1. Introduction
The goal of this paper is to encourage reflection on the methodologies and research questions that fuel work in corpus linguistics and variationist sociolinguistics.Footnote 1 That there is, as I will argue, considerable overlap between the two fields will be well-known to many (though maybe not all) readers. But then again, reminding practitioners in both fields of the common ground that they share, and of the cross-pollination potential that this common ground creates, is perhaps an exercise not entirely lacking in merit. Let us begin by reviewing definitions of what a corpus is. The community of corpus analysts that is of interest in the present paper defines corpus linguistics as a methodology that draws on collections of more or less naturalistic texts or speech for the sake of conducting some sort of linguistic analysis.
-
1. A corpus will be considered a collection of texts or parts of texts upon which some general linguistic analysis can be conducted (Meyer Reference Meyer2002: xi).
-
2. A corpus is a collection of non-elicited usage events […] a sample of spontaneous language use that is (generally) realized by native speakers (Tummers et al. Reference Tummers, Heylen and Geeraerts2005: 231).
-
3. A corpus can be defined as a body of naturally occurring language (McEnery et al. Reference McEnery, Xiao and Tono2006: 4).
I would like to argue that to the extent that typical work in the variationist sociolinguistics, also known as the Language Variation and Change (henceforth: LVC) paradigm, is based on the analysis of fully transcribed sociolinguistic interviews or other naturalistic production data, LVC work is arguably based on corpora, albeit so-called specialized ones (McEnery et al. Reference McEnery, Xiao and Tono2006: 5). And therefore the variationist method is a proper subset of the corpus-linguistic family of methods.
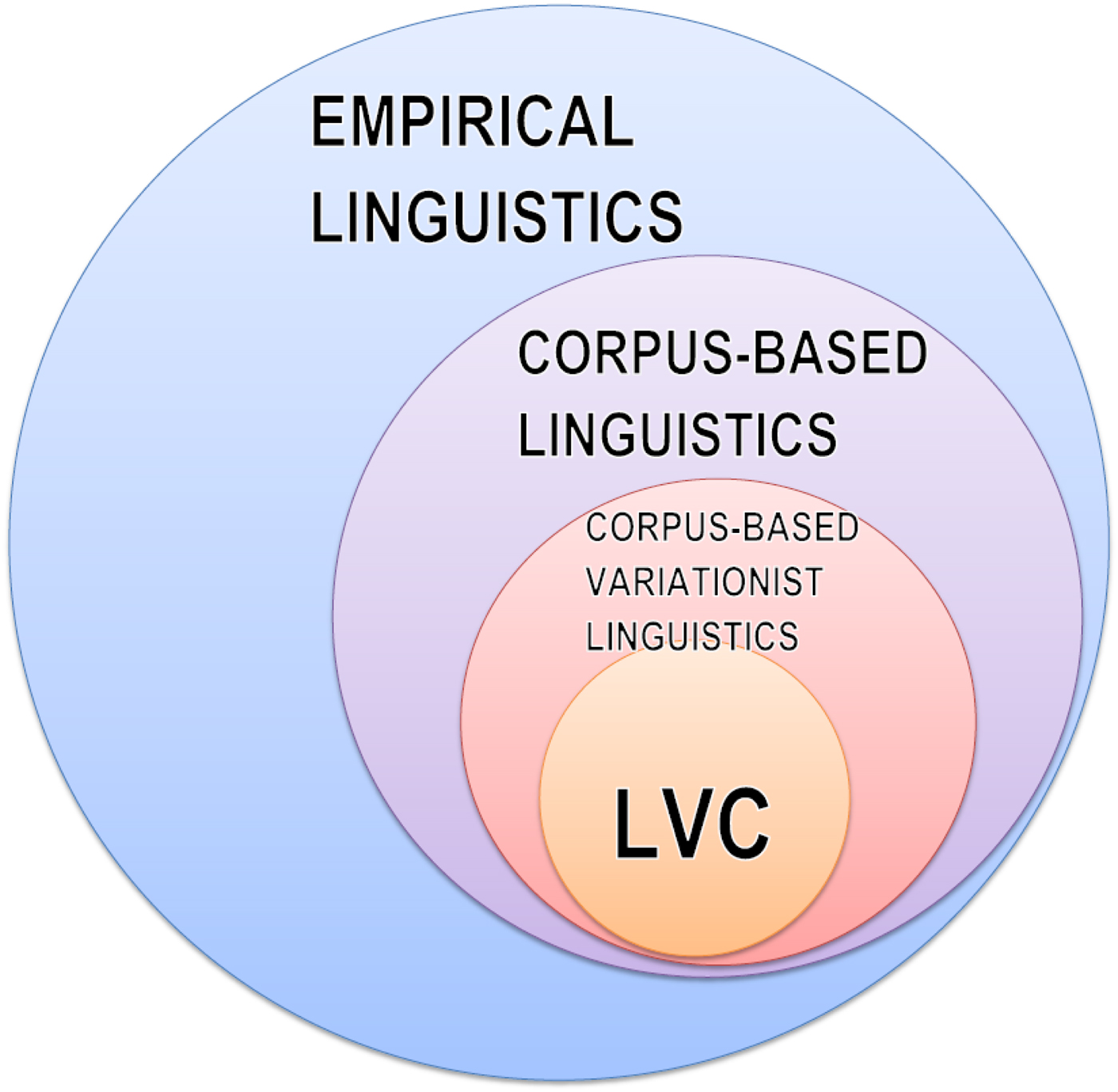
Figure 1 explores the relationship between LVC and other branches of empirical linguistics from a corpus-linguistic perspective. While of course not all empirical linguists rely on the observational analysis of naturalistic corpus data (see, for example, Rosenbach Reference Rosenbach2005 for an experimental analysis of syntactic variation), corpora are a fairly popular data source. So corpus-based linguistics comes within the remit of empirical linguistics. But crucially, not all corpus-linguistic research is concerned with linguistic variation in the variationist sense – see, for example, Nesselhauf (Reference Nesselhauf2005) for corpus-driven, frequency-based collocation research which does not focus on variation per se. There are also corpus-linguistic approaches to sociolinguistics (e.g., discourse analysis) that are not necessarily variationist (e.g., Baker Reference Baker2010, Friginal and Hardy Reference Friginal and Hardy2014). Note further that there is plenty of corpus research that is concerned with variation in a broader sense (e.g., Biber Reference Biber1988 and follow-up work) without using the variationist method in the narrower, LVC-inspired sense. This narrower sense would define corpus-based variationist linguistics (henceforth: CVL) as scholarship that meets the following three criteria:
-
1. CVL is concerned with “alternate ways of saying ‘the same’ thing” (Labov Reference Labov1972: 188), so CVL researchers properly define variables and variants.
-
2. CVL research observes the Principle of Accountability (Labov Reference Labov1969: 738), hence it is linguistic choice-making processes and not text frequencies that take centre stage.
-
3. CVL uses rigorous quantitative methodologies and statistical modeling (e.g., regression analysis) to explore the conditioning of linguistic variation.
This means that the remit of CVL as I define it here does not include research that is empirical but not corpus-based (consider, for example, experimental psycholinguistics in the spirit of Bock Reference Bock1986), or research that is corpus-driven but not concerned with variation (consider, for example, multiword expression research à la Rayson et al. Reference Rayson, Piao, Sharoff, Evert and Villada Moirón2010), or research that is corpus-based and actually concerned with variation but that does not use the variationist method (consider, for example, seminal register-variation research in the tradition of Biber Reference Biber1988). Recent CVL research that does fit the bill as defined above includes studies such as Gries (Reference Gries2005), Heylen (Reference Heylen, Kepser and Reis2005), Jaeger (Reference Jaeger2006), Bresnan et al. (Reference Bresnan, Cueni, Nikitina, Baayen, Boume, Krämer and Zwarts2007), Grondelaers and Speelman (Reference Grondelaers and Speelman2007), Hinrichs and Szmrecsanyi (Reference Hinrichs and Szmrecsanyi2007), Hilpert (Reference Hilpert2008), Lohmann (Reference Lohmann2011), De Cuypere and Verbeke (Reference De Cuypere and Verbeke2013), Levshina et al. (Reference Levshina, Geeraerts and Speelman2013), Schilk et al. (Reference Schilk, Mukherjee, Nam and Mukherjee2013), Theijssen et al. (Reference Theijssen, ten Bosch, Boves, Cranen and van Halteren2013), Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013), Claes (Reference Claes2014), Ehret et al. (Reference Ehret, Wolk and Szmrecsanyi2014), Grafmiller (Reference Grafmiller2014), Pijpops and Van de Velde (Reference Pijpops and Van de Velde2014), Wulff et al. (Reference Wulff, Lester and Martinez-Garcia2014), and Shih et al. (Reference Shih, Grafmiller, Futrell, Bresnan, Vogel and Vijver2015). The authors listed here have mostly not received formal training in variationist sociolinguistics, but the studies cited all utilize the variationist method as defined above. In short, this work would probably qualify in principle to be published in the journal Language Variation and Change.
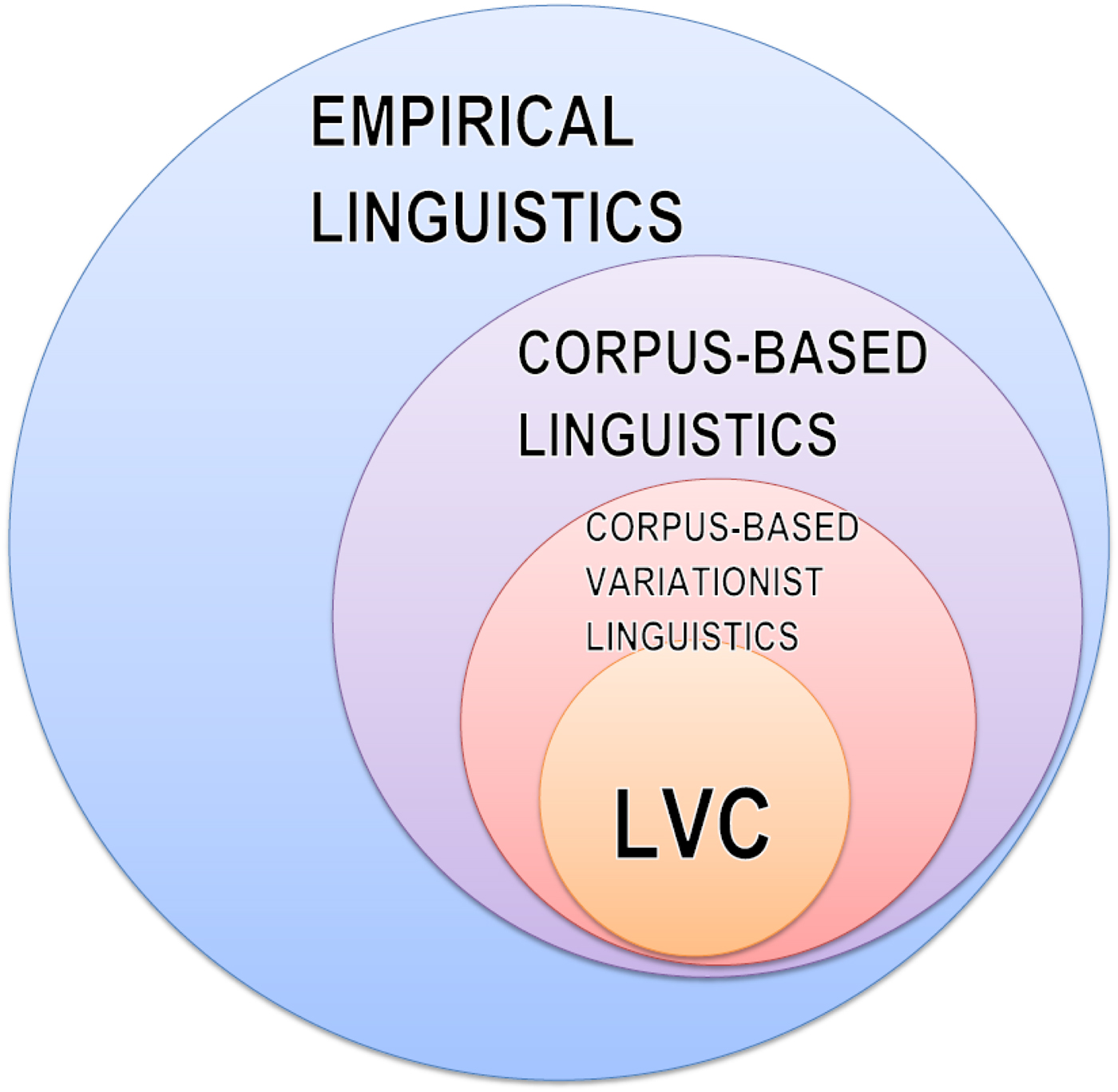
Figure 1: LVC versus other branches of empirical linguistics
Work by LVC practitioners, needless to say, also meets the criteria as set forth above, and so Figure 1 takes the liberty – perhaps somewhat provocatively – of mapping LVC as a sub-field of CVL, the justification being that the LVC approach can be seen as a particular way of doing CVL. That being said, it is clear that work by LVC practitioners is set apart from other work in the CVL domain by a number of emphases and practices that we will discuss in more detail in the next section. One should also keep in mind that this exercise in subsetting is to some extent anachronistic, in that historically speaking work in CVL has drawn inspiration from work in LVC, and not the other way round. Moreover, I concede that an argument could be made that the LVC circle in Figure 1 should extend beyond the CVL area, to the extent that LVC practitioners use, for example, experimental methods. And finally I hasten to add that the size of the circles is not necessarily proportional to the relative importance of the fields.
The remainder of this contribution is structured as follows. Section 2 catalogues a number of differences between CVL and LVC. In Section 3, I identify research questions and methodologies with regard to which LVC work may draw inspiration from work that has been carried out in the CVL community. Section 4 offers some concluding remarks.
2. Some differences between LVC and CVL
In terms of research emphases and practices, and as regards theoretical commitments, there are six major differences that distinguish work in LVC from work in CVL:
-
1. Almost needless to say, much LVC work takes an interest in how demographic factors such as speaker age, gender, education, or regional provenance engender variation. To the extent that CVL work is interested in sociolinguistic factors at all, it is typically rather macro-sociological drifts such as “economization” (the tendency toward informational compression) or “colloquialization” (use of informal language) that take centre stage (see, for example, Hinrichs and Szmrecsanyi Reference Hinrichs and Szmrecsanyi2007).
-
2. Since its inception, LVC as a field has taken a particular interest in phonetic variation (see Lavandera Reference Lavandera1978 for discussion). The focus on phonetic variation is by no means exclusive (see, for example, Weiner and Labov Reference Weiner and Labov1983 on the passive/active alternation), but it is undeniable that phonetics is going strong in the LVC community. By contrast, phonetic variation plays a minor role in CVL work (but see, for example, Rosenfelder Reference Rosenfelder2009), which instead tends to prioritize lexical (e.g., Heylen Reference Heylen, Kepser and Reis2005) and, in particular, grammatical (e.g., Lohmann Reference Lohmann2011) variation.
-
3. In the realm of language change, variationist sociolinguists have pioneered usage of the apparent-time construct (e.g., Bailey et al. Reference Bailey, Wikle, Tillery and Sand1991), which ingeniously allows the analyst to infer processes of change from synchronic datasets sampling multiple generations. Diachronically oriented CVL work, by contrast, prefers to track changes in real-time data (e.g., Szmrecsanyi et al. Reference Szmrecsanyi, Biber, Egbert and Franco2016a), drawing on increasingly massive historical corpora that cover, more often than not, a variety of written text types, such as A Representative Corpus of Historical English Registers (ARCHER) (Yáñez-Bouza Reference Yañez-Bouza2011).
-
4. More culturally speaking, fieldwork plays a big role in LVC training and research, and it is fair to say that many practitioners like to maintain a close relationship to their data. In the corpus community, by contrast, many corpus analysts are more than happy to draw on existing, publicly available (but anonymous) corpora. We also note that LVC analysts do not shy away from meticulous manual data annotation, which is seen as positive because manual annotation helps the researcher to keep in touch with the dataset. CVL analysts, by contrast, tend to be more interested in (semi-)automatic retrieval and annotation procedures. This difference may also partly explain why CVL analysts tend to be rather more enthusiastic about big data projects – the community is now turning to multi-billion word corpora such as, for example, the Corpus of Global Web-based English (Davies and Fuchs Reference Davies and Fuchs2015) – than LVC analysts are.
-
5. CVL analysts are often more adventurous than LVC analysts when it comes to experimenting with innovative analytic techniques. Corpus linguists have been the driving force beyond the development and application of more robust statistical techniques, which offer various practical and theoretical advantages compared to plain binary logistic regression. These innovative techniques include, for example, polytomous or multinomial regression (e.g., Han et al Reference Han, Arppe and Newman2013), multimodel inference (e.g., Grafmiller and Shih Reference Grafmiller and Shih2011), as well as more psychologically plausible models such as memory-based learning (e.g., Theijssen et al. Reference Theijssen, ten Bosch, Boves, Cranen and van Halteren2013) and naïve discriminative learning (e.g., Baayen et al. Reference Baayen, Hendrix and Ramscar2013).
-
6. Lastly, as regards theoretical commitment(s), corpus linguists tend to fall into two camps. On the one hand are those who eschew theoretical commitments and/or believe that doing corpus-driven linguistics is actually a theoretical commitment in its own right (e.g., Teubert Reference Teubert2005: 2). On the other hand are those who consider corpus linguistics a methodology to be utilized to address theory-inspired research questions. The vast majority of CVL analysts belong to the second category. The exact theoretical motivation for conducting CVL research varies substantially – the spectrum covers, for example, cognitive linguistics (e.g., Grondelaers and Speelman Reference Grondelaers and Speelman2007), psycholinguistics (e.g., Gries Reference Gries2005), dialectology/geolinguistics (Kolbe-Hanna and Szmrecsanyi Reference Kolbe-Hanna, Szmrecsanyi, Biber and Reppen2015), and second language acquisition research (e.g., Wulff et al. Reference Wulff, Lester and Martinez-Garcia2014) – but the least common denominator is that CVL analysts tend to view variation analysis as an exercise in usage-based linguistics, in the sense that grammar is seen as “the cognitive organization of one's experience with language” (Bybee Reference Bybee2006: 711). While this view is very mainstream in the CVL camp, the matter of usage- and experience-basedness appears to be a more controversial issue in the LVC community (see Guy Reference Guy2014 for discussion).
3. Cross-pollination potential
CVL is a comparatively young research orientation whose disciplinary roots are mainly in European-style corpus linguistics as represented in the work of scholars such as Geoffrey Leech, Christian Mair, and (to some extent) John Sinclair. But then again, historically speaking a major source of methodical inspiration for many people now engaging in CVL has been North American variationist sociolinguistics in the tradition of William Labov. Against this backdrop, this section investigates the extent to which inspiration may flow in the other direction as well: which features of CVL-style variation analysis may be of interest to LVC practitioners? In what follows, I discuss three areas with cross-pollination potential of this type: the tendency in CVL research to study more than one variable at a time (Section 3.1.), the more explicit attention paid to the nature of probabilistic knowledge (Section 3.2.), and the way CVL scholarship takes an interest in how register differences shape variation patterns (Section 3.3.).
3.1 More variables at a time
Much work in the LVC literature takes, in the parlance of Nerbonne (Reference Nerbonne2009: 176), a “single-feature-based” approach, in which the conditioning of individual (socio)linguistic variables is explored by looking at one variable at a time. This does not mean, of course, that multi-feature studies are completely absent from the LVC literature, or that their importance is not recognized: consider, for example, Rickford and McNair-Knox (Reference Rickford, McNair-Knox, Biber and Finegan1994), who study style-shifting based on a joint analysis of a comparatively large number of variables; Guy (Reference Guy2013), who investigates correlations among four sociolinguistic variables to show that individuals do not always use variables as coherently as one would think; or Meyerhoff (Reference Meyerhoff2017), who argues that conducting work at the intersection of language description and language variation necessitates looking at multiple variables (“symphonies of variation”). That being said, by and large it seems fair to say that the traditional way of doing things in variationist sociolinguistics is the single-feature way. By contrast, multi-feature research designs are comparatively more common, as I shall argue, in CVL circles, even though here as well much work is single-feature-based.
Multi-feature analysis has been an important theme in the corpus linguistics literature for a long while, going back at least to the Multi-Dimensional (MD) approach pioneered by Biber (Reference Biber1988). This particular approach is all about text frequencies and not at heart variationist, but the recent corpus literature showcases a number of ways to conduct variationist multi-variable research that may possibly inspire work in LVC. Corpus linguists have two motivations to investigate multiple variables: either to obtain a more reliable, stronger, or more multi-faceted linguistic signal through aggregation, and/or to investigate the extent to which variables are related or are interacting.
As to the first goal (increasing reliability), relevant work in the CVL tradition includes, for example, Szmrecsanyi (Reference Szmrecsanyi2013), a study that charts aggregate grammatical variation patterns in Great Britain's dialect landscape, based on data from the Freiburg English Dialect Corpus (FRED). The study is an exercise in “corpus-based dialectometry”, dialectometry being the branch of geolinguistics concerned with measuring, visualizing and analyzing aggregate dialect similarities or distances as a function of properties of geographic space. In this spirit, Szmrecsanyi (Reference Szmrecsanyi2013) investigates joint variation patterns of 57 grammatical variants (e.g., would versus used to as markers of habitual past, non-standard past tense done vs. standard did, and so on). Among other things, the analysis shows that linguistic gravity scores (see Trudgill Reference Trudgill1974), defined as two dialects’ population product divided by the square of travel time between them, is a better predictor of aggregate grammatical similarity than mere geographic as-the-crow-flies distance. In a somewhat similar spirit, Grieve et al. (Reference Grieve, Speelman and Geeraerts2011) aggregate over 40 high-frequency lexical alternation variables (e.g., if versus whether, maybe versus perhaps) in a 26-million-word corpus of letters to the editor covering written language usage in 206 cities from across the United States, and find that lexically speaking, there are five major dialect regions. With a similar interest in lexical variation, Ruette et al. (Reference Ruette, Ehret and Szmrecsanyi2016) conduct a joint analysis of no less than 303 lexical alternation variables (e.g., holiday versus trip, cost versus expense) in the Brown family of corpora of standard written-edited-published English, with the goal of determining the extent to which variation in the corpus material is systematically related to three lectal dimensions. In the order of their overall importance for explaining variation, these are discourse type/genre (informative versus imaginative), standard variety (British English versus American English), and real time period (1960s versus 1990s). Interestingly, in contrast to the other dimensions the study fails to identify distinctive lexical variables for the real-time dimension. CVL studies such as the ones sketched above share the view that single-feature study is inadequate when the objective is not to study particular features but to characterize multidimensional objects such as (dia)lects. Because the next feature down the road can and often does behave differently from a given feature (see Nerbonne Reference Nerbonne2009; Szmrecsanyi Reference Szmrecsanyi2013, chapter 7 for extended discussions), multi-feature analysis is needed to reliably characterize (dia)lects.
As for the second motivation, examples of studies going multi-variable in order to investigate the extent to which variables are related or are interacting include Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013), who investigate the English genitive, as in (1), and dative alternation, as in (2), in ARCHER, which covers written English in the Late Modern English period.
-
(1)
-
a. The president's speech (the s-genitive)
-
b. The speech of the president (the of-genitive)
-
-
(2)
-
a. The linguist sent the president a letter (the ditransitive dative variant)
-
b. The linguist sent a letter to the president (the prepositional dative variant)
-
Among other things, Wolk et al. aim to determine the extent to which the two alternations exhibit cross-constructional parallels. What they find is that the animacy constraint – animate possessors tend to favor the s-genitive, animate recipients tend to favor the ditransitive dative variant – started to weaken in both alternations at around the same point in real time. This raises the possibility that this set of grammatical changes had not only language-internal but also language-external causes, for the study observes (Wolk et al. Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013: 413) that the decline of the animacy constraint is in some genres paralleled by an increasing usage frequency of expressions referring to inanimate and collective entities.
A second example for CVL research looking into intercorrelations between variables is Hinrichs et al. (Reference Hinrichs, Szmrecsanyi and Bohmann2015), a study that investigates the relative importance of prescriptivism vis-à-vis other cultural developments that potentially constrain variation and change in written styles. Utilizing a variationist research design, the study is specifically concerned with relativizer choice in restrictive relative clauses with inanimate antecedents, as in (3):
-
(3)
-
a. This is the house that Jack built.
-
b. This is the house which Jack built.
-
c. This is the house _____ Jack built.
-
In written/edited/published British and American English from the 1961–1992 period as sampled in the Brown family of corpora, alternation among relativizers is undergoing a massive shift from which, as in (3b), to that, as in (3a), and the study takes an interest in the factors driving this change. On the one hand, style guides – in particular American ones – prescribe relative that and proscribe relative which in restrictive relative clauses; on the other hand, that is the more informal option compared to bookish which (see e.g., Tagliamonte et al. Reference Tagliamonte, Smith and Lawrence2005). To investigate whether prescriptivism or colloquialization is responsible for the shift, Hinrichs et al. (Reference Hinrichs, Szmrecsanyi and Bohmann2015) annotated tokens for a variety of language-internal (e.g., relative clause length) and language-external (e.g., genre) factors. Crucially, their annotation also included information about additional variables and features regulated by prescriptivism, such as the proscribed use of stranded prepositions and the prescribed avoidance of the passive voice in the corpus texts under analysis – the assumption being that if the that-shift is a prescriptivism-driven change, then those writers who use that at the expense of which should also be those who avoid, for example, preposition stranding and the passive voice. Using regression analysis Hinrichs et al. show, among other things, that avoidance of which correlates with avoidance of the passive voice (a formal feature) and a preference for the active voice (which happens to also be the colloquial option), but not with other prescriptive rules advocating formal variants. This, Hinrichs et al. interpret as evidence that we are dealing with a colloquialization change that, unusually, is backed up by the infrastructure of prescriptivism.
In summary, the CVL research reviewed in this section would seem to suggest that variationist analysis can profit from multi-feature research designs. More specifically, I have argued that the study of joint variation patterns yields, on the one hand, a more robust and reliable characterization of multidimensional (dia)lects – or community grammars, for that matter. On the other hand, multi-feature analysis can help us better understand how different features and variables interact, and to state, in the words of Nerbonne (Reference Nerbonne2009: 177), “general laws of linguistic variation”.
3.2 More attention to probabilistic knowledge
As befits a community that is in the business of conducting variationist sociolinguistics, LVC analysts are, as we have seen in Section 2, more often than not particularly interested in how language-external factors such as speaker age, gender, or education constrain variation patterns. This is not to say that LVC analysts are not also interested in the role that language-internal constraints play – on the contrary, constraint rankings and related measures play a key role in variationist/comparative sociolinguistics (Tagliamonte Reference Tagliamonte, Chambers, Trudgill and Schilling-Estes2001).
But recent CVL work suggests that there may be even more (theoretical) mileage to be gained from taking a close look at language-internal constraints, and from considering both what these reveal about the nature of (implicit) linguistic knowledge, and how this knowledge is dynamic across space, time, and speakers’ lifetimes. Take for example the variation-centered, usage- and experience-based probabilistic grammar framework developed by Joan Bresnan and collaborators (Bresnan Reference Bresnan, Featherston and Sternefeld2007, Bresnan and Ford Reference Bresnan and Ford2010). This research program marshals essentially variationist analysis methods to investigate syntactic variation phenomena such as the English dative alternation in naturalistic corpus data with optional experimental back-up (see below). The goal is to infer the extent and nature of grammatical knowledge from how language-internal constraints regulate language variation. Three assumptions inform this line of research: First, grammatical variation is sensitive to multiple and sometimes conflicting probabilistic constraints, which influence linguistic choice-making in subtle ways that may remain invisible unless analyzed quantitatively. Second, speakers have robust predictive capacities, and thus grammatical knowledge must have a probabilistic component. Third, this probabilistic component is derived in large part from language experience, and so is subtly, but fluidly (re)constructed throughout speakers’ lives.
It would seem that this theoretical orientation is a better fit for the LVC enterprise – in which probabilistic modeling has, needless to say, played a huge role right from the outset (e.g., Labov Reference Labov1969, Cedergren and Sankoff Reference Cedergren and Sankoff1974) – than certain more formal, less stochastic and more categorical theoretical orientations. To highlight the potential of the framework for understanding variation, consider for example Bresnan and Hay (Reference Bresnan and Hay2008), who investigate two publicly accessible corpora (Switchboard and the Origins of New Zealand English corpus) with an interest in how well probabilistic grammars designed to predict American English dative choices between sentences like those in (2) generalize to the syntactic choices that speakers of New Zealand English make. The study finds that for speakers of New Zealand English, animacy of the recipient is a more powerful determinant of these choices than it is for speakers of American English: “non-animate recipients are more likely to be used in the double object construction in the NZ than in US spoken data” (Bresnan and Hay Reference Bresnan and Hay2008: 252). Along similar lines, de Marneffe et al. (Reference de Marneffe, Grimm, Arnon, Kirby and Bresnan2012) investigate materials drawn from the Child Language Data Exchange System (CHILDES) to study whether children's dative choices are sensitive to the same constraints that regulate adults’ dative choices, and report that there is “usage-based continuity between child and adult grammars” (de Marneffe et al. Reference de Marneffe, Grimm, Arnon, Kirby and Bresnan2012: 26). A third example for this line of research is Szmrecsanyi et al. (Reference Szmrecsanyi, Grafmiller, Heller and Röthlisberger2016b) , who investigate three grammatical alternations (the genitive alternation, as in (1) above, the dative alternation, as in (2) above, and the particle placement alternation, as in ex. (3), in the International Corpus of English (ICE):
-
(4)
-
a. The linguist looked up the word. (verb-particle-object order)
-
b. The linguist looked the word up. (verb-object-particle order)
-
The goal of the study was to determine, among other things, the extent to which probabilistic constraints (and, by inference, the knowledge that language users have about these constraints) is stable as opposed to culturally malleable across native (e.g., British English) and postcolonial (e.g., Indian English) varieties of English. Analysis shows that there are subtle but significant “probabilistic indigenization” effects, defined as “the process whereby stochastic patterns of internal linguistic variation are reshaped by shifting usage frequencies in speakers of post-colonial varieties” (Szmrecsanyi et al. Reference Szmrecsanyi, Grafmiller, Heller and Röthlisberger2016b: 133). For example, in the particle placement alternation, increasing length of the direct object consistently favours the verb-particle-object order, but the effect is stronger in native varieties of English than in indigenized L2 varieties of English. The generalization is that the strength of such indigenization effects is proportional to the extent to which variables/alternations are tied to particular lexical anchors, such as particle verbs.
An interesting feature of research in this spirit is that corpus-based variation analysis can be optionally supplemented by experiments. Bresnan (Reference Bresnan, Featherston and Sternefeld2007: 76–84), for example, used a scalar rating task based on corpus materials (transcriptions of spoken dialogue passages) as stimuli to model subjects’ responses regarding the naturalness of dative variants in contexts. These responses were compared to the predictions of the dative alternation regression model reported in Bresnan et al. (Reference Bresnan, Cueni, Nikitina, Baayen, Boume, Krämer and Zwarts2007). The experiment showed that the likelihood of finding a particular linguistic variant in a particular context in a corpus tends to correspond to the intuitions that speakers have about the acceptability of the variants – hence, speakers’ implicit knowledge about language must be to some extent probabilistic.
The research designs reviewed in this section all take an interest in how mutable the effect of language-internal constraints is, in the (implicit) knowledge of this mutability, and in how this sort of mutability can be interpreted as a function of geographic, social, and/or cultural factors. This focus may be attractive to LVC analysts thanks to its compatibility with the variationist method, and because it offers a “balanced diet” (Guy Reference Guy2014: 59) consisting of both (abstract) constraints on variation plus a healthy dose of usage- and experience-based reasoning. Variationist datasets are rich data sources to further study the intersection between knowledge and variation, and LVC analysts may consider taking advantage of this.
3.3 More registers
It is clear that style and style-shifting have been of core interest to variationist sociolinguistics for as long as the field has existed, and interest in these concepts is not abating (see e.g., Bell Reference Bell1984, Rickford and McNair-Knox Reference Rickford, McNair-Knox, Biber and Finegan1994, and the articles in Eckert and Rickford Reference Eckert and Rickford2001). At the same time, though, LVC analysts tend to be especially interested in one particular register: vernacular speech as manifested in sociolinguistic interviews. Tagliamonte, for example, writes in her Reference Tagliamonte2012 textbook that “variation in language is most readily observed in the vernacular of everyday life” (page 2; see also Chambers Reference Chambers2003: 6). To some extent, of course, this focus on vernacular speech is linked to the research community's interest in phonetic variation (see Section 2): there is no point in considering written genres if one is interested in pronunciation features. But beyond that, vernacular speech does have a special status in LVC theorizing. It is in this style where variation is thought to be at its best, that is, most systematic: it is “the style in which the minimum attention is given to the monitoring of speech” (Labov Reference Labov1972: 208). What is more, there is a sense in the LVC community that variation grammars are stable in the face of style/genre/register-shifting, and that therefore variation patterns observed in vernacular speech can be generalized to other styles and registers (Guy Reference Guy2005; see also Labov Reference Labov2010: 265 and Rickford Reference Rickford2014: 596):
For the most part, stylistic variation is quantitatively simple, involving raising or lowering the selection frequency of socially sensitive variables without altering other grammatical constraints on variant selection; indeed, it is commonly assumed in VR [Variable Rule] analyses that the grammar is unchanged in stylistic variation..
Guy Reference Guy2005: 562At least to outsiders it would seem that this is a theory-driven a priori assumption rather than an empirical truth (but see Travis and Lindstrom Reference Travis and Lindstrom2016). Corpus linguists in particular would feel that this is an issue begging for more data-driven investigation and an open mind. Corpus linguists, after all, tend to emphasize that register variation is rampant in human language (Ferguson Reference Ferguson1983: 154), and so it is not surprising that register variation is an important topic – perhaps even the most important topic – in the corpus linguistics literature. And to many corpus linguists and CVL analysts it is just not immediately obvious that register-induced variation should be quantitatively simple, and that constraints on variation should be stable across registers.
Much previous corpus work on register differences has focused primarily on the text frequencies of particular linguistic features in particular registers: how often or rarely do we find particular linguistic features, such as passive constructions or causative verbs, in particular registers? The flagship method in this line of research is once again the Multi-Dimensional (MD) approach developed by Douglas Biber (Reference Biber1988), which measures co-occurrence patterns of linguistic features via frequency analysis. MD analysis has produced a number of invaluable results, but this line of research represents just one way of thinking about the difference that register makes. An alternative, variationist way of approaching register variation would ask not how frequently particular features are used in particular registers, but the following question: when speakers can choose between different ways of saying the same thing, what is the extent to which they draw on different choice-making processes in different registers?
This issue, while under-researched, should be dear to the hearts of both LVC and CVL practitioners. Indeed, preliminary corpus work suggests that linguistic choice-making is more sensitive to the situational context than many analysts of variation would suspect. Thanks to the fact that many major corpora are multi-genre corpora (for example, the well-known British National Corpus samples dozens of spoken and written registers), corpus linguists have had no choice other than to take register variation seriously, and have been developing ever more sophisticated research designs to control for register-induced variation (see e.g., Gries Reference Gries2015). And these sophisticated designs tend to show that choice-making processes may not be the same in different registers. Consider Grafmiller (Reference Grafmiller2014), who studies a number of publicly accessible corpora such as the Switchboard corpus and the Boston University Noun Phrase Corpus. The target phenomenon is the English genitive alternation exemplified in (1) above, which is conditioned by numerous semantic, syntactic and phonological constraints. Grafmiller models the influence of these factors across six registers/genres (conversation, learned writing, non-fiction, general fiction, western diction, press) using a regression design. His analysis uncovers substantial interactions between external, stylistic constraints and the probabilistic weights that language-internal constraints on genitive variation have. In model 1 (p. 482), for example, no less than five (possessor animacy, possessor givenness, possessor/possessum length, type-token ratio, possessor text frequency) of the nine language-internal constraints under study turn out to have significantly different effect sizes across registers. In short, Grafmiller (Reference Grafmiller2014) demonstrates that the probabilistic grammar of genitive choice is, in fact, massively sensitive to register effects.
Why should variationist sociolinguists care? Under the reasonable assumption that English genitive variation is not entirely atypical, massive register sensitivity à la Grafmiller (Reference Grafmiller2014) raises important theoretical and methodological questions about the nature and scope of variation, and about the interaction of this variation with socioculture: how different do probabilistic effects have to be before we can speak of entirely different grammars – do we need different effect directions, or will significantly different effect strengths do? And if we do find that different registers come with different register grammars, is that another way of saying that we are essentially dealing with polyglossic or multilingual behavior, as suggested by Guy (Reference Guy2015)? In the mind of many corpus analysts, these are questions worth asking, but to do so we need more empirical/variationist work to explore the differences that register makes. This means that we need to go beyond sociolinguistic interviews and vernacular speech (see also Rickford and Wasow Reference Rickford and Wasow1995: 128–129, D'Arcy and Tagliamonte Reference D'Arcy and Tagliamonte2015), to embrace, in a corpus-linguistic spirit, the full range of registers that we see when language is used.
4. Conclusion
I have argued in this article that the research questions and research methods in corpus-based variationist linguistics (CVL) are very close to those in the Language Variation and Change (LVC) community, and vice versa: variationist sociolinguists typically base claims about variation patterns on transcribed collections of naturalistic (vernacular) production data, and in so doing in fact utilize corpus-linguistic methods. On the other hand, CVL analysts adhere to the variationist method (definition of variables/alternations, accountability, statistical modeling) when they analyze corpus data. The fact that there are, as we have seen, a number of emphases and practices that set LVC work apart from work in CVL does not negate the fact that there is substantial overlap.
So what? The upshot is that it would seem unreasonable to set up a rigid dichotomy between CVL and LVC. This is no surprise to the vast majority of CVL practitioners, who historically speaking have drawn much inspiration from work in variationist sociolinguistics, methodologically and otherwise. In the LVC community, there are likewise many people who understand the extent of the cross-pollination potential. Having said that, I believe that there is comparatively more potential in the LVC community to more fully embrace the opportunities that inter-subdisciplinarity would afford. It is against this backdrop that I have sketched in this paper three ways in which CVL work may help inspire new ways of analyzing variation in LVC. CVL practices with cross-pollination potential along these lines include first, multi-feature designs, to increase empirical reliability and to facilitate the study of intercorrelations between variables; second, methodologies to explore the intersection between knowledge and variation (how malleable are language-internal constraints on variation?); and third, a commitment to consider the full breadth of registers that we find in corpora of naturally occurring language, for the sake of understanding better the nature and scope of variation.