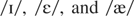In the following article, I will present the results of an acoustic
analysis of the short front vowels1
In order
to allow for a dialect-neutral terminology of etymological categories, I
will adopt the method put forward by Wells (1982) and identify the short front vowels in terms of
lexical sets, that is, using a cover term for each of the vowels. These
are kit, dress, and trap (corresponding to the
conventional IPA notation
and Traeger-Smith IH/EH/AE, respectively). For a discussion of
the advantages of lexical sets over phonemic symbols see Batterham (1995).
(henceforth SFVs) in the speech of 30
speakers of Intermediate New Zealand English (henceforth NZE). It has
frequently been pointed out that the realization of these vowels in NZE is
different from that in most other standard varieties of English, in that
the
kit vowel has a more centralized realization, whereas
dress and
trap are both raised and fronted (
Bauer, 1986;
Wells,
1982).
Whereas previous studies of the SFVs in NZE (both acoustic and other)
have predominantly focused on the speech of modern NZE speakers (cf. Maclagan, 1982), the extensive corpus of older speech
recordings which are now part of the ONZE (Origins of New Zealand English)
corpus based at the University of Canterbury allowed for a detailed
analysis of the first and second generation speakers of New Zealand
English (Gordon et al., 2004). With respect to
the SFVs, the present study bridges the gap between the first and second
generation of speakers and the modern ones.
The next section gives some background information on the SFV shift in
NZE, and a brief outline of earlier work on this subject. The following
two sections give information about the speaker sample and the
methodology. Then I will present the overall patterns found in the
analysis as well as argue for a push-chain scenario and elliptical
distributions in transitional vowel systems. The next section is concerned
with the results of a CART (classification and regression tree) analysis
of a number of phonemic conditioning factors. The final section presents
correlation tests to corroborate the hypotheses.
BACKGROUND
The basic mechanism of the NZE front vowel shift can be described as a
process that converts a system with three short front vowels into one of
two front vowels (dress and trap) and a central vowel
(kit). Furthermore, the commonplace assumption is that the steps
are interrelated and therefore form a so-called “chain-shift,”
a quality change in a number of adjacent segments of the same type under
the maintenance of the original set of phonemic distinctions. What is less
clear, however, is whether all three steps of the shift are endemic and
have occurred after the arrival of the first settlers in New Zealand or
whether raising and fronting of dress/trap and
centralization of kit was already present in the speech of those
speakers. Earlier analyses have taken polar views, which means that they
have adopted a viewpoint of either exclusive innovation in NZE (which is
the view of Bauer, 1979, 1992) or exclusive conservatism vis-à-vis
British English (Trudgill, 1986). Later analyses
have arrived on the more reconciliatory conclusion that raised/fronted
variants of dress and trap were already present in the
speech of the earliest settlers, and that this process continued in New
Zealand (as well as in the other Southern Hemisphere varieties) afterwards
(Trudgill, Gordon, & Lewis, 1998). In
addition, kit centralization has been analyzed as an endemic
phenomenon (Gordon, Campbell, Hay, Maclagan, Sudbury, & Trudgill, 2004). There are relatively few examples of
centralized kit in Gordon et al.'s (2004) study of the first and second generation of NZE
speakers (1850–1900). Thus, it seems that the crucial period for KIT
centralization was the subsequent Intermediate Period, which will be
discussed here.
I will furthermore argue that there is compelling evidence that the
centralization of KIT is the result of a push-chain relation between the
SFVs, which has been a matter of considerable debate in earlier analyses.
Whereas Trudgill et al. (1998) as well as
Watson, Maclagan, and Harrington (2000) argued
for a pull-chain scenario, Bauer (1979) as well
as Gordon et al. (2004) favored a push-chain
account of the SFV shift.
It should also be noted that the NZE short front vowel shift stands
out as a true exception to the general principles of chain-shifting
outlined by Labov (1994:138), who concedes that
“this [the NZE short front vowel shift] clearly violates
Principle III (since a short front vowel is moving to the back in a chain
shift) and Principle II (since short front vowels are rising
together).”
THE SPEAKERS
Thirty speakers from the Intermediate Archive were analyzed. This
corpus consists of interviews of about 100 New Zealanders born between the
1890s and the early 1930s. The length of the interviews vary considerably,
the shortest ones being about half an hour of running speech, whereas
others last for up to two hours. The interviews were conducted by
historians between 1991 and 1994 and cover a wide range of topics, from
the interviewee's family background to childhood memories and local
history. The sample was subsequently divided up according to age and
gender. Speakers were grouped into three age groups: EARLY (born between
1895 and 1905, 4 males and 7 females), MEDIUM (born between 1910 and 1920,
5 males and 5 females), and LATE (born after 1925, 4 males and 5 females).
This allows for a fairly high-resolution picture of subsequent stages of
vowel movements within one generation.
METHOD
The data was analyzed using the PRAAT program for phonetic analysis
(www.praat.org). For each token, frequency
measurements of the first two formants (F1 and F2) were taken at the
turning point of each vowel. If no such turning point could be identified,
the measurement was taken at mid-point. Only stressed tokens were
measured, and an overall number of 70–100 tokens were aimed at for
each lexical set per speaker. For some speakers, it was not possible to
obtain more than 40 tokens for some categories due to either too short a
duration of the interview or articulatory modes (e.g., long stretches of
whispery phonation in the speech of a number of older speakers).
Since individual vocal tract physiologies are known to hamper the
between-speaker comparability of raw frequency values, the data was
normalized using the algorithm proposed by Lobanov (1971), whereby a normalized formant frequency value is
calculated on the basis of the formula presented next (for a discussion of
this procedure vis-à-vis a number of other normalization
strategies, see Disner, 1980):
where Fi is a given formant,
Fi is the average of the formant
Fi across all monophthongs,
SDi the standard deviation of
Fi about its mean for all monophthongs. In
order to allow for comparability of the normalized values with other
studies based on Hertz-scales, the normalized values were rescaled
according to the procedure outlined in Disner (1980), that is, on the basis of an idealized schwa
with formants at 500, 1500, and 2500 hertz and standard deviations of 150,
500, and 300 Hz for the first three formants, respectively.
The tokens were then coded for the variables shown in Table 1. The data were subsequently fed into a CART
(classification and regression tree) analysis program component of the R
program for statistical analyses. Most of the results presented in the
next section are based on that analysis.
Independent variables coded for as potential predictors of formant
frequency in NZE short front vowels. Each token has been coded for
categories and subsequently analyzed using the CART component of the R
statistics program
OVERALL PATTERNS
As Figures 1a, b show, the global pattern
of change within the intermediate sample is fairly consistent. The younger
speakers have higher realizations of dress and trap as
well as a more central realization of kit, which matches the
overall developments in the SFV system of NZE over the last 150 years. For
comparison, Figures 1c, 1d, 1e, and 1f show SFV averages for the Mobile Unit (MU)
speakers analyzed in Gordon et al. (2004). Figures 1e, f show modern speakers (cf. Maclagan, 1982). The data on which Figures 1c, 1d, 1e, and 1f are
based were kindly made available to me by Margaret Maclagan. The only
discontinuity is in the behavior of the kit vowel in the speech
of the LATE MALES,2
The six subsamples will
be spelled out in upper-case characters in this study.
who have a
less central realization than the corresponding vowel in the medium male
sample. For the males, the decrease in the F2 dimension for the
kit mean within the Intermediate sample is in the order of 256
Hz. Given the simultaneous raising/fronting of
dress
(−52 Hz in the F1 and 153 Hz in the F2 dimension), this brings about
a change that increases both the distance between
kit and
dress,
3 Henceforth, the term
“distance” will be used in an empirical (i.e., mathematical)
sense as an expression of Euclidean distance between two points in linear
two-dimensional space, such as a vowel plot in hertz.
as well as
shifting the basic typology of the two vowels relative to each other. That
is, whereas the difference between
kit and
dress was one
of height for the earlier speakers, especially the males, it develops into
a system where both vowels are of approximately the same height, but
contrast on a front-back (or, in acoustic terms, F2) dimension.
F1/F2 averages of kit, dress, and trap
for all groups of Intermediate speakers (Figures 1a, b), pre-Intermediate
speakers (1c, d), and modern speakers (1e, f) (cf. Gordon et al., 2004; Maclagan,
1982). Note that the data plotted in Figures
1e, f are non-normalised. High F1 values correspond to openness.
Similarly, the F2 axis corresponds to the front-back dimension, where
higher F2 values correspond to more fronted articulation.
(continues)
Figure 2 plots the position of the three
SFVs and their respective contextual variants. Only those categories that
occurred at least five times within any subgroup are plotted.
Impressionistically, three characteristics stand out. First, there is
substantial categorial overlap between a number of contextual variants in
the lexical sets of kit and dress in the speech of the
EARLY and MEDIUM MALES as well as the EARLY FEMALES. Second, there is an
obvious stretch in the categories of kit in the F2 dimension in
the speech of the EARLY MALES. Third, there is no categorial overlap
between the lexical sets of dress and trap for any group
of speakers in the sample.
Mean frequency values of the first two formants of the lexical sets of
kit, dress, and trap as well as their
contextual variants. Each of the six groups of Intermediate speakers is
plotted. The contextural variants are given in IPA, where
.
(continues)
Evidence for a push-chain scenario
Table 2 sums up the Euclidean distances
between the mean values of the SFVs for all six groups of speakers.The
numbers indicated in Table 2 suggest a fairly
clear picture. The most significant increase in terms of Euclidean
distance between kit and dress occurs between the EARLY
and the MEDIUM age groups for both genders, whereas DRESS and TRAP are
dragged apart only later, that is, between the MEDIUM and the LATE stage.
This behavior would suggest a pull-chain scenario, if it weren't for
the following point: In the speech of the early speakers, the distance
between kit and dress is extremely small, and there is
substantial overlap of various allophones of both lexical sets (cf. Figure 2). Thus, it is hard to see how such a system
could be viewed as an initial state in the vowel shift. In addition, a
pull-chain scenario would probably assume that the second step in the
shift was the movement of dress to a higher position, followed by
trap. However, this seems unlikely, given the consistent increase
of the distance between dress and trap over time in the
sample. Under the pull-chain assumption, you would probably expect an
initial increase, followed by a decrease of distance between the two
lexical sets. We would also expect to find speakers with centralized
kit, but not-yet raised dress under this scenario. As
will be shown later, this is not the case, whereas the reverse possibility
holds. It is therefore more likely that the system of the early speakers
is a transitional one in which dress has already been raised
sufficiently to trigger a reactive centralization of kit. With
respect to dress and trap, it seems reasonable to
extrapolate an earlier stage where the two lexical sets were closer to
each other.
Euclidean distances between the mean values of the lexical sets of
kit, dress and trap in the speech of the six
groups of Intermediate speakers
The “Split System” in the EARLY MALE
sample
It is obvious from looking at the plots in Figure
2 that the EARLY MALE group of Intermediate speakers stands out
with respect to both the overall means of dress and kit
as well as the structural set-up of the contextual variants. They are the
only group that has allophones of kit as the most fronted tokens,
but they also have centralized variants, which leads to a striking stretch
in the F2 dimension for kit. It seems clear that the kit
items that occupy the front part of the overall distribution are those
that are followed by a velar consonant. What is less clear, however, is
whether the front categories represent variants that have not yet
undergone centralization, or whether this early group of speakers shows a
strategy of both fronting and raising prevelar variants of kit
and simultaneously centralizing others.
4 It
should also be noted that there is a striking mismatch in terms of
conditioning factors in the arrangement of the contextual variants of
kit in that group. Whereas the front categories share the same
place of articulation (velar), the centralized ones are predominantly
followed by fricatives (i.e., manner of articulation). The implications of
this observation will be discussed later.
My auditory assessment
of those items suggested that there are in fact a number of tokens that
are similar to the realization of
kit in Australian English
(AusE) (i.e., as [i]), as well as some that are closer to the RP
value (
). This impression is supported by the data given in Bernard
(1970), which states mean formant frequency
values of 365 Hz for F1 and 2220 Hz for F2 for modern AusE kit,
which is in the vicinity of the EARLY MALE realization of pre-velar tokens
of kit. Secondly, a similar system is described by Lass (1987) and Wells (1982) for
modern South African English, although the conditioning factors differ
(Lass reports as the main conditioning factors for kit
fronting/raising: kit in initial position, after /h/,
and next to velars/palato-alveolars).
However, it is less clear how an elliptical distribution such as that
of the EARLY MALES should shift at all, rather than merge. It has been
recognized that a given vowel (i.e., as an etymological category) does not
necessarily behave as a coherent category in a vowel shift. (See M. Gordon
2001, 2002 for a
summary, as well as Labov 1994, 2001 for ample evidence of transitional
allophonization of vowels which undergo a shift.) Rather, different
contextual variants can shift at different rates, or even in different
directions. This seems to have happened at the early stages of
kit centralization in NZE, however, the modern resolved system
has restored a uniform etymological category of kit.
Discussion
We have seen that it was in the Intermediate Period where the shift in
the short front vowels came to its completion, resulting in the modern
set-up with two front vowels and a central vowel. In addition, it could be
demonstrated that there was a stage where the SFV system had the peculiar
distributional property of an unusually elliptical5
I originally employed the term “skinny
distribution” in the description of the kit vowel space for
these speakers, upon which one of the reviewers justly remarked that this
might be too metaphorical a term for what is essentially a statement about
vowel space geometry. I have therefore resorted to the expression
“unusually elliptical,” which means that the deviation around
a mean in one dimension (here F2) vastly exceeds that in another dimension
(here F1), and more so than is the case in some reference distribution.
With the data at hand, it seems clear that the ratio of F2/F1 is
unusually large in the case of the EARLY MALE distribution of kit
compared to the other SFV distributions in the present sample.
distribution in the top two heights (
kit and
dress),
where one segment (
kit) occupies an unusually large space in the
front-back (or F2) dimension. This has two implications for the study of
vowel shifts, a general one as well as a more specific one (i.e., specific
to the study of the NZE short front vowel shift). In general terms, the
process of condensing the available vowel space for a given vowel in one
articulatory dimension (in our case, the front/back dimension of
kit) in an intermediate stage of a vowel shift imposes limits on
the usefulness of mean values of an entire lexical set or etymological
category (such as
kit or
dress), since these mean values
may obscure both the pathways of movement of meaningful smaller units
within a lexical set (such as, e.g.,
kit before alveolar
fricatives), as well as certain differences between speaker groups (such
as EARLY MALE and EARLY FEMALE, who have similar mean values in the
lexical set of
kit, but differ markedly in their degree of
consistency around the mean). An analysis that is based solely on overall
means cannot capture the difference between the two putative scenarios
depicted in
Figure 3.
Two possible scenarios for the NZE front vowel shift in the top two
heights. The upper circle (or ellipse) represents an idealized
distribution of kit vowels (solid line), the lower one that of
dress (dashed line).
Apart from the general implication of this finding as a demonstration
of the existence of highly elliptical vowel distributions in general (as
opposed to, e.g., an assumption of mutually implied degree of
innovativeness within a given subgroup of the speech community that
undergoes the shift), this might also link the history of the short front
vowel shift in NZE to that of AusE, which behaved similarly with respect
to dress and trap, but raised and fronted kit
rather than centralizing it. That is, it can be hypothesized that at an
earlier stage, both varieties had at their disposal a range of
kit variants spanning the entire range between (roughly)
,
but generalized different means only later. This hypothesis seems to be
confirmed by ongoing research on the Intermediate Period in AusE (P.
Trudgill & E. Gordon, personal communication).
In addition, we have seen that it is through the study of such smaller
units that apparent temporal discontinuities can be accounted for as a
resolution of formerly overlapping lexical sets rather than the absolute
position of a given lexical set (cf. kit in the MEDIUM and LATE
MALE groups).
Another point that I would like to raise in relation to the short
front vowel shift in NZE is of a more terminological nature and relates to
the notions of “kit centralization” or
“centralized kit.” Heretofore, this term has been
used in a rather loose fashion in order to explain both the process as
well as the outcome of a historical process. Given the nature of the short
front vowel system of NZE in the early Intermediate Period, those terms
acquire a certain amount of denotational ambiguity, in that it is not
clear whether what is referred to in any given instance of usage of these
terms is a centralized kit mean of the overall lexical set or the
existence of centralized variants in the speech of any subgroup in the
speech community (an age or gender cohort, a social class, an individual).
That is, the kit vowel in the speech of a given subgroup or an
individual can be both noncentralized (in that it has a mean position in
the vicinity of dress, cf. Fig. 2a)
and centralized (with the simultaneous existence of central allophones) at
the same time, which implies that some conceptual clarification is
probably advisable in future studies on this topic.
On a more sociolinguistic note, two things have to be pointed out
regarding the role of the female speakers in the sample. First of all,
they tend to clearly be spearheading the chain-shift in most of its
various dimensions. That is, any given female group has more progressive
mean values (more centralized for KIT, more raised for
dress/trap) than their corresponding male
counterparts of the same age cohort (cf. Fig.
1). This confirms the tenet of the leading role of women in
nonstigmatized sound change, that is, sound change “from
below” (Labov, 2001). On the other hand,
my analysis should have made clear the limited usefulness of overall mean
values of lexical categories in an unstable system. For example, both the
MALE and the FEMALE speakers of the EARLY group have rather similar mean
values for KIT, but differ considerably in the arrangement of the
contextual categories (cf. Fig. 2).
Whereas the EARLY MALES have a system where kit can be either
the most fronted element as well as the most central one of the SFVs, this
does not hold true for the EARLY FEMALES, who are much more consistent and
do not show the same degree of allophonization. For these two groups of
speakers then, it is the MALES who have both the most conservative as well
as the most innovative realizations of kit, which brings about a
cancelling out around a mean that is close to that of the females.
FACTOR ANALYSIS
Coarticulation
Apart from pointing out the distributional properties of the SFV
during the shift, we have mentioned in passing that these distributions do
not represent random clusterings of
kit/dress/trap tokens, but tend to have
internal structure depending on the phonemic environment they occur in. I
will briefly review the effects of adjacent phonemes on vowels, before
moving on to whether these expected patterns show up in the sample. With
respect to place of articulation, Stevens and House (1963:125) have found that: “In the environment
of front vowels, for example, ‘velar’ consonants (being
palatal variants in English) have a high F2-locus (above 200 cps) whereas
the F2-loci for postdental and labial consonants are below the F2 values
for the vowels.”
We would therefore expect a distribution where pre- and postvelars
occur towards the front end of a distribution, whereas vowels in the other
environments are more central. With regard to F1 effects, they found both
a displacement of vowel frequencies towards those of the adjacent
consonants (which is always a downward shift) and a shift towards a
neutral value (i.e., that of schwa, in the vicinity of 500 Hz) if the
articulatory target of the vowel is far from that of the surrounding
consonants.
As for manner of articulation, Stevens and House (1963:126) state that: “One feature of the data
[…] is the tendency for F2-values for vowels in the
environments of fricative consonants to be lower for front vowels and
higher for back vowels relative to corresponding values for stop
consonantal environments. This difference is most evident in the vowels
.” In addition, Wright (1986)
has found a shrinking of the overall perceptual vowel space for vowels in
nasal environments. For a more comprehensive survey of the relationship of
vowel targets and phonemic context, see chapter 4 of Harrington and
Cassidy (1999).
CART (classification and regression tree)
As a second step in the analysis, all tokens were coded for the
categories outlined in Table 1, and subsequently
subjected to a CART (classification and regression tree) analysis. This
method is appropriate for continuous dependent variables such as vowel
formant frequencies. As described by Mendoza-Denton, Hay, and Jannedy
(2003:128–129):
The construction of classification trees is essentially a
type of variable selection. […] Classification trees are
an attractive method of data exploration because they can handle
interactions between variables automatically. They also have the advantage
of being completely non-parametric. No assumptions are made about the
underlying distribution of the data. These features make them less
powerful for detecting patterns in the data, but fairly reliable in terms
of the patterns found. Classification trees do assume that the effect
being modelled is organised into discrete factors. An analogous class of
models, regression trees, deals with continuous data. […]
A classification tree begins with the data to be analysed and then
attempts to split it into two groups […]. Ideal splits
minimise variation within categories and maximise variation across
categories.
For the mathematical foundations of CART, see Breiman, Friedman,
Olshen, and Stone (1984). The important thing
with respect to the following exposition of internal factors involved in
the NZE SFV shift are that divisions that CART finds are always binary at
any node down the hierarchy of the overall set of divisions found in the
data set, and that interacting categories are readily identified as
successively branching nodes.
This section discusses the outcome of that analysis for a number of
internal factors, that is, the variables PRE-PLACE, PRE-MANNER, PLACE,
MANNER (cf. Table 1; the analysis of the other
factors mentioned in Table 1 is not completed).
The complete trees were built, and it is these coding categories that show
up consistently in all speaker groups.
The importance of the prealveolar environment
In terms of the coding categories PRE-PLACE, PRE-MANNER, and MANNER,
the patterning of the SFV vowel tokens followed the predictions we would
make on the basis of the studies mentioned earlier in the subsection on
coarticulation. That is, all three lexical sets showed a set-up where
vowels in velar environments show high F2 values in all groups and across
all three lexical sets. Vowels following nonvelars and/or preceding
nonvelars except alveolars tended to have F2-values below the mean for
their respective lexical set. As far as manner of articulation is
concerned, fricative and stop environments behave as expected, that is,
vowels in fricative environments show consistently lower-than-average
F2-values, whereas those in stop environments show higher ones. Contrary
to the results reported by Wright (1986), vowels
in nasal environments consistently showed higher formant frequency values
in all lexical sets, which might probably be best explained by an
articulatory expansion of the prenasal vowel space in order to offset the
loss of perceptual distinctness between lexical sets in these
environments.
More importantly, however, was a striking mismatch between the three
lexical sets with regard to prealveolar vowels. Whereas prealveolars are
“well-behaved” in the lexical sets of kit and
trap (with the exception of the LATE FEMALE group, where
prealveolars have a higher F2 value in trap), that is, they are
consistently realized with a significantly lower second formant than the
mean, exactly the opposite holds true in the lexical set of
dress. For all groups of speakers, prealveolar allophones of
dress fall into the class of front allophones. In addition, they
also tend to be the closest class in all three lexical sets, with 4 out of
6 groups showing low F1 values in kit, and 4 out of 5 in
dress. In trap, low F1 values are categorical6
I use the term “categorical” here in
reference to the mean formant frequency value in relation to the mean of
the whole lexical set in all speaker groups, that is, if a given coding
category has lower values across all groups of speakers, that category has
“categorically lower Fx values.” This does not exclude the
possibility of there being tokens with aberrant values.
for
prealveolars. This implies that if we understand the chain-shift in the
top two heights as a movement of
dress down the F1 axis and up
the F2 axis (i.e., fronting and raising) and a reactionary movement of
kit down the F2 axis, we can identify the prealveolar variant as
spearheading the movement of both categories. Furthermore, it is probably
not accidental that the prealveolars are the most frequent contextual
variant (764 out of 1558 tokens in the lexical set of
kit, 993
out of 1749 in the lexical set of
dress, and 713 out of 1270 in
trap).
CORRELATIONS BETWEEN VOWELS FOR INDIVIDUAL
SPEAKERS
Having identified the primary conditioning factors governing the SFV
shift in Intermediate NZE, I will now turn to the question of how both the
movements of the three lexical sets as well as their phonemic subsets
relate to each other. If the chain-shift hypothesis is correct, we would
expect a positive correspondence between F1-values of dress and
trap as well as between F1-values for dress and
F2-values for kit. In addition, we can test the hypothesis that
the shift came about as a push-chain, which led to the transitional stage
where the lexical sets of dress and kit were close to
each other. If this is true, we would expect to find speakers with high
dress, and uncentralized kit. We can furthermore
corroborate the claim that prealveolars are “special,” in that
they seem to be carrying the overall shift and should therefore show the
tightest correspondences in the dimensions mentioned earlier.
Table 3 sums up the Spearman's
correlation coefficients for both the lexical sets as a whole as well as
for the coding-category PLACE. The coding-categories DENTAL and
POST-ALVEOLAR (i.e., vowels before dentals and postalveolars) did not show
up in the speech of every speaker and are not listed separately. Figure 4 plots mean formant frequency values of each
individual speaker in those dimensions where correlations are expected to
hold, that is, the F2 value of kit versus F1 of dress
(Fig. 4a and 4b, where (a) shows the mean values
for the overall sets as a whole and (b) for prealveolars) and the F1 of
dress against the F1 for trap (Fig.
4c and 4d).
Correlation coefficients and their significance levels
Individual mean values in those dimensions that are assumed to be
interrelated [i.e., F2 for kit vs. F1 for dress in
Figures 4a (all environments) and 4b (prealveolars), as well as F1 for
dress vs. F1 for trap in 4c (all), and 4d
(prealveolar)]. Each point represents mean values for a single
speaker. The line represents a nonparametric scatterplot smoother fit
through the data (Cleveland,
1979).
Two conclusions can be drawn from the correspondence test results
indicated in Table 3. First, there is a solid
positive correlation between the first formant frequency value of
dress and the F2 of kit. That is, the lower the F1 of
dress, the lower the F2 of kit tends to be. Translated
into articulatory terms, the height of dress correlates with the
centralization of kit. Along similar lines, it is clear that
there is a height correlation between the lexical sets of dress
and trap, whereby a low F1 value for dress corresponds
to a low F1 for trap.
Secondly, it should be noted that the correlations are tighter if we
look exclusively at prealveolar vowels. As far as the relationship between
kit and dress is concerned, it can be said that it is
the prealveolars that carry the shift, whereas the expected correlation
between the F1 of dress and the F2 of kit fails to reach
significance for prevelars and prelabials. The same holds true for the
relationship between dress and trap, although there is a
(weaker, but still highly significant) correlation in the other categories
as well. We can then conclude that the developments in the SFV system in
NZE have justifiably been analyzed as a chain-shift, where the movement of
one vowel triggers a subsequent displacement of the next one on its way
(through articulatory space). In addition, we have identified a class of
allophones that carries the shift (the prealveolars), and have therefore
adduced additional evidence regarding the importance of looking at
phonemic environments in studies of vowel change. Furthermore, the plots
in Figure 4 provide evidence for the push-chain
hypothesis. Recall from Table 1 and Figure 2 that the EARLY speakers have a set-up
wherein the means of kit and dress are fairly close to
each other, which was hypothesized to be indicative of a stage where
dress had raised, but kit was still a front vowel. In
terms of correspondences, we would then expect there to be individual
speakers who have a low mean F1 in dress (i.e., a high
dress vowel), as well as a relatively high F2 in kit.
This is exactly what we find in Figures 4a and
4b, in which the upper left corner is populated, whereas the lower
right one is not. We can therefore conclude that it is a push-shift, and
that it is sequential, that is, the elliptical distribution does not come
about by grouping together speakers of different degrees of
innovativeness, but represents a true transitional stage exemplified in
the speech of one and the same speaker.
CONCLUSION
In this article I have presented the results of an acoustic analysis
of the short front vowels in Intermediate New Zealand English. Group means
were given for each lexical set as a whole as well as for a number of
allophonic categories. It was shown that the Intermediate Period saw a
change in the typology of the short front vowels, whereby an earlier
system of three front vowels changes into a set-up with two front vowels,
dress and trap, and a central vowel, kit.
Furthermore, it could be observed that the behavior of the kit
vowel is less straightforward than the movement of the overall means over
time suggest. Rather, different allophonic categories shift at different
rates, and centralization is never into empty territory sensu
stricto, since a more centralized mean in a later group of speakers
is occupied by one or more innovative allophones in the speech of an
earlier group. In addition, there is one group of speakers (the EARLY
MALES) that shows a most pronounced stretch in the F2 dimension of the
kit vowel, which suggests the possibility of a temporary system
with both fronted as well as centralized allophones of kit.
The results of a CART analysis indicate that it is mainly the
prealveolar environment that carries the structure-changing properties of
the shift, in that prealveolars are ahead of their lexical set as a whole
in both raising and centralization. Other environmental factors (manner
and place of articulation of the preceding consonant, as well as manner of
articulation of the following one) pattern similarly in all three lexical
sets, which is in keeping with general assumptions regarding contextual
effects, that is, that they influence similar vowels in the same way.
A number of correspondence test results were discussed. It could be
shown that the historical process that converted a system of three short
front vowels into one of two front vowels and a central vowel is indeed a
chain-shift, and that the centralization of kit clearly occurred
last. I would therefore assume the following chronology:
- Raising of trap (pre-Intermediate7
Suggesting an earlier (i.e., pre-Intermediate) period of
trap-raising is based on the analyses in Gordon et al. (2004), as well as on the discrepancy of the
relationship between dress and trap vis-à-vis
dress and kit in the Intermediate Period. Whereas there
is substantial overlap between a number of allophones of dress
and kit in the speech of earlier Intermediate speakers, no such
overlap can be observed between dress and trap. In
addition, the distance between trap and dress increases
over the Intermediate Period. But there still is trap-raising in
the Intermediate Period, so that an alternative hypothesis would be to
assume that this process would be rather different from that of
dress-raising/kit-centralization, in that it would
be strictly mechanical and rather unmotivated, which does not sound too
appealing from an Occamian point of view. In addition, Trudgill (2004) argued strongly in favor of
trap-raising in 19th century England.
- Raising/Fronting of dress; incipient centralization of
kit as well as temporary raising of kit (early
Intermediate, “split”)
- Further raising of dress and trap
- Full centralization of kit; resolution of the
kit/dress overlap (MEDIUM and LATE FEMALES, LATE
MALES).
- Additional raising of dress/ trap (late
Intermediate).
Having established the major pathways of the short front vowel shift
in Intermediate New Zealand English, future work will take into account a
larger number of internal factors (such as syllable structure, minimal
pair effects, vowel length) as well as social ones. In addition, more can
be said about the significance of elliptical distributions in vowel shifts
and the exceptional status of the NZE shift with regard to the theoretical
framework of Labov (1994). Both points are part
of my ongoing research on these topics and will be explored further.