1. Introduction
With the advent of computers and the Internet, corpus linguistics has become one of the most rapidly advancing fields in linguistics. Various corpora are now available via the Internet and more and more user-friendly tools have been developed. As the technology becomes increasingly available, there is a growing interest in using corpora for pedagogical purposes. One of the ideas of exploiting corpora for teaching is called data driven learning or DDL (Johns, Reference Johns1991). The past decade has seen a growing body of research that investigates the effects of DDL in the classroom, though precise descriptions are needed to claim in what areas DDL works and how it is different from other means of instruction (Boulton, Reference Boulton2008, Reference Boulton2012).
DDL has been introduced in several different ways in actual classroom tasks. Broadly speaking, it is an approach that presents linguistic data to learners for the purpose of helping them inductively find patterns of use in the data by themselves, instead of being provided with rules deductively. On closer inspection, however, there are many different ways of presenting linguistic data to learners, including printed copies of selected concordance lines, direct access to concordances on computer, and direct access to the corpus analysis software itself without showing concordances in the beginning. DDL/corpus use may therefore have different effects depending on how it is used pedagogically. For example, when using printed materials, the selection of search words and examples is strictly controlled, whereas access to corpus software itself allows the learner much greater freedom. DDL can be targeted to promote “convergence” learning, where learners are deliberately led to specific goals, or “divergence” learning, where learners are encouraged to be a ‘traveller’ and find something unexpected – “serendipitous” learning (Bernardini, Reference Bernardini2000).
With increasing availability of computers in the classroom, learners have more opportunities for free access to corpus tools while writing, although this is still limited to the cases where language teachers are familiar with the corpus resources available. This study addresses the problem of how and where the use of corpora could best facilitate learning in the process of foreign or second language (L2) writing. In particular, we focus on the relationship between types of learner errors in writing and how readily they can be corrected by accessing the information in corpora. To this end, error identification was conducted semi-automatically using natural language processing (NLP) techniques called edit distance (Section 3). The errors were classified according to surface structure taxonomies into omission, addition, and misformation. Each error identified was also tagged for part-of-speech information for further scrutiny (e.g., omission of determiners). In so doing, we investigated how and to what extent corpus evidence helped learners correct their lexico-grammatical errors in L2 writing.
We begin with a review of empirical research into the effects of DDL especially in L2 writing. This is followed by research questions and the description of our experimental design. Finally, we present the results of the experiment and discuss theoretical and methodological as well as pedagogical implications of the study.
2. Review
As the communicative approach (CA) has thrived and aroused interest in the learner and the learning process, information and communication technology (ICT) has affected the role of the teacher, focusing on learning rather than teaching (Boulton Reference Boulton2009a). DDL is one specific use of ICT, in which learners are exposed to a large amount of authentic data from corpora and encouraged to take the initiative in examining the language and noticing the patterns in it (Boulton, Reference Boulton2009a). Since Tim Johns pioneered DDL (Johns, Reference Johns1984, Reference Johns1986), corpora have been expected to play an important role in writing instruction. Flowerdew (Reference Flowerdew2010) claims that corpora are useful in writing classes because interacting with corpora facilitates learners’ mastery over phraseological patterning (i.e., collocations, colligations and semantic preferences and prosodies), as these features are not readily available in either dictionaries or grammar books. However, corpora have not been in widespread use for writing instruction (Flowerdew, Reference Flowerdew2010; Lee & Swales, Reference Lee and Swales2006) for various reasons, including the user-friendliness of corpora, the training of both students and teachers, and a better understanding of the effectiveness of corpora in writing performance (Flowerdew Reference Flowerdew2010). Further, learners’ cultural backgrounds might hamper them from using corpora voluntarily (Boulton, Reference Boulton2009a). Let us examine each of these issues in more detail.
First, teachers can be reluctant to use corpora if corpus tools are not sufficiently user-friendly (Kosem, Reference Kosem2008), or if texts sampled in corpora are too difficult for learners to exploit (Chujo, Utiyama & Nishigaki, Reference Chujo, Utiyama and Nishigaki2007; Kennedy & Miceli, Reference Kennedy and Miceli2001; Osborne, Reference Osborne2004). Ready-made and user-friendly interfaces (Granger & Meunier, Reference Granger and Meunier2008) and easily accessible and readable corpora for lower-level learners (Chujo et al., Reference Chujo, Utiyama and Nishigaki2007) are awaited.
Second, teachers’ reluctance to use corpora might also stem from the fact that they do not have a pedagogical background in using corpora, and thus teacher training is needed (Mukherjee, Reference Mukherjee2004; O’Keeffe & Farr, Reference O’Keeffe and Farr2003). Moreover, it seems that student training is indispensable for the exploitation of corpora because students themselves need to interact with the corpus. Lee and Swales (Reference Lee and Swales2006) provide examples of tasks in which students familiarize themselves with corpus use. However, many learners would rather be told what to do by a teacher, and are reluctant to take responsibility for their learning (Boulton, Reference Boulton2009a). Culture might also influence students’ attitudes, learning styles and behavior in class; oriental culture, for instance, is “patriarchal collectivistic” (Brown Reference Brown2007: 161). It may be difficult for learners to modify classroom behavior that they are familiar with (Bernardini, Reference Bernardini2004).
Third, although some previous studies have shown results favorable toward corpus use (e.g., Lee & Swales, Reference Lee and Swales2006; Chambers & O’Sullivan, Reference Chambers and O’Sullivan2004; Gaskell & Cobb, Reference Gaskell and Cobb2004; Yoon & Hirvela, Reference Yoon and Hirvela2004; Yoon, Reference Yoon2008), there is still a lack of evidence for the effects of corpus use on L2 writing. One of the few studies to note is Boulton (Reference Boulton2009b), where 132 intermediate and lower level English learners were divided into four groups to compare their ability to cope with linking adverbials (e.g., but, in fact, and anyway) by consulting traditional resources (a bilingual dictionary or a grammar book) against corpus resources (short context data or concordance lines). The results showed that as a reference source during the test, corpus data, especially concordance lines, helped learners answer fill-in-the-blanks-type test questions more effectively than traditional materials, and that both corpus and traditional resources were equally useful for remembering the target items – even though the learners had had no training in using corpus data. In Boulton (Reference Boulton2008), 113 lower-intermediate learners completed binary choice tests of picked / picked up and looked / looked up before and after consulting printed concordance lines. The results again suggest that corpus data was useful in providing support for them to produce correct answers.
Another example is Gaskell and Cobb (Reference Gaskell and Cobb2004). Twenty lower-intermediate English learners submitted ten essays over a fifteen-week semester and corrected errors by using concordances. When the learners were provided with online concordance links for five common errors along with appropriate instructions, nearly all corrections (80–100%) were made accurately. Without the links, substantially fewer (60–70%) of them were accurate. In terms of overall errors, while three error types (word order, capitals/punctuation, and pronouns) significantly reduced in error rate, the error rate of the other three types (articles, subject-verb agreement, and noun pluralization) increased significantly.
Pérez-Paredes, Sánchez-Tornel, Alcarez Calero and Aguado Jiménez (Reference Pérez-Paredes, Sánchez-Tornel, Alcarez Calero and Aguado Jiménez2011) compared guided and non-guided corpus consultation by tracking student-computer interaction. Their study defines ‘guidance’ as explanation of what a corpus is and how it can be used in class, which includes the use of POS tags (e.g., ADJECTIVE + of + NOUN) and wildcards (e.g., was … by). Thirty-seven intermediate or upper-intermediate English learners completed two focus-on-form tasks dealing with it-clefts and subject-verb inversion after negative/restrictive adverbials. First, they were presented with examples extracted from the British National Corpus (BNC); second, they used the corpus to find relevant sentences and infer patterns; third, they applied the target structures. The results showed that the learners with guided consultation visited slightly more and different websites and conducted more BNC searches, though none of the learners in either group used wildcards or tags. Pérez-Paredes, Sánchez-Tornel and Alcarez Calero (Reference Pérez-Paredes, Sánchez-Tornel and Alcarez Calero2012) explore the search behavior of 24 upper-intermediate English learners by tracking student-computer interaction during focus-on-form tasks dealing with it-clefts. One group used the BNC, other web services and/or guided corpus consultation, the other used only the BNC: the performance of the first group was higher. Neither group of learners used POS tags, regular expressions or wildcards, and both tended to use the BNC search interface in the same way as if they were using Google.
From the above studies, some points become clear. First, as Johns argued (1991: 12), DDL seems to be beneficial for intermediate and lower-level English learners as well as at more advanced levels, contrary to language teachers’ typical assumption. Second, corpus data as a reference in L2 writing is especially useful when learners revise their drafts after receiving some kind of feedback on errors. Third, the effects of reducing errors vary, depending on the types of errors involved. Fourth, with corpus consultation guidance, learners can use corpus data more frequently for their research, although they may not use POS tags, regular expressions, or wildcards, which would enable them to conduct more efficient searches.
However, several points still remain unclear. For example, although the proficiency level in L2 is an important variable in L2 processing (Hahne, Reference Hahne2001; Perani, Paulesu, Galles, Dupoux, Dehaene, Bettinardi, Cappa, Fazio & Mehler, Reference Perani, Paulesu, Galles, Dupoux, Dehaene, Bettinardi, Cappa, Fazio and Mehler1998; Rossi, Gugler, Friederici & Hahne, Reference Rossi, Gugler, Friederici and Hahne2006), little is known about how much proficiency is required to understand concordance lines and how proficiency levels influence learners’ use of corpora in language analysis. It is also not clear how much and what kind of training in corpus use will be needed. In addition, previous studies often ignore whether corpus use has different effects on different types of errors such as morphological, lexical, and syntactic errors. According to Ferris (Reference Ferris2002), it is especially difficult to treat lexical errors such as word choice errors and unidiomatic sentence structures because there are no explicit rules learners can follow to detect, correct and avoid such lexical errors. More empirical studies are needed to determine whether corpus use is effective in improving L2 writing, and how DDL works if indeed it is effective.
3. Method
3.1 Aims and research questions
This study investigates the effects of corpus use on the correction of grammatical and lexical errors after feedback at the revision stage, with special focus on the influence of learners’ proficiency levels on their corpus use and the instructional effects on how to use a corpus. The following research questions will be addressed:
(1) Is error feedback with guided corpus consultation effective in L2 writing, especially in revising surface structures such as grammatical and lexical errors? If so, are there any differences in three types of surface structure errors: misformation, omission and addition (see definitions of these error types in Section 3.3.2)?
(2) Are there any parts of speech that are more readily corrected when corpus information is provided?
(3) Depending on the level of proficiency, are there any differences in the students’ use of a corpus in correcting their errors?
3.2 Participants
In total, 93 undergraduate students from two universities participated in the study. Group A was composed of 68 students with an upper-intermediate level of proficiency at a private university in Tokyo. Their average score on the TOEIC (Test of English for International Communication, or equivalent tests such as Jitsuyō Eigo Ginō Kentei – EIKEN Test in Practical English Proficiency) was 605.5 with a range from 370 to 955. The average TOEIC score is roughly equivalent to A2+ to B1 in the Common European Framework of Reference for Languages (CEFR). Group B consisted of 25 students, whose average TOEIC score was 322.7 (ranging from 190 to 435), equivalent to A1 to A2 in the CEFR. While the course for group A focused on reading, group B’s course objective was to improve their receptive skills with a special emphasis on basic grammar, aided by computers. Two of the authors taught these courses at their respective universities.
3.3 Instruments
3.3.1 Essay tasks
Two sets of timed essay tasks were used in this study. In the first task, the students were asked to write an essay entitled: “Introduce your friend, family member, or someone you know.” The task was timed for fifteen minutes and no access to dictionaries or online resources was allowed. For the second task, the participants were asked to revise their essays, partly involving the use of corpus resources. Before the revision, special instruction was provided to introduce the use of concordancers as a reference resource.
3.3.2 Coded feedback and instructions for corpus tools
(a) Coded feedback on surface structure errors
There is no empirical evidence that unsupervised access to corpus data by students with varying degrees of proficiency ensures accuracy in revising their L2 writing. In order to see the effects of guided feedback with the support of corpus evidence, we deliberately controlled the points for revision in the drafts by identifying two problematic segments in each essay (either single words or phrases in a sentence) containing either sentence-level, lexical or grammatical errors: the first one was intended to be corrected by referring to the corpus data, the second without it. Each of the two errors was highlighted with a different color to distinguish between them. Students received their drafts with coded feedback and were asked to work on revising them, focusing on the highlighted words or phrases. Special codes were also used for showing erroneous segments and how to deal with them. Three main types of errors were identified: (i) misformation errors, where one grammatical form is used in place of another; (ii) omission errors, where lexical items such as prepositions or articles are omitted; and (iii) addition errors, which contain a redundant item. For example, the sentence My parents talk him very often has a missing preposition error (type ii). In this case, a special symbol (V) was inserted before the pronoun him:
(1) My parents talkV him very often.
Underlining was given to show what search word to use in concordance tools. The following example shows the case for a misformation error (type i):
(2) I have a long-term friendshipXof Yohei.
In this case, the preposition of should be replaced with something else, which is indicated by the symbol (X) with the suggested search word underlined (i.e., friendship). In the case of addition errors (type iii), the following code was used:
(3) I thank Xto him from the bottom of my heart.
The surface structure taxonomy errors were chosen because we compiled corpora of students’ essays together with their proofread versions and automatically identified the above three types of errors using edit distance (basically similar to the Levenshtein distance, with misordering correction features). For further details, see Tono and Mochizuki (Reference Tono and Mochizuki2009).
(b) Instructions for corpus tools
In the revision session, prior to the revision activities, the students received fifteen to twenty minutes’ instruction on how to use the corpus tools. An online corpus query system called the Intelligent Tools for Creating and Analysing Electronic Text Corpora for Humanities Research (hereafter, IntelliText) was introduced. This was developed by the Centre for Translation Studies at the University of Leeds (Wilson, Hartley, Sharoff & Stephenson, Reference Wilson, Hartley, Sharoff and Stephenson2010). IntelliText is a publicly available online corpus query system, in which the users can search ready-made corpora including the BNC, or upload their own corpora; they can also crawl the web to collect their own texts. The interface is relatively user-friendly, as long as the search is limited only to word or phrase levels. For this particular experiment, we used the BNC and instruction was given on how to correct errors using the tool by way of a revision manual. The revision manual included the examples (1) to (3) above. Thus, in example (2), a symbol of crossing (X) signifies a problematic use of the preposition of. The students were then instructed to search for the preceding underlined word friendship using IntelliText, and to examine the concordance lines to identify which preposition should follow friendship in this context, by sorting right or left contexts in keyword-in-context (KWIC) lines. Students were encouraged to work on the other error types as well to familiarize themselves with the corpus interface and how to interpret the search results.
3.4 Procedure
The following procedure was adopted:
(a) The first timed essay task was given (fifteen minutes in class).
(b) Three weeks after the first task, the revision session was held, in which the students were given coded feedback for two grammar points on their original essays.
(c) Instruction was provided for IntelliText (fifteen to twenty minutes).
(d) The students undertook a revision session for 25 minutes, although it turned out that most of the students completed their revisions within fifteen minutes.
After collecting the students’ first timed essays, the instructors selected two errors: one that needed to be corrected with corpus reference, another without it. The selection of errors was not random in terms of types of errors, but it was randomly selected in terms of the opportunities for use in the essays. It was difficult to prepare a single pool of errors a priori due to the nature of the free composition tasks, so initially we estimated the types of errors which were likely to need corpus reference (e.g., collocation errors, wrong choices of prepositional complements, etc.) and those which were not (e.g., inflection or agreement errors). The instructors, who were two of the present authors, then analyzed the types of errors in the essays and refined the selection of errors based upon such observations.
Each error was highlighted differently so that students could easily distinguish them. In this experiment, only a single error for each error type was deliberately chosen, regardless of the total number of errors in their essays. This is because some students, especially from a group with lower proficiency of English, ended up producing only two or three sentences. Therefore, in the lower group, there were some essays where it was difficult to identify any errors to be corrected due to the limited number of words and sentences produced.
In addition to correcting the errors identified by the instructors, if time remained, the students were encouraged to correct any other problematic elements, either on their own or by using the tool. Throughout the revision session, they were instructed to indicate clearly whether their correction was based on corpus information or not, by using markers such as underlining and circling or their mother tongue on their draft.
4. Results
4.1 The effects of corpus use over different surface structure taxonomy errors
Table 1 summarizes the highlighted errors and their surface structure taxonomy. For Group A 136 errors were selected and for Group B, 52. In the case of Group B, there were four essays which had only a single error to be corrected with guided corpus consultation. On the other hand, in five essays students were instructed to correct a phrase which contained two errors; for example, She write letter yesterday should be changed to She wrote a letter yesterday by correcting the verb inflection according to verb tense (i.e., misformation) and adding the indefinite article a (i.e., addition). Therefore, although there were 25 students in Group B, the total number of errors was 52. This was not the case for Group A.
Table 1 Distribution of error types highlighted in students’ essays

After the revision, all the sentences with highlighted errors were extracted and a parallel dataset was prepared for the original (i.e., before revision) sentences aligned with the revised sentences. An automatic error identification program was used to identify and tag the erroneous parts by comparing the original and revised essays. Since there was a possibility that the students could not correct errors properly, two of the present authors went through all the revisions and identified whether the corrections were successful and what kind of surface structure taxonomy would apply for that correction.
Table 2 shows the proportion of correct vs incorrect revisions using the corpus across different error types; Table 3 shows the results of corrections with no reference to corpus information.
Table 2 Distribution of correct and incorrect revisions with corpus reference
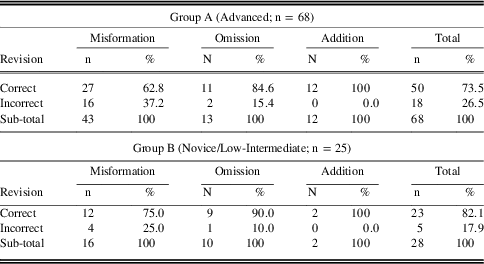
Table 3 Distribution of correct and incorrect revisions without corpus reference
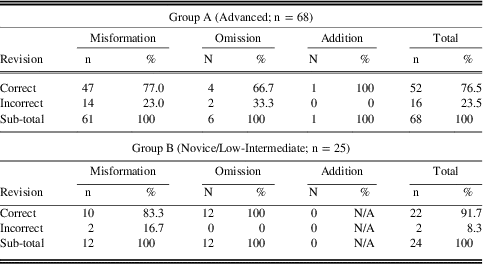
Overall, errors that needed no corpus access were relatively easily corrected, which was expected as we had deliberately chosen those errors which could be corrected without checking against corpora, such as tense and agreement errors, inflection errors, and other morphological errors. It should be remembered though that the purpose of the present study is not to compare corpus use against non-use in the revision task; instead, our main concern is how successful guided feedback is with corpus support across different types of errors. To test the independence between the two variables (success rate of error categories vs. error types), Fisher’s Exact test was used. This is similar to the Chi-square test, but it works better for the contingency table with small numbers, which tends to produce expected frequencies below five and makes Chi-square inaccurate. The results of Fisher’s Exact test shows that in Group A, the success rate of error correction was related to (i.e., not independent of) error types (p=.016; two-tailed) when the corpus tool was used. In other words, the corrections of omission and addition errors were significantly more successful than those of misformation errors. In Group B, however, there was no significant relationship (p=.744). This is a very interesting finding, which will be discussed later. Without corpus use, there was no clear difference in the success rate of error corrections across error types (Group A: p=.712; Group B: p=.478).
Due to their lower proficiency in English, Group B’s essays were shorter and contained simpler words and structures than in Group A, and thus did not contain so many errors. As a result, the highlighted errors selected for revision without corpus use were all very simple grammatical errors, which is the reason why Group B got higher accuracy rates for error corrections than Group A. Inevitably this would make comparisons between groups problematic; however, it does not affect the discussion here which only seeks to compare error types within a group, or within the population as a whole, and not between groups.
In sum, the results show that there is an interaction between error types and the effects of corpus use in revision tasks. Omission and addition errors were corrected significantly more accurately than misformation errors when corpus data was used in Group A. This is partly due to the way corpus data was referred to. In the case of omission or addition errors, with proper scaffolding such as underlining to explicitly indicate which words to look for in concordances, it is relatively easy for learners to check whether or not particular words should go with the search word. On the other hand, it is difficult to decide which words to search for in the case of misformation errors. While showing learners that there is a misformation error is relatively easy, coded feedback has limitations in that it cannot provide further information for search word candidates for misformation errors. The concordance lines provide a useful guide for word combinations or collocations, but to deal with misformation errors, learners need to guess the causes of errors, for example whether they relate to simple word forms or morphological errors or lexical choice errors. For the latter case, learners need to go on to guess what other words should replace the misformed words.
4.2 The effects of corpus use on correction across different grammatical errors
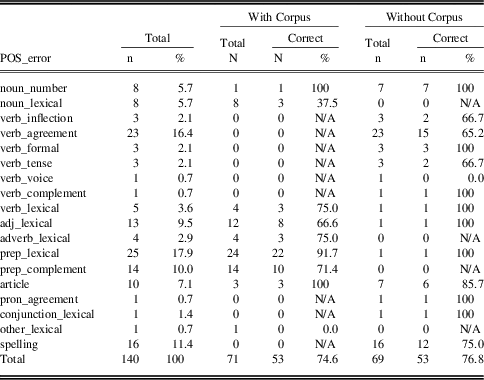
The distribution of grammatical errors which are corrected appropriately with or without use of corpus needs further analysis. Table 4 shows the distribution of grammatical errors in Group A across different POS patterns and their corrections with or without corpora. Note that these errors were pre-selected deliberately by the instructors for coded feedback, as mentioned before. Overall, the most frequently selected POS errors were prepositions (n=39, i.e., 27.9%) and the most frequent type of grammatical errorsFootnote 1 was lexical errors: (1) lexical errors with choice of prepositions (n=25, i.e., 17.9%); (2) verb agreement errors (n=23, i.e., 16.4%); (3) spelling errors (n=16, i.e., 11.4%); (4) errors of prepositions as particles (n=14, i.e., 10.0%); and lexical errors with choice of adjectives (n=13, i.e., 9.5%). The majority of the preposition errors were either addition or omission errors, as discussed in section 4.1. Regarding lexical errors with choice of prepositions, the majority of errors fall into either omission or addition errors. Compared to the overall ratio of errors (76.5% being misformation errors), the ratio of omission and addition errors was exceptionally high in this POS pattern. Since it was easy to correct omission and addition errors, most students seemed to have corrected their errors in a target-like manner.
Table 4 Group A: Distribution of POS errors and the ratio of correctly revised errors with or without corpus access

The top three error categories assigned to corpus use were lexical choices of prepositions (prep_lexical), errors of prepositions as verbal or adjectival complements (prep_complement), and lexical choices of adjectives (adj_lexical). The findings show that the participants in Group A successfully corrected most of these items using corpus data (91.7% for prep_lexical, 71.4% for prep_complement, and 63.6% for adj_lexical). On the other hand, among those error categories selected for revision with no corpus access, the four most frequent categories were verb agreement errors, spelling errors, noun number agreement errors and article errors. Without using corpora, these errors were also fairly accurately revised in Group A (verb_agreement 65.2%, spelling 75.0%, noun_number 100.0%, article 85.7%). Verb agreement errors resulted in relatively low levels of accuracy in revision. Again, these findings were not surprising because different types of errors were selected for revision with or without corpus use. In particular, it was expected that learners would be able to correct grammatical errors such as agreement and spelling errors without any information from corpora, but that they would find it difficult to choose words to replace inappropriate collocations, so most lexical choice errors were selected for corpus use. This instructional design seemed to work well in this case. We are aware that in a true experimental design, a control group would be necessary to compare corpus use / non-use for all these similar errors. However, previous research (cf. Gaskell & Cobb Reference Gaskell and Cobb2004; Todd Reference Todd2001) often fails in this very aspect of choosing the words or phrases suitable for correction with corpus data, which is why we designed our task in such a way that coded feedback actually helped learners focus on those areas where corpus data was needed.
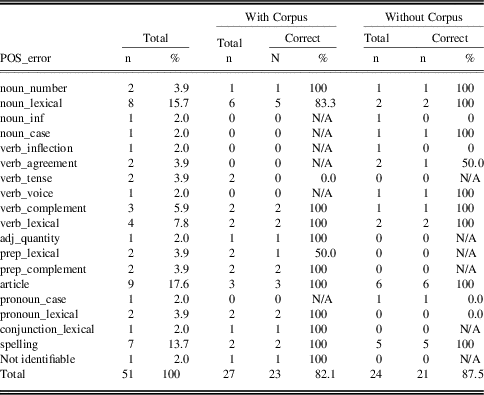
In Group B (Table 5), the five most frequent errors were article errors, lexical errors with choice of nouns, spelling errors, verb lexical choice errors, and verb complement errors. In terms of part of speech, the most frequently identified error type was article errors, as compared to preposition errors in Group A. Since Group B was less advanced, they were prone to more mechanical errors involving function words, article errors being typical examples.
Table 5 Group B: Distribution of POS errors and the ratio of correctly revised errors with or without corpus access
Table 5 shows that there are eight occurrences for noun lexical choice errors for group B. Six of the 8 occurrences were to be revised with reference to a corpus, two without any corpus information. Items corrected based on the corpus include arrange, replaced by arrangement in a sentence originally composed as Because there is some arrange in his playing. Also, due to was changed to thanks to in he can play baseball due to very hard practice everyday. Thus all errors related to articles and spellings were successfully corrected irrespective of use of the corpus.
In Group B, there were many more errors than Group A which did not seem to require corpus information for revision: (a) verb inflection; (b) verb lexical choice; (c) prepositional particle; and (d) pronoun lexical choice. For example, the omission of the verb be can easily be corrected by adding is in Matsuda Shota starring in a Liar game and Don ki ho-te. Other examples include the omission of the to-infinitive in I want communicate him more; and misformation errors of pronouns as in him major is economics, which was revised to his major is economics. Therefore, the overall correction rates were also quite high in Group B, due to the fact that their errors were relatively simpler and no extra corpus support was needed.
5. Discussion
We have seen the effects of using corpus data for revising compositions by focusing on lexico-grammatical points in student essays. Clearly there is a lot more than simply checking grammar in corpora, but for Japanese learners of English, this is the most realistic use of corpora for L2 writing in actual classroom settings. We have also argued that this study is not a simple comparison of error correction with or without corpus use. Coded feedback was integrated to attract the learners’ attention to particular collocation patterns, allowing us to investigate the efficacy of this approach compared to the ordinary random access of corpora in writing.
Let us go back to our research questions. The first one was: “Is error feedback with guided corpus consultation effective in L2 writing, especially in revising surface structures such as grammatical and lexical errors? If so, are there any differences in three types of surface structure taxonomy errors: misformation, omission and addition?” Our answer is positive. The guided error feedback with a special focus on errors with choice of lexical items and the availability of corpus evidence for reference seemed to help the learners revise their drafts appropriately, especially in Group A who had a higher level of proficiency and produced longer essays than Group B. The findings also show that omission and addition errors are more easily corrected than misformation errors. For instance, by using coded feedback (V for omission) in (4a), learners were able to search for the word talk and sort by the right context of concordance lines, and then retrieve the preposition about as its most suitable collocate, as in (4b). The same applies to addition errors (5).
(4) a. I talkV everything with her.
b. I talk about everything with her.
(5) a. introduce aboutX my mother
b. introduce my mother
Misformation errors were found to be more difficult to correct even with corpus data, though it was sometimes successful, as in (6). In this case, the same kind of corpus query operations did work, i.e., searching for the left context of the node word prize in order to identify a suitable collocate win, as in (6b).
(6) a. took X a prize
b. win a prize
A number of counterexamples show instances of unsuccessful revision. No addition errors were incorrectly revised in either Group A or Group B, but in the misformation and omission errors in (7) from Group B, it was expected that the writer would revise person to people and add in before group. However, he or she revised as (7b).
(7) a. There are two person X V group.
b. There are two persons of group.
The second research question was: “Are there any parts of speech that are more readily corrected when corpus information is provided?” The findings show that, of all error types, omission or addition errors of prepositions were most likely to be accurately corrected with the help of the corpus. Again this has to do with the operations of KWIC lines, which highlight presence or absence of particular prepositions as collocates for the search words. It is relatively straightforward for learners to master this way of checking errors. This is not the case, however, when the search word has multiple parts of speech, as in (8). Given the coded feedback in (8a), the learner looked up the underlined word work and could not immediately find an appropriate collocate, because the word work has both noun and verb usages, and collocates differ accordingly. In such cases, there is a tendency to choose among the first few options from the beginning of the concordance lines. Here, the student was not trained to conduct POS searches, and ended up choosing the preposition of for the noun use of works, as in the works of... Without knowing how to use the functions of the concordancer, it would be very difficult to narrow down the search to the desired collocates – especially where there are many choices of collocates, or where learners have an insufficient command of English to guess which words are appropriate.
(8) a. he works inX Panasonic
b. he works *of Panasonic
The same kind of confusion of multiple POSs was found in the cases of (9) and (10). The word graduate has both noun and verb uses, and the corrections students made in (9b) and (10b) both arose from looking up the noun use of the search word graduate. This kind of error can be avoided if learners have enough grammar knowledge to parse the sentence for POS, but looking at concordance lines tends to lead them to simply trust the concordance lines and pick up whatever is available there. More training to read concordance lines and figure out the usage including parts of speech would seem to be necessary.
(9) a. he graduatedV a university
b. he graduated *of a university
(10) a. he will graduateV his university
b. he will graduate *of his university
The third research question was: “Depending on the level of proficiency, are there any differences in the students’ use of a corpus in correcting their errors?” In the present study, we prepared two groups of learners with upper-intermediate and lower levels of English. No clear difference was found between the two groups in terms of the effects of corpus use. One of the biggest reasons for this is that since we relied on their own essays, the quality and quantity of their essays differed widely, thus resulting in a collection of relatively simple errors for the lower-level group (Group B), which made it easier for them to correct errors in a target-like manner. Group A performed very well, but corpus use did not make a significant difference in their performance of correcting errors accurately in their revision task because different types of errors were assigned to corpus and non-corpus correction tasks.
Finally, where time allowed, the students were encouraged to use corpora to revise other parts of their text in addition to the two specified errors, and here there does seem to be a marked difference between proficiency levels. In Group A, almost all the learners used corpora for at least two other error corrections in each essay, whereas the learners in Group B did almost nothing. The higher-level students in Group A were ready to exploit corpus tools more fully than Group B, which may indicate that more proficient learners tend to understand the usefulness of corpus data better as a reference resource. It might also be that the students in Group A finished the task more quickly because of their higher level of proficiency, and thus had more time to explore the corpus data, which might facilitate more learning.
6. Conclusion
This paper addressed an issue of empirical validation of the effects of DDL in the classroom. Specifically, we investigated the effects of corpus use on L2 writing in terms of revision tasks. Following hands-on instruction in using a corpus tool, students’ papers were coded for deliberately selected errors to see whether they could exploit corpus data for revising their drafts. There was a significant difference in the accuracy of error corrections among different types of surface structure errors in a group with upper-intermediate proficiency. In order to effectively use corpora to support L2 writing, more research is needed to examine the relationship between the information provided by the corpus software at different levels of sophistication and the types of language problems to be solved. This study has at least shed some light on the positive effects of corpus use on L2 writing, but many questions remain. A more rigid experimental design would help to contrast corpus use against non-use in more controlled settings. For example, the selection of errors to be corrected with and without use of corpus data was randomly conducted, but it should be possible to correct all errors without sticking to a single example of each type. The use of corpus data could also be more carefully controlled and observed with some kind of tracking and logging system. The role of corpora for revising drafts could be expanded from lexico-grammatical elements to paragraph, discourse, and text structure dimensions. At the same time, learner variables such as proficiency levels, computer literacy, motivation, cognitive styles, and L1 knowledge could be taken into account in the experiment design, since proficiency levels and computer literacy are likely to impact revision using guided corpus consultation, and applying the newly learned skills to their own revision is related to the subjects’ motivation and cognitive styles.
Finally, we would like to stress that corpus consultation was just one activity conducted in class, as overreliance on corpora for classroom language learning may lead to imbalanced lesson planning (Boulton, Reference Boulton2009b; Pérez-Paredes, Reference Pérez-Paredes2010). We hope that the results of this research will provide insight into the role of corpora in the classroom not just as a buzzword, but as a solid, pedagogical part in language teaching and learning.