


1 Introduction
The last three decades have witnessed the appearance of a large number of studies on the various discourse functions of like (e.g. Underhill Reference Underhill1988; Buchstaller Reference Buchstaller2004; D'Arcy Reference D'Arcy2006; Tagliamonte & D'Arcy Reference Tagliamonte and D'Arcy2007; Cheshire, Kerswill, Fox & Torgersen Reference Cheshire, Kerswill, Fox and Torgersen2011; Durham et al. Reference Durham, Haddican, Zweig, Johnson, Baker, Cockeram, Danks and Tyler2012). We have learned much about how like, particularly quotative be like, is constrained in several varieties of English and what happens to these constraints and social meanings of like once it enters a new variety (e.g. Buchstaller Reference Buchstaller2006; Buchstaller & D'Arcy Reference Buchstaller and D'Arcy2009). While we assume generally that the lexical form of discourse like will be adapted into the linguistic system of any new variety it enters, so that in Southern English varieties in the UK it will appear most commonly as [laɪk], or for Scottish varieties [lʌik], we still know relatively little about the conversational phonetics of like in its various discourse functions in different varieties of English.
Drager's (Reference Drager2009, Reference Drager2011) work on like in a New Zealand high school is a notable exception. While investigating three different functions of like (grammatical, quotative and discourse particle), she found that like does indeed have different phonetic realisations across functions. For example, quotative like tends to be less diphthongal than like used in other functions. Drager (Reference Drager2011) takes her finding of the systematically different realisation of like functions as evidence that these items are stored in the mind in such a way that functional distinctions are maintained, and that there must be a direct link between lemma-based and acoustically rich information.
In the UK too, there is anecdotal evidence of like reduction: in London English, like may be pronounced as monophthongal [la:k] or with final consonant reduction [laɪ], whereas in Edinburgh we find reduced forms such as [lɪk]. Thus, like is subject to different system-internal pressures in New Zealand, London and Edinburgh, which allows us to test Drager's argument further, whilst providing a regional comparison. The current study has two goals. It aims to (a) determine the nature of the sociophonetic variation of different functions of like among adolescents in London and Edinburgh, and (b) explore which factors may explain this variation. We will extend our investigative frame beyond the phonetic and contextual predictors investigated by Drager and also include factors, such as prosody and word probability, to uncover whether any reductive processes may be conditioned by the linguistic context in which like occurs rather than discourse function. Thus, the findings will enable us to reflect on the theoretical arguments proposed by Drager (Reference Drager2011). This is because further evidence of contextual conditioning of function-based reduction would undermine arguments in favour of function-based storage of phonetic detail in the mind. Based on the speech of teenagers in London and Edinburgh, we demonstrate that the phonetic makeup of like depends first and foremost on contextual factors.
2 Like: functions, forms, development and reduction
This section outlines the different functions of like and justifies the current study. More detail is provided on research that has investigated the phonetics of different functions of like as well as descriptions of /l/, /aɪ/ and /k/ realisations in London and Edinburgh. The section concludes with our hypotheses regarding the two questions raised above.
2.1 Like and its functions
Various forms of like can be differentiated. In order to make our data comparable with the majority of other studies conducted in the tradition of variationist sociolinguistics, we follow D'Arcy (Reference D'Arcy2007: 392–5) in differentiating between these. The lexical item under investigation can, of course, be used in a variety of standard forms: as a verb (I just love Ireland, I like the music and everything there; Edinburgh 004, Jenna, 15), adverb (our teacher looks like postman Pat; Edinburgh 002, Debbie, 14), conjunction (they pure talk to us like we're something scraped off their shoe; Edinburgh 009, Skye, 14), noun (the likes ), and suffix, as in massive- like (London 023, Thomas, 13). With the exception of like used as a noun, all of these occur in our corpus, from which examples have been taken. We provide subcorpus (Edinburgh, London) and speaker information (speaker number, participant-selected pseudonym and age) following the example.
We are particularly interested in the vernacular forms of like and differentiate between approximative adverbs, discourse markers, discourse particles and quotative be like, as defined in D'Arcy (Reference D'Arcy2007).
Approximative adverbs signal approximation and are substituted frequently with about or around (Schourup Reference Schourup1983: 30): Um, I haven't been for like three years now (London 013, April, 14).
Discourse markers mark discourse and information structure outside the clause: I don't know, when you go through to like Glasgow and stuff. Like Glasgow's really nice and stuff but I'm kind of always glad I did like grow up in Edinburgh (Edinburgh 015, Lucy, 14).
Discourse particles mark discourse and information structure within clauses. They are used for focus. They also tend to occur before new information that has just been introduced in the interaction (Dailey-O'Cain Reference Dailey-O'Cain2000): Like we wouldn't really like go on a train to like Birmingham or something like that, it would just be like too far (London 023, Thomas, 13).
Quotative be like conveys a sense of approximation and introduces reported speech (So she was like , aye, it looks like cellulitis; Edinburgh 011, Terrance Charles Desmond, 16), thought (But they try and speak Scottish it's stupid, it’ s like go and talk your ain language; Edinburgh 009, Skye, 14) or action; for example, gestures, noises, etc. Be like alternates with say, think, go and other verbs that express speech or introduce quotation.
Several scholars have assumed that discourse marker, particle and quotative like have all evolved out of the use of like as a preposition and then conjunction (Romaine & Lange Reference Romaine and Lange1991; Andersen Reference Andersen2001; Buchstaller Reference Buchstaller2001). Romaine and Lange (Reference Romaine and Lange1991: 261) outline a path for the grammaticalisation of like, which very much hinges on it developing functions of the conjunction. Once like had reached this point, it was able to take clausal complements. Like introduces full sentential clauses in this function; thereby paving the way for developing discourse marker and quotative functions.
D'Arcy (Reference D'Arcy2005) argues that the development of discourse marker functions is more complex than Romaine and Lange had assumed, and that the discourse marker developed from the use of like as a sentence adverb.Footnote 2 She further explains that the discourse particle represents the beginning of a new developmental cline in the evolution of like, rather than developing alongside the discourse marker. Once like has developed discourse marker functions, it enters syntactic structure and, with time, generalises ‘from one maximal projection to another’ (Reference D'Arcy2005: 204). She provides evidence for her argument with apparent time data from Toronto, which suggests that clause-internal like was a later development. Thus, the discourse particle differs from previous like functions in that it represents a move back into the syntax (rather than further to the edge) as well as a reduction in scope. Conversely, the discourse marker moved further towards the syntactic edge and involved scope broadening.
It is widely assumed that discourse marker like also predates the development of quotative like. The latter is believed to have emerged during the last three decades of the twentieth century (Butters Reference Butters1982; Blyth et al. Reference Blyth, Recktenwald and Wang1990; Romaine & Lange Reference Romaine and Lange1991; Tagliamonte & D'Arcy Reference Tagliamonte and D'Arcy2004). There is disagreement as to how precisely this happened. Several scholars have argued that like, in its vernacular functions, has gone through a process of grammaticalisation (Romaine & Lange Reference Romaine and Lange1991; D'Arcy Reference D'Arcy2005; Tagliamonte & D'Arcy Reference Tagliamonte and D'Arcy2007), that is, lexical forms have developed grammatical functions. This happens gradually and in certain contexts (Hopper & Traugott Reference Hopper and Traugott1993: xv). According to Romaine & Lange (Reference Romaine and Lange1991: 261), once the conjunction function was introduced and like was able to take clausal complements, the quotative was able to evolve in contexts where a like-introduced clause is a quotation. Here, like is reanalysed as a quotative complementiser and a dummy be is inserted into the quotative frame as English clauses need to contain a verb (Romaine & Lange Reference Romaine and Lange1991: 261).
D'Arcy (Reference D'Arcy2015: 53) provides evidence that questions the grammaticalisation development outlined by Romaine & Lange, in addition to the status of like in be like as a complementiser. She cites Buchstaller's (Reference Buchstaller2014) proposition as an alternative scenario by which the quotative was formed by the discourse marker filling the syntactic slot adjacent to be. D'Arcy (Reference D'Arcy2015) also entertains the possibility that be like may actually be on a trajectory of lexicalisation rather than grammaticalisation, i.e. it has become a lexical rather than a grammatical structure. This relies on the assumption that the discourse marker and the verbal element be function as a unit: they have developed a new meaning, new constraints and new ways of use. She provides several pieces of evidence for her argument relating to a presumed lack of constraint reorganisation and context expansion (Tagliamonte & D'Arcy Reference Tagliamonte and D'Arcy2007; Durham et al. Reference Durham, Haddican, Zweig, Johnson, Baker, Cockeram, Danks and Tyler2012; Haddican, Zweig & Johnson Reference Haddican, Zweig, Johnson, Biberauer and Walkden2015; but see Butters Reference Butters1982: 149; Ferrara & Bell Reference Ferrara and Bell1995: 279; Tagliamonte & D'Arcy Reference Tagliamonte and D'Arcy2004), decategorialisation and semantic bleaching.Footnote 3
It has been pointed out that the definition of grammaticalisation and lexicalisation hinges on one's view of grammar and the lexicon. For those who do not draw a line between the two, the need to differentiate these two processes holds less importance. Vandelanotte (Reference Vandelanotte, Buchstaller and van Alphen2012) argues that we may best view the development of be like as a case of constructionalisation, putting the locus of language change on the clause rather than the verb be like. He questions the analysis of like as a complementiser on several grounds (see Vandelanotte Reference Vandelanotte, Buchstaller and van Alphen2012: 176–9); instead analysing the construction of which be like forms a part as a reporting clause which functions as a conceptually dependent head and the reported clause as a conceptually autonomous complement (Reference Vandelanotte, Buchstaller and van Alphen2012: 181). In a construction grammar framework, he argues that constructionalisation was involved in the initial formation of a be like construction. Through analogical extension, there was then a meaning shift from imitation clauses involving be like, which were brought into correspondence with reporting clauses, and were added to the inventory of reporting clauses slotting into a broader taxonomy. He views this development as the continued analogical integration of be like into ‘the “canonical” direct speech and thought construction’ (Reference Vandelanotte, Buchstaller and van Alphen2012: 189), rejecting a grammaticalisation scenario in the strict sense that involves mechanisms such as decategorialisation as well as a scenario by which the be like construction may be developing into a formulaic phrase. The advantage of this analysis is that variants of the be like construction can be viewed as analogical extensions from like to particles with similar functions slotting into the same direct speech and thought construction.
This correlates with Buchstaller (Reference Buchstaller2014), who treats be like as the combination of be and a discourse marker. Similarly to Vandelanotte (Reference Vandelanotte, Buchstaller and van Alphen2012), Buchstaller (Reference Buchstaller2014: 15–17) views quotation as a set of constructions that expresses reportativity and the be like quotative as a subconstruction of the type Noun Phrase + be + like + Quote.Footnote 4 Lexical slots in a productive construction normally can be filled with other material via analogical extension. Therefore, other words, usually discourse markers, such as all, kinda, totally, can all fill the same lexical slot in the same way as like. Similarly, be can be replaced by other copula verbs. Thus, Buchstaller proposes a more general copula-based construction type for these innovative quotative constructions with additional schematic slots: Noun Phrase + Copula + (Discourse Marker) + Quote. Buchstaller's focus on the productivity of this construction opens up a new view into its future development. Moreover, it focuses on the emergence of a new construction, rather than solely on be like. We believe the focus on the reporting clause is key, and we will return to its relevance to our study in the discussion section.
While there is disagreement regarding the evolution of be like, it is clear that it spread into British English in the early 1990s. It was unattested until then (Tagliamonte & Hudson Reference Tagliamonte and Hudson1999) but has been found in several locations across England and Scotland in data gathered from the mid 1990s. It is particularly frequent among adolescent speakers but not used at all, or to very low degrees, by older speakers. Cheshire et al. (Reference Cheshire, Kerswill, Fox and Torgersen2011) compare different quotative functions in London. Be like occurs 20 to 24 per cent of the time among the younger age group in Hackney and Havering. However, when the youngest age groups are subdivided into ages 4–5, ages 8–9, ages 12–13 and ages 16–19, the use of be like rises to 46 per cent among the 16–19-year-olds. Meyerhoff & Schleef (Reference Meyerhoff, Schleef and Lawson2013) report a similar number for native adolescents of approximately the same age in Edinburgh: 47 per cent of quotatives were occurrences of be like.
While previous research has focused on how the linguistic and social constraints play out in different varieties of English, system-specific pressures must surely act as an important factor influencing the phonetic form of like in its various functions as it spreads from one variety to another. We now turn to precisely these kinds of questions, starting with varieties outside the UK before moving on to London and Edinburgh.
2.2 Like reduction
In Drager's (Reference Drager2011) investigation of like reduction among New Zealand adolescents, a core argument is the relationship between phonetic realisation and token frequency. It is assumed that greater reduction occurs among more frequent words and various references are cited that seem to support this assumption; for example, Bybee (Reference Bybee2001), Zipf (Reference Zipf1929). Furthermore, the notion is discussed that more predictable items are more likely to be phonetically reduced (e.g. Jurafsky, Bell, Gregory & Raymond Reference Jurafsky, Bell, Gregory, Raymond, Bybee and Hopper2001; Jurafsky, Bell & Girand Reference Jurafsky, Bell, Girand, Gussenhoven and Warner2002; Bell, Jurafsky, Fosler-Lussier, Girand, Gregory & Gildea Reference Bell, Jurafsky, Fosler-Lussier, Girand, Gregory and Gildea2003). For example, Jurafsky et al. (Reference Jurafsky, Bell, Gregory, Raymond, Bybee and Hopper2001) predict that items with a higher probability will be subject to a larger degree of reduction. Drager applies this notion to individual speakers, rather than words, as the probability that a speaker uses like varies between individuals. While this is an interesting notion, it should not preclude us from also giving due consideration to word predictability in our statistical models. This is particularly the case when investigating an item such as like, as the quotative function of it is highly limited in what lexical items can precede it: it has to be preceded by a form of be.
Furthermore, Drager assumes that each function of like is a different lemmaFootnote 5 as they all have different meanings and grammatical roles. The main goal of her paper is to test whether these different lemma, which she assumes share the same word form, are realised differently phonetically. Her analysis is limited to two grammatical functions (the lexical verb and the adverb) and two discourse functions (the discourse particle and the quotative). These functions were selected as they all occur sentence-medially.
Her results reveal that the three different functions of like (grammatical, quotative and discourse particle) do indeed have different phonetic realisations in her data. Table 1 summarises her results. It also includes information on community-specific realisations of like in two communities of practice: the common-room girls and the non-common-room girls.
Table 1. Summary of phonetic realisations of like functions (adapted from Drager Reference Drager2011: 703)

The largest degree of reduction is observed for the quotative, which may be surprising given frequency-based predictions and the fact that the discourse particle is reported to be more frequent than the quotative (e.g. D'Arcy Reference D'Arcy2007: 396; Drager Reference Drager2011: 698). This is certainly the case for our corpora based on adolescent speech from London and Edinburgh (see table 3). Considering the much higher frequency of the discourse particle, a larger degree of reduction would be expected for this function of like. Many have argued for the link between word frequency and reductive sound change (e.g. Bybee Reference Bybee2001; Phillips Reference Phillips2006; cf. Dinkin Reference Dinkin2008), and although this does not refer explicitly to function frequency, a similar effect for different like functions is not an unrealistic expectation. However, no such link between frequency of like function and reduction has been documented. This finding in itself may be a clue for a contextual dependency of reduction. Indeed, Drager points towards two such potential effects: the prosodic context in which like occurs, particularly accentedness, and word contextual probability effects. We will test for both these factor groups in our study but will, at this point, mostly elaborate on the latter in order to clearly separate different contextual probability effects.
Drager (Reference Drager2011) found evidence of frequency-linked monophthongisation in New Zealand, in that speaker-predictability matters: high users reduce more. Tamminga (Reference Tamminga and Santana-LaBarge2014), in her study of /aɪ/-raising in like, did not find current evidence of the effects of word frequency. She compared like in its adjective, conjunction, discourse marker and preposition functions. With regard to /aɪ/-raising, she identifies a major divide between function and content words, rather than word frequency, in the evolution of the phenomenon.
However, there are other frequency measures, which we will now explore. The Probabilistic Reduction Hypothesis predicts that more reduction occurs in items with a higher probability (Jurafsky et al. Reference Jurafsky, Bell, Gregory, Raymond, Bybee and Hopper2001). The hypothesis generalises frequency-based (Zipf Reference Zipf1929; Rhodes Reference Rhodes, Hurch and Rhodes1996) and predictability-based models (Fowler & Housum Reference Fowler and Housum1987), as it assumes that word probability is conditioned by a whole host of contextual aspects. These may include preceding and following words, syntactic and lexical structure, discourse factors and semantic expectation. Therefore, it may be necessary to use a variety of different measures of probability to uncover probabilistic reduction effects. Jurafsky et al. (Reference Jurafsky, Bell, Gregory, Raymond, Bybee and Hopper2001) demonstrate this for a subset of measures in their study on reduction in lexical production. While high-frequency function words were more sensitive to the predictability of neighbouring words, content words were less sensitive to the surrounding context. They demonstrated strong effects of relative frequency.
Thus, rather than focusing on one frequency measure, a combined approach appears the most logical. In this article, among other factors, we focus on one aspect of probabilistic linguistic knowledge; namely, local probabilistic relations between words. Previous research suggests that strongly related words or words that are predictable from neighbouring words are more likely to be phonologically reduced than less strongly related words (Krug Reference Krug1998; Bush Reference Bush1999; Bybee & Scheibman Reference Bybee and Scheibman1999). Jurafsky et al. (Reference Jurafsky, Bell, Girand, Gussenhoven and Warner2002) argue that differences in the phonetic realisation of lemmas that have the same word form are reduced or disappear once contextual predictability is considered. If this is indeed the case and our statistical analyses reveal that it is not like function but contextual factors that predict reduction, claims that items are stored in the mind in such a way that functional distinctions are maintained are much less convincing. This is precisely what Drager concludes based on her results. She argues that the different phonetic realisations for different functions of like give support to production models with an acoustically rich lemma level or one that is directly indexed to acoustic information.
Drager (Reference Drager2011: 704) argues that it is unlikely that all function-based peculiarities are due to contextual predictability, for two reasons. First, there is substantial variability in the distribution of phonetic features, and second, follow-up perception experiments showed that individuals were able to match certain like realisations to certain functions.
The ultimate test to determine what factors influence the form of like is to study the form itself while exploring as many potential predictors as possible, including like function. We will derive specific hypotheses based on this discussion at the end of this section. However, before we do this, we will explore what precisely the details of /l/, /aɪ/ and /k/ are in London and Edinburgh and whether there are any local system-internal factors that we should consider.
2.3 Like in Edinburgh and London
2.3.1 /l/
Analysis of /l/ reduction usually focuses on lenition of the liquid consonant; in other words, whether /l/ is darkened or vocalised (Ash Reference Ash1982; Carter & Local Reference Carter and Local2007; Turton Reference Turton2014). Although /l/ lenition is found typically in coda position in words such as dull or bulb, rather than in onset position, as in love or like, it is not uncommon to find such lenition processes occurring in onset position in rapid or reduced speech.
In her analysis of like, Drager (Reference Drager2011) takes the duration of /l/ in relation to the following vowel in order to gauge reduction: more reduced tokens should have shorter /l/s. We will follow her in this procedure in order to render our data comparable. This procedure helps to normalise the duration of /l/. Measuring the duration of /l/ alone across different rates of speech would bias our reduction results towards fast speech. Measuring instead the duration of /l/ relative to the following vowel controls for speech rate effects.
Although most studies of London /l/ focus on vocalisation, this normally affects only coda and pre-consonantal positions. In the onset position, /l/ remains light in London, but may be slightly palatalised (Beaken Reference Beaken1971: 339; Tollfree Reference Tollfree, Foulkes and Docherty1999: 174). Scottish English /l/, in contrast, is often described as showing dark or velarised variants in all positions (Aitken Reference Aitken and Trudgill1984: 102); however, studies conducted in Edinburgh (Speitel Reference Speitel1983) and Glasgow (Stuart-Smith Reference Stuart-Smith, Foulkes and Docherty1999: 210) reveal that /l/ is subject to sociolinguistic variation, with middle-class and female speakers having lighter variants.
2.3.2 /aɪ/
Although middle-class Londoners exhibit near-RP price realisations, such as [äɪ] and [aɪ], working-class suburban London English is described as having a backer nucleus, transcribed as [ɑɪ] (Wells Reference Wells1982: 308; Tollfree Reference Tollfree, Foulkes and Docherty1999: 168; Hughes, Trudgill & Watt Reference Hughes, Trudgill and Watt2012: 77), or even rounded [ɒɪ] in more ‘vigorous “dialectal” Cockney’ (Wells Reference Wells1982: 308).
However, this is unlikely to be relevant to the West London adolescents investigated in our study; particularly as more recent research suggests a shift from traditional Cockney forms (often associated with East London) and towards a new variety, that of Multicultural London English (MLE) (Kerswill, Torgersen & Fox Reference Kerswill, Torgersen and Fox2008; Cheshire et al. Reference Cheshire, Kerswill, Fox and Torgersen2011). Speakers of MLE tend to produce a more fronted and/or monophthongal [a:]-like variant (Fox Reference Fox2007; Kerswill et al. Reference Kerswill, Torgersen and Fox2008; Cheshire et al. Reference Cheshire, Kerswill, Fox and Torgersen2011). Data for our corpus were collected in Ealing, a suburban district of West London. MLE occurs less frequently in these peripheral areas of London, particularly among the white population. Nonetheless, a handful of our speakers may, impressionistically, be categorised as speakers of a near-MLE variety. However, most of our speakers produced [ɑɪ] or [aɪ] tokens. Although [ɑɪ] is still very much present in suburban London, standard [aɪ] tokens seem to be more common amongst younger white speakers (Fox Reference Fox2007). price realisations are summarised in table 2.
Table 2. Summary of price realisations in London

Scottish English price has gained attention from being subject to the Scottish Vowel Length Rule (SVLR) in some contexts: certain vowels (particularly /i/, /u/, /aɪ/) are normally short, but lengthened before /r/, voiced fricatives, a morpheme boundary and when occurring in word-final open syllables. This means speakers have two perceptibly different diphthongs in price and prize, with like taking the shorter realisation, as it precedes a stop, giving something like [lʌik] for Standard Scottish English (SSE) speakers (Scobbie et al. Reference Scobbie, Hewlett, Turk, Foulkes and Docherty1999: 236). Middle-class Edinburgh speakers from areas such as Morningside may have [əɪ]~[ae] for price~prize, which may be neutralised to just [ae] (Chirrey Reference Chirrey, Foulkes and Docherty1999: 226; Stuart-Smith Reference Stuart-Smith, Kortmann and Upton2008: 58) and is often perceived as ‘over-refined’ (Johnston Reference Johnston1985: 39).
2.3.3 /k/
Variation in /k/ typically involves some kind of glottal reinforcement (preglottalisation) preceding the stop, or/and a more advanced form of lenition in full glottal replacement (glottalling). It is reported that all speakers of Edinburgh English demonstrate regular glottalisation of word-final /k/ to some extent (Chirrey Reference Chirrey, Foulkes and Docherty1999: 229); however, this is subject to sociolinguistic conditioning (Speitel Reference Speitel1983: 36). For MC speakers, the majority variant is [kh~k], but WC speakers may show glottalised and fully glottalled forms [ʔk~ʔ]. This may be a change in progress, led by young females, paralleling word-final /t/ glottalling in Edinburgh (although /k/ is some way behind).
Many Cockney speakers display frequent glottalling of the voiceless stops /p,k/ as well as /t/. This can occur intervocalically (e.g. lucky) and finally (e.g. like; Wells Reference Wells1982: 323; Cruttenden Reference Cruttenden2001: 170). In Beaken's (Reference Beaken1971: 274) study of WC children in London's East End, word-final /k/s had some form of glottalisation almost 100 per cent of the time, about half of which were fully glottalled (e.g. [ʔk~ʔ]).
2.4 Conclusion
Thus, with the exception of /k/, the phonetic detail of like is rather different in London and Edinburgh: like tokens occur in varieties with somewhat different system-internal pressures. This makes separate statistical models highly advisable. Most importantly, however, our review of /l/, /aɪ/ and /k/ indicates that all three features are variable in both cities. Some of these are already subject to reduction. This is particularly the case for /k/ in London and Edinburgh and /aɪ/ in London. Thus, if there is any evidence for function-specific reduction, we would expect it to occur in /k/ or the vowel.
Our review of the evolution of like would suggest that more reduction should occur in the more established vernacular functions of like: the discourse marker or the discourse particle. The case should be particularly strong for the discourse particle, as it is the most frequent function of like. However, we have also indicated in our review that contextual factors may override any of the local or function predictions. We have identified two such contextual factors to which we will pay particular attention: the prosodic context in which like occurs and word-contextual probability effects. We can formulate two specific hypotheses based on these deliberations:
-
(H0) Contextual dependency of like realisation: like function will not be a significant factor in the statistical analysis as variation is completely explained by contextual factors, e.g. prosody and word probability.
-
(H1) Functional dependency: like function will be a significant factor in the statistical analyses – alongside contextual factors, which may help us explain why function matters.
We will now turn to our methodology and explain how we will address our hypotheses and our research questions, as outlined in the introduction.
3 Methods
3.1 Data
The data for this study come from 21 Edinburgh-born teenagers (8 males, 13 females) and 24 London-born teenagers (12 males, 12 females). The data were originally collected in the course of a study conducted on the acquisition of variation among adolescents in these locales. More detail of this can be found in Schleef, Meyerhoff & Clark (Reference Schleef, Meyerhoff and Clark2011). Data were collected in two high schools in comparable social settings and of similar social makeup; one in West Edinburgh and one in West London. Students ranging from upper-working to lower-middle-class backgrounds were interviewed in friendship pairs in order to facilitate a casual atmosphere. The teenagers were all aged between 12 and 18, with a mean age of 14; a locally born female research assistant carried out sociolinguistic interviews in Edinburgh, and another locally born female assistant did likewise in London. The interviews were transcribed orthographically using ELAN (Brugman & Russel Reference Brugman, Russel, Lino, Xavier, Ferreira, Costa and Silva2004), resulting in a time-aligned, searchable corpus.
3.2 Coding and acoustic analysis
In a first step, no more than the first 55 like realisations per person were coded as one of the functions outlined in section 2.1 (i.e. quotative, discourse marker, discourse particle, approximative adverb, etc.). We used these for acoustic analysis. We limited these to the first 55 tokens of like per person in order to avoid the data from some high users of like biasing the analysis. We established a limit of 55, as there seemed to be a natural gap in speaker-specific token frequencies: while many speakers used up to 40 tokens of like in their interview, no speaker had token frequencies between 46 and 55. Conversely, if speakers did use more than 55 tokens, they would often use many more; sometimes more than 100 tokens in a single interview. This was the case for 16 speakers. For the remaining 29 speakers, all occurrences of like were included in the analysis as they used fewer than 55 tokens of like in the interview.
In addition, all quotatives in the transcripts were coded as one of the following: quotatives be like, say, think, go, this is, zero quotative and other less frequently occurring quotative verbs, such as tell, shout, etc. We used these to calculate speaker-specific probabilities of using quotative like. Each realisation of like was coded twice in ELAN by two paid, independent research assistants. Cases of coding disagreement were resolved by a third researcher.
The coded data were then extracted from ELAN and imported into a spreadsheet for further coding; for example, for preceding and following words, person, tense, speaker sex, etc. Again, this followed the same procedure of double, independent coding by two research assistants and disagreement resolution via a third party. Tokens that could not be categorised (reliably) under one of the main vernacular functions in table 3 were coded as ‘unclear/other’. This generated 804 tokens of like from the Edinburgh speakers and 803 tokens of like from the London speakers. The data in table 3 present the distribution of all functions of like among the teenagers recorded in Edinburgh and London. A regional comparison indicates that most functions of like are used in roughly the same frequency by adolescents in Edinburgh and London. The use of discourse markers is somewhat higher in London, while quotatives are used somewhat more frequently in Edinburgh. In both locations, the discourse particle is the most frequent function of vernacular like.
Table 3. Functions of like for adolescents in London and Edinburgh

The first 55 like tokens per speaker were then subjected to an acoustic analysis. Firstly, the vowel and the preceding and following element, /l/ and /k/, were determined and then labelled in Praat (Boersma Reference Boersma2001). To determine the boundaries between sounds, we followed Drager (Reference Drager2011: 698) as closely as possible. Vowel formants in 10 ms intervals, duration of /l/, vowel and /k/ were then measured using a Praat script. Speech rate was also determined by means of a Praat script, which calculates vowels per second based on a three-word window in Praat; that is, the three words preceding and following the token of like.
The preceding and following phonological environment of each like and the quality of the /k/ were also determined, following Drager (Reference Drager2011: 698) as closely as possible. For the latter, the categories were as follows: /k/ is (a) present; (b) deleted; (c) reduced but with release; (d) reduced but there is no evidence of release in the spectrogram; (e) realised as a fricative; and (f) glottalled.Footnote 6
In the next step, prosodic characteristics were determined. The two words before like and the two words following like (if any) were noted and the pitch pattern inspected while listening to the utterance. It was noted (1) whether like is accented or unaccented, and (2) whether like is (intonation) phrase-final or not phrase-final. Finally, (3) the boundary strength following like, using the Break Index Tier (Beckman & Hirschberg Reference Beckman and Hirschberg1993) was determined. A break index is a numerical value that is meant to represent perceived degrees of juncture in an utterance. Break indices can be assigned to perceived junctures between words and between the final word and the silence at the end of the utterance. Ratings range from 0 to 4. Beckman & Hirschberg (Reference Beckman and Hirschberg1993: 1–2) outline the break index values as follows:
-
0 for cases of clear phonetic marks of clitic groups; e.g. the medial affricate in contractions of ‘did you’ or a flap as in ‘got it’.
-
1 Most phrase-medial word boundaries.
-
2 A strong disjuncture marked by a pause or virtual pause, but with no tonal marks; i.e. a well-formed tune continues across the juncture. OR a disjuncture that is weaker than expected at what is tonally a clear intermediate or full intonation phrase boundary.
-
3 Intermediate intonation phrase boundary; i.e. marked by a single phrase tone affecting the region from the last pitch accent to the boundary.
-
4 Full intonation phrase boundary; i.e. marked by a final boundary tone after the last phrase tone.
Strictly speaking, this is not an ordered factor as perceived juncture and intonation combine to result in a score; however, the intonation phrase does not enter as a criterion until break index 2. The break index can provide an indication of the prosodic position in which like occurs. Specifically, it will be an indication of the perceived break following like and where in the intonation phrase different functions of like may occur. Position within the intonation phrase and the type of break following like may influence the phonetic detail of like. We would expect like tokens occurring in a 0 or 1 environment to be more reduced than those occurring in a break index 3 environment.
Before processing the vowel formant values, the database was inspected for errors and formant traces were corrected by hand. The F2–F1 distance was calculated, and a line was then fitted to the values for the F2–F1 distance. The value of this slope is used as the measure of monophthongisation, referred to as the DIPH value. If the result of the slope is positive, the space between F1 and F2 is increasing; thereby indicating a particular token is more diphthongal. A value closer to zero indicates that the vowel quality is the same throughout, and therefore more monophthongal. Due to the focus on the F2–F1 distance, there was no need to normalise the data.
Moreover, we included various measures of probabilistic linguistic knowledge. Following Drager (Reference Drager2011: 697), we calculated the speaker-specific relative token frequency, or probability of the quotative based on all occurrences of quotatives in the data. The measure was calculated by dividing the number of times a speaker produces quotative like by their total number of quotatives. Speaker-specific probabilities for other functions of like were not possible, given the difficulty in defining the envelope of variation for these. We also extracted bigram frequency information for our data using the SUBTLEX UK corpus (Heuven, Mandera, Keuleers & Brysbaert Reference Heuven, Mandera, Keuleers and Brysbaert2014), which consists of 201.3 million words. The SUBTLEX corpora, based on film and TV subtitles from BBC broadcasts, are new and improved frequency measures for US and UK English. SUBTLEX contains data from over 45,000 broadcasts. Therefore, they include actual speech alongside scripted speech. While this offers an advantage over corpora based on written texts (e.g. Brown, CELEX) and much smaller speech corpora (e.g. the spoken component of the BNC), we approach the results with some caution, given that scripted speech has been shown not to reflect the proper linguistic and social conditioning of variables such as be like (Dion & Poplack Reference Dion and Poplack2007).
Nevertheless, until there is a corpus of natural speech large enough to cope with the statistical measures used in the present article, SUBTLEX is by far the most appropriate tool for bigram and frequency analyses. Figure 3 illustrates the good degree of overlap in bigrams between our corpus and SUBTLEX. The presence of bigrams, such as was like in SUBTLEX, also demonstrates its reflection of casual speech. In addition, we are assured in our choice by work in psychology which has demonstrated that word processing times are highly improved in SUBTLEX, compared with previously used frequency estimates (see Brysbaert & New Reference Brysbaert and New2009).Footnote 7
SUBTLEX bigram frequencies are further used as a measure of conditional probability (Jurafsky et al. Reference Jurafsky, Bell, Gregory, Raymond, Bybee and Hopper2001), by calculating how likely a word is to occur given the previous word was like, and how likely like is to occur given the previous word. The conditional probability is derived by counting how often the two words in question occur together and then dividing this number by the number of times the first word occurs. Independent of the measure we take, we would expect more reduction with higher probabilities.
In an attempt to make our results comparable with those of Drager (Reference Drager2011), we focused on specific functions of like in our analysis. We conflated grammatical functions of like into one category; specifically, lexical verb and adverb were conflated. These were contrasted with other functions of like: the quotative, the discourse particle and the discourse marker. Approximative adjectives do not form part of the analysis as token counts were deemed too low to yield any reliable results. Unclear and ‘other’ tokens (such as utterance-final sentence adverbs) were also removed from analysis. The independent variables used in the current analysis, and the levels coded for under each variable, are outlined below:
-
• Function of like: grammatical, discourse marker, discourse particle, quotative be like
-
• /l/ to V ratio between duration of /l/ and vowel: continuous (higher values indicate a longer /l/ to vowel duration)
-
• Speech rate based on vowels per second: continuous
-
• Duration of /l/, vowel and /k/ in milliseconds (ms): continuous
-
• Bigram predictability – bigram count following (like + word), bigram count preceding (word + like): continuous
-
• Conditional probability as above, but with conditional probabilities instead of counts: continuous
-
• Speaker-specific probability of using quotative like: continuous
-
• Diphthongisation (DIPH) value – high values indicate more diphthongal realisation of vowel: continuous
-
• /k/ realisation: present, deleted, reduced, fricated, glottalled
-
• Accentedness of like: accented, unaccented
-
• Position in intonation phrase: like is phrase-final, like is not phrase-final
-
• Boundary strength (BS) following like: 0, 1, 2, 3, 4Footnote 8
-
• Preceding phonological context: vowel, pause, nasal, liquid, plosive, fricative and affricate, glide
-
• Following phonological context: vowel, pause, plosive, consonant other than plosiveFootnote 9
-
• Speaker sex: male, female
4 Results
Results are given in four distinct steps. In the initial step, we provide a summary characterisation of the different functions of like. We then explore the vowel quality of like and finally proceed to investigate /l/ and /k/.
4.1 Like function as dependent variable
Drager (Reference Drager2011) focuses on predicting the particular function of like by using the probability of the function as the response variable and the phonetic and contextual values as the predictors. This is somewhat unusual, given that the dependent variable (i.e. the variable being tested) typically would be the phonetic realisation, and the discourse function would be the predictor. We run analyses of this kind in section 4.2; however, in order to provide a comparison with Drager (Reference Drager2011), section 4.1 uses the probability of like function as the dependent variable, to assess whether a particular function can be predicted from its phonetic realisation.
Our data differ from Drager's in some ways, and we believe we can improve on exploring the complexity of our data by using different statistical techniques. Drager considers three functions of like in her paper, resulting in three models. However, as we have four possible options – discourse marker (DM), discourse particle (DP), grammatical (Gram) and quotative (Quot) – we will need six models to be able to consider each pairing. Thus, we are asking whether a particular function of like (e.g. whether it is a discourse marker or a quotative) can be predicted by the phonetic realisation of each of its segments, as well as other contextual factors listed in section 3.2. If indeed the phonetic factors emerge as the most important, this would lend weight to the idea that items are stored in the mind in such a way that functional distinctions are maintained.
Because of the large number of predictors for this model, we took advantage of the binary choice in dependent variables by running a series of random forests. This has the added benefit of including highly collinear predictors (such as bigram counts and their conditional probability, or accentedness and boundary strength) in the same model, as random forests are well equipped to deal with such predictors, as well as small sample sizes.
The importance of the predictors for Edinburgh and London can be viewed from the dotplots in figures 1 and 2, alongside the ctrees in the Appendix. Each shape represents a different pairwise combination of functions of the dependent variable. The lines represent the cut-off for significance: everything to the left of the line is considered non-significant in each comparison (Strobl, Malley & Tutz Reference Strobl, Malley and Tutz2009: 342). Although there are six separate lines on each of these plots, they are very tightly clustered, and any points approaching the lines should be taken as not significant.
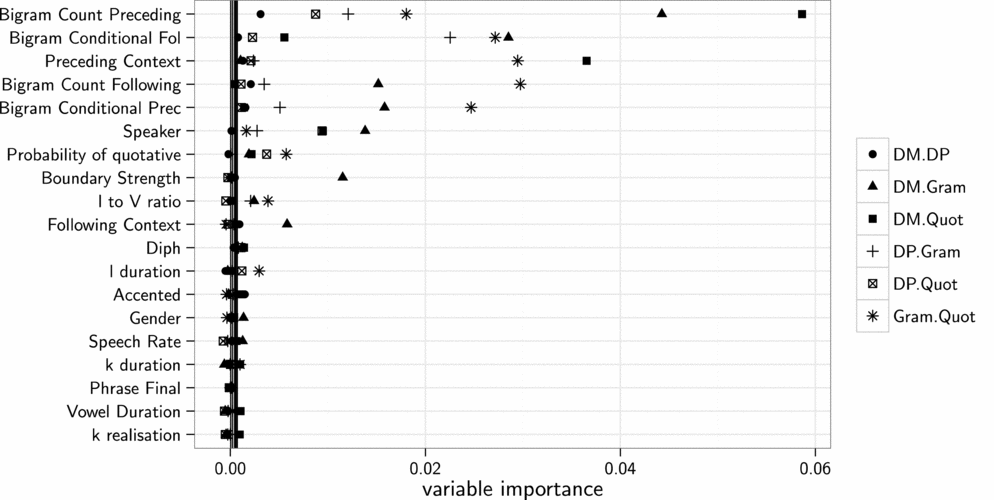
Figure 1. Variable importance of factors from random forest in Edinburgh across combinations of discourse marker (DM), discourse particle (DP), grammatical (Gram) and quotative (Quot) like

Figure 2. Variable importance of factors from random forest in London
Overall, we can see that bigram frequency of the preceding and following words, and the preceding context overwhelmingly are the most important factors for predicting what kind of function of like we have.Footnote 10 For example, frequent combinations with like and a specific preceding word relate to a variety of functions of like, not one specific function. Depending on the comparison, discourse markers and discourse particles are often associated with low bigram frequencies of that particular type, while the grammatical and quotative functions are often associated with high bigram frequencies. Some frequent combinations are listed in figure 3.

Figure 3. Top ten bigram frequencies for like and the preceding word in our corpus and in the SUBTLEX corpus
Boundary strength, accentedness, /l/ and /l/ to vowel duration, and following context also play a role for most or some combinations in both cities. In combinations that include the quotative, we also find the probability of a speaker using the quotative to be a significant predictor. This finding is unsurprising and somewhat circular: if a token of like is uttered by a speaker who has a high probability of using quotative like, then that token is more likely to be quotative like in comparison to other speakers.
The ctrees, built using R's party package (Hothorn, Hornik & Zeileis Reference Hothorn, Hornik and Zeileis2006), give us more of an insight into how each factor contributes. As an example, figure 4 illustrates a conditional inference tree for discourse marker vs grammatical like in Edinburgh. If the bigram with the following word is not particularly frequent (less than 3,350 occurrences in SUBTLEX), it is more likely to be a discourse marker. If it is very frequent, the likelihood of the realisation is decided by the boundary strength: a weaker boundary indicates a grammatical element, whereas a stronger boundary is more likely to be preceded by a discourse marker. The other trees (which can be viewed in the Appendix) vary in their complexity; however, they demonstrate that the function can be accounted for with similar patterns of contextual factors.

Figure 4. Conditional inference tree for discourse marker (DM) vs grammatical (gram) like in Edinburgh
The forests and trees for this dataset inform us that the context of the sentence (i.e. bigrams or boundary strength) is the overwhelming predictor of the type of like.Footnote 11 However, there are some small indications, in some combinations that contain the quotative, that phonetic factors may play a role in determining the type of like. Diphthongisation/monopthongisation, /k/ and /l/ to vowel duration demonstrate some small effects.
We will now explore more closely these phonetic factors and create three models that take the phonetic realisation as the dependent variable; that is, the l-to-vowel duration, the degree of monophthongisation/diphthongisation and the quality of /k/ respectively. This tests whether different functions of like do nonetheless differ significantly in the quality of /l/, /aɪ/ and /k/, despite the contextual constraints. Therefore, the research question in this section is somewhat different. Rather than asking whether a particular function of like (e.g. whether it is a discourse marker or a quotative) can be predicted by the phonetic realisation of each of its segments, as well as other contextual factors, we are now asking whether monophthongisation, /k/ quality and l-to-vowel duration can be predicted from the factors listed in section 3.3. The most important question here is: will the function of like be selected as a significant predictor or not?
4.2 Vowel quality
Tables 4 and 6 provide the results of the linear regression models for the vowel quality in London and Edinburgh. They list significant factors in column 1, and in columns 2, 3, 4 and 5, the estimate, the standard error, the t-value and the p-value are listed respectively. We further provide the estimate of the intercept. The estimates given in the regression models help us interpret the effect of a relevant factor level on vowel quality. A negative quantity implies a larger degree of monophthongisation, while a positive quantity implies a larger degree of diphthongisation than the respective reference level.
Table 4. Coefficients of a general mixed-effects linear regression of monophthongisation and diphthongisation with speaker as random effect – London

We can see from table 4 that among our London adolescents, two factors achieve statistical significance. Like tokens followed by a boundary strength of 1 are the most monophthongal like tokens, followed by boundary strength 3.Footnote 12 Thus, prosodic factors do indeed influence the realisation of like, as we had expected. In addition, the function of like does influence the degree of monophthongisation as well: quotatives are more monophthongal among London adolescents, which mirrors Drager's results in New Zealand.
The box plot in figure 5 summarises the results for like in London. The additional bars demonstrate that quotatives are significantly more monophthongal than discourse markers and discourse particles. Discourse particles differ significantly from quotative and grammatical like, and grammatical functions of like are only significantly different from discourse particles. Although significant, the boxplot shows that the differences are very fine-grained. Moreover, the results point towards the conclusion that, in London, break type 1 is a favourable environment in which monophthongisation is more frequent. Table 5 outlines the breakdown of break type by like function.

Figure 5. Degrees of diphthongisation of like in its different functions – London
Table 5. Occurrence of like in five boundary strength contexts in both London and Edinburgh

Table 6 shows that the results for Edinburgh are very similar to our London findings. Boundary strength (BS) is a significant factor. However, in Edinburgh, like tokens followed by a juncture strength of 3 are the most monphthongal like tokens, followed by BS 1. In contrast to BS2, BS1 and BS3 are less diphthongal than BS0, although this is only marginally the case for BS1. The difference between 1, 2 and 3 is not significant. We will return to this point in our discussion.
Table 6. Coefficients of a general mixed-effects linear regression of monophthongisation and diphthongisation with speaker as random effect – Edinburgh

As in London, the function of like influences the degree of monophthongisation. Figure 6 shows that discourse particles are most diphthongal – more so than discourse markers, and significantly more so than grammatical like and quotatives. Discourse markers are the next most diphthongal, but not significantly more so than grammatical like. Quotatives are the most monophthongal, with significantly lower DIPH values than discourse particles and discourse markers, but not grammatical like.

Figure 6. Degrees of diphthongisation of like in its different functions – Edinburgh
In Edinburgh, there is also a gender effect: males are more likely to realise the vowel as a monophthong across all four functions. There is no significant interaction effect between gender and function; thereby indicating that the gender effect occurs independently of like function. The fact that males are more likely to realise the vowel as a monophthong is not terribly surprising. Many studies have shown that men use vernacular features more than women, especially in cases of stable variation and language change above the level of awareness (Labov Reference Labov2001). However, given the relatively recent introduction of like and its use by younger age groups, we are not in a position to make an assessment about the nature of the variation; that is, whether or not variation in the vowel quality of /ai/ is stable. It is similarly unlikely that monophthongised like occurs above the level of awareness (yet), given the recentness of the phenomenon. Future research is needed to uncover what precisely the status of the observed variation is: by collecting data from different age groups and by conducting perception and ethnographic work to investigate the extent to which monophthongisation is perceived by speakers and the stylistic work it may do.
The significant factor of vowel duration indicates that long vowels are more monophthongal. The situation is somewhat more complex but space constraints do not permit a full treatment of this issue. In brief, more fine-grained analyses suggest, by selecting a binary cut-off between monophthongal (i.e. a DIPH value of around 0) and diphthongal tokens, duration correlates with the diphthongal tokens only.
4.3 /l/ to vowel duration
The /l/ to vowel duration provides an indication of the length of /l/ relative to the vowel: a low /l/ to vowel ratio indicates a short /l/ relative to the vowel duration. More reduced tokens should have shorter /l/s.Footnote 13 In Drager's (Reference Drager2011) study, tokens with a short /l/ to vowel ratio were more likely to be quotative like than grammatical like. The results for /l/ to vowel duration in London (table 7) and Edinburgh (table 8) indicate that like function does not correlate significantly with the duration of /l/. Considering this finding, we provide only a brief report of the results.
Table 7. Coefficients of a general mixed-effects linear regression of /l/ to vowel duration with speaker as random effect – London

Table 8. Coefficients of a general mixed-effects linear regression of /l/ to vowel duration with speaker as random effect – Edinburgh

In London, the boundary strength following like has a significant effect. A BS of 0 is associated with a longer /l/ to vowel duration, while BS1 and 3 reflect the results we found for vowel quality in that they are associated with a larger degree of reduction – and in relation to /l/ – a shorter /l/ to vowel duration. Table 7 also indicates that males have a higher /l/ to vowel duration.
In Edinburgh, conversely, the preceding phonological context constrains /l/ to vowel duration in like. The /l/ to vowel duration is highest when the preceding context is a vowel, followed by stops, pauses and fricatives. The fricative context, which results in the shortest /l/ to vowel duration, differs significantly from vowels and stops, but not pauses.
4.4 /k/ realisation
The results for /k/ in London (table 9) and Edinburgh (table 10) also indicate that like function is not a significant factor in determining the realisation of /k/. In tables 9 and 10, a higher value indicates an increased likelihood of /k/ reduction.
Table 9. Coefficients of a general mixed-effects linear regression of /k/ with speaker as random effect – London

Table 10. Coefficients of a general mixed-effects linear regression of /k/ with speaker as random effect – Edinburgh

In London, again the boundary strength following like has a significant effect. A BS of 0 is associated with the fullest /k/ realisation, while BS1 is significantly more reduced. Table 9 also indicates that fuller /k/ realisations are associated with more diphthongal realisations of the vowel, suggesting that /k/ and vowels in like are reduced in tandem. Finally, the realisation of /k/ is influenced significantly by the following context. This is the case in London as well as Edinburgh (see table 10). In both locales, we observe the highest degree of /k/ reduction before stops and the least degree of reduction before vowels. Other consonants and pauses fall in between these two extremes. This is in line with findings for /t/ reduction, particularly T-glottalling, for which a consonant > pause > vowel hierarchy is often documented (see Schleef Reference Schleef2013 for an overview).
We can also see that in Edinburgh the number of times like and the preceding word occur together shows a significant effect. Figure 7 indicates that a fully realised /k/ is the most common variant found, but if the bigram is very frequent it is more likely to be reduced in some way (log-scale between 9 and 10; that is, between about 8,000 and 22,000 occurrences in the SUBTLEX corpus). This is in accordance with the predictions made by Jurafsky et al. (Reference Jurafsky, Bell, Gregory, Raymond, Bybee and Hopper2001, Reference Jurafsky, Bell, Girand, Gussenhoven and Warner2002).

Figure 7. /k/ realisation for Edinburgh speakers against the log of bigram count preceding (i.e. number of times like and its preceding word occur together)
In conclusion, both results for /l/ and /k/ confirm our findings made in the random forests analysis: the function of like correlates mostly with contextual factors rather than phonetic factors. Predictability of the preceding and following words, the preceding and following segments, and BS emerge as highly significant. Different functions of like occur in specific contexts, which have not resulted in significantly different phonetic details for them.
However, this does not explain all the findings pertaining to vowel realisation. In London and Edinburgh, the vowel is the only non-contextual feature that seems to be sensitive to the function of like: quotative be like is more likely to be monophthongised than other functions of like. This means there are three independent speech communities (New Zealand, London and Edinburgh) across which the price vowel is subject to different phonetic and phonological pressures, and in all three the data show that the quotative is most monophthongal. This is highly suggestive of a contextual explanation for the monopthongisation of like in this function.
5 Discussion
5.1 Summary
The discussion focuses on the monopthongisation of quotative like. It attempts to provide an explanation for this phenomenon and illuminate its relevance. We argue that it is rather premature to make claims about the cognitive representation of functions of like based on our evidence and that the more monophthongal nature of quotative like is due to the context in which it occurs. Before we develop a clearer notion of the contextual position in which be like has developed in section 5.3, we summarise and explain the relevance of the findings we've made for our contextual factors and our frequency factors in section 5.1, and we discuss the potential relevance of our findings to theoretical arguments regarding the evolution of be like in section 5.2.
Our results reveal that like function is an impressive predictor of monophthong-isation, yet never on its own: contextual factors appear to matter as well. Our data suggest that quotative be like is most frequently followed by a BS1 break (see table 5); in other words, it is not followed by a strong disjuncture and occurs within, rather than at the edge of, an intonation phrase boundary: quotative and quote tend to be part of the same intonation phrase. The other three like types also occur frequently in this prosodic context; however, in contrast to be like, they also occur quite frequently in other prosodic contexts (see table 5). Those in which be like occurs are less variable than those of the other three like functions. While the grammatical function of like is similarly restricted to be like with regard to its prosodic context, in contrast to be like, it also occurs in a BS0 context. Thus, prosody does seem to play an important role in the contextual embedding of different functions of like.
What makes these findings relevant is that the monopthongisation of /aɪ/ is constrained in a similar manner to the prosodic embedding of be like: quotative like, more often than other like functions, occurs in a favourable environment for monophthongisation. The most diphthongal tokens of like occur in a BS0 environment, which is a context in which be like hardly ever occurs. In London, like tokens in BS1, 2 and 3 contexts are more likely to be more monophthongal. They represent favourable environments for monophthongisation. Thus, like, here, appears in a slot where reduction is likely to occur. This makes quotative like tokens least likely to be diphthongal, as they seldom occur in a BS0 context.
In Edinburgh, the situation is similar, yet more complex: the most diphthongal tokens of like also occur in a BS0 environment, which is a context in which be like hardly ever surfaces. Here, like tokens in BS3 contexts are more likely to be monophthongal, the second most frequent context for be like to occur. This situation is rendered more complex by the fact that BS1 and BS2 contexts do not differ significantly from BS0 contexts, BS3 contexts and each other: they lie in between these two extremes. Nonetheless, quotative like tokens are least likely to be diphthongal, as they seldom occur in a BS0 context; moreover, most of these like tokens occur in an environment in which monophthongisation can certainly happen. Thus, in both locations quotative like appears in a slot where reduction is likely to occur. The fact that in Edinburgh the situation is more complicated and that in both locations BS1, BS2 and BS3 do not differ from each other at a significant level, suggests that BS is merely a reflection of a more important underlying process, and that our study may not have caught fully the factors that constrain monophthongisation. Something else seems to be going on. We will return to this below.
While prosody does play a role, bigram frequency does not seem to be a contextual factor that influences the monophthongisation of like, as we had anticipated. Our models of variable importance tell us that the preceding word does matter (in the prediction of like, not a specific function of it); however, our analysis of monophthongisation, where function emerges as a significant effect, indicates that bigram frequency by itself does not interact with like function. For example, while was like is a frequent bigram that predicts the quotative, other highly frequent bigrams predict other functions; for example, I like is grammatical, and like tends to be a discourse marker or discourse particle.
5.2 Development of be like
When we consider the proposals regarding the process through which quotative be like has developed – grammaticalisation, lexicalisation and constructionalisation – our conclusions have to remain rather modest. Our findings are only tangentially relevant to this debate: they confirm that one of the like functions, quotative be like, has been placed in a position to split off in form from the others. In section 5.3, we offer an explanation of what exactly this position is. Since our data are not of a historical nature, we have little to contribute to the discussion of how like got into this position because we would expect reduction in all three processes implicated.
Grammaticalisation normally includes (a) pragmatic shift, (b) desemanticisation, (c) decategorialisation and (d) phonetic reduction (e.g. Bybee Reference Bybee, Joseph and Janda2003). This makes sense, as grammaticalised items tend to be used more frequently and hence become more predictable, thereby resulting in the loss of phonetic substance (Heine Reference Heine, Joseph and Janda2003: 583). Highly grammatical elements, such as auxiliaries and prepositions, are often subject to reduction. Grammatical elements tend to be more reduced than lexical ones (e.g. nouns).
It is clear from our data that reduction is associated more strongly with the quotative than it is with the other like functions. However, the findings of our study do not mean that be like has been grammaticalised because both grammaticalisation and lexicalisation may involve reduction (Lehman Reference Lehmann, Wischer and Diewald2002: 1). Lexicalisation is in fact very strongly associated with reduction (Brinton & Traugott Reference Brinton and Traugott2005). An analysis of be like as part of a construction too would lead us to expect reduction because reporting clause constructions generally tend not to be particularly prominent prosodically (e.g. Halliday & Matthiessen Reference Halliday and Matthiessen2004: 446). We believe prosodic constraints are key to understanding why it is that like in the quotative is reduced more than the other functions of like. The remainder of our discussion focuses on this issue of reduction rather than the evolution of be like, and we develop a clearer notion of what precisely it is that reduces like in the be like quotative more than the like serving other functions.
5.3 Like reduction
We would like to propose that our findings for monopthongisation and break type are due to one unifying development. The evolution of be like, by whatever process, has brought quotative like under the influence of rhythmic and reduction patterns of reporting clauses which are fundamentally an outcome of their relation to the reported clause.
Halliday & Matthiessen (Reference Halliday and Matthiessen2004: 446) argue that in spoken English, the reporting clause is normally less prominent than the reported clause. It is proclitic, i.e. – in Halliday's terms – non-salient and pre-rhythmic, if it comes first. There is a very good reason for this: the reporting clause has only one function; namely, to indicate that the reported clause is projected.
Clauses such as he said, I was like and she's like have one thing in common: they usually consist of precisely one foot (or rhythm group). In English, each foot consists of one or more syllables. Some syllables carry stress, while others do not. These are often referred to as strong/salient and weak respectively (Halliday & Matthiessen Reference Halliday and Matthiessen2004: 12). In English natural speech there is a tendency for strong syllables to occur in equal intervals, and stress may shift in order to maintain an even alternation of strong and weak beats. In verbs, the final syllable is said to carry main stress if it is heavy, which it is in be like. However, sentential stress tends to shift as the first word of the reported clause is likely to be stressed. Thus, like is often weakened because it occurs right before the beginning of the next foot, the beginning of the reported clause.Footnote 14
Indeed, our own data show this. Quotative like tends not to be accented. While stress and accent are not the same thing, the fact that quotative like is unlikely to receive an accent is certainly also due to the argument presented above: its position in the reporting clause. Only 13 per cent of like tokens in quotatives are accented, in contrast to 44 per cent of discourse marker like, 17 per cent of discourse particle like and 37 per cent of grammatical like functions. Nonetheless, our statistical analysis does not select accentedness as a significant predictor for monophthongisation but considers like function and break type better predictors for our monophthongisation models. This is an indication that in the quotative context, like wound up in a small syntactic unit in which reduction is highly likely as several contextual factors conspire to reduce like. The most typical context for quotative be like is an unaccented like within a proclitic reporting construction followed by a short break and a prominent reported clause.
Thus, it is very much the context in which like occurs that determines its form. Wichmann (Reference Wichmann, Narrog and Heine2011) has made similar proposals; specifically, regarding grammaticalisation, namely that many descriptions of reduction and elision that occur in the process of grammaticalisation are due to the loss of prosodic prominence, which ultimately leads to segmental changes. While this is an interesting argument, it does seem to contradict the observation that discourse markers often receive tonic stress and are followed by a pause (Schiffrin Reference Schiffrin1987, cited in Aijmer Reference Aijmer2002: 32) rather than being reduced. But Halliday & Hasan (Reference Halliday and Hasan1976: 271) observe two patterns: ‘there is a general tendency in spoken English for conjunctive elements as a whole to be, phonologically, either tonic (maximally prominent) or reduced (minimally prominent) rather than anything in between’. This is in line with our findings: the evolution of like has led to some functions of like being more or less accented than others, which sheds light on reduction processes in language change. Our data suggest that language change that involves syntactic reanalysis and increased clausal integration,Footnote 15 changes in position and large loss of structural independence, as is the case for be like, is likely to entail prosodic modifications and also reduction.
This reduction-friendly context, in which be like surfaces, trumps any frequency effects that may occur. For example, although the discourse particle is the most frequent function of like, it is not the most reduced function (see literature review). Nor is there an effect for speakers who are more likely to use be like to produce more reduced like tokens in this construction. Nonetheless, in our study, it is only the vowel that seems to be sensitive to the function of like. Why we were unable to document similar like function-specific effects for /l/ and /k/ is an interesting question. It is possible that such effects are too variable to rise above statistical significance. In addition, social groupings that we were unable to investigate here may very well be relevant at a very local level, similar to the communities of practice documented in Drager (Reference Drager2011). After all, Drager's ethnographic study resulted in data that are contextually more variable than ours and at times extremely informal. This may explain some of the differences between our findings and Drager's, and represents an important area of future research.
Future research may also involve different measures of predictability. As one of the reviewers has pointed out, discourse context may be an important factor by which the be like quotative is predictable. The quotative is associated particularly with direct reporting in narratives. This activity type as well as its lexical embedding (be and a quotation) make this particular like more predictable. This is very different from the discourse marker and the discourse particle, which occur more freely. Their occurrence is much harder to predict; consequently, as the reviewer points out, auditory cues matter more for these than for quotative be like.
It also remains to be investigated to what extent the ‘design’ of the quotative – be that say, go or be like – prepares the context for a particular person's voice whose speech, thoughts or actions are to be reported and the way it is characterised and stylised. Klewitz & Couper-Kuhlen (Reference Klewitz and Couper-Kuhlen1999: 477–8) argue that ‘foreshadowing’ a voice lexically, prosodically or paralinguistically is not uncommon. Moreover, it is not stretching a point to assume that the choice and phonetic design of the quotative itself may contribute to this stylisation. Again, an in-depth knowledge of the community in question is key.
Finally, the precise prosodic characteristics with which the be like quotative occurs remain to be determined in much more detail. It is most likely a bundle of prosodic characteristics that marks reported speech and may involve not only breaks but also pitch, volume and rhythm (see Klewitz & Couper-Kuhlen Reference Klewitz and Couper-Kuhlen1999). This may be best explored by including in the investigation the reporting as well as the reported passage.
6 Conclusion
We have shown in this study that different functions of like may vary in their phonetic realisation of the vocalic element of like. Thus, this patterning is not at all limited to English in New Zealand. At a more theoretical level, this is evidence that different lemmas with the same word form (or to use alternative terminology: different lexemes with the same stem) can vary in their phonetic realisation. Drager (Reference Drager2011) reaches a similar conclusion in her study, and argues that her results challenge theoretical models that assume a single phonetic representation for polysemous and homophonous words that share a word form, as these models would predict the same realisation of all functions of like. However, we diverge in our conclusion. We do not believe that the evidence presented provides much additional support to production models with an acoustically rich lemma level, or one that is indexed directly to acoustic information. We do not dismiss the possibility that the lemmas under consideration may be indexed to separate phonological representations. Our own data do not provide clear evidence to suggest that items are stored in the mind in such a way that functional distinctions are maintained.
Jurafsky et al. (Reference Jurafsky, Bell, Girand, Gussenhoven and Warner2002) argue that differences in the phonetic realisation of lemmas that have the same word form are reduced or disappear once contextual predictability is considered. This certainly seems to be the case for the functions of like as well as /l/ and /k/, but even vowel reduction is significantly dependent not only on function, but also on contextual factors. Thus, phonetic reduction seems to be due to syntactic and prosodic constraints. We have found evidence that probability effects matter at the word level of like, but rarely ever at the functional level.
These findings make claims that like is stored in the mind in such a way that functional distinctions are maintained much less convincing. But in spite of like reduction being context rather than function driven, the fact that some functions of like occur more frequently in environments in which they are subject to reduction is interesting nonetheless. Previous research has shown that diffusion of a sound change can be affected by the relative frequency of the immediate linguistic context. If certain words occur more often in a particular environment that favours change, these words may change more quickly (Bybee Reference Bybee2002). Thus, if one of the like functions occurs consistently in a particular environment that renders like tokens more amenable to reduction, over time, language change may lead to a continued divergence in form. Quotative like may become increasingly independent of the current prosodic and syntactic constraints. Different descriptions of phonological representation may then be useful. However, for the moment, the form of like can be predicted from context, and any claims that involve activation of different functions of like without a phonological buffer strike us as premature.
Appendix

Figure A1. Edinburgh discourse marker vs discourse particle

Figure A2. Edinburgh discourse marker vs grammatical

Figure A3. Edinburgh discourse marker vs quotative

Figure A4. Edinburgh discourse particle vs grammatical

Figure A5. Edinburgh discourse particle vs quotative

Figure A6. Edinburgh grammatical vs quotative

Figure A7. London discourse marker vs discourse particle

Figure A8. London discourse marker vs grammatical

Figure A9. London discourse marker vs quotative

Figure A10. London discourse particle vs grammatical

Figure A11. London discourse particle vs quotative

Figure A12. London grammatical vs quotative





























