


Introduction
How do children make a start on word production and, consequently, on the development of a phonological system linked with production? One view that has steadily gained adherents over the past several years is that children begin with item learning, in accord with exemplar models of adult phonology (e.g., Beckman & Edwards, Reference Beckman and Edwards2000; Johnson, Reference Johnson, Johnson and Mullenix1997, Reference Johnson, Solé, Beddor and Ohala2007; Munson, Edwards & Beckman, Reference Munson, Edwards, Beckman, Cohn, Fougeron and Huffman2012; Pierrehumbert, Reference Pierrehumbert2003a, Reference Pierrehumbert, Bod, Hay and Jannedyb). In this model coarse-grained (phonological) representations and categories emerge (self-organize) under the effects of cumulative exposure to frequent phonetic patterns (see Foulkes, Reference Foulkes2010; Foulkes & Hay, in press; Wedel, Reference Wedel2007). Children do not learn sounds before words (as per Kuhl, Reference Kuhl2004, for example) but instead induce sound categories from the whole-word forms that they hear in input speech (Feldman, Griffiths & Morgan, Reference Feldman, Griffiths, Morgan, Taatgen and van2009; Ferguson & Farwell, Reference Ferguson and Farwell1975; Swingley, Reference Swingley2009). These familiar forms gain salience from matches to the infant's well-practiced vocal patterns (DePaolis, Vihman & Keren-Portnoy, Reference DePaolis, Vihman and Keren-Portnoy2011; DePaolis, Vihman & Nakai, Reference DePaolis, Vihman and Nakai2013; Majorano, Vihman & DePaolis, Reference Majorano, Vihman and DePaolis2014); the better retention of matching or selected word forms results in the surprisingly accurate production of first words (Ferguson & Farwell, Reference Ferguson and Farwell1975).
What happens next – the critical work of pattern generalization that leads to an incipient phonological system – is eloquently described for second-language (L2) learning in Ellis, Reference Ellis2005:
The bulk of language acquisition is implicit learning from usage. . .Implicit learning supplies a distributional analysis of the problem space: Frequency of usage determines availability of representation. . .with generalizations arising from conspiracies of memorized utterances collaborating in productive schematic linguistic constructions. (pp. 305–6, emphasis added)
Although Ellis is focusing here on (semantic and syntactic) constructions rather than phonological learning, his words apply equally well to first-language phonological development (Vihman, Reference Vihman2002, Reference Vihman2014; Vihman & Croft, Reference Vihman and Croft2007). He continues:
Related exemplars. . .work together in implicit memory, their likenesses harmonizing into an attractor state, and it is by this means that linguistic prototypes and categories emerge. (Ellis, Reference Ellis2005, p. 307).
In early language acquisition the similar fashioning of a small number of known word forms into motoric routines, schemas or phonological templates follows on from the early period of item learning, with knowledge of individual sounds and sequences of sounds later emerging as a natural consequence of the networking of related word forms – similar onsets, nuclei, stressed syllables, and so on (Vihman, Reference Vihman1981). Since neither intentional instruction nor well-developed learning strategies – nor even understanding of the communicative uses of verbal production – are likely to be present at the time of a child's first word uses (in contrast with L2 learning), however, the initial step, the early registering of exemplars and their vocal expression, is likely to be protracted; it often extends over a period of some months.
From the usage-based perspective (Bybee, Reference Bybee2001, Reference Bybee2006) that Ellis adopts, then, ‘performance’ (in the sense of on-going experience with both perception and production) is continually being registered and transformed into ‘competence’, in adults as well as in children; sounds and sound sequences heard and produced in particular lexical frames become interconnected, most densely so where recurrence is the most frequent, resulting in what is termed a ‘phonological system’ (Wedel, Reference Wedel2007). From the developmental perspective of dynamic systems theory (Thelen & Smith, Reference Thelen and Smith1994), similarly, action and perception are continually interacting as the child develops, building on his or her personal experiential history; this is the key source of knowledge, not only in motoric but also in cognitive areas (see also Campos, Anderson, Barbu-Roth, Hubbard, Hertenstein & Witherington, Reference Campos, Anderson, Barbu-Roth, Hubbard, Hertenstein and Witherington2000; Spencer, Thomas & McClelland, Reference Spencer, Thomas and McClelland2009; Vihman, Reference Vihman2014; Vihman, DePaolis & Keren-Portnoy, in press).
But how does this perspective affect our understanding of the particular problem of early bilingual lexical and phonological development? Do bilingual children begin with one system or with two? The question has generated controversy for over 30 years, with regards to phonology (e.g., Khattab, Reference Khattab, Cole and Hualde2007; Lleó & Kehoe, Reference Lleó and Kehoe2002; Paradis, Reference Paradis2001) as well as lexicon and morphosyntax (e.g., DeHouwer, Reference DeHouwer, Kroll and DeGroot2005; Genesee, Reference Genesee1989; Paradis & Genesee, Reference Paradis and Genesee1996; Pearson, Fernández & Oller, Reference Pearson, Fernández and Oller1995; Vihman, Reference Vihman1985; Volterra & Taeschner, Reference Volterra and Taeschner1978). In fact, for all of this time it has dominated the literature on bilingual development, perhaps as a putative test of the central theoretical issue that divides the fields of both linguistics and psycholinguistics. If Universal Grammar provides as innate knowledge the set of distinctive features, phonological structures, processes or constraints found in all languages (such as the ‘minimal word’, for example, or other pre-set stages in the prosodic hierarchy: Demuth, Reference Demuth, Morgan and Demuth1996, Reference Demuth2006), then the bilingual child can be expected to have ‘two systems from the start’, or as soon as the appropriate parameter settings have been triggered by exposure to input from each language. On the other hand, if knowledge of linguistic features, structures and processes is induced or constructed individually by each child, based on exposure to input and item learning, as sketched above and proposed in more detail below, the system must be emergent; in that case the question of one system vs. two need not arise at all for the earliest period of language use.
Attempts have been made to settle the question for early phonological development based on production studies, with respect to phonetic inventories (Schnitzer & Krasinski, Reference Schnitzer and Krasinski1994, Reference Schnitzer and Krasinski1996), process use (Berman, Reference Berman1977), acoustic analyses (Deuchar & Clark, Reference Deuchar and Clark1996; Kehoe, Reference Kehoe2002; Kehoe, Lleó & Rakow, Reference Kehoe, Lleó and Rakow2004), and phonotactic (Ingram, Reference Ingram1981) or prosodic structures (Lleó, Reference Lleó2002). The dominant current view seems to be that there are two phonological systems from the start, but with some interaction (Meisel, Reference Meisel, Cenoz and Genesee2001; Lleó & Kehoe, Reference Lleó and Kehoe2002). The position is more programmatic than empirically testable, however, as it is difficult to demonstrate definitively that a child has one system or two at any given point in a period of high variability and continuing change. Furthermore, allowing for “some interaction” effectively forecloses the possibility of any definitive test.
On the item-learning account with which we began no phonological system as such need be posited for the earliest period. Once the child has produced a number of words, preferred ‘whole-word’ patterns or templates are implicitly generalized from the child's existing forms (i.e., with “implicit learning from usage”: Ellis, Reference Ellis2005, p. 305) – or extended from ‘overlearned’ motoric routines – and applied to less easily assimilated, more challenging adult-word targets (Vihman & Croft, Reference Vihman and Croft2007), initiating the first systematic organization. Based on three children – each acquiring English along with French, Hebrew or Estonian – Vihman (Reference Vihman2002) showed that in each case one or more templates, or idiosyncratic child phonological patterns, were used to adapt words from both of the child's languages (cf. also Brulard & Carr, Reference Brulard and Carr2003).
Here we explore these ideas further by supplementing template data with quantitative analysis and comparison of prosodic structures, over the period of production of the first 100 words, in the two languages of five children bilingual with English, one each learning German and Spanish and three learning Estonian (including the English–Estonian bilingual included in Vihman, Reference Vihman2002). Before presenting the data and analyses, however, we will outline the process of template formation as we understand it.
Templates and emergent systematicity
The child's first identifiable words tend to be relatively accurate, in the sense that the length in syllables typically matches that of the target and omissions and substitutions are rare, while reordering (metathesis) or other radical changes in segmental sequencing and content virtually never occur (see the first five or six words of nearly 50 children acquiring 10 languages: Appendix I, Menn & Vihman, Reference Menn, Vihman, Clements and Ridouane2011). These first words reflect the item learning described above; the child's word forms can be termed selected, in that the adult target word forms are selected (through the implicit matching process) for their accessible structure (see also Fikkert & Levelt, Reference Fikkert, Levelt, Avery, Dresher and Rice2008).
Once the child has produced some 10 to 50 words he or she typically begins to attempt more challenging adult words, ‘adapting’ some of them to existing well-practiced output routines. Priestly (Reference Priestly1977) provided the classic example of his son's response to the challenge of producing disyllabic words with codas (CVCVC) by fitting them into the template <CVjVC>: e.g., basket [bajak], berries [bajas], cupboard [kajat], fountain [fajan]. The resulting changes to targets are difficult if not impossible to account for in terms of straightforward phonological substitution rules, processes or constraints.
The templates characterize an early period in phonological development: Contrast Waterson (Reference Waterson1971), who provides similarly recalcitrant data, with Smith (Reference Smith1973), whose data, from an older and far more lexically advanced child, illustrate the regularity that children arrive at once the period of reliance on templates has passed. We assume that that period begins when the child's ‘ambition’ or inclination to produce more complex and diverse adult target forms outstrips the pace of their advances in motoric or articulatory control and speech planning. Once a sufficient vocabulary has been established, with concomitant growth in the range of prosodic structures and segmental sequences familiar from production practice, we see the fading of wholesale adaptations and a shift to more regular substitutions alongside more adult-like word forms. This shift comes at different lexical points for different children, reflecting individual differences in the balance of ‘ambition’ and resources.
The process underlying the development of a template can be understood in at least two ways. On the one hand, we can see the child as working from an internal schema induced or implicitly abstracted away from his experience of producing words (Vihman, Reference Vihman2002); this can be termed “secondary distributional learning” (Vihman, Reference Vihman2014). On the other hand, we can conceptualize the process as the extension of a motoric routine or procedure, in which the child's intent to repeat a familiar adult word triggers the motoric ‘readiness’ or ‘motor memory’ that has successfully achieved word production previously. Under either interpretation, the template permits further word learning and use without exceeding the child's existing phonetic resources. In addition, the existence of readily available production routines can support attention to and memory for increasing numbers of words (Keren-Portnoy, Vihman, DePaolis, Whitaker & Williams, Reference Keren-Portnoy, Vihman, DePaolis, Whitaker and Williams2010), which may stimulate the development of new, more complex phonological patterns even while the child's existing patterns continue to constrain output. Over a period of months or years the child's increasingly well-interconnected lexical knowledge will result in an ever more independently accessible phonological network – that is, in a phonological system, with the most densely packed and frequently accessed interconnections between words within each language, presumably, but with potentially accessible links between words of the two languages as well. We return to this point in the Discussion.
The templates used are generally similar, both within and across languages (see the templates described for children acquiring seven different languages in Vihman & Keren-Portnoy, Reference Vihman and Keren-Portnoy2013): Children everywhere are constrained by the same limitations on articulation, speech planning and memory for segmental strings in a time of rapid lexical advance. However, differences in frequency of occurrence and rhythmic or accentual patterning in the adult language also shape templates differently (Vihman, in press): Whereas English templates are typically monosyllabic and may include diphthongs or codas, for example, disyllabic templates with open syllables are more characteristic of many European languages (as has been noted before in case studies of children learning English alongside a language that provides more disyllabic or longer targets: e.g., Bhaya Nair, Reference Bhaya Nair1991; Ingram, Reference Ingram1981). The templates arrived at by children learning languages with iambic accent or medial geminates often neglect the onset consonant, which may be omitted (<VC(C)V>), a pattern not seen in children acquiring English (see Keren-Portnoy, Majorano & Vihman, Reference Keren-Portnoy, Majorano and Vihman2009 [Italian]; Savinainen-Makkonen, Reference Savinainen-Makkonen2000, Vihman & Velleman, Reference Vihman and Velleman2000 [Finnish]).
There is thus ample evidence of template formation by individual children learning different languages, with some related differences in prosodic structures. Accordingly, it should be possible to determine objectively whether the bilingual children whose data we examine are producing distinct structures or templates in each of their languages or are resorting to the same familiar routines or patterns in both languages. To do this we will lay out in some detail our criteria for identifying prosodic structures, which express the range of overall shapes and length in syllables of a child's variant forms in either language, with the requirement that a minimum of 10 variant word shapes (roughly 10% of the data sampled) be observed for a structure to be posited as a phonological category for a given child. Templates necessarily constitute a subset of any given child's most produced prosodic structures, with two differences: First, templates are identifiable by the child's overuse (i.e., overselection) of certain patterns in comparison with other children learning the same language or pair of languages, or by their adaptation of target forms to fit the constraints of the preferred pattern; second, templates may be further specified segmentally, such that particular consonants occur medially or finally, for example, or particular consonant or vowel melodies are overproduced (see Vihman & Keren-Portnoy, Reference Vihman and Keren-Portnoy2013, for extensive illustration in studies of monolingual children).
Our research questions will be two-fold:
-
(1) How similar are the prosodic structures produced by bilingual children in their two languages?
-
(2) To what extent do bilingual children deploy distinct templates in each language or, to the contrary, extend patterns more typical of one of their languages to the language they are learning in parallel?
Method
Participants
Data are included here from the first 100 spontaneously produced words recorded in five diary studies of children bilingual with English (see Table 1, ordered by age at first word):
Table 1. Participant age ranges and vocabulary sampled.

-
1. M (first-born, female) was raised in England with Spanish as the home language and recorded by her diarist mother, using on-line transcription as well as audio- and video-recordings (Deuchar & Quay, Reference Deuchar and Quay2000). Deuchar and Quay's Appendix II, a cumulative lexicon of first word-uses from M's first word to age 1;10, was the primary data source, supplemented by an appendix to Quay, Reference Quay1993, in which variant forms are included.
-
2. Hildegard (first-born, female) was raised in the United States with an English-speaking mother and a German-speaking father (diarist father: Leopold, Reference Leopold1939).
-
3. Raivo (second-born, male) was raised in the United States with Estonian and some English in the home; English was spoken in the nursery school attended half time from 14 months (diarist mother: Vihman, Reference Vihman1981, Reference Vihman1982, Reference Vihman2014 [Appendix III]).
-
4. Maarja (first-born, female) was raised in Estonia with an English-speaking mother and an Estonian-speaking father; Estonian was spoken in the nursery school attended full time from 17 months (diarist mother: see Vihman & Vihman, Reference Vihman, Vihman, Arnon and Clark2011).
-
5. Kaia (second-born, female) was raised in Estonia with an English-speaking mother and a bilingual older sister (Maarja), who mainly used English with her, and an Estonian-speaking father; Estonian was spoken in the nursery school attended full time from 17 months (diarist mother: unpublished data).
Data
The data to be used here derive mainly from on-line transcription (supplemented by recordings of M and Raivo). The longitudinal word lists were analyzed for prosodic structures and templates, beginning with the first recorded words and continuing until 100 different words had been produced spontaneously (for Hildegard we included all of the words recorded through the month of the 100th word, resulting in 110 words). Words lacking a stable, convincingly established adult target (e.g., variable onomatopoeia) are not included. As can be deduced from the ages given in Table 1, the period covered includes the age at first word combinations for most of the children.
Analysis of prosodic structure use
The goal of this analysis is to assess the relative similarity of each child's use of prosodic structures in the two languages. Imitated word forms and also variant shapes of a single word type (hereafter, ‘word shapes’) that reflect potentially distinct prosodic structures are included but are not counted in reaching the total of 100 words. For example, Leopold (Reference Leopold1939) gives [bɑ], [bɑ˳], [baɪ] and [bɑɪ] as variants for Hildegard's word Ball Footnote 1 . Of these, CV (the first two variants) and CVV (the other two) are potentially distinct prosodic structures; this means that we include two word shapes in the analysis of Hildegard's single German word type Ball , [bɑ], [bɑ˳] (counted as one CV word shape) and [baɪ], [bɑɪ] (one CVV word shape). In other words, devoicing of the vowel and differences in the quality of the low vowel as transcribed do not give rise to distinct prosodic structures, so that only one variant for each structure is counted in the analysis.
The structures distinguished for the quantitative analysis depend on child use: Where fewer than 10 words occur in a given structure in the two languages combined, that structure is included with the closest more general pattern in analyzing usage in the two languages. For example, Hildegard produces 45 of her first 100 words with a CV structure (and two with syllabic C) and also 15 with a CVV structure (10 with [aɪ] or [ɑɪ], the remainder with [ɔɪ] or [ɑu]); thus for Hildegard we distinguish CVV from CV. In contrast, Kaia has only 7 CVV and 8 CV word shapes in the period of production of her first 100 words but 20 CV: shapes; accordingly, for this child CV and CVV are combined into a single category but CV: constitutes a category of its own. Finally, no more than one variant shape of a given word is included in any one prosodic structure (so Hildegard's CV and CVV structures each include only one, not both of the variants of Ball mentioned above).
Differences in word length in syllables and presence or absence of an onset consonant, complex nucleus or coda are treated as providing potentially different prosodic structures, whereas differences in voicing, vowel quality, and consonantal place or manner are not (although structures involving consonant harmony, if they include 10 or more words, are treated separately from structures of the same length in syllables lacking harmony; thus, for example, Raivo has two distinct structures, C1VC1 and CVC words without harmony [C1VC2]). Where targets have clusters, CC is generally produced with C: e.g., for Raivo, prillid ‘glasses’ [pʰö], pliiats ‘pencil’ [pi:] (both CV), klots ‘block’ [tɔt] (C1VC1), trepid ‘steps’ [papa] (REDUP.). Clusters seldom occur in the child forms; when they do, as in Hildegard's form [ˈprəti] for pretty, they are combined with the related category for singletons (C1VC2V in this case). Syllabic consonants are used by some children but do not reach the criterial 10 for any and are thus combined with the next simplest structure, CV, wherever they occur.
Thus the total number of word shapes included varies by child (see Table 1), depending on how often imitations or variant shapes were recorded and how many belong to potentially distinct prosodic structures. This variability across the child data on which the analyses are based may reflect differences in either the children or the investigators, but it should not affect within-child analyses or comparisons based on proportions rather than absolute numbers. Furthermore, since each word shape produced reflects, in effect, one child ‘vote’ for that prosodic structure, and since the larger data set arrived at by including differing word shapes for a single target provides a more representative sample of the child's phonological abilities and preferences, this relatively inclusive yet objectively defined approach to selecting the database should provide a reliable foundation for the analyses of interest here, despite the inevitable vagaries of diary data collected by different investigators over a period of over 70 years.
For each child we also look for evidence of ‘overuse’ of structures or adaptation, meaning generalization of a structure to assimilate words whose target form is not well matched to it; either of these phenomena provides good reason to posit a child phonological template. Furthermore, whereas the prosodic structures are defined exclusively in general terms based on their constituent consonant and vowel sequences, the templates are defined as narrowly as possible (i.e., identifying as part of the template any particular vowel or vowel height, backness or rounding, or consonant or consonant place or manner, consistent with all variants reflecting the child's use of the pattern). For this analysis we count proportion of word types, not shapes, that conform to the template, since templates are defined in terms of adult word forms assimilated to a preferred child shape or structure. Accordingly, we require that at least 10% of a child's word types should include variants displaying a particular structure to establish template use.
For each child we present and describe the first 10 words recorded (including all variant forms), to consider in full the child's start on identifiable word production. We then provide a quantitative analysis of the set of prosodic structures the child uses in each language, from the first words to a cumulative lexicon of 100 spontaneously produced word types, as outlined above. Finally, we analyse and illustrate the use of phonological templates by each child, identifying both target forms that fit the template and that the child thus produces more or less accurately (selected words) and target forms that the child modifies in a more radical way to fit the template, i.e., by truncation, reduplication, consonant harmony, onset consonant omission, metathesis or other modifications (adapted words: Vihman & Velleman, Reference Vihman and Velleman2000).
Results
We note that, based on one shape per word within each prosodic structure included in the analysis, the proportion of identifiably English word shapes differs by child (Table 2, ordered by proportion of English).
Table 2. Number of word shapes produced in each language (and proportion of total word shapes).

1. M, Spanish and English
Table 3 shows the first 10 words reported for M, which stretched over a period of four months (Deuchar & Quay, Reference Deuchar and Quay2000). As is often the case for the early words of a bilingual child, it is impossible to determine the source language for some of M's forms (see muu/ moo [mˌ:], no /no [nəʊ, no] and carro /car [ka]). Despite the fact that all but one of her first words are simple monosyllables of the form C or CV(V), however, Deuchar and Quay are able to ascribe the remaining words to either English (four words) or Spanish (three) based on context (to establish meaning) and phonological match to the potential targets.
Table 3. M's first ten words.
Target words from English (italics), Spanish ( bold face italics , with gloss in English) or indeterminate (both possible targets provided).

Figure 1 shows the proportional distribution of prosodic structures in M's forms for words in each language (104 word shapes; the 22 word shapes with indeterminate targets are excluded). Most of M's words continue to have the simple CV structure in both languages until she reaches a cumulative lexicon of 30 words, at nearly 16 months. (Note that because only 9 of M's words have diphthongs, CVV is combined with CV here.) This structure remains the one most heavily used throughout the period covered here. Many words are truncated to fit the pattern: Besides the words in Table 3 ( tatai, carro, casa ), see also zapato “shoe” [pa], banana [ba], cabeza “head” [ka], babero “bib” [ba], media “sock” [me]; this necessarily results in a good many CV-homonyms: botón/ button, bebé/ baby, buggy, bucket, bajar “go down” and babero all take the shape [ba], for example, while an additional four forms are given as [pa]. (Note that, according to Deuchar and Quay, the child made no reliable voicing contrast in either language before age 1;10.) From 16 months on, however, M's structures expand to include, in both languages, the open-syllable longer words more typical of Spanish (CVCV: mummy [məmi], mamá [mama]), the closed monosyllables most characteristic of English (CVC: box [bɒk], bang [baŋ], pan “bread” [pan]) and vowel-initial disyllables, less common in either language (VCV: sapo “frog” [apu], apple [apu], tapa “lid, top” [apa]; there are only 9 of these words altogether).

Figure 1. The proportional distribution of M's prosodic structures in word forms based on targets deriving from English (N = 56) as compared with Spanish (N = 48). REDUP = reduplication.
As can be seen in Figure 1, words from both languages participate in all structures. However, CVC structures are the most common in English (and far more frequent than in Spanish), while Spanish words, aside from the dominant CV forms, occur more frequently as disyllables. A chi-square test reveals a significant difference in the distribution of child phonological structures in the two languages (12.6, df = 4, p = 0.013). If the ten first words of Table 1 are set aside, on the grounds that these first words are the most constrained by immature production experience and therefore the least informative as regards any emergent child phonological system or systems, the result is an even sharper separation (14.2, df = 4, p = 0.007).
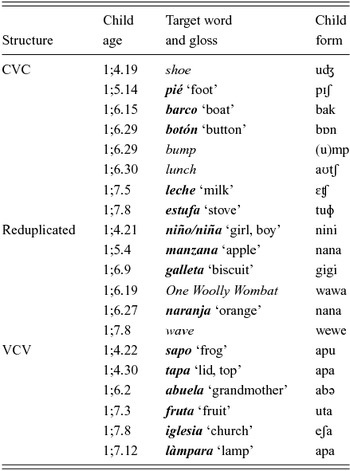
Towards the end of this period M begins to re-form or adapt some English words to fit into the structures more typical of Spanish and also to adapt Spanish words to fit into characteristic English structures (Table 4). Thus, wave takes the form [wewe], unexpected for English, a week after the 100-word period, while pié, barco, leche and estufa take the forms [pɪʃ], [bak], [ɛʧ] and [tuɸ], respectively – unusual for Spanish (see, for example, Macken, Reference Macken1978, Reference Macken1979, for case studies of two monolingual Spanish-learning children). Counting word types rather than word shapes, the CVC forms occur for 26% of all of the words M used within this period and thus can be considered to represent a phonological template for her, as can reduplicated forms (11%) but not VCV forms (8%).
Table 4. M's later words, adapted to preferred templates.
Target words from English (italics) or Spanish ( bold face italics , with English gloss).
2. Hildegard, German and English
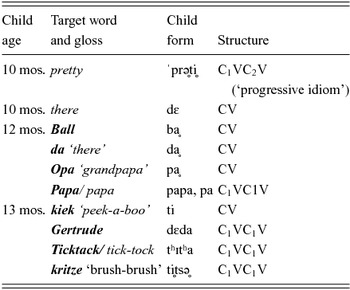
Table 5 shows Hildegard's first ten words (Leopold, Reference Leopold1939). Leopold identifies the targets of six words as German (including an aunt's name) and those of two as English; two are indeterminate. Whereas almost all of M's earliest words fit a single structure, CV, Hildegard's include three: the unusually advanced form for pretty (termed a “progressive idiom” by Moskowitz, Reference Moskowitz1970), which we categorize as C1VC2V (disregarding the cluster, which occurs in no other child word forms), the CV structure for the next few words produced, and disyllabic forms with harmony for the remaining words. Most of these forms (many of them whispered) resemble their targets quite closely. The onsets of Papa and Ticktack harmonize in their target forms but those of Gertrude and kritze do not; since Hildegard has not yet produced a velar at this point, however, the harmony in her forms must be considered a natural consequence of the production of velars as coronals rather than an adaptation of the adult form to fit the harmony pattern.
Table 5. Hildegard's first ten words.
Target words from English (italics), German ( boldface italics ) or indeterminate (both possible targets provided).
The six prosodic structures seen in Hildegard's later words, up to age 1;8, are shown in Figure 2 (based on 108 word forms with an identifiable target language; the 22 forms with indeterminate targets are excluded). These are all those that include at least 10 words in each structure, regardless of language source – so that, for example, the CVCV structure includes both the 10 harmony forms and the four later words that Hildegard produces as C1VC2V, all of them following the labial-coronal melody established in her first word, pretty (bitte “please”, Bleistift “pencil”, water and Fritschen, a name).

Figure 2. The proportional distribution of Hildegard's prosodic structures in word forms based on targets deriving from English (N = 63) as compared with German (N = 40). REDUP = reduplication.
As with M, the single largest category in both languages is the simplest structure, CV. The next most frequently used structure differs for the two languages, however, with nearly one quarter of the English child forms being reduplicated (vs. 12% of the German child forms), while 19% of the German forms are open diphthongal monosyllables (vs. 8% for English). A chi-square analysis shows a near-significant difference in the distribution of child forms by language (10.9, df = 5, p = 0.054). If the first 10 words are disregarded the difference is significant (13.0, df = 5, p = 0.024).
Both input languages make use of diphthongs. Although Hildegard produces bye-bye as [b
![]() b
b
![]() ] and
wauwau
“woofwoof” as [wawa] at 15 mos., down as [da] at 16 mos. and
Auto/
auto as [ʔata, ʔada] at 17 mos., she correctly reproduces the vowel nucleus in all words with the front-rising diphthongs [aɪ] or [ɔɪ] in either language from 16 months on –
ei!
(term expressing affection, while stroking cheek) [ʔaɪ] (16 mos.),
heiss
“hot” [h
] and
wauwau
“woofwoof” as [wawa] at 15 mos., down as [da] at 16 mos. and
Auto/
auto as [ʔata, ʔada] at 17 mos., she correctly reproduces the vowel nucleus in all words with the front-rising diphthongs [aɪ] or [ɔɪ] in either language from 16 months on –
ei!
(term expressing affection, while stroking cheek) [ʔaɪ] (16 mos.),
heiss
“hot” [h
![]()
![]() ], highchair [ʔaɪta], I [ʔaɪ], night-night [ŋaɪŋaɪ] (17 mos.),
Bleistift
“pencil” [baɪti], light [haɪ],
mein
/mine [maɪ],
Nackedei
“naked” [daɪ],
nein
“no” [naɪ], oil [ʔɔɪ] (18 mos.), eye [aɪ],
Ei
“egg” [aɪ], ride [haɪhaɪ] (20 mos.).Footnote
2
The back-rising diphthong [aʊ] first appears at 18 months:
auf, aus
, out “from, out of” [ʔaʊ], but
Bauch
“tummy” is produced as [ba] in the same month. Finally, at 19 months we have an imitation of
Auge
“eye” as [ʔɑʊ] and spontaneous use of
Frau
“lady” [ʔɑʊ] (also produced at 20 months as [wa, wɑʊ, vɑʊ]), and at 20 months spontaneous productions of both
Haus
/house [haʊʃ] and
miau
/meow [mi|ʔaʊ]. The gradual increase in diphthong use thus illustrates the child's parallel advances in the two languages.
], highchair [ʔaɪta], I [ʔaɪ], night-night [ŋaɪŋaɪ] (17 mos.),
Bleistift
“pencil” [baɪti], light [haɪ],
mein
/mine [maɪ],
Nackedei
“naked” [daɪ],
nein
“no” [naɪ], oil [ʔɔɪ] (18 mos.), eye [aɪ],
Ei
“egg” [aɪ], ride [haɪhaɪ] (20 mos.).Footnote
2
The back-rising diphthong [aʊ] first appears at 18 months:
auf, aus
, out “from, out of” [ʔaʊ], but
Bauch
“tummy” is produced as [ba] in the same month. Finally, at 19 months we have an imitation of
Auge
“eye” as [ʔɑʊ] and spontaneous use of
Frau
“lady” [ʔɑʊ] (also produced at 20 months as [wa, wɑʊ, vɑʊ]), and at 20 months spontaneous productions of both
Haus
/house [haʊʃ] and
miau
/meow [mi|ʔaʊ]. The gradual increase in diphthong use thus illustrates the child's parallel advances in the two languages.
Hildegard has a tendency, which puzzles her diarist father, to settle for short periods of time on a single pattern for several somewhat similar adult words: See, for example, the disyllabic pattern <CV:i>, which emerges at 18 months: bottle [ba:i], dolly [da:i], followed at 19 months by Joey [do:i] and water [wɔ:i] (cf. also Ball , produced once at 16 mos. as [ba:i]). Of these, Joey is accurate (given the absence of any affricate in repertoire), dolly is easily understood as deriving in an expected way from omission of a difficult C2, but bottle and water are good examples of child holistic adaptation to a preferred or more familiar production form, where specific segmental substitutions would offer an inadequate account (the post-tonic t/d flap of American English is followed by syllabic liquids in the target forms here, but no general phonological process account takes flap+liquid to [i]). The form [da:i] also comes to be used for candy at 22–23 months, alongside dry [dai], with consistent contrasts in vowel length, according to Leopold (cf. also cry [dai], drei “three” [dai], both reported from 22 or 23 months). Based on the criterion of 10+ uses out of 100 words, however, we cannot formally identify a template <CV.i> within the period covered here.
The pattern CVCi constitutes another of Hildegard's non-reduplicated disyllabic structures and also applies to both languages: baby [bebi] (14 mos.), buggy [babi] (18 mos.), bobby[-pin] [babi] (19 mos.), and then stocking, Bleistift and Nackedei , all produced as [dadi] at 19 months. (Recall that Bleistift was more accurately produced as [baɪti] at 18 mos. – and note that buggy later took on the simpler and less accurate shape [bai], which became its stable form by 22 mos.). Leopold notes that “there may have been a general predilection for the form [dadi] at this period; it had no less than five widely different meanings” (1939, p. 66): Nackedei , stocking, Jasper and Taschentuch “handkerchief” in addition to the entry he is discussing, Bleistift ; a similar comment regarding the “great [dadi] merger” is to be found under the entry for Nackedei (recall also M's overuse of [ba/pa]). Vihman (Reference Vihman1981) describes an analogous tendency toward “collecting homonyms” in her son Raivo's phonological development; Waterson (Reference Waterson1971) was the first to recognize the phenomenon of “schemas”, or small groups of words produced in a similar way. Here again, although no quantifiable template use can be identified as such, overuse of a pattern suggests incipient development of a template and shows that, as with M, these patterns are not constrained to apply to only one of the child's languages but serve as a temporary response to challenges posed by either language.
3. Raivo, Estonian and English
Raivo's first 10 words, produced at 13 and 14 months, are shown in Table 6. Of these words only shoe and hiya are identifiably English; four are Estonian and four could derive from either language. There are a total of 12 distinct word-shape variants here; since we count only one variant of the same shape per structure for any given word type (e.g., only one of the two distinct syllabic-consonant forms for shoe, [∫ˌ] and [çˌ]), only viska and pall / ball have two structures each. The words with their variants fit into six different prosodic structures; these are, in order of appearance in Table 6: (i) syllabic consonant, (ii) closed monosyllable, (iii) open monosyllable with single-vowel nucleus, (iv) open monosyllable with diphthongal nucleus, (v) reduplicated disyllable and (vi) VCV.
Table 6. Raivo's first ten words.
Target words from English (italics), Estonian ( boldface italics ) or indeterminate (both possible targets provided).
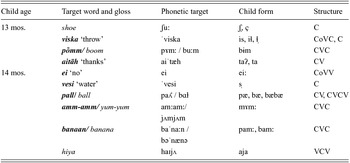
Figure 3 shows the distribution across prosodic structures of the 156 word forms of identifiable origin that Raivo produced over the period of his first 100 words (10 additional words were indeterminate).Footnote 3 Here again words from both languages participate in all structures, with both the basic CV and closed monosyllables being frequent in each, the CVV structure less so. Multisyllabic structures are frequent in Estonian but less so in English. A chi-square test shows that the two languages did not differ significantly in the distribution of child forms by language, whether the first 10 words are included (4.98, df = 6, p = 0.547) or not (5.57, df = 6, p = 0.473).

Figure 3. The proportional distribution of Raivo's prosodic structures in word forms based on targets deriving from English (N = 30) as compared with Estonian (N = 127). REDUP = reduplication, CH = consonant harmony.
In an analysis of this child's templatic patterns Vihman (Reference Vihman2014) reports that “two basic word-shape types may be distinguished for all recorded word forms in either language (imitated as well as spontaneous): closed monosyllables and open disyllables” (p. 324; this statement disregards the large proportion of CV shapes in both languages, which may be taken to be a kind of simplest-structure default). That analysis distinguishes three subgroups of CVC templates (with fricative, nasal and stop coda) and two subgroups of CVCV templates (with glottal or glide and with stop or nasal onset). Table 7 presents all of the words and variant forms produced, from the tenth word until the end of the period covered here, as represented in one subgroup for each of these patterns: CVC with fricative coda (19%); CVCV with stop onsets (14%.)
Table 7. Raivo's later words, selected or adapted (starred forms) to preferred templates.
Target words from English (italics), Estonian ( boldface italics ) or indeterminate (both possible targets provided). C consonant, V vowel, F fricative, Co optional consonant; im. imitated.
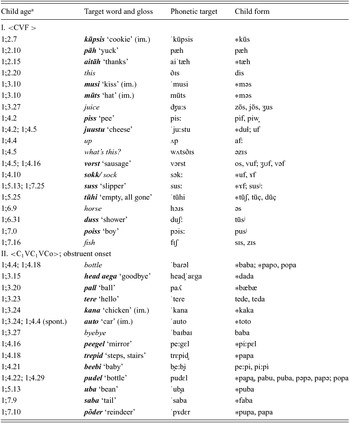
aWhere two ages are given, separated by a semicolon, they correspond to the ages at which two or more variant forms were produced, as indicated by the corresponding semicolon under ‘child form’. Variants separated by comma were recorded on the same day.
Note that words from both languages are represented in both templates, but not equally: We find 12 Estonian, six English and one indeterminate word conforming to the <CVF> template, 12 Estonian and two English words conforming to the disyllabic template. Given that Raivo's vocabulary as a whole has four Estonian words to every English word, English is overrepresented in the first case and underrepresented in the second. Observe also that the “homonym strategy” described in Vihman (Reference Vihman1981) and mentioned above in connection with Hildegard's data is illustrated here: The use of [baba] or [papa] for bottle, byebye, trepid and pudel , along with the use of [məs] to imitate both musi and müts (noted in Vihman, Reference Vihman2002), is reminiscent of Hildegard's repeated use of [dadi].
4. Maarja, Estonian and English
Maarja's first 10 words, produced at 12 to 14 months, are shown in Table 8.
Table 8. Maarja's first ten words.
Target words from English (italics) or Estonian ( boldface italics ).
C consonant, V vowel.

Of these only daddy and mommy are identifiably English; five are Estonian and four, many of them onomatopoeic, could derive from either language. Maarja's first words show multiple variants for a single word type, giving a total of 15 shapes, with two to three distinct structures counted for aitäh, kuku /uh-oh, mõmm-mõmm and daddy. A striking characteristic of these first words is the strong presence of front-rising diphthongs and disyllables ending in [i], not only in the words the child attempts but also in the forms she produces for those words.
Figure 4 shows the distribution across prosodic structures of the 145 word shapes of identifiable origin that Maarja produced over the period of her first 100 words (7 additional words were indeterminate). Note that for this child a distinction between short- and long-vowel nucleus and diphthong is relevant in monosyllables, since more than 10 words fall into each of those structures over the 100-word period. In fact Maarja makes the least use of the simplest structure, CV, of all of the children. This is in part the result of her frequent use of long (CV:) monosyllables (17% of her 152 word shapes), which leads to the separate categorization of long- and short-vowel structures. In fact, the three children learning English alongside Estonian, with its pervasive vowel and length contrasts, make comparable (and relatively low) use of the CV structure.Footnote 4

Figure 4. The proportional distribution of Maarja's prosodic structures in word forms based on targets deriving from English (N = 81) as compared with Estonian (N = 64).
Like the other children Maarja makes some use of all structures in both languages, although the typical split between monosyllabic structures in English and disyllabic structures in the other language is particularly dramatic here. A chi-square test shows a highly significant difference in the distribution of prosodic structures by language, regardless of the inclusion (22.3, df = 6, p = 0.001) or exclusion of the first 10 words (31.6, df = 6, p = 0.000).
Vihman and Vihman (Reference Vihman, Vihman, Arnon and Clark2011) describe a templatic “palatal pattern” in Maarja's data, which they define as encompassing both <Vi> (e.g., kalli-kalli [kɤɪ:]) and <CoVCi> ( kassi [ˈɑs:i]). In a figure tracking Maarja's lexical growth and template use this pattern is seen to peak at 15 months at nearly 70% occurrence in all of the child's word forms and to then drop back by about 15%, to something like the starting proportion, by 17 months, the age at which Maarja's 100th word was recorded. (Comparative analysis of input speech to a monolingual Estonian-learning child revealed about 36% such palatal patterns.) Table 9 presents the relevant word forms, in either language, for the word structures in question over the first 100-word period (following the first ten words). Including the first words, the total comes to 36 word types (36%) with one or more palatal-pattern tokens.
Table 9. Maarja's later words, selected for or adapted to her palatal template.
Target words from English (italics) or Estonian ( boldface italics ). Obj. = form used as object of transitive verb; BT = baby talk term. Adapted forms are starred.
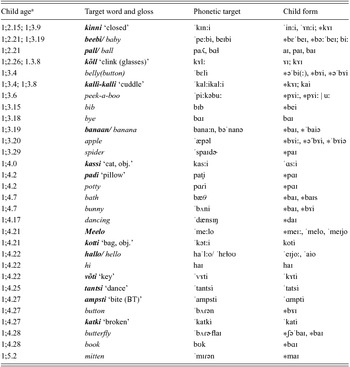
aWhere two ages are given, separated by a semicolon, they correspond to the ages at which two or more variant forms were produced, as indicated by the corresponding semicolon under ‘child form’. Variants separated by comma were recorded on the same day.
Taking all tokens into account – the maximum number of productions involving either a front-rising diphthong or the CVCi pattern – we find (Table 9) that the former (39 tokens) is over four times more frequent than the latter (8 tokens); this imbalance is also apparent on the basis of the more broadly defined structures in Figure 4. By our analysis, the <CVi> pattern is a template, seen in child tokens of 26 of the first 100 words produced (two of them in Table 8: aitäh, pai ), whereas the nine disyllabic words ending in /–i/ (all but mummy and daddy are Estonian) may simply reflect the high frequency of this pattern in the adult language. The disyllabic pattern is emergent in the child's production: It is accurately used for all four targets in /-i/ in her first words but then occurs only twice before 1;4.22 ( kinni, kotti ); thereafter it is deployed more consistently.
We note that the targets in Table 9 include 11 Estonian, 15 English and four indeterminate words altogether, which corresponds closely to the overall linguistic distribution of words in the child's vocabulary in this period; thus the child is making no active distinction between her languages here but instead is falling back on her favored production pattern for these words as need arises, within the constraints of her phonetic resources and the channeling or guidance afforded by experience with speech in either language. Furthermore, “homonym collection” can be seen here again as the forms [paɪ/baɪ] and [pɤi/bɤi] recur over the period 1;2.15 to 1;4.7 for the expression of no fewer than 14 different words, some of which, like pall , belly and bye or even spider, padi and potty, could be seen as selected for their match to a familiar motor routine; other words, in contrast, can only be seen as adapted, more or less radically, to fit the preferred template (e.g., peek-a-boo, banana, apple, bath, and three weeks later, book). Both languages are involved in this “great [bVɪ] merger”, to paraphrase Leopold, and indeed Maarja is as likely to deploy the high-frequency Estonian mid-back unrounded vowel [ɤ] for English as for Estonian targets.
5. Kaia, Estonian and English
Kaia's first 10 words, produced over the period 11 to 16 months, are shown in Table 10. Kaia's first word, like Hildegard’s, is a progressive idiom – a form well in advance of any others produced for months after its occurrence. It was repeatedly whispered, as if as a personal marker of attentional focus, in response to the passage of one of four kittens born when Kaia was 10 months old. This is one of the five child words with indeterminate language source. Two of the remaining words are in English, three in Estonian. The prosodic structures produced over the period 14–16 months, when word production began in earnest, are varied in shape, from the simple CV to CVC (with nasal harmony), VCV and reduplicated disyllable; none of these has the C1 - C2 structure of the surprisingly precocious form for kiisu/ kitty, independently noted by both mother and grandmother.
Table 10. Kaia's first ten words: Target words from English (italics) or Estonian (boldface italics).
C consonant, V vowel; REDUP = reduplication.

Figure 5 shows the distribution across prosodic structures of the 127 word shapes of identifiable origin that Kaia produced over the period of her first 100 words (12 additional words were indeterminate). Although Kaia produces proportionately more English words as CV(V) or as reduplicated disyllables, more Estonian words as VCV or other open-syllable words, the overall distribution of her structures is not significantly different by language, either with (chi-square = 4.16, df 6, p = 0.654) or without the first 10 (6.87, df 6, p = 0.333).

Figure 5. The proportional distribution of Kaia's prosodic structures in word forms based on targets deriving from English (N = 39) as compared with Estonian (N = 72).
To explore Kaia's use of templates we consider, in Table 11, the two main structures she produced after the first 10 words, VCV (27 words) and reduplication (18 words). Here again it is evident that words from both languages are both selected and adapted to fit into each of these templates. For example, apple is produced relatively accurately within the <VCV> structure, while pacifier, monkey, doggy, ducky and orange (juice) are each more or less radically adapted to fit into it. In Estonian a larger number of words naturally fit the pattern, which features a medial geminate in most of the cases cited here: The child form is essentially accurate for emme, anna, õue, aua and appi but is adapted in more or less surprising ways to fit juua, lamp/ lamp) and lutti. With regards to reduplication, similarly, target forms like choochoo, night-night and byebye are already reduplicated and thus lend themselves to selection for the pattern while apple and blanket are more surprising in this structure. Of the more numerous reduplicated Estonian words, however, most fit without much need for adaptation ( tudu, kuku, kaka, pipi ), suggesting that in both of these cases the Estonian phonological patterns are affecting the child's production of English words.
Table 11. Kaia's later words, adapted to her VCV and reduplication templates.
Target words from English (italics) or Estonian (boldface italics). Adapted forms are starred.
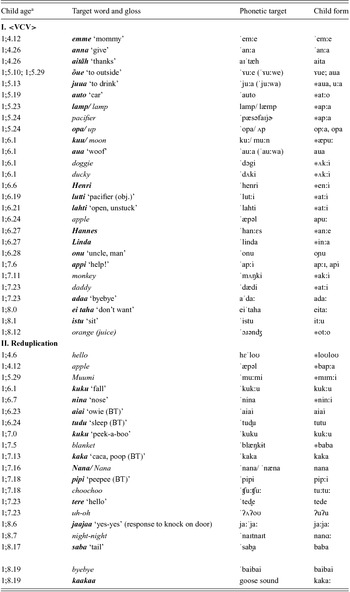
aWhere two ages are given, separated by semicolon, they correspond to the ages at which two or more variant forms were produced, as indicated by the corresponding semicolon under ‘child form’. Variants separated by comma were recorded on the same day.
Discussion
We have reviewed the evidence for phonological differentiation in the two languages of five children over the period of production of their first 100 words. The children varied in the proportion of different word shapes identifiably produced in each language (from .18/.76 to .53/.42: Table 2), but all of them drew on both their languages in producing their first 10 interpretable words. The clear child reliance on two separate systems sometimes reported for a child learning English along with another language (Italian: Ingram, Reference Ingram1981; Hindi: Bhaya Nair, Reference Bhaya Nair1991) was not strongly evident here. Of the five children, only two – one learning Spanish with English, the other Estonian with English – showed a significant difference between languages in the overall distribution of prosodic structures. Interestingly, exclusion of the first ten words led to a sharper distinction between the prosodic structures used for their two languages for every one of the children, resulting in three significantly different distributions out of the five. This suggests that as children gain production experience they are better able to match the ambient language patterns and begin to build two distinct systems.
Ferguson and Farwell's (Reference Ferguson and Farwell1975) finding that first words are relatively accurate is again largely confirmed here. Despite the restriction to the prosodic structures C/CV(V) and VC, for example, M's first words match the target forms in syllable selection, although with omission of syllables in longer words ( tatai, carro, casa ) and of codas and clusters in words with onset consonant (book, clock): See Table 3. A similar observation can be made for Hildegard's first words (Table 5). Raivo's first words show a wider range of structures but are similarly close to the targets, if we allow for the compression of viska , for example, to a syllabic fricative (Table 6). All of this supports the suggestion of item learning in the first words, with implicit selection of targets to fit each child's available production resources.
Maarja displays more complex first word forms than the other children, with evidence of palatal-pattern selection and use already in six of her first 10 words, as discussed above (Table 8); for comparison, the other two children learning Estonian and English target only four (Raivo) and two (Kaia) seemingly ‘palatal’ forms among their first 10 words and produce at most only one such form. Kaia, similarly, shows an early attraction to the target words that feature the <VCV> and reduplication patterns to which she later adapts many words (Table 10).
Finally, as a follow-up to Vihman (Reference Vihman2002), we looked more rigorously at template formation and use. Here we found that, whatever templatic pattern the child deploys, words from not only one but both languages are selected as matches to the pattern or fitted into it; this was true of all five children, although the somewhat sparser data base for M and Hildegard made formal template identification more difficult, based on our criteria. The evidence of template formation, which is typically seen, as here, after production of the very first words (e.g., Vihman & Croft, Reference Vihman and Croft2007), might seem to run counter to the statement made above, that the children distinguish the patterns of the two languages more sharply in production as they gain experience with word use. But the contradiction disappears when we consider the analyses adopted: On the one hand, analysis of the overall distribution of word shapes shows that the children gradually broaden the range of structures they are able to remember, plan and produce; this no doubt contributes to the separation between the two languages. At the same time, template analysis reveals that diverse word types come to be increasingly represented by similar phonological patterns, with regression in accuracy as the children adapt or assimilate target forms to their most favoured structures. Furthermore, template use is dynamic, changing over time as the child's lexical and phonological knowledge develops and changes.
In summary, none of the children maintains a consistent phonological distinction between the languages in the form of different structures and templates. Instead, each child shows some influence of the ambient languages in the distribution of structures they use but also some indiscriminate use (or overuse) of well-practiced structures, which we characterise as templates, regardless of target language. The children continually draw on what they know rather than restricting themselves to ‘separate systems’. This observation is in accord with the exemplar model for emergent phonology: A child's first word structures are individual rather than universal – despite strong commonalities across both children and languages; some of the words produced subsequently fall into more or less narrowly constrained individual templates, in accordance with which the child both selects and adapts target words, constructing phonological links that may serve as one level of connections in the network that will begin to approximate an adult linguistic system for each language.
A paradox and a proposed solution
The finding that children do not sharply distinguish between their languages in production is paradoxical, however. Perception studies tell us that bilingual infants differentiate their ambient languages from early on (Bosch & Sebastian-Galles Reference Bosch and Sebastián-Gallés1997, Reference Bosch, Sebastián-Galles, Cenoz and Genesee2001; see also Mehler, Jusczyk, Lambertz, Halsted, Bertoncini & Amiel-Tison, Reference Mehler, Jusczyk, Lambertz, Halsted, Bertoncini and Amiel-Tison1988). Details of the voice, emotion, and situational context are retained in exemplar learning, so differentiation by speaker should help to separate the linguistic sources of words the child learns (e.g., Menn, Schmidt & Nicholas, Reference Menn, Schmidt and Nicholas2009, Reference Menn, Schmidt, Nicholas, Vihman and Keren-Portnoy2013; Pierrehumbert, Reference Pierrehumbert, Bod, Hay and Jannedy2003b; for experimental evidence of early exemplar effects in infant speech processing, see Houston & Jusczyk, Reference Houston and Jusczyk2000, Reference Houston and Jusczyk2003; Singh, Morgan & White, Reference Singh, Morgan and White2004). If we accept the evidence that infants are able to differentiate their languages from the first months of life, then how do we account for these findings, which suggest that bilingual children do not necessarily separate their languages in categorizing words by prosodic structure or template?
The solution to the paradox may lie in the findings of DePaolis and colleagues to the effect that infants’ own output has a significant effect on their processing of speech (DePaolis et al., Reference DePaolis, Vihman and Keren-Portnoy2011, Reference DePaolis, Vihman and Nakai2013; Majorano et al., Reference Majorano, Vihman and DePaolis2014). In the case of the bilingual child, this means that the perceptual experience with two languages afforded by the input from parents and others is importantly supplemented by their own output, which – given constrained speech production resources as regards both motoric control and speech planning – constitutes a compromise between child capacities and the specific shaping provided by exposure to the ambient languages. Thus, as the child first embarks on word production, she hears herself producing words of either language in a very similar way and in her own voice. The child's own production provides not only auditory but also proprioceptive cues, as well as eliciting the added attention associated with the effort of production (Elbers & Wijnen, Reference Elbers, Wijnen, Ferguson, Menn and Stoel-Gammon1992). It is not surprising then that the resulting structures come to be particularly salient to the child, at least for a time, leading to the overgeneralization and systematization that we see in template use. In other words, the child's own voice and simpler articulatory gestures (and habitual gestural sequences or routines) can be assumed to temporarily overlay the distinct linguistic sources deriving from differing adult voices, language rhythms and prosodic structures (see also Foulkes, Reference Foulkes2010). Such a production effect may not be apparent in the child's first word uses, whose simple form often makes it difficult to identify the linguistic source (the period of ‘no system’), but it becomes readily observable as lexical production increases and the typological differences seen in cross-linguistic studies emerge along with greater systematicity (Vihman, in press). The emergence of more detailed phonological structure, along with a return to more exact retention of adult word forms, can be expected to follow.
How separate are the linguistic systems of older bilinguals?
Researchers no longer disagree as to whether child bilinguals can differentiate their languages; clearly they can. Differences in form (as regards both phonology and the syntactic frames experienced in running speech) generally identify lexical items as belonging to one language or the other. At the same time, the meanings of early words, like their initial phonetic shapes in the child's output, may be largely shared, if the child's experiences are similar in the two language settings and usage is comparable.
The key questions surround the issue of abstractness of representation. The evidence provided here demonstrates initial item-learning followed by steady system building, implemented through distributional learning like that which underlies advances in receptive knowledge in the first year (or the L2 learner's “generalizations arising from conspiracies of memorized utterances”: Ellis, Reference Ellis2005, p. 305). This evidence casts doubt on arguments supporting innate knowledge of linguistic principles. Children initiate learning with specific words and phrases and can gradually gain knowledge, from that initial item learning, of the phonetic and semantic specificity and the distinct forms of linguistic patterning inherent in bilingual input.
But how separate are the linguistic systems of older bilinguals? Although an adult speaker with long experience and ongoing practice of both of his languages necessarily has deep and extensive grammatical knowledge of two linguistic systems, current neurolinguistic research has made any claim of separate loci in the brain for each language seem highly implausible, not to say naïve (e.g., Abutalebi, Cappa & Perani, Reference Abutalebi, Cappa, Perani, Kroll and DeGroot2005; Green & Abutalebi, Reference Green and Abutalebi2013). One can more justifiably speak of the dynamics of processing and the phonological, syntactic, semantic and lexical networks that underpin that processing. Activation of one language in the course of either receptive or expressive processing has been shown to arouse activation of related forms and meanings in the other (e.g., Kroll, Bobb & Wodniecka, Reference Kroll, Bobb and Wodniecka2006 and various chapters in Kroll & DeGroot, Reference Kroll and DeGroot2005). Thierry & Wu (Reference Thierry and Wu2007) provide striking ERP evidence of such activation in Chinese late L2 English learners. Similarly, experimental studies have provided evidence of both translation and semantic priming across the two languages of bilingual speakers (e.g., Schoonbaert, Duyk, Brysbaert & Harsuiker, 2009). Complementarily, Mägiste (Reference Mägiste1979) long since showed that bilinguals are detectably slower than monolinguals in fast-response tasks in both their languages (and trilinguals slower still), again suggesting some degree of parallel activation of all linguistic networks in the course of processing.
Although everyday competition between two languages is generally resolved satisfactorily, as required within a given discourse situation, bilinguals sometimes experience unique on-line difficulties that reveal automatic (implicit) phonological and/or semantic associations that cross language boundaries. Consider the following anecdotal bilingual production phenomena that reveal unconscious links and involuntary access based at least partly on cross-linguistic phonological similarity:
-
(1) Estonian luik /luik/ “swan”, produced by a fluent adult bilingual for järv /jærv/ “lake”, with probable phonological interference from English lake – possibly influenced by the thematic (and collocational) “swan”-”lake” association;
-
(2) mushrooms, produced by a bilingual 6-year-old for Estonian neerud /ne:rut/ “(cooked) kidneys” – the slip apparently mediated by the phonological association of neerud with Estonian seened /se:net/ “mushrooms” (Ce:CV plus plural -d), perhaps supported by the visual similarity of the foods (Vihman, Reference Vihman1981, p. 249). Mysteriously, the associated Estonian word itself was not accessed at the moment of production.
-
(3) socket, produced by an Arabic-English bilingual 7-year-old, in a picture-naming activity, for Arabic [sˤɑtəl] “bucket” (Khattab, Reference Khattab2013, p. 455).
-
(4) Production, as part of a counting routine, of the English number nine, a homonym of Welsh nain /naɪn/ “grandma”, led a Welsh preschool child to spontaneously add: a taid “and grandpa” – showing that she had suddenly noticed the cross-linguistic phonetic association.
Similarly, speakers sometimes experience repeated difficulty with correct production of one of a pair of closely linked words. In the case of bilingual usage, such difficulty can spread from a first to a second and even a third language: For example, the author initially confused the names of her sister and daughter, both beginning with V; over 40 years the confusion spread to the words sister/daughter themselves (and eventually to brother-in-law/son-in-law as well), and also to the other languages she regularly uses, Estonian õde “sister”/tütar “daughter” and French soeur/fille, where no phonological link is detectable, either cross-linguistically or within the pairs. Here a single semantic link has given rise to a long-term multilingual spread of activation.
In short, anecdotal as well as experimental evidence lends intuitive support to the growing number of studies that now show that ‘non-selective’ language processing and use is typical for adults, meaning that the languages of a multilingual are ever accessible and competing for control – generally below the level of consciousness. There is all the less reason to expect sharp separation of language use in children, who must gradually move from knowledge of individual lexical items to more integrated construction of phonological systems for each language, combining their early receptive knowledge of rhythms and phonotactic sequencing with their emergent motoric routines and practice. The very concept of ‘system’ could profitably be re-examined, not least in the acquisition literature: How should the distinction between ‘representation’ and ‘processing’ be established, in either adults or children? The question deserves more attention than it has so far received.
















