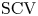
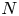
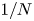



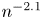
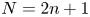

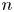
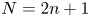

1. Introduction
Concentrated matrix exponential (CME) distributions can be effectively used to approximate distributions with low squared coefficient of variation or to approximate deterministic delay. Compared with phase-type (PH) distributions, where the squared coefficient of variation ( $\mathrm {SCV}$) of an order
$\mathrm {SCV}$) of an order  $N$ distribution is not less than
$N$ distribution is not less than  $1/N$, the
$1/N$, the  $\mathrm {SCV}$ of an order
$\mathrm {SCV}$ of an order  $N$ CME with complex eigenvalues can be less than
$N$ CME with complex eigenvalues can be less than  $n^{-2.1}$, for odd
$n^{-2.1}$, for odd  $N=2n+1$ orders [Reference Horváth, Horváth and Telek10]. Recently, it has been shown that, due this property, CME distributions with complex eigenvalues can be used for efficient numerical inverse Laplace transformation (NILT), such that the Laplace transform function is evaluated at complex points [Reference Horváth, Horváth, Al-Deen Almousa and Telek9].
$N=2n+1$ orders [Reference Horváth, Horváth and Telek10]. Recently, it has been shown that, due this property, CME distributions with complex eigenvalues can be used for efficient numerical inverse Laplace transformation (NILT), such that the Laplace transform function is evaluated at complex points [Reference Horváth, Horváth, Al-Deen Almousa and Telek9].
In this paper, we focus on CME distributions with real eigenvalues only (CME-R distributions), which we also apply for NILT with real values only. This problem was already considered in [Reference Airapetyan and Ramm3,Reference Gaver6] and the importance of such NILT methods has been recognized also in the field of nuclear magnetic resonance spectroscopy [Reference Koskela, Kilpeläinen and Heikkinen12,Reference Nishiyama, Frey, Mukasa and Utsumi13], where the Laplace domain description is available only along the real axes. For the investigation of CME-R distributions, we follow a similar approach as in [Reference Horváth, Horváth and Telek10]: We consider a special subset of CME distributions whose eigenvalues are real and whose non-negativity is ensured by construction, and we derive a formula for computing the  $\mathrm {SCV}$ efficiently.
$\mathrm {SCV}$ efficiently.
Using this efficient computational method for the  $\mathrm {SCV}$ based on the parameters of the considered subset of matrix exponential distributions, in the first part of the paper, we introduce two optimization procedures for finding CME-R distributions. For orders up to
$\mathrm {SCV}$ based on the parameters of the considered subset of matrix exponential distributions, in the first part of the paper, we introduce two optimization procedures for finding CME-R distributions. For orders up to  $n=120$, we optimize all
$n=120$, we optimize all  $n$ model parameters, and for higher orders we formulate a heuristic optimization problem which—independently of the order—optimizes seven parameters.
$n$ model parameters, and for higher orders we formulate a heuristic optimization problem which—independently of the order—optimizes seven parameters.
In the second part of the paper, we discuss the application of CME-R distributions for NILT. Similar to the CME (with complex eigenvalues)-based NILT method [Reference Horváth, Horváth, Al-Deen Almousa and Telek9], our method, referred to as a CME-R method, also belongs to the Abate–Whitt framework [Reference Abate and Whitt1], however, an adaptation step is required for CME-R distributions to be used for NILT according to the Abate–Whitt framework.
The main findings of the paper are as follows:
• The
 $\mathrm {SCV}$ of CME-R can be as low as $\sim n^{-1.85}$, which is only slightly higher than the $\mathrm {SCV}$ of CME ($\sim n^{-2.1}$) for odd $N=2n+1$ orders.
$\mathrm {SCV}$ of CME-R can be as low as $\sim n^{-1.85}$, which is only slightly higher than the $\mathrm {SCV}$ of CME ($\sim n^{-2.1}$) for odd $N=2n+1$ orders.• The problem of NILT transformation with real arithmetic has been considered many times, for example [Reference Airapetyan and Ramm3,Reference Koskela, Kilpeläinen and Heikkinen12,Reference Nishiyama, Frey, Mukasa and Utsumi13]. One of the most efficient numerical methods for NILT with real arithmetic is the Gaver method [Reference Gaver6,Reference Stehfest14,Reference Valko and Abate15]. Compared with the Gaver method, on the one hand, the CME-R method is more sensitive numerically, but on the other hand, it is Gibbs oscillation free, gradually improving with the order, monotonicity and bound preserving. That is, when computing a probability from its Laplace transform description with the CME-R method, the result is always between zero and one, while the result computed by the Gaver method can be negative or larger than one.





The rest of the paper is organized as follows. We introduce the class of CME distributions with real eigenvalues and one of its subclass in Section 2. To find CME-R distributions with low  $\mathrm {SCV}$ a general and a heuristic optimization problem is introduced in Sections 3 and 4. A CME-R-based NILT method is presented in Section 5 and analyzed in Section 6.
$\mathrm {SCV}$ a general and a heuristic optimization problem is introduced in Sections 3 and 4. A CME-R-based NILT method is presented in Section 5 and analyzed in Section 6.
2. CME distributions with real eigenvalues
In this section, we give a general form for matrix exponential (ME) distributions with real eigenvalues and present a subclass of matrix exponential distributions which is non-negative by constriction. We also give an efficient calculation method for the moments (and thus the  $\mathrm {SCV}$) of ME distributions in this subclass.
$\mathrm {SCV}$) of ME distributions in this subclass.
Definition 1 Order  $N$ ME functions (referred to as ME(
$N$ ME functions (referred to as ME( $N$)) are given by
$N$)) are given by
 \begin{equation} f(t)=\mathbf{\alpha}e^{\mathbf{A}t}(-\mathbf{A})\mathbf{1}, \end{equation}
\begin{equation} f(t)=\mathbf{\alpha}e^{\mathbf{A}t}(-\mathbf{A})\mathbf{1}, \end{equation}where  $\mathbf {\alpha }$ is a real row vector of dimension
$\mathbf {\alpha }$ is a real row vector of dimension  $N$,
$N$,  $\mathbf {A}$ is a real matrix of dimension
$\mathbf {A}$ is a real matrix of dimension  $N\times N$, and
$N\times N$, and  $\mathbf {1}$ is the column vector of ones of dimension
$\mathbf {1}$ is the column vector of ones of dimension  $N$. Furthermore,
$N$. Furthermore,  $\mathbf {\alpha }$ is such that
$\mathbf {\alpha }$ is such that  $\mathbf {\alpha }\mathbf {1}>0$ and
$\mathbf {\alpha }\mathbf {1}>0$ and  $f(t)\geq 0$ for
$f(t)\geq 0$ for  $t\geq 0$.
$t\geq 0$.
Definition 2 Order  $N$ ME distributions are distributions whose probability density function (pdf) is an ME function
$N$ ME distributions are distributions whose probability density function (pdf) is an ME function  $f(t)$ such that
$f(t)$ such that  $\int _{t=0}^{\infty } f(t)\,\mathrm {d}t=1$.
$\int _{t=0}^{\infty } f(t)\,\mathrm {d}t=1$.
Definition 3 Order  $N$ PH distributions are distributions whose probability density function (pdf) is an ME function
$N$ PH distributions are distributions whose probability density function (pdf) is an ME function  $f(t)$ such that
$f(t)$ such that  $\alpha \geq 0$,
$\alpha \geq 0$,  $\mathbf {A}\mathbf {1}\leq 0$, the nondiagonal elements of matrix
$\mathbf {A}\mathbf {1}\leq 0$, the nondiagonal elements of matrix  $\mathbf {A}$ are non-negative and
$\mathbf {A}$ are non-negative and  $\int _{t=0}^{\infty } f(t)\,\mathrm {d}t=1$.
$\int _{t=0}^{\infty } f(t)\,\mathrm {d}t=1$.
When the ME distribution has only real eigenvalues (ME-R), the pdf in (1) can be rewritten as
 \begin{equation} f(t)= \sum_{i=1}^{\# \lambda} \sum_{j=1}^{\# \lambda_i} \gamma_{ij} t^{j-1} e^{-\lambda_i t}, \end{equation}
\begin{equation} f(t)= \sum_{i=1}^{\# \lambda} \sum_{j=1}^{\# \lambda_i} \gamma_{ij} t^{j-1} e^{-\lambda_i t}, \end{equation}where  $\# \lambda$ is the number of different eigenvalues,
$\# \lambda$ is the number of different eigenvalues,  $\# \lambda _i$ is the multiplicity of eigenvalue
$\# \lambda _i$ is the multiplicity of eigenvalue  $\lambda _i$, and
$\lambda _i$, and  $N= \sum _{i=1}^{\# \lambda } {\# \lambda _i}$ is the order of the distribution. In this representation, the
$N= \sum _{i=1}^{\# \lambda } {\# \lambda _i}$ is the order of the distribution. In this representation, the  $\gamma _{ij}$ coefficients are real and can be negative as well.
$\gamma _{ij}$ coefficients are real and can be negative as well.
Let  $\mu _i$ be the
$\mu _i$ be the  $i$th moment of the ME function, that is,
$i$th moment of the ME function, that is,
 \begin{equation} \mu_i=\int_{t=0}^{\infty}t^{i} f(t)\,\mathrm{d}t. \end{equation}
\begin{equation} \mu_i=\int_{t=0}^{\infty}t^{i} f(t)\,\mathrm{d}t. \end{equation}The squared coefficient of variation ( $\mathrm {SCV}$) of the ME function is
$\mathrm {SCV}$) of the ME function is
 \begin{equation} \mathrm{SCV}:=\frac{\mu_2\mu_0}{\mu_1^{2}}-1. \end{equation}
\begin{equation} \mathrm{SCV}:=\frac{\mu_2\mu_0}{\mu_1^{2}}-1. \end{equation} Unfortunately, the order  $N$ ME distribution with a minimal
$N$ ME distribution with a minimal  $\mathrm {SCV}$ is not known for
$\mathrm {SCV}$ is not known for  $N>2$. We refer to ME distributions with numerically minimized
$N>2$. We refer to ME distributions with numerically minimized  $\mathrm {SCV}$ as a concentrated ME (CME) distribution. CME distributions with complex eigenvalues have been investigated recently in [Reference Horváth, Horváth and Telek10]. Here, we examine CME distributions with real eigenvalues only (CME-R). Finding CME-R distributions requires the solution of the following constrained nonlinear optimization problem:
$\mathrm {SCV}$ as a concentrated ME (CME) distribution. CME distributions with complex eigenvalues have been investigated recently in [Reference Horváth, Horváth and Telek10]. Here, we examine CME distributions with real eigenvalues only (CME-R). Finding CME-R distributions requires the solution of the following constrained nonlinear optimization problem:
 \begin{align*} \min_{\substack{\# \lambda \in \{1,\ldots,N\},\# \lambda_i (i\in\{1,\ldots,\# \lambda\}), \\ \lambda_i (i\in\{1,\ldots,\# \lambda\}), \\ \gamma_{ij} (i\in\{1,\ldots,\# \lambda\},j\in\{1,\ldots,\# \lambda_i\})}} \quad & \textrm{SCV}(f(t))\\ \text{subject to}\quad & f(t) \geq 0,\quad \forall t\geq 0,\quad \sum_{i=1}^{\# \lambda} \# \lambda_i = N \end{align*}
\begin{align*} \min_{\substack{\# \lambda \in \{1,\ldots,N\},\# \lambda_i (i\in\{1,\ldots,\# \lambda\}), \\ \lambda_i (i\in\{1,\ldots,\# \lambda\}), \\ \gamma_{ij} (i\in\{1,\ldots,\# \lambda\},j\in\{1,\ldots,\# \lambda_i\})}} \quad & \textrm{SCV}(f(t))\\ \text{subject to}\quad & f(t) \geq 0,\quad \forall t\geq 0,\quad \sum_{i=1}^{\# \lambda} \# \lambda_i = N \end{align*}where the parameters define  $f(t)$ according to (2) and
$f(t)$ according to (2) and  $\textrm {SCV}(f(t))$ is the
$\textrm {SCV}(f(t))$ is the  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $f(x)$ according to (3) and (4).
$f(x)$ according to (3) and (4).
Unfortunately, it is rather difficult to check if  $f(t)$ satisfies the
$f(t)$ satisfies the  $f(t) \geq 0$ constraint for a given set of parameters and due to that, this optimization problem is very hard. Instead of the solution of this constrained optimization problem, we use a workaround approach, similar to the one in [Reference Horváth, Horváth and Telek10]. We restrict our attention to a specific subclass of the ME-R distributions, which is non-negative for
$f(t) \geq 0$ constraint for a given set of parameters and due to that, this optimization problem is very hard. Instead of the solution of this constrained optimization problem, we use a workaround approach, similar to the one in [Reference Horváth, Horváth and Telek10]. We restrict our attention to a specific subclass of the ME-R distributions, which is non-negative for  $t\geq 0$ by construction, and optimize the
$t\geq 0$ by construction, and optimize the  $\mathrm {SCV}$ only for that subset.
$\mathrm {SCV}$ only for that subset.
The subset of our interest, which was introduced already in [Reference Éltető, Rácz and Telek5], has the form
 \begin{equation} f_{n}(t)=c \prod_{i=1}^{n} (\lambda t-\tau_i)^{2} e^{-\lambda t}\quad \text{with } N=2n+1. \end{equation}
\begin{equation} f_{n}(t)=c \prod_{i=1}^{n} (\lambda t-\tau_i)^{2} e^{-\lambda t}\quad \text{with } N=2n+1. \end{equation}Using this subset, the optimization problem simplifies to
 \begin{equation} \min_{\tau_1, \ldots \tau_n} \textrm{SCV}(f_n(t)), \end{equation}
\begin{equation} \min_{\tau_1, \ldots \tau_n} \textrm{SCV}(f_n(t)), \end{equation}where the parameters define  $f_n(t)$ according to (5) and
$f_n(t)$ according to (5) and  $f_n(t)$ defines the
$f_n(t)$ defines the  $\mathrm {SCV}$ according to (4). We note that the
$\mathrm {SCV}$ according to (4). We note that the  $\mathrm {SCV}$ is insensitive to multiplication and scaling, that is,
$\mathrm {SCV}$ is insensitive to multiplication and scaling, that is,  $\textrm {SCV}(c_1 f_n(t c_2))=\textrm {SCV}(f_n(t))$, consequently the optimization problem is independent of
$\textrm {SCV}(c_1 f_n(t c_2))=\textrm {SCV}(f_n(t))$, consequently the optimization problem is independent of  $c$ and
$c$ and  $\lambda$. To simplify the discussion about the optimization of the
$\lambda$. To simplify the discussion about the optimization of the  $\mathrm {SCV}$, for the rest of this section we assume
$\mathrm {SCV}$, for the rest of this section we assume  $\lambda =c=1$.
$\lambda =c=1$.
Theorem 1 The  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $f_{n}(t)= \prod _{i=1}^{n} (t-\tau _i)^{2} e^{-t}$ is
$f_{n}(t)= \prod _{i=1}^{n} (t-\tau _i)^{2} e^{-t}$ is
 \begin{equation} \mathrm{SCV}=\frac{(\sum_{i=0}^{2n} a_{i} (i+2)!) (\sum_{i=0}^{2n} a_{i} i!)}{(\sum_{i=0}^{2n} a_{i} (i+1)!)^{2}}-1, \end{equation}
\begin{equation} \mathrm{SCV}=\frac{(\sum_{i=0}^{2n} a_{i} (i+2)!) (\sum_{i=0}^{2n} a_{i} i!)}{(\sum_{i=0}^{2n} a_{i} (i+1)!)^{2}}-1, \end{equation}where the  $a_i$ coefficients are the coefficients of the order
$a_i$ coefficients are the coefficients of the order  $2n$ polynomial
$2n$ polynomial
 \begin{equation} \prod_{i=1}^{n} (t-\tau_i)^{2} = a_{2n} t^{2n} +a_{2n-1} t^{2n-1} + \cdots + a_1 t + a_0. \end{equation}
\begin{equation} \prod_{i=1}^{n} (t-\tau_i)^{2} = a_{2n} t^{2n} +a_{2n-1} t^{2n-1} + \cdots + a_1 t + a_0. \end{equation}Proof. Using that  $\int _{t=0}^{\infty } t^{k} e^{- t} \,\mathrm {d}t = k!$ for
$\int _{t=0}^{\infty } t^{k} e^{- t} \,\mathrm {d}t = k!$ for  $k=\{0,1,\ldots \}$, we have
$k=\{0,1,\ldots \}$, we have
 \begin{equation} \mu_k=\int_{t=0}^{\infty} t^{k} f_n(t)\,\mathrm{d}t = \int_{t=0}^{\infty} t^{k} \sum_{i=0}^{2n} a_{i} t^{i} e^{- t} \,\mathrm{d}t = \sum_{i=0}^{2n} a_{i} (i+k)!, \end{equation}
\begin{equation} \mu_k=\int_{t=0}^{\infty} t^{k} f_n(t)\,\mathrm{d}t = \int_{t=0}^{\infty} t^{k} \sum_{i=0}^{2n} a_{i} t^{i} e^{- t} \,\mathrm{d}t = \sum_{i=0}^{2n} a_{i} (i+k)!, \end{equation}from which
 $$\mathrm{SCV}=\frac{\mu_2\mu_0}{\mu_1^{2}}-1=\frac{(\sum_{i=0}^{2n} a_{i} (i+2)!) (\sum_{i=0}^{2n} a_{i} i!)}{(\sum_{i=0}^{2n} a_{i} (i+1)!)^{2}}-1.$$
$$\mathrm{SCV}=\frac{\mu_2\mu_0}{\mu_1^{2}}-1=\frac{(\sum_{i=0}^{2n} a_{i} (i+2)!) (\sum_{i=0}^{2n} a_{i} i!)}{(\sum_{i=0}^{2n} a_{i} (i+1)!)^{2}}-1.$$Remark 1 The computation of the  $a_0,\ldots ,a_{2n}$ coefficients from
$a_0,\ldots ,a_{2n}$ coefficients from  $\tau _1, \ldots , \tau _n$ according to (8) is a nontrivial task. The following procedure implements this in a computationally efficient iterative way based on the following relation
$\tau _1, \ldots , \tau _n$ according to (8) is a nontrivial task. The following procedure implements this in a computationally efficient iterative way based on the following relation
 $$\prod_{i=1}^{n} (t-\tau_i)^{2} = \left(\prod_{i=1}^{n-1} (t-\tau_i)^{2}\right) (t^{2} -2 \tau_n t + \tau_n^{2}).$$
$$\prod_{i=1}^{n} (t-\tau_i)^{2} = \left(\prod_{i=1}^{n-1} (t-\tau_i)^{2}\right) (t^{2} -2 \tau_n t + \tau_n^{2}).$$ Let  $\mathbf {a}^{(n)}$ be the vector of the
$\mathbf {a}^{(n)}$ be the vector of the  $a_i$ coefficients, that is,
$a_i$ coefficients, that is,  $\mathbf {a}^{(n)}=[a_{0},a_{1},\ldots ,a_{2n}]$. Then,
$\mathbf {a}^{(n)}=[a_{0},a_{1},\ldots ,a_{2n}]$. Then,  $\mathbf {a}^{(n)}$ can be obtained by the following procedure
$\mathbf {a}^{(n)}$ can be obtained by the following procedure
 \begin{align*} & \mathbf{a}^{(0)}=[1]; \\ & \mathrm{For}(i=1,i\leq n, i+{+})\\ & \qquad \mathbf{a}^{(i)} = [0,0,\mathbf{a}^{(i-1)}] - 2 \tau_i [0,\mathbf{a}^{(i-1)},0] + \tau_i^{2} [\mathbf{a}^{(i-1)},0,0]; \end{align*}
\begin{align*} & \mathbf{a}^{(0)}=[1]; \\ & \mathrm{For}(i=1,i\leq n, i+{+})\\ & \qquad \mathbf{a}^{(i)} = [0,0,\mathbf{a}^{(i-1)}] - 2 \tau_i [0,\mathbf{a}^{(i-1)},0] + \tau_i^{2} [\mathbf{a}^{(i-1)},0,0]; \end{align*}where  $[0,0,\mathbf {a}^{(i-1)}]$ is a vector of dimension
$[0,0,\mathbf {a}^{(i-1)}]$ is a vector of dimension  $2i+1$ whose first two elements are zero and the next
$2i+1$ whose first two elements are zero and the next  $2i-1$ elements are from
$2i-1$ elements are from  $\mathbf {a}^{(i-1)}$.
$\mathbf {a}^{(i-1)}$.  $[0,\mathbf {a}^{(i-1)},0]$, and
$[0,\mathbf {a}^{(i-1)},0]$, and  $[\mathbf {a}^{(i-1)},0,0]$ are defined similarly.
$[\mathbf {a}^{(i-1)},0,0]$ are defined similarly.
The  $f_n(t)$ function of CME-R with a minimal
$f_n(t)$ function of CME-R with a minimal  $\mathrm {SCV}$ has the general structure as shown in Figure 1 for
$\mathrm {SCV}$ has the general structure as shown in Figure 1 for  $n=9$: Between the zeros of
$n=9$: Between the zeros of  $f_n(t)$ (which are at
$f_n(t)$ (which are at  $t=\tau _i$, indicated by downward arrows) there are small peaks, and there is a large main peak between two zeros, which are further apart. This structure is valid for orders
$t=\tau _i$, indicated by downward arrows) there are small peaks, and there is a large main peak between two zeros, which are further apart. This structure is valid for orders  $n\geq 7$. For orders
$n\geq 7$. For orders  $n<7$,
$n<7$,  $f_n(t)$ with a minimal
$f_n(t)$ with a minimal  $\mathrm {SCV}$ is such that all zeros are the left of the main peak and the right of the main peak
$\mathrm {SCV}$ is such that all zeros are the left of the main peak and the right of the main peak  $f_n(t)$ decays due to the exponentially decaying multiplier
$f_n(t)$ decays due to the exponentially decaying multiplier  $e^{-\lambda t}$. In Figure 1,
$e^{-\lambda t}$. In Figure 1,  $f_n(t)$ is scaled such that
$f_n(t)$ is scaled such that  $\mu _0=\mu _1=1$.
$\mu _0=\mu _1=1$.

Figure 1. The peaks and zeros of  $f_n(t)$ for
$f_n(t)$ for  $n=9$ with 2 zeros on the right of the main peak.
$n=9$ with 2 zeros on the right of the main peak.
3. Optimizing the $\tau _i$ parameters

In this section, we discuss the numerical solution of the optimization problem in (6). This numerical optimization can be performed with various optimization methods. For low orders ( $n\leq 12$), Wolfram Mathematica can solve this optimization problem in less than 5 min. Table 1 contains the obtained results. The
$n\leq 12$), Wolfram Mathematica can solve this optimization problem in less than 5 min. Table 1 contains the obtained results. The  $1/\mathrm {SCV}$ column of the table indicates the minimal order of phase-type distribution needed, to obtain such a low
$1/\mathrm {SCV}$ column of the table indicates the minimal order of phase-type distribution needed, to obtain such a low  $\mathrm {SCV}$, since the minimal
$\mathrm {SCV}$, since the minimal  $\mathrm {SCV}$ of an order
$\mathrm {SCV}$ of an order  $N'$ phase-type distribution is
$N'$ phase-type distribution is  $1/N'$. For example, the
$1/N'$. For example, the  $\mathrm {SCV}$ of CME-R with order
$\mathrm {SCV}$ of CME-R with order  $N=25$ is less than the
$N=25$ is less than the  $\mathrm {SCV}$ of any phase-type distribution of order
$\mathrm {SCV}$ of any phase-type distribution of order  $N'=84$.
$N'=84$.
Table 1. The  $\mathrm {SCV}$ and its inverse for low order CME-R.
$\mathrm {SCV}$ and its inverse for low order CME-R.

For higher orders, efficient optimization tools, allowing high precision computation, are required to perform the optimization. In the numerical optimization of the parameters, we had success with evolution strategies. We found the covariance matrix adoption evolution strategy (CMA-ES) [Reference Hansen7] to be the most efficient method for this optimization problem.
More precisely, even more accurate evolution strategy methods, for example, the BIPOP-CMA-ES with restarts [Reference Hansen8] failed to find the global optimum even for low-order cases, because they distribute the  $\tau _i$ points on the left and the right of the main peak of
$\tau _i$ points on the left and the right of the main peak of  $f_n(t)$ suboptimally.
$f_n(t)$ suboptimally.
With appropriate initial guess, CMA-ES keeps the number of points left and right to the main peak fixed and optimizes the position of the left and right points much faster than the BIPOP-CMA-ES method. Generally, the  $\mathrm {SCV}$ optimized by the CMA-ES method decreased smoothly with increasing order. For the few
$\mathrm {SCV}$ optimized by the CMA-ES method decreased smoothly with increasing order. For the few  $\mathrm {SCV}$ values that were out of trend, we repeated the optimization with different initial guess, which resulted in in-trend values in each case.
$\mathrm {SCV}$ values that were out of trend, we repeated the optimization with different initial guess, which resulted in in-trend values in each case.
The computation time of the CMA-ES method is around one day at  $n=120$. The method provided CME-R distributions with
$n=120$. The method provided CME-R distributions with  $\mathrm {SCV}$ values as shown in Figure 2. In the figure, the PH
$\mathrm {SCV}$ values as shown in Figure 2. In the figure, the PH $(2n+1)=1/(2n+1)=1/N$ curve represents the minimal
$(2n+1)=1/(2n+1)=1/N$ curve represents the minimal  $\mathrm {SCV}$ of PH distributions [Reference Aldous and Shepp4], while the dashed line represents the
$\mathrm {SCV}$ of PH distributions [Reference Aldous and Shepp4], while the dashed line represents the  $\mathrm {SCV}$ of matrix exponential distributions with complex eigenvalues (CME) of order
$\mathrm {SCV}$ of matrix exponential distributions with complex eigenvalues (CME) of order  $N=2n+1$ [Reference Horváth, Horváth and Telek10].
$N=2n+1$ [Reference Horváth, Horváth and Telek10].

Figure 2. The minimal  $\mathrm {SCV}$ computed by the CMA-ES method as a function of the order in a log–log scale.
$\mathrm {SCV}$ computed by the CMA-ES method as a function of the order in a log–log scale.
3.1. Required precision of the floating point arithmetic
For higher orders, the computation of the  $\mathrm {SCV}$ based on
$\mathrm {SCV}$ based on  $\tau _1,\ldots ,\tau _n$ might cause numerical issues if the applied floating point arithmetic is not sufficiently accurate. Indeed, the computation of the
$\tau _1,\ldots ,\tau _n$ might cause numerical issues if the applied floating point arithmetic is not sufficiently accurate. Indeed, the computation of the  $a_0,\ldots ,a_{2n}$ coefficients based on (8) and then the computation of the
$a_0,\ldots ,a_{2n}$ coefficients based on (8) and then the computation of the  $\mathrm {SCV}$ based on (7) require high precision arithmetic.
$\mathrm {SCV}$ based on (7) require high precision arithmetic.
The precision loss in computing the  $\mathrm {SCV}$ increases with increasing order, as both the maximum value of the
$\mathrm {SCV}$ increases with increasing order, as both the maximum value of the  $a_i$ parameters and the
$a_i$ parameters and the  $i!$ factorials increases rapidly in (7), but the (unnormalized) moments in (9) increase relatively slowly, because the
$i!$ factorials increases rapidly in (7), but the (unnormalized) moments in (9) increase relatively slowly, because the  $a_i$ parameters have alternating sign. Using the Precision function of Mathematica, we made numerical investigations in order to characterize the required floating point arithmetic as a function of the
$a_i$ parameters have alternating sign. Using the Precision function of Mathematica, we made numerical investigations in order to characterize the required floating point arithmetic as a function of the  $n$. The results are shown in Figure 3. We found that the precision loss in computing the
$n$. The results are shown in Figure 3. We found that the precision loss in computing the  $\mathrm {SCV}$ is approximately
$\mathrm {SCV}$ is approximately  $0.95 n$ digits.
$0.95 n$ digits.

Figure 3. Precision loss during the computation of the  $\mathrm {SCV}$ as a function of the order.
$\mathrm {SCV}$ as a function of the order.
That is, computing the  $\mathrm {SCV}$ for
$\mathrm {SCV}$ for  $n=100$ (i.e., order
$n=100$ (i.e., order  $N=201$) results in
$N=201$) results in  $95$ digits precision loss, thus to obtain the
$95$ digits precision loss, thus to obtain the  $\mathrm {SCV}$ in standard double precision the computation of (8) and (7) needs to be performed with extended floating point arithmetic whose precision is
$\mathrm {SCV}$ in standard double precision the computation of (8) and (7) needs to be performed with extended floating point arithmetic whose precision is  $95$ digits larger than the one of double precision. We assume that the number of accurate digits in standard double precision numbers is approximately
$95$ digits larger than the one of double precision. We assume that the number of accurate digits in standard double precision numbers is approximately  $20$, and in the implementation of the optimization procedure, for order
$20$, and in the implementation of the optimization procedure, for order  $2n+1$, we computed the
$2n+1$, we computed the  $\mathrm {SCV}$ with
$\mathrm {SCV}$ with  $20+0.95n$ digit precision arithmetic.
$20+0.95n$ digit precision arithmetic.
We note that the input data of this procedure ( $\tau _1,\ldots ,\tau _n$) and its results (
$\tau _1,\ldots ,\tau _n$) and its results ( $\mathrm {SCV}$) need to be represented in only standard double precision.
$\mathrm {SCV}$) need to be represented in only standard double precision.
4. Heuristic optimization
Since the direct applicability of CMA-ES for the optimization of all  $\tau _i$ (
$\tau _i$ ( $i=1,\ldots ,n$) parameters is limited to
$i=1,\ldots ,n$) parameters is limited to  $n\leq 120$ due to the high number of parameters to optimize, for higher orders we needed to simplify the optimization problem.
$n\leq 120$ due to the high number of parameters to optimize, for higher orders we needed to simplify the optimization problem.
To reduce the complexity of the optimization procedure, first we investigated the location of the optimal  $\tau _i$ parameters, which are summarized in Figure 4. According to the figure, the main properties of the optimal
$\tau _i$ parameters, which are summarized in Figure 4. According to the figure, the main properties of the optimal  $\tau _i$ (
$\tau _i$ ( $i=1,\ldots ,n$) parameters are as follows:
$i=1,\ldots ,n$) parameters are as follows:
• the
$\tau _i$ parameters are located in the interval $(0,3.8n)$,• the largest gap between the
$\tau _i$ parameters represents the main peak of the function and is located at around $2.3n$,• the number of
$\tau _i$ parameters right of the main peak is gradually increasing with $n$ and it is in the range of $0.1n - 0.2n$,• the
$\tau _i$ parameters are dense around zero and the distance between the consecutive $\tau _i$ values increases gradually for larger values (aside from the main gap, cf. Figure 5).










Figure 4. Results of the CMA-ES method, which optimizes  $n$ parameters for order
$n$ parameters for order  $n$. The plot depicts the location of the zeros of
$n$. The plot depicts the location of the zeros of  $f_n(t)$, denoted by
$f_n(t)$, denoted by  $\tau _i$ (
$\tau _i$ ( $i=1,\ldots ,n$), normalized by the order for different orders up to
$i=1,\ldots ,n$), normalized by the order for different orders up to  $n=100$.
$n=100$.

Figure 5. The optimal location of the zeros of  $f_n(t)$ for
$f_n(t)$ for  $n=90$ obtained by the CMA-ES optimization method. The zeros are denoted as
$n=90$ obtained by the CMA-ES optimization method. The zeros are denoted as  $\tau _1,\ldots , \tau _{90}$.
$\tau _1,\ldots , \tau _{90}$.
Based on these properties of the  $\tau _i$ values, we developed a heuristic optimization procedure which intends to mimic the same properties based on a limited number of parameters.
$\tau _i$ values, we developed a heuristic optimization procedure which intends to mimic the same properties based on a limited number of parameters.
We approximate the location of the  $\tau _i$ parameters with two polynomial curves, one for
$\tau _i$ parameters with two polynomial curves, one for  $\tau _i$ values left to the main peak and one for right to it, which intuition is gained from Figure 5 and related numerical experiments. Thus,
$\tau _i$ values left to the main peak and one for right to it, which intuition is gained from Figure 5 and related numerical experiments. Thus,
 \begin{equation} \tau_i = \left\{ \begin{array}{ll} \theta (i- \phi)^{a}, & \text{if } i\leq i^{*},\\ \Theta (i- \Phi)^{A}, & \text{if } i^{*}< i \leq n, \end{array}\right.\end{equation}
\begin{equation} \tau_i = \left\{ \begin{array}{ll} \theta (i- \phi)^{a}, & \text{if } i\leq i^{*},\\ \Theta (i- \Phi)^{A}, & \text{if } i^{*}< i \leq n, \end{array}\right.\end{equation}where  $i^{*}$ denotes the number of
$i^{*}$ denotes the number of  $\tau _i$ parameters left to the main peak and
$\tau _i$ parameters left to the main peak and  $a$ and
$a$ and  $A$ are the shape parameters left and right to the main peak. We could optimize the
$A$ are the shape parameters left and right to the main peak. We could optimize the  $i^{*}$,
$i^{*}$,  $\theta$,
$\theta$,  $\Theta$,
$\Theta$,  $\phi$,
$\phi$,  $\Phi$,
$\Phi$,  $a$,
$a$,  $A$ parameters of the polynomial curves in (10) directly, however we transform the optimization problem to the following set of more expressive parameters:
$A$ parameters of the polynomial curves in (10) directly, however we transform the optimization problem to the following set of more expressive parameters:  $i^{*}$,
$i^{*}$,  $p_{\textrm {min}}$,
$p_{\textrm {min}}$,  $p_{\textrm {max}}$,
$p_{\textrm {max}}$,  $p$,
$p$,  $w$,
$w$,  $a$,
$a$,  $A$, where
$A$, where  $p_{\textrm {min}}$ and
$p_{\textrm {min}}$ and  $p_{\textrm {max}}$ are the smallest and largest
$p_{\textrm {max}}$ are the smallest and largest  $\tau _i$ parameters, and
$\tau _i$ parameters, and  $p$ and
$p$ and  $w$ are the location of the main peak and its width.
$w$ are the location of the main peak and its width.
The relation between the optimization parameters and the parameters of the polynomial curves are provided by the following equations
 \begin{equation} \tau_1 = p_{\textrm{min}},\quad \tau_{i^{*}} = p-w/2,\quad \tau_{i^{*}+1} = p+w/2,\quad \tau_{n}= p_{\textrm{max}}, \end{equation}
\begin{equation} \tau_1 = p_{\textrm{min}},\quad \tau_{i^{*}} = p-w/2,\quad \tau_{i^{*}+1} = p+w/2,\quad \tau_{n}= p_{\textrm{max}}, \end{equation}where we apply the following constraints:
 $$i^{*}< n-1,\quad 0 < p_{\textrm{min}} < p-w/2 < p+w/2 < p_{\textrm{max}},\quad a>0, \quad A>0.$$
$$i^{*}< n-1,\quad 0 < p_{\textrm{min}} < p-w/2 < p+w/2 < p_{\textrm{max}},\quad a>0, \quad A>0.$$ \begin{align} \phi & = \frac{(p-w/2)^{1/a} - i^{*} p_{\textrm{min}}^{1/a}}{(p-w/2)^{1/a}-p_{\textrm{min}}^{1/a}} ,\quad \theta=p_{\textrm{min}} (1-\phi)^{{-}a}, \end{align}
\begin{align} \phi & = \frac{(p-w/2)^{1/a} - i^{*} p_{\textrm{min}}^{1/a}}{(p-w/2)^{1/a}-p_{\textrm{min}}^{1/a}} ,\quad \theta=p_{\textrm{min}} (1-\phi)^{{-}a}, \end{align} \begin{align} \Phi & = \frac{n (p+w/2)^{1/A} - (i^{*}+1) p_{\textrm{max}}^{1/A}}{(p+w/2)^{1/A}-p_{\textrm{max}}^{1/A}} ,\quad \Theta=p_{\textrm{max}} (n-\Phi)^{{-}A}. \end{align}
\begin{align} \Phi & = \frac{n (p+w/2)^{1/A} - (i^{*}+1) p_{\textrm{max}}^{1/A}}{(p+w/2)^{1/A}-p_{\textrm{max}}^{1/A}} ,\quad \Theta=p_{\textrm{max}} (n-\Phi)^{{-}A}. \end{align}Applying (12) and (13), the optimization problem modifies to
 $$\min_{i^{*},p_{\textrm{min}},p_{\textrm{max}},p,w,a,A}\frac{(\sum_{i=0}^{2n} a_{i} (i+2)!) (\sum_{i=0}^{2n} a_{i} i!)}{(\sum_{i=0}^{2n} a_{i} (i+1)!)^{2}}-1,$$
$$\min_{i^{*},p_{\textrm{min}},p_{\textrm{max}},p,w,a,A}\frac{(\sum_{i=0}^{2n} a_{i} (i+2)!) (\sum_{i=0}^{2n} a_{i} i!)}{(\sum_{i=0}^{2n} a_{i} (i+1)!)^{2}}-1,$$where  $i^{*},p_{\textrm {min}},p_{\textrm {max}},p,w,a,A$ defines
$i^{*},p_{\textrm {min}},p_{\textrm {max}},p,w,a,A$ defines  $\tau _1, \ldots , \tau _n$ according to (12), (13), and (10) and
$\tau _1, \ldots , \tau _n$ according to (12), (13), and (10) and  $\tau _1, \ldots , \tau _n$ defines
$\tau _1, \ldots , \tau _n$ defines  $a_0,\ldots ,a_{2n}$ according to (8).
$a_0,\ldots ,a_{2n}$ according to (8).
The number of parameters of this optimization problem is  $7$ for any order
$7$ for any order  $N=2n+1$. For
$N=2n+1$. For  $n>50$, the computational complexity of this heuristic optimization procedure is significantly less than for the CMA-ES method, when optimizing all
$n>50$, the computational complexity of this heuristic optimization procedure is significantly less than for the CMA-ES method, when optimizing all  $\tau _i$ parameters. Due to the reduced complexity of the optimization procedure, we could optimize CME-R distributions for up to
$\tau _i$ parameters. Due to the reduced complexity of the optimization procedure, we could optimize CME-R distributions for up to  $n=5000$.
$n=5000$.
For order  $N=2n+1$, we start the optimization with the following initial values of the parameters, which are good approximates of the optimal parameters according to our numerical experiences.
$N=2n+1$, we start the optimization with the following initial values of the parameters, which are good approximates of the optimal parameters according to our numerical experiences.

The  $\mathrm {SCV}$ values obtained from the
$\mathrm {SCV}$ values obtained from the  $7$ parameter optimization procedure are depicted in Figure 6 for different orders up to
$7$ parameter optimization procedure are depicted in Figure 6 for different orders up to  $n=5000$. In the figure, the solid line indicates the
$n=5000$. In the figure, the solid line indicates the  $\mathrm {SCV}$ values obtained by the CMA-ES optimization of the heuristic (7 parameter) procedure. To demonstrate the decay of the
$\mathrm {SCV}$ values obtained by the CMA-ES optimization of the heuristic (7 parameter) procedure. To demonstrate the decay of the  $\mathrm {SCV}$ values, the
$\mathrm {SCV}$ values, the  $n^{-1.85}$ curve is plotted next to it. The decay of the CME-R curve drops below the
$n^{-1.85}$ curve is plotted next to it. The decay of the CME-R curve drops below the  $n^{-1.85}$ curve at
$n^{-1.85}$ curve at  $n=2000$ and decays faster from that point on. Additionally, the figure contains the CME curve, which is the
$n=2000$ and decays faster from that point on. Additionally, the figure contains the CME curve, which is the  $\mathrm {SCV}$ of the concentrated matrix exponential distribution with complex eigenvalues and its supporting decay curve
$\mathrm {SCV}$ of the concentrated matrix exponential distribution with complex eigenvalues and its supporting decay curve  $n^{-2.1}$. At
$n^{-2.1}$. At  $n=2000$, the
$n=2000$, the  $\mathrm {SCV}$ of the CME distribution is one order of magnitude smaller than the
$\mathrm {SCV}$ of the CME distribution is one order of magnitude smaller than the  $\mathrm {SCV}$ of the CME-R distribution.
$\mathrm {SCV}$ of the CME-R distribution.

Figure 6. The minimal  $\mathrm {SCV}$ of the CME and the CME-R distributions of order
$\mathrm {SCV}$ of the CME and the CME-R distributions of order  $n$ as a function of
$n$ as a function of  $n$ in a log–log scale. To indicate the decay rates, the
$n$ in a log–log scale. To indicate the decay rates, the  $n^{-1.85}$ and the
$n^{-1.85}$ and the  $n^{-2.1}$ curves are plotted as well.
$n^{-2.1}$ curves are plotted as well.
5. Numerical ILT with CME-R
In this section, we discuss the application of CME-R for NILT in the Abate–Whitt framework [Reference Abate and Whitt1]. The Laplace transform of a real- or complex-valued function  $h(t)$ is defined as
$h(t)$ is defined as
 $$h^{*}(s)=\int_{t=0}^{\infty}e^{{-}st}h(t)\,\mathrm{d}t.$$
$$h^{*}(s)=\int_{t=0}^{\infty}e^{{-}st}h(t)\,\mathrm{d}t.$$The goal of NILT is to obtain  $h(t)$ from
$h(t)$ from  $h^{*}(s)$. The NILT methods in the Abate–Whitt framework use the approximation
$h^{*}(s)$. The NILT methods in the Abate–Whitt framework use the approximation
 \begin{equation} h(T)\approx \sum_{k=1}^{M}\frac{\eta_k}{T}h^{*}\left(\frac{\beta_k}{T}\right), \end{equation}
\begin{equation} h(T)\approx \sum_{k=1}^{M}\frac{\eta_k}{T}h^{*}\left(\frac{\beta_k}{T}\right), \end{equation}where  $\eta _k$ and
$\eta _k$ and  $\beta _k$ are real or complex numbers that depend on
$\beta _k$ are real or complex numbers that depend on  $M$, but not on the transform function
$M$, but not on the transform function  $h^{*}$ or the argument
$h^{*}$ or the argument  $T$.
$T$.  $M$ is called the order of the approximation, and indicates the number of
$M$ is called the order of the approximation, and indicates the number of  $h^{*}$ evaluations needed to calculate the ILT.
$h^{*}$ evaluations needed to calculate the ILT.
The Abate–Whitt framework has an integral-based interpretation [Reference Horváth, Horváth, Al-Deen Almousa and Telek9] using that
 \begin{align} h(T) & \approx \sum_{k=1}^{M}\frac{\eta_k}{T}h^{*}\left(\frac{\beta_k}{T}\right) =\sum_{k=1}^{M}\frac{\eta_k}{T}\int_{t=0}^{\infty}e^{-({\beta_k}/{T})t}h(t)\,\mathrm{d}t\nonumber\\ & =\sum_{k=1}^{M}\frac{\eta_k}{T}\int_{t=0}^{\infty}e^{-({\beta_k}/{T})t}h(t)\,\mathrm{d}t =\int_{t=0}^{\infty}h(tT)\sum_{k=1}^{M}\eta_k e^{-\beta_k t}\,\mathrm{d}t\nonumber\\ & =\int_{t=0}^{\infty}h(tT)g_M(t)\,\mathrm{d}t, \end{align}
\begin{align} h(T) & \approx \sum_{k=1}^{M}\frac{\eta_k}{T}h^{*}\left(\frac{\beta_k}{T}\right) =\sum_{k=1}^{M}\frac{\eta_k}{T}\int_{t=0}^{\infty}e^{-({\beta_k}/{T})t}h(t)\,\mathrm{d}t\nonumber\\ & =\sum_{k=1}^{M}\frac{\eta_k}{T}\int_{t=0}^{\infty}e^{-({\beta_k}/{T})t}h(t)\,\mathrm{d}t =\int_{t=0}^{\infty}h(tT)\sum_{k=1}^{M}\eta_k e^{-\beta_k t}\,\mathrm{d}t\nonumber\\ & =\int_{t=0}^{\infty}h(tT)g_M(t)\,\mathrm{d}t, \end{align}where
 \begin{equation} g_M(t)=\sum_{k=1}^{M}\eta_k e^{-\beta_k t}. \end{equation}
\begin{equation} g_M(t)=\sum_{k=1}^{M}\eta_k e^{-\beta_k t}. \end{equation}If  $g_M(t)$ was the Dirac impulse at
$g_M(t)$ was the Dirac impulse at  $t=1$, then (15) would provide
$t=1$, then (15) would provide  $h(T)$ exactly. When
$h(T)$ exactly. When  $g_M(t)$ is a good approximate of the Dirac impulse, we assume that (15) closely approximates
$g_M(t)$ is a good approximate of the Dirac impulse, we assume that (15) closely approximates  $h(T)$.
$h(T)$.
Similar to [Reference Horváth, Horváth, Al-Deen Almousa and Telek9], using the fact that  $g_M(t)$ is non-negative, we measure the quality of the approximation of the Dirac impulse function with the
$g_M(t)$ is non-negative, we measure the quality of the approximation of the Dirac impulse function with the  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $g_M(t)$. The
$g_M(t)$. The  $\mathrm {SCV}$ of the Dirac impulse is
$\mathrm {SCV}$ of the Dirac impulse is  $0$, therefore we assume that the lower the
$0$, therefore we assume that the lower the  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $g_M(t)$, the better it approximates the Dirac impulse function.
$g_M(t)$, the better it approximates the Dirac impulse function.
As it is discussed in the previous section, the pdf of CME-R is
 \begin{equation} f_n(t)= c \prod_{i=1}^{n} (\lambda t-\tau_i)^{2} e^{-\lambda t} = \sum_{i=0}^{2n} a_{i} t^{i} e^{-\lambda t}. \end{equation}
\begin{equation} f_n(t)= c \prod_{i=1}^{n} (\lambda t-\tau_i)^{2} e^{-\lambda t} = \sum_{i=0}^{2n} a_{i} t^{i} e^{-\lambda t}. \end{equation}Assuming that  $c$ and
$c$ and  $\lambda$ are set such that
$\lambda$ are set such that  $\mu _0=\mu _1=1$, the above pdf is concentrated around
$\mu _0=\mu _1=1$, the above pdf is concentrated around  $1$. Additionally, the
$1$. Additionally, the  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $f_n(t)$ can be set to be low, in which case
$f_n(t)$ can be set to be low, in which case  $f_n(t)$ is a close approximate of the Dirac impulse.
$f_n(t)$ is a close approximate of the Dirac impulse.
To apply CME-R distributions for NILT in the Abate–Whitt framework according to (14), we still need to approximate  $f_n(t)$ (defined in (17)) with
$f_n(t)$ (defined in (17)) with  $g_M(t)$ (defined in (16)) such that the
$g_M(t)$ (defined in (16)) such that the  $\eta _j$ and
$\eta _j$ and  $\beta _j$ parameters are real.
$\beta _j$ parameters are real.
To this end, we set the  $\beta _j$ parameters to be equidistant around
$\beta _j$ parameters to be equidistant around  $\lambda$ and set the
$\lambda$ and set the  $\eta _j$ parameters such that the set of the first
$\eta _j$ parameters such that the set of the first  $M$ coefficients of the Taylor series of
$M$ coefficients of the Taylor series of  $f_n(t)$ and
$f_n(t)$ and  $g_M(t)$ are identical.
$g_M(t)$ are identical.
That is, for  $-m\leq j \leq m$, we choose
$-m\leq j \leq m$, we choose  $\beta _j=\lambda +j \delta$ and solve
$\beta _j=\lambda +j \delta$ and solve
 \begin{equation} \textrm{Taylor}(t^{i} e^{-\lambda t},2m+1) = \textrm{Taylor}\left(\sum_{j={-}m}^{m} \nu_{ij} e^{-(\lambda+j \delta) t},2m+1\right) \end{equation}
\begin{equation} \textrm{Taylor}(t^{i} e^{-\lambda t},2m+1) = \textrm{Taylor}\left(\sum_{j={-}m}^{m} \nu_{ij} e^{-(\lambda+j \delta) t},2m+1\right) \end{equation}for the unknowns  $\nu _{ij}$. In (18), the
$\nu _{ij}$. In (18), the  $n$th coefficient of the Taylor series of
$n$th coefficient of the Taylor series of  $f(t)$ is
$f(t)$ is  $\lim _{t\to 0} ({d^{n}}/{dt^{n}}) ({f(t)}/{n!})$ and
$\lim _{t\to 0} ({d^{n}}/{dt^{n}}) ({f(t)}/{n!})$ and  $\textrm {Taylor}(f(t),k)$ denotes the vector of the
$\textrm {Taylor}(f(t),k)$ denotes the vector of the  $\{0,1,\ldots , k\}$ coefficients of the Taylor series of
$\{0,1,\ldots , k\}$ coefficients of the Taylor series of  $f(t)$.
$f(t)$.
It is worth noting that the  $\nu _{ij}$ coefficients, computed according to (18), are in close connection with the finite difference coefficients from numerical differentiation [Reference Keller and Pereyra11], as
$\nu _{ij}$ coefficients, computed according to (18), are in close connection with the finite difference coefficients from numerical differentiation [Reference Keller and Pereyra11], as  $\nu _{ij}={c_{ij}}/{(-\delta )^{i}}$, where
$\nu _{ij}={c_{ij}}/{(-\delta )^{i}}$, where  $c_{ij}$ are the aforementioned finite difference coefficients. The problem of approximating
$c_{ij}$ are the aforementioned finite difference coefficients. The problem of approximating  $f_{n}(t)$ in (17) in the form of
$f_{n}(t)$ in (17) in the form of  $g_M(t)$ in (16) can be formulated using Laplace transformation and the finite difference method as it is shown in the Appendix.
$g_M(t)$ in (16) can be formulated using Laplace transformation and the finite difference method as it is shown in the Appendix.
Based on  $t^{i} e^{-\lambda t} \approx \sum _{j=-m}^{m} \nu _{ij} e^{-(\lambda +j \delta ) t}$, we have
$t^{i} e^{-\lambda t} \approx \sum _{j=-m}^{m} \nu _{ij} e^{-(\lambda +j \delta ) t}$, we have
 \begin{equation} f_n(t)=\sum_{i=0}^{2n} a_{i} t^{i} e^{-\lambda t} \approx \sum_{j={-}m}^{m} \sum_{i=0}^{2n} a_{i} \nu_{ij} e^{-(\lambda+j \delta) t} = \sum_{j={-}m}^{m} \eta_j e^{-\beta_j t} \triangleq f_{m,n}(t), \end{equation}
\begin{equation} f_n(t)=\sum_{i=0}^{2n} a_{i} t^{i} e^{-\lambda t} \approx \sum_{j={-}m}^{m} \sum_{i=0}^{2n} a_{i} \nu_{ij} e^{-(\lambda+j \delta) t} = \sum_{j={-}m}^{m} \eta_j e^{-\beta_j t} \triangleq f_{m,n}(t), \end{equation}with
 \begin{equation} \eta_j=\sum_{i=0}^{2n} a_{i}\nu_{ij}=\sum_{i=0}^{2n} \frac{a_{i} c_{ij}}{(-\delta)^{i}} \quad \text{and}\quad \beta_j=\lambda+j \delta. \end{equation}
\begin{equation} \eta_j=\sum_{i=0}^{2n} a_{i}\nu_{ij}=\sum_{i=0}^{2n} \frac{a_{i} c_{ij}}{(-\delta)^{i}} \quad \text{and}\quad \beta_j=\lambda+j \delta. \end{equation}That is,  $f_{m,n}(t)$ is the order
$f_{m,n}(t)$ is the order  $m$ approximation of the order
$m$ approximation of the order  $n$ CME-R distribution
$n$ CME-R distribution  $f_n(t)$.
$f_n(t)$.
The  $f_{m,n}(t)$ expression is in the form (16), which allows the application of the Abate–Whitt NILT framework according to
$f_{m,n}(t)$ expression is in the form (16), which allows the application of the Abate–Whitt NILT framework according to
 \begin{equation} h(T) \approx h_{m,n}(T) = \sum_{j={-}m}^{m} \frac{\eta_j}{T} h^{*}\left(\frac{\beta_j}{T}\right) . \end{equation}
\begin{equation} h(T) \approx h_{m,n}(T) = \sum_{j={-}m}^{m} \frac{\eta_j}{T} h^{*}\left(\frac{\beta_j}{T}\right) . \end{equation}The order of the NILT approximation is  $M=2m+1$, that is, we need to evaluate
$M=2m+1$, that is, we need to evaluate  $h^{*}(s)$ in
$h^{*}(s)$ in  $2m+1$ real points to obtain
$2m+1$ real points to obtain  $h_{m,n}(t)$.
$h_{m,n}(t)$.
A possible setting of parameter  $\delta$ is, for example,
$\delta$ is, for example,  $\delta = {\lambda }/{20 m}$, which means that
$\delta = {\lambda }/{20 m}$, which means that  $\beta _j\in [0.95\lambda ,1.05\lambda ]$. According to our numerical investigations,
$\beta _j\in [0.95\lambda ,1.05\lambda ]$. According to our numerical investigations,  $m \approx 1.3n$ gives an accurate approximation of the derivatives in this case. The effect of these parameters are discussed below, and the consideration about the numerical precision of the computations in the next section, is obtained using this setting of
$m \approx 1.3n$ gives an accurate approximation of the derivatives in this case. The effect of these parameters are discussed below, and the consideration about the numerical precision of the computations in the next section, is obtained using this setting of  $\delta$ and
$\delta$ and  $m$.
$m$.
5.1. Required precision of the floating point arithmetic
Similar to Section 3.1, the precision-related considerations of this section are obtained using the Precision function of Wolfram Mathematica.
We emphasize again that in (17), the  $\tau _i$ parameters can be represented with standard double precision for
$\tau _i$ parameters can be represented with standard double precision for  $n\leq 100$, but the
$n\leq 100$, but the  $a_i$ parameters need to be represented in higher precision. In Section 3.1, we reported that for computing the
$a_i$ parameters need to be represented in higher precision. In Section 3.1, we reported that for computing the  $\mathrm {SCV}$ with approximately
$\mathrm {SCV}$ with approximately  $20$ digit precision, the required precision of
$20$ digit precision, the required precision of  $a_{i}$ was
$a_{i}$ was  $20+0.95n$. Unfortunately, the alternating sign of
$20+0.95n$. Unfortunately, the alternating sign of  $\nu _{ij}$ makes the computation of
$\nu _{ij}$ makes the computation of  $\eta _j$ in (20) even more sensitive numerically. To obtain an appropriate accuracy for
$\eta _j$ in (20) even more sensitive numerically. To obtain an appropriate accuracy for  $f_{m,n}(t)$ (such that the accuracy of the
$f_{m,n}(t)$ (such that the accuracy of the  $\mathrm {SCV}$ computed from (17) is approximately
$\mathrm {SCV}$ computed from (17) is approximately  $20$ digits), the precision of the
$20$ digits), the precision of the  $a_i$ parameters have to be set to
$a_i$ parameters have to be set to  $50+6n$ digits. This requirement was obtained based on a similar precision loss analysis as the one in Figure 3.
$50+6n$ digits. This requirement was obtained based on a similar precision loss analysis as the one in Figure 3.
Starting from  $a_i$ parameters of
$a_i$ parameters of  $50+6n$ digit precision and
$50+6n$ digit precision and  $\nu _{ij}$ parameters of at least the same precision, and then computing the
$\nu _{ij}$ parameters of at least the same precision, and then computing the  $\eta _j$ parameters according to (20) results in a numerical accuracy of approximately
$\eta _j$ parameters according to (20) results in a numerical accuracy of approximately  $20+3.4 m$ digits (for
$20+3.4 m$ digits (for  $m=1.3n$ and
$m=1.3n$ and  $\delta =\lambda /20m$, as discussed below).
$\delta =\lambda /20m$, as discussed below).
This  $50+6n$ digit precision of the
$50+6n$ digit precision of the  $a_i$ parameters and the
$a_i$ parameters and the  $20+3.4 m$ digit precision of the
$20+3.4 m$ digit precision of the  $\eta _i$ parameters are sufficient for NILT. Sufficient means that the precision of
$\eta _i$ parameters are sufficient for NILT. Sufficient means that the precision of  $\sum _{j=-m}^{m} \eta _j$ is approximately
$\sum _{j=-m}^{m} \eta _j$ is approximately  $20$ digits, where the
$20$ digits, where the  $\eta _j$ parameters have large absolute value and alternating sign and
$\eta _j$ parameters have large absolute value and alternating sign and  $\sum _{j=-m}^{m} \eta _j=f_{m,n}(0)$ is a small positive number, since
$\sum _{j=-m}^{m} \eta _j=f_{m,n}(0)$ is a small positive number, since  $f_{m,n}(t)$ approximates the Dirac impulse. That is, for NILT the
$f_{m,n}(t)$ approximates the Dirac impulse. That is, for NILT the  $\eta _j$ parameters can be pre-computed and stored with
$\eta _j$ parameters can be pre-computed and stored with  $20+3.4 m$ digit precision.
$20+3.4 m$ digit precision.
The  $\beta _j$ parameters are very simple to obtain from
$\beta _j$ parameters are very simple to obtain from  $\lambda$ and
$\lambda$ and  $\delta$. It is a nice feature of the NILT method based on (21) that the
$\delta$. It is a nice feature of the NILT method based on (21) that the  $\beta _j$ parameters and the
$\beta _j$ parameters and the  $h^{*}(\beta _j/T)$ transform function values can be computed in standard double precision arithmetic and only the summation in (21) needs to be computed with high (
$h^{*}(\beta _j/T)$ transform function values can be computed in standard double precision arithmetic and only the summation in (21) needs to be computed with high ( $20+3.4 m$ digit) precision.
$20+3.4 m$ digit) precision.
In the following, we summarize the steps and the respective precision requirements for NILT with CME-R. We can pre-compute the  $\eta _j$ and
$\eta _j$ and  $\beta _j$ parameters and store them in a file. In the NILT procedure, we use these stored
$\beta _j$ parameters and store them in a file. In the NILT procedure, we use these stored  $\eta _j$ and
$\eta _j$ and  $\beta _j$ parameters to calculate
$\beta _j$ parameters to calculate  $h(T)$ from
$h(T)$ from  $h^{*}(s)$.
$h^{*}(s)$.
Steps of pre-computation:
• Starting from the
$c$, $\lambda$, $\tau _1,\ldots ,\tau _n$ parameters given in standard precision, transform the parameters to $50+6n$ digit precision and compute the $a_i$ parameters based on (17) with $50+6n$ digit precision.• Compute the
$\nu _{ij}$ coefficients with at least $50+6n$ digit accuracy. (As long as $\delta$ is rational, the $\nu _{ij}$ parameters are rational numbers which can be obtained in “integer divided by integer” form without any precision loss).• Compute the
$\eta _j$ parameters according to (20) with $50+6n$ digit accuracy.• Store the
$\eta _j$ parameters with $20+3.4 m$ digit accuracy.• Compute the
$\beta _j$ parameters according to (20) with standard accuracy.• Store the
$\beta _j$ parameters with standard accuracy.
















NILT procedure:
• Read
$\eta _j$ with $20+3.4 m$ digit accuracy.• Read
$\beta _j$ with standard accuracy.• Compute
$h^{*}(\beta _j/T)$ with standard accuracy (if it does not incur significant ($>5$ digits) precision loss due to $h^{*}$).• Transform the resulting
$h^{*}(\beta _j/T)$ to $20+3.4 m$ digit accuracy representation• Compute
$\sum _{j=-m}^{m} ({\eta _j}/{T}) h^{*}({\beta _j}/{T})$ with $20+3.4 m$ digit accuracy.










Due to the large absolute value and the alternating sign of the  $\eta _j$ parameters, the final accuracy of the summation is going to be approximately
$\eta _j$ parameters, the final accuracy of the summation is going to be approximately  $20$ digits.
$20$ digits.
5.2. Accuracy of the NILT procedure
Approximating  $h(T)$ by
$h(T)$ by  $h_{m,n}(T)$ contains two approximation errors, since
$h_{m,n}(T)$ contains two approximation errors, since  $h(T)\approx h_{n}(T)$ and
$h(T)\approx h_{n}(T)$ and  $h_n(T)\approx h_{m,n}(T)$, where
$h_n(T)\approx h_{m,n}(T)$, where  $h_n(T) \triangleq \int _{t=0}^{\infty } h(t T) f_n(t) \,\mathrm {d}t$. The difference between
$h_n(T) \triangleq \int _{t=0}^{\infty } h(t T) f_n(t) \,\mathrm {d}t$. The difference between  $h(T)$ and
$h(T)$ and  $h_n(T)$ is due to the fact that
$h_n(T)$ is due to the fact that  $f_n(t)$ (the pdf of the chosen CME-R) differs from the Dirac impulse. We can measure the accuracy of this approximation independent of
$f_n(t)$ (the pdf of the chosen CME-R) differs from the Dirac impulse. We can measure the accuracy of this approximation independent of  $h(T)$ using the
$h(T)$ using the  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $f_n(t)$. As discussed in Section 4, the
$f_n(t)$. As discussed in Section 4, the  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $f_n(t)$ changes according to
$f_n(t)$ changes according to  $n^{-1.85}$. The exact values of the
$n^{-1.85}$. The exact values of the  $\mathrm {SCV}$ for
$\mathrm {SCV}$ for  $n=1,\ldots ,12$ are given in Table 1 and for higher orders in Figure 6.
$n=1,\ldots ,12$ are given in Table 1 and for higher orders in Figure 6.
The difference between  $h_n(T)$ and
$h_n(T)$ and  $h_{m,n}(T)$ is due to the approximation of
$h_{m,n}(T)$ is due to the approximation of  $f_n(t)$ by
$f_n(t)$ by  $f_{m,n}(t)$. Since
$f_{m,n}(t)$. Since  $f_n(t)$ is such that
$f_n(t)$ is such that  $\int _t f_{n}(t) \,\mathrm {d}t=\int _t t f_{n}(t) \,\mathrm {d}t=1$, we used
$\int _t f_{n}(t) \,\mathrm {d}t=\int _t t f_{n}(t) \,\mathrm {d}t=1$, we used  $|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|$ as an error measure of the approximation and considered
$|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|$ as an error measure of the approximation and considered  $|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}$ to be appropriate accuracy for the
$|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}$ to be appropriate accuracy for the  $h_n(T)\approx h_{m,n}(T)$ approximation. For a given
$h_n(T)\approx h_{m,n}(T)$ approximation. For a given  $n$, the accuracy of the
$n$, the accuracy of the  $h_n(T)\approx h_{m,n}(T)$ approximation is determined by
$h_n(T)\approx h_{m,n}(T)$ approximation is determined by  $\delta$ and
$\delta$ and  $m$. According to our numerical experiences, for fixed
$m$. According to our numerical experiences, for fixed  $n$ and
$n$ and  $\delta$, the modification of
$\delta$, the modification of  $m$ has two contradicting effects. When
$m$ has two contradicting effects. When  $m$ increases, the
$m$ increases, the  $|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|$ measure of the error decreases, but the precision loss of the computation increases.
$|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|$ measure of the error decreases, but the precision loss of the computation increases.
The choice of  $\delta$ is also a trade-off. A lower
$\delta$ is also a trade-off. A lower  $\delta$ value requires a lower
$\delta$ value requires a lower  $m/n$ ratio, which means a more efficient NILT, because the order of the NILT is
$m/n$ ratio, which means a more efficient NILT, because the order of the NILT is  $M=2m+1$ (the Laplace transform function needs to be evaluated in
$M=2m+1$ (the Laplace transform function needs to be evaluated in  $2m+1$ points), while the
$2m+1$ points), while the  $\mathrm {SCV}$ of
$\mathrm {SCV}$ of  $f_{m,n}(t)$ is characterized by
$f_{m,n}(t)$ is characterized by  $n$. That is, decreasing
$n$. That is, decreasing  $\delta$ is beneficial for efficient NILT, but using a lower
$\delta$ is beneficial for efficient NILT, but using a lower  $\delta$ value also increases the numerical precision loss.
$\delta$ value also increases the numerical precision loss.
Since the quantitative effect of  $m$ and
$m$ and  $\delta$ depends on multiple factors, we used numerical investigations to determine the highest
$\delta$ depends on multiple factors, we used numerical investigations to determine the highest  $\delta$ value that provides the required accuracy (
$\delta$ value that provides the required accuracy ( $|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}$). Table 2 summarizes the results. Our numerical investigations indicate that for a given
$|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}$). Table 2 summarizes the results. Our numerical investigations indicate that for a given  $m$ value the best choice of
$m$ value the best choice of  $\delta$ is the one provided in the table, because using a lower
$\delta$ is the one provided in the table, because using a lower  $m$ violates the
$m$ violates the  $|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}$ inequality and consequently the
$|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}$ inequality and consequently the  $h_n(T)\approx h_{m,n}(T)$ approximation is poor, while using larger
$h_n(T)\approx h_{m,n}(T)$ approximation is poor, while using larger  $\delta$ increases precision loss, thus the required precision exceeds the values reported in the previous section.
$\delta$ increases precision loss, thus the required precision exceeds the values reported in the previous section.
Table 2. The required number of points and their distances for accurate derivative approximation. The derivative approximation is assumed to be accurate when  $|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}.$
$|\int _t t f_{m,n}(t) \,\mathrm {d}t-1|<10^{-4}.$

Our recommended values of the parameters,  $\delta = {\lambda }/{20 m}$ and
$\delta = {\lambda }/{20 m}$ and  $m \approx 1.3n$, offer a potential compromise between efficiency and precision loss.
$m \approx 1.3n$, offer a potential compromise between efficiency and precision loss.
6. Numerical experiments
To investigate the properties of the proposed NILT method using CME-R, we compared it with other methods of the Abate–Whitt framework, namely the CME [Reference Horváth, Horváth, Al-Deen Almousa and Telek9], Euler [Reference Abate, Choudhury and Whitt2], and Gaver–Stehfest [Reference Stehfest14] methods. The CME method is an obvious choice, as the proposed method can be thought of as its real eigenvalue counterpart. The Euler method was chosen since, aside from the CME method, it had the best overall performance in the tests of [Reference Horváth, Horváth, Al-Deen Almousa and Telek9]. Finally, the Gaver–Stehfest method (referred to as the Gaver method in the following) was included because, unlike the CME and Euler method (and similar to the CME-R method) it can be implemented using real arithmetic. A short summary of these methods can be found in [Reference Horváth, Horváth, Al-Deen Almousa and Telek9].
First, in Figure 7, we examine the  $g_M(t)$ functions (defined in (16)) corresponding to the different NILT methods, to assess some of their characteristics. In each of the Abate–Whitt framework methods, if
$g_M(t)$ functions (defined in (16)) corresponding to the different NILT methods, to assess some of their characteristics. In each of the Abate–Whitt framework methods, if  $g_M(t)$ approximates the Diract impulse at
$g_M(t)$ approximates the Diract impulse at  $t=1$ well, then we expect the NILT method to provide a close approximation of
$t=1$ well, then we expect the NILT method to provide a close approximation of  $h(t)$. Figure 7 shows that the main peak of the Euler and Gaver methods is more concentrated than that of the CME and CME-R methods, respectively. On the other hand, contrary to the CME and CME-R methods, the
$h(t)$. Figure 7 shows that the main peak of the Euler and Gaver methods is more concentrated than that of the CME and CME-R methods, respectively. On the other hand, contrary to the CME and CME-R methods, the  $g_M(t)$ of the Euler and Gaver methods oscillate heavily and have high negative peaks, which leads to Gibbs oscillation for
$g_M(t)$ of the Euler and Gaver methods oscillate heavily and have high negative peaks, which leads to Gibbs oscillation for  $h(t)$ functions with discontinuity. A more in-depth discussion of these characteristics and their consequences can be found in [Reference Horváth, Horváth, Al-Deen Almousa and Telek9].
$h(t)$ functions with discontinuity. A more in-depth discussion of these characteristics and their consequences can be found in [Reference Horváth, Horváth, Al-Deen Almousa and Telek9].

Figure 7. The  $g_{M}(t)$ function of the CME-R method, which intends to approximating the Dirac impulse function and the associated functions of the Euler, Gaver, and CME methods for order
$g_{M}(t)$ function of the CME-R method, which intends to approximating the Dirac impulse function and the associated functions of the Euler, Gaver, and CME methods for order  $10$ and
$10$ and  $20$.
$20$.
To compare the previously mentioned NILT methods, we performed NILT using the above methods with orders  $M=30$, 50, 100 on the functions in Table 3. We considered two performance metrics: the 1-norm of the error of the NILT over the
$M=30$, 50, 100 on the functions in Table 3. We considered two performance metrics: the 1-norm of the error of the NILT over the  $[0,T]$ time interval, and the required numerical precision in digits for the calculations. To approximate the 1-norm of the error, we used that
$[0,T]$ time interval, and the required numerical precision in digits for the calculations. To approximate the 1-norm of the error, we used that
 \begin{equation} e_1=\|h-h_n\|_1=\int_0^{T} |h(t)-h_n(t)|\,\mathrm{d}t\approx \frac{1}{K}\sum_{k=1}^{K} \left|h\left(\frac{kT}K\right)-h_n\left(\frac{kT}K\right)\right|, \end{equation}
\begin{equation} e_1=\|h-h_n\|_1=\int_0^{T} |h(t)-h_n(t)|\,\mathrm{d}t\approx \frac{1}{K}\sum_{k=1}^{K} \left|h\left(\frac{kT}K\right)-h_n\left(\frac{kT}K\right)\right|, \end{equation}where  $h(t)$ is the original time domain function and
$h(t)$ is the original time domain function and  $h_n(t)$ is its NILT approximation. We used
$h_n(t)$ is its NILT approximation. We used  $T=5$ for the interval and
$T=5$ for the interval and  $K=100$ points to approximate the integral.
$K=100$ points to approximate the integral.
Table 3. The set of test functions used for the numerical evaluation of the NILT methods.

To evaluate the required precision, we determined what is the  $p_{\textrm {min}}$ minimal precision which guarantees that the error of the calculation is affected only by the error of the NILT method and not by the numerical precision. To do so, we performed the calculations with a sufficiently high
$p_{\textrm {min}}$ minimal precision which guarantees that the error of the calculation is affected only by the error of the NILT method and not by the numerical precision. To do so, we performed the calculations with a sufficiently high  $p_{\textrm {calc}}$ initial precision, and for every NILT method and order we subtracted from it the
$p_{\textrm {calc}}$ initial precision, and for every NILT method and order we subtracted from it the  $p_{\textrm {norm}}$ precision of the 1-norm error, that is,
$p_{\textrm {norm}}$ precision of the 1-norm error, that is,
 $$p_{\textrm{min}}=p_{\textrm{calc}}-p_{\textrm{norm}}+2,$$
$$p_{\textrm{min}}=p_{\textrm{calc}}-p_{\textrm{norm}}+2,$$where the extra two digits ensure that the first two digits of the 1-norm error are accurate. The results of the NILT computations can be found in Table 4. We can see that for smooth functions ( $e^{-t}$,
$e^{-t}$,  $\sin {t}$, i.e., those without discontinuity), the Gaver and the Euler method have the lowest 1-norm error (indicated by boldface numbers), and it also decreases rapidly with increasing order. The CME and the CME-R method are significantly worse in this regard, but if extremely high accuracy is not required, both are usable alternatives. For functions with discontinuity, the CME method gives the lowest 1-norm error, the Gaver and the CME-R method have similar performance, while the Euler method has slightly smaller error than the Gaver and CME-R methods for smaller orders, but the error increases for higher orders.
$\sin {t}$, i.e., those without discontinuity), the Gaver and the Euler method have the lowest 1-norm error (indicated by boldface numbers), and it also decreases rapidly with increasing order. The CME and the CME-R method are significantly worse in this regard, but if extremely high accuracy is not required, both are usable alternatives. For functions with discontinuity, the CME method gives the lowest 1-norm error, the Gaver and the CME-R method have similar performance, while the Euler method has slightly smaller error than the Gaver and CME-R methods for smaller orders, but the error increases for higher orders.
Table 4. 1-norm error of the ILT methods for the test functions.

For every computation, the CME method requires the lowest precision. When using the CME method, standard double precision is always sufficient in the examined cases. The Euler method has slightly higher precision requirements. It can be applied using double precision for moderate orders—if extremely high accuracy is not required. If we want to attain high accuracy (e.g.,  $10^{-16}$ for
$10^{-16}$ for  $h(t)=e^{-t}$ with order 50 NILT), naturally, we need to apply the appropriately high precision, as shown in Table 4. Double precision is not enough in case of the Gaver method, not even for lower orders. The required precision is around 20–30 digits for order
$h(t)=e^{-t}$ with order 50 NILT), naturally, we need to apply the appropriately high precision, as shown in Table 4. Double precision is not enough in case of the Gaver method, not even for lower orders. The required precision is around 20–30 digits for order  $10$ and 60–70 digits for order
$10$ and 60–70 digits for order  $100$ NILT, even if only lower accuracy is needed. The CME-R method demands the highest precision: approximately
$100$ NILT, even if only lower accuracy is needed. The CME-R method demands the highest precision: approximately  $50$ digits for order
$50$ digits for order  $10$ and as high as
$10$ and as high as  $170$ digits for order
$170$ digits for order  $100$ NILT.
$100$ NILT.
Based on the above, the CME method is the best overall NILT method, but the Euler method can be used with lower error, if it is known that the time domain function is smooth. However, both require complex arithmetic and the ability to evaluate the Laplace domain function in complex points. If only real arithmetic is available, or the Laplace domain function cannot be evaluated in complex points, then the Gaver method is more efficient than the CME-R method, because it requires lower precision and has smaller error for smooth functions. The CME-R method should be used if the CME and Euler methods cannot be used, and we want to avoid overshoot.
7. Conclusion
In this paper, we investigated concentrated matrix exponential distributions with real eigenvalues (CME-R). We gave an efficient numerical method for generating CME-R for high orders and obtained that for order  $N=2n+1$, the squared coefficient of variation is lower than
$N=2n+1$, the squared coefficient of variation is lower than  $n^{-1.85}$ (for sufficiently high orders).
$n^{-1.85}$ (for sufficiently high orders).
Using CME-R distributions, we also proposed an NILT method (referred to as the CME-R method). To summarize the presented numerical results, complex analysis based NILT methods are superior to the real analysis based ones. If only real analysis based NILT is available, then the Gaver method is less intensive numerically (lower precision arithmetic is required for its use than for CME-R), while due to the non-negativity of the matrix exponential function  $g_M(t)$, the CME-R method is free of Gibbs oscillation, gradually improving with the order, monotonicity and bound preserving.
$g_M(t)$, the CME-R method is free of Gibbs oscillation, gradually improving with the order, monotonicity and bound preserving.
Our C++ implementation for CME-R optimization and Mathematica implementation for CME-R-based NILT are available at http://webspn.hit.bme.hu/~telek/tools.htm.
Funding statement
This work is supported by the OTKA K-123914 and the NKFIH BME-NC-TKP2020 projects.
Appendix. Finite difference method
Starting from (17), to get a form similar to (14) we use the following steps:
 \begin{align} h(T) & \approx h_n(T) \triangleq \int_{t=0}^{\infty} h(t T) f_n(t) \,\mathrm{d}t = \int_{t=0}^{\infty} h(t T) \sum_{i=0}^{2n} a_{i} t^{i} e^{-\lambda t} \,\mathrm{d}t\nonumber\\ & = \int_{u=0}^{\infty} h(u) \sum_{i=0}^{2n} a_{i} \frac{u^{i}}{T^{i}} e^{-\lambda u/T} \frac{\mathrm{d}u}{T} = \sum_{i=0}^{2n} \frac{a_{i}}{T^{i+1}} \int_{u=0}^{\infty} h(u) u^{i} e^{-\lambda u/T} \,\mathrm{d}u\nonumber\\ & = \left.\sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i}}{T^{i+1}} \frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda/T}, \end{align}
\begin{align} h(T) & \approx h_n(T) \triangleq \int_{t=0}^{\infty} h(t T) f_n(t) \,\mathrm{d}t = \int_{t=0}^{\infty} h(t T) \sum_{i=0}^{2n} a_{i} t^{i} e^{-\lambda t} \,\mathrm{d}t\nonumber\\ & = \int_{u=0}^{\infty} h(u) \sum_{i=0}^{2n} a_{i} \frac{u^{i}}{T^{i}} e^{-\lambda u/T} \frac{\mathrm{d}u}{T} = \sum_{i=0}^{2n} \frac{a_{i}}{T^{i+1}} \int_{u=0}^{\infty} h(u) u^{i} e^{-\lambda u/T} \,\mathrm{d}u\nonumber\\ & = \left.\sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i}}{T^{i+1}} \frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda/T}, \end{align}because from  $h^{*}(s) = \int _{u=0}^{\infty } h(u) e^{-s u} \,\mathrm {d}u$ we obtain
$h^{*}(s) = \int _{u=0}^{\infty } h(u) e^{-s u} \,\mathrm {d}u$ we obtain
 $$\left.\frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda/T} = ({-}1)^{i} \int_{u=0}^{\infty} h(u) u^{i} e^{-\lambda u/T} \,\mathrm{d}u.$$
$$\left.\frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda/T} = ({-}1)^{i} \int_{u=0}^{\infty} h(u) u^{i} e^{-\lambda u/T} \,\mathrm{d}u.$$Compared to the form of the Abate–Whitt approximation in (14),  $h_n(T)$ in (A.1) contains the derivatives of
$h_n(T)$ in (A.1) contains the derivatives of  $h^{*}(s)$.
$h^{*}(s)$.
Based on the finite difference method of numerical differentiation, the  $i$th derivative of
$i$th derivative of  $h^{*}(s)$ can be obtained as
$h^{*}(s)$ can be obtained as
 $$\left.\frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda} \approx \sum_{j={-}m}^{m} \frac{c_{ij}}{\Delta^{i}} h^{*}(\lambda+j\Delta),$$
$$\left.\frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda} \approx \sum_{j={-}m}^{m} \frac{c_{ij}}{\Delta^{i}} h^{*}(\lambda+j\Delta),$$where  $i< 2m + 1$ and the
$i< 2m + 1$ and the  $c_{ij}$ coefficients can be obtained as discussed in [Reference Keller and Pereyra11].
$c_{ij}$ coefficients can be obtained as discussed in [Reference Keller and Pereyra11].
Based on this approximation of the derivatives and assuming  $\Delta =\delta /T$ and
$\Delta =\delta /T$ and  $m\geq n$, we have
$m\geq n$, we have
 \begin{align} h(T) & \approx h_{n}(T) = \sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i}}{T^{i+1}} \left.\frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda/T}\nonumber\\ & \approx h_{m,n}(T) \triangleq \sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i}}{T^{i+1}} \sum_{j={-}m}^{m} \frac{c_{ij}}{\delta^{i}/T^{i}} h^{*}(\lambda/T+j\delta/T)\nonumber\\ & = \sum_{j={-}m}^{m} h^{*}(\underbrace{(\lambda+j\delta)}_{\beta_j}/T) \underbrace{\sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i} c_{ij}}{\delta^{i}}}_{\eta_j}/T= \sum_{j={-}m}^{m} \frac{\eta_j}{T} ~h^{*}\left(\frac{\beta_j}{T}\right). \end{align}
\begin{align} h(T) & \approx h_{n}(T) = \sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i}}{T^{i+1}} \left.\frac{d^{i}}{ds^{i}} h^{*}(s)\right|_{s=\lambda/T}\nonumber\\ & \approx h_{m,n}(T) \triangleq \sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i}}{T^{i+1}} \sum_{j={-}m}^{m} \frac{c_{ij}}{\delta^{i}/T^{i}} h^{*}(\lambda/T+j\delta/T)\nonumber\\ & = \sum_{j={-}m}^{m} h^{*}(\underbrace{(\lambda+j\delta)}_{\beta_j}/T) \underbrace{\sum_{i=0}^{2n} ({-}1)^{i} \frac{a_{i} c_{ij}}{\delta^{i}}}_{\eta_j}/T= \sum_{j={-}m}^{m} \frac{\eta_j}{T} ~h^{*}\left(\frac{\beta_j}{T}\right). \end{align}