


1 Introduction
A large body of research has shown that the age of first exposure to a second language is a major determinant in the success (or lack thereof) of adult language learners to acquire the speech patterns of their second language (L2) (Flege, Munro & MacKay Reference Flege and Strange1995). Consequently, it does not come as a surprise that the cognitive constraints that affect individual bilinguals have a robust effect on language change in cases where two or more languages coexist in a speech community (Thomason & Kaufman Reference Thomason and Kaufman1988, Winford Reference Winford2005). Additionally, one could also claim that sociolinguistic factors arising from complex societal language contact situations affect the linguistic behavior of individual bilinguals. The present study examines intonational production in a group of Catalan–Spanish bilinguals differing in age, gender and language dominance. First, a sociophonetic profile of an intonational variable is provided, investigating the effects of age, gender and language dominance on intonational production in the first or native language (L1) of the bilinguals in both Spanish and Catalan. Second, this study addresses the question of whether the effects of sequential early bilingualism that have been found for the production and perception of vowels and consonants can also be extended to the production of intonational categories, for which much less is known. This is done by examining intonational production in the second or non-native language of the bilinguals and comparing it with that of native or dominant speakers of each language. Finally, the interaction of the first- and second-language intonational categories are investigated by comparing the production of the L1 with that of the L2 of each bilingual.
In the present study, the productions of proficient bilinguals who grew up in a bilingual society were examined. Our participants live on the island of Majorca, Spain, where Catalan and Spanish are co-official. The two languages are used in all spheres of communication, from the administration, to school system, to the most informal registers (Villaverde Reference Villaverde2005). Migration has been the cause of the rapid recent population growth of Majorca, which has doubled in less than fifty years (Salvà Reference Salvà2005). In the 1950s, the economic landscape of Majorca changed drastically from one based on subsistence farming to one based on mass tourism. Thousands of migrant workers came from rural monolingual Spanish-speaking regions to work in the tourism industry. According to the 2003 official census, the number of residents who were born on the Spanish mainland and currently reside on Majorca represents 26.8% of the total population of the island (Salvà Reference Salvà2005). This migratory wave happened at a time in which Catalan was seen not as a prestigious language but rather as a minority language, and thus migrants might have seen little need to learn the language of the island (Boix & Vila Reference Boix and Vila1998, Salvà Reference Salvà2005). The Estatut d'Autonomia ‘Statute of Autonomy’ or ‘State's Rights’ of the Autonomous Community of the Balearic Islands were signed in 1982. This statute included Catalan as a co-official language (together with Spanish), after decades of persecution of the language under the fascist regime (1939–1975). This allowed for the introduction of Catalan in the schools as well as in many other communication settings. Today, both Catalan and Spanish are widely used on the island, and it is difficult to pinpoint which of the two languages is the majority language.
Most sociolinguistic research on Catalan and Spanish in Majorca deals with issues of language choice (Villaverde Reference Villaverde2005). Very little is known about the effects of language contact on the features of these two languages from a variationist perspective. Previous research on the sociophonetics of alveolar laterals in Majorca (Pieras Reference Pieras1999) suggested that Catalan ‘dark’ /l/ is being slowly abandoned in favor of Spanish ‘clear’ /l/ even by speakers who frequently use Catalan. Regarding other phonetic features, one possibility would be that the two languages are gradually becoming more similar (i.e. symmetric convergence) by developing shared features. Another possibility, as Pieras suggests for alveolar laterals, is that one language is adopting the features of the other (i.e. asymmetric convergence). Minority languages tend to adopt the features of the majority language in cases of gradual language shift (Thomason & Kaufman Reference Thomason and Kaufman1988). However, it is less clear what the direction of influence might be in situations where the two languages seem to have equal or similar status. In the present article we address the following question: Have Catalan and Spanish developed shared intonational features or are they in the process of doing so?
As stated above, a second goal of this paper is to investigate the effects of linguistic experience (i.e. language dominance) on intonational production in bilinguals and to examine the patterns of interaction of L1 and L2 sounds (i.e. intonational phonetic categories) in the linguistic behavior of bilinguals. Previous research has established that bilingual adults who were exposed to their non-native language during childhood are more likely to ‘succeed’ in learning the phonetic patterns of their L2 than bilinguals who began learning their L2 in adulthood. This has been found both for production (Oyama Reference Oyama1976, Flege et al. Reference Flege, Munro and MacKay1995, Flege, Yeni-Komshian & Liu Reference Flege, Yeni-Komshian and Liu1999, Piske, Flege, MacKay & Meador Reference Piske, Flege, MacKay and Meador2002, Fowler, Sramko, Ostry, Rowland & Hallé Reference Fowler, Sramko, Ostry, Rowland and Hallé2008) and perception of segments (Pallier, Bosch & Sebastián-Gallés Reference Pallier, Bosch and Sebastián-Gallés1997, Sebastián-Gallés & Soto-Faraco Reference Sebastián-Gallés and Soto-Faraco1999, Flege & MacKay Reference Flege and MacKay2004). One hypothesis attributes the effects of sequential learning on L1 and L2 speech performance to the patterns of interaction or interference between the native and non-native phonetic systems. According to this explanation, speech patterns attuned to the native language act as a filter that ‘interferes’ with the way a non-native language is acquired and later used (Flege Reference Flege and Strange1995, Pallier, Dehaene, Poline, LeBihan, Argenti, Dupoux & Mehler Reference Pallier, Dehaene, Poline, LeBihan, Argenti, Dupoux and Mehler2003, Flege Reference Flege, Cole and Hualde2007). The stage of acquisition of the native language may determine the strength of the interference between the L1 and L2 phonetic categories, i.e. the earlier a bilingual is exposed to her second language, the easier it is for her to acquire its speech patterns because the strength of L1 categories is lower. In particular, this paper addresses the following questions:
(i) Are there effects of language dominance or sequential language learning on intonational production in highly proficient, early bilinguals?
(ii) Do bilinguals produce different intonational contours in their two languages or do they rather produce identical pitch contours?
(iii) Is there evidence of L2 influence on the L1 beyond the more commonly found L1 effects on the L2 (Guion Reference Guion2003)?
This study is specifically concerned with intonational production. Research on the effects of bilingualism on intonation is rather scarce when compared to research on segmental production and perception (Mennen Reference Mennen, Trouvain and Gut2007). However, it is important to assess the potential effects of bilingualism on intonational production. Differences in speech prosody, including intonation, contribute to the perception of a foreign accent and have a hindering effect on speech comprehension (Willems Reference Willems1982, Boula de Mareüil & Vieru-Dimulescu Reference Boula de Mareüil and Vieru-Dimulescu2006). Several recent papers have shown that bilinguals have a tendency to transfer the intonational patterns used in their native language to their non-native one (McGory Reference McGory1997, Atterer & Ladd Reference Atterer and Ladd2004, Elordieta & Calleja Reference Elordieta and Calleja2005, Gut Reference Gut2005, O'Rourke Reference O'Rourke2005). The ability of learners to develop intonational patterns that resemble those used by native speakers of the target, non-native language has been found to correlate with patterns of language use and age of acquisition (O'Rourke Reference O'Rourke2005). Additionally, there seems to be some evidence that simultaneous bilinguals develop different intonational categories for their two languages. These categories may not be identical to the ones produced by native, monolingual speakers of the two languages (Queen Reference Queen1996, Elordieta & Calleja Reference Elordieta and Calleja2005).
Some evidence suggests that the intonational features of a receding, minority language may be adopted by speakers of a majority language (Colantoni & Gurlekian Reference Colantoni and Gurlekian2004). Colantoni & Gurlekian (Reference Colantoni and Gurlekian2004) claim that the intonational characteristics of Buenos Aires Spanish result from early contact with Italian varieties, which occurred during the formation of this Spanish dialect at the turn of the 20th century. While Colantoni & Gurlekian (Reference Colantoni and Gurlekian2004) suggest that this is largely due to the features of the speech of Italian migrants (i.e. Italian-accented Spanish), since these intonational features are now characteristic of the entire Buenos Aires speech community, one might speculate that Spanish monolinguals residing in Buenos Aires must have had to adopt the characteristics of Italian-accented Spanish into their own Spanish. This is relevant because it shows that intonation is a largely malleable linguistic component, since it may be adopted in language contact situations even by speakers who do not speak the source language or do not speak it proficiently.
To our knowledge, only one paper has examined the interaction between native and non-native intonational categories in bilinguals. Mennen (Reference Mennen2004) found that four out of five Dutch–Greek bilinguals (who acquired Greek as adults, in a formal setting) displayed peak alignment patterns in their Greek that were similar to Dutch alignment patterns and differed from those displayed by native speakers of Greek. Mennen (Reference Mennen, Trouvain and Gut2007) also analyzed these bilinguals’ productions of a Dutch (L1) intonational contrast that involves the timing of pitch peaks associated with syllables containing short vs. long vowels. There is no equivalent intonational contrast in Greek. It was found that, except for one of the five participants, the bilinguals reduced the phonetic distinctiveness of the Dutch intonational contrast, as compared with a group of Dutch monolinguals. Mennen interpreted these findings to suggest that knowledge of the intonational system of the L2 might affect the L1 even in cases in which bilinguals continue to be L1-dominant, i.e. even for late L2 learners who use their L1 frequently.
Let us now introduce the intonational variable that is the focus of the present study. We are concerned with the shape of utterance-final pitch accents in Catalan and Spanish declaratives. This feature was selected as a variable due to the reported differences between dialects of Catalan and Spanish in this respect. Simonet (Reference Simonet2009, Reference Simonet2010a) studied in detail the acoustic characteristics of Majorcan Catalan utterance-final pitch accents in read-aloud speech. It was found that these pitch accents display a clearly observable falling pitch track from the syllable preceding the last stressed syllable in the utterance to the last stressed syllable itself. Additionally, the falling pitch track has a less steep slope between the final stressed syllable and the utterance endpoint than that between the pre-stressed and the stressed syllables. Simonet (Reference Simonet2009) proposes the H+L* phonological notation for these Majorcan Catalan pitch accents. This notation captures the presence of a local H as well as a local L* associated with the final stressed syllable. Simonet (Reference Simonet2010a) further showed that the temporal alignment of valleys in these falling accents is determined by the temporal position of the previous H and not by another prosodic landmark, such as a syllable boundary. Previous research on a Peninsular variety of Catalan (Prieto Reference Prieto, Solà, Lloret, Mascaró and Saldanya2002, in press; Astruc Reference Astruc2005; Prieto, Aguilar, Mascaró, Torres & Vanrell Reference Prieto and Jun2009) also noticed that utterance-final pitch accents in this language present evidence for the existence of an L* tone associated with the last stressed syllable in the utterance. Prieto et al. (Reference Prieto, Aguilar, Mascaró, Torres and Vanrell2009) and Prieto (in press) propose the L* phonological notation to account for utterance-final pitch accents in this Catalan variety. On the other hand, Astruc (Reference Astruc2005) proposes the H+L* notation for some of the utterance-final pitch accents of this particular Catalan variety. In sum, multiple evidence suggests that utterance-final pitch accents in Catalan, including Majorcan Catalan, have an L* tone. While the phonological presence of a leading H tone in a bi-tonal H+L* pitch accent is still unclear (Astruc Reference Astruc2005, Prieto et al. Reference Prieto, Aguilar, Mascaró, Torres and Vanrell2009, Simonet Reference Simonet2009, Prieto in press), that of an L* tone seems to be robust, especially for Majorcan Catalan, the dialect that concerns us here. It needs to be added that it has also been proposed that Central Catalan utterance-final pitch accents may be labeled with the L+!H* notation (Estebas Reference Estebas2009). The evidence for this type of pitch accent in Majorcan Catalan, however, is nonexistent (Simonet Reference Simonet2009, Reference Simonet2010a). Therefore, this possibility will not be further pursued here.
Turning to the case of Spanish, Face (Reference Face2002) showed that utterance-final pitch accents in Castilian Spanish mostly presented small, downstepped rising-falling trajectories, with rise onsets (valleys) co-occurring with stressed-syllable onsets and rise offsets (peaks) occurring within the bounds of stressed syllables. Face (Reference Face2002) proposed the L+H* phonological notation for these pitch accents. Further evidence has been presented elsewhere (Prieto, van Santen & Hirshberg Reference Prieto, van Santen and Hirshberg1995, Elordieta & Calleja Reference Elordieta and Calleja2005, Estebas & Prieto Reference Estebas and Prieto2009). Other data discussed in Face (Reference Face2002) show no observable rise, but rather a leveled, flat pitch trajectory followed by a fall on the final post-stressed syllable(s). The latter tonal patterns (non-falling) may also be interpreted as a downstepped L+H* or H* pitch accent because, crucially, the pitch track does not fall from the pre-stressed to the stressed syllable while it does from the stressed to the post-stressed one. This provides evidence for the presence of an intended high target in the utterance-final stressed syllable. On the other hand, falling utterance-final pitch accents have also been reported for some varieties of Castilian Spanish (Estebas & Prieto Reference Estebas and Prieto2009). The geographical distribution of falling vs. rising utterance-final pitch accents in Castilian Spanish is still unknown. In the absence of this type of information, we will largely assume here that Castilian Spanish dialects have a rising-falling utterance-final pitch accent, since most of the evidence points in that direction.
Of importance here is the fact that an H* tone is posited to exist in Spanish utterance-final pitch accents in the position where Majorcan Catalan presents an L* tone. Phonetic differences in the shape of utterance-final pitch accents between the two languages are apparent, i.e. some are concave-falling (Catalan) while others are rising-falling or convex-falling (Spanish). Evidence exists supporting the understanding that the difference between Catalan and Spanish utterance-final pitch accents is categorical, with Catalan requiring an L* tone (and thus an intended low target) and Spanish requiring an H* tone (and thus an intended high target). Examples of utterance-final pitch accents in Catalan and Spanish can be observed in Figures 1, 2 and 3. Note the shapes of pitch contours in utterance-final words, which have lexical stress on the penultimate syllable.
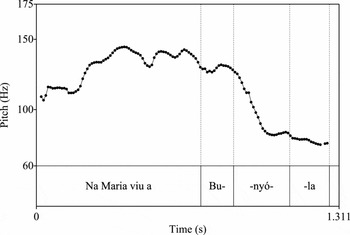
Figure 1 Pitch track of the Catalan sentence Na Maria viu a Bunyola ‘Maria lives in Bunyola’. Concave-falling utterance-final pitch contour.
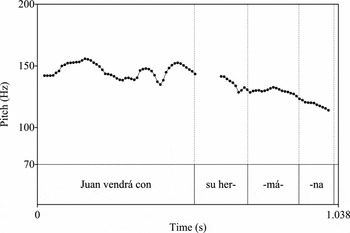
Figure 2 Pitch track of the Spanish sentence Juan vendrá con su hermana ‘Juan will come with his sister’. Convex-falling utterance-final pitch contour.
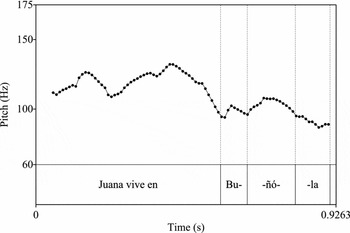
Figure 3 Pitch track of the Spanish sentence Juana vive en Buñola ‘Juana lives in Bunyola’. Rising-falling utterance-final pitch contour.
The existence of a robust difference in this respect does not go without challenges (Estebas & Prieto Reference Estebas and Prieto2009). One could say that these differences reflect tendencies rather than a categorical dichotomy between (all varieties of) Catalan and (all varieties of) Spanish. Based on previous descriptions, we assume here that there is a tendency for Majorcan Catalan to display utterance-final pitch accents with a falling configuration (L* or H+L*) and for Castilian Spanish utterance-final pitch accents to have a rising-falling shape (H* or L+H*). The first step towards our analysis of the data is to show that the speakers recorded for the present study show these tendencies in their native languages, Spanish and Catalan. For the most part, it will be seen that this is indeed the case. Therefore, the issue of whether or not these descriptions account for most of the dialects of Catalan and/or Spanish becomes of a secondary nature for our present goal, which is to describe the situation in Majorca.
The structure of the paper is as follows. The ‘Method’ section describes the data collection procedures, including the materials, the social attributes of the participants and the acoustic analyses. Two analytical procedures are described, one based on pitch scaling values extracted from the midpoint of relevant syllables and another one based on curve-fitting over the relevant section of the utterance-final pitch track. The ‘Results’ section is divided into three main subsections, addressing the three main goals of the paper. First, we present a sociophonetic profile of the intonational variable in the two languages by examining the L1 productions of Catalan- and Spanish-dominant participants as a function of gender and age. Second, we compare the Catalan and then the Spanish productions of dominant and non-dominant speakers in order to investigate the effects of experience on bilingual speech production (i.e. the effects of sequential learning). Third, we study the L2 productions of the speakers using their own L1 productions as a point of comparison, rather than those of dominant speakers of the L2, in order to investigate the patterns of L1–L2 interactions of a group of proficient early bilinguals. The ‘Discussion’ and ‘Conclusion’ sections summarize the findings and describe their implications for the fields of language contact, language change and bilingualism.
2 Method
2.1 Participants
A group of 40 Catalan–Spanish bilinguals participated in the experiments reported here. A language background questionnaire (LBQ) was administered to several potential participants. The LBQ was based on the one used in, among others, Flege & MacKay (Reference Flege and MacKay2004). The questionnaire was administered in the language of choice of the speakers and it inquired mainly about first language learned and patterns of frequency of use in daily life. (See also Simonet Reference Simonet and Ortega-Llebaria2010b for an accent rating experiment whose goal was to corroborate the patterns of language dominance of these speakers using speech performance data rather than survey responses.)
Two groups of 20 bilinguals each were formed, i.e. 20 Catalan-dominant and 20 Spanish-dominant bilinguals. The participants were classified as Catalan- (or Spanish-)dominant if they claimed that Catalan (or Spanish) was their family language and the language they learned first (during early childhood) and also if they had higher self-reported percentages of use of Catalan (or Spanish) than Spanish (or Catalan) in all of the communicative settings about which the questionnaire inquired. Balanced numbers of males and females were asked to participate. The 40 bilinguals were classified as a function of their age (older (O) and younger (Y)), gender (male (M) and female (F)) and first or dominant language. Eight groups of five speakers each were formed:

The older participants were born mostly during the 1950s and the younger ones, mostly during the 1970s or early 1980s.
All of the Catalan-dominant speakers were born in Majorca and had lived locally throughout their lives. While the younger Spanish-dominant participants were also born in Majorca, the older Spanish-dominant speakers where all born in the Iberian Peninsula, in a monolingual Spanish-speaking region (e.g. in the provinces of Albacete, Jaén or Granada). This is representative of the community (Villaverde Reference Villaverde2005). This difference between the younger and the older Spanish-dominant subjects may have a large effect on their command of Catalan (L2). Another difference between the two age groups is that, due to political reasons, the speakers in the older generation were provided schooling exclusively in Spanish while the speakers in the younger generation were provided schooling in both Catalan and Spanish. This is true for both groups of bilinguals, i.e. Spanish-dominant and Catalan-dominant. Therefore, while the younger participants are highly fluent, early bilinguals who were first exposed to their L2 at most by age 6, the onset of mandatory bilingual schooling in Majorca, the participants in the older generation are not necessarily so. For instance, the older Catalan-dominant speakers are literate in both Spanish and Catalan, although some may be more fluent or proficient reading in Spanish (L2) than in Catalan (L1). On the other hand, the older Spanish-dominant speakers are mostly literate only in Spanish (L1). In all cases, however, the populations from which the participants have been sampled use (or are exposed to) both Catalan and Spanish on a daily basis.
All of the younger speakers were recorded while reading both Catalan and Spanish materials, while the older speakers were recorded exclusively in their dominant language. While the older Catalan-dominant participants are literate in Spanish, some expressed a mild level of concern for being recorded in Spanish. This was apparently due to the fact that some felt that their Catalan-accented Spanish was unacceptable for a recording. Thus, since Spanish-dominant speakers were going to be recorded only in Spanish for obvious reasons, the decision was made to record both groups of older subjects only in their dominant language.
2.2 Recordings
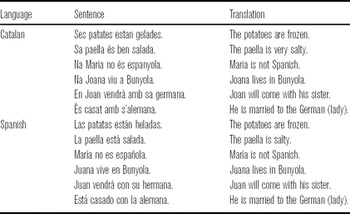
In order to elicit comparable data across the two languages, the decision was made to analyze pitch contours in read-aloud speech, using cognates. No prompts for the sentences were provided to the speakers and they were not asked to use any specific contour. Five different quasi-randomizations were provided to the subjects. The materials were controlled for: (i) lexical-stress configuration (only paroxytones), (ii) quality of the stressed vowel (only /a/ or /o/), (iii) quality of the post-stressed vowel (only /a/ in Spanish, and schwa in Catalan), and (iv) surrounding consonants (only voiced consonants). The sentences are shown in Table 1.
Table 1 Catalan and Spanish materials.
There were six target sentences in each randomization, interspersed among many (n = 53) distractors. The distractors had different prosodic configurations so as to minimize the use of repetitive intonation. Target sentences were never adjacent. A total of 1200 sentences were collected from the younger subjects: 6 (target sentences) × 20 (speakers) × 5 (iterations) × 2 (languages). From the older subjects, a total of 600 sentence tokens were recorded. This amounts to a total of 1800 sentence tokens gathered, 30 per speaker and language.
Numerous (464, 25.7%) sentence tokens were discarded for various reasons. The most important reason for rejection of sentence tokens was that many sentences were produced with list intonation; that is, they presented a final rise, which was arguably due to the fact that subjects anticipated following materials and applied a list reading. This type of list intonation was found in the productions of all speakers, but much more so in the productions of the Catalan-speaking older males. We do not know what may have caused these group differences in the use of list intonation. Among other reasons for exclusion of sentences were: devoicing of a significant portion of a vowel in the utterance-final word, disfluencies, creaky voice, the inadvertent omission of a sentence. These are simply treated as missing data points.
The speakers were recorded in a quiet room, in their home or workplace, using a solid-state digital recorder (Marantz PMD660) and a head-worn dynamic microphone (Shure SM10A). Speech was digitized at 44.1 kHz (16-bit quantization) and later down-sampled at 22.05 kHz.
2.3 Metrics
Pitch tracks were generated for each sentence using Praat (Boersma Reference Boersma2001). Three temporal landmarks were hand-segmented:
p1: the midpoint of the vowel in the pre-stressed syllable of the utterance-final word;
p2: the midpoint of the vowel in the stressed syllable of the utterance-final word;
p3: the midpoint of the vowel in the post-stressed syllable of the utterance final word.
Segmentation was performed on time-aligned sound-wave and spectrographic displays. The vowels were segmented using standard procedures and mostly following F2 trajectories and their intensity (dB) levels. After vowel segmentation, the cursor was placed on the approximate midpoint of each of the target vowels. See Figure 4 for an example of a segmented utterance-final word.

Figure 4 Example of segmented utterance-final Catalan word (s'alemana ‘the German, fem’). Pitch values were extracted from three temporal landmarks: mid-point of pre-stressed vowel (p1), mid-point of stressed vowel (p2), mid-point of post-stressed, utterance-final vowel (p3).
Pitch values were extracted from p1, p2 and p3 in ERB units instead of Hz (Hermes & van Gestel Reference Hermes and van Gestel1991). Subsequently, the differences in pitch scaling between p1 and p2 and then between p2 and p3 were calculated: Difference1 = p2 – p1 and Difference2 = p3 – p2. Scaling difference between two adjacent points is taken as a dependent variable (ScalDiff), with position of the difference as a factor (Difference1 vs. Difference2).
This metric captures the notion of whether there is an H* or an L* tone associated with the utterance-final stressed syllable. The presence of an L* is suggested by a greater scaling difference between p1 and p2 (Difference1) than between p2 and p3 (Difference2), i.e. a concave fall. The presence of an H* is suggested by either (i) a rise from p1 to p2 followed by a fall from p2 to p3 (i.e. a rise-fall), or (ii) a smaller fall between p1 and p2 than between p2 and p3 (i.e. a convex fall). Since most recent work on intonational production investigates exclusively temporal alignment patterns, it is important to highlight here that the difference between Catalan and Spanish examined here is one of shape (rise-fall or convex-fall vs. concave-fall) and not alignment. We could have opted for analyzing the alignment of peaks and valleys in these pitch accents (Simonet Reference Simonet2010a). However, this would result in a binary classification of pitch accents: (i) H followed by L in falls or (ii) L followed by H in rises. Differences in alignment between the two languages would be uninformative. We would have no gradient, quantitative way of capturing the difference between the two pitch accent types. A metric that allowed us to capture the potential existence of gradience in the data was needed, since potential sound changes in progress or patterns of sociophonetic variation are gradient and not categorical. Furthermore, bilingual individuals are likely to produce gradient, and not catastrophic, modifications to their speech when using their L2. A case in point is the study of vowels. While classifications into phonetic categories or allophones have their place, quantitative acoustic analyses based on spectral structure have been able to reveal gradient sound changes in progress, such as chain shifts (Labov Reference Labov1994), and detailed modifications produced by L2 speakers (Flege Reference Flege1987) that classification into discrete allophones would not have been able to show.
This analysis has two limitations. First, it is based exclusively on one pitch value per syllable, which is arguably too crude. Second, there is no obvious mathematical way of linking the size of a given fall (ScalDiff) between the first two points (Difference1) with that between the second and third points (Difference2) of the same sentence token, i.e. it can only link distributions of data. On the one hand, in robust between-speaker comparisons, this method may still be able to show differences in pitch shape. On the other hand, for within-speaker comparisons, where small differences are expected, a much more sensitive metric is needed. These limitations were overcome by a second acoustic analysis.
In the second analysis, curve fitting over the entire utterance-final pitch track (p1-to-p3) was used, with quadratic polynomial equations as the basis. Each pitch track section was submitted to an individual regression model in order to calculate its best-fit quadratic curve using the least-squares method. The y-intercept was determined at p2. The coefficients of the corresponding quadratic equation were extracted from the model and submitted to inferential statistics.
In quadratic polynomial equations (ax2 + bx + c), coefficients have a straightforward interpretation (Andruski & Costello Reference Andruski and Costello2004). The c-coefficient is the y-intercept and the b- and a-coefficients together indicate the shape and direction of the curve. The b-coefficient expresses the slope of the tangent at the y-intercept. The a-coefficient indicates how wide or narrow the curve of the parabola is and whether the parabola is convex or concave. An equation with a negative b- and a negative a-coefficient describes a convex-falling curve. One with a negative b- and a positive a-coefficient describes a concave-falling curve. One with a positive b- and a negative a-coefficient describes an exponentially rising curve. Finally, one with a positive b- and a positive a-coefficient describes a logarithmically rising curve or a rising-falling curve (Andruski & Costello Reference Andruski and Costello2004).
The goodness of fit of the polynomials was investigated by extracting the r 2 values returned by the regression models. Overall, quadratic polynomial equations were found to capture the target pitch tracks appropriately. The r 2 values had a mean of 0.943, and a standard deviation of .083. As a comparison, cubic (ax3 + bx2 + cx + d) polynomials were also fitted to the target pitch tracks. Unsurprisingly, cubic polynomials were found to be a better fit to the target contours (mean of 0.971 and standard deviation of .044). Quadratic polynomials were finally selected because their three coefficients have a straightforward interpretation and the fit gain of cubic polynomials (based on r 2 values) was considered to be negligible (i.e. considering the increased cost of having to run statistics over one further coefficient). In order to improve the reliability of the quadratic polynomials used, all the curves that had an r 2 lower than 0.9 were excluded from further analyses. The mean r 2 of the resulting data set improved from 0.943 to 0.972, with a standard deviation of .02.
The second acoustic analysis overcomes the limitations of the first one because it (i) is based on a close approximation of the entire target pitch track, (ii) provides a direct index of shape (e.g. concave vs. convex) for each contour, and (iii) captures the potential gradience between a concave and a convex pitch contour.
3 Results
3.1 Native utterances: Catalan versus Spanish
Do Spanish and Catalan utterance-final pitch accents differ from each other? Does the age or gender of speakers affect the realization of these pitch accents in at least one of the languages? Is there evidence of gradual intonational convergence between the two languages? We hypothesize that, overall, Spanish utterance-final pitch accents (as produced by Spanish-dominant bilinguals) show a rising-falling or a convex-falling trajectory while Catalan accents (as produced by Catalan-dominant bilinguals) show a concave-falling configuration (Simonet Reference Simonet2010a). We have no specific hypotheses regarding age or gender variation. A combination of age and gender differences may suggest the existence of a process of gradual convergence (or divergence) between the two languages. The age and gender of the speakers were considered in order to provide an approximate sociophonetic profile of utterance-final pitch accents in the two languages.
In order to address these questions, inferential statistics were run over a subset of the data. In particular, only the native (L1) productions of all 40 participants were considered: (i) the Catalan productions of the 20 Catalan-dominant speakers and (ii) the Spanish productions of the 20 Spanish-dominant speakers (844 sentence tokens). Note that the analysis of this data subset is fully based on between-speaker comparisons. Since we found that an examination of the ScalDiff data was robust enough to capture the between-speaker differences, we exclusively report on ScalDiff data in this section. (A replication of these analyses using the second procedure yielded identical results.)
The data were fitted by a linear mixed-effects regression model with ScalDiff as response, position of the scaling difference (Difference1 vs. Difference2), language (Catalan vs. Spanish), age group (older vs. younger) and gender (male vs. female) were used as fixed factors (Baayen Reference Baayen2008). Individual speaker was used as a random intercept. The mixed-effects regression model was further submitted to an ANOVA summary. Degrees of freedom are not reported since it is at present unclear how to best report them (Baayen Reference Baayen2008: 269). We were exclusively interested in the potential interactions between position and the other factors. The fixed effects and the interactions among other factors are irrelevant for our purposes since we were concerned with identifying differences in the full utterance-final pitch track (Difference1 vs. Difference2) as a function of the participants’ attributes.
The ANOVA summary revealed significant interactions between position and language (F = 302.95, p < .001), position and age (F = 149.61, p < .001), position and gender (F = 12.34, p < .001), and position, language and gender (F = 6.13, p = .01), but not between position, language and age, position, gender and age and no four-way interaction. Of importance here are the significant interactions between (i) position and language, (ii) position, language and gender, and the absence of a four-way interaction. Figures 5 and 6 display mean pitch contours as a function of language, gender and age.

Figure 5 Stylized mean (95% CIs) pitch contours (scaling of p1, p2, p3) of the Catalan (L1) productions of the Catalan-dominant speakers as a function of their age and gender.

Figure 6 Stylized mean (95% CIs) pitch contours (scaling of p1, p2, p3) of the Spanish (L1) productions of the Spanish-dominant speakers as a function of their age and gender.
The analysis revealed that the differences in the size of the pitch excursions (Difference1 vs. Difference2) varied as a function of language, with Catalan speakers producing a larger fall in Difference1 than in Difference2 (thus a concave-falling track) and Spanish speakers producing a smaller fall (sometimes a rise) in Difference1 than in Difference2 (thus a convex-falling track or a rising-falling contour). While age interacted with position, it is important to highlight that age was not involved in any three- or four-way interaction; that is, the effects of age disappear when language and/or gender are included in the prediction.
In order to explore other interactions beyond that between position and language, we examined the potential effects of gender and age for both language groups separately. This was justified by the results of the main model. For the Catalan data, an ANOVA summary of a mixed-effects regression model yielded significant interactions between position and age (F = 65.21, p < .001) but not between position and gender (F = 2.27, p = .1) and no three-way interaction. Thus, the younger speakers differed in their pitch accent use from the older ones but there were no gender differences. The reasons for these age effects are explained below. Regarding the Spanish data, the ANOVA summary of the corresponding model revealed significant interactions between position and age (F = 74.7, p < .001) and between position and gender (F = 28.93, p < .001) but no three-way interaction. This suggests that, while all four groups of speakers differ from each other, the relationship (difference) between older and younger males is similar to that between older and younger females.
Finally, a series of paired t-tests examined the interactions by analyzing the potential effects of position for the eight groups of speakers separately: CTMY (diff. = −0.37, t = −9.89, p < .001), CTFY (diff. = −0.45, t = −11.71, p < .001), CTMO (diff. = .07, t = 0.79, p = .4), CTFO (diff. = .0003, t = .003, p = .9), SPMY (diff. = 0.28, t = 8.71, p < .001), SPFY (diff. = .02, t = 0.58, p = .5), SPMO (diff. = 0.66, t = 10.25, p < .001), SPFO (diff. = 0.43, t = 5.52, p < .001). These planned comparisons are justified by the existence of interactions in previous regression models. (Welch t-tests examining pitch contours in individual speakers' data are reported in Tables 2 and 3.) On average, Catalan-speaking younger males and females showed a preference for steeply-falling concave trajectories, Catalan-speaking older males and females produced falling straight trajectories, Spanish-speaking younger females produced falling straight trajectories as well, and Spanish-speaking younger males and older males and females tended to produce convex falls.
Table 2 Welch t-tests of ScalDiff as a function of position of the scaling difference (Difference1 vs. Difference2) further broken down by individual participant. Catalan productions of Catalan-dominant speakers.

Table 3 Welch t-tests of ScalDiff as a function of position of the scaling difference (Difference1 vs. Difference2) further broken down by individual speaker. Spanish productions of Spanish-dominant speakers.

The analyses reported here suggest that there are robust differences in the shape of utterance-final pitch accents between Catalan and Spanish in Majorca, as expected. These differences were found to be affected by the age and the gender of the speakers. Regarding Catalan, the younger participants produced concave falls while the older participants produced straight falls. Regarding Spanish, a scale from rising-falling to straight-falling contours (with flat-then-falling and convex-falling configurations in between) was found. The younger females produce straight falls and are thus on one extreme of the scale while the older males produce rising-falling or flat-then-falling configurations and are thus on the opposite extreme. Younger male and older females tend to use configurations in the middle of the gradient scale.
In this subsection, we have provided an approximate sociophonetic profile of utterance-final pitch accent variation in the Spanish and Catalan of Majorca. The following sections examine L2 productions.
3.2 Catalan utterances
Do Spanish-dominant bilinguals transfer the phonetic characteristics of their native (Spanish) utterance-final pitch accents to their L2 (Catalan)? In other words, do Catalan-dominant (L1) and Spanish-dominant (L2) Catalan–Spanish bilinguals differ in their production of Catalan utterance-final pitch accents? Following previous findings, we hypothesize that non-native speakers transfer the intonational characteristics of their L1 to their L2 and, therefore, Catalan- and Spanish-dominant speakers use different types of utterance-final pitch accents even when speaking the same language, Catalan.
In order to address this question, a data subset was extracted. This subset included only the Catalan productions of the 20 younger bilingual participants, 10 Catalan-dominant (L1) and 10 Spanish-dominant (L2) participants (493 sentence tokens). Recall that older subjects were exclusively recorded in their dominant language. Note once again that the analysis of this data subset is fully based on between-speaker comparisons. As in the preceding section, since we found that an examination of the ScalDiff data was robust enough to capture the between-speaker differences, we exclusively report on ScalDiff data here.
The data were submitted to a linear mixed-effects regression model with ScalDiff as response, speaker as a random intercept, and position of the scaling difference (Difference1 vs. Difference2), native language (Catalan- vs. Spanish-dominant), and gender as fixed factors. Only the potential interaction between position of the scaling difference and the other fixed factors are relevant for our present purposes.
An ANOVA summary of the regression model revealed a significant position by native language interaction (F = 235.08, p < .001), a significant position by gender interaction (F = 42.95, p < .001) and a significant three-way interaction between position, native language and gender (F = 16.15, p < .001). Figure 7 plots mean contours as a function of dominant language and gender. The interactions were further explored with a series of four paired t-tests, one per group, with ScalDiff as the dependent variable and position of the scaling difference as a factor: CTMY (diff. = −0.37, t = −9.89, p < .001), CTFY (diff. = −0.45, t = −11.7, p < .001), SPMY (diff. = 0.24, t = 6.37, p < .001), SPFY (diff. = −0.10, t = −2.82, p < .01).
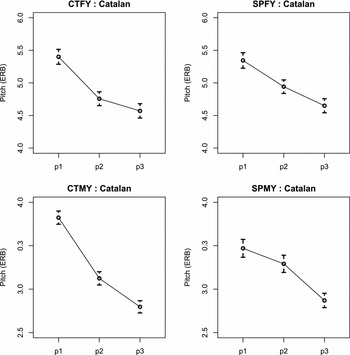
Figure 7 Stylized mean (95% CIs) pitch contours (scaling of p1, p2, p3) of the Catalan productions of ten Catalan-dominant (L1) and ten Spanish-dominant (L2) bilinguals further broken down by gender.
The analysis performed on the Catalan utterances revealed that the Spanish-dominant male participants, when speaking Catalan (L2), were found to use convex-falling pitch contours. This pattern is similar to the one described for the Spanish (L1) productions of these male subjects (see preceding section) and different from the Catalan productions of the Catalan-dominant participants reported in this section and also in the preceding one. These data suggest that Spanish-dominant males transfer their Spanish (L1) utterance-final pitch accents when speaking Catalan (L2). On the other hand, Spanish-dominant females were found to use slightly concave falls. These contours differed from those used by the Spanish-dominant males and approximated those used by the Catalan-dominant speakers. Note that, although it is in the same direction, the difference between Difference1 and Difference2 is smaller for the Spanish-dominant females than for the two groups of Catalan-dominant bilinguals. Notwithstanding the fact that the contours used by the Spanish-dominant females are less concave (i.e. more straight) than those used by the Catalan-dominant speakers, it seems that the Spanish-dominant females have managed to acquire the utterance-final pitch accent of their L2, Catalan (or a similar one). This is further explored below.
3.3 Spanish utterances
Do Spanish-dominant (L1) and Catalan-dominant (L2) Catalan–Spanish bilinguals differ in their production of Spanish utterance-final pitch accents? Do Catalan-dominant speakers transfer their native contours to their non-native language? Based on previous research on intonation in bilingualism and on the results reported in the preceding subsection, we hypothesize that Catalan-dominant speakers transfer their Catalan pitch contours into their Spanish productions. It is possible, however, that they have managed to develop a ‘Spanish-like’ contour for their Spanish (L2).
A subset of the data was extracted, i.e. the Spanish (L1) productions of the younger Spanish-dominant bilinguals and the Spanish (L2) productions of the younger Catalan-dominant bilinguals (475 sentence tokens). The data were submitted to a mixed-effects linear regression model with ScalDiff as response, speaker as random intercept, and position of the scaling difference (Difference1 vs. Difference2), native language (Spanish- vs. Catalan-dominant) and gender as fixed factors. Only the interactions involving position are relevant to answer our research question.
An ANOVA summary of the model returned a significant position by native language interaction (F = 88.67, p < .001), a significant position by gender interaction (F = 41.57, p < .001) but no three-way interaction (F = 3.25, p = .07). Figure 8 plots mean contours as a function of native language and gender. Four paired t-tests were used to explore the interactions, one per group. The t-tests were run with ScalDiff as the dependent variable and position of the scaling difference as factor: CTMY (diff. = −.05, t = −1.57, p = .1), CTFY (diff. = −0.20, t = −6.9, p < .001), SPMY (diff. = 0.28, t = 8.71, p < .001), SPFY (diff. = .02, t = 0.58, p = .5).
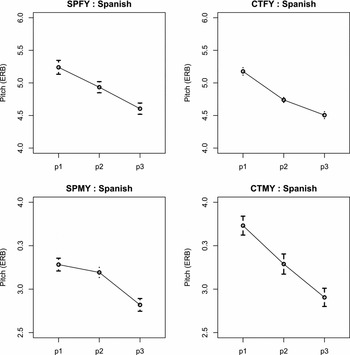
Figure 8 Stylized mean (95% CIs) pitch contours (scaling of p1, p2, p3) of the Spanish productions of ten Spanish-dominant (L1) and ten Catalan-dominant (L2) bilinguals further broken down by gender.
The analysis carried out on the Spanish data indicates that, in opposition to Spanish-dominant speakers, the Catalan-dominant males were found to produce straight-falling pitch configurations, while the Catalan-dominant females were revealed to produce slightly concave pitch trajectories. Since this is broadly the described pattern for Catalan, we infer that Catalan-dominant females tend to transfer the utterance-final pitch accents of their L1 to their L2 (or a similar one). On the other hand, notice that the Catalan-dominant males used straight falls, as did the Spanish-dominant females. It is perhaps noteworthy that Catalan-dominant males seem to slightly assimilate to Spanish productions with which they are in contact.
3.4 Catalan-dominant speakers' utterances
Do Catalan-dominant speakers maintain separate statistical distributions (i.e. phonetic categories) for utterance-final pitch accents in their two languages? Do they, on the other hand, use fundamentally the same intonational pattern for their L1 and L2? The findings reported in the preceding sections suggest that Catalan-dominant bilinguals transfer the utterance-final pitch configuration of their L1 into their L2. Therefore, it seems that Catalan-dominant speakers have not developed a separate phonetic category for their L2 utterance-final pitch accent category. On the other hand, since these are highly proficient, early L2 learners, it is possible that small (though non-negligible) differences between L1 and L2 patterns might be revealed by a careful scrutiny using a sensitive metric. Note also that the five Catalan-dominant males were found to use concave falls in their Catalan and straight falls in their Spanish. Is this difference significant?
In order to address these questions, a subset of the data was used. In particular, we extracted all the productions (L1 + L2) of the younger Catalan-dominant participants. Recall that only the younger participants were recorded in their two languages. Since the analyses reported here involve the examination of within-speaker comparisons, a sensitive metric is needed. As we argued above, a study of pitch values in syllable midpoints might be too crude to reveal L1 vs. L2, within-speaker differences. Therefore, we report here on an analysis of the coefficients returned by quadratic polynomials fitted to the relevant section of pitch tracks. Results of statistical models using ScalDiff as a response are also reported as a point of comparison, in line with findings reported in previous sections.
ScalDiff data were submitted to a linear-mixed effects regression model with speaker as a random effect, and position of the scaling difference (Difference1 vs. Difference2), language mode (L1 vs. L2) and gender as fixed factors (499 sentence tokens). The model returned a significant position by mode interaction, but no three-way interaction. Since gender did not participate in any significant interactions, a second model was fitted with the same response, speaker as a random effect, and position and mode as fixed factors. An ANOVA summary of the model returned a significant effect of position (F = 276.5, p < .001), and, most importantly, a significant position by mode interaction (F = 75.8, p < .001). In other words, the scaling difference between Difference1 and Difference2, and thus the shape of utterance-final pitch contours, varied as a function of language mode.
These results show that both Catalan-dominant males and females produce slightly different contours in their two languages. In particular, these bilingual speakers produce more concave (greater curvature) pitch contours in their L1 (Catalan) than in their L2 (Spanish). This finding comes from the fact that the difference in steepness between Difference1 and Difference2 is much larger in their Catalan (L1) than it is in their Spanish (L2). Note that this is the expected direction according to a gradient scale between concave-falling and convex-falling accents; that is, if we assume that Catalan utterance-final pitch accents are fundamentally concave while Spanish accents are not (or are less so).
The slope (b-) and curvature (a-)coefficients returned by quadratic polynomials were submitted to two separate linear mixed-effects regression models as response, speaker as random effect, and language mode (L1 vs. L2) and gender as fixed factors. The model in which slope (b-)coefficients were used as response revealed no effects of gender and no significant interaction between mode and gender. Consequently, gender was excluded as a factor and a new mixed-effects regression model was fitted with mode as the only fixed factor. The results of the model revealed significant effects of mode on the slope coefficients (Intercept estimate = −106.2; L2 estimate = 13.1, t = 4.07, p < .001). The effects came from the fact that, while both L1 and L2 pitch contours were steeply falling, Spanish (L2) productions were significantly less steep than Catalan (L1) productions. Regarding the curvature (a-)coefficients, the original model returned no significant effects of gender and no interaction between mode and gender. Therefore, the a-coefficients were also submitted to a new model with mode as the only fixed factor. The model returned significant effects of mode (Intercept estimate = 303.6, L2 estimate = −188.7, t = −7.08, p = .001). While both L1 and L2 productions display a concave-falling shape (positive a- and negative b-coefficients), pitch contours were found to have a greater degree of concave curvature in Catalan (L1) than in Spanish (L2) as suggested by the ScalDiff differences. By-speaker t-tests applied to curvature (a-)coefficients revealed that five of the Catalan-dominant bilinguals (three males, two females) have different distributions for L1 and L2 pitch contours. For the other five particpants, the tests held no significance while there might be a trend for some of them. (See Table 4 below.)
Table 4 Welch t-tests of curvature (a-)coefficients as a function of language mode (Catalan vs. Spanish) further broken down by individual speaker. Catalan- and Spanish-dominant younger bilinguals.

The analyses carried out on the productions of the Catalan-dominant bilinguals revealed that these participants maintained different statistical distributions for utterance-final pitch accents in Catalan (L1) and Spanish (L2). In particular, it was found that the Catalan-dominant bilinguals produced pitch accents with a greater concave curvature and, overall, a steeper falling direction in Catalan (L1) than in Spanish (L2). On the one hand, it is clear that Catalan-dominant bilinguals tend to use concave-falling pitch accents in their two languages. This is evidence for the presence of a low target associated with the utterance-final stressed syllable (L*) in both languages. This supports an interpretation according to which bilinguals transfer the intonational patterns of their L1 into their L2, since L* tones are hypothesized for Catalan but not Spanish. In other words, L2 categories are assimilated to L1 categories. On the other hand, the attested statistical differences between L1 and L2 contours were in the direction of the expected difference between Catalan and Spanish (as spoken by dominant speakers), i.e. robustly concave in Catalan and less so (straighter) in Spanish. These differences support an interpretation according to which the Catalan-dominant bilinguals (at least some of them) have managed to learn a new statistical distribution, and thus a new phonetic category, for utterance-final pitch accents in their L2. Ultimately, however, this new phonetic category is not identical to the one used by dominant speakers of Spanish, as shown in the preceding subsection.
3.5 Spanish-dominant speakers' utterances
Do Spanish-dominant speakers maintain different statistical distributions (i.e. phonetic categories) for utterance-final pitch accents in their two languages? In order to answer this question, we examined the Spanish (L1) and Catalan (L2) productions of the younger Spanish-dominant bilinguals. Once again, recall that only the younger participants were recorded in their two languages. Based on the findings reported in the preceding subsection, we hypothesize that these bilinguals also have separate acoustic distributions for L1 and L2 patterns. On the one hand, recall that the Spanish-dominant younger females were found to produce straight falls in their Spanish (L1) and slightly concave falls in their Catalan (L2). Is this difference significant? On the other hand, the younger males were found to use convex falls in both their Spanish (L1) and their Catalan (L2). Is this indicative of a fully merged intonational phonetic category?
The results of a linear mixed-effects regression model fitted to the ScalDiff data as response, with speaker as a random effect, and position of the scaling difference (Difference1 vs. Difference2), language mode (L1 vs. L2) and gender as fixed effects, revealed a significant position by mode interaction, as well as a significant position by gender interaction. No three-way interaction was found. Since a three-way interaction was not found, a second mixed-effects model was fitted with the same response and with position and mode as fixed factors. The regression model returned significant effects of position (F = 55.73, p < .001) and a marginally significant position by mode interaction (F = 4.21, p = .04).
A regression model in which slope (b-)coefficients were used as response, mode (L1 vs. L2) and gender were used as fixed factors and speaker was a random intercept revealed that gender was not significant and it did not interact with mode. A second model, one in which the only fixed factor was mode, returned non-significant effects of mode (Intercept, L1 estimate = −88.03, t = −13.39; L2 estimate = −3.91, t = 1.04, p = .2).
Regarding curvature (a-)coefficients, once again, there was no interaction between the fixed factors mode and gender. However, the factor gender reached significance. The data were resubmitted to a model with both fixed factors but without an interaction between the two. The results of this model returned significant effects of mode (Intercept estimate = 184.3, t = 1.97; L2 estimate = −131.1, p < .001) and gender (Males estimate = 422.63, p < .01). The large difference between males and females comes from the fact that females produce, on average, slightly concave falls (positive curvature degrees) while males produce, also on average, convex falls (negative curvature degrees). The effects of mode were apparently caused by higher curvature values for L2 than for L1 productions, i.e. more concave in the L2 than in the L1 in the case of females and more straight (less convex) in the L2 than in the L1 in the case of males. The effects of mode in this subset of the data, however, are probably not entirely reliable. By-speaker t-tests applied to curvature (a-)coefficients (see Table 4) revealed that only four of the 10 Spanish-dominant bilinguals (two males, two females) have different distributions for L1 and L2 pitch contours. However, for one of the speakers (sp14fy), the effect was in the opposite direction. In other words, only three out of 10 bilingual participants reliably maintain separate L1 and L2 phonetic categories, as evidenced by a-coefficients. Perhaps there is a trend in some of the other subjects.
The results of the statistical analyses carried out on three different metrics revealed a trend for Spanish-dominant bilinguals to maintain separate intonational categories for utterance-final pitch accents in their two languages. On the other hand, notice that these differences between L1 and L2 patterns are rather small, i.e. the only differences were those of the curvature (a-)coefficients while no differences were attested for slope at the y-intercept and only marginal effects were found for ScalDiff. Additionally, by-subject analyses revealed that only three speakers robustly maintained a difference.
The results of the two linear mixed-effects regression models applied to the curvature (a-)coefficients (i.e. the first to the Catalan-dominant and the second to the Spanish-dominant bilinguals) suggested that, although both groups tended to maintain the L1 and L2 intonational categories separate (i.e. in two different statistical distributions), the size of the effect was larger for the Catalan-dominant (estimate = −188.7) than for the Spanish-dominant bilinguals (estimate = −131.1). Could this be indicative of a difference between Catalan- and Spanish-dominant subjects in their patterns of L1–L2 interactions?
In order to investigate whether there was an interaction between mode and native language group, the data were submitted to a mixed-effects regression model with a-coefficients as response, speaker as random effect, and mode (L1 vs. L2) and native language group (Catalan-dominant vs. Spanish-dominant) as fixed factors. The data were recoded so that the direction of the difference would be the same across language groups. The results revealed mode (Interface estimate = 311.06, Spanish estimate = −182.4, t = −5.9, p < .001) and native language (estimate = −315.8, t = −2.7, p < .01) effects and a marginally non-significant interaction (estimate = 78.4, t = 1.7, p = .08). Figure 9 plots a-coefficients as a function of mode and group.

Figure 9 Means (95% CIs) of curvature (a-)coefficients of the Catalan (circles) and Spanish (triangles) productions of ten Catalan-dominant and ten Spanish-dominant bilinguals further broken down by gender.
In sum, as a group, both the Catalan-dominant and Spanish-dominant bilinguals investigated in the present paper seemed to be able to maintain different statistical distributions, thus different phonetic categories, for utterance-final pitch accents in their L1 and their L2. There seems to be a trend for Catalan-dominant bilinguals to maintain a larger separation between L1 and L2 utterance-final pitch accents than that maintained by the Spanish-dominant bilinguals. This is suggested by the fact that while five Catalan-dominant bilinguals were found to robustly maintain an L1–L2 difference, only three Spanish-dominant subjects were found to do the same. This trend might be negligible depending on the specific metric used to capture it, since a statistical model analyzing the entire data set found a marginally non-significant interaction.
4 Discussion
We have examined utterance-final pitch accents in Catalan and Spanish, as produced by two main groups of bilingual speakers. It has been found that Catalan and Spanish, as spoken in Majorca, differ in their realization of utterance-final pitch accents in declaratives. On average, this language difference is due to Catalan displaying concave falls and Spanish presenting convex falls. We believe that this difference in performance is motivated by a difference in the intonational phonology of these languages. Catalan data show evidence of an L tone associated with the utterance-final stressed syllable (H+L* or L*), which triggers the concave shape of the contour, while Spanish data suggest the presence of an H tone in the same prosodic position (H* or L+H*), which causes the convex shape of the contour. This difference was expected based on previous descriptions of the languages (Face Reference Face2002; Prieto Reference Prieto, Solà, Lloret, Mascaró and Saldanya2002, in press; Estebas & Prieto Reference Estebas and Prieto2009; Prieto et al. Reference Prieto, Aguilar, Mascaró, Torres and Vanrell2009) under investigation, including the specific varieties investigated here (Simonet Reference Simonet2010a). Since one of the goals of the present paper was to provide a sociophonetic profile of the production of utterance-final pitch accents in a language contact situation, we referred to this difference as an ‘intonational variable’.
4.1 Intonation in bilingual societies
In order to provide a sociophonetic profile, we analyzed the production of this variable in the dominant language of forty participants as a function of their gender and age. Age and gender differences, together with other attributes such as socioeconomic class or level of education, may provide an apparent-time indication of whether a given variable is in the process of changing in the community (Labov Reference Labov2001). However, only subsequent longitudinal, real-time investigations may be able to corroborate whether a variable was indeed a sound change in progress or not.
Regarding the Catalan data, it was found that the younger participants used concave-falling contours, presenting robust evidence for the presence of an L* or H+L* utterance-final pitch accent. On the other hand, the older Catalan-dominant speakers produced, on average, straight-falling configurations. In fact, while the older females produced steep straight falls, the older males tended to produce flatter straight contours. The age differences were unexpected. While these differences could be indicative of a sound change in progress, the absence of a gender difference interacting with the effects of age seems to argue against this explanation. Furthermore, there is reason for caution in interpreting the Catalan data collected from the older subjects. Since these subjects were provided childhood schooling in Spanish exclusively, it is possible that their reading proficiency in Catalan is affected by their (lack of) experience. It is likely that the read-aloud productions of the older Catalan-dominant participants are not as representative of their own speech as those of the younger speakers, who were provided schooling in both Catalan and Spanish. The effects of age attested here for the Catalan-dominant speakers need to be interpreted with extreme caution. Thus, they are left for future research.
The interpretation of the Spanish findings is probably more straightforward. We have no reason to expect wide differences in reading fluency in Spanish by the two age groups since both received early schooling in Spanish (the younger subjects also received schooling in Catalan). Both gender and age effects were found in the Spanish productions of the Spanish-dominant subjects. In particular, we found a gradient scale with rising-falling contours on one extreme (older males) and straight-falling contours on the other (younger females). The productions of the older speakers, the older males in particular, were more in line with what had previously been described for Castilian Spanish (Face Reference Face2002) than the productions of the younger groups, especially the younger females. Note also that the contour produced, on average, by the younger females was more similar to the contour produced by the Catalan speakers than it was the one produced by the other three groups of Spanish speakers. This suggests that, in the Spanish of Majorca, utterance-final pitch accents are in the process of changing. This change, led by younger females, with younger males following behind, may be motivated by intensive contact with Catalan. It seems that the utterance-final pitch accents of Spanish are becoming more similar to Catalan, i.e. are converging towards Catalan. This is a significant finding.
Vildomec, cited in (Thomason & Kaufman Reference Thomason and Kaufman1988: 42), wrote that
whereas some adherents of substratum theories maintain that pronunciation, particularly intonation, melody and rhythm of speech, are among the features most persistently dictated by the Lm . . . it has often been observed that, after a relatively short stay, immigrants to America speak their Lm with an English ‘accent’. (Vildomec Reference Vildomec1971: 91)
In other words, according to Vildomec, ‘adherents of substratum theories’ claim that intonation is not a malleable linguistic feature and that bilinguals tend to use the intonational patterns of their native language in both their native and non-native languages. While Vildomec adds that immigrants to America may end up speaking their L1 with an English accent, no experimental evidence exists supporting this claim for intonational production in societal language contact. Mennen Reference Mennen2004 showed that learning of the intonational patterns of an L2 may affect intonational production in the L1 in the speech of adult L2-learners. However, studies of societal language contact tend to assume that L2-to-L1 transfer of prosodic features occurs only when speakers are no longer dominant in their L1 and thus transfer features from their dominant (which is actually their L2 or the language they acquired second) to their non-dominant language (their family or heritage language, i.e. the one they acquired first) (Thomason & Kaufman Reference Thomason and Kaufman1988: 42). The findings of the present paper suggest that intonational convergence (i.e. adoption of L2 intonational features into the bilingual's L1) in societal language contact is possible even in cases in which the speakers participating in the change continue to be dominant in their first or family language. In our opinion, this comes to support the hypothesis put forward in Colantoni & Gurlekian (Reference Colantoni and Gurlekian2004) to explain the case of Buenos Aires. As mentioned above, while Colantoni & Gurlekian (Reference Colantoni and Gurlekian2004) explain that some of the intonational features found in the Spanish of Buenos Aires may have originally been introduced by Italian migrants to Argentina (L2 learners of Spanish), monolingual speakers of Spanish residing in the city at the time must have had to imitate those features in their own speech, eventually spreading the feature to the entire speech community. Thus, adoption of the intonational patterns of a second (or other) language may occur even when a speaker is dominant in her native language or possibly even when a speaker is not bilingual. Turning to the case of Majorca, while concave or straight utterance-final falling pitch accents could have originally been introduced in the Spanish of Majorca by Catalan-dominant speakers (L2 learners of Spanish, i.e. Catalan-accented Spanish), some Spanish-dominant speakers seem to be introducing this variant into their own speech and thus participate in the diffusion of this variant. This shows that, in language contact, linguistic innovations may be introduced both by dominant and non-dominant speakers of the receiving and the source languages (Winford Reference Winford2005). Evidently, future research is needed to test this interpretation and its implications.
4.2 Intonation in bilingual individuals
The results of the within-language, between-subjects analyses carried out here on both Catalan and Spanish productions showed that sequential learning has an effect on intonational production. In particular, it was found that bilinguals showed a tendency to transfer the intonational patterns of their native language to their non-native one. These findings agree with previous ones on the intonational behavior of simultaneous and late bilinguals (Atterer & Ladd Reference Atterer and Ladd2004, Mennen Reference Mennen2004, Elordieta & Calleja Reference Elordieta and Calleja2005). The analyses reported in the present paper add to a growing body of evidence suggesting that even early and extensive exposure to the L2 may not be enough for bilinguals to develop a native-like command of the speech patterns of their L2 (e.g. Pallier et al. Reference Pallier, Bosch and Sebastián-Gallés1997). Only bilinguals who continue to use their native language more frequently than their non-native language were investigated here. Research carried out by Flege and colleagues has shown that early bilinguals who have higher frequencies of use of their L2 than their L1 may be able to acquire the speech patterns of their second language in a native-like manner (Flege, Frieda & Nozawa Reference Flege, Frieda and Nozawa1997, Guion, Flege & Loftin Reference Guion, Flege and Loftin2000, Piske et al. Reference Piske, Flege, MacKay and Meador2002, Flege & MacKay Reference Flege and MacKay2004). Our data do not allow us to tease apart the potential effects of sequential learning vs. frequency of L1–L2 use in our group of 20 Catalan–Spanish bilinguals. While the present paper provides important new knowledge regarding the intonational patterns of early bilinguals, only further research that orthogonally varies the effects of use and age of acquisition would be able to add to the current discussion of whether sequential learning effects are due to a loss of plasticity after the critical period or to patterns of L1–L2 interaction affected by recent linguistic experience. Our data were able to provide a more complete sociophonetic profile of the production of utterance-final pitch accents in both the Catalan and Spanish varieties spoken in Majorca by adding L2 (i.e. dominant and non-dominant) productions, which are representative of both contact varieties.
Initially, the finding that Catalan-dominant and Spanish-dominant bilinguals used different intonational patterns when using the same language suggested that the two groups of bilingual participants had not developed a separate category for utterance-final pitch accents in their non-native language and were thus fundamentally using the same phonetic category in their two languages. In order to verify whether this was the case, the L1 and L2 productions of the participants were compared in a series of within-speaker comparisons. The within-speaker analyses showed a trend for bilinguals to maintain separate statistical distributions for utterance-final pitch accents in their two languages. This trend was robust in the case of the Catalan-dominant speakers and much less so in the case of the Spanish-dominant participants. Let us now examine the relevance of this finding from the perspective offered by Flege's Speech Learning Model (SLM; Flege Reference Flege and Strange1995).
First, we did not find evidence for the application of phonetic category dissimilation. Flege's SLM states that after the formation of a new category for an L2 speech sound, dissimilation (i.e. acoustic-perceptual dispersion) tends to apply due to the fact that the acoustic-perceptual space of a bilingual becomes more ‘crowded’. However, while some studies have found evidence for the application of a dissimilatory process (Flege & Eefting Reference Flege and Eefting1987, Flege, Schirru & MacKay Reference Flege, Schirru and MacKay2003), others have failed to do so (Flege Reference Flege1987, Reference Flege1991; Sancier & Fowler Reference Sancier and Fowler1997; Fowler et al. Reference Fowler, Sramko, Ostry, Rowland and Hallé2008). In the present study, many early bilinguals were found to maintain separate statistical distributions for utterance-final pitch accents in their two languages. We interpret these results to suggest that they have developed a new (or separate) phonetic category for utterance-final pitch accents in their L2. However, the new patterns were not identical to the ones produced by native speakers of the target language. Moreover, the difference between the native and non-native phonetic categories of the bilinguals was not greater (but smaller) than the between-speaker differences. Thus, our findings show that new-category formation does not necessarily lead to dissimilation. That is, even though dissimilation may be a possibility when bilinguals develop a new category for their L2 (Flege & Eefting Reference Flege and Eefting1987, Flege et al. Reference Flege, Schirru and MacKay2003), the L1 category may still act as a powerful ‘attractor’ to the corresponding L2 category for some bilinguals.
Second, evidence of category assimilation of intonational phonetic categories was found. The Catalan-dominant bilinguals tended to produce Spanish (L2) contours that differed from the ones produced by the Spanish-dominant bilinguals in Spanish. In particular, Catalan-dominant speakers produced concave-falling contours (L*) in their Spanish that resembled the ones they used in their native language (Catalan). The Spanish-dominant bilinguals were also found to produce fundamentally similar intonational categories both in their native and non-native languages (convex-falling, i.e. H*). Interestingly, however, there were important differences between the utterance-final pitch accents produced by the Spanish-dominant males and those produced by the Spanish-dominant females. While the Spanish-dominant males were found to produce ‘Spanish-like’ (rising-falling or convex-falling) contours in their two languages, the Spanish-dominant females were found to produce contours that lay somewhere in between the ones produced by the males in the same native language group and those produced by the Catalan-dominant participants. Flege's SLM states that the learning of an L2 might also have an effect on the L1 in cases of phonetic category assimilation. That is, even though it is possible that bilinguals use their L1 categories to produce similar sounds in their L2, it is also possible for L2-learning to trigger the development of a merged L1–L2 phonetic category that may lie somewhere in between the native and non-native categories (in an acoustic-perceptual multi-dimensional space). However, the question remains as to what may have motivated the Spanish-dominant females to develop an intermediate, merged category while the males fundamentally transferred their L1 intonational patterns into their L2. As outlined above, one possibility is that there exists an ongoing process of intonational convergence between Catalan and Spanish in Majorca. According to this interpretation, Spanish-dominant females are the leaders of a convergence process, which would explain why their L1 categories reside somewhere in between the ones of Catalan-dominant bilinguals and of Spanish-dominant males. This is an asymmetric convergence process, since it causes Spanish to ‘become more like’ Catalan regarding this intonational feature but leaves Catalan fundamentally unaffected in this respect.
Finally, it is important to consider here the apparent differences in their ability to maintain separate subsystems between the Catalan- and the Spanish-dominant bilinguals. While Catalan-dominant bilinguals, as a group (evidenced by three acoustic metrics, robustly for five subjects), used different types of utterance-final pitch accents, most of the Spanish-dominant participants did not maintain separate statistical distributions (a robust difference was observed for only one acoustic metric and then for only three subjects). We might speculate here that the specific sociolinguistic situation affecting Catalan and Spanish utterance-final pitch accents in Majorca is affecting the performance of bilinguals in their two languages. We have proposed above that utterance-final pitch accents are in the process of changing in the Spanish variety spoken in Majorca (but not in Catalan). It is possible that the fact that Spanish-dominant speakers are gradually converging with Catalan-dominant speakers (perhaps a socially-motivated, contact-induced sound change) has motivated some of them to develop a merged L1–L2 category (especially the young females) and thus makes it difficult for them to maintain separate L1 and L2 intonational phonetic categories. Perhaps these bilinguals interpret both ‘Spanish-like’ (rising-falling, flat-then-falling, convex-falling) and ‘Catalan-like’ (concave-falling) contours as allowed variation in the Spanish of Majorca. More research on the sociolinguistic situation in Majorca is needed before we can make a definitive interpretation of these results. Furthermore, at present, our knowledge of the social-indexical factors that affect bilingual speech production in general is very limited. Perhaps the present findings will encourage future research in this direction.
5 Conclusion
The present study investigated the acoustic characteristics of utterance-final pitch accents in read-aloud declaratives in two contact language varieties, i.e. Catalan and Spanish in Majorca. Importantly, we examined the productions of both Catalan and Spanish as spoken by a large group of bilinguals differing in their experience with the two languages. This paper had two main goals: (i) offering a sociophonetic profile of intonational variation in a bilingual speech community, and (ii) investigating the potential interaction of cross-linguistic intonational features in bilingual individuals. In other words, we addressed the individual, cognitive aspects of bilingualism while considering the social aspects of language contact in a bilingual community.
The main finding of the sociophonetic profile of the production of utterance-final pitch accents was that the Spanish of Majorca seems to be gradually converging towards Catalan. That is, the variety of Spanish spoken in Majorca seems to be adopting (one of) the intonational features characteristic of Majorcan Catalan, the variety with which it is in contact. The mirror claim cannot be made regarding Majorcan Catalan. Exclusively regarding the specific phonetic feature examined here, it is proposed that there exists a process of asymmetric convergence between the two languages; that is, we hypothesize that the phonetic features of the Majorcan Catalan utterance-final pitch accent studied here will diffuse across the entire community, eventually becoming characteristic of both the Catalan and the Spanish varieties spoken in Majorca.
The latter claim can only be confirmed (or falsified) in future research. First, we did not take into account the socioeconomic status of the speakers, which is customary in the field. In general, it is only when interactions between age, gender and socioeconomic status are found that claims of sound change ‘in progress’ are made. Second, only real-time, longitudinal studies of the community are able to eventually reveal whether a given pattern of sociophonetic variation is actually indicative of a sound change in progress. A large scale, real-time study of intonational variation in Majorca is needed. On the other hand, since most research on the sociolinguistic fabric of Majorca deals with issues of language choice (Villaverde Reference Villaverde2005) and not issues of phonetic variation, we consider the present paper to be an important contribution in this respect. On a wider scale, sociophonetic studies of intonational variation are needed in order to find out how it is that intonational change proceeds and whether it differs from segmental change or not. This paper also contributed to such an enterprise.
Turning to our second goal, perhaps the most important contribution of the present paper has been its examination of the patterns of interaction of native and non-native intonational categories within the performance of the participants. L1–L2 interactions are sometimes examined in the L2 speech literature (Sancier & Fowler Reference Sancier and Fowler1997, Fowler et al. Reference Fowler, Sramko, Ostry, Rowland and Hallé2008). These patterns of interaction are fundamental in some L2 speech learning theories (Flege Reference Flege, Cole and Hualde2007). However, interactions have only been investigated for segmental production and perception. Our knowledge of the bilingualism issues affecting prosodic or intonational production is scarce. While Mennen (Reference Mennen2004) showed L2 effects on L1 production of tonal alignment in the speech of four adult late bilinguals, the evidence for L2-to-L1 influence was rather indirect. The present paper investigated the L1 and L2 productions of a large number of early bilinguals comparing two similar phonetic categories and using an identical metric for the two languages. Our study of L1–L2 interactions makes a significant contribution to the L2 speech learning field by adding a necessary new dimension, i.e. intonational production.
Finally, a trend was found for Catalan-dominant bilinguals to be more likely than Spanish-dominant bilinguals to produce language-specific intonational patterns for their L1 and L2 productions. We hypothesized that this could be related to our finding that Spanish utterance-final pitch accents seem to gradually become ‘more like’ Catalan even for Spanish-dominant speakers. That is, it is possible that Spanish-dominant bilinguals in Majorca (especially the younger females, the leaders in this convergence process) have developed a merged L1–L2 category that they produce both in their L2 and their L1. A gradient process of phonetic convergence, at the level of the bilingual community, may be mirrored by a gradient process of phonetic convergence (i.e. category merging) at the level of the bilingual individual. Further research is needed to test this hypothesis as well as to investigate the relationship between the social-indexical forces shaping societal language contact situations and cognitive constraints (and speech performance) in bilingual individuals.
Acknowledgements
The present paper is a modified version of one chapter of my University of Illinois doctoral dissertation. I gratefully acknowledge the guidance of José Ignacio Hualde, Anna María Escobar, Jennifer Cole and Zsuzsanna Fagyal. I am grateful to Denielle Weigand for assistance. Finally, I am thankful to three anonymous reviewers and to John Esling, editor of this journal, for their comments, which have greatly improved this paper. All errors remain my own.













