


1. Introduction
What makes readers attend to words? One relevant factor is whether the word is focused or non-focused. For instance, when presented with the same sentence twice, readers are more likely to notice change in focused words than in non-focused words (Sturt, Sanford, Stewart, & Dawydiak, Reference Sturt, Sanford, Stewart and Dawydiak2004). Thus, readers are more likely to notice a change from cider to beer in (2) than in (1).
Another relevant factor is what we will call word category: lexical words attract more attention than grammatical words. For instance, Rosenberg, Zurif, Brownnell, Garrett, and Bradley (Reference Rosenberg, Zurif, Brownnell, Garrett and Bradley1985) asked participants to detect all instances of the letters t or a in a written text, and found a higher detection rate for lexical words compared to grammatical words. In this paper, we bring together research on focus and research on word category and argue for a unified understanding. In two behavioral experiments, we explore relations and commonalities between the two effects: the effect of linguistic focus (vs. non-focus) and the effect of word category (lexical vs. grammatical). Experiment 1, a letter detection study, measures attention to individual letters in grammatical and lexical elements. Experiment 2, a change blindness study, measures attention to grammatical and lexical words. For both studies, we expect that readers attend more to lexical words than to grammatical words, and more to focused than to non-focused constituents. In addition, we expect an interaction between these two factors. These expectations are based on Boye and Harder (Reference Boye and Harder2012) and on earlier studies.
1.1. previous studies of attention guided by focus
At the core of our studies lies the assumption that different parts of a sentence may not be processed at the same depth (cf. Ferreira & Patson, Reference Ferreira and Patson2007). Rather, the depth of processing is guided by selective attention (cf. Sanford, Reference Sanford2002). Such variations in sentence processing have been established by various online and offline methods. Eye-tracking studies with their relatively direct measures of visual attention have given valuable insights into processing load (cf. Engbert, Longtin, & Kliegl, Reference Engbert, Longtin and Kliegl2002; Engbert, Nuthmann, Richter, & Kliegl, Reference Engbert, Nuthmann, Richter and Kliegl2005; Rayner, Reference Rayner1998, Reference Rayner2009; Rayner, Ashby, Pollatsek, & Reichle, Reference Rayner, Ashby, Pollatsek and Reichle2004; Reichle, Pollatsek, Fisher, & Rayner, Reference Reichle, Pollatsek, Fisher and Rayner1998; Reichle, Pollatsek, & Rayner, Reference Reichle, Pollatsek and Rayner2006; Reichle, Warren, & McConnell, Reference Reichle, Warren and McConnell2009). For instance, studies of eye saccades indicate that processing load increases for words that are low in frequency or unpredictable.
When it comes to examining processing depth, other methods have been used to examine the depth of attention and depth of comprehension. A number of change blindness studies have demonstrated that informants are better at detecting changes in focused words than in non-focused words. Cases in point are the reading studies by Sturt et al. (Reference Sturt, Sanford, Stewart and Dawydiak2004) and by Price (Reference Price2008) which showed higher detection rates for clefted constituents, and a listening study by Price (Reference Price2008) which showed higher detection rates for stressed constituents. In the same vein, McKoon, Ratchliff, Ward, and Sproat (Reference McKoon, Ratchliff, Ward and Sproat1993) found that informants are better at recalling words placed in focus position (e.g., nouns in object position) than words outside focus position.
Semantic processing also seems deeper for focused than for non-focused words. Work on discourse processing suggests that comprehenders economize their processing resources: they do not process all parts of the discourse maximally and to the same degree (cf. Ferreira & Patson, Reference Ferreira and Patson2007, on good enough processing). Incongruent words are more easily noticed when focused e.g. by means of clefting (Bredart & Modolo, Reference Bredart and Modolo1988) or pitch accent (Kristensen, Wang, Petersson, & Hagoort, Reference Kristensen, Wang, Petersson and Hagoort2013).
The empirically supported link between linguistic focus (as created by clefting, stress patterns, etc.) and attention is in line with standard linguistic theories of focus (e.g., Lambrecht, Reference Lambrecht1994, pp. 212–213). Yet, the link has mainly been found for clefts, pseudo-clefts, and pitch accent and is under-studied for other types of linguistic focus, e.g., focus by means of focus particles like precisely and only.
1.2. previous studies of attention to lexical vs. grammatical words
As mentioned, there is also evidence for a link between attention and the distinction between lexical and grammatical words. Letter detection studies suggest that readers attend more to letters appearing in lexical words than to letters in grammatical words or affixes (Drewnowski & Healy, Reference Drewnowski and Healy1977; Foucambert & Zuniga, Reference Foucambert and Zuniga2012; Healy, Reference Healy1976; Koriat & Greenberg, Reference Koriat and Greenberg1994; Koriat, Greenberg, & Goldshmid, Reference Koriat, Greenberg and Goldshmid1991; Rosenberg et al., Reference Rosenberg, Zurif, Brownnell, Garrett and Bradley1985; Smith & Groat, Reference Smith, Groat, McConkie, Kolers, Wrolstad and Bouma1979) – at least when grammatical words are frequent (Roy-Charland & Saint-Aubin, Reference Roy-Charland and Saint-Aubin2006). In letter detection studies, readers of a text are instructed to mark all occurrences of a specific letter, e.g., the letter t. A disproportionate number of target letters are missed when the letter occurs in grammatical words like the. Letter detection is not as direct a measure of visual attention as eye-tracking, but comparisons of eye-movement measures for reading tasks with and without letter detection show that detection tasks are informative about word class processing in normal reading (Greenberg, Inhoff, & Weger Reference Greenberg, Inhoff and Weger2006).
It is heavily debated why more letters are missed in grammatical words than in lexical words. The unitization account by Drewnowski and Healy (Reference Drewnowski and Healy1977) proposes that letters are missed because readers tend to process stimuli at the highest level available to them. Once a reader has identified a unit (e.g., a phrase), the reader may move on to the next available high-level unit (e.g., the next available phrase), without necessarily completing the identification of lower-level units (such as words and letters within the phrase). When a unit is highly frequent or highly familiar, it may therefore be quickly identified, and its lower levels are left uncompleted. Based on these processing assumptions, the unitization account posits that high-frequency grammatical words like the tend to be missed because they are read as part of larger units, e.g., short syntactic phrases. As a refinement of the original unitization account, Hadley and Healy (Reference Hadley and Healy1991) suggest that grammatical words tend to be processed in the parafovea of the eye during reading because they are part of such larger units. However, studies by Saint-Aubin and Klein (Reference Saint-Aubin and Klein2001) have demonstrated that there are more omissions for letters in grammatical words than in lexical words even when parafoveal processing is not available, e.g., when words are displayed in column format or one word at a time.
Some models have put special emphasis on the high frequency and high familiarity of function words. Following the unitization account, Moravczik and Healy (Reference Moravcsik and Healy1995) argue that familiarity of word meaning plays a crucial role in letter detection: if word meaning is quickly accessed, readers skip the later-stage, lower-level process of identifying letters. By manipulating the linguistic context in the letter detection task, they demonstrated fewer detection errors when the had an unusual meaning, was contrastive, or had an ambiguous referent. Yet, Saint-Aubin and Poirier (Reference Saint-Aubin and Poirier1997) find that the frequency of word meaning is not as important as word function (cf. also the structural account by Greenberg & Koriat, Reference Greenberg and Koriat1991), and a subsequent study by Moravcsik and Healy (Reference Moravcsik and Healy1998) shows that, even when meaning is controlled for, slight variations in word function have a modulating effect on letter detection. For instance, more letters are detected when the is used as an adverb (Third, get lots of sleep and you will feel the better for it) than when it is a definite article.
In the guidance-organization (GO) model by Greenberg, Healy, Koriat, and Kreiner (Reference Greenberg, Healy, Koriat and Kreiner2004), the unitization account and the structural account are combined. The GO model assumes that letter processing occurs at a later stage than word processing, but it also specifies that structural processing of text guides eye-movement to the semantically informative parts (for a critique of the GO model, see Roy-Charland, Saint-Aubin, Klein, & Lawrence, Reference Roy-Charland, Saint-Aubin, Klein and Lawrence2007). The difference between attention to grammatical and lexical words is therefore seen as building on structural differences between these two word categories.
1.3. critique of the distinction between content and function words
A considerable portion of the research on the lexical–grammatical distinction has been carried out based on a distinction between content words (representing lexical words) and function words (representing grammatical words). The distinction between content and function items is, however, problematic in several respects. Most importantly, it is based on an assumption that two classes of linguistic items can be distinguished according to their semantics: content word have content, while function words do not (cf., e.g., Harley, Reference Harley2006, p. 118, on meaningfulness). Yet, some conceptual content (or functions) may be expressed by both content and function items. An example from English is ‘possession’, which may be expressed both by means of content words, i.e., the full verbs have and own in (3), and by means of a function item, i.e., the clitic ’s in (4).
Other examples of lexical and grammatical elements expressing similar content are:
– Number expression: In English, the meaning ‘plurality’ can be expressed both by the grammatical suffix -s (as in cars) and by the lexical expression more than one (as in more than one car).
– Illocutionary value: In English, the meaning ‘directive’ or ‘command’ can be expressed both grammatically, e.g., by means of word order (Go away!), and lexically (I order you to go away).
1.4. critique of the distinction between open- and closed-class words
The content vs. function distinction may be seen, then, as a theoretically flavored name for pre-theoretical classifications. Linguists and psycholinguists therefore frequently define this distinction in terms of the distinction between open- and closed-class words (e.g., Harley, Reference Harley2006, p. 118; Segalowitz & Lane, Reference Segalowitz and Lane2000). This second distinction is empirically well-founded (deciding between open vs. closed classes is a matter of counting class members), but entirely theoretically unanchored: like the distinction between content and function items, it is supposed to relate to the distinction between lexicon and grammar, but it is not theoretically motivated that the lexicon should solely consist of open-class items, and it is possible to find lexical items that belong to closed classes. For instance, some languages have closed classes of adjectives (e.g., Schachter & Shopen Reference Schachter, Shopen and Shopen2007). Consider also adpositions (including English prepositions like of, by, in, and on). They form closed classes, but there is a strong tradition for considering them content words (see Mardale, Reference Mardale2011, for discussion), and there is empirical evidence that at least some of them are lexical (e.g., Bennis, Prins, & Vermeulen, Reference Bennis, Prins and Vermeulen1983; cf. Section 1.5).
The lack of a theoretical anchor for the two distinctions means that they are inadequate for theoretically based hypothesis formation, and that it is difficult to account for the empirical differences with which they correlate. In particular, it is difficult to link either of the two distinctions to attention. Rosenberg et al. (Reference Rosenberg, Zurif, Brownnell, Garrett and Bradley1985) assume the following link between closed-class items and attention:
“In some sense, properties of closed-class items less readily intrude themselves into conscious attention – they tend toward ‘invisibility’. Without arguing the point in detail here, we assume that one plausible account of this pattern is that it arises because of differences in the way that the products of the word retrieval systems discussed above relate to processes of sentence analysis and interpretation, and hence to processes of conscious report.”
(Rosenberg et al., Reference Rosenberg, Zurif, Brownnell, Garrett and Bradley1985, p. 291)But this is a (rather vague) ad-hoc assumption, rather than a theoretically motivated account. Still, as discussed above, studies based on these distinctions often led to clear results: content or open-class items attract more attention than function or closed-class items. This indicates that, while the distinctions are pre-theoretical and inaccurate, there is empirical back-up for the intuitions they were created to capture.
1.5. the ProGram theory: a new classification of lexical vs˙. grammatical words
A recent usage-based theory of the lexical–grammatical distinction by Boye and Harder (Reference Boye and Harder2012) – henceforth, the ProGram theory – captures the same intuitions, while at the same time providing a theoretical link between this distinction and attention. In fact, it takes attention properties to lie at the core of the distinction. According to the ProGram theory, the lexical–grammatical distinction is a means for prioritizing information. Lexical items (including roots, lexical words, phrases) are defined as items that are by convention potentially discursively primary. That is, they can be used to convey the main point of an utterance – equivalent to the focus of the sentence. In contrast, grammatical items (including affixes, grammatical words, and schematic morphosyntactic constructions) are defined as items that are by convention discursively secondary. They cannot be used to convey the main point of an utterance (as long as conventions are adhered to – i.e., outside contrastive and metalinguistic contextsFootnote 1), but serve an ancillary role in relation to lexical hosts. Consider the sentence in (5).
In some contexts, hate would be discursively primary (e.g., when discussing attitudes towards swimming), in others, swim would be primary (e.g., when discussing things that the child hates to do), in still others, child or always would be primary. According to the ProGram theory, however, only the lexical morphemes child, always, hate, and swim have the potential to be discursively primary. The grammatical morphemes the, have, -s, -ed, and -ing are secondary by convention. This does not mean that they cannot carry important information, only that they cannot carry the main information in a complex message (the primary/foreground information). This is evident from the fact that, if the grammatical morphemes are omitted from (5), the sentence can still be understood, although this requires extra contextual support: child always hate swim. In contrast, omitting the lexical morphemes, or replacing them with smurf has fatal communicative consequences: the smurf has smurf smurfed smurfing.
In other words, lexical items are by convention potential attention-getters or foreground elements, whereas grammatical items are background elements. This idea is also compatible with the intuition that “structure-supporting units recede to the background as the meaning of the sentence evolves” (Koriat & Greenberg, Reference Koriat and Greenberg1994, p. 345).
Knowing the conventions of a given language includes knowing which items are lexical and which are grammatical. This amounts to knowing which items to direct the attention towards. The ProGram theory assumes that when reading (5) any proficient language user familiar with the conventions of the English language will, during a superficial scan, know that child, always, hate, or swim constitute the most important part of the message, and will concentrate her or his attention on these morphemes.
According to the ProGram theory, then, the functional rationale behind the lexicon–grammar distinction is that it enables us to economize resources by prioritizing the parts of complex linguistic messages to be processed. For psycholinguistic studies like the present one, the ProGram theory provides a set of criteria for distinguishing between grammatical and lexical items.
2. Criteria for categorizing words as grammatical vs. lexical
Here we will concentrate on the ProGram criteria that are concerned with focusability (Boye & Harder, Reference Boye and Harder2012). Focus points out what is discursively primary. It thus follows from the definition of lexical items as potentially discursively primary and the definition of grammatical items as discursively secondary that (outside metalinguistic or contrastive contexts where conventions are overridden) only the former can be focused. Thus, dogs is a lexical word, because it can be focused in, for example, what I like is dogs. Grammatical items can be in the scope of a focus marker, as is the case with plural -s in what I like is dogs, and with the article a in what I like is a dog, but in that case they are still not selectively focused. Compare (6) and (7), for instance.
In both (6) and (7), the focus particle exactly scopes over and focuses a noun phrase (one apple and an apple, respectively), and in both sentences it can be read as focusing the noun phrase as a unified whole. Only in (6), however, can it be read as selectively focusing the determiner. In other words, it can be read as highlighting the number meaning of one in (6), but not the indefiniteness meaning of an in (7). This is because the determiner one in (6) is a lexical word, whereas the determiner an in (7) is a grammatical word. Accordingly, some lexical items can be focused independently of other items, as in I have exactly one, whereas this is never the case with grammatical items.
Based on this, diagnostic tests can be used to determine whether a word is lexical or grammatical. In Danish and English, a word is lexical if it fulfills one or more of the following three criteria, all of which are instantiations of the focusability criterion (from Kristensen & Boye, Reference Kristensen and Boye2016). If it does not fulfill any of the criteria, it is grammatical. The lexical word family happens to fulfill all three criteria:Footnote 2
1. The word can be selectively focused in a focus construction. Example: It is family that matters.
2. The word can be selectively focused by means of a focus particle such as only, exactly, or not. Example: not family.
3. The word can be selectively addressed in later discourse, using, for instance, a wh-question or an anaphor (in other words, the word can be referred to anaphorically in isolation from syntagmatically related words). Example: Family is everything. – It is what? (where it addresses family, and what addresses everything).
In our two experiments, we used the set of diagnostic tests to distinguish between lexical and grammatical words. A Danish article like en is diagnosed as grammatical: like its English counterpart a(n) (cf. above), this word cannot be focused or be addressed in later discourse. Articles thereby differ from Danish pronouns like denne (corresponding to English this), which can be focused and can be referred to in later discourse. The diagnostic tests also allow us to distinguish between the Danish verb form have ‘have’ as a lexical full verb (8) and as a grammatical auxiliary (9). The full verb form can be focused by means of a negation, while the auxiliary cannot: in parallel to what holds for (6) and (7), in both (8) and (9) the focus particle ikke ‘not’ scopes over a verb phrase, and in both sentences it can be read as focusing the verb phrase as a unified whole, but in (9) it cannot be read as focusing the auxiliary har selectively.


These classifications are in full harmony with traditional classifications. More controversially, however, the theoretically based criteria suggest that a distinction between lexical and grammatical words should be made even within closed word classes. For instance, the English preposition off and pronoun that are lexical by the focusability criterion, whereas the preposition of and the pronoun it are grammatical (Boye & Harder, Reference Boye and Harder2012, p. 21; cf. also Koriat & Greenberg, Reference Koriat and Greenberg1994).
Recent studies have shown that classifications based on the ProGram theory and its criteria are significant for the description of aphasic speech. For instance, Ishkhanyan, Sahraoui, Harder, Mogensen, and Boye (Reference Ishkhanyan, Sahraoui, Harder, Mogensen and Boye2017) demonstrated that French pronouns classified as lexical based on focusability are less severely affected in agrammatic aphasia than pronouns classified as grammatical, and Martínez-Ferreiro, Ishkhanyan, Rosell-Clarí, and Boye (Reference Martínez-Ferreiro, Ishkhanyan, Rosell-Clarí and Boye2019) found that Spanish prepositions classified as grammatical are more severely affected than prepositions classified as lexical in aphasias with motor predominance, while the opposite pattern was found in aphasias with sensory predominance (e.g., Bennis et al., Reference Bennis, Prins and Vermeulen1983; cf. Boye & Bastiaanse, Reference Boye and Bastiaanse2018, on Dutch verbs).
3. Hypotheses of the current studies
We conducted two studies in order to examine how attention during reading is affected by word category and focus. Parts of the results of the two experiments have been published in Danish for a Danish audience (Christensen, Reference Christensen2015a, Reference Christensen, Hansen and Hougaard2015b; Vinther, Boye, & Kristensen, Reference Vinther, Boye and Kristensen2014). Experiment 1 examined attention to specific letters during a letter detection task. Experiment 2 examined attention to omitted words in a change detection paradigm.
Both experiments used a 2×2 factorial design with the factors focus (focused vs. non-focused) and word category (grammatical vs. lexical). The word category manipulation occurs at the word level, while the focus manipulation concerns constituents rather than single words. The reason for focusing at the constituent level is that, by definition, grammatical words in isolation cannot be focused: grammatical items are defined as discursively secondary, and non-focusability is a criterion of grammatical status. By Lambrecht’s definition (see Section 1.1 above), focus is a property of constituents, and focus markers such as clefting and focus particles scope over whole constituents. We therefore constructed target items where target words were part of larger focused or unfocused constituents.
For the focus conditions of the two experiments, we constructed example sentences in which the grammatical or lexical target word was part of a focused constituent (e.g., a noun phrase), as in (10), where the target word den (definite article, grammatical) or denne (demonstrative pronoun, lexical) is part of a clefted noun phrase constituent.

It is natural – and compatible with the ProGram theory of Boye and Harder (Reference Boye and Harder2012) – to expect that words do not attract the same share of attention when they are only part of the focused constituent as when they constitute the entire focused constituent. Nevertheless, the overall hypotheses were as follows:
1. Letters and words in the lexical condition are more attended to than letters and words in the grammatical one (grammar-as-background hypothesis).
2. Letters and words in focused constituents are more attended to than letters and words in non-focused constituents (focus hypothesis).
3. There is an interaction between the lexical vs. grammatical contrast and the focus vs. non-focus contrast (interaction hypothesis).
The first hypothesis is based on the ProGram theory in Boye and Harder (Reference Boye and Harder2012). Earlier studies have confirmed similar hypotheses (see Section 1.2), but those hypotheses were not based on a direct theoretical link between attention and the lexical–grammatical distinction, and, as already discussed, the distinctions between lexical and grammatical target items were not based on theoretically anchored criteria.
The second hypothesis is based on results from psycholinguistic studies using the change blindness paradigm (Price, Reference Price2008; Sanford, Molle, & Emmott, Reference Sanford, Molle and Emmott2006; Sturt et al., Reference Sturt, Sanford, Stewart and Dawydiak2004) and other types of attentional paradigms with focus manipulations (e.g., Bredart & Modolo, Reference Bredart and Modolo1988). To our knowledge, the focus hypothesis, however, has not yet been systematically tested with the letter detection paradigm.
As for the third hypothesis, the ProGram theory defines the grammatical–lexical distinction in terms of discourse prominence and thus links it to attention and to focus. This implies that focus and the grammatical–lexical distinction draw on the same cognitive resources: both are means for prioritizing and directing attention.
4. Experiment 1: letter detection
The letter detection paradigm was originally developed to study the micro-structure of reading processes and the effects of phonetic manipulations (Corcoran, Reference Corcoran1966; Healy, Reference Healy1994). In Experiment 1 we used the paradigm to test the three hypotheses mentioned above. We focused on the letters n and t, which occur frequently in both lexical and grammatical words, and translated the hypotheses above into the following specific predictions:
1. Participants notice target letters more frequently in lexical words than in grammatical words.
2. Participants notice target letters more frequently in focused words than in non-focused words.
3. Focus and word category interact such that the effect of focus is different for grammatical words compared to lexical words.
4.1. methods
4.1.1. Stimuli
We constructed a 480-word text about an old lady who describes trivial facts in a very detailed way, and created four different versions of the text (one for each condition of the 2×2 factorial design; see Table 1). The text had two parts with experimental sentences embedded in the running text. For the first part of the story, the participants were asked to detect the letter n. For the second part, they had to detect the letter t. Each part was followed by four comprehension questions to ensure that participants read the text thoroughly. These questions were heterogeneous and were not designed to enter an analysis. The text contained a total of 16 sentences with target items. To avoid repetition effects and overt attention to target words, the items varied and included different kinds of material.
table 1. The four conditions of Experiment 1

The four conditions of Experiment 1 are exemplified by an experimental item with the target den/denne (in English: the/this) which is focused using a cleft-construction. The target item is underlined in this table, but not in the experimental stimuli.
Manipulation of word category. There were two types of target words: determiners and verbs (see supplementary materials Appendix A Table A.1, available at: http://doi.org/10.1017/langcog.2020.30). The 11 determiner items were presented as part of an NP constituent, and the difference between the grammatical and the lexical conditions involved a change in the target word (e.g., from grammatical den to lexical denne). We aimed at contrasting lexical and grammatical words that were similar or identical with respect to length (syllables), semantic domain, degree of semantic vagueness, orthography, position of the word in the sentence, position of the target letter in the word, position on the text line, and whether the word was (part of) new or previously introduced information. The additional 5 items were verbs that could function both as grammatical verbs (auxiliaries) and as lexical verbs (full verbs). For verb items, the orthography of the target word was identical, but sentences in the grammatical condition contained an additional non-finite verb. It was not possible to balance the word contrasts with respect to frequency. For 10 of the 16 contrasts, the grammatical word was much more frequent than the lexical one, for 5 contrasts (nogle–mange, nogle–mange, haft–haft, været–været, fået–fået) the lexical word was considerably more frequent than the grammatical word, and for 1 contrast (blevet–blevet), there was only a small frequency difference (see supplementary materials Appendix A Table A.1).
Manipulation of focus. In the focused conditions, the target occurred in a constituent which was focused by means of either a cleft construction (4 items) or a focus particle (12 items). The focus particles used were bare ‘merely’, især ’especially’, kun ‘only’, lige præcis ‘exactly’, lige netop ‘just’, netop ‘just’, and udelukkende ‘solely’.
The four conditions of the experiment are shown in Table 1. The four different versions of each item occurred in separate text versions presented to different participants (i.e., differing between subjects). In this way, each item occurred only once in each text. For each text version, all four conditions were represented four times (i.e., differing within subject).
4.1.2. Procedure
A total of 84 participants took part in the experiment. All were Sociology students from the University of Copenhagen (age 20–41, mean 22.6; 26 male and 58 female), and all were native speakers of Danish. The participants completed the experiment at the same time seated in a lecture hall, and they were randomly assigned one of the four text versions. The participants received an oral instruction that the purpose of the experiment was to examine multitasking during reading. They were instructed to read and comprehend the text, while at the same time striking out all instances of a specific letter (t or n) using a pen or pencil. They were also told that there would be comprehension questions. The participants each received four sheets of paper for each text part with the blank side facing up. The first sheet contained part one of the text, the second contained comprehension questions for part one, the third contained part two of the text, and the fourth contained comprehension questions for part two. The procedure was identical for the two text parts (cf. Figure 1).

Fig. 1. Procedure for the letter detection study (Experiment 1). Upon a starting signal, the participants were instructed to turn over the sheet with the text. They then read the story as fast as they could while comprehending and marking the specified letter (t or n) with a pen or pencil. They were instructed to turn the blank side up once they had finishing reading. Using a large digital clock each participant individually registered how much time they had spent (max. 3 minutes per text part). The participants then answered the four comprehension questions of each text part also using pen and paper.
4.2. analysis
Vinther et al. (Reference Vinther, Boye and Kristensen2014) report an ANOVA and a mixed model analysis of Experiment 1. For simplicity and for an easy comparison with Experiment 2, we report a reduced mixed model here. A mixed model is a statistical model containing both random and fixed effects. A single mixed model analysis can replace traditional by-item and by-subject ANOVAs. Our generalized linear mixed model analysis was conducted in R version 3.1.1 (R Core Team, 2014) using the lme4 package (Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2014). It used a binomial link function. The dependent variable was the number of missed letters in target words. If the target letter was missed in a word that has more than one occurrence of the target letter (e.g., the word denne, which has two occurrences of the target letter n), it counted as only one missed letter. The procedure for fitting the model was to start out with a model that included as random effects subject and item, and as fixed effects the main effects of the experiment: word category (lexical or grammatical target word), focus (focused vs. not focused), and the interaction between the two. To control for frequency effects, we added the log-transformed corpus frequency of all target items. We then tried to add other variables such as random slopes, the type of target letter (t or n), and stress pattern (whether the target word could be read as stressed, unstressed, or both), but the model did not converge with any of these extra variables, and they were therefore not included in the final model. Reported p-values were obtained using the summary function of lme4, and reported confidence intervals (CI) were calculated using the profile method of the confint function. The log-transformed frequencies were found through corpus searches in the Danish national corpus KorpusDK (DSL, 2007), a 56-million-word sampled collection of written texts. Only exact matches (not inflected forms) were included. Some target word forms cover more than one use, so we manually corrected the frequency measures to include only the relevant instances (for details on the procedure, see supplementary materials Appendix A). For frequency calculations of ens, denne, dette, dit, mange, meget, nogle, and noget, only prenominal uses were considered relevant. For det, den, en, and et, only grammatical uses were considered relevant, and for the verbs haft, blevet, været, and fået we did separate calculations for auxiliaries and full verbs.
4.3. results
Figure 2 shows the percentage of correctly detected letters. The winning mixed model (see supplementary materials Appendix B Table B.1) had by-subject and by-item random intercepts, and the fixed effects were word category (lexical vs. grammatical), focus (focus or no focus), the interaction between word category and focus, and finally the log-transformed corpus frequency.

Fig. 2. Results of the letter detection study (Experiment 1). The figure shows the percentage of correctly detected letters across all participants.
The mixed model showed a significant effect of corpus frequency of target words: the higher the frequency, the more letters were overlooked. There was no significant main effect of focus. There was no significant main effect of word category either, but there was a trend towards more letters being overlooked in grammatical compared to lexical items (z = –1.931, p < .053).
Importantly, even when taking the role of corpus frequency into account, the model also showed a significant interaction between word category and focus (z = –2.038, p < .05). Visual inspection of the raw data in Figure 2 does not show this clearly, but the interaction plot of the fitted model in Figure 3 shows a larger difference between the two grammatical conditions than between the two lexical ones. The interaction between focus and grammar indicates that the differences between grammatical items in focused and non-focused constituents is different from that between lexical items in focused and non-focused constituents, in accordance with our interaction hypothesis.

Fig. 3. The interaction between word category and focus.
5. Experiment 2: change blindness study
Psycholinguistic paradigms and measures differ with respect to sensitivity. We therefore conducted an additional experiment using a different psycholinguistic paradigm. Experiment 2 used the change blindness paradigm, which has attested sensitivity to focus manipulations. Previous change blindness studies have found reduced change blindness for focused words in clefts (Sturt et al., Reference Sturt, Sanford, Stewart and Dawydiak2004), for stressed words (Sanford et al., Reference Sanford, Molle and Emmott2006), and for visual highlighting provided by font differences (Sanford et al., Reference Sanford, Molle and Emmott2006). Unlike the letter detection paradigm, which measures only attention to individual letters, the text-change design also provides a measure for depth of processing (Sanford, Reference Sanford2002). Readers often overlook changes in already processed information and may therefore be blind to changes between two presentations of almost identical texts (Sturt et al., Reference Sturt, Sanford, Stewart and Dawydiak2004). The level of change blindness is not just sensitive to whether information is old or new, but also to foreground vs. background differences. When changes occur in visually highlighted parts of a text, change blindness is reduced (cf. Sanford et al., Reference Sanford, Molle and Emmott2006).
We designed Experiment 2 to test the three general hypotheses (cf. Section 3), which we translated into the following specific predictions:
1. Participants notice changes more frequently in lexical words than in grammatical words.
2. Participants notice changes more frequently in focused words than in non-focused words.
3. Focus and word category interact such that the effect of focus is different for grammatical words compared to lexical words.
5.1. methods
5.1.1. Stimuli
We constructed 10 experimental sentences and 10 filler sentences in Danish (see supplementary materials Appendix A Table A.2). The sentences were constructed to be long enough to elicit change blindness, but short enough to be read during the presentation time. Each experimental item occurred in four different conditions differing only with respect to focus and word category of the target word (cf. Table 2).
table 2. The four conditions of Experiment 2 as they appeared during the first presentation
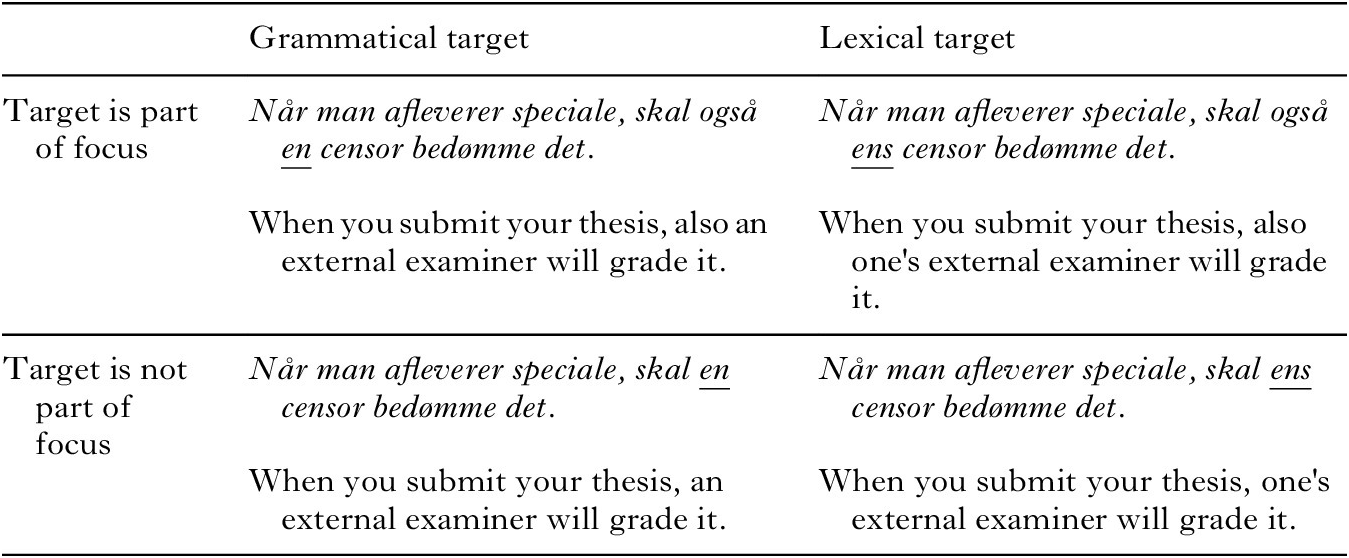
The conditions are exemplified by an experimental item with the target en/ens (in English: a/one’s) which is focused using the focus particle også ‘also’. The target word (which is removed after the first presentation) is underlined in this table, but not in the experimental stimuli.
The design was within-subject – that is, all subjects read all 4 conditions of each item (i.e., there were 40 target trials per subject). In order to reduce learning effects, we changed the word material between the four presentations of an item. Each participant would read one of the versions from Table 2, but the other three conditions of that item used a different material for non-target words. For instance, one of the three alternatives to the item presented in Table 2 was Når man afleverer synopsisopgaver, skal (også) en/ens eksaminator vurdere den ‘When you hand in synopsis assignments, (also) an/one’s examiner must assess it’. Participants never read a sentence with the same word material more than once. All sentences were acceptable both with the target words included (as in the first presentation of the sentence) and with the target word omitted (as in the second presentation of the sentence).
Manipulation of word category. A list of the ten target words is shown in the supplementary materials Appendix A Table A.2. As in Experiment 1, we aimed at contrasting lexical and grammatical words that were similar or identical with respect to length (syllables), semantic domain, degree of semantic vagueness, orthography, position of the word in the sentence, position on the text line, and whether the item was (part of) new or previously introduced information. There were two types of target words: determiners and verbs. The seven determiner items were presented as part of an NP constituent. One example is the grammatical determiner en ‘a(n)’ vs. lexical ens ‘one’s’ presented as part of the NP en/ens censor ‘an/one’s external examiner’ (cf. Table 2). The three verb items were verbs that could function both as grammatical verbs (auxiliaries) and as lexical verbs (full verbs). As in the case of Experiment 1, we judged it impossible to balance the word contrasts with respect to frequency. However, while for 5 of the 10 contrasts studied in Experiment 2 the grammatical word was much more frequent than the lexical one, for 4 contrasts (nogle–mange, noget–meget, haft–haft, fået–fået) the lexical word was considerably more frequent than the grammatical word, and for 1 contrast (blevet–blevet) there was only a small frequency difference (see supplementary materials Appendix A Table A.2).
Manipulation of focus. In the focus condition, the NP containing the determiner was focused by means of a focus particle, and verb items occurred with the negation ikke ‘not’.
5.1.2. Procedure
A total of 32 participants completed the experiment. All were university students (age 20–27, mean 22.3; 4 male and 28 female) with non-impaired vision, hearing, and reading skills, and all were native speakers of Danish. All participants completed the experiment one at a time at an HP laptop. Participants were assigned one of four text versions semi-randomly, balancing the number of each text version in the experiment. The stimuli were presented visually on the screen, and responses were logged with the software PsychoPy (Peirce, Reference Peirce2007). The experimenter gave participants an oral introduction and also attended three practice trials. At the experiment proper, the participant was alone in the room. The participants were told that the aim of the experiment was to test reading comprehension in a condition where they had to recollect words. All participants read 40 target sentences and 10 filler sentences. Following the procedure in Figure 4, participants were shown two presentations of a target sentence (first with the target word, then without it). Upon the second presentations, they used button presses to report if they detected any change in any of the words. If a change was reported, they were instructed to identify the change, i.e., to type the word that had been changed or omitted. Both types of responses – detection and identification of the change – were logged and further analyzed.

Fig. 4. Procedure for change blindness study (Experiment 2). Each trial started with an ISI (Inter-stimulus Interval) with a white fixation cross shown for 100 ms. The first presentation of the sentence had a duration of 600 ms and was followed by an ISI of 250 ms. The second presentation of the sentence (the ‘change detection’ phase) had a duration of maximally 800 ms. The stimuli were the same as during the first presentation, but the font color was yellow instead of white, and one of the words was omitted. During the ‘change detection’ phase, the participant was instructed to press ‘1’ to indicate a change and ‘0’ to indicate that the two sentences were identical. Only if the participant pressed ‘1’ was the ‘identification screen’ displayed, and the participant was prompted to type the word that appeared during the first presentation, but not during the second presentation.
The filler sentences consisted of different sentence types. For half of the filler trials, the second presentation contained a change to another word. Responses to fillers were logged, but not analyzed further. For 1 out of 6 trials, participants were asked to answer a comprehension question in order to ensure that they were reading for comprehension rather than memorizing. The questions were heterogeneous and were not designed to enter an analysis. Therefore the answers were logged but not analyzed further.
5.2. analysis
Two mixed model analyses were carried out following the same procedure as in Experiment 1. The dependent variables were number of detected changes (first model) and number of identified changes (second model). Both models included as random effects subject and item. The fixed effects were the log-transformed corpus frequency of target items as well as the main effects of the experiment: word category of the target word (lexical vs. grammatical), focus (focused vs. not focused), and the interaction between the two. As in Experiment 1, we tried to include other relevant variables including random slopes, but the model did not converge with any of these variables, and we therefore included only the variables mentioned above. The two winning models are reported in the supplementary materials Appendix B Tables B.2 and B.3.
5.3. results
The rates for change detection and change identification are shown in Figure 5. Participants sometimes detected a missing word without being able to type it correctly, as evident from the larger rates in change detection compared to change identification.

Fig. 5. Results of change blindness study (Experiment 2). The left bar chart shows the percentage of correctly detected changes during the ‘change detection phase’ of the experiment across all participants. The right bar chart shows the percentage of all words for which not only was the change detected by the participants, but in which the original word was also correctly identified (i.e., typed in correctly).
The effect of word category was significant for both change detection (z = 4.320, p < .001) and change identification (z = –4.789, p < .001): Participants detected and identified significantly more changes in the lexical condition than in the grammatical one. There were no significant effects of the other fixed effects, i.e., no effect of corpus frequency, no effect of focus, and no interaction between focus and word category – neither for change detection, nor for change identification.
6. Discussion
Using different paradigms, Experiment 1 and Experiment 2 tested the same three general hypotheses: (1) that grammatical words are less attended to than lexical ones (grammar-as-background hypothesis); (2) that words in focused constituents are more attended to than those in non-focused constituents (focus hypothesis); and (3) that word category and focus interact (interaction hypothesis).
The grammar-as-background hypothesis was confirmed by Experiment 2, and Experiment 1 showed a trend in the same direction. Readers paid less attention to grammatical words than to lexical words, in line with Boye and Harder’s (Reference Boye and Harder2012) assumption that grammatical elements are discursively secondary, and consequently less attended to.
The focus hypothesis was not confirmed by the experiments. Previous studies have suggested that the attention of readers is guided by focus (Bredart & Modolo, Reference Bredart and Modolo1988; Price, Reference Price2008; Sanford et al., Reference Sanford, Molle and Emmott2006; Sturt et al., Reference Sturt, Sanford, Stewart and Dawydiak2004). The readers in Experiment 1 and Experiment 2, however, did not attend more to focused constituents than to non-focused ones.
The interaction hypothesis was confirmed by Experiment 1, but not by Experiment 2. In Experiment 1, the focus manipulation was more pronounced for grammatical words than for lexical ones. Judging from Figure 3, letter detection rates for lexical words did not differ much across the focus conditions (focus vs. non-focus), but, for grammatical words, readers more often noticed letters in focused constituents than in non-focused ones.
It is striking that the unconfirmed focus hypothesis is the least controversial of the three experimental hypotheses. In what follows we discuss possible reasons for these findings.
6.1. the grammar-as-background hypothesis
The change blindness study (Experiment 2) shows that omitted lexical words are detected more frequently than omitted grammatical words. Change detection rates have previously been interpreted as a proxy of depth of processing (Price, Reference Price2008; Sanford et al., Reference Sanford, Molle and Emmott2006; Sturt et al., Reference Sturt, Sanford, Stewart and Dawydiak2004). Our study is the first to find a difference in detection rates for grammatical vs. lexical elements. Building on the interpretations of previous change blindness studies, we suggest that word category guides depth of processing.
While Experiment 1 showed no significant effect of word category, it showed a trend indicating that the missed letter effect was more pronounced for grammatical than lexical words. This trend is in line with previous letter detection studies which found increased letter detection rates for ‘content words’ compared to ‘function words’ (Foucambert & Zuniga, Reference Foucambert and Zuniga2012; Koriat et al., Reference Koriat, Greenberg and Goldshmid1991; Rosenberg et al., Reference Rosenberg, Zurif, Brownnell, Garrett and Bradley1985; Roy-Charland & Saint-Aubin, Reference Roy-Charland and Saint-Aubin2006; Smith & Groat, Reference Smith, Groat, McConkie, Kolers, Wrolstad and Bouma1979). Compared to these previous studies, Experiment 1 has a theoretically more well-founded basis, replacing the intuition-based distinctions between content and function words and between open- and closed-class words with a distinction between lexical and grammatical words based on criteria entailed by the ProGram theory in Boye and Harder (Reference Boye and Harder2012).
The confirmation of the grammar-as-background hypothesis is a strong argument for distinguishing between lexical and grammatical items. We suggest the following account of the difference:
1. Grammatical words are conventionalized as discursively secondary, while lexical words are conventionalized with the potential to be discursively primary.
2. In order to economize with cognitive processing resources, discursively prominent words (including words with the potential to be discursively primary) are visually more attended to and processed more deeply than non-prominent (including discursively secondary) words.
The ProGram theory does not define lexical items as discursively primary, but as potentially discursively primary. In a given context, lexical items can also be discursively secondary. Nevertheless, the detection rates of our experiments show a difference in discourse prominence between lexical and grammatical items. The reason for this, we believe, is that lexical items, because of their primary uses, are entrenched with a higher inherent discourse prominence than grammatical items.
6.2. the focus hypothesis
Neither of the two studies showed significant effects of focus on attention to letters (Experiment 1) and words (Experiment 2). It was not confirmed that readers attend more to elements in focused than in non-focused constituents. To our knowledge, there are no previous accounts of focus effects on letter detection (though Moravcsik & Healy, Reference Moravcsik and Healy1998, find effects of preposing), but, for the change blindness paradigm, the effect of focus is well-established. It is therefore surprising that our change blindness study did not find increased detection rates for focused compared to non-focused constituents. Previous studies used a wide variety of attention-capturing devices, including clefting (Sturt et al., Reference Sturt, Sanford, Stewart and Dawydiak2004) and pitch accent (Price, Reference Price2008; Sanford et al., Reference Sanford, Molle and Emmott2006), as well as non-linguistic visual highlighting (Sanford et al., Reference Sanford, Molle and Emmott2006). Our text-change study used a different kind of focus marking – focus particles – although the letter detection study also used clefting. Taken together, these focus manipulations may have been more subtle than those used in previous studies, and this may explain why our experiments did not confirm the focus hypothesis.
Alternative or supplementary explanations may be found in two other aspects of our study designs. First, the meanings of our target words were relatively abstract or semantically bleached. They may have been too abstract or semantically bleached to attract attention to a degree which is affected – to a measurable extend – by focus differences (cf. Sturt et al., Reference Sturt, Sanford, Stewart and Dawydiak2004, p. 884). Earlier studies of focus contrasts employed target words whose meaning were relatively concrete compared to the words in our study. For example, we employed words like the verb have ‘have’, whereas Sturt et al. used target nouns such as beer and cider.
Second, our target words were not independently focused (because grammatical words cannot be focused) but were part of focused constituents (see Section 3). We may reasonably expect that words do not attract the same share of attention when they are only part of the focus domain as when they constitute the entire focus.
Our results might be taken to suggest that the lexical vs. grammatical distinction is a stronger indicator of discourse prominence than the distinction between focus and non-focus: first, only the grammar vs. lexicon hypothesis was confirmed; second, our results show that even grammatical words in focused constituents attract less attention than lexical words in non-focused constituents. This conclusion would be highly surprising in light of the fact that the grammar-as-background hypothesis is far more controversial than the focus hypothesis. Our study was not designed with the purpose of measuring whether word category or focus is better at attracting attention, however, and we believe that the disconfirmation of the focus hypothesis is a design artifact.
6.3. the interaction hypothesis
Experiment 1 showed an interaction between focus and the lexicon–grammar distinction. This interaction suggests that, as claimed by the ProGram theory, the grammatical–lexical distinction is linked to attention, just as focus is. Both focus and the grammatical–lexical distinction are means for prioritizing and directing attention.
Compared to target letters in lexical words, the target letters in grammatical words gain more attention from being part of a focused constituent. This does not mean that the grammatical words become focused themselves: they cannot be focused (cf. Section 2); accordingly, even when they are found in focused constituents, they receive less attention than lexical words. What it means is that only when a constituent is focused do all parts of the constituent gain attention.
A plausible account of the fact that grammatical words gain more attention by occurring in a focused constituent than lexical words is that they have a much bigger potential for gaining attention because they are inherently less prominent than lexical ones.
This interaction was found only in Experiment 1. The change detection and change identification measures in Experiment 2 did not show the same sensitivity. The difference may indicate that the interaction occurs at an early stage of processing. While letter detection is an online measure, change detection and change identification may reflect later processing steps. Further research on online and offline differences may clarify whether word category and focus interact at early stages only.
7. Conclusion
Readers are better at detecting changes made to lexical words, and they showed a trend towards being better at detecting specific letters in lexical words than in grammatical words. This supports our hypothesis that the prioritization of processing resources mirrors that of discourse prominence in language use, with grammatical words being coded as discursively secondary.
We found no main effect of focus for either of the two experiments, which may be due to the type of focus-marking, the extensive scope of the focus, or to targets that were semantically vague in both the grammatical and lexical conditions. In spite of that, Experiment 1 showed an interaction, indicating that target letters in grammatical words (compared to lexical words) gain more attention from being part of a focused constituent.
Supplementary materials
To view supplementary materials for this paper, please visit http://dx.doi.org/10.1017/langcog.2020.30.








