To acquire a human language, children must not only learn individual words, but must also discover the distinct kinds of words that are represented in their language (or grammatical categories, e.g. nouns, verbs, determiners) and how they map to meaning. Even within their first years, infants make significant headway in this arena. By age 0 ; 9, they distinguish between two very broad kinds of words: content words (e.g. nouns, verbs, adjectives) vs. function words (e.g. determiners, prepositions) (Shi, Werker & Morgan, Reference Shi, Werker and Morgan1999). By age 1 ; 1, they begin to make finer distinctions among the content words, teasing apart the grammatical form noun (e.g. ‘cat’) and mapping this form specifically to objects and object categories (e.g. cats). Over the next several months, they make finer distinctions still, teasing apart the forms adjective and verb, and mapping each to its associated range of meanings (properties and events, respectively) (Waxman & Lidz, Reference Waxman, Lidz, Kuhn and Siegler2006, for a review; Waxman & Booth, Reference Waxman and Booth2003).
How do infants accomplish this task? Because languages vary in the way that each grammatical form is marked in the ‘surface’ of the input (e.g. whether or not a modifier typically precedes or follows the noun, whether or not the nouns, adjectives and determiners are marked for grammatical gender), infants' accomplishments must rest upon an ability to glean grammatical form-class information from the surface structure of the utterances that they hear. But this claim – that the surface structure of a language provides reliable cues to grammatical category assignment – has been a controversial one. In the 1950s, structural linguists observed that words from the same grammatical category tend to appear in the same distributional environments (Harris, Reference Harris1951). For example, words that appear with the morpheme -ed in English also tend to appear with the morpheme -s. Based on this observation, several researchers proposed that distributional regularities may serve as cues to grammatical form-class assignment (Maratsos, Reference Maratsos, Levy, Schlesinger and Braine1988; Maratsos & Chalkley, Reference Maratsos, Chalkley and Nelson1980; Kiss, Reference Kiss1973). However, this proposal was not endorsed universally. At issue was whether there is in fact sufficient structure in the language input to support the acquisition of grammatical categories and, if so, whether infants are in fact sensitive to the kinds of regularities present (Chomsky, Reference Chomsky1965; Pinker, Reference Pinker and MacWhinney1987).
For decades this challenge appeared insurmountable. In recent years, however, researchers using computational tools to examine the language input have documented that the distributional evidence available in naturalistic, child-directed speech may in fact offer strong cues to grammatical form-class assignment (Mintz, Newport & Bever, Reference Mintz, Newport and Bever2002; Redington, Chater & Finch, Reference Redington, Chater and Finch1998; Cartwright & Brent, Reference Cartwright and Brent1997). In a compelling recent demonstration, Mintz (Reference Mintz2003) introduced the notion of frequent frames, a distributional pattern defined as two words that bracket one intervening word (e.g. I __ you). In an analysis of six corpora involving adult–child conversations, Mintz identified the most frequent frames in adults' speech. (See (1–6) below for some representative examples.) He then considered whether within each such frame, the intervening words tended to belong to the same grammatical category. For some frames (e.g. (1–3)), the intervening words were predominantly verbs; for others (e.g. (4–6)), the intervening words were predominantly nouns. This suggests that frequent frames constitute a distributional unit that could, in principle, support the acquisition of distinct grammatical classes. Moreover, recent work reveals that young children and adults are sensitive to distributional patterns like these (Gómez, Reference Gómez2002; Gómez & Maye, Reference Gómez and Maye2005; Mintz, Reference Mintz2002). Taken together, these recent demonstrations have breathed new life into the hypothesis that distributional information in the input could support the discovery of distinct grammatical forms.
(1) I __ it
(2) you __ to
(3) I __ you
(4) the __ and
(5) a __ on
(6) the __ is
However, evidence to this effect has thus far focused primarily on the distributional information available in English. Because languages differ considerably in how the grammatical forms are marked on the surface of utterances, the scarcity of cross-linguistic evidence represents a gap that is important to fill. Consider, for example, free word order languages like Turkish, where the sequences in which words can appear vary freely. In such languages, the relevant distributional units may not be sequences of co-occurrences among words (as in the frequent frames for English); instead they may be sequences of co-occurrences among sublexical morphemes (Mintz, Reference Mintz2008). In principle, then, the distributional units that emerge as central in one language may differ from those that emerge in another.
Interestingly, we need not look as far as Turkish to appreciate the importance of cross-linguistic evidence. Even in languages more closely related to English, certain linguistic features may have consequences on the clarity and force of the distributional evidence for grammatical form classes. For example, Romance languages like French, Spanish and Italian exhibit considerable homophony among key function words. Although homophony is also present in English, it is primarily evident among content words, as opposed to function words. In cases involving content words, frequent frames may help to disambiguate among candidate meanings (e.g. The brush is mine. vs. I brush your hair.). In Spanish, however, homophony is not only evident among content words, but is also common among determiners (la, los, las, una, unos, unas) and other function words. For example, los can function either as an article (e.g. los niños juegan ‘the children play’) or as an object pronoun (e.g. Ana los quiere aquí ‘Ana wants them here’); que can mean either ‘what’ or ‘that’; and como can mean either ‘how’, ‘as’ or ‘eat’. In cases involving homophony among function words, the consequences for a frequent frames approach may be considerable: because function words are so frequent in the input, they often serve as framing elements in frequent frames. This particular type of homophony could therefore have adverse consequences on the clarity of distributional cues (Pinker, Reference Pinker and MacWhinney1987; Cartwright & Brent, Reference Cartwright and Brent1997). Chemla, Mintz, Bernal & Christophe (Reference Chemla, Mintz, Bernal and Christophein press) recently reported that even in the face of this kind of homophony, the distributional evidence in a frequent frames analysis of French remained robust. However, because the Chemla et al. analysis considered the input to only one French-acquiring child, additional cross-linguistic evidence is clearly warranted.
In addition to homophony, there are other linguistic phenomena that could have consequences on the clarity and force of a distributional analysis. Consider, for example, a linguistic phenomenon known as noun dropping (Torrego, Reference Torrego1987; Snyder, Senghas & Inman, Reference Snyder, Senghas and Inman2001). Noun dropping refers to a process by which nouns are omitted from the surface of a sentence when their meaning is recoverable from context (e.g. Quiero una azul ‘I want a blue (one)’, El pequeño está dormido ‘The little (one) is sleeping’). Notice that noun dropping, which is more ubiquitous in some languages than others, is relevant to distributional analyses because, as a result of this syntactic process, nouns and adjectives often appear within the same frequent frames (e.g. following a determiner and preceding another element) (Waxman & Guasti, Reference Waxman and Guastiin press; Waxman, Senghas & Benveniste, Reference Waxman, Senghas and Benveniste1997).
In view of these observations, our goal is to advance the cross-linguistic developmental evidence for distributional approaches in three key directions. First, we examine the distributional evidence available to young children acquiring Spanish and compare it to the evidence available to children acquiring English. Second, we consider the relative clarity of frequent frames for identifying the grammatical categories noun, verb and adjective. Third, we consider for the first time a new distributional environment. In addition to the frames described by Mintz (Reference Mintz2003), in which two lexical items serve as framing elements (e.g. you__ it), we also consider phrase-final sequences in which the final utterance boundary serves as a framing element (e.g. the__.).
Our decision to consider these end-frames was motivated by evidence that for young learners in particular, ends of utterances have a privileged status (Slobin, Reference Slobin, Ferguson and Slobin1973). Infants and young children are sensitive to the prosodic cues that signal phrase boundaries (Hirsh-Pasek, Kemler Nelson, Jusczyk, Wright Cassidy, Druss & Kennedy, 1987). Thus, these prosodic cues might serve as framing elements. Moreover, in infant- and child-directed speech, key words are often placed in utterance-final position and tend to receive exaggerated pitch peaks and increased durations (Fernald & Mazzie, Reference Fernald and Mazzie1991). Finally, children more successfully identify words presented in utterance-final, as compared to utterance-medial, position (Fernald & McRoberts, Reference Fernald and McRoberts1993; Shady & Gerken, Reference Shady and Gerken1999). Put succinctly, because infants and young children are attentive to phrase boundaries (and especially to those occurring in utterance-final position), if utterance boundaries constitute framing elements, and if the ends of phrases contain information that is relevant to grammatical form (Gleitman & Wanner, Reference Gleitman, Wanner, Wanner and Gleitman1982; Morgan & Newport, Reference Morgan and Newport1981), then end-frames may constitute a potent source of information. Thus, by including both mid-frames (following Mintz, Reference Mintz2003) and end-frames, we have an opportunity to consider the accuracy of a frequent frames approach when the frames occur in different locations within the utterance (mid- and end-frames), and when they are bounded by different kinds of framing elements (words and utterance boundaries).
METHOD
Input corpora
We selected six parent–child corpora from the CHILDES database (MacWhinney, Reference MacWhinney2000); three in Spanish (Irene (Ojea, Reference Ojea and MacWhinney2000), Koki (Montes, Reference Montes1987) and María (López-Ornat, Fernández, Gallo & Mariscal, Reference López-Ornat, Fernández, Gallo and Mariscal1994)), and three in English (Eve (Brown, Reference Brown1973), Naomi (Sachs, Reference Sachs and Nelson1983) and Nina (Suppes, Reference Suppes1974)). We analyzed the utterances of the adult speakers in all sessions in which the child speaker was 2 ; 6 or younger. The English corpora were among those previously examined by Mintz (Reference Mintz2003). This ensured that our execution of the frequent frames analysis mirrored that reported by Mintz, and provided a point of comparison for Spanish.
Distributional analysis procedure
Our analytic procedure follows that of Mintz (Reference Mintz2003).
Gathering the frames
Following Mintz (Reference Mintz2003), we defined a frame as two linguistic elements with one word intervening. We considered two different types of frames. In the case of mid-frames (A__B), the two framing elements were words (denoted by A and B), and the intervening word (denoted by __ ) varies. This is the frame analyzed by Mintz (Reference Mintz2003). In the case of end-frames (A__.), the first framing element was a word, the second an utterance-final boundary, and the intervening word varies. We segmented every adult utterance into three-element frames. For example, the utterance ‘Look at the doggie over there’ yielded five frames: four mid-frames (‘look __ the’, ‘at __ doggie’, ‘the __ over’, ‘doggie __ there’) and one end-frame (‘over __.’). We did not include any frames that crossed an utterance boundary.
Selecting the frames
Next, we tabulated the frequency of each frame and selected for analysis the forty-five most frequent mid-frames and the forty-five most frequent end-frames.Footnote 1 These constitute our two groups of frequent frames.
Identifying the intervening words
We then listed all of the intervening words (both types (e.g. dog, cat, run) and tokens (e.g. every instance of dog, cat and run)) that appeared within each frequent frame; each list constituted a frame-based category.
Identifying the grammatical category assignment of intervening words. We assigned each intervening word to a grammatical category (noun, verb, adjective, preposition, adverb, determiner, wh-word, conjunction or interjection). This step of the analysis was carried out by a native speaker of each language; a native Spanish speaker categorized all the words in the Spanish corpora and a native English speaker categorized those in the English corpora. To ensure that the same criteria were applied across the two languages, grammatical category assignments in each language were then checked by a Spanish–English bilingual. For any word that could be assigned to more than one grammatical category (e.g. in English, party is both a noun and verb; in Spanish, vino is both a noun and a verb), the corpus was consulted to identify the correct assignment. In every case, the corpus provided adequate evidence to assign the word's grammatical category.
Quantitative evaluation procedure
Our quantitative evaluation focuses on the accuracy, or consistency, of the frame-based categories. To compute ‘Accuracy’, we compared every pair of words that occurred within any frame (See Mintz (Reference Mintz2003) and Redington et al. (Reference Redington, Chater and Finch1998) for full details). We identified each pair as either a ‘Hit’ (the two words were members of the same grammatical category) or a ‘False Alarm’ (the two words were members of different grammatical categories). We then calculated Accuracy by computing the proportion of Hits (Accuracy=Hits / (Hits+False Alarms)).
In the analyses reported here, we focus on Accuracy for token frequencies. However, it is important to point out that several different analyses yielded the very same pattern of results. First, independent analysis on word types and tokens revealed the same pattern. Second, in addition to Accuracy, we also analyzed the ‘Completeness’ of the frame-based categories. This measure considers the proportion of word pairs from the same grammatical category that were grouped together in the same frame (see Mintz (Reference Mintz2003) for details). In the face of these strongly converging measures, we decided to report the results on Accuracy for token frequencies because this most closely reflects our goal of determining whether frequent frames are equally consistent across different languages and distributional environments. Finally, note that an analysis that strives for high Accuracy (even at the expense of Completeness) would result in categories with high internal consistency. Once this is achieved, some of the categories could be merged (based, for example, on their degree of overlap) in order to achieve higher Completeness (Mintz, Reference Mintz2003).
Baseline categorization: comparison to chance
To obtain a baseline categorization measure, we used a Monte Carlo method. Specifically, we computed accuracy scores for random word categories that were generated for each corpus. To accomplish this task, the intervening words within all of the frame-based categories were randomly distributed to form ‘dummy’ categories, which matched the frame-based categories in size. This random shuffling of the intervening words was repeated 1000 times, with accuracy computed on each shuffle. Accuracy scores obtained from these 1000 shuffles provided a baseline against which to compare the results from the frame-based categories and compute significance levels. For example, if only 2 out of 1000 shuffles matched the score obtained by the frame-based categorization method, the frame-based Accuracy score was said to be significantly above chance with a probability of 0·002.
RESULTS AND DISCUSSION
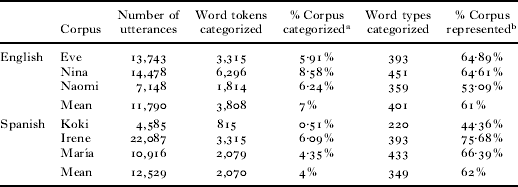
Table 1 offers an overview of the corpora for each child. Although there is within- and between-language variation in the size of the corpora, preliminary analyses ensured that there were no significant differences between the English and Spanish corpora in the total number of utterances analyzed, or in the number of types or tokens categorized by the frequent frames analysis (all p's >0·3). Moreover, for every child, the words categorized by this analysis comprised a large fraction of the corpus (see Table 1, last column). This is important because it reveals that the frequent frames analysis ‘captured’ the words that predominate in the child's input.
TABLE 1. Descriptive statistics for each corpus
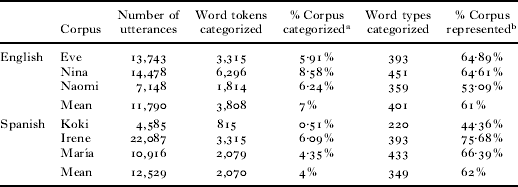
a # of tokens categorized in frequent frames/total # of tokens in the corpus.
b Percentage of tokens in the corpus whose types were categorized by frequent frames.
(e.g. If ‘jacket’ is categorized only once by frequent frames, but it appears 35 times in the corpus, the ‘% represented’ would be 35 / total # of tokens in the corpus.)
Comparing frequent frames (actual) to baseline (chance)
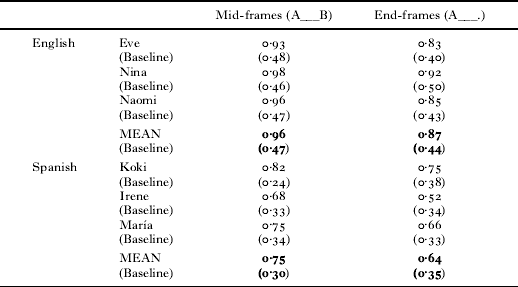
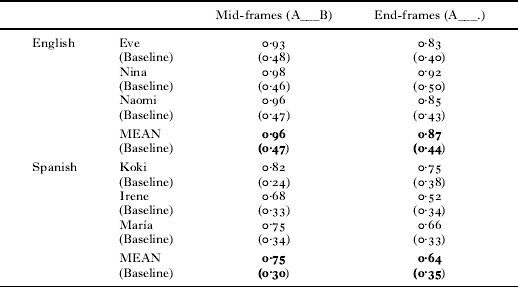
For each corpus, we compared the Accuracy score for the frame-based categories to the corresponding baseline measure (derived using the Monte Carlo method described above) (see Table 2). The Accuracy scores for all corpora were significantly higher than baseline (all p's <0·001). This documents that, in the input for each child, there is indeed consistent distributional information within frequent frames that converges on grammatical categories. This replicates Mintz (Reference Mintz2003) and extends the work to a new frame-type (end-frames) and to a new language (Spanish).
TABLE 2. Accuracy scores (token frequency) for each frame-type in each corpus
Comparing across languages, frame-types and grammatical class
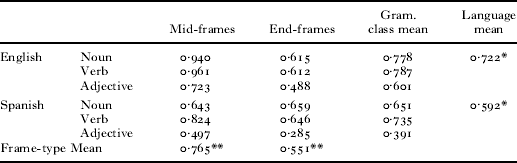
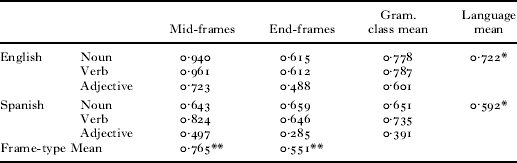
We next asked whether there were systematic differences in accuracy between the two languages, between the two types of distributional environments and between the grammatical classes. To address this question, we aggregated the frame-based categories for each language and frame-typeFootnote 2 and calculated the accuracy score within each. We then categorized each frequent frame by the modal grammatical class of its intervening words (e.g. if the frame contained more nouns than words from any other grammatical class, it was classified as a Noun-frame). We submitted these accuracy scores to a three-way ANOVA: language (English vs. Spanish) by frame-type (mid-frame vs. end-frame) and by grammatical class (noun-frame vs. verb-frame vs. adjective-frame) (see Table 3). A main effect of language indicated that accuracy was higher in English (M=0·72) than Spanish (M=0·60) (F(1,209)=5·022, p=0·026, ηp2=0·023). A main effect for frame-type indicated that accuracy was higher for mid-frames (M=0·77) than for end-frames (M=0·55) (F(1,209)=13·374, p<0·001, ηp2=0·06). A main effect for grammatical class revealed higher accuracy for verb-frames (M=0·76) than for noun-frames (M=0·71), and higher accuracy for noun-frames than for adjective-frames (M=0·50) (F(2,209)=5·154, p=0·007, ηp2=0·047). All differences among these means were statistically reliable (Tukey's HSD, all p's <0·05) (see Table 3). A subsequent analysis based on the data from each individual child's corpus ensured that these effects were not an artifact of the particular corpora we selected or of aggregating data from different corpora.Footnote 3
TABLE 3. Accuracy scores for each language, frame-type and grammatical class
* Significantly different from each other, p<0·05.
** Significantly different from each other, p<0·001.
These findings provide support for the hypothesis that the clarity of the distributional information available in frequent frames varies across languages, and within languages it varies across different distributional environments and grammatical form classes. In particular, the analyses reported here, coupled with a glance at Table 3, suggest that in both languages, frequent frames contain robust cues for identifying the grammatical forms noun and verb, but weaker cues for the form adjective. This outcome for adjectives, although consistent with our proposal, should be interpreted with some caution. Our analysis identified numerous noun- and verb-frames in each language, and the accuracy of these frames tended to be high. By contrast, we identified only a handful of adjective-frames (three and six, for Spanish and English, respectively). Because these also included a number of nouns and verbs, their accuracy was relatively low. Interestingly, and as predicted, although this pattern was evident in both languages, a glance at Table 3 suggests it was especially pronounced in Spanish.
GENERAL DISCUSSION
The current evidence provides support for the claim that the distributional information in frequent frames contains cues that could be useful to young children as they establish the main grammatical categories of their native language. This work extends previous evidence in three ways. First, it broadens the empirical base, examining the input available to children acquiring Spanish as their mother tongue, and comparing it to the input available to children acquiring English. We demonstrate that even in the face of linguistic features that may render the distributional evidence in Spanish less clear on the surface (including homophony and noun drop), frequent frames nonetheless offer robust cues to grammatical form class.
Second, this work casts a wider distributional net, considering not only frames that occur in utterance-medial positions and consist of only lexical items as framing elements (mid-frames), but also frames that occur in utterance final position and include utterance-final boundaries as framing elements (end-frames). We demonstrate for the first time that in both English and Spanish, end-frames carry distributional cues to grammatical form class. Perhaps not surprisingly, the distributional information for end-frames (which, by definition, are less constrained by their surrounding elements than are mid-frames) is less accurate than that for mid-frames. Yet end-frame information, however noisy, may be especially useful to young children (Slobin, Reference Slobin, Ferguson and Slobin1973), as they are better able to recognize words that occur at the ends of utterances (Fernald & McRoberts, Reference Fernald and McRoberts1993; Shady & Gerken, Reference Shady and Gerken1999).
Third, to the best of our knowledge, this is the first investigation to consider the relative accuracy of the distributional evidence available in frequent frames for the discovery of each of these grammatical categories. We found that frequent frames contained robust cues for the grammatical forms noun and verb, but weaker cues for adjectives, and that this pattern, although evident in both languages, appeared to be more pronounced in Spanish than in English.
On the whole, there were more commonalities than differences between the two languages, suggesting that this linguistic unit (the frame) stands as a powerful source of information for children acquiring either English or Spanish. At the same time, differences between the languages did emerge, which are likely due to linguistic features of the input. For example, in Spanish (as in other Romance languages) there is considerable homophony among function words (e.g. the word la can function either as a determiner (la niña juega ‘the girl plays’) or as a clitic (ella la puso aquí ‘she put it(f) here’)). These function words, which are highly frequent, often emerge as framing elements, and because they are homophonous, they affect the clarity of the distributional cues. Consider, for example, the mid-frame la __ a, which occurred frequently in Spanish. When la was used as a determiner, this frame picked out primarily nouns (e.g. Lleva la muñeca a tu cuarto ‘Take the doll to your room’), but when la was used as a clitic, the very same frame picked out primarily verbs (e.g. No la vuelvas a tocar ‘Don't it-clitic go to touch again’). Examples like this, considerably more common in Spanish than English, compromised frame accuracy.
Noun-drop also appears to have compromised accuracy in Spanish relative to English, especially in cases in which determiners emerged as framing elements. Consider, for example, the end-frame un ___., in which the intervening words included nouns (e.g. Dame un dulce ‘Give me a candy’) and adjectives (e.g. Eres un presumido ‘You are a vain (one)’). The distributional overlap between nouns and adjectives as a consequence of noun-drop was also evident, though less frequent, in mid-frames.
These observations suggest that certain features, including homophony and noun-drop, may indeed compromise the clarity of the distributional evidence available in frequent frames in Spanish. However, this is not to say that as a whole, the distributional evidence available to Spanish-acquiring children is weaker, less informative or impoverished, relative to English. After all, children acquiring Spanish and English exhibit comparable developmental milestones. For example, between ages 1 ; 9 and 2 ; 0, infants learning either English or Spanish begin to distinguish adjectives from nouns, mapping the former primarily to object properties (e.g. color, texture) and the latter to object categories (e.g. dog, animal) (Waxman, Braun & Weisleder, in prep). Instead, we suggest that children acquiring different languages will rely on different kinds of distributional information to establish the grammatical categories of their language.
More specifically, the particular distributional cues that are most informative in one language may be different from those that are most informative in another. For example, in fixed word order languages like English, distributional evidence based on co-occurrences of words may be quite informative. But, in languages with rich inflectional morphology (e.g. Spanish, French, Italian), we suspect that additional cues to grammatical form class may be gleaned from distributions of morphemic, phonetic or prosodic properties. For example, our results suggest that differentiating between the roles of two homophonous words (particularly when they are function words) might be important for grammatical class assignment. Therefore one potential avenue for future research may be to explore whether there are differences in the phonetic or prosodic characteristics of homophonic pairs.
It will also be informative to focus on developmental matters. There is considerable evidence documenting that features of parental input vary not only across languages but also across development. In particular, the complexity of infant-directed speech changes over the first few years. How might these developmental changes affect the clarity of the distributional evidence? Perhaps the earliest input, like the input we have analyzed here, offers clearer distributional evidence to support the discovery of grammatical form classes. However, it is also possible that the early input, which is characterized by short utterances and exaggerated intonational contours (Fernald & Simon, Reference Fernald and Simon1984), can facilitate the identification of individual words in the continuous speech stream, but contains relatively little information to support the discovery of distinct grammatical forms.
It will also be important in future work to ascertain how frequent the frequent frames must be, and what proportion of the tokens available in the corpus they must capture, if they are to be informative. For example, in each of the corpora analyzed here, fewer than 10% of the tokens were categorized in the frequent frames analysis. Although this may seem, at first glance, to cast doubt on the utility of a frequent frames approach, a more careful examination reveals that these word types make up 44–76% of the tokens in the corpus (see Table 1, last column). Thus, those words that were categorized constitute among the most commonly used words in the child's input, suggesting that frequent frames may offer information about grammatical categories for many of children's early words.
In sum, we have shown that there are distributional regularities in the linguistic input to children acquiring either English or Spanish that could, in principle, support the acquisition of distinct grammatical categories. Of course, because infants are sensitive to distributional regularities in domains other than language (Fiser & Aslin, Reference Fiser and Aslin2002), the evidence presented here has broader implications for development. The challenge facing infancy researchers is to discover how infants make use of these regularities across development and across languages.
APPENDIX
Representative examples of noun-, verb- and adjective-frames for each language (English and Spanish) and frame-type (mid- and end-frames)
ENGLISH MID-FRAMES
the __ is (139 tokens, 78 types)
baby(2), bag(1), barn(1), basket(1), bear(2), blanket(1), book(1), bookcase(1), box(2), boy(3), brush(1), bug(3), bus(1), car(2), chicken(1), clip(1), cord(1), couch(1), cow(2), cream(1), crib(1), crumb(1), dinosaur(1), dog(4), doggie(3), doll(1), donkey(1), door(2), duck(4), egg(1), elbow(1), elephant(3), family(1), fish(2), floor(1), flower(1), fox(2), girl(2), gob(1), grass(1), head(1), horse(8), house(2), ice(1), juice(1), kangaroo(1), kite(1), kitty(3), lady(2), lamb(2), lipstick(1), lock(1), man(5), mommy(2), monkey(1), moon(6), mouse(3), neck(1), nest(1), nurse(1), ocean(1), paper(1), pig(2), powder(1), rabbit(4), radio(1), rest(1), roof(1), rooster(1), sleeper(1), smoke(2), squirrel(2), sun(6), this(1), tray(1), truck(4), window(1), zoo(1)
you __ the (446 tokens, 103 types)
arranging(1), at(1), ate(1), bite(1), boo(1), break(1), bring(7), broke(2), catch(3), chase(1), cleaning(1), close(6), closed(3), closing(3), cook(1), count(1), cover(1), crack(5), cracked(1), cracking(2), cut(1), cutting(4), do(1), draw(2), drawing(1), drink(1), drop(1), dropped(6), eat(1), eating(3), fed(4), feed(8), find(11), finish(1), fit(4), fix(3), for(3), found(2), get(14), give(6), giving(1), got(6), hang(1), have(3), hear(5), held(1), hide(1), hitting(1), hold(6), hugging(1), hurt(1), keep(1), knock(1), know(1), leave(1), let(1), like(27), loving(1), make(14), making(6), mean(1), moving(1), on(4), open(4), pat(2), patting(2), paying(1), pick(1), popped(1), pull(1), pulling(3), push(3), pushing(3), put(73), putting(21), read(9), reading(1), remember(4), roll(4), rolling(1), run(1), say(1), see(14), shut(2), smell(1), spilled(1), take(17), taking(4), tearing(2), think(4), throw(5), throwing(1), to(2), took(4), tore(1), turn(6), unscrew(1), unsticking(1), unwind(1), unwrapping(1), use(1), want(30), washing(1), with(4)
a __ one (50 tokens, 17 types)
big(5), black(2), blue(4), brown(2), chocolate(1), fine(1), grape(2), green(7), little(7), new(4), nice(3), nother(1), purple(5), red(2), touch(1), white(1), yellow(2)
SPANISH MID-FRAMES
la __ de (247 tokens, 121 types)
actuaciónn(1), amigan(3), barban(1), basuran(1), bocan(1), bolsan(4), botellan(1), busquen(1), cabezan(2), cacan(2), cajan(1), cajitan(1), caman(3), cámaran(1), camisan(1), camisetan(1), canciónn(20), cancioncillan(1), cantabasn(1), cantidadn(1), caran(15), caritan(2), casan(9), casitan(12), chaquetan(1), cintan(1), colan(1), colitan(1), comidan(3), cositan(1), cremalleran(1), cunan(2), cunitan(2), electricidadn(1), encimaadv(1), eran(3), espaldan(3), esponjan(2), esquinan(1), faldan(1), florn(2), foton(2), gorran(1), granjan(1), habitaciónn(4), hermanan(2), historian(7), hojan(2), hojitan(1), horan(2), jefan(1), llaven(1), madrastran(3), madren(1), maestran(2), mamán(12), maninan(1), maniton(3), manon(11), mantan(1), manzanillan(1), meriendan(1), mesitan(1), mitadn(2), muevasv(2), musiquitan(3), naricinan(1), naricitan(1), narizn(1), novian(1), orejan(1), orejinan(1), paciencian(1), papitan(2), parten(2), patitan(1), películan(5), pelotan(2), pieln(1), piernan(2), piezan(1), plusvalían(1), posiciónn(1), puertan(1), pulseran(1), resoluciónn(1), revistan(4), rotaadj(1), sabesv(1), señoran(4), sensaciónn(1), sillan(2), tapan(2), tartan(2), tenemosv(1), tiendan(8), tratav(1), últimaadj(1), uñan(2), vacan(2), vanan(1), vidan(1), vozn(3), zapatillan(1)
le __ a (169 tokens, 42 types)
avisov(1), cantamosv(1), cogistev(1), cuentasv(2), cuentesv(3), dav(1), dabasv(1), dasv(1), decíav(1), decíasv(1), dicev(3), dicesv(10), dicesv(9), digasv(1), dijistev(8), doyv(1), enseñasv(1), guv(1), gustav(3), gustabanv(1), gustanv(1), hacev(1), hacesv(1), hicistev(3), ibav(1), ibasv(3), pasav(4), pasabav(2), pasov(2), pedistev(1), pegasv(1), perdiov(2), ponev(1), quieresv(1), regalamosv(1), tocav(5), vav(14), vamosv(16), vanv(1), vasv(60), vev(1), voyv(5)
un __ de (122 tokens, 37 types)
amigon(1), bastoncillon(1), beson(1), bibin(1), bocatan(1), cachiton(1), carteln(1), censon(1), chanchiton(1), cuenton(1), daikirin(1), dibujiton(2), galiton(1), gnomon(1), hueson(2), huevon(1), juegon(2), libriton(2), lunarn(1), ositon(1), paqueten(2), parn(2), pedaciton(4), pellejiton(1), pendienten(2), pocoadj(30), poquititoadj(1), poquitoadj(45), pupuyun(1), rojoadj(1), solomillon(1), sorbiton(3), tipon(1), trozon(1), vason(1), zapaton(2)
ENGLISH END-FRAMES
that__. (378 tokens, 158 types)
afterwards(1), airplane(2), alright(3), animal(4), apart(1), awful(1), baby(3), be(1), becca(1), better(3), bibbie(1), blanket(2), block(1), blouse(1), blue(1), book(5), bottle(3), box(3), boy(2), button(3), cake(1), called(15), card(2), carton(1), cereal(1), chair(1), chirp(1), clay(1), cookie(1), corner(2), cute(1), d(1), daddy(1), darling(1), dog(3), doggy(2), dolly(3), door(1), easterbunny(2), either(1), eve(9), first(1), fit(3), flower(1), foot(2), for(2), frasers(1), frosting(1), fun(1), funny(3), game(2), girl(2), go(3), good(3), gun(1), hand(1), hard(1), hat(1), help(1), here(2), hole(3), home(3), honey(6), horse(2), hot(2), house(3), hurt(2), hurts(1), in(1), ink(1), is(18), it(4), jar(1), jumped(1), kangaroo(1), kitty(1), knife(1), lamb(1), leila(1), letter(1), lion(1), long(1), makes(1), man(4), many(2), mean(1), means(2), mess(1), milk(1), mom(2), naomi(2), necessary(1), needs(1), nina(3), noise(6), nomi(24), off(2), okay(1), on(3), one(25), page(1), painful(1), papa(1), paper(2), part(3), pen(2), pencil(1), picture(13), piece(2), pillow(1), plate(2), please(1), pool(1), pot(1), present(2), pretty(1), puppet(1), puzzle(1), rabbit(2), racketyboom(2), rain(1), red(1), right(8), round(1), sarah(2), seat(1), shoe(2), side(2), song(1), sounds(1), soup(1), space(1), spell(1), spells(2), spoon(1), squeezes(1), stick(1), stool(1), story(2), stuff(1), sweetie(3), then(1), there(3), thing(2), tonight(1), too(2), tower(1), toy(1), train(2), tree(1), trip(1), two(1), valentine(2), water(1), way(14), what(1), window(2), you(1)
it__. (223 tokens, 152 types)
again(35), all(4), alone(7), along(2), anymore(3), apart(3), around(4), away(16), awhile(2), back(12), back(7), becca(1), before(1), belong(4), belongs(1), better(2), big(1), black(1), blue(3), break(2), bright(1), broke(3), broken(2), called(6), carefully(1), clean(1), cold(3), comes(3), cromer(1), cute(4), did(2), didn't(1), do(2), does(5), doesn't(1), doing(2), down(11), dried(1), drip(1), drop(1), either(3), eve(8), fantastic(1), feel(2), fell(1), first(6), fits(3), fixed(1), flies(1), fly(1), from(2), fun(8), funny(3), go(19), goes(7), going(3), goldie(1), gone(1), good(13), green(1), hard(4), here(11), hit(1), hmm(1), honey(12), horse(1), hot(2), hurt(6), hurts(3), in(24), into(2), is(115), isn't(1), itches(1), later(5), linda(1), look(1), louder(1), melted(1), moves(1), need(1), nina(1), no(2), nomi(27), nomi's(1), normally(1), now(4), off(40), okay(1), on(23), open(2), out(11), out(14), please(1), popped(1), pretty(1), rachel(1), raining(3), rattles(1), red(2), rest(1), right(2), rolled(1), rubs(1), sad(1), say(2), scary(1), shut(1), sideways(1), silly(1), sleeping(1), slowly(1), softly(1), somewhere(2), special(1), spin(1), stew(1), stop(1), sunny(1), sways(2), sweetheart(2), sweetie(1), swims(1), that(1), then(4), there(8), this(1), to(3), today(2), together(9), tomorrow(1), too(7), tore(1), untied(1), up(27), warm(1), was(5), wasn't(1), went(2), what(1), where(2), whistles(2), whole(1), will(3), with(2), work(1), works(2), would(1), yeah(4), yes(4), yet(3), yourself(4)
is__. (728 tokens, 120 types)
asleep(1), awake(1), baby(2), barking(1), better(1), bigger(2), billowing(1), black(1), blue(7), broken(6), called(7), clipclop(1), cold(3), colleen(1), coming(1), cool(2), cromer(2), crying(1), dancing(1), different(1), doing(1), dolly(3), drawing(1), eating(4), empty(2), eve(7), evecummings(1), fine(1), finished(1), fraser(2), frasers(1), fred(1), froggy(1), frosty(1), funny(1), furniture(1), good(1), grass(1), green(1), happening(1), hard(1), he(37), heavy(1), here(3), home(1), honey(4), hot(5), humm(1), hungry(1), indeed(2), inside(1), it(179), jackie(1), jenko(1), jim(1), jumping(1), kanga(1), left(1), lemon(2), light(1), like(1), little(1), locked(1), missing(1), mommys(1), next(1), nice(2), nina(2), nomi(9), now(1), nuzzling(1), ohio(3), ok(1), one(1), open(1), out(3), outside(1), painting(1), papa(5), racketyboom(1), raking(1), reading(1), ready(1), red(4), ricci(1), right(1), roo(1), running(1), saying(1), she(17), sleeping(6), smaller(1), snoopy(1), soap(1), soup(1), stuck(3), sugar(1), tea(1), that(212), there(4), this(80), time(1), timmy(1), tired(3), today(1), too(1), upsidedown(1), walking(1), weak(1), wearing(1), what(4), where(1), white(1), who(1), woopsie(1), working(1), yawning(1), yellow(4), yes(1), yours(1)
SPANISH END-FRAMES
los __. (369 tokens, 171 types)
abrimosv(1), amiguetesn(1), ángelesn(1), animalesn(1), anisesn(1), autobusesn(1), bambisn(2), barcosn(2), barriletesn(3), bebesn(3), bebitosn(1), besosn(1), bibisn(2), bichosn(1), bocatasn(1), bracitosn(3), brazosn(2), caballitosn(1), caballosn(2), cablesn(1), cacharritosn(1), cacharrosn(1), calcetinesn(3), carrosn(2), catalanesn(1), cerealesn(1), chicosn(1), chiquitosn(1), ciervosn(1), cochesn(2), coloresn(1), columpiosn(5), comenv(1), comov(1), conejitosn(1), conejosn(2), conocev(2), contamosv(2), cordonesn(1), cristalesn(1), cucharrosn(1), cuentov(1), cuentosn(3), deprep(3), deditosn(3), dedosn(1), demásadj(13), descuidasv(1), diablitosn(1), díasn(2), dibujitosn(1), dibujosn(1), dientesn(7), dosadj(9), elefantesn(2), elotesn(1), elotitosn(1), enemigosn(1), enseñov(1), fantasmasn(1), fideosn(1), gallegosn(2), gallosn(1), ganóv(1), gaton(1), guardamosv(1), guardesv(1), guardov(1), heladosn(1), hicistev(1), honguitosn(6), huesosn(1), jamasesn(1), juguetesn(10), lavov(1), leotardosn(2), libritosn(5), mayoresadj(1), metov(1), mezclamosv(2), mickeysn(1), mimitosn(1), mocosn(2), moquetesn(1), moquitosn(1), morosn(2), mosqueterosn(2), mosquitosn(1), mueblesn(2), muñecosn(3), muñequitosn(4), nenesn(12), nerviosn(2), niñitosn(1), niñosn(15), númerosn(3), ojinosn(3), ojitosn(5), ojosn(8), ositosn(2), ososn(3), otrosadj(3), pajarinosn(2), pajaritosn(1), palitosn(1), palotesn(1), pantalonesn(4), papásn(3), papelitosn(1), pasajerosn(1), patitosn(5), patosn(2), pecesn(3), pedacitosn(1), pedalesn(2), pegotitosn(1), pellejitosn(1), pelosn(1), pequeñitosadj(1), perdiov(1), perritosn(7), perrosn(1), pescaditosn(4), petesn(1), piececitosn(1), piesn(15), pifufosn(5), pisosn(1), pollitosn(2), ponemosv(1), pongasv(1), poquísn(1), portalesn(1), primosn(1), quepron(1), quesitosn(1), quierev(1), quieresv(1), quillitosn(2), recogesv(1), regalamosv(1), regalóv(1), regalov(1), regalosn(1), reyesmagosn(7), sacóv(2), saltitosn(1), saposn(1), secov(2), semaforosn(1), señoresn(4), silloncillosn(2), techosn(1), tienev(1), titosn(1), toquenv(1), tumbamosv(1), tuyospron(4), vagonesn(7), varonesn(1), vecinosn(1), veráv(1), vesv(1), vestidosn(1), videosn(1), viov(1), virisv(1), zapatitosn(6), zapatosn(8)
te __. (310 tokens, 134 types)
acaloresv(1), acercasv(1), aclarasv(2), acuerdasv(39), adviertov(1), ahogasv(2), alejesv(1), apetecev(3), apuestasv(2), atrevesv(1), ayudov(2), bajamosv(1), bañamosv(1), bañasv(1), bañastev(2), buscov(1), caesv(4), caiganv(1), caigasv(1), cantev(1), cantemosv(1), casv(1), castigav(1), cojav(1), conozcov(1), costipasv(1), cuentev(2), cuentov(1), dav(2), decia(1), dejo(2), dice(4), dicen(2), diga(1), digo(13), dija(1), dijo(4), dio(1), diste(4), dolIa(1), doy(1), duelev(3), ehint(1), enfadabasv(1), enfadasv(3), enfadruscasv(1), enseñov(1), ensuciasv(1), entendív(1), enterasv(1), entiendev(1), entiendov(7), escapesv(1), escondasv(4), escuchev(1), escuchov(1), escurresv(1), explicov(1), expliquesv(1), gustav(27), gustanv(4), gustov(3), hacev(5), hagav(1), hagov(1), hizov(1), hundesv(1), importav(2), lavanv(1), levantasv(1), levantastev(1), llamasv(6), llevav(1), manchasv(3), manchesv(2), matesv(1), matov(1), mojav(2), mojastev(1), mojesv(1), molestav(2), molestev(1), muerdav(1), ocurrav(1), oív(2), oigov(1), oyev(1), parecev(15), parezcav(1), pasav(11), pasabav(1), pasov(1), pegav(1), pegasv(1), peinamosv(1), peinov(2), perdonov(1), pincharv(1), ponev(3), pongov(1), preocupesv(2), pusov(1), quéwh(1), quemov(1), quierov(1), quitov(1), quitóv(1), rebelastev(1), riesv(2), riñov(1), sabesv(2), sabríasv(1), sacov(1), salev(1), salióv(1), secav(2), secov(1), sequev(2), sequemosv(1), sientasv(3), sientesv(1), tirastev(1), vav(1), vasv(2), vayasv(1), vev(6), veamosv(1), veíav(1), venv(1), veov(4), vestimosv(2), vistev(2)
está __. (287 tokens, 158 types)
abajoadv(1), abiertoadj(1), acáadv(1), acabandov(2), adóndewh(1), agarradov(1), agustoadj(1), ahíadv(19), altoadj(1), angelinesn(1), apagadaadj(1), apísimaadj(1), apuntandov(1), aquíaadv(14), arregladitaadj(1), arregladitoadj(1), asíadv(1), bailandov(1), bañandov(5), batidoadj(1), bienadv(18), bonitoadj(2), buenísimoadj(1), buenoadj(5), cabezan(1), calentitoadj(1), calienteadj(6), cansadaadj(1), cansaditoadj(1), cariñon(1), carlitosn(2), carnen(1), carninan(1), cerradaadj(1), cerradoadj(2), chicaadj(1), chupandov(1), colonian(1), columpiandov(1), comiendov(1), cuquin(1), dentroadv(1), descalzadaadj(1), descalzoadj(1), descansandov(2), diciendov(3), disfrazadoadj(1), distraídoadj(1), dondecon(1), dormidaadj(1), dormidoadj(1), duraadj(1), durmiendov(2), duroadj(1), ehint(3), enprep(1), enfermitaadj(1), enseñaselav(1), esv(1), escuchandov(1), esponjan(1), estan(3), estornudandov(1), feaadj(2), fríaadj(1), frioadj(1), grabandov(1), graciasint(1), gritandov(2), grovern(3), guapaadj(4), guapoadj(1), guardadaadj(1), guardaditaadj(1), gustandov(1), hablandov(1), haciendov(25), hayv(1), hijan(3), igualadj(1), irenen(3), jugandov(4), kokin(3), ladet(1), ladrandov(1), limpioadj(1), limpitaadj(3), limpitoadj(1), lindaadj(1), llorandov(5), lloviendov(4), luisn(2), maladv(1), malaadj(1), malitoadj(1), mamán(2), mamin(1), manon(1), marían(4), masticadinadj(1), mejoradj(1), merendandov(1), mintiendov(1), mirandov(1), mojadoadj(1), nadan(1), nenan(2), niñan(5), noadv(2), ocupadoadj(1), oscuroadj(2), otraadj(2), pacon(1), papán(5), pedrinn(1), pequeadj(1), pequeñoadj(2), perritan(1), peterpann(3), piezan(1), prohibidoadj(1), pulseran(1), quéwh(7), quedandov(2), quiénwh(1), quillin(1), quiquen(1), retorcidoadj(1), revistan(1), ricaadj(4), ricoadj(12), rotaadj(2), rotitaadj(1), rotitoadj(1), rotoadj(2), sacandov(1), santin(1), secoadj(1), sentadoadj(3), solitoadj(2), sucioadj(2), suficienteadj(1), tampocoadv(1), tardeadv(4), terminamosv(1), titon(1), tocandov(1), todoadj(3), tolumpiandov(1), tristeadj(1), usadoadj(1), vacilandov(1), valeint(1), verdadint(2), vestidaadj(1)