1 Introduction
In this paper, we investigate the phonetic realization of vowels in Southern Ute, a Native American language that belongs to the Southern Numic branch of the Northern Uto-Aztecan family. Southern Ute is most closely related to Southern Paiute, Chemehuevi, and Kawaiisu (Simons & Fennig Reference Simons and Fennig2017). It is a severely endangered language that is only spoken fluently by approximately 40 out of around 1400 tribe members (Oberly et al. Reference Oberly, White, Millich, Cloud, Seibel, Ivey and Cloud2015). The fluent speakers are all tribal elders. Many of them are in their eighties or older. They reside on the Southern Ute reservation in the town of Ignacio and neighboring areas in southwestern Colorado. Most of the speakers are not literate in Southern Ute, which has an official orthography (Givón Reference Givón2011) as well as an alternative writing system (Charney Reference Charney1996). In our study, only one of the eight speakers had working knowledge of either orthography.
Similar to other Native American languages, published and unpublished work on the grammar of Southern Ute is exceedingly rare. It consists mainly of three dictionaries (Goss Reference Goss1961, Charney Reference Charney1996, Givón Reference Givón2016), a grammar book (Givón Reference Givón2011), a doctoral dissertation (Oberly Reference Oberly2008), and one journal article (Oberly & Kharlamov Reference Oberly and Kharlamov2015).Footnote 1 Two of the dictionaries (Charney Reference Charney1996, Givón Reference Givón2016) and the grammar (Givón Reference Givón2011) provide limited summaries of the sound inventory that are based primarily on Givón’s impressionistic transcriptions made during conversations with tribal elders in the 1970s and 1980s. Charney (Reference Charney1996) and Givón (Reference Givón2011, Reference Givón2016) also focus heavily on orthography as each author advocates a specific writing system. The dissertation (Oberly Reference Oberly2008) presents a pilot phonetic study of the Southern Ute sound system that is based on a subset of the dataset used in the current study (selected tokens from four of the eight speakers). The only previously published instrumental phonetic study (Oberly & Kharlamov Reference Oberly and Kharlamov2015) addresses a specific phenomenon of vowel devoicing and does not examine other patterns or contrasts.
1.1 Southern Ute sounds
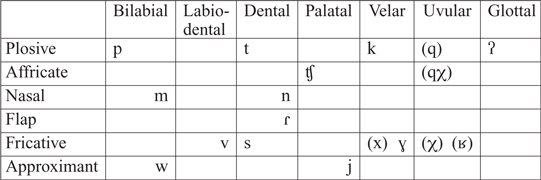
The most detailed non-instrumental accounts of the sound inventory of Southern Ute can be found in Givón (Reference Givón2011, Reference Givón2016). As shown in Figure 1, Givón identifies up to nine vowel sounds. This includes five phonemes, /i ɯ u ø a/, and three or four allophones, [ɛ ɔ æ ɨ].Footnote 2 The consonantal inventory (which is relevant to the discussion of vowel allophony) is provided in Table 1 (based on Givón Reference Givón2016). Other sources, such as the preface to Charney’s dictionary (Charney Reference Charney1996), do not distinguish between phonemes and allophones and do not provide phonetic descriptions for the vowels. Such sources only list similar-sounding words from North American varieties of English or other languages, which makes it difficult to determine the exact backness and height for the vowels they identify.
Table 1 Southern Ute consonants (based on Givón Reference Givón2016; allophones are in parentheses),


Figure 1 Southern Ute vowels (based on Givón Reference Givón2011, Reference Givón2016; allophones are in parentheses).
For the phonemes, Givón (Reference Givón2016) states that the /i/ is a close front vowel that is ‘roughly like the English vowel in “see”, “please” or “Louise”’ (p. 4). The /ɯ/ is a close back unrounded vowel with no English counterpart. The /u/ is a close back rounded vowel that is ‘roughly like the English vowel in “stupid”, “shoot” or “rouge”’ (p. 5). The /ø/ is a mid front rounded vowel that ‘can be seen in French, as in feu (“fire”), or in German, as in moeglich [sic] (“possible”)’ (p. 6). The /a/ is an open central vowel that is ‘roughly like the English vowel in “father”, “car”, “John” or “top”’ (p. 5). The similar-sounding English words that are mentioned in Charney (Reference Charney1996) include police for the /i/, number for the /ɯ/, boot for the /u/, her for the /ø/, and father for the /a/. Examples of Southern Ute words containing the five vowel phonemes can be seen in (1) below (based on Givón Reference Givón2016). The orthographic form (in italics) is written in Givón’s alphabet in which the glottal stop is represented with a vertical line (ˈ), irregular stress is marked with an acute accent (ˈ) placed above the stressed vowel, and voiceless vowels are underlined.
-
(1)


For the allophones, Givón (Reference Givón2016) describes the mid back [ɔ] as an allophone of /ø/ that is used before and after velar and uvular consonants and ‘is pronounced roughly as in the English words “door”, “four” or “more”‘ (p. 6). Charney (Reference Charney1996: vii) states that the allophony is triggered by adjacency to velars and compares the allophone to the English vowel in note. This allophonic pattern is reflected in both orthographies of the language. The official system in Givón (Reference Givón2011) uses the graphemes <ɵ>∼<o>. The alternative system in Charney (Reference Charney1996) uses <ö> and <o>.
Givón (Reference Givón2016) also identifies two allophones for the /a/, the mid front unrounded [ɛ] and the low front [æ]. They appear ‘in proximity to the front vowels /i/ or /ø/ or the glide /j/, most commonly preceding but sometimes following /a/’ (p. 5). The [ɛ] is supposed to be favored by younger speakers who ‘pronounce it as in the English words “men” or “get”‘ (p. 5). The [æ] is presumably used by older speakers and it ‘resembles more the vowel in English words “cat”, “nap” or “man”‘ (p. 5). Charney (Reference Charney1996) only identifies one allophone that occurs next to [i] and [j] and compares its pronunciation to that of the English vowel [ɛ] in bet. The /a/ ∼ [ɛ/æ] difference is not reflected in the tribe’s official orthography (Givón Reference Givón2011) that only uses the grapheme <a>. However, it is shown in the system in Charney (Reference Charney1996) that uses both <a> and <e>.
The earlier analysis in Givón (Reference Givón2011) also includes the allophone [ɨ]. It is described as a high central vowel that is a positional variant of /ɯ/. The allophone is used in unstressed syllables after non-back (labial, dental or palatal) consonants, which happens ‘typically, but not consistently’ (p. 17). The [ɨ] is no longer listed in Givón (Reference Givón2016) and it is not mentioned in Charney (1996), which suggests that it may not in fact be part of the vowel system. A general summary of the allophonic patterns and examples provided in Givón (Reference Givón2011, Reference Givón2016) can be found in Table 2.
Table 2 Southern Ute vowel allophony (based on Givón Reference Givón2011, Reference Givón2016).

Southern Ute vowels can also be phonemically short or long. According to Givón (Reference Givón2016), the length contrast affects all vowels and it is independent of stress. Length is reflected in both orthographies by using either a single or a double vowel grapheme (e.g. <a> /a/ vs. <aa> /aː/). There is no phonetic description of what constitutes a short or a long vowel in Givón (Reference Givón2016) but Charney (Reference Charney1996: iv) states that long vowels are ‘twice as long’. An example of a length-based minimal pair is provided in (2) (based on Givón Reference Givón2016).
-
(2)
Furthermore, the vowels of Southern Ute can be stressed or unstressed. According to both Charney (Reference Charney1996) and Givón (Reference Givón2016), two stress patterns are possible: (i) stress on the second syllable (most common) and (ii) stress on the first syllable (rare and marked in both orthographies with the acute accent placed above the vowel). Long vowels are not discussed explicitly but the examples in the dictionaries show that initial syllables with long vowels are always stressed. Givón (Reference Givón2016) or Charney (Reference Charney1996) do not provide any detail on how stress is realized phonetically or how it interacts with pitch accent. Examples of stress placement can be found in (3), including a stress-based minimal pair (3a, b) and a word with a long vowel in the stressed first syllable (3c) (based on Givón Reference Givón2016).
-
(3)

Finally, Southern Ute vowels can be devoiced. The process of vowel devoicing is found in several Native American languages of the Rockies and the Plains, including other Numic languages (e.g. Comanche; see Charney Reference Charney1993). In Givón (Reference Givón2016: 8), devoiced vowels are described as ‘silenced or whispered’. Charney (Reference Charney1996: x) states that they are ‘expressed with a puff of air’. The acoustic study in Oberly & Kharlamov (Reference Oberly and Kharlamov2015) reveals that their phonetic realization is more complex. Devoiced vowels can be fully voiceless, partially devoiced, or fully reduced/deleted but with a measurable effect on the duration, intensity and voicing of the preceding consonant. An example of a word containing a devoiced vowel in the second syllable is given in (4) (based on Givón Reference Givón2016):
-
(4)
1.2 Goals and structure
The goal of the current study is to provide a phonetic description of Southern Ute vowels that can be used as a baseline for future research as well as development of pedagogical materials. This is part of a larger endeavor to document language use by the remaining fluent speakers in order to assist with language revitalization efforts (see Oberly et al. Reference Oberly, White, Millich, Cloud, Seibel, Ivey and Cloud2015). We investigate (i) the general vowel space of Southern Ute, (ii) allophonic alternations affecting vowels, (iii) differences between phonologically short versus long vowels, and (iv) differences associated with stress, including the question of whether stressed syllables carry pitch accent. We address these questions by examining the acoustic measures of F1 and F2 that signal vowel quality and can therefore be used to investigate the general vowel inventory, vowel allophony, and stress-related vowel reduction (see Lindblom Reference Lindblom1963, Gay Reference Gay1978). We also use the measures of duration, spectral emphasis and f0 to examine vowel quantity, stress, and pitch accent (see Fry Reference Fry1955, Lieberman Reference Lieberman1960, Lehiste Reference Lehiste1970, Beckman Reference Beckman1986, Traunmuller & Eriksson Reference Traunmuller and Eriksson2000). Since the phonetic aspects of vowel devoicing in Southern Ute have previously been investigated in detail (Oberly & Kharlamov Reference Oberly and Kharlamov2015), in this study we focus specifically on the non-devoiced vowels.
In the rest of the paper, we provide an overview of the methodology and present the results for F1 and F2, vowel duration, spectral emphasis, and f0. We follow up with a general discussion and conclusions on how our findings relate to the previous accounts of Southern Ute, descriptions of related Uto-Aztecan languages, and the literature on vowels in general.
2 Method
2.1 Participants
Our findings are based on recordings from eight fluent Southern Ute speakers, including four females and four males. At the time of recording, their ages ranged from 68 years to 90 years (mean age 76.9 years). All eight speakers acquired Ute as their first language. They all learned English later in life, and three speakers also indicated learning Spanish as an L3. Only one speaker was literate in Southern Ute. A summary of speaker characteristics is provided in Table 3.
Table 3 Speaker information.

L2/L3 = second/third language, E = English, S = Spanish
2.2 Materials and procedures
Speech tokens came from a translation task, which made it possible to elicit data from the speakers who were not literate in the language. Speakers were presented with 202 English words or short phrases from the list in Oberly (Reference Oberly2008) that contains various sound sequences possible in Southern Ute.Footnote 3 The words were presented orally one word at a time, and speakers were asked to translate them into Southern Ute and produce them both in isolation and in a carrier sentence (Maas taani …máyku /ˈmaːs ˈtaːni, …ˈmajku/ ‘He always says …’). Sample stimulus items are provided in (5).
-
(5)

The list includes items with the regular stress placement on the second vowel when the first vowel is short (5a, b), irregular stress on the initial short vowel (5c, d), and regular stress on the initial long vowel (5e, f). The full list of stimulus items can be found in Oberly (Reference Oberly2008).
Recording took place indoors on the Southern Ute reservation in Colorado. Speakers’ responses were captured in. wav format at a rate of 16 bits and with a sampling frequency of 44,100 Hz using a Marantz PMD671 portable solid state digital recorder and a Countryman Isomax E60P5T omnidirectional head-mounted microphone with a frequency response of 30 Hz to 20 kHz. Recording settings and microphone distance were kept constant across the sessions.
2.3 Data analysis
As shown in Table 4, a total of 6195 vowel tokens were included in the study. Segmentation and measurements were done with Praat (Boersma & Weenink Reference Boersma and Weenink2017). Vowel boundaries were determined manually on the basis of formant structure (i.e. beginning and end of a clear F2). We used only those tokens where segmental boundaries could be identified unambiguously and only analyzed the vowels in non-devoicing environments.
Table 4 Vowel tokens: summary.

A Praat script was written to obtain five acoustic measures for each vowel: F1, F2, duration, spectral emphasis, and f0. F1 and F2 were measured in Hz at the vowel midpoint and transformed to z-scores, which scales the original values to compensate for between-speaker differences in vocal tract morphology (for plotting and statistical testing purposes; see Lobanov Reference Lobanov1971). Vowel duration was measured in milliseconds, followed by log-transformation (for statistical tests; see Chladkova, Escudero & Boersma Reference Chladkova, Escudero and Boersma2011). For spectral emphasis, which is a measure of vocal effort that correlates with stress (see Eriksson et al. Reference Eriksson, Bertinetto, Heldner, Nodari and Lenoci2016), the study used the method described in Traunmuller & Eriksson (2000). It is based on calculating the difference between (i) the overall intensity of the vowel and (ii) the intensity in a low-pass-filtered signal (with a cutoff frequency of 1.5 f0), which produces a normalized measure of energy in the higher frequency bands. Prior to measuring intensity, the individual word tokens were normalized on the basis of the speakers’ average intensity during the entire recording session. For f0, the vowel’s mean fundamental frequency was measured over the middle 50% of the vowel. The measurement was done in Hz (for illustrative reasons) as well as ERB (for statistical testing; see Moore & Glasberg Reference Moore and Glasberg1983, Glasberg & Moore Reference Glasberg and Moore1990).
Plotting and statistical analyses were done in R (R Core Team 2017). Vowel plots show the F1 × F2 vowel space (using transformed values). The plots were generated with the ‘phonR’ package (McCloy Reference McCloy2016). Boxplots show the median, the interquartile range and the maximum and minimum values (excluding outliers). They were created using the standard R ‘boxplot’ function. Inferential statistics were done using the ‘afex’ package (Singmann et al. Reference Singmann, Bolker, Westfall and Aust2017) that fits data in mixed models with Imer and calculates p-values using parametric boot- stapping. Dependent variables were the (transformed) measures of F1, F2, duration, spectral emphasis, and f0. Fixed effects differed depending on the measure and the research question and included such factors as vowel identity (/i ɯ u ø a/), lexical stress (stressed, unstressed), phonemic length (short, long), preceding and following environments (allophony trigger present vs. absent), word-finality (non-word final vs. word-final), speaker gender (female, male), and two-way interactions of the fixed effects. Speakers and words were always entered as random effects (including by-speaker slopes, when applicable; see Barr et al. Reference Barr, Levy, Scheepers and Tily2013). We also added speech type (citation form vs. carrier sentence) as a random effect to account for the differences between the two contexts.Footnote 4 Model selection process always started with a model containing all relevant fixed effects and the full random effects structure. If the full model did not converge, this was followed by reducing the random effect structure (starting with the item structure). The maximal models that converged are described in the Results section. Pairwise comparisons were done using the least-squares means method with Bonferroni adjustment for multiple comparisons using the ‘emmeans’ package (Lenth Reference Lenth2018).
3 Results
3.1 F1 and F2
Results for F1 and F2 are illustrated in Figure 2, which presents z-score-transformed group means (2A) and individual speaker means (2B) for the phonemes /i ɯ u ø a/ as identified in Givón (Reference Givón2016). Individual variability is shown with ellipses that correspond to +/− one standard deviation.

Figure 2 F1 × F2 vowel space for the five phonemes /i ɯ u ø a/ identified in Givón (Reference Givón2016); z-score-transformed group means (A) and individual speaker means (B); ellipses correspond to +/– one standard deviation.
As reflected in Figure 2, mean F1 was low for the three close vowels (/i/: M = 357 Hz; /u/: M = 370 Hz; /ɯ/: M = 390 Hz), intermediate for the mid vowel /ø/ (M = 471 Hz), and high for the open vowel /a/ (M = 646 Hz). Statistical testing revealed that the effect for vowel identity was significant (χ2(4) = 3,927.9, p < .001). The effects for stress, speaker gender and phonemic length as well as the interactions involving these factors were not significant (all ps > .05). Pairwise tests indicated that the /i ∼ u/ contrast was not significant (p > .1). All other vowel pairs showed significant differences (all ps < .01). This indicates that the close vowels /i u/ were produced higher than the /ɯ/, the /i ɯ u/ were all higher than the /ø/, and the /ø/ was in turn higher than the /a/ (i.e. /i u/ > /ɯ/ > /ø/ > /a/).
For F2, the highest value was observed for the front vowel /i/ (M = 2,323 Hz), followed by the /ɯ/ (M = 1,564 Hz), the /a/ (M = 1,548 Hz), the /u/ (M = 1,271 Hz), and the /ø/ (M = 1,263 Hz). Mixed modelling showed significant effects for vowel identity (χ2(4) = 2,781.9, p < .001) and lexical stress (χ2(1) = 7.9, p = .005) as well as a significant interaction between stress and length (χ2(1) = 5.5, p = .02). The effects for length and gender and the rest of the interactions did not reach significance (all ps > .1). Pairwise comparisons showed that the differences in F2 were not significant in two pairs: /ɯ ∼ a/ and /u ∼ ø/ (both ps > .05). For all other pairs, differences in F2 were significant (all ps < .001). This shows that the /i/ was front, the /ɯ/ and the /a/ were central, and the /u/ and the /ø/ were back (i.e. /i/ > /ɯ a/ > /u ø/). Furthermore, long unstressed vowels had higher F2 than long stressed vowels (M Unstressed = 1,652 Hz, M Stressed = 1,611 Hz; p = .04), which signals a slightly more retracted position for the long stressed vowel category in general.
For the allophonic patterns, the first alternation involves the /ø/ that is expected to retract to [ɔ] when adjacent to a velar or a uvular consonant (Givón Reference Givón2016). For F1, statistical testing showed a significant fixed effect for the following environment (χ2(1) = 6.2, p = .01), with vowels showing higher mean F1 when followed by back consonants (M = 481 Hz) than other sounds (M = 465 Hz). The following environment was also significant for F2 (χ2(1) = 4.4, p = .04), with lower values observed in front of velars and uvulars (M = 1,235 Hz) than elsewhere (M = 1,350 Hz). Effects and interactions involving the preceding environment and stress were not significant for either F1 or F2 (all ps > .1). (The interaction of phonemic length and environment could not be investigated statistically due to the limited number of long /ø/ tokens.) Taken together, the findings for F1 and f2 indicate only slight lowering and retraction of the vowel in front of back consonants. This can be seen in Figure 3, which shows z-score-transformed F1 and F2 values for the prototypical realization of the /ø/ and its positional allophone.

Figure 3 F1 × F2 vowel space for the /ø/ ∼ [ɔ] alternation; z-score-transformed group means (A) and Individual speaker means (B) for the prototypical realization (marked as ø In black) and the positional allophone (marked as ɔ; In grey); ellipses correspond to +/− one standard deviation.
For the low central vowel /a/, Givón (Reference Givón2016) suggests that it undergoes either fronting to [æ] or both fronting and raising to [ɛ] when it is either preceded or followed by /j i ø/. For F1, statistical modeling showed no significant effects or interactions involving environment, stress or length (all ps > .05). For F2, there was a significant effect for the preceding environment (χ2(1) = 12, p < .001), with F2 being slightly higher when the /a/ was preceded by /j i ø/ (M = 1,577 Hz) than when preceded by other sounds (M =1,541 Hz). The rest of the main effects and interactions did not reach significance for F2 (all ps > .1). This indicates slight fronting but not raising of the vowel, which can be seen in Figure 4. The figure shows z-score-transformed group means (panel A) and individual speaker means (panel B) for the prototypical realization of the /a/ and its positional allophone.

Figure 4 F1 × F2 vowel space for the /a/ ∼ [ɛ/æ] alternation; z-score-transformed group means (A) and individual speaker means (B) for the prototypical realization (marked as a; in black) and the positional allophone (marked as æ; in grey); ellipses correspond to +/− one standard deviation.
The /ɯ/ ∼ [ɨ] alternation is described in Givón (Reference Givón2011) as optional fronting of the /ɯ/ in unstressed syllables after labial, dental, and palatal consonants. For F1, the unstressed subset of the /ɯ/ tokens showed no significant effects for either the preceding or following environment (both ps > .1). For F2, there was a significant effect for the preceding environment (χ2(1) = 5.1, p = .02). F2 was lower after front consonants (M = 1,540 Hz) compared to other sounds (M = 1,632 Hz). The effect for the following environment was not significant for F2 (p > .1). (The small number of long /ɯ/ tokens made it impossible to investigate the length x environment interaction.) As reflected in Figure 5, which shows z-score-transformed formant values for the prototypical realization of the /ɯ/ and the positional allophone, this indicates retraction rather than fronting of the vowel after labial, dental, and palatal consonants.

Figure 5 F1 × F2 vowel space for the /ɯ/ ∼ [ɨ] alternation; z-score-transformed group means (A) and individual speaker means (B) for the prototypical realization (marked as ɯ; in black) and the positional allophone (marked as ɨ; in grey); ellipses correspond to +/− one standard deviation.
3.2 Vowel duration
For vowel duration, mixed modelling showed significant effects for phonemic length (χ2(1) = 103.1, p < .001), stress (χ2(1) = 26.3, p < .001), vowel identity (χ2(4) = 33.4, p < .001), speaker gender (χ2(1) = 21.2, p < .001), and word-finality (χ2(1) = 191.7, p < .001). There were also significant interactions between length and vowel identity (χ2(4) = 14, p = .007) and stress and vowel identity (χ2(4) = 42.6, p < .001). The interactions involving stress, length, gender and word-finality were not significant (all ps > .05).
As reflected in Figure 6, phonologically long vowels showed greater duration than phonologically short vowels (M Short = 113 ms, SD = 54; M Long = 173 ms, SD = 68). In pairwise comparisons, the difference was significant for all five vowel pairs (/i/: M = 119 ms, SD = 57; /iː/: M = 152 ms, SD = 60; /ɯ/: M = 103 ms, SD =61; /ɯː/: M = 193 ms, SD = 86; /u/: M = 103 ms, SD = 51; /uː/: M = 153 ms, SD = 58; /ø/: M = 111 ms, SD = 55; /øː/: M = 193 ms, SD = 84; /a/: M = 113 ms, SD = 51; /aː/: M = 181 ms, SD = 67; all ps < .001).

Figure 6 Duration (ms) for underlyingly short (unshaded) vs. long (shaded) vowels.
The interaction between stress and vowel identity can be seen in Figure 7. Unstressed vowels were shorter compared to the stressed realizations (M Unstressed = 112 ms, SD = 55, M Stressed = 137 ms, SD = 66). Pairwise testing indicated that the difference was not significant for the /a/ (M Unstressed = 115 ms, SD = 52, M Stressed = 140 ms, SD = 68; p > .05) but it was significant for all other vowels (/i/: M Unstressed = 119 ms, SD = 58, M Stressed = 131 ms, SD = 57; /ɯ/: M Unstressed = 98 ms, SD = 58, M Stressed = 143 ms, SD = 80; /u/: M Unstressed = 104 ms, SD = 54, M Stressed = 130 ms, SD = 57; /ø/: M Unstressed = 101 ms, SD = 53, M Stressed = 137 ms, SD = 65; all ps < .05).

Figure 7 Duration (ms) for the unstressed (unshaded) vs. stressed (shaded) realizations of the five vowels.
Vowels were also longer in word-final syllables than in non-final positions (M Word-final = 169 ms, SD = 72; M Non-final = 114 ms, SD = 55). This was independent of phonemic length, stress or gender. Vowels also had slightly longer duration when produced by female than male speakers (M Female = 123 ms, SD = 62; M Male = 117 ms, SD = 56), which was also independent of other factors.
3.3 Spectral emphasis
For spectral emphasis, statistical testing revealed significant main effects for stress (χ2(1) = 166.7, p < .001), vowel identity (χ2(4) = 466.2, p < .001), and speaker gender (χ2(1) = 1,277.6, p < .001). There were also significant interactions between stress and vowel identity (χ2(4) = 20.7, p < .001) and stress and speaker gender (χ2(1) = 97.3, p < .001). Phonemic length did not reach statistical significance and did not interact with stress (both ps > .1).
Figure 8 provides the means for the vowel phonemes separated by stress. Stressed realizations always showed greater spectral emphasis than their unstressed counterparts (M Unstressed = 4 dB, SD = 2.31; M Stressed = 5.4 dB, SD = 2.9). The increase in spectral emphasis was significant in pairwise tests for all five phonemes (/i/: M Unstressed = 3.2 dB, SD = 1.8, M Stressed = 4.8 dB, SD = 2.8; /ɯ/: M Unstressed = 4.2 dB, SD = 2, M Stressed = 5.6 dB, SD = 2.5; /u/: M Unstressed = 3.3 dB, SD = 1.9, M Stressed = 4.9 dB, SD =2.8; /ø/: M Unstressed = 4.4 dB, SD = 2.3, M Stressed = 5.7 dB, SD = 3.1; /a/: M Unstressed = 5.3 dB, SD = 2.6, M Stressed = 6.4 dB, SD = 2.8; all ps < .001). These results indicate that the five vowels were all produced louder when stressed, with higher spectral emphasis values seen for the more open vowels.

Figure 8 Spectral emphasis (dB) for the unstressed (unshaded) vs. stressed (shaded) realizations of the five vowels.
The interaction between stress and speaker gender is shown in Figure 9. The figure provides spectral emphasis values for the unstressed and stressed vowels produced by the female speakers (M Unstressed = 3.4 dB, SD = 2.2; M Stressed = 4.2 dB, SD = 2.4) and the male speakers (M Unstressed = 5.3 dB, SD = 2; M Stressed = 7.3 dB, SD = 2.6). Pairwise comparisons revealed that the differences between unstressed and stressed vowels were significant both within and across genders (all ps < .001). This suggests that the stressed vowels were produced with greater loudness by both genders and that male speakers showed higher overall spectral emphasis as well as a greater increase in spectral emphasis from the unstressed to stressed categories.

Figure 9 Spectral emphasis (dB) for the unstressed (unshaded) and stressed (shaded) vowels produced by female vs. male speakers.
3.4 f0
For f0, statistical modelling showed significant effects for stress (χ2(1) = 373.4, p < .001), vowel identity (χ2(4) = 83, p < .001), length (χ2(1) = 12.6, p < .001), and speaker gender (χ2(1) = 2,459.4, p < .001). There were also significant interactions between stress and vowel identity (χ2(4) = 17.88, p = .001) and stress and length (χ2(1) = 17.5, p < .001). The interaction between gender and stress was not significant (p > .1).
Figure 10 provides the results for the five phonemes separated by stress. As can be seen in the figure, stressed vowels showed higher f0 than unstressed vowels (M Unstressed = 162 Hz, SD = 33; M Stressed = 180 Hz, SD = 35). Pairwise tests indicated that the difference between stressed and unstressed realizations was significant for all 5 phonemes (/i/: M Unstressed = 162 Hz, SD = 35, M Stressed = 182 Hz, SD = 35; /ɯ/: M Unstressed = 168 Hz, SD = 33, M Stressed = 179 Hz, SD = 38; /u/: M Unstressed = 165 Hz, SD = 33, M Stressed = 188 Hz, SD = 35; /ø/: M Unstressed = 167 Hz, SD = 28, M Stressed = 189 Hz, SD = 31; /a/: M Unstressed = 159 Hz, SD = 32, M Stressed = 176 Hz, SD = 35; all ps < .001).

Figure 10 f0 (Hz) for the unstressed (unshaded) vs. stressed (shaded) realizations of the five vowels,
The interaction between stress and length is illustrated in Figure 11, which shows f0 for the unstressed versus stressed short and long vowels (short: M Unstressed = 163 Hz, SD = 33, M Stressed = 182 Hz, SD = 33; long: M Unstressed = 147 Hz, SD = 30, M Stressed = 176 Hz, SD = 39). In pairwise tests, only the difference between short and long stressed vowels was not significant (p > .1). All other pairs showed significant differences (all ps < .05). This indicates that both short and long vowels had higher f0 when stressed and that the lowest f0 was seen for the unstressed long vowels.

Figure 11 f0 (Hz) for the unstressed (unshaded) vs. stressed (shaded) short and long vowels.
For the effect of speaker gender, female speakers showed higher f0 than male speakers (M Female = 184 Hz, SD = 27; M Male = 140 Hz, SD = 28). In the absence of an interaction between gender and stress, this reflects a higher overall pitch in female speech.
4 Discussion
In this study, we investigated the phonetic realization of Southern Ute vowels, including the general vowel space, vowel allophony, vowel quantity, and stress. Our goal was to provide instrumental phonetic data that can be compared to the previous auditory accounts of the language and can be used as a baseline for future research, which will facilitate language revitalization efforts. The findings are based on recordings from eight fluent speakers of Southern Ute from the last generation to acquire the language as their L1. We analyzed over 6000 vowel tokens, which made it possible to not only describe the observed patterns but also model them statistically.
Our results for F1 and F2 show five distinct vowel categories, including three close vowels, one mid vowel, and one open vowel. The number of categories and their overall distribution across the three height levels are consistent with the five-phoneme inventory in Givón (Reference Givón2016) that also includes three close, one mid, and one open vowel. The size of the inventory is also in line with other Numic languages (e.g. Southern and Northern Paiute, Sapir Reference Sapir1930, Thornes Reference Thornes2003) as well as the cross-linguistic preference for a five-phoneme vowel system (Schwartz et al. Reference Schwartz, Boe, Vallee and Abry1997). Furthermore, the vowels /i u a/ match Givón’s descriptions with respect to backness, with /i/ being front, /u/ being back, and /a/ being central. F2 data also reveal fronting of long unstressed vowels. This has not been mentioned in the previous accounts of Southern Ute but has been attested in other languages with lexical stress that also show an interaction between stress and backness (e.g. less peripheral articulation of unstressed vowels; Delattre Reference Delattre1969, Ortega-Llebaria & Prieto Reference Ortega-Llebaria and Prieto2011).
Some of our findings for vowel formants do not fully support the previous accounts. For example, the /ɯ/ is described in Givón (Reference Givón2011, Reference Givón2016) as a close back unrounded vowel. Our data indicate that its F2 is significantly higher than the F2 of the back rounded /u/ and not significantly different from the F2 of the open central vowel /a/. This suggests that the vowel is more central than previously described. It also has significantly lower F1 than either /i/ or /u/ but higher F1 than the /ø/, which suggests a near-close placement. Thus, the phoneme would be better represented as the close central vowel /ɨ/, with its phonetic realization being the near-close centralized [ɪ̈], or as the close-mid central vowel /ɘ/, with a slightly raised phonetic realization. This would be in line with the recent instrumental accounts of the corresponding vowel phoneme being either /ɨ/ or /ɘ/ in related Numic languages, including Comanche, Kawaiisu and Northern Paiute (Haynes Reference Haynes2010, Herrick Reference Herrick2011, Thomas Reference Thomas2017). It would also be consistent with the general preference for avoiding back unrounded vowels that is seen in the world’s languages (Lindblom Reference Lindblom, Ohala and Jaeger1986, Schwartz et al. Reference Schwartz, Boe, Vallee and Abry1997).
Givón (Reference Givón2011) also specified that the /ɯ/ was fronted in unstressed syllables after labial, dental and palatal consonants. This pattern was omitted without comment from the updated chapter on Southern Ute sounds in Givón (Reference Givón2016), suggesting that the alternation may have disappeared due to sound change or it may have been misidentified. Our results show that instead of triggering fronting, adjacency to non-back consonants leads to slight backing of the vowel. This type of dissimilatory behavior has not been described in any of the previous auditory accounts of Southern Ute, and it is also rare and highly constrained cross-linguistically (see Flemming Reference Flemming2003). One possible explanation that will need to be investigated in future research is that if the vowel was originally a back /ɯ/ that has undergone centralization, speakers may be using backing as means of maintaining articulatory distinctness, since the centralization of /ɯ/ makes it more distinct from the back consonants but less distinct from the front consonants.
Results for the /ø/ are also not fully in line with the earlier descriptions that treat the /ø/ as a mid front rounded vowel that gets retracted to [ɔ] next to velar and uvular consonants (Givón Reference Givón2011, Reference Givón2016). Determining the status of the /ø/ is especially important considering that the inventories of related Numic languages contain either the close-mid back rounded /o/ or the open-mid back rounded /ɔ/ rather than the front rounded /ø/ (e.g. Northern and Southern Paiute, Panamint, Shoshoni, Comanche, Proto Uto-Aztecan; Sapir Reference Sapir1930, Langacker Reference Langacker1970, Charney Reference Charney1993, Elzinga Reference Elzinga1999, Gould & Loether Reference Gould and Loether2002, Thornes Reference Thornes2003, McLaughlin Reference McLaughlin2006, Haynes Reference Haynes2010). A vowel inventory containing the /ø/ rather than the /o/ (or /ɔ/) would also be rare cross-linguistically (Maddieson Reference Maddieson, Dryer and Haspelmath2013) and would not be maximized according to the Dispersion Theory (Liljencrants & Lindblom Reference Liljencrants and Lindblom1972, Becker-Kristal Reference Becker-Kristal2010). Our data indicate that when looking at the phoneme in general (i.e. by averaging across the two allophones), it does not differ significantly in F2 from the /u/. Furthermore, despite being reflected in both orthographies, only slight retraction and slight lowering happen in front of back consonants. Even at the level of individual tokens, the vast majority of productions are either central or back. This shows that the prototypical realization of the vowel is substantially further back than previously reported. As there are no recordings to accompany Givón’s original field notes, it is not possible to determine whether the vowel was always non-front or whether it underwent sound change that led to retraction. However, the current findings clearly indicate that in present day Southern Ute, the phoneme would be more accurately represented either as an /ɵ/ that undergoes retraction to [o] (or [ɔ]) next to back consonants or an /o/ (or /ɔ/) that gets fronted to [ɵ] next to non-back sounds. The latter analysis would also bring the vowel inventory of Southern Ute in line with the inventories of other Numic languages as well as the cross-linguistic preference for the back rounded vowels.
For the /a/ ∼ [ɛ/æ] alternation, our study offers only partial support for the previous accounts in Givón (Reference Givón2011, Reference Givón2016). The allophony is supposed to be conditioned by the presence of /j i ø/ either before or after the vowel, with the positional allophone being [æ] for older speakers and [ɛ] for younger speakers (who would have been adults in their 30s through 50s as there were no more children or young adults speaking the language fluently in the 1970s and 1980s when Givón’s data were collected). Our results show that only the preceding environment plays a role at a statistically significant level. Furthermore, although some of the individual tokens clearly fall within the [ɛ]-range, at the group level this allophony involves slight fronting but not raising of the vowel. This suggests that the most common positional allophone is [æ]. Considering that Givón’s data were gathered over 40 years ago, the speakers who took part in our study are the original ‘younger’ group and, if the previous description of the age-based difference is accurate, they appear to have transitioned from [ɛ] to [æ].
The findings for segmental duration substantially expand our understanding of how the phonemic length contrast is realized in Southern Ute. As noted in the Introduction, there is no phonetic description for this contrast in Givón (Reference Givón2016), while Charney (Reference Charney1996) states that long vowels are two times longer than short vowels. This is also how long vowels are often described in the grammars and dictionaries of other Uto-Aztecan languages (e.g. for the long vowels of Shoshoni, ‘pronunciation is generally held twice as long as for a short vowel’, Gould & Loether Reference Gould and Loether2002: 10). Our data confirm that phonemically long vowel have greater duration, which is consistent with the findings for other languages with phonemic vowel length differences (e.g. Chickasaw - Gordon Reference Gordon2004; Yakut - Vasilyeva, Arnhold & Järvikivi Reference Vasilyeva, Arnhold and Jârvikivi2016). At the same time, durational differences are fairly modest at the group level, with the long vowels not being twice as long as the short vowels (as suggested in Charney Reference Charney1996). Vowel lengthening is also seen in final positions, which has not been mentioned in the previous accounts of Southern Ute despite being attested in other Uto-Aztecan languages (e.g. Northern Paiute; Haynes Reference Haynes2010) as well as many other language families (e.g. the Muskogean family - Johnson & Martin Reference Johnson and Martin2001, Gordon & Munro Reference Gordon and Munro2007; the Indo-European family - Delattre Reference Delattre1966).
We also observed a significant relationship between vowel length and stress. The use of duration as a cue to stress has long been established in the literature (Fry Reference Fry1955, Lieberman Reference Lieberman1960, Klatt Reference Klatt1976). However, since vowel length is already contrastive in Southern Ute, it was important to determine whether speakers rely on duration to signal not only vowel quantity but also stress (see Berinstein Reference Berinstein1979). Our results reveal modest but statistically significant lengthening of the majority of vowels in stressed positions, which confirms that Southern Ute speakers use duration to differentiate between stressed and unstressed vowels. The observed differences are more limited than what is often found in languages without phonemic length differences (e.g. English; Lunden Reference Lunden2017) but they are in line with the findings for languages with a phonological vowel quantity contrast (e.g. Chickasaw; Gordon Reference Gordon2004). Consequently, the claim in Givón (Reference Givón2016) that duration and stress do not interact may hold true at the phonological level but not necessarily at the phonetic level.
Results for spectral emphasis provide further insight into the phonetics of stress in Southern Ute. As noted in the Introduction, spectral emphasis is a measure of vocal effort.
Sounds produced with greater vocal effort show increased intensity and more high-frequency content (Allen Reference Allen1971, Ternstrom, Bohman & Sodersten Reference Ternstrom, Bohman and Sodersten2006). As stressed vowels have greater intensity than their unstressed counterparts and these differences are largely limited to the upper parts of the spectrum (Sluijter & van Heuven Reference Sluijter and van Heuven1996), spectral emphasis measures have been found to be a reliable cue to stress in both production and perception of speech (Sluijter & van Heuven Reference Sluijter and van Heuven1996, Sluijter, van Heuven & Pacilly Reference Sluijter, van Heuven and Pacilly1997, Haynes 2003, Eriksson et al. Reference Eriksson, Bertinetto, Heldner, Nodari and Lenoci2016). In our study, we observed higher spectral emphasis values for the stressed category, which signals that stressed vowels were louder than their unstressed counterparts. This matches the results for spectral emphasis in other languages (e.g. English, Italian, Swedish; Haynes 2003, Eriksson & Heldner Reference Eriksson and Heldner2015, Eriksson et al. Reference Eriksson, Bertinetto, Heldner, Nodari and Lenoci2016) and, more generally, the finding that higher intensity is associated with the stressed category (e.g. in Chickasaw; Gordon Reference Gordon2004). Spectral emphasis was also higher for the more open vowels, which is in line with previous research that has shown an inverse relationship between vowel height and loudness (e.g. Lehiste Reference Lehiste1970). Furthermore, we found higher overall levels of spectral emphasis and a greater increase in values (from unstressed to stressed) in male speakers. This is consistent with the findings for other languages that also show greater loudness and a more prominent difference between unstressed and stressed vowels in male speakers (e.g. English and Swedish; Traunmuller & Eriksson Reference Traunmuller and Eriksson2000, Eriksson & Heldner Reference Eriksson and Heldner2015, Eriksson et al. Reference Eriksson, Bertinetto, Heldner, Nodari and Lenoci2016).
The fifth and final acoustic measure investigated in the current study was f0. Fundamental frequency is a correlate of pitch accent (Huss Reference Huss1978, Ladd Reference Ladd1996, Sluijter & van Heuven Reference Sluijter and van Heuven1996, Gordon Reference Gordon2014). In languages with lexical stress, pitch accents are usually realized on stressed syllables in words under focus, with stressed vowels showing higher f0 when accented (e.g. see the English findings in Sluijter & van Heuven Reference Sluijter and van Heuven1996). There are, however, stress languages that do not associate pitch accents with stressed syllables (e.g. Kuot; Lindstrom & Remijsen Reference Lindstrom and Remijsen2005), so it was important to determine the relationship between accent and stress in Southern Ute. Given the nature of our dataset (i.e. words produced in either isolation or embedded in the same declarative carrier sentence), all word tokens were produced under focus and with declarative intonation, which is when stress and accent can be expected to covary. Our results showed higher f0 for the stressed vowels, which confirms that stress is cued by pitch accent in declaratives in Southern Ute. There was also an interaction with phonemic length, with the lowest f0 observed for the long unstressed vowels. This is consistent with Vasilyeva, Arnhold & Järvikivi (Reference Vasilyeva, Arnhold and Jârvikivi2016) who found lower f0 for long Yakut vowels, presumably because they are long enough to allow for changes to the fundamental frequency. We also observed higher f0 values in female tokens, which is the usual finding given the physiological differences in vocal tract morphology between female and male speakers (e.g. Hillenbrand et al. Reference Hillenbrand, Getty, Clark and Wheeler1995).
As our study only aimed to provide an initial description of the phonetic realization of Southern Ute vowels, we leave a number of issues for future research. One such issue is the source of the substantial variability that is seen within each of the five phonemic categories. While it is not uncommon for languages with smaller inventories to allow for substantial allophony (e.g. Kabardian; Gordon & Applebaum Reference Gordon and Applebaum2006), only three allophonic patterns have so far been identified for Southern Ute. Determining the full system of allophonic relations affecting the vowels also requires examination of additional parameters that speakers may be relying on, including the role of such factors as rhoticity that can be used to enhance distinctness of allophones. It is also important to investigate the extent to which such patterns are phonologized (as presented in Givón Reference Givón2011, Reference Givón2016) or whether they are purely phonetic coarticulatory effects that may not be perceptually salient (as suggested by the modest differences in acoustic measures in our study). Our findings for f0 also provide only an initial insight into the intonational system of Southern Ute. Future research will need to examine pitch accent in words produced without intonational focus as well as to provide a general description of the intonational patterns of the language. Additional research is also needed to evaluate how the pronunciation of vowels changes in connected speech (see Strange et al. Reference Strange, Weber, Levy, Shafiro, Hisagi and Nishi2007) and how the productions of fluent speakers who acquired the language as L1 differ from the speech of non-fluent speakers who learned Southern Ute as L2 (see Haynes Reference Haynes2010).
5 Conclusions
This study investigated the phonetic realization of vowels in Southern Ute, a highly endangered and underdescribed Native American language. The observed phonetic values match some of the earlier auditory descriptions of the language, such as the overall number of phonemic categories, the three-level height system, and the backness of three (out of five) vowels. Other previous accounts find either partial or no support, including tongue backness of the remaining two vowel phonemes as well as the descriptions of allophonic processes affecting vowels. We also show how stress and vowel quantity are cued in the language. These results help us understand how the vowel system of Southern Ute relates to the systems of other Uto-Aztecan languages and the literature on vowels in general. The current findings also provide a quantitative baseline for future research and revitalization efforts.
Acknowledgments
We express our deepest gratitude to the Southern Ute speakers who took part in the study. We are also very grateful for the feedback received from the editor, anonymous reviewers, and audiences at scholarly meetings.