





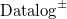
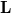
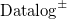
1 Introduction
Datalog and its extensions have long been important languages in databases and at the foundation of many rule-based reasoning formalisms. Continuous theoretical and technical improvements have led to the development of highly efficient Datalog systems for widespread practical use in a variety of applications (see e.g, Maier et al. Reference Maier, Tekle, Kifer and Warren2018).
However, in many such real-world applications the observations and facts that serve as the input are not actually certain but rather associated with some (possibly unknown) level of uncertainty. One particularly important situation where such a setting occurs are settings where observations are made by machine learning (ML) systems.
For example, say a database contains a relation that labels images of animals with the class of animal observed in the image. In modern settings, such labels are commonly derived from the output of ML systems that attempt to classify the image contents. Generally, such systems output possible labels for an image, together with a score that can be interpreted as the level of confidence in the labels correctness (cf., Mishkin et al. Reference Mishkin, Sergievskiy and Matas2017; Lee et al. Reference Lee, Jung, Agarwal and Kim2017).
When the labelling in our example is used in further logical inference, the level of confidence in the individual labels would ideally also be reflected in any knowledge inferred from these uncertain observations. However, classical logical reasoning provides no way to consider such information and requires the projection of uncertainty levels to be either true or false, usually via some simple numerical threshold. Beyond the overall loss of information, this can also lead to problematic outcomes where logical conclusions are true despite their derivation being based on observations made with only moderate confidence. With observations from ML systems becoming a commonplace feature of many modern reasoning settings, the projection to binary truth values is severely limiting the immense potential of integrating ML observations with logic programming.
Related Work There are two natural ways to interpret uncertain observations as described in the example above. One can consider them as the likelihood of the fact being true, that is, the level of confidence in a fact is interpreted as a probability of the fact holding true. Such an interpretation has been widely studied in the context of Problog (Raedt et al. Reference Raedt, Kimmig and Toivonen2007), Markov Logic Networks (Richardson and Domingos Reference Richardson and Domingos2006), and probabilistic databases (Suciu et al. Reference Suciu, Olteanu, RÉ and Koch2011; Cavallo and Pittarelli Reference Cavallo and Pittarelli1987). However, generally such formalisms make strong assumptions on the pairwise probabilistic independence of all tuples which can be difficult to satisfy. An approach to probabilistic reasoning in
 $\mathrm{Datalog}^\pm$
based on the chase procedure was proposed very recently by Bellomarini et al. (Reference Bellomarini, Laurenza, Sallinger and Sherkhonov2020).
$\mathrm{Datalog}^\pm$
based on the chase procedure was proposed very recently by Bellomarini et al. (Reference Bellomarini, Laurenza, Sallinger and Sherkhonov2020).
Alternatively, one can express levels of confidence in a fact in terms of degrees of truth as in fuzzy logics (cf. HÁjek Reference HÁjek1998). That is, a fact that is considered to be true to a certain degree, in accordance with the level of confidence in the observation.
There have been a wide variety of approaches of combining logic programming with fuzzy logic. Pioneering work in this area by Achs and Kiss (Reference Achs and Kiss1995), Ebrahim (Reference Ebrahim2001), and VojtÁs (Reference VojtÁs2001) introduced a number of early foundational ideas for fuzzy logic programming. The first also considers fuzziness in the object domain (expressing the possibility that two constants may actually refer to the same object), via fuzzy similarity relations on the object domain. This idea was further expanded in the context of deductive databases by Iranzo and SÁenz-PÉrez (Reference Iranzo and SÁenz-PÉrez2018).
One limiting factor of these approaches in our intended setting is the reliance on the GÖdel t-norm (see, Preining Reference Preining2010) as the basis for many-valued semantics. The GÖdel t-norm of two formulas
 $\phi$
,
$\phi$
,
 $\psi$
is the minimum of the respective truth degrees of
$\psi$
is the minimum of the respective truth degrees of
 $\phi$
and
$\phi$
and
 $\psi$
. While this simplifies the model theory of the resulting logics, the resulting semantics are not ideal for our envisioned applications in which we want to combine uncertain observations from AI systems with large certain knowledge bases. Further discussion of the important differences between semantics based on the GÖdel t-norm and the Łukasiewicz t-norm (see, HÁjek Reference HÁjek1998), which we propose to use in this paper, is provided in Section 2.
$\psi$
. While this simplifies the model theory of the resulting logics, the resulting semantics are not ideal for our envisioned applications in which we want to combine uncertain observations from AI systems with large certain knowledge bases. Further discussion of the important differences between semantics based on the GÖdel t-norm and the Łukasiewicz t-norm (see, HÁjek Reference HÁjek1998), which we propose to use in this paper, is provided in Section 2.
Finally, Probabilistic Soft Logic (PSL) was introduced by Bach et al. (Reference Bach, Broecheler, Huang and Getoor2017) as a framework for fuzzy reasoning with semantics based on Łukasiewicz logic. PSL is a significantly different language with different use cases than our proposed languages. It allows for negation in rule bodies as well as disjunction in the head, in addition to certain forms of aggregation. Semantically it treats all rules as soft constraints and aims to find interpretations that satisfy rules as much as possible. Similar ideas have also been proposed in fuzzy description logics, see for example, Bobillo and Straccia (Reference Bobillo and Straccia2016), Borgwardt and PeÑaloza (Reference Borgwardt and PeÑaloza2017), Stoilos et al. (Reference Stoilos, Stamou, Pan, Tzouvaras and Horrocks2007), or Lukasiewicz and Straccia (Reference Lukasiewicz and Straccia2008) for an overview of fuzzy DLs.
Contributions We propose extensions of Datalog and
 $\mathrm{Datalog}^\pm$
, that is, Datalog with existential quantification in the head, to the many-valued semantics of infinite-valued Łukasiewicz logic. We argue that these languages offer natural semantics for practical applications with uncertain data while preserving key theoretical properties of the classical (two-valued) case. Overall, the contributions of this paper are summarised as follows.
$\mathrm{Datalog}^\pm$
, that is, Datalog with existential quantification in the head, to the many-valued semantics of infinite-valued Łukasiewicz logic. We argue that these languages offer natural semantics for practical applications with uncertain data while preserving key theoretical properties of the classical (two-valued) case. Overall, the contributions of this paper are summarised as follows.
-
• We introduce MV-Datalog as Datalog with Łukasiewicz semantics. We discuss adaptions of the standard minimal model concept to fuzzy models where every fact takes the least possible truth degree. We show that for consistent inputs, unique minimal models always exist and give a characterisation of such minimal models. Our results hold also for K-fuzzy models, that is, interpretations that satisfy formulas of the program only to degree K rather than fully.
-
• We show that MV-Datalog is suitable for practical applications. For one, our characterisation reveals that finding K-fuzzy models is feasible by building on standard methods as from the classical setting. In particular, we also show fuzzy fact entailment in MV-Datalog has the same complexity as fact entailment in Datalog.
-
• We propose
 $\mathrm{MV-Datalog}^\pm$
as practice oriented extension of MV-Datalog by existential quantification in the head. To obtain intuitive semantics for logic programming we deviate from standard semantics of many valued existential quantification and instead argue for the use of strong existential quantification. We discuss fundamental model theoretic properties and challenges of
$\mathrm{MV-Datalog}^\pm$
and show how our characterisation result for MV-Datalog can be extended to capture a natural class of preferred models of
$\mathrm{MV-Datalog}^\pm$
, providing the foundation for a system implementation of
$\mathrm{MV-Datalog}^\pm$
.
$\mathrm{MV-Datalog}^\pm$
as practice oriented extension of MV-Datalog by existential quantification in the head. To obtain intuitive semantics for logic programming we deviate from standard semantics of many valued existential quantification and instead argue for the use of strong existential quantification. We discuss fundamental model theoretic properties and challenges of
$\mathrm{MV-Datalog}^\pm$
and show how our characterisation result for MV-Datalog can be extended to capture a natural class of preferred models of
$\mathrm{MV-Datalog}^\pm$
, providing the foundation for a system implementation of
$\mathrm{MV-Datalog}^\pm$
.




Structure The rest of this paper is structured as follows. Terminology, notation and further preliminaries are stated in Section 2. Throughout Section 3, we introduce MV-Datalog and our main results for minimal fuzzy models in MV-Datalog. The further extension to
 $\mathrm{MV-Datalog}^\pm$
is presented in Section 4. We conclude with final remarks and a brief discussion of future work in Section 5. Proof details that had to be omitted from the main text due to space restrictions are provided in the Appendix A of the arXiv version of this paper (cf., Lanzinger et al. Reference Lanzinger, Sferrazza and Gottlob2022).
$\mathrm{MV-Datalog}^\pm$
is presented in Section 4. We conclude with final remarks and a brief discussion of future work in Section 5. Proof details that had to be omitted from the main text due to space restrictions are provided in the Appendix A of the arXiv version of this paper (cf., Lanzinger et al. Reference Lanzinger, Sferrazza and Gottlob2022).
2 Preliminaries
We assume familiarity with standard notions of Datalog and first-order logic. Throughout this document, we consider only logical languages with no function symbols.
Datalog Fix a relational signature
 $\sigma$
and a (countable) domain
$\sigma$
and a (countable) domain
 $\mathit{Dom}$
. A (relational) atom is a term
$\mathit{Dom}$
. A (relational) atom is a term
 $R(u_1,\dots,u_{\#R})$
where
$R(u_1,\dots,u_{\#R})$
where
 $\#R$
is the arity of relation symbol
$\#R$
is the arity of relation symbol
 $R\in \sigma$
and for
$R\in \sigma$
and for
 $0 \leq i \leq \#R$
,
$0 \leq i \leq \#R$
,
 $u_i$
is a variable or a constant. If all positions of the atom are constants we say that it is a ground atom (or fact). A (Datalog) rule r is a first-order implication
$u_i$
is a variable or a constant. If all positions of the atom are constants we say that it is a ground atom (or fact). A (Datalog) rule r is a first-order implication
 $\varphi \rightarrow \psi$
where
$\varphi \rightarrow \psi$
where
 $\varphi$
is a conjunction of relational atoms and
$\varphi$
is a conjunction of relational atoms and
 $\psi$
consists of a single relational atom. We say that
$\psi$
consists of a single relational atom. We say that
 $\varphi$
is the body of r (
$\varphi$
is the body of r (
 $\mathrm{body}(r)$
) and
$\mathrm{body}(r)$
) and
 $\psi$
is the head of r (
$\psi$
is the head of r (
 $\mathrm{head}(r)$
). A rule is safe if all free variables in the head of a rule also occur in its body. A Datalog program is a set of safe Datalog rules. The models of a Datalog program are the first-order interpretations that satisfy all rules. For two models
$\mathrm{head}(r)$
). A rule is safe if all free variables in the head of a rule also occur in its body. A Datalog program is a set of safe Datalog rules. The models of a Datalog program are the first-order interpretations that satisfy all rules. For two models
 $\mathcal{I}, \mathcal{I}'$
of a Datalog program, we say that
$\mathcal{I}, \mathcal{I}'$
of a Datalog program, we say that
 $\mathcal{I} \leq \mathcal{I}'$
if every every ground atom satisfied by
$\mathcal{I} \leq \mathcal{I}'$
if every every ground atom satisfied by
 $\mathcal{I}$
is also satisfied by
$\mathcal{I}$
is also satisfied by
 $\mathcal{I}'$
. The minimal model of a Datalog program
$\mathcal{I}'$
. The minimal model of a Datalog program
 $\Pi$
is the model
$\Pi$
is the model
 $\mathcal{I}$
of
$\mathcal{I}$
of
 $\Pi$
such that for all other models
$\Pi$
such that for all other models
 $\mathcal{I}'$
of
$\mathcal{I}'$
of
 $\Pi$
it holds that
$\Pi$
it holds that
 $\mathcal{I} \leq \mathcal{I}'$
.
$\mathcal{I} \leq \mathcal{I}'$
.
A database D is a set of ground atoms, logically interpreted as a theory consisting of an atomic sentence for each ground atom. We say that
 $\mathcal{I}$
is a model of a program and a database
$\mathcal{I}$
is a model of a program and a database
 $({\Pi}, D)$
, if
$({\Pi}, D)$
, if
 $\mathcal{I}$
is a model of both
$\mathcal{I}$
is a model of both
 ${\Pi}$
and D. We write
${\Pi}$
and D. We write
 ${\Pi},D \models \varphi$
if formula
${\Pi},D \models \varphi$
if formula
 $\varphi$
is satisfied for every model of
$\varphi$
is satisfied for every model of
 $({\Pi}, D)$
. Note that this is equivalent to satisfaction under the minimal model of
$({\Pi}, D)$
. Note that this is equivalent to satisfaction under the minimal model of
 $({\Pi}, D)$
.
$({\Pi}, D)$
.
 $\mathrm{Datalog}^\pm$
The extension of Datalog with existential quantification in the head, led to the well studied
$\mathrm{Datalog}^\pm$
The extension of Datalog with existential quantification in the head, led to the well studied
 $\mathrm{Datalog}^\pm$
(CalÌ et al. Reference CalÌ, Gottlob and Lukasiewicz2012). A
$\mathrm{Datalog}^\pm$
(CalÌ et al. Reference CalÌ, Gottlob and Lukasiewicz2012). A
 $\mathrm{Datalog}^\pm$
rule is either a Datalog rule or a first-order formula of the form
$\mathrm{Datalog}^\pm$
rule is either a Datalog rule or a first-order formula of the form
 $\varphi \rightarrow \exists \mathbf{y}\ \psi(\mathbf{y})$
where
$\varphi \rightarrow \exists \mathbf{y}\ \psi(\mathbf{y})$
where
 $\varphi$
is again a conjunction of relational atoms and
$\varphi$
is again a conjunction of relational atoms and
 $\psi$
is a relational atom that mentions all variables in
$\psi$
is a relational atom that mentions all variables in
 $\mathbf{y}$
. A
$\mathbf{y}$
. A
 $\mathrm{Datalog}^\pm$
program is a set of safe
$\mathrm{Datalog}^\pm$
program is a set of safe
 $\mathrm{Datalog}^\pm$
rules. Models in
$\mathrm{Datalog}^\pm$
rules. Models in
 $\mathrm{Datalog}^\pm$
are defined in the same way as for plain Datalog. Note that existential quantification ranges over the whole (infinite) domain
$\mathrm{Datalog}^\pm$
are defined in the same way as for plain Datalog. Note that existential quantification ranges over the whole (infinite) domain
 $\mathit{Dom}$
rather than the active domain of the program/database. It follows that, in contrast to Datalog,
$\mathit{Dom}$
rather than the active domain of the program/database. It follows that, in contrast to Datalog,
 $\mathrm{Datalog}^\pm$
programs do not have a unique minimal model. Furthermore, fact entailment in
$\mathrm{Datalog}^\pm$
programs do not have a unique minimal model. Furthermore, fact entailment in
 $\mathrm{Datalog}^\pm$
is undecidable in general but vast decidable fragments are known.
$\mathrm{Datalog}^\pm$
is undecidable in general but vast decidable fragments are known.
Oblivious Chase Fact entailment in
 $\mathrm{Datalog}^\pm$
(and Datalog) is closely linked to the so-called chase fixed-point procedures. In the following, we will be particularly interested in a specific chase procedure called the oblivious chase. We give only the minimal necessary technical details here and refer to CalÌ et al. (Reference CalÌ, Gottlob and Kifer2013) for full details.
$\mathrm{Datalog}^\pm$
(and Datalog) is closely linked to the so-called chase fixed-point procedures. In the following, we will be particularly interested in a specific chase procedure called the oblivious chase. We give only the minimal necessary technical details here and refer to CalÌ et al. (Reference CalÌ, Gottlob and Kifer2013) for full details.
For any formula
 $\varphi$
, we write
$\varphi$
, we write
 $\mathrm{mars}(\varphi)$
for the set of free variables in the formula. Given a database D, we say that a
$\mathrm{mars}(\varphi)$
for the set of free variables in the formula. Given a database D, we say that a
 $\mathrm{Datalog}^\pm$
rule r is obliviously applicable to D if there exists a homomorphism
$\mathrm{Datalog}^\pm$
rule r is obliviously applicable to D if there exists a homomorphism
 $h \colon \mathrm{mars}(r) \to \mathit{Dom}$
such that all atoms in
$h \colon \mathrm{mars}(r) \to \mathit{Dom}$
such that all atoms in
 $h(\mathrm{body}(r))$
are in D.
$h(\mathrm{body}(r))$
are in D.
Let r be a
 $\mathrm{Datalog}^\pm$
rule that is obliviously applicable to D via a homomorphism h. Let h’ be the extension of h to the existentially quantified variables
$\mathrm{Datalog}^\pm$
rule that is obliviously applicable to D via a homomorphism h. Let h’ be the extension of h to the existentially quantified variables
 $\mathbf{y}$
in
$\mathbf{y}$
in
 $\mathrm{head}(r)$
such that for each
$\mathrm{head}(r)$
such that for each
 $y \in \mathbf{y}$
, h’(y) is a fresh constant, called a labelled null, not occurring in D (
$y \in \mathbf{y}$
, h’(y) is a fresh constant, called a labelled null, not occurring in D (
 $h'=h$
when r is a Datalog rule). Let
$h'=h$
when r is a Datalog rule). Let
 $\psi$
be the atomic formula in
$\psi$
be the atomic formula in
 $\mathrm{head}(r)$
. The result of the oblivious application of r, h to D is
$\mathrm{head}(r)$
. The result of the oblivious application of r, h to D is
 $D' = D \cup h'(\psi)$
. We write
$D' = D \cup h'(\psi)$
. We write
 $D \xrightarrow[]{r,h} D'$
. Let D be a database and
$D \xrightarrow[]{r,h} D'$
. Let D be a database and
 ${\Pi}$
a
${\Pi}$
a
 $\mathrm{Datalog}^\pm$
program. The oblivious chase sequence
$\mathrm{Datalog}^\pm$
program. The oblivious chase sequence
 $\mathit{OChase}({\Pi}, D)$
is the sequence
$\mathit{OChase}({\Pi}, D)$
is the sequence
 $D_0, D_1, D_2, \dots$
with
$D_0, D_1, D_2, \dots$
with
 $D=D_0$
such that for all
$D=D_0$
such that for all
 $i \geq 0$
,
$i \geq 0$
,
 $D_i \xrightarrow[]{r_i,h_i} D_{i+1}$
and
$D_i \xrightarrow[]{r_i,h_i} D_{i+1}$
and
 $r_i \in {\Pi}$
, the chase sequence proceeds as long as there are oblivious applications r,h that have not yet been applied. We refer to the limit of the oblivious chase sequence as
$r_i \in {\Pi}$
, the chase sequence proceeds as long as there are oblivious applications r,h that have not yet been applied. We refer to the limit of the oblivious chase sequence as
 $\mathit{OLim}({\Pi}, D)$
. Every oblivious application r,h induces a grounding of r where all variables (including the existentially quantified ones) are assigned constants according to h and any existential quantification is removed. We refer to the set of all ground rules induced in this way by the applications in
$\mathit{OLim}({\Pi}, D)$
. Every oblivious application r,h induces a grounding of r where all variables (including the existentially quantified ones) are assigned constants according to h and any existential quantification is removed. We refer to the set of all ground rules induced in this way by the applications in
 $\mathit{OChase}({\Pi}, D)$
as
$\mathit{OChase}({\Pi}, D)$
as
 $\mathit{OGround}({\Pi}, D)$
. Note that for every
$\mathit{OGround}({\Pi}, D)$
. Note that for every
 ${\Pi}$
and D,
${\Pi}$
and D,
 $\mathit{OLim}({\Pi}, D)$
is unique up to isomorphism.
$\mathit{OLim}({\Pi}, D)$
is unique up to isomorphism.
Łukasiewicz Logic While there are many semantics for many-valued logic, in this paper we will consider infinite-valued Łukasiewicz logic
 $\mathbf{L}$
(see, HÁjek Reference HÁjek1998). Some of our techniques are particular to Łukasiewicz logic and the results given in this paper generally do not apply to other many-valued logics.
$\mathbf{L}$
(see, HÁjek Reference HÁjek1998). Some of our techniques are particular to Łukasiewicz logic and the results given in this paper generally do not apply to other many-valued logics.
For some relational signature
 $\sigma$
, we consider the following logical language, where R is a relational atom (in
$\sigma$
, we consider the following logical language, where R is a relational atom (in
 $\sigma$
) and a formula
$\sigma$
) and a formula
 $\varphi$
is defined via the grammar
$\varphi$
is defined via the grammar
 \begin{equation*} \varphi ::= R \mid \varphi {\odot} \varphi \mid \varphi {\oplus} \varphi \mid \varphi \rightarrow \varphi \mid \neg \varphi.\end{equation*}
\begin{equation*} \varphi ::= R \mid \varphi {\odot} \varphi \mid \varphi {\oplus} \varphi \mid \varphi \rightarrow \varphi \mid \neg \varphi.\end{equation*}
For a signature
 $\sigma$
and domain
$\sigma$
and domain
 $\mathit{Dom}$
, let
$\mathit{Dom}$
, let
 $\mathit{GAtoms}$
be the the set of all ground atoms with respect to
$\mathit{GAtoms}$
be the the set of all ground atoms with respect to
 $\sigma$
and
$\sigma$
and
 $\mathit{Dom}$
. A truth assignment is a function
$\mathit{Dom}$
. A truth assignment is a function
 $\nu \colon \mathit{GAtoms} \to [0,1]$
, intuitively assigning a degree of truth in the real interval [0,1] to every ground atom. By slight abuse of notation, we also apply
$\nu \colon \mathit{GAtoms} \to [0,1]$
, intuitively assigning a degree of truth in the real interval [0,1] to every ground atom. By slight abuse of notation, we also apply
 $\nu$
to formulas to express the truth of ground formulas
$\nu$
to formulas to express the truth of ground formulas
 $\gamma$
,
$\gamma$
,
 $\gamma'$
according to the following inductive definitions.
$\gamma'$
according to the following inductive definitions.
 \begin{equation*} \begin{array}{ll} \nu(\neg \gamma) &= 1 - \nu(\gamma) \\[5pt] \nu(\gamma {\odot} \gamma') &= \max \{0, \nu(\gamma) + \nu(\gamma') -1 \} \\[5pt] \nu(\gamma {\oplus} \gamma') &= \min \{1, \nu(\gamma) + \nu(\gamma') \} \\[5pt] \nu(\gamma \rightarrow \gamma')& = \min \{1, 1 - \nu(\gamma) + \nu(\gamma')\}. \end{array}\end{equation*}
\begin{equation*} \begin{array}{ll} \nu(\neg \gamma) &= 1 - \nu(\gamma) \\[5pt] \nu(\gamma {\odot} \gamma') &= \max \{0, \nu(\gamma) + \nu(\gamma') -1 \} \\[5pt] \nu(\gamma {\oplus} \gamma') &= \min \{1, \nu(\gamma) + \nu(\gamma') \} \\[5pt] \nu(\gamma \rightarrow \gamma')& = \min \{1, 1 - \nu(\gamma) + \nu(\gamma')\}. \end{array}\end{equation*}
That is,
 ${\odot}$
is the usual Łukasiewicz t-norm and
${\odot}$
is the usual Łukasiewicz t-norm and
 ${\oplus}$
is the corresponding t-conorm, which take the place of conjunction and disjunction, respectively. Implication
${\oplus}$
is the corresponding t-conorm, which take the place of conjunction and disjunction, respectively. Implication
 $\gamma \rightarrow \gamma'$
could equivalently be defined as usual as
$\gamma \rightarrow \gamma'$
could equivalently be defined as usual as
 $\neg \gamma {\oplus} \gamma'$
. Note that De Morgan’s rule holds as usual for
$\neg \gamma {\oplus} \gamma'$
. Note that De Morgan’s rule holds as usual for
 ${\odot}$
and
${\odot}$
and
 ${\oplus}$
.
${\oplus}$
.
For rational
 $K \in (0,1]$
we say that a formula
$K \in (0,1]$
we say that a formula
 $\varphi$
is K-satisfied by
$\varphi$
is K-satisfied by
 $\nu$
if for every grounding
$\nu$
if for every grounding
 $\gamma$
of
$\gamma$
of
 $\varphi$
over
$\varphi$
over
 $\mathit{Dom}$
it holds that
$\mathit{Dom}$
it holds that
 $\nu(\gamma) \geq K$
. Whenever we make use of K in this context we assume it to be rational. In the context of rule-based reasoning it may be of particular interest to observe that an implication is 1-satisfied exactly when the head is at least as true as the body. For a set of formulas
$\nu(\gamma) \geq K$
. Whenever we make use of K in this context we assume it to be rational. In the context of rule-based reasoning it may be of particular interest to observe that an implication is 1-satisfied exactly when the head is at least as true as the body. For a set of formulas
 $\Pi$
, we say that a truth assignment
$\Pi$
, we say that a truth assignment
 $\nu$
is a
$\nu$
is a
 $K-$
fuzzy model if all formulas in
$K-$
fuzzy model if all formulas in
 $\Pi$
are K-satisfied by
$\Pi$
are K-satisfied by
 $\nu$
.
$\nu$
.
In place of the database in the classical setting, we instead consider (finite) partial truth assignments, that is, partial functions
 $\tau: GAtoms \to (0,1]$
that are defined for a finite number of ground atoms. Let
$\tau: GAtoms \to (0,1]$
that are defined for a finite number of ground atoms. Let
 $({\Pi}, \tau)$
be a pair where
$({\Pi}, \tau)$
be a pair where
 $\Pi$
is a set of formulas and
$\Pi$
is a set of formulas and
 $\tau$
is a partial truth assignment, a K-fuzzy model of
$\tau$
is a partial truth assignment, a K-fuzzy model of
 $(\Pi, \tau)$
is a K-fuzzy model
$(\Pi, \tau)$
is a K-fuzzy model
 $\nu$
of
$\nu$
of
 ${\Pi}$
where
${\Pi}$
where
 $\nu(G) = \tau(G)$
for every ground atom G for which
$\nu(G) = \tau(G)$
for every ground atom G for which
 $\tau$
is defined. Whenever we talk about formulas
$\tau$
is defined. Whenever we talk about formulas
 ${\Pi}$
and partial truth assignments
${\Pi}$
and partial truth assignments
 $\tau$
we use
$\tau$
we use
 $\mathit{ADom}$
to refer to their active domain, that is, the subset of the domain that is mentioned in either
$\mathit{ADom}$
to refer to their active domain, that is, the subset of the domain that is mentioned in either
 ${\Pi}$
or
${\Pi}$
or
 $\{G \in \mathit{GAtoms} \mid \tau(G) \text{ is defined.}\}$
. We write
$\{G \in \mathit{GAtoms} \mid \tau(G) \text{ is defined.}\}$
. We write
 ${\mathit{GAtoms}[{\mathit{Adom}]}}$
to indicate
${\mathit{GAtoms}[{\mathit{Adom}]}}$
to indicate
 $\mathit{GAtoms}$
restricted to groundings over
$\mathit{GAtoms}$
restricted to groundings over
 $\mathit{Adom}$
.
$\mathit{Adom}$
.
K-fuzzy models and their theory have been introduced and studied in the context of logic programming by Ebrahim (Reference Ebrahim2001) but under different many-valued semantics based on the GÖdel t-norm.
Example 1. Consider a labelling of images as described in the introduction, represented by predicate
 $\mathit{Label}$
. Additionally, we have a predicate corresponding to whether the image was taken in a polar region. Suppose we have the following observations for image
$\mathit{Label}$
. Additionally, we have a predicate corresponding to whether the image was taken in a polar region. Suppose we have the following observations for image
 $i_1$
.
$i_1$
.
 \begin{equation*} \tau(\mathit{Label}(i_1, \mathrm{Whale})) = 0.8 \qquad \tau(\mathit{PolarRegion}(i_1)) = 0.7. \end{equation*}
\begin{equation*} \tau(\mathit{Label}(i_1, \mathrm{Whale})) = 0.8 \qquad \tau(\mathit{PolarRegion}(i_1)) = 0.7. \end{equation*}
Now we consider satisfaction of the following ground rule under the semantics studied by Ebrahim (Reference Ebrahim2001) in contrast to Łukasiewicz semantics.
 \begin{equation*} \mathit{Label}(i_1, \mathrm{Whale}) {\odot} \mathit{PolarRegion}(i_1) \rightarrow \mathit{Orca}(i_1). \end{equation*}
\begin{equation*} \mathit{Label}(i_1, \mathrm{Whale}) {\odot} \mathit{PolarRegion}(i_1) \rightarrow \mathit{Orca}(i_1). \end{equation*}
If we interpret implication and
 ${\odot}$
under the semantics proposed by Ebrahim (Reference Ebrahim2001), the body has truth
${\odot}$
under the semantics proposed by Ebrahim (Reference Ebrahim2001), the body has truth
 $0.7$
(the GÖdel t-norm of
$0.7$
(the GÖdel t-norm of
 $0.8$
and
$0.8$
and
 $0.7$
). The implication evaluates to the maximum of
$0.7$
). The implication evaluates to the maximum of
 $0.3$
(
$0.3$
(
 $=1-$
truth of the body) and the truth of the head. Hence, a model that 1-satisfies the rule would have to satisfy
$=1-$
truth of the body) and the truth of the head. Hence, a model that 1-satisfies the rule would have to satisfy
 $\mathit{Orca}(i_1)$
with truth degree 1. This can be unintuitive, especially in the context of logic programming, since the truth degree of the fact is not inferred from the truth of the body.
$\mathit{Orca}(i_1)$
with truth degree 1. This can be unintuitive, especially in the context of logic programming, since the truth degree of the fact is not inferred from the truth of the body.
In Łukasiewicz semantics, the body has truth degree
 $0.5$
following the intuition that the conjunction of two uncertain observations becomes even less certain. For the implication to be 1-satisfied it suffices if
$0.5$
following the intuition that the conjunction of two uncertain observations becomes even less certain. For the implication to be 1-satisfied it suffices if
 $\mathit{Orca}(i_1)$
is true to at least degree
$\mathit{Orca}(i_1)$
is true to at least degree
 $0.5$
. We see that the inferred truth degree of the head naturally depends on the truth of the body.
$0.5$
. We see that the inferred truth degree of the head naturally depends on the truth of the body.
3 MV-Datalog and minimal fuzzy models
In this section, we propose the extension of Datalog to Łukasiewicz semantics for many-valued reasoning. We show that MV-Datalog allows for an analogue of minimal model semantics in the fuzzy setting. Moreover, we give a characterisation of such minimal models in terms of an optimisation problem over the ground program corresponding to the oblivious chase.
3.1 MV-Datalog
Definition 1 (MV-Datalog Program) An MV-Datalog program
 ${\Pi}$
is a set of
${\Pi}$
is a set of
 $\mathbf{L}$
formulas of the form
$\mathbf{L}$
formulas of the form
 \begin{equation*} B_1 {\odot} B_2 {\odot} \dots {\odot} B_n \rightarrow H, \end{equation*}
\begin{equation*} B_1 {\odot} B_2 {\odot} \dots {\odot} B_n \rightarrow H, \end{equation*}
where all
 $B_i$
, for
$B_i$
, for
 $1 \leq i \leq n$
, and H are relational atoms.
$1 \leq i \leq n$
, and H are relational atoms.
As noted in Section 2, we consider a partial truth assignment
 $\tau$
in the place of a database. We will therefore also refer to
$\tau$
in the place of a database. We will therefore also refer to
 $\tau$
as the database. We call a pair
$\tau$
as the database. We call a pair
 ${\Pi}, \tau$
of an MV-Datalog programme and database an MV-instance. We can map a MV-Datalog program
${\Pi}, \tau$
of an MV-Datalog programme and database an MV-instance. We can map a MV-Datalog program
 ${\Pi}$
naturally to a Datalog program by substituting
${\Pi}$
naturally to a Datalog program by substituting
 ${\odot}$
by
${\odot}$
by
 $\land $
. We refer to the resulting Datalog program as
$\land $
. We refer to the resulting Datalog program as
 ${\prod^{\mathit{crisp}}}$
. For the respective crisp version of
${\prod^{\mathit{crisp}}}$
. For the respective crisp version of
 $\tau$
we write
$\tau$
we write
 $D_\tau$
for the database containing all facts G for which
$D_\tau$
for the database containing all facts G for which
 $\tau(G)$
is defined and greater than 0.
$\tau(G)$
is defined and greater than 0.
Analogous to fact entailment in classical Datalog, we have the central decision problem K-Truth, whether a fact is true to at least a degree c in all models, as follows.
K-Truth
Input MV-instance
 $({\Pi}, \tau)$
, ground atom G,
$({\Pi}, \tau)$
, ground atom G,
 $c \in[0,1]$
$c \in[0,1]$
Output
 $\nu(G) \geq c$
for all K-fuzzy models
$\nu(G) \geq c$
for all K-fuzzy models
 $\nu$
of
$\nu$
of
 $({\Pi}, \tau)$
?
$({\Pi}, \tau)$
?
MV-Datalog is a proper extension of Datalog in the sense that for
 $K=1$
and when all ground atoms in the database are assigned truth 1, its models coincide exactly with those of Datalog programs.
$K=1$
and when all ground atoms in the database are assigned truth 1, its models coincide exactly with those of Datalog programs.
Note that in contrast to Datalog, MV-instances do not always have models. For example, consider a program consisting only of rule
 $R(x) \rightarrow S(x)$
. For any
$R(x) \rightarrow S(x)$
. For any
 $K > 0$
, there is a database
$K > 0$
, there is a database
 $\tau$
that assigns truth 1 to R(a) and some truth less than K to S(a) such that the rule is not K-satisfied. This is a consequence of the definition of a K-fuzzy model
$\tau$
that assigns truth 1 to R(a) and some truth less than K to S(a) such that the rule is not K-satisfied. This is a consequence of the definition of a K-fuzzy model
 $\nu$
of
$\nu$
of
 $({\Pi}, \tau)$
, which requires the truth values in
$({\Pi}, \tau)$
, which requires the truth values in
 $\nu$
to agree exactly with
$\nu$
to agree exactly with
 $\tau$
, for every fact for which
$\tau$
, for every fact for which
 $\tau$
is defined. In some settings it may be desirable to relax this slightly and consider K-fuzzy models
$\tau$
is defined. In some settings it may be desirable to relax this slightly and consider K-fuzzy models
 $\nu$
where
$\nu$
where
 $\nu(G) \geq \tau(G)$
where
$\nu(G) \geq \tau(G)$
where
 $\tau(G)$
is defined.Footnote 1 Our semantics cover such a relaxation since it can be simulated by straightforward rewriting of the programme: for every relation symbol R that occurs in
$\tau(G)$
is defined.Footnote 1 Our semantics cover such a relaxation since it can be simulated by straightforward rewriting of the programme: for every relation symbol R that occurs in
 $\tau$
add rule
$\tau$
add rule
 $R(\mathbf{x}) \rightarrow R'(\mathbf{x})$
, and replace all other occurrences of R in the programme by R’.
$R(\mathbf{x}) \rightarrow R'(\mathbf{x})$
, and replace all other occurrences of R in the programme by R’.
Ebrahim (Reference Ebrahim2001) introduced minimal K-fuzzy models to study logic programming with the GÖdel t-norm, as the intersection of all K-fuzzy models, where truth values of an intersection are taken to the minimum between the two values. We will use the following alternative (but equivalent) definition here that will be more convenient in our setting. For two truth assignment
 $\nu$
,
$\nu$
,
 $\mu$
we write
$\mu$
we write
 $\nu \leq \mu$
when for all
$\nu \leq \mu$
when for all
 $G \in \mathit{GAtoms}$
, it holds that
$G \in \mathit{GAtoms}$
, it holds that
 $\nu(G) \leq \mu(G)$
. We similarly write
$\nu(G) \leq \mu(G)$
. We similarly write
 $\nu < \mu$
if
$\nu < \mu$
if
 $\nu \leq \mu$
and
$\nu \leq \mu$
and
 $\nu(G)<\mu(G)$
for at least one
$\nu(G)<\mu(G)$
for at least one
 $G \in \mathit{GAtoms}$
.
$G \in \mathit{GAtoms}$
.
Definition 2. Let
 ${\Pi}, \tau$
be an MV-instance. We say that a K-fuzzy model
${\Pi}, \tau$
be an MV-instance. We say that a K-fuzzy model
 $\mu$
of
$\mu$
of
 $({\Pi}, \tau)$
is minimal if for every K-fuzzy model
$({\Pi}, \tau)$
is minimal if for every K-fuzzy model
 $\nu$
of
$\nu$
of
 $({\Pi}, \tau)$
it holds that
$({\Pi}, \tau)$
it holds that
 $\mu \leq \nu$
.
$\mu \leq \nu$
.
Minimal K-fuzzy models behave very similar to minimal models in Datalog. In particular, the two following propositions state two key properties allows us to focus on a single minimal fuzzy model for the problem K-Truth.
Theorem 1. Let
 ${\Pi}$
,
${\Pi}$
,
 $\tau$
be an MV-instance. For every rational
$\tau$
be an MV-instance. For every rational
 $K\in (0,1]$
, if
$K\in (0,1]$
, if
 $({\Pi}, \tau)$
is K-satisfiable, then there exists a unique minimal K-fuzzy model for
$({\Pi}, \tau)$
is K-satisfiable, then there exists a unique minimal K-fuzzy model for
 $({\Pi}, \tau)$
.
$({\Pi}, \tau)$
.
Proof. We show that for every set of K-fuzzy models S, the infimum of S, defined as the truth assignment
 $\nu'$
with
$\nu'$
with
 $\nu'(G) = \inf_{\nu\in S} \nu(G)$
for all
$\nu'(G) = \inf_{\nu\in S} \nu(G)$
for all
 $G \in \mathit{GAtoms}$
, is also a K-fuzzy model for
$G \in \mathit{GAtoms}$
, is also a K-fuzzy model for
 $({\Pi}, \tau)$
.
$({\Pi}, \tau)$
.
For any ground rule
 $\gamma$
and
$\gamma$
and
 $\nu \in S$
, the body truth value
$\nu \in S$
, the body truth value
 $\nu(\mathrm{body}(\gamma))$
is given by
$\nu(\mathrm{body}(\gamma))$
is given by
 $\max\{0, \left(\sum_{i=1}^\ell \nu(G_i)\right) - \ell + 1\}$
where the body of
$\max\{0, \left(\sum_{i=1}^\ell \nu(G_i)\right) - \ell + 1\}$
where the body of
 $\gamma$
consists of ground atoms
$\gamma$
consists of ground atoms
 $G_1,\dots,G_\ell$
. Hence, since we have
$G_1,\dots,G_\ell$
. Hence, since we have
 $\nu'(G_i)\leq \nu(G_i)$
for every
$\nu'(G_i)\leq \nu(G_i)$
for every
 $1\leq i\leq \ell$
by construction, it also holds that
$1\leq i\leq \ell$
by construction, it also holds that
 $\nu'(\mathrm{body}(\gamma))\leq \inf_{\nu \in S} \nu(\mathrm{body}(\gamma))$
.
$\nu'(\mathrm{body}(\gamma))\leq \inf_{\nu \in S} \nu(\mathrm{body}(\gamma))$
.
Therefore also
 $\nu'(\mathrm{body}(\gamma)) \leq (1-K)+\inf_{\nu \in S} \nu(\mathrm{head}(\gamma))$
, since all
$\nu'(\mathrm{body}(\gamma)) \leq (1-K)+\inf_{\nu \in S} \nu(\mathrm{head}(\gamma))$
, since all
 $\nu \in S$
are K-fuzzy models. That is, there exists a rational
$\nu \in S$
are K-fuzzy models. That is, there exists a rational
 $r = \max\{0, \nu'(\mathrm{body}(\gamma))-1+K\}$
(recall that we only consider rational K) such that r is less or equal to
$r = \max\{0, \nu'(\mathrm{body}(\gamma))-1+K\}$
(recall that we only consider rational K) such that r is less or equal to
 $\nu(\mathrm{head}(\gamma))$
for every
$\nu(\mathrm{head}(\gamma))$
for every
 $\nu \in S$
and
$\nu \in S$
and
 $\nu'(\mathrm{body}(\gamma)) \leq (1-K)+ r$
. Then,
$\nu'(\mathrm{body}(\gamma)) \leq (1-K)+ r$
. Then,
 $\nu'(\mathrm{head}(\gamma)) = \inf_{\nu \in S} \nu(\mathrm{head}(\gamma)) \geq r$
and therefore also
$\nu'(\mathrm{head}(\gamma)) = \inf_{\nu \in S} \nu(\mathrm{head}(\gamma)) \geq r$
and therefore also
 $\nu'(\mathrm{body}(\gamma)) \leq (1-K)+ \nu'(\mathrm{head}(\gamma))$
, that is,
$\nu'(\mathrm{body}(\gamma)) \leq (1-K)+ \nu'(\mathrm{head}(\gamma))$
, that is,
 $\nu'$
K-satisfies
$\nu'$
K-satisfies
 $\gamma$
. We see that
$\gamma$
. We see that
 $\nu'$
is indeed a K-fuzzy model and clearly for every
$\nu'$
is indeed a K-fuzzy model and clearly for every
 $\nu \in S$
we also have
$\nu \in S$
we also have
 $\nu' \leq \nu$
. Taking the infimum over all K-fuzzy models of
$\nu' \leq \nu$
. Taking the infimum over all K-fuzzy models of
 $({\Pi}, \tau)$
then yields the unique minimal K-fuzzy model for
$({\Pi}, \tau)$
then yields the unique minimal K-fuzzy model for
 $({\Pi}, \tau)$
.
$({\Pi}, \tau)$
.
Proposition 2. Let G be a ground atom,
 $c \in [0,1]$
, and
$c \in [0,1]$
, and
 $\mu$
the minimal K-fuzzy model of
$\mu$
the minimal K-fuzzy model of
 $({\Pi}, \tau)$
. Then
$({\Pi}, \tau)$
. Then
 $\mu(G) \geq c$
if and only if
$\mu(G) \geq c$
if and only if
 $\nu(G) \geq c$
for all K-fuzzy models of
$\nu(G) \geq c$
for all K-fuzzy models of
 $({\Pi}, \tau)$
.
$({\Pi}, \tau)$
.
Of particular importance to our main result is the fact that fuzzy models are, in a sense, only more fine-grained versions of classical models. In particular, since the classical case corresponds to every observation having maximal truth degree, fuzzy models are in a sense bounded from above by classical models.
Lemma 3. Let
 $({\Pi}, \tau)$
be an MV-instance. Let
$({\Pi}, \tau)$
be an MV-instance. Let
 $\nu$
be a minimal K-fuzzy model of
$\nu$
be a minimal K-fuzzy model of
 $({\Pi}, \tau)$
. Then for every
$({\Pi}, \tau)$
. Then for every
 $G \in \mathit{GAtoms}$
, we have
$G \in \mathit{GAtoms}$
, we have
 $\nu(G)>0$
only if
$\nu(G)>0$
only if
 ${\prod^{\mathit{crisp}}}, D_\tau \models G$
.
${\prod^{\mathit{crisp}}}, D_\tau \models G$
.
3.2 Characterising minimal fuzzy models
Minimal K-fuzzy models are a natural tool for query answering. In the following we show that we can in fact characterise the minimal K-fuzzy model for
 $({\Pi}, \tau)$
in terms of a simple linear program
$({\Pi}, \tau)$
in terms of a simple linear program
 $\mathit{Opt}^K_{\prod,\tau}$
defined over the ground rules induced by the oblivious chase sequence
Footnote 2
for
$\mathit{Opt}^K_{\prod,\tau}$
defined over the ground rules induced by the oblivious chase sequence
Footnote 2
for
 ${\prod^{\mathit{crisp}}}, D_\tau$
.
${\prod^{\mathit{crisp}}}, D_\tau$
.
Let
 $({\Pi}, \tau)$
be an MV-instance. Let
$({\Pi}, \tau)$
be an MV-instance. Let
 $\Gamma=\{\gamma_1, \dots, \gamma_m\}$
be the ground rules in
$\Gamma=\{\gamma_1, \dots, \gamma_m\}$
be the ground rules in
 $\mathit{OGround}({\prod^{\mathit{crisp}}}, D_\tau)$
. Let
$\mathit{OGround}({\prod^{\mathit{crisp}}}, D_\tau)$
. Let
 $\mathcal{G}=\{G_1,\dots,G_n\}$
be all of the ground atoms occurring in rules in
$\mathcal{G}=\{G_1,\dots,G_n\}$
be all of the ground atoms occurring in rules in
 $\Gamma$
. For every
$\Gamma$
. For every
 $G_i \in \mathcal{G}$
we associate
$G_i \in \mathcal{G}$
we associate
 $G_i$
with a variable
$G_i$
with a variable
 $x_i$
in our linear programme that intuitively will represent the truth degree of
$x_i$
in our linear programme that intuitively will represent the truth degree of
 $G_i$
. For
$G_i$
. For
 $\gamma_j$
of the form
$\gamma_j$
of the form
 $G_{j_1},\dots,G_{j_\ell} \rightarrow G_{j_\mathit{head}}$
define
$G_{j_1},\dots,G_{j_\ell} \rightarrow G_{j_\mathit{head}}$
define
 \begin{equation*} \mathrm{Eval}(\gamma_j) := \sum_{k=1}^\ell \left(1-x_{j_k} \right)+ x_{j_{\mathit{head}}},\end{equation*}
\begin{equation*} \mathrm{Eval}(\gamma_j) := \sum_{k=1}^\ell \left(1-x_{j_k} \right)+ x_{j_{\mathit{head}}},\end{equation*}
which directly expresses the satisfaction of rule
 $\gamma_j$
, with variable
$\gamma_j$
, with variable
 $x_{j_k}$
representing the truth of
$x_{j_k}$
representing the truth of
 $G_{j_k}$
. The linear programme
$G_{j_k}$
. The linear programme
 $\mathit{Opt}^K_{\prod,\tau}$
is then defined as follows
$\mathit{Opt}^K_{\prod,\tau}$
is then defined as follows
 \begin{equation} \begin{array}{llr} \text{minimise} & \sum_{i=1}^n x_i \\[5pt] \text{subject to} & \mathrm{Eval}(\gamma_j) \geq K & \text{for } 1 \leq j \leq m\\[5pt] & x_i = \tau(G_i) & \text{for i where $\tau(G_i)$ is defined}\\[5pt] & 1 \geq x_i \geq 0& \text{for } 1 \leq i \leq n. \end{array} \end{equation}
\begin{equation} \begin{array}{llr} \text{minimise} & \sum_{i=1}^n x_i \\[5pt] \text{subject to} & \mathrm{Eval}(\gamma_j) \geq K & \text{for } 1 \leq j \leq m\\[5pt] & x_i = \tau(G_i) & \text{for i where $\tau(G_i)$ is defined}\\[5pt] & 1 \geq x_i \geq 0& \text{for } 1 \leq i \leq n. \end{array} \end{equation}
Recall, a solution of a linear programme is any assignment to the variables, a feasible solution is a solution that satisfies all constraints, and an optimal solution is a feasible solution with minimal value of the objective function. With this in mind we can state our main result for MV-Datalog, a characterisation of minimal K-fuzzy models in terms of optimal solutions of
 $\mathit{Opt}^K_{\prod,\tau}$
.
$\mathit{Opt}^K_{\prod,\tau}$
.
Theorem 4. Let
 ${\Pi}$
,
${\Pi}$
,
 $\tau$
be an MV-instance. Then
$\tau$
be an MV-instance. Then
 $\mathbf{x}$
is an optimal solution of
$\mathbf{x}$
is an optimal solution of
 $\mathit{Opt}^K_{\prod,\tau}$
if and only if
$\mathit{Opt}^K_{\prod,\tau}$
if and only if
 $\nu_\mathbf{x}$
is a minimal K-fuzzy model of
$\nu_\mathbf{x}$
is a minimal K-fuzzy model of
 $({\Pi},\tau)$
By construction, any feasible solutions of
$({\Pi},\tau)$
By construction, any feasible solutions of
 $\mathit{Opt}^K_{\prod,\tau}$
induces a K-fuzzy model
$\mathit{Opt}^K_{\prod,\tau}$
induces a K-fuzzy model
 ${\nu_\mathbf{x}}$
that assigns
${\nu_\mathbf{x}}$
that assigns
 ${\nu_\mathbf{x}}(G_i)=x_i$
and 0 to all other ground atoms not in
${\nu_\mathbf{x}}(G_i)=x_i$
and 0 to all other ground atoms not in
 $\mathcal{G}$
. Similarly, in the other direction we can observe that any K-fuzzy model
$\mathcal{G}$
. Similarly, in the other direction we can observe that any K-fuzzy model
 $\nu$
of
$\nu$
of
 $({\Pi}, \tau)$
can be used to construct a feasible solution of
$({\Pi}, \tau)$
can be used to construct a feasible solution of
 $\mathit{Opt}^K_{\prod,\tau}$
. This natural correspondence of solutions of
$\mathit{Opt}^K_{\prod,\tau}$
. This natural correspondence of solutions of
 $\mathit{Opt}^K_{\prod,\tau}$
and K-fuzzy models of
$\mathit{Opt}^K_{\prod,\tau}$
and K-fuzzy models of
 $({\Pi}, \tau)$
is formalised in the following lemma.
$({\Pi}, \tau)$
is formalised in the following lemma.
Lemma 5. Let
 ${\Pi}$
,
${\Pi}$
,
 $\tau$
be an MV-instance. The following statements hold:
$\tau$
be an MV-instance. The following statements hold:
-
1. For any feasible solution
$\mathbf{x}$
of
$\mathit{Opt}^K_{\prod,\tau}$
,
${\nu_\mathbf{x}}$
is a K-fuzzy model of
$({\Pi}, \tau)$
. -
2. For any K-fuzzy model
$\nu$
of
$({\Pi}, \tau)$
, the solution
$\mathbf{x}$
with
$x_i = \nu(G_i)$
is a feasible solution of
$\mathit{Opt}^K_{\prod,\tau}$
. -
3.
$\mathit{Opt}^K_{\prod,\tau}$
is feasible if and only if
$({\Pi}, \tau)$
is K-satisfiable.











We say that a ground rule
 $\gamma \in \Gamma$
is
$\gamma \in \Gamma$
is
 $\nu$
-tight if
$\nu$
-tight if
 $\nu(\gamma)=K$
, that is
$\nu(\gamma)=K$
, that is
 $\nu(\mathrm{body}(\gamma))-1+K = \nu(\mathrm{head}(\gamma))$
. When a rule is not tight we refer to
$\nu(\mathrm{body}(\gamma))-1+K = \nu(\mathrm{head}(\gamma))$
. When a rule is not tight we refer to
 $\nu(\mathrm{head}(\gamma)) - (\nu(\mathrm{body}(\gamma))-1+K)$
as the
$\nu(\mathrm{head}(\gamma)) - (\nu(\mathrm{body}(\gamma))-1+K)$
as the
 ${\nu_\mathbf{x}}$
-gap of the rule. The gap is at least 0 for any K-satisfied ground rule. We will be interested in the structural relationships between tight rules. We refer to the ground atoms in
${\nu_\mathbf{x}}$
-gap of the rule. The gap is at least 0 for any K-satisfied ground rule. We will be interested in the structural relationships between tight rules. We refer to the ground atoms in
 $\mathcal{G}$
for which
$\mathcal{G}$
for which
 $\tau$
is not defined as the derived ground atoms of
$\tau$
is not defined as the derived ground atoms of
 $\mathit{Opt}^K_{\prod,\tau}$
.
$\mathit{Opt}^K_{\prod,\tau}$
.
Lemma 6. Let
 $\nu$
be a minimal model of an MV-instance
$\nu$
be a minimal model of an MV-instance
 ${\Pi}, \tau$
. Let
${\Pi}, \tau$
. Let
 $\mathcal{G}'$
be a non-empty set of ground atoms for which
$\mathcal{G}'$
be a non-empty set of ground atoms for which
 $\nu$
assigns truth greater than 0. Then there exists at least one
$\nu$
assigns truth greater than 0. Then there exists at least one
 $\nu$
-tight ground rule in
$\nu$
-tight ground rule in
 $\mathit{OGround}({\prod^{\mathit{crisp}}}, D_\tau)$
such that
$\mathit{OGround}({\prod^{\mathit{crisp}}}, D_\tau)$
such that
 $\mathrm{head}(\gamma)\in \mathcal{G}'$
and
$\mathrm{head}(\gamma)\in \mathcal{G}'$
and
 $\mathrm{body}(\gamma)\cap \mathcal{G}' = \emptyset$
.
$\mathrm{body}(\gamma)\cap \mathcal{G}' = \emptyset$
.
Proof of Theorem 4. Observe, that by Lemma 3 and the fact that the chase produces all atoms that can be entailed by
 $({\Pi}, \tau)$
, it follows that we do not have to consider solutions with atoms other than the set
$({\Pi}, \tau)$
, it follows that we do not have to consider solutions with atoms other than the set
 $\mathcal{G}$
considered in the definition of
$\mathcal{G}$
considered in the definition of
 $\mathit{Opt}^K_{\prod,\tau}$
.
$\mathit{Opt}^K_{\prod,\tau}$
.
For the if direction, let
 $\mu$
be a minimal model of
$\mu$
be a minimal model of
 $({\Pi}, \tau)$
with
$({\Pi}, \tau)$
with
 $\mu(G) = 0$
for all ground atoms
$\mu(G) = 0$
for all ground atoms
 $G \not \in \mathcal{G}$
. By Lemma 5,
$G \not \in \mathcal{G}$
. By Lemma 5,
 $\mu$
induces a feasible solution
$\mu$
induces a feasible solution
 $\mathbf{x}$
of
$\mathbf{x}$
of
 $\mathit{Opt}^K_{\prod,\tau}$
where
$\mathit{Opt}^K_{\prod,\tau}$
where
 $x_i = \mu(G_i)$
. Suppose this solution is not optimal and let
$x_i = \mu(G_i)$
. Suppose this solution is not optimal and let
 $\mathbf{y}$
be an optimal solution of
$\mathbf{y}$
be an optimal solution of
 $\mathit{Opt}^K_{\prod,\tau}$
. Let
$\mathit{Opt}^K_{\prod,\tau}$
. Let
 $\mathcal{G}' \subseteq \mathcal{G}$
be the set of ground atoms G where
$\mathcal{G}' \subseteq \mathcal{G}$
be the set of ground atoms G where
 ${\nu_\mathbf{y}}(G) < \mu(G)$
. Since we assume that
${\nu_\mathbf{y}}(G) < \mu(G)$
. Since we assume that
 $\sum y_i < \sum x_i$
, this set is not empty. By Lemma 6 there exists a
$\sum y_i < \sum x_i$
, this set is not empty. By Lemma 6 there exists a
 $\mu$
-tight rule
$\mu$
-tight rule
 $\gamma$
where the head is in
$\gamma$
where the head is in
 $\mathcal{G}'$
but none of the body atoms of
$\mathcal{G}'$
but none of the body atoms of
 $\gamma$
are. It follows that
$\gamma$
are. It follows that
 \begin{equation*} {\nu_\mathbf{y}}(\mathrm{head}(\gamma)) < \mu(\mathrm{head}(\gamma)) = \mu(\mathrm{body}(\gamma)) -1+K= {\nu_\mathbf{y}}(\mathrm{body}(\gamma)) -1+K. \end{equation*}
\begin{equation*} {\nu_\mathbf{y}}(\mathrm{head}(\gamma)) < \mu(\mathrm{head}(\gamma)) = \mu(\mathrm{body}(\gamma)) -1+K= {\nu_\mathbf{y}}(\mathrm{body}(\gamma)) -1+K. \end{equation*}
Hence,
 ${\nu_\mathbf{y}}$
does not K-satisfy
${\nu_\mathbf{y}}$
does not K-satisfy
 $\gamma$
. By Lemma 5 this contradicts the assumption that
$\gamma$
. By Lemma 5 this contradicts the assumption that
 $\mathbf{y}$
is a feasible solution with lower objective than
$\mathbf{y}$
is a feasible solution with lower objective than
 $\mathbf{x}$
.
$\mathbf{x}$
.
For the other direction, let
 $\mathbf{x}$
be an optimal solution of
$\mathbf{x}$
be an optimal solution of
 $\mathit{Opt}^K_{\prod,\tau}$
. Suppose now that
$\mathit{Opt}^K_{\prod,\tau}$
. Suppose now that
 ${\nu_\mathbf{x}}$
is not a minimal K-fuzzy model of
${\nu_\mathbf{x}}$
is not a minimal K-fuzzy model of
 $({\Pi}, \tau)$
. Hence, there exists some model
$({\Pi}, \tau)$
. Hence, there exists some model
 $\nu'$
with
$\nu'$
with
 $\nu' < {\nu_\mathbf{x}}$
. Let
$\nu' < {\nu_\mathbf{x}}$
. Let
 $\mathbf{y}$
be the solution of
$\mathbf{y}$
be the solution of
 $\mathit{Opt}^K_{\prod,\tau}$
induced by
$\mathit{Opt}^K_{\prod,\tau}$
induced by
 $\nu'$
. Since at least one atom is less true, and none are more true in
$\nu'$
. Since at least one atom is less true, and none are more true in
 $\nu'$
we have
$\nu'$
we have
 $\sum y_i < \sum x_i$
, contradicting the optimality of
$\sum y_i < \sum x_i$
, contradicting the optimality of
 $\mathbf{x}$
for
$\mathbf{x}$
for
 $\mathit{Opt}^K_{\prod,\tau}$
.
$\mathit{Opt}^K_{\prod,\tau}$
.
Since the oblivious chase is polynomial with respect to data complexity (without existential quantification) and fi§nding optimal solutions of linear programmes is famously polynomial (Khachiyan Reference Khachiyan1979), our characterisation of minimal K-fuzzy models also directly reveals the complexity of K-Truth. Recall that for
 $K=1$
,
$K=1$
,
 $\mathbf{\textsf{P}}$
-hardness is inherited from classical Datalog (see Dantsin et al. Reference Dantsin, Eiter, Gottlob and Voronkov2001).
$\mathbf{\textsf{P}}$
-hardness is inherited from classical Datalog (see Dantsin et al. Reference Dantsin, Eiter, Gottlob and Voronkov2001).
Corollary 7. Fix a rational
 $K\in (0,1]$
. K-Truth is in
$K\in (0,1]$
. K-Truth is in
 $\mathbf{\textsf{P}}$
with respect to data complexity. Moreover, 1-Truth is
$\mathbf{\textsf{P}}$
with respect to data complexity. Moreover, 1-Truth is
 $\mathbf{\textsf{P}}$
-complete in data complexity.
$\mathbf{\textsf{P}}$
-complete in data complexity.
To conclude this section we briefly note why it is important to use the oblivious chase as a basis for the ground rules that make up
 $\mathit{Opt}^K_{\prod,\tau}$
. Consider the programme
$\mathit{Opt}^K_{\prod,\tau}$
. Consider the programme
 $P(x), Q(x) \rightarrow S(x)$
and
$P(x), Q(x) \rightarrow S(x)$
and
 $R(x) \rightarrow S(x)$
. In plain Datalog, S(a) can be inferred simply if either P(a) and Q(a), or R(a) are in the database. However, in the many-valued setting the truth of S(a) depends on the truth of all three facts, P(a), Q(a), and R(a) since it needs to be at least as true as
$R(x) \rightarrow S(x)$
. In plain Datalog, S(a) can be inferred simply if either P(a) and Q(a), or R(a) are in the database. However, in the many-valued setting the truth of S(a) depends on the truth of all three facts, P(a), Q(a), and R(a) since it needs to be at least as true as
 $P(x) {\odot} Q(a)$
and at least as true R(a). Technically this means
$P(x) {\odot} Q(a)$
and at least as true R(a). Technically this means
 $\mathit{Opt}^K_{\prod,\tau}$
needs to consider all possible paths of inferring each ground atom, and this exactly corresponds to the oblivious chase applying rules once per homomorphism from the body into the instance.
$\mathit{Opt}^K_{\prod,\tau}$
needs to consider all possible paths of inferring each ground atom, and this exactly corresponds to the oblivious chase applying rules once per homomorphism from the body into the instance.
3.3 Classical behaviour for certain knowledge
We are particularly interested in settings where one wants to combine large amounts of certain knowledge, for example, classical knowledge graphs and databases, with additional fuzzy information. Going back to our example from the introduction, we have such a scenario if we want to reason on properties of the animals in the pictures by using pre-existing biological and zoological ontologies. Ideally, we want inference on the ontologies to behave exactly as in the Datalog and only differ in behaviour when such certain knowledge is combined with fuzzy observations and consequences of fuzzy observations. Note that particularly in the context of ontologies the question of fuzziness has also been studied extensively in the field of fuzzy description logics, see for example, Borgwardt and PeÑaloza (Reference Borgwardt and PeÑaloza2017), Stoilos et al. (Reference Stoilos, Stamou, Pan, Tzouvaras and Horrocks2007), Lukasiewicz and Straccia (Reference Lukasiewicz and Straccia2008). Notably, the
 $\mathcal{EL}$
family of descrioption logics, which is closely related to rule based languages, has also been studied specifically with fuzzy semantics based on Łukasiewicz logic and shown undecidable by Borgwardt et al. (Reference Borgwardt, Cerami and PeÑaloza2017).
$\mathcal{EL}$
family of descrioption logics, which is closely related to rule based languages, has also been studied specifically with fuzzy semantics based on Łukasiewicz logic and shown undecidable by Borgwardt et al. (Reference Borgwardt, Cerami and PeÑaloza2017).
We show now that MV-Datalog indeed exhibits such ideal behaviour. In particular, when we consider Lemma 3 but with a database consisting only of certain knowledge in
 $\tau$
, that is, ground atoms for which
$\tau$
, that is, ground atoms for which
 $\tau$
evaluates to 1, we can state the following.
$\tau$
evaluates to 1, we can state the following.
Theorem 8. Let
 ${\Pi}$
,
${\Pi}$
,
 $\tau$
be a MV-Datalog program and database. Let
$\tau$
be a MV-Datalog program and database. Let
 $D^1$
be the classical database containing all
$D^1$
be the classical database containing all
 $G\in \mathit{GAtoms}$
where
$G\in \mathit{GAtoms}$
where
 $\tau(G) =1$
. If
$\tau(G) =1$
. If
 ${\Pi}, \tau$
is 1-satisfiable, then for every ground atom G,
${\Pi}, \tau$
is 1-satisfiable, then for every ground atom G,
 ${\prod^{\mathit{crisp}}}, D^1 \models G$
if and only if
${\prod^{\mathit{crisp}}}, D^1 \models G$
if and only if
 $\mu(G)=1$
where
$\mu(G)=1$
where
 $\mu$
is the minimal 1-fuzzy model of
$\mu$
is the minimal 1-fuzzy model of
 $({\Pi},\tau)$
.
$({\Pi},\tau)$
.
Beyond the conceptual importance of Theorem 8, the statement also has significant practical consequences. Our characterisation of minimal K-fuzzy models provides a clear algorithm for computing minimal K-fuzzy models via the oblivious chase and then solving
 $\mathit{Opt}^K_{\prod,\tau}$
. Using the oblivious chase is important for our characterisation, since different ground rules with the same head may differ in how true their body is. In classical Datalog it is of course sufficient to infer the head once, which can require significantly less effort in practice. According to Theorem 8 (and by uniqueness of minimal fuzzy models) it is not necessary to compute the truth degree of those facts that are entailed by
$\mathit{Opt}^K_{\prod,\tau}$
. Using the oblivious chase is important for our characterisation, since different ground rules with the same head may differ in how true their body is. In classical Datalog it is of course sufficient to infer the head once, which can require significantly less effort in practice. According to Theorem 8 (and by uniqueness of minimal fuzzy models) it is not necessary to compute the truth degree of those facts that are entailed by
 ${\prod^{\mathit{crisp}}}, D^1$
via
${\prod^{\mathit{crisp}}}, D^1$
via
 $\mathit{Opt}^K_{\prod,\tau}$
. An implementation can use this observation to produce less ground rules (i.e., not the full oblivious chase) and smaller equivalent versions of
$\mathit{Opt}^K_{\prod,\tau}$
. An implementation can use this observation to produce less ground rules (i.e., not the full oblivious chase) and smaller equivalent versions of
 $\mathit{Opt}^K_{\prod,\tau}$
with less computational effort.
$\mathit{Opt}^K_{\prod,\tau}$
with less computational effort.
We conclude that MV-Datalog is well suited for combining large amounts of certain knowledge with fuzzy observations. Not only are the semantics on certain data equivalent to those of classical Datalog, but the computation of minimal fuzzy models also exhibits desirable properties in the presence of certain data.
4
$\mathrm{MV-Datalog}^\pm$

Existential quantification in the head of rules provide a natural way of dealing with the common problem of incomplete or missing data by declaratively stating that certain facts must exist. Such usage is especially powerful in applications where rule-based reasoning is used for complex data analysis (see e.g., Bellomarini et al. Reference Bellomarini, Gottlob, Pieris and Sallinger2017). In the following, we introduce
 $\mathrm{MV-Datalog}^\pm$
as an extension of MV-Datalog with a focus on providing a fuzzy reasoning language that is useful for such applications.
$\mathrm{MV-Datalog}^\pm$
as an extension of MV-Datalog with a focus on providing a fuzzy reasoning language that is useful for such applications.
To obtain semantics matching our intuition for such a system, we propose an alternative to the commonly studied semantics for existential quantification for Łukasiewicz logic. We then identify certain preferred models that exhibit desired conceptual and computational behaviour as the basis for reasoning in
 $\mathrm{MV-Datalog}^\pm$
.
$\mathrm{MV-Datalog}^\pm$
.
4.1 Strong existential quantification in Łukasiewicz semantics
The semantics of existential quantification in Łukasiewicz logic is commonly defined as
 $\nu(\exists \mathbf{x} \varphi(\mathbf{x})) = \sup\{\nu(\varphi[\mathbf{x}/\mathbf{c}]) \mid \mathbf{c} \in \mathit{Dom}^{|x|}\}$
where
$\nu(\exists \mathbf{x} \varphi(\mathbf{x})) = \sup\{\nu(\varphi[\mathbf{x}/\mathbf{c}]) \mid \mathbf{c} \in \mathit{Dom}^{|x|}\}$
where
 $\varphi[\mathbf{x}/\mathbf{c}]$
is the substitution of variables
$\varphi[\mathbf{x}/\mathbf{c}]$
is the substitution of variables
 $\mathbf{x}$
in
$\mathbf{x}$
in
 $\varphi$
by constants
$\varphi$
by constants
 $\mathbf{c}$
(cf. HÁjek Reference HÁjek1998).
$\mathbf{c}$
(cf. HÁjek Reference HÁjek1998).
However, with our focus set on practical applications, we propose alternative semantics for existential quantification that match the semantics of
 ${\oplus}$
. To contrast between the aforementioned semantics of
${\oplus}$
. To contrast between the aforementioned semantics of
 $\exists$
we refer to our semantics as strong existential quantification.
$\exists$
we refer to our semantics as strong existential quantification.
 \begin{equation*} \nu(\exists \mathbf{x}\ \varphi(\mathbf{x})) = \min\{1, \sum_{\mathbf{c} \in \mathit{Dom}^{|x|}} \nu(\varphi[\mathbf{x}/\mathbf{c}])\}.\end{equation*}
\begin{equation*} \nu(\exists \mathbf{x}\ \varphi(\mathbf{x})) = \min\{1, \sum_{\mathbf{c} \in \mathit{Dom}^{|x|}} \nu(\varphi[\mathbf{x}/\mathbf{c}])\}.\end{equation*}
We refer to
 $\mathbf{L}$
extended with strong existential quantification as
$\mathbf{L}$
extended with strong existential quantification as
 $\mathbf{L}_\exists$
(following standard syntax of first order existential quantification). Such semantics for quantification in Łukasiewicz logic have also recently been studied more generally in a purely logical context by Fjellstad and Olsen (Reference Fjellstad and Olsen2021).
$\mathbf{L}_\exists$
(following standard syntax of first order existential quantification). Such semantics for quantification in Łukasiewicz logic have also recently been studied more generally in a purely logical context by Fjellstad and Olsen (Reference Fjellstad and Olsen2021).
Definition 3 A
 $\mathrm{MV-Datalog}^\pm$
program is a set of
$\mathrm{MV-Datalog}^\pm$
program is a set of
 $\mathbf{L}_\exists$
formulas that are either MV-Datalog rules or of the form
$\mathbf{L}_\exists$
formulas that are either MV-Datalog rules or of the form
 \begin{equation*} B_1 {\odot} B_2 {\odot} \cdots {\odot} B_n \rightarrow \exists \mathbf{x}\ \varphi(\mathbf{x}, \mathbf{y}), \end{equation*}
\begin{equation*} B_1 {\odot} B_2 {\odot} \cdots {\odot} B_n \rightarrow \exists \mathbf{x}\ \varphi(\mathbf{x}, \mathbf{y}), \end{equation*}
where
 $B_i$
are relational atoms,
$B_i$
are relational atoms,
 $\mathbf{y}$
are the variables in the body, and
$\mathbf{y}$
are the variables in the body, and
 $\varphi$
is formula that contains only a relational atom that uses all variables of
$\varphi$
is formula that contains only a relational atom that uses all variables of
 $\mathbf{x}$
.
$\mathbf{x}$
.
Note that we generally do not restrict the domain in the semantics of
 $\mathbf{L}$
formulas. Thus, as in
$\mathbf{L}$
formulas. Thus, as in
 $\mathrm{Datalog}^\pm$
, interpretations are not constrained to the active domain of
$\mathrm{Datalog}^\pm$
, interpretations are not constrained to the active domain of
 ${\Pi}$
and
${\Pi}$
and
 $\tau$
but allow for the introduction of new constants. As noted above, the introduction of new constants provides a natural mechanism to deductively handle missing and incomplete data. Our proposed use of strong existential quantification is motivated by its behaviour in cases of incomplete information as illustrated in the following example.
$\tau$
but allow for the introduction of new constants. As noted above, the introduction of new constants provides a natural mechanism to deductively handle missing and incomplete data. Our proposed use of strong existential quantification is motivated by its behaviour in cases of incomplete information as illustrated in the following example.
Example 2. We consider the following example rule, expressing that every company has a key person, to illustrate the difference between the two semantics for
 $\exists$
.
$\exists$
.
 \begin{equation*} \begin{array}{ll} \mathit{Company}(y)& \rightarrow \exists x\ \mathit{KeyPerson}(x, y). \end{array} \end{equation*}
\begin{equation*} \begin{array}{ll} \mathit{Company}(y)& \rightarrow \exists x\ \mathit{KeyPerson}(x, y). \end{array} \end{equation*}
Suppose we have the following database, we know for certain that Acme is a company and we are
 $0.8$
degrees confident that Amy is the key person of Acme.
$0.8$
degrees confident that Amy is the key person of Acme.
 \begin{equation*} \tau(\mathit{KeyPerson}(\mathrm{Amy}, \mathrm{Acme})) = 0.8, \qquad \tau(\mathit{Company}(\mathrm{Acme})) = 1. \end{equation*}
\begin{equation*} \tau(\mathit{KeyPerson}(\mathrm{Amy}, \mathrm{Acme})) = 0.8, \qquad \tau(\mathit{Company}(\mathrm{Acme})) = 1. \end{equation*}
We discuss the case in a 1-fuzzy model in the following. With existential semantics via the supremum of matching ground atoms, the first rule implies the existence of some new
 $\mathit{KeyPerson}(\mathrm{N}_1, \mathrm{Acme})$
with truth degree 1. With strong existential quantification, the first rule implies only truth degree
$\mathit{KeyPerson}(\mathrm{N}_1, \mathrm{Acme})$
with truth degree 1. With strong existential quantification, the first rule implies only truth degree
 $0.2$
for some
$0.2$
for some
 $\mathit{KeyPerson}(\mathrm{N}_1, \mathrm{Acme})$
since the known observation
$\mathit{KeyPerson}(\mathrm{N}_1, \mathrm{Acme})$
since the known observation
 $\mathit{KeyPerson}(\mathrm{Amy}, \mathrm{Acme})$
already contributes
$\mathit{KeyPerson}(\mathrm{Amy}, \mathrm{Acme})$
already contributes
 $0.8$
degrees of truth to the head.
$0.8$
degrees of truth to the head.
Intuitively, the new constant
 $\mathrm{N}_1$
assumes the role of the unknown other object that possibly is the key person. In traditional semantics for
$\mathrm{N}_1$
assumes the role of the unknown other object that possibly is the key person. In traditional semantics for
 $\exists$
we have to infer (in a 1-fuzzy model) that
$\exists$
we have to infer (in a 1-fuzzy model) that
 $\mathrm{N}_1$
is certain to control Acme. In contrast, under strong existential semantics, the confidence in
$\mathrm{N}_1$
is certain to control Acme. In contrast, under strong existential semantics, the confidence in
 $\mathrm{N}_1$
being the key person is determined by the known observation that Amy might be the key person.
$\mathrm{N}_1$
being the key person is determined by the known observation that Amy might be the key person.
4.2 Preferred models for
$\mathrm{MV-Datalog}^\pm$

When considered in full generality, our proposed strong existential quantification semantics reveal a variety of theoretical challenges. To allow for K-fuzzy models
 $\nu$
where
$\nu$
where
 $\{G \in \mathit{GAtoms} \mid \nu(G)>0\}$
is not finite would require the introduction of further technical complexity in the definition. Furthermore, it can be necessary for a model to introduce multiple new constants per ground rule to satisfy an existential quantification in certain situations as illustrated by the following example.
$\{G \in \mathit{GAtoms} \mid \nu(G)>0\}$
is not finite would require the introduction of further technical complexity in the definition. Furthermore, it can be necessary for a model to introduce multiple new constants per ground rule to satisfy an existential quantification in certain situations as illustrated by the following example.
Example 3. Consider database
 $\tau$
with
$\tau$
with
 $ \tau(S(a)) = 0.8, \tau(T(a)) = 0.2 $
and program
$ \tau(S(a)) = 0.8, \tau(T(a)) = 0.2 $
and program
 ${\Pi}$
${\Pi}$
 \begin{equation*} \begin{array}{ll} S(x) & \rightarrow \exists y\ P(x, y) \\ P(x, y) & \rightarrow T(x). \end{array} \end{equation*}
\begin{equation*} \begin{array}{ll} S(x) & \rightarrow \exists y\ P(x, y) \\ P(x, y) & \rightarrow T(x). \end{array} \end{equation*}
Then there is no 1-fuzzy model with only one new constant. However, there is a solution where the facts
 $P(a, n_1), P(a, n_2), P(a, n_3), P(a, n_4)$
, with new constants
$P(a, n_1), P(a, n_2), P(a, n_3), P(a, n_4)$
, with new constants
 $n_1,\dots,n_4$
, are all assigned truth degree
$n_1,\dots,n_4$
, are all assigned truth degree
 $0.2$
.
$0.2$
.
Infinite models and the phenomenon illustrated by Example 3 present interesting topics for further theoretical study. For practical applications we propose to avoid these corner cases and focus on natural preferred models that avoid these issues and provide predictable outcomes.
Recall that the oblivious chase sequence introduces new constants exactly once for every possible true grounding of the body. This limitation on the number of new constants provides a natural balance between not overly restricting facts with null values in models while also avoiding extreme situations as in Example 3 where arbitrarily many constants are introduced to satisfy the rule for a single ground body. We also restrict minimality of fuzzy models to only those ground atoms without labelled nulls. Minimising also the truth of atoms with labelled nulls would intuitively correspond to a kind of soft closed-world assumption, where we want to infer truth of statements under the assumption that the unknown information is minimal.
Definition 4. Let
 ${\Pi}, \tau$
be an
${\Pi}, \tau$
be an
 $\mathrm{MV}^\pm$
-instance. Let
$\mathrm{MV}^\pm$
-instance. Let
 $\mu$
,
$\mu$
,
 $\nu$
be two K-fuzzy models of
$\nu$
be two K-fuzzy models of
 $({\Pi}, \tau)$
. We say that
$({\Pi}, \tau)$
. We say that
 $\mu \leq_{a} \nu$
if for all
$\mu \leq_{a} \nu$
if for all
 $G \in {\mathit{GAtoms}[{\mathit{Adom}]}}$
it holds that
$G \in {\mathit{GAtoms}[{\mathit{Adom}]}}$
it holds that
 $\mu(G) \leq \nu(G)$
.
$\mu(G) \leq \nu(G)$
.
Definition 5. We say that a K-fuzzy model
 $\nu$
of
$\nu$
of
 $\mathrm{MV-Datalog}^\pm$
instance
$\mathrm{MV-Datalog}^\pm$
instance
 $({\Pi}, \tau)$
has an oblivious base if
$({\Pi}, \tau)$
has an oblivious base if
 $\mathit{OLim}({\prod^{\mathit{crisp}}}, D_\tau)$
is finite, if for every
$\mathit{OLim}({\prod^{\mathit{crisp}}}, D_\tau)$
is finite, if for every
 $G\in\mathit{GAtoms}$
it holds that
$G\in\mathit{GAtoms}$
it holds that
 $\nu(G) > 0$
only if
$\nu(G) > 0$
only if
 $G \in \mathit{OLim}({\prod^{\mathit{crisp}}}, D_\tau)$
. We say that
$G \in \mathit{OLim}({\prod^{\mathit{crisp}}}, D_\tau)$
. We say that
 $\nu$
is a preferred K-fuzzy model if it is minimal with respect to the partial ordering
$\nu$
is a preferred K-fuzzy model if it is minimal with respect to the partial ordering
 $\leq_{a}$
of all K-fuzzy models with an oblivious base.
$\leq_{a}$
of all K-fuzzy models with an oblivious base.
This definition of preferred models captures the previously outlined intuition of which kinds of models we want to consider for practical applications. That is, we propose preferred models as the desired output of an
 $\mathrm{MV-Datalog}^\pm$
system. An
$\mathrm{MV-Datalog}^\pm$
system. An
 $\mathrm{MV}^\pm$
-instance does not necessarily have a unique preferred model. The question of how to compare preferred models among each other is left as an open question.
$\mathrm{MV}^\pm$
-instance does not necessarily have a unique preferred model. The question of how to compare preferred models among each other is left as an open question.
We now extend the definition of
 $\mathit{Opt}^K_{\prod,\tau}$
from Section 3.1 to programme
$\mathit{Opt}^K_{\prod,\tau}$
from Section 3.1 to programme
 ${\exists\text{-}\mathit{Opt}^K_{\prod,\tau}}$
for an
${\exists\text{-}\mathit{Opt}^K_{\prod,\tau}}$
for an
 $\mathrm{MV}^\pm$
-instance
$\mathrm{MV}^\pm$
-instance
 ${\Pi}, \tau$
. Let
${\Pi}, \tau$
. Let
 $\mathcal{G}$
and
$\mathcal{G}$
and
 $\Gamma$
be as in the previous definition of
$\Gamma$
be as in the previous definition of
 $\mathit{Opt}^K_{\prod,\tau}$
. For ground rules that are the result of grounding a rule without existential quantification, Eval is defined the same as it was for
$\mathit{Opt}^K_{\prod,\tau}$
. For ground rules that are the result of grounding a rule without existential quantification, Eval is defined the same as it was for
 $\mathit{Opt}^K_{\prod,\tau}$
. Otherwise, let
$\mathit{Opt}^K_{\prod,\tau}$
. Otherwise, let
 $\gamma$
be a ground rule obtained from grounding of an existential rule. Let
$\gamma$
be a ground rule obtained from grounding of an existential rule. Let
 $G_h$
be the atom in the head of
$G_h$
be the atom in the head of
 $\gamma$
and let N be the labelled nulls at the positions in
$\gamma$
and let N be the labelled nulls at the positions in
 $G_h$
that were existentially quantified in the original rule before grounding. We say that a ground atom G matches
$G_h$
that were existentially quantified in the original rule before grounding. We say that a ground atom G matches
 $G_h$
if G can be obtained from
$G_h$
if G can be obtained from
 $G_h$
by replacing the labelled nulls in N by some other values of the domain. Let
$G_h$
by replacing the labelled nulls in N by some other values of the domain. Let
 $G_{\beta_1},\dots, G_{\beta_k}$
be the ground atoms in
$G_{\beta_1},\dots, G_{\beta_k}$
be the ground atoms in
 $\mathcal{G}$
that match
$\mathcal{G}$
that match
 $G_h$
. We can then extend our previous definition of Eval to groundings of existential rules as
$G_h$
. We can then extend our previous definition of Eval to groundings of existential rules as
 \begin{equation*} \mathrm{Eval}(\gamma) := \sum_{j=1}^\ell \left(1-x_{\alpha_j} \right)+ \sum_{i=1}^k x_{\beta_i}\end{equation*}
\begin{equation*} \mathrm{Eval}(\gamma) := \sum_{j=1}^\ell \left(1-x_{\alpha_j} \right)+ \sum_{i=1}^k x_{\beta_i}\end{equation*}
with variables
 $x_{\alpha_j}$
and
$x_{\alpha_j}$
and
 $x_{\beta_i}$
corresponding, respectively, to the truth values of the ground atoms in the body and the head. Then
$x_{\beta_i}$
corresponding, respectively, to the truth values of the ground atoms in the body and the head. Then
 ${\exists\text{-}\mathit{Opt}^K_{\prod,\tau}}$
is the linear programme defined the same as
${\exists\text{-}\mathit{Opt}^K_{\prod,\tau}}$
is the linear programme defined the same as
 $\mathit{Opt}^K_{\prod,\tau}$
, but with objective function
$\mathit{Opt}^K_{\prod,\tau}$
, but with objective function
 \begin{equation} \begin{array}{llr} \text{minimise} & \sum_{i=1}^n w_i x_i, \\ \end{array} \end{equation}
\begin{equation} \begin{array}{llr} \text{minimise} & \sum_{i=1}^n w_i x_i, \\ \end{array} \end{equation}
where
 $x_i$
provides the truth value of
$x_i$
provides the truth value of
 $G_i$
,
$G_i$
,
 $w_i= 1$
if
$w_i= 1$
if
 $G_i \in {\mathit{GAtoms}[{\mathit{Adom}]}}$
and
$G_i \in {\mathit{GAtoms}[{\mathit{Adom}]}}$
and
 $w_i=0$
otherwise. That is, ground atoms that contain nulls do not contribute to the objective. Recall from Example 3 that this does not imply that they can be simply set to be fully true.
$w_i=0$
otherwise. That is, ground atoms that contain nulls do not contribute to the objective. Recall from Example 3 that this does not imply that they can be simply set to be fully true.
Theorem 9. Let
 ${\Pi}$
,
${\Pi}$
,
 $\tau$
be a MV-Datalog program and database where
$\tau$
be a MV-Datalog program and database where
 $\mathit{OLim}({\prod^{\mathit{crisp}}}, D_\tau)$
is finite. The following two statements hold.
$\mathit{OLim}({\prod^{\mathit{crisp}}}, D_\tau)$
is finite. The following two statements hold.
-
1. If
$({\Pi}, \tau)$
has a preferred K-fuzzy model, then
${\exists\text{-}\mathit{Opt}^K_{\prod,\tau}}$
is feasible. -
2. For any optimal solution
$\mathbf{x}$
of
${\exists\text{-}\mathit{Opt}^K_{\prod,\tau}}$
, we have that
$\nu_\mathbf{x}$
is a preferred K-fuzzy model for
$({\Pi}, \tau)$
.






From our definition of preferred models we are naturally interested in identifying cases where the oblivious chase is finite. There exist syntactic restrictions for which we can show that this is always the case. In particular, we can identify programmes where the oblivious chase is finite based on the notion of weakly acyclic programmes as studied by Fagin et al. (Reference Fagin, Kolaitis, Miller and Popa2005). Technical details of this question are discussed in Appendix B of the arXiv version of this paper (cf., Lanzinger et al. Reference Lanzinger, Sferrazza and Gottlob2022).
5 Conclusion and outlook
We have introduced MV-Datalog and
 $\mathrm{MV-Datalog}^\pm$
, two many-valued rule-based reasoning languages following Łukasiewicz semantics. We provide theoretical foundations for MV-Datalog by characterising its minimal models in terms of an optimisation problem and showing that fuzzy fact entailment in MV-Datalog has the same complexity as fact entailment in Datalog. For
$\mathrm{MV-Datalog}^\pm$
, two many-valued rule-based reasoning languages following Łukasiewicz semantics. We provide theoretical foundations for MV-Datalog by characterising its minimal models in terms of an optimisation problem and showing that fuzzy fact entailment in MV-Datalog has the same complexity as fact entailment in Datalog. For
 $\mathrm{MV-Datalog}^\pm$
we introduce alternative semantics for existential quantification in Łukasiewicz logic that better match the popular usage of
$\mathrm{MV-Datalog}^\pm$
we introduce alternative semantics for existential quantification in Łukasiewicz logic that better match the popular usage of
 $\exists$
for handling missing data. As a first starting point for the practical use of
$\exists$
for handling missing data. As a first starting point for the practical use of
 $\mathrm{MV-Datalog}^\pm$
we introduce preferred models and show how to compute them.
$\mathrm{MV-Datalog}^\pm$
we introduce preferred models and show how to compute them.
We argue that MV-Datalog and its extensions can be effective languages for reasoning in settings with uncertain data. Therefore the development of a system based on the results given here is the natural next step to validate efficiency and effectiveness in comparison to other formalisms. This also entails the study of how the computation of minimal or preferred models can be further optimised, ideally requiring fewer ground rules than the methods described here.
Beyond practical considerations, a variety of natural theoretical questions have been left open. Prime among them are the questions of how fuzzy models of MV-Datalog behave with stratified negation, and how to handle the behaviour of
 $\mathrm{MV-Datalog}^\pm$
instances with an infinite oblivious chase. The latter is particularly intriguing since truth degrees effectively decreases monotonically along paths of derivation. We therefore suspect there to be relevant classes of problems where the oblivious chase is infinite but instances always permit finite fuzzy models.
$\mathrm{MV-Datalog}^\pm$
instances with an infinite oblivious chase. The latter is particularly intriguing since truth degrees effectively decreases monotonically along paths of derivation. We therefore suspect there to be relevant classes of problems where the oblivious chase is infinite but instances always permit finite fuzzy models.
Finally, there is an intriguing possibility of combining MV-Datalog semantics with the probabilistic semantics of Problog to reason about uncertainty and likelihood as two orthogonal concepts at the same time.
Supplementary material
To view supplementary material for this article, please visit http://doi.org/10.1017/ S1471068422000199.



