



Introduction
A recent productive line of research in language acquisition has discovered – and then partially dispelled – a surprising comprehension-production asymmetry (see Clark & Hecht, Reference Clark and Hecht1983), in which children were found to produce 3rd-person subject-verb (SV) agreement before they could be shown to comprehend it (e.g., Johnson, de Villiers, & Seymour, Reference Johnson, de Villiers and Seymour2005; Pérez-Leroux, Reference Pérez-Leroux2005). The latest studies, however, indicate a narrowing period between the evident development of these production and comprehension abilities (e.g., in French, Barrière, Goyet, Kresh, Nazzi, & Legendre, Reference Barrière, Goyet, Kresh, Nazzi and Legendre2016; in Spanish, Gonzalez-Gomez, Hsin, Barrière, Nazzi, & Legendre, Reference Gonzalez-Gomez, Hsin, Barrière, Nazzi and Legendre2017). The inconsistent pattern of results in this literature, and the corresponding lack of an overarching account of an asymmetry or its absence, is perhaps unsurprising, given that the studies are often limited in modality and in linguistic structure. With respect to modality, the inferences drawn from this line of research tend to contrast novel comprehension results with previously attested production abilities, with the latter typically reflecting spontaneous speech sampled from a comparable population (as in all the above-cited research). With respect to linguistic structure, SV agreement acquisition studies usually restrict the presented stimuli to canonical word-orders, so that claims about the generality of the knowledge acquired remain highly circumscribed (but see the variety of structures tested in French, including in Barrière et al., Reference Barrière, Goyet, Kresh, Nazzi and Legendre2016; Culbertson, Koulaguina, Gonzalez-Gomez, Legendre, & Nazzi, Reference Culbertson, Koulaguina, Gonzalez-Gomez, Legendre and Nazzi2016; Legendre, Barrière, Goyet, & Nazzi, Reference Legendre, Barrière, Goyet and Nazzi2010a; Legendre et al., Reference Legendre, Culbertson, Zaroukian, Hsin, Barrière and Nazzi2014; Nazzi, Barrière, Goyet, Kresh, & Legendre, Reference Nazzi, Barrière, Goyet, Kresh and Legendre2011). The current study addresses these two existing limitations. We explore the reported SV agreement comprehension/production asymmetry during first-language acquisition by collecting comprehension and production data in a single sample of participants – namely, Mexican-Spanish-speaking monolingual preschoolers – and test their comprehension of declarative sentences displaying two word orders, both acceptable in the presented context but of differing frequency in child-directed speech.
Cross-linguistic acquisition of SV agreement: linguistic and methodological issues
For virtually all of the languages in which the acquisition of SV agreement comprehension has been studied, comparisons with available production data have suggested that children reliably produce 3rd-person SV agreement at an earlier age than the corresponding comprehension abilities emerge. For example, in English, children reliably produce contrastive 3rd-person SV agreement (i.e., using singular /-s/ as well as the default form displayed by the plural with singular and plural subjects, respectively) between ages 2;6 and 3;10 in their spontaneous speech (Brown, 1973), but they have not been found to comprehend such contrasts reliably in experimental settings until age 4;0–6;0 (Johnson et al., Reference Johnson, de Villiers and Seymour2005; Legendre, Culbertson, Zaroukian, Hsin, Barrière, & Nazzi, Reference Legendre, Culbertson, Zaroukian, Hsin, Barrière and Nazzi2014). Likewise, in Spanish, children tend to produce error-free 3rd-person SV agreement of both singular and plural forms around age 1;6–1;7 in spontaneous productions (Montrul, Reference Montrul2004), but reliable comprehension has not been found experimentally before age 3;5 (Gonzalez-Gomez, Hsin, Barrière, Nazzi & Legendre, Reference Gonzalez-Gomez, Hsin, Barrière, Nazzi and Legendre2017; Pérez-Leroux, Reference Pérez-Leroux2005). German (Brandt-Kobele & Höhle, Reference Brandt-Kobele and Höhle2010) and Xhosa (de Villiers & Gxilishe, Reference de Villiers and Gxilishe2008; Gxilishe, Smouse, Xhalisa, & De Villiers, Reference Gxilishe, Smouse, Xhalisa and De Villiers2009) also display this asymmetry.
Data from children acquiring French do disrupt the pattern somewhat (Barrière et al., Reference Barrière, Goyet, Kresh, Nazzi and Legendre2016; Culbertson et al., Reference Culbertson, Koulaguina, Gonzalez-Gomez, Legendre and Nazzi2016; Legendre et al., Reference Legendre, Barrière, Goyet and Nazzi2010a; Legendre, Culbertson, Barrière, Nazzi & Goyet, Reference Legendre, Culbertson, Barrière, Nazzi, Goyet, Torrens, Escobar, Gavarro and Gutierrez2010b; Legendre et al., Reference Legendre, Culbertson, Zaroukian, Hsin, Barrière and Nazzi2014; Nazzi et al., Reference Nazzi, Barrière, Goyet, Kresh and Legendre2011). In particular, French-speaking children display successful SV agreement comprehension in pointing and preferential looking tasks by 30 months of age (in the prefixal agreement paradigm: Legendre et al., Reference Legendre, Culbertson, Zaroukian, Hsin, Barrière and Nazzi2014; Barrière et al., Reference Barrière, Goyet, Kresh, Nazzi and Legendre2016), while they show sensitivity to these agreement markers in head-turn preference tasks as early as 14 months (Culbertson et al., Reference Culbertson, Koulaguina, Gonzalez-Gomez, Legendre and Nazzi2016), and spontaneously produce them as early as 24 months (Thordardottir, Reference Thordardottir2005). That is, there is some indication from French-speaking children that SV comprehension may precede production, or, at least, that comprehension emerges in closer temporal proximity to production than in the other languages studied.
However, the kind of production data with which these comprehension findings are ordinarily compared can be subjected to some criticism. Typically, those are spontaneous production data rather than elicited productions (e.g., Brown, 1973; Montrul, Reference Montrul2004). This is potentially problematic because the patterns found in children's spontaneous productions suggest that young children especially tend to be “grammatically conservative” (that is, their most frequent utterances reflect constructions that they regularly hear in their linguistic environment – and not innovative utterances that may be the output of a grammatical pattern they are still in the process of learning; Snyder, Reference Snyder2011). Indeed, the few exceptions to the reliance of research in this domain on spontaneous production are found in the context of cross-dialectal studies of English (e.g., Barrière, Kresh, Aharodnik, Legendre & Nazzi, Reference Barrière, Kresh, Aharodnik, Legendre, Nazzi, Rispoli and Ionin2019; Miller, Reference Miller2012), and they have led to contradictory results: either disparity (Miller, Reference Miller2012) or a close relation (Barrière et al., Reference Barrière, Kresh, Aharodnik, Legendre, Nazzi, Rispoli and Ionin2019) between comprehension and production of 3rd-person singular and plural subject-verb agreement markers (i.e., morphemes indicating specific SV agreement). Highlighting the importance of the methodology used to extract SV agreement production in young children, Jakubowicz and Rigaut's (Reference Jakubowicz and Rigaut2000) elicited production study of French SV agreement revealed that in a picture-elicitation task children age 2;0–2;7 answered questions like “What is X doing?” with correct agreement 86%-92.4% percent of the time (depending on their MLU score), but they produced the correct agreement markers less often in spontaneous speech (45.5%-71%) in an open play session with an experimenter and a parent. This somewhat muddled collection of findings indicates that drawing inferences about children's underlying competence from spontaneous productions alone may misconstrue the sophistication of their grammatical representations, leading some researchers to draw conclusions of a competence-driven asymmetry that could instead reflect nothing more than differences in experimental conditions. Or, of course, it could reflect differences between the particular samples of children studied – and thus it would also be preferable from a methodological standpoint to elicit evidence of comprehension and production within-participants in a single study.
Another feature of most existing studies on the acquisition of 3rd-person SV agreement is the restricted nature of word orders (or constructions) presented as stimuli for comprehension – a design decision that is not without consequences for the conclusions that can be drawn from experimental research. To our knowledge, most studies of SV agreement comprehension in first-language acquisition have used stimuli embodying those languages’ basic word orders. In these languages, the SV agreement marker surfaces on a verb in a sentence-medial position (e.g., in English, “she sit-S here,” or German, Sie fütter-T einen Hund, “she is feeding a dog”). Sentence-medial positions are associated with processing disadvantages (e.g., Sundara, Demuth, & Kuhl, Reference Sundara, Demuth and Kuhl2011), which may be partially responsible for depressing comprehension accuracy. A contrasting familiarity-based hypothesis, however, would argue for the advantageousness of presenting SV agreement markers for comprehension in their basic word order constructions (or “canonical positions”): familiarity with the syntactic structure of a stimulus could plausibly facilitate its accurate interpretation (see, e.g., Ambridge, Kidd, Rowland, & Theakston, Reference Ambridge, Kidd, Rowland and Theakston2015). Both Johnson and colleagues (2005) and Barrière and colleagues (2019) found that the sentence-medial marker was comprehended more reliably than the sentence-final one.
The only tested language not following the sentence-medial SV agreement marker pattern is colloquial spoken French, which has been argued to have sentence-initial SV agreement as a consequence of the syntactic reanalysis of preverbal subject pronouns (clitics) into number agreement markers (Legendre et al., Reference Legendre, Barrière, Goyet and Nazzi2010a). Interestingly, French-learning children as a group have been shown to acquire SV agreement earlier than their cross-linguistic peers, when comprehension of either the preverbal or canonical postverbal agreement paradigm is tested using preferential looking/point procedures (Legendre et al., Reference Legendre, Culbertson, Zaroukian, Hsin, Barrière and Nazzi2014). There is also a minimal disparity between the age at which French-learning children have been found to comprehend SV agreement (and not only in this salient position, but more generally: see Barrière et al., Reference Barrière, Goyet, Kresh, Nazzi and Legendre2016; Culbertson et al., Reference Culbertson, Koulaguina, Gonzalez-Gomez, Legendre and Nazzi2016; Koulaguina, Legendre, Barrière, & Nazzi, Reference Koulaguina, Legendre, Barrière and Nazzi2019) and to produce it reliably (Thordardottir, Reference Thordardottir2005). However, these studies and others (e.g., Bassano, Reference Bassano2000; Rasetti, Reference Rasetti2003) are grounded in spontaneous production data, or else they are measured via parental questionnaire (e.g., using a French version of the CDI, as in Barrière et al., Reference Barrière, Goyet, Kresh, Nazzi and Legendre2016), potentially missing the full measure of the competence possessed by the tested children.
The acquisition of SV agreement in (Mexican) Spanish
Spanish affords a promising opportunity to explore three hypotheses relating to these observations from the literature: whether comprehension and production truly are acquired asymmetrically in young monolingual learners, whether the representations associated with comprehension performance are more general than mere reflections of children's linguistic input, and the extent to which comprehension reflects lexical knowledge (that would predict similar performance with the same verbs across different word order conditions). Spanish is typically considered to have a default subject-verb-object sentence structure (i.e., it is an SVO language) but also displays a somewhat flexible word order (Gutiérrez-Bravo, Reference Gutiérrez-Bravo2013). It allows location-related prepositional phrases (PPs: e.g., “on the couch,” “under the tree”) to be placed at the beginning of a sentence regardless of the type of verb used, the status of the subject, etc. (Kempchinsky, Reference Kempchinsky2002; see also Ordóñez & Treviño, Reference Ordóñez and Treviño1999). While features concerning the relative importance of information in a sentence can drive PP-fronting in Spanish, they need not (Kempchinsky, Reference Kempchinsky2002), which suggests an adequate degree of functional equivalence between (intransitive) V-PP (e.g., cenan en la cocina “(they) eat in the kitchen”) and PP-V (e.g., en la cocina cenan “in the kitchen (they) eat”) word orders.
The preverbal (i.e., left-peripheral) position that is available in Spanish-speaking adults’ grammar appears to emerge early in the speech of children who are acquiring Spanish as well (Bel, Reference Bel2005; Villa-García, Reference Villa-García2011). To our knowledge, no work has been published on the frequency of preverbal PPs in child-directed Spanish, although our own preliminary corpus analyses of children's language interactions with caregivers suggest they appear extremely infrequently (only 8% of child-directed utterances containing a PP have the PP preceding the verb; see Villa-García, Reference Villa-García2011, for the suggestion of a similar pattern among other fronted constituents). However, Grinstead (Reference Grinstead2004) shows that fronting of overt subjects and of objects and, crucially, of adverbs – which function similarly to the PPs that we test in this study, both being adjuncts – emerges early in child Spanish productions (i.e., around age 2–2;6). This suggests that this preverbal position is available to even the youngest speakers for a variety of uses (see also Hsin, Reference Hsin2014; Villa-García, Reference Villa-García2011).
The present study
The present study investigates when during development children acquiring Mexican Spanish gain competence with 3rd-person SV agreement – in production as well as comprehension. We assessed comprehension abilities using videos and a pointing task that varied the number reflected in the agreement marker (singular /-∅/, e.g., besa, or plural /-n/, e.g., besan) and the surface position of the agreement marker (sentence-medial or sentence-final). Complementing this comprehension data, we also elicited the production of SV agreement using visual stimuli. Our reporting focuses on the effects of number (singular vs. plural), as only plural agreement is overtly marked; the age of participants, testing children ranging from 3.5 to 5.5 years of age given previous data showing an emergence of 3rd-person SV agreement comprehension in Spanish around 3.5 years of age; and the possibility of a position-related effect on comprehension.
Methods
Participants
There were 51 monolingual Mexican Spanish-speaking participants (M age = 4;7; SD = 0;7; range = 3;6–5;7; 28 girls). They were tested in their private schools/preschools (N = 3 sites) in a large city in central Mexico, which served predominantly middle-class children. Each participant completed both position conditions (medial and final) and a production task during a single test administration. All participants who began the experiment completed it.
Materials
Prior to administration with child participants, the materials were piloted with adult native speakers of Spanish.
Comprehension task
Visual stimuli
Eight pairs of videos of two boys performing a variety of “intransitive” actions were developed and used in both conditions. The two videos in each pair could only be distinguished by the number of actors engaged in the activity. Either one boy performed the action alone (singular video), or the two boys performed the action jointly together and simultaneously (plural video); both boys appeared in every video (see Fig. 1). Videos were 6 seconds long. A video of the boys dancing in a celebratory manner was created to supply implicit feedback for the video matching the verbal stimulus (see below) on the side of the correct video after each trial (as done previously in, e.g., Gonzalez-Gomez et al., Reference Gonzalez-Gomez, Hsin, Barrière, Nazzi and Legendre2017).

Figure 1. Still image from one video pair (dibujar “draw”: left: singular action; right: plural action).
Verbal stimuli
Auditory stimuli consisted of short null subject sentences having either an intransitive verb + prepositional phrase for the sentence-medial condition (e.g., cena en la cocina “(he) dines in the kitchen” vs. cenan en la cocina “(they) dine in the kitchen”) or a prepositional phrase + intransitive verb for the sentence-final condition (e.g., en la banca salta “on the bench (he) jumps” vs. en la banca saltan “on the bench (they) jump”: see Appendix 1). Eight familiar verbs, referring to the eight actions in the videos, were used: escribir “write”, saltar “jump”, correr “run”, comer “eat”, llorar “cry”, jugar “play”, dibujar “draw”, and leer “read”. These verbs were chosen because they are known by many children according to the Mexican Spanish adaptation (Jackson-Maldonado, Thal, Marchman, Bates, & Gutierrez-Clellen, Reference Jackson-Maldonado, Thal, Marchman, Bates and Gutierrez-Clellen1993) of the MacArthur CDI “Words and phrases” (Fenson et al., Reference Fenson, Dale, Reznick, Thal, Bates, Hartung and Reilly1993) and can all be used intransitively.
Production task
A subset of the visual stimuli and procedure of the Diagnostic Evaluation of the Language Variation (DELV; Seymour, Roeper & De Villiers, Reference Seymour, Roeper and de Villiers2005) was adapted for the purpose of this study to measure children's subject-verb agreement productions. The DELV stimuli in that section consist of pairs of pictures depicting ethnically diverse children and adults. The left picture systematically depicts two individuals (i.e., animals, children, or adults) instigating an event while the right picture depicts a single individual of the same semantic category performing the same action. We elected to use an adaptation of the DELV rather than a less constrained elicitation task, in order to increase our chances of obtaining reliable, analyzable responses.
In the English version, the task is a sentence completion task during which the experimenter first produces a sentence that describes the left plural version of the picture (e.g., The horses eat hay) after they have described different elements of the pictures (e.g., horses, hay, rabbit, carrots) and prompts the child to produce the singular version of the same verb (e.g., but the rabbit…) while pointing at the singular version of the picture depicting a rabbit eating carrots: the elicitation of the 3rd-person singular in English is motivated by the fact that this feature varies across different varieties of English (Barrière et al., Reference Barrière, Kresh, Aharodnik, Legendre, Nazzi, Rispoli and Ionin2019).
We adapted this section to Mexican Spanish so that the 3rd-person singular items were elicited for half of the set of stimuli and the 3rd-person plural for the other half, given that our purpose was to assess children's ability to produce the singular and the plural 3rd-person agreement makers.
Procedure
Comprehension task
Each child was tested individually in a quiet space within their kindergarten. Children sat in front of a 22″ LCD touchscreen monitor (Planar PX2230MW). The experimenter sat behind the child and produced each of the stimulus utterances live. Task presentation order was counterbalanced.
In the comprehension task, first, the child was told that she would see images on the screen and be asked to touch some of them. The participant saw four training trials that displayed pairs of familiar objects (e.g., an apple and a house). After 12 seconds of visual presentation, the live experimenter said: viste la casa? muéstrame con tu dedo la casa, dónde está la casa? (“Did you see the house? Point where the house is, where is the house?”). When the child touched the image, the monitor's background changed color to indicate that the response had been recorded. After the training trials, the introductory video of the boys appeared, while the experimenter explained that the child would now see videos of them doing different activities and that again the child would be asked to tap one of the videos.
The test phase then began, consisting of eight trials. During each trial, each video was played twice in silence on one of the sides of the screen, followed by the other video. The experimenter then said: viste? cenan en la cocina, muéstrame con tu dedo en cuál imagen cenan en la cocina, dónde cenan en la cocina (“Did you see? Dine-3PL in the kitchen, point where dine-3PL in the kitchen, where dine-3PL in the kitchen?”). The two videos then reappeared simultaneously in their original locations, during which time the child would touch the matching video. The background changed color, and the celebratory video appeared on the side of the correct response (supplying implicit feedback). The side, order of single- vs. dual-actor, and task presentation order were counterbalanced across participants. The task took about ten minutes to complete.
Production task
The procedure was similar to the standard DELV administration and so took about five to seven minutes to complete. At the beginning of the testing the experimenter told children: Ahora te voy a enseñar unas imágenes y te voy a decir algo sobre cada una. Quiero que mires las imágenes y que termines lo que voy a decir (“I am now going to show you some pictures, and I am going to tell you something about each image. I want you to look at them carefully and to finish what I am going to say”). Children were then presented with 2 training items followed by 10 test items. In each trial elements of the pictures were first described by the experimenter and then participants were expected to complete sentences, for example, Veo unas colas cortas y veo una cola larga. El gato tiene cola corta, pero los perros… (“I can see a short tail and I can see a long tail. The cat has a short tail, but the dogs…”). The task elicited the production of 5 plural verbs (i.e., tener “have”, dormir “sleep”, lavar “wash” in the present and two instances of estar “be” in the past) and 5 singular verbs (i.e., tener “have”, andar “ride”, empujar “push”, nadar “swim”, jugar “play”) in the canonical position (see Appendix 2). Because of the alternative response structure available in Spanish, in which the verb is elided in this second clause, during the training the experimenter encouraged participants to utter the full, unelided verb phrase by asking them to listen closely and say the complete sentence. The resulting production score considers the accurate production of 3rd-person singular and plural agreement markers in the context of these sentences.
Analysis plan and results
Planned analyses
Analyses of the data were conducted with three aims in mind: to test participants’ responses against chance levels, to explore the roles of different factors (i.e., age, number) in conditioning participants’ response patterns, and to assess relationships between production and comprehension ability. For the first aim, t-tests were used, setting μ to the relevant comparison value. For the second and third aims, regression models were used, with fixed-effect terms to explore factors of interest (i.e., age, number, production skill, position). The R software package (R Core Team, 2019) was used to conduct all analyses, and within R, lmer4 was used for regression models (Bates, Mächler, Bolker, & Walker, Reference Bates, Mächler, Bolker and Walker2015) and ggplot2 (Wickham, Reference Wickham2016) was used to produce visualizations of the data.
Production task
In the production task participants could produce up to ten correct responses: five singular and five plural. Overall, on average, they produced 8.80 correct responses (SD = 1.45): 4.43 correct singular utterances (SD = 0.78) and 4.37 correct plural utterances (SD = 0.94). Both of these values were significantly greater than chance, where chance was defined as 50% accuracy: for singular items, t(50) = 17.67, p < .001; for plural items, t(50) = 14.27, p < .001. All but three participants answered at least two singular items and two plural items correctly. Four types of errors were documented: exchanging singular for plural forms or vice versa, producing a bare present participle (without the inflected auxiliary verb), producing only the subject noun of the target phrase, and failure to supply a response. Sixteen participants produced a singular verb where a plural was needed; 2 participants produced a plural verb where a singular was needed. Nine participants produced a bare present participle. The object noun alone was produced as a response by 11 of the participants (all but one of these did so only once), while 7 participants produced an uninterpretable response. As attested by the high average accuracy on singular and plural items across the sample, however, the incidence of all of these errors was quite low (13.65% of all trials).
A mixed logit regression model was used to explore the relationship between Age (in days) and Number (singular vs. plural) to accuracy of responses. There was a significant effect of Age, b = 0.46, SE = 0.12, p < .01, but not of Number, b = −0.16, SE = 0.20, p = .43. Accuracy was also compared against chance separately for the older and younger children, according to a median age-split of the sample. Both groups on average performed at above-chance levels in both conditions (all ps < .001; see Figure 2). Moreover, accurate responses on singular items were significantly correlated with accurate plural responses, r(49) = 0.43, p = .002. Given this moderately strong correlation, as well as the near-ceiling performance by many of the participants, to facilitate subsequent analyses we collapsed singular and plural production accuracy into a single Production Score.

Figure 2. Number of correct production responses in Younger and Older groups, separated by number (Singular vs. Plural).
Comprehension task: accuracy
Accuracy results are presented in Figure 4. Overall, participants pointed to the video that corresponded to the verbal stimulus in 68.75% of trials (SD = 20.03%), which was significantly different from the 50% chance level, t(50) = 6.68, p < .001. A mixed logit model was built with three fixed-effect terms – Number (singular vs. plural), Position (medial vs. final), and Age (in days) – as well as a random-effect term for participant. Two of the three fixed-effect terms yielded significant coefficient estimates: accuracy differed by Number, b = 1.52, SE = 0.18, p < .001, where a positive b is indicative of greater accuracy on plural trials, as well as by Age, b = 0.61, SE = 0.16, p < .001, where a positive b is indicative of greater accuracy among older participants (see Figure 3). Position did not significantly predict accuracy, b = 0.07, SE = 0.17, p = .66. There were no significant interactions among the predictors.
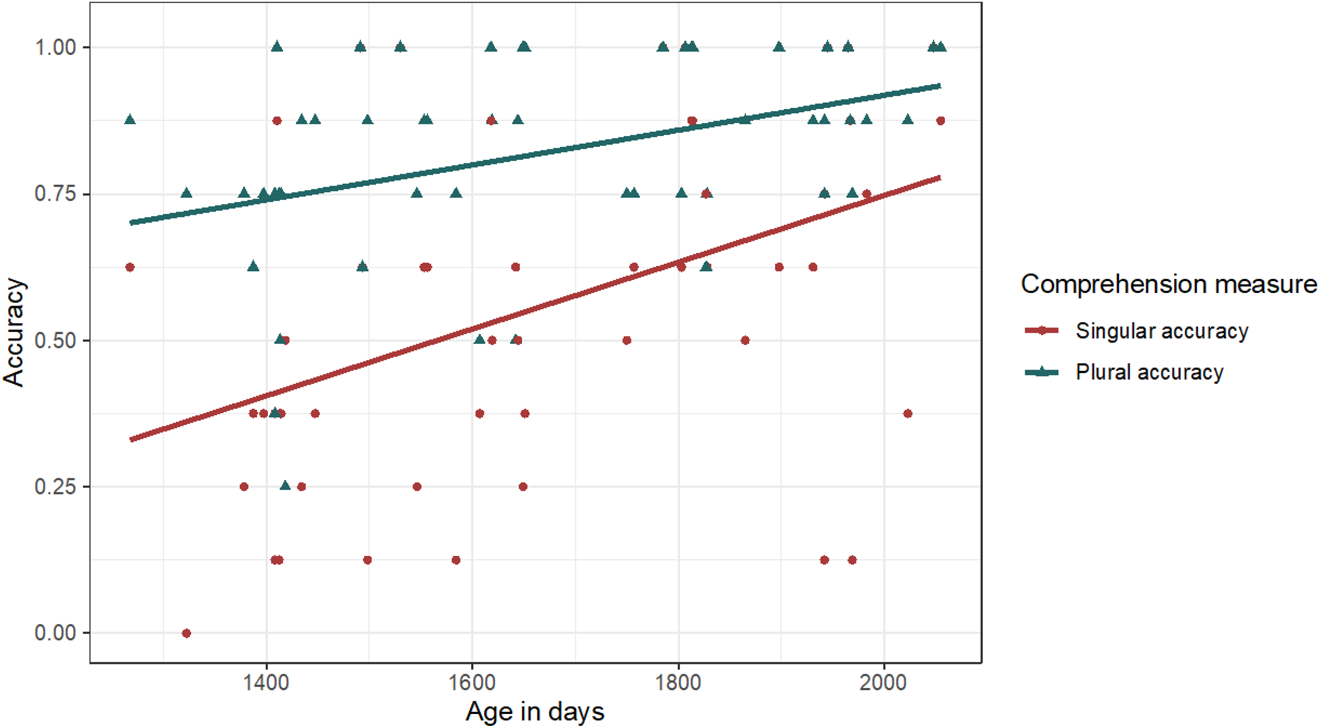
Figure 3. Scatterplot of comprehension accuracy by participant age, separating accuracy on singular and plural trials. Trendline represents best-fit linear regression line.
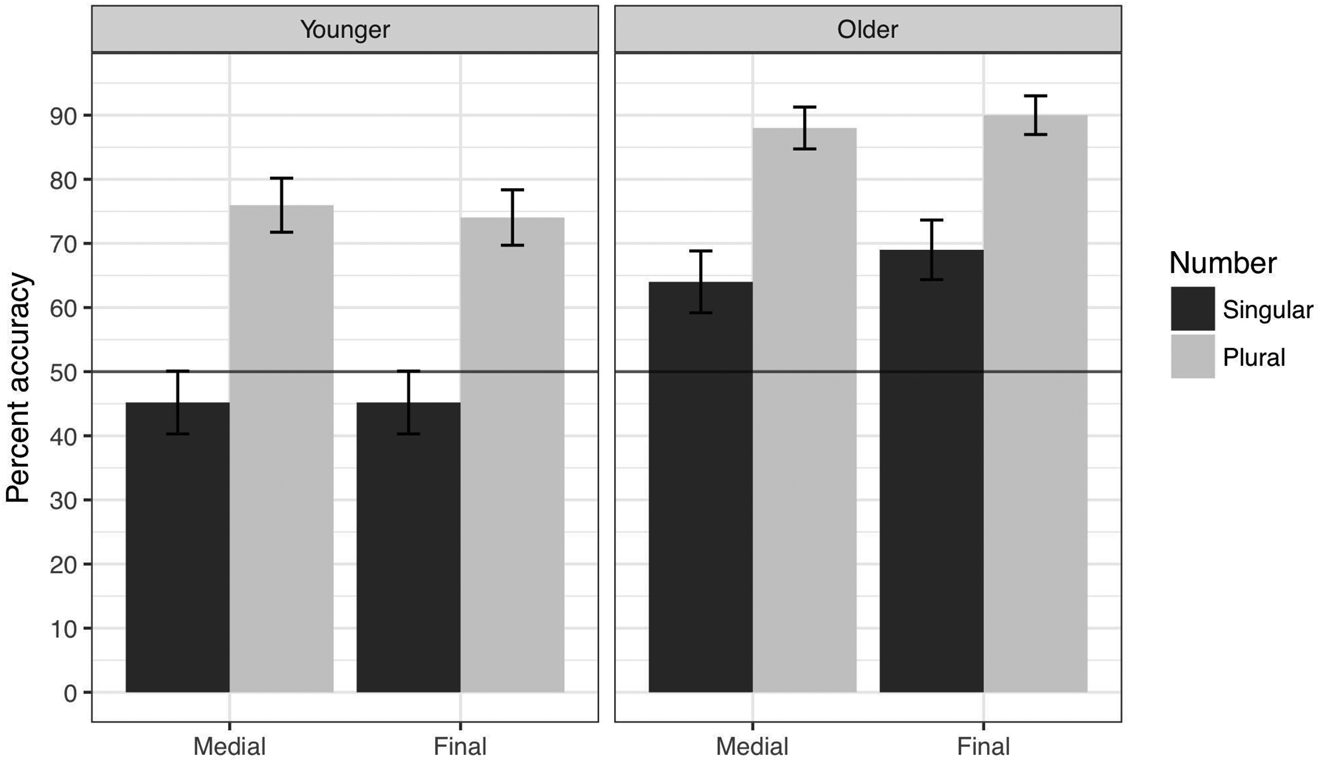
Figure 4. Comprehension accuracy separated by Number, sentential Position, and Age Group.
Because of the significant effect of age revealed by the regression model, we also explored separately whether the difference from the 50% chance level that was found for the whole sample held for both younger and older children when a median-age split was applied. When considering singular and plural responses collectively, we found that accuracy was better than chance for both the older group, M = 77.75%, t(24) = 8.39, p < .001, and the younger group, M = 60.10%, t(25) = 2.63, p < .014. In addition, upon inspection of the bar plots relative to chance-level performance and the associated standard errors (Figure 4), it appeared that younger and older children might have performed differently on singular trials, despite the absence of a significant interaction in the regression model. We therefore further divided the data in order to examine this apparent difference, which revealed a disparity in accuracy relative to chance on singular trials. Specifically, the younger children were at chance in their responses to singular trials, M = 45.19%, t(25) = −0.89, p = .38, while the older children were above chance, M = 66.35%, t(25) = 3.13, p = .004. As can be seen clearly in Figure 4, in contrast, both age groups responded with above-chance accuracy on plural trials.
To examine the association between production skill and the other variables of interest, we then added to the model a fixed-effect term for Production Score. In this model, Number remained a significant predictor of accuracy, b = 1.52, SE = 0.18, p < .001, as did Age, b = 0.43, SE = 0.17, p = .014. Position remained non-significant, b = 0.07, SE = 0.17, p = .66. However, Production Score also explained significant variance in accuracy, b = 0.18, SE = 0.09, p = .044. There were no significant interactions among these variables. Comparing this model with the previous model, which excluded the Production Score term, revealed a significant improvement in fit when this term was incorporated, χ 2(1) = 3.93, p = .047.
Comprehension task: sensitivity
Sensitivity analyses were developed to reflect the proportion of a child's points to a given video type (singular or plural) that was linked to hearing that verbal stimulus type (see Johnson et al., Reference Johnson, de Villiers and Seymour2005). For each participant, we computed two proportional sensitivity scores to capture the detection rate of the agreement markers. We computed one sensitivity score for singular trials and one for plural trials, by dividing the hit rate (i.e., the points to the singular video when a singular verbal stimulus was presented) by the sum of the hits and false alarms (i.e., all points to the singular video). In multimodal preference tasks (i.e., where participants are asked to map auditory stimuli to visual ones), participants can sometimes show a preference for one type of visual stimulus regardless of the auditory stimulus that is presented with it. Sensitivity analyses are used to compensate for those preferences: they represent a contingent value based on the number of times a participant's selection of one video or the other can be attributed to the auditory stimulus. That is, whereas an accuracy measure simply computes the proportion of video-selection responses that aligned with the auditory stimulus, the sensitivity measure computes how often the selection of a singular or plural stimulus was correct in light of the overall frequency of the selection of each.
Sensitivity results are presented in Figure 6. Overall, sensitivity scores were 0.70 (SD = 0.22), which was significantly different from the 0.5 chance level, t(50) = 6.38, p < .001. A linear mixed-effect model was built with three fixed-effect terms – Number (singular vs. plural), Position (medial vs. final), and Age (in days) – to predict sensitivity, with the sensitivity summary score across the two crossed conditions as the outcome variable. As with the accuracy calculations, here Age was a strong predictor of sensitivity, b = 1.01, SE = 0.27, p < .001. However, in contrast to the accuracy findings, sensitivity was only marginally predicted by Number, b=−0.53, SE = 0.29, p = .07, with a negative coefficient estimate indicating greater sensitivity on singular trials (see Figure 5). Position had no significant association with the outcome variable, b = 0.01, SE = 0.03, p = .96, and there were no significant interactions.
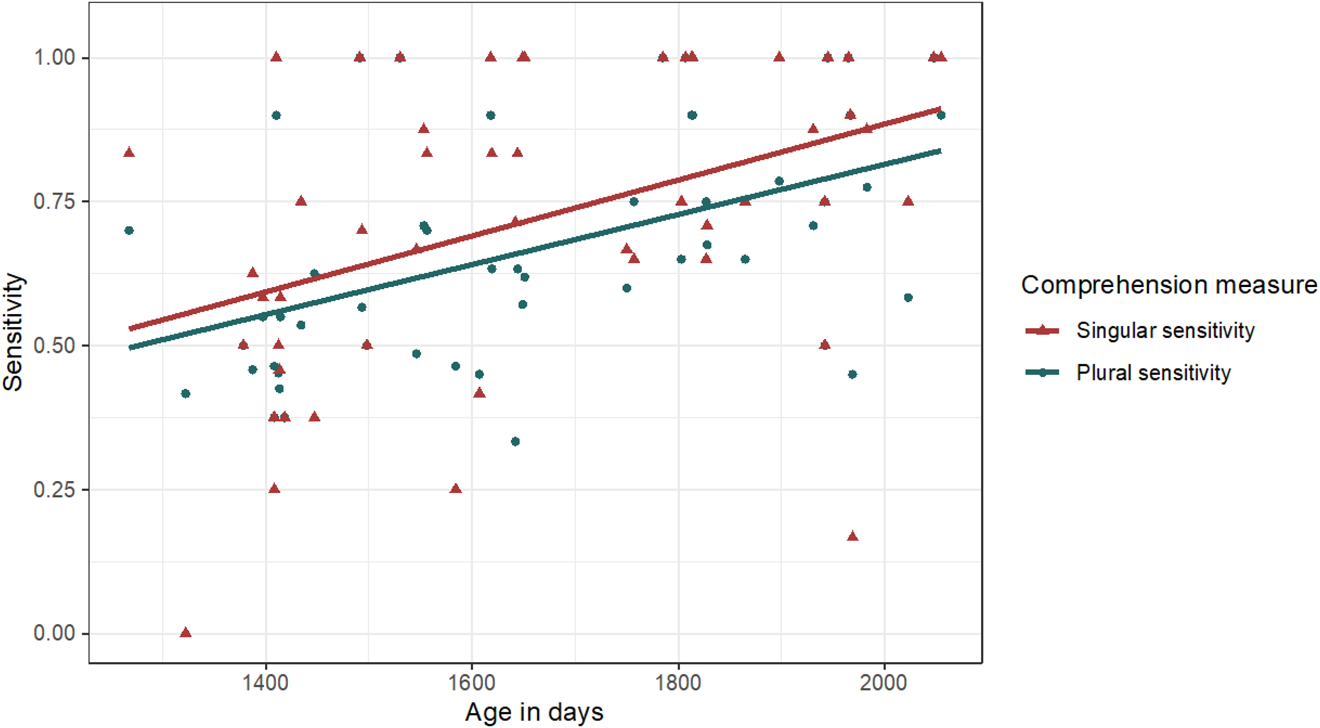
Figure 5. Scatterplot of comprehension sensitivity by participant age, separating sensitivity to singular and plural trials. Trendline represents best-fit linear regression line.

Figure 6. Comprehension sensitivity separated by Number, sentential Position, and Age Group.
Again we explored whether the significant effect of Age was associated with below-chance performance by the younger children, using t-tests against the 0.5 chance level on the median-split sample. Sensitivity was found to be greater than chance for both the older group, M = 0.80, t(24) = 8.57, p < .001, and the younger group, M = 0.60, t(25) = 2.31, p = .030. Unlike for the accuracy measure, inspection of the sensitivity bar plots did not indicate that younger or older children may have performed at chance levels in any condition.
Last we incorporated the Production Score as a predictor of sensitivity into the model as specified above. The effect of Age remained, b = 0.69, SE = 0.30, p = .03, as did the marginal coefficient estimate for Number, b = −0.53, SE = 0.29, p = .07. Position continued to be non-significant, b = 0.01, SE = 0.29, p = 0.96. However, Production Score did explain significant additional model variance, b = 0.37, SE = 0.16, p = .020. This model fit the data better than the model that did not contain the production accuracy variable, χ 2(1) = 5.83, p = .016.
Discussion
Our results demonstrate that children acquiring Spanish display comprehension of 3rd-person SV agreement in the age range of 3;6 to 5;7, and that while comprehension increases over the 2-year period reflected in that age range, even the younger children showed above-chance comprehension of the presented forms. These results also show that participants’ processing of this agreement paradigm (as presented) was position-independent, their comprehension being similar in the medial and final position. Furthermore, while comprehension accuracy on plural trials was higher than on singular trials, sensitivity to singular stimuli was higher than it was to plural agreement in the comprehension task. Sensitivity analyses also revealed that older and younger children both comprehended the agreement marker at above-chance levels. The production results show performance above chance level for the older and younger children, but better accuracy was found for the older children. Critically, comprehension ability of SV agreement, as measured by both accuracy and sensitivity, was predicted by production ability and age.
The comprehension results showed a significant effect of participant age when examining both outcome measures (i.e., accuracy and sensitivity). Nevertheless, this effect was associated with above-chance sensitivity for both the younger and the older children in our sample, indicating that we may not yet have reached the lower age bound at which Spanish-acquiring children can comprehend 3rd-person SV agreement (contra Pérez-Leroux, Reference Pérez-Leroux2005). While sensitivity was above chance in both the older and younger groups, this was not the case with the accuracy measure: younger children displayed chance-level accuracy on singular trials. However, this chance-level performance may be due to design-related rather than knowledge-related factors – that is, it may be an artifact of the plural bias that has been found and discussed in other intermodal comprehension tasks (e.g., Gonzalez-Gomez et al., Reference Gonzalez-Gomez, Hsin, Barrière, Nazzi and Legendre2017). (Similar issues may be encountered when certain protocol features exacerbate an overreliance on default forms, e.g., non-finite root forms: Legendre et al., Reference Legendre, Culbertson, Zaroukian, Hsin, Barrière and Nazzi2014.) In such cases, alternative summary measures like the sensitivity calculation can reveal mastery that would otherwise be obscured – and can reveal that apparent mastery, according to other measures, is driven in part by response bias. But given the fact that no such disparity was detected in younger children's sensitivity to the singular form, this finding underscores the importance of summarizing data in multiple ways in preparation for hypothesis testing.
In light of the full set of results we uncovered, the present findings represent a narrowing of the gap reported in the literature between the age of development of 3rd-person SV comprehension abilities in Spanish-speaking (age 3;6) and French-speaking children (age 2;6), and a widening between Spanish- and English-speaking (age 4;0) children, which our future research will continue to explore by testing younger children in both Spanish and English.
From a methodological standpoint, our findings highlight the question of the kind of outcome measure to use in forced-choice tasks like the ones presented here: accuracy, reflecting the proportion of points to a visual stimulus that match the verbal one, or sensitivity, reflecting the proportion of points to a visual stimulus that are motivated by the verbal one. Given the difficulty in generating equivalently appealing visual stimuli to represent different meanings, a measure like the sensitivity computation serves to minimize the potential of a preference for one of the stimulus types and to focus the analysis on genuine comprehension ability. Indeed, in contrast to the results of our accuracy analyses that suggested greater success on plural than on singular trials, sensitivity scores showed that participants were more sensitive to the singular cue than to the plural one – somewhat surprisingly given that it is the plural that is overtly marked (see, e.g., Morales Reyes & Montrul, Reference Morales Reyes and Montrul2020, on L1 and L2 Spanish comprehension in older children, where accuracy was higher on plural than on singular items).
The marginally stronger sensitivity to the singular form, however, might find an explanation in the relative reliability of the singular and plural markers we tested: the bare word-final vowel is an exceedingly reliable cue to singularity, while the word-final /-n/ is not as reliable a cue to plurality. In addition to marking the third-person plural, /-n/ also marks second-person plural in Mexican Spanish, and it is a frequent final phoneme in (singular) nouns (e.g., buzón “mailbox”, opción ‘option’) and adjectives (e.g., marrón “brown”, holgazán “lazy”). It is also frequently found in (singular) deverbal nouns like canción “song” or decisión “decision”. In many of these singular /-n/ words, the syllable for which /-n/ is the coda is stressed, lending it additional salience – as a potential cue to morphological singularity. And although the tested singular forms share a final phoneme, either /-a/ or /-e/, that occurs in myriad nouns and adjectives in Spanish, they are associated with singular number in those contexts as well, or, with default (singular) number in verbs. Hence the forms associated with the tested 3rd-person singular markers in this study are more reliable than the plural one.
The present study also extends recent work on the trajectory, and generalizability, of SV agreement acquisition by exploring the role of the position of the verb on which the agreement morpheme surfaces within the stimulus utterance. We tested comprehension of the 3rd-person agreement marker in two positions: a more canonical and frequent structure (e.g., cenan en la cocina “(they) dine in the kitchen”); and one that places the marker in a processing-advantageous sentence-final position that lends it more phonological salience (e.g., en la cocina cenan “in the kitchen (they) dine”). The fact that we found no difference between these conditions suggests that it is not merely familiarity with the complete sentences that participants heard that facilitates comprehension of 3rd-person SV agreement; rather, children were also able to attend to the interpretation-relevant cue in the medial position (cf. Barrière et al., Reference Barrière, Kresh, Aharodnik, Legendre, Nazzi, Rispoli and Ionin2019, who found that differences in position-dependent agreement interpretation in English were related to the linguistic variant of English that children were acquiring). The similarity of responses across agreement marker positions found in the current study indicates the presence of an abstract representation of SV agreement that can be used to comprehend an utterance whether its surface form reflects the canonical order or not (contrasting with Sundara et al., Reference Sundara, Demuth and Kuhl2011, studying younger children). Given that the sentence-final structure is minimally familiar to children, it is implausible that they would be able to retrieve identical utterances from their memory and apply those to comprehension here (cf. item-based theories of acquisition; Tomasello, Reference Tomasello2003; more specifically Blom, Paradis, & Sorenson Duncan, Reference Blom, Paradis and Sorenson Duncan2012, on English 3rd-person singular agreement). Instead, they likely developed an abstract representation of “singularity” and “plurality” for application whenever the relevant morpheme is encountered, which also provides evidence against a lexically based account of grammatical development.
These results add to the growing literature on the comprehension of plural-marking morphology (e.g., nominal plurals; Arias-Trejo, Cantrell, Smith, & Canto, Reference Arias-Trejo, Cantrell, Smith and Canto2014) in Spanish first-language acquisition, and they serve to diminish the apparent developmental disparity between early Spanish comprehension and production (age 1;6; Montrul, Reference Montrul2004) of SV agreement (also documented for English in Barrière et al., Reference Barrière, Kresh, Aharodnik, Legendre, Nazzi, Rispoli and Ionin2019). While older than Montrul's (Reference Montrul2004) participants, the participants in this study performed well above chance in the production of both singular and plural items. The errors that our participants made in production tended to reflect 3rd-person SV agreement errors, and specifically the use of the singular form where the plural was needed; the second most frequent error in which a verb form was produced involved children producing the bare present participle. Although both of these errors involve a failure to produce the third-person singular agreement, they could also be instantiations of non-finite root forms (Davidson & Legendre, Reference Davidson, Legendre, Núñez-Cedeño, Cameron and López2003; Wexler, Reference Wexler1998): tense is omitted from both (although aspect is indeed represented in the present participle response). These error patterns suggest that while participants overwhelmingly responded with target forms in the production task, their mastery of SV agreement in Spanish is still incomplete, for the purposes of production just as it is for comprehension.
The link between comprehension and production found in our study attests that both manifestations of the acquisition of 3rd-person SV agreement appear to go hand in hand, further weakening initial hypotheses that this aspect of morphosyntax represents a special case of a comprehension-production asymmetry/dissociation (although the present study cannot definitively rule out such a dissociation). The significant relationships between comprehension and production abilities suggest that comprehension and production may indeed develop in tandem in individuals. The data that we have do not allow for directional, causal claims one way or the other, but they do show that a strong asymmetry between production and comprehension abilities is absent, at least in our sample. It is a matter of collecting data in both of these modalities from the same sample of participants, in addition to developing protocols that are of roughly equivalent difficulty in each modality so that, in principle, children's grammatical resources can be equivalently called upon in both. Future research should explore the possibility of collecting multiple measures of comprehension and production in the same sample to further refine theoretical hypotheses, as well as adopting alternative experimental approaches that would be better suited to studies with even younger children (e.g., multimodal preferential looking). The inclusion of multiple measures in each modality would be especially useful for characterizing production abilities, in light of the possible influence of grammatical conservatism on spontaneous productions and of the potential for reluctance to “perform” verbally in elicited production tasks in an unfamiliar setting with an unfamiliar experimenter, and so forth.
To conclude, the present study found clear evidence of Mexican 3;6–5;6-year-old children's ability to use both singular and plural third-person agreement morphology to map verbal stimuli to their appropriate referents, independently of the sentential position of the agreement marker (and indeed the verb itself). We therefore have yet to identify the lower age limit of 3rd-person SV agreement comprehension in Spanish, comprehension that appears to stem from an abstract representation of how verbal agreement relates to meaning. Furthermore, our results indicate that the comprehension and production of subject-verb agreement go hand in hand, suggesting that this aspect of morphosyntax might not represent a special case of a comprehension-production asymmetry/dissociation as previously thought.
Acknowledgements
This study was conducted with the support of two National Science Foundation (NSF) grants (BCS-1251707 and 1548147) to G.L. and I.B. and a Laboratoire d'excellence Empirical Foundations of Linguistics (LABEX EFL) grant (ANR-10-LABX-0083) grant to T.N. We especially thank the day-care centers – “Reino Infantil,” “La abejita,” and “Bosque de los niños” – in Mexico City and the children and their parents for their kindness and cooperation.
Appendices
Appendix 1. Instructions and items presented from the Spanish DELV.
Ahora te voy a enseñar unas imágenes y te voy a decir algo sobre cada una. Quiero que mires las imágenes y que termines lo que voy a decir. Now I am going to show you some images and I will tell you something about each one. I want you to look at the images and complete what I tell you.
1. Veo unos papalotes pequeños y veo un papalote grande. Los niños tienen papalotes pequeños y la niña… I see small butterflies and I see a large butterfly. The boys have small butterflies and the girl…
2. Veo unas colas cortas y veo una cola larga. El gato tiene cola corta, pero los perros… I see some long tails and I see a short tail. The cat has a short tail, but the dogs…
3. Veo unas colchonetas y veo una cama. La niña siempre descansa en una cama y los niños… I see some mattresses and I see a bed. The girl always rests on a bed and the boys…
4. Veo unos caballos y veo una bicicleta. Las niñas siempre andan en bicicleta y el niño… I see some horses and I see a bicycle. The girls always ride on bicycles and the boy…
5. Veo unos platos y veo unos vasos. La niña siempre lava vasos y los niños… I see some plates and I see some glasses. The girl always washes glasses and the boys…
6. Veo un carrito y veo una carreola. Las niñas siempre empujan el carrito y la mamá siempre… I see a buggy and I see a stroller. The girls always push the buggy and the boys…
7. La niña nada y el niño… The girl swims and the boy…
8. El niño juega basketball pero la niña… The boy plays basketball but the girl…
9. Veo un conejo y veo unos caballos. El conejo come zanahorias y los caballos… I see a rabbit and I see some horses. The rabbit eats carrots and the horses…
10. Estas niñas no podían levantarse de la cama y su mamá les dio medicina. Hoy ya no están enfermos. Por qué les dio su mama medicina ayer? These girls couldn't get out of bed and their mom gave them medicine. Today they are not sick. Why did their mom give them medicine yesterday?
Appendix 2. Sample items from the comprehension task. Sentence-medial items presented with singular agreement morphology; sentence-final items presented with plural agreement morphology. Medial and final items separated by a forward slash
1. Saltan en la banca. They jump on the bench. / En la banca saltan. On the bench (they) jump.
2. Corren en la calle. (They) run in the street. / En la calle corren. In the street (they) run.
3. Lloran en el jardín. (They) cry in the garden. / En el jardín lloran. In the garden (they) cry.
4. Comen en la cocina. (They) eat in the kitchen. / En la cocina comen. In the kitchen (they) eat.
5. Escriben en la mesa. (They) write on the table. / En la mesa escriben. On the table (they) write.
6. Dibujan en al pizarrón. (They) draw on the chalkboard. / En el pizarrón dibujan. On the chalkboard (they) draw.
7. Leen en el sillón. (They) read on the sofa. / En el sillón leen. On the sofa (they) read.
8. Juegan en el parque. (They) play in the park. / En el parque juegan. In the park (they) play.






