INTRODUCTION
Adult learners of a second (L2) or foreign (FL) language often experience difficulties in the perception and production of L2 segmental and prosodic features. These difficulties stem from a range of factors, such as the influence of their L1 sound system (Bohn & Flege, Reference Bohn and Flege1992; Flege, Reference Flege and Strange1995; Flege et al., Reference Flege, Bohn and Jang1997), the quantity and quality of the L2 input (e.g., Moyer, Reference Moyer, Piske and Young-Scholten2009), the age of onset of learning (Flege et al., Reference Flege, Yeni-Komshian and Liu1999), or the amount of L1 use (Flege & MacKay, Reference Flege and MacKay2004), among others. In FL contexts,Footnote 1 where exposure to the target language and contact with speakers of the language is limited, mastering FL pronunciation becomes even more challenging. Research has shown, for example, that even English majors, who have undergone more than 10 years of formal language instruction and received explicit training in phonetics, show multiple features of their L1 in their interlanguage (Monroy-Casas, Reference Monroy-Casas2001).
Because of the challenging nature of L2 speech, and under the assumption that developing an accurate perception of the FL phonology plays a key role in subsequent productions (Flege, Reference Flege and Strange1995), a significant body of research has focused on the effects of phonetic training on the perception and production of L2 sounds (e.g., Aliaga-García & Mora, Reference Aliaga-García, Mora, Watkins, Rauber and Baptista2009; Carlet, Reference Carlet2017; Gómez-Lacabex et al., Reference Gómez-Lacabex, García-Lecumberri and Cooke2008; Iverson et al., Reference Iverson, Hazan and Banister2005; Logan et al., Reference Logan, Lively and Pisoni1991; Rato, Reference Rato2013). Such training can be extremely beneficial given that developing intelligible L2 speech typically requires a vast amount of experience with the L2. In this respect, one of the most common perceptual training paradigms is High Variability Phonetic Training (HVPT), a technique that presents learners with multiple instantiations of the target sounds embedded in various phonetic contexts and produced by different speakers (Logan et al., Reference Logan, Lively and Pisoni1991). Research shows that this technique can be beneficial after relatively short interventions (e.g., five 30-minute sessions in Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019; four 45-minute sessions in Carlet & Cebrian, Reference Carlet and Cebrian2014; eight sessions of 15–20 minutes in Thomson, Reference Thomson2011) and that it can facilitate the formation of robust phonetic categories for L2 sounds, as gains are generalized to untrained phonetic contexts (Thomson, Reference Thomson2011) and words (Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019; Nishi & Kewley-Port, Reference Nishi and Kewley-Port2007), to the production domain (Bradlow et al., Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997; Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019; Lambacher et al. Reference Lambacher, Martens, Kakehi, Marasinghe and Molholt2005; Rato, Reference Rato2013; Thomson, Reference Thomson2011), and they are maintained over time (Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019; Lively et al., Reference Lively, Pisoni, Yamada, Tohkura and Yamada1994; Nishi & Kewley-Port, Reference Nishi and Kewley-Port2007; Rato, Reference Rato2013).
Research using HVPT has explored a range of conditions, including learner-related variables such as overall musical ability and tonal memory (Ghaffarvand Mokari & Werner Reference Ghaffarvand Mokari and Werner2017), or L2 proficiency level (Wong, Reference Wong, Mompean and Fouz-González2015). However, most variables and research variations are related to training conditions (see Barriuso & Hayes-Harb, Reference Barriuso and Hayes-Harb2018). These include, among others, the modality of stimulus presentation (e.g., auditory only vs. audiovisual), the type of stimulus (e.g., synthetic/manipulated, naturally produced, or both), the length of training and training sessions (e.g., a single day vs. several weeks), participants’ control over training (e.g., strict schedule vs. self-paced), the number of contrasts being trained (e.g., from two to multiple), the type of task (discrimination vs. identification), or the provision of feedback (with or without). While research has shown that perceptual training can have a very positive impact on different aspects of L2 learners’ perception and production, and even though certain aspects of the technique have been established as best practices (e.g., the use of immediate feedback, multiple speakers/phonetic environments), there are still issues that require attention if perceptual training is to become a mainstream tool in L2/FL instruction (Thomson, Reference Thomson2018). One such issue is the type of response labels used in perception tasks, as these labels are the visual referents to which learners associate the aural input they receive.
PERCEPTUAL TRAINING AND THE CHOICE OF RESPONSE LABELS
As noted above, the aim of HVPT is to help learners improve their perception (and possibly production) of the L2 phonology. More specifically, this type of training helps learners improve their perception of L2 speech by helping them reallocate selective attention to phonetic dimensions that they do not normally attend to because they are not relevant for the categorization of sounds in their L1 (Logan et al., Reference Logan, Lively and Pisoni1991). Thus, perceptual training is essentially a way of helping learners perceive and categorize sounds accurately. The theoretical rationale behind this is that, by facilitating the formation of long-term representations (or categories) for the L2 sounds, the learners’ perception and production will improve (Flege, Reference Flege and Strange1995, Reference Flege, Meyer and Schiller2003).
In perceptual training research, different tasks have been used depending on the purpose of the investigation (see Logan & Pruitt, Reference Logan, Pruitt and Strange1995). Two common perceptual training tasks often used to enhance learners’ perception of L2 speech are discrimination and identification tasks (Carlet, Reference Carlet2017). In discrimination tasks, listeners are presented with two or more stimuli in a row and they have to decide whether they belong to the same or different categories. In identification tasks, learners listen to a stimulus and have to choose the category to which the stimulus belongs from various options that are presented to them in the form of response labels. While both discrimination and identification tasks can be used in perceptual training, research suggests that identification tasks seem to be particularly suitable for the development of new phonetic categories (Carlet, Reference Carlet2017; Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019). The reason for this is that discrimination tasks require listeners to compare several tokens that are physically present, whereas identification tasks require listeners to compare the stimuli they hear to their preexisting long-term memory representations of the target categories (Bohn, Reference Bohn, Burmeister, Piske and Rohde2002 cited in Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019).
Beyond the traditional distinction between abstract categories (phonemes) and speech sounds (phones) and taking into account the conceptual aspect of the HVPT training process, the units of the L2 phonology can be referred to in various ways. Flege’s (Reference Flege and Strange1995) Speech Learning Model (SLM), one of the most influential models of L2 speech, uses the construct of phonetic category to refer to long-term memory representations of L1 and L2 sounds. The model states that L2 sounds “may at first be identified in terms of a positionally defined allophone of the L1, but as L2 learners gain experience in the L2, they may gradually discern the phonetic difference between certain L2 sounds and the closest L1 sound(s)” (p. 263). The model then argues that learners can create new phonetic categories for the L2 sounds that are independent of those previously established for their L1 sounds.
The notion of phonetic category as described in Flege’s SLM to refer to long-term memory representations of L2 sound categories resembles that of phonological concept in recent proposals in the approach known as Cognitive Phonology. All-purpose cognitive processes, such as categorization and language-specific phonological concepts, are considered to determine how people categorize sounds (Couper, Reference Couper, Reed and Levis2015). As Fraser (Reference Fraser2006) points out, concepts “group together aspects of reality that are different from some other known aspect of reality” (p. 59). As a case in point, “developing the concept of BROWN involves understanding what is ‘not-brown’ (Wittgenstein, 1958/1974)” (cited in Fraser, Reference Fraser2006). According to Fraser (Reference Fraser, Mahboob and Lipovsky2009), concepts are formed through a process of abstraction from reality. They are learned not only through exposure to positive examples of the concept but also through negative examples that do not belong to the category and through examples of instances at the boundaries of the category. A process of “concept formation” (see e.g., Couper, Reference Couper2006, Reference Couper2011; Fraser, Reference Fraser2001, Reference Fraser2006; Mompean, Reference Mompean, Luque-Agullo, Bueno-González and Tejada-Molina2003) would be precisely what learners are required to do when they are asked to identify the categories to which stimuli belong in an identification task and receive immediate feedback on their performance. For instance, presenting students with multiple examples of /æ/ and /ʌ/ pronounced by different speakers in different phonetic environments, asking them to identify the sounds they hear as examples of /æ/ or /ʌ/, and giving them immediate feedback on whether their response is right or wrong would be a way of helping them create concepts for these two vowels.
In light of the above, the provision of feedback and the labels used in the response options play a key role in identification tasks used for perceptual training. The feedback listeners receive informs them of whether their performance is appropriate or not and conditions their subsequent responses (Logan & Pruitt, Reference Logan, Pruitt and Strange1995). When immediate feedback on the learners’ responses is provided in these tasks, learners receive feedback on how accurate their phonetic categories (or concepts) are for the L2 sounds. Because feedback in perceptual training tasks can have a significant impact on learners’ representations of the L2 concepts/categories, the response labels with which learners associate the feedback they receive play a crucial role in how learners interpret and conceptualize the input to which they are exposed. As Carlet and Cebrian (Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019) note, while listeners in a discrimination task are merely informed of whether the stimuli they hear belong to the same category or not, the feedback they receive in an identification task informs them of whether they have correctly associated the stimulus they heard with one particular response label.
The type of response labels used varies across studies, including orthographic labels (letters or keywords), ad hoc visuals, phonetic symbols, or a combination of these. The use of orthographic labels is common given their straightforward character and familiarity to learners. Yet, their use is not devoid of problems, particularly because sound-spelling correspondences in languages such as English are far from consistent. Thomson (Reference Thomson2011), for example, used nautical flags as response labels to prevent associations between training stimuli and potentially inaccurate sound-spelling associations students might have previously learned. Nonetheless, he also considered that the use of these nonorthographic labels “may have introduced a layer of complexity that detracted from the goal of focusing attention on phonetic information, while using known orthographic labels might have facilitated learning” (p. 760). Thomson’s view was partly based on his previous research indicating that reference to orthography may, in some cases, lead to more intelligible pronunciation (Thomson & Isaacs, Reference Thomson and Isaacs2009).
Another option is to use phonetic symbols from some standard set, usually the International Phonetic Alphabet (IPA). Phonetic symbols provide consistent sound-symbol correspondences, yet one potential caveat with their use as response labels is that they may represent an additional difficulty for learners. Hence, studies have often used a combination of phonetic symbols and keywords (Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019; Nishi & Kewley-Port, Reference Nishi and Kewley-Port2007), or phonetic symbols, keywords, and pictures (Ortega et al., Reference Ortega, Mora, Mora-Plaza, Kirkova-Naskova, Henderson and Fouz-González2021) to guide listeners and ensure that they understand the different options. In other studies, it is hard to discern whether symbols or letters are used because some IPA symbols are often based on or resemble letters from the Roman or Greek alphabets. Nevertheless, no previous study has investigated the potential of these two types of response labels (orthographic and phonetic symbols) for perceptual training, an issue that seems particularly relevant given the ubiquity of phonetic symbols in language teaching and learning materials.
The use of phonetic symbols for pronunciation training/instruction has been long advocated by researchers (Lintunen, Reference Lintunen2004; McMullan, Reference McMullan1988; Mompean, Reference Mompean2005), although symbols have also been considered to be unnecessary (e.g., Cant, Reference Cant1976). One of the arguments against their use is that learning them may be challenging for students. This view often derives from the association of phonetic notation (i.e., the use of phonetic symbols to refer to sounds in languages) with phonetic transcription (i.e., the use of phonetic symbols to record words and utterances), even though the former does not imply the latter. In the field of pronunciation teaching, phonetic transcription was advocated by members of the Reform Movement considering that it ensured “both considerable facilitation and an exceedingly large gain in exactness” (Jespersen, Reference Jespersen1904, p. 176). Yet phonetic transcription is probably an unnecessary goal for most L2 learners.
Leaving phonetic transcription aside, phonetic symbols on their own might prove useful as orthography-independent labels for speech sounds. As Mompean and Lintunen (Reference Mompean and Lintunen2015) point out, given the strong auditory component involved in pronunciation work, sounds tend to be perceived by learners as more “elusive and less ‘tangible’ than written language” (p. 296). As they state, because it is usually hard for learners to develop conceptual images of sounds, the former may be able “to ‘freeze’ those sounds (and the abstract concepts they instantiate) into a repertoire of visual symbols for reference and further work” (ibid.).
As mentioned in the preceding text, identification tasks help learners create or shape their long-term memory representations for the L2 sounds, which could be considered analogous to the formation of concepts. As Couper (Reference Couper2011) points out, one key aspect that facilitates the formation of concepts is the use of an adequate metalanguage that allows teachers and students to communicate adequately and precisely about the target concepts. In this respect, phonetic symbols can serve as a potentially suitable, orthography-independent metalanguage to refer to L2 sound categories (Fouz-González, Reference Fouz-González2020). Nevertheless, their potential has not yet been investigated empirically. For this reason, and considering the key role response labels play in identification tasks, the present study explored potential differences between using two different types of response labels in an HVPT paradigm. Identification tasks were used to train EFL learners’ perception of a range of English vowels. In particular, the study investigated potential differences between using phonetic symbols or keywords as labels for the target vowels to be identified. The study addressed four research questions (RQs):
RQ1. To what extent does the use of phonetic symbols versus keywords as response labels affect the participants’ perception gains?
RQ2. To what extent do these labels foster generalization of gains to untrained nonwords?
RQ3. To what extent do these labels foster generalization of gains to real words?
RQ4. To what extent do the labels foster long-term gains?
METHOD
PARTICIPANTS
Seventy-five Spanish-speaking university students volunteered to take part in the study, although four eventually dropped out. Therefore, only the data from 71 learners are considered. The participants were all Spaniards. There were 58 females and 13 males (M = 21.4 years, SD = 2.3). The students were enrolled in a 4-year degree program in English Studies at University of Murcia (Spain). Their English proficiency level according to the Common European Framework of Reference (CEFR) for languages was Upper Intermediate (B2). The participants had passed the official university entrance exams (B1) and two English language courses in the first year of their degree (B2.1 and B2.2). Only three participants had not yet passed the second course (B2.2). Moreover, participants had undergone formal instruction in an EFL context from the age of six, when primary education begins compulsorily in Spain and children start learning English. Even though infant education (0–6 years) is not compulsory in Spain, it is offered in almost every school. Schools with noncompulsory infant education (0–6 years) typically include English instruction from age 3–6 years.
Participants were recruited from a semester-long English Phonetics and Phonology course (henceforth Phonetics course). The course, which consisted of 4 hours of class time per week, was taught in the first semester of the second year. All participants were also enrolled in four additional courses during that first semester, so they had virtually the same amount of exposure to English during the study. Participants took part in the study at the start of their module. Participation was completely optional and students could choose between a spectrogram reading assignment or participating in the HVPT sessions. If accepted, participation in the study replaced one of the course assignments (10% of the final mark). All activities (HVPT sessions and alternative assignment) were completed outside of class hours.
Participants had been provided with some articulatory and acoustic description of English vowels (the focus of the study) as part of their Phonetics course. Students had been taught that vowels vary along articulatory dimensions such as tongue height, tongue backness, and lip posture. Furthermore, they had been presented with a vowel chart representing the acoustic vowel system of Standard Southern British English (SSBE). The vertical and horizontal dimensions of the chart had also been related to values of the first (F1) and second (F2) vowel formants, respectively. The relationship of roundedness with the third formant (F3) had also been pointed out. Although symbols were used to refer to vowels and participants should be familiar with the values they represent, they had not been used for perceptual and/or production training at any point.
TARGET SOUNDS
The targets addressed in this study were eight vowels that tend to be problematic for Spanish learners of English, both in EFL and in L2 contexts, namely /iː ɪ æ ʌ ɜː e ɒ ɔː/ (see e.g., Flege & Wayland, Reference Flege and Wayland2019; Monroy-Casas, Reference Monroy-Casas2001; inter alia.). The reference variety for English was SSBE (Roach, Reference Roach2004), the variety adopted as a reference model in the participants’ Phonetics course. The reference variety for Spanish used for comparison purposes in the participants’ course was Castilian Spanish (Martínez-Celdrán et al., Reference Martínez-Celdrán, Fernández-Planas and Carrera-Sabaté2003).
The previously mentioned vowels cause problems to the target population for at least three main reasons. Firstly, Spanish has a relatively transparent orthography insofar as vowel sounds are always represented with the same vowel letter and vice versa (e.g., /a/ = <a> sal /sal/ “salt”; /e/ = <e> pez /peθ/ “fish”; /o/ = <o> sol /sol/ “sun”). In contrast, English has multiple sound-to-grapheme (e.g., /ʌ/ = <u> strut, <o> some, <ou> tough) and grapheme-to-sound correspondences (e.g., <u> = /ʌ/ strut, /uː/ June, /ʊ/ pull). This lack of one-to-one correspondence between English spelling and pronunciation often leads Spanish learners to make vowel substitutions based on the grapheme-to-sound correspondences in Spanish (e.g., person /ˈpɜːsn̩/ pronounced as [ˈperson]—see Monroy-Casas, Reference Monroy-Casas2001).
Secondly, the Spanish monophthongal vowel inventory is smaller (five vowels: /a e i o u/) than the English one (12 vowels: /æ ʌ ɑː e ɜː ə ɒ ɔː ɪ iː ʊ uː/). One consequence of this is that vowels are relatively separated (or dispersed) in the Spanish acoustic vowel space, while the distances between neighboring vowels are typically smaller in English. Furthermore, given that the acoustic vowel space is more crowded in English than in Spanish, the space covered by a single Spanish vowel may overlap with several English vowels (e.g., Spanish /i/ vs. English /iː - ɪ/). This can lead Spanish learners of English to associate a binary contrast in English such as /iː - ɪ/ with a single segment in their L1 (e.g., /i/) in both perception and production (Flege et al., Reference Flege, Bohn and Jang1997), a phenomenon referred to as single-category assimilation (Best & Tyler, Reference Best, Tyler, Bohn and Munro2007). However, there is evidence that a binary contrast in the L2 may be perceived as more than two categories in the learners’ L1, a phenomenon referred to as multiple-category assimilation (Escudero & Boersma, Reference Escudero, Boersma, Skarabela, Fish and Do2002). Thus, English /iː/ and /ɪ/ are associated with Spanish /i/, but English /ɪ/ is also associated with Spanish /e/ (Cebrian, Reference Cebrian2019).
Lastly, there are acoustic differences between vowels that seem similar between the two languages and that Spanish learners associate but do not occupy the same position in the acoustic space (Delattre, Reference Delattre1964). Spanish learners, for example, associate English /uː/ with Spanish /u/ (Cebrian, Reference Cebrian2019), but the Spanish vowel is more back than the English one. Note also that vowel duration is not contrastive in Spanish, but it is a feature of some English vowels, with two degrees of length being linguistically relevant (i.e., long vs. short). The actual length of a vowel depends on the influence of the phonetic context. Vowels are longer, for example, before sonorants and voiced obstruents than before voiceless obstruents (Cruttenden, Reference Cruttenden2014). Yet a length contrast is maintained if the phonetic context is the same (e.g., beat vs. bit). Interestingly, there is evidence that, in differentiating English binary contrasts such as /iː - ɪ/ (Kondaurova & Francis, Reference Kondaurova and Francis2010) or even considering vowel tokens as typical examples of their English category (Mompean, Reference Mompean2001), L1 Spanish learners of English rely mostly on vowel duration whereas L1 English speakers rely predominantly on vowel quality. These quantitative and qualitative differences often cause transfer from the learners’ L1 in the form of L2 English vowels with different quality and/or duration, such as family /ˈfæmli/ pronounced as [ˈfamili], girlfriend /ˈgɜːlfrend/ as [ˈgelfren], or horses /ˈhɔːsɪz/ as [ˈhorsis] (Monroy-Casas, Reference Monroy-Casas2001).
Four English monophthongs were not considered for this study for various reasons, although they also cause problems for Spanish EFL learners due to their spelling and/or vowel quality. The unstressed vowel /ə/ was not taken into account because the stimuli used in the current study (see following text) were individual monosyllabic nonwords, which therefore act as stressed syllables. Moreover, two vowels in the close back region of the vowel chart (i.e., /ʊ/, /uː/) were excluded given their low functional load as was the open back long monophthong /ɑː/; the pair /æ - ʌ/ was prioritized given its higher functional load (Brown, Reference Brown1988; Catford, Reference Catford and Morley1987).
STIMULI
Stimuli in this study consisted of different sets of CVC nonwords and real words produced by six native speakers of SSBE (three females, three males). Following Carlet (Reference Carlet2017), the speakers used for training and testing were different so that gains from pre- to posttest could also be interpreted as generalization to novel voices. The voices of four speakers (two females, two males) were used for the training phase of the study while the voices of the other two speakers (male and female) were used during the testing phase.
The recordings took place in a soundproof professional recording studio. Stimuli were recorded using Audacity, with a Shure SM58 microphone, a Scarlett Solo audio interface, and a MacBook Pro computer, with a sampling rate of 44.1kHz. Speakers produced the stimuli containing the target vowels in carrier sentences (i.e., I say_____). The recording sessions were monitored by one of the researchers to ensure that the nonwords (see following text) were pronounced as expected. The researcher kept a record of stimuli that were not deemed adequate so that speakers recorded them again at the end of the session. Next, all the stimuli were checked auditorily and independently by the two authors to ensure that they were acceptable examples of the target vowels. A list with the training and testing stimuli can be found as online supplementary materials, including the transcriptions of all items so that their CVC structure is known, as well as conventional spelling (real words) and suggested spellings (nonwords). Participants never saw the stimuli in spelling or transcription. These were used, however, for the native speakers who produced them.
Training Stimuli
Training stimuli consisted of 24 monosyllabic (CVC) nonwordsFootnote 2 per target vowel (i.e., 192 nonwords). Participants were presented with 24 nonwords × 8 vowels × 4 speakers. Thus, there were 768 stimuli in total, which were presented to participants twice (i.e., 1,536 stimuli).
The nonwords were constructed respecting CV and VC phonotactic regularities in English. The reason to use nonwords for the training stimuli was to help learners focus their attention on phonetic form, which might incidentally reduce their cognitive load. The perception of segments should not be thought of as an entirely bottom-up process (Binder, Reference Binder, Hickok and Small2016); rather, as with all perceptual recognition tasks, identification of sensory input is influenced as much by what is available from the sensory input as by what listeners expect to hear. “Top-down” effects include, among others, lexical (or meaning) factors. Related to this, researchers have often argued that it is difficult for L2 learners to process form and meaning at the same time (VanPatten, Reference VanPatten1990). Meaning is generally of greater importance for communication, often at the expense of attention to form. Thus, for learners to benefit most from phonetic input, it should be presented in contexts where competing demands for attention are minimal (Thomson, Reference Thomson2011). Recent work by Ortega et al. (Reference Ortega, Mora, Mora-Plaza, Kirkova-Naskova, Henderson and Fouz-González2021) as well as by Thomson and Derwing (Reference Thomson, Derwing, Levis, Le, Lucic, Simpson and Vo2016) suggests that using nonwords in phonetic training paradigms can yield greater improvements than using real words. The authors argue that nonwords facilitate directing attention to phonetic detail and avoid interference from learners’ phonolexical representations in which the target sounds may not be accurately encoded (Ortega et al., Reference Ortega, Mora, Mora-Plaza, Kirkova-Naskova, Henderson and Fouz-González2021).
To provide learners with exposure to the target vowels in a wide range of phonetic contexts, nonwords were created with vowels either preceded or followed by any of the following six consonants: /f v s z tʃ dʒ/. Of the 24 nonwords per vowel, two items per target vowel started with each of those consonants and two items ended in one of them. These six consonants were chosen because they vary on a wide range of phonetic dimensions, providing ample phonetic variability. The consonants exploit a voicing distinction (voiceless: /f s tʃ/; voiced: /v z dʒ/), three primary (labiodental: /f v/; alveolar: /s z/; postalveolar: /tʃ dʒ/), and two secondary (labialized: /tʃ dʒ/ and nonlabialized /f v s z/) places of articulation, two manners of articulation in terms of obstruency (fricative: /f v s z/; affricate: /tʃ dʒ/), and two degrees of sibilance (sibilant: /s z tʃ dʒ/; nonsibilant: /f v/).
The stridents (i.e., fricatives and affricates) used in this study have intense noise spectra that are acoustically very distinct from a vowel. Therefore, stridents were considered a suitable type of consonant to either precede or follow vowel nuclei and they were used to control the contexts in which vowels were presented (i.e., either starting or ending in the previously mentioned consonants). When nonwords did not start or end with a strident, they ended in consonants formed by obstructing the airflow in the oral cavity. This included oral (/p b t d k g/) and nasal (/m n/) stops in both onset and coda. The only nonobstruent consonant used was the palatal approximant /j/ in onset positions. Stops are also relatively suitable consonants insofar as their production involves blocking airflow in the vocal tract. This occlusive feature gives rise to acoustic patterns that are very distinct from those of vowels, with relatively long “silent” gaps (with no energy above the voicing component on a spectrogram) followed by rapid formant transitions into (stop + vowel) or out of (vowel + stop) the neighboring vowel. Nasal stops also involve distinct acoustic patterns, with frequency regions with little energy and formants that are strongly damped compared to those of vowels. Finally, it should be mentioned that coarticulatory effects are pervasive in any string of sounds in spoken language. Some degree of (noncontrastive) nasalization, for example, is expected in the vowels preceding or following nasals. However, continuant consonants that lead to perceivable vowel quality changes such as diphthongization and/or velarization (e.g., coda /l/) or retroflexion/rounding (e.g., /r/, /w/) were avoided. Despite potential coarticulatory effects to various degrees depending on the type of CVC combination, the use of consonants other than stridents had the aim of increasing the phonetic variability to which participants in the study were exposed.
Testing Stimuli
Testing stimuli combined a subset of the nonwords participants had been exposed to during training (i.e., trained nonwords), a set of nonwords that participants had not seen during training (i.e., untrained nonwords), and a set of real words (also untrained). Untrained nonwords and real words were included to explore whether potential gains could be generalized to stimuli that participants had not seen during training as well as to real words.
Each target vowel was featured in 12 trained nonwords and 12 untrained nonwords. Half the trained nonwords started with the consonants described in the preceding text (i.e., /s_ z_ f_ v_ tʃ_ dʒ_/) and the other half ended in them (i.e., /_s _z _f _v _tʃ _dʒ/). All 12 untrained nonwords started with these six consonants. Each of these initial consonants was used twice per target vowel, one ending in a voiceless consonant and one ending in a voiced one, to exploit a wider phonetic variability. The use of nonstrident consonants (the same as in the training stimuli) at either side of the CVC context when stridents were not used had the same purpose.
As regards real words, each vowel was featured in at least four items, although for some vowels a higher number of stimuli were included to cover the wider range of spellings with which they are associated. Hence, four items were used for /æ/ (<a>), /e/ (<e>), /ɒ/ (<o>, <a>), and /ɔː/ (<or>, <ar>); six items were used for /iː/ (<ee>, <ea> and <ie>) and /ɪ/ (<i> and <y>); and eight items were used for /ʌ/ (<u>, <o>, <ou>) and /ɜː/ (<ir>, <ur>, <or>, <er>).
All items in the tests were pronounced by two different speakers, so listeners were presented with twice the number of items per sound. Thus, pre-, post-, and delayed posttest consisted of three sections: trained nonwords (12 items × 8 vowels × 2 speakers = 192 items), untrained nonwords (12 items × 8 vowels × 2 speakers = 192 items), and untrained real words (44 items featuring the 8 vowels with the spellings explained in the preceding text × 2 speakers = 88 items). The testing stimuli were the same for pre-, post-, and delayed posttests.
PROCEDURE
Participants followed a 4-week HVPT paradigm with identification tasks in which the response labels were either phonetic symbols representing the target vowels or common monosyllabic words that contained those vowels. The phonetic symbols used for the target vowels represent vowel quantitative and qualitative differences and they are used as a de facto standard in most contemporary works on British English, EFL textbooks, and pronunciation dictionaries such as Cambridge English Pronouncing Dictionary (Roach et al., Reference Roach, Setter and Esling2011) or Longman Pronunciation Dictionary (Wells, Reference Wells2008).
The testing and training tasks were administered with TP, an open-source application for developing and administering speech perception tasks (Rato et al., Reference Rato, Rauber, Kluge, Santos, Mompean and Fouz-González2015). These tasks were administered in a language lab at the researchers’ university. At the beginning of the study, learners were randomly assigned to one of three groups of 25 participants. Group 1 (G1) was trained using phonetic symbols as response labels, Group 2 (G2) using keywords, and Group 3 (G3) acted as a control group. Four participants eventually dropped out, leaving the number of participants per group at 24 (G1), 25 (G2), and 22 (G3). A pretest was administered a week before training, a posttest 1 week after training, and a delayed posttest 4 weeks after training finished. To avoid depriving G3 participants of instruction, they were offered the possibility to receive training after the delayed posttest. Between pretest and delayed posttest, however, G3 participants did not take part in any activities related to the study. The four training sessions for G3 were combined to fit into a one-evening session before the exam period, with breaks of 15–20 minutes between sessions. Nevertheless, the gains made by G3 when they received training have not been analyzed and are not reported here given that their training took place in just one day and therefore the treatment conditions are not comparable.
During training, learners received immediate feedback on their responses after every trial. Feedback in TP is given in the form of a tick or a cross indicating whether the listener’s response is right or wrong. If the participants’ responses are wrong, TP shows the right answer, the stimulus is played again, and the listener has to click on the right response before hearing the next trial. Additionally, cumulative feedback was offered at the end of each training session, showing the total score in the task (i.e., the number of correct responses), the number of incorrect responses, as well as the duration of the session. In the pre-/post- and delayed posttests, participants were shown the cumulative feedback screen when they finished (i.e., their score out of the 472 trials and the time spent in the test), but they did not receive trial-by-trial feedback.
Testing Procedure
The response labels in the tests were common monosyllabic words featuring each vowel. The labels were the same for all the participants regardless of the type of training. No phonetic symbols were used in the tests to prevent participants in G2 from thinking of any of those symbols during the tasks. The keywords used in the tests were different from those that participants in G2 saw during training; they were tree, fish, hat, bus, shirt, red, clock, and horse.
To familiarize participants with the procedure of the identification tasks, a short training session was conducted before the tests. Participants were asked to listen to five nonwords featuring the five Spanish vowels (laj, jer, ñik, jok, pul) and had to associate the vowel sound they heard with one of five different nonwords featuring those five vowels (pat, nel, ril, ñol, ruk). These were presented as response labels on a screen displayed for the whole room with an overhead projector. The five nonwords were played twice in random order. Because TP was set up in testing mode and no trial-by-trial feedback was offered in the test, the practice trials with Spanish nonwords were played for the whole class outside TP and participants had to respond by showing a card featuring one of the five nonwords. After students showed their cards to the researchers, the right answer was displayed for the whole class. Students did not have problems identifying the vowels in the training trials or understanding the procedure. Next, to ensure that participants were familiar with the pronunciation of the (real) keywords they would see as labels during the test, the keywords were presented to participants using PowerPoint slides where each keyword was played twice (spoken by a female and a male voice). Additionally, before starting the perception test, a short task was conducted in TP to familiarize learners with the software and the procedure. In this task, participants listened to the keywords on the screen and had to click on the word they heard (each keyword was played six times). No feedback was offered in this task because the target words clearly matched the options (e.g., participants heard the word shirt and had to choose among tree, fish, hat, bus, shirt, or red).
Training Procedure
To create training sessions in which vowels were presented on a wide range of phonetic environments, the training stimuli were divided into six blocks of 32 nonwords each. Each training block featured the eight vowels either preceded or followed by two of the previously mentioned consonants (Figure 1, left), and each context (e.g., /sV/, /zV/) featured the target vowel in two different nonwords (combining voiced and voiceless beginnings/endings whenever possible).
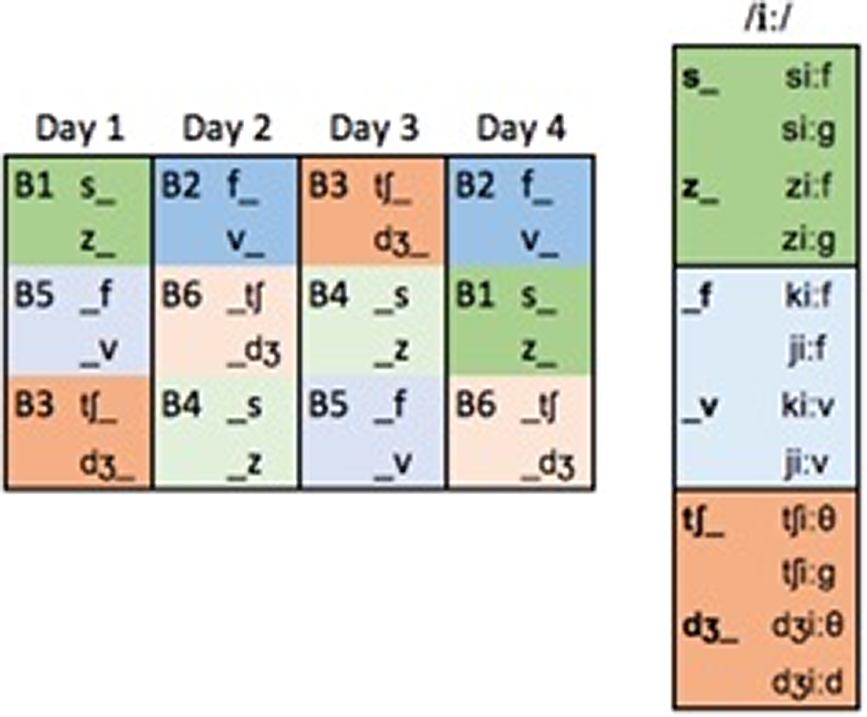
FIGURE 1. Training blocks arranged according to phonetic contexts (left) and example of the nonwords used for /iː/ on day 1 (right).
On each training day, learners were presented with three different blocks featuring the target vowels flanked by three different places of articulation (Figure 1, left). As a case in point, on day 1, participants were exposed to blocks 1, 5, and 3, featuring the eight target vowels in four nonwords in /sV/ and /zV/ contexts, four in /Vf/ and /Vv/ contexts, and four in /tʃV/ and /dʒV/ contexts. Figure 1 (right) shows an example of the nonwords used for /iː/ on day 1, which included three different blocks (B1 /sV/, /zV/; B5 /Vf/, /Vv/; and B3 /tʃV/, /dʒV/). Thus, on each training day, each vowel was featured in 12 nonwords that were produced by four different speakers (i.e., 48 stimuli per vowel), and students were exposed to 384 stimuli (12 nonwords × 8 vowels × 4 speakers). In total, there were six different training blocks (i.e., 768 different stimuli) that were presented twice (i.e., 1,536 stimuli).
The training sessions were administered once a week, with the whole training period extending over 4 weeks. The two experimental groups received training on the same days, one group after another (alternating the order each week). Training sessions took approximately 30 minutes. Using four training sessions allowed us to present learners with the whole set of training stimuli twice, combining three different training blocks on each training day (Figure 1) and, therefore, offering learners high stimulus variability.
The sessions consisted in a six-forced-choice identification task in which participants were given trial-by-trial feedback on their performance and cumulative feedback at the end of each session. The vowel pairs that tend to be confused with the Spanish vowels were always presented together: /iː - ɪ/ (Spanish /i/), /æ - ʌ/ (Spanish /a/), /e - ɜː/ (Spanish /e/), and /ɒ - ɔː/ (Spanish /o/) (see e.g., Cebrian, Reference Cebrian2019; Monroy-Casas, Reference Monroy-Casas2001). Even if L2 vowels are sometimes assimilated to more than two L1 categories (e.g., English /ɪ/ to Spanish /e/), the response options were arranged in the preceding pairs to guarantee that pairs that seem to be more challenging always appeared together. Each pair was presented with three other pairs in four different combinations (i.e., /iː ɪ æ ʌ e ɜː/; /ɒ ɔː iː ɪ æ ʌ/; /e ɜː ɒ ɔː iː ɪ/; /æ ʌ e ɜː ɒ ɔː/), also including other potentially confusable vowels and ensuring that every vowel appeared with equal frequency.
The two groups were exposed to the same stimuli on each training session, but G1 saw phonetic symbols as response labels (Figure 2, left) and G2 saw keywords in conventional spelling (Figure 2, right). The keywords used for G2 were see, if, map, up, birth, leg, box, and born.

FIGURE 2 Sample screenshot of the response labels participants in G1 (left) and G2 (right) saw during the training sessions.
RESULTS
To explore potential differences in the improvement made between groups, a gain score was calculated by comparing the learners’ scores (i.e., number of correct identifications) in the posttest with their scores in the pretest for trained nonwords (RQ1), untrained nonwords (RQ2), and untrained real words (RQ3). Additionally, to analyze potential differences in the participants’ long-term improvements (RQ4), a long-term gain score was calculated by comparing the learners’ scores in the delayed posttest with their performance in the pretest. This score reflected improvements in the participants’ perception of the target vowels a month after having received training.
To explore whether there were significant differences between groups before training, the three groups’ pretest scores were analyzed with one-way independent ANOVAs. No significant differences were found between groups for any class of items; that is: trained nonwords (F(2,68) = 0.339, p = .71, w2 = 0.000), untrained nonwords (F(2,68) = 0.165, p = .85, w2 = 0.000), or real words (F(2,68) = 0.186, p = .83, w2 = 0.000).
The gain and long-term gain scores were analyzed with one-way independent ANOVAs, with those two scores as the dependent variables and group as the independent variable. When significant differences between the groups were found, these were further explored with post hoc tests using Holm’s correction. If the data from one of the groups were not normally distributed, Kruskal–Wallis tests were used and the data were further analyzed with Dunn’s post hoc comparisons and Holm’s correction. The descriptive statistics for the three groups’ scores in the different testing times for trained and untrained nonwords as well as for real words are presented in Table 1. The descriptive statistics for the gain and long-term gain scores are presented in Table 2.
TABLE 1. Descriptive statistics for the pretest, posttest, and delayed posttest including the % of the mean scores considering the maximum score in the task

Note. The maximum scores in the tests were 192 for trained and untrained nonwords and 88 for untrained real words.
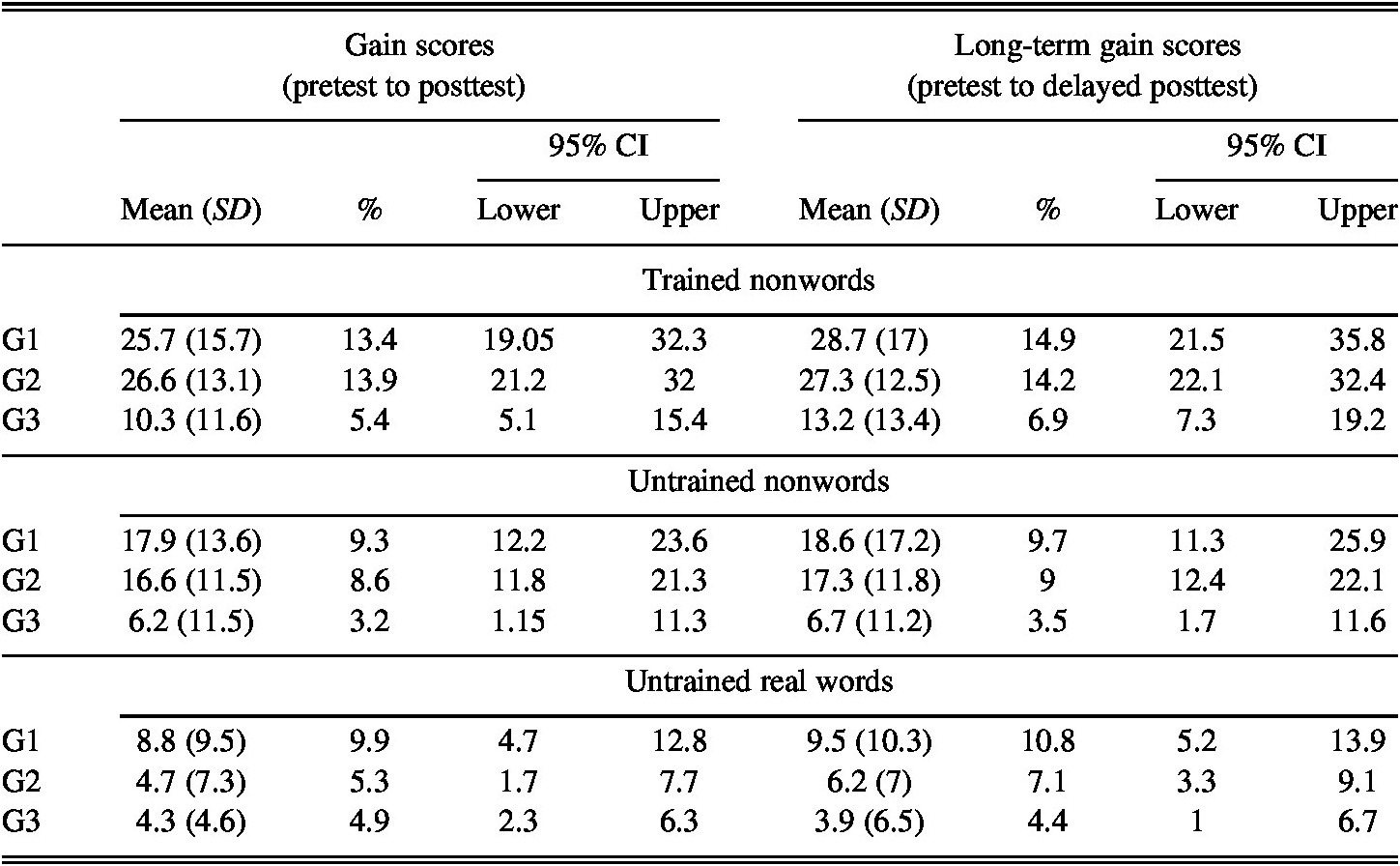
TABLE 2. Descriptive statistics for the participants’ gain and long-term gain scores including the % of the mean scores considering the maximum score in the task
Note. The maximum scores in the tests were 192 for trained and untrained nonwords and 88 for untrained real words.
IMPROVEMENT IN TRAINED NONWORDS
The analysis of the improvement participants made in trained nonwords from pre- to posttest revealed that there were significant differences in the gains made between groups (F(2,68) = 10.384, p = <.001, w2 = 0.21). Post hoc tests revealed significant differences between G1 and G3 (p = <.001, d = 1.1), and between G2 and G3 (p = <.001, d = 1.31), but not between G1 and G2 (p = .8, d = −0.07). In other words, the improvement fostered by the different training conditions was significantly different from the improvement made by the control group, but there were no significant differences between the two experimental groups (see Figure 3). Because participants were enrolled in a Phonetics course and receiving formal EFL instruction at the time of the study, some gains by participants in the control group were expected. Nevertheless, despite some improvements from pre- to posttest by G3, the gains made by the two experimental groups were more than double the improvement made by the control group (Table 2).

FIGURE 3. Mean scores and 95% CIs for trained nonwords.
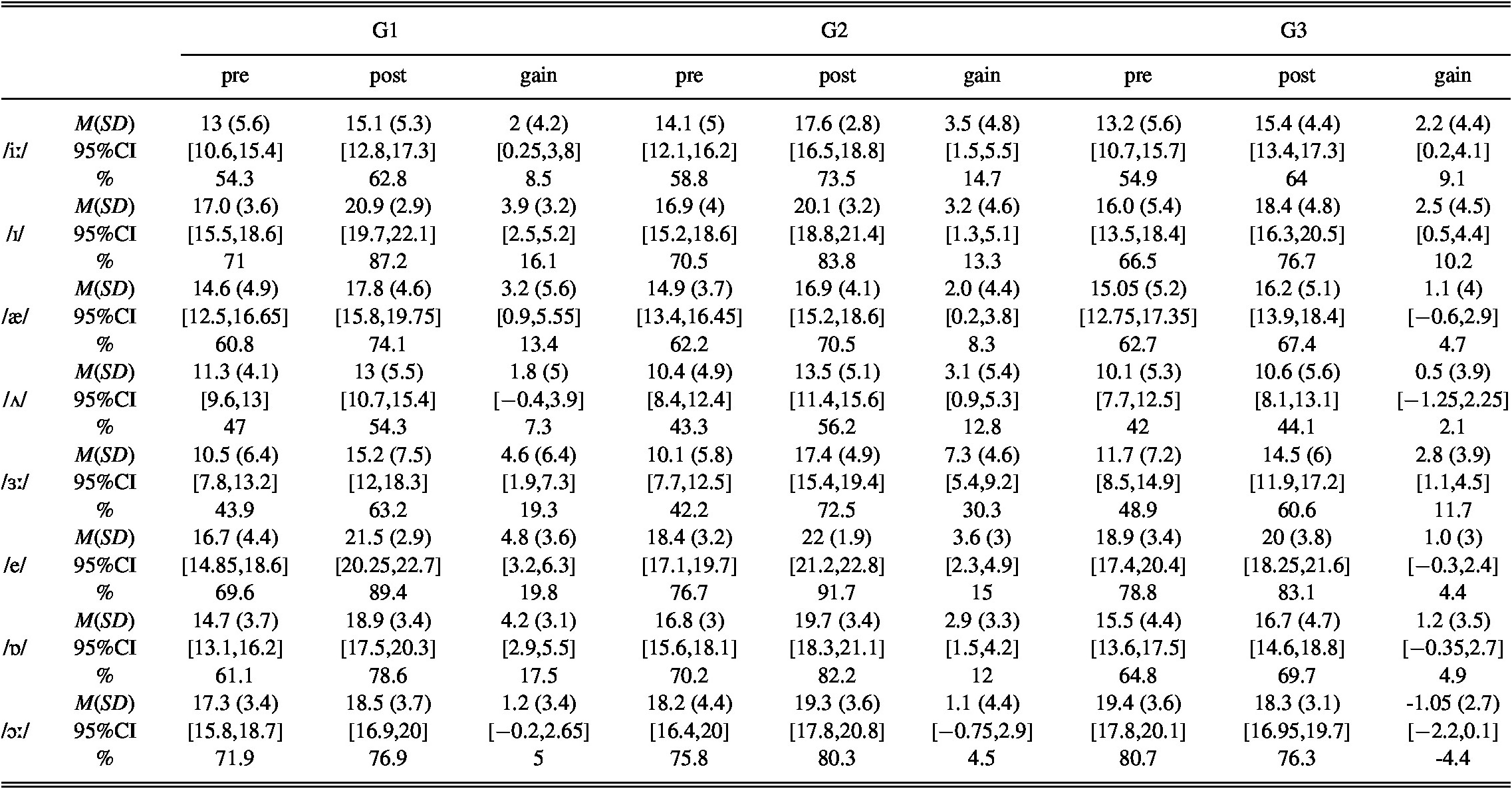
A closer inspection of the results obtained for each target vowel in trained nonwords from pre- to posttest shows that the differences between groups were significant for three of the target vowels, namely /ɜː/, /e/, and /ɒ/. Post hoc tests showed that the differences in the improvement made in items featuring /ɜː/ were significant between G2 and G3; in items featuring /e/, between G1 and G3 and between G2 and G3; and in items featuring /ɒ/, between G1 and G3 (Table 3). The pre- and posttest scores as well as the improvement made by each group for the different target sounds in trained nonwords are presented in Table 4.
TABLE 3. Results from the analysis of the improvement made in trained nonwords (pretest to posttest)
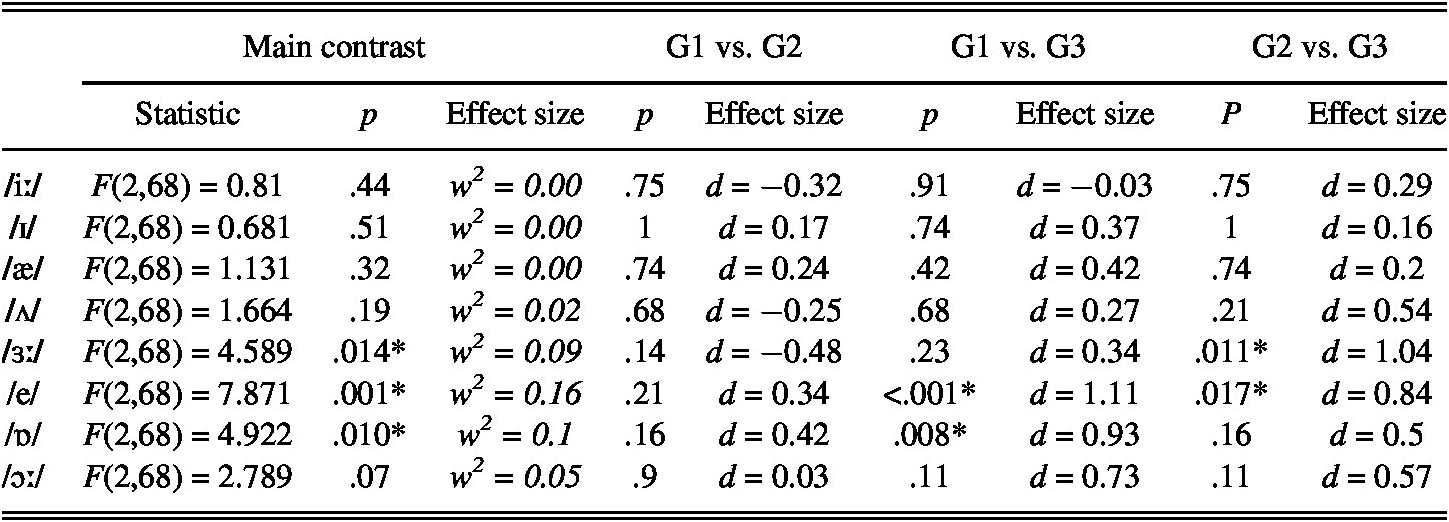
TABLE 4. Descriptive statistics and gain per sound in trained nonwords, including the % of the mean score considering the maximum score in the task

Note. The maximum score for each vowel was 24 (12 tokens × 2 speakers).
IMPROVEMENT IN UNTRAINED NONWORDS
The analysis of gains in untrained nonwords from pre- to posttest also revealed significant differences between groups (F(2,68) = 6.208, p = .003, w2 = 0.13). As with trained nonwords, post hoc tests revealed significant differences between G1 and G3 (p = .006, d = 0.92) and between G2 and G3 (p = .01, d = 0.89), but not between G1 and G2 (p = .7, d = 0.11); that is, the gains fostered by both treatments were significantly different than the improvement made by the control group (Figure 4), but there were no significant differences between the two experimental groups (also see Table 2).

FIGURE 4. Mean scores and 95% CI for untrained nonwords.
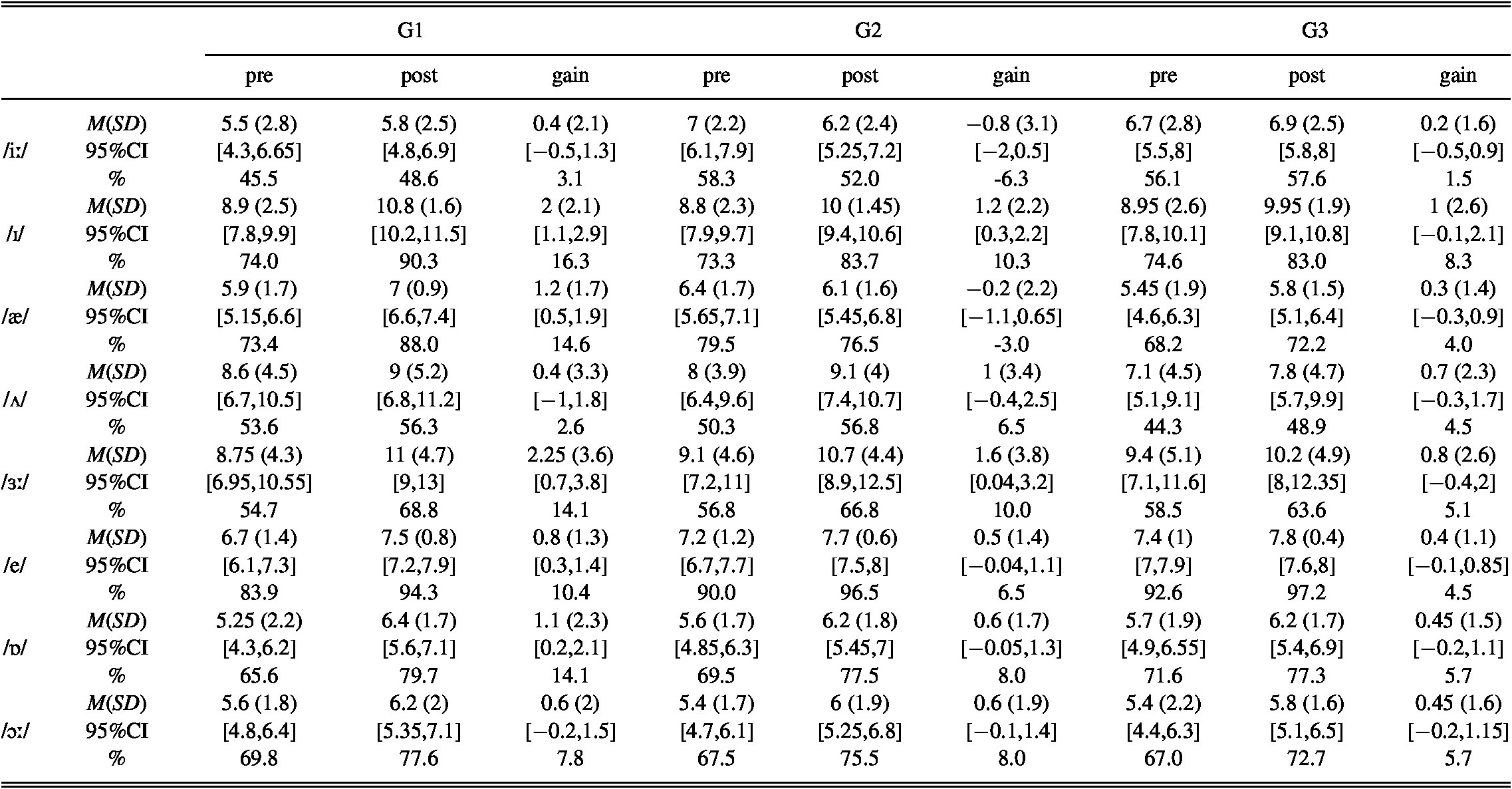
The analysis comparing the gains made for each target vowel from pre- to posttest revealed significant differences between groups for /ɜː/, /e/, /ɒ/, and /ɔː/ (Table 5). Post hoc tests showed that the differences between groups reached the significance level in the improvement made for /ɜː/ between G1 and G3 and between G2 and G3; for the differences between G1 and G3 for /e/; and between G2 and G3 for /ɔː/. The adjusted p-values of the post hoc pairwise comparisons did not reach the 0.95 level of significance in the improvement made for /ɒ/. The descriptive statistics of the scores for individual sounds in untrained nonwords as well as the improvement made per sound are presented in Table 6.
TABLE 5. Results from the analysis of the improvement made in untrained nonwords (pretest to posttest)
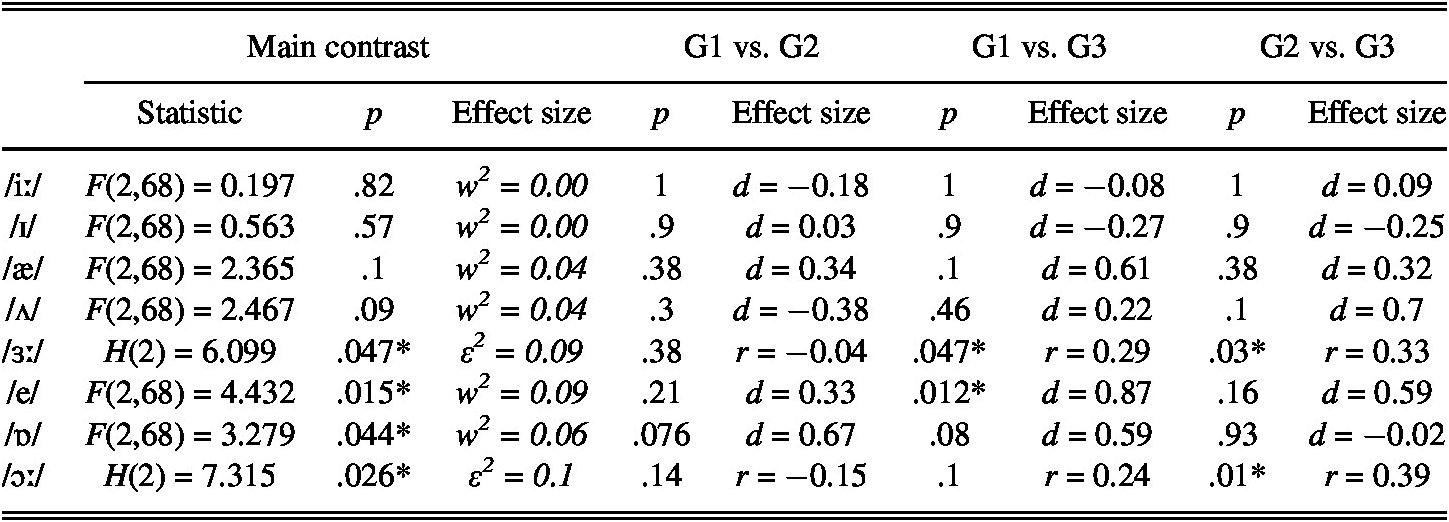
TABLE 6. Descriptive statistics and gain per sound in untrained nonwords including the % of the mean score considering the maximum score in the task

Note. The maximum score for each vowel was 24 (12 tokens × 2 speakers).
IMPROVEMENT IN UNTRAINED REAL WORDS
Regarding the improvements made in real words from pre- to posttest, no significant differences were found between groups (F(2,68) = 2.568, p = .084, w2 = 0.04). The gains made by G1 almost doubled the ones by G2 and G3 (Table 2), but the standard deviations were quite high, which indicates that the improvements made by different participants varied considerably. The participants’ scores at pretest, posttest, and delayed posttest are illustrated visually in Figure 5.

FIGURE 5. Mean scores and 95 CI for untrained real words.
The analysis of the gain scores for each target vowel from pre- to posttest revealed that the only significant difference between groups was found in the improvement made for /æ/ between G1 and G2 (Table 7). Nonetheless, it is important to note that, except for /ʌ/, the gains made by G1 were generally higher than those of G2 and G3 (Table 8).
TABLE 7. Results from the analysis of the improvement made in untrained real words (pretest to posttest)

TABLE 8. Descriptive statistics and gain per sound in untrained real words including the % of the mean score considering the maximum score in the task
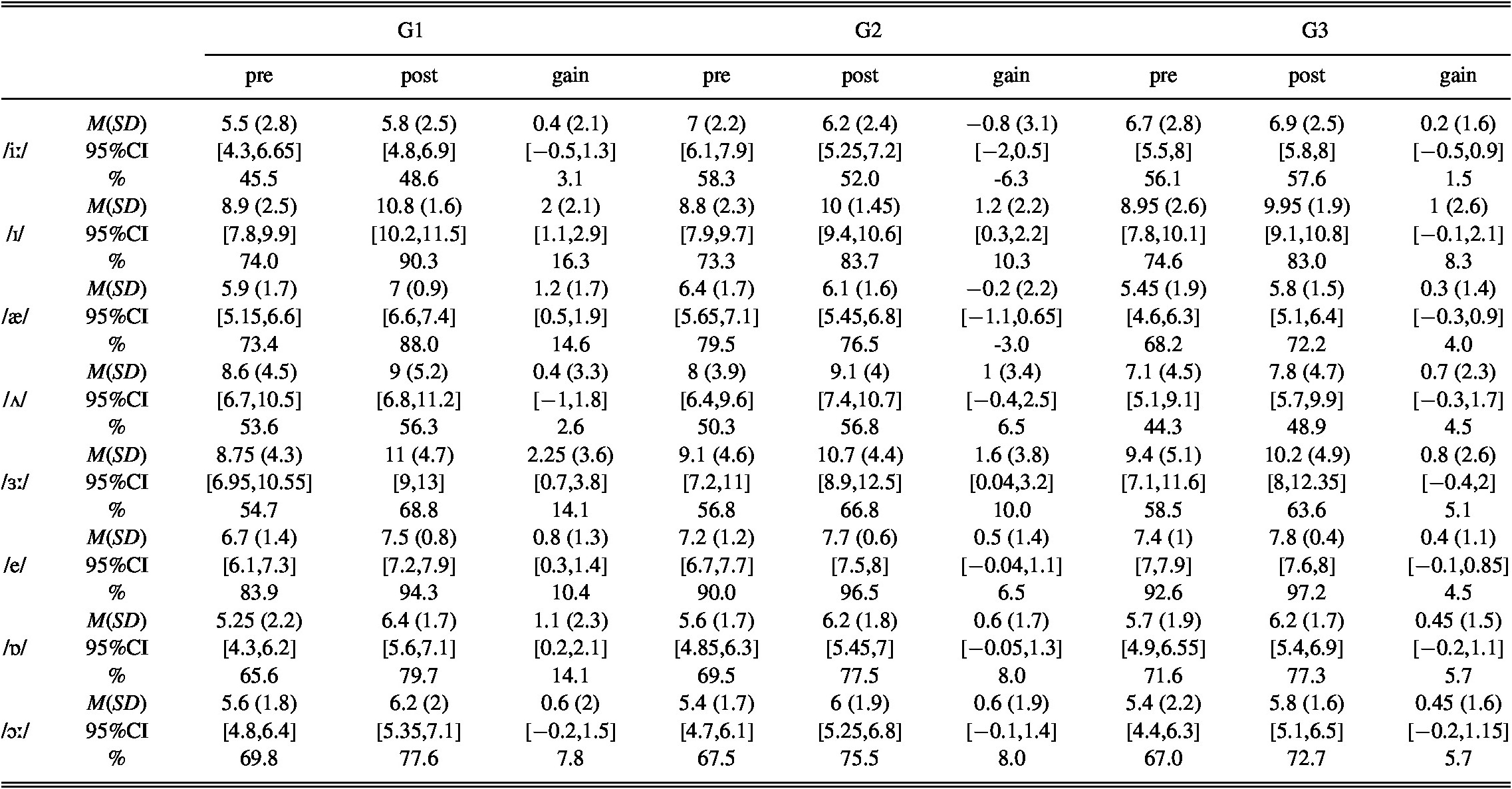
Note. The maximum scores were 12 for /iː/ and /ɪ/, 8 for /æ/, /e/, /ɒ/, and /ɔː/, and 16 for /ʌ/ and /ɜː/ (these are the number of tokens per vowel × 2 speakers).
LONG-TERM GAINS
The fourth RQ addressed the extent to which training with phonetic symbols or keywords as response labels would foster different long-term gains. As explained in the following text, to analyze whether the long-term gains fostered by training were different between groups, a long-term gain score (see Table 2) was calculated by comparing the participants’ scores in the pretest with their scores in the delayed posttest (i.e., a month after training had finished). As can be seen in Table 2, the experimental groups’ long-term gain scores (pretest to delayed posttest) in trained and untrained nonwords as well as in real words are slightly higher than their gain scores (pretest to posttest), which shows that the gains fostered by training were maintained a month after training (the groups’ mean scores at the different testing times can be seen in Table 1).
To explore potential differences in the groups’ improvements from the pretest to the delayed posttest formally, their long-term gain scores were analyzed with one-way ANOVAs. The comparison of the groups’ long-term gain scores for trained nonwords revealed significant differences between groups (F(2,68) = 7.96, p = <.001, w2 = 0.16). Post hoc tests revealed significant differences between G1 and G3 (p = .001, d = 1.003) and between G2 and G3 (p = .002, d = 1.08), but not between G1 and G2 (p = .73, d = 0.09). The results for untrained nonwords also revealed significant differences between groups (F(2,68) = 5.17, p = .008, w2 = 0.10); more specifically, between G1 and G3 (p = .013, d = 0.81) and between G2 and G3 (p = .02, d = 0.92), but not between G1 and G2 (p = .73, d = 0.09). Finally, the results for real words revealed no significant differences between groups (F(2,68) = 2.82, p = .06, w2 = 0.04). Thus, the data for long-term gains are in line with the differences in the improvement made from pre- to posttest, with significant differences between groups occurring mainly between the control group and the two experimental groups (i.e., with no differences between the different treatments), and in trained and untrained nonwords (this is illustrated visually in Figures 3, 4, and 5).
DISCUSSION
The results reported above show that both phonetic symbols and keywords helped learners improve their perception of the target vowels in trained nonwords (RQ1), untrained nonwords (RQ2), and, to a lesser extent, real words (RQ3). The results also indicate that the improvement of the two experimental groups was generally superior to that of the control group, but no significant differences were found between the group receiving training with phonetic symbols and the group using keywords except for one of the target vowels in real words. Finally, the data show that gains were maintained over time and that the differences in the long-term gains between groups followed the same trend as that of pre- to posttest gains; that is, with differences occurring mainly between the experimental groups and the control group, but not between the two experimental groups.
Although training had a positive effect on the participants’ perception of the target sounds, there is still room for improvement, especially for vowels such as /iː/, /ʌ/, and /ɔː/, whose scores were rather low from pretest and did not show much improvement after training. It is important to note that, of the eight target vowels addressed, significant differences in the improvement made between groups were only found for three vowels in trained (G1 vs. G3: /e/, /ɒ/; G2 vs. G3: /ɜː/, /e/) and untrained (G1 vs. G3: /ɜː/, /e/; G2 vs. G3: /ɜː/, /ɔː/) items, and for one vowel in real items (G1 vs. G2: /æ/). Nevertheless, some of the between-group comparisons revealed almost medium and medium effect sizes even though the differences between groups were not found to be statistically significant (e.g., G1 vs. G3 for /ɔː/ in trained nonwords, G1 vs. G2 in untrained nonwords for /ɒ/, or G2 vs. G3 for /ʌ/ in untrained nonwords). Thus, the data show that training did not have the same impact on every vowel.
L2 speech models describe the likelihood of developing accurate categories for the L2 sounds as dependent on the similarity between the L1 and the L2 categories (e.g., Best & Tyler, Reference Best, Tyler, Bohn and Munro2007; Flege, Reference Flege and Strange1995). In a recent study investigating the perceived similarity between SSBE and Spanish monophthongs and diphthongs, Cebrian (Reference Cebrian2019) found that /ɜː/ was the least assimilated sound among the vowels addressed in the present study. It was assimilated to Spanish /e/ 64% of the time, with a goodness of fit (GOF) rating of 3 out of 7, and to /a/ and /o/ 14% and 13% of the time, with GOF ratings of 3.4 and 3.9, respectively. Thus, /ɜː/ could be considered to be a “new” sound (in terms of Flege’s Reference Flege and Strange1995 SLM) and it should be relatively easy for students to improve, which is in line with the data in this study.
The learners’ identification scores for /e/ were relatively high from the pretest (above 69.6%), but this was one of the vowels for which training was most beneficial. In Cebrian’s study, learners assimilated three English vowels to the Spanish category for /e/, namely /e/ (97% of the time, GOF: 5.3), /ɪ/ (66%, GOF: 5.3) and /ɜː/ (64%, GOF: 3). While English /e/ and /ɪ/ presented the same GOF scores, /e/ was consistently assimilated to Spanish /e/ much more frequently than /ɪ/ and /ɜː/. In this regard, /e/ could be considered to be a “similar” sound in terms of the SLM and it should be particularly difficult for learners to perceive differences between the L2 and L1 categories for this vowel. However, the fact that learners may be able to perceive /ɪ/ and /ɜː/ as more “different” may have also boosted their accurate identifications of the instances of /e/ and reduced the number of identifications of instances of /e/ as /ɪ/ or /ɜː/. Regarding /ɒ/ and /ɔː/, they were consistently assimilated to Spanish /o/ in Cebrian’s study, 76% and 75% of the time, respectively, and with similar GOF scores (4.7 and 4.1). As Cebrian notes, this could be considered to be an example of a single-category assimilation in terms of the Perceptual Assimilation Model of Second Language Speech Learning (PAM-L2; Best & Tyler, Reference Best, Tyler, Bohn and Munro2007) because both phones are judged as equally good/poor instances of Spanish /o/. The model predicts poor discrimination for this type of assimilation and therefore the fact that significant differences between groups were found for /ɒ/ and /ɔː/ in this study is encouraging—even though the gains made for /ɔː/ in this study were generally small.
Finally, /iː/-/ɪ/ and /æ/-/ʌ/ tend to be assimilated to Spanish /i/ and /a/, respectively, and were considered to be amongst the most difficult to improve. Thus, the fact that /æ/ was one of the sounds for which significant differences between groups were found in the present study is considered to be positive. Nevertheless, the participants’ identification scores for /ɪ/ in this study were comparatively higher than for /iː/ and the ones for /æ/ were higher than for /ʌ/. The data in Cebrian’s study show that while /iː/-/ɪ/ are both identified as Spanish /i/, the former is exclusively assimilated to /i/ and the latter is more often assimilated to /e/.Footnote 3 Hence, it may be easier for learners to perceive differences between English /ɪ/ and Spanish /i/ and therefore categorizing /ɪ/ correctly may also be easier. Researchers have often noted that, unlike L1 speakers, L2 learners tend to rely excessively on durational rather than qualitative differences to distinguish /iː/-/ɪ/ (Kondaurova & Francis, Reference Kondaurova and Francis2010). Consequently, participants in this study may have focused excessively on duration when hearing examples of /iː/ that were not necessarily “long” and may have incorrectly identified them as /ɪ/. Finally, both /æ/-/ʌ/ were assimilated to Spanish /a/ in Cebrian’s study to a similar extent and with similar GOF ratings. The fact that participants’ identification of /ʌ/ in this study was so resistant to change may have been due to the influence of spelling in the keywords used for /ʌ/ (bus) and /æ/ (hat). Considering that Spanish learners perceive /æ/ and /ʌ/ as very similar to Spanish /a/, seeing <a> in the keyword for hat (the response alternative for /æ/ in the test, featuring its only possible spelling) may have maximized the effects of equivalence classification (Flege, Reference Flege1987), leading participants to identify instances of both vowels as the vowel in hat because <a> is the visual referent they have for this vowel in their native language (i.e., /a/). Nonetheless, it should be pointed out that testing the predictions made by L2 speech learning models was not the aim of this study and, therefore, the preceding interpretation must be taken with caution.Footnote 4
As regards the use of phonetic symbols versus keywords as response labels for perceptual training studies, the main aim of the study, the participants’ responses to a posttest questionnaire canvassing their opinions toward training with both types of labels suggest that, although perceptions were positive toward both labels, the group trained with symbols perceived the HVPT training as more beneficial and engaging and were more willing to use it (Fouz-González & Mompean, Reference Fouz-González and Mompeanin press). However, the analysis of the differential gains fostered by these labels in this study shows that, except for /æ/ in real stimuli, no significant differences were found between the “symbols” (G1) and the “keywords” (G2) groups. An almost medium effect size was found in the comparison of the gains made by G1 and G2 for /ɒ/ in untrained nonwords, but it did not reach statistical significance. The fact that both experimental groups made similar improvements suggests that both types of labels (keywords and phonetic symbols) offer advantages for perceptual training. As a case in point, keywords are relatively straightforward to use in that they should be easily recognised by students, consequently making it reasonably easy to compare other sounds to those in a keyword. Nevertheless, it may be the case that using a given keyword featuring the target sound with a specific orthography (e.g., <ur> for /ɜː/) limits the extent to which perceptual gains are generalized to words where the vowel is represented with other spellings (e.g., to <ir>, <or>, <er>). Symbols should not pose problems in this regard, as they are a consistent and orthography-independent way of representing speech. This is partly supported by the data for real words, the only type of stimuli where significant differences were found between G1 and G2 (though only for one target sound, with an almost medium effect size). Overall, G1’s mean improvement in real words was almost double the improvement made by G2 and G3. The improvement made by G2 was very similar to that of the control group. This may have been due to the influence of orthography in the labels for G2, which may have hindered the learners’ identification of vowels they would expect to be spelt differently, or, as further explained in the following text, to the activation of fossilised interlanguage forms. On the contrary, participants in G1 could have been less influenced by the effects of spelling and may have found it easier to concentrate on phonetic form when presented with real words, as they had visual referents (i.e., symbols) that are independent of orthography and that can be directly associated with the concepts (or mental representations) of the target sounds.
Carlet and Cebrian (Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019) argue that the response labels provided in an identification task (be it phonetic symbols or orthographic labels) may facilitate the learners’ focusing on phonetic form. This is presumably because listeners are offered immediate feedback on the associations of the stimuli they hear with their long-term memory representations of the target sounds precisely through those labels. Research suggests that orienting the learners’ attention to phonetic form can help learners improve their perception of L2 sounds and that it can play a role in phonetic category formation (Guion & Pederson, Reference Guion, Pederson, Bohn and Munro2007). It could be argued, then, that phonetic symbols could be used as orthography- and lexical-independent referents to which listeners may resort when focusing on phonetic form. They can act as facilitators in the creation of accurate concepts when learners focus on form and analyze the input to which they are exposed. However, this must be interpreted with caution and should be further investigated in future research, as no significant differences were found between G1 and G2 for the majority of target vowels.
The absence of significant differences between groups in real words and the fact that gains were comparatively smaller for G2 suggest that it is harder for learners to make improvements in real words, which may be explained by the fact that it is easier for learners to focus on form and avoid the activation of inaccurate phonolexical representations when they are presented with nonwords (see Ortega et al., Reference Ortega, Mora, Mora-Plaza, Kirkova-Naskova, Henderson and Fouz-González2021; Thomson & Derwing, Reference Thomson, Derwing, Levis, Le, Lucic, Simpson and Vo2016). These findings have implications for theories of L2 learning and the use of words/nonwords in perceptual training. Nonwords such as the ones used in the current study do not exist as conventionalized L2 lexical items. Thus, they cannot be used for the acquisition of lexical chunks or units in L2 teaching. Nevertheless, the aim of perceptual training is not to increase L2 learners’ vocabulary size but to help them improve the perception and production of L2 phonology, with the ultimate aim of improving their listening comprehension and speaking skills. As pointed out in the introduction, this requires a vast amount of experience with the L2. Over the past decades, the importance of input has been increasingly acknowledged in the L2 literature (e.g., Krashen, Reference Krashen1985; Moyer, Reference Moyer, Piske and Young-Scholten2009). According to Flege (Reference Flege2018), the quantity and quality of input may be even more important for successful L2 speech learning than the age at which L2 learners are first exposed to their L2. In this respect, the use of nonwords, as long as they are phonotactically well-formed (or “legal”), may be suitable to provide part of the extensive oral input L2 learners need. Learners need to be exposed to phonotactically permissible combinations of segments, either through real words that could be described as minimally “authentic” data (in that they are decontextualized) or through phonotactically legal nonwords. Moreover, and although they cannot be used for vocabulary building, nonwords can be advantageous in L2 speech learning insofar as they minimize lexical effects associated with real words (e.g., familiarity, lexical frequency) as well as the activation of inaccurate phonolexical representations of words they already know.
Related to the importance of input in L2 learning, increased exposure to the target language cannot be ruled out as also contributing to the three groups’ improvements because all the courses in the participants’ degree are taught in English. Additionally, it is important to highlight that all the participants, including those in the control group, were receiving explicit training in phonetics at the time of the study. Given the role explicit phonetic information plays in second language pronunciation performance (Saito, Reference Saito2013), some improvements in the performance by participants in the control group (G3) were expected. However, the combination of the form-focused instruction provided by the HVPT together with the information learners had from the Phonetics course was expected to produce the greatest gains for G1 and G2. Even though the differences between groups did not reach statistical significance for every sound or every type of stimuli (trained nonwords, untrained nonwords, and real words), the results from the ANOVAs comparing the improvements made by each group clearly show G1 and G2’s superiority over G3 (also see Figures 3, 4, and 5). In trained items, the improvement made by G1 (13.4%) and G2 (13.9%) was superior to that by G3 (5.4%). The trend is similar for untrained nonwords, with G1 improving by 9.3% from pre- to posttest, G2 by 8.6% and G3 by 3.2%. Finally, the results in real words show that G1’s gains were almost double (9.9%) the ones by G2 (5.3%) and G3 (4.9%).
According to Plonsky and Oswald’s (Reference Plonsky and Oswald2014) recommended effect size benchmarks for between-groups contrasts in L2 research (small r = 0.25, d = 0.40; medium r = 0.40, d = 0.70; and large r = 0.60, d = 1.00), the effect sizes for the differences between groups that were found to be significant in this study are generally medium or large. The largest effect sizes can be found in the differences between the groups’ improvement for trained nonwords (with medium and large effects), followed by untrained nonwords (with medium and almost medium effects). Considering the mean effect sizes for between-group contrasts reported by Lee et al. (Reference Lee, Jang and Plonsky2015) in their meta-analysis of the effectiveness of L2 pronunciation instruction, the effect sizes in this study are generally in line with the field-specific mean effect sizes for studies conducted in FL settings (d = 0.98), with short instructional treatments (d = 0.73 for interventions shorter than 4.25h), with intermediate learners (d = 0.80), and for studies targeting vowels (d = 0.99). However, the effect sizes in this study are superior to the mean effect size of studies using computers for pronunciation instruction (d = 0.24). This offers further evidence in favour of the potential of computer-assisted pronunciation training in general, and of HVPT in particular, which is especially encouraging given that the targets posed especial difficulty for the target group and that the duration of training was relatively short (i.e., 2 hours in total). Nonetheless, it should be born in mind that the effect sizes in this study reflect differences in improvements in the learners’ perception, whereas the ones reported in recent metanalyses often focus on measures of participants’ production (see Saito & Plonsky, Reference Saito and Plonsky2019; Sakai & Moorman, Reference Sakai and Moorman2018). Thus, these comparisons have to be interpreted with caution. Even though perception-based training has proved particularly effective to help learners improve different segmental and suprasegmental dimensions of L2 pronunciation (Lee et al., Reference Lee, Plonsky and Saito2020), the effect sizes of the transfer of perceptual-based training gains to the production domain are not always large (Sakai & Moorman, Reference Sakai and Moorman2018). Therefore, it may be the case that the medium-large effect sizes observed in perception gains in this study are not as large for the production domain, or that the two response labels explored foster different gains in production.
It is important to note that the pre-, post-, and delayed posttests for the three groups used keywords as labels to measure the participants’ perception of the target vowels. This was considered to be a suitable option for pretesting students’ perception in the absence of previous training and to prevent participants in G2 from thinking of phonetic symbols during the tasks. By using keywords, learners had to identify the target vowels according to referents they already have, as participants were majoring in English and the keywords used were very common words that should be very familiar to them. The orthographic component of those labels should not impose an added difficulty to the task, as opposed to other types of labels that would have required additional training before the pretest. Given this, the group receiving training with symbols (G1) may have been at a disadvantage compared with the group receiving training with keywords (G2), as the labels of the tests were different than the ones G1 used for training. This is considered to be positive regarding the potential of symbols, as participants in G1 could extrapolate the gains obtained from training to a different task format.
Finally, it should be noted that the voices used for testing and training were different and therefore any gains from pre- to posttest can also be considered to be instances of generalization of gains to novel speakers. All this suggests that the gains fostered by training can be considered to be robust, as they were not context- or speaker-dependent and they were maintained over time (see Lively et al., Reference Lively, Pisoni, Yamada, Tohkura and Yamada1994; Logan & Pruitt, Reference Logan, Pruitt and Strange1995). Hence, the results presented in the preceding text offer further evidence of the potential of HVPT paradigms to help learners improve their perception of challenging L2 sounds (Carlet, Reference Carlet2017; Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019; Logan et al., Reference Logan, Lively and Pisoni1991; Rato, Reference Rato2013; Thomson, Reference Thomson2011; Wong, Reference Wong, Mompean and Fouz-González2015). Furthermore, the target aspects addressed usually show traits of fossilization in the interlanguage of upper-intermediate EFL learners, as evinced in Monroy-Casas’s (Reference Monroy-Casas2001) study with learners of a similar profile to those in the current study. Thus, the improvements participants made are especially noteworthy, as the duration of training was relatively short (four sessions of approximately 30 minutes) and the target aspects are considered to be particularly difficult to modify.
CONCLUSION
The results of this study show that the perceptual training administered had a positive impact on the learners’ perception of the target vowels and that using phonetic symbols as labels in phonetic training paradigms can be as effective as using sample words, even when the symbols do not coincide with the letter values in the Roman alphabet.
The study presents some limitations, which also offer directions for future research. Concerning the participants, the fact that all the participants were relatively high-proficiency (i.e., upper intermediate) EFL learners for which the target vowels tend to be fossilized was considered important to explore the potential of the different labels used to modify their perception of such challenging aspects. However, because participants were majoring in English and taking a Phonetics course, they may have been more predisposed to improve accuracy than the average EFL learner (i.e., not majoring in English and without a particular interest in phonetics and phonology).
Moreover, while using phonetic symbols should not be a problem if they coincide with their value in the Roman alphabet (e.g., /r/, /l/, /s/, /t/), for English vowel sounds, the average EFL learner will have to become familiarized with the symbols first. Therefore, future studies should investigate potential differences between the type of labels used for students who have not received prior training in phonetics or with phonetic symbols, students with different proficiency levels, or with different motivation to learn the L2.
Additionally, the number of real words used to measure the participants’ perception was limited to a manageable set to avoid an excessively long test. Future studies should investigate the extent to which gains from these two different training conditions can be generalized to the whole range of spellings featuring different vowels in real words. Finally, given the positive impact perceptual training has on the production domain, future studies should also explore whether there are differences between using phonetic symbols or keywords as response labels in perceptual training paradigms in the extent to which gains can be generalized to production.
To conclude, the results of the present study offer relevant pedagogical implications for pronunciation instruction in general and perceptual training in particular. Research suggests that directing the learners’ attention to phonetic information can facilitate the formation of novel phonetic categories (Guion & Pederson, Reference Guion, Pederson, Bohn and Munro2007). As Thomson (Reference Thomson2011) notes, orienting the learners’ attention to phonetic information can help learners incorporate more of the input they receive into their emerging L2 categories. Thus, providing learners with labels with which to categorize L2 speech could be an effective way of enhancing their capacity to analyze the FL/L2 and to create or reinforce their L2 perceptual categories or concepts. Assuming that improvements in the participants’ perception of FL sounds can lead to improvements in their production (Bradlow et al., Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997; Carlet & Cebrian, Reference Carlet, Cebrian, Nyvad, Hejná, Højen, Jespersen and Sørensen2019; Flege, Reference Flege and Strange1995; Fouz-González, Reference Fouz-González2020; Lambacher et al., Reference Lambacher, Martens, Kakehi, Marasinghe and Molholt2005; Thomson, Reference Thomson2011), helping learners improve their perceptual categories for FL sounds by helping them create accurate concepts seems to be a suitable approach for pronunciation training. These labels would not only be useful for HVPT sessions but also for other situations in which learners are exposed to the FL, as they would allow learners to think about and analyze the input they receive, as well as monitor their performance when speaking in the FL. In the case of keywords, they should be familiar to learners and therefore relatively easy to use. As regards phonetic symbols, they are systematic and not influenced by orthography; this should facilitate learners’ “visualization” of the target sounds regardless of the orthography with which they are represented, which should, in turn, be less prone to transfer from the L1 or the activation of inaccurate phonolexical representations of words they already know.
Supplementary Materials
To view supplementary material for this article, please visit http://dx.doi.org/10.1017/S0272263120000455.