


INTRODUCTION
Experiments have become increasingly popular in political science (Druckman et al. 2006; Mutz Reference Mutz2011). Although they provide unparalleled ability to identify whether one factor causes another, scholars have frequently voiced concerns about the potential limitations of experimental research. Foremost among these concerns are questions about external validity, or the “extent to which conclusions [of a given study] can be applied across different populations or situations” (McDermott Reference McDermott2011, 34). This point is critical, as scholars aim to use experimental work to answer questions of import to political science as a discipline and politics at large (Kinder and Palfrey Reference Kinder and Palfrey1993).
Although the idea of external validity broadly applies to the replicability of an experimental finding across various contexts, the characteristics of the subjects participating in a given experiment have emerged as especially critical factors (McDermott Reference McDermott2011). Discussion about subject characteristics has largely focused on implicit or explicit comparisons between three types of samples: undergraduate student samples, adult convenience samples, and national adult samples. Indeed, McDermott (Reference McDermott2002:334) has gone so far as to label these concerns a “near obsession” among critics of experiments. Long-term concerns about student samples stem from the idea that students may be so sufficiently different from “everyday citizens” that generalizations are impossible in most cases (Brady Reference Brady2000; Benz and Meier 2008; Gerber and Green Reference Gerber and Green2008; Sears Reference Sears1986).
In response to these worries, many scholars have shifted focus to samples of adults (McGraw Reference McGraw2011), with a more recent turn toward adult convenience samples obtained via Amazon’s Mechanical Turk (MTurk). MTurk’s popularity rests in its relatively low cost and high accessibility for most scholars. Despite the fact that recent research suggests that MTurk produces results that replicate canonical experiments in both psychology and political science (Berinsky et al. Reference Berinsky, Huber and Lenz2012), much of the recent discussion about the use of MTurk samples has cautioned against excessive use of this medium for subject recruitment. Concerns have focused on the fact that, despite countless studies, scholars know very little about these individuals. It is unclear why they have opted in to MTurk, why they are willing to participate in countless studies for – in some cases – mere pennies, and how their motivation affects the quality of their work.Footnote 1
Underlying concerns about experimental subjects are thus two related questions. First, under what conditions can the results of studies with undergraduate samples and adult convenience samples such as MTurk be replicated with samples drawn from different populations? Second, from an external validity point-of-view, is there an inherent benefit to relying upon samples of “everyday citizens” who are not students, even if they are convenience samples?
To answer these questions with the highest degree of internal validity, it is necessary to compare the results from identical experiments conducted with different samples at approximately the same time. Our paper is one of the first to do just that, and in particular the first political science paper to compare results from common types of undergraduate, adult convenience, and adult national samples.
Although there are an unlimited number of different studies that we could have conducted across these three samples, we narrowed our focus based on a theoretically-relevant dimension: the fact that in some cases experimenters have reason to expect a heterogeneous treatment effect whereas in others cases they do not. We thus chose four experiments that allow us to capture common and theoretically-meaningful potential moderators. These moderators reflect factors that might affect how different types of people process political information in general (such as their party identification) as well as how they might process political information when they know they are in an experiment (such as their previous experience taking experiments). Both are common attributes of political science experiments, and thus good places to start for investigating key questions about external validity.
We conducted each of the four experiments with an undergraduate sample recruited via a university subject pool, an adult convenience sample recruited via Amazon’s Mechanical Turk, and a diverse national sample,Footnote 2 for a total of 12 separate studies. Hewing to the questions above, our key goal in each study is to compare the results across all samples as well as to long-held theoretical predictions. While previous work has offered arguments about various samples (Sears Reference Sears1986), analyzed the role of sample characteristics in already-existing research (Morton and Williams Reference Morton and Williams2010), relied on simulations to trace the effects of sample differences (Druckman and Kam Reference Druckman and Kam2011), considered mode effects (Barabas and Jerit Reference Barabas and Jerit2010), or focused on the characteristics of one sample type (Berinsky et al. Reference Berinsky, Huber and Lenz2012), our paper is the first to use original experiments deliberately designed to compare these three different samples in parallel.
Our investigation is timely for several reasons. First, scholars have begun to think more critically about how the experimental process affects the types of conclusions drawn from experiments (Barabas and Jerit Reference Barabas and Jerit2010; Druckman and Leeper Reference Druckman and Leeper2012). Our paper contributes to this growing body of work. Second, our research comes at a time when concerns about student samples continue to fuel enthusiasm for experimental research that relies on “adult” (i.e. non-student) subjects.Footnote 3 Although experimentalists are careful to note that a sample’s usefulness depends upon having variance on relevant moderators (Druckman and Kam Reference Druckman and Kam2011), it remains the case that the large majority of experimental studies published in the discipline’s top three journals do not rely on student samples (see Web Appendix A). Third, we have seen the recent expansion of local convenience samples of adults (Kam et al. Reference Kam, Wilking and Zechmeister2007) as well as adult convenience samples – such as MTurk – recruited over the Internet (Berinsky et al. Reference Berinsky, Huber and Lenz2012; Iyengar Reference Iyengar2011), but scholars have only begun to identify the conditions under which such samples are substitutable for more nationally-diverse ones.
CONCERNS ABOUT SAMPLE CHARACTERISTICS
The goal of an experiment is to compare subjects who have been randomly assigned to different stimuli. In its most basic form, one group receives one version of a stimulus and another group receives a different version. Post exposure, group differences in response are used as evidence of a stimulus effect (Druckman and Leeper Reference Druckman and Leeper2012). Worries about samples, then, hinge on the possibility that these differences might reflect attributes of the subjects included in a particular study rather than the power of the treatment to leave a broader political footprint across time and place.
When might this outcome arise? One way in which a sample might be considered “narrow” is if the subjects differ in theoretically-relevant ways from populations to which experimenters may wish to generalize. Writing about undergraduates, for example, Sears (Reference Sears1986:522) argues that they “are quite uncertain about many of their values, preferences, abilities, and emotions, and for good reason. Many of these dispositions are still developing.” Indeed, these considerations have frequently motivated how scholars choose their samples (see Web Appendix B for examples). With adult convenience samples like MTurk, there are also several possibilities. Because MTurk relies on people who are often willing to take political experiments for little compensation, it is possible that they have levels of knowledge, experience, or partisanship that vary from the general citizenry (although, notably, Berinsky et al. Reference Berinsky, Huber and Lenz2012 find few such differences between their MTurk and nationally-representative samples). As a result, forming inferences based on these convenience samples may lead scholars to overstate or understate the power of a given stimulus despite the fact that experiment participants are technically adults (Shadish et al. Reference Shadish, Cook and Campbell2002).
A sample’s narrowness might also arise due to attributes of the subject pool. Given their varying rules and structure, in some subject pools it is likely that participants will have participated in numerous previous studies. As a result, they would have gained experience being debriefed and learning about the experimental process (including the types of manipulations that experimenters frequently use). In short, they may have become savvier.Footnote 4 Such savviness can affect subsequent experimental behavior. Kam (Reference Kam2007), for example, notes that subjects who are savvy can deliberately control their responses to such an extent that they undermine measures designed to test implicit beliefs about various topics. More generally, savviness can increase vigilance, suspicion of experimental studies, and a desire to search for the “twist” rather than taking the experimenter’s word about the goals of the study (Cook et al. Reference Cook, Bean, Calder, Frey, Krovetz and Reisman1970). When subjects are savvy, it seems reasonable to suspect that considerations will be brought to mind that would not arise in the midst of the hustle-and-bustle of everyday life. Put another way, these savvier subjects heighten the artificiality of the experimental setting (McDermott Reference McDermott2011).
At its core, savviness reflects the number of studies that a subject has taken and any requirements of the subject pool to which they belong (Dalen et al. Reference Dalen, Stanton and Roberts2001; Steffens Reference Steffens2004). While we may assume that undergraduate students are more likely to have taken numerous studies as part of subject pools and that members of opt-in platforms such as MTurk may also engage in unlimited participation, increasingly adult subjects who are part of platforms which purport to offer representative samples are also participating in many studies. Indeed, political scientists commonly rely on YouGov and the GfK Group – services that maintain large national subject pools of adults (e.g. Banks and Valentino Reference Banks and Valentino2012; Brooks and Geer Reference Brooks and Geer2007; Hopkins and King Reference Hopkins and King2010). At the same time, these adult subject pools do not have the same requirements as undergraduate pools. Undergraduate subject pools have a stronger educational norm (Brody et al. Reference Brody, Gluck and Aragon2000) and thus require that researchers conclude studies by offering educational materials that explain the goals of each experiment, a requirement that speeds up learning about the experimental process. Thus, we expect that all participants in subject pools will become savvier as they take more studies, but also that the savviness gradient should be much steeper for those in undergraduate pools.
Typically concerns about experiments arise due to undergraduates, yet we have presented arguments as to why they could also apply to adult samples. We do not mean to suggest that our four experiments capture every possible source of narrowness. Rather, our goal in this paper is to investigate dimensions which, arguably, have formed some of the most ardent criticisms of the experimental method in political science.
Scope of analysis
As with the degrees of variation related to experimental subjects, from a substantive point of view there is also an infinite number of experimental designs that we could use to examine sample differences. After considering the full range, we chose to focus on framing studies (Chong and Druckman Reference Chong and Druckman2007; Kinder Reference Kinder2003; Nelson et al. Reference Nelson, Bryner and Carnahan2011). Framing is ideal for our purposes for three reasons: it is a prominent line of inquiry in political behavior research, it has long-standing theoretical expectations, and it has frequently been the subject of experimentation (Chong and Druckman Reference Chong and Druckman2010). Our four framing studies reflect different ways in which results may or may not reflect the narrowness of the subject pool. Our first study has no predicted heterogeneous treatment effect. It just includes a single question that asks people to report on their political news consumption and varies the set of response options. Our second study requires subjects to read a news article and report their opinion, and we expect heterogeneity based on respondents’ partisanship. Our third and fourth studies do not require much reading, but might be affected by a subject’s degree of savviness.
RESEARCH DESIGN
The undergraduate sample was recruited through a subject pool based in a political science department at a large public institution in the Midwest. The adult convenience sample was recruited through MTurk following procedures similar to Berinsky et al. (Reference Berinsky, Huber and Lenz2012). We focus on MTurk as the source of our adult convenience sample because, as Berinsky et al. note, it is becoming a popular method for researchers who wish to use adults that (a) presumably do not have the pitfalls of undergraduates that Sears (Reference Sears1986) highlighted, and (b) are not as expensive as nationally-representative samples.Footnote 5 Lastly, our diverse, adult national sample was recruited via YouGov, and our analyses of this sample are weighted to be nationally-representative. YouGov is widely used, including some high-profile cases in which a nationally-representative sample is desired (such as the Cooperative Congressional Election Study and the Cooperative Campaign Analysis Project).Footnote 6 Table 1 contains a full summary of our experiments. For each set of experiments, we will compare the results from each sample to existing theoretical expectations and also compare estimates across samples.
Table 1 Overview of Studies

As much as possible, we strove to have studies with similar sample sizes to ensure approximately equivalent statistical power. Yet, we acknowledge that in some cases study logistics dictated otherwise. To ensure that sample differences do not affect our ability to discern group differences, we rely on a priori power analyses (Levine and Ensom Reference Levine and Ensom2001).Footnote 7 As three of four experiments are replications of previous studies, we use the effect sizes observed in these previous studies as a baseline and then calculate the sample size necessary to observe significant group differences at that effect size with power between 0.8 and 0.9 and 0.05 ⩽ α ⩽ 0.10.Footnote 8 Our samples meet these thresholds in all but one case, even when we analyze the results by theoretically-important covariates. To the extent that in some samples we do not see significant group differences, this result is thus not a function of sample size differences.
Finally, in all cases we conducted randomization checks using factors measured prior to treatment. Results show that randomization was successful in all studies.
Demographic comparison
We begin by comparing the demographic characteristics of our samples (Table 2). As a benchmark for comparison we also present data from the 2008 American National Election Study (ANES). In addition, we compare our undergraduate and MTurk samples to other experiments that relied on the same subject types. We compare our undergraduates to the student subjects in Taber and Lodge (Reference Taber and Lodge2006)Footnote 9 and we compare our MTurk participants to Berinsky et al. (Reference Berinsky, Huber and Lenz2012). We do so to ensure that there is nothing unusual about the particular samples we have recruited and that results are based on “typical” samples.
Table 2 Demographics and Experimental Experience Across Samples

* Berinsky et al. (Reference Berinsky, Huber and Lenz2012) report the mean income ($55,332) and the median income ($45,000).
** Berinsky et al. (Reference Berinsky, Huber and Lenz2012) report the average years of education (14.9), which suggests their sample is consistent with our sample.
*** Berinsky et al. (Reference Berinsky, Huber and Lenz2012) report the average number of studies about politics that MTurk participants have taken, which makes it difficult to compare our measure to their results.
Table 2 points to a couple of notable comparisons. First, as expected, the YouGov sample comes closest to the ANES, though the MTurk sample performs better than the undergraduate sample on a number of demographic factors. Particularly notable are the income comparisons, which show that our undergraduate sample is much wealthier than either MTurk or YouGov. The MTurk sample, however, is distinctly younger and better educated than YouGov and ANES and, notably, nearly 20% of the sample report that they are current undergraduate students – an important figure for scholars who opt to rely on MTurk as an adult sample.Footnote 10 Even more importantly, however, the MTurk sample is distinctly more Democratic – in fact, less than 15% of these subjects report that they identify as Republicans. The distribution of partisanship in our undergraduate sample actually comes closer to the distribution of partisanship in our YouGov sample and the ANES sample than the MTurk sample.
Comparing our student and MTurk samples to samples of similar groups in existing work points to some differences. While our student sample is equally as Democratic as the sample in Taber and Lodge (Reference Taber and Lodge2006), the racial make-up differs markedly. This difference is likely due to the differences in student populations at the institutions where these studies were conducted.Footnote 11 Our MTurk sample is quite similar to Berinsky et al. (Reference Berinsky, Huber and Lenz2012). In particular, the two samples are nearly equivalent in age and are largely similar on gender, race and the percentage identifying as Republican.
In addition to the traditional demographic characteristics we also present information about the number of studies these subjects have taken, which will be crucial for our savviness investigation. For now, we note a few striking comparisons. As the bottom row of Table 2 shows, our undergraduate students are the least experienced of our subject groups. Indeed, our MTurk and YouGov participants average over 30 studies.Footnote 12 While these differences may be surprising given conventional wisdom about undergraduate subject pools, they are unsurprising given sample construction: undergraduate students typically spend only a limited period in a subject pool and subject pools typically limit the number of studies conducted in a given semester. In contrast, MTurk participants can take as many studies as available (and numerous studies are often available). Similarly, YouGov panel members can also remain on the panel for as long as they wish, leading to potentially higher rates of study accumulation. We return to the implications of these numbers later in the paper.Footnote 13
STUDIES 1, 2, 3: QUESTION-WORDING
Our first experiment is based on Schwarz et al.’s (Reference Schwarz, Hippler, Deutsch and Strack1985) canonical study of response option effects. In this experiment, subjects were asked how much time on a typical day they spend following the news and were randomly assigned to receive one of two response option scales: a “low scale” that ranged from “up to 30 minutes” to “more than 2.5 hours” or a “high scale” that ranged from “up to 2.5 hours” to “more than 4.5 hours.” Following Schwarz et al.’s explanation, people do not typically store a precise answer to questions like this one in long-term memory that are ready to be accessed. Instead, they use the response scale to help formulate their answer, as it provides an indication of the amount for the average respondent.
Beginning with this study is beneficial for several reasons. First, this study is the “simplest” in the sense that we do not expect a heterogeneous treatment effect (while still acknowledging the possibility that the overall size of treatment effects may be larger for those in one sample versus another). Subjects are not required to read an article or even a particularly long question. There are no detailed instructions and they are not presented with any novel information on any topic. They simply answer a question about their news habits. Second, Schwarz et al. obtain clear results that have since been replicated in a variety of contexts and using a variety of samples.
Following Schwarz et al., we look for the effect of differing response scales by comparing the percentage of people who reported following the news for more than 2.5 hours. Table 3 displays the results. In each of our three samples, the results are conceptually equivalent to each other and to what Schwarz et al. observed: subjects assigned to the high scale were significantly more likely to report that they follow news more than 2.5 hours per week (based on two-tailed t-tests; p-values reported in Table 3). Notably, when we compare the size of the estimates we do see a larger effect size for our undergraduate sample relative to the other two (with our MTurk and YouGov estimates being statistically non-distinguishable; see p-values marked in the table, based on F-tests). Given that the difference we obtain is based on the idea that people often do not have a precise answer to questions like this one stored in long-term memory, these results suggest that undergraduates in college are on average even less aware of how much time they spend following the news relative to those outside of college.
Table 3 Question Wording Study: Comparison of Response Option Effects by Sample

STUDIES 4, 5, 6: AIRLINE OWNERSHIP POLICY
We now move to a second experiment in which we do expect a politically-relevant heterogeneous treatment effect. This one is modeled after canonical framing experiments in which subjects are randomly assigned to read a newspaper article framed positively or negatively around a political issue (Nelson et al. Reference Nelson, Clawson and Oxley1997). In our case the issue has to do with ownership of U.S. airlines, and in particular whether foreigners should be allowed to own greater shares of airlines than present law allows. Right now, the Civil Aeronautics Act of 1938 prohibits foreign investors from holding more than 25% of voting stock in any U.S. airline.
Amidst the financial turmoil the industry has endured over the past few years, there have been calls to relax those requirements. The pro and con arguments, which we feature as the main manipulation in our study, have focused mostly on the distribution of economic benefits and costs, particularly as they affect more affluent and densely-populated areas versus less affluent mid-size and smaller cities. The major pro-argument is the possibility of better on-board service enjoyed by the members of the public who fly, whereas the major con-argument is the potential loss of service outside of the country’s largest metro areas. The economic aspect of the issue thus speaks directly to distributional questions. To the extent that people are highly concerned about distributional issues, we expect them to view the considerations raised in the frame to be applicable and thus exhibit framing effects (Chong and Druckman Reference Chong and Druckman2010). This point is important because, although this issue is obscure for many respondents,Footnote 14 there are strong partisan differences in concern about distributional issues. In particular, Democrats demonstrate far greater concern about them than Republicans, with Independents in between.Footnote 15 These partisan differences, then, should lead to conditional framing effects (Haider-Markel and Joslyn Reference Haider-Markel and Joslyn2001), in which Democrats are most likely to be moved by our framing while Republicans and Independents are far less so, if at all.
We measure opinions using the following question:
Would you support or oppose allowing foreign investors to own greater shares of U.S. airlines?
The response options ranged from 1 (“Support strongly”) to 7 (“Oppose strongly”). Table 4 presents the results of a shift from the positive to negative frame, in which a positive value represents more opposition to increased foreign ownership of U.S. airlines. All studies included checks for reading ease and comprehension, to ensure that any sample differences were not due to these reading issues.Footnote 16
Table 4 Framing Effects in Airline Ownership Study
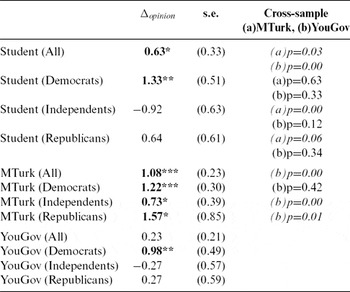
* p < 0.1, **p < 0.05, ***p < 0.01, two-tailed t-tests
We first analyze the samples as a whole. We see large framing effects for the whole student and MTurk samples, which is expected given that they both have far more Democrats than the YouGov sample. These overall figures mask important partisan heterogeneities, however. Following our earlier arguments, we disaggregate our sample by partisanship and see a clear pattern. In all three samples, Democrats are framed in precisely the way that we would expect given the differences across treatments. Indeed, when we compare cross-sample group differences (Column 4 of Table 4), we see that the Democrats in all three samples are statistically equivalent.
We see distinctly different patterns among others. In particular, we see marked differences between MTurk participants and the two other samples. While in the YouGov and undergraduate samples we see no evidence of framing effects for both Republicans and Independents, we do see evidence for these two groups among MTurk participants (which is especially notable for Republicans, given that they are such a small share of the MTurk sample). In fact, the MTurk Republicans are actually more affected by our frame than the MTurk Democrats. Furthermore, while the group differences among Independents and Republicans are statistically similar when we compare YouGov and student subjects (Column 4 of Table 4), our MTurk results are significantly different from both of the other samples. As a next step, and to see if such cross-sample differences persist, we turn to two other studies that consider different approaches to framing. These will focus specifically on subjects’ experience taking studies.
ASSESSING SAVVINESS: SOME INITIAL CONSIDERATIONS
Thus far, with the exception of evidence of larger group differences in our first set of studies, students and YouGov samples appear to respond similarly once theoretically-relevant moderators are taken into account. This was not consistently the case for our MTurk sample. Our next step is to investigate a second possible source of heterogeneity in subjects’ responses: savviness.
What does it mean for a subject to be experimentally savvy? Following previous research, savviness typically stems from two factors. The first is the sheer number of studies a person has taken (Dalen et al. Reference Dalen, Stanton and Roberts2001; Steffens Reference Steffens2004). We have already seen from Table 2 that there is significant variation along this dimension, as students have on average taken far fewer studies than the adults from either our convenience or diverse, national adult sample. All else constant we expect to see that people who have taken more studies are more experimentally savvy. The second factor is learning and training about experimental procedures (Steffens Reference Steffens2004). Participants who receive information about experimental procedures learn more about the experimental process (Morton and Williams Reference Morton and Williams2010). Indeed, informing individuals about the purposes of the study after completion (i.e. “debriefing”) is deliberately designed to increase subject knowledge about the experimental process (Brody et al. Reference Brody, Gluck and Aragon2000). Given the additional information included in the debriefing, it is likely that savviness increases with the number of studies taken at a much faster rate among people who are regularly debriefed versus those that are not. This distinction matters for our sample comparison because post-experimental debriefing is a requirement for all studies in many undergraduate subject pools (including the one that we used), but typically only a requirement for experiments with adult subjects if the study involves deception (Morton and Williams Reference Morton and Williams2010). Given these two factors affecting savviness, we expect that although the undergraduates have on average taken fewer studies than adults, they may grow equally savvy given debriefing exposure. While the adults in both the convenience and nationally-representative pools are largely forming impressions on their own through repeated participation, the undergraduate subjects are continually informed about the purpose of the studies they have taken.
To examine the consequences of experience taking studies, we create two groups using the number of studies taken (which we call our high and low experience subjects). In order to ensure the robustness of our results, we consider this split in two ways: the median of the number of studies taken and the mean of the number of studies taken. Moreover, in order to ensure that our results are not a function of a particular split, we conduct additional sample-specific tests and use different measures to proxy savviness. Finally, we also conduct a series of checks to ensure that there are no systematic differences among subjects who have taken more studies that might be accounting for our results. We find no evidence of this.Footnote 17
In the next two experiments we use this measure—and the various checks on this measure—to examine the impact of experience via two different types of social information manipulations.
STUDIES 7, 8, 9: DEATH PENALTY
Our first savviness experiment is a 2 × 2 study in which we manipulate the content of a message subjects receive as well as the types of instructions they receive prior to the message. Our design is similar to Cook et al. (Reference Cook, Bean, Calder, Frey, Krovetz and Reisman1970), whose study explicitly considered the way experience with experiments affects responses to stimuli. In their study all subjects received a message about a controversial topic, but were randomly assigned along two factors: the direction of the message (pro or con) and the experimenter’s instructions. On this latter factor, some subjects were told to specifically focus on the structure of the message—its wordiness, clarity, and delivery (i.e. the “sentence structure condition”)—while others were simply told to listen to the message (i.e. the “basic condition”). Cook et al. (Reference Cook, Bean, Calder, Frey, Krovetz and Reisman1970) show that highly experienced subjects were more likely to ignore the instructions, leading to equivalent post-treatment outcomes in the sentence structure and basic conditions. This finding was consistent with the idea of savvy subjects searching for a “twist” and disbelieving that an experiment that relies on a controversial topic is really about studying sentence structure. In contrast, among low-experience subjects, there was a statistically-significant difference in the post-treatment responses. This pattern is consistent with the idea that they took the experimenter’s instructions at face-value.
We replicate this study through a virtually identical experiment, with the major difference being that the subjects in Cook et al.’s study heard the message while in ours they read it on a computer screen. The controversial issue we use is the death penalty, and we ensure the validity of our message by relying on the treatment Mutz (Reference Mutz1992) used about the same issue:
Many citizens and community leaders on both sides of this issue are convinced that the death penalty [will succeed/will never succeed] in winning the support of the American people and its leaders.
Subjects in our experiment were randomly assigned to either receive the positive or negative version of this message, and then also randomly assigned to receive one of the two following sets of instructions: half were asked to focus on the wording and structure of the statement, while others were simply instructed to read it. All subjects were then asked a question about their support for the death penalty (using a 1–5 scale).
We present our findings in Table 5. Our focus here is not on what differences, if any, occur between the two content cues (i.e. the positive and negative cues). Rather, we are interested in whether those differences differ among people based on the instructions that they received (and their degree of experience taking experiments). For this reason, the cells in Table 5 include difference-in-difference estimates. If the positive cue has the same effect in both the basic and sentence structure treatments, then that would suggest that people are paying equal amounts of attention to the content of the cue despite half of them being instructed otherwise (i.e. they are savvy enough to ignore the instructions). On the other hand, if the instructions move people differently, then that would suggest that some people are paying attention to the sentence structure rather than the content.Footnote 18
Table 5 Death Penalty Opinion (Difference-in-difference estimates of a change from the negative to positive cue across the basic versus sentence structure conditions; s.e. in parentheses)

*p < 0.1, **p < 0.05, ***p < 0.01, two-tailed t-tests
First, we see that our YouGov sample acts as we would expect given the relationship between high and low experience. Among those with high experience, there is no difference between the responses to the structure and basic conditions. In contrast, we see a significant difference between the structure and basic conditions for the low experience subjects.Footnote 19 A similar pattern emerges for our undergraduate students—we see no differences among the high experience subjects and significant differences among those with low experience.
In contrast, here again our MTurk sample looks different than the others. While, as expected, we see no significant differences among our high experience MTurk participants, we also see no differences among those with low experience, a result that does not conform to expectations and previous findings. This pattern is robust to different approaches to measuring experience.Footnote 20
As a final step, we compare cross-sample differences (the rightmost column of Table 5). First, we see no significant cross-sample differences among high experience participants in all three samples, nor do we see significant differences between the low experience MTurkers and any of our subjects with high experience (a pattern suggesting high degrees of savviness even among the less experienced MTurkers). Among the low experience subjects, we see differences between the YouGov and undergraduate samples, in which the students are moved much less on average. One possible reason for this distinction is the idea that there are two paths to experience. Since even our lowest experience student participants completed at least one study prior to participating in this experiment, it is possible that learning through experimental debriefing has a more powerful influence on experience than simply taking repeated studies. It seems reasonable that one experience with being debriefed might be sufficient to know that “tricks” can occur during experiments. If that is the case, then it is possible that low experience undergraduates are still slightly savvier than low experience YouGov participants (a suspicion reinforced by the fact that the difference between the basic and structural conditions is smaller for undergraduates). Further reinforcing this point is the fact that when we limit attention to students who participated in only one study prior to this experiment, the difference between the basic and structural conditions is significantly larger than that reported in Table 5 (and statistically equivalent to the YouGov figure).
STUDIES 10, 11, 12: ELECTORAL COLLEGE
Our last study examines savviness in a different way. Conducting this second savviness study is important because, although partisanship is a common moderator in political behavior studies (such as our airline ownership framing study), previous experience taking studies is not (even though it is a common way in which experimental subjects differ). Thus, it is still useful to conduct a robustness check in another situation in which we believe that experience taking studies should moderate responses.
In our final study we consider a somewhat stronger form of social information: a modified “bogus pipeline” (BPL) experiment. The BPL technique (Jones and Sigall Reference Jones and Sigall1971; Roese and Jamieson Reference Roese and Jamieson1993) is a process in which subjects are led to believe that the experimenter has some increased insight into the subjects’ thought process. This is generally untrue—the experimenter simply misleads subjects in order to change their behavior. Key to the BPL is the idea that subjects believe that the experimenter somehow has an insight into their attitudes and values. Although BPL was initially suggested as a useful means of correcting for social desirability bias (Jones and Sigall Reference Jones and Sigall1971), scholars began to criticize this approach because it required a “naive” study participant (i.e. one who did not have much experience taking experiments; see Ostrom Reference Ostrom1973, Sigall and Page Reference Sigall and Page1972). The more experienced the participant, this line of thinking suggested, the less likely he would believe that the experimenter really knew something about him (Ostrom Reference Ostrom1973). While this critique certainly limits the practicality of this approach for obtaining measures of individual beliefs, it makes a BPL-style experiment useful for our purpose.Footnote 21
Here we rely on a modified BPL in which subjects were initially told that our computer algorithm determined that they find statements supported by political scientists to be most persuasive. All subjects were given this information after they had answered a series of various political questions, including knowledge questions, opinion questions, questions about educational background, and other preference questions. This arrangement was deliberate so that it was conceivable to the subject that the researcher might actually have insight about them.Footnote 22 Subsequently, subjects were randomly assigned to receive a message that was either “congruent,” a cue in line with what we had identified as their most persuasive source (i.e. political scientists), or “incongruent,” a cue supported by a different group (i.e. a majority of the public). The particular treatments are again based on Mutz (Reference Mutz1992), except this time focused on the Electoral College:
A majority of [citizens/political scientists], both Republicans and Democrats alike, are in favor of eliminating the Electoral College, the body of electors appointed by each state that formally elect the President and Vice President of the United States. Occasionally in American history the Electoral College vote has differed from the popular vote, which meant that the person who became President did not receive the majority of the popular vote.
After receiving this statement, subjects were asked to report their opinion on whether to abolish the Electoral College (using a 1-5 scale). Table 6 presents the results, again split by subjects’ degree of experience taking studies (following our death penalty study as well as past BPL experiments). Each of the numbers in the table refers to the difference in opinion between those who received the congruent cue versus those that received the incongruent cue. We would expect any significant movement to be in the negative direction, as that would indicate that the incongruent cue is less persuasive than the congruent cue.
Table 6 Change in Electoral College Opinion Based on Congruence (s.e. in parentheses)

*p < 0.1, **p < 0.05, ***p < 0.01, two-tailed t-tests
To the extent there are no differences in opinion, then we would have evidence that subjects saw through the bogus pipeline prompt (which is what we would expect for high experience subjects). As we see in the top half of Table 6, this is precisely what happened among those with high experience. There were no significant differences in opinion based on whether people saw a congruent or incongruent cue.
The pattern looked different among those with low experience. Here we first see that the YouGov respondents act in line with past work on the bogus pipeline. Those with low experience did not see through the stimulus and thus were persuaded by what they learned from the experimenter. This difference is significantly different from what happened with the high experience subjects. We do not observe similar differences among those with low experience in either the MTurk or undergraduate samples.
Our results for the student and MTurk samples do not match theoretical predictions. Yet we believe that it is worth probing the student results a bit further, as an alternative explanation seems reasonable. Our BPL assumes that subjects find political scientists to be a credible source of information regarding the Electoral College. Yet, given that our undergraduate students were taking political science courses when they took our study, it is possible that such credibility was lacking (for a variety of reasons, not least of which is dissatisfaction with their coursework in the middle of a semester). To address this alternative explanation, we conducted an additional test on the student sample—we told them that they found statements supported by the majority of the public to be most persuasive. Then, we offered them either congruent or incongruent statements in a manner identical to what we presented above. The results here were altogether different. Here, again, we see no significant differences among those with high experience (μ = 0.16, σ = 0.33) yet the low experience subjects exhibit a marginally significant difference (μ = −0.54, σ = 0.41). When we conducted this second BPL study on our MTurk subjects, however, we still did not observe any differences among low (or high) experience subjects. Thus, we can conclude that at least our student samples are displaying a degree of savviness that is consistent with what we’d expect when the BPL assumptions are satisfied.
Taken together, the results from our two savviness studies demonstrate that high experience taking studies leads to savviness, regardless of the context in which you take studies (via YouGov, via MTurk, or as part of a student subject pool). This point underscores why researchers need to be careful about using subjects who have participated in many previous studies when attributes of the experiment might heighten demand characteristics. Lastly, we also found evidence consistent with an unusually high degree of savviness among MTurk participants relative to others.
CONCLUSION
To address concerns about external validity in experiments, in this paper we have focused on two aspects of narrowness—cognitive factors and heightened savviness—that might (a) limit the generalizability of student samples, and (b) initially suggest the superiority of adult samples (even if they are convenience samples).
Having described the results from our twelve different studies, where do we stand? We address this question in two ways. First, did the results follow theoretical expectations and, second, how did the size of the results compare across samples? On the first question, we see a noticeable difference between our MTurk sample and the other two. The student and YouGov samples consistently produced results that were in line with theoretical expectations, especially once we accounted for relevant moderators. Our MTurk results look different, at least for the experiments that required a bit more “buy-in” from our subjects. When subjects were required to read an article, or trust information from the experimenter, our MTurk sample produced results at odds with what we would predict. In this paper we do not have space to thoroughly consider all of the reasons why such divergence might occur. Yet, from the perspective of replicability, our results do serve to sound a note of caution when using MTurk to produce generalizable results for all but the simplest experimental designs.
Second, there were various points where the effect sizes differed, even though directionally the results followed theoretical expectations. When such differences arose, we offered some potential explanations. Yet we realize that future studies are necessary to thoroughly test them. For now, we would simply conclude that these patterns underscore why researchers who rely upon one type of sample should carefully document reasons why the size of any effect they observe might be larger or smaller with an alternative population or at an alternative moment in political history.
While it may not surprise most readers that undergraduate samples can produce results that differ from those with adult samples, it is important to note that convenience sample adults may also not produce replicable results. Even more importantly, while we believe we have made a series of reasonable arguments to explain why our undergraduate samples may have differed from our adult samples, we find it more difficult to explain why our MTurk sample produced different results (even once we accounted for factors such as partisanship and savviness).Footnote 23 We thus leave this question as an important task for future work, particularly given the increasing use of MTurk samples among political scientists.
Given the broad nature of the question that motivates our work—Under what conditions do sample characteristics affect an experiment’s external validity?—we are only able to scratch the surface in one paper. As we noted at the outset, we have limited ourselves to two types of concerns about external validity and, in addressing them, focused on framing studies. In the future it would be fruitful to expand the analysis to non-framing-based experiments, other framing studies with different types of frames, other types of subject attributes, and other types of generalizability concerns (especially other attributes of the “artificiality” of the lab that have raised suspicion). Nevertheless, we believe that our empirical examination with three commonly-used samples across four experiments provides valuable information for researchers to consider when designing experiments and presenting results.
SUPPLEMENTARY MATERIAL
To view supplementary material for this paper, please visit http://dx.doi.org/10.1017/S2052263014000074.







