


Formation of the English plural typically involves affixing a /-z/ suffix to a noun. For most nouns, this /-z/ suffix undergoes predictable changes in phonological realization depending on the phonology of the segment that precedes it: after a sibilant fricative, the suffix takes a syllabic allomorph (e.g., ash [æʃ]–ashes [æʃ-əz]); after a voiced nonsibilant segment, it takes a voiced, nonsyllabic allomorph (e.g., rig [ɹɪɡ]–rigs [ɹɪɡ-z]); and after a voiceless nonsibilant segment, it takes a voiceless, nonsyllabic allomorph (e.g., cat [kæt]–cats [kæt-s]). In the majority of English plural nouns, then, the phonological shape of the plural suffix is determined by the phonology of the preceding segment, and the noun stem itself does not change.
However, there is a small set of nouns, all of which end in a voiceless anterior fricative, to which this /-z/ suffix attaches in an irregular way. Rather than the suffix assimilating to the stem-final segment, the stem-final segment assimilates to the suffix. These nouns show a pattern of rightward voicing assimilation, which I will henceforth call “stem-final fricative voicing.” Three examples are given in (1), (2), and (3), showing the three fricatives that undergo this alternation, /s f θ/.
(1) sg. house [hɑʊs]–pl. houses [hɑʊz-əz]
(2) sg. leaf [lif]–pl. leaves [liv-z]
(3) sg. path [pæθ]–pl. paths [pæð-z]
This voicing alternation affects only a subset of English nouns ending in /s f θ/: nouns such as kiss, cuff, and death do not undergo it (*[kɪz-əz], *[kʌv-z], *[dεð-z]).
Anecdotal reports indicate that stem-final fricative voicing occurs variably and may be being lost over time, yielding, for example, [hɑʊs-əz], [lif-s], and [pæθ-s] (Becker, Nevins, & Levine, Reference Becker, Nevins and Levine2012:236; Ringe & Eska, Reference Ringe and Eska2013:143). This would constitute a familiar process of regularization, or analogical leveling. This paper tests such reports of variation and change in the voicing of stem-final voiceless fricatives among the small set of English nouns that traditionally undergo this alternation. Specifically, I use large audio corpora to examine the phonological shape of these plural nouns in natural speech, aiming to answer the following questions:
1. Can we confirm previous anecdotal reports that stem-final fricative voicing is variable?
2. If yes, what social and linguistic factors condition the variation?
3. And is this variation part of ongoing change?
After summarizing the historical developments that led to present-day stem-final fricative voicing and outlining the methodology of the present study, I demonstrate that this voicing is indeed variable. Moreover, it shows phonological class-specific behavior by which /f/-final and /θ/-final nouns show stable variation in voicing in apparent time (though at different overall rates), while houses, the only plural of an /s/-final noun considered here, is rapidly losing voicing in apparent time. Additional factors that affect stem-final fricative voicing, in some cases interacting with the identity of the stem-final fricative itself, are the frequency of a noun in its plural form, the morphological complexity of a plural form, proper nounhood, voicing of a following segment, speaker level of education, and speaking style.
Following this, I argue that the fricative-specific and frequency-sensitive patterning of variable stem-final voicing is reminiscent of patterns seen in young children's production of irregular forms elsewhere in the English lexicon. Accordingly, I close by discussing the possible role of children's regularization errors in shaping the present-day patterns of stem-final fricative voicing in adult language.
BACKGROUND
History of stem-final fricative voicing
The voicing alternation presented in (1), (2), and (3) has its source in two characteristics of Old and Early Middle English, both of which have been lost in the present day (Lass, Reference Lass and Lass2000:142; Ringe & Eska, Reference Ringe and Eska2013:142). First, the plural suffix was uniformly the syllabic morpheme /-əs/, with none of the allomorphic alternations attested today. Second, there was a regular, allophonic process of voicing of anterior fricatives /f s θ/ intervocalically. As a result, nouns such as [wʊlf] ‘wolf’, [paθ] ‘path’, and [huːs] ‘house’ formed the regular plurals [wʊlv-əs] ‘wolves’, [pað-əs] ‘paths’, and [huːz-əs] ‘houses’. This voicing alternation was also observable elsewhere in the language, for instance in the formation of denominal verbs such as [bað-ən] ‘to bathe’ and [huːz-ən] ‘to house’ from the nouns [baθ] ‘bath’ and [huːs] ‘house’.
As Ringe and Eska (Reference Ringe and Eska2013:142–144) explained, a series of contact-induced and language-internal changes between the 12th and 15th centuries created a number of lexical exceptions to the productive rule of intervocalic anterior fricative voicing. These exceptions, which contained voiceless anterior fricatives in intervocalic position, likely led to the loss of intervocalic voicing as a productive rule. Nevertheless, a number of forms that were historically subject to the rule ([wʊlv-əs], [pað-əs], [huːz-əs], and so forth) preserved their voicing, presumably newly marked as exceptions themselves.Footnote 1 This means that, around the 15th century, stem-final fricative voicing in a plural form like wolves changed from having its source in a regular and productive rule of intervocalic voicing, to having its source in a lexical listing pairing the singular wolf with the voiced plural wolves, in a similar way to how the noun child in Present-Day English is lexically listed as having the exceptional plural children.
Presumably, speakers today still have an irregular rule voicing the stem-final fricative in the plural of this small set of exceptional nouns and a much more regular and productive rule that affects the plural /-z/ suffix in other plural forms. This paper addresses the extent to which the items in the irregular voicing set still undergo it today: in other words, whether analogical leveling with voiceless models has regularized them.
Present-day status of stem-final fricative voicing
Jespersen (Reference Jespersen1942:258–264), Lass (Reference Lass and Lass2000:145), and Ringe and Eska (Reference Ringe and Eska2013:143) all mentioned that at least some items in the voicing set voice only variably. Lass (Reference Lass and Lass2000:145) further described stem-final fricative voicing as “recessive,” implying that it may be being lost diachronically. However, the closest we get to an actual production study of present-day stem-final fricative voicing is a judgment study by Becker et al. (Reference Becker, Nevins and Levine2012). In this study, English-speaking subjects heard two plural forms for a number of /f/-final and /θ/-final nouns and were asked which they preferred: one with stem-final voicing (e.g., [pæðz] ‘paths’) or one without (e.g., [pæθs]). Stimuli included nouns that have been historically subject to stem-final fricative voicing in the plural (e.g., calf, bath) as well as nouns that have not (e.g., fife, cough), with this latter category including a number of polysyllabic items (e.g., giraffe, zenith). Becker et al. found significant effects of syllable count, stress pattern, and preceding vowel on speakers’ preferences for stem-final voicing: speakers prefer voicing in the plurals of monosyllabic items, items containing long vowels, and, when an item is polysyllabic, in iambs rather than trochees. However, Becker et al. did not separate out those items for which stem-final fricative voicing is attested historically (e.g., calf, bath) from those for which it is not (e.g., fife, cough, giraffe, zenith), and it is very possible that at least the monosyllabic effect is due to this confound: the stems that traditionally or standardly undergo stem-final fricative voicing, according to Jespersen (Reference Jespersen1942:258–264) and Ringe and Eska (Reference Ringe and Eska2013:143), are all monosyllables.
Becker et al. (Reference Becker, Nevins and Levine2012) also found no effect in their study of a number of factors that turn out to matter in the present study, namely the identity of the stem-final fricative, an item's frequency, its morphological complexity, and a speaker's age. This is perhaps unsurprising, since, to reiterate, they considered a larger set of nouns than just those that have been historically subject to stem-final fricative voicing.
As it stands, then, no study has examined the production of stem-final fricative voicing in natural speech. To answer the research questions listed in the introduction, this paper presents data from three large audio corpora of present-day American English speakers’ pronunciations of the words that are traditionally subject to stem-final fricative voicing.
METHODOLOGY OF THE CORPUS STUDY
Defining the variable
The set of nouns that undergo stem-final fricative voicing in the plural has changed over time. Some nouns have definitively left the class of those that undergo the alternation: for instance, Jespersen (Reference Jespersen1942:260) cited the archaic form cleves as a historical plural of cliff (with stem-final fricative voicing plus a vowel change, neither of which are attested in this form today). Others are noted by Jespersen as having joined the voicing set, including moth and scarf. Moreover, Becker et al. (Reference Becker, Nevins and Levine2012:236) cited anecdotal reports of stem-final fricative voicing in the plurals of giraffe and photograph and Hayes (Reference Hayes2011:195) of stem-final fricative voicing in the plurals of gulf, chief, and epitaph. Thus, it is very difficult to know a priori which nouns undergo fricative voicing in the plural without carrying out a corpus study of the pronunciation of the plurals of every /f/-final noun in English, if not also the /s/-final and /θ/-final ones.
This was untenable for the current paper. Instead, the decision was made to examine only the set of nouns identified by Jespersen (Reference Jespersen1942) as either variably or categorically undergoing stem-final fricative voicing in the plural. This restricts the present investigation to the maintenance or loss of fricative voicing from those items that were traditionally subject to it, rather than the present-day extension of fricative voicing to items that were not traditionally subject to it. The latter topic is nonetheless a question of considerable interest, as there are several reasons to suspect that it may be occurring. These include the anecdotal reports of expansion by Becker et al. (Reference Becker, Nevins and Levine2012) and Hayes (Reference Hayes2011) cited earlier, the historical precedent for such an expansion by forms like scarves, and a brief note by Jespersen (Reference Jespersen1942:264) that certain British English dialects may have widespread fricative voicing in the plurals of nouns that were not historically subject to the anterior fricative voicing rule, such as faces, places, and prices. However, this is a different question from that of maintenance or loss of fricative voicing among those nouns that traditionally underwent it, so I leave it for future research.
The 34 nouns listed in (4) were selected for study, due to Jespersen's (Reference Jespersen1942:258–264) identification of them as either categorically or variably undergoing stem-final fricative voicing in the plural.
(4) Nouns identified by Jespersen (Reference Jespersen1942:258–264) as undergoing stem-final fricative voicing in the plural
a. /f/-final: beef, calf, dwarf, elf, half, hoof, knife, leaf, life, loaf, oaf, roof, scarf, self, sheaf, shelf, staff (in the meaning ‘stick’), thief, turf, wharf, wife, wolf Footnote 2
b. /s/-final: house
c. /θ/-final: bath, cloth, lath, moth, mouth, oath, path, sheath, truth, wreath, youth
Throughout this paper, I refer to these nouns as “lexemes” and the three phonological groupings they form (/f/-final, /s/-final, /θ/-final) as “phonological subsets” or “classes.” In graphs and throughout the text, I present the lexemes given in (4) in their singular form. This is because standard spelling conventions require that plural forms of the /f/-final lexemes be spelled as if stem-final fricative voicing has applied, and this may be confusing in a paper that demonstrates that this voicing often in fact has not applied. Despite this choice, what is at issue in this paper is speakers’ production of the plural forms of these lexemes.
Data collection
Three corpora were selected for study:
• Switchboard (Godfrey & Holliman, Reference Godfrey and Holliman1997): A corpus of short telephone conversations between strangers on assigned topics, collected between 1991 and 1992. Switchboard consists of 2400 such conversations collected from 542 different speakers, amounting to over 250 hours of speech and approximately 3 million transcribed words.
• Fisher (Cieri, Graff, Kimball, Miller, & Walker, Reference Cieri, Graff, Kimball, Miller and Walker2004): Like Switchboard, a corpus of short telephone conversations between strangers on assigned topics, collected between 2002 and 2003. Fisher consists of over 11,000 such conversations, amounting to approximately 2,000 hours of speech.
• The Philadelphia Neighborhood Corpus (PNC, Labov & Rosenfelder, Reference Labov and Rosenfelder2011): A corpus comprising 40 years’ worth of sociolinguistic interviews with 318 different native Philadelphians, carried out by trained student fieldworkers at the University of Pennsylvania between 1973 and 2012. The PNC contains approximately 150 hours of speech and approximately 1.6 million transcribed words.
These corpora were chosen because they are large, transcribed, time-aligned, and all reflect conversational speech.
Transcripts of all three corpora were searched for plural forms of the 34 lexemes listed in (4). Where the presence or absence of stem-final fricative voicing is encoded in a plural form's spelling (i.e., for /f/-final lexemes, which vary in the orthography of their plurals between final <-ves> and final <-fs>), both possible spellings were searched for. All searches included a wildcard character preceding the lexeme to bring up single-word compound forms (e.g., werewolves, warehouses, tablecloths) where they occurred. A Praat script (Boersma & Weenink, Reference Boersma and Weenink2015) was then used to match each hit in a transcript to its corresponding occurrence in the audio for subsequent auditory coding (see the Dependent variable section).
Of the 34 lexemes listed in (4), no hits were found for the plurals of oaf, sheaf, staff, turf, wharf, lath, or sheath, so no data on these lexemes will be reported. One lexeme was additionally omitted from study: self. The plural of this item turned out to occur incredibly infrequently except as part of the anaphoric pronouns themselves, ourselves, and yourselves. As part of those pronouns, the lexeme was overwhelmingly frequent: 3854 instances of -selves pronouns across the three corpora compared to 41 instances of the bare plural selves. Such an imbalanced ratio of bimorphemic forms to monomorphemic forms is not found for any other lexeme in (4). The closest is cloth, which occurs six times in the data in a compound form (e.g., tablecloths) compared to one time in its bare form cloths, but a 6:1 ratio is a far cry from the 94:1 ratio displayed by selves. Self is thus an outlier among the lexemes in (4) for its overwhelming frequency in a compound plural form.
Additionally, a second characteristic makes self an outlier: the bimorphemic forms in which it overwhelmingly occurs are all function words (specifically, pronouns). No other lexeme in (4) is or forms part of a function word. For these reasons—its near-exclusive function word status, its near-exclusive bimorphemicity, not to mention its extreme frequency, dwarfing the second-most frequent plural form in the data, houses, by four times—self was omitted from study, as any one of these factors could potentially contribute to its being phonologically different from the other lexemes in (4).
Before auditory coding, search results were culled to omit items that were homographs with the plural forms under study but represented a different lexeme (e.g., the verb lives, the verb leaves). Similarly excluded from study were items where a string at the end of a plural form was a homograph with one of the plural nouns under study but bore no etymological relation to it (e.g., the moths in mammoths, the paths in psychopaths), again to ensure that the items under study were only those that were historically subject to voicing.
In all, analyzed here are 2361 tokens of the 26 lexemes retained from the 34 given in (4). Table 1 breaks this down by stem-final fricative.
Table 1. Total number of tokens obtained for each stem-final fricative

Coding
Dependent variable
Two undergraduate research assistants at the University of Manchester listened to every token in the data individually,Footnote 3 coding each one as voiced, voiceless, or reject (due to a token being unclear, ambiguous, or mistranscribed). They then met to compare their coding. Rates of agreement for their judgments of voiced versus voiceless are 88% (κ = .76) for each of Fisher and the PNC, and 84% (κ = .68) for Switchboard; these results reflect good reliability, according to Clopper (Reference Clopper, Di Paolo and Yaeger-Dror2011:190). The two coders then relistened to each token on which they disagreed and either arrived at an agreement or rejected the token from study. As such, the results presented here constitute only those instances in which both coders agreed on the voiced versus voiceless judgment.Footnote 4
It is well documented that so-called voiced consonants in English, especially word-final ones, may not be fully voiced articulatorily (see Davidson, Reference Davidson2016:35–36, for a recent review) and that perception of the so-called voiced/voiceless contrast in final consonants may be better attributed to the differing durations of prevoiced versus prevoiceless vowels than to the presence or absence of consonant voicing (Raphael, Reference Raphael1972). This means it is debatable whether the coders were actually coding vocal fold vibration or some other cue. Still, the high rate of agreement between them indicates that, whatever they were hearing, they were hearing the same thing. I continue to refer to the phenomenon under study here as “voicing,” with “voiced” and “voiceless” forms, while acknowledging that vocal fold vibration may not be the operative acoustic measure.
Independent variables
All tokens were coded for the following linguistic and social predictors of stem-final fricative voicing.
Identity of stem-final fricative
Irregular forms have been found to show class behavior, or subregularities, in first language acquisition (Yang, Reference Yang2002) and language processing (Regel, Opitz, Müller, & Friederici, Reference Regel, Opitz, Müller and Friederici2015). Thus, we can ask whether the set of lexemes that voice in the plural divides into phonological subsets: namely, whether /f/-final lexemes behave differently from /θ/-final lexemes and from the /s/-final lexeme house. Items were accordingly coded for the final fricative of their stem: /f/ (as in leaf, wolf), /s/ (exclusively in house), or /θ/ (as in bath, wreath).
Stem identity
Each token was coded for the lexical identity of its stem, to be incorporated as a random effect in statistical modeling (discussed further in the Morphological complexity section). For instance, houses, green houses, and frat houses were all coded as having the stem house.
Morphological complexity
Compound words typically take regular morphology even when their monomorphemic stems do not: hence, according to Pinker (Reference Pinker1994:141–144), the past tense of grandstand is grandstanded, not *grandstood, and the plural of lowlife is lowlifes, not *lowlives. Accordingly, we can hypothesize that stems that form the second part of a lexicalized compound will be less likely to voice than those that do not.
Given this, each plural instance of the lexemes in (4) was coded for whether it appeared as the second member of a lexicalized compound (e.g., housewives, birdhouses, tablecloths). This was assessed as follows: each time a plural form appeared as the second element of a noun–noun or adjective–noun pair, the pair (in its singular form) was looked up in the Oxford English Dictionary. If it appeared as an entry or subentry, it was coded as a lexicalized compound, regardless of the specifics of its orthography (hence two-word steak houses, hyphenated half-truths, and single word bookshelves were all coded as compounds, because they all appear as [sub]entries in the OED). In rare cases, a pair did not appear in the OED, but the speaker had uttered the pair with compound stress (Chomsky & Halle, Reference Chomsky and Halle1968:16), that is, more stress on the first element than the second. (Compare the stress pattern of the lexicalized compound gréen houses ‘glass buildings where plants are grown’ to that of the noncompound grèen hóuses ‘houses that are green’.) Pairs uttered with compound stress were also coded as compounds. Examples of items that were pronounced with compound stress but are not listed in the OED as lexicalized compounds are drop cloths and frat houses.
For all three phonological subsets (/f/-final items, /s/-final items, and /θ/-final items), it is more common in this data that a lexeme surfaces in its bare form than as part of a lexicalized compound (bare-to-compound ratio for /f/-final lexemes: 14:1, /s/-final lexemes: 6:1, /θ/-final lexemes: 4:1).
Proper noun
The Toronto hockey team is famously the Maple Leafs, not the Maple Leaves (Pinker, Reference Pinker1994:145). Like compounds, proper nouns are often exempt from irregular morphology. As such, we can hypothesize that proper nouns will be less likely to show stem-final fricative voicing than common ones, so each token was coded for whether it was part of a proper noun (e.g., Snow White and the Seven Dwarfs, Houses of Parliament) or not.
Frequency of lexeme in its plural form
Frequency plays a well-documented role in diachronic leveling and in synchronic regularization among child language learners, with low-frequency items more likely to regularize than high-frequency ones (Hooper, Reference Hooper and Christie1976; Phillips, Reference Phillips1984; Yang, Reference Yang2002). We can thus hypothesize that, if stem-final fricative voicing turns out to be variable, we will find a positive correlation between frequency and maintenance of voicing.
The frequency of each of the lexemes in (2) in its plural form was obtained from the SUBTLEXus corpus (Brysbaert & New, Reference Brysbaert and New2009), a corpus of word frequencies based on the subtitles of 8388 American television programs, amounting to 51 million words. Brysbaert and New found these frequency measures to do a better job of predicting lexical decision times for speakers of American English than any previously used frequency metrics.
Where a plural form could be spelled in two different ways depending on whether it has undergone stem-final fricative voicing or not (namely, any /f/-final lexeme, e.g., wolves ~ wolfs), frequencies of each of the two possible spellings were obtained and summed together. Unsurprisingly, given the fact that stem-final fricative voicing is standard in the plurals of most of the lexemes listed in (4a), the <-ves> spelling generally turned out to be much more frequent than the <-fs> spelling; sometimes the <-fs> spelling was not even attested in SUBTLEXus.
Frequencies were transformed to the Zipf scale presented in van Heuven, Mandera, Keuleers, and Brysbaert (Reference van Heuven, Mandera, Keuleers and Brysbaert2014). This scale takes the log10 of an item's frequency per billion words. As van Heuven et al. discussed, this provides an intuitive logarithmic scale from 1 (very low frequency) to 7 (very high frequency). To improve regression model convergence, Zipf values were centered around the median for statistical analysis.
It is important to note that for all items in the data, it is the plural frequency of the stem, not necessarily the plural frequency of the word, that is used to test for effects of frequency on variation and change in stem-final fricative voicing. That is, when a plural appeared as part of a lexicalized compound (e.g., steak houses, half-truths, bookshelves), it is the frequency of the stem in its plural form (houses, truths, shelves) that was used in modeling. This is because SUBTLEXus provides no frequency measures for two-word or hyphenated items, only items that are standardly written as a single word without a space. Steak houses and half-truths (and, for that matter, steakhouses and halftruths) do not appear in SUBTLEXus, so their frequencies cannot be obtained, even though the frequency of a conventionally single word compound like bookshelves can. For this reason, plural stem frequency rather than plural word frequency was used to test the role of frequency in stem-final fricative voicing.
Two of the lexemes in (4) turn out to be polysemous: calf, which can refer to either the animal or the muscle, and bath, which can refer to either the method of cleansing or the bathroom in a house (as in “three beds, two baths”). Both meanings of each lexeme appear in the data. SUBTLEXus does not provide separate frequency measures for each meaning of a lexeme, so the frequency of these items was simply coded as the general overall frequency of calves+calfs and baths, respectively.
Voiced counterpart
Paradigm uniformity effects have been found to play a role in synchronic variation: a word's phonetic realization can be influenced by the phonetic realization of morphologically related words (see Seyfarth, Reference Seyfarth2016:80–86, for a recent review). Accordingly, we can hypothesize that lexemes that have an invariably voiced counterpart elsewhere in the English lexicon (e.g., bath with /θ/ has the counterpart bathe with /ð/) will be more likely to show fricative voicing in the plural than lexemes that do not (e.g., path).
To test this, each token was coded for whether its stem has a voiced counterpart elsewhere in the English lexicon (typically a verb). Of the lexemes listed in (4), the following were identified as having a voiced counterpart: bath (bathe), calf (calve), cloth (clothe), half (halve), house (house [v.]), life (live [v.], live [adj.]), mouth (mouth [v.]), shelf (shelve), thief (thieving, thievery), wreath (wreathe).
Voicing of following segment
Devoicing of English /z/ is well attested in two environments: phrase-finally (e.g., leaves ‖), and before a following voiceless obstruent (e.g., leaves fall) (Myers, Reference Myers2010; Smith, Reference Smith1997). This means that there may be instances in which a speaker intends to utter a form with stem-final fricative voicing, but, due to devoicing of the /z/ plural suffix followed by concomitant devoicing of the stem-final fricative that precedes it (itself due to English phonotactic restrictions on voicing agreement in final obstruent clusters [Hayes, Reference Hayes2011:134]), the token comes out sounding as if voicing was not applied. So, we can hypothesize that plural nouns that occur phrase-finally or before a voiceless consonant will be less likely to have been heard as having stem-final fricative voicing than plural nouns that occur before a voiced segment. To this effect, tokens were coded for whether the first segment of the word following the plural noun was voiced or voiceless or whether there was no following word (due to the speaker pausing or ending their turn). Voiced/voiceless coding was obtained automatically from the CMU Pronouncing Dictionary 0.7 (Weide, Reference Weide2008); if a word was not in the dictionary, voicing was input by hand.
It is worth noting that we would expect cross-word assimilatory devoicing to be at play for /f/-final and /θ/-final items, but not for tokens of houses and its derivatives. In houses, a vowel separates the stem-final fricative from the plural /z/ suffix. Even if the /z/ suffix devoices, we would not expect concomitant devoicing of the stem-final fricative in house, which does not form a final obstruent cluster with the plural suffix.
Speaker year of birth
Speaker year of birth, as recorded in each corpus, was examined as a way of assessing change in apparent time. This measure was centered on the median and rescaled to decades to facilitate regression modeling and interpretation.
In analyzing the data for potential change in progress, the question arose of whether to use speaker year of birth or speaker age at recording (i.e., year of recording − speaker year of birth) as the relevant measure. This question does not arise in the typical apparent-time study, where data comes from recordings taken over a short period of time, and year of birth and age at recording effectively share a one-to-one mapping. But by compiling the 40 years of interviews in the PNC with Switchboard and Fisher, we effectively conflate both real and apparent time. A speaker born in 1960 who was interviewed in the PNC in 1975 would have been 15 years old at the time of recording, whereas a speaker born in 1960 but interviewed in 2002 for Fisher (or the PNC, for that matter) would have been 42. If stem-final fricative voicing is subject to age-grading—changes within individuals as they age of a variable that is diachronically stable in the community (Sankoff, Reference Sankoff, Ammon, Dittmar, Mattheier and Trudgill2005:1003)—then conflating data from a 15-year-old speaker and a 42-year-old speaker simply because both were born in 1960 would lead us to lose valuable information.
However, there is no a priori reason to believe that stem-final fricative voicing is subject to age-grading. As Chambers (Reference Chambers2009:201) observed, age-graded changes are rare; moreover, classic age-graded variables are those where one variant bears a clear and strong social evaluation in the community, such as [ɪŋ] ~ [ɪn] variation and negative concord (Labov, Reference Labov2001:chap. 3). Overt prescriptions concerning stem-final fricative voicing are not attested in the same way that they are for these variables: this variation seems to be generally below the radar, so it is unlikely that it is age-graded, or that we are in danger of obscuring any age-related pattern when we analyze the data by speaker date of birth.Footnote 5
Additionally, data from the PNC only make up 16% of the total data analyzed here: it is a small corpus compared to Switchboard and Fisher. Indeed, 87% of the data in the present study was collected between 1991 and 2004. Despite the inclusion of PNC data, the present study is effectively an apparent-time analysis over a short span of 13 years. Still, where I examine potential change in progress, I also confirm that any year-of-birth effect present in the overall data set is also present in the subset of data collected between 1991 and 2004, to get as close to a true apparent-time study as possible without dramatically reducing token counts.
Speaker sex
Each corpus reported each speaker's sex as female or male. One speaker, from Fisher, whose sex was given as not available was omitted.
Speaker level of education
Fisher and the PNC report speaker education level in years of schooling, but Switchboard reports it on a four-point scale (less than high school, less than college [but not less than high school], college, more than college).Footnote 6 This meant that speaker education levels for Fisher and PNC speakers had to be coerced onto Switchboard's scale. To do this, speakers whose years of schooling was given as 8 or fewer were coded as “less than high school,” 12 or fewer as “less than college,” 16 or fewer as “college,” and greater than 16 as “more than college.” This was further coerced into “less than college” (“less than high school” + “less than college”) versus “college or more” (“college” + “more than college”) to deal with small token counts and model convergence problems.Footnote 7
Corpus
Corpus (PNC, Switchboard, or Fisher) was included as a fixed-effect predictor as the different conversational settings of the PNC (sociolinguistic interviews) versus the other two corpora (phone conversations) may result in different patterns of variation.
Statistical modeling
Statistical modeling of the data was carried out using mixed-effects logistic regression in R (R Core Team, 2017) via the lme4 package (Bates, Mächler, Bolker, & Walker, Reference Bates, Mächler, Bolker and Walker2015). Modeling for this study had to be undertaken with care, for a number of reasons. First, token counts are not large, especially for /θ/-final lexemes (Table 1). As a result, particularly complex statistical models (including more than one or two interactions) typically failed to converge. Additionally, a downside of working with corpus data is that not all independent variables will be consistently coded or recorded across the different corpora. This meant that occasionally high-dimension coding had to be reduced to a lower dimension, as in the example of speaker level of education, where years of schooling in Fisher and the PNC had to be coerced to Switchboard's four-point scale.
Modeling proceeded as follows. The data from the three phonological subsets (/f/-final, /s/-final, /θ/-final) was pooled and analyzed in a model that was as maximal as possible while still resulting in successful convergence. This model included all fixed-effect predictors enumerated in the previous section. It also included a random effect of item. For /f/-final and /θ/-final items, this random effect coded for the stem of the word recorded for that data point (e.g., bath, path, knife, leaf).Footnote 8 For /s/-final items, this random effect coded for the actual word recorded, even if it was a lexicalized compound (e.g., firehouse, opera house, outhouse). This is because all /s/-final items have the same stem—house—so using stem as the random effect for /s/-final items, as was done for /f/-final and /θ/-final items, would create statistically problematic isomorphy with the fixed effect of stem-final fricative identity.
A random effect of speaker was not included, because the data in this study come from 1506 different speakers; the mean number of tokens per speaker in the data is 1.6 and the median is 1. Random speaker effects are meant to prevent individual speakers who contributed many tokens to a data set from erroneously skewing the results (Johnson, Reference Johnson2009), but this single-speaker influence is hardly possible in a data set where no speaker contributed a predominance of tokens.
Then, each fixed-effect predictor was assessed for significance in the pooled data as follows. A base model including only the random intercept of item was compared to a model containing that same random intercept and one fixed-effect predictor from the full model in a chi-square test comparison of models using R's analysis of variance function. (A predictor that achieved a large effect size and statistically significant p-value in the full model was selected for this step.) This one-predictor model was then compared to a second model containing that same fixed-effect predictor plus one more (again, another predictor that appeared to be accounting for a considerable amount of variation based on the full model) in another chi-square test analysis of variance model comparison. Subsequent comparisons proceeded in this way until all fixed-effect predictors had been tested for the significance of their contribution. The results of this set of comparisons allowed the researcher to create a final model, one that contained only those predictors that made a significant (p < .05) contribution to the model.Footnote 9
Because irregular forms often show phonological class behavior, it was important to assess whether any predictors that affected variation and change in the pooled data operated in the same way on each phonological subset: that is, whether /f/-final lexemes, /s/-final lexemes, and /θ/-final lexemes all patterned in the same way. Including multiple interactions between stem-final fricative identity and the other predictors of interest resulted in pervasive model convergence difficulties. As a result, in addition to the pooled model, separate models were fitted for /f/-final lexemes, /θ/-final lexemes, and houses and its derivatives.
Throughout the Results section, I discuss the effect of each predictor on the pooled data, then enumerate whether this holds for the three different phonological subsets (/f/-final, /s/-final, and /θ/-final).
RESULTS
General pattern
Rates of stem-final fricative voicing by identity of stem-final fricative are plotted in Figure 1. Quite generally, we can see from this figure that stem-final fricative voicing in the set of lexemes studied here is indeed variable: for no phonological subset does the rate of voicing ever exceed 85%.

Figure 1. Rate of stem-final fricative voicing by identity of stem-final fricative.
Stem-final fricative voicing rate also clearly varies according to the identity of the stem-final fricative itself: the historically regular voicing rule has fragmented into differently variable rules for the three phonological subsets. The /s/-final and /θ/-final subsets both undergo fricative voicing at a significantly lower rate than the /f/-final subset (/s/-final: β = −.98, p = .007; /θ/-final: β = −.99, p = .01).
Lexeme specificity
Figure 2 breaks down the data of Figure 1 by lexeme. There is one dot for each lexeme studied, sized by the number of tokens of that lexeme in the data. The log10 of the token count for each lexeme was taken to better visualize vastly different token counts. Lexemes have been sorted from highest to lowest voicing rate. In cases of polysemy, lexemes with different meanings have been plotted separately.
We see from Figure 2 that although /f/-final lexemes (black dots) do undergo stem-final fricative voicing at an overall higher rate than lexemes ending in /θ/ or /s/, not all /f/-final lexemes voice at a uniformly high rate: the lexemes loaf, calf (with its ‘muscle’ meaning), and roof all voice 50% of the time or less.Footnote 10
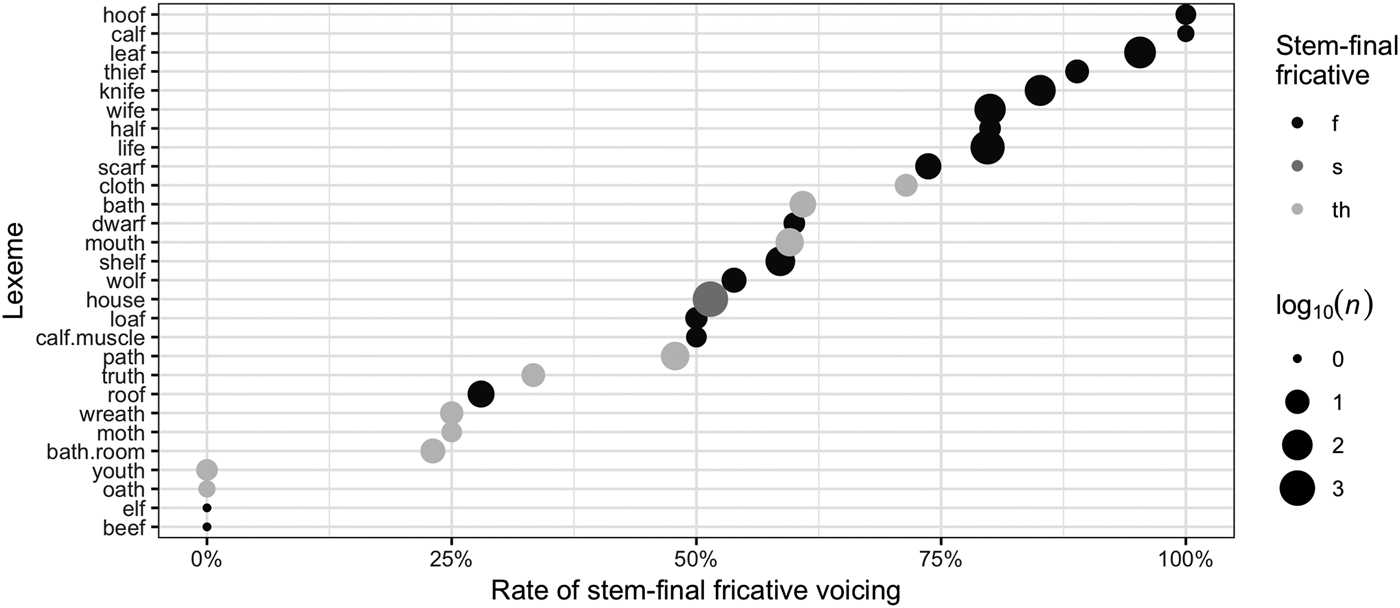
Figure 2. Rate of stem-final fricative voicing by lexeme. Dot size reflects the log10 of the number of tokens of that lexeme in the data. Lexemes have been sorted from highest to lowest voicing rate.
Figure 2 does show, though, that all /θ/-final lexemes (lightest gray dots) undergo fricative voicing at a fairly low rate. No /θ/-final lexeme shows more than 75% voicing; the highest is cloth, voicing at a rate of 71% (though n = 7).
Figure 2 also shows that the different meanings of polysemous lexemes do not necessarily undergo stem-final fricative voicing at the same rate. For instance, we see considerably different voicing rates for calf with the meaning ‘animal’ versus calf with the meaning ‘muscle’ (100% versus 50%, though n = 2 and 4, respectively), and bath with the meaning ‘method of cleansing’ versus bath as an abbreviated form of bathroom, as when describing the number of rooms in a house (61% versus 23%; n = 23 and 13, respectively).
Overall, we see general effects of more voicing across the board of /f/-final lexemes and less voicing of /θ/-final lexemes, but also lexeme-specific behavior within those phonological subsets. This motivates the inclusion of a random effect of lexeme in the logistic regression models used here, as well as testing for the role of other lexeme-specific predictors, namely frequency.
Frequency of lexeme in its plural form
A first indication that the plural frequency of a lexeme may be playing a role in stem-final fricative voicing variation is the finding, presented in the Lexeme specificity discussion, that /f/-final lexemes voice more than /θ/-final lexemes do. The plural forms of the /f/-final lexemes in this data are on average more frequent than the plural forms of the /θ/-final lexemes. (Average Zipf scale frequency, /f/-final: 3.56, /θ/-final: 3.06.) Indeed, as Figure 3 demonstrates, the lexemes in this data with the highest plural form frequency all end in /f/ (apart from the lone /s/-final lexeme house).

Figure 3. Rate of stem-final fricative voicing by frequency of plural form. One dot per lexeme. Dot size reflects the log10 of the number of tokens of that lexeme in the data.
Figure 3 plots the rate of stem-final fricative voicing for each lexeme by the frequency of that lexeme, in its plural form, on the Zipf scale.Footnote 11 This allows us to visualize the role of plural form frequency within the two categories of /f/-final and /θ/-final lexemes.
Plural form frequency has a significant positive effect on stem-final fricative voicing in the data overall (β = .82, p = .001), as well as when we subset out the data by stem-final fricative (/f/-final: β = .94, p = .015; /θ/-final: β = 1.07, p = .032). In all cases where frequency achieves significance, its coefficient is positive; that is, the more frequent the plural form of a lexeme is, the more its final fricative voices in the plural.
Overall, then, we see two effects of frequency in the data: (i) on a macro level, /f/-final lexemes, whose plurals are on average more frequent than those of /θ/-final lexemes, voice more; (ii) within the subsets of /f/-final and /θ/-final lexemes, lexemes whose plurals are more frequent are more likely to voice.
However, it is important to note that the frequency–voicing correlation is not perfect. Houses has a Zipf scale frequency of 4.28—higher than the plurals of many /f/-final lexemes—yet it does not display a concomitantly high rate of voicing. I return to this point in the Discussion section.
Morphological complexity
Figure 4 plots the rate of fricative voicing by the identity of a lexeme's final fricative and whether it appeared as part of a morphologically complex form in order to assess whether stem-final fricative voicing is indeed less likely in compounds (Pinker, Reference Pinker1994:141–144).

Figure 4. Rate of stem-final fricative voicing by identity of stem-final fricative and item's compound status.
Morphological complexity is a significant negative predictor of stem-final fricative voicing in the pooled data (β = −.68, p = .003), but this effect turns out to be present in the /f/-final subset only (β = −1.15, p = 6.1 × 10−5); it does not reach significance for the /s/-final or /θ/-final subsets. Only in the plurals of /f/-final lexemes, then, do we find morphological complexity disfavoring voicing.
Why should this be fricative-specific? Pinker's (Reference Pinker1994:143) proposal for why a compound like lowlife does not get irregular plural morphology (*lowlives) was that a lowlife is a type of person, not a type of life; for this reason, the irregular morphology of the component life does not percolate up to the compound. Are there more idiomatic /f/-final compounds than /s/-final or /θ/-final compounds? In fact, this appears to be the case. The disfavoring effect of morphological complexity in the /f/-final subset is driven entirely by four items: lowlife, bookshelf, and two compounds that are also proper nouns: Timberwolves (the Minnesota basketball team) and Maple Leafs (the Toronto hockey team). Omitting these four items from the /f/-final data eliminates the significant effect of morphological complexity, even though a large number of compound forms remain (e.g., exacto knife, pocket knife, personal life, housewife, werewolf, bay leaf). The role of proper noun–hood in blocking voicing will be discussed next; as for lowlife and bookshelf, it appears that speakers must be failing to decompose them, as Pinker proposed. (A bookshelf is perhaps seen as a piece of furniture rather than a type of shelf.) So, morphological complexity does play a role in blocking stem-final fricative voicing, but only in those cases in which a compound is opaque. The large number of transparent /s/-final compounds (e.g., birdhouse, courthouse, dollhouse, firehouse, steakhouse, townhouse, warehouse) and /θ/-final compounds (e.g., tablecloth, bike path, career path, half-truth) prevent the emergence of a similar disfavoring effect of morphological complexity in those subsets.
Proper noun status
Pinker (Reference Pinker1994:145) proposed that speakers will be unlikely to apply irregular morphology to a proper noun because what is pluralized is a name, not a noun, and a plural must be based on a noun, rather than a name, in order to receive that noun's irregular morphology. Stem-final fricative voicing by an item's proper noun status is plotted in Figure 5. /θ/-final items are not included as no /θ/-final items appeared in the data as proper nouns.

Figure 5. Rate of stem-final fricative voicing by identity of stem-final fricative and item's proper noun status.
Token counts are very imbalanced; proper nouns are rare in the data (20 tokens out of a total of 2361, and all but two are /f/-final). However, proper noun status is a significant, negative predictor of stem-final fricative voicing in the pooled data (β = −1.65, p = .004) and in the /f/-final subset (β = −2.06, p = .001).
The proper nouns ending in /f/ in this data are primarily instances of three lexicalized forms: Snow White and the Seven Dwarfs (a movie title that, in its published form, is not spelled with stem-final fricative voicing), Maple Leafs (the Toronto hockey team, which also has no stem-final fricative voicing in its official spelling), and Timberwolves (the Minnesota basketball team, which does have stem-final fricative voicing in its official spelling). Despite the spelling of Timberwolves, however, 80% of tokens of that team name were produced without stem-final fricative voicing (n = 5). Pinker's proposal appears to be upheld, then, even when failure to apply irregular morphology contrasts with an official codified spelling.
Voicing of following segment
Figure 6 examines whether there is less audible voicing of fricatives that precede a voiceless segment or a pause. Indeed, in the pooled data, we find negative effects on stem-final fricative voicing of a following voiceless segment (β = −.58, p = 1.12 × 10−4) and a following pause (β = −.41, p = .003): just as predicted, stem-final fricative voicing is heard less often in these two environments compared to when a plural noun precedes a voiced segment.

Figure 6. Rate of stem-final fricative voicing by identity of stem-final fricative and voicing of following segment.
This same pattern is found in the /f/-final subset (effect of a following voiceless segment compared to a following voiced one: β = −1.23, p = 1.5 × 10−7; effect of no following segment: β = −.49, p = .029). In the /θ/-final subset, we also find a negative effect on stem-final fricative voicing of a following pause compared to a following voiced segment (β = −1.33, p = .016), though the environment of a following voiceless segment does not reach significance; this is consistent with Smith's (Reference Smith1997) finding that phrase-final is a stronger environment for devoicing than prevoiceless consonant is. Surprisingly, the effect of phrase-finality on stem-final fricative voicing is even attested in houses and its derivatives (β = −.38, p =.043), where assimilation of the stem-final fricative to a devoiced plural suffix is not expected to occur, given the intervening vowel. The effect is weak, though; it could be representative of rare cases in which devoicing extends all the way through the vowel of the plural suffix to the stem-final fricative.
Given this, it appears that phrase-final and prevoiceless contexts underestimate the rate of application of stem-final fricative voicing. We must assume that some of the tokens in these contexts that were heard by coders as voiceless actually had stem-final fricative voicing applied to them, but that this voicing was effectively “undone” by the devoicing of final /z/ and the spreading of this voicelessness to the stem-final fricative. By contrast, because there is no evidence from the literature that a voiced word-initial consonant can cause a voiceless consonant that precedes it to voice (Jansen, Reference Jansen2007; Myers, Reference Myers2010), we have no reason to believe that any tokens in prevoiced environments that were coded as having stem-final fricative voicing actually did not have that voicing underlyingly and only gained it via assimilation. Prevoiced tokens thus give us the most accurate representation of the rate of stem-final fricative voicing in this data. However, because omitting all tokens in other environments would restrict the data too severely, I retain them, but include the important predictor of following segment voicing when modeling.
Paradigm uniformity
Figure 7 shows the rate of stem-final fricative voicing by the identity of the stem-final fricative and whether a lexeme has a voiced fricative-final counterpart in the lexicon or not. This predictor tests whether, among /f/-final lexemes, the plurals of calf, half, life, shelf, and thief show stem-final fricative voicing at a higher rate than the plurals of beef, dwarf, elf, hoof, knife, leaf, loaf, roof, scarf, wife, or wolf; and, among /θ/-final lexemes, whether the plurals of bath, cloth, mouth, and wreath show stem-final fricative voicing at a higher rate than the plurals of moth, oath, path, truth, or youth. /s/-final items are not plotted, as they represent a single lexeme (house) for which there is a voiced counterpart.

Figure 7. Rate of stem-final fricative voicing by identity of stem-final fricative and presence of voiced fricative-final counterpart in the lexicon.
Though it looks like this factor could be having the predicted effect for /θ/-final items, it turns out not to be a significant predictor for that subset of data, nor for /f/-final items or for the data pooled across the two stem-final fricatives. There is no evidence that paradigm uniformity plays a role in stem-final fricative voicing variation.
Year of birth
Figure 8 shows the rate of stem-final fricative voicing by the identity of the stem-final fricative and a speaker's year of birth. We see, first of all, that the trend line for the /f/-final subset is effectively flat. The trend line for the /s/-final subset is pitched downward, reflecting less stem-final fricative voicing of houses and its derivatives among speakers born more recently. The trend line for the /θ/-final subset appears nearly parallel to that for the /s/-final subset, but the shaded confidence interval is very wide in the early years and could just as well accommodate a flat line.

Figure 8. Rate of stem-final fricative voicing by identity of stem-final fricative and speaker's year of birth. Trend lines represent generalized linear smooths with 95% confidence intervals shaded in gray. Dot size reflects the number of tokens from that birth year + stem-final fricative combination in the data.
In the pooled data, speaker year of birth is a significant, negative predictor, with a β of −.16 (reflecting the change in log-odds of stem-final fricative voicing with each decade of speakers born since 1960) and a p-value of 2 × 10−6. This holds even when we restrict the data to only those tokens collected in the period from 1991 to 2004, when the bulk of the data in this study was collected, giving a more accurate picture of the apparent-time trend (β = −.18, p = 1.8 × 10−5).
However, this apparent-time change does not reach significance in the /f/-final or /θ/-final subsets on their own. It is only in houses and its derivatives that the change is concentrated (β = −.24, p = 10−7).Footnote 12
What we see, then, is that the historical stem-final fricative voicing rule has fragmented. It remains robust for /f/-final lexemes. It applies at only a low rate—and, as far as these data show, a stable rate—for /θ/-final lexemes. And in houses and its derivatives, it is being lost in apparent time. Young speakers’ voicing rate for the plural of house is much more in keeping with their rate for the plurals of bath or mouth than their (near-categorical) rate for the plurals of wolf or life.
External factors: education, corpus, sex
Two external factors achieve significance in the pooled data, but their effects turn out to be driven by the houses subset. These are a speaker's education level (coded as “less than college” versus “college or more”) and the corpus from which data was collected (Switchboard, Fisher, or PNC). Both are plotted in Figure 9 (education on the left, corpus on the right; speakers whose education level was unknown or otherwise not coded have been omitted from the left panel). In both the pooled data and the houses subset, stem-final fricative voicing is disfavored by speakers who have no college education (pooled data: β = −.48, p = 2.8 × 10−5; houses: β = −.74, p = 3 × 10−6) and by speakers in the PNC (pooled data: β = −1.02, p = 3 × 10−10; houses: β = −1.08, p = 3 × 10−8).

Figure 9. Rate of stem-final fricative voicing by identity of stem-final fricative, speaker's education level (left), and corpus (right).
Recall that the houses subset is the only phonological subset that shows change in apparent time, away from stem-final fricative voicing. What these results indicate is that this change is led by less educated speakers and is similarly more advanced among speakers in the PNC. Taking education as a proxy for social class, and bearing in mind that the at-home, sociolinguistic interviews of the PNC are a less formal setting than the between-strangers, assigned-topic, over-the-phone conversations of Switchboard and Fisher, this is what we would expect from a change from below: led by speakers from lower social classes and with the innovative, nonstandard variant used more in informal speech (Labov, Reference Labov2001).
Given this, then, it is surprising that there is not a concomitant strong effect in the houses data of speaker sex. Figure 10 plots the rate of stem-final fricative voicing by stem-final fricative and sex. There appears to be a slight effect of more stem-final fricative voicing among men, and indeed this does surface in the regression on the pooled data (β = .22, p = .028). But it does not reach significance in any of the three phonological subsets; the closest it gets is a borderline effect in /f/-final items (β = .33, p = .056). Still, more use of the innovative variant (that is, nonapplication of voicing) by women is what we would expect in the case of a change in progress away from stem-final fricative voicing, even if the effect is not demonstrated in the subset of data where change is most robust.

Figure 10. Rate of stem-final fricative voicing by identity of stem-final fricative and speaker sex.
Summary
This paper started out with three research questions, which I answer here by summarizing the results.
1. Can we confirm previous anecdotal reports that stem-final fricative voicing is variable?
2. If yes, what social and linguistic factors condition the variation?
3. And is this variation part of ongoing change?
The answer to the first question is yes. This section has demonstrated that stem-final fricative voicing is now variable in all three phonological subsets of lexemes whose plurals historically underwent it: /f/-final lexemes, as in wolf; the /s/-final lexeme house; and /θ/-final lexemes, as in bath. Some lexemes were already attested by Jespersen (Reference Jespersen1942) as being variable in their voicing (e.g., roof, path, youth), but we additionally see present-day variability in a number of lexemes for which Jespersen did not mention it (e.g., shelf, house). This study is the first to provide empirical data on variation in speakers’ production of the plural forms of these items.
There is an additional question that demands further investigation, concerning whether stem-final fricative voicing has expanded to any lexemes that did not traditionally undergo it, as indicated anecdotally by Becker et al. (Reference Becker, Nevins and Levine2012) and Hayes (Reference Hayes2011). Indeed, I note that a voiced token of psychopaths was observed in the data for this study (though it was omitted from analysis as per the coding criteria described earlier). A systematic study of stem-final fricative voicing extension is an important topic for future work, particularly given the historical evidence that the set of lexemes that undergo the voicing alternation has both expanded and contracted over time.
Concerning the second and third questions, a major factor conditioning variability in stem-final fricative voicing is the identity of the stem-final fricative. /f/-final lexemes and /θ/-final lexemes show stably variable voicing in apparent time, though at different overall rates: /f/-final lexemes show voicing at a relatively high rate; /θ/-final lexemes at a relatively low rate. This indicates that analogical leveling of /θ/-final plurals must have started some time ago, while any concomitant change in /f/-final plurals is still only incipient. Change in the plural of the /s/-final house, by contrast, is robust; stem-final voicing in this lexeme drops from a rate of 65% among speakers born in the 1940s (n = 139) to a rate of 38% among speakers born in the 1980s (n = 92).
Additional factors are at play. As has been documented in other studies of speakers’ production of irregular items (Bybee & Slobin, Reference Bybee and Slobin1982; Hooper, Reference Hooper and Christie1976; Yang, Reference Yang2002), frequency plays a role in the analogical leveling of stem-final fricative voicing. The difference in overall voicing rate between /f/-final lexemes and /θ/-final lexemes correlates with the different relative frequencies of those two phonological classes. Moreover, within each of the /f/-final and /θ/-final subsets, we find voicing to correlate with plural form frequency. Proper nouns and opaque compounds additionally disfavor stem-final fricative voicing (an effect that manifests only for /f/-final lexemes for reasons of data sparsity), and there is less voicing before a pause if not also before a voiceless segment, presumably due to an independent effect of voicelessness assimilation that may obscure the application of stem-final fricative voicing. Finally, where change is most robust—in the /s/-final lexeme house—we find traditional hallmarks of a change from below (Labov, Reference Labov2001): less voicing among less-educated speakers and in the more casual sociolinguistic interviews of the PNC as compared to the corpora of telephone conversations.
DISCUSSION
The present study has found evidence for phonological class behavior in both variation and change in stem-final fricative voicing: /f/-final lexemes are consistent in stably voicing at a high rate, /θ/-final lexemes in stably voicing at a low rate, and houses and its derivatives are changing over time. The tendency for irregular forms to show class behavior is well attested, both in language processing (Regel et al., Reference Regel, Opitz, Müller and Friederici2015) and in first language acquisition (Yang, Reference Yang2002). In this section, I suggest that the patterns in the data presented here are reminiscent of how children learn irregular forms, and that these adult language patterns may have their source partly in child language acquisition errors.
Yang (Reference Yang2002:79) observed class behavior in native English-speaking children's successful acquisition of English irregular past tense forms. He showed that irregular English past tenses can be grouped into a number of phonologically defined subsets, or classes: these include verbs for which the vowel of the rhyme changes to /ɔ/ and the coda changes to /t/ (e.g., catch–caught, think–thought, bring–brought, buy–bought); verbs for which the past tense is zero-inflected (e.g., put, hit, hurt, cut); verbs for which the vowel of the rhyme backs but no other change occurs (e.g., get–got, take–took, write–wrote, win–won), and so forth. Yang showed that, within a given class, the more frequently a verb is used in the adult's input to the child, the more accurately the child learns the irregular form. Less frequently used verbs are less likely to be learned in their irregular form and more likely to be regularized by children. Crucially, however, this frequency behavior is only visible on a class level. Ordering all irregular verbs from most to least frequent does not show a cleanly decreasing effect of learning accuracy. It is only when verbs are grouped into their phonological classes and then sorted from most to least frequent within those classes that Yang found a clear correlation with learning accuracy.
The reason that simply ordering all irregular verbs from most to least frequent does not cleanly correlate with learning accuracy is what Yang called “the free-rider effect”: the importance of the overall frequency of a class in boosting the learning accuracy of the low-frequency members of that class. An infrequent item can still be learned with a relatively high rate of accuracy if it belongs to the same class as one or more very high-frequency items. For instance, the past tense forms hurt and drew occur at comparable frequencies in adult language, yet children achieve much higher accuracy on hurt than on drew (Yang, Reference Yang2002:81). Yang argued that this can be attributed to hurt’s membership in a class that also contains the high-frequency hit, let, set, cut, and put: hurt gets a “free ride” learnability boost from those high-frequency forms. The past tense form drew, by contrast, has no such high-frequency counterparts in its class, so it receives no boost.
We can see similar patterns at play in the present study. Figure 3 shows a number of /f/-final lexemes (black dots) whose frequency in their plural form is roughly equivalent to that of one or more /θ/-final lexemes (lightest gray dots). However, in nearly all cases, the /f/-final lexeme achieves a higher rate of stem-final fricative voicing than the /θ/-final lexeme does. Compare, for instance, loaf (Zipf scale frequency of plural form: 2.77; voicing rate: 50%), scarf (Zipf scale frequency of plural form: 2.83; voicing rate: 74%), and youth (Zipf scale frequency of plural form: 2.85; voicing rate: 0%). The three have comparable plural frequencies, but we see much higher voicing rates for the two /f/-final lexemes than the /θ/-final lexeme. This may reflect a “voicing boost” coming from high-frequency, high-voicing /f/-final lexemes like life (Zipf scale frequency of plural form: 5.15; voicing rate: 80%) and leaf (Zipf scale frequency of plural form: 4.66; voicing rate: 95%), not to mention the anaphoric -selves pronouns, which were omitted from the present study, but are highly frequent and were found in pilot work to voice at a high rate of 84% (n = 128). This suggests a role for first-language acquisition processes in synchronic patterns of stem-final fricative voicing variation in adult speech. This irregular voicing alternation may be more accurately learned for lexemes whose plural form frequency is high, as well as for items in the same phonological class as them—that is, lexemes that end in the same fricative. Lexemes whose plural form has a lower absolute frequency, and those in the same phonological class as them, show more regularization.
However, the frequency/irregularity correlation is not perfect. A clear exception is seen for house, whose plural form has the third-highest frequency in this study (Zipf score: 4.28), but which is rapidly losing voicing in apparent time. A possible reason for this is the lack of other /s/-final fricative voicing lexemes to support house: in a class of its own, its high frequency is not enough to maintain its irregularity. Indeed, Yang (Reference Yang2002:82) found exactly this sort of pattern in the production of irregular past tense forms by “Abe,” a child in the CHILDES corpus. Despite the high frequency of go and come, Abe performed poorly at producing the past tenses of these verbs, which Yang attributed entirely to their being the sole members of their respective classes.
All this being said, there is an additional conservative effect operating on the plurals of /f/-final lexemes: orthography. The /f/-final items are the only ones in the set in (4) that change their spelling in the plural (from <f> to <v>). So, another possible explanation for the patterns presented here is that there is a general trend toward across-the-board leveling of stem-final fricative voicing, well underway for /θ/-final lexemes, and rapidly progressing for house, but blocked (or at least strongly slowed) in /f/-final lexemes because of the standardizing influence of their spelling. If accurate, this would be an interesting and perhaps novel case of orthography influencing the trajectory of language change.Footnote 13
Because orthography and frequency are so strongly connected in this study—six of the top seven most frequent lexemes change their spelling in the plural—it is important to tease apart their effects. To this end, a direction for follow-up research is to investigate stem-final fricative voicing among preliterate children. Do young children already voice /f/-final plurals at a high rate due to the frequency boost they receive for these forms in the input? Or do they regularize /f/-final plurals at a level comparable to that shown for /θ/-final and /s/-final plurals, only to grow out of this after learning how they are standardly spelled?
CONCLUSION
This paper has provided the first corpus-based study of stem-final fricative voicing in a small set of English plural nouns (e.g., houses [haʊzəz], leaves [livz], paths [pæðz]). I have demonstrated that stem-final fricative voicing in the set of lexemes considered here is variable and shows clear phonological class behavior. /f/-final lexemes voice at a high, stable rate in apparent time; /θ/-final lexemes at a low, stable rate in apparent time; and the /s/-final lexeme house is rapidly losing voicing in apparent time. The frequency of a lexeme in its plural form and the overall frequency of the phonological class it belongs to both play significant roles in the variation, with more frequent plurals and lexemes in the more frequent /f/-final class resisting leveling. This pattern is reminiscent of the nature of the errors children produce as they acquire the English past tense. As such, it suggests that the source of the variation may lie in children's first-language acquisition errors. More generally, it underscores that a careful consideration of the morphophonological conditions on variation can enrich our understanding of a variable phenomenon.
The connection between child language acquisition errors and diachronic directions of change has been observed before in other studies of analogical leveling (Hooper, Reference Hooper and Christie1976), though the present study's specific demonstration of child language-like phonological class behavior in adults’ probabilistic production is, to my knowledge, new. Truly connecting the dots between children's regularization errors and the variation and change in stem-final fricative voicing documented here will require case studies of children's production of these irregular plural forms, particularly given the potentially confounding factor of orthography. Since the items studied here are all nouns, many of them quite common and early-learned (e.g., houses, wolves, baths), this should not be particularly difficult to do. Future work that expands on the results presented here will be able to shed even more light on the connection between children's acquisition errors and patterns of language variation and change.











