





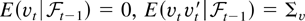

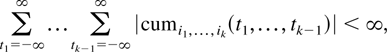

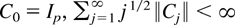



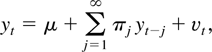





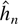
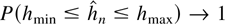
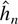
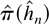










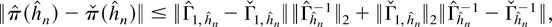


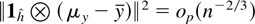
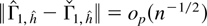

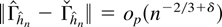
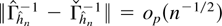
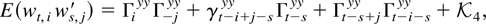
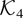
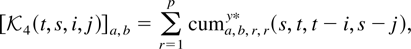

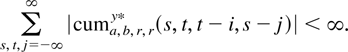

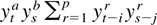

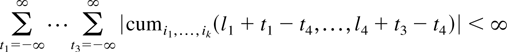
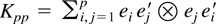










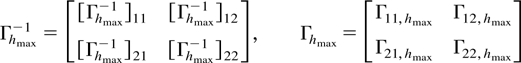

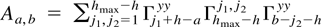

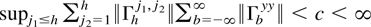
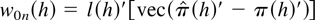






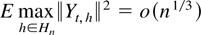





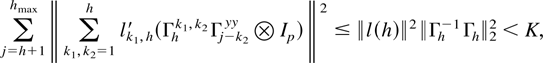

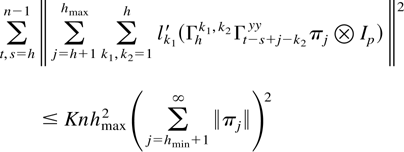

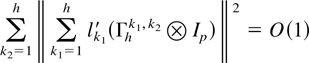









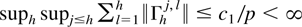
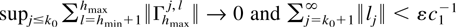

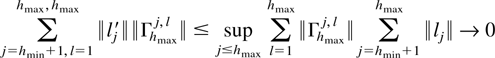
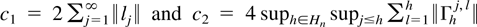














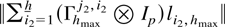
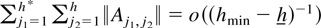
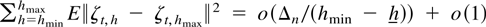

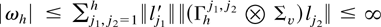

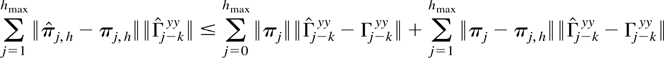
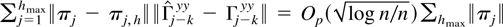
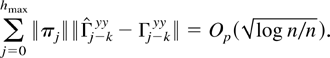
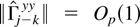
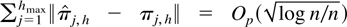
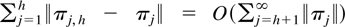
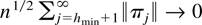

Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Preminger, Arie
and
Sakata, Shinichi
2007.
A model selection method for S‐estimation.
The Econometrics Journal,
Vol. 10,
Issue. 2,
p.
294.
Chiuso, Alessandro
2007.
The role of vector autoregressive modeling in predictor-based subspace identification.
Automatica,
Vol. 43,
Issue. 6,
p.
1034.
Chiuso, Alessandro
Pillonetto, Gianluigi
and
De Nicolao, Giuseppe
2008.
Subspace identification using predictor estimation via Gaussian regression.
p.
3299.
Bauer, Dietmar
2009.
Estimating ARMAX systems for multivariate time series using the state approach to subspace algorithms.
Journal of Multivariate Analysis,
Vol. 100,
Issue. 3,
p.
397.
Chiuso, A.
2010.
On the Asymptotic Properties of Closed-Loop CCA-Type Subspace Algorithms: Equivalence Results and Role of the Future Horizon.
IEEE Transactions on Automatic Control,
Vol. 55,
Issue. 3,
p.
634.
Chiuso, Alessandro
Muradore, Riccardo
and
Marchetti, Enrico
2010.
Dynamic Calibration of Adaptive Optics Systems: A System Identification Approach.
IEEE Transactions on Control Systems Technology,
Vol. 18,
Issue. 3,
p.
705.
Jordà, Òscar
and
Kozicki, Sharon
2011.
ESTIMATION AND INFERENCE BY THE METHOD OF PROJECTION MINIMUM DISTANCE: AN APPLICATION TO THE NEW KEYNESIAN HYBRID PHILLIPS CURVE*.
International Economic Review,
Vol. 52,
Issue. 2,
p.
461.
Mayoral, Laura
and
Dolores Gadea, María
2011.
Aggregate real exchange rate persistence through the lens of sectoral data.
Journal of Monetary Economics,
Vol. 58,
Issue. 3,
p.
290.
Theodoridis, Konstantinos
2011.
An Efficient Minimum Distance Estimator for DSGE Models.
SSRN Electronic Journal,
MAYORAL, LAURA
2013.
HETEROGENEOUS DYNAMICS, AGGREGATION, AND THE PERSISTENCE OF ECONOMIC SHOCKS.
International Economic Review,
Vol. 54,
Issue. 4,
p.
1295.
Lee, Yoon-Jin
Okui, Ryo
and
Shintani, Mototsugu
2013.
Asymptotic Inference for Dynamic Panel Estimators of Infinite Order Autoregressive Processes.
SSRN Electronic Journal,
Veen, Gijs
Wingerden, Jan‐Willem
Bergamasco, Marco
Lovera, Marco
and
Verhaegen, Michel
2013.
Closed‐loop subspace identification methods: an overview.
IET Control Theory & Applications,
Vol. 7,
Issue. 10,
p.
1339.
Jondeau, Eric
and
Pelgrin, Florian
2014.
Estimating aggregate autoregressive processes when only macro data are available.
Economics Letters,
Vol. 124,
Issue. 3,
p.
341.
Jondeau, Eric
and
Pelgrin, Florian
2014.
Estimating Aggregate Autoregressive Processes When Only Macro Data are Available.
SSRN Electronic Journal,
Hwang, Eunju
and
Shin, Dong Wan
2014.
Infinite-order, long-memory heterogeneous autoregressive models.
Computational Statistics & Data Analysis,
Vol. 76,
Issue. ,
p.
339.
Gadea, Maria Dolores
and
Mayoral, Laura
2015.
Uncertainty, model selection, and the PPP puzzle.
Oxford Economic Papers,
Vol. 67,
Issue. 3,
p.
614.
Lee, Yoon-Jin
Okui, Ryo
and
Shintani, Mototsugu
2018.
Asymptotic inference for dynamic panel estimators of infinite order autoregressive processes.
Journal of Econometrics,
Vol. 204,
Issue. 2,
p.
147.
Mayer, Alexander
2020.
(Consistently) testing strict exogeneity against the alternative of predeterminedness in linear time-series models.
Economics Letters,
Vol. 193,
Issue. ,
p.
109335.
Zhang, Erhua
Song, Xiaojun
and
Wu, Jilin
2022.
A non‐parametric test for multi‐variate trend functions.
Journal of Time Series Analysis,
Vol. 43,
Issue. 6,
p.
856.
Baek, ChaeWon
and
Lee, Byoungchan
2022.
A Guide to Autoregressive Distributed Lag Models for Impulse Response Estimations*.
Oxford Bulletin of Economics and Statistics,
Vol. 84,
Issue. 5,
p.
1101.