1 Introduction
While the use of online three-dimensional synthetic worlds or virtual worlds for social networking and entertainment purposes is well-established, their use in education contexts is developing (de Freitas, Reference De Freitas2006; Falloon, Reference Falloon2010). In the language-learning domain, interest is emerging in this type of environment. Research to date concerning language learning in synthetic worlds has shown that these environments may reduce student apprehension (Schwienhorst, Reference Schwienhorst2002), increase students’ sense of social presence and community (Ornberg, Reference Ornberg2003; Nowak & Biocca, Reference Nowak and Biocca2004) and favour collaborative learning (Henderson, Huang, Grant, & Henderson, Reference Henderson, Huang, Grant and Henderson2009; Dalgarno & Lee, Reference Dalgarno and Lee2010).
Peterson (Reference Peterson2010) suggests that the beneficial aspects of interaction in synthetic worlds are reinforced by the presence of avatars. Avatars are semi-autonomous agents represented in the digital space which can perform actions when commanded by the user (Peachey, Gillen, Livingston & Smith-Robbins, Reference Peachey, Gillen, Livingston and Smith-Robbins2010). They can display a range of nonverbal communication acts. In non-computer-mediated communication contexts, nonverbal acts play important roles in communication (Kendon, Reference Kendon1982). Research suggests nonverbal and verbal acts of communication are part of a single system with the same underlying mental processes (McNeill, Reference McNeill2000). Presently there is an increased interest in the role such acts play in second language acquisition (see McCafferty & Stam, Reference McCafferty and Stam2008). Increasingly, studies show the importance of nonverbal communication for second-language learners (Gullberg, Reference Gullberg2012).
This study of verbal and nonverbal communication in Second Life (SL) builds upon our previous work to understand multimodal communication structures through learner participation and learning practices (Vetter & Chanier, Reference Vetter and Chanier2006; Ciekanski & Chanier, Reference Ciekanski and Chanier2008). The study extends our research to a three-dimensional learning environment and incorporates kinesic acts within the nonverbal mode.
First, we provide a methodological framework for the study of communication acts in synthetic worlds. We offer a classification of verbal and nonverbal acts in the synthetic world SL, outlining connections between verbal and nonverbal communication acts built into the environment. Secondly, we apply this methodological framework to a course in SL which formed part of the European projectFootnote 1 ARCHI21, where a Content and Language Integrated Learning (CLIL) approach was chosen for students of Architecture. We present our data analysis from the experimentation designed around this course. This experimentation explored whether nonverbal communication acts are autonomous in SL or whether interaction between verbal and nonverbal communication acts exists; and whether the nonverbal acts of communication play the same role in the synthetic world as in face-to-face environmentsFootnote 2.
The rationale behind our study is that evaluation of potential benefits of the SL environment for language learning and teaching requires a deep understanding of the affordances of this environment. This includes i) understanding the communication modalities SL offers; ii) how students use these; iii) their impact on interaction, and iv) studying such questions within a pre-defined methodological framework.
2 A methodological framework defining verbal and nonverbal acts in the synthetic world Second Life
Although a dominant focus of research in Language Sciences was verbal communication, the relationship between verbal and nonverbal communication recently stimulated research in Second Language Acquisition (SLA) (McCafferty & Stam, Reference McCafferty and Stam2008). This recent research has concentrated on the nonverbal categories of proxemics understood as the individual use of space to communicate and how this impacts on the behaviour of the individuals involved and kinesics: “the study of the body's physical movement” (Lessikar, Reference Lessikar2000:549). Within kinesics, the majority of research concerns the influence of gesture on SLA. The domain of computer supported collaborative work has also investigated the relationships between verbal and nonverbal communication acts and the role of such relationships for collaboration (Kraut, Fussell & Siegel, 2003; Fraser, Reference Fraser2000). The above studies suggest relationships between verbal and nonverbal communication and the role of nonverbal communication in SLA and in collaborative activities as significant. Synthetic worlds introduce the nonverbal communication mode into computer-mediated language learning. This exciting possibility for collaborative distance language learning remains largely unexplored.
The SL environment supports multiple modes of communication which can be employed in interaction to construct discourse. Specifically, nonverbal and verbal modes offer several modalities for communication. Here we propose a classification of these modalities, illustrating relationships between the modes and modalities built into the environment and highlighting how these differ from first-world environments. Initially identifying possible communication acts in our framework permits us to develop a method for coding and transcribing screen recordings to analyse learner participation and multimodal practices.
2.1 Verbal mode
2.1.1 Verbal modalities in SL akin to face-to-face ones
Oral communication occurs through various synchronous modalities. The public audio channel, allowing “proximity transmission” (Wadley & Gibbs, Reference Wadley and Gibbs2010:188), enables users to converse within a 60-metre radius. This modality takes spatial proximity and orientation of users into consideration. Another user's voice becomes louder if the avatars are facing each other and when the proximity between users increases.
2.1.2 New verbal modalities
A second audio modality is the group audio or “radio transmission” (Wadley & Gibbs, Reference Wadley and Gibbs2010:188). This allows communication between members of a common group who are spatially separated. A one-to-one private audio channel also allows users to communicate verbally without being in proximal contact through their avatars. These latter modalities offer new possibilities for language learning not available in face-to-face classrooms, where oral interaction necessitates visual contact with interlocutors.
Written communication in SL differs from face-to-face pedagogical communication, where synchronous written communication is predominantly unidirectional through the teacher using the board. Written communication acts in the synthetic world may be synchronous or asynchronous and are multidirectional. Different users can communicate with other users by simultaneously using several written modalities.
The synchronous public text chat can be used simultaneously by users and read when avatars are within a 20-metre proxemic range. Secondly, a group text chat feature allows communication within the same group at arbitrary virtual locations. Finally, an instant messaging feature for synchronous and asynchronous communication, allows users to communicate, no matter where they are, inworld or offline. The latter two features can be used in parallel with the public text chat.
2.2 Nonverbal mode
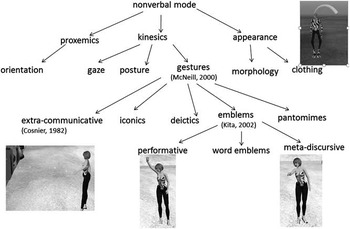
Some authors have divided nonverbal communication in SL into user-generated and computer-generated acts (Antonijevic, Reference Antonijevic2008), also described as rhetorical and non-rhetorical nonverbal communication (Verhulsdonck & Morie, Reference Verhulsdonck and Morie2009). A user-generated nonverbal act involves a user consciously selecting an act of nonverbal communication and deliberately performing this act. Computer-generated acts, however, are predefined in the system and the user does not deliberately choose to display these. In our methodological framework, we prefer to sub-divide the categories of nonverbal communication by their communicative act rather than with reference to how they are encoded by the user and synthetic world. We will refer to the modalities of proxemics, kinesics and avatar appearance. Figure 1 shows our classification of nonverbal acts identified in SL. Full details of this classification are discussed in Wigham & Chanier, Reference Wigham and Chanier2011. In this paper, we exemplify a few of these categories.

Fig. 1 Nonverbal communication in SL
2.2.1 Proxemic acts
The range of proxemic acts available to SL users includes choosing to move their avatar, i.e., making the avatar walk, run or fly; orientating their avatar and positioning their avatar with respect to others. Because proxemic acts in SL are user-controlled, we must consider their importance for interaction. Indeed, proxemic nonverbal communication has been the focus of various studies in different synthetic worlds (Jeffrey & Mark, Reference Jeffrey and Mark1998; Yee, Bailenson, Urbanek, Chang & Merget, Reference Yee, Bailenson, Urbanek, Chang and Merget2004). These studies show that the way people move and approach others and their positioning of avatars in relation to others is affected by how space in the synthetic world is perceived. Avatar gender also influences the proxemic space users choose between interacting avatars.
In SL, we note the wish of the synthetic-world designers to associate proxemic acts with verbal communication, particularly in association with the proxemic dimension of voice loudness. Firstly, in the written communication, a user may increase or decrease the distance at which a message can be read publicly by using the whisper or shout function. This is displayed nonverbally through a pantomime gesture. Secondly, as previously mentioned, the audio channel takes the spatial proximity and orientation of users into consideration.
2.2.2 Kinesic acts
The kinesic act of gaze is a predefined cue having, with relation to the verbal mode and the nonverbal category of proxemics, the function of mimicking interactional synchrony. When an avatar is moved in a certain direction, nearby avatars’ heads automatically turn to this direction, imitating the proxemic coordination of movements between interlocutors and complementing the verbal communication. Another predefined gaze movement is an automatic ‘lookat feature’ whereby avatars gaze at any avatar joining their group. Ventrella (Reference Ventrella2011) underlines the relationship between gaze acts and verbal acts in SL: avatars respond to another avatar's written communication in the public chat channel by turning their gaze towards the avatar who generated the written communication. Ventrella (Reference Ventrella2011) suggests these subconscious social acts reflecting face-to-face communication help users feel acknowledged and welcome.
The kinesic act of posture is also incorporated into SL. When there is a significant pause in written or oral communication, the user's inactivity in the verbal mode automatically sets the posture of his/her avatar to that of a ‘spectator’: “the avatar slumps over forward as if to fall asleep while standing” (Ventrella, Reference Ventrella2011:85).
Deictic acts are encoded in SL when a user touches or manipulates a media object in the synthetic world. There is no distinction between the deictic gesture to show that an avatar is touching an object or if s/he is manipulating or editing the object, for example, changing the size, colour or script of objects.
Kendon (Reference Kendon1982) defines pantomime gestures as movements of the hands and arms always in the visual description of an action or an object. In SL numerous avatar animations portray the avatar as visually imitating an action. These include the avatar animations of crying, smoking, and typing (see Figure 2).

Fig. 2 Examples of avatar pantomimes for crying, smoking and typing
Links between pantomimes and verbal modalities occur: users can make their avatar perform pantomimes by typing a command in the public text chat window and when users communicate in the written mode their avatars portray the typing pantomime. If users decide to use the whisper or shout features in the written mode, their avatars also perform pantomimes complementing the written communication.
SL also includes examples of emblems. These cultural gestures often replace verbal communication, despite the possibility of translating the gestures by a word or an expression. We will not develop them here.
Finally, iconic gestures, described by McNeill (Reference McNeill2000) as representations of an action or object, are found in SL. They have a very direct relationship with the semantic content of a verbal utterance showing physical, concrete items. In SL examples include gestures to illustrate scissors and a sheet of paper. Indicators of emotional states are also expressed through iconic gestures in SL, in contrast to face-to-face communication which uses facial expressions.
2.2.3 Avatar appearance
In SL, users may change their avatar's morphology and clothing. This type of nonverbal communication is not the focus of this paper. However, during our study we noticed that when participants felt at ease, efficiently manipulating the learning environment (to which they were almost all newcomers), they quickly changed their avatars’ appearance to become less based on human morphology (see Figure 3), continuously using pantomime gestures or scripting their avatars appearance. We are currently undertaking research to understand the impact of such changes of appearance on the students’ interaction and discourse.

Fig. 3 Avatar appearances
3 The ARCHI21 course and its research protocol
3.1 The ARCHI21 ‘Building Fragile Spaces’ course and participants
The pedagogical scenario of this study is the ‘Building Fragile Spaces’ course which ran in February 2011 and formed the first work package of the ARCHI21 project. A dual-focused approach to language learning is at the core of this project, the subject content being architecture and the languages (L2) French and English. CLIL aims to eliminate “the artificial separation between language instruction and subject matter classes” (Brinton, Snow & Wesche, Reference Brinton, Snow and Wesche2003:2) by teaching non-language subjects through a foreign, second or other additional language (Marsh, Marsland, & Stenberg, Reference Marsh, Marsland and Stenberg2001). Providing curriculum content in a L2 can lead to increased subject knowledge and enhanced language proficiency (Dalton-Puffer & Smit, Reference Dalton- Puffer and Smit2007; Coyle, Hood & Marsh, Reference Coyle, Hood and Marsh2010).
The course was a five-day intensive design studio. This is a typical face-to-face set up within architectural education: professionals work with small student groups, over a short period, developing design ideas. The CLIL pedagogical scenario for the course was designed by architecture teachers from the ENSAPM school and language teachers from our university (UBP). The course's architectural focus was the design and construction of an immersive SL environment for the ARCHI21 project. This was based on the belief that 3D synthetic worlds are an exciting new design field for architectural experimentation. They allow the design of innovative architectural projects between multiple users in the same space, providing opportunities for collaboration. They also allow building to be visualised in new and effective ways.
The course had the goal of developing working models for spatial archetypes, landscapes and identity. The rationale behind the development of L2 skills was the future need for the students to be able to work abroad and to collaborate with foreign architects. Architecture teachers worked face-to-face with students, constantly switching between French (which was a L2 for half of the students) and English. Language tutors, who had no architectural subject knowledge, worked at a distance using the synthetic world environment for synchronous activities with students and the online platform for spoken interaction VoiceForum (Fynn, Mammad, & Gautheron, Reference Fynn, Mammad and Gautheron2004) for asynchronous activities.
‘Building Fragile Spaces’ involved eight female and nine male students, aged between 21 and 25 years. Students ranged from first year undergraduates to second year Masters’ students. French was the mother tongue of nine of the seventeen students. The mother tongues of the remaining eight were Spanish, Chinese, Italian, Korean and Arabic.
The participants were divided into four workgroups. This division was thematic and linguistic: each workgroup received a different architectural brief and had a dominant second language (see Table 1). Only two students had previously used SL.
Table 1 Workgroups

Following the CLIL approach, all the language activities closely assisted architectural ones. The pedagogical scenario for the language activities included introductory sessions to SL, focusing on the communication tools and how to move within the environment; introductory sessions to building collaboratively in the synthetic world; and a series of group reflective sessions inworld (see Figures 4a and 4b). This paper focuses on one collaborative building session completed by the participants in English or in French depending on the target language of their workgroup.

Fig. 4 a) course environments; b) distance language activities
3.2 The Buildjig activity
The activity ‘Buildjig’, on which this study focuses, is an introductory building activity (see figure 4b) in the target language. The objectives were two-fold:
• Architectural design learning objectives: Introduce students to building techniques; assemble a presentation kiosk designed by architecture tutors as an example of how students could present their project work.
• L2 learning objectives: Develop communication techniques in the L2 concerning the referencing of objects; practise oral skills.
So as to encourage collaboration and interaction, the activity was designed to incorporate a two-way information gap. It employed one of the six learnings suggested by Lim (Reference Lim2009:7) for inworld curricular design in synthetic worlds: “learning by building.” The activity required the exchange of information between students, each of whom possessed information unknown to the other participant but of importance in solving the problem.
Students worked in subgroups for the activity. One student was designated as the ‘helper’; the other as the ‘worker’. The helper directed the worker in assembling the kiosk from a set of objects. S/he was not allowed to manipulate the objects him/herself (see Figure 5). The helper had a two-dimensional representation of the final kiosk. The worker, on the other hand, did not have the final shape of the kiosk but the three three-dimensional objects from which to construct the kiosk. To solve the problem, students had to exchange information about the two-dimensional characteristics of the objects in comparison to their three-dimensional characteristics inworld. The activity demanded nonverbal interaction with the objects in the environment, in terms of the building actions, and verbal interaction between the students in order for successful activity completion.

Fig. 5 Helper and worker in the Buildjig activity (the bear avatar is the researcher recording their actions)
Including the language tutor's presentation of the activity, and a short group debriefing, the activity lasted 50 minutes. The activity was the second time that the students met with the language tutors inworld.
3.3 Research protocol
Researchers, present inworld in the form of small animal avatars (see Figure 5), observed the workgroups and recorded screen and audio output. The role they took was that of ‘observer as participant’ (Gold, Reference Gold1958) as they had minimal involvement in the setting being studied. A small animal figure was chosen because the researchers believed that, in comparison to a robot figure, the bear's harmless look would bother the students less. Also considering the study by Yee and Bailenson (Reference Yee and Bailenson2007), which suggests that the height of an avatar influences users’ behaviour, the researchers chose a small avatar that was an animal figure to dissuade participants from addressing the bear in their interactions. It was, thus, hoped that the researcher's avatar would be as unobtrusive as possible.
Pre-course and post-course questionnaires were administered using an online survey tool. These were analysed using a spreadsheet application. Semi-directive online interviews were also conducted with five students following the course. The students were selected on a volunteer basis but we ensured that at least one student from each workgroup was interviewed. The learner interaction data as well as the learning design and research protocol were structured into an open-access LEarning and TEaching corpus (LETEC) (Chanier & Wigham, Reference Chanier and Wigham2011)Footnote 3.
Here, we consider four screen recordings of the buildjig activity with subgroups of the four workgroups. The two ESL subgroups were composed of pairs, whilst the FLE subgroups were composed of three students with one ‘helper’ and two ‘workers’ due to the uneven number of participants on the course. The screen recordings, each 50 minutes in length, include the activity introduction and a debriefing activity. Here, we focus solely on the building activity itself. For each subgroup, the screen recording lasted, on average, 25 minutes.
Identifying communication acts in SL allowed the development of a method for coding and transcribing screen recordings of interactions. Building upon previous research (Ciekanski & Chanier, Reference Ciekanski and Chanier2008) and methodology applied to LETEC corpora (Mulce-doc, 2010), each modality and communication act was identified. Thus, acts were defined and each act tagged (see Table 2).
Table 2 Data analysis codes for different acts

Two scales of analysis were adopted. On a macro level, the qualitative data analysis software Nvivo was used to i) annotate screen recordings qualitatively and ii) code users’ verbal and nonverbal acts. This allowed the balance between the uses of different modalities to be analysed. To annotate the verbal and nonverbal acts of the participants, each act was identified by type; by actor; by a time in the audio-track, which was synchronised with the screen recording; and by the duration of the act (see Table 2). Any silence in the audio track was coded i) to show the continuity of the audio signal and, therefore, the total time that students had available for verbal interaction and ii) to place nonverbal acts on the same time scale, permitting us to analyse relationships between acts of different types during the data analysis.
On a micro level, the qualitative data analysis software was used to code the verbal acts which included a reference to an object by type of reference made. Examples 1 and 2 show the transcription of two verbal acts, in which a reference to an object was coded (in bold). In (1), the reference was coded under ‘reference by colour’. (2) was coded as ‘reference by description’.
(1)
[mm:ss, quentinrez, tpa] I think it's it's easier to err just err pick up the + the black
(2)
[mm:ss, romeorez, tpa] it seems like two squares+ two twisted squares
Full transcription details are detailed and exemplified in Saddour, Wigham & Chanier (Reference Saddour, Wigham and Chanier2011). In brief, our transcription methods highlight the start time of each turn in the format minutes:seconds, the actor's code and the type of communication act, shown by its code. Pauses which are less than three seconds are shown by the symbol + which represents one second. Longer pauses are coded as a separate turn with the code ‘sil’ for silence. Overlap within a verbal turn is shown by (actor_code: transcription). For the nonverbal acts of movement, kinesics and production, a description of the nonverbal act is given, based upon a grid developed during the transcription process.
4 Analysis
Having defined our framework, we now quantitatively and qualitatively study how the verbal and nonverbal modes of communication are used in the synthetic world SL to understand i) whether nonverbal communication acts are autonomous in SL or whether interaction between verbal and nonverbal communication exists and ii) whether nonverbal acts of communication play the same role in the synthetic world as they do in the first world.
4.1 Activity achievement
The building jigsaw activity was the second time that the students met inworld with the language tutors. Although the building involved in the activity was beyond abilities of the language tutors, who were not sure whether they could complete the building task alone, our data shows that the activity was pitched at the level of the students. In a post-questionnaire, when asked whether it was too difficult to communicate with their partner during the activity, on a scale from five (totally agree) to one (don't agree at all) the students rated the activity at three (no opinion). Although none of the groups fully completed the activity within the allocated time, the work of groups GE and GS strongly resembled the finished design. GA, after taking some time to get into the activity had started the task and, after the activity, decided to remain inworld to finish their work. The building work of GL, on the other hand, had barely commenced, a student in the worker role trying to build the kiosk by himself.
4.2 Floor space related to verbal acts
Analysis of the use of the verbal and nonverbal modes was conducted with reference to floor space. We consider the floor space as the sum of the total length of all acts within a specific mode for an individual actor with reference to the total length of all acts communicated in this mode (including silence for the verbal mode) by all actors present. In this section, we study floor space related to verbal acts. We start by examining floor space in the audio modality before turning to floor space in the textchat modality. In Section 4.3, we then study floor space with reference to nonverbal modes.
4.2.1 Audio modality
Figure 6 shows the distribution of public audio floor space within the groups, according to participants’ roles.

Fig. 6 Distribution of public audio floor space with respect to role during activity and workgroup
In GE, the students’ verbal (audio only) acts accounted for 89.62% of the possible verbal floor space, compared to 59.87% for GA, 44.51% for GS and 4.17% for GL. In the two groups in which the students accounted for the majority of all verbal acts (GA and GE), the language tutor accounted for less than 2.2% of the verbal communication. For group GS the language tutor accounted for 0.11% of the total verbal communication, and in group GL the tutor occupied nearly double the amount of verbal floor space compared to that of the students (7.91% compared to 4.17%).
Our results show verbal floor space was not balanced between students in the roles of helper and worker. In groups GA, GE and GS the helper occupied, on average, 21.56% more of the verbal floor space than the workers in each group.
4.2.2 Text chat modality
The group text chat modality was infrequently employed in the verbal mode, accounting for only 31 acts compared to 781 verbal acts in the public audio modality. One possible reason for a reliance on the audio modality is the nature of the activity: speaking frees the participants’ hands, allowing the participants to communicate whilst carrying out the building actions or whilst moving their avatar in order to view objects from different perspectives, both of which require the use of the computer mouse and keyboard.
The group GL utilised the public text chat modality more than any other group with 23 acts in total. This is of interest when compared to the use of the public audio modality. Concerning the latter, the actors in this group performed 38 verbal acts, of which 31 were performed by the language tutor. In this group, the student in the helper role (wuhuasha) continuously placed his avatar at a considerable distance from the other students. One interpretation of the choice of modalities is that students adapted their communication strategies to the environment: there is an emergent understanding that as the distance between avatars increases, the users can no longer ‘hear’ each other because the public audio channel takes users’ proximity into account.
Group GL's advancement of the object construction was near none compared to other groups. This may be explained by their reliance on text chat which did not allow students to manipulate objects and communicate simultaneously. Another interpretation is that the proxemic distance between avatars impacted on the students’ involvement in the activity. The majority of the communication acts did not concern the activity per se but consisted of the workers trying to establish communication with the helper and the language tutor (tfrez1) encouraging students to move into a closer task space so as to encourage audio communication (see 3 and 4).
(3)
[tpc, zeinarez, 02:01]: wuhuasha
(4)
[tpc, tfrez1, 02:04]: wuhuasha vous pouvez vous déplacer (wuhuasha can you move ?)
The verbal acts performed by wuhuasha occurred when the language tutor placed her avatar near to the student's avatar. When the tutor moved physically away, wuhuasha had no further participation in the communicative exchange. This suggests that, as in the first world, distance matters for communication purposes.
We note that wuhuasha, at A2 level, was the weakest student of the FLE groups. Instances which may be clear for students in face-to-face environments may indeed require extra ‘effort’ in synthetic worlds. Students, particularly at lower levels may have difficulty in “performing” their avatar (Verhulsdonck & Morie, Reference Verhulsdonck and Morie2009:6) whilst focussing on the activity and their language production. Wuhuasha had difficulties managing the different facets of SL and did not recognise the importance of proxemic distance in the environment's communicative rules. It appears important to stress to learners the need to place their avatars proxemically near to each other so as to encourage verbal communication (and specifically audio communication). This is in order to avoid communication difficulties and breakdown in collaboration.
4.3 Floor space related to nonverbal acts
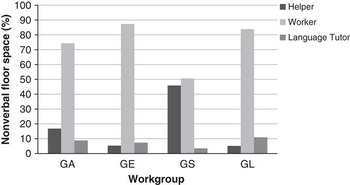
We now focus on the nonverbal communication mode and floor space distribution within this mode. Apart from GS, the nonverbal floor space distribution between the students in the helper-worker roles was considerably different (see Figure 7). The language tutors’ usage of nonverbal communication occupied between 3.49% and 10.98% of the floor space within each group.

Fig. 7 Distribution of nonverbal floor space with respect to role during activity and workgroup
Deictic gestures accounted for 60% of nonverbal communication in the four workgroups (see Figure 8). 78.17% of deictic gestures were performed by students in the worker role. This predominance can be explained by the nature of the activity: interaction with objects in SL, e.g., modifying the position of an object, requires the avatar to touch the object. The environment portrays this as a pointing gesture. No iconic gestures or emblems were used by the actors in the activity studied. However, pantomimes of typing, dancing and eating were present.

Fig. 8 Distribution of nonverbal communication cues identified for the four workgroups
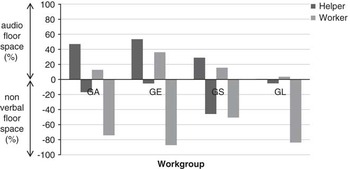
In all four workgroups, students in the worker role occupied more nonverbal than audio floor space (see Figure 9). The results for the students in the helper role were more varied. In the FLE group GA, the helper occupied more audio floor space than the worker but less nonverbal floor space. The helper occupied more audio floor space than nonverbal floor space. In the FLE group GL, the helper occupied slightly less audio floor space than the worker and significantly less nonverbal floor space. The helper occupied slightly more nonverbal floor space than audio floor space. In the ESL group GE, the helper occupied significantly more of the audio floor space than the nonverbal floor space whilst in the GS group the helper's communication was more evenly distributed between the two modes. Due to the nature of the helper-worker roles, the modalities the students used were organised differently.

Fig. 9 Distribution of nonverbal and audio floor space
The dominance of deictic gestures in the nonverbal communication is of interest. No verbal acts draw a counterpart's attention to such a gesture and verbal deictic references were very infrequently used. They accounted for only 5.16% of all verbal acts made which included a reference to an object. One possible explanation is that when a worker interacts with an object, if the helper displays both the worker and the object on his computer screen, s/he can ascertain with which object the worker is interacting. Students may not have needed to draw attention to objects through verbal communication because they were always obvious in the nonverbal mode.
Another, more plausible, explanation is that the students preferred verbal references to objects (instead of verbal deictic references) which pertained to more specific characteristics to avoid ambiguity. Although the number of verbal references to objects differed depending on the students’ role, both helpers and workers most frequently employed references concerning the object name, the object size or a description of the object (see Table 3). Thus, students adapted their communication strategies to the environment: uncertain of their counterpart's view of the environment choosing specific references to objects which lacked ambiguity helped identify and refer to objects quickly and securely.
Table 3 Top categories of verbal acts referencing objects by type and student role with examples

4.4 Shared visual space for collaborative activity
This explanation is strengthened when we consider the acts performed in the nonverbal category of movement. To help object identification, avatar movement, positioning and orientation were frequently employed in parallel with a reference to an object in the verbal mode. Students used the position of an avatar as a static point from which to refer to an object to be identified. This strategy, however, was frequently unsuccessful in identifying the object. In example 5, the student in the helper role refers to an object “in front of us”. The worker does not correctly identify this object because his subsequent nonverbal act prompts the helper to tell him “don't touch don't touch the bIG:”. The reference is misunderstood by the student.
(5)
[tpa, quentinrez, 17:38-17:54]: okay so I've got the euh + euh ++ because we can + I + I think it's it's easier to euh just euh pick up the + the black and the the big and the little hole (romeorez: yeah but) so (romeorezrez: the) just (romeorezrez: the big) which one of them (in front of us)
[tpa, romeorez, 17:53-18:03]: the first big dome + don't touch don't touch the bIG: the big the hole is in front of uS: okay the big is good but the little I one I think umm
In the post-questionnaire, this student stated that he used the SL camera view nearly all the time. The camera allows users to detach their point of view from the avatar they control, allowing the user to gain multiple perspectives. In a subsequent interview, the student stated that his use of this view had no impact on the interaction for at all times he could clearly hear his partner. However, no students asked their partners, before making a reference to an object in relation to another static point (e.g., the student's avatar), whether their counterpart was using the camera view or not: the students did not try to establish common ground in terms of their shared visual space before communicating verbal references to objects.
Kraut et al. (Reference Kraut, Fussell and Siegel2003) and Clark and Krych (Reference Clark and Krych2004) argue that in distance collaborative activities participants must have shared visual access to the collaborative activity space so as to help establish deictic references. This is perhaps one of the reasons that students used few deictic references in their verbal communication. We also suggest that this is also true when searching to establish references with reference to the position of an avatar: it appears fundamental that both students are aware of their physical orientation to one another. It is perhaps for this reason that students preferred avatar movement and orientation as a form of reference.
4.5 Language difficulties and nonverbal acts
Students used avatar movement and orientation to help mark the position of an object. In example 6, the helper specifically decides to position his avatar in the same place in which he wishes the worker to position the object with which the pair is working.
(6)
[tpa, romeorez, 1:19-1:30]: oh do you know what I'm going to take my avatar and put me where you have to put the things I think it's useful like that … (it's easier you know)
[mvt, romeorez, 1:24-1:34]: walks towards dome object
[tpa, quentinrez, 1:29-1:34]: (yeah yeah) totally yes totally (romeorez: so) + you respect it
[tpa, romeorez, 1:34-1:37]: so the little fountain is like here
[tpa, quentinrez, 1:38-1:47]: okay I see it (romeorez: okay) okay so (romeorez: and the+like here) it exactly on your place or
[tpa, romeorez, 1:47-1:49]: exactly on my place
[tpa, quentinrez, 1:49-1:51]: okay so I do that okay that's it
In a post-course interview, of the ‘critical-event recall’ type, after having viewed the video corresponding to example 6, the student quentinrez described the fact of moving his avatar to where the object had to be placed as a strategy to overcome his poor vocabulary concerning position and direction:
in fact it's because + I'd say directions and rotations because we have a very poor vocabulary when we're speaking and try to describe a position or a direction or something to do with orientation in fact that is the specific area where we are really missing lexis + orientation [authors’ translation]
4.6 Ambiguity of verbal deictics and nonverbal acts
We remark that, in all instances when the students decided to adopt, for the first time, the strategy of moving an avatar to refer to an object or to mark the position of an object, it was following a non-successful verbal communication to try to describe the object or how to position the object.
For example, GA group encountered a difficulty in the verbal communication concerning which object was to be manipulated. This difficulty arose because the students were not aware of what was in their partner's field of vision when they used determiner ‘cet’ (see example 7). When the worker asked a question to try to decipher which object the helper was referring to, the helper decided to move her avatar, running over to the object in question. Thus, in her later verbal communication we can see that she moves from talking about ‘cet’ to talking about ‘celui’. To compensate for the difficulties in knowing what is in her partners’ field of vision and not rely on deictic words alone, the student uses nonverbal communication to make explicit her verbal communication. Indeed, at first, the deictic word ‘cet’ was entirely context dependent. Its meaning could shift and was non-unique. By using nonverbal communication alongside a verbal deictic word the student secures the context for her reference, anchoring the deictic word to a specific object in the environment. We suggest that, because in this situation shared visual access to the collaborative activity space is not guaranteed, that explicitness in the nonverbal communication helps to secure the reference.
(7)
[tpa, crispis, 14:14-14:17]: vous allez deplacer le + cet object (you're going to move the + this object)
[tpa, prevally, 14:18-14:19]: lequel (which one)
[tpa, crispis, 14:20-14:21]: ah je vais m'approcher (ah I'll go over to it)
[mvt, crispis, 14:20-14:22] runs over to object [tpa,prevally, 14:22-14:23]: ah ca (oui) (ah that (yes))
[tpa, crispis, 14:23-14:23]: (celui) + (this one)
[mvt, crispis, 14:24-14:25] moves backwards from object towards prevally
[tpa, crispis, 14:24-14:26]: euh de rien (euh no problem)
It is interesting to notice that in our post-course questionnaires, 13 of the 16 students who responded, agreed with the statement that “in distance communication situations, being able to communicate through an avatar (–movements, gests, appearance) allows you to engage more in the conversation”.
The numerous examples of the use of avatar movement and positioning to clarify verbal acts and the importance the students attach to this for their communication beg the question as to whether synthetic worlds enable the direct transfer of face-to-face strategies as regards spatial reference to objects. In these examples we note that users must accommodate to the properties of the environment by using nonverbal communication in association with verbal communication or they risk miscommunication and, thus, reduced success in the building activity.
4.7 Proxemics and verbal interactions
The verbal mode was also used in association with the nonverbal mode to organise the proxemic positioning of the students’ avatars. We found that students did not instinctively move or orientate their avatars in the formation of groups at the beginning of activities and did not naturally position their avatars to face each other as we believe they would in face-to-face situations. For an example, see Figure 10 in which we can observe an avatar using the oral mode to communicate (indicated by the wave icon) and another avatar replying by written communication. These avatars are interacting; however, they have their backs to each other.

Fig. 10 Avatar proxemics
Our data also shows that at the beginning of sessions, the language tutors (tfrez2 in the example), on numerous occasions, explicitly ask the students to organise the proxemic positioning of their avatars using the verbal mode before beginning activities (see example 8). During this organisation, the language tutors systematically use the names of the students’ avatars. We interpret this as a shift from a face-to-face strategy concerning forms of address to one which is more suited to the synthetic world. Indeed, in face-to-face communication it is uncommon to mention interlocutors’ names in each utterance when they are in front of the speaker. Rather, gaze and orientation of the speaker may have the same function.
(8)
[tpa, tfrez2, 1:14-1:29] Please can you just come and stand in a circle around me so perhaps Hallorrann you can just yep + Hallorann can you turn around so you are facing me + great and Romeorez a little bit forward please
Ventrella (Reference Ventrella2011: 8-9) explains the impact that nonverbal communication may have on the communication and perceptions of communication in synthetic worlds should users not be aware of their virtual “faux pas”. He quotes the example of a popular avatar that started to get a bad reputation as a snob due to her nonverbal communication. This, despite extra attempts to be sociable. The computer-generated nonverbal communication meant that the avatar's gaze was frequently directed at nothing in particular. Although the user was not aware of snubbing people, the nonverbal communication of her avatar meant that she gained a bad reputation with other users. The language tutors in our experimentation seemed sensitive to this. They used the verbal mode to organise the nonverbal mode, so as to facilitate verbal communication but were also aware of class dynamics: they helped students become aware of their avatar behaviour and positioning with respect to others.
5 Conclusion
This paper develops an original methodological framework for the study of multimodal communication in the synthetic world SL. In response to specific learning goals of an architectural CLIL course, the study applies this framework to examine how verbal and nonverbal modes were used during a collaborative building activity in students’ L2 and how this usage differs from face-to-face contexts.
Our work proposes a classification of the communication possibilities in SL and offers a description of the verbal and nonverbal modes of communication. We have underlined relationships between the two modes that are built into the environment. For example, the link between users’ proxemic acts and the public audio modality and the links between iconic gestures and verbal acts of interjection. We also highlighted some of the differences between SL's communication modes with respect to those of face-to-face communication, exemplifying how these may be of interest for communication within pedagogical contexts. For example, multidirectional synchronous written communication possibilities and the use of iconic gestures rather than facial expressions to display emotional states.
Our study of the collaborative building activity, based on a method to organise the data collected in screen recordings and its coding and transcription, suggests that the distribution of the use of the verbal and nonverbal modes is dependent on the role that the student undertook during the activity and the particular instructions that the student in each role was given: students in the helper role predominantly preferring verbal communication whilst students in the worker role preferred nonverbal communication. However, interaction between the two modes was apparent. The nonverbal modality of avatar movement was used as a strategy to overcome verbal miscommunication in particular concerning direction and orientation. Avatar movement also had the function of securing the context for verbal deictic references to objects. Such references were infrequently used in the verbal communication. Both helpers and workers preferred references to objects by object name, size and colour. We suggest that this is a sign that the students adapted to the environment: such references avoid ambiguity whilst deictic references are hard to understand due to participants being unaware as to whether they share visual access to the collaborative activity space or not. The camera feature of the environment, unavailable in the first world, contributes to this uncertainty. Should language tutors wish to exploit the synthetic world environment, thus, for “learning by building”, it may be important to develop the proficiency of learners to express orientation and direction in the design of the pedagogical scenario. For example, by providing scaffolding activities.
Interaction between both modes was also evident concerning the proxemic organisation of students. Proxemic norms for communication from the first world were not immediately transferred inworld: students did not instinctively place their avatars in the formation of groups or facing each other. The data analysis further suggests that the proxemic organisation of students had an impact on the quantity of the students’ verbal production and the topics discussed in this mode. Our study shows that proxemic closeness is important for L2 activities which involve collaboration and, more specifically, building. There is, thus, a need in pedagogical scenarios to explicitly introduce students to the nonverbal communication in the environment to accelerate the emergence of communication norms when students work together. In doing so, we believe, language production and learning in subsequent collaborative activities can be facilitated.
Three-dimensional synthetic worlds introduce possibilities for nonverbal communication in distance language learning. We hope our paper will contribute to some of the methodological reflections needed to better understand the affordances of such environments, including the possibilities they offer for nonverbal communication.