1 Introduction
Vowel nasalisation in American English is a textbook example of an allophonic phonological rule (Davenport & Hannahs Reference Davenport and Hannahs1998; Kager Reference Kager1999; Rogers Reference Rogers2000; Ladefoged Reference Ladefoged2001; McMahon Reference McMahon2002; Hayes Reference Hayes2009; Ogden Reference Ogden2009; Zsiga Reference Zsiga2013).Footnote 2 Vowels don't contrast in nasality in English and nasal vowels occur only before tautosyllabic nasal consonants, as illustrated in the examples (1a–d) below. The rule also interacts opaquely with nasal deletion, resulting in nasalised vowels without a following nasal consonant, as in (1e) (Selkirk Reference Selkirk1972; Kahn Reference Kahn1976).
(1)

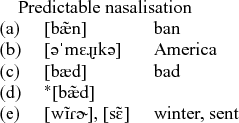
However, it has been claimed that English vowels are nasalised much less than nasalised vowels in comparable languages that have a nasal contrast among vowels and a neutralising process of vowel nasalisation before or after nasal consonants (Cohn Reference Cohn1993). In addition, partial nasalisation of the vowels adjacent to nasal consonants seems to be a universal coarticulatory effect (Maddieson Reference Madison1984; Beddor Reference Beddor, Huffman and Krakow1993). Thus, there is reason to suspect that this textbook example of an allophonic rule should be removed from phonology textbooks and only used in phonetics textbooks.
The first question to be dealt with in this article is thus whether it can be established if this pattern in English is a language-specific phonological process or phonetic universal coarticulation due to some general physiological characteristics of sound production and motor control (e.g. the mechanics of phasing of articulatory gestures) or a language-specific phonetic effect. To shed light on this issue I will review a range of studies on the production and perception of nasalised vowels in English, and contextually nasalised as well as contrastively nasal vowels in a few other languages in comparison. The result is that most studies produce evidence for the phonological analysis and a good number produce non-decisive results.
The perceptual side relates to an orthogonal issue, the mental representation of these nasalised vowels. If this is an allophonic phonological rule and nasalisation is completely predictable from context, classic generative phonological analysis would leave vowel nasality out of lexical representations. From this generative perspective, there would be even more reason to consider nasalisation absent from underlying phonological representations if we are dealing with a purely phonetic effect. However, this is only one way of doing phonological analysis. Competing models predict specification of this type of predictable nasality in lexical representations. In Optimality Theory, Lexicon Optimisation (Prince & Smolensky [1993] Reference Prince and Smolensky2004) is said to generate underlying representations with full specification also of (non-alternating) predictable feature values (Prince & Smolensky [1993] Reference Prince and Smolensky2004; Inkelas Reference Inkelas1994; Kager Reference Kager1999; Burzio Reference Burzio, Durand and Laks1996, Reference Burzio and Boucher2002; Tesar et al. Reference Tesar, Alderete, Horwood, Nishitani, Merchant, Prince, Garding and Tsujimura2003; Beckman & Ringen Reference Beckman and Ringen2004; Merchant & Tesar Reference Merchant and Tesar2008). However, Krämer (Reference Krämer2012) argues for a model of Lexicon Optimisation that generates underlying representations resembling those advocated in Radical Underspecification (Archangeli Reference Archangeli1988), and Tesar (Reference Tesar2014) argues for a model of learning representations that generates representations as assumed in Contrastive Underspecification (Steriade Reference Steriade, Bosch, Need and Schiller1987, Reference Steriade and Goldsmith1995). See as well Hyman (Reference Hyman2015) for an argumentation for abstract underlying forms.
Furthermore, in usage-based models of phonology, abstract phonological representations of phonological items are by and large rejected. In Exemplar Theory (Bybee Reference Bybee2001; Pierrehumbert Reference Pierrehumbert, Bybee and Hopper2001, Reference Pierrehumbert, Gussenhoven and Warner2002) one would expect that a language user stores all phonetic detail of every rendition of every lexical item the respective user encounters either in others’ productions or his/her own. Thus, even non-phonological nasalisation would be present in mental representations (the exemplars or exemplar clouds).
The answer to the first question, i.e. whether English nasalisation is phonological or phonetic, thus doesn't automatically provide the answer to the second question, i.e. whether surface nasal vowels are stored as such or in an impoverished form in the mental lexicon. Both questions in tandem, repeated below as question (2a) and question (2b), provide a testing ground for the three competing views sketched above and summarised in (3).
(2) Central questions
(a) Is English vowel nasalisation phonological or phonetic?
(b) Is nasalisation present in mental representations of words/morphemes?
(3) Competing points of view
(a)
i. Phonetic
ii. Phonological
(b)
i. No. Lexical representations are abstract and redundancy-free.
ii. Yes. Lexical representations are abstract and maximally specific.
iii. Yes. Lexical representations are phonetic and very detailed.
Fortunately, there are quite a number of phonetic and psycho- as well as neuro-linguistic studies that examine vowel nasalisation in English with a range of different methods (e.g. Lahiri & Marslen-Wilson Reference Lahiri and Marslen-Wilson1991; Cohn Reference Cohn1993; Krakow Reference Krakow, Huffman and Krakow1993; Solé Reference Solé1992, Reference Solé1995; Ohala & Ohala Reference Ohala, Ohala, Connell and Arvaniti1995; Chen Reference Chen1997; Fowler & Brown Reference Fowler and Brown2000; Flagg et al. Reference Flagg, Cardy and Roberts2006; Chen et al. Reference Chen, Slifka and Stevens2007; Byrd et al. Reference Byrd, Tobin, Bresch and Narayanan2009; McDonough et al. Reference McDonough, Lenhert-LeHouiller and Bardham2009; Beddor et al. Reference Beddor, McGowan, Boland, Coetzee and Brasher2013; Proctor et al. Reference Proctor, Goldstein, Lammert, Byrd, Toutios and Narayanan2013). This article looks at the results of these studies to synthesise them into an answer to the above questions.
The review of studies on nasalisation to be undertaken in this article reveals the following. Vowel nasalisation in English is a phonological process. Speakers of English can distinguish nasal and oral vowels out of context. The evidence considered here relating to the question of mental storage is less clear. However, the results are more easily compatible with an underspecification account than an exemplar-theoretic approach.
The article is structured as follows. Section 2 reviews a range of phonetic and psycholinguistic studies on the production of these vowels. Section 3 concentrates on perception studies. (Note that the aim was not a review of all studies on English nasalised vowels.) Section 4 discusses the results and concludes.
2 Production
Production can be investigated from two sides, i.e. the acoustic properties of vowels and articulatory data. Especially where the nasality of vowels is concerned, on the acoustic side, we could, for example, look at the spectral properties of vowels and compare expected nasal with expected oral vowels of constant height, backness and lip rounding and search for differences in formant structures. It is generally acknowledged that nasality has an effect on the first formant (Fant Reference Fant1960; Hawkins & Stevens Reference Hawkins and Stevens1985), reducing its amplitude significantly (House & Stevens Reference House and Stevens1956; Stevens et al. Reference Stevens, Andrade and Céu Viana1988). Furthermore, nasality is visible in the spectrogram by additional low amplitude formants below and above F1. One could also directly measure nasal airflow with a nasometer. However, one could argue that nasal airflow is not compulsory if the same acoustic effect can be achieved by different means, thus, on the articulatory side, it is interesting to track velum lowering, which might have an acoustic nasalisation effect even if it doesn't result in significant nasal airflow.
In addition, we will have to compare both vowel onsets and vowel offsets in both nasal and oral environments. Furthermore, English vowel nasalisation is said to be constrained by the prosodic environment. Thus syllabification of the vowel and adjacent nasal as tauto- or hetero-syllabic have to be taken into consideration, as well as other parameters, e.g. degree of stress/prominence on the vowel.
2.1 Nasal airflow
One of the few papers that explicitly discuss whether English vowel nasalisation should be considered a phonetic or a phonological process is Cohn's (Reference Cohn1993) study. She measures the degree of nasal airflow in NV and VN, and compares the English data with French and Sundanese. French has contrastively nasal vowels, unlike English, and Sundanese has a phonological process of vowel nasalisation, that it might have in common with English.
Cohn bases her division between phonetics and phonology on Keating's (Reference Keating, Kingston and Beckman1990) reasoning that phonological processes should affect the whole segment, while phonetic processes can affect only parts of it. Furthermore, she invokes the criterion of gradience. Phonetic processes are gradient, while phonology is categorical.
Cohn notes that the differentiation between phonetic implementation rules and postlexical phonological rules might be difficult due to their similar nature. Phonetic implementation rules, however, apply across the board, whenever the phonetic context is given, and don't stop at syllable or word boundaries or other abstract ‘obstacles’.
The two additional languages in Cohn's comparison have the following properties with regard to nasality. In French, nasality is contrastive on vowels. In Sundanese, progressive nasal assimilation nasalises all vowels following a nasal consonant in the word. The process is stopped by other consonants. An exception to the latter is found in infixation. When an infix with an oral consonant is placed between a nasal and the following vowel(s) in the morpheme, nasalisation propagates to these vowels nevertheless (e.g. /ɲiar/– |ɲĩãr| ‘seek’, |ɲãlĩãr| ‘seek.plural’; Cohn Reference Cohn1993: 55).Footnote 3 This overapplication of the process excludes interpretation as a phonetic spill-over effect.
We thus have two types of nasal vowels to compare with the English nasal vowels, contrastively nasal ones as well as those phonologically nasalised by their context. For French she shows that nasal vowels are nasal throughout and there is an abrupt transition in nasal airflow. Unlike in English, prenasal vowels are not nasalised at all. In Sundanese nasalised vowels, nasal airflow steadily decreases with increasing distance from the nasal trigger.
The English nasal-adjacent vowels show a similar slow transition. As one can see in figures 1 and 2, they are more or less the same for pre- and postnasal vowels.

Figure 1. Nasal airflow charts for French and Sundanese (Cohn Reference Cohn1993)

Figure 2. Nasal airflow charts for English pre- and postnasal vowels (Cohn Reference Cohn1993)
Cohn analyses her data with a target-interpolation model. Phonological specification as either [–nasal] or [+nasal] causes a quick change in nasal airflow between contrarily specified adjacent segments, while nasal airflow is allowed to increase or decrease slowly through segments that are underspecified for nasality. Thus we see the abrupt change from the oral consonant to the nasal vowel and back in French, while English vowels, underspecified for nasality, allow nasal airflow to increase or decrease and trail off at the far end of the nasal. The Sundanese vowels are assumed to be specified for [+nasal] via feature spreading. The glide in figure 1(c) is underspecified though, since the rule only targets vowels.
The important result here is that Cohn concludes that English nasalised vowels are not phonologically [+nasal]. The data show almost equal amounts of nasalisation in nasal-adjacent vowels. The English phonological rule of nasalisation, however, is usually assumed to be regressive only. A further argument against a phonological analysis of English vowel nasalisation is the relative weakness of nasal airflow in these vowels and that it is incomplete. While nasal airflow decreases in Sundanese vowels as well, it stays at a higher level and lasts throughout the vowel's duration. Cohn also provides nasal airflow charts for English words in which a postvocalic nasal has been deleted, or almost deleted. Here the vowels show more stable nasal airflow, like those in French. In these cases she assumes [+nasal] to relink to the vowel phonologically when the nasal's root node is deleted.
2.2 Nasography
Solé (Reference Solé1992, Reference Solé1995) compares American English and European Spanish vowel nasalisation and draws the opposite conclusion to Cohn. To determine the extent of nasalisation she uses a nasograph to monitor velopharyngeal port opening. In addition to comparing two languages in which nasalisation is thought to have a potentially different status as definitely phonetic in Spanish and maybe phonological in English, she compares the realisation of nasalisation in different speech rates. Since phonetic nasalisation is a transition effect, its temporal extension should be independent of the speech rate and corresponding duration of vowel and following nasal. Phonological nasalisation should show a duration that is relatively stable in relation to the duration of the vowel it affects, i.e. it should be longer in slow speech and shorter in fast speech, but covering approximately the same proportion of the preceding vowel.
Solé compares three speakers from each language at four different speech rates, from very slow and overarticulated, as produced for a deaf lip reader, to as fast as the subject manages. The nasograph measures the amount of light that falls into the cavity under velum lowering. Solé points out that due to physiological differences among speakers the degree of velum lowering is difficult to compare across subjects; however, the onset and temporal extent of velum lowering can be compared, as well as the point when velum lowering reaches its maximum for each subject. Stimuli are specifically constructed nonce words containing a sequence of two vowels with stress on the second and either a following coronal oral or nasal stop. Vowels vary in height in the stimuli since vowel nasalisation is known to have different effects on vowels of different heights.
Solé's results are very clear-cut: while nasalisation expands over a large portion of the English vowels and varies in correlation with speech rate, the Spanish vowels show very little nasalisation as well as very little variation in the different speech rates. The timing of velum lowering is connected to the overall length of the vowel in her English data and to the onset of the closure for the nasal consonant in the Spanish data, accordingly varying with speech rate in the former and remaining largely constant in the latter language. For English subjects, velum lowering begins with the onset of the vowel and reaches its maximum about halfway through the vowel. In Spanish, most of the prenasal vowel is oral and velum lowering starts very late and reaches its maximum only at the beginning of the nasal consonant. She thus concludes that vowel nasalisation in English is the result of articulation targeting a vowel that is specified as [+nasal] by the phonology, while the articulatory target in Spanish is an oral vowel.
The data stand in extreme contrast to the airflow measurements in Cohn's study, suggesting that nasal airflow is not the only physical effect that creates the impression of nasality of vowels. One might as well take the opposite stance and argue that velar port opening itself is not the crucial indicator of nasality, since that doesn't necessarily already produce a perceptible acoustic effect. However, the crucial issue is the comparison with another language that either uses nasality on vowels or doesn't. Thus, at this point we have two studies, one comparing English nasalised vowels with the nasal vowels in languages that are known to use nasality on vowels and one comparing English with a language that is not suspected to use nasality on vowels. At first sight the results indicate that English vowel nasalisation is neither like that of the contrastively nasalised vowels of French nor like the progressively nasalised vowels of Sundanese and nor like the un-nasalised prenasal vowels of Spanish. Discussing Cohn's results, Solé (Reference Solé1995: 4) points out that ‘there is no reason to assume that French contrastively nasal vowels (specified as [+nasal] in the lexicon) should have the same phonetic output as phonologically but noncontrastively nasalised vowels (i.e. specified as [+nasal] in the phonological component).’Footnote 4 One might add that one doesn't necessarily expect that either from nasal vowels that received their specification of [+nasal] through a regressive spreading rule in a language without contrastive nasal vowels (i.e. English) and nasal vowels that received their [+nasal] specification through a progressive iterative spreading rule in a language with contrastively nasal vowels (i.e. Sundanese).
For both studies, i.e. Cohn's and Solé’s, one can criticise the small group size. Observations of phonetic details from two or three speakers can hardly be considered an appropriate sample size that allows us to generalise over the whole population. They might have been unlucky and recruited subjects who do not have the process as part of their phonology, and just display an extreme case of gestural overlap. American English, with its millions of speakers, is subject to regional and social variation, like any other language. It could also be speculated that the intrusive measuring technologies used in these two studies had an effect on the data produced in each. Luckily, more production studies and language comparisons with different technologies are available.
2.3 Velum tracing
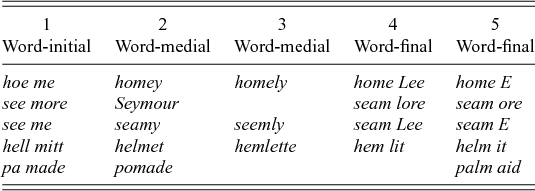
To figure out whether syllable structure and stress have an influence on vowel nasalisation, Krakow (Reference Krakow1989, Reference Krakow, Huffman and Krakow1993) carried out a series of experiments with the Velotrace (Horiguchi & Bell-Berti Reference Horiguchi and Bell-Berti1987), a device that monitors velum movement during speech production, and Selspot for lip point tracking. Her stimuli for syllable structure are given in table 1. These stimuli were produced twelve times each by two test subjects. In the data in the first and second column one can expect the vowel and the nasal to be heterosyllabic, in the third and fourth column they are tautosyllabic, while in the fifth they might be either. In addition, with these stimuli, Krakow also tests for the influence of word boundaries and stress. If set 1 shows different velum movement alignment than set 2 the word boundary plays a role. While if in set 2 homey behaves differently from pomade we see an influence of stress, since homey is stressed on the first and pomade on the second syllable.
Table 1. Krakow's stimuli for experiment on syllables
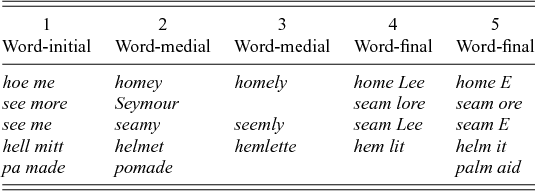
Krakow records the temporal alignment of lip closure (therefore only labial nasals) and velum lowering. If velum lowering initiates before lip closure is achieved, this indicates nasalisation of the preceding vowel. In particular, in the third and fifth set Krakow detects significant overlap of velum lowering with the preceding vowel. Thus, nasalisation happens if the nasal is in the same syllable as the preceding vowel, but not if they are divided by a syllable boundary. Furthermore, she found a difference between homey- and pomade-type words. The former show velum lowering anticipated in the vowel, while the latter do not. One could speculate that the nasal is ambisyllabic in words such as homey, while in pomade it isn't. A reason could be that stressed syllables are required to be heavy in English (e.g. Giegerich Reference Giegerich1992). However, one would have thought that a long vowel/diphthong gives sufficient weight to a syllable. Such analytic speculations apart, we see that abstract prosodic structure (syllable structure and stress) determines whether or not nasalisation applies in an otherwise phonetically identical environment.
Krakow carried out a separate experiment to determine the influence of stress, and of vowel height. Using the Velotrace again, she made subjects produce nonce words that had nasal plus the high vowel i, nasal plus the low vowel a, the high vowel plus nasal and the low vowel plus nasal and all in stressed and unstressed condition. Her data show that stressed vowels show more nasalisation. Furthermore, there is a dramatic difference in velum lowering for prenasal and postnasal vowels. In postnasal vowels the velum is already at a relatively high place at vowel onset and moves further up towards the midpoint of the vowel, while for prenasal vowels, velum height starts to decline dramatically at vowel onset already, and arrives at a lower position at the midpoint of the vowel than it is at the onset of the postnasal vowels.
Here we see a clear difference between nasalisation of postnasal vowels and of prenasal vowels.
In summary, Krakow provides articulatory evidence for a characterisation of English vowel nasalisation as happening to vowels preceding tautosyllabic nasals.
2.4 Spectral analysis
Chen (Reference Chen1997) provides a spectrum-based nasality measure, by combining three nasality-relevant amplitudinal values and comparing this coefficient in supposedly nasal(ised) and oral vowels. She also compares English and French nasal(ised) and oral vowels. Since nasality is present in the acoustic signal by a lowering of the amplitude of the first formant (A1) as well as higher amplitude peaks above and below this formantFootnote 5 (P1 and P0, respectively), to get a stronger indicator, Chen creates two values by subtracting P0 from A1 and P1 from A1 separately.
The A1-P1 value is expected to be up to 18dB lower in (nonhigh) nasalised vowels than in oral ones, while A1-P0 is expected to fall by 8–11dB in nasal vowels.
Chen recorded eight native speakers of English and could thus obtain more reliable data than the studies discussed above which used only two subjects.
The measurements by and large showed highly significant differences between oral and nasal vowels in English speakers. For high vowels the results were a bit weaker than for nonhigh vowels. Comparing English and French values for nasal and oral vowels, Chen finds a slight difference between English and French oral and nasal vowels respectively: the mean A1-P1 value was 3.5 and 3.8 dB higher for oral and nasal vowels respectively in English than in French. While nasality is contrastive in French, it does not have this function in English. One could thus have assumed nasalisation to be substantially weaker in English, which is not the case. This would have been the case if the value for oral vowels had differed less and that for nasal vowels more. The slightly weaker nasalisation effect might be attributable to the presence of high vowels in the English data and their absence in the French data. Chen herself speculates that the differences emerge from different ways of measuring. First, while, for English, vowels in oral versus nasal contexts were used (e.g. bed vs men), the French data consisted only of nasal vowels which were measured at three different points and then the most and the least nasalised part of the vowel was calculated. Thus, there are no data for truly oral vowels for French in the comparison. One can thus conclude that Chen found a significant difference between oral and nasalised vowels in English but no significant difference between nasal vowels in English and French, contradicting Cohn's (Reference Cohn1993) results (which were based on two subjects).
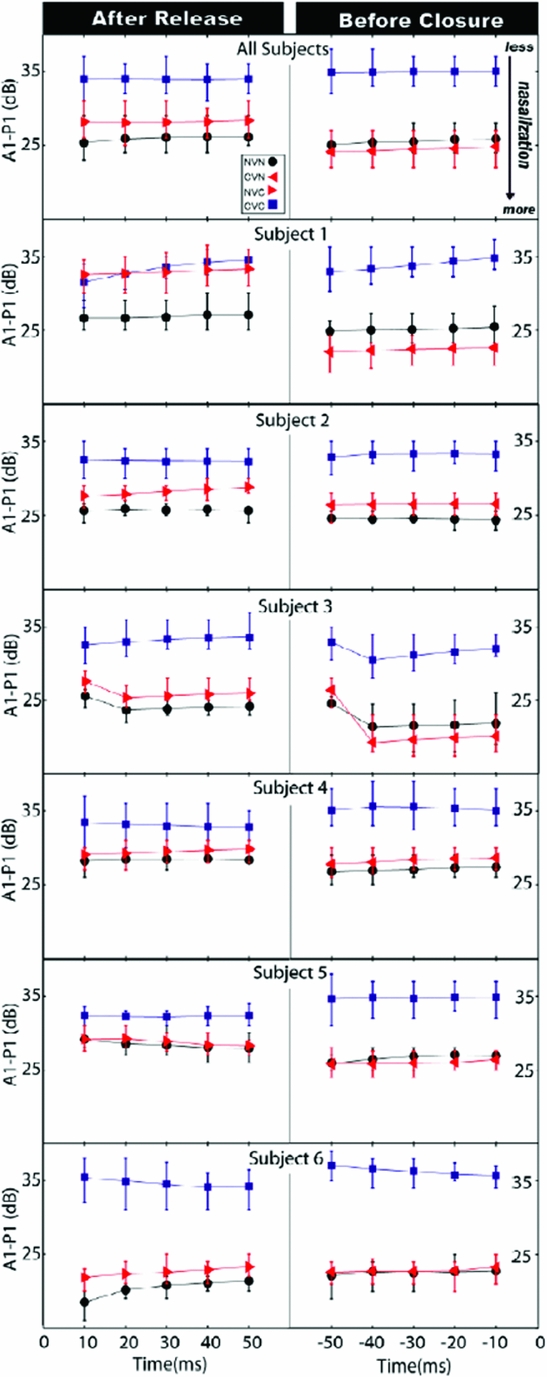
It is noteworthy that the English nasalised vowels were followed as well as preceded by a nasal, while the environment we are looking for is vowels followed by a nasal. However, given the claim in the literature that there is always misalignment of velum lowering, it is crucial to find out if nasalisation is more severe in prenasal vowels than in postnasal vowels. Chen et al. (Reference Chen, Slifka and Stevens2007) look at the three constellations in question, postnasal, prenasal and internasal vowels. However, they only look at /i/. The result, in a nutshell, is that vowels may be nasalised in both pre- and postnasal position, but that internasal position doesn't lead to more nasalisation of the affected vowel. They extracted 900 tokens of the high vowel /i/ from a corpus of words read by six males, which covered the environments CVN, NVC, NVN and the control condition CVC (e.g. team, neat, mean, peat) and automatically compiled values of the spectral pole at 1kHz (i.e. P1 in the previous study) as an indicator of nasality to calculate the A1-P1 value. They found that both NVN and CVN significantly differ from CVC. NVC also differs from CVC, though the effect seems to be a bit weaker. They report data on the initial 50ms and final 50ms. However, the data for the initial 50ms for CVN as well as the data for the final 50ms for NVC words are missing in the paper. This omission is unfortunate since only the missing values would have enabled us to determine if there is a difference between NVC and CVN words. If one of the two nasalisation patterns was phonological and the other phonetic we would have expected, for example, that the phonological nasalisation would extend further into the vowel than the phonetic coarticulation. The result that there is velum lowering from N into the following V, as there is velum lowering during the offset of V before N, is not particularly surprising. Thus, while this study seems to corroborate Cohn's conclusions, it doesn't provide any evidence.
However, one can look at the only figure they provide and extract some speculative results. Their speaker 1 (of six) doesn't show nasalisation in the initial portion of V in the NVC context, but he does show strong nasalisation in the NVN condition. Since the CVN data for this context are not provided, we can only extrapolate that the nasalisation in the initial part of V in NVN is caused by the postvocalic N, since prevocalic N doesn't cause velum lowering in the following V. The initial V portion of NVC shows weaker nasalisation (a higher A1-P1 value) in all but one participant. Furthermore, the A1-P1 values of the final 50ms of the whole group are lower in all N-adjacent data (i.e. CVN and NVN) than those of the initial 50ms in NVX words. Recall that a lower value indicates a lower velum, i.e. more nasalisation. Thus, there seems to be a qualitative difference in post-N nasalisation and pre-N nasalisation, with pre-N nasalisation showing more extreme velum lowering. Subject 1’s NVN data also suggest a longer duration of velum lowering in the V in pre-N contexts. See figure 3.
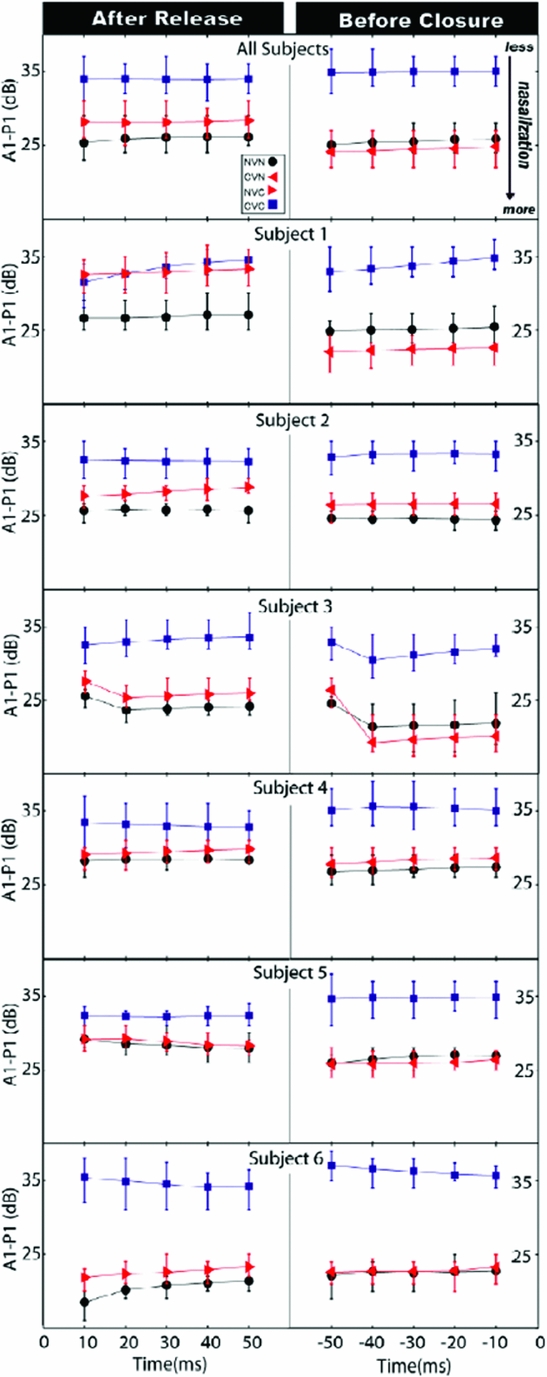
Figure 3. The mean and the lower and upper quartiles of A1-P1 over the initial and final 50ms of the vowel. Time 0 denotes the closure/release of the nasal consonant; negative time indices indicate time before the nasal consonant closure, and positive time indices indicate time after the consonant release (Chen et al. Reference Chen, Slifka and Stevens2007)
Beddor (Reference Beddor, Trouvain and Barry2007) compares vowel nasalisation in English, Ikalanga and Thai, by checking 10ms intervals of vowels in FFT spectra, looking for a low-frequency nasal formant and visible broadening of F1 as well as lowering of F1 amplitude. Even though Beddor focuses on the influence of the following non-nasal consonant on the extent of vowel nasalisation in VNC sequences, we can use her data to set English vowel nasalisation in a cross-linguistic context. While the extent of vowel nasalisation varies in English depending on the voicing and manner of the following oral consonant (more vowel nasalisation before voiceless than before voiced stop), Ikalanga doesn't show such a connection. Her data also show that the onset of vowel nasalisation is much earlier, or the portion of the vowel that is nasalised much bigger, in English than in Ikalanga. The same result becomes especially clear in her comparison of English with Thai, in which she takes vowel length/tenseness into account. While the English tense vowels are much shorter than the Thai vowels, there is still a marked difference in length in the English vowels. Both types of English vowels are nasalised in over half of their total duration, whereas the Thai vowels are much less nasalised. The short vowel is roughly 50 per cent nasalised, while in the long vowels nasalisation starts long after half of the vowel's total duration. In the English vowels, nasalisation starts approximately at the same absolute time into the vowel, at about 40ms, as shown in figure 4. While one could hypothesise that the differences in extent of vowel nasalisation are due to the relative length of shortening, i.e. short vowels are followed by longer nasal consonants than long vowels, and the total duration of nasalisation stays constant across contexts, as Beddor does, this is clearly not the case. However, as Beddor puts it, ‘there is a trade-off’, i.e. the shorter nasal consonants are preceded by a longer stretch of nasalised vowel in both languages.

Figure 4. Nasalisation in English and Thai V(:)N sequences (Beddor Reference Beddor, Trouvain and Barry2007: fig. 5)
Even though it wasn't on her agenda, Beddor shows that contextual vowel nasalisation is more extensive in American English than it is in both Ikalanga and Thai. Put together with Cohn's observation, this puts English vowel nasalisation somewhere in between full-scale nasalisation, as known from French and Sundanese, and low-level phonetic overlap, as apparently observed in Ikalanga and Thai.
2.5 Magnetic Resonance Imaging
A very different way to detect nasalisation in vowels is through direct observation of the articulators. Real-time Magnetic Resonance Imaging (MRI) makes it possible to observe velum lowering directly. Byrd et al. (Reference Byrd, Tobin, Bresch and Narayanan2009) conducted an MRI study of English nasals, taking into consideration the coordination of the place constriction gesture and velum lowering in contexts varying in syllable structure and stress. This study thus parallels Krakow's (Reference Krakow1989, Reference Krakow, Huffman and Krakow1993) work not only in terms of which prosodic environments were compared, but also in the articulatory parameters that are used to determine segmental alignment of nasality.
Byrd et al. recorded four native speakers of American English in two experiments. The parts of this experiment relevant for our discussion compared phasing of lingual and velar gesture of the coronal nasal in syllable-final (e.g. tone ode) and syllable-initial (e.g. toe node) position. In the second stimuli set, stress conditions were manipulated, i.e. stressed–unstressed (e.g. tonative), unstressed–stressed (e.g. denote) and stressed–stressed (e.g. toe node). For the syllable conditions, Byrd et al. found a significant misalignment of velum lowering achievement and oral closure achievement in the coda and geminate environment (i.e. tone ode and tone node), whereas both gestures were left aligned in the onset condition (toe node). They noted a longer mean of constriction formation duration for the velum than for the tongue tip, that is velum lowering always started significantly earlier than tongue tip raising.
They also compare the length of velum lowering in the different conditions and report that only two subjects had significantly longer velum lowering in the coda condition than in onset. This variable is interesting for determining how far the preceding vowel is nasalised in the different environments and whether nasalisation is regressive only or also happens from nasal onsets to following vowels, as observed by Cohn. One would expect velum lowering for codas to be consistently longer than for onsets, unless the segment, as measurable in, e.g., oral closure duration, is shorter in the coda than in onsets.
In the stress conditions, Byrd et al. report to have found no effect of stress. However, since the left-alignment patterns of velum opening and alveolar closure differ markedly from the coda environment, this experiment further corroborates the importance of syllabification for velum lowering.
While this study confirms the connection between syllabification and nasalisation, we still don't know reliably if nasalisation happens between nucleus and coda or more generally in vowels tautosyllabic with a nasal consonant.
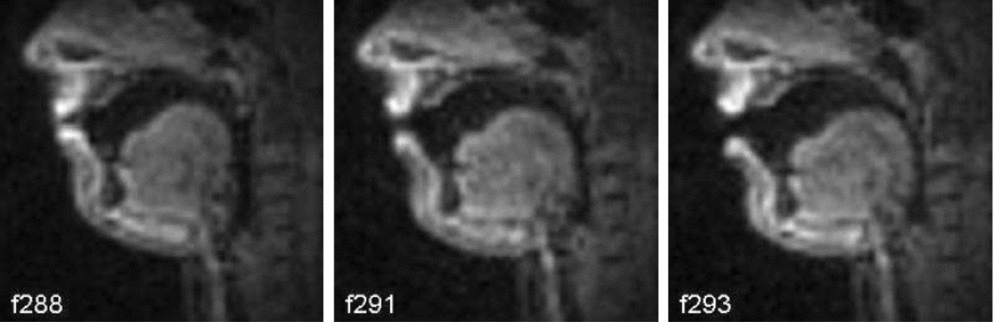
Another aspect of the pattern, i.e. whether English allegedly nasalised vowels are different from ‘properly’ nasalised vowels in other languages, is illuminated by Proctor et al.’s (Reference Proctor, Goldstein, Lammert, Byrd, Toutios and Narayanan2013) MRI study in which they compare English and French vowels. Proctor et al. record two native speakers of French and two native speakers of English, one Australian and one American. In the comparison of prenasal tautosyllabic vowels and French nasal vowels, Proctor et al. produce quite clear results:
In English, the pattern of velic timing in coda nasal consonants is more like that observed in French nasal vowels in that velum lowering precedes achievement of the tautosyllabic vowel target; unlike in any French type of nasal segment, this results in tongue-velum coordination patterns spread over a much larger part of the syllable in English, and C-Velum durations up to five times larger than any observed in French [.] (Proctor et al. Reference Proctor, Goldstein, Lammert, Byrd, Toutios and Narayanan2013: 478)
This statement is illustrated by the frames from their MRI recordings, contrasting French nasal vowel (figure 5) and vowel plus nasal (figure 7), and English vowel plus nasal sequences (figure 6). I placed the English frames between the French for ease of comparison. As one can see, the velum of the English speaker is already open (f147) when the French speaker initiates velum lowering for the nasal vowel (f291), while velum lowering in the French coda nasal is aligned with the alveolar closure (f204) and the nasal cavity is closed off before the oral closure (f201).

Figure 5. French nasal vowel production in [pã] pan ‘pane’

Figure 6. English nasalised vowel production in [v![]() n] in Yvonne
n] in Yvonne

Figure 7. French vowel + nasal coda consonant production in [pan] panne ‘failure’
For the comparison of French nasal and English nasalised vowels we are provided with only three frames per syllable in figures 5–7. The frame rate was 33.18 f.p.s. and Proctor et al. provide mean time intervals for initiation of velic lowering after labial closure for the four participants, which show that in this respect the English consonantal velum lowering matches the French vocalic velum lowering (rather than the consonantal).
Even though we are dealing again with data from two participants per language only, this last articulation study directly contradicts Cohn's finding that nasalisation in English nasalised vowels is much weaker and shorter than in French contrastively nasal vowels.
2.6 Summary
The first study reviewed here (Cohn Reference Cohn1993) found that nasal airflow in English nasal vowels is weaker than in other languages which have unambiguously phonologically nasal vowels and suggests that English vowel nasalisation is thus not a phonological process but rather a matter of gestural timing inaccuracy. However, all other studies discussed above point in the opposite direction. Krakow (Reference Krakow1989, Reference Krakow, Huffman and Krakow1993) establishes the connection between nasalisation and syllable structure and stress, as well as the regressive nature of this assimilation process. The results on syllable structure are confirmed by Byrd et al. (Reference Byrd, Tobin, Bresch and Narayanan2009). However, the latter don't find the connection between nasalisation and stress. The observation that there is regressive but no significant progressive nasalisation finds further support in Chen et al.’s (Reference Chen, Slifka and Stevens2007) study.
Cohn's claim that there is a difference between English nasal vowels and phonologically nasal vowels in other languages is challenged convincingly by a range of studies, starting with Solé (Reference Solé1992, Reference Solé1995), who compares prenasal vowels in Spanish and American English and concludes that Spanish vowel nasalisation is much less extensive and doesn't vary with speech rate as English nasalisation does, followed by Chen (Reference Chen1997), who establishes that there is a significant difference between nasal and oral vowels in English but no significant difference between English and French nasal vowels. This is confirmed by Proctor et al. (Reference Proctor, Goldstein, Lammert, Byrd, Toutios and Narayanan2013). The more general claim that English nasalisation is phonetically weaker than nasalisation in other languages is further challenged by Beddor (Reference Beddor, Trouvain and Barry2007), who finds more robust nasalisation in English than in two other languages, Thai and Ikalanga. The claim that English nasalisation is nothing more than the universally observed misalignment of velum lowering for postvocalic nasal consonants is thus not tenable.
While most of the later authors are not concerned with the question, nor do they frame their discussion in this direction, the evidence produced in these studies taken together suggests that American English has a phonological process of regressive tautosyllabic vowel nasalisation. All studies but Cohn's point in this direction.
In the next section we review perception studies to see if these conclusions can be corroborated.
3 Perception
While we can debate whether we can measure everything we can hear, the more reliable method seems to be to find out what is perceived by a listener. Given that such subphonemic or allophonic details of the speech stream are only subconsciously perceived, the task isn't exactly trivial either.
Since English vowels don't contrast in nasality one might wonder if native listeners perceive the oral–nasal contrast on vowels at all and whether this has consequences for the choice of analysis.
3.1 The perception of nasal(ised) vowels as such, and in context
Perception experiments by Kawasaki (Reference Kawasaki, Ohala and Jaeger1986) show that listeners can distinguish between nasal and oral Vs in isolation, but judge V in VC and VN as the same. That is, the presence of a following nasal consonant masks the nasality on the preceding vowel. Kawasaki played NVN stimuli to test subjects in which the amplitude of the second nasal was reduced by various degrees up to complete muting. Kawasaki's choice of test subjects provides an interesting twist to the study. She recruited students with at least basic training in linguistics as well as linguistically naive test persons. These students provided the reverse results from those obtained from the linguistically naive group. The linguistics students detected nasality on prenasal vowels, but didn't perceive it as reliably on (nasal) vowels not followed by nasal consonants, while the naive speakers didn't report nasality on the vowels followed by a clearly audible nasal but perceived the nasality of vowels better with increasing attenuation of the following nasal. Whatever we may think now of the effects of studies in linguistics on students, the behaviour of the untrained group is compatible with the interpretation that they access abstract mental representations rather than surface forms when asked whether they hear a nasal or an oral vowel. Nasality on vowels is detected (even though not contrastive in the language) when it cannot stem from an assimilatory process, i.e. when the following nasal is missing, while it is ignored when an external source for it is present in the signal. This claim must be somewhat puzzling at first glance, since these stimuli are not existing underlying representations in the mental lexicon of any of these subjects, because English doesn't have this contrast. Thus one has to assume that, in the laboratory setting of the experiment, these participants construct abstract mental representations for which they apply the rules of English phonology.Footnote 6
3.2 Gating and guessing of lexical items
While Kawasaki muted her nasals, including the transition from the vowel, in five steps, Lahiri & Marslen-Wilson (Reference Lahiri and Marslen-Wilson1991; henceforth L&M) successively removed slices of the signal starting with the nasal consonant and cutting off more and more temporal slices from the preceding vowel to create the stimuli for their gating experiment. For these clipped stimuli participants were asked to supply existing words, which then could end in either a nasal or an oral consonant, e.g. bin or bill. The study was carried out with both English speakers and speakers of Bengali, testing altogether 28 subjects for English and 60 for Bengali. Bengali has contrastive nasality in vowels as well as an assimilatory process that nasalises prenasal vowels. In addition to thus potentially getting information about how far nasalisation extends perceptibly into the vowel they also probe whether listeners use the phonetic surface signal for lexical processing or access more abstract mental representations. In a nutshell, while the Bengali subjects respond to truncated CVN stimuli with CṼ lexical items, English subjects respond with CVC items. When confronted with oral vowels both groups activate both CVN as well as CVC lexical items.
As just mentioned, Bengali has a regressive nasalisation process, like English, but also contrastive nasalisation, as illustrated in (4). The nasalisation process thus neutralises the contrast in prenasal position, while in English it is allophonic.
(4)
If one removes the final consonant from the words in (4) one would naively expect that the truncated form resulting from (a) and (b), i.e. [bã], as a stimulus would elicit both forms, while the truncated form of (c), i.e. [ba], elicited only (c) itself, but not (a) or (b). What L&M found was that the truncated form of (c) (and its English equivalent) elicited both (a) and (c) in both languages. Tables 2–4 show the participants’ responses in percentages, with the stimuli given on the left and the different response types in separate columns on the right.
Table 2. Bengali triplets (Lahiri & Marslen-Wilson Reference Lahiri and Marslen-Wilson1991: 27)

Table 3. English doublets (Lahiri & Marslen-Wilson Reference Lahiri and Marslen-Wilson1991: 275)

Table 4. Bengali doublets (Lahiri & Marslen-Wilson Reference Lahiri and Marslen-Wilson1991: 279)

Bengali has several CVC–CVN minimal pairs for which a minimally different CṼC lexical item is missing. Apart from some speakers inventing non-existing CṼC items in response to truncated CVN stimuli of this type, the figures in table 4 look strikingly similar to the English data in table 3.
Now looking only at the responses to CVN in table 3, one could as well conclude that English subjects perform at chance level and thus have no clue of what they are doing there. However, the responses to CVC truncates clearly show that this is not the case. Had they been completely unaware of the nasality on the V of the CVN stimuli we would expect the same response to CVC as was found for CVN, i.e. wild guessing.
The issues that are at stake here, before one draws any conclusions, are whether nasality is perceivable in English and whether it is relevant. If it were not perceivable for English subjects we would not see this marked difference between CVC and CVN stimuli. However, since above half of the responses to CVN are CVC one could say that it is irrelevant for most subjects or most of the time. A phonetic or optimal perception account, i.e. one in which listeners are assumed to exploit every surface detail for lexical access, would have predicted a much higher number of CVN responses to the CVN stimuli, unless what we see here is simply bad performance on the perception of nasality.
Finally, the low CVN response to CVN stimuli could be an artefact of the methodology. We saw in the preceding section that, according to some measures, nasal airflow starts relatively late in English nasalised vowels. L&M also present responses by gate. That is, they show the percentage of CVN and CVC responses at the different cut-off points in the stimuli. The CVN stimuli already show a relatively high rate of CVN responses to CVN stimuli at the earliest gate (i.e. the stimuli with most of the vowel on the side of the N removed), which shows that nasality is perceptible already early on in the vowel.
L&M's experiment has been replicated, with some modifications, by Ohala & Ohala (Reference Ohala, Ohala, Connell and Arvaniti1995; henceforth O&O). Probably as a matter of convenience, O&O replace Bengali with Hindi, which has the same patterns. They object that the sudden silence in the gated stimuli used by L&M could be interpreted as the silence of the closure phase of a stop and this explains some of the preferences for stops. For this reason, they placed white noise at the end of each stimulus rather than silence. Furthermore, they conjecture, the subjects’ guesses of the target word could be influenced by lexical frequency. There are more words in English ending in an obstruent than in a nasal. This introduces another bias for oral guesses. They accordingly turn the experiments into a 2AFC (2-Alternative Forced Choice) and 3AFC test, offering one CVN and one CVC choice in English and the Hindi pairs that lack a CṼC option, and one CVN, one CVC and one CṼC option to choose from for each auditory stimulus.
In the crucial pair, English CVC versus CVN (table 5a,b), subjects identify CVN targets correctly at a very high rate already relatively early on in O&O's setup, while in L&M's experiment this target had a very high rate of CVC responses (59.3%), which is the core argument for L&M's claim that listeners access underlying representations in which the redundant nasality is not present.
Table 5. Comparing L&M and O&O's results

Note: Guesses as percentage; highest value in bold-face, target cell in grey shade, target = lowest value in italics.
While O&O's subjects do identify CṼC very accurately (table 5g), they interpret CVN to a high degree as CṼC (table 5f), which indicates that they parse positive acoustic cues to nasality as a contrastive property of the V, a choice that English participants don't have.
Moreover, O&O's subjects give a high number of CVC responses to CVN stimuli when there is no CṼC competitor. This is puzzling. However, it is worth taking the above-mentioned results into consideration here: in triplets, CVN targets elicit a higher rate of incorrect CṼC responses than correct CVN guesses, and they have a high success rate with CṼC targets. Accordingly, one could conclude the same for O&O's non-English participants as L&M concluded for English. The chance level performance on CVN targets that don't have a CṼC competitor and the high preference of CṼC in the face of truncated CVN targets for which a CṼC competitor exists suggest that the Hindi speakers ignore vowel nasality if it can only be an effect of an allophonic rule but parse it as a contrastive feature whenever possible. In conclusion, in lexical access they activate abstract forms in which the redundant aspects of the signal are stripped off.
Finally, O&O's study has to be taken with a pinch of salt. The fact that O&O's English subjects perform slightly better on CVN targets than on CVC targets is as suspicious as the bad performance of English subjects on the same targets in L&M's study was to O&O. One could speculate that the white noise has the opposite effect of that of L&M's silence alleged by O&O: the white noise could be acoustically closer to nasality than to an oral stop and listeners use this information erroneously. After two test words they know that the next word is going to end in that kind of signal. We can expect to get different results again if we repeat the experiment with a different kind of noise masking the target consonant, e.g. a high-frequency beep.
One could further speculate that, especially in the white noise setup, listeners become aware of the goal and design of the task very soon after the experiment has started and subconsciously zoom in on the vowels to identify the missing consonant.
3.3 Forced choice lexical identification of cross-spliced stimuli
With a slightly different methodology Fowler & Brown (Reference Fowler and Brown2000) also tested whether nasality or its absence on a vowel is used by listeners to identify the following consonant. They spliced and cross-spliced CṼNV and CVCV nonce words to create incongruent (or misleading) stimuli of the type CṼCV and CVNV for a 2AFC reaction time experiment (subjects had to press left button for nasal, right button for oral consonant) with 18 participants.
The results show that misleading stimuli slow down consonant recognition and the effect is stronger when nasal consonants are preceded by oral vowels, with a delay of 68ms for incongruent V|N versus a delay of 37ms for incongruent Ṽ|C stimuli). Furthermore, they don't find a difference between nasals and orals in the congruent spliced condition. The cross-splicing didn't have any effect on the error rate in consonant identification, which was negligible in both conditions, spliced and cross-spliced.
If listeners strongly relied on a vowel's nasality to identify the following consonant we wouldn't expect an asymmetry since nasality excludes oral consonants while oral vowels could still be followed by a nasal (e.g. if coarticulation was optional). While Fowler & Brown discuss their results in the context of a gestural parsing model, they are compatible as well with a phonological analysis in which the feature [nasal] on a vowel is interpreted as the result of spreading from the following nasal consonant. The presence of the spreading rule in the grammar leads listeners to either ignore the nasality on the vowel (since it is derived by rule and therefore not contrastive) or identify it with the following consonant. This also explains the lag in reaction time for nasals preceded by oral vowels. A nasal consonant comes as a surprise if it hasn't spread its nasality to the preceding vowel. Surprisingly, a nasal vowel doesn't necessarily lead listeners to expect only nasal consonants since they access underlying representations, i.e. forms without nasality on vowels.
3.4 Magnetoencephalography
Flagg et al. (Reference Flagg, Cardy and Roberts2006) used similar cross-spliced stimuli but measured processing with magnetoencephalography (MEG), which records neural activity. They tested 105 randomised trials of each of the four conditions, i.e. congruent nasal, congruent oral, incongruent nasal–oral and incongruent oral–nasal, with eight subjects. As figure 8 shows, their results were the opposite of Fowler & Brown's. Subjects reacted more slowly to the incongruent condition of nasal vowel–oral consonant sequences than to oral vowel–nasal consonant sequences.

Figure 8. Overall M50 peak latency (Flagg et al. Reference Flagg, Cardy and Roberts2006: 267, fig. 4)
To explain this mismatch in results it is crucial to note that Flagg et al. used nonce words rather than cross-spliced real words and measured subjects’ passive reactions to these auditory stimuli rather than forcing them to choose between the two options of oral versus nasal consonant. We thus can't attribute this effect to lexical access or phoneme recognition. Flagg et al. note that the difference in reaction time cannot be the result of the different sizes of lexical search spaces after a nasal and an oral vowel, respectively. In English, a nasal vowel can only be followed by three consonants, /m, n, ŋ/, while the set of possible consonants is much bigger after an oral vowel. One would thus have expected the reverse result, greater delay in congruent stimuli of oral vowels followed by oral consonants. What this experiment rather shows is that the subjects react to a violation of constraints on surface structures, or, in Flagg et al.’s words, it reveals ‘subjects’ abstract phonological knowledge’ (Reference Flagg, Cardy and Roberts2006: 267). In English, nasal vowels are only expected if derived by assimilation to the following nasal consonant. Thus, a nasal vowel that is not followed by a nasal consonant constitutes a severe violation of surface constraints. A nasal consonant preceded by an oral vowel, however, may easily be interpreted as underparsing of the nasal feature on the vowel that is expected from the nasalisation process, i.e. the hearer assumes that s/he didn't notice the predictable feature on the vowel. If the predictable feature of the vowel is followed by a consonant that can't be its source this must be because the vowel itself is nasal and the word thus can't be an English word, or the nasal has been deleted.
3.5 Error rates in forced choice identification
This kind of nonce-word experiment has the flaw that we are not probing existing lexical representations (which does not hold for all nonce-word experiments). McDonough et al. (Reference McDonough, Lenhert-LeHouiller and Bardham2009) carried out lexical decision experiments in which, as in Lahiri & Marslen Wilson's study, the final C/N was removed from the stimulus. Rather than complete the word, as in Lahiri & Marslen-Wilson's experiment, subjects had to choose a picture. While previous studies focused on nasality only, McDonough et al. also tested for place of articulation (PoA) of the final consonant. This is interesting because PoA of stops is phonetically cued in the transition from and to adjacent vowels in their formant structure. However, unlike nasality, these PoA-induced alterations in a vowel's formants pertain only very briefly. Finally, unlike nasality of consonants, information on PoA is not present in the stop itself.
McDonough et al. designed two experiments. In their first experiment they only tested if there is any difference in processing between PoA and nasality. Stimuli were pairs of existing words of English that differed only in PoA or only in nasality in the last consonant (such as tack and tap, and bong and bog, respectively), with the final consonant of each word removed. The 11 participants were presented with one of these stimuli at a time and had to choose between two pictures (e.g. the pictures for pan and pad when listening to pa) by clicking on it. They had 18 word pairs, 11 for nasality and 7 for PoA, and listeners were presented six times with each item. In this task they didn't measure reaction time, but only error rate. The error rates, presented in figure 9, show that even though they were altogether very low, they were much higher for PoA than for nasality.

Figure 9. Relative errors in McDonough et al.’s 2AFC discrimination task
The second experiment was an eye-tracking experiment that tested for identification speed; it not only tracked the difference between nasality and PoA but also between the three different PoA, labial, alveolar and velar.
3.6 Eye-tracking
McDonough et al. used a group of the same size and the same stimuli, with the difference that this time they didn't remove the final consonant. On auditory exposure to the target word, subjects had to choose between four pictures, two distractors, which differed substantially from the target, a competitor which only differed from the target in one feature (e.g. nasality) and one representing the target word. Figure 10 presents the proportion of looks to target; the offset of the vowel is marked as 0 and the line at 200ms marks the earliest point at which the authors assume it to be possible to see an effect of the information the subjects obtained in the vowel transition, due to general neural processing speed of visual input. Poa_b encodes labial stops, poa_a alveolars, and poa_v the velars. According to McDonough et al., the diagram shows that nasality on the vowel is used to identify the following consonant.
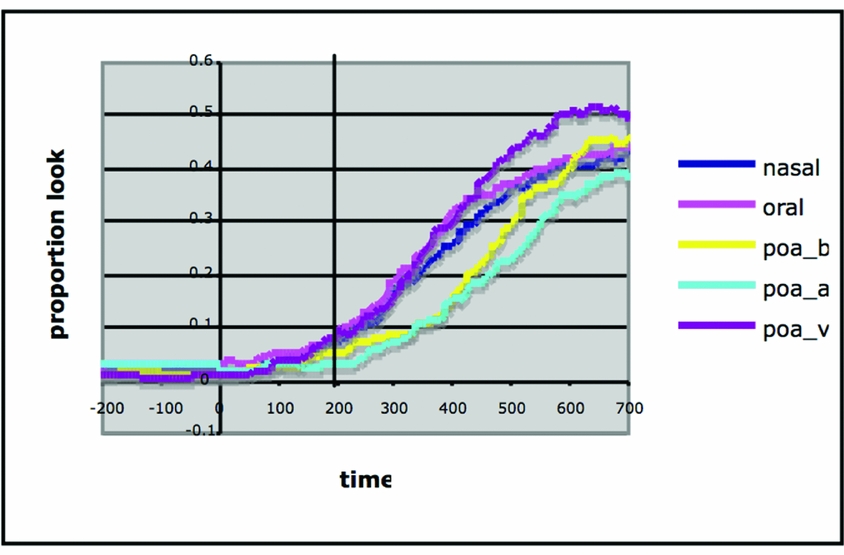
Figure 10. Proportion of looks to target (McDonough et al. Reference McDonough, Lenhert-LeHouiller and Bardham2009)
It is striking that what is prominent among the overlapping lines early on are the oral vowels rather than the nasal ones. The nasal vowels (the dark blue line) only seem to approach the level of attention of oral targets (pink line) at the very end of the graph past the 500ms mark. While McDonough et al. conclude that nasality is used early on in the preceding vowel to identify whether the following consonant is oral or nasal, it seems rather that the absence of nasality is used to determine that the following consonant is not nasal.
Furthermore, there is a marked difference in processing speed for the different PoAs. Words ending in velars are identified almost as fast as oral/nasal words. While both labials and alveolars lag considerably behind, the authors comment only on the bad performance of alveolars, noting that the alveolars in many of the stimuli were actually debuccalised. The resulting glottal stops do not cause any significant modification of the formant structure in preceding vowels and participants thus didn't receive any positive phonetic cues as to their PoA.
The potential effect of nasality on vowels in speeding up identification of a following consonant was also studied in an eye-tracking test battery carried out by Beddor and colleagues (Reference Beddor, McGowan, Boland, Coetzee and Brasher2013). They also produce evidence that the absence of nasality is used as an early cue to the nature of the following consonant. While they don't directly compare oral targets paired with nasalised distractors and nasalised targets paired with oral distractors, the data suggest that target identification is slower for postvocalic oral consonants than for postvocalic nasal consonants.
Beddor et al. are mainly interested in showing that small temporal differences in auditory stimuli result in differences in online processing. To that end, they create stimuli with early onset of nasalisation and stimuli with late onset of nasalisation by cross-splicing existing English words that end in an oral consonant with words that end in a nasal consonant. From four natural stimuli, e.g. bet, bed, bent, bend, they thus create another two from the first half of bed and the last two-thirds of bend and the first half of bet cross-spliced with the last two-thirds of bent. Every stimulus was matched with a picture representing its meaning. After a familiarisation phase, subjects, who were American university students, were presented with two pictures and one auditory stimulus at a time, i.e. a 2-AFC task. The subjects’ reactions were monitored with a head-mounted eye-tracker. Identification of the target was unsurprisingly faster in CVNC–CVC target–competitor pairs (e.g. bend–bed) with early onset of vowel nasalisation, compared to CVNC–CVNC pairs in which the last consonant differed in voicing (e.g. bent–bend), as shown by the bars in the box in the centre in figure 11. The cross-spliced stimuli with late onset of vowel nasalisation showed a weaker effect (shown on the left in figure 11) and those with a voiced final consonant didn't show an effect of nasalisation, i.e. CVlateND was identified at the same speed regardless of whether the competitor contained a nasal or not (leftmost two bars in figure 11).

Figure 11. Mean latency of first correct fixations on CVNC and CVC stimuli according to auditory stimulus and competitor (bar type) and coda voicing (voiced: left set of bars; voiceless: right set) (Beddor et al. Reference Beddor, McGowan, Boland, Coetzee and Brasher2013: 2356, 2359)
A similar effect was found with CVC targets with a CVNC competitor (rightmost box in figure 11). Identification speed for CVT–CVD pairs was the same as for the late-onset vowel nasalisation stimuli rather than the natural CVNC tokens. Again, when both the final C in the target and in the competitor were voiced there was no nasality effect. The recognition speed difference between early onset nasalisation targets and voiceless oral targets suggests that vowel nasalisation is used as a positive cue to the identity of the postvocalic consonant.
In a second experiment, Beddor et al. cut out the nasal consonant from their stimuli. This creates potentially natural stimuli since, as mentioned in the introduction, postvocalic nasals are optionally deleted under certain circumstances. Two-thirds of Beddor et al.’s test subjects nevertheless identified the correct stimuli at the same speed as those without nasal excision. However, here it becomes interesting which kind of information one looks at in an eye-tracking experiment. While the mean latency of first correct fixations suggests that there is no difference between CṼNC–CVC pairs and CṼC–CVC pairs (figure 12), the pooled proportion of correct fixation data shows a very different picture (figure 13). Here one sees that the proportion of looks to target remained relatively low for the stimuli with N excision, while it rose much higher for those with the N in place.

Figure 12. Mean latency of first correct fixations on CVNC–CVC visual trials according to auditory stimulus (bar type) and coda voicing (voiced: left set of bars; voiceless: right set) (Beddor et al. Reference Beddor, McGowan, Boland, Coetzee and Brasher2013: 2360)

Figure 13. Pooled proportion correct fixations on trials with auditory [CṼC] (pluses) and [CṼearlyNC] (circles) in voiced and voiceless conditions. Dotted lines indicate location of N excision; arrows indicate 200ms eye movement programming delay (Beddor et al. Reference Beddor, McGowan, Boland, Coetzee and Brasher2013: 2360)
Subjects thus keep going back and forth between the two pictures, or even look more at the distractor, as the proportion of looks to target remains at around 0.3 even after the rise at the critical 400ms point for the voiced stimuli. Also for the voiceless condition the proportion of correct fixations remains considerably lower for the stimuli with N excision than the stimuli with N, and only arrives at a maximum proportion at around 0.6, while the CṼNC stimuli get close to 1.0 in both conditions.
This indicates that the point of first correct fixation, as defined by Beddor et al., is not necessarily the point in time when a lexical decision has been made in favour of the target. We can conclude from this that listeners do not treat nasality on vowels in the same way as other cues to contrastive features. One could say they don't have faith in this auditory cue and keep the final lexical decision on hold until the end of the vowel.
As Beddor et al. note, vowel nasalisation is not a reliable cue for the nasality of a postvocalic consonant since nasalisation may stem from other sources as well.
3.7 Summary of perception studies
Kawasaki (Reference Kawasaki, Ohala and Jaeger1986) found that naive American English listeners detect nasality on vowels better the more the following nasal is attenuated and ignore nasality on vowels if they are followed by a clearly audible nasal consonant. They are thus capable of perceiving the nasal/oral distinction on vowels but ignore it when it is predictable.
Lahiri & Marslen-Wilson (Reference Lahiri and Marslen-Wilson1991) found that nasality on vowels doesn't help English listeners much in disambiguating between lexemes ending in a nasal or an oral consonant. The absence of nasality, however, is used to zoom in on the lexemes ending in an oral consonant. Ohala & Ohala (Reference Ohala, Ohala, Connell and Arvaniti1995) didn't accept Lahiri & Marslen-Wilson's explanation of their data, i.e. that listeners access abstract lexical representations devoid of the surface nasalisation on methodological grounds. Their revised rerun of the same experiment produces the opposite results for nasal targets. Listeners do take the nasality into account when listening to a truncated stimulus. However, if we consider their Hindi experiment, one can make the same conclusions on redundant features as Lahiri & Marslen-Wilson drew for English: nasality on a vowel is only used if it can be interpreted as a contrastive feature of the vowel itself and ignored if it can only come from the following consonant.
Fowler & Brown (Reference Fowler and Brown2000) provide more data that point in the same direction as Ohala & Ohala's conclusions (if not their data). However, the absence of vowel nasalisation delays correct identification of a lexeme more than the presence of nasalisation on a vowel preceding an oral consonant. If phonetic cues were processed directly one would have expected both mismatches to result in the same delay.
In an experiment with nonce words that use the same congruent/incongruent placement of nasality as Fowler & Brown, Flagg et al. (Reference Flagg, Cardy and Roberts2006) produce exactly the opposite result: in the discussion above this was attributed to the fact that they use nonce words, i.e. the subjects can't access existing lexical items and the effect must be due to a violation of surface phonotactic constraints. These constraints ban nasal vowels from the grammar unless they are derived by contextual nasalisation. Or rather improbable patterns in stimuli in the sense that they have zero frequency in the stored perceptual memory cause these results. However, under this interpretation we would again expect a balanced delay in both conditions, incongruent nasal and incongruent oral.
McDonough et al. (Reference McDonough, Lenhert-LeHouiller and Bardham2009) showed that nasality is perceived differently from place of articulation of a final consonant, thus corroborating that vowels are in fact audibly nasalised (contra Cohn). In their follow-up eye-tracking study the same team reconfirms that nasality is used to identify postvocalic consonants. However, as discussed above, it looks more as if what is used to speed up lexical access is the absence of nasalisation.
Beddor and colleagues (Reference Beddor, McGowan, Boland, Coetzee and Brasher2013) revealed that nasality is immaterial in the identification of postvocalic nasals if they are competing with a form that ends in a voiced oral stop, while it speeds up processing if the competitor ends in a voiceless stop. They also show that deletion of the nasal consonant does not significantly hamper recognition.
4 Discussion and conclusions
The phonetic and psycholinguistic studies reported here produced contradictory results. First, in section 2, we saw that not all acoustic studies managed to find reliable acoustic effects of nasalisation. This first resulted in the rejection of vowel nasalisation as a phonological process, since the detected nasalisation was less prominent than in other languages with either contrastive nasal vowels or reported regressive nasalisation processes. Subsequent studies, however, found strong effects of nasalisation in the production of prenasal vowels as well as parallels with languages in which vowel nasalisation is considered to be phonological and differences with languages in which nasalisation is not even suspected to be present on vowels. This firstly proves the trivial insight that it is impossible to prove the nonexistence of something. Just because we cannot measure something yet doesn't mean it doesn't exist. Our technologies might simply not be at a point where we are able to measure a phenomenon successfully. Second, if we take all production studies together the overwhelming evidence suggests that vowel nasalisation in English is ‘more’ than the alleged universal misalignment of velum lowering and stop gesture reported in phonetics textbooks, but rather is akin to nasality and nasalisation patterns recognised as phonological in other languages.
The perception studies produced mixed, often contradictory, results. However, it seems clear that speakers of English are able to perceive nasal vowels reliably – as long as they are not followed by a nasal consonant. While some studies conclude that the acoustic correlates of vowel nasalisation are used as a cue to speed up recognition of the following consonant, a closer look at the results casts doubt on this conclusion. The data suggest that listeners use vowel nasalisation in a way different from other, more direct cues for contrastive categories. More specifically, contextually predictable nasality is ignored as a feature of the vowel it is found in, as already shown by Kawasaki. This latter insight lends support to the hypothesis that listeners access abstract lexical representations devoid of predictable contextual phonetic information.
Interpretation of data from phonetic, psycho- and neurolinguistic studies is rendered extremely difficult not only by the nature of the data themselves, which was especially obvious in the MMN and eye-tracking studies, but also by the theoretical background, or lack thereof, of the experimenters, and, accordingly, the kinds of questions they ask. For example, while for our inquiry syllable structure and stress are crucial variables, these seemed to be regarded as irrelevant in some of the studies reported here. We should thus be careful in drawing conclusions on these matters. However, the studies by Krakow and Byrd et al. converge on the role of syllable structure. We can conclude on the basis of these studies that English vowel nasalisation is sensitive to syllable structure in that the vowel and the following nasal have to be part of the same syllable.
Furthermore, the theoretical background and questions asked by the individual research teams or researchers have an impact on how results are presented and which results are shown. The discussion of several studies here was a challenge for this reason and we had to resort to speculations in the absence of the figures we would have needed, based on graphs that in some cases didn't even transparently display the crucial data they were supposed to show.
While there is a wealth of experimental studies on vowel nasalisation in English, making use of a wide range of techniques and technologies, drawing clear conclusions that support one hypothesis or another is a daunting task if the researchers carrying out the studies had different questions in mind. Nevertheless, we can still make some cautious claims. Studies converge on the insight that English vowel nasalisation is a phonological process that applies to vowels followed by a tautosyllabic nasal. A further argument comes from a functional perspective. Nasals, unlike oral stops, have strong internal cues while stops don't (Henke et al. Reference Henke, Kaisse, Wright and Parker2012 and references cited there). Thus, phasing velum lowering before the closure for the nasal is redundant and may even mask the cues to the place of articulation of the nasal consonant. The place cues of stops are usually found in the transition of the formants of the preceding (or following) vowel, because they don't have internal acoustic cues. To enhance perceptibility of the place of articulation of an oral stop it could be helpful to provide cues for this earlier in the preceding vowel. However, what we found here was that nasality is detectable much earlier in the preceding vowel than in the place of articulation of the following consonant, i.e. the opposite of what is expected.
The second question, whether nasality is stored as part of the vowel in underlying representation, is more difficult to answer. Lahiri & Marslen-Wilson's strong claim that listeners access abstract lexical representations that are devoid of predictable information (i.e. vowel nasalisation) could not be corroborated straightforwardly. Some of the other studies produced results that can be considered a challenge for this hypothesis, at least as formulated by L&M. However, the competing phonetic hypothesis makes us expect more clear-cut results in perception studies. Under the strong phonetic (or exemplar-theoretic) hypothesis that the lexicon stores all phonetic detail and that phonetic detail is used for recognition once it is available in the signal, we would have expected that postvocalic nasal consonants are either identified much faster than oral consonants even if the nasal consonant itself is removed from the stimulus or at least with equal speed as oral consonants. This was only weakly confirmed by faster access under very specific circumstances. While it looks as if phonetic timing does play some role in perception, its role is much less significant than expected from this perspective. What is mysterious for the phonetic approach are the asymmetries that turn up time and again and the fact that predictable nasality is processed differently from contrastive nasality or other contrastive features. From the discussion of the various perception studies in section 3 we can thus conclude that while differences in timing are perceptible, they are not linguistically used to the full extent. A surprising result of some of the studies was that the absence of nasalisation was a more robust cue for the identification of the following consonant.
A reasonable explanation of these mysteries and this mismatch between stimuli and lexical retrieval is the phonological underspecification hypothesis. While vowel nasalisation is real and phonological, it is not necessarily used as a direct cue in lexical identification because this kind of nasalisation is not present in the lexical representations that are accessed in word recognition.
To sum up, the textbooks on English phonology don't have to be rewritten and native speakers of American English (at least) don't have any nasal vowels in their mental lexicon.