


This paper examines the nature of the relation between the availability of null subjects and the “richness” of verbal subject agreement, known as Taraldsen's Generalisation (Adams, Reference Adams1987; Rizzi, Reference Rizzi1986; Taraldsen, Reference Taraldsen1980), from the point of view of grammar change in Medieval French. The original generalization based on synchronic observations states that a language having sufficiently discriminating, or nonsyncretic, subject agreement entails the possibility of nonexpression of subjects. In terms of diachronic developments, it was argued that there is a causal relation between the loss of nonsyncretic subject agreement and the emergence of obligatory subject pronouns (e.g., Ewert, Reference Ewert1943; Vennemann, Reference Vennemann and Li1975:298), the underlying intuition being that overt subjects take over the role of identifying the subject's person which can no longer be fulfilled by verbal inflection due to its phonological erosion. Haspelmath (Reference Haspelmath1999:14) said that “… in languages that are losing their rich subject agreement morphology on the verb … speakers will increasingly tend to choose the option of using the personal pronoun, because the verbal agreement does not provide the information required for referent identification in a sufficiently robust way.”
This diachronic scenario, however, was questioned for Medieval French on the grounds of an apparent temporal lag between the loss of null subjects and loss of agreement (e.g., Roberts, Reference Roberts and Svenonius2014; Schøsler, Reference Schøsler, Sampson and Ayres-Bennett2002). However, opposite assumptions have been made about the temporal sequence of the two changes, due to the unavailability of a systematic quantitative study of syncretization. We present a corpus-based study spanning the Medieval French period to evaluate two hypotheses. First, we test the predictions generated by the hypothesis that null subjects and nonsyncretic agreement exponents are related at the clause level, both being dependent on the same functional head. The second hypothesis we explore is based on Yang's (Reference Yang2002) variational learning model whereby the agreement exponents and subject expression are not strictly connected at the clause level. Instead, in the process of language learning (possibly over the speaker's lifespan) syncretic endings create a bias against the null subject grammar, which eventually drives it to extinction.
NULL SUBJECTS AND SUBJECT AGREEMENT IN FRENCH
Our estimates are based on the corpus of the project “Modéliser le changement: les voies du français” (MCVF) and Penn Supplement to MCVF (2010), which together include 35 syntactically parsed texts (n ≈ 1 million words [Appendix B]). On the assumption that null subjects correspond to phonologically null personal pronominal elements, observations about the emergence of overt subjects are given here as the estimated probability of overt personal pronominal subjects against null subjects, with demonstrative, nominal, and other kinds of overt subjects being excluded from consideration. The assumption is warranted by the fact that the rate of overt subjects that are not personal pronouns stays the same throughout the Medieval period, whereas the rate of overt pronominal subject increases and the rate of null subjects decreases in a dramatic fashion. Furthermore, null subjects in pro-drop languages and overt pronominal subjects in obligatory subject languages are said to be distributionally equivalent (e.g., Hirschbühler, Reference Hirschbühler1992).
Our dataset includes all finite clauses with either an overt pronominal or null subject (n = 56615), excluding imperatives, subject relatives, and wh-questions targeting subjects because of their idiosyncratic subject syntax.Footnote 1 We also excluded all coordinated clauses introduced by the coordinating conjunction et and the conjunctive adverb si, since those license subject ellipsis throughout the Medieval period. Although these connectives are sometimes used even when there is no potential antecedent in the preceding clause, we take the nearly stable rate of subject omission with et and si (see Appendix C, Figure 1C) to mean that there are few true subject omission environments with these connectives. Subject ellipsis under coordination with et is still allowed in Modern French, while si itself fell out of use as a conjunctive adverb.Footnote 2 The nonexpression of referential subjects occurred in Medieval French, and Old French in particular, in contexts where their expression would be obligatory in Modern French (e.g., Foulet [Reference Foulet1928] and much literature since). During the Medieval period nonexpression became more and more rare, for both main and subordinate clauses, as seen in Figure 1. As has been noted before, subordinate clauses favor overt subjects more than main clauses (e.g., Foulet, Reference Foulet1928; Franźen, Reference Franzén1939; Hirschbühler, Reference Hirschbühler1992; Roberts, Reference Roberts and Svenonius2014; Vance, Reference Vance1997; Zimmermann, Reference Zimmermann2014; among others), though null subjects can be found in all types of subordinates (Fontaine, Reference Fontaine1985; Hirschbühler & Junker, Reference Hirschbühler and Junker1988; Kaiser, Reference Kaiser2009; Prévost, Reference Prévost, Carlier and Guillot2018; Roberts, Reference Roberts1993).
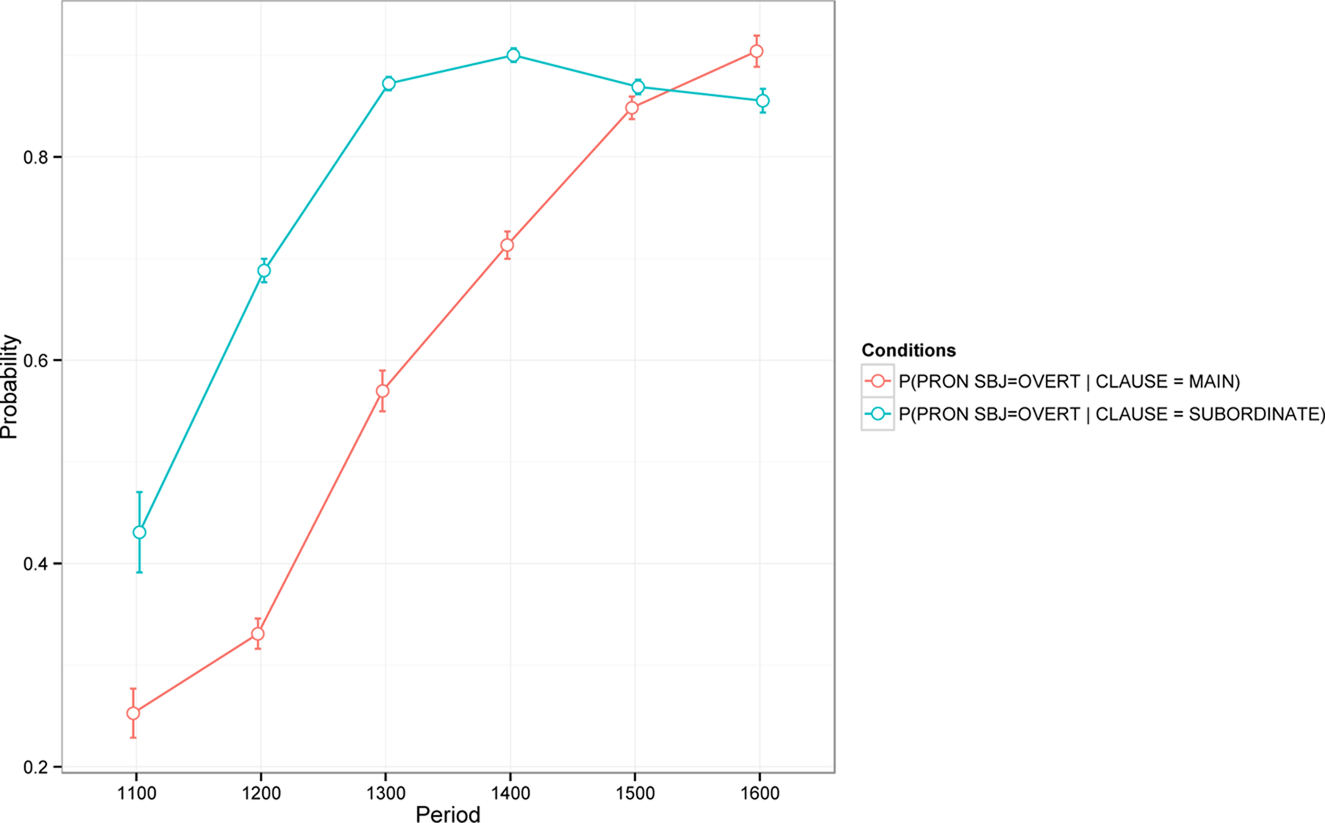
Figure 1. Overt pronominal subjects in main and subordinate clauses (n = 76150).
Subject agreement syncretization
French went from a language characterized by nonsyncretic agreement inherited from Late Latin to a language with a largely syncretic agreement paradigm (Bettens, Reference Bettens2015; Buridant, Reference Buridant2000; De Jong, Reference De Jong2006; Dees, Meilink, van Reenen-Stein, & van Reenen, Reference Dees, Meilink, van Reenen-Stein and van Reenen1980; Foulet, Reference Foulet1935; Marchello-Nizia, Reference Marchello-Nizia1992; Morin, Reference Morin2001). We can say that there is no systematic person marking on the verb in Modern French, and the only subject agreement feature present is number.Footnote 3 In contrast, as evidenced by the system of rhymes used in Old French versification, verbal paradigms had a much less syncretic nature during that period (e.g., Bettens, Reference Bettens2015).
Overall, there are three classes of changes that resulted in syncretism, namely, the drop of the final -t after vowels, e-insertion, and s-insertion. The first two changes can be seen as related on the hypothesis of Dees et al. (Reference Dees, Meilink, van Reenen-Stein and van Reenen1980) and van Reenen and Schøsler (Reference van Reenen and Schøsler1987) that e-insertion was a compensatory process “keeping” root consonants from the final position where they would have fallen. As we will see below, they are also much closer in time and in how they spread to each other than to the third one, s-insertion. Appendix A details the main changes in verbal agreement, by verb Group and tense-aspect form. These are:
A. innovative final -e: 1st person, Group I, present indicative & subjunctive
The use of the ending -e instead of zero for the 1st person singular subjects with Group I verbs began in the 12th century, and, by the beginning of the 15th century, generalized onto the roots ending in a consonant, the zero ending lingering for longer with stems ending in a vowel (Marchello-Nizia, Reference Marchello-Nizia1992:200). A handful of verbs whose stems etymologically ended in -e, such as monstre-r ‘to show’ were not affected by this change.
B. innovative final -e (i.e., becoming final as a result of the drop of -t): 3rd person, Group I, present indicative & subjunctive
The emergence of final -e as a consequence of the disappearance of the final -t in the context of the 3rd person singular subjects is generally considered to predate the changes in the 1st person singular contexts.
C. innovative final -e: 3rd person, Group II, present subjunctive
The alternation between -et and an innovative -e as the endings of the 3rd person singular present subjunctive in Group II also resulted in syncretism.
D. innovative final -a: 3rd person, Group I, preterite & future indicative (did not result in syncretism)
E. innovative final -a: 3rd person, Group II future indicative (did not result in syncretism)
F. innovative final Ø: 3rd person, Group II, preteriteFootnote 6
In Group II, the ending -t alternated with zero in the context of the 3rd person singular in preterite. This case is special in that the innovative zero ending was on the rise up until the mid-14th century when it suddenly went into a sharp decline, the old ending reinstalling itself completely. In our discussion of the spelling-pronunciation correspondence below we take this fact to indicate that the mid-14th century was a cut-off point in spelling-pronunciation contiguity, and, therefore, it gives support to the assumption that, until that point, spelling and pronunciation went largely hand in hand.
G. innovative final -s: 1st person, Group II, present and preterite indicative
The variation between a new, syncretic ending -s and nonsyncretic zero for the 1st person singular with Group II verbs, from the 14th century (Marchello-Nizia, Reference Marchello-Nizia1992:201). This change is indeed delayed compared to the spread of -e. Marchello-Nizia (Reference Marchello-Nizia1992:202) observed that, in the case of the stems ending in a vowel, it takes longer for the new variant to establish itself. There is also a limited number of verbs with stems ending in -s for etymological reasons (e.g., finis < Lat. finisco ‘to finish’).
H. innovative final -s: 1st person, Group I, imperfect and future conditional
I. innovative final -s: 1st person, Group II, imperfect and future conditional
These changes can be used to model phonological changes at least until the 14th century. One of the strongest arguments in support of spelling reliability for phonological reconstruction is the novel observation, which we will discuss in more detail below, that the dropping of the final -t in verbs with stems ending in u/i is abruptly arrested and reversed just after the mid-14th century, when the French Royal Chancellerie is known (first mention 1342) to have introduced exams for the scribes requiring them to adhere to the standardized spelling rules (De Jong, Reference De Jong2006:25). While spelling unification had been taking place already for several decades, De Jong (Reference De Jong2006) observed a sharp increase in what she called “parasitic consonants” after around 1340, which she attributed to the prescriptions of the official examiners. Consequently, after that point, we can only estimate verbal syncretism based on the change trajectory in the manuscripts written before that date.
Quantifying the emergence of the new endings
To establish the temporal profile of the surface changes in verbal endings, we calculated the ratio of the “new” endings to the sum of the new and “old” endings for each text in the corpus. In order to be able to identify the subject's person in an automated way, we limited ourselves to clauses with overt nominal or pronominal subjects. This means that we took a subset of all the cases of new endings appearing in the corpus. In order to determine whether considering only overt subjects skews the results, we look at ending choice in a sample of clauses with null subjects manually annotated for subject person and conclude that there is no significant difference in the rate of new endings between null versus overt subject contexts. Thus, we can confidently estimate the rise of the new endings from a sample of clauses with overt subjects. Figures 2 and 3 show the rise of new endings divided into two major groups, namely, final -t deletion and e-insertion on the one hand, both of which resulted in an innovative -e ending, and s-insertion on the other. (Observation numbers together with a proportion of the new endings in each text are given in Tables 5B–9B, Appendix B).

Figure 2. Innovative -e (changes A, B, C) and -a endings (changes D, E).
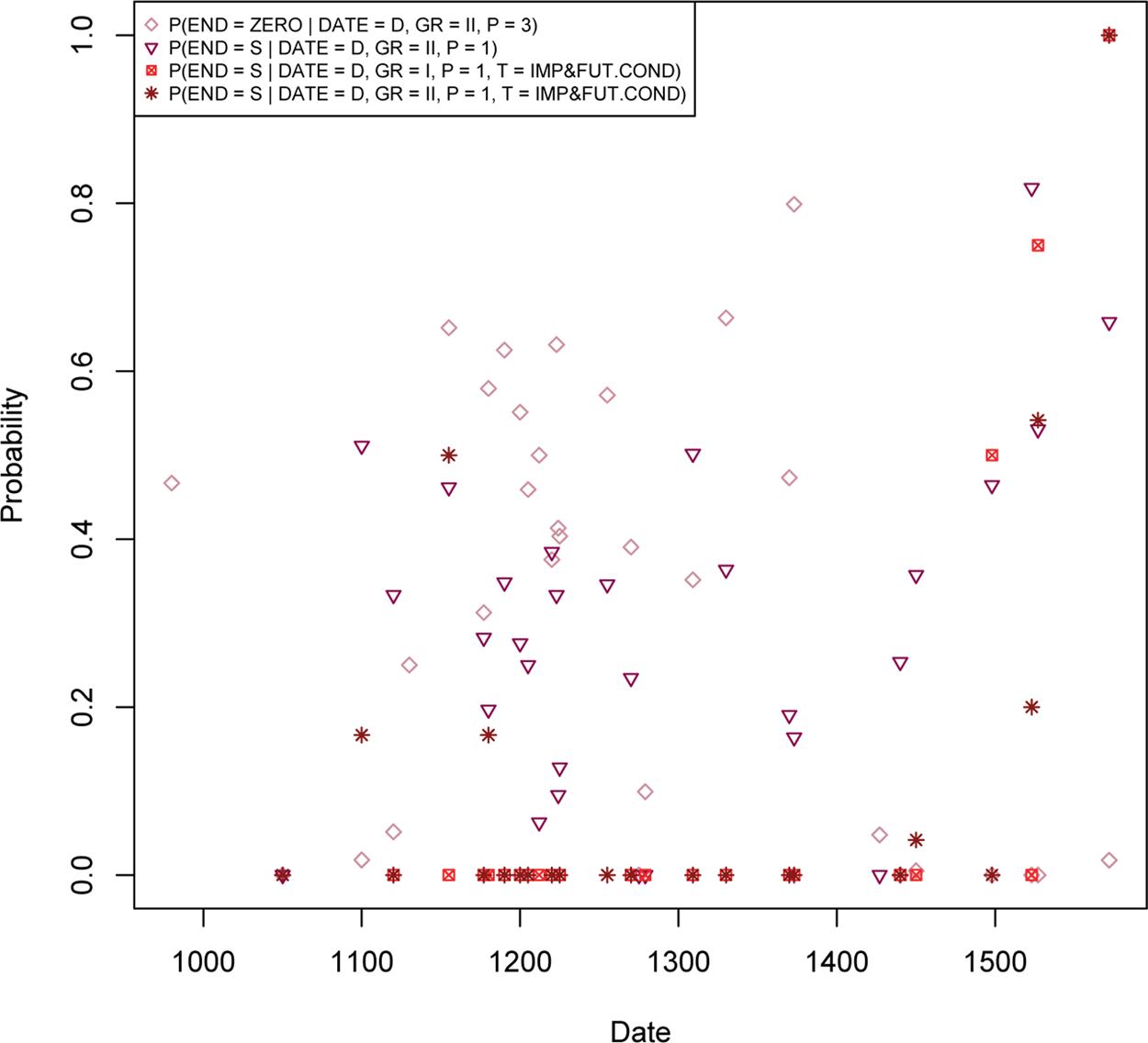
Figure 3. Innovative zero (change F) and -s ending (changes G, H, I).
Comparing now Figures 2 and 3 with Figure 1, on the assumption that the spelling innovations reflected changes in the verbal agreement phonology, there is no reason to assume that there was a temporal lag between the emergence of new syncretic endings and the rise of overt pronominal subjects. However, we see that, while the appearance of new -e and -a endings roughly parallels the emergence of overt subjects, innovative zero and -s follow a very different trend. The next question is whether we can establish a nonaccidental relation between the rise of new endings and overt subjects.
CLAUSE-LEVEL RELATION MODEL
We will first explore a classic line of analysis that relates null subjects and nonsyncretic agreement via a certain structural property giving rise to both; let us call it Agr head. The two changes are thus viewed as a consequence of the loss of the grammar with Agr head. We show that an approach that maintains a clause-level relation between subject expression and the type of ending makes incorrect predictions about the rise of the new endings and overt pronominal subjects. We will then suggest a more flexible approach whereby syncretic endings, rather than being a direct manifestation of an alternative structure without Agr, are consequences of an independent phonological change that favors the alternative grammar. Thus, the second approach dissociates null subjects from a particular set of endings in terms of surface observations, but maintains that syncretization eventually led to the disappearance of a grammar-generating null subjects.
AgrP-Grammar
As part of the first model, we assume that the initial grammar was characterized by the presence of a person feature-specified head Agr.Footnote 4 We will assume that person features introduce conditions on the denotation of a pronoun. A long semantic tradition ascribes to such features the status of presupposition triggers (e.g., Cooper, Reference Cooper1983; Heim, Reference Heim, Harbour, Adger and Bejar2008; Heim & Kratzer, Reference Heim and Kratzer1998; Kratzer, Reference Kratzer2009; Sauerland, Reference Sauerland, Harbour, Adger and Bejar2008). In addition to that, we will assume that a pronoun needs to be accompanied by an element triggering a presupposition about its reference, whether it comes as part of the morphological form of the pronoun itself or as a verbal ending.Footnote 5 Taking the existence of the constraint for granted, we propose that person features on Agr introduce presuppositions about the subject's reference. In the absence of Agr a pro will be left uninterpreted.
TP-Grammar
We model the replacement of null subjects with overt ones and of old endings with new ones as a passage from the initial AgrP-Grammar to an alternative grammar where verbal endings correspond to the spellout of head T, unspecified for the person feature.Footnote 6 Since T does not carry person features, it does not introduce presuppositions necessary for a felicitous use of a pro.
If TP-Grammar replaces AgrP-Grammar, null subjects will become unavailable. Assuming the Constant Rate Hypothesis of Kroch (Reference Kroch1989), our model predicts that the rate of replacement of AgrP-Grammar by TP-Grammar should be the same whether it is measured as the rise of overt pronominal subjects or of new syncretic endings. For the general case, the Constant Rate Hypothesis (CRH) states that a grammatical change has the same rate of spreading in all grammatical environments, where the rate is taken to correspond to the slope coefficient of a logistic regression model. However, Kauhanen and Walkden (Reference Kauhanen and Walkden2017), following up on the discussion in Paolillo (Reference Paolillo2011), pointed out that the standard way of assessing statistical significance (Kroch, Reference Kroch1989; Pintzuk, Reference Pintzuk1995; Santorini, Reference Santorini1993) of a putative Constant Rate effect is statistically unsound: “if the result is not statistically significant, then it is concluded that there is support for a [Constant Rate Effect]. However, it is not sound to treat a nonsignificant value as evidence for the null hypothesis, since it was assumed to begin with.” We will maintain therefore that, whenever the result of an independence test on regression coefficients is nonsignificant, it does not contradict the CRH; rather it provides direct evidence for it.
Thus, we expect the rates of the emergence of overt pronominal subjects and of the new endings to be not significantly different. One caveat of the prediction is that even stable null subject grammars allow for overt subjects. This makes it impossible to classify a given overt pronominal subject as an instance of AgrP-Grammar or TP-Grammar, since both of them are expected to generate overt pronominal subjects. The only context that sets the two apart clearly are expletive subjects, which are consistently null in null-subject languages (e.g., Jaeggli & Safir, Reference Jaeggli, Safir, Jaeggli and Safir1989).Footnote 7 We therefore will compare the rise of overt expletive subjects with the rise of the new endings. There are at least three other immediate predictions. First, the rise of the new endings should proceed at the same rate in different contexts: if the emergence of the new endings reflects the disappearance of Agr, on the CRH we do not expect this change to proceed differently depending on the verb type or the subject person. Second, there should be no increase in the frequency of null subjects in the contexts of new syncretic endings. This is so because the AgrP-Grammar that, by hypothesis, is the only grammar that can license null subjects, is associated with spellout rules which do not output syncretic endings, such as -e in the context of the 1st and 3rd person subjects, overt or null. Finally, there should be no increase in subject expression with old, nonsyncretic endings: although AgrP-Grammar, associated with nonsyncretic endings, does sometimes generate overt subjects, their distribution is governed by constraints that produce the same rate of subject expression during the course of existence of grammar AgrP.
PERFORMANCE OF THE CLAUSE-LEVEL RELATION MODEL
Testing the main hypothesis
In order to evaluate the hypothesis that the emergence of overt expletive subjects and syncretic verbal endings are two manifestations of the disappearance of the grammar with a person feature-specified Agr head, we fitted the data on the appearance of overt expletives and the new endings to logistic regression models plotted in Figure 4 (parameter estimates in Table 1). The model Ending predicts whether the verbal ending, Y, is new (or syncretic) by contrast with an old or nonsyncretic verbal ending as a function of time.Footnote 8 We compare this model with an Expletive subject model that predicts whether the expletive subject realization, Y, is new (or overt) by contrast with an old realization where the pronominal subject is null. For the sake of comparison, we also plotted the data on the overt personal pronominal subjects.

Figure 4. Spread of new endings and overt pronominal subjects.
Table 1. Logistic regression estimates for the new endings and overt pronominal subjects (numbers of observations of null and overt expletive and personal pronominal subjects are given in Table 4B in Appendix B)

The coefficients are not very different from each other but not identical either. To further test the CRH, we test for the contribution of the slope by comparing two mixed-effect models. The first predicts the new form Y, whether it is an overt expletive subject or a syncretic verbal ending, by contrast with an old form, that is, a null subject or a nonsyncretic verbal ending. The prediction is still a function of time, but we also add a random intercept αc for each context c: either a morphological context or a subject context.Footnote 9 Informally, this model means that the global model intercept may be further parametrized for each specific context, but the slope is constrained to be identical for both contexts. We compare this model to an extended version, where this time we add a random slope βc, thus allowing the slope to vary for each context. Since the slope models the rate of change, this second model allows the rate of change to differ for each context. We test whether the slope introduces a significant difference between the two models (with a log likelihood ratio test which is χ2 distributed [df = 2]). The test has p = 0.04, and so we conclude that the introduction of the slope does better predict the data, and thus, on the CRH, these results are not compatible with the analysis of the two diachronic phenomena as stemming from the same grammatical change, which we identified as a passage from a grammar with Agr head to a grammar without it. In the remainder of this section, we will explore three other predictions made by the clause-level relation model and show that none is borne out.
Syncretization in different contexts
The model for agreement syncretization merges nine different syncretization patterns (see Appendix A). If syncretization is a consequence of the TP-Grammar associated with the new spellout rules winning over the old AgrP-Grammar, then these developments are expected to have the same rate. In order to test this, we modeled them separately, as illustrated in Figure 5 (Table 11B in Appendix B shows the estimates).

Figure 5. Logistic regression models of the emergence of the new endings.
Upon visual inspection, we see that the spread of the new ending -e has more or less the same profile in all of its contexts. In contrast, it differs from the spread of -a and -s, contrary to what was predicted by the clause-level relation model. Thus, individual endings spread at different rates, and the innovations seem to group into classes in terms of their phonological environments.Footnote 10
Spread of the new endings with null subjects
Another prediction made by the clause-level relation model is that there should be no increase in the new endings in the context of null subjects. We do find occurrences of -e in the context of the 1st or 3rd person singular null subjects (see Table 9B in Appendix B), yet such occurrences of new endings with null subjects are not frequent: at all times they stay below 20 per text. One way to explain away their occurrence is to analyze them as etymological vowels that create noise in the passage from the old to new endings. However, if that is indeed noise, we expect it not to become stronger with time. To test this expectation, we fit the data on the appearance of -e in the context of the 1st person singular overt and null subjects to a logistic regression. As Figure 6 shows, the trend is the same (see Table 12B in Appendix B for the estimates).

Figure 6. Rise of -e with Group I verbs in the context of the 1st person singular subjects.
This result is unexpected if -e with null subjects is just an etymological residue. Rather, the observation that the new ending spreads at similar rates in the context of null and overt subjects suggests that we are witnessing one and the same (phonological) change operating in different contexts. In other words, the choice of ending is independent of the expression of the subject, contrary to what is predicted by the structural model relating subject expression and ending type as manifestations of a particular grammar. Note that we do not need to check the spread of different types of new endings with overt and null subjects, since the clause-level relation model predicts that no new endings increase with null subjects and is therefore falsified even by one case of the contrary.
Spread of overt subjects with old endings
The final prediction that we derive from the clause-level relation model is that there should be no increase in subject expression in the context of verbs with old, nonsyncretic endings. We compared the rate of subject expression in the contexts of verbs with the old nonsyncretic endings -t, zero on the one hand and new syncretic endings -e, -s on the other. We estimated the probability of having an overt pronominal subject for finite clauses with verbs ending in -e (Group I & II), -t (Group I & II), -s (Group II), and zero (Group I & II) endings, as shown in Figure 7 (Table 13B in Appendix B).Footnote 11 Clearly, the subject expression rate grows over time for the nonambiguous endings.Footnote 12 Relatedly, Ranson (Reference Ranson2009) concluded, based on the three texts she examined, that ending ambiguity is not a good predictor of subject expression.

Figure 7. Pronominal subject expression with old and new endings.
In sum, we have shown that a number of predictions generated by a model that assumes that subject expression and agreement type are related at the clause level via a certain functional head are not borne out. Namely, new endings spread at different rates depending on the ending type, which is unexpected if both are generated by a new grammar that is supposed to spread at the same rate on the CRH. In addition, new endings spread both with overt and null subjects, contrary to the model's assumption that null subjects are generated only by the old AgrP-Grammar, where the Agr head spells out as old, nonsyncretic endings. Finally, the expectation that there would be no increase in overt subjects in the context of old, nonsyncretic endings, which, by hypothesis, are generated by the AgrP-Grammar producing overt subjects at a constant (relatively low) rate, is also not borne out. The overall conclusion is that a model that assumes a strict dependency at the clause level between what type of endings are used and whether or not pronominal subject is expressed is not supported by the diachronic data. However, we need to deal with another possible explanation for why we do not find a complete parallelism between ending syncretization and pro-drop disappearance, namely, that the verb ending changes registered in the written texts are not reflective of the phonological reality and therefore cannot be used to evaluate a clause-level relation hypothesis.
SPELLING-PRONUNCIATION PROBLEM
For the purposes of the present study, the problem of the correspondence between pronunciation and spelling entails two independent questions. The first one is whether the spelling innovations had phonological substance. The second question about the spelling-pronunciation relation is concerned with the emergence of phonological innovations behind conservative orthography. The state of Modern French witnesses the fall of all the stops and sibilants (at least in an isolated pronunciation) that used to correspond to the present-day word-final consonantal graphemes, not just the final -t whose disappearance we tracked above. Again, judging from the Modern French spelling-pronunciation correspondence, this change is mostly not reflected in spelling. For the second part of our study, where we attempt to estimate the general level of syncretism in the system, it is important to know until what point in time we can equate presence in the spelling with phonological presence. Fortunately, it seems that we can estimate this date with a great deal of precision due to the co-occurrence of two independently attested facts. First, there exists a historical record of the first centralized spelling standardization in the mid-14th century. Second, our data show that the disappearance of the final -t with Group II verbs with unstressed roots ending in -i/-u, which, if it had followed a statistically expected trajectory, would have reached its completion around that time, was stopped and reversed in the late 14th century (Figure 8). This presumably shows the effect of the spelling standardization that marked the end of the strict spelling-pronunciation correspondence.
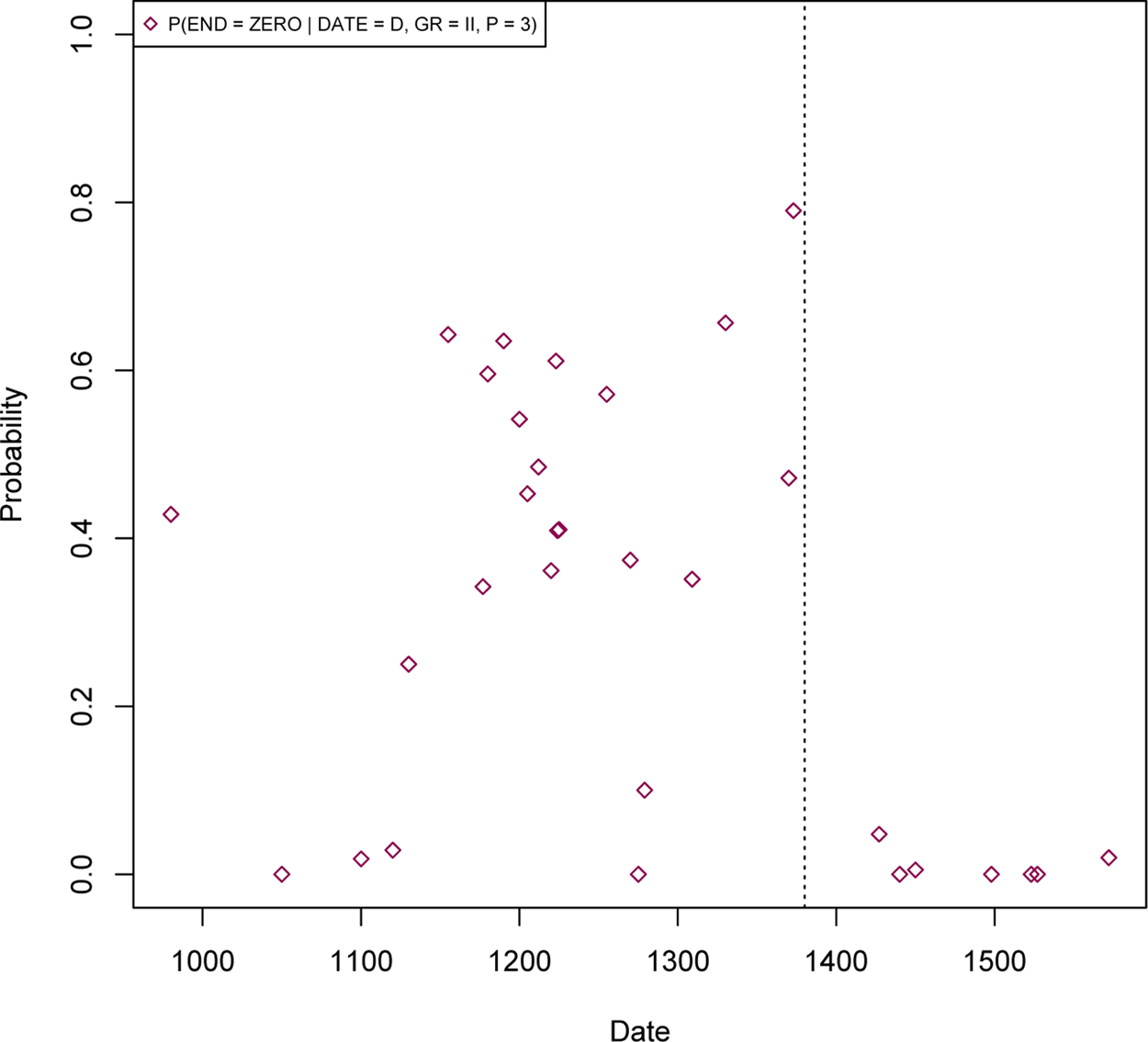
Figure 8. Change reversal for Group II verbs in preterite with 3rd person subject.
There seems to be a consensus that the rise of the new endings reflected the phonological reality rather than simply a change in orthographical conventions (Dees et al., Reference Dees, Meilink, van Reenen-Stein and van Reenen1980; Fouché, Reference Fouché1931; Goyette, Reference Goyette1993; Marchello-Nizia, Reference Marchello-Nizia1992; Morin, Reference Morin2001; van Reenen & Schøsler, Reference van Reenen and Schøsler1987). Arguments against a possible claim that what we observe in texts is just variation in writing conventions can be divided into the following groups. First, as we saw, the emergence of -e as a final grapheme in the context of Group I verbs with a 3rd person singular subject in present indicative and subjunctive follows a logistic curve whose slope is indistinguishable from the slope of the curve modeling the emergence of -e with Group I verbs in the context of 1st person singular subjects in present indicative and subjunctive.Footnote 13 These results fit well with the hypothesis of Dees et al. (Reference Dees, Meilink, van Reenen-Stein and van Reenen1980) and van Reenen and Schøsler (Reference van Reenen and Schøsler1987) about /e/-insertion being a compensatory process triggered by the instability of the final stops to preserve the integrity of the root. The appearance of -e as a final grapheme with the 3rd person singular subjects on this view results from the fall of the final /t/ (e.g., aimet > aime ‘(he) loves’ and aint > aime ‘(he) would love’), whereas its appearance with the 1st person singular subjects results from a compensatory /e/-insertion to keep the root final consonants from not being pronounced (e.g., aim > aime ‘(I) love’ and ‘(I) would love’). Although the quasi-identity of slopes is only indicative, this is expected on the hypothesis that this is a paradigm-wide morphophonological process. That is, given the CRH, it is entirely expected for a morphophonologically conditioned change to proceed at the same rate in different environments (cf., Fruehwald, Gress-Wright, & Wallenburg, Reference Fruehwald, Gress-Wright, Wallenberg, Kan, Moore-Cantwell and Staubs2009). Second, according to our estimates, in the context of the 3rd person subjects syncretization happened earlier than with the 1st person singular subjects, which makes sense if the fall of the final stops that were not part of the root (again, aimet > aime ‘(he) loves’ and aint > aime ‘(he) would love’) preceded the emergence of a “compensatory” /e/ following root-final consonants. In contrast, on the hypothesis that what we observe are changes in spelling conventions, although not theoretically impossible, it would look like a series of strange coincidences if, first, different spelling conventions in different contexts were changing at very same rates, and, second, if they first changed in the context of the 1st and then of the 3rd person subjects. Third, according to Fouché (Reference Fouché1931:180) and Marchello-Nizia (Reference Marchello-Nizia1992:201), in the context of the 1st person singular subjects in indicative and subjunctive, the -e grapheme first spread in the context of consonant-final and only later vowel-final roots (e.g., cri-er ‘to shout’ where in the context of the 1st person singular subjects cri was replaced by crie). Again, this fits a phonology-based account of the change, since the sequence of spreading across contexts can be described in terms of phonologically natural classes, whereas this appears as a mysterious plotting of the scribes on the spelling convention-based account. Lastly, a phonologically motivated change affecting final vowels has precedence in the history of Late Latin, where all the final vowels ended up falling except for those cases where their fall would have led to an unacceptable consonant cluster (see the discussion in Goyette [Reference Goyette1993] and references therein). In Old French, reflexes of this process are the so-called “etymological e,” that is, root-final -e following certain consonant clusters, as in siffle-r (from Latin sibila-re > sifila-re > sifla-re) (cf., don-er from Latin dona-re, which lost its root final /a/ in Late Latin, unlike siflare). It is not so surprising then to see another round of “compensatory” root final /e/, this time as an epenthetic process meant to keep the root final consonants from falling. In view of these arguments, none of which supports an account of the new endings in terms of spelling convention changes, we conclude that our results based on written source can be plausibly projected onto the phonological reality and thus used to test a model structurally relating syncretism, introducing changes and pro-drop disappearance. Similarly, Fruehwald et al. (Reference Fruehwald, Gress-Wright, Wallenberg, Kan, Moore-Cantwell and Staubs2009) analyzed data on the loss of final fortition in (Bavarian) Early New High German, observable in orthographic variation of the period, for example, tak versus tag ‘day (acc. sg),’ rat versus rad ‘counsel (acc.sg),’ and argued that this variation clearly represents a phonological change in progress rather than shifting scribal tradition. When it comes to determining at what point the phonological reality behind conservative spellings changed, the reconstructions of the timing of the fall of the final consonants rely mostly on the analysis of rhymes (matching versus nonmatching), hypercorrections (insertions of etymologically absent consonants), omissions of etymologically present consonants, commentaries in the grammars of the time, and analyses of the borrowing from French into other languages that likely reflected the spelling at the time of borrowing. The dating question is important to us in as much as we want to take into account final consonant instability when evaluating the overall degree of syncretism or ambiguity in the verbal system. De Jong (Reference De Jong2006) undertook a statistical analysis of the rhymes in three texts written in the Parisian dialect in the 13th-14th centuries. She looked at the frequency of the nonmatching rhymes for a given grapheme (e.g., escript ‘text’–(je) pris ‘I take’) compared with that of the matching rhymes (e.g., moult ‘many’–(je) doubt ‘I doubt’), taking higher-than-chance frequencies to be indicative of the grapheme nonpronunciation. One of the general conclusions of De Jong (Reference De Jong2006:176) is that the nonpronunciation of the final consonantal graphemes increases dramatically in the 14th century. This is the period when the mismatching rhymes, including mismatches involving our consonants of interest, begin to be observed in her corpus (cf., Foulet, Reference Foulet1935). Importantly, De Jong (Reference De Jong2006:174) linked the emerging mismatch between spelling and pronunciation with a particular historical event, namely, the introduction by the Royal Chancellery in Paris of the standard exams for the scribes in 1342. We found a rather dramatic argument in favor of this hypothesis in the form of the reversal of the final -t disappearance in the preterite forms of certain Group II verbs (Figure 8). We cannot conceive of any plausible explanation of this development in phonological terms. Rather, it seems to result precisely from an artificially introduced norm.
CHANGE AS A VARIATIONAL LEARNING OUTCOME
As was demonstrated above, the long-standing intuition going back to at least Foulet (Reference Foulet1928) that it was the impoverishment of the verbal endings that triggered the loss of null subjects cannot be impelemented as a model in which non-syncretic endings and null subjects are considered manifestations of the same grammatical property. However, given that overall the new endings and overt pronominal subjects (whether personal or expletive) spread at almost the same rates, illustrated in Figure 4, it would likewise be counterintuitive to conclude that we should give up altogether on all the models which assume a non-accidental relation between the two changes.
Sprouse and Vance (Reference Sprouse, Vance and deGraff1999) proposed the first, to our knowledge, reinforcement learning model to explain the loss of null subjects, appealing to the processing difficulty associated with their parsing. In this model, a null subject has a greater chance of inducing a parsing failure than its competitor, an overt pronominal subject. Since, by the authors’ assumption, speakers tend to produce grammatical forms at frequencies at which they have encountered them in their speech community, failures to parse null subjects will lead to the decrease in the frequency of null subjects in the output of the speakers, which in turn will reduce the ambient frequency of null subjects on the next cycle. The cycle repeats until null subjects vanish from the speech community.
Below we suggest a model of the loss of null subjects which builds on the variational learning model proposed in Yang (Reference Yang2002, Reference Yang2010). Ambiguous endings are considered within this model as the main factor that creates a parsing difficulty for null subjects (contra Sprouse & Vance [Reference Sprouse, Vance and deGraff1999]).
General framework
Yang's (Reference Yang2002, Reference Yang2010) model is based on the assumption that children have innate access to multiple grammatical systems and, in the course of language learning, use the input data to probabilistically evaluate the available options. They may either converge on a single grammar, or, as adults, they may end up with multiple grammars used at certain probabilities, which corresponds to the case of synchronic variation. Depending on whether the next generation arrives at the same or different probability distribution, we get the case of diachronically stable variation or diachronic change respectively. Hypothesizing what kind of data contributes to the probabilistic evaluation of the grammars, we can approximate the course of the competition based on corpus distributions of the relevant data.
Formally, we use Yang's (Reference Yang2002, Reference Yang2010) model as a way to estimate the probabilities P(G = G1) of using the grammar G1 and P(G = G2) of using the grammar G2 from a data set X = x1 …xn in which, for a specific example x ∈ X, we are not sure which of G1 or G2 actually generated x. Informally, the estimation procedure is iterative and increases P(G = Gi) when Gi successfully parses an example x while it decreases P(G = Gj) (i ≠ j). The iterative procedure runs as follows:
• Select randomly a clause x in the data set X
• Select randomly Gi in proportion to its probability
• Analyze x with Gi
○ If Gi succeeds in analyzing x, provide Gi a reward and Gj a penalty: P(G = Gi) increases and P(G = Gj) decreases.
○ If Gi fails in analyzing x, provide Gi a penalty and Gj a reward: P(G = Gi) decreases and P(G = Gj) increases.
Using the notation Gi ↛ x to indicate that Gi fails to parse x, we can define the notion of penalty of a grammar Gi as ci = P (Gi ↛ x). That is, ci is the probability that Gi fails to analyze an example in X. This quantity can be estimated simply by counting the proportion of a grammar's failures in the data set. Given this notion, for the case where we have two grammars G1, G2 with penalties c1, c2, Narendra and Thathachar (Reference Narendra and Thathachar1989) proved the following theorem:
 $${\rm lim}_{t \to \infty} \,{\rm P}\lpar {{\rm G} = {\rm G}_1 \vert {\rm T} = {\rm t}} \rpar = \displaystyle{{{\rm c}_2} \over {c_1\; + \; c_2}}\;;{\rm} {\rm lim}_{t\to \infty} \,{\rm P}\lpar {{\rm G} = {\rm} {\rm G}_2 \vert {\rm T} = {\rm t}} \rpar {\rm} = \displaystyle{{{\rm c}_1} \over {c_1\; + \; c_2}}$$
$${\rm lim}_{t \to \infty} \,{\rm P}\lpar {{\rm G} = {\rm G}_1 \vert {\rm T} = {\rm t}} \rpar = \displaystyle{{{\rm c}_2} \over {c_1\; + \; c_2}}\;;{\rm} {\rm lim}_{t\to \infty} \,{\rm P}\lpar {{\rm G} = {\rm} {\rm G}_2 \vert {\rm T} = {\rm t}} \rpar {\rm} = \displaystyle{{{\rm c}_1} \over {c_1\; + \; c_2}}$$The probability of using a grammar Gi is proportional to the number of observed failures of Gj in the data set (i ≠ j). Specifically P(G = Gi) = 1 when Gj always fails and P(G = Gi) = 0 when Gj never fails.
Diachronic stability and change
The outcome of the learning process (possibly over the lifespan) may stay the same or it may change from one generation to another. In the model we are considering, the only reason why learning may not converge on grammar Gi is if its penalty probability ci is greater than zero, that is, if there are some subset input data that Gi fails to parse. Once ci associated with Gi becomes greater than zero, a language may leave a diachronically stable state and enter a state of diachronic change. Moreover, an increase in the frequency of the data unparseable with Gi in the next generation will lead to the increase in ci, and so on to the point when Gi gets completely demoted. Emergence of such data may have nothing to do with the grammatical options themselves and may stem from phonological changes as well as from a second language interference.
Applying this to the loss of null subjects in Medieval French, let us assume that the initial winning grammar (Agr-P Grammar) is the one that licenses null pronominal subjects. Its competitor (the TP-Grammar) only generates clauses with an overt subject. Notice that this model incorporates the Taraldsen/Rizzi insight about a categorical, core grammar-based dependency between functional head features and null subjects. In order to model the competition between these two grammars, the crucial parameters are the penalty probabilities of the grammars. By hypothesis, AgrP-Grammar fails each time the information about a subject's reference cannot be retrieved from the verbal ending, which is the case whenever the ending is ambiguous. An ending is classified as ambiguous in case the speaker has been exposed to a data sample where the ending occurs in the context of overt subjects with various (more than one) person specifications.
In the case of ambiguous endings, the Agr head cannot be projected during the parse, since there is not enough information to give it semantic content. In contrast, TP-Grammar fares well with all kinds of endings (as long as tense information can be read off of them), but fails when chosen to parse null-subject clauses. In those cases in the absence of a subject DP providing presupposition triggering features, the domain of the external argument of the verb is left underspecified, and the composition does not converge. Now a diachronically stable null subject situation is predicted to obtain in case there are no problematic data of the kind described above, that is, there are no ambiguous endings and the penalty probability cAgr is 0. This means that AgrP-Grammar never fails and in every generation ends up driving the competing TP-Grammar out, since the latter cannot parse some of the AgrP-Grammar's output, namely null-subject clauses.
Estimating failure probabilities
To estimate cAgr, we exhaustively classify verbal endings as ambiguous or unambiguous. We define an ending as ambiguous if it does not correspond to a unique combination of person and number features (see Appendix A). We coded every finite clause in the corpus (as usual, with the exclusion of subject wh-clauses and imperatives) as to whether the verbal ending is unambiguous. In the case of endings that were ambiguous already in the earliest texts, all clauses with a finite verb having such an ending have been coded as ambiguous. In the case of endings classified as having emerging ambiguity, namely, those that became ambiguous later than in the earliest texts, we classified clauses dated before the first attested cases of ambiguity as having unambiguous predicates and those dated after the ambiguity emerged as having ambiguous predicates. The failure probability cAgr is then estimated as the frequency of clauses with ambiguous predicates at a given date. In the case of TP-Grammar the estimate of cTP is even more straightforward: it is the frequency of null-subject clauses.
The predicted value of PTP given cAgr and cTP as estimated using the matrix above is plotted in Figure 9 (observation numbers on which cTP and cAgr are based are given in Appendix B, Tables 4B and 10B, respectively).

Figure 9. Parsing probability of the TP-Grammar.
Discussion
We estimated the parsing probability of the TP-Grammar based on our estimates of the probabilities with which this grammar and its competitor, AgrP-Grammar, encounter data that they cannot parse. The parsing probability of the TP-Grammar grows steadily during the Medieval period.
Recall that the parsing probability of the TP-Grammar in the limit is the ratio of the probability of AgrP-Grammar to fail to the sum of the AgrP-Grammar and TP-Grammar probabilities to fail. This means that the greater the probability of the AgrP-Grammar to fail, the greater, eventually, will be the probability of the TP-Grammar to be used. Given how we estimate the AgrP-Grammar's probability to fail, that is, as the frequency of ambiguous endings, it is clear that our estimate of the TP-Grammar probability to be used is dependent on the frequency of ambiguous endings. Thus, this model, without assuming that ending ambiguity and subject expression depend on the same underlying factor, puts the two in a relation of direct dependency. This is a welcome configuration given the desiderata expressed above, namely, finding a model which would dissociate the two phenomena at the clause level but would relate them in the course of language evolution. It is worth stressing here that a given ending in this model does not reveal which grammar was used to generate it: by assumption, the spread of syncretic endings is a phonological phenomenon which is “blind” to the syntactic origins of the string it is operating on.
As Figure 10 shows, the curve corresponding to the parsing probability of the TP-Grammar is roughly parallel to the estimated probabilities of personal and pronominal subject expression. Intuitively, the probability of the expletive subject expression corresponds to the probability of the TP-Grammar to be chosen for production, since this is the only grammar that can generate overt expletive subjects. What we observe, then, is the TP-Grammar parsing probability lagging significantly behind its production probability. One explanation for the apparent lag is that our estimate of the ending ambiguity, to which the TP-Grammar production probability is directly related, is overly conservative. We have already mentioned on several occasions that the spelling standardization of the mid-14th century seems to have had a visible effect on the manuscripts upon which our corpus is based. The phenomenon we discussed is the reintroduction of the final -t for the Group II verbs with unstressed roots in -i/-u. Given the disappearance of the inflectional -t after vowels prior to 1300, the same should have happened to the -t following glides and stops shortly thereafter (cf., a suggestion in Buridant [Reference Buridant2000:250]). And we know for a fact that eventually final inflectional stops did fall in all the environments. However, presumably due to the spelling standardization, we do not observe these changes and, therefore, cannot take them into account in our estimates of ending ambiguity, which gives the impression that the latter lags seriously behind the production probability reflected in the rate of overt expletive subjects.

Figure 10. Parsing probability of the TP-Grammar (non-conservative*).
We can see what happens to the parsing probability of the TP-Grammar if we make a less conservative assumption about final consonant fall. That is, let us assume that, in addition to the endings -e, -s, zero following i/u, and -eies, the following endings were ambiguous as well by virtue of effectively not being pronounced from 1400 on and thus resulting in verbal forms homophonous with either 1st or 2nd person singular forms: -t, -eiet, -it, -et, -at. In Figure 10, one can see that this less conservative estimate is almost identical to the estimated production probability in the form of overt expletives.
One may argue, however, that this parallelism, in general, is not a particularly interesting result, since, in addition to the frequency of ambiguous endings, the TP-Grammar parsing probability in the limit inversely depends on the relative frequency of null subjects, which, of course, decreases over time. Consequently, the question is whether ending ambiguity actually plays an important role in predicting the TP-Grammar parsing probability.
One way to evaluate the role of the endings for the outcome of the grammar competition is to design a variational learning-based model in a way that would not make reference to them at all and to compare this “ending-less” model to the model that does take them into account, such as the one that we have just considered. To this end, we use the measure of grammar fitness proposed in Yang (Reference Yang2000) and used, in particular, in variational learning models of the loss of V-to-T raising in Scandinavian in Heycock and Wallenberg (Reference Heycock and Wallenberg2013) and the loss of OV in Latin in Danckaert (Reference Danckaert2017). Fitness of grammar G is defined as the proportion of clauses that only G generates out of all clauses that G generates, or the proportion of unambiguous clauses in the output of G.
Fitness of the AgrP-Grammar cannot be straightforwardly estimated from our data, since, by hypothesis, all the attested stages of historical French correspond to mixed grammar states, that is, to the outputs of the two competing grammars. This follows from the assumption that, whenever we find overt expletive subjects, the TP-Grammar must have been at work and from the fact that expletive subjects are found in the earliest attested texts (e.g., Prévost, Reference Prévost, Carlier and Guillot2018; Zimmermann, Reference Zimmermann2014). Instead, we can approximate the fitness measure of the AgrP-Grammar on the basis of a language that is currently in a “pure” pro-drop state. The estimated probability of null subjects is around 0.7 for pro-drop languages such as Italian or Spanish (e.g., Bates, Reference Bates1976; Nagy, Aghdasi, Denis, & Motut, Reference Nagy, Aghdasi, Denis and Motut2011; Otheguy, Zentella, & Livert, Reference Otheguy, Zentella and Livert2007:778). That is, by assumption, the AgrP-Grammar produces unambiguous clauses with the probability of 0.7. Now the fitness of TP-Grammar corresponds to the estimated probability of expletive subjects in a nonpro-drop language, such as English, which obviously cannot be anywhere near 0.7.Footnote 14 Given these approximations, Fitness(AgrP-Grammar) >> Fitness(TP-Grammar). By the Fundamental Theorem of Language Change (Yang, Reference Yang2000:239), which states that the winner in the long run is always the grammar with a greater fitness, this model predicts that AgrP-Grammar wins hands down, contrary to the historical facts. We thus conclude that a model that factors in ending ambiguity fares better than a model that does not, which supports the assumption that there is a causal relation between ending syncretization and null-subject disappearance.
CONCLUSIONS
The goal of this paper was to bring parsed corpus data and statistical modeling to bear on the old-standing puzzle of the relation between the disappearance of null subjects and verbal subject agreement syncretization in the historical development of French. We engaged the Constant Rate Hypothesis in order to explore a model that relates the two changes as reflexes of one underlying structural shift and showed that it generates predictions that are not supported by the data. The key feature of the failed predictions is the independence of the two developments. Specifically, we found that the increase in overt personal pronominal subjects was uniform across old and new endings, and, likewise, that the spread of the new syncretic endings was uniform across clauses with null and overt subjects.
A second model that we explored related the two changes via the step of language learning whereby one change (ending syncretization) promotes the appearance of sentences that disadvantage a grammar with a null-subject option and thus automatically favor the overt-subject grammar, thus causing null-subject disappearance. We approached this model from two perspectives.
First, we focused on what we assumed to be the parsing capacities of the two competing grammars and used the linear reward-penalty theorem to estimate the evolution of the probabilities of the two grammars over time by estimating their failure probabilities at each time point. Crucially, the failure probability of a null-subject grammar is taken to be directly related to the frequency of ambiguous endings in the data. This was the core assumption meant to capture the intuitive link between agreement quality and subject expression in the process of language change. Another crucial assumption, which made the model compatible with the facts concerning the surface-level independence of subject and ending types, was that the type of ending is determined by a phonological process that is entirely independent of which grammar is picked by the speaker to generate a given sentence.
As a second possibility, we estimated fitness of null and overt subject grammars based on the data from pure state languages. This time the measure did not rely on ending ambiguity. Estimated this way, fitness gives an advantage to the null-subject grammar, and on Yang's Fundamental Theorem it is expected to win, contrary to the historical facts. We conclude, thus, that so far the best model of null-subject disappearance is one that factors in the increase in ending ambiguity without assuming a categorical clause-level dependency between the two phenomena.
Synchronic studies of variation in null-subject expression in Romance languages, to the best of our knowledge, fail to establish verbal ending ambiguity as a relevant factor, and thus leave us with a puzzle as to the nature of Taraldsen's generalization. For instance, Nagy and Heap (Reference Nagy and Heap1998) reported that whether an ending is ambiguous is not a good predictor of subject expression in Francoprovençal. The same conclusion is reached in Carvalho and Child (Reference Carvalho and Child2011) based on Spanish material. This agrees with Ranson's (Reference Ranson2009) conclusions and our own observations concerning the diachronic French data. Our work thus supplements synchronic variationist studies in that we offer a diachronic model that can capture the relation without postulating a clause-level dependency. This suggests that, in some cases, the study of natural language variation must include the temporal dimension, otherwise some potentially highly relevant factors will remain “invisible.”
It has to be noted that our conclusions do not rule out in principle a clause-level dependency between surface forms. Such an outcome could, for instance, be the result of a competition between Agr- and TP-Grammars, whereby by the end of a variational learning cycle they end up in a complementary distribution with respect to tense/aspect environments. An analysis along these lines would need to be worked out for the systems where the only contexts disfavoring subject omission are certain tense/aspectual forms syncretic with respect to subject person, such as, for instance, some Northern Italian, Franco-Provençal, and Occitan dialects (Manzini & Savoia, Reference Manzini and Savoia2005), Hebrew (Shlonsky, Reference Shlonsky2009), Finnish (Koeneman, Reference Koeneman, Ackema, Brandt, Schoorlemmer and Weerman2006), Irish (Speas, Reference Speas1995), Russian (Bizzarri, Reference Bizzarri2015).
This study is part of a more general agenda of using diachronic material for the study of interfaces, that is, formal relations between syntax, morphology, phonology, and semantics/pragmatics. Another prominent group of what seems to be parallel and potentially related changes is the disappearance of nominal case marking and word order changes. Simonenko, Crabbé, & Prévost (Reference Simonenko, Crabbé, Prévost, Dickinson, Hinrichs, Patejuk and Przepiórkowski2015) showed that the remnants of the case opposition in Medieval French disappear within approximately the same timeframe as the possibility of having an OV order. It remains to be seen in further research if any of the models explored above can be used to explore the nature of the relation between these two changes.
SUPPLEMENTAL MATERIALS
Appendices A, B, and C can be found at: https://doi.org/10.1017/S0954394519000188

















