


1 Introduction
Chinese languages are known for their lexical tones, the syllabic tone melodies which form part of the phonological representations of words. These tone categories are conventionally represented in Chao digits with five distinctive pitch levels, ranging from 1, the pitch floor, to 5, the pitch ceiling (Chao Reference Chao1968). Standard Mandarin, for instance, contrasts four such tone melodies, [55, 35, 214, 51], designated Tone 1–Tone 4, respectively. Many studies have shown that their phonetic shapes can be quite variable, which is particularly true for Tone 3, a low tone. For one thing, Tone 3 is realized as [21] when followed by a non-low tone and as [214] in pre-pausal position. Moreover, when followed by another Tone 3, it is realized as [35] (e.g. Chao Reference Chao1968). Phonologically, [21] is commonly represented as L, while [214] and [35] often give rise to a trailing H-tone in the representation (Duanmu Reference Duanmu2007: 236–237). By contrast, the high tone (Tone 1) is the most stable one among the four tones. This asymmetry between the H- and L-tone melodies of Standard Mandarin has been addressed in a number of studies which together suggest that the L is more marked, more variable and less salient than H. First, van de Weijer & Sloos (Reference van de Weijer and Sloos2014) summarized the order of acquisition of Mandarin tones as Tone 1 > Tone 4 > Tone 2 > Tone 3, indicating that Tone 1 is the easiest to acquire and Tone 3 the hardest. Second, a brain-damaged Mandarin speaker was observed to produce only high level tones (Liang & van Heuven Reference Liang and van Heuven2004), suggesting that H is the default tone. Third, typological surveys of Chinese languages show that H-tone melodies are substantially more frequent than L-tone melodies (Jiang Reference Jiang and Chen1999) and less often subject to sandhi processes (Lu Reference Lu2001). Lastly, nearly level pitch is more likely to be parsed as H by Chinese listeners, unless it is very low (Whalen & Xu Reference Whalen and Xu1992), suggesting that L-tones are less salient than H-tones and as a result need some form of enhancement.
To a large extent, the apparently adverse conditions that beset the phonetic realization of Mandarin Chinese Tone 3 also apply to intonational L-tones. Significantly, L-tones in accented syllables, ‘starred’ L-tones, tend to be pronounced with more care than other L-tones and resemble the L-tone of Mandarin. Pierrehumbert (Reference Pierrehumbert1980: 68) observes that while more prominent realizations of H* will have higher f0, those for L* should have decreased f0, as illustrated in her Figure 2.9. Perceptual confirmation for Dutch was provided by Gussenhoven & Rietveld (Reference Gussenhoven and Rietveld2000), who found that L* needs to have lower pitch and H* higher pitch for perceived surprise on the part of the speaker to increase, a result attributed to increased pitch range in the signaling of surprise. Earlier, Leben (Reference Leben1976) described the realization of English L* as a ‘dip’. Importantly, as noted by Pierrehumbert (Reference Pierrehumbert1980: 69), lowering of L* is limited by a nearby low baseline and pitch range expansion will thus quickly lead to saturation at the low end. As a result, intonational L* may be enhanced by other features. A fall from mid-pitch preceding the low pitch, for instance, has been reported for European Portuguese (Vigário & Frota Reference Vigário and Frota2003), Stockholm Swedish (Bruce Reference Bruce1977), and the Borgloon variety of Limburgish (Peters Reference Peters, Riad and Gussenhoven2007; see also Gussenhoven Reference Gussenhoven and de Lacy2007: 263). Quite analogously to the analyses of Tone 3 (see below), there may be uncertainty over the attribution of the pre-L* fall to a H-tone, as opposed to allowing a phonetic implementation rule to create it (for Swedish, see also Riad Reference Riad, Kehrein and Wiese1998: 225). The interpretation of L*-lowering as a form of hyperarticulation is supported by the fact that non-starred L-tones may lack these enhancing features and instead be subject to undershoot, as illustrated by Arvaniti (Reference Arvaniti2016: 11), who notes that the L-tones of the Romani interrogative contour L* HL% on phrase-final syllable in [laˈtʃʰo] ‘nice’ behave differently. The focal L* shows an f0 dip on a considerably lengthened rhyme, but the final L% is ‘undershot’, a case of contour truncation. This stands to reason, since L* is associated with an accented syllable and as such represents a tonal basis for emphasis. Going by the evidence provided by Chinese lexical Ls and focus-marking L*s, it would thus appear that adding f0 flanks and lengthening the syllable rhyme are effective ways of enhancing L-tones.
The Kaifeng dialect of Mandarin, spoken in east central Henan, China, provides an excellent opportunity to investigate the nature of L-enhancements further. Earlier impressionistic descriptions of the dialect (Zhang, Chen & Cheng Reference Zhang, Chen and Cheng1993, Liu Reference Liu1997) distinguish four citation tones, represented as [24, 41, 55, 31/312] (see Table 1). The first three tones represent a rising, a falling and a high level tone, respectively, but descriptions of the fourth tone vary. Zhang et al. (Reference Zhang, Chen and Cheng1993) regard it as a falling tone starting from the mid-range and ending at the pitch floor, transcribing it as [31], whereas Liu (Reference Liu1997) considers it a dipping tone, transcribing it as [312]. The choice between these two transcriptions will inevitably affect the overall phonetic and phonological analysis. Below, we will provisionally take the fourth tone to be L, assuming a symmetrical four-way system LH, HL, H and L, adopting the representations of tonal phonology (Goldsmith Reference Goldsmith1976, Duanmu Reference Duanmu2007).
Table 1 Tone scale notations of Kaifeng Mandarin LH, HL, H and L, with their traditional tonal category labels in brackets.

The tonal categories in modern Chinese dialects are defined etymologically and referred to in the traditional nomenclature of the four tones in Middle Chinese, ping, shang, qu and ru. The sinological literature sub-classifies each tonal category into yin and yang tones, depending on the voicing status of the onset consonant (Chen Reference Chen2000) and assigns numerical labels to them. Thus, the four tonal categories in Standard Chinese, yinping, yangping, shang and qu, are labelled Tone 1 to Tone 4, respectively. Often, as in the case of Kaifeng Mandarin, the phonetic shapes of the tones used in these etymological classes differ from those in Standard Chinese. For instance, Standard Chinese Tone 4 is a fall from high to low, while Tone 4 in Kaifeng Mandarin is phonologically equivalent to Standard Chinese Tone 3 (see Table 2). While the phonological analysis of [24, 41, 55] as LH, HL and H, respectively, is unproblematic, it is less evident in the case of the proposed L for Kaifeng Tone 4. The analysis is supported by the pitch curve obtained by rudimentary instrumentation by Chao (Reference Chao1922), which resembles the pitch curve of the low tone (Tone 3) in Beijing Mandarin. In addition, a pilot study by Wang & Liang (Reference Wang and Liang2015) suggests that Kaifeng Mandarin L has a low dipping pronunciation with a weakly rising trend in the final portion of the syllable.
Table 2 A comparison of traditional tone categories, tone labels and phonological tones in Standard Chinese and Kaifeng Mandarin.

The goal of this investigation is, first, to provide detailed acoustic information on the realization of Kaifeng Mandarin L and, second, to evaluate the variation that is encountered in terms of possible enhancements of a low tone.
2 Method
2.1 Design
Kaifeng Mandarin syllables have a single optional consonant in the onset, while the rhyme has an obligatory vowel and an optional coda nasal [n] or [ŋ], which may appear after monophthongs. A corpus of 35 tonal minimal quadruplets was prepared, shown in Table 3. All of them have an onset consonant, of which 18 are aspirated plosives or affricates, six unaspirated plosives or affricates, seven fricatives and four sonorants; seven quadruplets have a nasal coda and four have diphthongal rhymes, while the remaining 24 have monophthongal vowels without a coda. Vowel height is balanced by including both high and low vowels in the rhyme, by the side of three quadruplets with retroflex approximants in the rhyme (Lee-Kim Reference Lee-Kim2014).
Table 3 Stimuli used in the audio recording including 140 characters varying in tone, segmental makeup and syllable structure.

2.2 Participants
Ten native speakers of Kaifeng Mandarin participated in the experiment. All of them were born and raised in Kaifeng and lived in the inner city at the time of the experiment. None of them reported any speaking or hearing deficiencies. The age and gender distribution is as follows: 27–30 (M = 4), 31–50 (M = 1, F = 1), 51–60 (M = 2, F = 2). They use Kaifeng Mandarin in their daily communication and nine of them can speak Standard Chinese at varying proficiency levels (see Table 4 for more detailed information). Among the ten speakers, ZBR cannot speak Standard Chinese at all. Four young speakers (XYC, FGH, TJQ, QHC) are native bilinguals of both Kaifeng Mandarin and Standard Chinese. The Standard Chinese proficiency for the other older speakers is either near-native or recognizably Kaifeng-accented.
Table 4 Ten participants with information of gender, age (years), and their self-reported proficiency in Standard Chinese.

2.3 Procedure
The audio recordings were conducted in quiet rooms, where the subjects were seated in front of a laptop. The reading materials were visually and randomly presented one per slide at the centre of the screen with the help of Prorec software (Huckvale Reference Huckvale2014). The participants read each word once, and were asked to repeat it if they were uncertain about the quality of their first pronunciation. Each word was presented twice, resulting in 280 slides (140 syllables * 2 repetitions). After a participant had read a word, the experimenter would click a button to make the slide with the next character appear. The audio data were digitized via a Samson C01U Pro USB condenser microphone placed at a 10 cm distance from the speaker's mouth on a microphone stand. The starting and ending time of each presentation slide were collected for automatic segmentation of the recordings of each of the 280 slides.
2.4 f0 extraction
For each speaker, 280 recorded words were automatically segmented in Prorec according to the starting and ending time of each slide. Phonetic annotation and f0 extraction of these 2,800 speech files were carried out in Praat (Boersma & Weenink Reference Boersma and Weenink1992–Reference Boersma and Weenink2015). Rhymes for every syllable were identified in the waveform and spectrogram and boundaries were manually labeled (see Figure 1). With the aid of a Praat script (Xu Reference Xu2013), vocal pulse marking was checked and manually corrected. The raw f0 measurements were smoothed with a trimming algorithm (Xu Reference Xu1999) and output files with information about time-normalized f0, duration, maximum f0, minimum f0 and f0 velocity were automatically generated. One hundred and forty-nine recordings, 5.32% of the total, were excluded from further analysis due to mispronunciations, while 15 stimuli (13 Ls and 2 HLs) had so much jitter that they could not be included in the f0 analysis. Their phonetic properties will be discussed in Section 3.5. From the 2,636 remaining speech files, 21 equidistant f0 measurements (in Hz) were taken from the rhymes.

Figure 1 Phonetic annotation of a recorded word in Prorec. The rhyme of each syllable is manually labeled in a Praat textgrid.
2.5 f0 normalization
In order to eliminate speaker f0 range differences (10.39, sd = 1.22 ST with a reference value of 100 Hz), we transformed the raw f0 data into speaker-specific z-scores in three steps. First, for each speaker, values were averaged point-by-point across the syllables in each of the four tone categories. Second, the grand average f0mean and standard deviation f0sd of the f0 measurements per speaker over the dataset obtained in step 1 (21 averaged points * 4 tone categories) were calculated. Third, raw f0 measurements for all the stimuli of the speaker f0x (in Hertz) were transformed into speaker-specific z-scores, using z = (f0x – f0mean)/f0sd (Rose Reference Rose1987). After the normalization, the z-normalized f0 values were used for graphical and statistical purposes.
3 Results
3.1 Rhyme duration
In terms of rhyme duration, Tone L is the longest (249.19 ms, sd = 52.56), followed by LH (229.25 ms, sd = 55.99), while HL and H are the shortest (209.02 ms, sd = 37.31 and 203.52 ms, sd = 54.32, respectively). A one-way between-subjects ANOVA yielded a significant effect of tone on rhyme duration (F(3,2632) = 111.62, p < .001). Dunnett's T3 post hoc tests revealed that significant differences were found between the members of each pair of tones except that between HL and H.
Figure 2 presents the etymological tone classes and the phonological tones in the two dialects together with their mean durations. Because the phonological counterpart of Kaifeng Mandarin L in Standard Mandarin, Tone 3, a low tone, is the longest of its set of four tones, the longer duration of Kaifeng Mandarin L is associated with its phonology, not with its etymological tone class. Standard Mandarin Tone 4, the etymological equivalent of Kaifeng Mandarin L, is in fact the shortest of the four tones in that dialect, and is phonologically HL.

Figure 2 Durations of four tone categories ordered according to their etymological class in Kaifeng Mandarin (panel (a)) and Standard Chinese (panel (b), data from Xu Reference Xu1997). The data in panel (a) are from ten speakers (N = 2636; LH = 663, HL = 652, H = 656, L = 665). Horizontal bars stand for ±2 standard errors.
3.2 f0 contours
The mean f0 contours of the four tones are shown in panels (a)–(d) in Figure 3. In each panel, the ten colored curves were obtained by averaging over the maximally 70 tokens per tone per speaker and are plotted as functions of normalized time (0–100). Figure 3 suggests there may be more variation in the tone shape of L than in LH, HL and H, especially in the second half of the f0 contour. LH (panel (a)) starts with a low f0 onset, and rises to the mid-range. Four speakers (CJY, QHC, WCX and ZBR) have rising contours, while the other six speakers have weakly dipping contours, whereby the f0 curves fall slightly during the initial 25% of the rhyme duration and rise thereafter. All ten speakers produced both consistently rising and weakly dipping realizations of LH, with 33.18% of the 663 LH melodies exhibiting rising contours, the rest being weakly dipping. HL (panel (b)) starts with the highest f0 onset and falls sharply to the end of the syllable. The shape of the contours is consistent across the ten speakers, but some variation occurs in the duration of the target for the L-tone in HL, as depicted in an extreme case produced by QHC, where the fall begins in the first half of the rhyme. Finally, H (panel (c)) has a high onset and remains fairly constant throughout the rhyme. Two speakers (QHC and ZBR) have a slightly rising contour. Section 3.3 presents the way in which the variation in L deviates from that in the other tone categories.
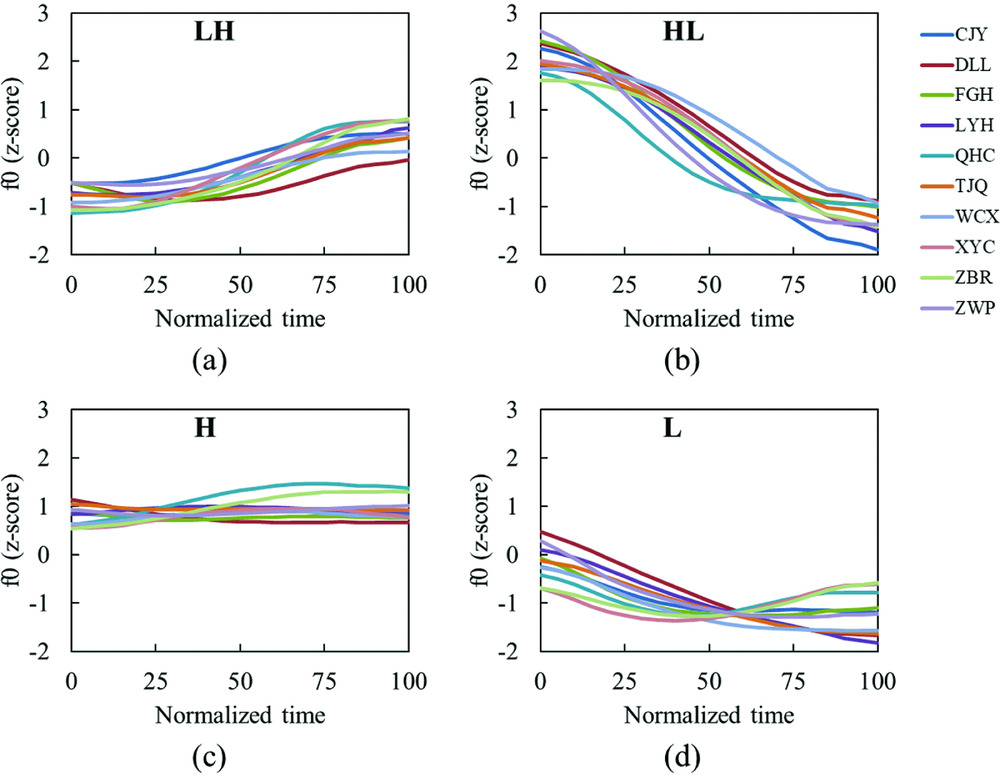
Figure 3 Tonal contour from ten speakers (averaged across tokens). The four tones are grouped in separate panels ((a)–(d)).
3.3 L-specific variation
A widely employed method for revealing the ways in which the data for the four tones represented in Figure 3 differ from each other is by determining their f0 shape and f0 height (Jongman et al. Reference Jongman, Wang, Moore, Sereno, Li, Tan, Bates and Tzeng2006), more specifically their f0 slope and mean f0 (z-score). Accordingly, mean f0 was obtained by averaging the 21 points, while f0 slope was defined as the coefficient of the linear regression line for the 21 points of each tone with the corresponding real timestamps as the independent variable. Following Peng (Reference Peng2006), we plot the mean f0 against the overall f0 slope to access the variability of each token. Figure 4 is a scatterplot for the citation tones in Kaifeng, with each token represented as a plot symbol. As expected, realizations of H have higher f0 (0.90, sd = 0.45), while realizations of L are lower (−0.97, sd = 0.29), with plot symbols located above and below the horizontal axis, respectively. Mean f0 of HL (0.33, sd = 0.42) is generally greater than that of LH (−0.28, sd = 0.39). Results of a one-way between-subjects ANOVA show that there was a significant effect of tonal category on mean f0 (F(3,2632) = 2794.58, p < .001) and post-hoc comparisons using the Dunnett's T3 test indicated that mean f0 of all four tones differed significantly from each other. As for the horizontal dispersion, HL and LH are discretely located on the left and the right of the central vertical axis (HL: –19.74, sd = 5.10; LH: 7.25, sd = 3.42). The relatively flat slopes for LH are due to the initial fall of the weakly dipping contours (see Section 3.2). The areas for the relatively flat slopes of H (1.14, sd = 3.30) and LH overlap somewhat. An overall analysis of variance yielded a significant tone effect on f0 slope (F(3,2632) = 4898.29, p < .001); Dunnett's T3 post hoc tests revealed significant differences in f0 slope between each pair of tone categories. To examine the variation of the contour shapes, ANOVAs were performed for each of the four tones separately, with f0 slope as the dependent variable and speaker as the independent variable. There was a significant speaker effect on f0 slope for each of the tones (LH: F(9,653) = 95.17, p < .001, η2 = .567; HL: F(9,642) = 50.94, p < .001, η2 = .417; H: F(9,646) = 114.58, p < .001, η2 = .615; L: F(9,655) = 288.39, p < .001, η2 = .798). Generally, therefore, inter-speaker variation in f0 slope is greater than intra-speaker variation, but the effect size is largest for L. It indicates that 80% of the total variation in f0 slope of L is accounted for by variation between speakers, as opposed to 40–60% for the other tones.

Figure 4 Scatterplot for the citation tones in Kaifeng Mandarin with the horizontal axis showing the slope and the vertical axis showing the mean f0. Ten speakers; N = 2636, LH = 663, HL = 652, H = 656, L = 665.
As can be seen in Figure 4, L is the only tone whose range of realizations reaches from a slope as steeply falling as that of HL through a slope as flat as that of H to a slope as slightly rising (or dipping) as that of LH. Further inspection of the data shows that the 80% explained variation for L in the ANOVA is due to the existence of three speaker-specific f0 slopes for the second half of the contour in the case of L (see panel (d) of Figure 3). That is, dipping, a contour shape involving flanking movements on both sides of the low targets, is utilized only by speakers XYC, QHC and ZBR, while low falling is typically seen in speakers DLL, TJQ and LYH, where f0 gradually falls towards the low pitch target. A fall with a sustained low stretch after the low point of the fall is used by WCX, FGH, ZWP and CJY. Such speaker-specific variation has no counterpart in the other three tone categories. While it is true that the contours for H include rising as well as falling slopes and those for LH include rising slopes as well as almost flat shapes due to the existence of an initial falling slope, these variations are primarily caused by variation within each of the speakers, rather than by systematic variation between the speakers. This intra-speaker variation was captured by the standard deviation of f0 slope calculated per subject per tone. The averaged standard deviation for L is indeed the smallest (0.275), followed by HL (0.348), LH (0.356) and H (0.426). A one-way within-subjects ANOVA showed that the effect of tone was significant (F(3,27) = 17.646, p < .001), indicating that the four tones differ in intra-speaker variation. Paired sample t-tests indicated that intra-speaker variation for L was significantly smaller than each of the other three tones (L–HL: t(9) = 6.148, p < .001; L–LH: t(9) = 4.06, p = .003; L–H: t(9) = 6.597, p < .001). In the next subsection, the smaller intra-speaker variation in the realization of L is considered in more detail in order to establish how consistent the three speaker subgroups are in the realization of the subtypes.
3.4 Variation of the L-tone
In the case of L in particular, f0 slope is not a realistic measure of f0 shape. As a result of the reduction of L to a single slope in the above analysis, the data for L overlap somewhat with those for HL and LH. In order to represent the variation for L more realistically, separate regressions were carried out over the first and second sets of 11 sampling points, respectively, such that two coefficients were obtained for each realization. A dipping realization is defined by a negative slope for the first half of the contour and a positive slope for the second half, a falling contour by a sequence of two negative slopes, while a falling plus a low level realization will be assigned a negative slope for the first half and a flatter slope for the second half (whether positive or negative). Panels (a)–(c) in Figure 5 exemplify how these data characterize the dipping, falling and falling + lengthening subtypes on the basis of selected tokens.

Figure 5 Examples of the dipping (a), falling (b) and falling + lengthening (c) subtypes of L, with two linear regression lines superimposed on the f0 sampling points. Slope 1 (solid line) and Slope 2 (dashed line) are the coefficients of the first and last 11 sampling points with their corresponding real time points as the independent variable.
Figure 6 shows scatterplots of the realization of the three subtypes of L for the dipping, falling and falling + lengthening subtypes of L in panels (a)–(c). Each speaker was categorically assigned to a slope subtype (dipping for XYC, QHC and ZBR; falling for DLL, TJQ and LYH; lengthened falling for WCX, FGH, ZWP and CJY), on the basis of the tone shapes in Figure 3. Data points for each subtype turn out to fall within a unique band along the horizontal axis, between 0 and 10 for the dipping subtype (panel (a)), between –10 and 0 for the falling subtype (panel (b)), and between –5 and 5 for the lengthened falling subtype (panel (c)). With just one exception, all the data points of the dipping subtype are located on the right of the central vertical axis, indicating that virtually all tokens of L produced by XYC, QHC and ZBR are dipping (Slope 2: N = 205, mean = 5.27, sd = 2.20). Similarly, with only three exceptions, the data points of the falling subtype are positioned on the left of the central vertical axis, indicating that DLL, TJQ and LYH realize L as a falling contour (Slope 2: N = 194, mean = –6.51, sd = 2.99). Finally, Slope 2 of the lengthened falling subtype (panel (c)) as produced by the four remaining speakers is located around the central vertical axis (Slope 2: N = 266, mean = −0.24, sd = 2.46). By contrast, all three subtypes begin with a falling slope (Slope 1). These data show in more detail that the intra-speaker variation is considerably smaller than the inter-speaker variation and that the inter-speaker variation concerns the treatment of L in the second half of its syllable rhyme. Results from a one-way between-subjects ANOVA revealed a significant group effect on Slope 2 (F(2,662) = 1062.71, p < .001). Dunnett's T3 post hoc tests revealed that significant differences were found between each pair of the three subtypes.

Figure 6 Intra-speaker variation in the realization of L. Each realization is represented as a point in the Slope 1/Slope 2 plane. Ten speakers’ data are grouped separately in panels (a)–(c), on the basis of the subtypes the speakers were assigned to. Panel (a): XYC (N = 67), QHC (N = 69) and ZBR (N = 69); panel (b): TJQ (N = 67), DLL (N = 70) and LYH (N = 57); panel (c): WCX (N = 62), FGH (N = 67), ZWP (N = 70) and CJY (N = 67).
To see if there was a durational effect of slope type, the Pearson correlation coefficient between rhyme duration and Slope 2 was established. It turned out to be positive and significant (r = .43, N = 665, p < .001), indicating that rising Slope 2s tend to be longer than level and falling ones. A scatterplot summarizes the results (Figure 7). This effect is further confirmed by the results from a one-way between-subjects ANOVA, which yielded a significant effect of the three different subtypes on the rhyme durations of syllables (F(2,662) = 89.14, p < .001; dipping: N = 205, mean = 280.38, sd = 56.41; lengthened falling: N = 266, mean = 247.94, sd = 29,89; falling: N = 194, mean = 217.95, sd = 53.83). Dunnett's T3 post hoc tests revealed significant differences for each pair of subtypes.

Figure 7 Slope 2 as a function of rhyme duration. Subtypes indicated by the colour of the plot symbols (N = 665).
The histogram in Figure 8, which bins the lowest values at each of the 21 sampling points for the three subtypes of L, confirms that the location of the f0 minimum within the rhyme reflects the contour differences among the subtypes. The median of the dipping subtype lies at 45% of the rhyme duration, i.e. just before the halfway point. The lengthened falling subtype has a more variable location of the f0 minimum, including cases where it lies right at the end, when the level stretch is in fact slightly descending. The falling subtype has its most frequent location at the rhyme end, as expected. Overall, the location of the f0 minimum varies from the 25% position within the rhyme to the rhyme offset.

Figure 8 Frequency distribution of the f0 minima of the three subtypes of L over 16 points equally spaced over the last 75% of the rhyme, represented as percentages of the normalized rhyme duration on the x-axis. Red = falling subtype; green = lengthened falling subtype; blue = dipping subtype (N = 665).
3.5 Creak
Realizations of Kaifeng Mandarin L show varying degrees of creak. Creaky voice is characterized by the ‘irregularity of the interval between consecutive glottal pulses’, technically known as ‘jitter’ (Ladefoged Reference Ladefoged2003: 172). Figure 9 displays the waveforms and spectrograms of realizations with creak obtained from three speakers. Panel (a) shows a realization of L by ZBR in which creak occurs mainly in the central portion of the rhyme. The amplitude of the waveform decreases considerably at the point where creak begins. Although there is creak, the intervals between the pulses are regular, and the utterance can still be analyzed in terms of f0. The yellow speckles superimposed on the spectrogram are the pitch track obtained by manually labeling and calculating the intervals of the glottal pulses and smoothed in Praat (Boersma & Weenink Reference Boersma and Weenink1992–Reference Boersma and Weenink2015). Panel (b) shows a realization of L by FGH with more salient creak. Irregular pulses can be found from the 20% location to the offset of the rhyme. Panel (c) is a realization by LYH. The waveform and spectrogram show that from the onset of the periodicity to the 70% location of the rhyme, intervals between the pulses are brief and regular, while in the last 30% of the rhyme they become longer, such that f0 can no longer be measured.

Figure 9 Creaky voice in realizations of L. Panel (a): the waveform and spectrogram for syllable [pa] uttered by speaker ZBR, panel (b): the waveform and spectrogram for syllable [ta] produced by speaker FGH, panel (c): the waveform and spectrogram of syllable [tʂhou] generated by speaker LYH are provided.
Due to a lack of quantitative measurement of the gradience within creaky phonation, it is difficult to show how creak is distributed across the tone categories. Impressionistically, creak also occurs in LH and HL, though less often, while some realizations reveal a region of low amplitude and breathiness. Only 15 of our discarded tokens show a greater disturbance of the periodicity (e.g. panels (b) and (c) in Figure 9), of which 13 are L and two are HL.
4 Discussion
4.1 The analysis of the low tone as L
Our investigation of the four tone categories of Kaifeng Mandarin has established that:
(1) The rhymes of syllables with L are significantly longer than those of the other three tones.
(2) A greater inter-speaker variation is found in the tone shapes of L than those of LH, HL and H.
(3) A smaller intra-speaker variation is found in the case of L than in the case of LH, HL and H; the variation in L can be classified into three subtypes, dipping, falling and falling with lengthening, used by three subgroups of speakers.
(4) The slope of the f0 contours of L in the second half of the rhyme (Slope 2) is positively correlated with rhyme duration: rhymes with descending slopes in the second half are shorter than those with ascending slopes.
(5) Over all three L-subtypes, the time stamp of the f0 minimum lies within the last 75% of the duration of the rhyme, with a bias towards 45% in the dipping contour and towards 100% in the falling contour, while f0 minimum varies between 40% and 100% in the lengthened falling contour.
(6) Creaky phonation is a frequent feature of L, but it is neither consistent for L nor exclusive to L.
Unlike the interpretation of the rising, falling and high tones as LH, HL and H, respectively, the interpretation as L of the dipping, falling and falling + lengthened pronunciations of Tone 4 is not an immediately obvious analysis. Our investigation has revealed that these different forms reflect inter-speaker variation. The dipping contour, [312] in Liu (Reference Liu1997), was used by three of our ten speakers, while contour [31] of Zhang et al. (Reference Zhang, Chen and Cheng1993) was used by the other seven, four of whom in fact used a falling contour with a lengthened low target, representable as [311] (see Figure 3). Under the incorrect assumption of a HLH-tone, which might at first sight be an appropriate representation, the phonetic implementation would have to locate the low target as early as at 25% of the rhyme duration or as late as the rhyme offset, in the latter case without any implementation of the final H-target. Moreover, the brief duration of the initial fall suggests that initial H, too, is a dispensable element. These facts suggest that the most plausible hypothesis is that the f0 variation around the L target does not have a phonological origin. Before supporting this conclusion with phonological arguments, in Section 4.2 we attempt to explain the phonetic variation as different ways of enhancing the low target.
4.2 Explaining the variability in the realization of the isolated L-tone
We suggest that the explanation of the variety of f0 contours for phrase-final pronunciations of L lies in the intrinsic lack of salience of low pitch and the resulting need for its phonetic enhancement. An a priori expectation about the realization of a low tone is that it should have a low target. However, low targets are not easily lowered, unlike the way high targets can be raised (Pierrehumbert Reference Pierrehumbert1980: 68). Moreover, while a high f0 target typically stands out from a lower-pitched context, low pitch may be ambiguous between a tonal target and a low-pitched context, in particular in utterance-final position if utterances are expected to end in low pitch. Three types of enhancement are available to speakers. First, the low target (and the sonorant segment it coincides with) may be lengthened. In our data this is evident in the greater duration of L compared to the other three tone categories, as documented in Figure 2. We also found that Ls with an ascending Slope 2 are longer than those with a descending Slope 2, but even rhymes with a descending Slope 2 (230.90 ms, sd = 47.42) are longer than those of HL (209.02 ms, sd = 37.31) and H (203.52 ms, sd = 54.32) tone, while being equivalent to that of LH (229.25 ms, sd = 55.99), which has been shown to be longer than falling shapes for intrinsic reasons (Ohala & Ewan Reference Ohala and Ewan1973, Xu & Sun Reference Xu and Sun2002). That is, even if the extra duration is explained as a by-product of the flanking movements, part of the lengthening of L is independent of the f0 contour, as observed with reference to Standard Mandarin Tone 3 by Gussenhoven & Zhou (Reference Gussenhoven and Zhou2013). The long duration of Standard Chinese Tone 3 has in fact been shown to be perceptually relevant in distinguishing it from Standard Chinese Tone 2 (Blicher, Diehl & Cohen Reference Blicher, Diehl and Cohen1990).
Second, creaky phonation may replace regular phonation at the point where the lowest f0 is expected, the midpoint of the rhyme for the dipping subtype and the final portion for the falling subtype, and clearly serves as an enhancement of low pitch. A perceptual study by Ding, Jokisch & Hoffmann (Reference Ding, Jokisch and Hoffmann2010) demonstrated that a creaky or breathy realization of Tone 3 in Standard Chinese improves its recognition, showing that phonation contributes to the perceptual salience of the L-tone. Similar results are found in Yang (Reference Yang2015), who ran a tone identification experiment with stimuli taken from Standard Mandarin f0 continua produced by gradually altering the f0 contour of one natural tone exemplar into one of the other three in the four-tone set, leaving original phonation properties intact. It showed that speakers utilize phonation cues to identify the four tones, particularly Tone 3, even though the creak in the Tone 3 exemplar was not very obvious. It is possible that L-tones may naturally induce non-modal phonation, as pointed out by a reviewer, since LH and HL also have creak. A similar distribution of creak also holds for the tones in Standard Chinese (Belotel-Grenié & Grenié Reference Belotel-Grenié and Grenié2004). In fact, a larger and more clearly asymmetrical distribution of creak among different tone categories has been reported for Cantonese, a language with a more complex tone system (six non-checked tones and three checked tones). On the basis of a similar visual inspection of the disturbance of periodicity depicted in the waveform and spectrogram, Yu & Lam (Reference Yu and Lam2014) concluded that creak occurs more frequently in Cantonese Tone 4 ([21/11] in Chao digits) than other tones (24.2% of Tone 4 vs. 4.7% of the corpus). They also reported that Cantonese creaky Tone 4 is identified with a much higher accuracy than non-creaky Tone 4, while listeners also utilize creak in the perceptual separation of Tone 4 and Tone 6 ([22] in Chao digits). This suggests that languages with a greater functional load of f0 in conveying complex tonal contrasts, like Cantonese, tend to rely more on phonation cues in the production and perception of L-tones than languages like Mandarin, where pitch can adequately signal the L.
Third, the slight fall towards the low pitch target in the falling and dipping contours as well as the flanking f0-rise in the dipping contour can be seen as additions that place the low target in relief (Gussenhoven Reference Gussenhoven and de Lacy2007: 256; Evans, Yeh & Kulkarni Reference Evans, Yeh and Kulkarni2018: 525; see also ‘post-low bouncing’ in Prom-on, Liu & Xu Reference Prom-on, Liu and Xu2012). Although no perception data for the Kaifeng Mandarin tones have been reported, results from studies of Standard Chinese suggest that a low realization lacking f0 movements is more likely to be heard as H than as L (Whalen & Xu Reference Whalen and Xu1992; Cao Reference Cao2010a, b), indicating the lower perceptual salience of a bare, low pitched realization of L. The initial fall is also relevant for the discrimination between L and LH. Perception experiments in Standard Chinese indicate that discrimination of isolated Tone 2 and Tone 3, both of which can be said to have dipping realizations, is cued by the degree of the f0 initial fall, i.e., the frequency change from the onset f0 to the f0 minimum, as well as the timing of the f0 minimum. Specifically, Tone 3 is characterized by a greater f0 initial fall and a later f0 turning point compared with Tone 2 (see Jongman et al. Reference Jongman, Wang, Moore, Sereno, Li, Tan, Bates and Tzeng2006 and references cited there). Thus, a relatively greater f0 initial fall and a later L-alignment may be preferred for a better perceptual separation between a dipping L and a dipping LH.
The pronunciation of words with L under corrective focus suggests that speakers enhance the specific enhancements they use under broad focus, which further strengthens the case for interpreting the subtypes as alternative ways of enhancing L. Thus, the focus for phrase-final L is expressed by lengthening the L-target for speaker ZWP, but by increasing the f0 movement for speaker WC. Specifically, compared to the low–falling realization of L in the broad-focus condition, ZWP lengthens the low f0 level stretch, shown in panels (a)–(c) in Figure 10, in line with his realizations in citation forms (see Figure 3), while for WC (panels (d)–(f)), additional curvature is created in the focal L, achieved by raising the flanks on both sides of the L-target, resulting in a more dipped realization. This finding is in line with Shih's (Reference Shih1988: 84) informal observation that Northern speakers pronounce Standard Mandarin Tone 3 as falling–rising in isolation or sentence final position, but as low–falling elsewhere, while ‘Southern speakers often keep the low–falling pattern even in the final position in casual speech, and use the falling–rising pattern only in deliberate, emphatic speech, or in yes–no questions’.

Figure 10 Phrase-final L-tones produced in two focus conditions by ZWP (panels (a)–(c)) and WC (panels (d)–(f)), with data from Wang (Reference Wang2018). Pitch curves were averaged by ten repetitions per speaker. L-tones preceded by LH, HL and H are presented in separate columns. The vertical axis shows f0 in Hz. The duration of tones is normalized.
Emphasis in phrase-initial L-tone is generally cued by pitch range expansion of the low tone that raises the beginning of the initial fall, but not of the low target itself, as exemplified in Figure 11 for speaker ZWP. It shows pitch contours of L followed by LH, HL and H, with L pronounced in broad focus and corrective focus. In corrective focus, the pitch range is extended at the higher end, while the low target remains unaffected. This is not always true for HL in equivalent circumstances, where the end of the fall may be higher under corrective focus, along with a much higher beginning of the f0 fall.

Figure 11 Phrase-initial L-tones produced in two focus conditions by ZWP (data from Wang Reference Wang2018). Pitch curves were obtained by pooling over ten repetitions. L-tones followed by LH, HL and H are displayed in panels (a)–(c). The vertical axis shows f0 scales in Hz. The duration of tones is normalized.
4.3 Phonological arguments for the analysis as L
The phonetic and perceptual data discussed in Section 4.2 argue for an analysis of the low tone as L. There are four phonological arguments that support this analysis. First, it fits in with a symmetrical four-term set of word-melodies with LH, HL and H. Second, the representation fits a tone sandhi pattern whereby L is inserted between two H word melodies so as to create HL.H, which rule has a parallel in the insertion of H between two L word melodies, leading to LH.L. If our L were to be represented as HLH or ML, the rule would lose its character as an OCP repair, i.e., the separation of identical word melodies consisting of a single tone. Third, if the low tone was analyzed as monosyllabic HLH, it would run counter to the widely reported undershooting of the target of L, quite the reverse of what happens in Kaifeng Mandarin.Footnote 1 A fourth argument can be based on the pronunciation of the low tone in context, where it triggers phonetic behaviour that is associated with L-tones in languages more generally. As expected, tones are subject to coarticulatory effects of neighbouring tones (see Chen Reference Chen, Cohn, Fougeron and Huffman2012). In Kaifeng Mandarin, tonal coarticulation is bidirectional, involving both carry-over and anticipatory effects. The relevant finding is that the anticipatory effect on L is dissimilatory, and tends to raise the f0 of a preceding H-tone, as can be seen by comparing the f0 of H, HL and LH before L with that of the same tone melodies before the other three tones, as in Figure 12, which displays the f0 contours of the nonce disyllable /mama/ for all 16 tone combinations. In each panel, the first tone is kept constant and the second is varied. As mentioned in our second argument, Kaifeng Mandarin L is replaced with LH before another L, as shown in the thin dashed line in panel (d) of Figure 12. This derived LH does not appear to undergo raising due to the following L, but underlying LH as well as HL show quite sizable raising effects before L. In panel (a) of Figure 12, the f0 height and f0 offset of LH are raised by the following L compared with LHs before LH, HL and H. Similarly, both f0 peak and f0 offset of HL are raised before L compared with the HLs before LH, HL and H (panel (b) of Figure 12). These raising effects reach back to the initial portions of the rhyme within LH and HL. By contrast, no raising effect is found in the combination of level H with L (panel (c) of Figure 12). The f0 of H before L is only a little higher than that of H before LH, while remaining pretty close to the f0 of H before HL. (Tone sandhi is responsible for replacing H before H with HL, as shown in the thick dashed line in panel (c), which we here leave out of consideration.)

Figure 12 f0 contours of /mama/ sequence in Kaifeng Mandarin (data from Wang & Liang Reference Wang and Liang2015). Each f0 curve (ST re: 50 Hz) is pooled over 18 stimuli from three male speakers (six repetitions for each speaker). All speakers realize these tone patterns consistently. From panel (a) to panel (d), the first tone is kept intact and the second tone is varied. The duration of the onset nasal /m/ and the vocalic /a/ is normalized to one frame and two frames, respectively.
This local dissimilatory effect before L-tones has been described as f0 polarization (Hyman & Schuh Reference Hyman and Schuh1974), anticipatory dissimilation (Gandour, Potisuk & Dechongkit Reference Gandour, Potisuk and Dechongkit1994, Xu Reference Xu1997), H-raising (Connell & Ladd Reference Connell and Ladd1990), anticipatory raising (Xu Reference Xu1999) or pre-low raising (Lee, Prom-on & Xu Reference Lee, Prom-on and Xu2017) for a number of languages. For instance, in Standard Chinese, LH and L tend to raise the f0 of the preceding LH, HL and H (Xu Reference Xu1997). Similarly, in Thai, as reported by Potisuk, Gandour & Harper (Reference Potisuk, Gandour and Harper1997), high and rising tones are raised by the following low target. In Yoruba, a H-tone before an adjacent L-tone is raised (Connell & Ladd Reference Connell and Ladd1990). Also, long-distance raising effects on H induced by nonadjacent L has been reported in Yoruba (Laniran & Clements Reference Laniran and Clements1995), while Lee et al. (Reference Lee, Prom-on and Xu2017) show that the higher H* associated with the accented mora in Japanese is due to a pre-low raising effect. While Lee et al. (Reference Lee, Prom-on and Xu2017) argued that this effect is automatic, there is also speculation suggesting that it may partially be attributed to perceptual motivations. For instance, Gandour et al. (Reference Gandour, Ponglorpisit, Dechongkit, Khunadorn, Boongird and Potisuk1993) suggest that it is driven by the need to maximize the perceptual distance between contiguous tones. Potisuk et al. (Reference Potisuk, Gandour and Harper1997: 35) speculate that ‘the raising effect would enhance the perceptual separation of tonal categories in the face of a downward trend in f0 throughout a sentence’.
Just as in the case of the greater salience of the enhancement features under emphasis (Section 4.2), the raising effect is even greater when the triggering L-tone is focused, as exemplified in panels (a)–(f) in Figure 10, which compare f0 contours of disyllables with a phrase-final L-tone produced in broad focus as well as corrective focus, by speaker ZWP and WC, respectively. It shows that, for both speakers, correctively focused phrase-final L-tone induces a greater raising effect on the preceding LH, HL and H, which is comparable to that of Tone 3 focus in Standard Mandarin reported in Lee, Wang & Liberman (Reference Lee, Wang and Liberman2016). This suggests that pre-L raising is motivated by enhancement of L, as opposed to an enhancement of the preceding H-tone.
5 Conclusion
An acoustic investigation of the four lexical syllabic tone melodies of Kaifeng Mandarin produced by 10 speakers showed that in phrase-final position one of these tones has three different f0 contours depending on the speaker, dipping, falling and falling with lengthening. Fine-grained phonetic data documented the nature and extent of the variation of the four tone melodies. While intra-speaker variation was evident in all four, there was additionally large inter-speaker variation in the realization of one of these, analyzed as L. We have argued that this variation lies behind the divergent phonological characterizations that have been provided for this tone in Zhang et al. (Reference Zhang, Chen and Cheng1993) and Liu (Reference Liu1997).
Instead of analyzing these variant pronunciations of the low tone as phonologically different, we argued that they represent alternative ways of enhancing a low tone. In addition to f0 features, the low tone also stands out as being the longest as well as in having creak more often than the other three tones. After indicating that the perception of low tones is inherently more vulnerable than that of high tones or contour tones, we have argued that the various enhancements, initial fall, lengthening of the low target or the final rise, serve to increase the salience of the low target. Under corrective focus, the enhancements are further enhanced, which strengthens this explanation. The phonological analysis of the low tone as L, instead of ML or HLH, was further defended on the basis of four facts. First, L is the natural complement to a symmetrical four-melody system with H, HL and LH. Second, sequences of L.L are broken up by H, just as sequences of H.H are broken up by L, to produce LH.L and HL.H, respectively, which is another structural argument. Third, the adoption of a HLH melody would uncharacteristically fail to show undershoot of the target of L, which instead remains firmly low in all subtypes. Fourth, L triggers a raising of preceding HL and LH, in line with widely reported phonetic pre-L raising rules.
Thus, the lesson we draw from this investigation is that insightful phonological interpretations of the f0-contours of syllabic tone melodies may well deviate from faithful translations of phonetic forms into elements like Chao digits (e.g. 312) or phonological tones (HLH). In our case, the motivation of the phonological interpretation of the Kaifeng Mandarin low tone as L has led to an increased understanding of the reasons for phonetic forms to deviate from the phonological representation. Of course, while we have demonstrated a persistent presence of similar enhancements of intonational and lexical L in other languages, there is no implication that our three subtypes should make an appearance in L-tone realizations in all languages, any more than that L-tones in all languages will always be enhanced. A final question is why the Kaifeng speech community has not decided on a single way of enhancing their low tone, differently from Northern speakers of Standard Mandarin, where the dipping subtype would appear to be typical (Shih Reference Shih1988: 84). We believe that the answer may lie in the specific contrasts that the L-tone enters into, as observed by a reviewer. A resolution of this issue will therefore require a perceptual investigation in which the recognizability of different realizations of L is pitted against that of each of the three rival tone categories.
Acknowledgments
We gratefully acknowledge the comments by four anonymous reviewers and the editor on three earlier versions. This research was supported by a CSC scholarship awarded to the first author. Thanks are due to the participants in the production experiment. The data were collected in the spring of 2016 and analyzed by the first author as a part of a Ph.D. project supervised by Jie Liang at Tongji University in Shanghai. The results were interpreted and the article written under the supervision of Carlos Gussenhoven during Lei Wang's stay at Radboud Universiteit Nijmegen as a guest researcher in 2016/17.
















