the child had learned to say a neighbor (e.g., hat), then the base word could shift, and another set of rhyme neighbors selected, particularly to avoid the development of a limited number of neighborhoods. With careful planning, sets of neighbors could be chosen to gradually introduce words from sparser neighborhoods.
The second hypothesis is that LTs continue to struggle to develop representations for sparse words across time. While their typically developing peers move beyond reliance on recurring phonological strings in the input to form phonological representations that are strong enough to allow for word production, the LTs do not. This hypothesis should be tested in longitudinal datasets.
The third hypothesis is that these children fail to develop sufficiently robust phonological representations for words of average to low phonological neighborhood density for word production. In a severe case, it is possible that only words from the densest portions of the ambient language would form robust representations, and therefore active lexicons would be very small. If so, a logical question is whether LTs use gesture to encode words that are known, but are not produced verbally. If so, not only would there be further evidence of a phonological encoding deficit, but these words would be good targets for interventions designed to increase children's spoken lexicons by a gradual shift from gestured to spoken words.
Limitations and further research
An inevitable limitation in the current work is that the instrument used to determine the children's lexicons was a parent report instrument. While the validity of the MacArthur Communicative Development Inventories has been established (e.g., Dale, Bates, Reznick & Morisset, Reference Dale, Bates, Reznick and Morisset1989), Houston-Price, Mather and Sakkalou (Reference Houston-Price, Mather and Sakkalou2007) reported that parents underestimated the size of their children's receptive lexicons. This means that not only is the size estimate potentially inaccurate, but so too is the list of specific words that children understand. The current work could be improved upon with respect to the data source. First, the current findings should be replicated with other children, and across other ages. Second, test−retest receptive lexicon data might be useful. Third, an additional means for measuring word knowledge should be used to verify the words in children's receptive lexicons. Candidates are electrophysiological measures (Mills, Coffey-Corina & Neville, Reference Mills, Coffey-Corina and Neville1997) and preferential looking measures (e.g., Houston-Price et al., Reference Houston-Price, Mather and Sakkalou2007), as well as behavioral observations during play sessions within clinics or laboratories.
A second limitation is that only neighborhood density was explored in this research. The research set out to examine whether or not what we know about how dense and sparse word are processed in word recognition and word production could shed light on why late talkers are late, and so density was the variable of choice. However, it might be that phonotactic probability, or frequency-weighted densities, may yield similar results, or different results at different age points (e.g., Storkel, Reference Storkel2009).
A third limitation is that the children with fewer than 21 words in their lexicons were excluded from the analysis in order to use parametric statistics to address the research questions. Future work should consider alternative statistical procedures or analysis of individual variation to allow inclusion of these children.
CONCLUSION
This research has unveiled a unique characteristic of children's emerging lexicons, one that potentially sheds light on why late talkers are late. The results indicate a probable point of vulnerability in the learning mechanisms of children who are slow to develop an expressive lexicon.