1 Introduction
Recent studies on lexeme homophony have shown that seemingly homophonous words actually differ in phonetic details such as length and vowel quality (e.g. Gahl Reference Gahl2008, Drager Reference Drager2011). Likewise, realizational differences can be found with constituents of complex words. Kemps et al. (Reference Kemps, Ernestus, Schreuder and Baayen2005a, Reference Kemps, Wurm, Ernestus, Schreuder and Baayenb) showed that free and bound variants of a stem differ acoustically and that listeners make use of such phonetic cues in speech perception. Findings like these pose a challenge to traditional models of speech production which locate frequency information at the level of the phonological form, and which postulate that phonetic processing does not have access to morphological information (e.g. Levelt & Wheeldon Reference Levelt and Wheeldon1994, Levelt et al. Reference Levelt, Roelofs and Meyer1999).
Homophony below the level of the lexeme, however, has not received much attention so far. There are two questions that warrant closer inspection. The first concerns seemingly homophonous segments that do, or do not, represent morphemes. For example, the morphemic /s/ in laps might acoustically differ from the non-morphemic /s/ in laps e, as suggested by Walsh & Parker (Reference Walsh and Parker1983). The second question of interest concerns morphemes that share one phonological form while representing different meanings or functions. There could be fine phonetic differences between such morphemes, as for example between plural /s/ (as in two heaps) and 3rd person singular /s/ (as in she keeps).
In this paper, we investigate both questions using data from the Buckeye Corpus (Pitt et al. Reference Pitt, Dilley, Johnson, Kiesling, Raymond, Hume and Fosler-Lussier2007), we look into the issue of morpheme homophony by investigating the phonetic realization of different English /s/ and /z/ morphemes, which can denote plural, genitive, genitive-plural and 3rd person singular, as well as cliticized forms of has and is. In addition, we compare non-morphemic final /s/ and /z/ with their morphemic counterparts. We show that there are significant differences between many of the different kinds of /s/ and /z/. Our regression models with a number of pertinent covariates (e.g. speech rate, position in the phonological phrase, frequency, etc.) demonstrate, for example, that plural and non-morphemic /s/ and /z/ are significantly longer than most other /s/ and /z/ morphemes. These findings are unexpected from a theoretical perspective and pose further challenges to extant theories of morphology and widely accepted models of speech production.
The paper is structured as follows. In the next section we lay out in more detail the general problem of the relationship between morphological structure and the phonetic signal, and we will develop our research questions. Section 3 introduces the methodology of our corpus-based study. The results are presented in Section 4, followed by a discussion and conclusion.
2 Morphological structure and the phonetic signal
Traditionally, morphemes are defined as linguistic units that consist of a meaning and a phonological form. In the case of allomorphy, one meaning is linked to several phonological forms whose choice depends on constraints that can be phonological, morphological or lexical in nature. The allomorphs /s/, /z/ and /ız/ of the English plural morpheme are a textbook example of such allomorphy. If the base noun ends in a sibilant, /ız/ is chosen, if the base ends in a non-sibilant voiceless consonant, /s/ is chosen, and /z/ occurs in all other contexts. This distribution is exactly the same for the English 3rd person singular marker, i.e. the two morphemes are identical at the form level, both in terms of their exponents and in terms of their distribution. /s/, /z/ and /ız/ are also allomorphs of the genitive marker (though with slightly different distributional constraints, see Bauer et al. Reference Bauer, Lieber and Plag2013: 69, 129, 145). The plural morpheme, the genitive-plural morpheme, the genitive morpheme and the 3rd person singular morpheme thus share homophonous exponents. Similarly, the cliticized forms of has and is can be either /s/ or /z/ depending on the presence of voicing in the context, which makes them homophones to each other and homophonous to the /s/ and /z/ allomorphs of the plural, 3rd singular and genitive morphemes (Bauer et al. Reference Bauer, Lieber and Plag2013: 85). Crucially, there is nothing in the representation of the allomorphs that could cause systematic differences in phonetic implementation between the different morphemes, or between the same segments when they do not represent morphemes.
The said morphemes are treated in a similar way in standard feed-forward formal theories of morphology–phonology interaction (e.g. Chomsky & Halle Reference Chomsky and Halle1968, Kiparsky Reference Kiparsky and Yang1982). In such models the allomorphy is determined at a particular phonological cycle inside the lexicon, and at the level of underlying representations. Once the right underlying form is derived, the morphological boundary of the respective cycle is erased (a process called ‘bracket erasure’, see Chomsky & Halle Reference Chomsky and Halle1968, Kiparsky Reference Kiparsky and Yang1982) and the form leaves the lexicon. All further phonological processes are relegated to another module called ‘post-lexical phonology’ and later to the articulatory component, neither of which have access to morphological information. As in traditional structuralist accounts, there is nothing in the system that would allow for systematic phonetic differences between homophonous suffixes, or between morphemic and non-morphemic sounds.
In the framework of Prosodic Morphology, there is a complex mapping of morphological structure onto prosodic structure (e.g. Nespor & Vogel Reference Nespor and Vogel2007), with the phonological or prosodic word as the central notion. The different types of mapping are responsible for various morpho-phonological alternations (such as assimilation or resyllabification; see Plag (Reference Plag2003) for an introductory treatment and exemplification). Since prosodic boundaries may have phonetic correlates, it has been shown in many studies that morphemes at such boundaries may show systematic differences in phonetic implementation that correlate with differences in their prosodic position (see, for example, Keating Reference Keating, Harrington and Tabain2006). In this framework, any phonetic difference found between two phonologically homophonous affixes would therefore be derivable from a difference in the prosodic structure that goes with the two different affixes.
The distinction between lexical and post-lexical processes also features prominently in psycholinguistics. According to widely accepted models of speech production (e.g. Levelt et al. Reference Levelt, Roelofs and Meyer1999), the aforementioned morphemes and clitics would not differ in their realization from corresponding non-morphemic /s/, /z/ and /ız/. In these models, meanings are stored in the mental lexicon, and their corresponding forms are represented phonologically. Thus, what is used as a basis for articulation is the phonological form only, and the module called ‘articulator’ does not have access to any information regarding the lexical origin of a sound. Leaving stylistic and accentual differences aside, a certain string of phonemes in a given context will therefore always be articulated in the same way, irrespective of its morphemic status, and only modulo the phonetic variation originating from purely phonetic sources such as speech rate or context. It is yet unclear whether more nuanced versions of this model (such as Keating & Shattuck-Hufnagel Reference Keating and Shattuck-Hufnagel2002) could accommodate morpho-phonetic effects.
Recent research on the homophony of lexemes suggests that such a model of speech production may be insufficient. Gahl (Reference Gahl2008) investigated the acoustic realization of 223 supposedly homophonous word pairs such as time and thyme, and found that, quite consistently, the more frequent member of the pair, e.g. time, is significantly shorter than the respective less frequent one, e.g. thyme. This can be taken as evidence that two homophonous lexemes cannot be represented exclusively by one identical phonological form with information on their combined frequency, but that the individual frequencies must be stored with the respective lemmas and have an effect on their articulation.
Similarly, Drager (Reference Drager2011) found that the different functions of like go together with different acoustic properties. Whether like is used as an adverbial, as a verb, as a discourse particle or as part of the quotative be like has an effect on several phonetic parameters, including the ratio of the duration of /l/ to vowel duration, the pitch level and the degree of monophthongization of the vowel /aı/. These fine differences indicate that at the phonetic level two or more phonologically homophonous lemmas may differ. These effects seem to hold also for function words, as shown in Lavoie (Reference Lavoie2002), who investigated four and for – Jurafsky et al. (Reference Jurafsky, Bell and Girand2002) also found acoustic differences between the two words.
Below the word level, there is evidence that phonemically identical strings may systematically vary in their phonetic realization, depending on morphemic status. This seems to run counter not only to standard models of speech production but also to the structuralist and formal theories of phonology–morphology interaction. Kemps et al. (Reference Kemps, Wurm, Ernestus, Schreuder and Baayen2005b) found that phonologically segmentally identical free and bound variants of a base (e.g. help without a suffix as against help in helper) differ acoustically. Furthermore, the authors showed that Dutch and German listeners do make use of such phonetic cues in speech perception (see also Kemps et al. Reference Kemps, Ernestus, Schreuder and Baayen2005a).
In their experiments, Sugahara & Turk (Reference Sugahara, Turk, Bel and Marlien2004, Reference Sugahara and Turk2009) also found phonetic differences between the final segments of a monomorphemic stem as against the final segments of the same stem if followed by a suffix. Stems followed by certain suffixes had slightly longer rhymes than their monomorphemic counterparts.
There is also articulatory evidence on the variability of intergestural timing in monomorphemic and complex words which points at incongruities in the representations of homophones. In an electropalatographic study, Cho (Reference Cho2001) found that in Korean, timing of the gestures for [ti] and [ni] shows more variation when the sequence is heteromorphemic than when it is tautomorphemic, which indicates that morphological structure is reflected in the details of the articulatory gestures, with potential acoustic correlates in the speech signal.
The interpretation of these findings at the theoretical level is highly controversial, however. While some researchers (e.g. Kemps and colleagues, Jurafsky and colleagues) would argue for the incorporation of phonetic detail into lexical, i.e. morphological, representations, other researchers try to explain the findings as reflexes of other, e.g. prosodic or contextual, properties (e.g. Sugahara & Turk).
In view of the controversial findings and implications, homophony below the level of the lexeme seems worthy of closer inspection. If there are fine differences between supposedly homophonous free lexemes and between bound and free realizations of the same stem, there could well be systematic differences between morphemic and non-morphemic sounds, and differences between supposedly homophonous affixes. Not much research has been done in this area, but some experimental studies are available that have looked at morphemic (i.e. affixal) versus non-morphemic (strings of) sounds.
Walsh & Parker (Reference Walsh and Parker1983) carried out a production experiment with three homophonous word pairs and measured the length of /s/ in monomorphemic words and in words that were homophonous to the monomorphemic ones but contained a final morphemic /s/ (e.g. lapse versus laps). The experiment had three different conditions, and in each condition the word pairs were presented in a different context. The authors then compared the means of morphemic and non-morphemic /s/ across the three different conditions of their experiment. In two of the conditions there is a small difference of nine milliseconds in the means of the two different kinds of /s/, while the third condition shows no difference between morphemic and non-morphemic /s/. Based on these means the authors concluded that ‘the durational differences of final /s/s observed in Conditions I and II appear to be a function of the morphological status of the /s/’ (Walsh & Parker Reference Walsh and Parker1983: 204). Given the very small data set and other methodological problems such as the lack of any inferential statistical analysis, or the integration of any phonetic covariates, Walsh & Parker’s results may be met with great scepticism.Footnote [2]
In a similar study, Losiewicz (Reference Losiewicz1992) investigated the acoustic difference between morphemic, i.e. past tense, /d/ and /t/, and non-morphemic /d/ and /t/, and also found durational differences between the two sets of sounds. As Hanique & Ernestus (Reference Hanique and Ernestus2012) point out, however, Losiewicz’s study suffers from serious methodological problems, such as very small data sets and the use of insufficient frequency measures. Another problem that is not mentioned by Hanique & Ernestus is that Losiewicz tested both /t/ and /d/ without including voicing as a covariate.
Li et al. (Reference Li, Leonard and Swanson1999) investigated child-directed speech and found that plural -
 $s$
was longer than 3rd person singular -
$s$
was longer than 3rd person singular -
 $s$
, but they attributed this difference to the fact that plural nouns had a greater tendency to appear in utterance-final position in their data set, such that the effect could be conceived as by-product of utterance-final lengthening. In a more recent experimental study of mothers’ and young children’s speech, Yung Song et al. (Reference Yung Song, Demuth, Evans and Shattuck-Hufnagel2013) looked at the duration of /z/ in four monosyllabic plural forms as against two monosyllabic 3rd person singular forms and three non-morphemic forms. They found that in the mothers’ speech morphemic /z/ was longer than non-morphemic /z/, but the effect was restricted to utterance-final position. There was no significant difference between plural and 3rd person /z/.
$s$
, but they attributed this difference to the fact that plural nouns had a greater tendency to appear in utterance-final position in their data set, such that the effect could be conceived as by-product of utterance-final lengthening. In a more recent experimental study of mothers’ and young children’s speech, Yung Song et al. (Reference Yung Song, Demuth, Evans and Shattuck-Hufnagel2013) looked at the duration of /z/ in four monosyllabic plural forms as against two monosyllabic 3rd person singular forms and three non-morphemic forms. They found that in the mothers’ speech morphemic /z/ was longer than non-morphemic /z/, but the effect was restricted to utterance-final position. There was no significant difference between plural and 3rd person /z/.
Baker et al. (Reference Baker, Smith and Hawkins2007), also using experimental data, found acoustic differences (in durational and amplitude measurements) between morphemic and non-morphemic initial mis- and dis- (as in, e.g., distasteful versus distinctive). Again there are methodological problems, such as the fact that morphemic and non-morphemic strings did not only differ in morphemic status but also in phonological properties that may have directly affected their acoustic realization, such as stress. For example, distasteful may have a secondary stress on the first syllable (perhaps with additional differences in vowel quality) while distinctive may not, which may have an effect on duration and amplitude.
In sum, there is some evidence that there might be systematic duration differences between affixes and the corresponding homophonous non-morphemic sounds, but the data sets are very small and do not represent natural conversational speech, and the effects found are not always convincing due to methodological shortcomings. Nevertheless the previous results are promising enough to warrant further inquiry into the homophony of morphemic and non-morphemic sounds.
With regard to the acoustic differences between different homophonous suffixes, we have to say that to the best of our knowledge, this question has never been systematically investigated, although it potentially has important theoretical implications, as any effect found in this area would seem to run counter to established theories of morphology–phonology interaction and models of speech production. Systematic morpho-phonetic effects would raise the question of the place of phonetic detail in lexical representation and lexical processing.
A study is therefore called for that investigates the two aspects of suffix homophony on a larger scale, preferably using data from natural conversations. This paper presents such a study, testing the two null hypotheses given in (1) and (2).

3 Methodology
3.1 Data
Let us first look at morphemic /s/ and /z/. We investigate six morphemes that share the allomorphs /s/ and /z/, namely the 3rd person singular marker, the plural marker, the genitive marker, the combined genitive-plural marker, the cliticized form of has and the cliticized form of is. We focus in this paper on the duration of the two allomorphs /s/ and /z/. The allomorph /ız/, which is restricted to plural, genitive and 3rd person singular marking, is not considered.Footnote [3]
A note on our terminology is in order. We use capitalized ‘S’ as an umbrella term for the two segments /s/ and /z/ in word-final position. The term ‘morphemic S’ is used as an umbrella term for the clitics and suffixes. Furthermore, we use the term ‘base’ both for morphological bases as well as for hosts in cliticization, and for the string of sounds that precedes the final S in monomorphemic words.
The data source for this study is the Buckeye Corpus of Conversational Speech (Pitt et al. Reference Pitt, Dilley, Johnson, Kiesling, Raymond, Hume and Fosler-Lussier2007). This corpus comprises about 300,000 words from 40 long-time local residents of Columbus, Ohio, who were recorded conversing freely with an interviewer for about one hour each. In addition to the raw speech files, the Buckeye Corpus offers time-aligned written and phonetic transcriptions of the interviews.
Why do we use conversational speech instead of experimental data? While experimental data may provide a better opportunity to control potentially intervening variables in various ways, data obtained in this way sometimes also raise concerns about their validity. It has been shown, however, that, primarily due to modern statistical techniques such as mixed-effects regression (Baayen et al. Reference Baayen, Davidson and Bates2008), more natural data can be fruitfully employed to investigate issues of morpho-phonetic detail by including pertinent covariates that control for many sources of variability in the data (see, for example, Ernestus & Warner (Reference Ernestus and Warner2011) for an overview). We therefore opted for conversational data.
Examples of the different kinds of morphemic S from our data set are given in (3).

For the analysis of length differences between different types of morphemic S we needed items that consisted of a base and of one of the types of morphemic S introduced above. While the clitics can take all sorts of bases, affixal S is more restricted in this respect. To keep the set of items as homogeneous as possible, only items with verbs, nouns and pronouns (indefinite and personal) as bases entered the data set.
Using the POS-tagged orthographic transcription of the Buckeye corpus, 100 tokens of each morphemic S were randomly extracted. If a type occurred more than 12 times, all additional tokens were replaced by other, randomly sampled types. If less than 100 tokens were available for a certain kind of morphemic S, all available tokens were extracted. We limited the amount of data to these numbers due to the very time-consuming manual inspection and readjustment of the automatic segmentations of the Buckeye Corpus (see Section 3.2.1 for details). The overall set of morphemic items amounted to 460 (i.e. tokens), representing 293 types. Of these items, 11 were excluded because acoustic and visual inspection either revealed that the morphemic S was not realized as [s] or [z] in the speech signal (but, e.g., as [ız] or [ʃ], or omitted completely), or the final S was not unambiguously attributable to the item due to assimilation to an initial sibilant in the following word. There was also one case in which the speaker purposefully lengthened the S for stylistic reasons. After inspection of the distribution of the duration measurements we also excluded as outliers three items that were longer than 250 ms. Eventually, 448 items entered the acoustic analysis of morphemic S.
In order to investigate the potential difference between morphemic and non-morphemic S, we also sampled a set of non-morphemic word-final S tokens from the corpus. This sample was created as follows. In an initial step we extracted all words from the corpus that ended in [s] or [z], irrespective of their expected standard pronunciation. Multimorphemic words, irregular 3rd person singular forms (i.e. does, has and is), pronouns and determiners were manually removed from this initial set. If a monomorphemic word, i.e. type, was produced more than once by a speaker, only one randomly selected token of that type entered the pre-final data set (
 $N=3057$
tokens).Footnote
[4]
To arrive at a reasonably sized set of data, 240 words were randomly sampled from the pre-final data set. Thirty-four items with anomalies in the signal (similar to those mentioned in the previous paragraph for morphemic S) were excluded, as were seven outliers that were longer than 250 ms. The final data set consisted of 199 words with non-morphemic S, about half the number of items that was in the set of morphemic S.
$N=3057$
tokens).Footnote
[4]
To arrive at a reasonably sized set of data, 240 words were randomly sampled from the pre-final data set. Thirty-four items with anomalies in the signal (similar to those mentioned in the previous paragraph for morphemic S) were excluded, as were seven outliers that were longer than 250 ms. The final data set consisted of 199 words with non-morphemic S, about half the number of items that was in the set of morphemic S.
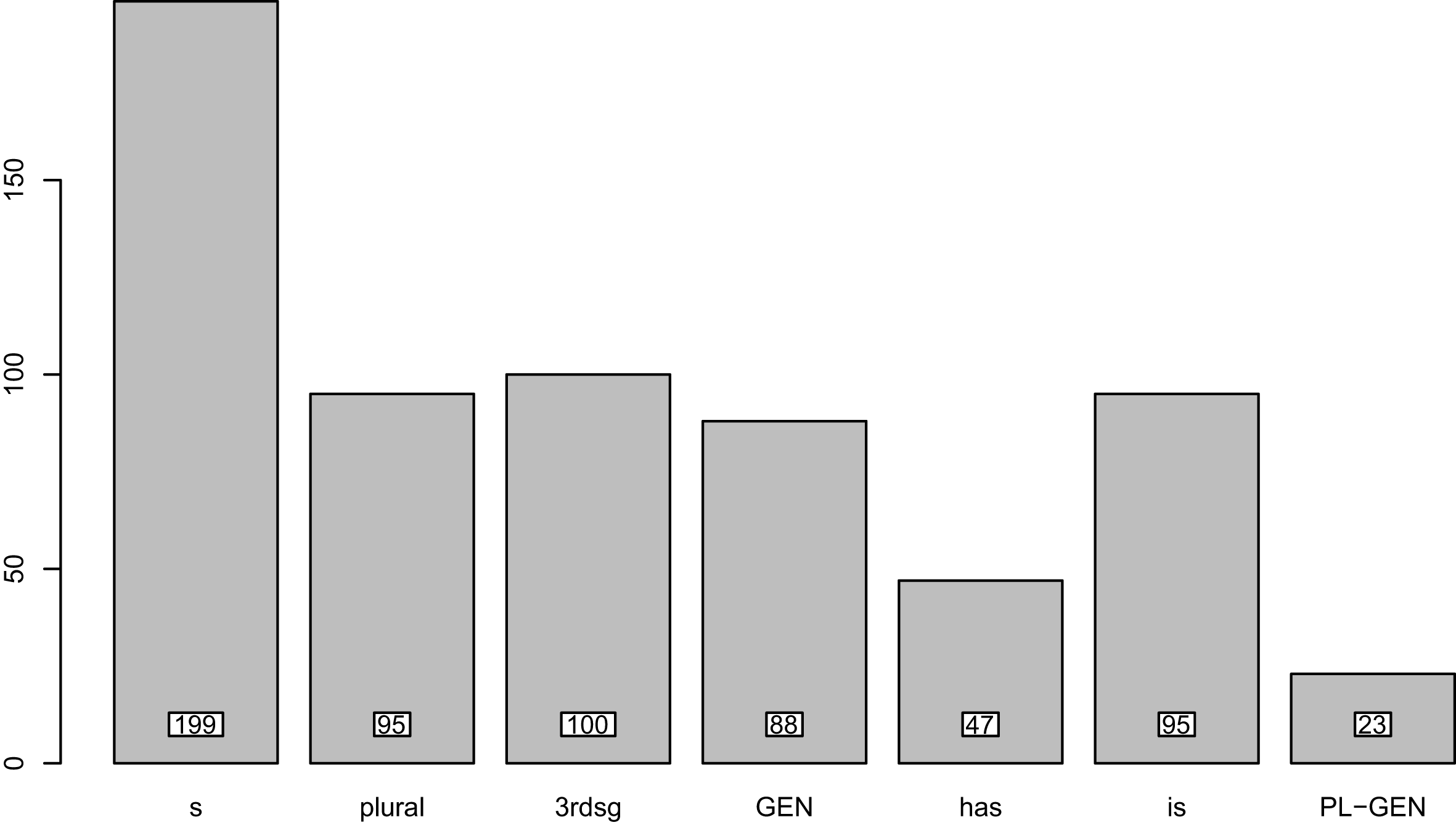
In the overall final data set, the different types of S were distributed as shown in Figure 1.
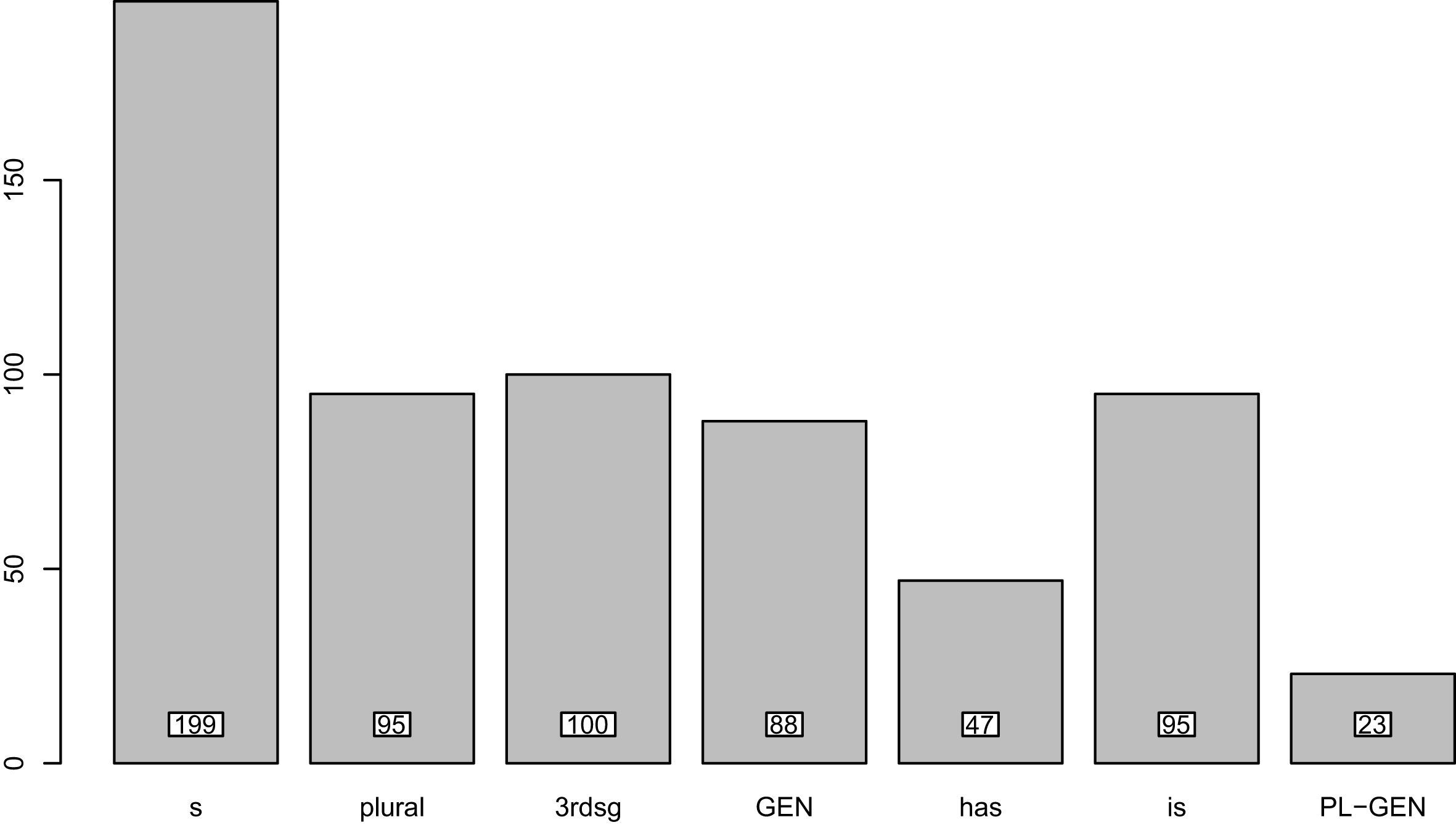
Figure 1 Distribution of different types of S in the data set. (Abbreviations: s = non-morphemic S, 3rdsg = 3rd person singular, GEN = genitive, PL-GEN = genitive-plural).
3.2 Analysis
3.2.1 Acoustic measurements
With the help of LaBB-CAT (Fromont & Hay Reference Fromont and Hay2008), a freely available speech corpus management system formerly known as ONZE Miner, the Buckeye transcripts were converted into textgrid files. These files could then be used for further segmentation and analysis with the help of the acoustic analysis software Praat (Boersma & Weenink Reference Boersma and Weenink2013).
Buckeye’s (partly automatic) phonetic annotations were manually checked for each item and adjusted where necessary. Boundaries marking the beginning of an item or of an S were moved to the zero crossing that was closest to the point where both spectrogram and waveform indicated the initiation of the gesture for the respective segment, i.e. in the case of S, the boundaries were set to the zero crossing closest to the onset of the friction visible in the waveform. Boundaries marking the end of an item and thus the end of an S were moved to the zero crossing closest to the point where the initiation of the gesture for the following segment became visible in both spectrogram and waveform. In cases with no following segment, the boundary was set to the point where the friction of the S dropped to silence. After manual checking and adjustment of all relevant intervals, relevant acoustic measurements such as length and voicing (for details, see Section 3.2.2) were taken automatically with the help of a Praat script.
We wanted to model the length of S both in absolute terms and in relative terms, i.e. in relation to the length of its base. Studies of geminates (e.g. Oh & Redford Reference Oh and Redford2012) have shown that differences in phonetic duration can be meaningfully interpreted as relative or absolute, depending, among other things, on the language under investigation. Given that very little is known about the absolute or relative length of affixes, it seemed reasonable to test both kinds of dependent variables. Therefore, the absolute duration of S in a given token was obtained from the duration of the segment in milliseconds, and the relative duration was calculated by dividing the absolute duration of the S by the duration of the whole word, i.e. by the sum of base duration and S duration.
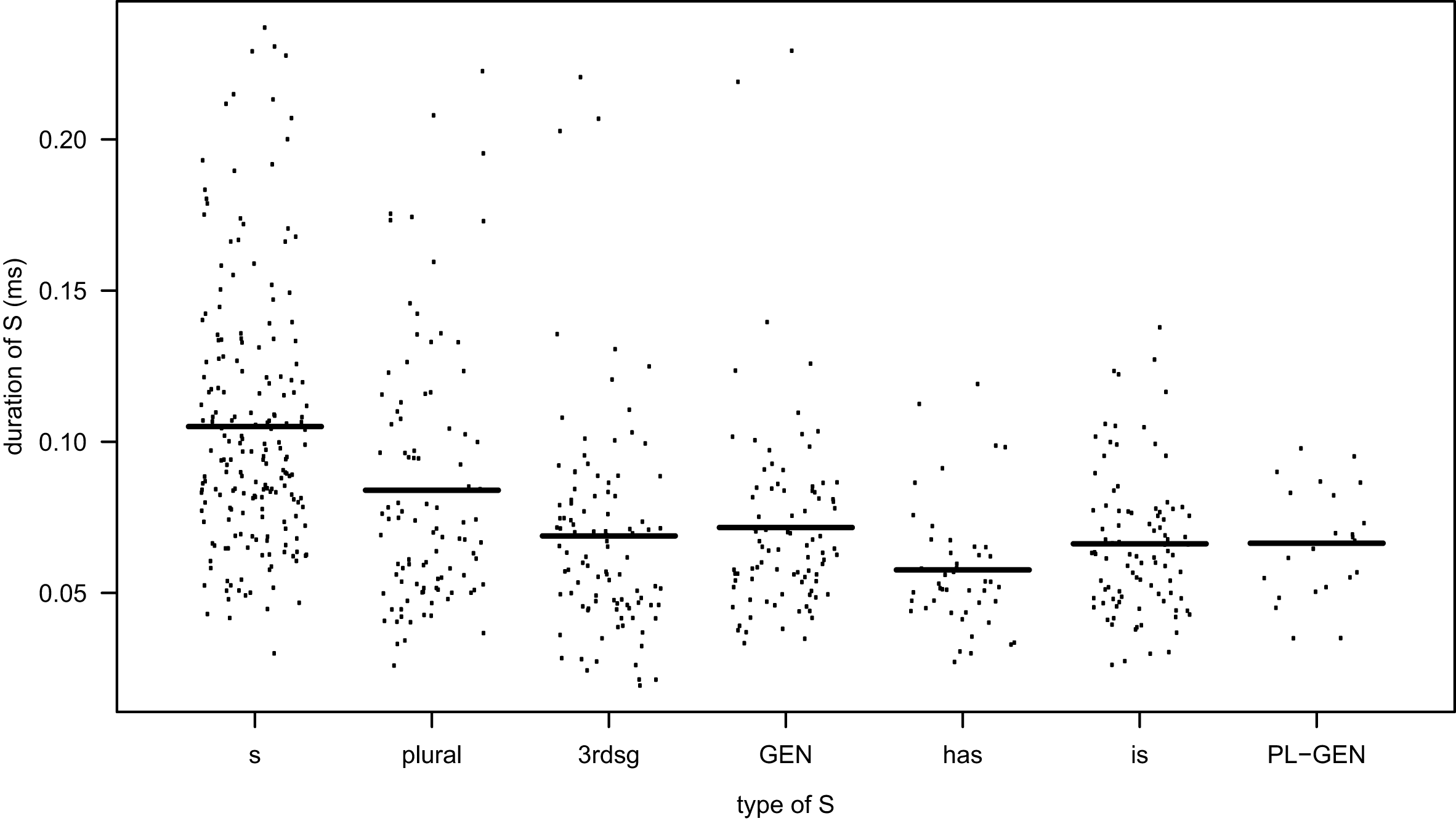
The distribution and means of the duration measurements by type of S are given in Figure 2. Each dot represents one measurement and the lines indicate the means.
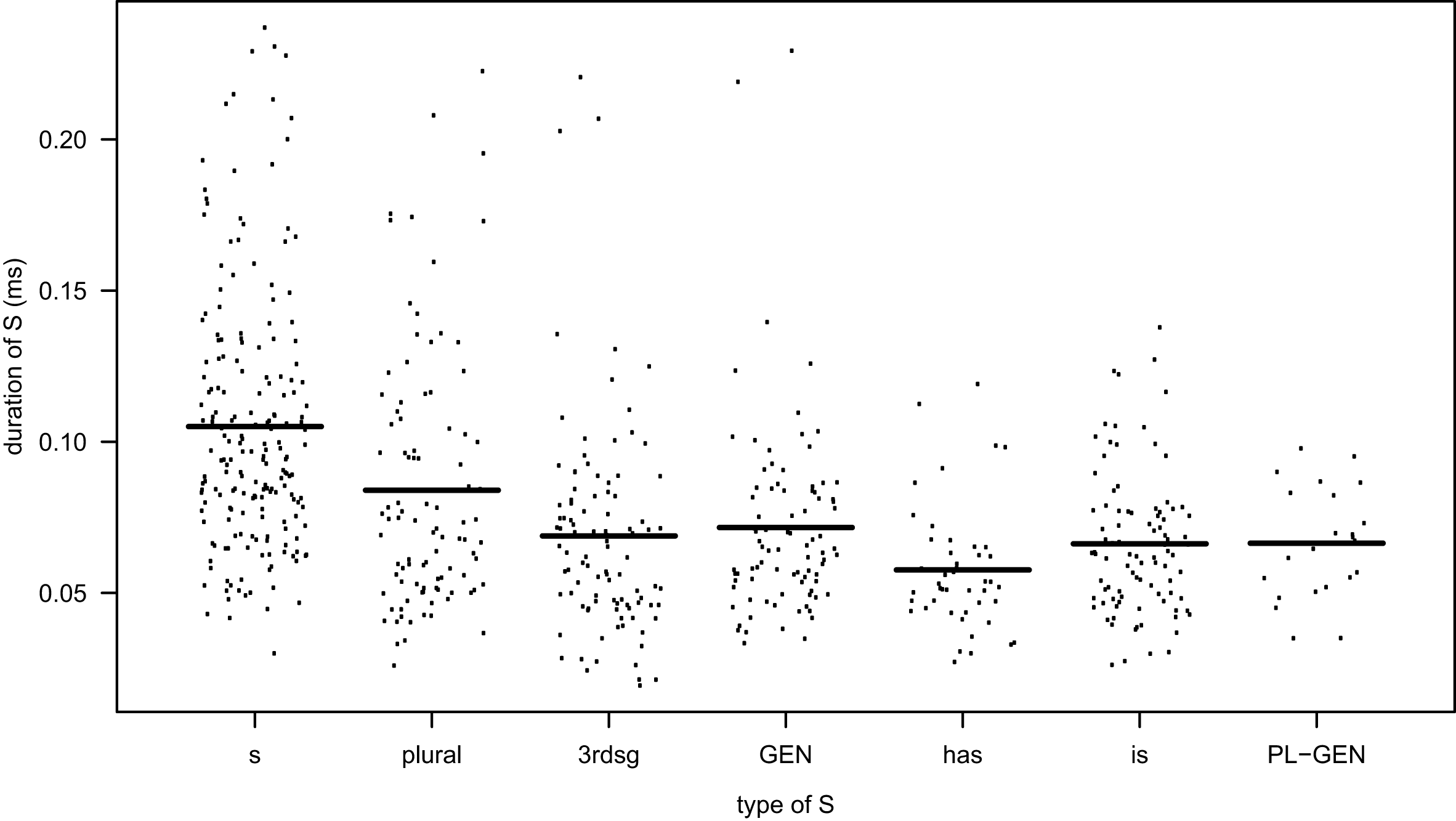
Figure 2 Duration of different types of S in the data set. (Abbreviations: s = non-morphemic S, 3rdsg = 3rd person singular, GEN = genitive, PL-GEN = genitive-plural).
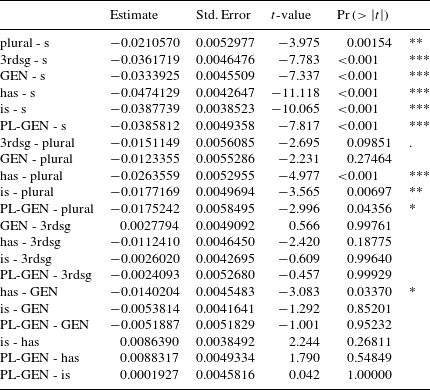
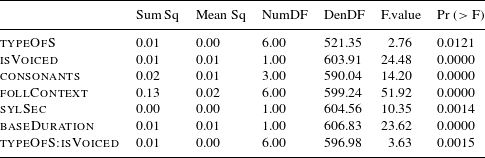
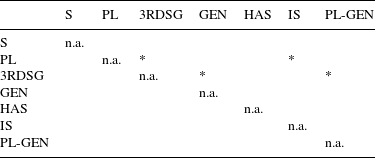
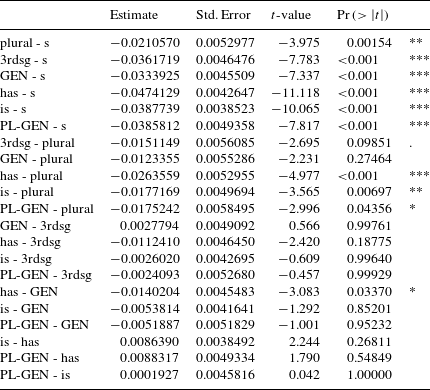
The distribution of the measurements shows rather clear differences between the different types of S, and an anova shows a significant effect of type of S (F = 20.196, p < 2. 2e–16). The results of pair-wise comparisons of the means using Tukey contrasts are summarized in Table 1.Footnote [5] We find ten significant contrasts. Non-morphemic S differs from all morphemic S’s, and there are four significant differences among the different types of morphemic S.
Table 1 Multiple comparison of means of duration of S (Tukey contrasts). (Significance codes: ‘***’
 $p<0.001$
, ‘**’
$p<0.001$
, ‘**’
 $p<0.01$
, ‘*’
$p<0.01$
, ‘*’
 $p<0.05$
.)
$p<0.05$
.)
While this may already look like a very interesting result, it has to be treated with great caution. Previous studies of the acoustic duration of words and individual sounds have shown that this acoustic parameter is subject to various acoustic and non-acoustic factors, such as speech rate, frequency, final lengthening or the phonological context of the surrounding segments. Variable durations for the same word type may also arise from more general processes of phonetic reduction, which may affect duration but also non-durational parameters such as vowel quality or number of segments and syllables. In any study interested in one particular factor, in our case the influence of morphological status, these other influences need to be controlled, for example as covariates in a regression analysis.
3.2.2 Covariates
The specific set of covariates chosen for the present study is very similar to that of other studies that have investigated duration effects in morphologically complex words using speech corpus data (for example Pluymaekers et al. Reference Pluymaekers, Ernestus and Baayen2005b, Reference Pluymaekers, Ernestus, Baayen, Booij and Fougeron2010; Hanique et al. Reference Hanique, Ernestus and Schuppler2013). In the following we will briefly discuss each of the covariates, starting with phonetic covariates, followed by covariates encoding lexical properties, and finally context-encoding variables.
Local speech rate. An obvious variable that needs to be controlled for is speech rate. We used two measures of speech rate. As one measure we calculated the speech rate in the discourse around each item (i.e. the ‘local’ speech rate in syllables per second). This was done by counting the number of syllables in the context of up to ten seconds immediately preceding and succeeding the item, if not interrupted beforehand, e.g. by a pause or by the interviewer. The number of syllables was then divided by the number of seconds of context that was considered. The inspection of the distribution of this variable showed two clear outliers with speech rates greater than 15 syllables per second. Furthermore, there was one item for which there were no surrounding syllables, so that no speech rate could be computed. Those three items were removed from the data set before statistical modeling, leading to a reduction of the set of items with non-morphemic S from 199 to 196.
Base duration. With regard to an even more local speech rate, we measured the length of the base. Other things being equal, a longer duration of the base will indicate a slower speech tempo. This measurement is also able to at least partially control for the lengthening effect of accentuation: as Turk & White (Reference Turk and White1999) show, word-final (non-morphemic) consonants are significantly longer if the word they belong to is accented.
Voicing. We included voicing to account for the effect of allomorphy. It is also well known that voicing affects the length of fricatives, with voiced fricatives being shorter (e.g. Klatt Reference Klatt1976). Based on an inspection of the distribution of the measurements taken by the algorithm used in Praat, an S was considered to be voiced if the algorithm could detect a periodic pitch pulse in more than 75 percent of the overall duration of the segment.
Number of syllables. We also included another measure of length, the number of syllables. As shown in Lindblom (Reference Lindblom1963) for Swedish vowels, and Nooteboom (Reference Nooteboom1972) for Dutch vowels, vowel segments may tend to be shorter if they are followed by more syllables (but see Hanique et al. (Reference Hanique, Ernestus and Schuppler2013) for somewhat different findings). It is unclear whether this effect can also be found in English, and whether it pertains to fricatives, but it seemed safe to include this covariate nevertheless. In any case, this effect can be conceptualized as a kind of compression effect, where words with more syllables undergo reduction. We used two kinds of syllable count. The first one was to extract syllable counts from CELEX (Baayen et al. Reference Baayen, Piepenbrock and Gulikers1995) where possible; in all other cases the number of vowels (or diphthongs) in a word was taken as an indication of its number of syllables. The second one was to count the syllabic nuclei that were actually pronounced.
Number of consonants immediately preceding S. Another factor influencing the length of consonantal segments is their occurrence in a cluster. Consonants in clusters tend to be shorter (e.g. Klatt Reference Klatt1976). We therefore included the number of consonants preceding S as a covariate, expecting that the more consonants precede the S the shorter the individual segments, including S, would become. Since this numerical variable had only four values (0, 1, 2 and 3) the variable was transformed into a categorical variable to prevent the model from coming up with nonsensical estimates (e.g. a word with 1.2 consonants in the rhyme). Consonants were counted on the basis of the actual pronunciations.
Frequency. Frequency also affects phonetic duration, with the general tendency of more frequent words exhibiting more reduction, i.e. shorter segment durations (e.g. Bybee Reference Bybee2001: 78; Jurafsky et al. Reference Jurafsky, Bell, Gregory and Raymond2001). We used two kinds of frequency, base frequency and form frequency. For base frequency we took the log-transformed frequency of the base in the spoken part of the Corpus of Contemporary American English (COCA, Davies Reference Davies2008). For words with non-morphemic S we took the frequency of the word. For the form frequency we calculated the log-transformed frequency of the word including the final S, ignoring what kind of S is attached in a given token. Thus, for the words with non-morphemic S, both frequency measures were identical. The frequencies were log-transformed to reduce the potentially harmful effect of skewed distributions in linear regression models.
Neighborhood density. We included phonological neighborhood densities as covariates, as it has been shown that the number of phonological neighbors may influence phonetic reduction (and hence word duration), as denser networks facilitate articulation (see, for example, Gahl et al. Reference Gahl, Yao and Johnson2012). Neighborhood density measures were taken from the clearpond database (Marian et al. Reference Marian, Bartolotti, Chabal, Shook and White2012). In this database neighbors are those words that differ in one segment from the word in question, with the difference originating from either substitution, addition or deletion of one segment (Marian et al. Reference Marian, Bartolotti, Chabal, Shook and White2012: 3).
Bigram frequency. Another potential factor influencing the duration of a word in running speech is the predictability of the word in its context (e.g. Jurafsky et al. Reference Jurafsky, Bell, Gregory and Raymond2001, Pluymaekers et al. Reference Pluymaekers, Ernestus and Baayen2005a, Bell et al. Reference Bell, Brenier, Gregory, Girand and Jurafsky2009, Torreira & Ernestus Reference Torreira and Ernestus2009). For content words, recent studies unanimously show that it is the upcoming context that may have an effect on different aspects of acoustic reduction (including duration, e.g. Pluymaekers et al. Reference Pluymaekers, Ernestus and Baayen2005a, Bell et al. Reference Bell, Brenier, Gregory, Girand and Jurafsky2009, Torreira & Ernestus Reference Torreira and Ernestus2009). To account for this durational effect we measured (and log-transformed) the bigram frequency of the item in question and its following word, also based on COCA.
Previous mention. Another reduction effect may arise from online priming. The more often a complex word or its base has been mentioned in the previous discourse, the shorter we expect its duration to be in a given case (e.g. Fowler & Housum Reference Fowler and Housum1987, Fowler Reference Fowler1988, Gahl et al. Reference Gahl, Yao and Johnson2012). We therefore included a covariate that counted the number of previous mentions in a time window of 30 seconds preceding the token in question.
Following context. It is known from the literature that the context may have an effect on the duration of consonants. Words and segments (especially fricatives) at the end of an utterance are subject to lengthening (e.g. Oller Reference Oller1973: 1244; Berkovits Reference Berkovits1993). Furthermore, the following segment may have an effect on the duration of the consonant preceding it (e.g. Klatt Reference Klatt1976, Umeda Reference Umeda1977). We therefore coded for each item the segment type of the word following the S as either vowel (‘V’), approximant (‘APP’), nasal (‘N’), affricate (‘AFF’), fricative (‘F’) or plosive (‘P’). If S was not followed by any sound, because it occurred at the end of an utterance, we coded the following segment item as ‘ <pause >’. We would expect an S in utterance-final position to be longer than an S we find in other positions.
Syntactic position. Similarly to what happens before pauses, segments before a syntactic or prosodic boundary are also lengthened (see, for example, Klatt Reference Klatt1976, Cooper Reference Cooper1976, Cooper et al. Reference Cooper, Paccia and Lapointe1978, Byrd et al. Reference Byrd, Krivokapic and Lee2006). For our data, determining the boundaries of intonation phrases turned out to be highly problematic and unreliable, and we therefore opted for a syntax-based coding. We coded each item for whether it occurred at the right boundary of a syntactic phrase (e.g. an NP). Such a coding can at least partially control for differences that might occur due to syntax-based prosodic effects, for example, between phrase-final plural nouns and pre-head genitives.
3.2.3 Statistical analysis
We devised two types of analysis, with different constellations of variables and different statistical models. In the first analysis we used absolute duration of S as the dependent variable (Model 1), whereas the second analysis had proportion of S as its dependent variable (Model 2).
Model 1 was fitted using mixed-effects regression, as implemented in the packages lme4 (Bates et al. Reference Bates, Maechler, Bolker and Walker2014) and lmerTest (Kuznetsova et al. Reference Kuznetsova, Brockhoff and Bojesen Christensen2014) for R (R Development coreteam 2011). Mixed-effects regression brings the variation of random effects such as subject or item under statistical control, and can deal with unbalanced data sets. The latter property is especially welcome since not all combinations of all values of the different predictors are represented in our data with equal frequency.
The mixed-effects model was fitted adhering to the following strategy. In the initial model, alongside the explanatory variable type of S, we included the control variables discussed in the previous section. This initial model was then reduced through step-wise exclusion of insignificant factors (e.g. Baayen Reference Baayen2008). A factor was only considered significant if it passed three tests. First, its
 $t$
-statistics had to yield a
$t$
-statistics had to yield a
 $t$
-value greater than 2 (or less than -2) when included in the model. Second, the Akaike information criterion (AIC) of the model including the factor had to be lower than the AIC of the model without it. Third, an ANOVA comparing the model including the factor to a model without it had to yield a
$t$
-value greater than 2 (or less than -2) when included in the model. Second, the Akaike information criterion (AIC) of the model including the factor had to be lower than the AIC of the model without it. Third, an ANOVA comparing the model including the factor to a model without it had to yield a
 $p$
-value lower than 0.05, thus showing that the inclusion of the factor did significantly improve the fit of the model. A variable under consideration was only retained in the model if it passed all three tests.
$p$
-value lower than 0.05, thus showing that the inclusion of the factor did significantly improve the fit of the model. A variable under consideration was only retained in the model if it passed all three tests.
One of the central assumptions of any linear regression model is a linear relationship between the dependent and independent variables. If this assumption is not met, the estimated coefficients may be highly unreliable. In this case, the dependent variable may often be transformed to alleviate any problem resulting from a lack of linearity. The Box–Cox transformation (Box & Cox Reference Box and Cox1964, Venables & Ripley Reference Venables and Ripley2002) can be employed to identify a suitable transformation parameter
 $\unicode[STIX]{x1D706}$
for a power transformation. For the transformation of the absolute duration measures used in Model 1 the optimal value of
$\unicode[STIX]{x1D706}$
for a power transformation. For the transformation of the absolute duration measures used in Model 1 the optimal value of
 $\unicode[STIX]{x1D706}$
was
$\unicode[STIX]{x1D706}$
was
 $\unicode[STIX]{x1D706}$
= 0.1010101.
$\unicode[STIX]{x1D706}$
= 0.1010101.
We also tested interactions between each covariate and the type of S. In addition, we tested an interaction between voicing and the number of consonants in the rhyme of the base-final syllable, since the presence of more consonants increases the distance between the S and the voiced nucleus of the syllable, which might lead to less assimilation.
Let us turn to Model 2. In this analysis the dependent variable was the relative length of S (proportion of S, calculated as the (non-transformed) absolute duration of the S divided by the duration of the whole word). As this variable is bounded between 0 and 1 and has a skewed distribution, linear regression is ruled out and a model is needed that can cope with these properties of the target variable. Beta regression (e.g. Ferrari & Cribari-Neto Reference Ferrari and Cribari-Neto2004) is such a model. We used the R package betareg (Cribari-Neto & Zeileis Reference Cribari-Neto and Zeileis2010) for this analysis. For the beta regression models a slightly different fitting strategy had to be adopted. This will be explained in more detail in Section 4.2.
Collinearity is an issue for two pairs of covariates, the first of which is the number of syllables and the duration of the base, the second the two frequency measures base frequency and form frequency. Standardly used residualization procedures have recently been shown to be inadequate tools to address these issues (e.g. Wurm & Fisicaro Reference Wurm and Fisicaro2014). We therefore adopted a different strategy. The number of syllables and the duration of the base were highly correlated and inclusion of both into our models led to suppression effects (e.g. Holling Reference Holling1983). Since the direction of influence on the duration of S was the same for both covariates, and models with only one of the two covariates showed that the influence of duration of the base on the duration of S was much stronger, we only included the duration of the base into our analyses. Similarly, base frequency and form frequency were highly correlated and showed the same direction in their effect on the duration of S when looked at individually. The effect of form frequency was much weaker, however. We therefore included only base frequency into our models.
3.2.4 Overview of the data
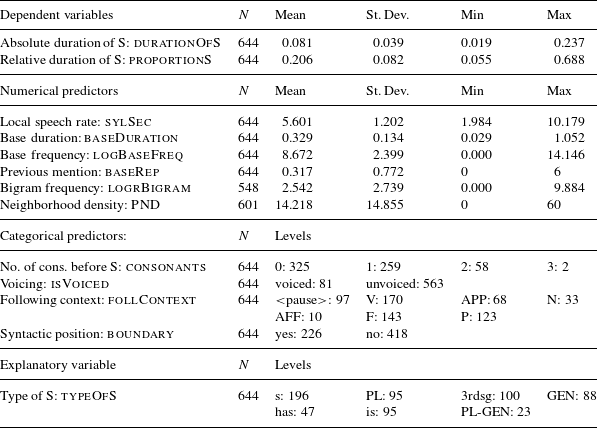
An overview of variables and their distributions is given in Table 2. The names of the (sometimes transformed) variables that entered the analysis are given in small capitals. Note that not all variables were available for all observed morphemes: some bases are not listed in clearpond (e.g. permeate or sandal), so no neighborhood density information could be used for these observations. Also, logrBigram was not calculated for observations that were followed by a speech pause in the recording.
Table 2 Summary of the dependent variables and covariates used in the initial models.

4 Results
4.1 Model 1: Absolute duration as dependent variable
Model 1 was fitted according to the procedure described above. The inspection of the residuals showed a non-normal distribution in both tails of the distribution. Following standard procedures (e.g. Crawley Reference Crawley2002, Baayen & Milin Reference Baayen and Milin2010), we removed outliers (defined as items with standardized residuals exceeding -2.5 or +2.5) and refitted the model (the removal of outliers resulted in the loss of 1.7% of the observations). The final model showed a satisfactory distribution of residuals.
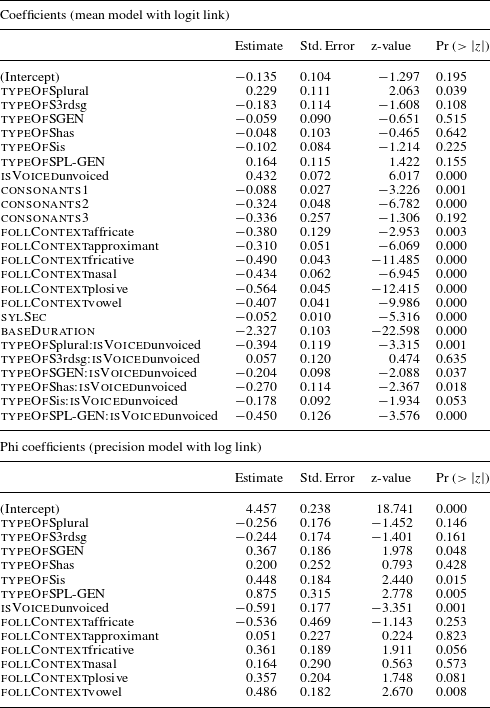
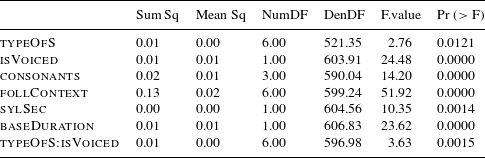
In the final model we find significant main effects of type of S (typeOfS), the following context (follContext), the number of consonants preceding S (consonants), speech rate (sylSec) and duration of the base (baseDuration). In addition, there is a significant interaction of type of S (typeOfS) and voicing (isVoiced). Regarding the random effects, we tested speaker and base, but only speaker-specific effects turned out to significantly improve model performance. The
 $p$
-values for the analysis of variance (or deviance) of Model 1 are documented in Table 3.
$p$
-values for the analysis of variance (or deviance) of Model 1 are documented in Table 3.
Table 3
 $p$
-values of fixed effects in Model 1, fitted to the Box–Cox-transformed durations of S.
$p$
-values of fixed effects in Model 1, fitted to the Box–Cox-transformed durations of S.
The
 $R$
-squared value of the model is 0.65, with the random effect explaining 6 percent of the variation, and the fixed effects 59 percent. We checked the effect sizes of the individual predictors by fitting models that lacked a particular predictor, and compared their
$R$
-squared value of the model is 0.65, with the random effect explaining 6 percent of the variation, and the fixed effects 59 percent. We checked the effect sizes of the individual predictors by fitting models that lacked a particular predictor, and compared their
 $R$
-squared values with the
$R$
-squared values with the
 $R$
-squared value of the model that contained all six predictors. The hierarchy in (4a) reflects the results. The decrease in the
$R$
-squared value of the model that contained all six predictors. The hierarchy in (4a) reflects the results. The decrease in the
 $R$
-squared value is greatest when taking out follContext, followed by isVoiced, followed by typeOfS, and so forth. Furthermore, we devised ANOVAs to check whether a model that lacked a given predictor performed better than a model that lacked a different predictor. This resulted in the hierarchy given in (4b), which gives the most powerful predictors on the left. The models that lack one of either follContext, typeOfS, isVoiced do not show a significant difference in pair-wise ANOVAs, but perform significantly worse than models that lack one of the variables to their right. It should be noted, however, that taking out either isVoiced or typeOfS also eliminates the interaction term from the model, such that we are actually losing two predictors in those cases. We therefore also fitted models with only one of the six variables. These models resulted in the hierarchy in (4c), which reflects decreasing
$R$
-squared value is greatest when taking out follContext, followed by isVoiced, followed by typeOfS, and so forth. Furthermore, we devised ANOVAs to check whether a model that lacked a given predictor performed better than a model that lacked a different predictor. This resulted in the hierarchy given in (4b), which gives the most powerful predictors on the left. The models that lack one of either follContext, typeOfS, isVoiced do not show a significant difference in pair-wise ANOVAs, but perform significantly worse than models that lack one of the variables to their right. It should be noted, however, that taking out either isVoiced or typeOfS also eliminates the interaction term from the model, such that we are actually losing two predictors in those cases. We therefore also fitted models with only one of the six variables. These models resulted in the hierarchy in (4c), which reflects decreasing
 $R$
-squared values from left to right. Overall, the morphological status of an S thus turns out to be a rather strong predictor of its acoustic duration.
$R$
-squared values from left to right. Overall, the morphological status of an S thus turns out to be a rather strong predictor of its acoustic duration.

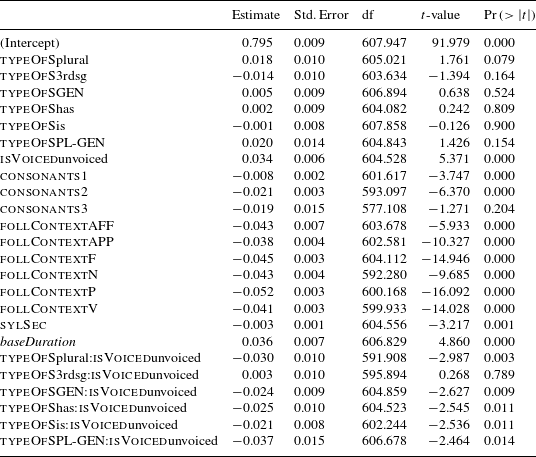
The estimates (and their
 $p$
-values) of Model 1 are documented in Table 4. The reference levels for the categorial predictors are the following: for typeOfS it is non-morphemic S, for follContext it is <pause>, for isVoiced it is voiced and for consonants it is 0. All coefficents can be interpreted as changes relative to these reference levels.
$p$
-values) of Model 1 are documented in Table 4. The reference levels for the categorial predictors are the following: for typeOfS it is non-morphemic S, for follContext it is <pause>, for isVoiced it is voiced and for consonants it is 0. All coefficents can be interpreted as changes relative to these reference levels.
Table 4 Fixed-effect coefficients and
 $p$
-values in Model 1 (mixed-effects model fitted to the Box–Cox-transformed durations of S).
$p$
-values in Model 1 (mixed-effects model fitted to the Box–Cox-transformed durations of S).
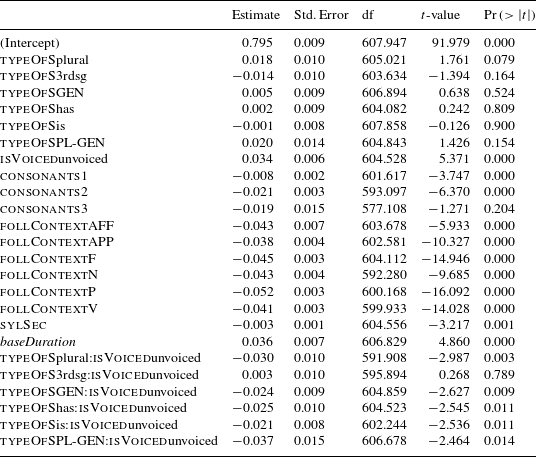
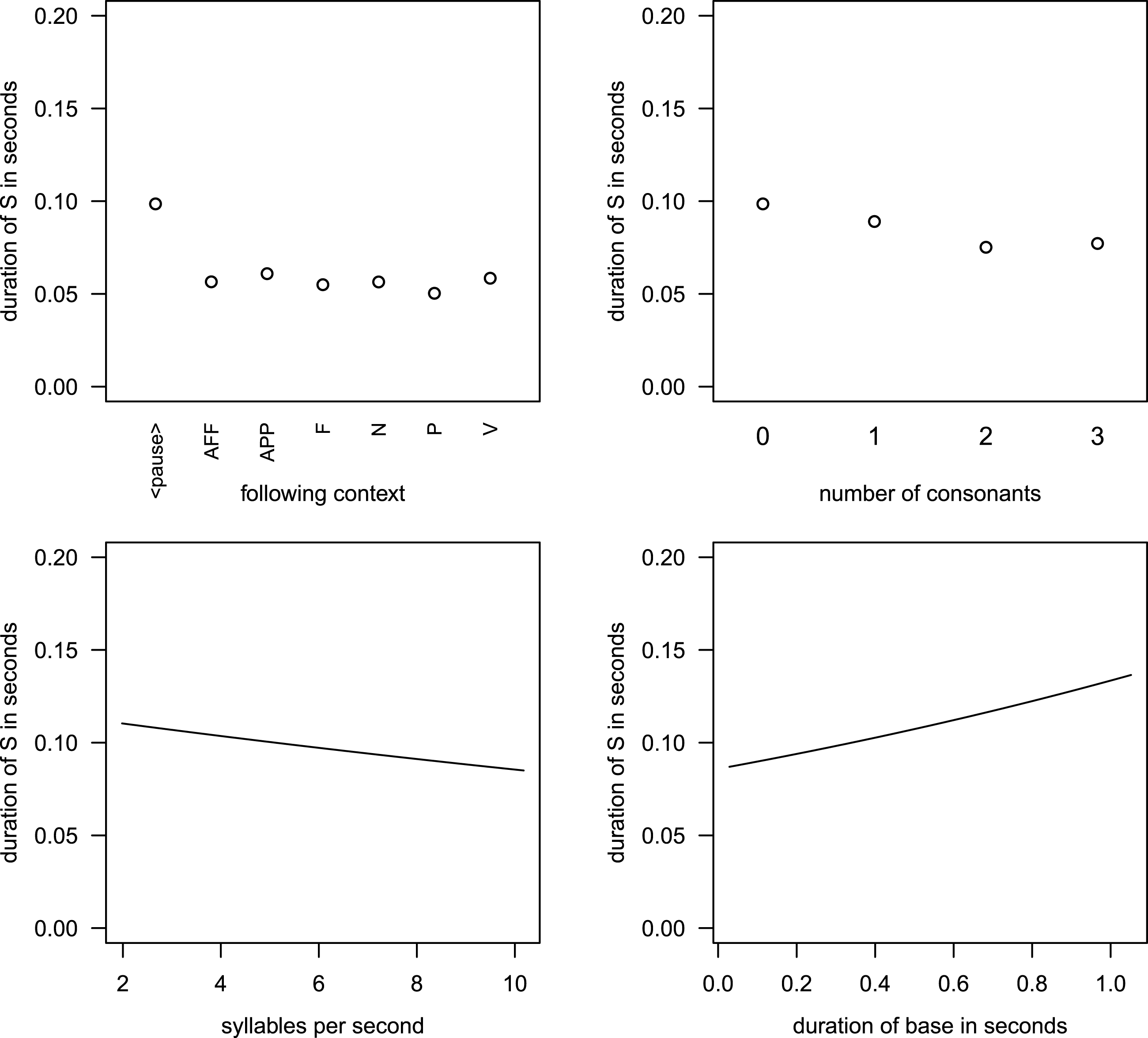
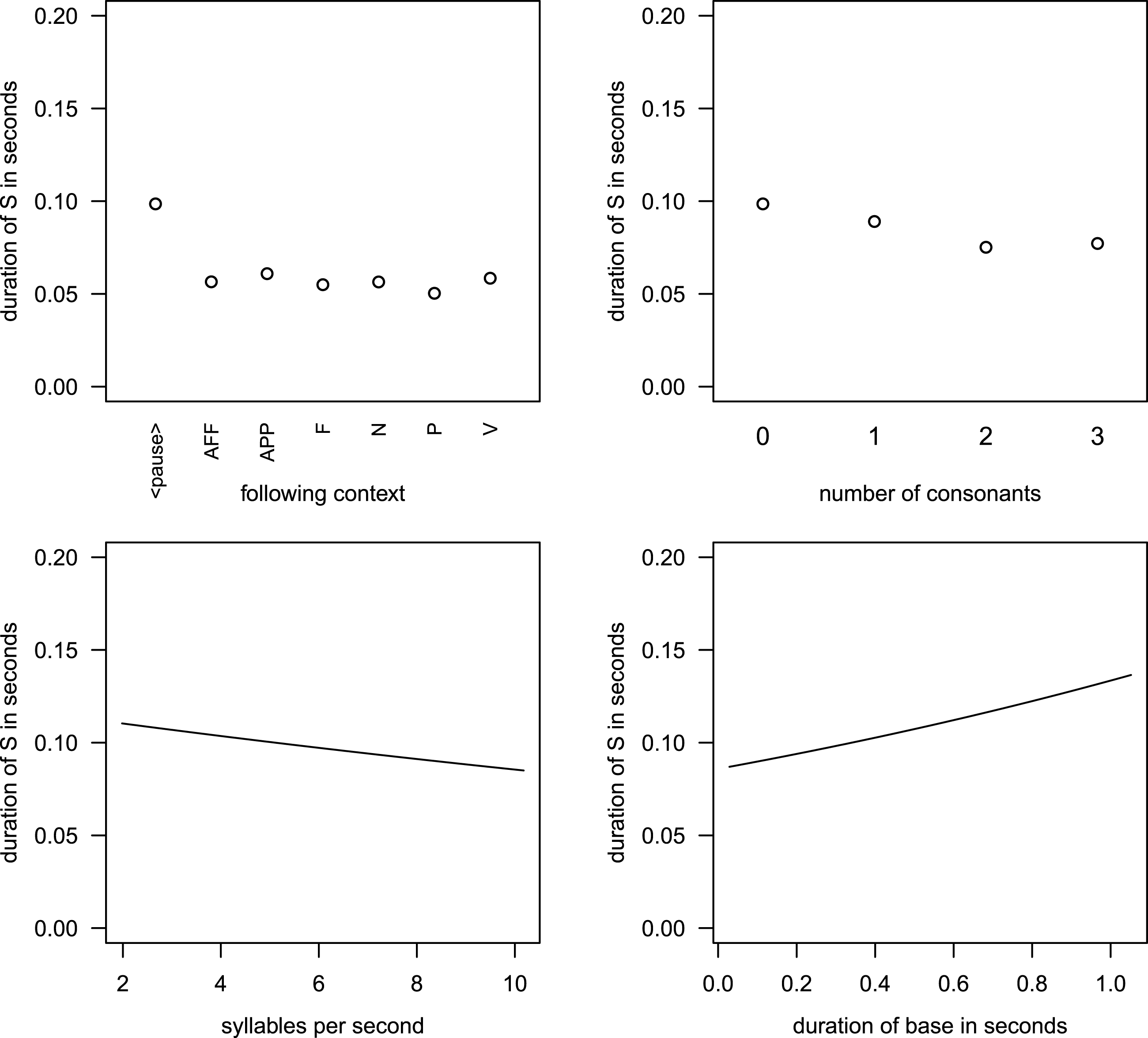
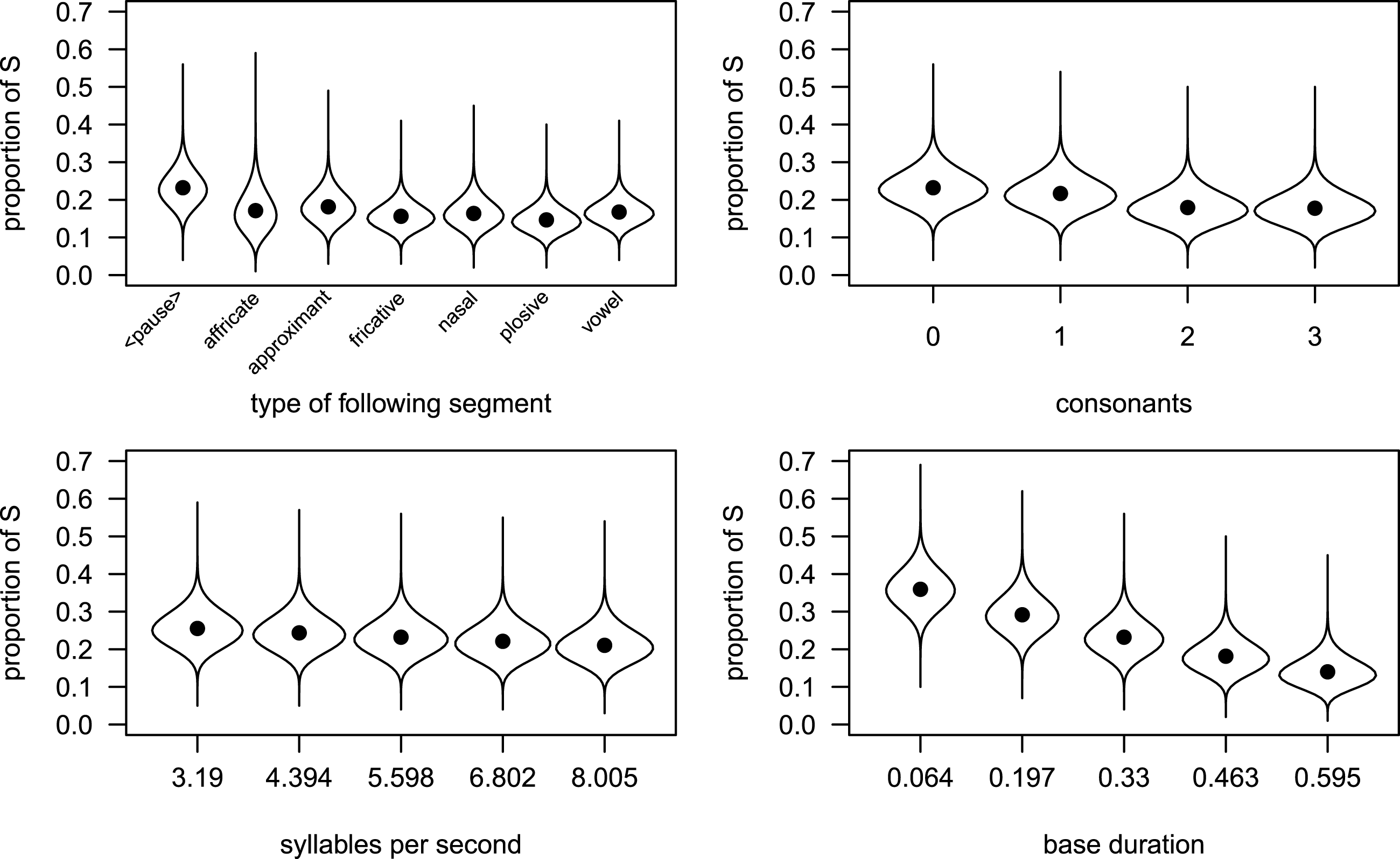
Figure 3 Partial effects of non-interacting covariates in Model 1, fitted to the Box–Cox-transformed absolute durations of S.
Figure 3 illustrates the effects of the non-interacting covariates in Model 1. The estimated values of the dependent variable are back-transformed into seconds. Three of the four covariates that come out as significant show the expected behavior. In the upper row the left panel (follContext) shows that before a pause, i.e. in utterance-final position, S is longer than in other positions where there is a segment following S. This can be interpreted as a clear final-lengthening effect. In comparison, the different types of following segments shown in the panel have a relatively small effect on the duration of S. Apparently, the strong effect size of follContext seen in (4) above is almost completely attributable to positional lengthening. The right panel of the upper row shows the effect of the number of consonants before S. The more consonants we find in the rhyme the shorter final S becomes, which is equally expectable.Footnote [6] The left lower panel gives us speech rate (sylSec). With faster speech, S becomes shorter, as predicted. In the right panel of the lower row we see the effect of baseDuration. Words that have a longer duration also have longer S’s, which also means that final S participates in the overall lengthening or shortening effects that affect the word as such. If we conceive of base duration as a measure of very local speech rate this is expected: if the very local speech tempo is low, the base duration is long, and one would expect the S to be long also. If, however, we expect a kind of compression effect (based on what was found for vowels in Dutch), this effect is unexpected and unclear in its interpretation. We fitted two separate models for monosyllables and disyllables, respectively, to hold syllable number constant. The same effect of base duration emerged in both of these separate models, which corroborates the idea that we find no compression effect, but S participating in lengthening or shortening effects of the word it occurs in.
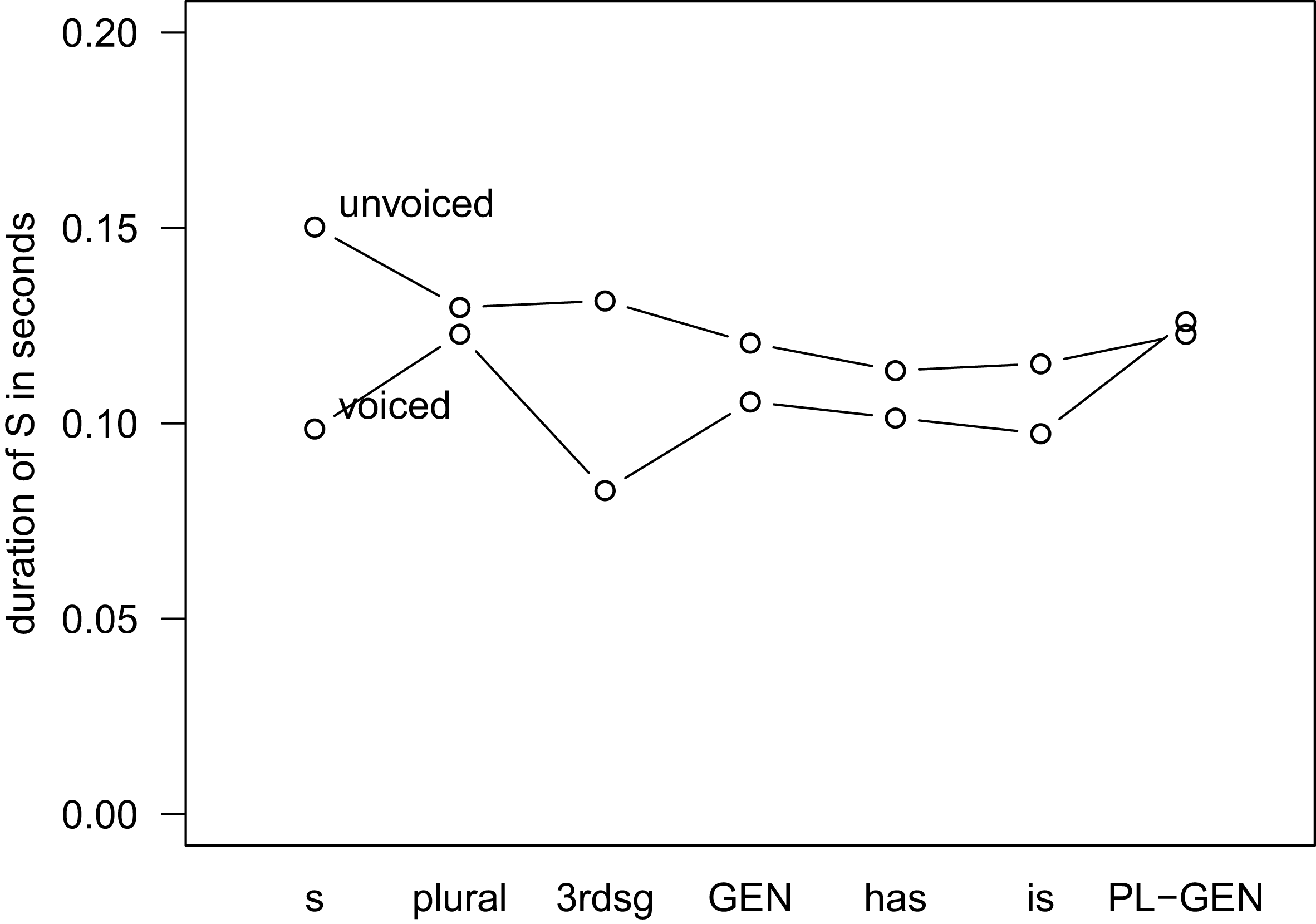
Let us now turn to the variable of interest, i.e. type of S, whose effect is plotted in Figure 4 in interaction with voicing. Again, the values of the dependent variable are back-transformed into seconds.
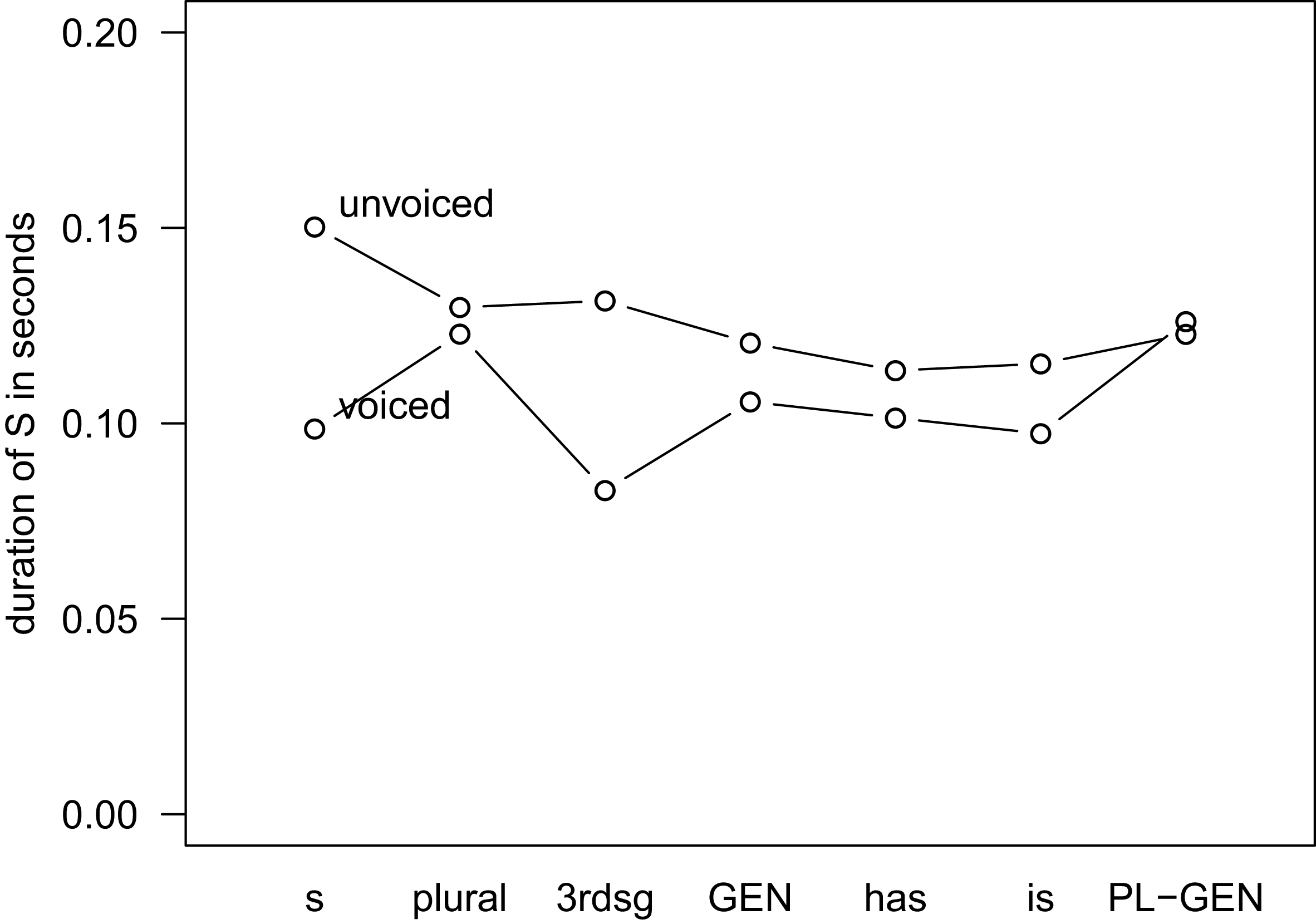
Figure 4 Interaction of type of S and voicing, Model 1 (Abbreviations: s = non-morphemic S, 3rdsg = 3rd person singular, GEN = genitive, PL-GEN = genitive-plural).
We can see that, apart from genitive-plural, voiced S is generally shorter than unvoiced S. This general trend is as expected. What is less expected is that the degree to which voiced realizations differ in duration from unvoiced realizations is dependent on the type of S. Non-morphemic and 3rd person singular S show a large difference in duration between voiced and unvoiced realizations, while plural, genitive and the two clitics show markedly smaller differences.
Testing of all pair-wise contrasts between the different types of S yields the significant contrasts shown in Tables 5 and 6. We compare the different types of S while holding voicing constant.
Table 5 Significant contrasts in duration between different types of voiced S. Significance codes: ‘***’
 $p<0.001$
, ‘**’
$p<0.001$
, ‘**’
 $p<0.01$
, ‘*’
$p<0.01$
, ‘*’
 $p<0.05$
.
$p<0.05$
.
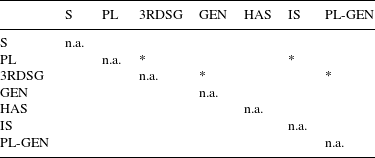
Table 6 Significant contrasts in duration between different types of unvoiced S. Significance codes: ‘***’
 $p<0.001$
, ‘**’
$p<0.001$
, ‘**’
 $p<0.01$
, ‘*’
$p<0.01$
, ‘*’
 $p<0.05$
.
$p<0.05$
.
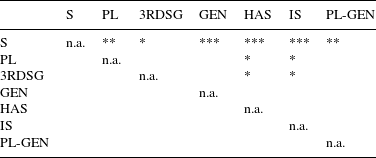
If we compare the two tables, we can first see that we find fewer contrasts for voiced realizations of S. This is not surprising for two reasons. First, this subset is much smaller, with 81 voiced as against 552 unvoiced items. Second, voiced items are generally shorter, which makes it harder to detect differences. However, even in this subset we find four significant contrasts. Third person singular S is significantly shorter than plural, genitive and genitive-plural. In addition, plural S is significantly longer than the is clitic.
For unvoiced S, 10 of the overall 21 possible pair-wise contrasts are significant. Non-morphemic S is significantly longer than all types of morphemic S. The other most remarkable pattern concerns the two clitics of has and is. They are significantly shorter than 3rd person singular S and plural S.
The results from Model 1 clearly indicate that the null hypotheses in (1) and (2) need to be rejected. We find robust differences between morphemic and non-morphemic S with unvoiced S. We also find robust differences between some types of morphemic S with both voiced and unvoiced S. These differences are present in natural conversational speech, and they cannot be attributed to purely phonetic or lexical effects since these effects were carefully controlled for.
4.2 Model 2: Relative duration
An inspection of the distribution of the relative duration measurements showed three outliers where the S was extremely long compared with the rest of the items, with proportions being larger than 54 percent. These three items were removed. The distribution of the measurements of relative length of S was substantially skewed, which is something that can be frequently observed with ratios that are bounded between 0 and 1. Beta regression is a kind of statistical model that can cope with these distributional properties. Beta regression models can contain two components, one that predicts the mean and a component for the precision phi (see Ferrari & Cribari-Neto Reference Ferrari and Cribari-Neto2004 for introduction and discussion). Broadly speaking, a predictor with a low precision coefficient means that the beta regression model estimates the values of this predictor to be more dispersed around the coefficient’s mean than in the case of a predictor with a high precision coefficent.
We fitted a beta regression model with the proportion of S as the dependent variable, and the same initial fixed effects as in Model 1 apart from baseDuration, since this variable had been used in the computation of the dependent variable. For the beta regression models a slightly different fitting strategy from that of mixed effects regression had to be adopted (see Ferrari & Cribari-Neto Reference Ferrari and Cribari-Neto2004 for details). The initial models started with only the mean component and all predictors. The initial model was then simplified in a step-wise procedure, removing all insignificant predictors. After the completion of simplification for the mean component, we added the precision component and then simplified this component applying again the standard step-wise procedures. After completion of this simplification procedure, we finally tested whether the inclusion of the precision component as a whole was justified by comparing the AIC of a model that had only the mean component with the model with both mean and precision components, and by using a likelihood ratio test. The inclusion of the precision parameters was justified by lower AIC scores and higher log-likelihood. The estimated coefficients for the means and the phi-values of the final model are given in Table 7. The reference levels are the same as with Model 1, so that all coefficients can be interpreted as changes relative to these reference levels. The bottom part of Table 7 documents the precision model, which outputs a significant effect for type of S, voicing and following context.
Table 7 Coefficients of final beta regression model, Model 2 (pseudo-
 $R^{2}$
of the model: 0.596).
$R^{2}$
of the model: 0.596).
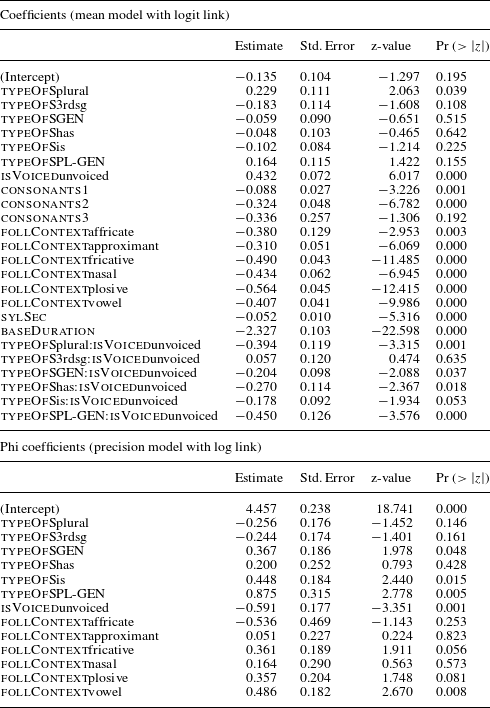
With regard to our explanatory variable, Model 2 tells us that both the means and the dispersion of the relative length of S are dependent on which kind of S we look at. For the means, the effect of type of S interacts with voicing. This is fully in line with the results from Model 1.
The behavior of the covariates in the mean model is very similar to their behavior in the model that tried to predict the absolute duration of S. This is illustrated in Figure 5.Footnote [7] Each panel shows the partial effect of a different covariate, with the values of the covariate given on the horizontal axis. The vertical axis corresponds to the estimated relative duration of S. The dots indicate the estimated means, and the bulb-shaped areas indicate the estimated beta density for the values of the covariates. The shapes of these areas inform us about the estimated dispersion around the mean: short areas (e.g. for fricatives in the upper-left panel) indicate that the model estimates the variance around the mean to be relatively low for this type of following context, while elongated areas (e.g. approximants in the same panel) suggest a relatively high variance.
The main effects of following context, number of consonants, base duration and number of syllables per second are found in both Model 1 and Model 2 and they go in the same direction as before. In middle position the proportion of S is smaller (see the negative coefficient for all segments), which means that we find the expected effect of final lengthening. This is in line with the results of pertinent investigations (e.g. Turk & Shattuck-Hufnagel Reference Turk and Shattuck-Hufnagel2007). With regard to rhyme structure, the more consonants there are in the rhyme the smaller the proportion of S becomes (see the negative coefficients), which is again an expectable effect. Higher speech rate leads to shorter realizations of S, and S participates in lengthening or shortening effects of the whole word.
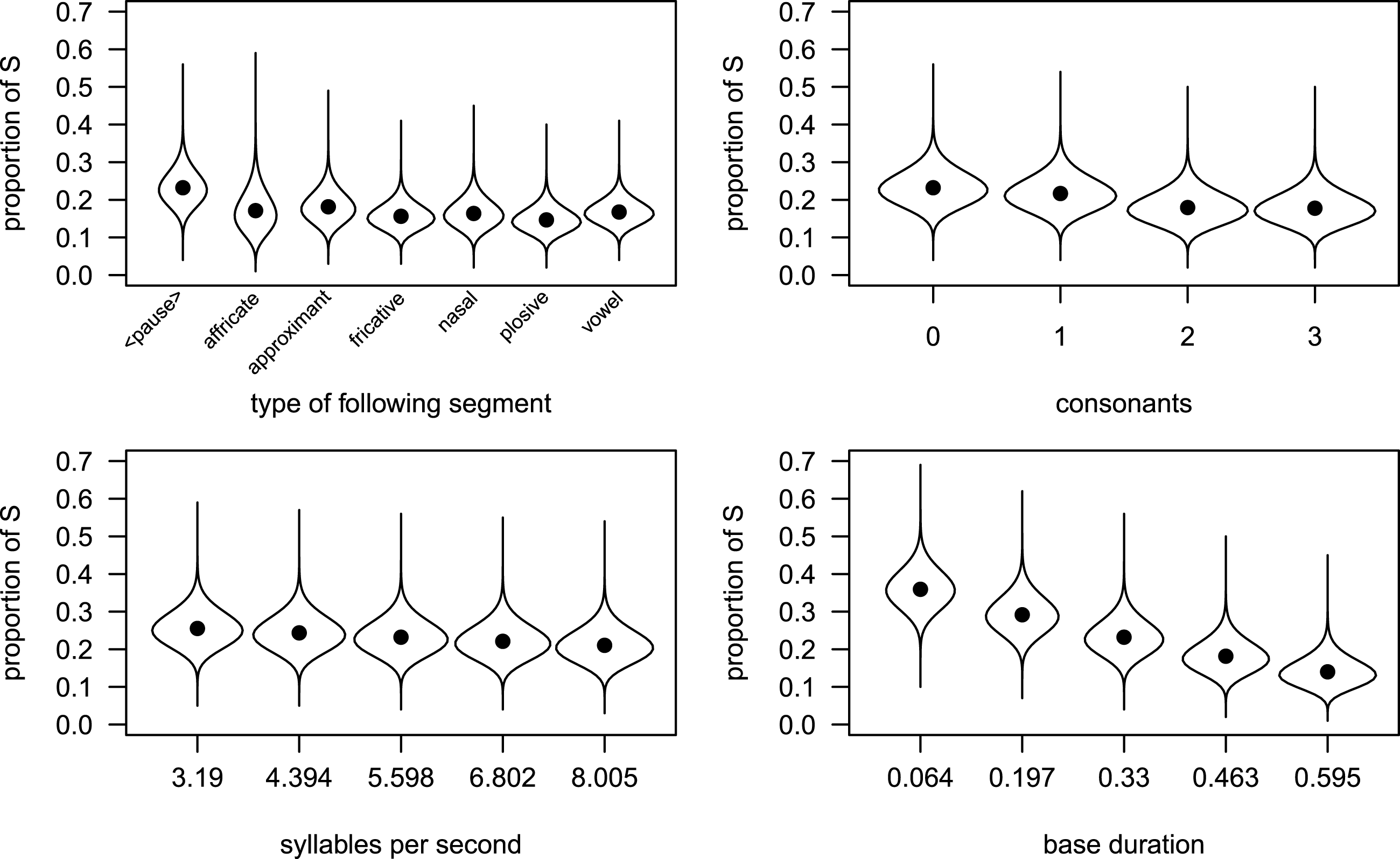
Figure 5 The effect of the non-interacting covariates on the relative duration of S, final beta regression model, Model 2.
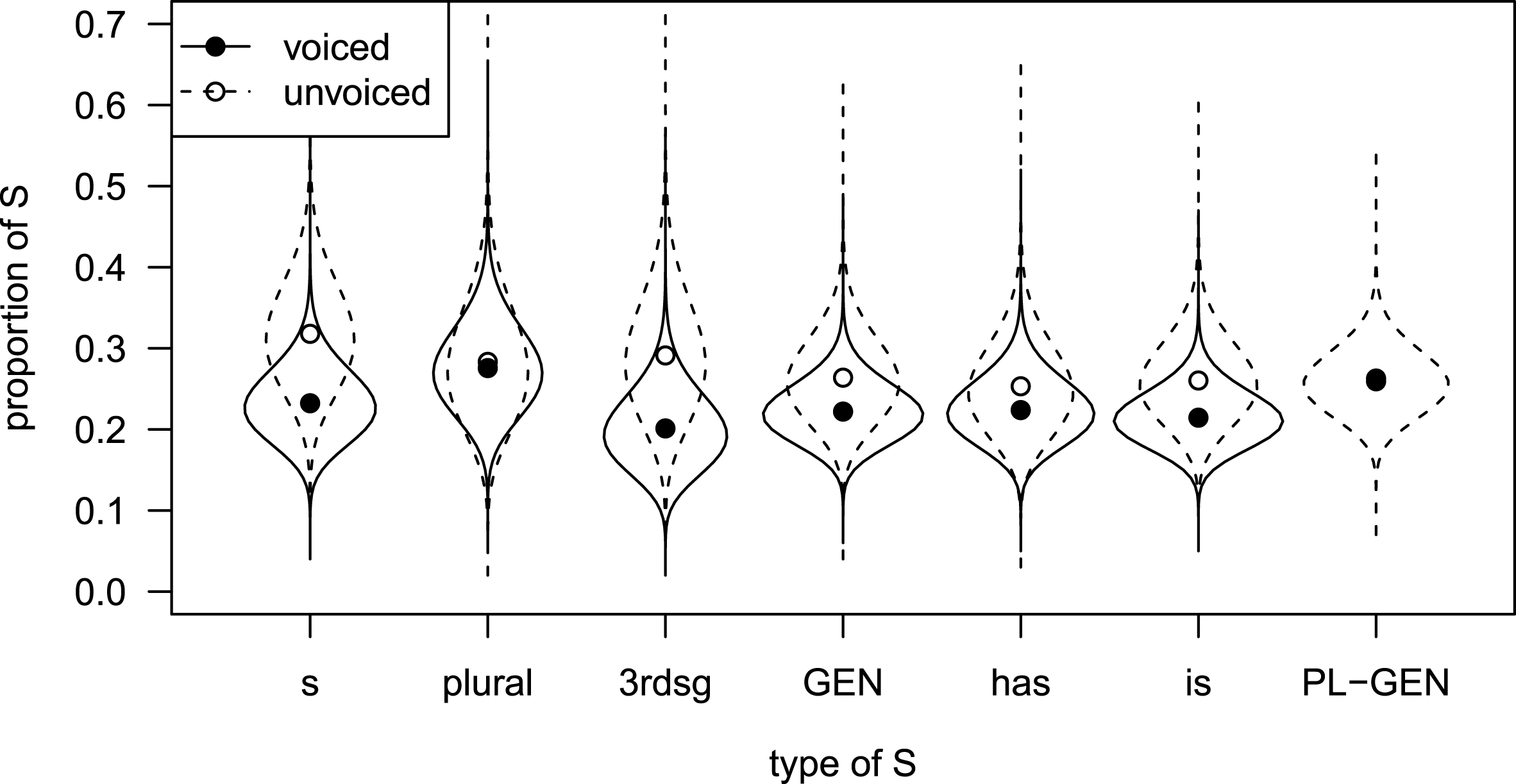
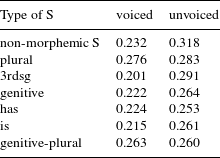
Let us turn to the variable of interest, type of S. Figure 6 shows the effect of the interaction between type of S and voicing on the estimated relative durations, and Table 8 gives the estimated means in unvoiced and voiced realizations for the different values of type of S.
An area surrounded by a solid line indicates the beta density for the voiced realizations of the associated morpheme type. The corresponding dashed area indicates the density for the unvoiced realizations. The filled and circled dots indicate the mean relative duration for voiced and unvoiced realizations (see Table 8). Note that the beta density is not shown for voiced genitive-plural. For this factor combination, the estimated precision coefficient phi exceeds the valid range for which the beta density can still be calculated. Thus, the variance is estimated to be virtually minimal – given that this estimation is based on only three observations, this result is not very surprising.

Figure 6 Effect of the interaction between morpheme type and voicing on the relative duration of S, final beta regression model, Model 2. (Abbreviations: s = non-morphemic S, 3rdsg = 3rd person singular, GEN = genitive, PL-GEN = genitive-plural).
Table 8 Predicted means of the different types of S for voiced and unvoiced realizations, final beta regression model, Model 2.
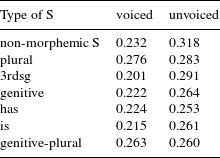
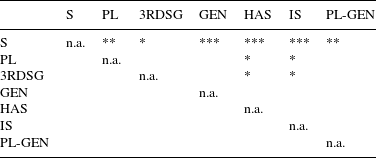
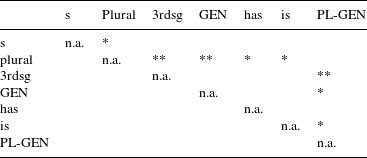
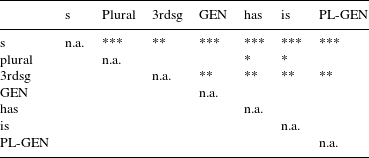
For the majority of types of S, the model estimates the mean relative duration to be different for voiced and unvoiced realizations. Investigation of the contrasts reveals that the differences for non-morphemic S, 3rd person singular, genitive and is are statistically significant (the difference for has is only marginally significant). Much more interesting with regard to our null hypothesis are, however, the differences between the different types of S. If we pair-wise compare the different estimates in the mean component of Model 2, we find eight significant contrasts for voiced realizations, and 12 (out of 21 possible ones) for unvoiced realizations. For these pairs, the beta regression estimates that the means of the relative duration differ significantly from each other. Tables 9 and 10 summarize the contrasts.
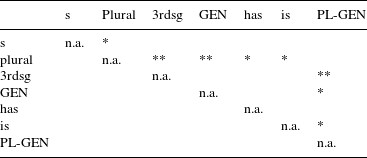
Table 9 Significant contrasts in relative duration between different types of voiced S.
Significance codes: ‘***’
 $p<0.001$
, ‘**’
$p<0.001$
, ‘**’
 $p<0.01$
, ‘*’
$p<0.01$
, ‘*’
 $p<0.05$
.
$p<0.05$
.
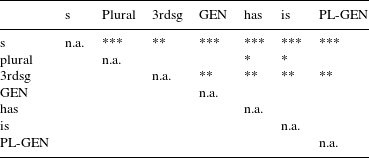
Table 10 Significant contrasts in relative duration between different types of unvoiced S.
Significance codes: ‘***’
 $p<0.001$
, ‘**’
$p<0.001$
, ‘**’
 $p<0.01$
, ‘*’
$p<0.01$
, ‘*’
 $p<0.05$
.
$p<0.05$
.
The pair-wise contrasts for the relative duration of the different types of S yield an interesting picture. For voiced realizations, plural is significantly longer than all other types of S, except for genitive-plural. Genitive-plural, in turn, is significantly longer than 3rd singular S and the is clitic. For unvoiced realizations, a different pattern emerges. Non-morphemic S is significantly longer than all other types of S. The two suffixes plural and 3rd person singular have similar relative durations, but they are significantly longer than the two auxiliary clitics has and is. In addition, 3rd person singular is also significantly longer than genitive and genitive-plural (plural shows a marginally significant contrast to genitive and genitive-plural,
 $p=0.06$
for both of these contrasts). The relative durations of the four clitics (i.e. has, is, genitive and genitive-plural, if the latter is analyzed as clitic) do not differ significantly from each other. In terms of relative duration of unvoiced realization, we can thus determine three groups: non-morphemic S, the suffixes and the clitics (the latter including genitive-plural).
$p=0.06$
for both of these contrasts). The relative durations of the four clitics (i.e. has, is, genitive and genitive-plural, if the latter is analyzed as clitic) do not differ significantly from each other. In terms of relative duration of unvoiced realization, we can thus determine three groups: non-morphemic S, the suffixes and the clitics (the latter including genitive-plural).
To summarize, the analysis of the relative duration of S has shown that there are many significant differences between different types of S, in particular between plural and the rest for voiced realizations, and between non-morphemic, suffixal and clitic S for unvoiced realizations. The results of Model 2 thus support and complement the results of Model 1, to the effect that the null hypotheses in (1) and (2) need to be rejected for both kinds of duration measurements.
5 Summary and discussion
5.1 Summary of results
Following in the footsteps of recent studies of free lexemes by, for example, Drager (Reference Drager2011) and Gahl (Reference Gahl2008), we tested whether the morphological status of S has an influence on the acoustic duration of this segment. We started out from two null hypotheses. The first stated that there are no durational differences between non-morphemic S and morphemic types of S. The second null hypothesis stated that there are no durational differences between the different homophonous types of morphemic S. We investigated the duration of the different types of S using conversational data. No matter whether we looked at the absolute duration of S or the relative duration of S, the type of S emerged as a strong, significant predictor of segmental duration. We found statistically significant differences between certain types of S. This means that we have to reject the two null hypotheses.
The details of the results are intricate, but the clearest outcomes can be found with unvoiced realizations. For this subset, the relative duration shows a pattern of differences that correlates with the type of morphological boundary. Words with no morphological boundary before S show the longest duration of S. Words with a suffixal S have shorter S’s, and cliticized S’s are even shorter (the difference between plural and genitive, and plural and genitive-plural was marginally significant). The results for voiced realizations are very similar and show a difference between the two suffixes and the two clitics. Even though the voiced realizations show fewer and somewhat different contrasts, they still clearly falsify both null hypotheses.
Our analyses of absolute and relative duration of the different types of S included pertinent covariates that controlled for purely phonetic effects known from the phonetic literature. The covariates whose effects are well established by other studies behave as expected, so that one can assume that the speech corpus data used for this study are generally reliable. Thus, the results, surprising though they may be, cannot be easily dismissed as due to an unsuitable sample, or an inadequate phonetic analysis.
5.2 Comparison of results to other studies
How do our results relate to those of previous studies? Let us first discuss the difference between morphemic S and non-morphemic S (Null Hypothesis 1, see (1)). Our results concerning the absolute duration of S seem to agree with Walsh & Parker (Reference Walsh and Parker1983), who also found differences between the two types of S. Such a statement would, however, be premature. As these authors did not employ any inferential statistics, or consider any covariates in their analysis, we cannot determine whether the small differences found in the means by Walsh & Parker are meaningful. It is noteworthy, however, that the mean difference observed by Walsh & Parker goes in the opposite direction from ours: in their data, morphemic S is longer, not shorter, as it is in our sample. However, their mean difference between the morphemic (i.e. plural in their experiment) and the non-morphemic /s/’s was only 6 ms, while we observed much larger differences in the means (e.g. 38 ms estimated difference between non-morphemic S and the has clitic, and 47 ms difference in the observed means, see Table 1).
In a more recent study that investigated nine monosyllabic word types ending in /z/, Song et al. (Reference Song, Demuth, Evans and Shattuck-Hufnagel2013) found a significant difference between plural and non-morphemic /z/ in utterance-final position, but not in non-final position. Morphemic /z/ was longer than non-morphemic /z/, but only by 7 ms.Footnote [8]
It is not clear where the discrepancies between those data and ours come from, but we may speculate about possible reasons. One reason might be the different kinds of item. In Walsh & Parker’s experimental study, morphologically complex words were compared with their simplex homophones, while in our data we tested the duration of S across the board, i.e. across many different, non-homophonous, types. It may well be that phonetic differences between phonologically homophonous word forms of two different lexemes arise from the competition of these lexemes (or their word forms) in speech production.
Another difference between Walsh & Parker’s and the present study is the nature of the data. The reading out loud of the stimuli list may have influenced the results in a way that we do not find in spontaneous speech. Gahl et al. (Reference Gahl, Yao and Johnson2012), for example, discuss studies that have failed to reproduce the well-established effect that more frequent words generally show shorter duration. The authors remark that this failure to replicate the effect may be due to the fact that speakers tend to read at a regular pace when asked to read word lists or words in short carrier phrases. This tendency has been found to override effects of lexical properties, such as word frequency.
Song et al.’s study is based on conversational speech, i.e. data that seem comparable to ours. However, their data set is restricted to monosyllables and to only nine different word types. Furthermore, the set of covariates in that study was small and potential variability in voicing was not taken into account when analyzing the duration of morphemic versus non-morphemic /z/. Another, and perhaps important, difference from our study is that Song et al.’s data comprise child-directed speech, which has been shown to differ from inter-adult speech in various ways (see, for example, Foulkes et al. Reference Foulkes, Docherty and Watt2005 for an overview and discussion). More research is certainly called for to replicate the effects observed in previous studies and the present one.
With respect to differences between different types of morphemic S, there are hardly any studies available with which we could compare our results. Song et al. (Reference Song, Demuth, Evans and Shattuck-Hufnagel2013) do not find a difference between 3rd singular and plural S, but they limited their data set to only three word types for each morpheme. Li et al. (Reference Li, Leonard and Swanson1999), also investigating mothers’ speech to their young children, found that plural S was longer than 3rd person singular S, but attributed this difference to the fact that plural nouns were more prone to appear in utterance-final position in their data set. In our data, we also found an effect of position but no interaction of position with type of S. The lack of studies and the contradictory results of the few existing studies call for more research into the phonetic realization of morphemic S in English.
5.3 Explanations and implications
The results of the present study raise important theoretical questions. Most importantly, it is unclear why the differences between different types of S that we find in our data would emerge in the first place. More specifically, one is tempted to ask the question why a certain type of S should be longer than some other S. For instance, why are the clitics particularly short and the suffixes rather long (and non-morphemic S even longer)? Which theory would predict such results?
At a very general level, our findings can be interpreted as support for the idea that there is morphological information in the phonetic signal, i.e. in post-lexical stages of speech production. This calls into question the distinction between lexical and post-lexical phonology, which has featured prominently in both theoretical linguistics, i.e. phonology, and psycholinguistics.
In phonology, there is a long tradition of theoretical mechanisms like bracket erasure and cyclic application of morpho-phonological rules, after whose application there is no possibility that one could trace any information about a sound’s origin or structural status in the acoustic signal. The findings of this paper thus seriously challenge central tenets of the traditional models of lexical phonology and morphology in the wake of Kiparsky (Reference Kiparsky and Yang1982) (see also, for example, Scheer Reference Scheer2010 and Coetzee & Pater Reference Coetzee and Pater2011 for critical discussion).
There are, however, some alternative explanations conceivable. We will first discuss a prosodic approach and then turn to psycholinguistic ones. In a prosodic phonology approach phonetic differences (for example in duration) between different types of S might emerge from different positions of these S’s in the prosodic structure. It has been claimed (e.g. Goad Reference Goad1998, Goad et al. Reference Goad, White and Steele2003) that plural S is an ‘internal clitic’, i.e. it is part of the prosodic word, as in (5), whereas 3rd singular S is an ‘affixal clitic’ adjoined to the prosodic word formed by its base, see (6). The auxiliary and genitive clitics would be analyzed as ‘free clitics’, given in (7).

This prosodic analysis thus posits a difference between free clitics and affixal clitics that would mirror the difference in duration between the clitics and the suffixes in our study: affixal clitics are shorter than free clitics. However, that would possibly predict that plural should be shorter than 3rd singular. This is, however, not the case. In unvoiced realizations there is no difference between plural and 3rd singular, and in voiced positions there is a difference but it goes in the opposite direction, i.e. plural is longer. In other words, the increasing degree of integration posited from free clitic to internal clitic is not mirrored by a consistent patterning of the acoustic correlate we measured.
In addition, it is not clear why the phonetic properties would pattern in the way they do. A prosodic account has no obvious explanation for why less prosodic integration would go together with shorter duration. On top of that it seems mysterious that voiced and unvoiced realizations can show different kinds of contrasts, although the prosodic structure remains the same for both voiced and unvoiced realizations.
An alternative to a prosodic account is exemplar-based models (e.g. Goldinger Reference Goldinger1998; Bybee Reference Bybee2001; Pierrehumbert Reference Pierrehumbert2001, Reference Pierrehumbert, Gussenhoven and Warner2002; Johnson Reference Johnson2004; Gahl & Yu Reference Gahl and Yu2006), which seem to be better equipped to deal with the kind of variation we find in our data. In such models a given word is linked to a frequency distribution over phonetic outcomes, as encountered in the environment of the speaker. These distributions are updated with new experiences, and subtle subphonemic differences in these experiences may result in representations that reflect these properties. For example, Pierrehumbert (Reference Pierrehumbert, Gussenhoven and Warner2002) demonstrates how such a model can deal with the phonetic variability of lexemes. It is conceivable that similar models can be implemented to account for the subtle phonetic properties of different bound morphemes. The details of such an account still need to be worked out in future studies, however, since available exemplar-based approaches have not included the subtle phonetic differences involved in the differentiation of allegedly homophonous affixes. One problem to solve in an exemplar model is the effects of the covariates. It is not obvious how these general effects could be derived in a pure, non-abstracting model (see also Pisoni & Levi Reference Pisoni, Levi and Gaskell2009 for discussion).
Turning to psycholinguistic models, well-established models of speech production and the mental lexicon seem equally unable to accommodate our findings. Levelt et al. (Reference Levelt, Roelofs and Meyer1999), for example, assume that phonological representations are composed of discrete segments and syllables, and the articulator module makes use of pre-programmed gestures that are stored in a syllabary (Levelt et al. Reference Levelt, Roelofs and Meyer1999: 5). The articulator cannot provide a pre-programmed gesture for each syllable of a language if different meanings cause differences in these gestures. In other words, in such models morphologically dependent subphonemic detail is not part of these representations and needs therefore to be accounted for by purely phonetic factors that influence articulatory implementation such as speech rate (e.g. Levelt Reference Levelt1989). For our data, such an account is ruled out.
There is also a line of psycholinguistic research that has looked at distinct processing properties of different kinds of morphemes. Using data from aphasia, second language acqusition and code switching, Myers-Scotton & Jake (Reference Myers-Scotton and Jake2000) propose a four-way distinction between different types of morpheme (the so-called ‘4-M model’). According to the 4-M model there are content morphemes and system morphemes, and the system morphemes are further subdivided into ‘early system morphemes’ and ‘late system morphemes’. These classes are not all very well defined, but it seems clear that plural belongs to the early system morphemes while genitive and 3rd person singular marking belong to the late system morphemes. The late system morphemes further consist of two subclasses, ‘bridge system morphemes’ and ‘outsider system morphemes’. According to Myers-Scotton & Jake (Reference Myers-Scotton and Jake2000), genitive S is a bridge morpheme, while 3rd person singular is an outsider morpheme. The proposed four-way classification of morphemes is supported by the differential behavior of these morphemes in aphasia, second language acquisition and code switching, and these authors relate the differences in behavior to differences in lexical access. For content and early system morphemes, lexical access happens at the lemma level, and for the late system morphemes at what they call the ‘functional level’, which is located at the level of the formulator (see, for example, Levelt Reference Levelt1989).
Unfortunately, it is not obvious how this model would be able to account for our results. Even if we assume that Myers-Scotton & Jake’s taxonomy is on the right track, there are severe problems. The first one is that their model does not say anything about the details of phonetic implementation, and it is unclear what the model would predict for this stage of speech production. If the 4-M model carries over to articulation (in ways still to be investigated), we would expect plural (being an early system morpheme) to pattern with the auxiliary clitics, which is obviously not the case. What is more, the 4-M model seems to rest on the assumption that the morphemes are accessed separately from their bases. More recent research in morphological processing has cast serious doubt on this idea, and the jury is still out on the question of the psycholinguistic status of individual inflectional morphemes.
To summarize, we have to state that both phonological theory and extant psycholinguistic models fail to provide a convincing explanation of the kind of morphologically-induced phonetic variation that we find in our data.
5.4 Directions for future research
As became obvious in the preceding paragraphs, more research is needed to address the many questions the present study raises. First, there is a need for investigations that replicate the effects reported in this paper. These should be both experimental (in order to specifically test the two null hypotheses introduced above) and based on data from other corpora of conversational speech (in order to be directly comparable to the present results that were based on the Buckeye corpus).
Another study that suggests itself given the present findings on S is to look at other homophonous affixes, inflectional -ed, i.e. /t/ and /d/ in particular. Based on the present study the hypothesis could be tested that non-morphemic D would be longer than morphemic D, and that suffix D (as in past tense forms) is longer than the clitics of would and had. Such a study is already under way in our laboratory, with promising initial results (Homann et al. Reference Homann, Plag and Kunter2014). One could also test whether inflectional D (as in the past tense) is different in duration from derivational D (as in three-wheeled, see Bauer et al. Reference Bauer, Lieber and Plag2013: 304, 306, 313).
If there are indeed systematic differences between the different types of S in speech production, one would also like to know whether language users are influenced by these differences in perception. Walsh & Parker (Reference Walsh and Parker1983) briefly report a follow-up perception experiment, but there is no proper statistical analysis that would support their conclusion that length does not serve as a perceptual cue.
A natural extension of the present study would therefore be the investigation of S with listeners. The difference in absolute duration between the estimated means of the shortest morphemic S (i.e. the has clitic) and non-morphemic S in our corpus data amounts to approximately 38 ms. This difference seems large enough to be potentially perceptible: the perceptual threshold for durational differences in fricatives has been estimated at about 25 to 30 ms (e.g. Klatt & Cooper Reference Klatt, Cooper, Cohen and Nooteboom1975, Shatzman & McQueen Reference Shatzman and McQueen2006).
To summarize, this paper presents the first larger study that has systematically investigated the relationship between morphemic status and phonetic implementation of homophonous affixes and their non-morphemic counterpart. This was done using natural conversation data. The analysis has yielded important evidence on the question of affix homonymy, revealing that phonologically homophonous bound morphemes can be phonetically distinct, and that morphemic and non-morphemic S may differ, too. This is unpredicted by current linguistic and psycholinguistic theories of the lexicon and grammar. Further studies are certainly called for to replicate the observed effects, and to develop new models of the mental lexicon and of the relationships between morphology, phonology and phonetic implementation.