1 Introduction
The team-orienteering problem (TOP) has broad applicability. Examples of possible uses are in factory and automation settings, robot sports teams (Baltes et al., Reference Baltes, Tu, Sadeghnejad and Anderson2017), and urban search and rescue applications. Throughout this paper, we chose the rescue domain as a guiding example. After a natural or man-made disaster, many tasks need to be accomplished efficiently and quickly. So task allocation is a crucial problem to avoid unnecessary casualties and economic losses (Gunn & Anderson, Reference Gunn and Anderson2015). There are many challenges for task allocation in rescue scenarios.
In disaster rescue, tasks include searching for survivors, extinguishing fires, cutting electrical wires, turning a valve to disconnect gas or water flow, transporting victims, breaking through a wall, connecting a fire hose, checking an area for gas leaks, etc. Most of these tasks have deadlines, for example, a time after which a victim’s condition deteriorates or a fire consumes a building. These kinds of complex scenarios are impossible to accomplish for a single agent, so teams of agents must be used. Furthermore, in disaster rescue, various tasks have different allocation importance with varying time and energy requirements (Yin et al., Reference Yin, Yu, Wang and Wang2007; Su et al., Reference Su, Wang, Jia, Guo and Ding2018).
Multi-robot systems (Zhang & Ueno, Reference Zhang and Ueno2007) due to their distributed parallel processing abilities have been used in various missions that require robust and fast performance such as monitoring (Saeedvand & Aghdasi, Reference Saeedvand and Aghdasi2016), tracking (Chang et al., Reference Chang, Wang and Wang2016), surveillance (Khamis et al., Reference Khamis, Hussein and Elmogy2015), hazardous industries (Jose & Pratihar, Reference Jose and Pratihar2016), etc. The multi-robot task allocation (MRTA) problem is one of the core issues in multi-robot systems (Nunes et al., Reference Nunes, Manner, Mitiche and Gini2017; Schwarzrock et al., Reference Schwarzrock, Zacarias, Bazzan, de Araujo Fernandes, Moreira and de Freitas2018; Saeedvand et al., Reference Saeedvand, Aghdasi and Baltes2019). In MRTA, the solutions for different applications also depend on the criteria used for optimization, such as distance traveled, time to completion, and energy consumed. The MRTA problem has been investigated extensively with several proposed approaches in the literature (Farinelli et al., Reference Farinelli, Zanotto and Pagello2017). The most recent taxonomy for MRTA problems proposes a comprehensive comparison (Nunes et al., Reference Nunes, Manner, Mitiche and Gini2017). In this taxonomy, the authors also discuss the relationship between the TOP with time windows (TOPTWs) and the job-shop scheduling problem (JSP). The JSP (similar to TOPTW) is sequencing the jobs and assigning their start and end times by performing scheduling (Nunes et al., Reference Nunes, Manner, Mitiche and Gini2017).
The orienteering problem (OP), initially defined by Tsiligirides, is the problem of selecting and ordering a set of tasks to maximize the total profit within a given time budget (Tsiligirides, Reference Tsiligirides1984). To date, some common extensions such as the team OP (TOP), the team OP with time windows (TOPTWs), and the time-dependent OP have been studied (Gunawan et al., Reference Gunawan, Lau and Vansteenwegen2016). In the context of the team OP, instead of one path, a certain number of paths are allowed, each allocated to one agent. In TOPTW, each node may have a time window associated with it, and agents can only visit the node and receive the reward during this time window (Labadie et al., Reference Labadie, Mansini, Melechovský and Calvo2012). Among the many extensions of TOP, the TOPTW matches closely to the task allocation problem in disaster rescue domains (Nunes et al., Reference Nunes, Manner, Mitiche and Gini2017).
Consequently, for rescue applications, in this paper, our primary focus is on the TOPTW with some additional differences. The major difference is that in TOPTW, most approaches only solve for a single-objective function, whereas in rescue domains several possibly conflicting objective functions must be optimized. For example, both the sum of the accumulated profits (e.g., tasks completed) and the sum of the task completion times are important features in the rescue domain. The second difference is that in our paper we also include a cost (energy consumption) associated with visiting a node. We included this factor because energy consumption is an important aspect of rescue domains. Third, in the TOPTW, the problem is assuming homogeneous robots and therefore applies the same time constraints to all robots. In rescue domains, mostly the tasks require a different duration of time with constraints, which may depend on the agents’ state and their current energy consumption.
Several algorithms have been proposed to solve the TA and TOP with extensions. These include the brute-force method (Park et al., Reference Park, Lee, Ahn, Bae and Tae2017; Huang et al., Reference Huang, Ding and Jin2018) and heuristics methods (Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017; Lin & Vincent, Reference Lin and Vincent2017; Vincent et al., Reference Vincent, Jewpanya, Ting and Redi2017; Koubaa et al., Reference Koubaa, Bennaceur, Chaari, Trigui, Ammar, Sriti, Alajlan, Cheikhrouhou and Javed2018; Bottarelli et al., Reference Bottarelli, Bicego, Blum and Farinelli2019). Many different heuristics and evolutionary computing methods have been applied in order to find good or optimal solutions in a reasonable amount of time. Metaheuristic approaches, such as tabu search (Tang & Miller-Hooks, Reference Tang and Miller-Hooks2005), particle swarm optimization (Vincent et al., Reference Vincent, Jewpanya, Ting and Redi2017), ant colony optimization (Montemanni & Gambardella, Reference Montemanni and Gambardella2009), variable neighborhood search (Campbell et al., Reference Campbell, Gendreau and Thomas2011), iterated local search heuristic (ILS) (Lin & Vincent, Reference Lin and Vincent2012), simulated annealing (SA) iterated local search heuristic (SAILS) (Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017), artificial bee colony (ABC) algorithm (Cura, Reference Cura2014), a hybrid approach (Gunawan et al., Reference Gunawan, Lau and Lu2018), biologically inspired approaches (Kube & Bonabeau, Reference Kube and Bonabeau2000), have all been used and worked well for some specific problems. Among the existing studies on TOPTW, most approaches are limited to single-objective functions. As for TOPTW with multiple objectives, the most common approaches transform it into a single-objective optimization problem and then use single-objective approaches to solve it. On the other hand, some researchers convert it into a bi-objective problem (Martín-Moreno & Vega-Rodríguez, Reference Martín-Moreno and Vega-Rodríguez2018). To the best of our knowledge, the original TOPTW has not been solved yet for MO problems.
Golden proved that the TOP is NP-hard (Golden et al., Reference Golden, Levy and Vohra1987). Furthermore, task allocation problems are NP-hard (non-deterministic polynomial-time hard), (Solomon, Reference Solomon1986; Savelsbergh, Reference Savelsbergh1985). Therefore, it is challenging and usually requires long computational time to find an optimal solution for non-trivial problems. In real-world problems, which are usually large instances of the TOP problem, optimal solutions are therefore intractable. Hence, evolutionary algorithms (EAs) have been used to find good, albeit non-optimal, solutions to MRTA and TOPTW. However, generally due to the significant variety of parameter choices, the use of the EAs can be problematic. On the other hand, in a rescue environment, MO solutions are often advantageous. MOEAs are based on Pareto-dominance concepts in which a set of solutions should represent suitable trade-offs between different objectives (Dong & Dai, Reference Dong and Dai2018). As suggested in the future works section of the recent survey (Gunawan et al., Reference Gunawan, Lau and Vansteenwegen2016), and to the best of our knowledge, only a few MO solutions are available for both MRTA and TOPTW in rescue applications. So far, the related literature on the TOPTW is limited to dealing with a maximum of two relevant conflicting objectives (Schilde et al., Reference Schilde, Doerner, Hartl and Kiechle2009; Vansteenwegen et al., Reference Vansteenwegen, Souffriau and Van Oudheusden2011; Jiang, Reference Jiang2016; Bederina & Hifi, Reference Bederina and Hifi2017; Nunes et al., Reference Nunes, Manner, Mitiche and Gini2017).
It is recommended that the MOEAs can dealt with using hyper-heuristics (Burke et al., Reference Burke, Hyde, Kendall, Ochoa, Özcan and Woodward2010; Guizzo et al., Reference Guizzo, Vergilio, Pozo and Fritsche2017; Alkhanak & Lee, Reference Alkhanak and Lee2018). Hyper-heuristics primarily choose or generate low-level heuristics (LLHs), while optionally selected optimization algorithms are applied afterward. Hence, the hyper-heuristics are independent of the underlying algorithms. The idea of employing MO hyper-heuristics comparing conventional algorithms is to create a robust and versatile algorithm. Opposite to EAs such as genetic or memetic algorithms (Abbaszadeh et al., Reference Abbaszadeh, Saeedvand and Mayani2012; Abbaszadeh & Saeedvand, Reference Abbaszadeh and Saeedvand2014), hyper-heuristic operates over the LLHs space, whereas metaheuristics (Yang, Reference Yang2010) operate on the solution space. So hyper-heuristic, instead of solving the problem directly, is a technique to select the best existing heuristics or generate a new heuristic (Burke et al., Reference Burke, Gendreau, Hyde, Kendall, Ochoa, Özcan and Qu2013). As a result, we can state a hyper-heuristic guides the search process on the LLHs such as metaheuristics and genetic operators. However, based on the advantages of the hyper-heuristic method, few attempts are made at applying hyper-heuristic to the OP (Toledo & Riff, Reference Toledo and Riff2015), and as we are aware, there is no research on TOPTW or MRTA problems. Motivated by this, we introduce our solution based on hyper-heuristics.
Robots are used in hazardous industries with a great risk for human operators such as defense projects (Diftler et al., Reference Diftler, Culbert, Ambrose, Platt and Bluethmann2003), rescue applications, and disaster response (DeDonato et al., Reference DeDonato, Dimitrov, Du, Giovacchini, Knoedler, Long, Polido, Gennert, Padır and Feng2015). The use of humanoid robots in different applications is increasing (Jin et al., Reference Jin, Lee and Tsagarakis2017; Saeedvand et al., Reference Saeedvand, Aghdasi and Baltes2018; Spenko et al., Reference Spenko, Buerger and Iagnemma2018). Humanoid robots still suffer from a lack of scientific theories, practical guidelines, and mechanical development constraints. However, the development of better and more capable humanoid robots in the future is inevitable. Rescue applications for robots, especially for humanoid robots are very interesting (Spenko et al., Reference Spenko, Buerger and Iagnemma2018). Over the last decade, different robotic challenges focused on disaster or emergency-response scenarios. For instance, the United States Defense Advanced Projects Research Agency (DARPA) proposed the DARPA robotic challenge to accelerate the development of disaster response robots. These robots are aimed to have the capability for early response and decreasing disasters breakdowns (Kaneko et al., Reference Kaneko, Morisawa, Kajita, Nakaoka, Sakaguchi, Cisneros and Kanehiro2015; Kohlbrecher et al., Reference Kohlbrecher, Romay, Stumpf, Gupta, Von Stryk, Bacim, Bowman, Goins, Balasubramanian and Conner2015). So a lot of the humanoid robots’ development projects are focused on these challenges (Diftler et al., Reference Diftler, Culbert, Ambrose, Platt and Bluethmann2003; Feng et al., Reference Feng, Whitman, Xinjilefu and Atkeson2015).
Although research on TOPTW and MRTA applications is popular, few algorithms are able to solve MO problems in disaster response for rescue environments. Thus, in this paper, we propose a robust and efficient MO and evolutionary hyper-heuristic algorithm for TOPTWs based on the humanoid robot’s characteristics in the rescue applications (MOHH-TOPTWR).
The theoretical contributions of this paper are as follows: (1) introducing a five-objective variant of TOPTW, (2) introducing for the first time a hyper-heuristic for a variant of TOPTWR, (3) combining 24 state-of-the-art algorithms as LLHs to propose the MOHH-TOPTWR algorithm with an efficient learning approach, (4) performing extensive experiments and statistical analysis to evaluate the proposed MOHH-TOPTWR algorithm regarding the humanoid robot characteristics for the first time (we consider humanoid robots’ variant walk energy consumptions for MOHH-TOPTWR), (5) expanding new benchmark instances based on the existing benchmark instances for TOPTW at rescue applications including humanoid robots’ heterogeneous energy consumptions, and (6) implementing and comparing two MOEAs as NSGA-III (Deb & Jain, Reference Deb and Jain2014) and MOEA based on decomposition (MOEA/D) (Zhang & Li, Reference Zhang and Li2007). We chose those algorithms because of their robustness and popularity.
This paper is organized as follows: Section 2 describes the problem based on robot’s resources application and its model as a mixed integer programming (MIP) problem. Then the MO optimization and the proposed objective functions are formulated. Section 3 discusses hyper-heuristics; it explains the upper confidence bound (UCB) selection strategy and introduces the main processes of the proposed approach and LLHs. The simulation results and performance of the proposed approach are discussed in Section 4, and concluding remarks are presented in Section 5.
2 Problem description
In this section, the MOHH-TOPTWR is described. To have more clear descriptions, we modeled the problem as an MIP formulation. Therefore, we first explain the general problem and then describe MO optimizations and their objective functions.
2.1 Problem and notation description
When allocating agents to tasks, in addition to the deadline, the task also includes the profit per accomplishing each task. In tasks with a deadline, for instance, when agents (robots) allocating to extinguish a fire of a building, the accomplishment time is the most critical aspect of the task allocation. Due to limited resources of available robots, a limited number of robots can enter the disaster environment. Thus, in a disaster environment, the number of robots is usually much less than the number of tasks (Su et al., Reference Su, Wang, Jia, Guo and Ding2018). Based on these characteristics, the TOPTWR is closer to TOPTW (Nunes et al., Reference Nunes, Manner, Mitiche and Gini2017). In general, TOPTW can be considered as hard time windows and soft time windows. In a TOPTW with hard time windows, commencing after the latest time constraint is not allowed (Labadie et al., Reference Labadie, Mansini, Melechovský and Calvo2012). In practice, because the robots’ travel time is usually stochastic and cannot be precisely predicted, the hard time windows are often relaxed (Wang et al., Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016). TOPTW with soft time windows is a generalization of TOPTW with hard time windows, which has many practical applications. In many rescue cases, relaxing the time windows may be more applicable (Wang et al., Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016) because it may result in better solutions requiring movement for shorter distance and fewer movements between task time. Hence, in this paper and in the TOPTWR, the soft time windows are considered as in Wang et al. (Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016). Note that in the MO platform, the user can choose the desired solution on the Pareto front (PF) whererin the user usually is able to select the desired outlines including solutions with hard time window choices.
Formally, the TOPTWR can be defined by stating a directed network
 $G=(T,L)$
, where
$G=(T,L)$
, where
 $T=\{1,2,\!...,n\}$
is the set of tasks’ locations. Also,
$T=\{1,2,\!...,n\}$
is the set of tasks’ locations. Also,
 $L=\{(t,t^{\prime}):t\neq t^{\prime}\in T\}$
. is the set of arcs path between locations. Each task
$L=\{(t,t^{\prime}):t\neq t^{\prime}\in T\}$
. is the set of arcs path between locations. Each task
 $t=1,\!...,n$
is associated with a profit
$t=1,\!...,n$
is associated with a profit
 $P_{t}$
, a time duration
$P_{t}$
, a time duration
 $S_{t}$
, and a closing time
$S_{t}$
, and a closing time
 $C_{t}$
. All paths must start from a starting location and end at the same location which usually is a location for starting a mission. The shortest travel time
$C_{t}$
. All paths must start from a starting location and end at the same location which usually is a location for starting a mission. The shortest travel time
 $TT_{t,t^{\prime}}$
which is needed to travel from location
$TT_{t,t^{\prime}}$
which is needed to travel from location
 $t$
to
$t$
to
 $t^{\prime}$
is known for each pair of locations
$t^{\prime}$
is known for each pair of locations
 $t$
and
$t$
and
 $t^{\prime}$
. In the real world,
$t^{\prime}$
. In the real world,
 $TT_{t,t^{\prime}}$
can be computed by different path planning algorithms such as the jump point search algorithm (Duchoň et al., Reference Duchoň, Babinec, Kajan, Beňo, Florek, Fico and Jurišica2014). The time of a route for each robot cannot exceed the given time constraint
$TT_{t,t^{\prime}}$
can be computed by different path planning algorithms such as the jump point search algorithm (Duchoň et al., Reference Duchoň, Babinec, Kajan, Beňo, Florek, Fico and Jurišica2014). The time of a route for each robot cannot exceed the given time constraint
 $T_{max}$
. Each robot must finish its allocated tasks before finishing its energy. Each task performing requirement is at most one robot (no need for simultaneous performing on one task). The visit is preferred to start before the location’s closing time
$T_{max}$
. Each robot must finish its allocated tasks before finishing its energy. Each task performing requirement is at most one robot (no need for simultaneous performing on one task). The visit is preferred to start before the location’s closing time
 $C_{i}$
.
$C_{i}$
.
Based on the given taxonomy in Nunes et al. (Reference Nunes, Manner, Mitiche and Gini2017), the TOPTWR could divide as a deterministic allocation. In the deterministic problems, typically we assume there are known tasks with time window constraints in advance which are more than robots. The TOPTWR problem is composed of two intertwined sub-problems: (i) finding best tasks’ assignment to robots that optimizes objective function
 $f(.)$
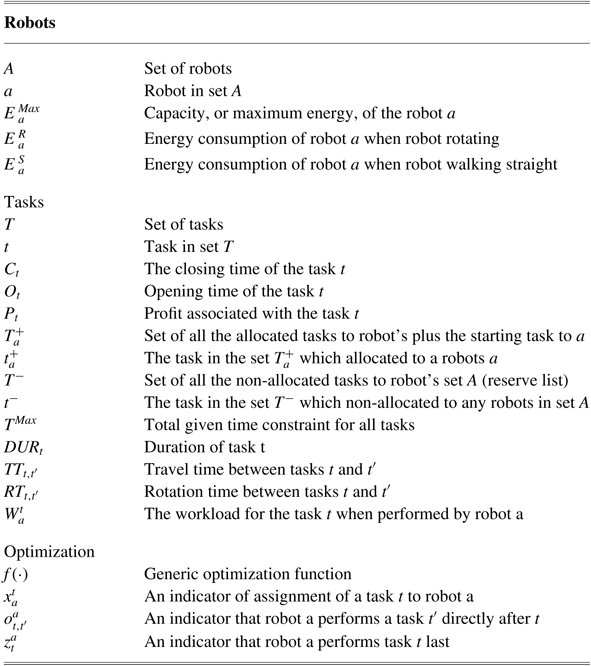
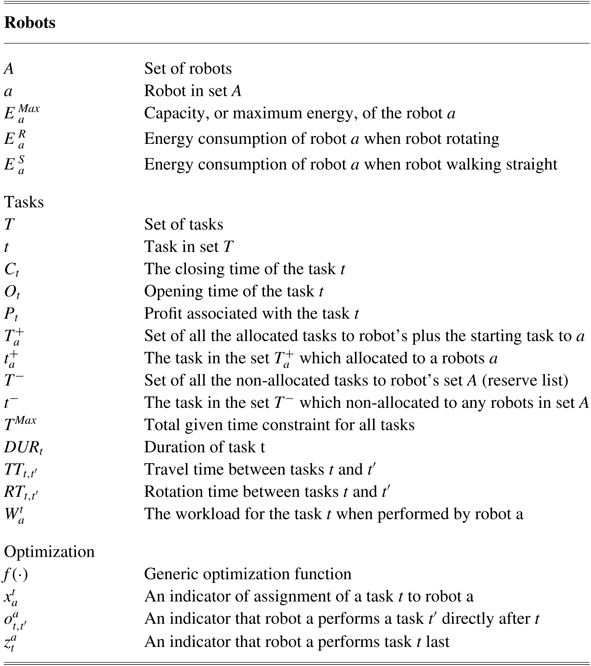
and (ii) finding best feasible order of tasks that result in optimal assignments. Table 1 shows the notation used in the paper.
$f(.)$
and (ii) finding best feasible order of tasks that result in optimal assignments. Table 1 shows the notation used in the paper.
Table 1 The notation used in the paper
For TOPTWR problem using Table 1, an MIP formulation is proposed (Equations (1)–(11)).
 \begin{equation}\forall a\in A, and\ t=start\ of\ a\qquad\qquad\qquad\qquad x_{t}^{a}=1\end{equation}
\begin{equation}\forall a\in A, and\ t=start\ of\ a\qquad\qquad\qquad\qquad x_{t}^{a}=1\end{equation}
 \begin{equation}\forall t\in T\qquad\qquad\qquad\qquad\qquad\qquad \sum a\in A^{{x}_{a}^{t}}=1\end{equation}
\begin{equation}\forall t\in T\qquad\qquad\qquad\qquad\qquad\qquad \sum a\in A^{{x}_{a}^{t}}=1\end{equation}
 \begin{equation}\forall a\in A\qquad\qquad\qquad\qquad\qquad\qquad \sum t\in T^{W_{t}^{a}x_{t}^{a}}\leq E\;_{a}^{Max}\end{equation}
\begin{equation}\forall a\in A\qquad\qquad\qquad\qquad\qquad\qquad \sum t\in T^{W_{t}^{a}x_{t}^{a}}\leq E\;_{a}^{Max}\end{equation}
 \begin{equation}\forall a\in A\qquad\qquad\qquad\qquad\qquad\qquad \sum t \in T^{DUR_{t}x_{t}^{a}} \leq T^{Max}\end{equation}
\begin{equation}\forall a\in A\qquad\qquad\qquad\qquad\qquad\qquad \sum t \in T^{DUR_{t}x_{t}^{a}} \leq T^{Max}\end{equation}
 \begin{equation}\forall a \in A, t^{\prime} \in T\qquad\qquad\qquad\qquad \sum t^{\prime} \in T^{O_{t,t^{\prime}}^{a}+{z_{t^{\prime}}^{a}}}=x_{t}^{a}\end{equation}
\begin{equation}\forall a \in A, t^{\prime} \in T\qquad\qquad\qquad\qquad \sum t^{\prime} \in T^{O_{t,t^{\prime}}^{a}+{z_{t^{\prime}}^{a}}}=x_{t}^{a}\end{equation}
 \begin{equation}\forall a \in A\qquad\qquad\qquad\qquad\qquad \sum t \in T_{t}^{a} z_{t}^{a}=1\end{equation}
\begin{equation}\forall a \in A\qquad\qquad\qquad\qquad\qquad \sum t \in T_{t}^{a} z_{t}^{a}=1\end{equation}
 \begin{equation}\forall t \in T\qquad\qquad\qquad\qquad\qquad T^{Max}\geq DUR_{t}\end{equation}
\begin{equation}\forall t \in T\qquad\qquad\qquad\qquad\qquad T^{Max}\geq DUR_{t}\end{equation}
 \begin{equation}\forall a \in A, t\in T_{a}^{+}, and\ t^{\prime} \in T\qquad\qquad\qquad o_{t,t^{\prime}}^{a}[F_{t}-TT(t,t^{\prime})+RT(t,t^{\prime})]\geq0\end{equation}
\begin{equation}\forall a \in A, t\in T_{a}^{+}, and\ t^{\prime} \in T\qquad\qquad\qquad o_{t,t^{\prime}}^{a}[F_{t}-TT(t,t^{\prime})+RT(t,t^{\prime})]\geq0\end{equation}
 \begin{equation}\forall a \in A, t \in T\qquad\qquad\qquad\qquad\qquad\qquad\qquad x_{t}^{a} \in \{0,1\}\end{equation}
\begin{equation}\forall a \in A, t \in T\qquad\qquad\qquad\qquad\qquad\qquad\qquad x_{t}^{a} \in \{0,1\}\end{equation}
 \begin{equation}\forall a \in A, t \in T_{a}^{+}, and\ t^{\prime} \in T\qquad\qquad\qquad\qquad\qquad o_{t}^{a} \in \{0,1\}\end{equation}
\begin{equation}\forall a \in A, t \in T_{a}^{+}, and\ t^{\prime} \in T\qquad\qquad\qquad\qquad\qquad o_{t}^{a} \in \{0,1\}\end{equation}
 \begin{equation}\forall a \in A, k \in T_{a}^{+}\qquad\qquad\qquad\qquad\qquad\qquad\qquad z_{k}^{a} \in \{0,1\}\end{equation}
\begin{equation}\forall a \in A, k \in T_{a}^{+}\qquad\qquad\qquad\qquad\qquad\qquad\qquad z_{k}^{a} \in \{0,1\}\end{equation}
where in Equation (1) every robot
 $ a $
has an initial starting location, in Equation (2) every task gets at most a robot. In Equation (3), no robot surpasses its energy constraints. In Equation (4), no robot exceeds the total surpasses’ time constraints. In Equation (5), every task has just one predecessor. In Equation (6), every last task has just one successor. In Equation (7), every robot has a last task. In Equation (8), task’s time between two successive tasks is long enough to allow for travel time including robots’ rotation time. Equation (9) indicator: robot
$ a $
has an initial starting location, in Equation (2) every task gets at most a robot. In Equation (3), no robot surpasses its energy constraints. In Equation (4), no robot exceeds the total surpasses’ time constraints. In Equation (5), every task has just one predecessor. In Equation (6), every last task has just one successor. In Equation (7), every robot has a last task. In Equation (8), task’s time between two successive tasks is long enough to allow for travel time including robots’ rotation time. Equation (9) indicator: robot
 $ a $
performs the task
$ a $
performs the task
 $ t $
. Equation (10) indicator: robot
$ t $
. Equation (10) indicator: robot
 $ a $
performs the task
$ a $
performs the task
 $ t^{\prime} $
after task
$ t^{\prime} $
after task
 $ t $
. Equation (11) indicator:
$ t $
. Equation (11) indicator:
 $ t $
is robot’s last task.
$ t $
is robot’s last task.
In the optimization formulation, the objective function
 $f(.)$
as a cost function can be minimized or maximized. It can also be single or MO. Thus, as we introduce an MO problem, first the MO problems are briefly described and then the considered objectives are described in the rest of this section.
$f(.)$
as a cost function can be minimized or maximized. It can also be single or MO. Thus, as we introduce an MO problem, first the MO problems are briefly described and then the considered objectives are described in the rest of this section.
2.2 Multi-objective optimization and proposed objective functions
In multi-objective problems (MOPs), the favorable objectives are in conflict with each other. Hence, it is not possible to optimize all of the objectives simultaneously. For MOPs, the general formulation is minimizing the objective as below:
 \begin{equation}\text{min}f(x) = \{f_{1}(x),f_{2}(x), .\,.\,.,f_{n}(x)\}, x \in Q, n\geq 2 \end{equation}
\begin{equation}\text{min}f(x) = \{f_{1}(x),f_{2}(x), .\,.\,.,f_{n}(x)\}, x \in Q, n\geq 2 \end{equation}
where
 $f(x)$
represents the set of objectives. Variable
$f(x)$
represents the set of objectives. Variable
 $x$
is the n-dimensional decision variable.
$x$
is the n-dimensional decision variable.
 $x$
is constrained to feasible region
$x$
is constrained to feasible region
 $Q$
which is limited by K-equality and J-inequality constraints (Coello et al., Reference Coello, Lamont and Van Veldhuizen2007). The PF is a set of non-dominated chosen optimal solutions. The objectives of PF cannot be improved without losing at least one other objective. Let’s assume the solution
$Q$
which is limited by K-equality and J-inequality constraints (Coello et al., Reference Coello, Lamont and Van Veldhuizen2007). The PF is a set of non-dominated chosen optimal solutions. The objectives of PF cannot be improved without losing at least one other objective. Let’s assume the solution
 $x^{*}$
. The solution
$x^{*}$
. The solution
 $x^{*}$
is referred to dominated solution by another solution
$x^{*}$
is referred to dominated solution by another solution
 $ s $
, if and only if
$ s $
, if and only if
 $s$
is equal to or better than
$s$
is equal to or better than
 $x^{*}$
with regard to all objectives
$x^{*}$
with regard to all objectives
 $\forall i:f_{i}(x^{*})\leq f_{i}(x), i \in \{1,2,\!..,n\}$
. In addition,
$\forall i:f_{i}(x^{*})\leq f_{i}(x), i \in \{1,2,\!..,n\}$
. In addition,
 $x^{*}$
should have at least one objective better than
$x^{*}$
should have at least one objective better than
 $x$
in one objective
$x$
in one objective
 $\exists i: f_{j}(x^{*})<f_{j}(x),j\in\{1,2,..,n\}$
.
$\exists i: f_{j}(x^{*})<f_{j}(x),j\in\{1,2,..,n\}$
.
As described before, various objectives of a multi-objective optimization problem (MOOP) conflict with each another. Thus, classical optimization problems usually fail to attain true Pareto-optimal solutions. Different existing MO algorithms have been successfully used to solve MOOPs including non-dominated sorting genetic algorithm (NSGA-II) (Deb et al., Reference Deb, Pratap, Agarwal and Meyarivan2002), state-of-the-art NSGA-III (Deb & Jain, Reference Deb and Jain2014), and MOEA/D (Zhang & Li, Reference Zhang and Li2007). Recent works on MOEAs have shown that the NSGA-III and MOEA/D algorithm performance are two of the best MOEAs. Thus, in this paper, the provided algorithm’s MOEA is modified based on NSGA-III and MOEA/D algorithms.
Based on the described MO structure of TOPTWR, as mentioned earlier, in this paper we consider the following five objectives for MOHH-TOPTWR.
(1) Maximizing profit collected for all tasks (
 $f_{1}$
)
(13)
\begin{equation}\text{max}\, f_{1}= \sum_{a\in A}\sum_{t_{a}^{+}\in T_{a}^{+}}P_{t_{a}^{+}}\end{equation}
$f_{1}$
)
(13)
\begin{equation}\text{max}\, f_{1}= \sum_{a\in A}\sum_{t_{a}^{+}\in T_{a}^{+}}P_{t_{a}^{+}}\end{equation}
(2) Minimizing the sum of the tasks’ completion times (
$f_{2}$
)
(14)
\begin{equation}\text{min}\, f_{2}= \sum_{a\in A}\sum_{t_{a}^{+}\in T_{a}^{+}} DUR_{t_{a}^{+}}+TT_{t_{a}^{+},t_{a}^{+}}, +\, RT_{t_{a}^{+},t_{a}^{+}},\end{equation}
(3) Minimizing robots’ total energy consumption (including robots’ physical rotations between tasks along with their walking distance), (
$f_{3}$
)
(15)
\begin{equation}\text{min}\, f_{3}= \sum_{a\in A}\sum_{t_{a}^{+}\in T_{a}^{+}} W_{a}^{t} DUR_{t_{a}^{+}}+E\;_{a}^{S}TT_{t_{a}^{+},t_{a}^{+}},+E\;_{a}^{R}RT_{t_{a}^{+},t_{a}^{+}},\end{equation}
(4) Minimizing robots’ fair energy consumptions (
$f_{4}$
)
(16)
\begin{align} & \text{min}\,f_{4}=\sqrt{\frac{1}{|A|}\sum_{a\in A}(Total_{a}-\mu)^{2}}, \mu=\frac{1}{|A|}\sum_{a\in A}Total_{a}\nonumber\\[5pt]
& Total_{a}=\sum_{t_{a}^{+}\in{T_{a}^{+}}} W_{a}^{t}\, DUR_{t_{a}^{+}}+E\;_{a}^{S} TT_{t_{a}^{+},t_{a}^{+}}, +\,E\;_{a}^{R} RT_{t_{a}^{+},t_{a}^{+}},\end{align}
(5) Minimizing tasks delays after their closing time (
$f_{5}$
)
(17)
\begin{equation}\text{min}f_{5}=\sum_{a\in A}\sum_{t_{a}^{+}\in T_{a}^{+}} Delay (C_{t_{a}^{+}})\end{equation}







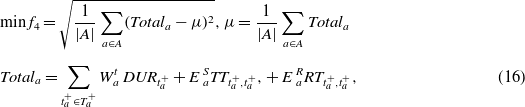


Maximizing
 $f_{1}$
aims to maximize the total profit in rescue application regarding the constraints defined in the proposed MIP formulation. Minimization of
$f_{1}$
aims to maximize the total profit in rescue application regarding the constraints defined in the proposed MIP formulation. Minimization of
 $f_{2}$
aims to reduce the total tasks’ accomplishment time due to rescue application. Minimization of
$f_{2}$
aims to reduce the total tasks’ accomplishment time due to rescue application. Minimization of
 $f_{3}$
aims to reduce the total consumed energy of the robots. This is useful when (i) the number of robots and their tasks’ maximum time
$f_{3}$
aims to reduce the total consumed energy of the robots. This is useful when (i) the number of robots and their tasks’ maximum time
 $T^{Max}$
is not restricted and robots can easily collect maximum profit in
$T^{Max}$
is not restricted and robots can easily collect maximum profit in
 $f_{1}$
, (ii) the robots have limited energy, and (iii) we need robots on another rescue mission, for instance, by completing a mission first on one building with some tasks and then completing another mission on the next building. Also, it is different from
$f_{1}$
, (ii) the robots have limited energy, and (iii) we need robots on another rescue mission, for instance, by completing a mission first on one building with some tasks and then completing another mission on the next building. Also, it is different from
 $f_{2}$
, because the energy consumption of each robot
$f_{2}$
, because the energy consumption of each robot
 $x$
is different for each task
$x$
is different for each task
 $t$
. Objective
$t$
. Objective
 $f_{4}$
aims to minimize fair energy consumption between all robots. This is useful when robots have limited energy, and we prefer not to have an out-of-battery robot for later missions. Finally, Objective
$f_{4}$
aims to minimize fair energy consumption between all robots. This is useful when robots have limited energy, and we prefer not to have an out-of-battery robot for later missions. Finally, Objective
 $f_{5}$
aims to minimize the total delay in performing assigned tasks regarding their closing time
$f_{5}$
aims to minimize the total delay in performing assigned tasks regarding their closing time
 $C_{t_{a}^{+}}$
for all robots, where
$C_{t_{a}^{+}}$
for all robots, where
 $Delay\, (C_{t_{a}^{+}})$
is a function that computes delay in performing an assigned task. In other words, this objective aims to start all tasks before their closing time.
$Delay\, (C_{t_{a}^{+}})$
is a function that computes delay in performing an assigned task. In other words, this objective aims to start all tasks before their closing time.
3 Proposed algorithm
In this section, we describe the proposed MOHH-TOPTWR. In this regard, first, we describe the hyper-heuristics methodology and UCB selection strategy, followed by an explanation on the procedures and operators of the proposed MOHH-TOPTWR.
3.1 Hyper-heuristics
In the last two decades, different heuristic algorithms and other search techniques have been proposed successfully. One of the stimulating issues to solve a problem is to select a suitable approach among a major range of algorithm choices. A hyper-heuristic is a high-level heuristic that uses a set of LLHs. Hyper-heuristics usually select or generate heuristics (Burke et al., Reference Burke, Hyde, Kendall, Ochoa, Özcan and Woodward2010). So a hyper-heuristic can be utilized to select the most appropriate heuristics and find the best method or sequence of LLHs (Chakhlevitch & Cowling, Reference Chakhlevitch, Cowling, Cotta, Sevaux and Sörensen2008; Burke et al., Reference Burke, Gendreau, Hyde, Kendall, Ochoa, Özcan and Qu2013). This was motivated by bringing less work because of the difficulties regarding the application of conventional search techniques, in which significant number of parameters must tune. Therefore, in this paper, hyper-heuristic is defined (Burke et al., Reference Burke, Hyde, Kendall, Ochoa, Özcan and Woodward2010) as an automated methodology for selecting or generating heuristics to solve hard computational search problems. In Burke et al. (Reference Burke, Hyde, Kendall, Ochoa, Özcan and Woodward2010), the authors also proposed a classification for hyper-heuristics consisting of two main dimensions including (i) the heuristic search space nature and (ii) the sources of heuristic feedback as follows. (i) construction heuristics starting with empty solutions or (ii) perturbation heuristics, which start with complete solutions (then iteratively improve solutions).
In this paper, hyper-heuristic with an online selection of perturbation heuristics is used in which search operators for MOEA is selected (Coello et al., Reference Coello, Lamont and Van Veldhuizen2007). Moreover, hyper-heuristic presented here uses a profit-based heuristic selection method: sliding multi-armed bandit (SlMAB) proposed in Fialho et al. (Reference Fialho, Da Costa, Schoenauer and Sebag2010).
3.2 Upper confidence bound
The MAB problem consists of a set of K-independent arms in which each arm has an unknown probability to obtain a reward (Mahajan & Teneketzis, Reference Mahajan and Teneketzis2008). So the goal is to maximize the accumulated reward by moving the arms in an optimal sequence. Inspired by the MAB, UCB selection strategy is proposed in Auer et al. (Reference Auer, Cesa-Bianchi and Fischer2002). In the UCB selection strategy, the ith given operator is associated with two values: (i) an estimated reward
 $\hat{r}_{i}$
for measuring the empirical reward of the ith operator over time and (ii) an operator executed times-dependent confidence interval. Equation (18) shows the UCB method’s operator selection with the best value:
$\hat{r}_{i}$
for measuring the empirical reward of the ith operator over time and (ii) an operator executed times-dependent confidence interval. Equation (18) shows the UCB method’s operator selection with the best value:
 \begin{equation}\max\limits_{i\in I}(\hat{R}_{i,t}+S\sqrt{2\text{log}\,N/n_{i,t}})\end{equation}
\begin{equation}\max\limits_{i\in I}(\hat{R}_{i,t}+S\sqrt{2\text{log}\,N/n_{i,t}})\end{equation}
where
 $i$
indicates the ith operator in a set of predefined operators
$i$
indicates the ith operator in a set of predefined operators
 $I,S$
is the scaling factor to control the trade-off between the exploration and exploitation, and
$I,S$
is the scaling factor to control the trade-off between the exploration and exploitation, and
 $\hat{R}_{i,t}$
is the gained average reward by the ith operator to that moment. Note that to have more exploitation the parameter
$\hat{R}_{i,t}$
is the gained average reward by the ith operator to that moment. Note that to have more exploitation the parameter
 $S$
must be decreased and for exploration vice versa.
$S$
must be decreased and for exploration vice versa.
 $n_{i,t}$
indicates the number of times the ith operator was executed to that moment and
$n_{i,t}$
indicates the number of times the ith operator was executed to that moment and
 $N$
is the overall number of operator executions at that moment.
$N$
is the overall number of operator executions at that moment.
The SlMAB algorithm is an original dynamic variant of the standard MAB. The SlMAB is used to solve the exploitation versus exploration trade-off in static settings optimally (Fialho et al., Reference Fialho, Da Costa, Schoenauer and Sebag2010). The SlMAB introduces a memory length adjustment and a credit assignment function. These allow a faster distinction of changes in the performance of LLHs. The SlMAB uses two main functions to compute the profit of each operator in Equation (19):
 \begin{equation}\hat{R}_{i,t+1}=\hat{R}_{i,t}(W/W+(ts-ts_{i}))+r_{i,t}(1/n_{i,t}+1)\end{equation}
\begin{equation}\hat{R}_{i,t+1}=\hat{R}_{i,t}(W/W+(ts-ts_{i}))+r_{i,t}(1/n_{i,t}+1)\end{equation}
Equation (19) shows how SlMAB computes the reward estimate
 $\hat{R}_{i,t+1}$
. In this Equation
$\hat{R}_{i,t+1}$
. In this Equation
 $i$
is the ith operator of a set of defined operators;
$i$
is the ith operator of a set of defined operators;
 $ts$
is the current time step or iteration,
$ts$
is the current time step or iteration,
 $ts_{i}$
is the last time step that operator
$ts_{i}$
is the last time step that operator
 $i$
was applied,
$i$
was applied,
 $r_{i,t}$
is the the ith operator’s given immediate or raw reward at the time step
$r_{i,t}$
is the the ith operator’s given immediate or raw reward at the time step
 $ts$
,
$ts$
,
 $W$
indicates the size of the sliding window (SL), and
$W$
indicates the size of the sliding window (SL), and
 $n_{i,t}$
is the ith operator’s number of applied times until the time step
$n_{i,t}$
is the ith operator’s number of applied times until the time step
 $ts$
. The SL is a type of memory that stores the last W rewards obtained by all operators.
$ts$
. The SL is a type of memory that stores the last W rewards obtained by all operators.
 $W$
can be obtained in several ways, but in Fialho et al. (Reference Fialho, Da Costa, Schoenauer and Sebag2010) the authors concluded that extreme credit assignment, which defines the reward of an operator as the best reward found in the SL, is the most robust operator selection method in combination with SlMAB.
$W$
can be obtained in several ways, but in Fialho et al. (Reference Fialho, Da Costa, Schoenauer and Sebag2010) the authors concluded that extreme credit assignment, which defines the reward of an operator as the best reward found in the SL, is the most robust operator selection method in combination with SlMAB.
Function includes the credit assignment component of SlMAB. This component is to maximize the chosen operator in Equation (18).
 \begin{equation}n_{i,t+1}=n_{i,t}(W/W+(ts-ts_{i}))+(1/n_{i,t}+1)\end{equation}
\begin{equation}n_{i,t+1}=n_{i,t}(W/W+(ts-ts_{i}))+(1/n_{i,t}+1)\end{equation}
where
 $n_{i,t}$
is the counter of ith operator until the time step
$n_{i,t}$
is the counter of ith operator until the time step
 $ts$
(application frequency). We adapted the SlMAB implementation to make it more well matched with the MOHH-TOPTWR proposed in this paper. Our main motivations for using SlMAB was the good learning capability of SlMAB and its excellent results in other works (Fialho et al., Reference Fialho, Da Costa, Schoenauer and Sebag2010; Guizzo et al., Reference Guizzo, Vergilio, Pozo and Fritsche2017).
$ts$
(application frequency). We adapted the SlMAB implementation to make it more well matched with the MOHH-TOPTWR proposed in this paper. Our main motivations for using SlMAB was the good learning capability of SlMAB and its excellent results in other works (Fialho et al., Reference Fialho, Da Costa, Schoenauer and Sebag2010; Guizzo et al., Reference Guizzo, Vergilio, Pozo and Fritsche2017).
3.3 MOHH-TOPTWR
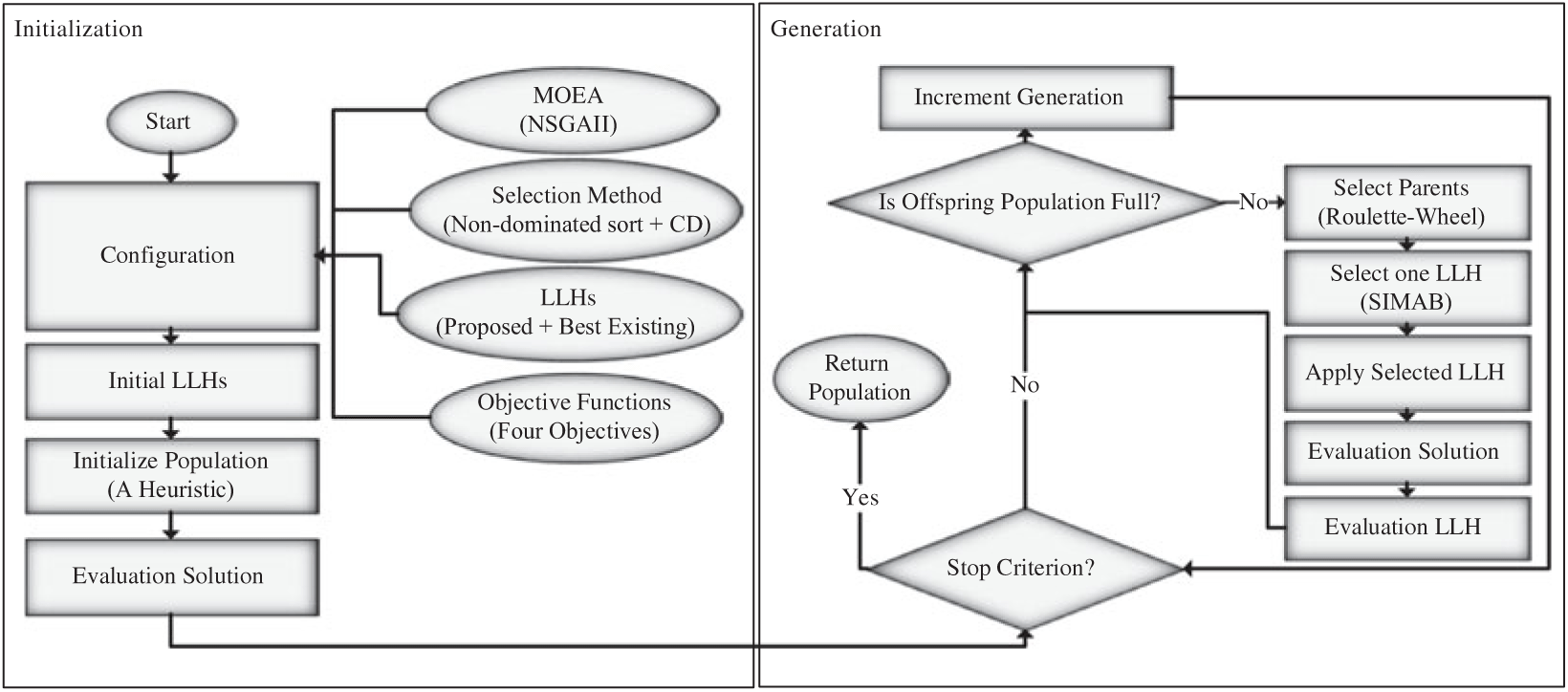
As described before in this paper, an MOHH-TOPTWR. The MOHH-TOPTWR is using online hyper-heuristic for selecting different LLHs. The LLHs used by MOEAs in order to solve the TOPTWR. The primary goal of MOHH-TOPTWR is to select the best combination of the state-of-the-art heuristics in the literature for each mating, and best existing mutation and crossover operators for similar problems in TOPTW. The hyper-heuristic used in this paper profits each LLH, updates and selects the best one in each mating. In this regard, it uses parents for generating offspring. The main steps and components of the MOHH-TOPTWRs are shown in Figure 1.
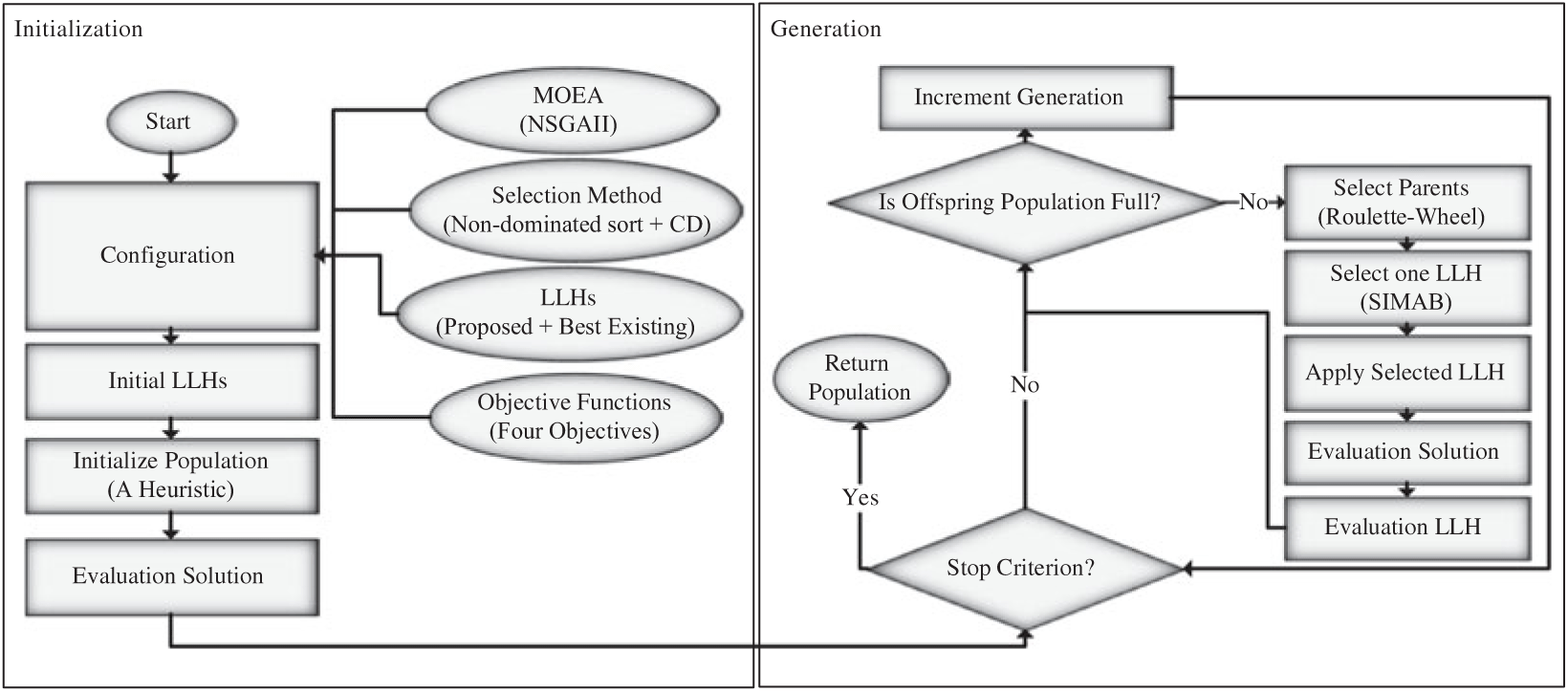
Figure 1 Multi-objective and evolutionary hyper-heuristic algorithm for TOPTW based on the humanoid robot’s characteristics in the rescue applications (MOHH-TOPTWR) workflow
In the first step of the proposed MOHH-TOPTWR, hyper-heuristic is initialized using some inputs given by the user as follows:
(i) An MOEA and its parameters to perform the optimization using the objective functions.
(ii) A selection method to select the next best LLH in each mating of the MOEA.
(iii) A set of LLHs to generate solutions compatible with the problem representation.
(iv) The objective functions to evaluate the solutions.
In this paper, an initial solution is constructed by inserting tasks subsequently into one of the paths based on Roulette-Wheel Selection method (Goldberg, Reference Goldberg1989). We use both NSGA-III (Deb & Jain, Reference Deb and Jain2014) and MOEA/D (Zhang & Li, Reference Zhang and Li2007) as the MOEAs to solve MOHH-TOPTWR.
The objective functions described in Section 2.2, though are not necessarily conflicting, may be optimized simultaneously and independently. Thus, the optimization process may find several non-dominated solutions regarding the five objectives described. The advantage is enabling the user to choose the non-dominated solution based on the rescue environment that best fits the PF purposes. The problem is represented as an array of tasks and optimized as a permutation problem. Due to this, we used the best existing new LLHs specific for this kind of problem. Moreover, we also implemented and adapted SlMAB as the selection method (see Sections 3.2 (Fialho et al., Reference Fialho, Da Costa, Schoenauer and Sebag2010)
The second step of MOHH-TOPTWR is initializing LLHs. Each LLH has an associated value for the two measures as
 $r_{i,t}$
, and
$r_{i,t}$
, and
 $ts$
. These values are updated in each genetic mating, which is used in Section 3.2. To compute
$ts$
. These values are updated in each genetic mating, which is used in Section 3.2. To compute
 $r_{i,t}$
and
$r_{i,t}$
and
 $ts$
, the following steps were followed:
$ts$
, the following steps were followed:
(i) Reward measure (
$r_{i,t}$
):
$r_{i,t}$
is an immediate reward given to LLH’s performance. The greater reward is a better recent performance by evaluating both parent and offspring domination states (between 0 and 1). For each LLH, the
$r_{i,t}$
value is computed by applying the ith LLH (such as mating parents and the generated offspring) as shown in Equation (21).
(21)where
\begin{equation}r_{i,t}=\frac{|\{{o\in O|\exists p\in P:p>O}\}|}{|P|\times|O|}+\frac{|\{{o\in O|\exists p\in P:p=O}\}|}{|P|\times|O|\times3}\end{equation}
$r_{i,t}$
is the computed reward value of the ith applied LLH.
$p$
is a parent in selected parents mating
$P,o$
is the offspring generated at the same mating
$O$
. This measure has a straightforward implementation using the explicitly well-known Pareto-dominance concept.(ii) Time measure (
$ts$
): Time measure
$ts$
indicates the count of the past matings since the last mating using that LLH. So the higher value of the
$ts$
indicates that LLH has been idle (
$ts$
is within the interval
$[0,\infty]$
). The update rules for
$ts$
are straightforward at each mating, and the
$ts$
value for the LLHs that are not applied increases in that mating (for the applied one the counter set to 0).















According to MOEA initialization strategy, (usually this is random), the population is initialized. However, based on the literature review, we use a semi-random insert operator (greedy construction heuristic), which is a multi-start version of the ILS operator proposed in Gunawan et al. (Reference Gunawan, Lau, Vansteenwegen and Lu2017) (operators will be described in Section 3.4 in detail). At each generation, the offspring population is generated after evaluating the initial population using the proposed objective functions. This generation procedure is performed until the stop criterion is met. In this regard, one parent or two parents are selected based on the nature of LLH to generate a new offspring. The selection strategy used in this work is Roulette-Wheel Selection method (Goldberg, Reference Goldberg1989). Thereafter, using the hyper-heuristic method, an LLH is selected to apply on selected parents and to produce new offspring. In this vein, if new solutions violate any constraint, a recovery algorithm is applied. If not, produced solutions are evaluated by the proposed objective functions, and this evaluation indicates the performance of the selected LLH (note that the produced offspring are added to the offspring pool). The
 $ts$
of each selected LLH is set to 0, and the other non-selected LLHs’
$ts$
of each selected LLH is set to 0, and the other non-selected LLHs’
 $ts$
are incremented by one. This routine continues until the new offspring population pool is not full.
$ts$
are incremented by one. This routine continues until the new offspring population pool is not full.
When the offspring population generations end, MOHH-TOPTWR returns the non-dominated solutions of the current population. The non-dominated solutions returned by MOHH-TOPTWR are the solutions that present the best trade-off between the introduced objectives. This is achieved by the defined MOEA, which in this paper are based on the NSGA-III method (Deb & Jain, Reference Deb and Jain2014) or the MOEA/D (Zhang & Li, Reference Zhang and Li2007) structure.
The following subsection presents the LLHs implemented in this work.
3.4 Low-level heuristics
MOHH-TOPTWR can use any type of operators as LLH. In this work, the recent state-of-the-art approaches for TOPTW such as local searches are implemented as LLHs. Hence, the crossover operator, local searches, or a combination of a mutation operator and a crossover operator is used.
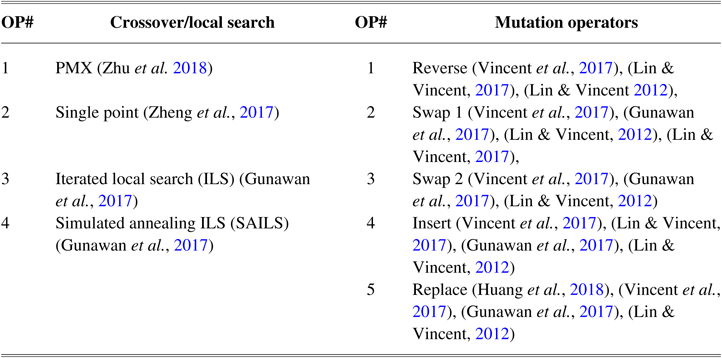
In this paper, we adapted and used four types of operators as crossover or local search operators and five mutation operators, all for permutation encoding based on the TOPTWR definitions. In this regard, the best efficient operators are extracted from the recent related algorithms on TOPTW. Most of these operators are common in most of the proposed approaches in the literature (Vansteenwegen et al., Reference Vansteenwegen, Souffriau, Berghe and Van Oudheusden2009; Cura, Reference Cura2014; Wang et al., Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016; Guizzo et al., Reference Guizzo, Vergilio, Pozo and Fritsche2017; Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017; Lin & Vincent, Reference Lin and Vincent2017; Nunes et al., Reference Nunes, Manner, Mitiche and Gini2017; Vincent et al., Reference Vincent, Jewpanya, Ting and Redi2017). Table 2 presents the operators used in this work.
Table 2 Operators used in the hyper-heuristic proposed in this paper
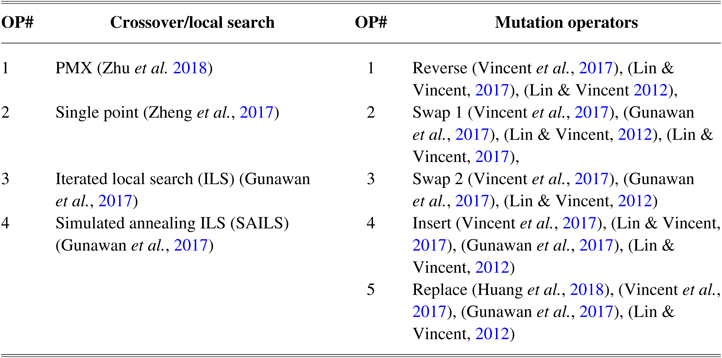
PMX = partially matched crossover; SAILS = simulated annealing (SA) iterated local search heuristic.
In the rest of this section, we first describe the crossover operators utilized, then explain mutation operators, and, finally, show how LLHs in the proposed hyper-heuristic are implemented.
In this paper, we utilized two crossovers partially matched crossover (PMX) and two-point crossover, which use two parents and produce two offspring. This was because of their popularity and extensive use in different MOEA algorithms (Zhu et al., Reference Zhu, Li, Teng and Yonglu2018).
On the other hand, we utilized two best local search operators, which are the core proposed metaheuristics in the literature. Based on the surveys in TOPTW, the proposed algorithms such as ILS obtained the best results compared to all other algorithms (Gunawan et al., Reference Gunawan, Lau and Vansteenwegen2016). These local search approaches use one parent and produce one offspring. In the most recent paper an ILS and SAILS (Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017) are proposed. These metaheuristic approaches are based on efficient local searches. The results of the SAILS, the best existing one in the literature, dominated most other proposed algorithms in TOPTW such as ant colony system (Montemanni & Gambardella, Reference Montemanni and Gambardella2009), variable neighborhood search (Tricoire et al., Reference Tricoire, Romauch, Doerner and Hartl2010), slow SA (Lin & Vincent, Reference Lin and Vincent2012), granular variable neighborhood search (Labadie et al., Reference Labadie, Mansini, Melechovský and Calvo2012), iterative three-component heuristic (Hu & Lim, Reference Hu and Lim2014), and hybridized greedy randomized iterated local search (Souffriau et al., Reference Souffriau, Vansteenwegen, Vanden Berghe and Van Oudheusden2013). As the authors explained in Gunawan et al. (Reference Gunawan, Lau, Vansteenwegen and Lu2017), the order of the used operators is decided after conducting some preliminary experiments; whereas in this paper, we aimed to find the best order in all possible best operators. Thus, we used its core local searches as a multi-start ILS and considered it as LLH. Despite the use of mutation operators such as reverse, etc., their metaheuristics platform is not capable of being used in the best combinations.
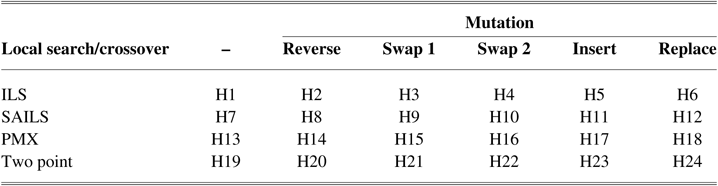
All of the five mutation operators shown in Table 2 are applied to one given solution approach (chromosome). These mutation operators are described as follows:
Reverse operator (Vincent et al., Reference Vincent, Jewpanya, Ting and Redi2017):
Step 1: Randomly select a robot
$ a $
in the set
$t^{-}$
and a task
$t_{a}^{+}$
in the set
$T_{a}^{+}$
, then select a random reverse count
$RC,0<RC<|T_{a}^{+}|$
, and reverse
$ RC $
count of the order of visiting tasks starting
$t_{a}^{+}$
.Step 2: Evaluate the feasibility of the modified path and compute the objective functions.
Step 3: If the feasibility is maintained and the objective of the modified path is improved, then keep the modified solution; otherwise, return the solution to the Step 1.







Swap 1 operator (Vincent et al., Reference Vincent, Jewpanya, Ting and Redi2017):
Step 1: Randomly select a robot
$a$
in the set.Step 2: Randomly select two tasks
$t_{a}^{+}$
and
$t_{a}^{+^{\prime}}$
in the same
$T_{a}^{+}$
.Step 3: Swap task
$t_{a}^{+}$
with
$t_{a}^{+^{\prime}}$
.Step 4: Evaluate the feasibility of the modified task’s order for the selected robot
$a$
and the objective functions.Step 5: If the feasibility is maintained and the objective functions of the modified path are improved, then keep the modified path; otherwise, return the path to Step 1.







Swap 2 operator (Vincent et al., Reference Vincent, Jewpanya, Ting and Redi2017):
Step 1: Randomly select a robot
$ a $
in set
$ A $
and tasks
$t_{a}^{+}$
in
$T_{a}^{+}$
.Step 2: Randomly select another robot
$ a^{\prime} $
in set
$ A $
and tasks
$t_{a}^{+^{\prime}}$
in
$T_{a}^{+}$
.Step 3: Swap task
$t_{a}^{+}$
with the task
$t_{a}^{+^{\prime}}$
.Step 4: Evaluate the feasibility of both the modified task’s order in
$ a $
,
$a^{\prime}$
, and their objective functions.Step 5: If the feasibility is maintained and the objective functions of the modified path are improved, then keep the modified path; otherwise, return the path to Step 1.












Insertion operation (Lin & Vincent, Reference Lin and Vincent2017):
Step 1: Randomly select a robot
$a$
in set
$ A $
and tasks
$t_{a}^{+}$
in
$T_{a}^{+}$
.Step 2: Randomly select a task
$t^{-}$
in
$T^{-}$
(reserve list).Step 3: Insert
$t^{-}$
next to
$t_{a}^{+}$
.Step 4: Evaluate the feasibility of the modified task’s order and objective functions.
Step 5: If the feasibility is maintained and the objective functions of the modified path are improved, then keep the modified path; otherwise, return the path to Step 1.








Replace operator (Vincent et al., Reference Vincent, Jewpanya, Ting and Redi2017):
Step 1: Randomly select a robot
$a$
in set
$A$
and tasks
$t_{a}^{+}$
in
$T_{a}^{+}$
.Step 2: Randomly select a task
$t^{-}$
in
$T^{-}$
(reserve list).Step 3: Swap task
$t_{a}^{+}$
with
$t^{-}$
.Step 4: Evaluate the feasibility of the modified task’s order and objective functions.
Step 5: If feasibility is maintained and the objective functions of the modified task’s order in
$a$
is improved, then keep the modified path; otherwise, return the path to step 1.









In the following section, first we briefly describe the crossover and local search approaches used in this work and then the proposed SAILS.
Partially matched crossover (Zhu et al., Reference Zhu, Li, Teng and Yonglu2018):
One of the most common types of crossover with this characteristic is PMX (Michalewicz, Reference Michalewicz2013; Karakatič & Podgorelec, Reference Karakatič and Podgorelec2015). In PMX, two chromosomes and two different crossing points are randomly chosen. Then each section is transferred from one chromosome into another chromosome (proceeds by position-wise exchanges). In other words, a portion of one parent’s genes is exchanged with a portion of the other parent’s genes and the remaining genes are copied or regenerated by mapping.
Single-point crossover (Zheng et al., Reference Zheng, Liao and Qin2017):
In Zheng et al. (Reference Zheng, Liao and Qin2017), an adaptive heuristic search algorithm GA (genetic algorithm) was used, which is commonly used to deal with optimization and search problems by relying on bio-inspired operators. For the route optimization process, authors adopt a single-point crossover to generate a high-quality route set. This process involves three steps: (1) two routes are selected randomly to be the parents, (2) a cut point is randomly determined, and (3) the new routes (named the offspring) are determined as concatenations of parts from the two parents.
Iterated local search (Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017):
In this work, three components of ILS, namely, perturbation, local search, and acceptance criterion are taken into consideration.
Step 1 (initialization): The initial solution that is generated by the greedy construction heuristic is treated as the current solution in ILS.
Step 2 (perturbation): Two different steps including exchange path and shake are implemented in perturbation. In this vein, if the number of iterations without improvement is larger than a predefined specific threshold, the exchange path is executed; otherwise, the shake is selected.
Exchange: Changes the order of the paths in the solution by swapping two adjacent paths every time.
Shake: Shake step is adopted from the one proposed in Vansteenwegen et al. (Reference Vansteenwegen, Souffriau, Berghe and Van Oudheusden2009) with some modifications in which two integer values, CONS and POST, are used. The value POST indicates the first position of the removing process in a particular path, while the value CONS indicates how many consecutive tasks remove a particular path.
Step 3 (local search): In local search, the authors used six different operations consecutively. In which two other operators, insert and replace, contribute to improving the quality of the solution. Thus, we just used these two operators as the local search core in ILS. (Note that other operators will be used in the proposed hyper-heuristic platform.)
Insert: The purpose of insert is to insert one unscheduled node (reserve task) to a particular path with its improvement probability. It is started by generating a feasible insertion points probability list per reserve node. Then it inserts a node with Roulette-Wheel selection (for details refer to Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017).
Replace: The replace operation is started by selecting the path with the highest remaining travel time and selecting one node with the highest profit. It is started by searching a feasible replace points per reserve node. Hence, once this operation is successful, the process will continue to the next reserved node and repeat the operation. This will continue until there is no possible replacement.
Step 4 (acceptance criterion): If the current solution is better than the previous solution, it updates the best-found solution so far.
Step 5 (intensification strategy): This work included the intensification strategy in ILS, which is the main difference with the standard ILS. The idea of the intensification strategy is that if improvement is not achieved for a certain number of iterations, it restarts the search from the best-found solution.
Simulated annealing iterated local search (Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017):
SAILS is a hybridization of ILS and SA, which helps SA to escape from local optima. The SA escapes from a local optimum by accepting a worse solution with a probability that changes over time. This SA algorithm works with three parameters
$T_{0}$
to the initial temperature,
$\alpha$
as a coefficient used to control the speed of the cooling schedule
$(0 < \alpha < 1)$
, and
$ InnerLoop $
as a number of iterations at a particular temperature.In the beginning, the current temperature
$Temp$
is defined as equal to
$T_{0}$
and decreases after
$InnerLoop$
iterations by using the following formula:
$Temp=Temp\times\alpha$
. In this work at a particular value of temperature (Temp), two components of ILS (perturbation, local search) with specific tuned parameters are applied. Other steps of SAILS are the same as that described for ILS in the previous paragraph.








Note that for more details of implementation, parameter tuning, and algorithm of both ILS and SAILS refer to (Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017).
Table 3 Low-level heuristics composition in MOHH-TOPTWR
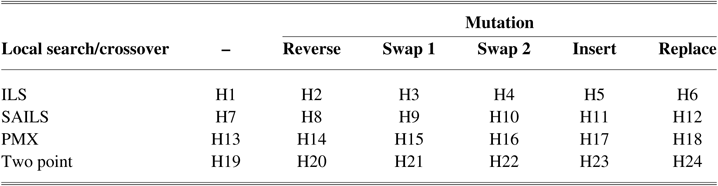
MOHH-TOPTWR = Multi-objective and evolutionary hyper-heuristic algorithm for TOPTW based on the humanoid robot’s characteristics in the rescue applications; ILS = Iterated local search; PMX = partially matched crossover; SAILS = simulated annealing (SA) iterated local search heuristic.
Table 3 presents the LLHs used in this paper, which is composed of the operators described in subsection3.4. As shown in this table, we included LLHs composed of local search or crossover operators, because this kind of operator is a distinguishing feature of evolutionary.
4 Experimental results
In order to evaluate the performance of the proposed hyper-heuristic algorithm, experiments were implemented in C# programming language on a laptop (i5-6360U 2.00 GHz with 8 GB RAM). Average running time (seconds) of the algorithms of over 20 runs for each instance was 600 seconds. We know unlike the population-based EA, there is no explicit concept of generation in ILS approaches. Thus, the running time of the proposed hyper-heuristic algorithm was set as the stopping criterion for other compared algorithms in same time durations for a fair comparison.
4.1 Benchmark instances
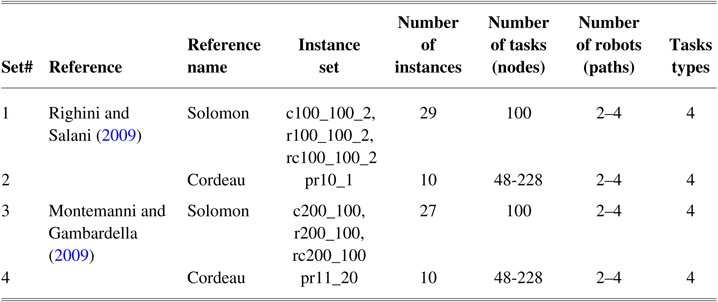
The main aim of this paper is to propose new algorithms for rescue and general humanoid robots’ energy consumption instances. In order to evaluate the performance of all the discussed algorithms, the algorithms were tested on the extended existing benchmark instances on TOPTW, which we presented with some modifications and supplementary. Hence, all algorithms were evaluated on the two well-known adopted sets of benchmark instances with supplemental package described below.
The benchmark TOPTW instances were initially proposed in Righini and Salani (Reference Righini and Salani2009) in which 39 problem instances generated from Solomon’s (Solomon, Reference Solomon1987) and Cordeau’s instances (Cordeau et al., Reference Cordeau, Gendreau and Laporte1997). Also, in Montemanni and Gambardella (Reference Montemanni and Gambardella2009) another set of 37 instances was proposed for the OPTW (see Table 4). These benchmark instances can be downloaded from Tang and Miller-Hooks (Reference Tang and Miller-Hooks2005). Based on the described TOPTWR in this paper, it is slightly different from TOPTW as follows. (i) Starting time window of tasks is considered open (in a rescue environment all tasks need to start and help victims) and (ii) robots are considered heterogeneous and consumed heterogeneous energy, whereas in the existing TOPTW benchmark instances heterogeneous energy consumptions per robots are not introduced. (iii) In addition to the maximum time constraints,
 $T^{Max}$
, energy constraints are observed for each robot
$T^{Max}$
, energy constraints are observed for each robot
 $E\;_{a}^{Max}$
. Thus, we produced a supplemental package for these benchmark instances including energy consumptions of heterogeneous humanoid robots per task. Also, we provided the energy consumption of robots by traveling a distance between two tasks. Table 4 provides the summary of the modified benchmark instances.
$E\;_{a}^{Max}$
. Thus, we produced a supplemental package for these benchmark instances including energy consumptions of heterogeneous humanoid robots per task. Also, we provided the energy consumption of robots by traveling a distance between two tasks. Table 4 provides the summary of the modified benchmark instances.
Table 4 Benchmark instances used in the study
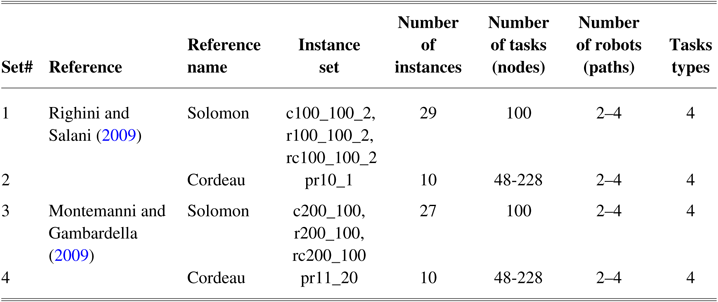
In addition to the standard benchmark, we defined four types of tasks in the last column. This column indicates that in each instance four types of task are included in which they are classified by task numbers. As a result, for instance, set with 100 number of tasks, tasks with number 1–25 will be in task type 1, tasks with numbers between 26 and 50 will be in task type 2, etc. For instance, a set with 48 number of tasks, the tasks with numbers 1–12 will be in task type 1, tasks with numbers 13–24 will be in task type 2, etc. Finally, for instance, set with 228 number of tasks, tasks with numbers 1–57 will be in task type 1, tasks with numbers 58–114 will be in task type 2, etc.
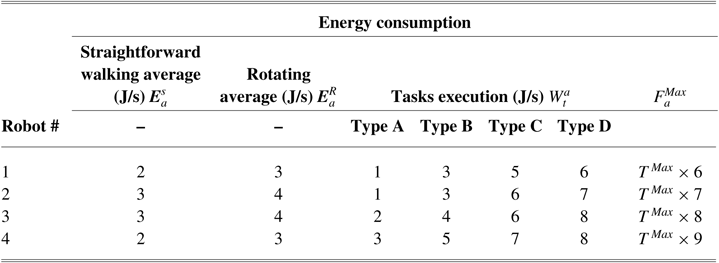
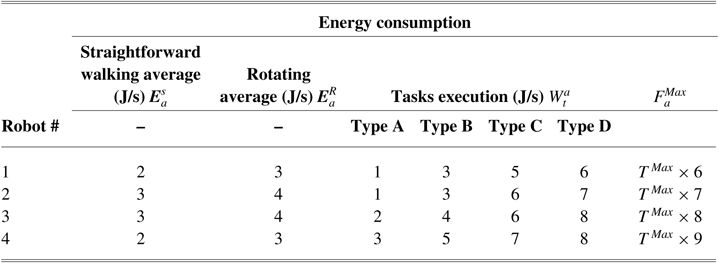
Table 5 presents robots’ energy consumption per robots’ straightforward walk, rotation, and the task workload (
 $T^{W\;_{t}^{a}x\;_{t}^{a}}$
) for each task type in joule/second unit (note that data are an approximation of our existing humanoid robots energy consumptions with Dynamixel actuators and 20 degrees of freedom. Using this table, we can compute each robot’s energy consumptions when the robot walks between tasks, multiplying the energy consumed during of the related robot by traveling the distance in the required time, which can be computed from the given benchmark instances presented in Table 4. To obtain the energy consumption of each robot for each task type, we need to multiply the time required per task
$T^{W\;_{t}^{a}x\;_{t}^{a}}$
) for each task type in joule/second unit (note that data are an approximation of our existing humanoid robots energy consumptions with Dynamixel actuators and 20 degrees of freedom. Using this table, we can compute each robot’s energy consumptions when the robot walks between tasks, multiplying the energy consumed during of the related robot by traveling the distance in the required time, which can be computed from the given benchmark instances presented in Table 4. To obtain the energy consumption of each robot for each task type, we need to multiply the time required per task
 $(C_{t}-O_{t})$
for a given benchmark instances (Table 4) by each task execution energy consumption. Also, in the last column of this table provides the maximum heterogeneous energy of each robot
$(C_{t}-O_{t})$
for a given benchmark instances (Table 4) by each task execution energy consumption. Also, in the last column of this table provides the maximum heterogeneous energy of each robot
 $E\;_{a}^{\rm max}$
. These values are computed by the related given
$E\;_{a}^{\rm max}$
. These values are computed by the related given
 $T_{\rm max}$
per benchmark instances.
$T_{\rm max}$
per benchmark instances.
Table 5 Robots’ energy consumption per robots’ walk and task type
4.2 Experiment organization
In order to evaluate the proposed algorithm, we configured the recent state-of-the-art algorithms in an MO platform and adapted them to the described problem and then the performance of each was compared. In this regard, we compared the following algorithms.
(I) SAILS (Gunawan et al., Reference Gunawan, Lau, Vansteenwegen and Lu2017): This algorithm outperformed all six recent algorithms in TOPTW. In addition, in the same research paper authors proposed one ILS algorithm.
(II) Multi-start SA (MSA) (Lin & Vincent, Reference Lin and Vincent2017): One recently proposed algorithm on TOPTW, which outperformed ABC (Cura, Reference Cura2014), and SA (Lin & Vincent, Reference Lin and Vincent2017).
(III) Multi-objective local search (MOLS) (Wang et al., Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016): Most recently proposed algorithm on vehicle routing problem simultaneous delivery and pickup and time window, which outperformed multi-objective memetic algorithm (Wang et al., Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016).
(IV) MOHH-TOPTWR-NSGA-III: The proposed hyper-heuristic algorithm that applies NSGA-III as MOEA in the proposed hyper-heuristic.
(V) MOHH-TOPTWR-MOEA/D: The proposed hyper-heuristic algorithm that applies MOEA/D as MOEA in the proposed hyper-heuristic.
Each algorithm was executed 20 times for each instance. For first three experiments, we defined both NSGA-III (Deb & Jain, Reference Deb and Jain2014) and MOEA/D (Zhang & Li, Reference Zhang and Li2007) as the MOEAs because of their popularity, superiority, and shortcoming against each other. Table 6 provides the essential parameters of algorithms. The parameters of each first three algorithms are set as in the related paper (for more detail refer to the related paper). Also, the MOEA/D parameters were set according to Wang et al. (Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016), and the NSGA-III parameters were set according to Deb and Jain (Reference Deb and Jain2014). The parameters required by Sliding Multi-Armed Bandit (SIMAB) were set after an empirical tuning. This tuning was done to properly balance the different intervals between the metrics
 $r_{i,t}$
and
$r_{i,t}$
and
 $ts$
.
$ts$
.
Table 6 Important parameters used in the MOHH-TOPTWR

SIMAB = Sliding Multi-Armed Bandit; MOEA/D = MO evolutionary metaheuristics algorithm based on decomposition; MOLS = Multi-objective local search; SAILS = simulated annealing iterated local search heuristic; MSA = multi-start simulated annealing.
For both NSGAII and MOEA/DD, usually, a high crossover probability and a very low mutation probability should be defined. For proposed MOHH-TOPTWR-NSGA-III and MOHH-TOPTWR-MOEA/D, we did not use such probabilities because if the hyper-heuristic algorithm selects an LLH, its operators are mandatorily applied. Hence, there is no need for expert user to select the operators’ configurations manually. So, elimination of manually configuration process is the main advantage of using a hyper-heuristic algorithm included with a learning part for the LLH’s selections (Guizzo et al., Reference Guizzo, Vergilio, Pozo and Fritsche2017).
4.3 Performance metrics
To measure the performance of an MO optimization algorithm, it is important to select a performance metric that can give a comprehensive comparison and that traditional single-objective approaches cannot be used (Zitzler et al., Reference Zitzler, Thiele, Laumanns, Fonseca and Da Fonseca2003). Based on this fact, in this paper, like most of the MOP algorithms comparisons (Wang et al., Reference Wang, Zhou, Wang, Zhang, Chen and Zheng2016), we used the following three metrics.
(i) Inverted generational distance (IGD) (Zhang et al., Reference Zhang, Zhou and Jin2008) was used to measure both the convergence and diversity of the non-dominated solutions obtained. The IGD calculates the distance of the true PF to another front. Thus, the lower the IGD of a front, the better the front is. Assume
$SL^{*}$
as non-dominated solutions of an MO algorithm and
$PF$
as a true Pareto-optimal set, then we can compute IGD in Equation (22).
(22)where
\begin{equation}D(SL^{*},PF)=\frac{1}{|SL^{*}|}\sum_{v\in SL^{*}} Dis(v,PF)\end{equation}
$Dis(v,PF)$
is the minimum Euclidean distance between
$v$
and the points in
$PF$
(ii) Hypervolume (HV) (Zitzler & Thiele, Reference Zitzler and Thiele1999) is used to specify the area in the objective space that was dominated at least by one of the non-dominated solutions. The larger the HV, the closer the corresponding non-dominated solutions toward the PF. Therefore, it reflects the closeness of the non-dominated solutions to the PF. HV also measures both the convergence and diversity.
(iii) Coverage metric (C-metric) (Zitzler, Reference Zitzler1999): C-metric or simply coverage is a commonly used metric for comparing two sets of non-dominated solutions. C-metric is a binary indicator. Let
$A$
and
$B$
be two approximation sets.
$C(A,B)$
gives the fraction of solutions in
$B$
that are dominated by at least one solution in
$A$
. Hence,
$C(A,B)=1$
means that all solutions in
$B$
are dominated by at least one solution in
$A$
, while
$C(A,B)=0$
implies that no solution in
$B$
is dominated by a solution in
$A$
, see the Equation (23).
(23)where
\begin{equation}C(A,B)=\frac{|\{b\in B\,|\,\exists a\in A: a\geq b\}|}{|\,B\,|}\end{equation}
$a\geq b$
suggests that solution
$a$
dominates or equals to solution
$b$
.





















Note that since the true Pareto-optimal set is unknown in this study, to compute the performance metrics, Pareto-optimal is approximated by the overall best approximately seen non-dominated solutions obtained by all algorithms in all experimental runs.
4.4 Experimental evaluation
To evaluate the algorithms referred to in Tables 7–10, we show the average values of IGD, HV, and C-metric for all 76 benchmark instances for all algorithms with two types of MOEAs (boldface values indicate superiority). Below the tables, we comprehensively discuss their results and compare their performances for three different numbers of robots.
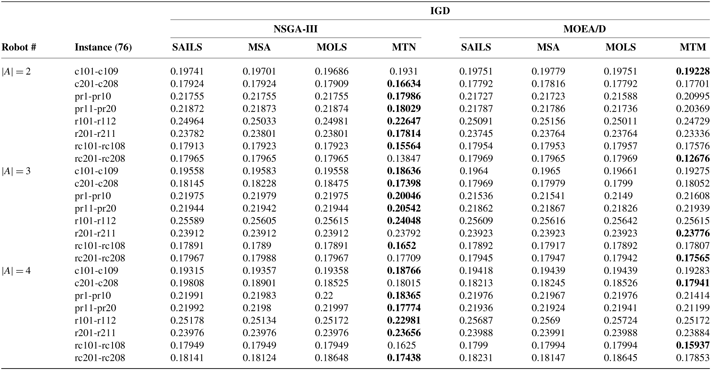
Table 7 Average values of IGD on the described benchmark instances; MOHH-TOPTWR-NSGA-III denoted as MTN and MOHH-TOPTWR-MOEA/D denoted as MTM (detailed results for Solomon and Cordeau instances with
 $|A|=2,|A|=3,|A|=4$
)
$|A|=2,|A|=3,|A|=4$
)

MOHH-TOPTWR = multi-objective and evolutionary hyper-heuristic algorithm for TOPTW based on the humanoid robot’s characteristics in the rescue applications; IGD = inverted generational distance; NSGA = non-dominated sorting genetic algorithm MOEA/D = MO evolutionary metaheuristics algorithm based on decomposition; MOLS = Multi-objective local search; SAILS = simulated annealing iterated local search heuristic; MSA = multi-start simulated annealing.
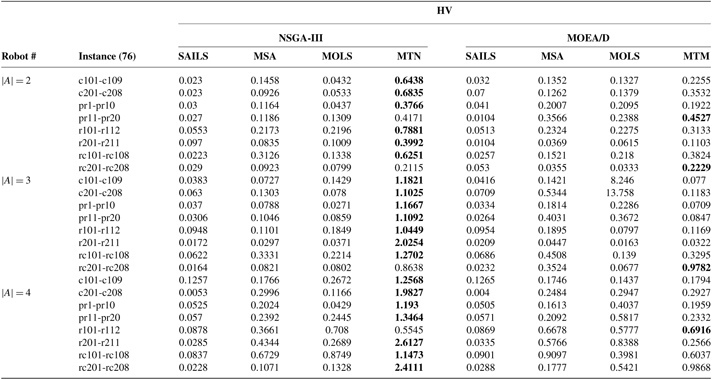
Table 8 Average values of HV on the described benchmark instances; MOHH-TOPTWR-NSGA-III denoted as MTN and MOHH-TOPTWR-MOEA/D denoted as MTM (detailed results for Solomon and Cordeau instances with
 $x_t^a = 1$
)
$x_t^a = 1$
)
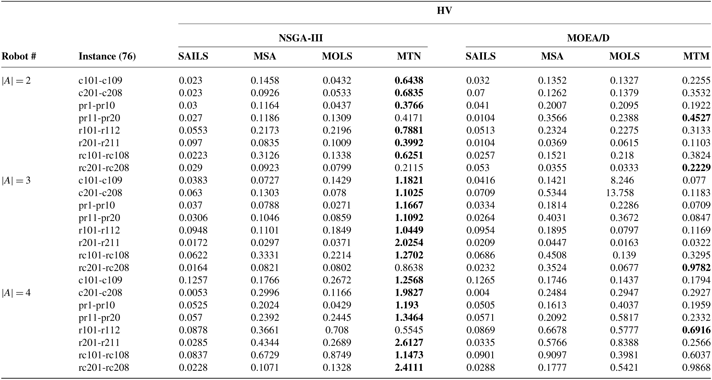
MOHH-TOPTWR = multi-objective and evolutionary hyper-heuristic algorithm for TOPTW based on the humanoid robot’s characteristics in the rescue applications; HV = hypervolume; NSGA = non-dominated sorting genetic algorithm; MOEA/D = MO evolutionary metaheuristics algorithm based on decomposition; MOLS = Multi-objective local search; SAILS = simulated annealing iterated local search heuristic; MSA = multi-start simulated annealing.
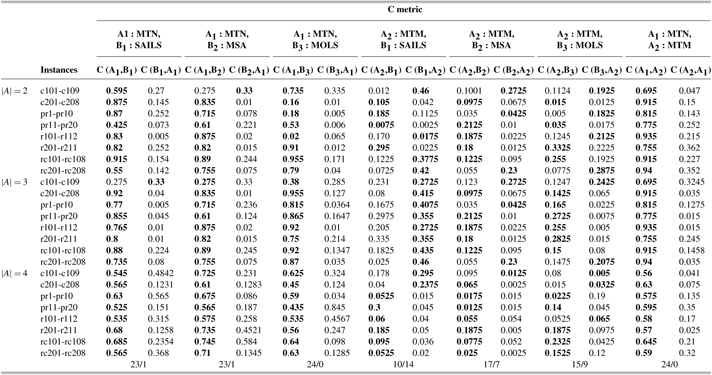
Table 9 Average values of C-Metric; MOHH-TOPTWR-NSGA-III denoted as MTN and MOHH-TOPTWR-MOEA/D denoted as MTM on the Solomon and Cordeau instances benchmark instances, A1: MTN, A2: MTM, B1: SAILS, B2: MSA, B3: MOLS (B1, B2, B3 are with MOEA/D and detailed results for
 $\sum {t \in {T^{W_{t}^a{x}_{t}^a}} \le E\;_{a}^{Max}} $
)
$\sum {t \in {T^{W_{t}^a{x}_{t}^a}} \le E\;_{a}^{Max}} $
)
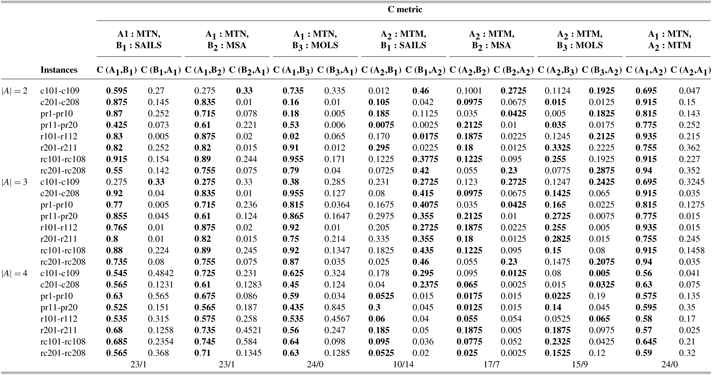
MOHH-TOPTWR = multi-objective and evolutionary hyper-heuristic algorithm for TOPTW based on the humanoid robot’s characteristics in the rescue applications; NSGA = non-dominated sorting genetic algorithm; MOEA/D = MO evolutionary metaheuristics algorithm based on decomposition; MOLS = Multi-objective local search; SAILS = simulated annealing iterated local search heuristic; MSA = multi-start simulated annealing.
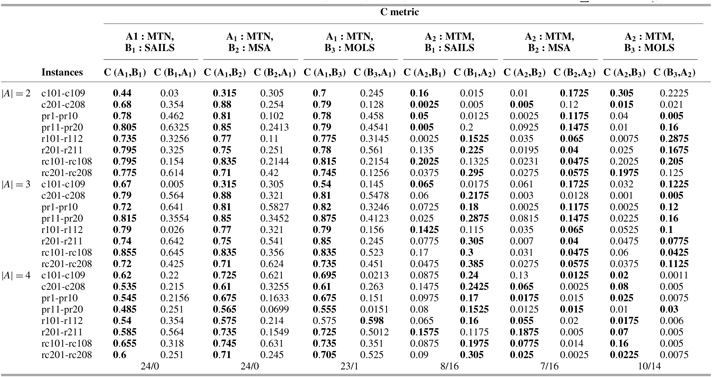
Table 10 Average values of C-Metric; MOHH-TOPTWR-NSGA-III denoted as MTN and MOHH-TOPTWR-MOEA/D denoted as MTM on the Solomon and Cordeau instances benchmark instances, A1: MTN, A2: MTM, B1: SAILS, B2: MSA, B3: MOLS (B1, B2, B3 are with NSGA-III and detailed results for
 $\sum {t^{\prime} \in {T^{o_{t,t^{\prime}}^a + z_{t^{\prime}}^a}} = x_t^a} $
)
$\sum {t^{\prime} \in {T^{o_{t,t^{\prime}}^a + z_{t^{\prime}}^a}} = x_t^a} $
)
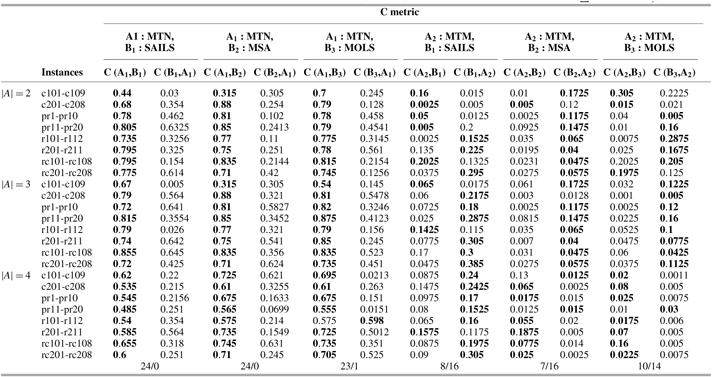
MOHH-TOPTWR = multi-objective and evolutionary hyper-heuristic algorithm for TOPTW based on the humanoid robot’s characteristics in the rescue applications; NSGA = non-dominated sorting genetic algorithm; MOEA/D = MO evolutionary metaheuristics algorithm based on decomposition; MOLS = Multi-objective local search; SAILS = simulated annealing iterated local search heuristic; MSA = multi-start simulated annealing.
A significant feature of the TOPTWR data set is that it may not hold for the different situations in rescue applications. Thus, previous single-objective or bi-objective optimization approaches for the benchmark instances cannot be directly used to solve the real-world TOPTWR instances (Martín-Moreno & Vega-Rodríguez, Reference Martín-Moreno and Vega-Rodríguez2018). Thus, they cannot effectively solve the many objective TOPTWR considered in this paper.
Two proposed algorithms based on the hyper-heuristic method proposed in this paper were compared with the best existing literature algorithms on the MO platform and each other since there is no previous benchmark algorithm. We extended the existing benchmark instances for TOPTW, hence our algorithms can be seen as the benchmark algorithms for TOPTWR instances and, as a result, can be compared with the future research.
Average values of the described metrics over 20 independent runs of all algorithms on the benchmark instances were calculated and are shown in Tables 7–10. We should note that due to space limitations, the values are shown as average for the same benchmark series, and standard deviations of the described metrics are not presented in the tables. From Tables 7–10, the following can be observed.
(I) For 76 instances, MOHH-TOPTWR-NSGA-III outperforms all other algorithms in most instances. Specifically, in all three robots MOHH-TOPTWR-NSGA-III outperforms other algorithms in 70 instances and is outperformed by MOHH-TOPTWR-MOEA/D in 6 instances in terms of IGD. Regarding HV, MOHH-TOPTWR-NSGA-III outperforms all other algorithms in 72 instances and is outperformed by MOHH-TOPTWR-MOEA/D in 4 instances. This means that MOHH-TOPTWR-NSGA-III can obtain better results than other algorithms in terms of both convergence and diversity.
(II) MOHH-TOPTWR-NSGA-III significantly outperforms other algorithms in terms of C-metric as follows. In MOEA/D platform: 23 instances against SAILS, 23 instances against MSA, 24 instances against MOLS, and 15 instances against MOHH-TOPTWR-MOEA/D; and in NSGA-III platform 24 instances against SAILS, and MSA and 23 instances against MOLS. This means that MOHH-TOPTWR-NSGA-III can obtain better results than other algorithms in terms of both convergence and diversity. Consequently, in this problem, MOHH-TOPTWR-NSGA-III shows better convergence performance.
(III) Excluding MOHH-TOPTWR-NSGA-III, MOHH-TOPTWR-MOEA/D outperforms other algorithms regarding IGD, HV, and C-metric in most of the instances, which shows its hyper-heuristic superiority against other state-of-the-art algorithms.
Finally, the relative benefits of the proposed hyper-heuristic are briefly discussed. In both MOHH-TOPTWR-NSGA-III and MOHH-TOPTWR-MOEA/D, a single-objective local search can be easily adapted for MO-TOPTWR. However, combining objective-wise local search with genetic operators preserved the diversity among subproblems along with adopting optimization of each objective, which promotes the convergence and diversity of search. This is the reason that both MOHH-TOPTWR-NSGA-III and MOHH-TOPTWR-MOEA/D are better than other algorithms in terms of both convergences and diversity in most of the instances.
5 Conclusion
This paper has introduced an MO variant of TOPTW for rescue applications (TOPTWR) based on the humanoid robots’ characteristics. In this regard, we considered heterogeneous tasks and robots with different energy consumptions per task. Also, we introduced five objectives in TOPTWR to give a user a chance to select a desired suitable solution based on the rescue situation. To achieve this, hyper-heuristic algorithms were designed for TOPTWR and named MOHH-TOPTWR. The MOHH-TOPTWR automatically selects LLHs (a combination of the state-of-the-art operators) during the MO evolutionary optimization. MOHH-TOPTWR with the hyper-heuristic algorithm in this paper reduces algorithm choice challenges and parameter tuning efforts on TOPTWR dramatically for the first time. We implemented MOHH-TOPTWR with two metaheuristics as NSGA-III and MOEA/D. Extensive experiments showed the effectiveness of the proposed algorithms in comparison to the state-of-the-art algorithms. The proposed algorithms can be seen as benchmark algorithms for MO-TOPTWR, which can be used for comparison by the future research.
In the future work, a different selection strategy can be implemented and evaluated. Moreover, other different MOEAs and hyper-heuristic techniques can be tested and compared on the MO-TOPTWR.
Acknowledgments
This work was financially supported by the ‘Chinese Language and Technology Center’ of National Taiwan Normal University (NTNU) from The Featured Areas Research Center Program within the framework of the Higher Education Sprout Project by the Ministry of Education (MOE) in Taiwan, and Ministry of Science and Technology, Taiwan, under Grant Nos. MOST 108-2634-F-003-002, MOST 108-2634-F-003-003, and MOST 108-2634-F-003-004 (administered through Pervasive Artificial Intelligence Research (PAIR) Labs) as well as MOST 107-2811-E-003-503. We are grateful to the National Center for High-performance Computing for computer time and facilities to conduct this research.