



Decades after the advent of the behavioral revolution in the study of politics, political representatives' behavior remains a key research subject in political science. Contemporary studies address topics such as political elites' strategic voting behavior (Brown and Goodliffe Reference Brown and Goodliffe2017), the micro-foundations of elite decision making (Linde and Vis Reference Linde and Vis2017), local interest representation by elites and its consequences (Rogers Reference Rogers2017), and elites' responsiveness to news and social media (Barberá et al. Reference Barberá2019). Systematic information about political elites is therefore frequently sought in the discipline (see Appendix Figure A1).
Despite this prolonged demand, there is a shortage of large-scale, cross-national and longitudinal sources of such information (Gerring et al. Reference Gerring2019). Consequences of this paucity include recurring and redundant data collection efforts, analyses limited to narrow time frames and single countries, varying data quality and evidence foundations, and adverse conditions for replication. Country- or topic-specific datasets often exist in isolation. Recently, scholars have thus called for more systematic datasets that bridge field-specific gaps in legislator data (Krcmaric, Nelson and Roberts Reference Krcmaric, Nelson and Roberts2020).
We approach this problem by unifying heterogeneous and collaborative micro-data collection efforts. A large volume of user-generated information about legislators is available on the web. We bring these sources together using the open-collaboration platforms Wikipedia and Wikidata to help overcome the limitations of previous projects and create a comprehensive data infrastructure. The Comparative Legislators Database (CLD) is a one-stop shop for rich, diverse and integrated individual-level data on national political representatives. Our focus on the national level is motivated by scholars’ interest in (see Appendix Section A) and the extensive availability of crowdsourced information about this group of legislators.
The CLD currently covers 45,540 contemporary and historical politicians elected to 338 legislative sessions in ten national legislatures: the Austrian Nationalrat, the Canadian House of Commons, the Czech Poslanecká Sněmovna, the French Assemblée, the German Bundestag, the Irish Dáil, the Scottish Parliament, the Spanish Congreso de los Diputados, the United Kingdom House of Commons and the United States Congress. Features are recorded in linked content-specific datasets and include political, sociodemographic, career, online presence, public attention and visual information. The database gains substantive coverage through an integration with renowned political science datasets, including information such as votes, speeches and legislation. This bridges the unconnectedness of datasets, thus strengthening the consistency and diversity of data across countries. In addition, the architecture of our database makes it easy to connect other existing and future datasets, which will make it possible to further develop, step by step, a centralized data pool. We provide free and fast open-source software with targeted access to the CLD. We illustrate the utility of the database with two example applications including the study of dynamics of public attention to political representatives and a comparative analysis of legislative turnover over several decades. The conclusion discusses further potential areas of application.
Existing Projects and Demand For Data
Considerable efforts have been made to assemble information about elected officials. Data projects have emerged especially for US legislatures, which are frequently the subject of political science research (for example, Bonica Reference Bonica2016; CQ Press 2018; Inter-university Consortium for Political and Social Research and McKibbin Reference McKibbin1997; Vote Smart 2018). Although less extensive, similar efforts have traveled beyond US borders, for instance for the UK House of Commons (Eggers and Spirling Reference Eggers and Spirling2014) or the German Bundestag (Sieberer et al. Reference Sieberer2020). While geographically confined and often equipped with a substantive and temporal focus, these single-country projects continue to assist research on political representatives.
In recent years, data collection efforts surrounding legislative elites have gained pace. Several projects have taken on the ambitious task of assembling information in a cross-national and longitudinal fashion (Azavea 2018; Bailer et al. Reference Bailer2018; Gerring et al. Reference Gerring2019; MySociety 2018; Wagner et al. Reference Wagner2017). The Parliamentary Careers in Comparison (Bailer et al. Reference Bailer2018) project, for example, collects fine-grained biographical and career-related data on parliamentarians in three European democracies since the Second World War. In an unprecedented effort, the Global Leadership Project (Gerring et al. Reference Gerring2019) relies on country experts to compile socio-demographic and political background information on over 38,000 politicians from 145 countries between 2010 and 2013.
Notwithstanding the contributions of these advances, they illustrate a pervasive data collection trade-off: an increase in spatial coverage comes at the cost of temporal scope and substantive depth, and vice versa. This compromise is rooted in gathering information mainly through primary data collection. Fielding expert surveys or employing human coders is expensive. Given limited project budgets, high development costs naturally require a trade-off and restrict a project's scope or substantive focus.
This trade-off has implications for the applicability of existing projects. Substantive problems and data requirements differ vastly. Projects with broad geographic coverage enable a comparative perspective, yet may lack detailed information required for more specific questions. Conversely, specialized projects may not be applicable to the countries at hand. Complementing data with the means of integrating into other projects or domain-specific datasets can go a long way. However, existing data projects usually do not provide such data linkage.
Finally, the increased costs of data collection have consequences for the public availability and lifespan of data projects. Resource-intensive approaches generate incentives to put data under embargo and to retain the first-user publication advantage. Limited financial-planning horizons also make it difficult to keep projects alive in the long run.
To provide a picture of the demand side for data on political representatives, we conducted a survey of articles published in five top political science journals between 2009 and 2018 (see Figure 1 and Appendix Section A). The results echo the landscape of existing projects and the consequences of the discussed trade-off.

Figure 1. Data on national legislators in 209 articles from five political science journals
Almost half of the surveyed studies engaged in original data collection (47 per cent). A majority of studies working with legislator data focus on the United States (63 per cent). Research comparing representatives from different countries is quite rare (10 per cent). The substantive demand is largely oriented at political behavior variables, such as roll-call votes or ideology estimates, reported in prominent single-country datasets. Studies usually also cover rather short time windows (median = 10 years) and focus primarily on recent sessions. We suspect a regional bias in the availability of single-country data, and restrictions in the applicability and accessibility of existing cross-national and longitudinal projects as the main causes of these patterns.
We respond to these findings by shifting the task from primary data collection to bringing together collaborative micro-data collection efforts and integrating existing projects. To achieve these objectives, we rely primarily on the open-collaboration platforms Wikipedia and Wikidata. These platforms provide a steady and mostly standardized flow of information. Our approach requires minimal employment of manual labor and financial resources, allowing the CLD to grow in all directions and making it sustainable.
Data Collection
Figure 2 illustrates our data collection and processing workflow, broken down into four steps. Step 1 (entity identification) uses Wikipedia as a starting point for three reasons. First, Wikipedia is one of the largest data sources on politicians in the world. Secondly, the micro-data collection efforts of the many volunteers on this platform allow us to crowdsource the primary data collection part. Thirdly, Wikipedia provides information on elected officials in a largely consistent structure across countries and over time. Legislators are commonly listed on parliament- and session-specific pages.Footnote 1
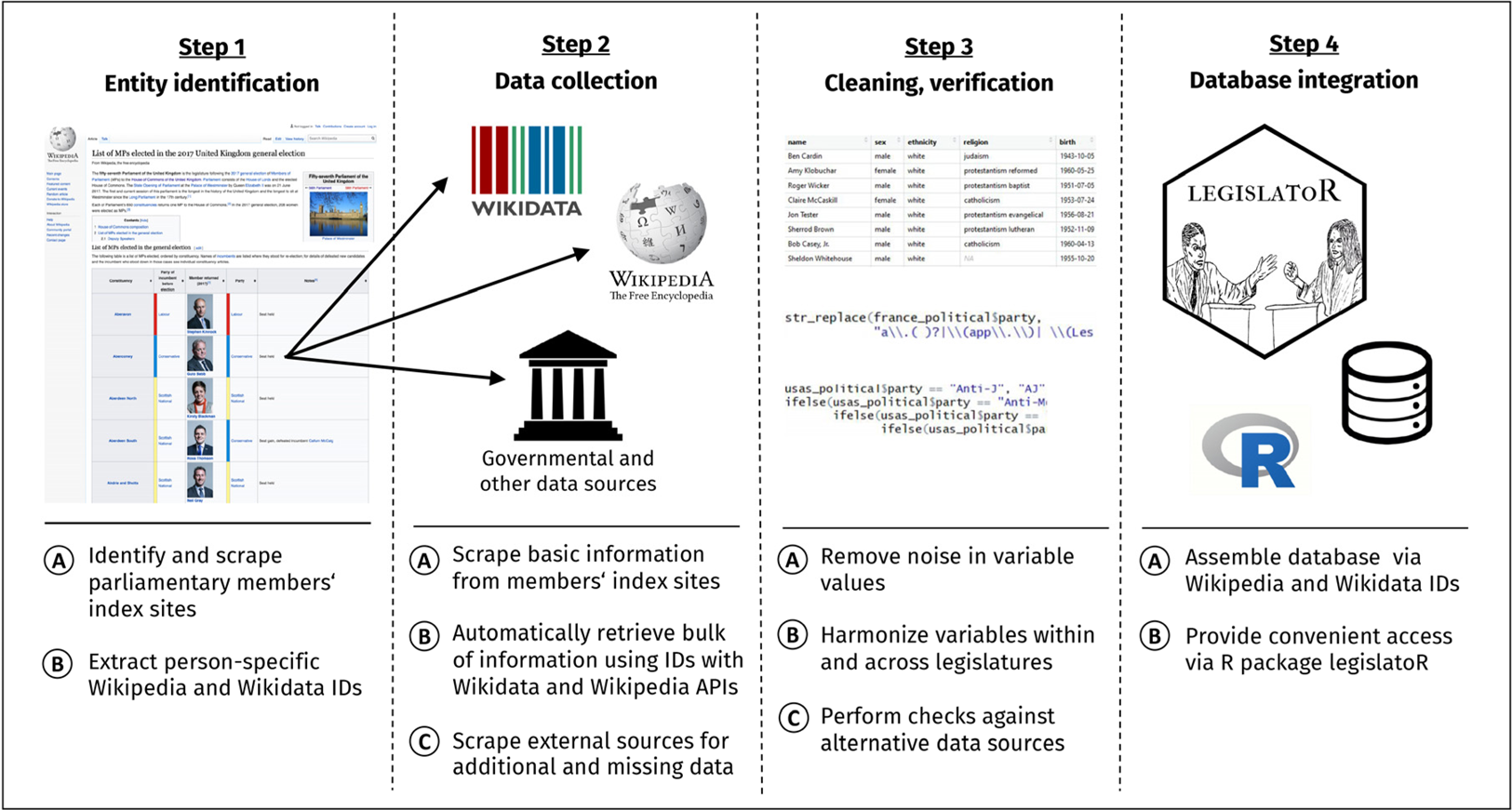
Figure 2. Data collection and processing workflow
In Step 2 (data collection), we scraped basic information from the index sites and used the gained IDs to query Wikipedia and Wikidata's Application Programing Interfaces (APIs) for various legislator features and external identifiers. Based partly on this information, we located and consulted other databases, such as parliamentary websites, to reduce the amount of missing information.
Data were cleaned, harmonized and verified in Step 3. Much of the data came from Wikidata, which is pre-structured, so little cleaning was necessary. Variables were harmonized across legislators to create consistent value schemes. To supervise data quality, checks against alternative data sources were performed for sampled entries.
In Step 4 (database integration), the legislature- and content-specific datasets were integrated into a global database. A consistent architecture across all tables was established and made openly accessible via the legislatoR R package. More details on individual steps are reported in Appendix Section B.
Content, Architecture and Access
The CLD consists of nine tables for each country (see Figure 3). A table with socio-demographic data (Core) sits at the center. It includes a legislator's name, sex, date of birth and death, ethnicity, religious affiliation, and geographic coordinates for place of birth and death. Political information is stored in a second table (Political). It provides the legislative period a representative was elected to, when that session started and ended, party affiliation, constituency, duration in office, government membership and leader indicators for each session.

Figure 3. Structure of the database
Two more tables deliver information about legislators' public offices (Offices) and professions (Professions). Both contain descriptions with Boolean values indicating membership. In accordance with growing interest in elite behavior on the internet, another table includes social media handles and URLs of personal websites (Social). To support image-based analyses, the CLD also provides a table that stores URLs of legislators' portraits (Portraits).
For every legislator's article, Wikipedia documents the process of information generation and its consumption. This metadata is stored in two additional tables. Revision records are reported with an identifier that locates information directly on Wikipedia (Wikipedia History). User names, (internet protocol addresses) IDs of (non-registered) editors, the date, time, size and comments of revisions are stored too. Long-term records of the daily views received by each page are reported since 2007 (Wikipedia Traffic).
A central feature of the CLD is its integration with other projects. A final table includes several individual identifiers, for instance, for linkage to official parliamentary websites or political science datasets (IDs). We have integrated the CLD with bills, votes and ideology estimates in the US Congress (Adler and Wilkerson Reference Adler and Wilkerson2018; Lewis et al. Reference Lewis2019), roll-call votes from the German and UK legislatures (Eggers and Spirling Reference Eggers and Spirling2014; Sieberer et al. Reference Sieberer2020), and plenary speeches held in Austria, the Czech Republic, Germany, Ireland, Spain and the UK (Herzog and Mikhaylov Reference Herzog and Mikhaylov2017; Rauh, De Wilde and Schwalbach Reference Rauh, De Wilde and Schwalbach2017). This integration offers the means to discover new avenues for research and perspectives on long-standing questions.
All tables come in a format familiar to social scientists: every row represents a politician, every column a variable. This makes it easy to extract, filter, transform, sort, aggregate and visualize information. To promote usability, tables are arranged in a relational fashion. Two legislator-specific keys, the Wikipedia page and the Wikidata ID, link all tables to the Core. This offers an intuitive organization that facilitates targeted access.
The CLD is hosted online and access is managed via R, an open-source software environment for statistical computing. We opted for R because it is one of the most popular data analysis programs used in the social sciences. We programmed an open R package that implements fast, targeted and memory-efficient access without having to download the full database. Appendix Section F contains instructions for installing and working with the package.
Application 1: Tracking Public Attention Paid to Legislators with Wikipedia Page Views
We present two applications that highlight the three core strengths of the CLD in comparison with existing projects. First, it facilitates the exploration of new and partly untapped data, such as metadata from Wikipedia. Secondly, it makes it easy to conduct comparative research on legislative elites. Thirdly, it helps evaluate long-term trends in elite behavior.Footnote 2
A central motivation to study political elites is their key role in shaping public discourse. However, politicians differ vastly in their factual power and the attention they attract from the public and the media. Scholars have quantified these traits using newspaper data, for instance (Ban et al. Reference Ban2019). Alternatively, we can use Wikipedia page traffic – that is, how often an entry has been accessed on a given day by ordinary users of the encyclopedia (Munzert Reference Munzert2018). More prominent politicians should receive more extensive attention. Figure 4 shows analyses of page traffic data for members of the 115th Congress between 2017 and 2018. Even in a sample of articles on high-profile political elites like these, there is considerable variation in attention. Panel 4b reports the ten top and bottom members by average daily views. Top-ranking politicians, with high name recognition and media presence, receive thousands of daily page views on average, whereas rank-and-file members get no more than a few dozen. This corroborates the face validity of the measure for public attention.
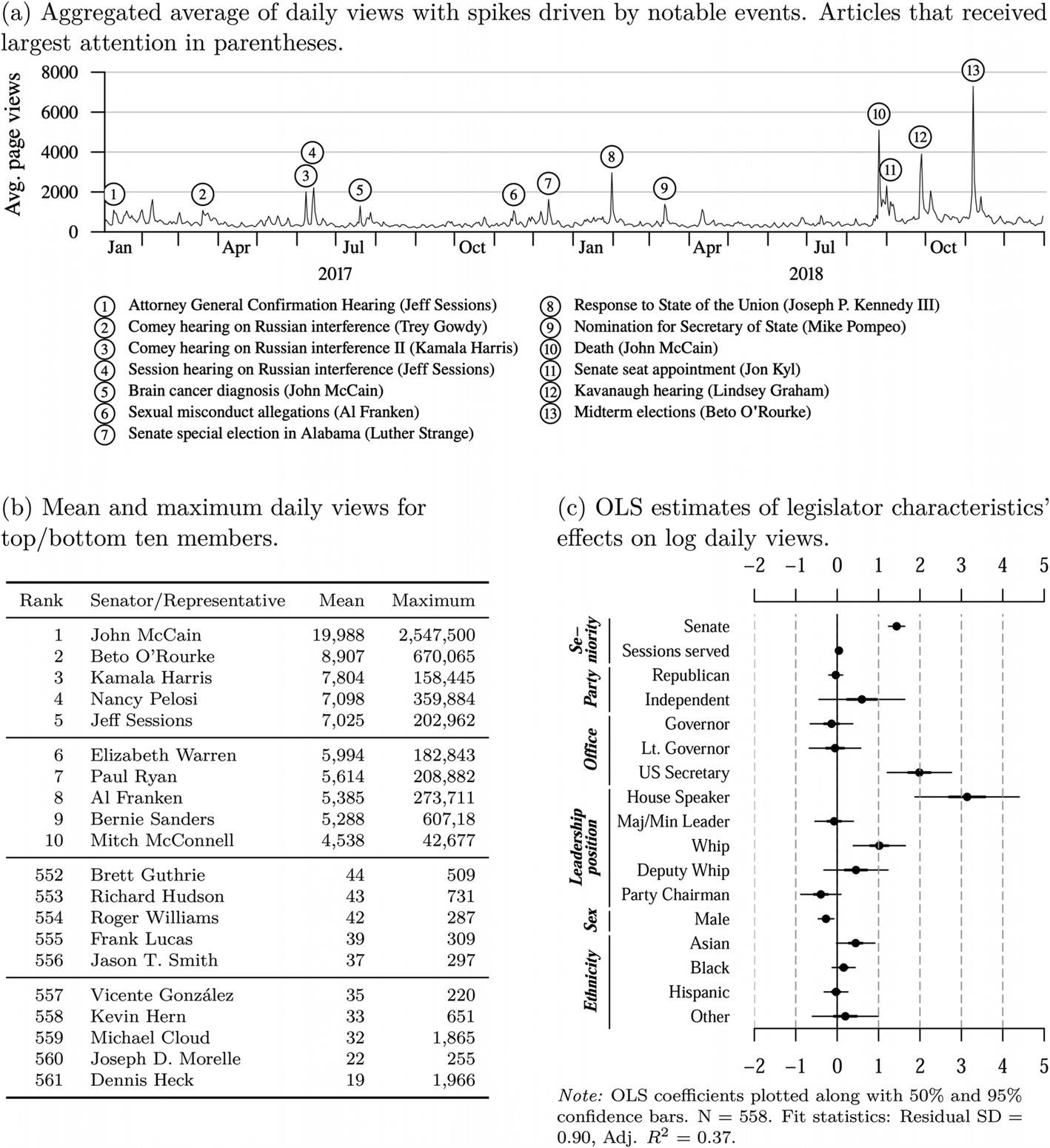
Figure 4. Descriptive statistics and predictive model of Wikipedia page views of members of the 115th US Congress
In addition to baseline differences, Panel 4a shows how offline events correspond to spikes in the time series of aggregated average daily views. While some events are directly linked to the legislator covered in the article (such as news on John McCain's brain cancer diagnosis and his death about one year later), others demonstrate how legislator activity can raise awareness in the public. Both Trey Gowdy and Kamala Harris's public attention benefited from their performance in the Comey hearings, and Joe Kennedy III attracted nationwide interest when he offered his response to the State of the Union in January 2018.
The ordinary least squares model in Panel 4c investigates whether attention to legislative elites in terms of Wikipedia article views is largely idiosyncratic and driven by exogenous shocks, or whether systematic factors have any predictive value. On average, senators are substantively more prominent than house members (corresponding to 370 per cent higher attention in terms of article views), and members with US secretary appointments receive more attention than former state officials (680 per cent). However, while prominent leadership positions, such as Speaker of the House, are also reflected in page views (2,480 per cent), the ranking of party leader positions does not translate into received attention. More attention is also paid to female legislators (24 per cent) and, in part, ethnic minorities (Asian 60 per cent). Overall, the structural factors predict a modest portion of the variance in logged daily views (adj. R 2 = 0.37).
Appendix Figures D1 to D8 provide replications of the page view analyses for the other legislatures represented in the CLD. Across all settings, spikes in aggregated viewership can be linked to significant events, the rankings of politicians by average page views have high face validity, and legislator characteristics predict a fair share of the variance in logged daily views. While more research is needed to evaluate the use of Wikipedia viewership metadata for analyzing political elites, we have shown that the data provides meaningful signals on the relative public attention legislators receive. Furthermore, the fact that the measure provides a metric that is comparable across contexts is beneficial for comparative research.
Application 2: Investigating Legislative Alternation and Renewal
Legislative turnover, the share of new (as opposed to re-elected) legislators, is an important measure of elite circulation. It serves as a diagnostic tool for assessing the representativeness and functioning of parliaments (Putnam Reference Putnam1976). Turnover can be categorized as either alternation or renewal (François and Grossman Reference François and Grossman2015). Alternation is an aggregate measure of newly incoming legislators that lumps together politicians who are entering parliament for the first time and past members who, after having lost their mandate at some point, are returning to parliament. Renewal refers to only new, first-term legislators. Prior comparative research focuses on alternation and is restricted to a few decades or, at best, the post-World War II period (Gouglas, Maddens and Brans Reference Gouglas, Maddens and Brans2018; Matland and Studlar Reference Matland and Studlar2004).
We use the CLD to trace both alternation and renewal during the entire history of ten legislatures (yielding more than double the number of sessions previously investigated). The solid line in Figure 5 represents the results for legislative alternation. For Germany, Ireland, Spain, the UK and the United States, we find averages of alternation that are 5 to 20 per cent larger than previously reported (Matland and Studlar Reference Matland and Studlar2004). This may be partly due to the prior omission of parliamentary foundation periods, which are characterized by greater instability and shortsightedness. For instance, the UK is commonly viewed as a consistently low-turnover country with an upward trend (Gouglas, Maddens and Brans Reference Gouglas, Maddens and Brans2018; Matland and Studlar Reference Matland and Studlar2004). Yet, we find turnover fluctuations of around 40 to 50 per cent. A large drop is only apparent after the Second World War, when it moved to around 20 per cent and has not displayed a clear direction since.

Figure 5. Legislative turnover in ten legislatures
Regarding renewal, we corroborate prior findings showing a substantive number of returning politicians among incoming legislators in France (François and Grossman Reference François and Grossman2015). Measuring only alternation can indeed hide potential vulnerabilities in the electoral connection, due to the retention of power and the manifestation of a ruling class. However, we observe similar patterns only for Ireland and Spain. For other countries, alternation is either congruent with renewal or has become so during the last few decades. Especially for the UK and the US, a drop in alternation rates is slightly compensated by the absence of returning politicians. That said, turnover reached alarmingly low levels, especially in the United States.
The applications illustrate the CLD's potential to examine diverse questions. Future research can build on these analyses and use the CLD to gain further insight into the historical development of individual career choices or how individuals achieve prominence on their way from being a freshman to a figure of importance in national politics.
Discussion
As with any large-scale data collection effort, the CLD comes with limitations and potential biases. In this section, we put them into perspective and point to future work on the database.
Coverage Bias
The collaborative micro-data collection efforts on Wikipedia and Wikidata are limited by the population of people contributing to these projects. In the CLD, this is reflected in an over-representation of legislatures from the Western hemisphere. We aim to address this issue by covering more legislatures over time. As full coverage of legislators was a key consideration in our choice of countries (see Appendix Section C for a comparison to existing, comprehensive lists of legislators), non-random missingness of elites within legislatures is currently not an issue. A more serious concern is item non-response – that is, non-randomly missing information on features. We checked missingness on various variables by legislatures (see Appendix Figure C1) and by core demographics (see Appendix Table C1). Religion, ethnicity and portrait data are generally sparsely populated, and recently active legislators are better covered than those from early sessions (recency bias). However, we do not find evidence of ethnic minority or gender biases (if anything, more missings occur for men, which is likely confounded with recency bias and women entering parliaments rather late).
Data Quality
We argue that the collaborative nature of Wikipedia and Wikidata works against measurement errors due to flawed variable codings. While anybody can edit information on these platforms at any time, Appendix Figure C2 shows that content creation on legislators’ Wikipedia pages balances editor experience and collective intelligence. To check whether this control mechanism works as expected, we compared the CLD with hand-coded information from other projects. Appendix Figure C3 shows an almost 100 per cent agreement for every variable we checked. In the few cases of disagreement, the CLD was either on par with other projects or yielded the correct information more often. We additionally conducted a Google search for official information on 500 randomly drawn legislators and confirmed most of the information in the CLD (see Appendix Figure C4). Where we could not confirm information, this was mostly because information was not traceable. Only in rare cases could we actually disconfirm information in the CLD. In any case, the CLD is updated frequently, so its quality and exhaustiveness should further increase over time.
Breadth of Coverage
The CLD does not claim to be complete in terms of features. While it is strong on both breadth and depth, the focus is on providing a consistent set of features over all covered legislatures and allowing extensibility by linking to other, more specialized data sources.
Conclusions
Learning about political representatives requires a diverse array of information. This includes behavioral data and metadata, as much as static characteristics and historical information. The CLD provides a central hub for these data and a starting point for students of legislative elites.
On a practical note, the CLD affords a first overview of potentially important data. This is followed by the swift and easy access to and integration of a variety of different types of data. Together, this helps researchers manage the focus of their project in two ways. First, it steers data collection and management efforts to where they are actually required. Secondly, it facilitates quick exploratory analyses to discover and sound out questions.
The CLD can enable substantive contributions to several topics. For instance, the Wikipedia Traffic table, combined with integrated roll-call or speech data, may be used to study the consequences of legislative behavior by analyzing whether it predicts shifts in public attention. Similarly, the Portraits table could be deployed in studies that investigate the behavioral consequences of facial features. In addition, the Professions table can serve as the basis for categorizing politicians in blue- and white-collar backgrounds. Combined with social media accounts in the Social table or integrated speech data, this facilitates the study of class-based differences in representatives' communication. Finally, revision records of legislators' personal Wikipedia biographies, in the Wikipedia History table, offer an opportunity to analyze the dissemination, targets and potential sources of political disinformation on Wikipedia. As the CLD grows in the years to come, its practical and substantive potential will expand further.
Supplementary material
Online appendices are available at https://doi.org/10.1017/S0007123420000897.
Acknowledgements
We would like to thank Lada Rudnitckaia, Johana Sperlova, Angela Peckham, Lorenzo Andreoli, Maximilian Bayer, and Toma Pavlov for excellent research assistance. We would also like to thank Christian Breunig, Benjamin Guinaudeau, Peter Selb, participants of the Center for Data and Methods Colloquium at the University of Konstanz, participants of the Conference on Comparative Research on Political Elites at the Hertie School, and the anonymous reviewers as well as the editor for their helpful feedback.
Data availability
Data replication sets are available in Harvard Dataverse at: https://doi.org/10.7910/DVN/GYSEGP.
Financial support
This research was supported by a grant of the Excellence Initiative of the German federal and state governments (GSC 1019) and by the Daimler and Benz Foundation (Funding period 2017/18; project ‘Citizen and Elite Activity on the Wikipedia Market Place of Political Information’).







