


Learning a second language (L2) includes building a non-native lexicon, which usually comes with certain difficulties, especially if the L2 is learned later in life. The learning circumstances for the L2 are rather different from how the first, native language (L1) is acquired (Gathercole, Hitch, Service & Martin, Reference Gathercole, Hitch, Service and Martin1997; Kuhl, Williams, Lacerda, Stevens & Lindblom, Reference Kuhl, Williams, Lacerda, Stevens and Lindblom1992; Werker & Tees, Reference Werker and Tees1984, among others). For many late learners, much of the learning occurs in a formal setting (i.e., classroom) and/or in an environment in which the L2 is rarely spoken (Darcy, Daidone & Kojima, Reference Darcy, Daidone and Kojima2013; Díaz, Mitterer, Broersma & Sebastián-Gallés, Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012; Weber & Cutler, Reference Weber and Cutler2004). Consequences of this limited experience with the L2 can be observed as deficits at virtually all levels of language processing, including the non-native lexicon. Vocabulary size in an L2 tends to be smaller than in the L1 (Bundgaard-Nielsen, Best & Tyler, Reference Bundgaard-Nielsen, Best and Tyler2011), as fewer words reach full integration into long-term memory (Gollan, Montoya, Cera & Sandoval, Reference Gollan, Montoya, Cera and Sandoval2008). In addition, the impoverished input that learners receive causes them to struggle with building robust phonolexical representations for newly-learned words. L2 phonolexical representations have repeatedly been found to lack relevant phonetic detail: that is, phonetic categories are ‘fuzzily’ or ‘weakly’ encoded into these representations. This is generally reflected in slower and more error-prone word recognition in the L2 compared to the L1 (Cook, Reference Cook2012; Cook & Gor, Reference Cook and Gor2015; Cook, Pandzda, Lancaster & Gor, Reference Lancaster and Gor2016; Lancaster & Gor, Reference Lancaster and Gor2016).
An additional obstacle to establishing accurate phonolexical representations for words in the L2 is that the late learners’ perceptual system is already optimized for perceiving the sound contrasts relevant to their L1 (Polka & Werker, Reference Polka and Werker1994; Werker & Tees, Reference Werker and Tees1984). The perception of any later-learned language is therefore modulated by the categories of the L1 phonetic inventory, as detailed, for instance, in L2 sound learning models (Best & Tyler, Reference Best, Tyler, Bohn and Munro2007; Flege, Reference Flege and Strange1995). However, when learning an L2, new phonetic categories need to be established. These new categories may give rise to sound contrasts that are not present in the L1, which often results in perceptual difficulties that are hard to overcome. A case in point is the struggle of German learners of English with the contrast between the open-mid front vowel /ε/ and the near open front vowel /æ/. According to the predictions of L2 learning models, this should be a ‘difficult’ distinction because German has only one open-mid vowel /ε/ (similar to English /ε/). /æ/ does not exist in German and German /ε/ is its closest L1 category. German learners of English hence tend to associate both English /ε/ and /æ/ to their L1 /ε/ category. Consequently, at least in the initial stages of learning, they have considerable difficulties in teasing the two vowels apart (Bohn & Flege, Reference Bohn and Flege1990; Eger & Reinisch, Reference Eger and Reinisch2017, Reference Eger and Reinisch2018; Flege, Bohn & Jang, Reference Flege, Bohn and Jang1997).
Crucially, to master the /ε/-/æ/ distinction, Germans not only need to establish two separate L2 categories corresponding to /ε/ and /æ/ (i.e., phonetic encoding) so that they can perceptually identify the two sounds, they also have to accurately encode these two phonetic categories into the representations of words in their L2 lexicon (i.e., phonolexical representations; Cook et al., Reference Cook, Pandza, Lancaster and Gor2016; Cook & Gor, Reference Cook and Gor2015). For instance, /ε/ has to be encoded into the representations of words like lemon, and /æ/ has to be encoded into those of words like dragon – and not the other way around. This encoding of phonetic categories in phonolexical representations has been shown to be difficult for L2 learners, above and beyond the phonetic identification of L2 sound categories. Learners perform poorly in tasks that involve the recognition of words containing sounds in difficult L2 contrasts even when their phonetic categorization of these contrasts is already within the native range (Amengual, Reference Amengual2016; Darcy et al., Reference Darcy, Daidone and Kojima2013; Díaz et al., Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012).
A likely explanation for the difficulties in lexical tasks is that the contrast is still not well encoded in the learners’ L2 phonolexical representations. In particular, evidence from eye-tracking (Escudero, Hayes-Harb & Mitterer, Reference Escudero, Hayes-Harb and Mitterer2008; Llompart & Reinisch, Reference Llompart and Reinisch2017; Weber & Cutler, Reference Weber and Cutler2004) suggests that the L2 category that is a worse fit to the native category is less reliably encoded in L2 words than the better fitting counterpart. This results in more errors with words containing the former (Broersma, Reference Broersma2005; Díaz et al., Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012; Simon, Sjerps & Fikkert, Reference Simon, Sjerps and Fikkert2014). In sum, phonolexical representations containing sounds involved in difficult L2 contrasts not only lack phonetic detail due to limited exposure to the L2, but are also fuzzier than those in the L1 lexicon because of perceptual problems with specific L2 categories (Broersma, Reference Broersma2012; Cutler, Weber & Otake, Reference Cutler, Weber and Otake2006; Darcy, Dekydtspotter, Sprouse, Glover, Kaden, McGuire & Scott, Reference Darcy, Dekydtspotter, Sprouse, Glover, Kaden, McGuire and Scott2012; see Cutler, Reference Cutler2015, for a review).
In the L2, as well as in the L1, sound category learning and phonolexical encoding needs to be accomplished while being exposed to variability coming from manifold sources, such as physiological differences (Ladefoged & Broadbent, Reference Ladefoged and Broadbent1957), signal distortions like speech in noise (Cooper, Brouwer & Bradlow, Reference Cooper, Brouwer and Bradlow2015), dialectal variation (Llompart & Simonet, Reference Llompart and Simonet2018; Sumner & Samuel, Reference Sumner and Samuel2009), foreign accents (Bradlow & Bent, Reference Bradlow and Bent2008; Sidaras, Alexander & Nygaard, Reference Sidaras, Alexander and Nygaard2009; Weber, Di Betta & McQueen, Reference Weber, di Betta and McQueen2014; Witteman, Weber & McQueen, Reference Witteman, Weber and McQueen2013), and personal idiosyncrasies (Norris, McQueen & Cutler, Reference Norris, McQueen and Cutler2003), to name but a few examples. In the native language, listeners are able to make up for such variability by flexibly adapting their perception to the input they receive. For instance, Norris et al. (Reference Norris, McQueen and Cutler2003) conducted a lexically-guided perceptual learning study on the /s/-/f/ contrast in Dutch. They presented an ambiguous sound between /s/ and /f/ embedded in either /s/-final or /f/-final words and subsequently examined the listeners’ categorization of that contrast. They found that listeners who heard the ambiguous sound in the /s/ context reported hearing more /s/ during categorization, and the opposite was true for those exposed to the same fricative in an /f/ context. In short, listeners used lexical knowledge to shift the boundary between the two phonetic categories to accommodate the deviant productions of the fricative sound.
Importantly, L2 learners have also been found to be flexible in their perception of at least some sound contrasts in the L2 – specifically sound contrasts that do not pose perceptual difficulties for them (Drozdova, van Hout & Scharenborg, Reference Drozdova, van Hout and Scharenborg2016; Reinisch, Weber & Mitterer, Reference Reinisch, Weber and Mitterer2013, Schuhmann, Reference Schuhmann2014; but see Bruggeman, Reference Bruggeman2016). For example, Reinisch et al. (Reference Reinisch, Weber and Mitterer2013) conducted an experiment similar to Norris et al. (Reference Norris, McQueen and Cutler2003) on the same Dutch /s/-/f/ contrast, but with German learners of Dutch as well as native Dutch speakers. They found that both groups exhibited similar shifts in categorization after perceptual adaptation. L2 learners were hence as able to adapt their perception of the Dutch /s/-/f/ contrast as L1 listeners. Note that /s/-/f/ is a sound contrast that is also part of the German inventory and German learners of Dutch are expected not to have difficulties with that distinction.
By contrast, not as much is known about how flexible L2 learners are with sounds involved in difficult L2 contrasts (i.e., contrasts in which sounds are perceptually confusable) and whether (and how) such flexibility may be related to the learners’ performance in these distinctions. Critically, some evidence suggests that unlike with easy L2 distinctions, flexibility or adaptability when it comes to difficult non-native categories may be problematic (Sjerps & McQueen, Reference Sjerps and McQueen2010). Sjerps and McQueen found that Dutch learners of English learned to treat the difficult English sound /θ/ (Cutler, Weber, Smits & Cooper, Reference Cutler, Weber, Smits and Cooper2004; Hanulikova & Weber, Reference Hanulikova and Weber2011) as a token of /f/ or /s/ in a perceptual learning study. Exposure to /θ/ in contexts where it replaced /f/ or /s/ triggered similar adjustments of /f/-to-/s/ category boundaries as the artificially constructed ambiguous sound between /f/ and /s/ in previous studies (e.g., Norris et al., Reference Norris, McQueen and Cutler2003). That is, the learners’ difficulty with the L2 category /θ/ resulted in ‘unnecessary’ or even ‘unwanted’ adaptation effects in the L1. While Sjerps and McQueen showed how a difficult L2 category can impact the perception of an L1 contrast, it still remains unclear how flexible L2 learners are in their perception of difficult L2 contrasts. Moreover, it remains to be shown whether flexibility (or lack thereof) for difficult L2 contrasts may relate to the learners’ mastery of the contrast, and in particular to how robustly that contrast is encoded into words in the L2 lexicon.
The present study addresses these questions with German learners of English by examining the phonolexical encoding and phonetic categorization of the difficult /ε/-/æ/ contrast and a contrast that is expected to be ‘easy’ for this group of learners, /i/-/ɪ/. German and English have a similar tenseness contrast for high front vowels. Therefore, native German speakers are predicted to straightforwardly associate each of the two English vowels with its German counterpart and treat this L2 contrast much like a native contrast (Best & Tyler, Reference Best, Tyler, Bohn and Munro2007; Flege, Reference Flege and Strange1995). Indeed, experimental evidence has shown that the perceptual match between the English and German categories is very robust (Iverson & Evans, Reference Iverson and Evans2007) and that German learners do not have difficulties in distinguishing these two English vowels (Bohn & Flege, Reference Bohn and Flege1990, Reference Bohn and Flege1992). Therefore this contrast was used as a within-language, within-participant baseline to the difficult /ε/-/æ/ contrast. The robustness of phonolexical encoding of the two L2 contrasts was assessed using a lexical decision task containing mispronunciations, while phonetic flexibility was investigated by means of a distributional learning task.
In the lexical decision task, learners were presented with real words that contained sounds from the contrasts /i/-/ɪ/ and /ε/-/æ/ as well as nonwords created by replacing the critical sounds by the other member of the contrast (Broersma, Reference Broersma2005; Díaz et al., Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012; Sebastián-Gallés, Echeverría & Bosch, Reference Sebastián-Gallés, Echeverría and Bosch2005). We took the learners’ ability to accept the real words and reject the mispronounced nonwords as an indicator of how well the critical vowels are phonologically represented in their L2 lexicon. Learners were expected to be substantially more accurate with items containing /i/ and /ɪ/ than with items containing /ε/ and /æ/ because, for them, the latter two categories are perceptually confusable at the phonetic level. In addition, based on previous findings with similar tasks and Dutch speakers (Broersma, Reference Broersma2005; Díaz et al., Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012; Simon et al., Reference Simon, Sjerps and Fikkert2014), we also expected that, within the difficult contrast, learners would have more difficulties with nonwords in which /æ/ was mispronounced as [ε] (e.g., *dr[ε]gon) than with nonwords in which /ε/ was mispronounced as [æ] (e.g., *l[æ]mon) because of the dominant role of /ε/ in the contrast. Crucially, measures derived from the learners’ performance in the lexical decision task were compared to performance in the distributional learning task, so as to relate their robustness of phonolexical encoding to their perceptual flexibility at the phonetic level.
Phonetic flexibility was measured by means of a distributional learning task. This task consisted of two parts in which learners were asked to categorize an /i/-/ɪ/ and an /ε/-/æ/ continuum. In each part, categorization phases were always preceded by exposure phases designed to bias perception towards one of the response options during categorization. Listeners were expected to show adaptation to the regularities in continuum step presentation during exposure and shift their category boundaries accordingly (Clayards, Tanenhaus, Aslin & Jacobs, Reference Clayards, Tanenhaus, Aslin and Jacobs2008; Escudero, Benders & Wanrooij, Reference Escudero, Benders and Wanrooij2011; Kleinschmidt, Raizada & Jaeger, Reference Kleinschmidt, Raizada, Jaeger, Dale, Jennings, Maglio, Matlock, Noelle, Warlaumont and Yoshimi2015; Munson, Reference Munson2011). By comparing the location of category boundaries following the different types of exposure, a measure was obtained of how flexible the L2 learners’ perception of each contrast was (see Munson, Reference Munson2011, for a detailed discussion of boundary-shifting distributional learning).
Distributional learning was used because it allowed us to examine how L2 listeners shifted phonetic category boundaries in an unsupervised manner. Contrary to other perceptual learning paradigms, we did not provide our listeners with explicit information about where the category boundaries should be located (see Lametti, Krol, Shiller & Ostry, Reference Lametti, Krol, Shiller and Ostry2014 for an explicit boundary-learning task) or other types of information such as lexical or visual context to anchor phonetic categories (Bertelson, Vroomen & de Gelder, Reference Bertelson, Vroomen and de Gelder2003; Norris et al., Reference Norris, McQueen and Cutler2003; Reinisch & Mitterer, Reference Reinisch and Mitterer2016). Moreover, given that our population were L2 learners, unsupervised distributional learning seemed more appropriate than, for example, training involving lexical information (e.g., as in Reinisch et al., Reference Reinisch, Weber and Mitterer2013) because distributional learning mostly relies on phonetic perception. The minimal involvement of the L2 lexicon in this task allowed us to avoid confounds in the observed effects due to differences in general L2 lexical knowledge among learners.
Our main goal was to assess how the phonolexical encoding of sound categories in the L2 relates to phonetic flexibility in easy and difficult L2 sound contrasts, for L2 learners as a group but, critically, also within the individual learners. For the easy /i/-/ɪ/ contrast, we expected learners to show flexibility because both their phonetic perception and phonolexical encoding should be quite robust, and it has already been shown that boundaries between sounds in easy contrasts can be shifted (Reinisch et al., Reference Reinisch, Weber and Mitterer2013). Moreover, no individual differences due to L2 experience and/or proficiency were expected because these factors do not appear to strongly modulate the learners’ perception of easy L2 contrasts (Bohn & Flege, Reference Bohn and Flege1990).
Regarding /ε/-/æ/, however, two main outcomes can be predicted: if flexibility comes with mastery of the contrast, learners with more robust phonolexical representations of words containing the sounds of the difficult L2 contrast (i.e., better in lexical decision) will also be those who are more flexible at the phonetic category level. Learners with fuzzier phonolexical representations (i.e., worse in lexical decision) should adapt their boundaries less during distributional learning. The alternative is that learners with more robust phonolexical representations shift less in the distributional learning task for /ε/-/æ/ than those exhibiting poorer phonolexical encoding. This is because new phonetic categories that are involved in difficult L2 contrasts differ from other categories in that their establishment is always effortful (to name but a few, see Aoyama, Flege, Guion, Akahane-Yamada & Yamada, Reference Aoyama, Flege, Guion, Akahane-Yamada and Yamada2004; Flege et al., Reference Flege, Bohn and Jang1997; Goto, Reference Goto1971; Sheldon & Strange, Reference Sheldon and Strange1982). These difficulties may impact the perception of the /ε/-/æ/ contrast so that the accurate distinction of the two sounds comes at the cost of flexibility.
Methods
Participants
Forty-two native speakers of German (21 females; mean age = 24.93, sd = 4.3), all students at the University of Munich, participated for a small payment. None of them reported hearing problems. Recruitment requirements were that (i) they had not learned any language other than German before starting to learn English (mean age = 9.61, sd = 2.21, range 4–12), (ii) had not spent more than 6 months in an English-speaking country, and (iii) were not enrolled in a language-program at the university. Two participants were discarded from all analyses because they did not fulfill these requirements. All participants filled out a language background questionnaire assessing a number of self-estimated measures of English proficiency and experience. From these measures, following Eger and Reinisch (Reference Eger and Reinisch2017), we calculated individual Proficiency/Experience Scores that were the mean of 5 parameters: self-rated comprehension and speaking skills, self-reported frequency of exposure and use of spoken English and self-estimated German accent in English. All measures were provided on a 1-to-7 scale in which 1 indicated good skills, frequent exposure/use and weak foreign accent, and 7 indicated the opposite. Table 1 shows the mean values for these five metrics as well as for the mean Proficiency/Experience Scores.
Table 1. Mean self-estimated English Proficiency/Experience measures for the German learners of English who participated in the study. Values close to 1 indicate good skills, frequent exposure/use and weak foreign accent; values close to 7 indicate poor skills, infrequent exposure/use and strong foreign accent.

Materials
A total of 304 English words was used for the lexical decision task. Words were mono-, di- or trisyllabic nouns, adjectives and verbs, and were selected to be commonly known to learners of English. 104 of these words belonged to the critical sound contrasts (i.e., /i/-/ɪ/ and /ε/-/æ/), 26 words per sound. The remaining 200 words were fillers involving the contrasts /p/-/t/, /k/-/m/, /b/-/v/, /ɔ:/-/u/. Filler contrasts were expected to be easy for our participants because they also exist in German. Importantly, half of the words were selected to be used as nonwords. Nonwords were created by exchanging the two sounds in each contrast (e.g., *l[æ]mon for lemon and *dr[ε]gon for dragon; the same for /i/-/ɪ/ and the fillers). That is, for each critical sound (/i/, /ɪ/, /ε/, /æ/), 13 words appeared as real words and 13 as nonwords containing a single-sound mispronunciation (see Appendix A for a list of words and nonwords for the two contrasts). For the critical contrasts, the mispronunciations always concerned the first stressed vowel of the words. For filler contrasts, the position of the mispronunciation varied such that participants could not adopt the strategy of focusing exclusively on the first two segments of the words. Lexical frequency was controlled within each contrast using the Zipf scale measures provided by Subtlex-UK (van Heuven, Mandera, Keuleers & Brysbaert, Reference van Heuven, Mandera, Keuleers and Brysbaert2014, see also Zipf, Reference Zipf1949). Lexical frequency for words of the two critical contrasts was comparable: /i/-/ɪ/ (4.63–4.55), /ε/-/æ/ (4.66–4.61).
For the distributional learning task, four English minimal pairs for each critical sound contrast were selected for recording (/i/-/ɪ/: cheap-chip, heat-hit, seat-sit, sheep-ship; /ε/-/æ/: bed-bad, bet-bat, pen-pan, said-sad).
Recordings
All words were recorded in a sound-attenuated booth by a 26-year-old native speaker of Standard Southern British English who lived in London until moving to Munich at the age of 22. All words for the lexical decision task were recorded in their correct word form and items designated to function as nonwords were additionally recorded with the critical sound substituted by the other member of the contrast. Care was taken that the substitutions sounded natural. Table 2 shows the mean F1, F2 and duration values of the real words with /i/, /ɪ/, /ε/ and /æ/ (e.g., record, happy), the real words that were the base for the mispronounced nonwords (i.e., Base Forms; e.g., lemon and dragon) and the mispronounced nonwords (e.g., *l[æ]mon, *dr[ε]gon). From these values, it can be seen that the native British speaker produced a large difference between the critical vowels of the two contrasts in both F1 and F2 and that values for mispronounced items were comparable to values for real words of the intended categoryFootnote 1.
Table 2. Mean formant values (F1, F2; in Hertz) for Real Words, Base Forms and Mispronounced Nonwords for the /i/-/ɪ/ and /ε/-/æ/ contrasts in the lexical decision task. Standard deviations are in parentheses.

Minimal pairs for the distributional learning task were recorded multiple times. The minimal pairs sheep-ship and bet-bat were selected for use in the experiment because their consonants are unproblematic for German learners of English, unlike, for instance, the final –d in bed-bad due to final devoicing in German (Fourakis & Iverson, Reference Fourakis and Iverson1984; Port & O'Dell, Reference Port and O'Dell1985). One recording of each word was chosen so that the two words in each pair were as similar as possible in recording quality, f0 contour and perceived speech rate. However, since it appeared that the vowels in bet and bat were consistently produced in creaky voice, we decided to replace the words’ onsets (/b/ and vowel) with recordings from tokens of bed and bad that appeared less creaky. Critically, the vowel duration was shortened to match the original durations of bet and bat from which the final stops were taken. No splicing was needed for the selected tokens of sheep and ship.
Two 21-step continua, one between sheep and ship and the other between bet and bat, were created through duration manipulation and formant shifting in Praat (Boersma & Weenink, Reference Boersma and Weenink2010). Vowel duration and F1 and F2 values for the endpoints were taken directly from the naturally-produced tokens and continuum steps were set to change linearly in the three dimensions (see Table 3 for endpoint values). The 21-step continua were then reduced to 11 steps leaving out every other step (i.e., steps 0, 2, 4, etc.) and pretested on 7 native speakers of German so as to find the perceptually most ambiguous steps. Participants categorized each continuum step 10 times and results showed that step 12 was closest to the category boundary for both contrasts. The final continua were built around this most ambiguous step (see Figure 1). This centering of the continuum was necessary to ensure that, when exposed to the distributions of stimuli, one of the peaks was always located close to the most ambiguous region for all participants (see Procedure below); pretests on native German speakers had shown that only then could distributional learning be observed.
Table 3. Duration and F1 and F2 values of endpoint vowels of the two continua used in the distributional learning task.


Figure 1. Number of presentations per continuum step in each of the two distributions presented in the distributional learning task. The distribution presented in exposure phases 1 and 3 is in black and the distribution presented in exposure phase 2 is in grey. Dashed lines depict the intended boundary for each distribution. The dotted line signals the most ambiguous step for German listeners as determined by the pretest.
Procedure
All participants completed the two tasks, lexical decision and distributional learning, in two experimental sessions that were separated by at least one and no more than three weeks. The order was consistent, with lexical decision preceding distributional learning. Participants were tested individually in a sound-attenuated booth. Experiments were run using Psychopy2 software (v.1.83.01; Peirce, Reference Peirce2007). Auditory stimuli were presented binaurally over headphones at a comfortable listening level.
Lexical decision
For the lexical decision task, individual presentation lists were built with all items appearing in full random order except that no two items of the same contrast could follow one another. Importantly, the sets of items presented as real words and as nonwords with mispronunciations were the same for all participants, so as to facilitate comparisons at the individual level. Participants were told (in English) that they would be hearing real English words and invented words that could sound similar to English words. They were instructed to press the “1” key on the computer keyboard if they considered the presented item to be a real English word and the “0” key if they thought it was not an existing word. They were asked to respond as fast as they could but being as accurate as possible. On every trial, two small boxes appeared on the computer screen: a green one, on the left-hand side, with word written on it, and a red one, on the right-hand side, with not a word written on it. After the button press, the selected box moved slightly upwards and the other box disappeared for 300ms. This was used to indicate to participants that their response had been stored. There was no time limit for responses and presentation of the next trial started 1.1s after the previous button press. Listeners were given ten practice trials (i.e., 5 words and 5 nonwords) before they started the experiment. None of the practice trials included words or nonwords containing the sounds of the critical contrasts. The lexical decision task took between 15 and 20 minutes to complete.
Distributional learning
The distributional learning task was divided into two parts. The first part was on the /i/-/ɪ/ contrast and the second on /ε/-/æ/ (i.e., order: easy-difficult). Each part consisted of three exposure-test sequences. During the exposure phases, listeners were asked to listen to randomized orders of tokens sampled from the continuum. The frequency with which each token was sampled was chosen such as to bias listeners’ perception towards one of the endpoint categories. A visual schematization of this sampling is shown in Figure 1. The distributions for exposure phases 1 and 3 were the same (black line), and were expected to trigger more /i/ and /ε/ responses, respectively. Exposure phase 2 was expected to result in more /ɪ/ and /æ/ responses (grey line). The third phase was included to test whether listeners would be able to shift their boundaries back to where they were after the first exposure once they had been exposed to the second distribution, which should produce the opposite biasing effect. The two distributions mirrored each other and always contained the same number of tokens at both sides of the intended (shifted) boundary (dashed lines in Figure 1).
Immediately following each exposure phase, listeners were prompted to perform a short categorization task on the selected 11 steps of the continuum they had just heard. Steps (henceforth referred to as going from 1 to 11) were presented 5 times each in fully random order. Participants were instructed to press “1” when the word they heard corresponded to a picture on the left-hand side of the screen (e.g., sheep) and “0” when the word was the one depicted on the right-hand side of the screen (e.g., ship). Orthographic representations of the words (SHEEP-SHIP and BET-BAT) were provided before the first categorization of each continuum. Just as in the lexical decision task, after the button press the selected picture moved slightly upwards and the other picture disappeared for 300ms. There was no time limit for responses and presentation of the next trial started 0.8s after the previous button press. The distributional learning task took approximately 25 minutes.
Results
Lexical decision
Three participants had to be excluded from all analyses due to missing files, which reduced the dataset from 40 to 37 participants. In addition, all trials in the lexical decision task that contained words with which listeners indicated to be unfamiliar (as assessed after the experiment) were removed on a by-participant basis. This resulted in an additional loss of 119 trials (0.01%), only 20 of which involved the critical sound contrasts (0.005% of critical trials). Overall performance in the lexical decision task was high (minimum correct = 73.81%; M = 85.68%, sd = 35.03).
In order to analyze lexical decision responses to words and nonwords and to take into account any possible bias to report hearing a word more often than a nonword (which is likely if participants do not detect the mispronunciation) all responses were converted into dʹ scores per participant per vowel (Macmillan & Creelman, Reference Macmillan and Creelman2005; Noguchi & Kam, Reference Noguchi and Kam2017; Pallier, Reference Pallier2002). dʹ is a measure of sensitivity that takes into account the likelihood that a ‘word’ response was given when the stimulus was a real (correctly pronounced) word (“Hit rate”) and the likelihood of responding ‘word’ when the item was a nonword (i.e., containing a sound substitution; “False alarm rate”). Individual dʹ scores per vowel were obtained by subtracting the z-transformed False alarm rate from the z-transformed Hit rate separately for each of the four L2 sounds examined (/i/, /ɪ/, /ε/, /æ/). The higher the dʹ scores, the better participants performed in lexical decision. When referring to dʹ scores of a given vowel in the remainder of the paper we will speak of dʹ scores for ‘/ε/-items’ when referring to the word set in which /ε/ was the intended vowel – that is, words with /ε/ and nonwords in which /ε/ had been substituted by [æ] – and analogously for the other vowels. dʹ scores for each set of items are shown in Figure 2.

Figure 2. Individual dʹ scores for items with the four critical vowels (/i/, /ɪ/, /ε/, /æ/) and all fillers pooled together. Black dots indicate mean values over all participants.
Lexical decision data were first submitted to a linear mixed-effect model (lme4 package 1.1-13, Bates, Mächler, Bolker & Walker, Reference Bates, Mächler, Bolker and Walker2015) in R (Version 3. 2. 2, R Core Team, 2017) with dʹ scores as the dependent variable and Sound Contrast as fixed factor. This analysis was performed in order to assess whether there was a difference between dʹ scores for the two contrasts. Sound Contrast was contrast coded such that /i/-/ɪ/ was coded as −0.5 and /ε/-/æ/ was coded as 0.5. The random-effects structure included a random intercept for participants and a random slope for Sound Contrast over participants. Significance of variables was assessed by means of Satterthwaite's approximation for degrees of freedom using the lmerTest package (Kuznetsova, Brockhoff & Christensen, Reference Kuznetsova, Brockhoff and Christensen2017). The model revealed a significant effect of Sound Contrast (b = −1.30; t = −9.47; p < .001). As expected, dʹ scores were higher – that is, performance was better – for the items containing the sounds from the /i/-/ɪ/ contrast than for the difficult /ε/-/æ/ contrast. Secondly, data were split by contrast in order to examine whether there were differences between the two vowels within each contrast. Two linear mixed-effect models – one for each contrast – were run with dʹ scores as the dependent variable and Vowel (/i/ vs. /ɪ/ and /ε/ vs. /æ/, respectively) as fixed factors. We contrast coded the vowels according to their acoustic properties, with the vowel with a lower F1 and a higher F2 in each contrast, /i/ and /ε/, coded as −0.5 and /ɪ/ and /æ/ as 0.5. Note that the effect of Vowel was not assessed together with the effect of Sound Contrast because the levels of the factor Vowel would have been nested within the levels of Sound Contrast (e.g., dʹ scores for /i/-items and /ɪ/-items are the dʹ scores for the /i/-/ɪ/ contrast). A random intercept for participants was included in each of the two models. A significant effect of Vowel was found in both models (/i/-/ɪ/: b = 0.33; t = 2.27; p = .029; /ε/-/æ/: b = −0.77; t = −5.81; p < .001). Learners were more accurate with /ɪ/-items than /i/-items and with /ε/-items than /æ/-items.
In order to assess to what extent the results of the lexical decision task relate to the learners’ self-estimated proficiency and experience with English, we conducted additional analyses testing possible correlations between the participants’ dʹ scores for each of the four sets of items and their Proficiency/Experience Scores from the language background questionnaire (see Participants section). Results showed that only dʹ scores for /ε/-items showed a medium-sized correlation with the self-reported measures (r(35) = −.36, p = .029). The other three correlations were substantially smaller and not significant (/æ/-items: r(35) = −.18, p = .29; /i/-items: r(35) = −.07, p = .70; /ɪ/-items: r(35) = −.04, p = .81). These results will be taken up in the Discussion.
In the following section, the individual dʹ scores for each of the four critical vowels were used to examine whether robustness of phonolexical encoding is related to phonetic flexibility. dʹ scores for /i/- and /ɪ/-items were used as separate predictors in the analysis of the distributional learning data for the /i/-/ɪ/ continuum. dʹ scores for /ε/- and /æ/-items were entered separately into the analysis of the distributional learning data for the /ε/-/æ/ continuum.
Distributional learning
Before we focused on the effects of distributional learning and listeners’ perceptual flexibility, a descriptive analysis of categorization performance was conducted. This was to ascertain that the endpoints of the easy and difficult contrasts were perceived as intended. For the easy contrast, learners correctly identified the two most /i/-like continuum steps (steps 1 and 2) as /i/ in 98.89% of the cases (minimum = 93.33%; sd = 10.49) and the two most /ɪ/-like continuum steps (steps 10 and 11) as /ɪ/ in 98.33% of the cases (minimum = 86.67%; sd = 12.81). For the difficult contrast, the endpoints and near-endpoint stimuli were correctly identified as /ε/ and /æ/ 98.11% (minimum = 76.67%; sd = 13.63) and 97.75% (minimum = 73.33%; sd = 14.84) of the time, respectively. This indicates that participants did not have problems distinguishing prototypical tokens of /ε/ and /æ/ at the phonetic level.
Data for the distributional learning task were thereafter analyzed separately for /i/-/ɪ/ and /ε/-/æ/ because performance for each contrast in the distributional learning task was to be related to contrast-specific measures of phonolexical encoding from the lexical decision task. For each contrast, data were submitted to a generalized linear mixed-effects model with a logistic linking function with Response (0 = ship and bat; 1 = sheep and bet) as the categorical dependent variable. Continuum Step, Exposure Phase and the dʹ scores from the lexical decision task were entered as fixed factors. Parameter estimates and significance values for all variables are reported as provided by the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015), which makes use of maximum likelihood estimation based on the Laplace approximation (Raudenbush, Yang & Yosef, Reference Raudenbush, Yang and Yosef2000).
Continuum Step was centered on zero (e.g., step 1 = −2.5, step 6 = 0, step 11 = 2.5) and was not allowed to interact with the other factors due to convergence problems (see Mitterer & Reinisch, Reference Mitterer and Reinisch2017, for a similar solution). Exposure Phase was re-coded as two linearly independent contrasts to which we will henceforth refer to as Bias and Sequence. “Bias” was coded to represent differences in categorization following the two distributions that should bias perceptual boundaries in opposite directions: that is, categorization patterns after exposure phases 1 and 3 were compared to categorization after exposure phase 2. Exposure phases 1 and 3 were coded as 0.5 and exposure phase 2 as −1. With this coding, a significant positive regression coefficient would indicate that listeners were sensitive to the type of distribution such that there were more “bet” and “sheep” responses following exposure phases 1 and 3 than following exposure phase 2. The second contrast, “Sequence”, assessed differences in the magnitude of shifts from exposure phase 1 to 2 vs. 2 to 3. In other words, it compared categorization following exposure phase 1 and 3, which should bias participants in the same direction. Exposure phase 1 was coded as −0.5, exposure phase 2 as 0 and exposure phase 3 as 0.5. In this case, a significant negative coefficient would mean that, following exposure phase 2, the bias in exposure phase 3 could not re-set listeners’ perceptual boundary to match perception after exposure phase 1.
The dʹ scores for each of the two vowels in the given contrast were entered as continuous variables centered around the mean of all participants’ dʹ scores for that vowel. Note that entering dʹ scores as a continuous variable allows for stronger conclusions than if participants were grouped based on these scores, a practice common in similar studies (e.g., Díaz, Baus, Escera, Costa & Sebastián-Gallés, Reference Díaz, Baus, Escera, Costa and Sebastian-Galles2008; Díaz, Mitterer, Broersma, Escera & Sebastián-Gallés, Reference Díaz, Mitterer, Broersma, Escera and Sebastián-Gallés2016). This is because significant effects using a continuous variable are harder to find as they critically depend on a (close to) linear effect of the variable. The two variables involving dʹ scores were not allowed to interact with each other but were allowed to interact with Bias and Sequence, as such an interaction would suggest a modulation of phonetic flexibility (as measured in distributional learning) by the quality of the learners’ phonolexical representations for a particular type of words (i.e., as measured by the dʹ scores). The models’ random-effects structure was the largest that resulted in model convergence: a random intercept for participants with random slopes for Continuum Step and Sequence over participants. The two models were as good a fit to the data as the model with a full random-effects structure in each case, as indicated by log-likelihood ratio tests.
/i/-/ɪ/ contrast
Table 4 shows the results of the model for the easy /i/-/ɪ/ contrast. The only significant effects found were those of Continuum Step and Bias. The effect of Continuum Step shows that participants’ responses differed depending on the continuum step to be categorized: the higher the continuum step (the more /ɪ/-like the vowel), the fewer “sheep” responses were given. The significant effect of Bias indicates that categorization after exposure to the /i/-biasing distribution (phases 1 and 3) resulted in more “sheep” responses than exposure to the /ɪ/-biasing distribution (phase 2). This confirms that distributional learning was overall successful at eliciting categorization shifts for the easy contrast. The fact that the effect of Sequence was not significant indicates that categorization responses following exposure phases 1 and 3 – that is, the categorization shifts from exposure phase 1 to 2 and 2 to 3 – did not differ. Finally, neither the dʹ scores for /i/-items nor the dʹ scores for /ɪ/-items had a significant effect on categorization, nor did they show a significant interaction with Bias or Sequence. This suggests that for the baseline contrast there was no difference whatsoever in the effects of distributional learning as a function of the listeners’ performance in the lexical decision task.
Table 4. Results of the mixed-effects regression model on the distributional learning data for /i/-/ɪ/.

/ε/-/æ/ contrast
Table 5 shows the results of the model for the difficult /ε/-/æ/ contrast. As for the easy /i/-/ɪ/ distinction, the model rendered significant effects of Continuum Step and Bias, while the effect of Sequence, dʹ scores for /ε/-items and dʹ scores for /æ/-items were not significant. Crucially, however, the interaction between Bias and dʹ scores for /ε/-items was significantFootnote 2. This shows that the higher the participants’ dʹ scores for words containing /ε/ and nonwords in which the /ε/ had been substituted by [æ] (e.g., *l[æ]mon), the smaller their shift in categorization; that is, the difference in responses following exposure to the biasing distributions in phases 1 and 3 vs. 2 was smaller.
Table 5. Results of the mixed-effects regression model on the distributional learning data for /ε/-/æ/.
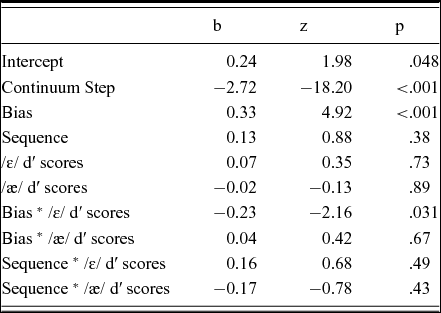
Figure 3 serves as an illustration of how this relationship is instantiated at an individual level. It shows the correlations between individual values for average shift (i.e., distance between 50% crossover points) in distributional learning with /ε/-/æ/ ((Exposure 1 – Exposure 2) + (Exposure 3 – Exposure 2) / 2) and dʹ scores for /ε/-items (left panel) and dʹ scores for /æ/-items (right panel). The negative-going regression line for the /ε/-items in the left panel mirrors the findings from the mixed-model regression analyses reported above (i.e., the interaction between Bias and dʹ scores for /ε/-items) that the higher the dʹ scores, the smaller the shifts in the distributional learning task. However, unlike the interaction in the mixed-effects regression model, the small-to-medium correlation did not reach significance (r(35) = −.26, p = .11). This is likely due to differences between the statistical methods.

Figure 3. Correlation plots for individual values for the average shift (i.e., distance between 50% crossover points) in distributional learning with /ε/-/æ/ ((Exposure 1 – Exposure 2) + (Exposure 3 – Exposure 2) / 2) and dʹ scores for /ε/ items (left panel) and dʹ scores for /æ/ items (right panel). The shaded areas indicate the 95% confidence intervals of the regression lines.
While the mixed-model reported above is based on all observations from the distributional learning task, the correlation takes into account only one aggregated value per participant, thereby losing information (note that dʹ scores were only one value per participant in both analyses). Moreover, mixed-effects modelling allows the specification of random variables (intercept and slopes) such that random variation between participants in their overall performance as well as their responsiveness to certain manipulations are taken into account. For these reasons, among others, mixed-effects regression models are regarded as having a higher sensitivity than analyses with aggregated values (Baayen, Davidson & Bates, Reference Baayen, Davidson and Bates2008; Koerner & Zhang, Reference Koerner and Zhang2017; Quené & van den Bergh, Reference Quené and van den Bergh2008). This is why, with a sample of 37 participants, it may be not too surprising that the small effect of the interaction reported above (i.e., p=.031)Footnote 3 did not surface as a significant correlation by p < .05 standards. For /æ/-items, the correlation between dʹ scores from the lexical decision task and the average shift in categorization was small and not significant (r(35) = −.06, p = .73), as was the corresponding interaction in the mixed-effects model reported above.
Discussion
The present study explored the relationship between the robustness of L2 phonolexical representations and phonetic flexibility in a non-native language. This relationship was tested with German learners of English for two English vowel contrasts that differ in the perceptual difficulties they cause to these learners. The /i/-/ɪ/ distinction (our L2 control) is easy from a phonetic standpoint because it is shared with our learners’ native language (Bohn & Flege, Reference Bohn and Flege1992). The /ε/-/æ/ contrast, however, is difficult to distinguish because /æ/ does not occur in German and both sounds are often perceived as members of the German category /ε/ (Bohn & Flege, Reference Bohn and Flege1990). Participants were tested on two tasks, a lexical decision task containing mispronunciations in which the two sounds of the contrasts were exchanged and a distributional learning task. Lexical decision performance (in dʹ scores) was taken as a measure of how robustly learners had encoded each of these sounds in their L2 phonolexical representations. The distributional learning task probed how flexible learners were with the two contrasts at a phonetic level, as assessed through their ability to adjust the boundary between phonetic categories. The central question was whether the robustness of L2 phonolexical representations is related to phonetic flexibility.
Results of the lexical decision task showed that German learners of English were, as expected, more accurate with items corresponding to the easy /i/-/ɪ/ contrast than with items containing /ε/ and /æ/. In addition, it was found that there were differences in how accurate learners were with the two vowels within each contrast. For /i/-/ɪ/, participants showed higher dʹ scores (i.e., were more accurate) for words containing /ɪ/ and nonwords in which this vowel was substituted by [i] (e.g., *w[i]nter) than for words with /i/ and the opposite pattern of mispronunciations (e.g., *n[ɪ]ddle). One possible explanation for this may be that /i/ is longer and more peripheral in the vowel space than /ɪ/ and therefore serves as a better perceptual anchor (Polka & Bohn, Reference Polka and Bohn2003, Reference Polka and Bohn2011), leading to better detection of an unexpected [i] instead of /ɪ/ than the other way around.
Nonetheless, the dʹ scores for neither of the vowels in the easy contrast related to how much learners shifted their boundary between /i/-/ɪ/ in distributional learning. This replicates previous findings showing that the phonetic boundary between two sounds of an L2 contrast that also occurs in the L1 can easily be shifted (Reinisch et al., Reference Reinisch, Weber and Mitterer2013) and confirms that /i/-/ɪ/ was an appropriate within-language, within-participant baseline for the difficult L2 distinction. Importantly, the magnitude of shift of the category boundary following distributional learning did not depend on the direction of shift (cf. no effect of Sequence, see Table 4). Distributional learning hence proved a robust measure of overall phonetic flexibility that appears consistent within participants.
While items involving the /ε/-/æ/ contrast systematically resulted in poorer performance in lexical decision than those involving /i/ and /ɪ/, there was also a difference between the two vowels within the difficult contrast. Learners were considerably more accurate with /ε/-items (i.e., words with /ε/ and nonwords of the *l[æ]mon type) than for /æ/-items (i.e., words with /æ/ and nonwords of the *dr[ε]gon type). The difference between the dʹ scores for the two vowels in the contrast is likely a reflection of the difficulties that German learners of English have with the new L2 category /æ/ at the lexical level. As mentioned in the introduction, English /ε/ appears to be more strongly encoded to words than English /æ/ because it is a better fit to the L1 category. Hence, for German learners of English, nonwords in which /ε/ is substituted by [æ] should be relatively easier to reject than nonwords in which /æ/ is substituted by [ε]. In this sense, the present results replicate previous findings on an asymmetric perception of this vowel contrast by Dutch (Broersma, Reference Broersma2005; Díaz et al., Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012; Simon et al., Reference Simon, Sjerps and Fikkert2014) and German learners of English (Llompart & Reinisch, Reference Llompart and Reinisch2017).
Our main finding was, however, that only the individual dʹ scores for /ε/-items (and not /æ/-items) predicted the magnitude of the shift in the distributional learning task for the difficult /ε/-/æ/ contrast. A factor that likely contributed to this finding is the learners’ familiarity with the type of mispronunciations in the /æ/-items (e.g., *dr[ε]gon). These mispronunciations are commonly heard in German-accented English (e.g., Eger & Reinisch, Reference Eger and Reinisch2017). Therefore, learners may have accepted nonwords like *dr[ε]gon not only because of their fuzzy representations for vowels in these words but also because hearing this type of mispronunciations from fellow native German speakers makes them sound acceptable (see Samuel & Larraza, Reference Samuel and Larraza2015). Mispronunciations in the /ε/-items (e.g., *l[æ]mon), in contrast, rarely occur in German-accented English, and thus learners are not likely to consider these nonwords acceptable merely on the basis of familiarity. Rather, if they accept these nonwords as existing, this should be attributed to their deficient phonolexical encoding of the critical vowel. This suggests that, in a task such as ours, dʹ scores for /ε/-items may be a more suitable probe to the individual phonolexical encoding of the /ε/-/æ/ contrast than dʹ scores for /æ/-items. Note that this argument is further strengthened by the finding that dʹ scores for /ε/-items were more strongly related to the learners’ self-reported measures of English proficiency and experience than those for /æ/-items.
In the Introduction, we proposed two different outcomes for our main relationship of interest: that is, the one between phonolexical encoding and perceptual flexibility for the /ε/-/æ/ contrast. On the one hand, if flexibility developed along general mastery of the contrast, better performance at distinguishing words from nonwords containing the sounds in the difficult contrast should be related to enhanced flexibility for this contrast. On the other hand, it is also possible that a better representation of the difficult sound contrast in the lexicon comes at the cost of flexibility with this contrast. In that case, learners with better scores in the lexical decision task should be more rigid with their category boundaries between /ε/ and /æ/. Our results are mostly in correspondence with this second possibility. The more accurate learners were with /ε/-items during lexical decision, the less they shifted their category boundary in the distributional learning task. In general terms, this finding fits well with previous research indicating that flexibility involving difficult non-native categories may be problematic (Sjerps & McQueen, Reference Sjerps and McQueen2010).
We argue that our pattern of results is probably due to the difficulties inherent in the acquisition of a contrast such as /ε/-/æ/ for German learners of English. In order to learn such a contrast, German L2 learners have to establish a new phonetic category in their already existing sound category space. Since the L1 acts like a perceptual sieve (Flege, Reference Flege and Strange1995; Trubetzkoy, Reference Trubetzkoy1977), it typically takes L2 learners a lot of effort to establish this new L2 category and to accurately separate it from both existing L1 and other L2 categories, with no guarantee of success (e.g., Bohn & Flege, Reference Bohn and Flege1990). It may therefore be the case that perceptual properties, such as phonetic flexibility, are developmentally distinct for difficult L2 contrasts. Although the design of our study does not allow us to establish a clear-cut causal or sequential relationship between greater robustness of phonolexical encoding (here for /ε/ words and *l[æ]mon-type nonwords) and rigidity (i.e., lack of flexibility) in phonetic categorization for /ε/-/æ/, two tentative explanations can be put forward for this connection. One account characterizes rigidity of phonetic categories as a consequence of a more robust phonolexical encoding and the other treats it as the cause of the observed enhanced lexical performance with /ε/-items.
The first alternative is that as phonolexical representations in the L2 become more robust, the boundary between the two L2 phonetic categories becomes more rigid. At the early stages of L2 learning, perceptual abilities with sounds in difficult L2 contrasts are limited (e.g., Bohn & Flege, Reference Bohn and Flege1990) and the encoding of these sounds to L2 phonolexical representations is often faulty. However, over time, learners become better at distinguishing these sounds at the phonetic level, and are able to phonolexically encode them to L2 word representations with a certain success (e.g., Díaz et al., Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012). As phonolexical representations become stronger, learners may become less flexible in their phonetic categorization and less likely to adapt to variation. Phonetic rigidity could therefore be the result of the learners’ need to keep their phonetic categories stable once they find themselves able to cope with the difficult non-native contrast with a certain degree of success at both the phonetic and the lexical level.
The second – in our view more likely – alternative is that establishing rigid phonetic categories for sounds in difficult contrasts facilitates their reliable encoding into the L2 lexicon. Given that the phonolexical encoding of difficult L2 contrasts is extremely challenging, it could be expected that inconsistencies or uncertainty at the phonetic level may have an impact on the degree of success in this encoding. Being excessively flexible or adaptable (i.e., constantly shifting the phonetic boundary between two categories) may be a source of uncertainty compromising the accurate encoding of the phonetic categories into phonolexical representations of words in the L2. By contrast, maintaining rigid phonetic boundaries – once they have been established – would be a way of keeping the phonetic categories stable. Since during L2 acquisition learners are expected to be constantly learning new L2 words and strengthening the representations for already known words (Darcy et al., Reference Darcy, Daidone and Kojima2013; Díaz et al., Reference Díaz, Mitterer, Broersma and Sebastián-Gallés2012), phonetic rigidity could therefore help improve the encoding of difficult sounds to individual phonolexical representations. This connection would then be apparent, as it is for /ε/-items, in a lexical recognition task such as ours. As mentioned above, there are potential reasons why this relationship does not hold for the /æ/-items.
In the present study, we purposefully focused on ‘the average’ German learner of English by targeting a rather homogeneous population whose English abilities were not expected to be close to native-like. This was confirmed in the lexical decision task, where our learners performed poorly on the difficult contrast, especially on /æ/-items but also on /ε/-items. A question that remains to be answered, therefore, is whether reaching a better performance in lexical tasks may yet have consequences on flexibility (vs. rigidity) for difficult contrasts. Once mastery of the difficult L2 contrast approaches native-like levels, will phonetic categories stay relatively rigid as those of the best performers with the /ε/-items in our lexical decision task, or will they become as flexible as the categories involved in L1 and easy L2 contrasts?
On the one hand, if difficult contrasts like /ε/-/æ/ reach a stage in which they are as well established as other less problematic contrasts, then flexibility would be expected to be ultimately attained. Here we showed that German learners of English consistently shifted the phonetic boundary between /i/-/ɪ/ (an easy L2 contrast) in a distributional learning task. If learners’ mastery of the difficult /ε/-/æ/ contrast can approximate that of /i/-/ɪ/ ─ especially at the lexical level, where a considerable difference between the two contrasts was observed ─ then we should eventually expect similar results with our experimental paradigm. On the other hand, if rigidity with the newly-established phonetic contrast is indeed central to achieving an accurate encoding of these sounds in the L2 lexicon (as hypothesized above), phonetic categories may still stay relatively rigid in order to avoid compromising phonetic and lexical abilities. However, note that quantifying how much experience with the L2 would be needed for learners to perform within the native range for difficult L2 contrasts in lexical tasks is far from easy, since sometimes not even early and extensive L2 learning guarantees native-like lexical processing (Navarra, Sebastián-Gallés & Soto-Faraco, Reference Navarra, Sebastián-Gallés and Soto-Faraco2005; Pallier, Colomé & Sebastián-Gallés, Reference Pallier, Colomé and Sebastián-Gallés2001; Sebastián-Gallés et al., Reference Sebastián-Gallés, Echeverría and Bosch2005).
In sum, the present study outlined a relationship between a more successful encoding of a sound involved in a difficult L2 contrast onto L2 phonolexical representations and a reduced flexibility or adaptability for that contrast at the phonetic category level. The German learners of English that were more successful at accepting words with /ε/ and rejecting nonwords in which /ε/ was substituted by the new L2 category [æ] (e.g., *l[æ]mon) shifted their perceptual boundary between /ε/ and /æ/ less in a distributional learning task. While our small effect needs to be interpreted with caution, and further research is needed to confirm and better understand this relationship, our findings suggest that a lack of flexibility at the phonetic level may be advantageous for difficult L2 sound distinctions, reinforcing the idea that the same phonetic flexibility that has been shown to be beneficial in first-language listening (e.g., Bradlow & Bent, Reference Bradlow and Bent2008; Norris et al., Reference Norris, McQueen and Cutler2003) may be costly when it comes to confusable non-native categories.
Appendix A. Words and nonwords used for the /i/-/ɪ/ and the /ε/-/æ/ contrasts in the lexical decision task. For nonwords, the base form is also presented.










