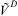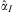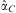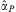Introduction
Distributive politics is a core issue in political economy, and scholars have developed a variety of models to explain how it works. In this article we test three key hypotheses that are derived from these models, using data that have not previously been applied to this problem.
The first is the ‘swing voter’ hypothesis, which predicts that politicians will allocate larger shares of distributive goods to interest groups or geographic areas that contain larger percentages of indifferent voters (those who are indifferent between the political parties on ideological grounds). The second is the ‘electoral battleground’ hypothesis, according to which distributive goods should be disproportionately allocated to electoral constituencies where the top two major parties have approximately equal numbers of supporters. This hypothesis is especially relevant in systems in which two major parties compete in first-past-the-post elections with geographically defined constituencies. The third is the ‘partisan supporters’ hypothesis, which conjectures that politicians will favour areas that contain a large percentage of their core supporters. They might focus their support in this manner to send clear signals to voters, induce a higher turnout or exploit informational advantages on policy preferences. For all three hypotheses, one underlying assumption is that politicians are mainly interested in winning elections, and that they target government transfers or projects to voters with given ideological attitudes or partisan leaning in order to attract their vote for this purpose.
Testing these hypotheses is difficult. It requires quantifying government spending across groups or geographic units of some sort (the dependent variable), as well as measuring the underlying partisan leanings or ideological attitudes of voters in each group or geographic unit (the key independent variables). The dependent variable is not too much of a problem, at least if one adopts the geographic approach, which is what all previous empirical studies have done by distributing spending across units such as districts, states or provinces. Measuring the key independent variables, however, poses a severe challenge. Researchers do not have good measures of the underlying partisan leanings or ideological attitudes of voters within each geographic unit. As a result, all but one of the previous studies uses proxy variables constructed from voting data or election outcomes. This approach is clearly problematic, however, since within models of distributive politics, voting decisions are – by assumption – endogenous to the distribution of government funds.Footnote 1
One important consequence of this endogeneity is that regression estimates of the effect of swing voters or electoral closeness on spending will often be biased toward zero. Overall, the pattern of estimates from existing studies is, in fact, quite mixed – some studies find statistically significant effects, but many do not. However, we do not know whether the large number of insignificant coefficients reflects the fact that there is truly no relationship, or whether it is simply the result of the endogeneity bias. Another consequence of endogeneity is that estimates of the effect of core supporters of the governing party will often be biased upward. We demonstrate these biases more clearly in a simulation exercise discussed below.
In this article we use survey data from exit polls, rather than voting data, to measure the party identification and ideological position of voters across constituencies. We then test the three hypotheses outlined above. The variables based on survey data (as we discuss in detail below) are likely to be more exogenous than variables based on votes. A second advantage of using survey data is that we can construct a direct measure of the fraction of ‘swing voters’ in each geographic unit, since we have the fraction that call themselves ‘Independents’ (not attached to either major party) and ‘moderates’ (not liberal or conservative). Previous studies have had to rely on proxy measures based on the variability of vote shares. The data are for US states, and the period we study is 1978–2002. The dependent variables measure the distribution of federal spending across states.Footnote 2
Our findings are easily summarized: We find little support for any of the three hypotheses listed above. We find no statistically significant support for either the swing voter hypothesis or the electoral battleground hypothesis. We find mixed support for the partisan supporters hypothesis. In any event, the magnitude of estimated coefficients is tiny, implying that any effects would be small. Thus, the allocation of federal spending to the states does not appear to be significantly distorted by strategic manipulation to win electoral support.
The use of survey data also allows us to go further than previous studies, by testing the hypothesis that government spending affects voting behaviour. We can estimate the impact of government spending in a geographic area on voting results by using survey-based measures of party identification and ideology as controls – in these analyses the dependent variable is vote choice and the independent variable of interest is the geographic distribution of federal spending. We find that spending has little or no effect on voters’ choices, while (not surprisingly) partisanship and ideology have large effects.
Before proceeding, we must discuss two important caveats to our measures. First, while it is likely that party identification and ideology are less affected by short-term forces than vote choices, party identification and ideology do change over time, both at the individual and aggregate levels, and may therefore be endogenous to federal spending. Secondly, since we rely on survey data – and our findings are largely null results – we must be especially attentive to measurement error.
Regarding the first concern, dozens of political science studies over more than fifty years have argued that party identification is very stable over time, and much less affected by particular short-term electoral circumstances than vote choice. This idea goes back at least to The American Voter, in whichFootnote 3 party identification is defined as a sense of personal, affective attachment to a political party based on feelings of closeness to social groups associated with the party. Green et al.Footnote 4 show that party affiliation is as stable as religious affiliation, and argue that ‘identification with the political party is analogous to identification with religious, class, or ethnic group’. In other words, according to these scholars, party identification is more of an identity than an opinion. Similarly, Goren shows that partisan identity is even more stable than core political values such as the principles of equal opportunity, limited government, traditional family values and moral tolerance.Footnote 5 Moreover, he shows that past party identification has a significant impact on current political values, while the reverse is not true. Ansolabehere et al. find that ideology is also quite stable, after correcting for measurement error.Footnote 6
Many scholars, however, are critical of the notion that party identification is affective. Party identification evolves over time, and many studies find evidence that it alters in response to changes in identifiable factors. These factors range from changes in individual personal circumstances (such as marriage, a new job or change in neighbourhood)Footnote 7 to more general forces (such as the mobilization of new or previously disenfranchised voters,Footnote 8 the performance of the economy under a partyFootnote 9 or major changes in the parties’ issue positions). For example, Abramowitz and SaundersFootnote 10 argue that the increased ideological polarization of the Democratic and Republican parties during the 1980s and 1990s generated a realignment of party loyalties along ideological lines, in part because this polarization made it easier for citizens to identify which party was the better match. As another example, the change in the parties’ positions on racial issues was a major determinant of realignment in the South.Footnote 11
While these factors are numerous, they are not likely to be problematic for our study for at least two reasons. First, these factors generally imply that aggregated party identification evolves slowly over time, while most of our analyses focus on short-term changes. Secondly, none of the factors is clearly related to the dependent variable of interest – geographically targeted federal spending.Footnote 12 Of course, we cannot rule out the possibility that some of the factors that influence the evolution of party identification might be indirectly related to the distribution of federal funds to the states, even in the short term. For example, although the empirical literature does not document such a relationship, it is possible that some voters respond to an increase in federal spending in their state by voting for the incumbent party, and that voting decisions influence voters’ party identification (at least as measured in exit polls or other surveys, possibly in order to avoid cognitive dissonance), and therefore that party identification is influenced by the distribution of spending. We argue, however, that party identification is noticeably ‘more exogenous’ than voting decisions. Thus, while the survey approach does not offer a definitive solution to the endogeneity problem, it is likely a step in the right direction.
Another potential concern with using survey or polling data is the underlying assumption that politicians use similar types of data – or at least highly correlated data – when making their decisions. Models of tactical spending are not explicit about the actual process political actors use to learn about voter preferences. Previous voting results, as well as polls and surveys, all provide important information. It is likely that rational politicians combine these various sources of information, rather than rely on a single measure. Polling data evidently looms large, however, as revealed by the large amounts of campaign spending devoted to collecting it. For example, in the 2008 US presidential election, the candidates spent $44.94 million on polling and survey research – 20 per cent of their overall campaign expenditure – making it the second largest item of campaign spending after campaign events (which accounted for 33 per cent).Footnote 13
A second concern, which is especially salient when using survey data, is measurement error. Survey research experts argue that measurement error varies considerably across items. Party identification appears to be relatively well measured, at least with respect to criteria such as reliability (inter-temporal stability in panels).Footnote 14 Other items, such as ideology, appear to be less reliable. However, while this may be a large problem for studies at the individual level, it is less of a problem for us since our focus is on state-level aggregates. We average hundreds or thousands of individuals, so even if the measurement error at the individual level is large, the measurement error in the aggregated measures should be small.Footnote 15 We revisit this issue in more detail below.
Previous Literature
One of the dominant theories in political economy is the ‘swing voter’ hypothesis. This theory posits that distributive goods will largely be allocated in favour of groups or regions that contain a conspicuous share of voters that are ideologically indifferent between the political parties. While voters with a clear partisan leaning rarely switch their vote to a different party, indifferent voters often do. If voters exchange their ideological stances for public funds and projects, then it is cheaper for politicians to ‘buy’ the votes of these indifferent (swing) voters, and competition for these voters will lead politicians to allocate disproportionate amounts of federal spending to regions or groups with many indifferent voters. Lindbeck and Weibull,Footnote 16 Dixit and LondreganFootnote 17 and StrombergFootnote 18 analyse models that capture this logic.
The logic of distributive politics is also affected by electoral rules. In particular, winner-takes-all systems create incentives to target constituencies that are likely to be pivotal.Footnote 19 In other words, battleground districts may be favoured both in public policy and campaign resources allocation.Footnote 20 The competitiveness of elections is particularly important in the US context, in which the electoral college system may encourage the channelling of resources toward states that are pivotal in the presidential electoral race.
A competing theory of distributive politics is that parties target spending to loyal voters.Footnote 21 This can be a rational strategy in the context of low-turnout elections such as those in the United States. If spending primarily mobilizes voters – either directly as a form of advertising or retrospective voting, or indirectly by buying the support of local elites or groups who engage in get-out-the vote efforts – then the marginal benefit of spending an additional dollar will be highest in areas with the highest density of a party's own voters. Credit-claiming issues may also provide incentives to target core areas. Who will attend the ribbon-cutting ceremonies for new bridges, schools, hospitals and libraries? In a heavily Democratic area the politicians will almost all be Democrats, and they will leave no doubt about which party is responsible for the locale's good fortune. In electorally marginal areas, however, roughly half of the politicians will be Democrats and half will be Republicans, and the impression is not likely to be as partisan or clear. Neither party may benefit much in terms of net votes (although individual politicians, running as incumbents, may benefit).
It is also possible that spending targeted toward loyal voters could simply reflect the fact that politicians are, at least to some extent, policy oriented.Footnote 22 Democratic politicians may prefer to spend on policies that tend to benefit Democratic voters, and likewise for Republicans. These alternate models are not necessarily incompatible with the swing voter hypothesis. For example, loyalists of the out-party may receive disproportionately small shares of the public dollar, while swing areas and loyal areas do equally well.
Finally, other theorists emphasize the importance of factors such as proposal power,Footnote 23 legislative seniority,Footnote 24 over- and under-representation,Footnote 25 committee structure, presidential leadership and universalism.Footnote 26 If factors such as these are the main drivers of distributive spending, then there may be little relationship between spending and partisanship or ideology.
There are many empirical studies of distributive politics, and the findings are mixed. In terms of the swing-voter hypothesis, studies of the allocation of New Deal spending have found some evidence that states with a more volatile presidential vote received more federal support.Footnote 27 However, Stromberg shows that these findings are not robust to the use of panel data methods with state fixed effects.Footnote 28 Similarly, a more recent study on federal budget allocation by contemporary presidentsFootnote 29 finds that states with more frequent presidential vote swings do not receive more funds. All of these studies use lagged presidential vote returns to measure the fraction of swing voters.
So far, there is little support for the battleground hypothesis, at least with respect to public spending. Wright finds that US states with close presidential races do not receive disproportionately more New Deal spending.Footnote 30 Similarly, Larcinese et al. find no evidence that states with close presidential races receive more federal monies.Footnote 31 On the other hand, several studies find that battleground states receive a disproportionate share of the advertising in presidential campaigns.Footnote 32 All of these studies use lagged presidential vote returns to measure the two-party balance in each state.
Several studies find evidence that loyal voters are rewarded. Some studies find a positive relationship between the share of federal spending going to an area and the Democratic vote in the area.Footnote 33 Since Democrats were the majority party in Congress during the years studied, this supports the idea that federal spoils go to the victors. However, the results might also reflect the behaviour of the Democratic party or characteristics of areas that tend to vote Democratic.Footnote 34 Some studies of US statesFootnote 35 find a positive relationship between federal spending and past vote for the incumbent president's party.Footnote 36
The empirical literature finds more support for ‘swing voter’ behaviour outside the United States. In particular, Indian states that are ‘swing’ but are also aligned with the governing parties are found to receive larger shares of public grants.Footnote 37 Dahlberg and JohanssonFootnote 38 find evidence that the more pivotal regions (of twenty) in Sweden were more successful in winning environmental grants from the central government. CramptonFootnote 39 finds a positive correlation between the competitiveness of the race and spending in Canadian provinces that are not ruled by the Liberal party. Milligan and Smart also study CanadaFootnote 40 and find that the closeness of an electoral race has a positive effect on spending, at least for seats held by the opposition party. Ward and John find evidence that central government aid to local governments in the UK goes disproportionately to marginal districts.Footnote 41 CaseFootnote 42 finds that during the Berisha administration in Albania, block grants tended to be targeted at swing communes. DenemarkFootnote 43 also finds evidence that marginal seats in Australia receive a disproportionate amount of local community sports grants.Footnote 44
Problems with Measures of Attitudes and Partisanship Based on Voting Data: a Simulation
As noted above, almost all of the existing empirical literature uses voting data to measure the percentage of swing voters, partisan balance or the partisan disposition of each state.
One powerful critique of these measures is that voting behaviour is endogenous. Most papers tend to use lagged values of the vote to mitigate the problem, but this is at best a partial solution for several reasons. The first has to do with the relationship between voting and policies. Voters can reward or punish politicians on the basis of their past budget allocations (retrospective voting) or on the basis of their promises about future allocations (prospective voting). Prospective voting is rational in an environment in which politicians keep their pledges. However, in this setting, lagged votes are a function of past promises, which by assumption should be equal to – or at least highly correlated with – current spending. If there is a high correlation, then measures based on past voting are not a satisfactory solution to the endogeneity problem. Even if voters are retrospective – so that past votes should not be automatically correlated with current spending – using lagged votes is potentially problematic. Secondly, budgetary allocations are quite persistent over time, because budgetary processes are sluggish and spending in any given year depends to a large extent on decisions made in previous years. As a result, even in the case of retrospective voting behaviour, lagged votes and current spending are related due to the strong correlation between past and current budgetary allocations. Finally, there is a third reason to suspect that lagged vote measures are not exogenous: omitted variables that are correlated with both voting and budgetary decisions. For example, some groups might be favoured in distributive policies because they are associated with ‘good values’ that citizens wish to preserve (such as farmers), and these groups might vote in particular ways (for example, they might favour conservative parties). The introduction of state fixed effects in panel regressions can deal with this problem when omitted factors are constant over time. Many potential omitted factors, however, are not time invariant. For example, changes in economic conditions, occupational structure, health outcomes, the cost of supplying various public goods or the flow of immigrants can simultaneously affect both political preferences and spending. In some cases we can simply measure these variables, but often measures are unavailable or noisy.Footnote 45
Since the measures used in the current literature to test concurrent theories of distributive politics are clearly endogenous under a variety of assumptions, regression estimates that use them are typically biased. The sign and magnitude of the bias, however, are more difficult to determine. In the simplest cases we can compute the expected bias analytically, but most regressions in the literature are fairly complicated, and typically include two or more vote-based measures in the same model. In such cases it is often quite difficult to calculate the signs and relative magnitudes of the biases analytically. We therefore ran a series of simulated regressions. These allow us to gauge the biases in a set of models that is similar to many of the standard models in the literature.Footnote 46
The simulations show that the endogeneity of voting data can lead to severely biased estimates. More specifically, using the standard deviation of observed votes, rather than the true number of Independents, can lead to either overestimation or underestimation of the impact of the number of Independents on the allocation of federal spending, depending on the specification and the set of variables included in the regression. The effect of electoral competition is often underestimated, but is sometimes also overestimated. Finally, using the observed votes to measure a region's partisanship leads to systematic overestimation of the impact of the number of partisan voters on spending.
We consider the following basic structure. Let j = 1 ,…, J index states, and let t = 1 ,…, T index years. Assume all states have the same population. Let Dj be the fraction of voters in state j that is loyal to party D, let Rj be the fraction that is loyal to party R, and let Ij be the fraction that is independent (swing voters). Also, let  $ {{\tilde{D}}_j}\, = \,{{D}_j}/({{D}_j}\, + \,{{R}_j}) $ be the fraction of all loyalists that is loyal to party D, and let
$ {{\tilde{D}}_j}\, = \,{{D}_j}/({{D}_j}\, + \,{{R}_j}) $ be the fraction of all loyalists that is loyal to party D, and let  $ {{\tilde{R}}_j}\, = \,{{R}_j}/({{D}_j}\, + \,{{R}_j})\, = \,1{\rm{ - }}{{\tilde{D}}_j} $. Let
$ {{\tilde{R}}_j}\, = \,{{R}_j}/({{D}_j}\, + \,{{R}_j})\, = \,1{\rm{ - }}{{\tilde{D}}_j} $. Let  $ {{\tilde{C}}_j}\, = 1{\rm{ - }}|{{\tilde{D}}_j}{\rm{ - }}{{\tilde{R}}_j}| $ be the two-party ‘competitiveness’, or partisan balance, of state j. Let
$ {{\tilde{C}}_j}\, = 1{\rm{ - }}|{{\tilde{D}}_j}{\rm{ - }}{{\tilde{R}}_j}| $ be the two-party ‘competitiveness’, or partisan balance, of state j. Let  $ X_{{jt}}^{D} $ be the per-capita transfers that party D offers to state j in year t, and let
$ X_{{jt}}^{D} $ be the per-capita transfers that party D offers to state j in year t, and let  $ X_{{jt}}^{R} $ be the offer made by party R. Let
$ X_{{jt}}^{R} $ be the offer made by party R. Let  $ S_{{jt}}^{D} $ be the ‘electoral support’ party that D receives in state j in year t, and let
$ S_{{jt}}^{D} $ be the ‘electoral support’ party that D receives in state j in year t, and let  $ S_{{jt}}^{R} $ be the support received by party R. Finally, let
$ S_{{jt}}^{R} $ be the support received by party R. Finally, let  $ \tilde{V}_{{jt}}^{D} $ be the fraction of votes that party D receives in state j in year t, and let
$ \tilde{V}_{{jt}}^{D} $ be the fraction of votes that party D receives in state j in year t, and let  $ \tilde{V}_{{jt}}^{R} \, = \,\,{\rm{1 - }}\tilde{V}_{{jt}}^{D} $. We assume:
$ \tilde{V}_{{jt}}^{R} \, = \,\,{\rm{1 - }}\tilde{V}_{{jt}}^{D} $. We assume:
 $$\,X_{{jt}}^{D} \, = \,{{\alpha }_I}{{I}_j}\, + \,{{\alpha }_C}{{\tilde{C}}_j}\, + \,{{\alpha }_P}{{\tilde{D}}_j}\, + \,\mu _{{jt}}^{D} $$
$$\,X_{{jt}}^{D} \, = \,{{\alpha }_I}{{I}_j}\, + \,{{\alpha }_C}{{\tilde{C}}_j}\, + \,{{\alpha }_P}{{\tilde{D}}_j}\, + \,\mu _{{jt}}^{D} $$ $$X_{{jt}}^{R} \, = \,{{\alpha }_I}{{I}_j}\, + \,{{\alpha }_C}{{\tilde{C}}_j}\, + \,{{\alpha }_P}{{\tilde{R}}_j}\, + \,\mu _{{jt}}^{R} $$
$$X_{{jt}}^{R} \, = \,{{\alpha }_I}{{I}_j}\, + \,{{\alpha }_C}{{\tilde{C}}_j}\, + \,{{\alpha }_P}{{\tilde{R}}_j}\, + \,\mu _{{jt}}^{R} $$ $$\quad \ \ \ S_{{jt}}^{D} \, = \,{{\beta }_I}X_{{jt}}^{D} {{I}_j}\, + \,(1\, + \,{{\beta }_P}X_{{jt}}^{D} ){{D}_j}\, + \, \varepsilon _{{jt}}^{D} $$
$$\quad \ \ \ S_{{jt}}^{D} \, = \,{{\beta }_I}X_{{jt}}^{D} {{I}_j}\, + \,(1\, + \,{{\beta }_P}X_{{jt}}^{D} ){{D}_j}\, + \, \varepsilon _{{jt}}^{D} $$ $$\quad \ \ \ S_{{jt}}^{R} \, = \,{{\beta }_I}X_{{jt}}^{R} {{I}_j}\, + \,(1\, + \,{{\beta }_P}X_{{jt}}^{R} ){{R}_j}\, + \, \varepsilon _{{jt}}^{R} $$
$$\quad \ \ \ S_{{jt}}^{R} \, = \,{{\beta }_I}X_{{jt}}^{R} {{I}_j}\, + \,(1\, + \,{{\beta }_P}X_{{jt}}^{R} ){{R}_j}\, + \, \varepsilon _{{jt}}^{R} $$ $$\tilde{V}_{{jt}}^{D} \, = \,S_{{jt}}^{D} /(S_{{jt}}^{D} \, + \,S_{{jt}}^{R} )\, \quad\qquad\qquad$$
$$\tilde{V}_{{jt}}^{D} \, = \,S_{{jt}}^{D} /(S_{{jt}}^{D} \, + \,S_{{jt}}^{R} )\, \quad\qquad\qquad$$where μ and ɛ are white noise error terms.
If αI > 0, βI > 0 and αC = αP = βP = 0, then we have a linearized approximation of the ‘swing voter’ model of Lindbeck and WeibullFootnote 47 and Dixit and Londregan.Footnote 48 If αP > 0, βP > 0, αI ≥ 0, βI ≥ 0 and αC = 0, then we have a version of the ‘machine politics’ modelFootnote 49 or what Fishbeck et al. call the mandate model. Finally, if αC > 0, αI ≥ 0, βI ≥ 0, βP ≥ 0 and αP = 0, then we have something approximating the model of Milligan and Smart,Footnote 50 or the electoral college model of Colantoni et al.,Footnote 51 StrombergFootnote 52 and others.Footnote 53
If researchers had direct measures of Ij, Dj and Rj, then they could construct  $ {{\tilde{C}}_j},\,{{\tilde{D}}_j} $ and
$ {{\tilde{C}}_j},\,{{\tilde{D}}_j} $ and  $ {{\tilde{R}}_j} $, and then directly estimate equations (1) and (2). In almost all cases, however, they do not. Instead, they use measures based on the actual vote shares,
$ {{\tilde{R}}_j} $, and then directly estimate equations (1) and (2). In almost all cases, however, they do not. Instead, they use measures based on the actual vote shares,  $ {{\tilde{V}}^D} $. Beginning with Wright,Footnote 54 researchers have often used the standard deviation of
$ {{\tilde{V}}^D} $. Beginning with Wright,Footnote 54 researchers have often used the standard deviation of  $ {{\tilde{V}}^D} $ over a set of elections within each state j as a proxy for Ij. Intuitively, if Ij is large, then
$ {{\tilde{V}}^D} $ over a set of elections within each state j as a proxy for Ij. Intuitively, if Ij is large, then  $ {{\tilde{V}}^D} $ will vary widely across elections in state j, and the standard deviation of
$ {{\tilde{V}}^D} $ will vary widely across elections in state j, and the standard deviation of  $ {{\tilde{V}}^D} $ in state j will be large.Footnote 55 Researchers also tend to use some historical average of
$ {{\tilde{V}}^D} $ in state j will be large.Footnote 55 Researchers also tend to use some historical average of  $ {{\tilde{V}}^D} $ as a proxy for
$ {{\tilde{V}}^D} $ as a proxy for  $ {{\tilde{D}}_j} $, and an analogous average as a proxy for
$ {{\tilde{D}}_j} $, and an analogous average as a proxy for  $ {{\tilde{R}}_j} $. Finally, researchers usually use some historical average of
$ {{\tilde{R}}_j} $. Finally, researchers usually use some historical average of  $ {\rm{ - }}|{{\tilde{V}}^D} {\rm{ - }}{{\tilde{V}}^R} | $ as a proxy for
$ {\rm{ - }}|{{\tilde{V}}^D} {\rm{ - }}{{\tilde{V}}^R} | $ as a proxy for  $ {{\tilde{C}}_j} $.
$ {{\tilde{C}}_j} $.
As noted above, there are many reasons why even historical voting measures are not exogenous: (1) rational prospective voting, (2) sluggish budgetary processes and (3) omitted variables that are correlated with both voting patterns and budgetary decisions. Although these three mechanisms are different, they have the same implication: patterns of current votes and current spending are interdependent. In the first case, the relationship between the contemporaneous vote and spending is driven by the link between past promises and current allocations. In the other two, it is due to the correlation of current spending with either past spending (because of inertia) or an omitted variable that is correlated with the vote. Rather than constructing complicated historical averages and autocorrelation structures that attempt to incorporate these features more precisely, we simply analyse the effect of the interdependence between vote and spending using contemporaneous voting data freely in our simulations. Let  $ \bar{V}_{j}^{D} \, = \,(1/T)\mathop{\sum}\nolimits_{t\, = \,1}^T \tilde{V}_{{jt}}^{D} $ be the mean of V D in state j over a sample of T years, and let
$ \bar{V}_{j}^{D} \, = \,(1/T)\mathop{\sum}\nolimits_{t\, = \,1}^T \tilde{V}_{{jt}}^{D} $ be the mean of V D in state j over a sample of T years, and let  $ {{\hat{I}}_j}\, = \,{{[(1/T)\mathop{\sum}\nolimits_{t\, = \,1}^T {{(\tilde{V}_{{jt}}^{D} {\rm{ - }}\bar{V}_{j}^{D} )}^2} ]}^{1/2}} $ be the sample standard deviation. Also, let
$ {{\hat{I}}_j}\, = \,{{[(1/T)\mathop{\sum}\nolimits_{t\, = \,1}^T {{(\tilde{V}_{{jt}}^{D} {\rm{ - }}\bar{V}_{j}^{D} )}^2} ]}^{1/2}} $ be the sample standard deviation. Also, let  $ {{\hat{C}}_{jt}}\, = \,1{\rm{ - }}|\tilde{V}_{{jt}}^{D} {\rm{ - }}\tilde{V}_{{jt}}^{R} | $ be the closeness of the election in state j in year t.
$ {{\hat{C}}_{jt}}\, = \,1{\rm{ - }}|\tilde{V}_{{jt}}^{D} {\rm{ - }}\tilde{V}_{{jt}}^{R} | $ be the closeness of the election in state j in year t.
We consider the following specifications:
 $$\openup 1pt{ & {\rm{Model}}\;1{\rm{a}}\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;1{\rm{b}}\;:\;X_{{jt}}^{D} \, = \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;1{\rm{c}}\;:\;X_{{jt}}^{D} \, = \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;2{\rm{a}}\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;2{\rm{b}}\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;2{\rm{c}}\;:\;X_{{jt}}^{D} \, = \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;3\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;4\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{I}_j}\, + \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr}$$
$$\openup 1pt{ & {\rm{Model}}\;1{\rm{a}}\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;1{\rm{b}}\;:\;X_{{jt}}^{D} \, = \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;1{\rm{c}}\;:\;X_{{jt}}^{D} \, = \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;2{\rm{a}}\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;2{\rm{b}}\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;2{\rm{c}}\;:\;X_{{jt}}^{D} \, = \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;3\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{{\hat{I}}}_j}\, + \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr & {\rm{Model}}\;4\;:\;X_{{jt}}^{D} \, = \,{{a}_I}{{I}_j}\, + \,{{a}_C}{{{\hat{C}}}_{jt}}\, + \,{{a}_P}\tilde{V}_{{jt}}^{D} \, + \,{{\mu }_{jt}} \cr}$$We only analyse party D, since analogous specifications for party R would simply duplicate the results. Note that in Model 4 we use the actual value of Ij rather than the vote-based measure. This value approximates the ‘encompassing models’ in Dahlberg and Johansson,Footnote 56 which include a survey-based measure of I, but a vote-based measure of VD.
In each simulation, we set J = 50 and T = 100, that is, fifty states over 100 years. Note that these parameters provide much more data on the time dimension than researchers actually have. We do this to focus attention more on the bias produced by endogeneity than on measurement error bias (which also plagues the literature). In all cases, I, D and R are drawn from independent uniform distributions on [0, 1]. Also, in each simulation, I, D and R are fixed for all 100 years (all t = 1 ,…, 100). Next, we choose values for the parameters αI, αC, αP, βI and βc. Finally, we draw μ D, μ R, ɛ D and ɛ R from independent uniform distributions. We set the standard deviations of μ D and μ R to σμ, and the standard deviations of ɛ D and ɛ R to σɛ.
We focus on four different cases. In Cases 1 and 2 there is no partisan targeting, that is, αP = 0. In addition, we assume there is no partisan voter response to transfers, that is, βP = 0. The difference between the two cases is the value of σμ, the degree to which the distribution of transfers across states is determined by random, idiosyncratic factors. In Case 1, σμ = 0.2, which indicates that the idiosyncratic factors are relatively important. In Case 2, σμ = 0.03, so the idiosyncratic factors are less important. In Cases 3 and 4 there is partisan targeting, with αP = 0.5. We also assume there is a partisan voter response, with βP = 0.5. The difference between the two cases is again the value of σμ, with σμ = 0.2 in Case 3 and σμ = 0.03 in Case 4. Within each case, we vary the parameters αI and αC. We fix βI = 1 and σɛ = 0.09 throughout the simulations.
For each vector of parameters we run 10,000 simulated regressions. Table 1 presents the results in four panels, each of which corresponds to one of the fours cases. Within each case, the rows correspond to different values for αI and αC. The true values are reported in the first two columns. The remaining columns report the averages of the estimates of the parameters of interest for various models  $ ({{\hat{\alpha }}_I},\,{{\hat{\alpha }}_C},\,{{\hat{\alpha }}_C}) $.Footnote 57 To give an example, if we take Model 2a, the first row gives the average estimates of, respectively, αI (0.01) and αC (0.09) when the true values of these parameters are both equal to zero.
$ ({{\hat{\alpha }}_I},\,{{\hat{\alpha }}_C},\,{{\hat{\alpha }}_C}) $.Footnote 57 To give an example, if we take Model 2a, the first row gives the average estimates of, respectively, αI (0.01) and αC (0.09) when the true values of these parameters are both equal to zero.
Table 1 Simulation Results

We observe a number of patterns. First, in most cases the average estimates of aP are biased upward. That is, there is a strong tendency to find ‘partisan targeting’ predicted by the mandate model or machine politics model, even when it does not exist. The effect is large when idiosyncratic factors have a large impact on transfers, which is a direct result of the assumption that independent voters respond to transfers in their voting behaviour. When one party happens to spend more than the other party in a state – whether due to the exogenous factors captured in μ D and μ R, or to actual partisan targeting – then many independent voters will vote for that party, producing a spurious additional correlation between transfers and votes.
Secondly, the average estimates of aI tend to be biased downward, but are sometimes biased upward. They can even have the wrong sign: this appears to be especially true when σμ is low and aI is high. The average estimates of aI are not even monotonic in the true value of αI, as we can see in Models 2b and 3 of Case 3.
Also, the average estimates of aI are often biased even when the true IJ is used (Model 4): this is because the other vote-based measures are endogenous and may be correlated with Ij. In fact, the bias on aI can be even larger using the true Ij: this is especially the case when the true Ij is low.
Thirdly, the average estimates of aC are sometimes biased downward and sometimes biased upward. When σμ is low the coefficient is generally underestimated, while if σμ is high then the coefficient can be biased both upwards and downwards, depending on the specification.
The difficulty in recovering the true parameters is well illustrated with Model 3, which is similar to many specifications used in the empirical literature. Here when σμ is high (Cases 1 and 3), the estimate of αP is systematically and substantially upward biased. If instead σμ is low (Cases 2 and 4), then we obtain a much more precise estimate of αP. This precision comes at the cost, however, of a deterioration in the estimates of αI. In fact, there appears to be a trade-off between the consistency of  $ {{\hat{\alpha }}_P} $ and the consistency of
$ {{\hat{\alpha }}_P} $ and the consistency of  $ {{\hat{\alpha }}_I} $. The intuition is straightforward. As noted above, a large degree of random variation in the allocation of spending induces more support to be directed at partisans simply by voters’ reaction to the spending. Many Independents therefore act as if they are partisans, generating a spurious positive correlation between observed votes and observed spending. At the same time, however, a more random allocation of funds facilitates the identification of the electoral response to spending. Since independent voters respond to spending, random variations in the allocation of funds will produce large fluctuations in their voting behaviour. Therefore the standard deviation of the vote is a relatively good measure of the proportion of independent voters. In fact, this means that we encounter a type of contradiction: the swing voter hypothesis is testable using voting data to measure the number of swing voters only insofar as it is false; that is, only insofar as funds are randomly allocated rather than targeted to independent voters.
$ {{\hat{\alpha }}_I} $. The intuition is straightforward. As noted above, a large degree of random variation in the allocation of spending induces more support to be directed at partisans simply by voters’ reaction to the spending. Many Independents therefore act as if they are partisans, generating a spurious positive correlation between observed votes and observed spending. At the same time, however, a more random allocation of funds facilitates the identification of the electoral response to spending. Since independent voters respond to spending, random variations in the allocation of funds will produce large fluctuations in their voting behaviour. Therefore the standard deviation of the vote is a relatively good measure of the proportion of independent voters. In fact, this means that we encounter a type of contradiction: the swing voter hypothesis is testable using voting data to measure the number of swing voters only insofar as it is false; that is, only insofar as funds are randomly allocated rather than targeted to independent voters.
The Data
We analyse US federal budget allocation to states from 1978 to 2002. We consider three dependent variables: (1) total federal spending per capita, (2) total spending other than direct transfers to individuals per capita and (3) federal grants per capita. The second variable should allow us to isolate the most manipulable items in the budget, since it removes the largest of the ‘non-discretionary’ or ‘entitlement’ programs, such as Social Security, Medicare, pensions for public officials, AFDC (TANF), etc.Footnote 58 The third variable is arguably the most targetable; while it is much smaller than the first or second, it still constitutes an important part of state finances. In all cases, our dependent variables are outlays.
It is important to note that there is a lag between the appropriation and spending of federal funds. This is relevant when estimating the effect of particular institutional and political variables, since current federal outlays have normally been appropriated in previous calendar years. For this reason, we will always consider lagged values of the political explanatory variables.
As noted above, one of the main independent variables of interest is the percentage of swing voters in a state. We use poll data to measure the share of ‘Independents’ (and also the share of Democrats and Republicans). This data comes from exit polls conducted by various news organizations – CBS News, CBS News/New York Times, ABC News, ABC News/Washington Post and Voter News Service.Footnote 59 Voters are surveyed briefly after leaving the polling booth, and asked how they voted. They are also asked to provide their party identification (Democrat, Republican, other or Independent) and their ideological leaning (liberal, conservative, moderate or don't know).Footnote 60 Importantly, these questions are designed to tap into voters’ general self-identification, rather than how they have just voted. Two typical forms of the party identification question are: ‘Regardless of how you voted today, do you normally think of yourself as a [Democrat], [Republican], [Independent], [Something Else]?’; and ‘Do you normally think of yourself as a [Democrat], [Republican], [Independent]?’ Two common forms of the ideology question are: ‘On most political matters, do you consider yourself [liberal], [moderate], [conservative]?’; and ‘Regardless of the party you may favor, do you lean more toward the liberal side or the conservative side politically [liberal], [conservative], [somewhere in between]?’Footnote 61
Using this information, we can construct state-level variables that report the percentage of voters that declare themselves Democratic, Republican or Independent. Due to the relatively small number of respondents in some states in some years, we aggregate the results over four-year periods (two elections). We also drop any cases with fewer than 100 respondents. This approach yields a sample size of 1,174 state-years for our analysis of total spending and grant spending, which is 2.1 per cent smaller than the maximum possible amount. In the resulting sample, the average number of respondents per state-period is about 3,700 and the median is about 3,300. Almost 87 per cent of the cases have more than 1,000 respondents, and only 1 per cent of the cases have fewer than 250. We assess the reliability of these variables with respect to exogeneity and measurement error problems in Section 4.1 below.
Endogeneity and Measurement Error in Survey Data
One concern is how well survey data can capture the distribution of partisanship within states. This issue is discussed extensively in Erikson et al.Footnote 62 They conclude that the partisanship measures derived from surveys correlate in the expected way with other observable measures, including other polls, election returns and party registration. We present some of our own checks below, and the results make us confident that these data capture the underlying distribution of partisanship by state relatively well and that they are preferable to using simple voting results.
Figure 1 plots the share of Democratic vote by state (averaged across all years) by the share of Democratic partisans in the survey data. Figure 2 does the same for Republicans. There is a clear positive correlation between votes and partisanship, especially for the Republican party. Although our purpose is to go beyond what can be captured by voting data, the correlation between the exit poll measures and observed votes is reassuring and suggests that our measure is a reliable indicator of partisanship. Of course, actual votes also include non-partisans, and final election results are crucially affected by the leaning, in a particular election, of independent voters. Hence, Figure 3 reports the aggregate Democratic share of votes at presidential elections and the share of Democratic supporters from exit polls: it clearly shows that partisanship is much more stable than what electoral results would suggest, and that using voting to measure partisanship can therefore be problematic.Footnote 63 In Figure 4 we report the standard deviation (over the period we consider) of presidential Democratic votes by state and compare with the standard deviation of party identification: again, this figure suggests that partisanship is much less volatile than voting. Hence, the exit poll data confirm the stable pattern of party identity variables found by other studies and support the notion that party identity is a long-term stable personal characteristic as opposed to the variable pattern of voting data.Footnote 64

Fig. 1 Democratic Vote Share and Partisanship by State

Fig. 2 Republican Vote Share and Partisanship by State

Fig. 3 Aggregate Democratic Vote and Partisanship over Time

Fig. 4 Standard Deviation of Democratic Vote and Partisanship by State Note: In this graph the states are listed in alphabetical order. The state code placement corresponds to the standard deviation of the Democratic vote in the state. The corresponding triangles represent the standard deviation of Democratic partisanship.
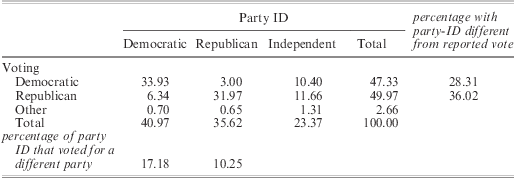
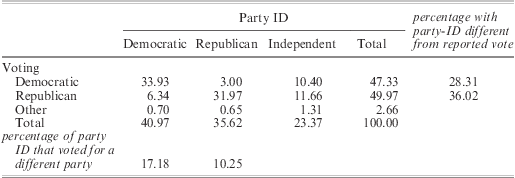
Although party identification is more stable over time than vote choice, it is not perfectly stable. It is likely that some of the observed instability represents real changes in respondents’ partisan loyalties. Some of the instability, however, might indicate unreliability in the measure, which is known to be a significant problem in surveys.Footnote 65 For example, a desire to avoid cognitive dissonance could induce voters to align their party identification response to the party for which they voted most recently.Footnote 66 For such voters, party identification is equivalent to voting data, and therefore equally endogenous. Table 2 provides some information about the possible magnitude of the problem in the exit poll data. The figures in the table show that, although there is a substantial overlap between party identification and reported voting choices, almost one in four voters declares himself/herself an Independent in spite of having voted for one of the two major parties. More than 28 per cent of respondents who reported having voted Democratic do not report a Democratic party identification. The percentage is 36 per cent for those voting Republican. Importantly, an overwhelming majority of self-declared Independents votes for one of the two major parties rather than for a third party or an Independent candidate. When we aggregate party identification at the state level, we again find an overall positive correlation between voting results and party identification in the states. This correlation is 0.31 for the Democratic party and 0.53 for the Republican party. Although the correlations between voting choices and party identification are positive, they are hardly overwhelming. The ‘slack’ indicates that party identification is not simply another measure of vote choice. Of course, we cannot entirely rule out cases of positive dissonance and other survey-related problems. It is indeed reasonable to presume that survey responses are not, for various reasons, entirely accurate. Our claim is more modest: using party identification constitutes a movement in the right direction, and therefore improves on existing studies.
Table 2 Cross tabulation of party ID and presidential voting decisions (percentage)
Examining split-ticket voting for different groups of identifiers helps us assess the degree to which party identification captures the relative degree of ‘independence’ in the vote choices of self-identified Independents and partisans. Data from the American National Election Study are revealing. A ticket splitter is defined as a respondent who voted for at least one Democrat and at least one Republican, in the elections for president, US House and US Senate held during the year of the survey.Footnote 67 For those respondents who voted in at least two races during the year of the survey, 42 per cent of pure Independents, 32 per cent of leaning Independents and 22 per cent of self-identified Democrats and Republicans were ticket splitters. These figures are similar to those in exit polls. In the exit poll data we have respondents’ vote choices for president, US House, US Senate and governor. For those respondents who voted in at least two races, 33 per cent of Independents (including leaners) and 22 per cent of partisans split their tickets in some fashion. Panel data allows us to use the initial party identification for each respondent and thereby mitigate the possibility of reverse causation (ticket splitters who self-identify as Independents, and those casting straight tickets who self-identify as partisans). We examine the 1992–1994–1996 elections, using party identification in 1992.Footnote 68 For those respondents who cast votes in at least four of the six or seven possible races, 75 per cent of pure Independents, 52 per cent of leaning Independents and 44 per cent of partisans exhibited at least one instance of a split. Thus, while party identification is not a perfect measure, it is quite stable over time and captures ‘independence’ in voting to a considerable extent.
Testing Distributive Politics Hypotheses Using Survey Data
One key prediction of the swing voter hypothesis is that states that have more Independents should receive more federal funds. The alternative theories of distributive politics conjecture that the competitiveness of elections and the share of loyal voters may also affect the distribution of federal funds to states. Thus, we will test these predictions by using measures of the share of Independents, of electoral closeness and of loyal voters that, differently from previous work, are not based on actual voting data but on survey data. Indicating with Dem, Rep and Ind, respectively, the share of Democrats, Republicans and Independents, we use Ind to measure the share of Independents and  $ (1{\rm{ - }}\left| {Dem{\rm{ - }}Rep} \right|) $ to measure closeness.
$ (1{\rm{ - }}\left| {Dem{\rm{ - }}Rep} \right|) $ to measure closeness.
We tried other measures of partisan and independent voters as well. Some voters may be ‘cross-pressured’, in the sense that they identify themselves with a party that is not the closest to them on the ideological dimension. This is the case for liberal Republicans (not uncommon in the Northeast) and conservative Democrats (still somewhat common in the South and West). Such voters are probably more prone to defect in any given election. Thus, we considered an alternative measure of independent voters, in which cross-pressured voters are included with the self-identified Independents. In this specification, partisan Democratic voters will therefore only be either liberal or moderate, while Republicans will only be either conservative or moderate. The substantive conclusions do not change when we use these variables, so we do not report the results.Footnote 69
As discussed in the introduction, swing voter models predict that states with a higher share of partisan and/or ideological voters should receive less funds, while models that stress the importance of loyal voters predict the opposite. If legislators reward their supporters, we should observe that incumbents divert money toward states that have a high share of voters that ideologically lean toward the incumbent legislator. In the US institutional setting, the incumbent is never a unitary actor, since federal budget allocation involves both Congress and the president. Therefore, we constructed different measures of partisanship by interacting the party affiliation of various actors with the shares of voters that declare themselves to have the same party affiliation as the actor under consideration. To evaluate whether the president favours his supporters we use the variable presidential copartisans, which is equal to the share of Democratic voters when the incumbent president is a Democrat and the share of Republican voters when the president is a Republican.Footnote 70
In addition to political considerations, a variety of demographic factors might directly affect federal spending. Thus, in all regressions we include per-capita income, percent of elderly, percent of population that is of school age, total state population unemployment and a dummy variable equal to one for state-years in which a natural disaster occurred.Footnote 71 Moreover, it is clear that the two states bordering the District of Columbia – Maryland and Virginia – receive more funds simply because of the spillover of federal government activities. A similar case can be made for New Mexico, because of the long-term investments in military spending. Thus, in the cross-section regressions we always include dummy variables for these three states.Footnote 72
The sources for all variables used in our analysis are reported in the Appendix.
Results
The simulation exercise shows that regressions based on voting data can be substantially biased. By using more exogenous measures based on exit polls, we should be able to obtain less biased estimates. It is therefore important to compare the results in the two cases in order to verify whether we obtain different estimates. We can then use the simulation exercise as a benchmark to evaluate the potential bias of estimated coefficients.
The key test of the swing voter model is whether the coefficients on the share of Independents is positive. Therefore, we compare the results obtained when the share of Independents from the exit polls is used as an explanatory variable with the results obtained when observed votes are used. In this case we use the standard deviation of Democratic votes in the previous three presidential elections. Since the ‘battleground state’ hypothesis stresses the role of state marginality, we also estimate regressions with closeness as the explanatory variable for spending. Results when the competitiveness of electoral races is measured using exit polls can then be compared with regressions when closeness is measured by using voting data. Finally, we test the alternative possibility that loyal voters get more funds. Again, we compare the results when the share of votes for the incumbent president is used as the explanatory variable with the results when exit polls’ partisan measures are used instead.
To evaluate the robustness of our results, we consider several possible variants of these basic models. We first consider specifications in which swing, pivotality and partisan measures are all included in the same regression. Since these measures are somewhat correlated, and since the various hypotheses regarding these variables are not logically incompatible with each other, specifications that include only one variable at a time might suffer from omitted variable bias. We also consider the possibility that the share of swing voters and the closeness could have a positive interaction. There is also the possibility that registration and primary laws induce people to register as Independents, which may then lead them to define themselves Independents in surveys. In particular, Massachusetts and Rhode Island allow citizens who are registered as Independents to vote in either major party primary (they simply choose on election day), while registered party members can only vote in that party's primary. Thus citizens have an incentive to register as an Independent. Therefore all regressions have been repeated with these two states excluded. We noticed very limited variations in the results (not reported).Footnote 73
The economic data are annual, but voting data are not available for years without an election. For these years we use the data from the closest previous election, which can generate autocorrelation in the residuals, along with the potential problems this generates for standard error estimates. Hence, in addition to using state-level clustered standard errors, we also run term-based regressions, in which each presidential term is collapsed into one observation and the spending and other control variables are averaged over the period.
Since we consider a large number of specifications, we only report the coefficients of our variables of interest in the main text (see Table 3).Footnote 74 We should point out that for the standard control variables, we do not find any significant surprises or noticeable differences across the various specifications. The percentage of the population that is elderly has a positive and significant effect on total federal outlays, while the percentage that is school-age children has a significant negative impact. The coefficient of population (in logarithm) is negative and significant in most specifications, while the coefficient of income per capita is negative and significant only when fixed effects are introduced.Footnote 75
Table 3 Summary of Spending Regression Results

Note: Each cell corresponds to a regression. In this table, we only report the coefficients of interest. Detailed results (and standard errors) can be found in the statistical appendix. β is the coefficient of the share of swing voters, γ is the coefficient of election closeness and δ is the coefficient of the share of partisan supporters. Models 1–6 test the three hypotheses separately; Models test them 7–8 jointly. In Models 1–3–5–7 our key variables are measured using exit poll data, in Models 2–4–6–8 they are measured using voting returns. When state fixed effects are not included, we introduce dummies for Maryland, Virginia and New Mexico. We use robust standard errors (clustered by state). * indicates significance at 10% level; ** at 5% and *** at 1%.
Share of Swing Voters
The key test of the swing voter hypothesis is whether there is a positive relationship between the share of Independents and spending. We begin with a simple scatter plot of the collapsed data, averaged over the period 1978–2002 (Figure 5). In each of the four graphs, the y-axis represents average federal spending other than direct transfers. The x- axis measures the share of swing voters in four different ways. In Figure 5(a), we use the average share of voters that identifies themselves as moderates; in 5(b) we use the share that identifies themselves as Independents; in 5(c) we use the share that identifies themselves both as moderate and independent; and in 5(d) we use the share that identifies themselves as both moderate and independent or who are cross-pressured (voters who are liberal and Republican or conservative and Democratic). Each graph also shows a line of the predicted values from a bivariate regression of spending on the corresponding x-variable. Evidently, the relationships are all relatively weak – none of the estimated slope coefficients are significant even at the 20 percent level. We can do a bit better by dropping the three states that are outliers in terms of average spending – Maryland, New Mexico and Virginia – or by including a dummy variable for these states. In this case the relationship between federal spending and the share of swing voters becomes statistically significant at the 10 percent level for the measure used in Figure 5(c), but not for the other three measures.

Fig. 5 Swing voters and targetable federal spending by state
Table 3 presents the main results, including estimates of the main coefficient of interest from Model 1 (with exit poll measures), Model 2 (with voting measures), Model 7 (with other political variables from exit polls also included) and Model 8 (with other political variables from voting data also included). We find little evidence that states with a larger share of independent voters receive more funds. This result is robust across various specifications, including whether we use yearly or term data, whether or not we include state fixed effects and whether we use federal expenditure, targetable spending or grants as our dependent variable.
The coefficients in Table 3 are not only statistically insignificant, they are also substantively small. For example, in Model 7 for grants, the point estimate implies that a one percentage point increase in the share of Independents in a state increases grants by about $2.80 per capita. The standard deviation of the share of Independents within a state is about 4 per cent, so a one-standard deviation increase in the share of Independents in a state increases grants by about $11.20. Since the average amount of grants per capita is about $500, this represents an increase of only about 2 per cent.
The situation is slightly different when we use the standard deviation of past vote. In this case, the coefficient is insignificant in cross-section regressions, but it becomes negative and significant in regressions with total federal spending (and, in one case, with targetable spending) when state fixed effects are included. This result is the opposite of what the swing voter model would predict: that a higher share of swing voters (measured by the standard deviation of the Democratic vote) induces less spending. However, this is also consistent with our simulations, in which we found that the coefficient of the share of independent voters tended to be biased downward when voting data are used, and could even assume a negative sign while the true parameter is positive. This result is particularly evident when we compare Models 7 and 8, that is, when we also consider closeness and partisan alignment within the same specification. A negative β in Model 8 (when voting data are used) is much more common than a negative β in Model 7 (when exit poll data are used), and is significant in some cases.
Overall, we find little support for the basic prediction of the swing voter model. States with more independent voters do not receive significantly more federal funds. Also, while based on the regressions with voting data one might be tempted to conclude that states with more Independents may actually be penalized, we can in fact conclude, also on the basis of our simulation exercise, that the negative sign is most likely due to endogeneity problems.
Battleground States
We conducted a similar investigation that focused on the competitiveness of the electoral races for president. In this case, the results using poll data (Model 3) and voting data (Model 4) are quite similar. For total and targetable spending, the coefficients on the competitiveness variable are negative – that is, states with closer races receive fewer funds – which is counter to the predictions of models based on the swing voter logic. However, this finding only holds in cross-section analysis. When we add state fixed effects, the coefficients on closeness become insignificant. The situation for grants is the reverse: the negative sign prevails when state fixed effects are included, but not in the cross-section analysis. The magnitudes are generally larger when we use poll data measures, except for grants. One important difference between the voting and exit poll regressions is that in the first case, the results are not robust to the inclusion of other political variables (Model 8), while the results in Model 7 (poll data) are quite similar to those of Model 3. We also found negative estimates when we removed the cross-pressured voters from the bulk of the partisans (not reported).
The main conclusion is that, when significant, the coefficient displays a sign that is opposite to what the ‘battleground states’ hypothesis would predict. Using voting data delivers a very incoherent set of results, which again conforms to the variability that we found in the simulation exercise. However, using the poll data does not seem to make any substantial difference in this case, although the results appear more robust to specification variations, at least in terms of the significance of the coefficients.
Partisan Supporters
An alternative to the swing voter hypothesis is that politicians reward loyal voters. We consider this possibility from the presidential point of view, since this is most common in the literature. Thus, we first consider the share of vote for the incumbent president's party as the relevant measure of state partisanship and use it as an explanatory variable of spending. On the other side, from the exit polls we know the share of voters that identifies themselves with each party and can therefore use this variable to measure partisanship. These alternative measures are considered in Models 5 and 6. Table 3 demonstrates that this is the only hypothesis that receives even partial support from the data. It is also clear, however, that using voting data to measure partisanship (Model 6) leads to a significant overestimation of this effect, which is consistent with the findings of our simulation exercise. In Model 6, the partisan share coefficient is always positive and, in some cases, significant at the 5 per cent level. In Model 5 the only significant coefficients are again positive, yet some negative coefficients occur and the magnitude of the effect is generally (although not always) smaller. Introducing other political variables (Models 7 and 8) induces some changes in magnitudes and significance levels. In this case the polling data measure of partisanship is always positive and, in four cases, significant at the 10 per cent level. Subtracting cross-pressured voters from the count of the partisans does not alter the results significantly. We conclude that this is the only hypothesis for which we find significant coefficients with the correct sign and never a significant coefficient with the wrong sign: the opposite of what we found in the previous cases. However, the estimated magnitudes remain rather small. Using the estimate of Model 7 for total federal spending with fixed effects and term time units (the largest significant  $ {{\hat \delta }} $ in Model 7), we have that a 1 per cent increase in the number of partisan supporters in a state corresponds to increased spending of $4.30 per capita.Footnote 76
$ {{\hat \delta }} $ in Model 7), we have that a 1 per cent increase in the number of partisan supporters in a state corresponds to increased spending of $4.30 per capita.Footnote 76
Reliability of Exit Poll Data
One concern is that our ‘null’ findings could be due to measurement error in the key independent variables. While measurement error in surveys is often a serious problem, two factors work to mitigate the problem in our case, as noted in the Introduction. First, previous worksFootnote 77 find that party identification is one of the most reliably measured items in surveys and polls. Second, other studiesFootnote 78 also find that aggregating across individuals sharply reduces measurement error.
A further concern is that the exit poll data have a 3-category scale of partisan identification (Democrat, Independent and Republican) rather than the 7-category scale typically found in surveys (Strong Democrat, Weak Democrat, Independent Leaning Towards Democrats, Independent, Independent Leaning Towards Republicans, Weak Republican and Strong Republican). Given our largely null findings, we are particularly concerned about possible measurement error. The main potential problem here is with the classification of ‘leaning’ Independents. Our measure includes these voters with Independents. However, many analysts argue that ‘leaning Independents’ vote more like weak partisans than ‘pure’ Independents. We check whether this matters using the Cooperative Congressional Election Study of 2006, which uses a 7-point classification that allows us to distinguish between ‘pure’ and ‘leaning’ Independents. First, we find that at the state level the correlation between the average party identification using 3-point scale and the average using the 7-point scale is 0.99. Secondly, again at the state level, the correlation between the share of ‘pure’ Independents and the share of ‘pure and leaning’ Independents is 0.67. This correlation is relatively high (although not as high as we would like). Thirdly, we conducted a cross-sectional analysis to predict the average distribution of federal government spending for the years 2000–2002, and found that the results are quite similar using both measures of Independents (these results are not reported but are available on request). In all cases, the coefficient on the variable measuring the share of Independents is small, negative and statistically insignificant.
Effects of Government Expenditures on Voting
Our previous results cast some doubt on the idea that voters are responsive to the receipt of federal funds. In fact, one of the premises of the swing voter model is that politicians can buy votes by allocating spending to certain groups: swing voters are then simply cheaper to buy, given their lack of unconditional attachment to a given party. Hence, in this section we turn to the other side of the coin and ask whether voters do in fact respond to favourable spending by rewarding incumbent politicians.
The relationship between spending and vote depends on how rational voters use their ballot to provide incentives to politicians. If voters are retrospective, they reward politicians for their past performance – that is, they are more likely to vote for an incumbent if they received more federal transfers when he or she was in power. On the other hand, if voters are prospective, then campaign promises should be the main driver of voting patterns.Footnote 79 The use of individual-level data can advance our understanding of voting behaviour in response to governmental transfers. Some recent studiesFootnote 80 examine individual-level survey data on ‘expressed political support’ and ‘vote intentions’, and find that beneficiaries of targeted transfers declare an increased political support or propensity to vote for the government implementing them, thus providing indirect evidence of retrospective voting behaviour. On the other hand, Elinder et al.Footnote 81 use survey data on individual voting from the Swedish Election Studies, and find that voters respond to promises rather than to implemented policies, which suggests that prospective voting is important.
In our work, we estimate the impact of federal spending on individual voting decisions using voting records from exit polls, which have the desirable feature of collecting information from actual voters when they exit the polling station. Our data also allow us to control for partisanship and ideology, which to a large extent mitigates possible endogeneity problems for the spending variable. On the other hand, since we have information on federal budget allocations to the states (outlays) but not on spending proposals, we can check whether voters respond to received transfers (that is, if they behave retrospectively), but not whether they react to promises (that is, if they are prospective).
We analyse voting decisions in presidential, gubernatorial, Senate and House elections. In the first three cases, the swing voter model would posit that incumbents are rewarded for voters’ receipt of federal funds, and therefore the dependent variable is a dummy equal to 1 if the voter chooses the incumbent (or a candidate from the incumbent's party). In the case of the House, we cannot predict how the funds flowing to a state should affect voting for particular incumbents, since many states have House incumbents from different parties running simultaneously. Moreover, we only know the state of each voter, not his/her district. Thus, in this case the dependent variable is a dummy equal to 1 if a vote is cast for a Democratic candidate, and the explanatory variable of interest is an interaction term between the amount received and the share of Democratic representatives from the state.Footnote 82
Table 4 reports our estimations when a state's total federal expenditure is used as the explanatory variable. It is clear that the fact that a state receives more federal funds does not induce its citizens to cast more votes in favour of incumbents. The coefficient of total federal expenditure can even be negative, and never reaches a 5 per cent significance level, in spite of the very large number of observations. On the contrary, partisanship and ideology have large effects. These results are consistent with BartelsFootnote 83 and others, who find that partisanship has a large impact on voting at both the presidential and congressional level.
Table 4 Effects of Spending on Voting Decisions

Note: The table reports probit coefficients. All regressions include a constant, year dummies, state fixed effects and the following control variables: income per capita, percentage of the population that is school age, percentage of the population over 65, total population, unemployment rate and dummy equal to 1 for unit-periods in which a natural disaster occurred. The House regressions also include dummies for Democratic partisanship, Republican partisanship, liberal ideology and conservative ideology. Partisan match is a dummy equal to 1 if the voter has the same partisanship as the incumbent politician. Ideology match is a dummy equal to 1 if the voter is liberal and the incumbent politician is a Democrat, or if the voter is conservative and the incumbent is Republican. Robust z-statistics in parentheses (clustered by state). * significant at 10%; ** significant at 5%; *** significant at 1%.
When we use targetable spending, our results do not show substantial variations, with the exception of a positive coefficient on the probability of voting for an incumbent governor. Even in this case, however, the significance level (10 per cent) appears rather weak for a sample of this size. For presidential elections we again encounter a negative coefficient, although it is only significant at the 10 per cent level. Grants are totally insignificant in the president, governor and senator equations. Instead, they appear to have a positive impact on the probability of voting for a Democrat in Congress when the majority of state representatives in Congress are Democrats. This is the only coefficient that is significant at the 5 per cent level. Although this might be explained by the inability to identify voters’ districts,Footnote 84 it is also consistent with related findings by other studies.Footnote 85
Overall, the evidence that receiving more federal funds induces voters to reward incumbent politicians is rather weak.Footnote 86 One possible objection to this conclusion is that, according to swing voter models, both candidates converge on the same platform in equilibrium; hence in equilibrium, we should expect no effect, but this does not imply that voters would not react to spending proposals. The idea that electoral competition induces platform convergence appears, in reality, to contradict the historical evidence. The two major American parties have often proposed very different platforms on spending, as well as on other matters.Footnote 87 Although identifying causal relationships is not straightforward, there appears to be a clear correlation between platform proposals and implemented policies, which is consistent with the ‘mandate’ model.Footnote 88 In addition, numerous studies of taxation, spending and macroeconomic policies find clear correlations between the partisan composition of Congress and policy outcomes, which are consistent with a model of policy divergence.Footnote 89 At the district level, the situation does not appear much different: individual candidates for the House have also been shown to systematically assume divergent positions.Footnote 90 In addition, Poole and Rosenthal and Lee et al. document stark differences in the roll call voting positions of Democrat and Republican representatives elected from districts with very similar partisan balances.Footnote 91
Another possible explanation for our findings is that although parties (or candidates) do not converge, our estimates nonetheless capture equilibrium behaviour that masks structural coefficients. For example, if candidates typically manage to meet voters’ expectations (or fulfill their campaign promises) regarding spending, then we may find little correlation in the data because we do not observe ‘out-of-equilibrium’ behaviour. Since rational prospective voters reward politicians based on the expectation that they will be faithful to their election pledges, we would only observe a reaction of voters to past policy if promises are not kept. Such a reaction is unlikely whenever a large share of campaign pledges is enacted, as is the case for the United States.Footnote 92 Thus, while our findings are consistent with the hypothesis that voters rarely respond with their votes to public spending in a clear and systematic way, further research is clearly needed to rule out other possibilities.
Conclusion
Our findings regarding the allocation of federal spending across US states are disappointing for theories of distributive politics, but are good news for the working of institutions that are designed to provide checks and balances and prevent legislators from abusing their power by tailoring budget allocations to their political goals. We find little robust evidence to support the notion that parties target areas with high numbers of swing voters. Using polling data, the estimated effect of the share of voters that self-identifies as Independent is statistically insignificant and usually substantively small. Using voting data, the estimated effect of the ‘volatility’ of the partisan vote is often negative, rather than positive as predicted by the swing voter model. We also find no consistent support for the notion that parties target battleground states, and limited and mixed support for the notion that parties target areas with high numbers of their partisan supporters. Finally, we find no significant effect of distributive spending on voting decisions. Thus, it seems most likely that, to the extent that partisan targeting occurs, it is driven more by the policy motivations of politicians or interest groups than by strategic calculations to win electoral support.
Alternatively, if politicians are informed about the preferences of particular groups of voters for some specific spending items, they might try to gain their support by increasing spending on such items at the expense of others. In this case, the strategic manipulation of the budget would affect its composition, but not necessarily the overall amount of funds allocated to a particular geographic unit.Footnote 93
Our findings might reflect features of distributive politics that are particular to the United States. The US Congress is one of the most powerful and decentralized national legislatures in the world. It strictly controls the public purse. Committees are powerful, and jealously guard their own jurisdictions. Strong norms of seniority rule give committee leaders and members a substantial degree of independence from party leaders. Individual senators and representatives frequently pursue their own re-election goals, working to ‘bring home the bacon’ for their state or district. The federal structure of the United States, with its strong and autonomous state governments, further complicates the situation. For example, many federal grants to states are either matching or project grants, and decisions by state governments therefore affect where federal money flows.
As a result of these factors, the president may have relatively little influence over the geographic distribution of federal expenditures. Perhaps, even though he would like to target swing states or swing voters, he cannot. As noted above, studies of other countries have found more support for the swing voter and battleground hypotheses. Further investigations in other institutional settings are necessary to establish the validity of this conclusion.
Appendix: Variable Definitions and Sources
• Exitpoll data. We use questions on reported vote, party identification and ideology. Party identification questions are typically of the form: ‘Regardless of how you voted today, do you normally think of yourself as a [Democrat], [Republican], [Independent], [Something Else]?’ ; ideology questions are typically of the form: ‘Regardless of the party you may favor, do you lean more toward the liberal side or the conservative side politically [liberal], [conservative], [somewhere in between]?’ The share of Democrats (or Republicans, Independents) is then constructed by aggregating individual observations by state. We have proceeded analogously for the ideology data. This information is available every two years but is aggregated over four-year periods to avoid small samples in some states. Only samples of at least 100 observations have been used. Very few cases have been deleted using this method. All regressions have been repeated not excluding these cases, and they deliver the same results. Once obtained, the 4-year aggregate data have been smoothed by assuming that variations in ideology and partisanship are gradual (and keeping the years of presidential elections fixed). For example, D 1985 = 0.25D 1984 +0.75D 1988; D 1986 = 0.5D 1984 + 0.5D 1988; D 1987 = 0.25D 1984 + 0.75D 1988. The data obtained using this procedure have been finally lagged by one period. The share of swing voters is measured by the share of Independents. Closeness is measured as 1−∣D−R∣. Partisanship for the incumbent president is D when the president is Democratic and R when the president is Republican. Sources: CBS News, New York Times, ABC News, Washington Post, Voters News Service.
• Spending data. Federal expenditure, targetable expenditure and grants are all in real and per capita terms. Targetable spending is total federal expenditure minus direct payments to individuals. Source: Statistical Abstract of the United States.
• Voting data. Defining
 $ \tilde{D} $ as the share of Democratic vote in the last election and $ \tilde{R} $ as the share of Republican vote in the last election, we always consider $ D\, = \,\tilde{D}/(\tilde{D}\, + \,\tilde{R}) $ and R = 1−D. Swingness is measured as the standard deviation of D in the previous three presidential elections. Election closeness is defined as 1−∣D−R∣. The share of vote for the incumbent president is D when the president is Democratic and R when the president is Republican. Source: Statistical Abstract of the United States.
$ \tilde{D} $ as the share of Democratic vote in the last election and $ \tilde{R} $ as the share of Republican vote in the last election, we always consider $ D\, = \,\tilde{D}/(\tilde{D}\, + \,\tilde{R}) $ and R = 1−D. Swingness is measured as the standard deviation of D in the previous three presidential elections. Election closeness is defined as 1−∣D−R∣. The share of vote for the incumbent president is D when the president is Democratic and R when the president is Republican. Source: Statistical Abstract of the United States.• Socio-economic data. Real income per capita, population (in logarithms), percentage elderly (above sixty-five), percentage school age (5–17) and unemployment rate are taken from the Statistical Abstract of the United States. Disaster declarations are taken from the Federal Emergency Management Agency.