



INTRODUCTION
Mainstream language teaching methodology holds that second language (L2) instruction should result in learners capable of using language in real-life contexts (Loewen, Reference Loewen2015). Functional language use is key in dominant meaning-oriented pedagogical approaches like task-based language teaching (Erlam, Reference Erlam2016), and becoming an independent L2 user is promoted by the Common European Framework of Reference (CEFR) for languages (Council of Europe, 2001). Yet, previous L2 vocabulary research has shown that real-life language use requires solid lexical knowledge in all skill areas (Webb & Nation, Reference Webb and Nation2017). Efficient L2 instruction and teaching should therefore incorporate a strong vocabulary component.
Solid vocabulary knowledge does not only include aspects related to vocabulary size (i.e., the number of words contained in the mental lexicon) and the strength of representation of different word knowledge components (pronunciation, orthography, meaning, etc.). It also refers to the ability to access the mental lexicon quickly and accurately (Pellicer-Sánchez, Reference Pellicer-Sánchez2015). Yet, most previous research is exclusively based on explicit offline measures that provide ample opportunities for conscious retrieval of vocabulary knowledge, but lack the sensitivity to track speed of lexical access (Godfroid, Reference Godfroid and Webb2020). Therefore, it has been argued that sensitive time-pressured measures may provide a deeper understanding of L2 vocabulary knowledge.
The aim of the present study is to investigate the value of combining explicit (pen-and-paper) and sensitive (reaction time) measures to assess the impact of L2 vocabulary instruction on the learning of 20 L2 French target verbs. Three prototypical instructional treatments in studies of vocabulary learning from written input will be compared: (a) contextualized input with meaning-focused activities only, (b) contextualized input with both meaning- and word-focused activities, and (c) decontextualized input with word-focused exercises only. To take into account the multidimensional nature of word knowledge, we will focus on form-, meaning-, and use-related word knowledge aspects.
MEASURING WORD KNOWLEDGE
WHAT IS INVOLVED IN WORD KNOWLEDGE?
Word knowledge is a multifaceted construct that can be broken down into partial knowledge aspects that relate to a word’s form (e.g., spelling), meaning (e.g., word associates), and use (e.g., grammatical functions) (Nation, Reference Nation2013). Hence, obtaining a clear picture of word knowledge requires the measurement of knowledge gains in a variety of aspects. Most studies, however, equated word knowledge with knowledge about the form-meaning link (Nation & Webb, Reference Nation and Webb2011) and did not take into account the variety of aspects that word knowledge entails. An exception (for an overview, see González-Fernandéz & Schmitt, Reference González-Fernández and Schmitt2019) is a study by Webb (Reference Webb2007) in which the effects of word learning from either sentence contexts or paired associate learning were investigated. This study addressed 10 aspects of word knowledge (active and passive knowledge of orthography, syntax, association, grammar, and meaning) and showed that learning from sentence contexts did not lead to more use-related learning gains than paired-associate learning. González-Fernández and Schmitt (Reference González-Fernández and Schmitt2019) examined the interrelatedness of recognition and recall of four word components (form-meaning link, derivatives, multiple meanings, and collocations) and investigated whether the four components referred to one or multiple constructs. Results indicated that all components were strongly intercorrelated and that knowledge development followed an implicational scale showing, for instance, that recognition knowledge develops before recall knowledge for all components tested.
We can conclude that studies that have adopted a multiple components approach have provided valuable insights. Hence, more multiple component studies are needed to better understand the effects of L2 vocabulary instruction. Moreover, it has been argued that a better understanding of the complex construct of L2 word knowledge would also entail pedagogical value. Multicomponent studies could indeed point to the aspects of L2 vocabulary learning that deserve teaching priority (Schmitt, Reference Schmitt2019). Therefore, the present study focuses on the three components involved in Nation’s L2 vocabulary knowledge framework, that is, form, meaning, and use.
EXPLICIT AND SENSITIVE MEASURES
Word knowledge develops incrementally throughout its different components as a result of recurrent exposures to lexical items (Schmitt, Reference Schmitt2010). Concomitantly, cumulative speed gains in lexical processing are achieved (Frishkoff et al., Reference Frishkoff, Perfetti and Collins-Thompson2011). Yet, measures that have the sensitivity to track speed of lexical processing have only scarcely been used in L2 vocabulary research (Pellicer-Sánchez, Reference Pellicer-Sánchez2015). Indeed, the majority of L2 vocabulary studies, including the previously cited multicomponent studies, used pen-and-paper tests such as multiple-choice recognition tests or translation tests, that allowed for conscious thinking and attentional control (Godfroid, Reference Godfroid and Webb2020).
The speed at which lexical items can be processed is considered to be an indicator of strength of lexical knowledge and an essential component of fluent language use (Godfroid, Reference Godfroid and Webb2020; Pellicer-Sánchez, Reference Pellicer-Sánchez2015). Therefore, sensitive measures are said to better represent the type of knowledge needed for fluent language use than traditional pen-and-paper measures (Elgort, Reference Elgort2018). Godfroid (Reference Godfroid and Webb2020) uses the term sensitive measures to refer to methods that have the sensitivity to track lexical processing speed by reaction time (RT) methodologies, whereby the element of time restriction is said to reduce the opportunities for conscious retrieval and attentional control (Elgort, Reference Elgort2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2015). The knowledge that sensitive measures may tap into can be of different nature. On the one hand, it can be readily available speeded-up knowledge (Pellicer-Sánchez, Reference Pellicer-Sánchez2015) that is explicit in nature, that is, knowledge that learners are aware of and can retrieve consciously from memory (Loewen, Reference Loewen2015, p. 20). If this type of knowledge has undergone a qualitative change, in that it has become fast, effortless, reliable, and invariable, it is called automatized explicit knowledge (Godfroid, Reference Godfroid and Webb2020). On the other hand, sensitive measures can also tap into tacit/implicit knowledge (Elgort, Reference Elgort2011; Sonbul & Schmitt, Reference Sonbul and Schmitt2013), that is, knowledge that is not available to learners’ conscious control or report (Elgort, Reference Elgort2018). In this article, we will use explicit measures to refer to traditional pen-and-paper measures that allow for conscious thinking and that tap into explicit knowledge. The term sensitive measures will be used for measures that intend to reduce the opportunities for attentional control by using an element of time restriction, and can tap into either speeded-up explicit, automatized explicit, or implicit/tacit knowledge.
Elgort (Reference Elgort2011) investigated the effects of deliberate decontextualized learning of pseudowords through word lists and flashcards on the development of tacit lexical knowledge by using a priming paradigm. Priming techniques assume that words are recognized more quickly (i.e., a facilitation effect) when preceded by orthographically related (i.e., form priming, e.g., junction-function) or semantically related (i.e., semantic priming, e.g., microwave-toaster) words. The priming tasks showed that the treatment induced a facilitation effect for both formal and semantic priming. Hence, it was concluded that tacit lexical knowledge could emerge from decontextualized deliberate word learning. Accordingly, Elgort et al. (Reference Elgort, Candry, Boutorwick, Eyckmans and Brysbaert2018) studied the effect of a form- (i.e., word writing) and meaning-focused (i.e., deriving word meaning from context) treatment on the deliberate learning of low-frequency words and nonwords in two parallel experiments. In a speeded lexical decision task (LDT), participants were asked to decide as accurately and as quickly as possible whether a letter string was either a real L2 word or a nonword. Results showed that word-focused instruction not only was amenable to higher accuracy but also facilitated faster processing.
While the previously mentioned studies display the added value of sensitive measures, RT measurement failed to be informative in other studies. Pellicer-Sánchez and Schmitt (Reference Pellicer-Sánchez and Schmitt2012) assessed whether RT measures would be appropriate for scoring the Yes–No vocabulary test, assuming that certainty and accuracy would be reflected by fast RT, whereas slow RT would indicate hesitation and inaccuracy. Yet, they found no advantage for RT over traditional measures. Similarly, Fukkink et al. (Reference Fukkink, Hulstijn and Simis2005) investigated whether time-pressured computerized L2 vocabulary learning (translation and gapped sentence exercise) would result in (a) faster lexical access during a LDT, (b) increased reading performance, and (c) text comprehension. It was found that the trained words were responded to faster during the experimental task, but this advantage was not transferable to reading speed and text comprehension. Finally, Sonbul and Schmitt (Reference Sonbul and Schmitt2013) used explicit traditional measures (i.e., multiple-choice form recognition and form recall) and a timed primed LDT to detect learning of collocations through two decontextualized conditions. Learning gains were revealed for the explicit measures but not for the sensitive measure.
In sum, while some previous studies indicate the potential of sensitive measures for L2 vocabulary research, other studies suggest that their role is not clear-cut. Therefore, more research that combines traditional and sensitive measures is warranted.
INSTRUCTIONAL TREATMENTS FOR L2 VOCABULARY LEARNING
While L2 vocabulary learning benefits from opportunities for incidental learning through repeated encounters in a variety of meaningful contexts, word-focused instruction (i.e., directing learners’ conscious attention to new vocabulary in either communicative or noncommunicative situations; Laufer, Reference Laufer and Hinkel2017), plays an important role in L2 word learning (Webb & Nation, Reference Webb and Nation2017). Yet, meaning-oriented language teaching methodologies, such as the strong versions of communicative teaching and task-based language learning, assume that L2 instruction is most efficacious through communication and functional language use (Ellis, Reference Ellis2009; Littlewood, Reference Littlewood2014). However, more flexible versions of meaning-oriented approaches advocate opportunities for word-focused instruction, such as the implementation of an explicit focus on lexical items before, during and/or after performing a meaningful tasks (e.g., Ellis, Reference Ellis2009; Van den Branden, Reference Van den Branden2016). Furthermore, Mason and Krashen (Reference Mason and Krashen2010) argue in favor of meaning-oriented research that meets the conditions for successful vocabulary learning, such as interesting and motivating comprehensible input. To discuss the role of contextualized input and word-focused instruction, the relevant literature will be reviewed that corresponds to three prototypical instructional conditions: (a) contextualized input with meaning-oriented activities only, (b) contextualized input with both meaning-oriented and word-focused activities, and (c) decontextualized input with word-focused exercises.
CONTEXTUALIZED INPUT WITH MEANING-ORIENTED ACTIVITIES
Numerous L2 vocabulary studies have shown that exclusively meaning-focused conditions yield lower learning gains than word-focused conditions (Laufer, Reference Laufer and Hinkel2017). However, it has been argued that in those studies, meaning-oriented techniques that promote successful word learning have not been used in an optimal way. As such, in a critical review of File and Adams (Reference File and Adams2010), Mason and Krashen (Reference Mason and Krashen2010) argue that the conditions in the reading-only treatment were not optimal for word learning, in that reading was not self-selected, readers had to follow along while the text was read out by the researcher, and the reading passage was very demanding, as only 78% of the words pertained to the 2,000 most frequent English words. Moreover, the authors state that the reading passages were not interesting to the participants. Indeed, topic interest and topic familiarity have shown to be beneficial to vocabulary learning (Lee & Pulido, Reference Lee and Pulido2017). Another factor that impacts vocabulary learning in meaning-oriented contexts is the number of encounters with new words. Pellicer-Sánchez and Schmitt (Reference Pellicer-Sánchez and Schmitt2010) used an authentic novel to investigate the relationship between frequency of occurrence and recognition of meaning and spelling, and recall of word class and meaning. It was found that in advanced L2 readers, substantial learning gains for all aspects occurred after 10 or more exposures to new vocabulary. Additionally, the presence of postreading activities may also impact vocabulary learning. While most studies supplemented reading with postreading comprehension activities, few studies used free meaning-focused postreading output activities, which could promote retention of text-relevant vocabulary (except for Rott, Reference Rott2004). As such, the role of providing opportunities for using new words in guided and unguided meaning-oriented output activities requires further inquiry (Coxhead, Reference Coxhead2011).
CONTEXTUALIZED INPUT WITH BOTH MEANING- AND WORD-FOCUSED ACTIVITIES
There is ample evidence that word-focused activities have beneficial effects on word learning (e.g., Laufer, Reference Laufer and Hinkel2017; Peters, Reference Peters2012; Webb & Nation, Reference Webb and Nation2017). The efficiency of word-focused activities can be explained by Hulstijn and Laufer’s (Reference Hulstijn and Laufer2001) Involvement Load Hypothesis (ILH), stating that the more attentional involvement a vocabulary task requires, the more efficient it is for subsequent vocabulary learning. ILH is rooted in Craik and Lockhart’s (Reference Craik and Lockhart1972) Depth of Processing Hypothesis (cited in, e.g., Schmitt, Reference Schmitt2008) that rests on the idea that the more attention is allocated to processing new information, the better the opportunities for learning will be. According to ILH, activities with a high involvement load are predicted to be more effective for L2 vocabulary learning than activities with a low involvement load, whereby involvement varies as a function of need (i.e., task completion requires using the word), search (i.e., task completion requires finding the word), and evaluation (i.e., deciding whether a word fits in the surrounding context). In two parallel experiments, Hulstijn and Laufer (Reference Hulstijn and Laufer2001) intended to find empirical evidence for ILH. Through a meaning recall test (i.e., provide an L1 translation or definition), it was found that results were better when targets were presented in a word list and had to be used in a writing task (49% and 67%) than reading with glosses (27% and 20%) or reading and completing a gapped text (29% and 40%).
Laufer and Girsai (Reference Laufer and Girsai2008) compared reading with comprehension questions, reading with vocabulary tasks and reading with translation tasks. The latter was found to induce high involvement and yielded the best results on a meaning recall and a form recall test (i.e., provide the L2 word form of an L1 meaning). Laufer and Rozovski-Roitblat (Reference Laufer and Rozovski-Roitblat2015) compared the impact of number of encounters with new words in reading only, reading with a dictionary, and reading with word-focused activities. Four vocabulary tests were administered: cued form recall (first letter of L2 word was given), meaning recall (supplying L1 translation of an L2 form), form recognition (multiple choice), and finally meaning recognition (multiple-choice L1 translation of L2 word form). The authors found that reading with word-focused exercises yielded the highest scores on all tests and concluded that task type is more influential than number of exposures.
DECONTEXTUALIZED INPUT WITH WORD-FOCUSED EXERCISES
To further explore the value of word-focused instruction, Laufer (Reference Laufer2006) used the L2 grammar taxonomy of Focus-on-Form (i.e., meaning-oriented practice with opportunities for attending to linguistic forms), and Focus-on-Forms (i.e., decontextualized noncommunicative practice) to compare the impact of reading with dictionary use and word lists supplemented with word-focused exercises in both incidental and deliberate learning conditions. On the meaning recall posttests for incidental learning, it was found that word lists supplemented with word-focused exercises yielded better learning outcomes than reading with dictionary use. Notwithstanding the efficiency of decontextualized vocabulary learning (Schmitt, Reference Schmitt2008), behaviorist paired-associate learning of word lists has pedagogically been disapproved of since the emergence of communicative approaches (Elgort, Reference Elgort2011). Similarly, translation practice has been discouraged in pedagogy but found support in L2 vocabulary studies (Hummel, Reference Hummel2010; Laufer & Girsai, Reference Laufer and Girsai2008; Schmitt, Reference Schmitt2008; Webb & Nation, Reference Webb and Nation2017).
Although it is accepted that effective L2 vocabulary learning depends on attention and maximal engagement with lexical items (Schmitt, Reference Schmitt2008), meaning-oriented paradigms are uncertain about the equilibrium between an explicit focus on linguistic features and authentic meaning-oriented instruction (Ellis, Reference Ellis2009; Littlewood, Reference Littlewood2014). Hence, in the context of L2 vocabulary instruction, more research is warranted on the role of contextualized input and word-focused instruction.
RATIONALE AND RESEARCH QUESTIONS
The aim of the present study is to investigate the value of combining explicit (pen-and-paper) and sensitive (RT) measures to assess form-, meaning-, and use-related learning gains resulting from three instructional treatments: (a) contextualized input with meaning-oriented but not word-focused activities [+CO−WF], (b) contextualized input with both meaning- and word-focused activities [+CO+WF], and (c) decontextualized input with word-focused exercises [−CO+WF].
The following research questions guided this study:
RQ1: What is the impact of [+CO−WF], [+CO+WF], and [−CO+WF] on L2 vocabulary learning as measured by explicit measures?
RQ 2: What is the impact of [+CO−WF], [+CO+WF], and [−CO+WF] on L2 vocabulary learning as measured by sensitive measures?
As previous findings point toward the efficiency of word-focused instruction (e.g., Laufer, Reference Laufer and Hinkel2017; Webb & Nation, Reference Webb and Nation2017), we expect for RQ1 that both word-focused conditions will outperform the meaning-only condition. Moreover, given the efficiency of decontextualized instruction (e.g., Schmitt, Reference Schmitt2008), we hypothesize that decontextualized word-focused instruction may fare better than contextualized word-focused instruction. For RQ2, previous findings (e.g., Elgort, Reference Elgort2011; Elgort et al., Reference Elgort, Candry, Boutorwick, Eyckmans and Brysbaert2018) suggest that the decontextualized word-focused instruction will lead to more accurate and faster processing than the other conditions.
METHOD
PARTICIPANTS
Participants were 313 Flemish (age 15–16) intermediate learners (global CEFR B1 proficiency level) of L2 French. Participants were pretested on vocabulary size (VocSize), which was used as a proxy for L2 proficiency (Schmitt, Reference Schmitt2010), and working memory span (WM), which was used as a measure of cognitive ability that plays a role in L1 and L2 word learning (Elgort et al., Reference Elgort, Candry, Boutorwick, Eyckmans and Brysbaert2018). On the basis of the mean scores on these tests (see Table 3), four roughly homogenized groups consisting of four or five intact classes were composed, that is, the three experimental groups, [+CO−WF] (n = 71), [+CO+WF] (n = 82), [−CO+WF] (n = 76), and the control group (n = 83). The control group only took part in the tests to monitor the validity of the experimental tasks, learning between the treatment sessions and possible pre- to posttest effects (Nation & Webb, Reference Nation and Webb2011). Participants were informed that the study dealt with optimizing learning materials. They were unaware that the focus was on vocabulary learning and that they would be tested afterward.
TARGET ITEMS
Targets were 20 real L2 French verbs and were selected as follows. Initially, 51 presumably unknown verbs were selected from French online news sites as potential target items. These verbs were tested in a meaning recognition test with last-year secondary school students (N = 228) who were comparable to the students who participated in the actual experiment in terms of age, years of instruction, and proficiency level. Next, another comparable group of secondary school students (N = 239) was asked to infer the meaning of the candidate targets in a variety of newspaper contexts. Finally, experienced L2 French teachers (N = 22) evaluated whether the meaning of 120 French verbs (including the potential targets) could be known by students at the end of secondary school. Results of the recognition and inferencing test, as well as the ratings from the teachers, were combined (Supplement 1) to obtain the final set of 20 target verbs (Figure 1).

FIGURE 1. Targets.
TREATMENTS
The study consisted of three conditions: two contextualized conditions (with and without word-focused activities) and one decontextualized condition (Table 1). Each treatment consisted of two sessions that took place during regular classroom hours on two consecutive days
TABLE 1. Overview of the three treatments

CONTEXTUALIZED CONDITIONS
As can be seen from Table 1, a lifelike online news site that included 10 articles based on authentic news items was created for both contextualized conditions ([+CO−WF] and [+CO+WF]). The articles were conceived in such a way that they would facilitate word learning. First, the items were selected to be interesting for the target audience (Lee & Pulido, Reference Lee and Pulido2017). Some examples of topics were plastic pollution in the oceans and parents who drug their unmanageable children. Second, each article (average length: 201.2 words, SD = 16.85) contained two targets that each occurred three times in the text. We assumed that reading the texts on two consecutive days, followed by repeated encounters and opportunities for retrieval during the activities, would result in at least 10 exposures per target (Pellicer-Sánchez & Schmitt, Reference Pellicer-Sánchez and Schmitt2010). To avoid unnatural redundancy due to the repeated use of the targets, all texts were checked by a native speaker. Third, targets were essential for comprehension and relevant to the message (Peters et al., Reference Peters, Hulstijn, Sercu and Lutjeharms2009; Peters, Reference Peters2012). For instance, understanding the target narguer (to mock) was essential for understanding an article about an escaped criminal using social media to mock the police. Fourth, Lextutor (https://www.lextutor.ca) was used to check the lexical coverage of all texts. Results revealed that 95.82% (SD = 0.70) of the words were high frequency vocabulary, that is, pertaining to the 3,000 most frequent words (Schmitt & Schmitt, Reference Schmitt and Schmitt2014). Finally, pilot testing of the texts confirmed that students (N = 71) of the same age enrolled in the same L2 program had no difficulties in understanding the articles.
The homepage (Figure 2) of the news site used in the contextualized conditions showed 10 news items. By clicking on each item, participants were directed to a split-screen page with the article on the left-hand side, and activities on the right-hand side (Figure 3). The types of activities were different for both contextualized conditions (for a detailed overview of the activities in the contextualized conditions, see Supplement 2). Participants in both contextualized treatments could continuously consult the articles while performing the activities.

FIGURE 2. Homepage of the news website.

FIGURE 3. Example website interface of a meaning-oriented activity.
Participants in [+CO−WF] read the articles and performed two types of activities. On day one, they answered multiple-choice comprehension questions about the content of each article (e.g., yes/no statements). On day two, participants were asked to reread each news item and to post a short free comment of about five lines per article (Figure 4). Using the targets in the output activity was not required nor suggested.

FIGURE 4. Example website interface of a writing activity.
Participants in [+CO+WF] were presented with the same news site. On day one, they answered multiple-choice comprehension questions that were both meaning- and word-focused. For instance, in the article entitled “Scandale: une agence de tourisme américaine éclabousse la reputation de Disneyland” (Scandal: a travel agency damages the reputation of Disneyland), it was asked which statement would best fit the title: On sauve/dégrade/améliore la réputation de Disneyland (The reputation of Disneyland is saved/harmed/improved). On day two, participants were asked to reread each news item and to post a short comment of about five lines per article in which they were required to use the targets.
DECONTEXTUALIZED CONDITION
Participants in the decontextualized group were provided with four vocabulary exercise blocks including four word lists related to (multi)media. Each word list contained five targets and eight to nine filler verbs, a translation and a sample sentence. By clicking on each block, they were directed to a split-screen page with a word list on the left-hand side and interactive exercises on the right-hand side (Figure 5). On day one, participants made the following exercises for each of the four training blocks: a drag-and-drop exercise about the form-meaning link, a fill-in-the-gap exercise on synonyms, a drag-and-drop exercise on verb structures, a picture-matching exercise, and an odd-man-out exercise. On day two, they were presented with the same word lists and were asked to translate 10 short sentences per block (L1 to L2), containing both targets and filler verbs. As in the contextualized conditions, participants in the decontextualized condition could continuously consult the word lists while performing the word-focused exercises.

FIGURE 5. Example website interface decontextualized condition.
All instructions in the activities (both contextualized and decontextualized) were given in learners’ L1 (Dutch) to ensure learners’ comprehension. Participants performed the tasks individually at their own pace, but were aware of the overall time frame of 80 minutes (Elgort, Reference Elgort2011). Piloting the materials had shown that sessions took 60 to 70 minutes. Participants were given a checklist to ensure that they completed all tasks. To have a rough indication of the time needed for task completion, participants were asked to write down their respective start and end time of the treatment. Accessing the website outside of the learning sessions was impossible. All sessions were led by the first author.
MEASUREMENT INSTRUMENTS
Explicit Measures
To address form-, meaning-, and use-related word knowledge components, vocabulary gains were measured by means of three pen-and-paper tasks (Figure 6). The form recognition test assessed receptive knowledge about the word form. Participants needed to indicate the real French target verb amongst three legally spelled pseudoverb variants. They could indicate their certainty on a five-point scale, ranging from “very sure” to “very unsure.” To discourage guessing, an “I don’t know” option was provided (e.g., Pellicer-Sánchez & Schmitt, Reference Pellicer-Sánchez and Schmitt2010). To assess knowledge about the meaning of the target verbs, a meaning recall tests was administered in which participants could demonstrate receptive knowledge of the meaning of the words by giving a translation, using the word in a sentence, explaining the word, and so forth (e.g., Webb, Reference Webb2007). With respect to use-related word knowledge, we assessed receptive knowledge about the grammatical patterns in which the target verbs occur. In the grammatical preference test, the targeted type of grammaticality was the verb’s complement structure. Participants were provided with four sentences in which targets were either correctly or incorrectly used (e.g., Chen & Truscott, Reference Chen and Truscott2010). In order to discourage guessing, an “I don’t know” option was provided (Nation & Webb, Reference Nation and Webb2011), as well as a “none of the above is correct” option (Ionin & Zyzik, Reference Ionin and Zyzik2014). There was one correct option per target.

FIGURE 6. Overview of explicit measures.
Sensitive Measures
To address speed of access to form-, meaning-, and use-related word knowledge components, we administered three time-pressured tasks (E-prime 2.0, Psychology Software Tools, http://pstnet.com).
Speed of access to the word form was tested trough a LDT in which participants had to decide whether a letter string was an existing L2 French word or not (e.g., Elgort et al., Reference Elgort, Candry, Boutorwick, Eyckmans and Brysbaert2018). After an exercise block (12 trials followed by feedback), each trial started with a 1,500 ms fixation cross, followed by stimulus presentation until response. Each response was followed by a 1,000 ms blank screen. Stimuli were presented in random order and consisted of 10 targets (e.g., huer, “to boo”), 10 matched verbs (e.g., tuer, “to kill”) pertaining to the most frequent 1,000 French words (i.e., the 1K frequency band, based on Lonsdale & Le Bras, Reference Lonsdale and Le Bras2009), 20 matched pseudoverbs (e.g., *fuer), and 20 fillers from various parts of speech. Speed of access to meaning-related word knowledge was assessed through a semantic relatedness task (SEMREL) in which participants had to decide whether prime-target pairs (e.g., kiffer–aimer, “to like–to love”) were semantically related or not (e.g., Frishkoff et al., Reference Frishkoff, Perfetti and Collins-Thompson2011). After an exercise block (10 trials followed by feedback), each trial started with a 1,500 ms fixation cross, followed by 1,000 ms prime presentation and 1,000 ms target presentation until response. Each response was followed by a 1,000 ms blank screen. The test consisted of 10 related and unrelated pairs containing the target verbs, 10 related and unrelated pairs containing well-known words, and 10 filler pairs. Stimuli were presented pseudorandomly to ensure an interval between related and unrelated pairs containing the target verb. Finally, with respect to use, speed of access to the grammatical patterns in which the target verbs occur was tested through a grammatical judgement task (GJT) in which participants had to decide whether sentences were well-formed or not (e.g., Godfroid et al., Reference Godfroid, Loewen, Jung, Park, Gass and Ellis2015). The targeted type of grammaticality was the verb complement structure (e.g., Je kiffe la musique électronique vs. Je kiffe *à la musique électronique, “I like electronic music” vs. “I like *to electronic music”). Sentences were matched for length and subject-verb-complement structure. Stimulus presentation was cut off at 3,250 ms, that is, mean RT in the pilot study plus 1 SD (Bley-Vroman & Masterson, Reference Bley-Vroman and Masterson1989). After an exercise block (16 trials followed by feedback), each experimental trial started with a 1,500 ms fixation cross, followed by sentence presentation until response or 3,250 ms, and a 1,000 ms blank screen. Stimuli consisted of 10 correct and 10 incorrect sentences including the targets, an identically conceived set of sentences containing K1 verbs, and 20 filler sentences. Stimuli were presented pseudorandomly to ensure a presentation interval between correct and incorrect sentences containing the targets.
PROCEDURE
Pretests
To test prior knowledge of the targets, participants completed a pretest containing 30 French verbs (20 targets and 10 fillers) in which they were asked whether they were familiar with each verb. If so, they were asked to demonstrate knowledge about the meaning of each verb by providing a translation, using the verb in a sentence, using I think it has to do with, and so forth. Following this test, participants’ L2 proficiency was established through an adapted version (Noreillie, Reference Noreillie2019) of the Vocablab test (Peters et al., Reference Peters, Velghe and Van Rompaey2019) consisting of 120 meaning recognition multiple-choice items (four distractors in Dutch and an I don’t know-option), covering the 1K–4K frequency bands (30 items per frequency band). Third, to determine participants’ WM, a computerized version of the OSPAN-test was administered (De Neys et al., Reference De Neys, d’Ydewalle, Schaeken and Vos2002). In this test, participants were presented with a series of math problems (e.g., IS (7 × 2) – 4 = 10?). In between each math problem, high-frequency Dutch words were presented shortly (800 ms) and had to be remembered. At the end of each sequence, participants were asked to write down the words in the order of appearance. Finally, a background questionnaire was administered to detect whether any of the participants had French as L1. Learners’ language background was also double-checked with their teachers.
Learning Sessions
Each condition consisted of two treatment sessions that took place during regular classroom hours on two consecutive days. Participants performed the tasks individually at their own pace. Participants were given a checklist to ensure that they completed all tasks. They also wrote down their respective start and end time of the treatment to have a rough indication of the time needed for task completion. Accessing the website outside of the learning sessions was impossible. All sessions were led by the first author.
Posttests
Six surprise vocabulary posttests (cf. supra) were administered at the end of the second learning session as well as 2 weeks later. Test sessions took 45 minutes. Tests were carefully sequenced to avoid testing effects, based on Nation and Webb (Reference Nation and Webb2011). For the explicit measures, the form recognition test was administered first because providing the L2 word form would not inform learners about the meaning, nor about grammatical use. Accordingly, the grammatical preference test was administered as last test so that the sentence contexts could not prime participants with meaning-related knowledge. For the sensitive measures, the same logic was adopted. LDT was administered first because word form recognition is not informative to meaning (SEMREL) and grammatical use (GJT). To avoid that sentence contexts would be informative for meaning-related knowledge, GJT was administered as final test. The pilot study had revealed that it was impossible to take six different tests within a 45 minutes time frame, which was considered the maximum duration to prevent test fatigue. It was therefore decided to split-up target words in two sets (A and B), which were counterbalanced within groups, that is, one half of each experimental group was tested on set A for the explicit tests and on set B for the sensitive measures, and vice versa for the other half of the group (Table 2).
TABLE 2. Distribution of targets over explicit and sensitive posttests

SCORING AND ANALYSES
Scoring
For the explicit tests, responses on the form recognition, meaning recall, and grammatical preference tests were scored binomially (0 or 1). Participants received 1 point when they indicated the correctly spelled verb for form recognition, provided any correct translation or answer that reflected the meaning of the word for meaning (tests were scored by two raters, interrater reliability = 99.24 %), and indicated the correctly built sentence for grammatical use. For the sensitive tests, accuracy (0 or 1) and RT on correct responses were recorded for LDT, SEMREL, and GJT.
Analyses
Linear mixed-effects models (lme) were used to analyze the data. We used R (R Core Team, 2018) and lme4 (Bates et al., Reference Bates, Maechler, Bolker and Walker2015) to compare [+CO−WF], [+CO+WF], and [−CO+WF]. Mixed-effects models have the advantage of including fixed factors and random effects related to participants and items (Linck & Cunnings, Reference Linck and Cunnings2015). We used the glmer function (generalized linear mixed-effects models) for dichotomous accuracy data and the lmer function for continuous RT data. A mixed-effects model was computed for each dependent measure according to the following procedure: We started with a null model including the dependent measure, Treatment as fixed factor, and Participants and Items as crossed random variables. The most adequate statistical model was fitted to the data by adding covariates that accounted for participant and item characteristics (i.e., vocabulary size, working memory, gender, and word length expressed as the total number of letters). Given the theoretical importance of vocabulary size for word learning (Schmitt, Reference Schmitt2010), we checked interactions between VocSize and Treatment. The estimation method was Restricted Maximum Likelihood for models created with lmer and Maximal Likelihood for models created with glmer. The significance of fixed effects for models created with lmer was with lmerTest (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017), p-values were based on t-tests with Satterthwaite’s degrees of freedom. For models created with glmer, p-values were based on Wald’s z. The final statistical model for each dependent variable consisted of factors and interactions that significantly contributed to the model and improved the model fit according to the AIC-index (Akaike Information Criterion). To compare [+CO−WF], [+CO+WF], and [−CO+WF], we applied the ghlt function of the multcomp package for multiple comparisons in R (Hothorn et al., Reference Hothorn, Bretz and Westfall2008) to the fixed factor Treatment in the final model, and used Holm correction to adjust for multiple comparisons (Bretz et al., Reference Bretz, Hothorn and Westfall2011). Nondichotomous RT distributions that deviated from normality were logarithmically transformed to bring them closer to normality. The values for VocSize and WM were standardized. For the sake of readability, RT in the average reports are the untransformed values in milliseconds.
RESULTS
WM AND VOCSIZE
Table 3 shows the descriptive statistics for the learner-related variables WM and VocSize (Cronbach’s alpha = .91). Although the descriptives reveal differences in the mean scores between the groups for VocSize and WM, a one-way ANOVA indicated that these differences did not reach significance (VocSize, F(3, 309) = 1.06, p = .368, and WM, F(3, 309) = 1.65, p = .178).
TABLE 3. Means and SD for WM (maximum = 60) and VocSize (maximum = 120)

RQ 1: Explicit Measures
Form-, meaning-, and use-related learning gains were measured immediately after the treatment and two weeks later. Table 4, which presents the descriptive statistics of the immediate explicit tests, shows that the average scores were highest for form. The control group performed near-chance for the form recognition test and near-zero for the meaning recall test. As can be seen from Table 5, the average results on the delayed posttests show a similar pattern. However, the scores on the delayed form recognition test in the experimental group should be interpreted with caution because scores of the control group also revealed an important increase from immediate to delayed test. This seems to indicate that there was a test effect that is probably due to the multiple encounters with the target words during the immediate posttests (Rice & Tokowicz, Reference Rice and Tokowicz2019).
TABLE 4. Immediate explicit posttests: average accuracy (in %)

TABLE 5. Delayed explicit posttests: average accuracy (in %)

Note: Four participants were administered an erroneous task and two participants were absent.
To check whether each of the three experimental conditions had led to significant learning gains as measured with explicit measures, we first developed a model that compared each experimental condition with the control condition. Results show that the three treatments were conducive to form-, meaning-, and use-related learning gains (see Supplement 3 for an overview) because they significantly outscored the control group (who only took the tests).
Table 6 displays the summaries of the models that were developed to compare [+CO−WF], [+CO+WF], and [−CO+WF]. The estimate levels for the fixed factor Treatment indicate that both word-focused groups systematically yielded higher scores than the context-only group. All models show the importance of the covariate VocSize for vocabulary learning. On the delayed test for use, female participants fared better than their male counterparts.
TABLE 6. Accuracy on explicit immediate and delayed posttests

Note: Intercept levels represent the values of [+CO−WF]. VocSize = vocabulary size, Gender(F) = female.
*p < .05; **p < .01; ***p < .001.
Pairwise comparisons between the experimental groups on the immediate posttests (Table 7) showed that for form, the two word-focused conditions significantly outperformed the context-only group and that [−CO+WF] significantly outperformed [+CO+WF]. This was not the case on the delayed posttests. For meaning, all groups significantly differed from each other, in that both word-focused groups outperformed the meaning-only group, and [+CO+WF] outperformed [−CO+WF]. For use, [+CO+WF] and [−CO+WF] significantly outperformed [+CO−WF]. However, no differences were observed between the two word-focused groups. Results on the delayed posttests were similar to the immediate posttests for meaning and use.
TABLE 7. Pairwise comparisons for explicit posttests
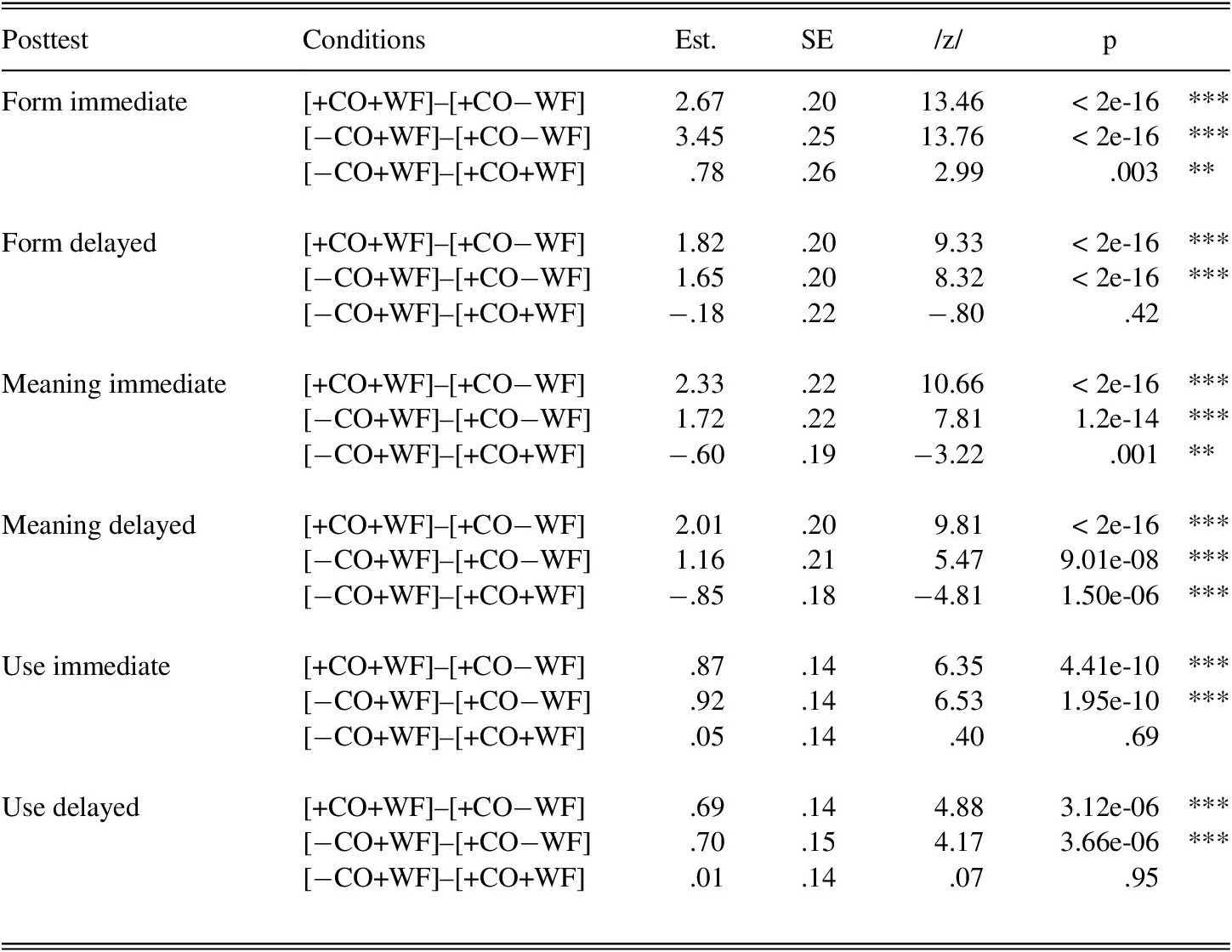
*p < .05; **p < .01; ***p < .001.
RQ 2: Sensitive Measures
Table 8 to Table 13 summarize average accuracy and RT for LDT, SEMREL, and GJT. Before analyzing RT data, we inspected the data for outliers. For LDT and SEMREL, responses faster than 200 ms and responses with 2.5 SD beyond a participant’s mean RT were considered outliers and removed from the dataset (immediate LDT: 2.03%; delayed LDT: 1.54%; immediate SEMREL: 1.19%; delayed SEMREL: 1.62%). For GJT, responses faster than 600 ms were considered too fast for proper processing (immediate GJT: 0.52%; delayed GJT: 1.34%). Not responding to trials or responding faster than 600 ms on more than one third of the trials was considered to reflect improper task performance.
TABLE 8. Immediate LDT: average accuracy (in %) and RT (ms) for critical items

Note: Results of one participant were discarded because of misunderstanding the task. One participant received an erroneous task. Results of two participants were excluded because of improper task performance.
TABLE 9. Delayed LDT: average accuracy (in %) and RT (ms) for critical items

Note: Two participants were absent, eight participants received an erroneous task and the data file of one participant was corrupted. Results of three participants were excluded because of improper task performance.
TABLE 10. Immediate SEMREL: average accuracy (in %) and RT (ms) for critical items

Note: One participant received an erroneous task and the data file of another participant was corrupted.
Before turning to the results of the mixed-effects analyses, a number of aspects need to be mentioned. For SEMREL, the high accuracy level in the control group for unrelated word pairs in both the immediate and delayed posttests showed that the unrelated category probably did not produce reliable evidence of vocabulary learning. Therefore, we only analyzed the related word pairs category. Second, for GJT, outcomes on the immediate posttest showed that performance on the violated category was near-chance for all groups. Therefore, this category was not included in further analyses. Third, as for the delayed explicit form recognition posttest (cf. supra), accuracy scores for the delayed LDT seem to suggest that the results were affected by a test effect (Rice & Tokowicz, Reference Rice and Tokowicz2019), due to repeated encounters with the target word forms during the immediate posttests. Finally, tendencies in RT between immediate and delayed posttests for SEMREL and GJT showed faster RT in the delayed posttests. Faster RT from immediate to delayed posttests that could not be ascribed to effects of the treatment were also observed in Pellicer-Sánchez (Reference Pellicer-Sánchez2015) and ascribed to a practice effect from taking the same test a second time.
To check whether each of the three experimental conditions led to learning gains as measured with sensitive techniques, we first developed a model that compared the accuracy of each experimental condition with the control group (for each dependent variable). Results showed that the three treatments led to significantly higher form-, meaning-, and use-related learning gains (see Supplement 3 for an overview) than the control condition.
Table 14 displays the accuracy summaries for the models that were created to compare the experimental conditions. VocSize impacted the results for form and meaning. On the immediate GJT, working memory modulated the scores.
TABLE 11. Delayed SEMREL: average accuracy (in %) and RT (ms) for critical items

Note: Two participants were absent and eight participants received an erroneous task. Three participants were excluded because of improper task performance.
Pairwise comparisons for accuracy (Table 15) showed that for LDT, both [−CO+WF] and [+CO+WF] significantly outperformed [+CO−WF] on the immediate posttests. Moreover, accuracy scores in [−CO+WF] were significantly higher than in [+CO+WF]. Results for SEMREL showed that both word-focused groups significantly outperformed the meaning-only group. Additionally, the decontextualized word-focused group outperformed the contextualized word-focused group. However, this difference had disappeared in the delayed posttests. Pairwise comparisons of GJT showed that for the immediate posttests, both word-focused groups outperformed the meaning-only group. Moreover, [−CO+WF] outperformed [+CO+WF] on the immediate posttest, but not on the delayed posttest.
TABLE 12. Immediate GJT: average accuracy (in %) and RT (ms) for critical items

Note: One participant was administered an erroneous task. Three participants were excluded because of improper task performance.
TABLE 13. Delayed GJT: average accuracy (in %) and RT (ms) for critical items

Note: Two participants were absent and eight participants were administered an erroneous task. Four Participants were excluded because of improper task performance.
TABLE 14. Accuracy on sensitive posttests
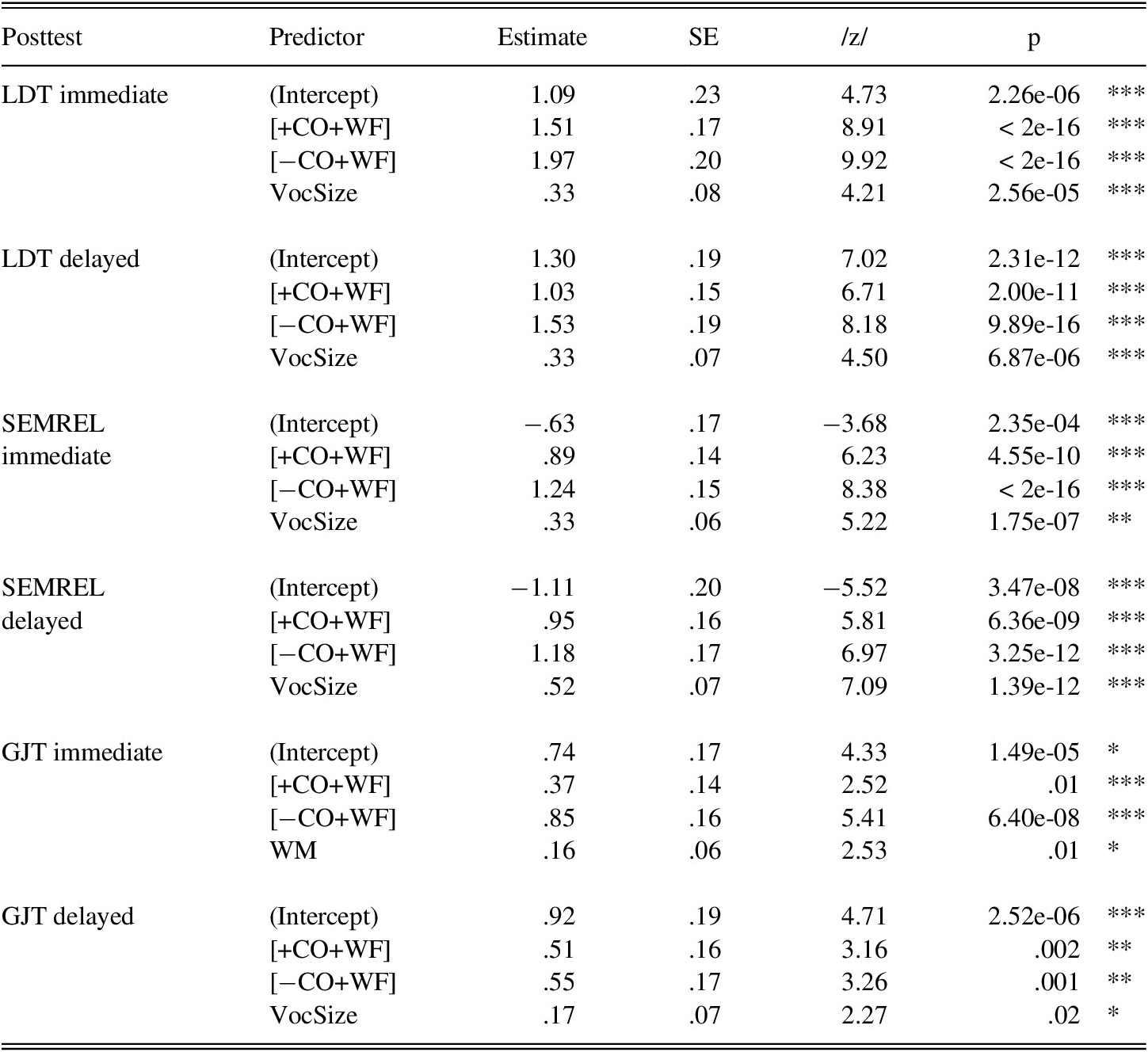
Note: Intercept levels represent the values of [+CO−WF]. VocSize = vocabulary size. WM = working memory.
*p < .05; **p < .01; ***p < .001.
TABLE 15. Pairwise comparisons for accuracy on sensitive posttests
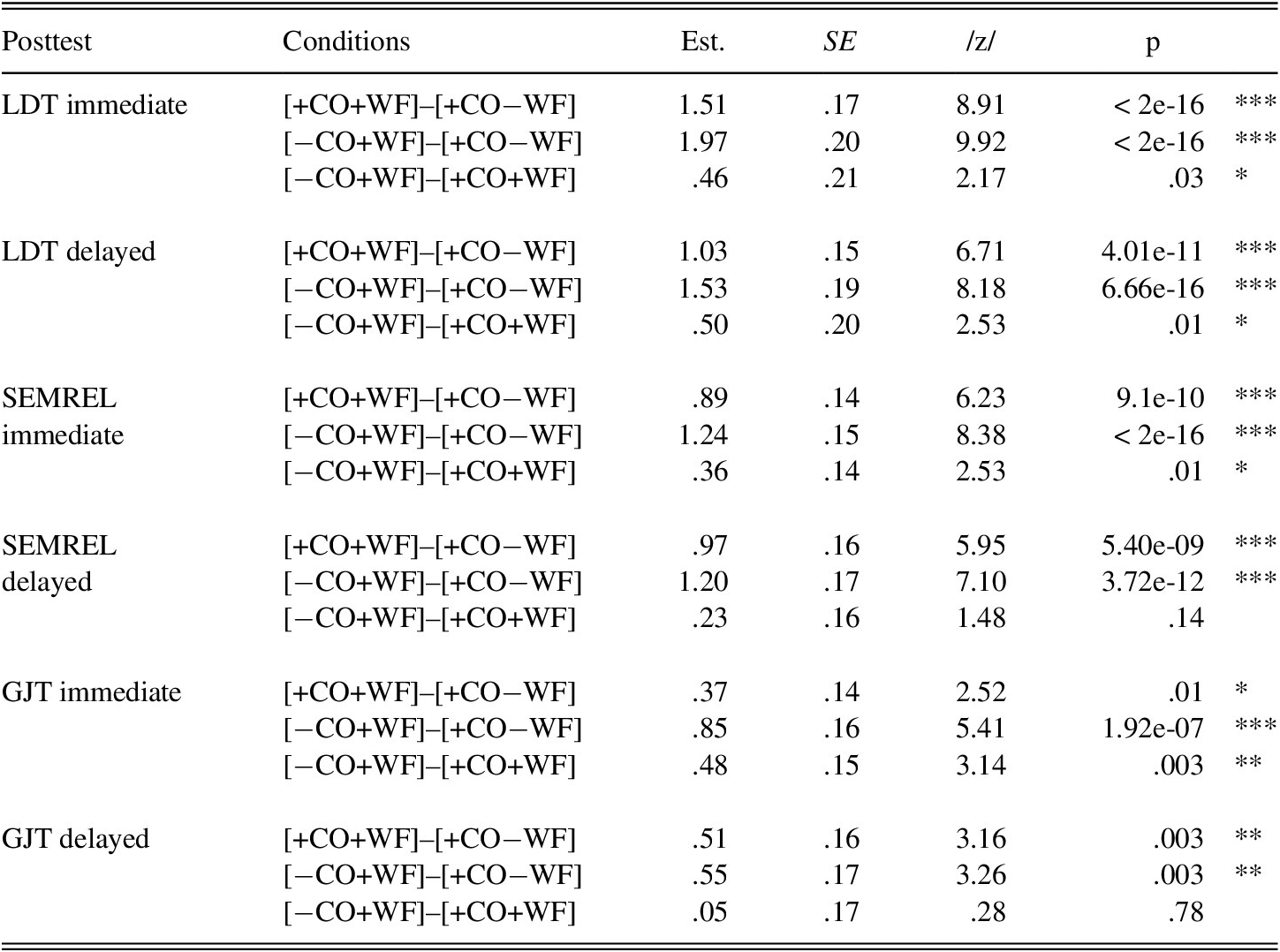
*p < .05; **p < .01; ***p < .001.
TABLE 16. Model summaries for RT
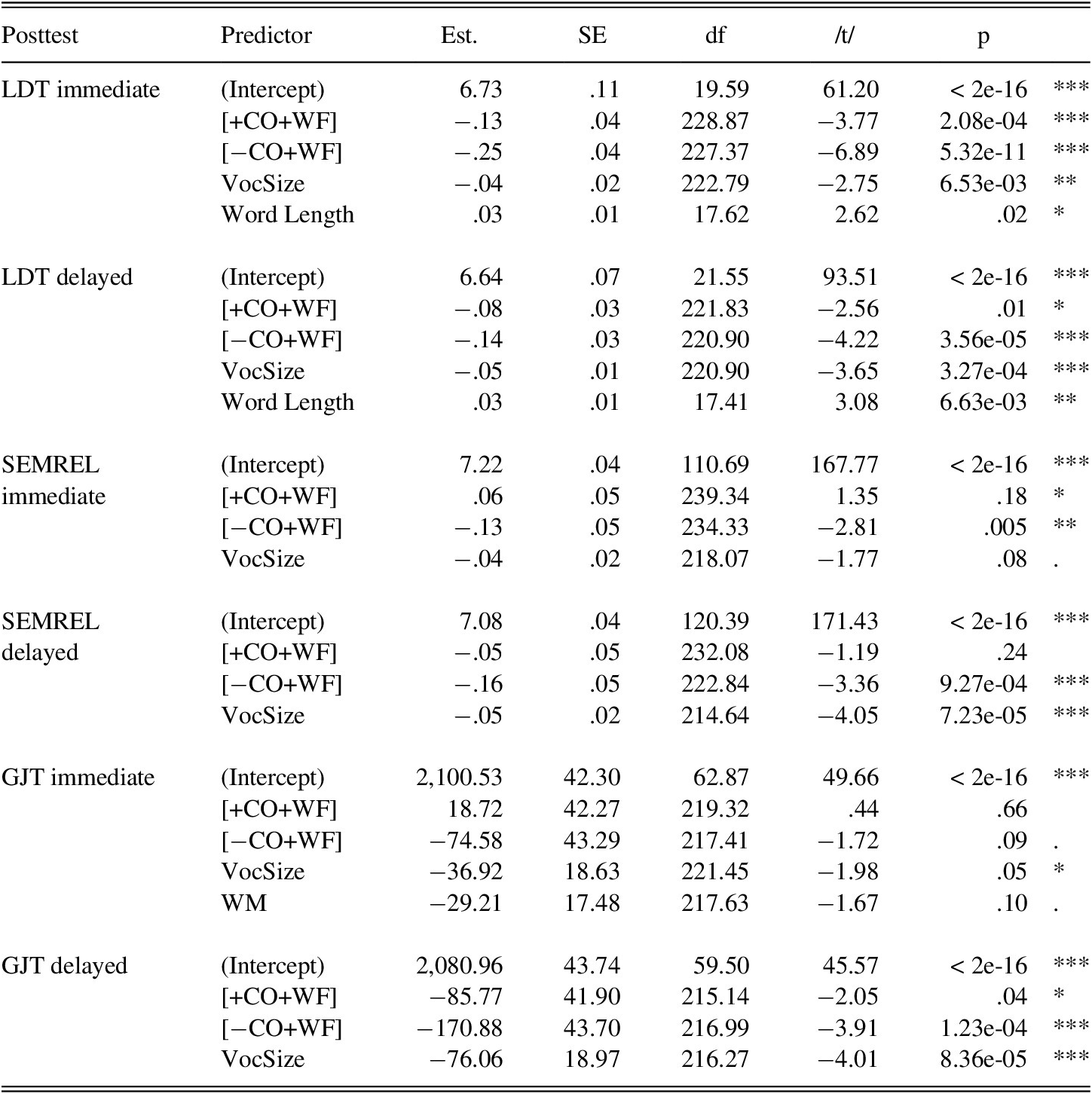
Note: Intercept levels represent the values of [+CO−WF]. Est. = Estimate, VocSize = vocabulary size, WM = working memory.
. p < .1; p < .1; *p < .05; **p < .01; ***p < .001.
The summaries of the models that were developed to compare RT (Table 16) showed that VocSize, Word Length, and WM modulated RT. The positive values for VocSize indicated that more proficient learners needed less time to make responses. The positive values for Word Length suggest that the longer the word, the longer it took participants to respond. The model estimates showed that for LDT, both word-focused conditions needed less time than the context-only condition. For GJT, learners with higher WM made faster responses.
Pairwise comparisons for RT (Table 17) showed significant differences between all groups for immediate LDT. Response times in [−CO+WF] were faster than in [+CO+WF] and [+CO−WF], while responses in [+CO+WF] were faster than [+CO−WF]. For SEMREL, RT were significantly different between both word-focused groups, indicating that the contextualized word-focused group needed more time than the decontextualized word-focused group to make correct responses on meaning relatedness. The same observation was found on the delayed test. For GJT, no significant RT differences were observed on the immediate posttests. For the delayed posttest, a significant difference was observed between [−CO+WF] and [+CO−WF].
TABLE 17. Pairwise comparisons for RT on sensitive posttests
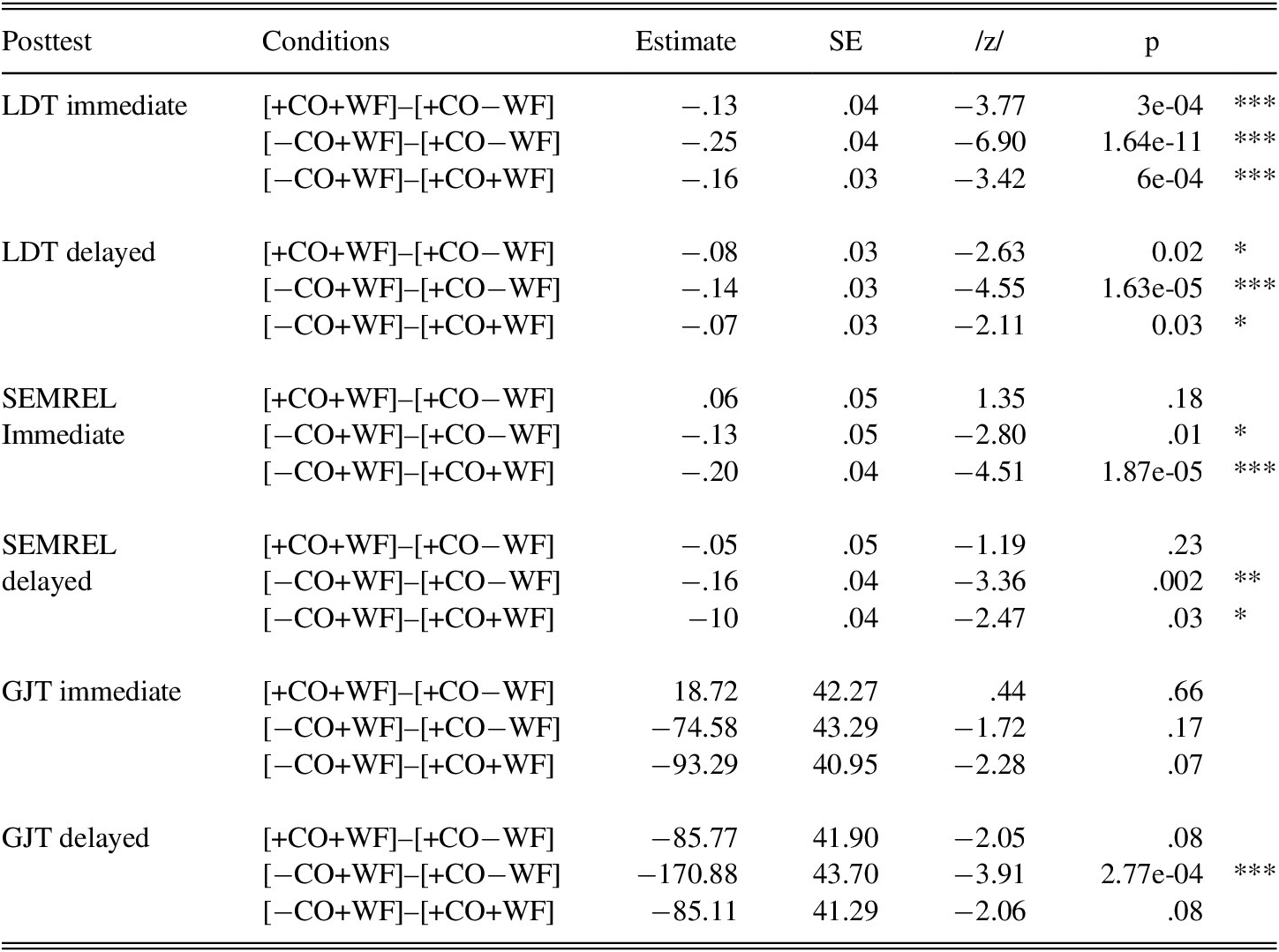
*p < .05; **p < .01; ***p < .001.
DISCUSSION
In this study, we investigated the value of combining explicit measures (i.e., pen-and-paper tasks) and sensitive measures (i.e., RT measurement) to assess the impact of three treatments: (a) contextualized input with meaning-oriented but not word-focused activities [+CO−WF], (b) contextualized input with both meaning- and word-focused activities [+CO+WF], and (c) decontextualized input with word-focused exercises [−CO+WF] on form-, meaning- and use-related aspects of 20 French target verbs.
RQ 1: What is the impact of [+CO−WF], [+CO+WF], and [−CO+WF] on L2 vocabulary learning as measured by explicit measures?
In answer to the first research question, our results confirm previous findings about the superiority of word-focused instruction when compared to meaning-oriented instruction (Laufer, Reference Laufer and Hinkel2017; Schmitt, Reference Schmitt2008).
For form recognition, both word-focused groups outperformed the context-only group. Further, the decontextualized word-focused group recognized significantly more targets than the contextualized word-focused group. Both observations can be explained by the notion of noticing, that is, making the learner aware that there is something new to learn by focusing the attention on the target words (Laufer, Reference Laufer and Webb2020). As both word-focused conditions indeed addressed the new vocabulary in a more targeted way than the context-only condition, they fostered for a better quality of attention (Webb & Nation, Reference Webb and Nation2017, p. 86), which resulted in better learning of the word forms. With regard to the decontextualized condition, presenting new words in isolation rather than as elements of a broader context involved even more deliberate noticing of the word forms (Webb & Nation, Reference Webb and Nation2017, p. 87), which probably led to stronger learning. Remarkably, the control group and the meaning-only group showed an increase in the test scores from immediate to delayed posttest. This increase suggests that recurrent focused encounters with the target words during the immediate posttest battery has promoted noticing to such an extent that it eventually resulted in learning that was detected 2 weeks later. Interestingly, these additional encounters enhanced the already existing form-related knowledge in the meaning-oriented group, but did not contribute to additional learning in both word-focused groups. Moreover, results even showed a decrease of the mean score for the decontextualized group. These observations may suggest that both word-focused treatments had fully achieved their potential for word form recognition immediately after the treatment.
With respect to meaning recall, our results show that both word-focused conditions outperformed the meaning-only condition. Their superiority can be explained in light of the ILH (Hulstijn & Laufer, Reference Hulstijn and Laufer2001), in that that the activities and the exercises in these conditions involved more engagement with the new words. As such, the word-focused activities in [+CO+WF] and the vocabulary exercises in [−CO+WF] were amenable to a high involvement load, as all three elements (need, search, and evaluation) were addressed. Moreover, the required use of the targets in written production on the second day of both treatments may have contributed to consolidating the initial form-meaning linkage that was established on day one. Other studies also underscored the importance of opportunities for productive knowledge development. Webb (Reference Webb2005), for instance, compared receptive (i.e., reading three L2 sentences with an L1 gloss) and productive (i.e., using an L2 word in a sentence) word learning. It was found that, when sufficient time was allotted, productive learning resulted in stronger receptive and productive meaning-related knowledge. Our findings are also consonant with Zou (Reference Zou2017) who compared the impact of vocabulary learning through cloze exercises, sentence writing, and composition writing. Both writing conditions turned out to be more efficient that the cloze condition. Interestingly, the composition-writing condition outperformed the sentence-writing condition, which was explained by the fact that composition writing relied strongly on the evaluation component.
Additionally, with respect to the decontextualized condition, it has been argued that bilingual encoding may facilitate the initial form-meaning linkage (Schmitt, Reference Schmitt2008; Webb & Nation, Reference Webb and Nation2017) and lead to deeper memory traces (Hummel, Reference Hummel2010). Yet, in our study, the contextualized word-focused treatment outperformed the decontextualized word-focused treatment. This observation contradicts some earlier findings where decontextualized treatments fared best on meaning recall tests in comparison to contextualized word-focused treatments (Laufer, Reference Laufer2006; Llach, Reference Llach2009). Our findings suggest that the news item contexts in which targets were embedded facilitated word learning, which seems compatible with contextual word learning frameworks such as the Lexical Quality Hypothesis (Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008). This hypothesis holds that each encounter with an unfamiliar word results in episodic memory traces that are related to both the linguistic and nonlinguistic encoding contexts. Indeed, learners’ responses on the meaning recall test demonstrated that word meanings were regularly retrieved through reactivation of the discourse contexts in which meanings were encoded, that is, the news items’ content. In addition to the encoding that occurred as a consequence of text-related and word-focused activities in the contextualized word-focused condition on day one, having to use the targets in the guided output activity of day two may have strengthened the words’ form-meaning link to such an extent that this treatment outclassed the decontextualized condition for meaning recall. An additional explanation for the superiority of contextualized over decontextualized instruction may be that the test format (i.e., providing the meaning) echoes better the contextualized learning condition, and hence facilitates better test performance (Nation & Webb, Reference Nation and Webb2011; Webb, Reference Webb2009). In the contextualized condition, ample clues for meaning establishment were indeed provided, while the decontextualized group could only rely on the L1 equivalent.
Lastly, regarding use, both word-focused groups scored equally well and outperformed the condition that was not word-focused. Previous research had shown that decontextualized word-focused instruction and productive use were amenable to the development of grammar-related word knowledge. Webb (Reference Webb2007) compared learning from word pairs versus contextual learning and found that decontextualized learning of word pairs promoted the development of grammatical knowledge. Although this finding seemed counterintuitive, the learning gains for grammar were ascribed to parallel learning in other word knowledge components and the overlap with L1 meaning. Likewise, Nation (Reference Nation2013, p. 82) argues that the learning burden for grammatical functions is lighter when a new item roughly parallels the L1 grammatical patterns. Further, Webb’s (Reference Webb2005) previously cited study also found that the writing task was more effective than a reading task for the development of receptive grammar-related knowledge. In our study, both the elements of an explicit focus on words and productive use may have had an additive effect for grammatical knowledge. In line with Webb’s (Reference Webb2007) hypothesis, this effect may have been enhanced by parallel learning in other components, such as meaning, which then spilled over to grammar.
RQ 2: What is the impact of [+CO−WF], [+CO+WF], and [−CO+WF] on L2 vocabulary learning as measured by sensitive measures?
In this study, sensitive measures were found to provide additional insights into the effects of the treatments with respect to speed of lexical access, the time course of meaning retrieval, and grammatical processing.
For form recognition, both word-focused conditions outperformed the context-only group on accuracy and RT, which is consistent with earlier research that compared meaning- and form-oriented L2 vocabulary instruction through a timed LDT (Elgort et al., Reference Elgort, Candry, Boutorwick, Eyckmans and Brysbaert2018). Furthermore, the decontextualized word-focused group achieved higher accuracy and faster lexical access than the contextualized word-focused group. This means that decontextualized noticing of word forms through word lists supplemented with word-focused exercises not only led to more accurate word form recognition, as indicated by the explicit measures, but it also resulted in higher time-pressured accuracy scores and facilitated faster lexical access. These results show that sensitive measures not only confirm the findings of the explicit tests in terms of accuracy but they also show that word-focused instruction is conducive to faster recognition of newly learned word forms than meaning-focused instruction.
With respect to meaning, the RT pattern of SEMREL seems to indicate that the two word-focused groups processed the task differently. Surprisingly, the contextualized word-focused group needed significantly more time than the other groups to make correct meaning-relatedness judgments on both test moments. This seems inconsistent with the superior performance for meaning of this group on the explicit measures. A possible explanation could be that the scrutiny of episodic memory traces about the articles’ content involved a processing cost reflected through longer RT. This finding suggests that sensitive measures can provide insights into how contextualized and decontextualized learning differentially affect the processing of the meaning of newly learned L2 words. Furthermore, although participants in the decontextualized treatment did not have the opportunity of scanning content-related memory traces, they yielded higher accuracy scores on SEMREL. A possible reason is that these participants may have been advantaged by the way stimuli were created. In SEMREL, most related pairs were synonyms. As participants in the decontextualized conditions were trained on exercises comprising translation and synonyms, speeded exercises echoing the learning condition may have been at their advantage. This facilitative effect of overlapping cognitive operations during initial learning and subsequent test taking has been referred to as transfer-appropriate processing (DeKeyser, Reference DeKeyser and DeKeyser2007). Yet, the advantage of decontextualized instruction was not observed at retention, which suggests the fragility of meaning-related L2 word knowledge acquired through decontextualized learning.
For use, both word-focused groups outperformed the context-only group on both the immediate and delayed posttests. It was also found that the decontextualized word-focused group identified correctly built sentences with newly learned verbs more accurately than the contextualized group, but only on the immediate posttests. These findings suggest that decontextualized deliberate word-focused learning supplemented with exercises on verb structure and translation practice can have beneficial effects on the rate at which correctly built grammatical structures can be detected shortly after learning. In this context, performing an experimental task such as a time-pressured grammatical judgment task may have been at the advantage of the decontextualized group. In contrast to the word-focused contextualized treatment, in which the target verbs were processed from the broader perspective of meaningful language use, the decontextualized group processed the verbs with a more narrow and more specific attentional focus on use-related properties, for example, through the example sentences in the word list, or the L1 to L2 sentence translation exercise. Additionally, as suggested by Webb (Reference Webb2007) and Nation (Reference Nation2013), the combination of L1 meaning and grammatical use during learning may have activated parallelisms with L1 structures that have resulted in more accurate and faster detection of correctly built sentences. Interestingly, this advantage was not continued at retention, which may suggest that decontextualized use-related learning loses its superiority over time. Finally, while no use-related differences were found between the two word-focused conditions for the explicit measures, the use-related sensitive measures provided two additional insights with respect to the impact of contextualized and decontextualized word-focused learning. As such, decontextualized learning is conducive to detecting correctly built sentences based on newly learnt verbs better and faster. However, this advantage was only found at the immediate level.
PEDAGOGICAL IMPLICATIONS
The insights gained from combining explicit and sensitive measures involve a number of pedagogical implications. First, both contextualized and decontextualized word-focused instruction show to be efficient for establishing form-, meaning-, and use-related receptive L2 vocabulary knowledge. More specifically, teachers might want to consider decontextualized learning to enhance knowledge related to the word form and the grammatical structures in which words are used. Additionally, focusing on both meaning and form benefits the learning of word meanings, immediately after instruction and at the long-term level. In sum, this study shows that new words are best learnt through meaningful contexts, in parallel with decontextualized techniques.
The present study also indicates the pedagogical value of prompting learners to use new L2 vocabulary either through decontextualized or meaning-oriented instruction and, in this way, echoes similar claims that have been made in the context of single word writing (Elgort et al., Reference Elgort, Candry, Boutorwick, Eyckmans and Brysbaert2018; Webb & Piasecki, Reference Webb and Piasecki2018), sentence writing (Webb, Reference Webb2007), text writing (Zou, Reference Zou2017), oral interaction (De la Fuente, Reference De la Fuente2006), collaborative output activities (Sun, Reference Sun2017), and task-based language learning (Ellis, Reference Ellis2009).
Taken together, our study provides support for L2 vocabulary teaching approaches that advocate a balanced L2 vocabulary course design. An example is Nation’s four strands approach (e.g., 2013) that states that an ideal vocabulary course consists of meaning-focused input, meaning-focused output, word-focused learning, and fluency development. Likewise, Schmitt (Reference Schmitt2008) states that “different teaching approaches may be appropriate at the different stages of acquisition” (p. 334), suggesting that an initial word-focused approach may be followed by meaning-oriented instruction, such as linked skills (Webb & Nation, Reference Webb and Nation2017). In this approach, learners engage with the same topic across different skills and engage with new words in a receptive and productive manner. Moreover, learners can benefit from significant and repeated encounters with new words and have ample opportunities for retrieval and use. Hence, the linked skills approach caters for both incidental and deliberate learning, and is compatible with task- and content-based L2 teaching approaches that advocate the implementation of word-focused instruction in the design of a task (Ellis, Reference Ellis2009; Van den Branden, Reference Van den Branden2016).
LIMITATIONS AND FUTURE RESEARCH
Our research is inevitably characterized by a number of limitations. First, while sensitive measures such as RT measures are said to better represent the type of knowledge needed for fluent language use (Elgort, Reference Elgort2018), the sensitive measures used in the present study were receptive time-pressured tests. Consequently, the outcomes of this study are indicative of fluency of access to receptive vocabulary knowledge only. Second, as ecological validity was an asset of this study, participants were tested on sensitive measures within their school environment. However, we made sure that controlled laboratory conditions were approximated by strictly applying procedures to guarantee silence and ensure attention. A third limitation concerns some aspects of the stimuli design. In SEMREL, the control group performed equally well for unrelated pairs as the other groups, suggesting that rejecting unrelated word pairs was a default strategy whenever an unfamiliar word was presented. This hypothesis seemed confirmed by the inverse response pattern that was observed in related word pairs. A closer look at our stimuli pointed toward the importance of including a large enough filler category with mid- and low-frequency words to mask critical pairs and discourage strategical responses. Fourth, the GJT turned out to be very demanding because of the 3,250 ms cutoff. Although this methodological choice was informed by previous research and seemed acceptable in the piloting phase of the study, younger participants may suffer more quickly than adults from frustration and test fatigue, especially in test batteries where the most demanding tasks are given last. As such, the task might have been more informative if more time was provided. Lastly, as we considered only one part of speech (i.e., verbs), caution regarding the generalizability of the findings to other parts of speech is warranted. Moreover, the use of the infinitive form of the target verbs in the decontextualized word-focused treatment (both in the word lists and in most of the vocabulary exercises) may have been at the advantage of the decontextualized word-focused group for the form-related tests (form recognition and LDT) given that the stimuli used in these test were presented in the infinitive form. In addition, using the infinitive form in the meaning recall test and SEMREL may also have facilitated the identification of the target verbs in the decontextualized group.
CONCLUSION
This study assessed the value of combining explicit and sensitive measures to gauge the impact of ecologically valid L2 vocabulary instruction. On the theoretical level, results indicate that sensitive measures can complement explicit measures, in that they provide additional insights into learning effects related to lexical processing. On the pedagogical level, this study advocates a balanced approach to L2 vocabulary teaching, with opportunities for decontextualized word-focused instruction supplemented with a combination of word-focused and meaning-oriented receptive and productive activities.
Supplementary Materials
To view supplementary material for this article, please visit http://dx.doi.org/10.1017/S0272263120000431.
























