Introduction
It is assumed, and often supported, that diagnostic criteria are reliable and valid indicators of underlying disorders (World Health Organization, 1992; American Psychiatric Association, 2013). Indeed, with the recent changes in criteria sets and requirements for individual criterion endorsement associated with the migration from the Diagnostic and Statistical Manual of Mental Disorders, fourth edition (DSM-IV; American Psychiatric Association, 2000) to DSM-5 (American Psychiatric Association, 2013), researchers have reported substantial consistencies in the dimensionality and diagnosis of a given disorder across a wide variety of disorders (Hasin et al. Reference Hasin, O'Brien, Auriacombe, Borges, Bucholz, Budney, Compton, Crowley, Ling, Petry, Schuckit and Grant2013; Regier et al. Reference Regier, Narrow, Clarke, Kraemer, Kuramoto, Kuhl and Kupfer2013; Grant et al. Reference Grant, Goldstein, Smith, Jung, Zhang, Chou, Pickering, Ruan, Huang, Saha, Aivadyan, Greenstein and Hasin2015), implying the structural validity (Loevinger, Reference Loevinger1957) of the criteria sets themselves.
Latent variable methods such as item response theory (IRT; Embretson & Reise, Reference Embretson and Reise2000) have become the preferred approach for assessing these assumptions and for determining the relative severity of individual criteria across a wide variety of personality (Balsis et al. Reference Balsis, Gleason, Woods and Oltmanns2007; Cooper & Balsis, Reference Cooper and Balsis2009), mood (Uebelacker et al. Reference Uebelacker, Strong, Weinstock and Miller2009) and substance use disorders (Langenbucher et al. Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004). Severity, from an IRT perspective, corresponds to the difficulty of endorsing a given criterion, and is directly related to its base rate of endorsement (i.e. threshold). Estimating individual criteria severities is critical because they identify the specificity of particular criteria as indicators of the underlying disorder. A number of researchers have argued both theoretically (e.g. Martin et al. Reference Martin, Chung and Langenbucher2008, Reference Martin, Sher and Chung2011, 2014) and empirically (e.g. Cooper & Balsis, Reference Cooper and Balsis2009; Casey et al. Reference Casey, Adamson, Shevlin and McKinney2012; Hagman & Cohn, Reference Hagman and Cohn2013; Lane & Sher, Reference Lane and Sher2015) that disorder criteria, including alcohol use disorder (AUD), fall along a continuum of severity, with endorsement of different criteria being indicative of varying levels of disorder severity. In this way, the ‘severity’ from IRT, positively, though imperfectly, relates to external, real-world measures of severity (e.g. hospitalization, long-term health, persistence of disorder, co-morbidity; Lane & Sher, Reference Lane and Sher2015). The inclusion of criteria with varying levels of severity (i.e. difficulty) is considered a hallmark of optimal test development/performance (Embretson & Reise, Reference Embretson and Reise2000; Reise & Waller, Reference Reise and Waller2009) because it ensures broad coverage of the underlying latent trait continuum and can be used to assess the trait more adequately across an entire population. Including criteria with a range of observed severities also allows for systematic investigations of particular symptoms of disorder that may be differentially diagnostic for particular groups of individuals, facilitating targeted interventions that isolate problematic cognitions and behaviors. However, others (Dawson et al. Reference Dawson, Saha and Grant2010) have suggested that individual AUD criteria severities may not confer much additional precision compared with criteria counts in determining overall disorder severity. However, we note that these suggestions are based upon analyses of a single study.
To date there has been no systematic investigation of the consistency (i.e. reliability) of the relative severities of criteria within a given disorder across studies. That is, we do not know the degree to which a criterion that is identified as severe compared with other criteria consistently surfaces as severe across repeated investigations with different study characteristics. If consistency is high then there would be confidence in the generalizability of findings for individual criteria across investigations.
However, to the extent to which consistency is low and is not accounted for by systematic differences between study characteristics, between-study variability in estimated criteria severities may be random. Such a situation would have profound implications for epidemiological and clinical studies of psychiatric disorders employing polythetic criteria. First, it indicates that even if two studies using standardized instruments found comparable prevalence rates of, say, AUD, this ostensible consistency may be illusory in that the symptom profiles of those diagnosing could be quite different despite being drawn from the same population. In such a case it would not be reasonable to conclude replicability, except in a superficial sense. Second, it also suggests that we should expect little gain in weighting criteria by their individual severities over simple criteria counts (Dawson et al. Reference Dawson, Saha and Grant2010) and that a given criteria set is not equipped to distinguish individuals across the continuum of the population distribution. Furthermore, it would suggest that previous investigations that have found differences in criteria severities as a function of age, gender, race, socio-economic status (SES), diagnostic time-frame and clinical diagnosis (see Table 1) may not be generalizable.
Table 1. Descriptive characteristics and median Spearman correlations between IRT criteria thresholds from published investigations

IRT, Item response theory; NESARC, National Epidemiological Study on Alcohol and Related Conditions; AUDADIS-IV, Alcohol Use Disorder and Associated Disabilities Interview Schedule-IV; NLAES, National Longitudinal Alcohol Epidemiologic Study; WHO/ISBRA, World Health Organization/International Society on Biomedical Research Collaborative Study; NSMHWB, National Survey of Mental Health and Well-Being (Australia); CIDI, Composite International Diagnostic Interview; COGA, Collaborative Study on the Genetics of Alcoholism; SSAGA, Semi-Structured Assessment for the Genetics of Alcoholism; DUI, driving under the influence; SAM, Substance Abuse Module; NSDUH, National Survey of Drug Use and Health; SAMHSA, Substance Abuse and Mental Health Services Administration; Thai-NMH Survey, Thai National Mental Health Survey; MINI-Thai, Mini International Neuropsychiatric Inventory, Thai module; MOAFTS, Missouri Adolescent Female Twin Study; MTFS, Minnesota Twin Family Study; SAGE, Study of Addiction: Genes and Environment; ED, emergency department, PRISM, Psychiatric Research Interview for Substance and Mental Disorders; DSM, Diagnostic and Statistical Manual of Mental Disorders; SCID, Structured Clinical Interview for DSM-IV; VATSPSUD, Virginia Adult Twin Study of Psychiatric and Substance Use Disorders; SARD, Substance Abuse Research Demonstration.
a Spearman rank-order correlation. Values represent median correlations between reported threshold estimates. Values in parentheses represent the range of correlations across samples. Note that estimates are probably positively biased due to imposed constraints on severity parameters in articles where multiple subsamples were analysed and differential item functioning assessed.
b Past-year drinkers.
c We could not confirm the reported metric for the IRT parameters, but based on the description and software used an IRT parameterization seemed likely.
d ⩾12 Drinks in the past year and ever drank 5+ drinks on ⩾1 occasion.
e ⩾12 Drinks in the past year.
f Young adult (18–24 years) subsample only.
g Authors created a combined measure of interpersonal and legal problems criteria.
h College students.
i Age 50+ years.
j Non-college, age 18–25 years.
k Tolerance severity not reported.
l Adolescent and young adult drinkers (12–21 years) only.
m We selected the authors’ ‘once per month’ binge drinking criteria for comparison of the IRT thresholds. Using the other criteria resulted in trivially different associations.
n Combination of community, adjudicated and clinical individuals.
In contrast, if there is variability in criteria severities that is explained by particular aspects of an individual study (age, gender, etc.) then (1) the generalizability of the severities of the overall criteria set may be supported and robust to external factors, if consistency is high, and (2) the influence of those factors may be considered robust and generalizable and provide strong grounds for targeting particular criteria in different groups of individuals. With respect to this latter point, substantial prior research has argued that endorsement of individual criteria within AUD should and do differ systematically as a function of different factors. For example, in the progression from adolescence to young adulthood and extending into later adulthood, symptoms associated with physiological dependence are initially considerably more difficult to endorse (Martin et al. Reference Martin, Chung, Kirisci and Langenbucher2006, Reference Martin, Chung and Langenbucher2008) while those associated with psychosocial consequences are relatively easier to endorse (Martin et al. Reference Martin, Kaczynski, Maisto, Bukstein and Moss1995). This is consistent with developmental psychopathology perspectives in which behavioral problems associated with impaired control are characteristic of the adolescent life stage and part of a more general externalizing spectrum (e.g. Martin et al. Reference Martin, Langenbucher, Chung and Sher2014).
In comparison, more durable neuroadaptations to a chronic drinking pattern associated with addiction (e.g. withdrawal, craving) are expected to manifest later in life (Langenbucher & Chung, Reference Langenbucher and Chung1995), although much research on tolerance shows high rates in adolescents and young adults, possibly due to both developmental factors (Silveri & Spear, Reference Silveri and Spear2001) and problems assessing this construct via self-report (e.g. O'Neill & Sher, Reference O'Neill and Sher2000). Additionally, drinking-related social and health problems are likely to be more severe in adulthood owing to the various role occupancies (e.g. wage earner, spouse/partner, parent) that carry greater responsibilities, as well as the fact that the effects of alcohol exposure on certain types of organ damage (e.g. brain, liver) are cumulative and dose dependent (e.g. Mezey et al. Reference Mezey, Kolman, Diehl, Mitchell and Herlong1988; Smith & Riechelmann, Reference Smith and Riechelmann2004) and that aging itself may represent a vulnerability to alcohol-related toxicity (e.g. Oscar-Berman, Reference Oscar-Berman, Noronha, Eckardt and Warren2000). We note, however, that the developing brain may be especially sensitive to some kinds of alcohol-related insult (e.g. Jacobus & Tapert, Reference Jacobus and Tapert2013).
Similar examples can be observed with respect to gender, in which women are less likely to endorse criteria related to quantity and frequency of alcohol consumption such as tolerance and withdrawal (Harford et al. Reference Harford, Yi, Faden and Chen2009; Srisurapanont et al. Reference Srisurapanont, Kittiratanapaiboon, Likhitsathian, Kongsuk, Suttajit and Junsirimongkol2012), presumably due to differences in total body water and gastric alcohol metabolism (Baraona et al. Reference Baraona, Abittan, Dohmen, Moretti, Pozzato, Chayes, Schaefer and Lieber2001). Also, cultural differences in the consumption and availability of alcohol have been suggested to be differentially indicative of underlying disordered use (e.g. Borges et al. Reference Borges, Ye, Bond, Cherpitel, Cremonte, Moskalewicz, Swiatkiewicz and Rubio-Stipec2010; Srisurapanont et al. Reference Srisurapanont, Kittiratanapaiboon, Likhitsathian, Kongsuk, Suttajit and Junsirimongkol2012). These previous findings lead to the hypothesis that such factors will account for substantial variability in individual criteria severities across studies and that ignoring them may undermine global reliability estimates.
Although receiving little attention, another factor that may account for variability in criteria severities across studies is the diagnostic instrument employed to assess AUD criteria. Historically, prior to the advent of structured (and semi-structured) diagnostic interviews, psychiatric diagnosis was plagued with unreliability across clinicians, cultures and age groups, amongst other factors (Cooper et al. Reference Cooper, Kendell, Gurland, Sharpe and Copeland1972; Sartorius et al. Reference Sartorius, Shapiro and Jablensky1974; Aboraya et al. Reference Aboraya, Rankin, France, El-Missiry and John2006). Since then, the adoption of structured interviews, also known as the ‘operational revolution’, has been credited with dramatic improvements in the internal and re-test reliabilities of diagnostic interviews (i.e. within-test reliability). However, to the extent that there is limited generalizability across different interviews and samples (i.e. between-test reliability), it is difficult to compare results from different studies. This is especially critical given recent initiatives concerning the reproducibility of research findings across science as a whole (Nosek & Lakens, Reference Nosek and Lakens2013; Collins & Tabak, Reference Collins and Tabak2014; Makel & Plucker, Reference Makel and Plucker2014). While individual studies are capable of identifying factors such as gender, age and ethnicity that could have an impact on criterion severities, because studies rarely employ more than one diagnostic instrument at a time, meta-analysis across studies is needed to evaluate the contribution of diagnostic instrument to variability in criterion severity.
In the current investigation, we focus on the consistency of IRT-estimated criteria severities across studies of DSM AUD. We chose AUD because there is a well-developed literature applying IRT models to AUD diagnostic criteria across a variety of samples using different measurement instruments, whereas similar studies are considerably less common for other substance use disorders (Hasin et al. Reference Hasin, O'Brien, Auriacombe, Borges, Bucholz, Budney, Compton, Crowley, Ling, Petry, Schuckit and Grant2013) and personality and mood disorders. Recent research suggests that the consistency of AUD criteria severities across studies may be questionable due to factors as banal as survey content (Lane & Sher, Reference Lane and Sher2015). The purpose of this meta-analysis is to synthesize the findings of the relative severities of AUD criteria, to gauge the extent to which the influential literature on IRT studies of AUD is generalizable, and to identify factors that lead to inconsistencies in which criteria are estimated as more/less severe.
The specific research question we address leads to a different approach to meta-analysis than is typically employed because the current interest is not individual effect estimates and their variability across studies, but rather the consistency in the relative ordering of criterion severity estimates across studies. It is appropriate to characterize consistency across studies using an intraclass correlation coefficient (ICC; Shrout & Fleiss, Reference Shrout and Fleiss1979). However, since we are interested in factors that contribute to (in)consistency beyond the individual criteria themselves, we estimate generalized ICCs using generalizability theory (GT; Cronbach et al. Reference Cronbach, Gleser, Nanda and Rajaratnam1972; Brennan, Reference Brennan2001).
Method
Data sources and study selection
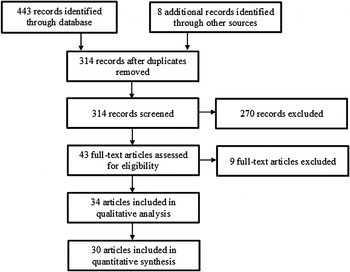
The PubMed/MEDLINE, Web of Science, ProQuest (including dissertation abstracts) and PsycINFO electronic databases were searched from 1 January 1977 up to 1 May 2015 using the search criteria ‘item response theory’ or ‘differential item function’, and ‘alcohol use disorder’, ‘alcohol abuse’ or ‘alcohol dependence’ (including variations of each phrase). The year 1977 was the year that the ninth revision of the International Classification of Diseases (ICD; World Health Organization, 1977, 1978) was released and subsumed the period in which the DSM and ICD began to assess AUDs using specific criteria sets. A total of 451 citations were identified by the search criteria, 314 of which were unique after duplicate records were removed. The abstracts for each of the 314 articles were screened for a focus on AUD and the use of IRT methodology. The IRT approach is often considered superior to a simple sum/average of indicator variables because it allows for the differential weighting of the indicators in the overall trait score. The individual weights estimated by an IRT analysis are known as the discriminations (i.e. slopes) and the estimated base rates of endorsement are known as the severities (i.e. thresholds). In the current investigation we focus specifically on severity parameters (see online Supplementary material for a brief discussion on criteria discriminations).
To be included in the meta-analysis, a paper needed to report discrimination and severity parameter estimates from an IRT analysis that assessed DSM-III, DSM-IIIR, DSM-IV, DSM-5, ICD-9 or ICD-10 AUD criteria (World Health Organization, 1977, 1978, 1992; American Psychiatric Association, 1980, 1987, 2000, 2013). We limited the search to two-parameter models (2PL; see online Supplementary material). See Fig. 1 for a flow diagram of the search and inclusion process. We identified a total of 34 published papers (30 unique samples) that performed IRTs on 49 different subsamples (see Table 1 and online Supplementary material). For clarity we refer to the 49 different IRT analyses conducted on a single sample within a given article or on multiple subsamples within the same article as individual ‘studies’ as they are the primary unit of measurement. Though our date range and consideration of various diagnostic systems were very inclusive, we note that the earliest study included in the meta-analysis was published in 2004 (Langenbucher et al. Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004), and all included studies assessed either DSM-IV or DSM-5 criteria sets, even if using instruments designed for ICD-9/10 criteria (e.g. Cherpitel et al. Reference Cherpitel, Borges, Ye, Bond, Cremonte, Moskalewicz and Swiatkiewicz2010).

Fig. 1. Flow diagram of identification and selection of studies.
Data extraction
The main outcome measures were the estimated severities for each criterion. The following additional information was extracted from all of the articles: authors, year of publication, sample characteristics (i.e. age and gender composition, clinical v. general population; we did not include SES, race or education in the analyses because there were very few studies that either reported sufficient information to be coded or split results by these groups), sample size, diagnostic instrument, diagnosis time-frame, number of criteria assessed, and reporting metric (unstandardized, standardized, IRT parameterized; see online Supplementary material). Two independent raters systematically parsed each article and coded the aforementioned variables. Agreement for the coding of criteria severities and discriminations was nearly perfect (ICCs ranged from 0.98 to 1.00). Agreement for the sample descriptive information was very good to excellent (the range for κ was 0.86 to 1.00; see online Supplementary material for additional details). Age was categorized into five groups (<18 years, primarily between 18–30 years, primarily between 30–50 years, >50 years, representative of the population 18 years or older), gender into five groups (exclusively men, primarily men, approximately equal men and women, primarily women, exclusively women), population into three groups (clinical, general population, a combination of clinical and general population), instrument into seven groups [Alcohol Use Disorder and Associated Disabilities Interview Schedule (AUDADIS), Composite International Diagnostic Interview (CIDI), Semi-Structured Assessment for the Genetics of Alcoholism (SSAGA), Substance Abuse and Mental Health Services Administration (SAMHSA), Psychiatric Research Interview for Substance and Mental Disorders (PRISM), Structured Clinical Interview for DSM-III-R (SCID), Other; Spitzer & Williams, Reference Spitzer and Williams1985; Bucholz et al. Reference Bucholz, Cadoret, Cloninger, Dinwiddie, Hesselbrock, Nurnberger, Reich, Schmidt and Schuckit1994; World Health Organization, 1997; Grant et al. Reference Grant, Dawson, Stinson, Chou, Kay and Pickering2003; Hasin et al. Reference Hasin, Samet, Nunes, Meydan, Matseoane and Waxman2006; Substance Abuse and Mental Health Services Administration, 2006], and time-frame into two groups (current, lifetime). When there was disagreement the two coders and first author (S.P.L.) jointly reviewed the article to resolve inconsistencies. Table 1 lists the relevant information for each of the included publications.
Data analysis
We calculated a traditional consistency-based ICC for any single randomly chosen study [i.e. ICC(3,1)] using a two-way mixed design in which criteria (treated as a fixed factor) was crossed with each individual study (treated as a random factor; Shrout & Fleiss, Reference Shrout and Fleiss1979). However, this approach is limited in that it cannot accommodate unbalanced designs (i.e. not all studies assessed the same criteria) and resulting missing data. We therefore opted for a GT approach. Given that different investigations used different samples of individuals where underlying severity is expected to be different (e.g. representative v. clinical populations) we performed all analyses on the raw severity estimates as well as on severity estimates that were standardized within study in order to eliminate systematic variance due to mean differences in criteria severities across studies. Doing so yielded the same pattern of results (see online Supplementary material). The basic GT model is the same analysis of variance model used to generate traditional ICCs (equation 1),
 $$P_{cs} = \mu + C_c + S_s + e_{cs} $$
$$P_{cs} = \mu + C_c + S_s + e_{cs} $$
Here, P cs is the severity parameter estimate for criterion, c, from study, s; μ is the grand mean for all severity parameter estimates. C c is the tendency for a criterion to generally be more or less severe across samples, and S s is the tendency for a study s to produce higher or lower severities across criteria. Variance components are estimated for this model using a multilevel model in which random effects are estimated for criterion (C c ) and study (S s ) using restricted maximum likelihood estimation. The analog to the traditional ICC(3,1) where the interest is in the reliability of the estimated severity for a fixed criterion set for any randomly selected investigation is then (Cranford et al. Reference Cranford, Shrout, Iida, Rafaeli, Yip and Bolger2006):
 $$R_{1F} = \displaystyle{{\sigma _{CRITERION}^2} \over {\sigma _{CRITERION}^2 + \sigma _{ERROR}^2}} $$
$$R_{1F} = \displaystyle{{\sigma _{CRITERION}^2} \over {\sigma _{CRITERION}^2 + \sigma _{ERROR}^2}} $$
We then constructed an expanded GT analysis that estimated additional variance components for diagnostic instrument, diagnosis time-frame, sample type, gender and age, as well as their interactions with criterion (equation 3),
 $$\eqalign{P_{csitnmag} =\, & \mu + C_c + S_s + I_i + T_t + N_n + M_m + A_a + G_g \cr & + \left( {CI} \right)_{ci} \,+\, \left( {CT} \right)_{ct} \,+\, \left( {CN} \right)_{cn} \,+\, \left( {CM} \right)_{cm} \,+\, \left( {CA} \right)_{ca} \cr & + e_{csitnmag}} $$
$$\eqalign{P_{csitnmag} =\, & \mu + C_c + S_s + I_i + T_t + N_n + M_m + A_a + G_g \cr & + \left( {CI} \right)_{ci} \,+\, \left( {CT} \right)_{ct} \,+\, \left( {CN} \right)_{cn} \,+\, \left( {CM} \right)_{cm} \,+\, \left( {CA} \right)_{ca} \cr & + e_{csitnmag}} $$
In this model P csitnmag is the severity parameter estimate for criterion, c, from study, s, where study was indexed by using a specific instrument (i), measuring AUD diagnosis on a current or lifetime time-frame (t), assessing clinical or non-clinical individuals (n), containing primarily male/female (m) and younger/older (a) participants, and being part of a group of studies that used the same or a partially overlapping sample (g). μ, C c and S s are as above but now we include effects for instrument (I i ), diagnosis time-frame (T t ), sample population (N n ), gender composition (M m ), age group (A a ) and being part of a group of studies that used overlapping samples (G g ). Importantly, we include two-way interaction terms between criterion and instrument, time-frame, sample population, gender and age as these may be systematic sources of variability across investigations. These interactions are analogous to moderators in traditional meta-analysis. The corresponding ICC(3,1), given that we are interested in the consistency of criterion severities for a single randomly selected study that is not due to instrument, time-frame, population, gender or age, is:
 $$R_{1R} = \displaystyle{{\sigma _{CRITERION}^2} \over {\left( \matrix{\sigma _{CRITERION}^2 + \sigma _{CRITERION{^\ast}INSTRUMENT}^2 \hfill \cr +\, \sigma _{CRITERION{^\ast}TIMEFRAME}^2 + \sigma _{CRITERION{^\ast}CLINICAL}^2 \hfill \cr+ \,\sigma _{CRITERION{^\ast}GENDER}^2 + \sigma _{CRITERION{^\ast}AGE}^2 + \sigma _{ERROR}^2 \hfill} \right)}}$$
$$R_{1R} = \displaystyle{{\sigma _{CRITERION}^2} \over {\left( \matrix{\sigma _{CRITERION}^2 + \sigma _{CRITERION{^\ast}INSTRUMENT}^2 \hfill \cr +\, \sigma _{CRITERION{^\ast}TIMEFRAME}^2 + \sigma _{CRITERION{^\ast}CLINICAL}^2 \hfill \cr+ \,\sigma _{CRITERION{^\ast}GENDER}^2 + \sigma _{CRITERION{^\ast}AGE}^2 + \sigma _{ERROR}^2 \hfill} \right)}}$$
The five interaction effects with criterion are included as sources of variance in the denominator because, while in the classic case these effects are assumed to be zero and equation 4 degenerates to equation 2, there may be genuine variation in those components that should be considered random if the interest is purely in absolute ordering of criteria across investigations.
Results
Fig. 2 a depicts the raw severity estimates plotted for each IRT analysis with criteria ordered by their median ranking across investigations. Fig. 2 b shows the same data but with criteria severities standardized within study to more clearly illustrate the reliability across studies and the different sources of systematic unreliability. The plots reveal considerable variability in severities across the different samples, even when standardized; but there is a systematic linear increase (especially in the standardized case) indicative of some degree of reliability. However, as highlighted by the different line patterns, indicating instrument type, line shading, indicating measurement time-frame, and markers, indicating sample composition, visually there appears to be systematic differences due to instrument, time-frame and sample composition.

Fig. 2. Raw (a) and standardized (b) thresholds for Diagnostic and Statistical Manual of Mental Disorders (DSM) alcohol use disorder criteria for the 49 studies. IRT, Item response theory; AUDADIS, Alcohol Use Disorder and Associated Disabilities Interview Schedule; CIDI, Composite International Diagnostic Interview; SAMHSA, Substance Abuse and Mental Health Services Administration; SSAGA, Semi-Structured Assessment for the Genetics of Alcoholism.
Table 1 presents the median Spearman rank-order correlation and the range between each study and all of the others (see online Supplementary material for full bivariate table). Table 2 shows the estimated variance components for the basic (model 1) and expanded (model 2) models. First, we note that the ICC estimate for the reliability of criteria severities for any randomly selected study using a two-way mixed model is 0.16, with an associated 95% confidence interval (CI) of 0.06–0.56 (Shrout & Fleiss, Reference Shrout and Fleiss1979). The parallel estimate and corresponding 95% bootstrapped CI from the multilevel model (model 1), which can accommodate all available data, was 0.27 (95% CI 0.24–0.29). However, when we fit the expanded model, the estimated ICC is reduced to 0.18 (95% CI 0.15–0.21). This is due in part to systematic variance in criteria severities that is associated with particular instruments (σ 2 = 0.09, s.e. = 0.02, p < 0.001), the age range of the participants (σ 2 = 0.07, s.e. = 0.02, p < 0.001) and measurement of AUD in clinical, population-based or mixed samples [σ 2 = 0.02, s.e. = 0.01, p = 0.068; see Higgins et al. (Reference Higgins, Thompson, Deeks and Altman2003) for interpreting significance of random effects in meta-analysis (suggested cut-off p < 0.10)]. Differences in criteria severities due to diagnosis time-frame and gender composition were not observed (p's > 0.215). The online Supplementary material contains additional analyses in which variance components are estimated on standardized data and where criteria severities are weighted by the relative size of a sample across included studies. Overall, standardizing (z) and weighting (w) increase the estimates of consistency, but estimates are still quite low (ICC w = 0.28; ICC z = 0.20; ICC wz = 0.26), and systematic instrument, diagnostic sample and age effects are still observed.
Table 2. Variance component estimates for basic and expanded models

s.e., Standard error; ICC, intraclass correlation; CI, confidence interval.
a Variance component could not be estimated.
b CIs were calculated using 1000 bootstrapped resamples.
While the major findings of this study are the generalizability coefficients presented above, which demonstrate the overall poor consistency of the relative severities of AUD criteria across the published literature and the large, systematic effects associated with both the diagnostic instrument employed and age, it is useful to isolate those criteria that tend to produce highly replicable relative severities and those that show more variation. Examining the random effects of which criteria are significantly more/less severe than the average severity across studies (σ 2 = 0.07, s.e. = 0.05, p = 0.087), only tolerance (b = −0.42, p = 0.021) and legal problems (b = −0.39, p = 0.041) were consistently significantly less and more severe criteria, respectively. The associated random-effects estimates from the criterion × instrument interaction indicated that many of the observed differences were localized to three instruments. Of the 84 random-effect estimates for the criterion × instrument interaction (12 criteria × 7 instruments), 13 reached significance (p < 0.10). Of those, five were associated with the AUDADIS, with withdrawal (b = −0.44, p = 0.015), hazardous use (b = −0.40, p = 0.032) and quitting/cutting down (b = −0.34, p = 0.057) estimated as less severe criteria than in the average study, and legal problems (b = 0.44, p = 0.041) and giving up important activities (b = 0.40, p = 0.029) estimated as more severe. In the SSAGA, tolerance (b = −0.37, p = 0.054) and larger/longer (b = −0.34, p = 0.073) were less severe while withdrawal (b = 0.54, p = 0.005) and time spent (b = 0.43, p = 0.026) were more severe. In the SAMHSA time spent (b = −0.49, p = 0.007) was less severe than in the average study, while larger/longer (b = 0.69, p < 0.001) and quitting/cutting down (b = 0.42, p = 0.023) were more severe. Lastly, time spent (b = 0.41, p = 0.029) was a more severe criterion for studies using other, survey specific, instruments.
While the random-effect variance of sample composition (i.e. clinical, mixed, population-based) was significant, there were no individual criteria that were significantly associated with greater/less severity for different types of samples. In contrast, for the 60 individual random-effect estimates for differences in criteria severities depending on age group (12 criteria × 5 age groups), seven were statistically significant. Studies that assessed adolescents had a tendency to find social problems as a less severe criterion (b = −0.33, p = 0.066) and quitting/cutting down as a more severe criterion (b = 0.52, p = 0.002). Studies that predominantly assessed young adults were more likely to find that tolerance (b = −0.61, p < 0.001) and time spent (b = −0.33, p = 0.046) were less severe criteria, while withdrawal (b = −0.37, p = 0.054) was a more severe criterion than average. Lastly, in samples that assessed representative populations quitting/cutting down was a less severe criterion (b = −0.32, p = 0.053) and tolerance was a more severe criterion (b = 0.28, p = 0.084).
Discussion
The introduction of structured and semi-structured diagnostic interviews tied to modern diagnostic criteria such as the DSM-III (American Psychiatric Association, 1980) was spurred by seminal studies showing the unreliability of psychiatric diagnosis such as the International Pilot Study of Schizophrenia (Sartorius et al. Reference Sartorius, Shapiro and Jablensky1974). While more explicit diagnostic criteria and interviews tailored to assess them represented a major advance over the less structured assessments and vaguer diagnostic systems that characterized the pre-modern era, there has been very little attention paid to the implications of generalizability of the diagnostic criteria themselves across interviews and operationalizations more generally. The validation work that has been done (both within- and between interviews) has focused almost exclusively on diagnosis or symptom count (e.g. Grant et al. Reference Grant, Harford, Dawson, Chou and Pickering1995, Reference Grant, Dawson, Stinson, Chou, Kay and Pickering2003, 2015; Chatterji et al. Reference Chatterji, Saunders, Vrasti, Grant, Hasin and Mager1997; Hasin et al. Reference Hasin, Carpenter, McCloud, Smith and Grant1997; Vrasti et al. Reference Vrasti, Grant, Chatterji, Üstün, Mager, Olteanu and Badoi1998; Canino et al. Reference Canino, Bravo, Ramírez, Febo, Rubio-Stipec, Fernández and Hasin1999; Ruan et al. Reference Ruan, Goldstein, Chou, Smith, Saha, Pickering, Dawson, Huang, Stinson and Grant2008), which ignores which criteria specifically are judged as present or absent. Therefore, it is possible for two interviews to be highly reliable in that they identify the same individuals as having a disorder, but the actual criteria being met are different.
Indeed, our primary finding is that the AUD criteria set evidences very low levels of consistency of criterion severity from one study to the next, and a considerable amount of this inconsistency appears attributable to the specific assessment employed and the age groups assessed. Thus, much of the inconsistency is not random and is a function of systematic study characteristics. Some symptoms such as withdrawal are highly severe symptoms by some assessments (e.g. SSAGA) and ‘middling’ severity symptoms by other assessments (e.g. AUDADIS). As such, we cannot make strong, generalizable statements about which criteria are intrinsically and universally likely to be more or less severe based upon the extensive, extant literature. However, the results do suggest a degree of local generalizability when such factors are taken into account. We do not view this lack of consistency as an inherent problem of the diagnostic systems themselves (DSM-IV and DSM-5) as much as the underappreciated issue of the operationalization of these criteria in research interviews (and by extension, in clinical practice where even greater variability of assessment may be likely) and the more appreciated issues associated with assessing different populations using the same criteria.
The highly significant criterion × instrument interaction is particularly notable because it suggests that although all of the AUD instruments are based on the same set of criteria definitions, subtle, and what otherwise might be considered trivial differences in wording or administration lead to marked differences in the level and ordering of criteria. Previous research has demonstrated that even ostensibly trivial changes in a diagnostic interview can lead to wildly different lifetime prevalence estimates of AUD (Vergés et al. Reference Vergés, Littlefield and Sher2011). The findings here suggest an even more serious concern, that the findings of a strong positive manifold among diagnostic criteria robustly found across instruments and samples and that support a unidimensional structure (Hasin et al. Reference Hasin, O'Brien, Auriacombe, Borges, Bucholz, Budney, Compton, Crowley, Ling, Petry, Schuckit and Grant2013) represents only ‘skin deep’ replication of the latent structure of AUD. That is, there is consistency in that only one latent factor is required to explain covariances among criteria, but a lack of consistency in the structure of that factor. This indicates low generalizability of the form of diagnosis when study features are ignored, especially among those who diagnose at low and moderate levels of DSM-5 diagnostic severity. This issue is potentially highly important if one is interested in specific criteria endorsements to guide treatment selection, such as those central to theories of physiological dependence (e.g. withdrawal, craving; Robinson & Berridge, Reference Robinson and Berridge1993; Langenbucher et al. Reference Langenbucher, Martin, Labouvie, Sanjuan, Bavly and Pollock2000). This is similarly important from a research perspective in apportioning variance to individual criteria due to exogenous variables or in considering alternative models of diagnosis (e.g. network models; Cramer et al. Reference Cramer, Waldorp, van der Maas and Borsboom2010; Borsboom & Cramer, Reference Borsboom and Cramer2013).
More expected is the highly significant criterion × age group interaction. A number of researchers have been interested in the structure of AUD in younger individuals and how if differs from adults (see Table 1). Some have considered the systematic differences in endorsement of specific criteria between adolescents and young adults to be due to measurement error, namely tolerance and withdrawal (Caetano & Babor, Reference Caetano and Babor2006). Consistent with those interpretations, our analysis suggests that tolerance is a lower threshold criterion for young people to endorse. However, contrary to those findings, ours suggest that withdrawal is on average a higher threshold criterion for young people. One way to reconcile these opposing findings, which was similarly advanced by Caetano & Babor (Reference Caetano and Babor2006), is by considering the diagnostic instrument used to assess the criteria. They suggest, as we find, that withdrawal is a relatively easy criterion to endorse in the AUDADIS compared with other instruments. Also, a majority of the adolescents included in the current meta-analysis completed instruments (e.g. SSAGA, SAMHSA) where withdrawal is a higher severity criterion that is more difficult to endorse across all age groups.
Other researchers suggest that the differing criteria endorsements as a function of age can be explained by developmental factors relating to various life role transitions (Christo, Reference Christo1998; Martin et al. Reference Martin, Chung and Langenbucher2008, Reference Martin, Sher and Chung2011, 2014). Our results are similarly consistent with these interpretations, and suggest that if researchers and clinicians explicitly (or implicitly) account for the observation that different symptoms carry different meaning for underlying severity depending on a participant's/patient's age (i.e. withdrawal is more severe for younger individuals while social consequences are more severe for older adults), then the generalizability of overall diagnoses should be increased. Indeed, if such age effects were to be explicitly estimated in research studies, and we assume that such accommodations can be made in the clinic, the estimated reliability coefficient in our analysis would increase from 0.18 to 0.36. However, we note that overall generalizability would still be low. If we in addition were able to account for differences associated with criteria endorsement for individuals belonging to various clinical subpopulations compared with those who are generally healthy, the generalizability estimate would further increase to 0.41, but is still low. However, substantively these effects can still be meaningful. Adjusting for and otherwise understanding that endorsement of certain criteria confer different information about where individuals are in the progression of alcohol use problems, as indexed by where they are likely to be in their drinking career and if they are probably experiencing problems due to other related causes, is likely to still be of substantial interest in guiding further research and practice with respect to treatment.
We did not observe differences in the severities of individual criteria as a function of gender or diagnosis time-frame, both of which could be hypothesized in light of previous research (Harford et al. Reference Harford, Yi, Faden and Chen2009; Shmulewitz et al. Reference Shmulewitz, Keyes, Beseler, Aharonovich, Aivadyan, Spivak and Hasin2010). However, we do not necessarily view this as a failure to replicate. A majority of the studies included in our analysis contained approximately equal numbers of men and women (n = 25, 51%) and assessed past-year AUD (n = 31, 63%), resulting in relatively little variability compared with the other moderators. Furthermore, these factors were highly correlated with the particular study they were associated with [e.g. National Epidemiological Study on Alcohol and Related Conditions (NESARC), National Survey of Drug Use and Health (NSDUH)], leading to little unique variability. Thus, the current analysis is not ideally suited for identifying such effects based on the relatively small sample of available IRT studies of AUD and the largely within-study nature of these factors – the latter of which is common to all meta-analyses barring access to raw data from individual studies (Cooper et al. Reference Cooper, Hedges and Valentine2009).
Substance use disorders and AUDs in particular have seen the most use of IRT in assessing criteria severity (Langenbucher et al. Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004; Hasin et al. Reference Hasin, O'Brien, Auriacombe, Borges, Bucholz, Budney, Compton, Crowley, Ling, Petry, Schuckit and Grant2013). Personality, mood, anxiety and psychotic disorders have been explored less extensively, but to the extent to which there is variability in sample characteristics or assessment instrument, we might expect the same low levels of agreement in criteria severity that we find with respect to AUDs.
One strategy for mitigating criteria severity inconsistency is through the use of integrative data analysis techniques (IDA; Curran et al. Reference Curran, Hussong, Cai, Huang, Chassin, Sher and Zucker2008; Curran & Hussong, Reference Curran and Hussong2009; Hofer & Piccinin, Reference Hofer and Piccinin2009). Such methods allow for underlying overlap between instruments from different investigations to be estimated and compared in light of their structural differences. These approaches could be used to optimize model estimation of severity parameters such that they are maximally consistent across samples. For such an approach to be successful, there needs to be sufficient overlap with respect to the specific wording of items, probes of items, and thresholds for determining whether or not a given symptom fulfills the criterion. Witkiewitz et al. (Reference Witkiewitz, Hallgren, O'Sickey, Roos and Maisto2016) recently conducted an IDA of data from four alcohol treatment studies, integrating data across four diagnostic instruments, and even after harmonizing across instruments identified differences in symptom endorsement as a function of age, treatment status and gender. Their findings suggest that studies utilizing different diagnostic interviews/instruments can be harmonized to maximize generalizability of diagnosis symptom structure, and underscore the importance of taking demographic factors into account (e.g. age, gender, culture) in making general statements about individual symptom severity.
We investigated why the SSAGA may have exhibited such different criterion severity ordering compared with the other instruments. We observed that for a number of criteria (e.g. withdrawal), symptoms must have occurred at least three times in the past year, whereas other instruments (e.g. AUDADIS) require that it only occurred more than once to qualify for endorsement of the criteria. This could have resulted in withdrawal and other criteria obtaining relatively higher thresholds/severities in the IRT analyses compared with criteria that did not, because they were incrementally harder to endorse. Additionally, another reason why withdrawal may be more severe in the SSAGA relative to, say, the AUDADIS is because it stipulates that individuals must have experienced the items ‘for most of the day for 2 days or longer’. Other instruments such as the AUDADIS and CIDI do not require that the items be experienced for such a long duration. We also note that steps are taken within the SSAGA to exclude experiences of hangover from qualifying towards withdrawal with fewer safeguards in the AUDADIS (Grant et al. Reference Grant, Dawson, Stinson, Chou, Kay and Pickering2003). We withhold judgment as to which operationalization is preferred, but rather note that resolution of these issues should improve the generalizability of findings across all studies. The analyses presented here are useful as exploratory tools to identify where differences between instruments, age composition and other factors might lead to differences in which criteria are deemed more/less severe.
One consideration that bears mention is that some criteria, in a classical test theory sense (Crocker & Algina, Reference Crocker and Algina1986), may inherently be more reliable in the way they are measured by virtue of how many items are used to assess them. This can also be the case for overall criteria sets within instruments. Furthermore, while the end result is a binary criterion endorsement (not a graded criterion score), such additional assessments (and qualification questions used by some instruments) can be used to provide resolution to criteria measurement. We were unable to assess the possible influence of these features given that individual criterion assessment is highly confounded within instrument, though both may explain part of the instrument variability we observed.
In general, we find that which AUD criteria are more or less likely to be endorsed is not consistent across studies. This is critical given the preferential focus on certain criteria in theoretical models and intervention research (e.g. Langenbucher et al. Reference Langenbucher, Martin, Labouvie, Sanjuan, Bavly and Pollock2000; De Bruijn et al. Reference De Bruijn, Van Den, De Graaf and Vollebergh2005). While factors such as age and type of sample explain part of this inconsistency (Caetano & Babor, Reference Caetano and Babor2006; Martin et al. Reference Martin, Chung and Langenbucher2008, Reference Martin, Sher and Chung2011, 2014), the typically overlooked factor of diagnostic instrument/interview, which is typically assumed to be essentially interchangeable, accounts for a majority of explainable unreliability.
While traditional psychiatric diagnosis is being actively challenged by alternative models such as the Research Domain Criteria (RDoC) initiative [National Institute of Mental Health, 2008; see also Litten et al. (Reference Litten, Ryan, Falk, Reilly, Fertig and Koob2015) for an extension of the RDoC framework to addictive disorders], future research should be aware of how instrument properties may account for observed results (Sher, Reference Sher2015). The issues we identify regarding instrument are not necessarily limited to traditional diagnosis but can extend to dimensional assessments as well.
With the results from our analysis in mind, if researchers were to a priori adjust for the systematic differences in criteria severities due to all of the factors we modeled (most notably instrument), the estimate of the reliability of criteria severities increases from 0.18 to 0.67, a substantial increase that suggests that the generalizability of their findings may be reasonable. However, the problem with diagnostic instruments remains because criterion operationalization had the largest impact on criteria severities, and which operationalization is preferred is an open and understudied topic.
Conclusion
There are strong reasons to question the broad generalizability of criteria severities from any individual IRT study of AUD, and, likely, other psychiatric disorders, without taking into account systematic factors. Some factors have been increasingly studied (e.g. age, gender) while others may be less recognized but even more important (e.g. instrument). The fact that there is considerable variability associated with particular diagnostic instruments highlights the need for further standardization of how diagnostic items are operationalized and administered. To the extent that these measurement concerns are rooted in assessment and sampling variability, even ostensibly alternative approaches to diagnosis (e.g. RDoC; National Institute of Mental Health, 2008) need to be attentive to underlying structural validity concerns.
Supplementary material
For supplementary material accompanying this paper visit http://dx.doi.org/10.1017/S0033291716000404
Acknowledgements
S.P.L. has had full access to the data and conducted the analyses under the supervision of K.J.S. and D.S. The project described was supported by grants R01AA024133, K05AA01724 and T32AA013526 from the National Institute on Alcohol Abuse and Alcoholism to K.J.S. and grant R01AA023248 from the National Institute on Alcohol Abuse and Alcoholism to D.S. The content is solely the responsibility of the authors and does not necessarily represent the official view of the National Institute on Alcohol Abuse and Alcoholism.
Declaration of Interest
None.