In monolingual (native) language comprehension, people continuously generate predictions about upcoming input (e.g., Altmann & Kamide, Reference Altmann and Kamide1999; Boland, Reference Boland2005; DeLong, Urbach & Kutas, Reference DeLong, Urbach and Kutas2005). In a seminal paper, Altmann and Kamide (Reference Altmann and Kamide1999) studied prediction in auditory language comprehension using a visual world paradigm. Participants listened to sentences such as The boy will eat the cake or The boy will move the cake. Eye movements were recorded while participants viewed a visual scene with four objects that could all be moved, but in which only one object (the cake) was edible. When participants heard the verb eat, participants initiated fixations to the picture of the cake more often before the onset of the word cake than after hearing the verb move. Altmann and Kamide concluded that the sentence context pre-activated the representation of the target word. Various recent models of monolingual sentence comprehension have now incorporated predictive processing (e.g., Levy, Reference Levy2008; MacDonald, Reference MacDonald2013; Pickering & Garrod, Reference Pickering and Garrod2013).
Using context information to generate predictions is fundamental in efficient language processing: it can speed up processing, solve ambiguities, and help the listener determine when to start an overt response in a dialogue (Kutas, DeLong & Smith, Reference Kutas, DeLong, Smith and Bar2011; Van Berkum, Reference Van Berkum2010). These facilitatory functions could be particularly relevant in L2 comprehension, which is often considered to be slower, less accurate, and more resource-consuming than L1 processing (Cook, Reference Cook, Groot and Kroll1997; Hahne, Reference Hahne2001; Weber & Broersma, Reference Weber, Broersma and Chapelle2012). On the other hand, L2 processing difficulty may also impede efficient prediction during language comprehension. However, in spite of its possible increased importance, there is very little research about whether bilinguals predict input in their L2 as native speakers do in L1 or whether L2 words and their features are just integrated incrementally when they are encountered in the input rather than before.
In a recent review, Kaan (Reference Kaan, Rothman and Unsworth2014) suggested that predictive processing in L2 is not inherently different from predictive processing in L1, but that it may be modulated by factors associated with non-native comprehension. For example, it is often assumed that predictions are based on statistical regularities extracted from the input throughout a person's lifetime (e.g., Bar, Reference Bar2007; MacDonald, Reference MacDonald2013). However, information stored in memory about how often a word tends to occur in a certain context (e.g., an edible object following the verb eat) may be different in L2 and L1 because the L2 has usually been practiced less (Gollan, Montoya, Cera & Sandoval, Reference Gollan, Montoya, Cera and Sandoval2008) and in different settings (e.g., native learning versus classroom learning). Less or different input in L2 may affect the content and strength of predictions. Importantly, if L2 is practiced less than L1, representations of lexical form, meaning and use as well as the links between them may be less consistent and less accurate in L2 (Gollan et al., Reference Gollan, Montoya, Cera and Sandoval2008). Weaker representations may lead to less efficient retrieval. And less efficient retrieval of lexical form or semantic associations may in turn lead to slower, less accurate or weaker predictions. Likewise, because bilinguals divide language use between L1 and L2, and therefore also have less L1 practice, L1 processing too may be different for monolinguals and bilinguals. If inconsistency of lexical representations indeed affects prediction skill during comprehension, then prediction skill is expected to increase with increased consistency of representations. This implies that predictive processing in L2 should become more native-like as L2 proficiency increases.
Furthermore, lexical competition is increased in L2 processing because of simultaneous activation of L1 words and because L2 speakers often misperceive phonemes, thereby increasing the number of words perceived as similar (Lagrou, Hartsuiker & Duyck, Reference Lagrou, Hartsuiker and Duyck2013a; Weber & Cutler, Reference Weber and Cutler2004). Increased competition can cause a delay in the selection of a predicted word, as well as in processing the context information used to generate a prediction. Finally, a number of other factors are thought to modulate prediction in monolingual language processing, such as resource limitations, emotional state and cognitive control. Kaan (Reference Kaan, Rothman and Unsworth2014) suggests that the effect of each of these factors may in turn interact with processing language (native or non-native), so that L2 data is required to evaluate the generalizability of each demonstration of prediction in monolingual language processing.
Some studies reveal effects of semantic context on target word recognition (Chambers & Cooke, Reference Chambers and Cooke2009; FitzPatrick & Indefrey, Reference FitzPatrick and Indefrey2007; Lagrou, Hartsuiker & Duyck, Reference Lagrou, Hartsuiker and Duyck2013b) in L2 processing. However, effects found at presentation of the target word do not allow us to distinguish facilitation of semantic integration from semantic prediction. A constraining sentence context may facilitate word integration upon presentation of the word in L2 processing, but whether or not bilinguals actively predict information, online and during sentence processing, to the same extent in L1 and L2, remains unclear.
Prediction in L2 Reading
In a study in the visual domain by Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa (Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013), native speakers of English and late Spanish–English bilinguals read sentences in English with predictable or less predictable sentence-final nouns. Event-related potentials were measured at the article preceding the sentence-final noun. The article was always congruent with the final noun, but not with the expected noun (e.g., Since it is raining, it is better to go out with an umbrella [EXPECTED]/a raincoat [UNEXPECTED]). If participants indeed predicted umbrella, a semantic anomaly effect should be elicited by the article a relative to an, because a is incongruent with umbrella. Thus, the target for prediction is the lexical form and the congruent article. The target is predicted based on semantic information from the sentence context. Martin et al. indeed found an N400-effect for the incongruent article for L1 readers, but not for L2 readers. The lack of an effect on the article was taken to indicate that L2 readers did not predict the target word (at least not as efficiently as L1 readers). For the target noun, the authors did find a significant N400-effect in central and parietal regions in both L1 and L2 readers, but the effect was significantly larger in L1 than in L2 readers. The N400-effect on the noun showed that even though the participants reading in L2 did not predict upcoming input, integration of a target word in the sentence was still easier if the sentence was constraining.
The lack of a prediction effect on the article in L2 comprehension in Martin et al.’s study (Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) may have resulted from the particular manipulation used. In particular, the lexical prediction effect was measured on the basis of the congruency of an article (a/an) with the predicted word. The particular phonological agreement rule manipulated does not exist in the bilingual participants’ L1. Martin et al. (Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) tested whether a group of intermediate L2 proficient participants, not participating in their experiment, knew the phonological article-noun agreement rule. Both an online and an offline test showed that intermediate L2 proficient participants were sensitive to the agreement rule. However, the intermediate L2 proficient group actually participating in the experiment may not have been able to apply the rule quickly enough for a prediction-incongruent determiner to modulate the N400 effect.
Therefore, in a second study in the visual domain, Foucart, Martin, Moreno and Costa (Reference Foucart, Martin, Moreno and Costa2014), used a similar sentence reading paradigm but measured the prediction effect by manipulating prediction congruency of the determiners’ gender in Spanish sentences (e.g., The pirate had the secret map, but he never found the [masc] treasure [EXPECTED]/ the [fem] cave [UNEXPECTED] he was looking for.). As in Martin et al., the target for prediction was the lexical form and the congruent article. The target is predicted based on semantic information from the sentence context. However, in this study the gender agreement rule between the target article and noun existed both in the late bilingual participants’ L1 (French) and L2 (Spanish). Here, the authors found an effect of congruency of the article and the predicted noun on the N400 elicited by the article both in L1 reading (by Spanish monolinguals and early Spanish–Catalan bilinguals) and in L2 reading (by late French–Spanish bilinguals), although the effect lasted for a shorter time in the late bilingual group. The results demonstrate that bilinguals reading in L2 can use semantic information from the sentence context to predict upcoming words and their gender. Foucart et al. suggested that the similarity between the article-noun agreement rule in late bilingual participants’ L1 and L2 may have made it easier for the participants to generate a prediction in time. In addition, half of the expected nouns included in the experiment were cognates, possibly adding to the facilitatory effect. The two studies described above show that bilinguals can predict lexical information in sentence reading, but that whether or not prediction occurs may depend on L1 and L2 language similarity.
Prediction in L2 listening
Both studies described above were conducted in the visual domain, but predictive language processing may well be more challenging in the auditory modality. For instance, the fact that auditory input unfolds over time, unlike written input, may make prediction more relevant because the listener cannot return to prior input or influence input rate, unlike in readingFootnote 1 . Predictive processing may also be more difficult in the auditory modality than in the visual modality for bilinguals because of increased cross-language co-activation due to misperceptions and misrepresentation in listening (Weber & Cutler, Reference Weber and Cutler2004).
Foucart, Ruiz-Tada and Costa (Reference Foucart, Ruiz-Tada and Costa2015) tested prediction in the auditory modality using an EEG paradigm similar to Foucart et al. (Reference Foucart, Martin, Moreno and Costa2014). Again, the target for prediction was the lexical form with the congruent article, and predictions were based on semantic information from the sentence context. The authors found that bilinguals listening in L2 are able to predict upcoming words based on sentence context. The participants in this study were all bilingual and they were only tested in their L2. Therefore, no direct comparison could be made between the size of the effect in L1 and L2 in bilinguals, or between the size of the effect in monolinguals (L1) and bilinguals (L1 or L2).
Visual world paradigm studies on prediction in L2 auditory processing have mainly focused on prediction based on morphosyntactic information. In a visual world experiment, Hopp (Reference Hopp2013) investigated whether German native and English–German bilingual listeners would show predictive looks to target objects whose gender agreed with an article in the auditory signal. Like native listeners, English–German bilinguals listening in L2 were more likely to look at the target objects whose gender agreed with an afore-mentioned article before the onset of the target object in the auditory signal, but only in the bilinguals who had native-like mastery of gender assignment.
Hopp (Reference Hopp2015) used a visual world paradigm to investigate whether English–German bilinguals integrate morphosyntactic information and verb semantics to generate predictions about upcoming semantic input during L2 auditory comprehension. In this experiment, picture displays including three possible actors and a control object were paired with an SVO (e.g., TheNOM wolf kills soon theACC deer) or an OVS (e.g., TheACC wolf kills soon theNOM hunter) sentence in German. Native listeners were more likely to look at expected patients (e.g., the deer) before the onset of the second NP in SVO sentences and at expected agents (e.g., the hunter) in OVS sentences. English–German bilinguals, on the other hand, were more likely to fixate patients before the onset of the second NP, independently of the case marking (nominative or accusative) of the first NP. Hopp concluded that there was an effect of semantic prediction in L2 based on information extracted at the verb, but that case information did not modulate predictions like in L1 listeners. Bilingual participants seemed unable to apply an L2 agreement rule not present in their L1 on the fly, or at least not quickly enough to support prediction. Hopp's findings are in line with recent findings of Mitsugi and Macwhinney (2016), who demonstrated that L1 English learners of Japanese with good offline knowledge of the Japanese case-marking system were unable to employ this knowledge online in order to generate predictions in a visual world eye-tracking experiment.
Dussias, Valdés Kroff, Guzzardo Tamargo and Gerfen (Reference Dussias, Kroff, R., Tamargo, E. and Gerfen2013) also focused on prediction based on morphosyntactic information, specifically, prediction based on article-noun gender agreement. A group of English–Spanish bilinguals (high and low proficiency), Italian–Spanish bilinguals and Spanish monolinguals saw a display with two pictures of items with the same or different grammatical gender. While looking at the display, they heard a sentence with an article that either agreed with the gender of one of the two items in the display, or with both. Spanish monolinguals looked at the target picture sooner in the different gender condition (when the article was a cue) than in the same gender condition. Highly proficient English–Spanish bilinguals, but not low proficient English–Spanish bilinguals, also looked at the target picture earlier in the different gender condition. Unlike the low proficient English–Spanish bilinguals, low proficient Italian–Spanish bilinguals looked at the target picture significantly earlier in the different gender condition, but only when the target item was feminine. Dussias et al.’s results suggest that highly proficient bilinguals use gender cues to anticipate information as monolinguals do, whereas low proficient bilinguals do not, unless their native language has a similar article-noun gender agreement system. Even though the effects Dussias et al. found for monolinguals and highly proficient bilinguals are likely to be anticipatory in nature, given their time course, the authors do not explicitly distinguish between effects anticipation and facilitation of integration.
These recent visual world studies on prediction in L2 listening reveal that it is especially difficult for bilinguals to process morphosyntactic features quickly enough to use them as a cue to generate predictions in L2. However, it remained unclear whether bilinguals also have difficulty anticipating semantic information in L2 processing, which would always lead to weaker L2 prediction effects, or, whether they selectively have difficulty applying language-specific and, difficult, grammatical rules quickly enough during predictive processing. Hopp (Reference Hopp2015) explicitly distinguishes prediction based on verb semantics and prediction based on case-marking. However, as Hopp proposes, the significant effect of prediction based on verb semantics (predictive looks to the patient object in both SVO and OVS sentences) in L2 listening can be interpreted in two ways: either the L2 listeners used semantic information extracted at the verb to guide predictive looks towards the most plausible sentence object in the picture display (the patient), or, on the basis of the first NP, fixations were directed to a plausible patient object, regardless of verb semantics. Therefore, it remains unclear whether bilinguals are able to use verb semantics to guide their predictions during non-native sentence comprehension as they do in L1.
Koehne and Crocker (Reference Koehne and Crocker2015) provided evidence that language learners are able to use semantic restrictions at the verb to predict upcoming referents. Participants learned novel, artificial verb, subject (man and woman) and object names by exposure to verbs with visual context, followed by exposure to nouns in SVO sentence context, in a visual world paradigm. Anticipatory eye-movements to the sentence target objects were found during presentation of the constraining verb. As each verb type was combined with each subject type, the anticipatory eye-movements to the target object could not have been based on information extracted at the sentence subject alone. Koehne and Crocker show that people can use verb semantics to predict upcoming information in early language learning. However, instruction specifically stressed semantic processing of the sentences. Also, a limited number of artificial verbs (six at most) and objects (18 at most) were used in the study. These two factors may have greatly inflated predictive processing when compared to natural L2 language processing.
Present Study
All previous studies on anticipating information in L2 listening have either focused on L2 listening alone, or they have compared a group of L2 listeners to a group of L1 listeners in a between-participants design. In the present experiment, Dutch–English bilinguals were tested in the native and non-native language. In addition, an English monolingual control group was tested in order to compare L1 with L2 listening in the same language (English) and L1 (English) listening by monolinguals with L1 (Dutch) listening by bilinguals. Comparing predictive processing within participants is important, as recent studies have shown effects of cognitive factors such as verbal fluency, vocabulary size (Rommers, Meyer & Huettig, Reference Rommers, Meyer and Huettig2015), working memory and processing speed (Huettig & Janse, Reference Huettig and Janse2016) on predictive language processing. There may also be factors inherent to bilingualism (and not L2 processing) that affect predictive processing. For example, bilinguals activate lexical information in both languages during L1 and L2 processing (e.g., Lagrou et al., Reference Lagrou, Hartsuiker and Duyck2013a). Bilinguals may therefore activate more information during language processing which in turn may slow down the prediction process. In addition, some authors suggest that bilinguals have increased cognitive control abilities compared to monolinguals (Woumans, Ceuleers, Van der Linden, Szmalec & Duyck, Reference Woumans, Ceuleers, Van der Linden, Szmalec and Duyck2015). Increased cognitive control may help suppress irrelevant information during predictive processing. For example, Zirnstein, Hell and Kroll (Reference Zirnstein, Van Hell and Kroll2015) recently found that that processing costs for unverified predictions were larger in low-control than in high-control bilingual participants. In this experiment, we will compare bilinguals listening to speech in L1 and L2 to eliminate effects of individual differences. As a control experiment, we will also compare bilinguals (L2) to monolinguals (L1) listening to the same language (English). Finally, to test whether there are any effects of speaker bi- or monolingualism on predictive language processing we will compare prediction effects in L1 processing in bilinguals (Dutch) to L1 processing in monolinguals (English).
Here, a visual world paradigm based on Altmann and Kamide's (Reference Altmann and Kamide1999) task was used. Participants listened to sentences such as Mary knits a scarf or Mary loses a scarf. Eye-movements were recorded while participants viewed a visual scene with four objects that could all be lost (neutral condition), but in which only one object (the scarf) was knittable (constraining condition). If participants predicted the target object in the constraining condition, this would result in a higher proportion of looks to the target object in the constraining condition than in the neutral condition before the onset of the target in the auditory stimulus. Based on Kaan (Reference Kaan, Rothman and Unsworth2014) we expected that bilinguals listening in L2 would not predict semantic properties of upcoming referents as fast and to the same extent as when listening in L1 because of modulating factors associated with L2 language processing, such as differences in stored statistical regularities and weaker, less accurate lexical representations. Further, we expected that bilingual participants listening in L1 would not predict semantic input to the same extent as monolinguals do in L1. This would be in line with the weaker links hypothesis (Gollan et al., Reference Gollan, Montoya, Cera and Sandoval2008) of bilingual language processing. This hypothesis states that bilinguals divide language use between L1 and L2, and therefore have less practice in each of their languages. Less practice in each language should lead to weaker links between semantics and phonology in bilinguals than in monolinguals and thereby to slower lexical access. In turn, these weaker links may result in slower or weaker predictive processing.
As opposed to previous studies on predictive processing in the non-native language, we opted for a design in which no language-specific agreement rule needed to be applied by the participants on the fly in order to measure the prediction effect or in order for the participant to make a prediction. This way, if we find an attenuation of the prediction effect in non-native listening, it cannot be attributed to difficulty applying a non-native agreement rule on the fly.
Finally, previous studies have suggested that predicting upcoming information during language processing serves as a learning mechanism (Dell & Chang, Reference Dell and Chang2013; Koehne & Crocker, Reference Koehne and Crocker2015; Mani & Huettig, Reference Mani and Huettig2012). For example, Mani and Huettig (Reference Mani and Huettig2012) found a significant positive correlation between prediction skill and expressive vocabulary in children. We therefore expect that prediction effects are modulated by language proficiency, so that bilinguals with a higher proficiency score show a stronger prediction effect than bilinguals with a lower proficiency score.
Methods
Participants
Bilinguals
Thirty native speakers of (Belgian or Netherlands) Dutch took part in the experiment (5 men and 25 women, mean age 24 years, range 20–41). They were recruited from the Ghent University participant database. All signed informed consent. All participants reported Dutch as their dominant and most proficient language in the LEAP-Q questionnaire (Marian, Blumenfeld & Kaushanskaya, Reference Marian, Blumenfeld and Kaushanskaya2007), and English as their second (25 participants) or third (5 participants) language. Belgian and Dutch students typically start to learn English at age ten or eleven in school, and their English proficiency is relatively high because of regular input from popular media and study books. None of the participants had immersion experience in an English-dominant environment. On average the participants reported that they were exposed to English 17% of the time, versus 73% to Dutch. Besides knowledge of English and Dutch, twenty-eight participants had knowledge of French, and nineteen participants had knowledge of German. Fewer than six participants had knowledge of other languages such as Spanish, Turkish, Portuguese, Polish or Italian. To assess language proficiency in both languages, participants carried out the LexTALE vocabulary knowledge test (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012) and provided self-ratings. The LexTALE is an unspeeded 60-item lexical decision task. It is an indicator of word knowledge and general language proficiency (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012). The bilinguals’ mean LexTALE scores and self-ratings are reported in Table 1. The LexTALE score and self-ratings show that the bilingual participants were more proficient in their native (Dutch) than in their non-native language (English).
Table 1. Participants’ mean scores on proficiency tests and mean ratings

a Scores consist of percentage correct, corrected for unequal proportion of words and nonwords (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012).
b Score based on means of self-assessed ratings on a scale of 1 to 10 (1=very low, 10=perfect) of speaking, listening and reading.
c Reported p-values indicate significance levels of dependent samples t-tests between scores for Dutch and English in bilinguals. Df of all t-tests = 29.
d Reported p-values indicate significance levels of independent samples t-tests between scores for bilinguals in Dutch and monolinguals in English. Df of all t-tests = 29.
e Reported p-values indicate significance levels of independent samples t-tests between scores for bilinguals and monolinguals in English. Df of all t-tests = 29.
Monolinguals
Thirty monolingual native speakers of English participated in the experiment (4 men and 26 women, mean age 20 years, range 18–28). They were recruited from the University of Southampton participant database. All signed informed consent. The monolinguals’ mean LexTALE scores and self-ratings are reported in Table 1. The LexTALE score shows that the bilingual and monolingual participants were matched on L1 proficiency.
Materials and design
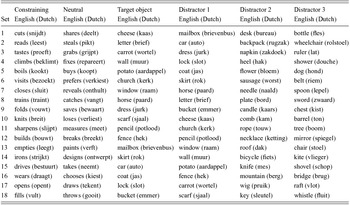
Eighteen stimulus sets were created. Each set consisted of a four-picture display, two sentences in Dutch and their translation equivalents in English. One of the two sentences was constraining; the other sentence was neutral. In the constraining condition, only one of the objects in the display was appropriate after the verb, whereas all objects in the display were appropriate after the verb in the neutral condition (see Figure 1). Appendix A contains the constraining and neutral verbs as well as the objects in the display for each stimulus setFootnote 2 .

Figure 1 Example Picture Display. The sentences belonging to this display were: Mary reads a letter and Mary steals a letter.
Likewise, eighteen filler sets were created. Each set again consisted of a display with four pictures, two sentences in Dutch and their English translation equivalents. In the filler sets, sentences could apply to either no, or two or three objects in the display. The stimulus and filler sentences were randomly assigned to two stimulus lists with the constraints that two sentences belonging to the same set were never in the same list, and each list contained an equal number of neutral and constraining sentences.
Pictures
The pictures were line drawings from a normed database by Severens, Van Lommel, Ratinckx and Hartsuiker (Reference Severens, Lommel, Ratinckx and Hartsuiker2005). Each target picture was included as unrelated picture in another stimulus set. This way, we ensured that target pictures did not inherently draw more overt visual attention than unrelated pictures. The names of the objects in each display were never semantically associated with the verb in the neutral condition and only the target object could be associated with the verb in the constraining condition (association norms from Deyne, Navarro & Storms, Reference Deyne, Navarro and Storms2013). The onsets of the names of objects in one display were never identical, nor were they identical to the onsets of the accompanying verbs.
Three repeated-measures ANOVAs with language (native, non-native) and picture type (target, distractor) as factors showed that object names were matched for frequency, phoneme count, and syllable count across languages and conditions (ps > .10) (Table 2). The selected object names were orthographically dissimilar (normalized orthographic Levenshtein distance ≤ .50, M = .15, SD = .13Footnote 3 ). The pictures had a mean H-statistic (a name agreement index) in Dutch of .62 (SD = .49) (Severens et al., Reference Severens, Lommel, Ratinckx and Hartsuiker2005)Footnote 4 . To our knowledge, no name agreement scores are available for the picture set for bilinguals in L2.
Table 2. Mean lexical characteristics of Dutch (native) and English (non-native) stimuli

Note. Standard deviations are indicated in parentheses.
a Zipf value (log10(frequency per million*1000) (van Heuven, Mandera, Keuleers, & Brysbaert, Reference van Heuven, Mandera, Keuleers and Brysbaert2014) retrieved from the SUBTLEX-US and SUBTLEX-NL databases (Brysbaert & New, Reference Brysbaert and New2009; Keuleers, Brysbaert, & New, Reference Keuleers, Brysbaert and New2010)
b CELEX database (Baayen, Piepenbrock, & Gulikers, Reference Baayen, Piepenbrock and Gulikers1995).
Sentences
Simple four-word SVO sentences were constructed for this experiment. The subject of the sentence was kept constant across all trials (Mary in English, Marie in Dutch). Repeated measures ANOVAs with language (native vs. non-native) and condition (neutral vs. constraining) as factors showed that verb frequency, phoneme count, and syllable count were matched across languages and conditions (all ps ≥ .10). Table 2 reports the lexical characteristics of the stimuli in English and in Dutch.
The article preceding the sentence final noun was always indefinite, and English nouns never started with a vowel. This ensured that the article could not be used as a prediction cue.
Recordings
Sentences were recorded in a sound attenuating room. A female native speaker of Dutch (34 years old) who majored in Dutch and English linguistics and literature at university pronounced the sentences for both the English and the Dutch recordings. English monolinguals rated her accent as 5.3 on a scale from 1 (very foreign accent) to 7 (native accent). We chose this speaker for our study because of her clear pronunciation in Dutch and English, and experience in recording psycholinguistic stimuli. Each sentence was recorded three times; the recording that we judged to have the most neutral prosody was selected for the experiment.
The length of the recording frames starting at verb offset, and ending at noun onset initially differed significantly between Dutch and English (t(35) = 10.87, p < .001). In the non-native condition, participants would therefore have less time to generate predictions about upcoming referents than in the native condition. To eliminate this confound, the fragment was lengthened by a factor 1.2 for the English sentences and shortened by a factor 0.8 for the Dutch sentences, using Praat (Broersma & Weenink, Reference Broersma and Weenink2014). This way, the length of the recording fragments was matched across languages (ps ≥ .10). The mean length of the verb onset – noun onset frame was now 691 ms in Dutch and 708 ms in English. None of the participants indicated having noticed the manipulation of the auditory stimuli.
Procedure
Participants were seated at a comfortable distance from the screen. They received written and verbal instructions to listen carefully to the sentences and to look at whatever they wanted as long as their gaze would not leave the screen (Huettig & Altmann, Reference Huettig and Altmann2005; McQueen & Huettig, Reference McQueen and Huettig2012). There was no explicit task. Eye movements were recorded from the right eye with an Eyelink 1000 eye-tracker (SR Research) with a sampling frequency of 1000 Hz. After successful calibration, the experiment began with two practice trials.
A fixation cross appeared on the screen for 500 ms, followed by the presentation of the four pictures in a two-by-two grid on the screen. Picture location was randomized. The auditory stimulus started to play 2200 ms after picture onset. This time lag was included to ensure that participants had enough time to see every object on the screen before verb onset. The trial ended when the sentence finished, and the next trial was started by the experimenter after drift correction. Bilingual participants were presented with the stimuli in one of the lists in a Dutch (native) block and with the other list in an English (non-native) block. Language and list order were counterbalanced. Monolingual participants were presented with the stimuli of one list in the first block and with the stimuli of the other list in the second block. Both lists were presented to the monolinguals in English. List order was counterbalanced. In each block, the participants heard nine constraining and nine neutral sentences. Across the two blocks, none of the verbs were repeated, but the object displays were repeated. The eye tracker was recalibrated between the two blocks. The entire experiment took approximately 17 minutes.
After the experiment, participants completed the following additional tests: LexTALE Dutch, LexTALE English (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012) (see Table 1 for results), backward translation of the English verbs used in the experiment (bilinguals only), backward translation of the English nouns used in the experiment (bilinguals only), and the LEAP-Q language background questionnaire (Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007). The tests were presented in that order on a Macbook in a quiet room. Completion of the additional tests took approximately 25 minutes.
Results
Figure 2 shows the time-course of target fixation as a function of condition for each language and speaker group. These probabilities reflect the number of samples of eye-data within a 50 ms time bin in which there was a fixation on the target picture, averaged over subjects and items.

Figure 2 Results. Time course of fixation probability to target by condition (constraining, neutral) starting from verb onset for bilinguals in L1, bilinguals in L2, and for monolinguals. Note: Whiskers indicate the mean ± standard error.
The graph shows that participants were more likely to fixate on target objects in the constraining condition than in the neutral condition. Fixation proportions for the constraining and neutral conditions start to diverge well before the mean noun onset time in each of the three groups.
The starting point of the time frame for our analysis was chosen based on visual inspection of a plot of the time-course of the grand mean of fixation probability (over languages and listener types) and was defined as the first 50 ms time bin after verb onset in which the grand mean fixation probability began a rising trend (Barr, Reference Barr2008). This method is conservative because by using the grand mean the choice cannot be biased by any hypothesis (Barr, Reference Barr2008). As it takes approximately 200 ms to plan and execute a saccade (e.g., Matin, Shao & Boff, Reference Matin, Shao and Boff1993; Saslow, Reference Saslow1967), we can assume that fixations that started earlier than 200 ms after noun onset were anticipatory in nature. Thus, the time frame for the analysis started at 350 ms after verb onset and ended 200 ms after noun onset. Each trial's individual verb onset and noun onset times were used to select the data. In addition to the analysis of the full time frame we analysed the data of the first four hundred milliseconds of data in the analysis frame aggregated into 100 ms time bins. This way, we tested when the effect of condition became significant in each group. In 3.39% of the samples in time frame from verb onset until 200 ms after noun onset there was a blink and 0.17% percent of the samples were out-of-screen. The out-of-screen and blink samples were included in the total sample count used to calculate proportions of looks to the target image.
The proportions of samples in the analysis time-frame in which there was a fixation to the target image were transformed using the empirical logit formula (Barr, Reference Barr2008). Our data set was analyzed with linear mixed effects models with the lme4 (version 1.1-8), car (2.0-25) and lmerTest (version 2.0-25) package of R (3.2.1) (R Core Team, 2013). This allowed for inclusion of participant, sentence and target image as random factors (Baayen, Davidson & Bates, Reference Baayen, Davidson and Bates2008).
For the analyses between languages in bilinguals, the fixed experimental factors were condition (constraining or neutral) and language (Dutch or English). The control variables list (A or B) and block (1 or 2) were also included as fixed factors. The models included random intercepts for participant, sentence and target picture. In each analysis we first fitted a model including all the fixed factors and interactions as well as the random intercepts for participant, sentence and target picture. If there was a significant effect of a factor, we added that factor as random slope for participant, sentence and target picture. For the comparison between listener types (monolinguals and bilinguals) in English and in Dutch listening, the fixed factors were condition (constraining or neutral) and listener type (monolingual or bilingual). All other factors were the same as in the within participants analysisFootnote 5 . To test whether there were any effects of English proficiency on predictive processing we compared each model without the factor lexTALE score (English) to the model with the factor lexTALE score and LexTALE as random slope for sentence and target picture using a likelihood ratio test. Eighteen trials were removed from the dataset because the verb was not translated correctly in the translation task that was performed after the main task, by that particular participant.
Comparison within Bilinguals (L1 vs. L2)
The fixation proportion was significantly higher in the constraining condition than in the neutral condition (β = −0.54, SE = .12, t = −4.49, p < .001), confirming our prediction manipulation. There was no significant interaction between language (L1 vs. L2) and condition (constraining vs. neutral) (β = 0.04, SE = .10, t = .40, p = .69). Nor were there any other significant main effectsFootnote 6 . English proficiency (lexTALE) score did not significantly improve the model fit (χ2 (19) = 15.2, p = .71)Footnote 7 .
Separate analyses for each language revealed that the effect of condition was significant in L1 (β = −0.65, SE = 0.17 t = −3.86, p = .001)Footnote 8 , and also in L2 (β = −0.56, SE = 0.15, t = −3.58, p < .001).
Comparison between L1 Monolingual listening (English) and L2 Bilingual listening (English)
The fixation proportion was significantly higher in the constraining condition than in the neutral condition (β = −0.69, SE = .12, t = −5.76, p < .001). The effect of condition did not interact with listener type (monolingual versus bilingual) (β = −.11, SE = .11, t = −.93, p = .36). Nor were there any other significant main effects. English proficiency (lexTALE) did not significantly improve the model fit (χ2 (22) = 24.72, p = .32). The effect of condition was also significant in the data of the monolinguals only (β = −.79, SE = .16, t = −4.87, p < .001).
Comparison between L1 Monolingual Listening (English) and L1 Bilingual Listening (Dutch)
The fixation proportion was significantly higher in the constraining condition than in the neutral condition (β = −.72, SE = .13, t = −5.57, p < .0001). There was no significant interaction between listener type (monolingual vs. bilingual) and condition (β = −.07, SE = .12, t = −.61, p = .55). Proficiency (English LexTALE score) did not contribute significantly to the model fit (χ2 (22) = 29.21, p = .14).
Time course analyses
In the bilinguals, the effect of condition became significant in the third 100 ms time bin of the analysis time frame (550–650 ms) (β = −.45, SE = .15, t = −2.94, p = .007). There was no significant interaction between language and condition (β = −.03, SE = .12, t = −0.21, p = .84). In a separate analysis of the bilingual data for each language, the effect of condition also became significant in the third time bin of the analysis frame in English (550–650 ms after verb onset) (β = −.47, SE = .20, t = −2.32, p = .03) and in Dutch (β = −.43, SE = .19, t = −2.24, p = .03).
In the comparison between listener types in English (L1 monolinguals vs. L2 bilinguals) the main effect of condition was not yet significant in the first two time bins (350–450ms after verb onset: β = .06, SE = .13, t = .46, p = .65, 450–550 ms after verb onset: β = −.19, SE = .14, t = −1.35, p = .18). However, the interaction between listener type and condition was significant in the first bin (β = −.25, SE = .12, t = −2.09, p = .04)Footnote 9 , and marginally significant in the second bin (β = −.22, SE = .12, t = −1.89, p = .06). In the third time bin, the effect of condition became significant (β = −.55, SE = .15, t = −3.78, p < .001), and the interaction between listener type (monolingual vs. bilingual) and condition was no longer significant (β = −.06, SE = .11, t = −.56, p = .57).
Finally, we compared the two listener types in L1 (English in monolinguals vs. Dutch in bilinguals). The effect of condition became significant in the second time bin in the analysis frame β = −.28, SE = .13, t = −2.09, p = .04. The interaction between listener type and condition did not reach significance β = −.13, SE = .12, t = −1.02, p = .31.
In a separate analysis of the monolingual data, the effect of condition was significant for the first time in the second time bin in the analysis frame (450–550 ms after verb onset) (β = −.41, SE = .18, t = −2.29, p = .03). At that time, the effect was not yet significant for the bilinguals in English (L2) (β = −.04, SE = .17, t = −.21, p = .83) or in Dutch (L1) (β = −.15, SE = .18, t = −.88, p = .38).
Discussion and conclusion
This study asked whether bilinguals predict information about upcoming referents on the basis of semantic context information during non-native comprehension, as monolinguals do in L1 comprehension. Following monolingual studies (e.g., Altmann & Kamide, Reference Altmann and Kamide1999), we found that bilinguals use linguistic context information to generate predictions about upcoming referents in their non-native language (English). This effect was of comparable magnitude in L1 listening in the same participants (Dutch) and in L1 listening by monolinguals in the same language (English). In addition, bilinguals listening in L1 (Dutch) predicted upcoming semantic information to a similar extent as monolinguals listening in L1 (English). English proficiency (lexTALE score) did not affect the prediction process. These findings confirm that bilinguals listening to non-native input are able to rapidly integrate auditory and visual input to constrain the subsequent domain of referenceFootnote 10 . Consistent with the weaker links hypothesis (Gollan et al., Reference Gollan, Montoya, Cera and Sandoval2008), time-course analyses suggested that bilinguals listening in either L1 or L2 predicted upcoming information slightly slower than monolinguals.
Kaan (Reference Kaan, Rothman and Unsworth2014) argued that predictive processing in a non-native language is not inherently different from predictive processing in the native language, but that other factors associated with non-native processing (e.g., cross-linguistic competition, inconsistent lexical representations in L2) can modulate prediction. No modulation of the prediction effect in the non-native language was found in the present study. Perhaps the modulating factors Kaan discussed only play a role under specific circumstances such as in sentences with infrequent words or cognates. Infrequent words are likely to have inconsistent representations because they are practiced less often. Also, no large cross-linguistic interference effects were expected because target words were never cognates. Furthermore, in visual world paradigm experiments like the present one, prediction processes may be facilitated as compared to EEG studies (e.g., Foucart et al., Reference Foucart, Ruiz-Tada and Costa2015), because visual candidates for prediction (pictures) are provided with each sentence (Kamide, Reference Kamide2008). Target words or target semantics were likely to be pre-activated along with the three other candidates.
Like us, Foucart et al. (Reference Foucart, Ruiz-Tada and Costa2015) found a significant prediction effect in L2 speech processing using an EEG paradigm. The authors measured the modulation of the N400 effect elicited by an article that was gender congruent or incongruent with the predicted noun in L2 listening. The article-noun agreement rule manipulated in this experiment exists both in the bilingual participants’ L1 and L2. Foucart et al. therefore suggested that prediction can be accomplished in L2 processing if the L2 is similar to the L1. Unlike in Foucart et al.’s study, no cognates were included as target words in our visual world experiment. Therefore, the prediction effect found in non-native listening in our experiment did not depend on target similarity between languages. However, English and Dutch are typologically similar languages, therefore Foucart et al.’s suggestion that prediction in L2 is facilitated by L1 and L2 similarity is still viable. The present experiment complements Foucart et al.’s results because we make a direct comparison between the prediction effect in bilinguals in L1, in L2 and in monolinguals in L1, and show that the magnitude of the prediction effect is the same in each language and speaker group.
Hopp (Reference Hopp2015) also found an effect of prediction in non-native listening using a visual world paradigm. Unlike native listeners whose predictions were based on semantic and case-marking information, the non-native listeners were unable to use case-marking information to modulate predictions. Non-native listeners’ predictive looks to likely patient objects may have been based on the semantic information extracted at the first NP in the sentence regardless of verb semantics, or on a combination of semantic information of the first NP and verb semantics. In the present experiment no picture of the first NP in the sentence was shown in the display, and only the verb distinguished the neutral from the constraining condition. Therefore, this study confirms that bilinguals listening in L2 can use verb semantics in order to predict features of upcoming input to the same extent in L1 and L2.
Previous studies showed that bilinguals have difficulty with predicting L2 input based on morphosyntactic information such as case or gender information (Dussias et al., Reference Dussias, Kroff, R., Tamargo, E. and Gerfen2013; Hopp, Reference Hopp2013, Reference Hopp2015). Predicting upcoming words together with morphosyntactic information (the gender of an article) is also difficult for bilinguals (Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013), unless the second language shares morphosyntactic features (e.g., gender-noun agreement rules) with the first (Foucart et al., Reference Foucart, Martin, Moreno and Costa2014, Reference Foucart, Ruiz-Tada and Costa2015). However, in line with Koehne and Crocker (Reference Koehne and Crocker2015) the results of the present study show that bilinguals have no difficulty predicting input based on semantic information. This suggests that bilinguals predict to a similar extent in L2 as monolinguals do in L1, but that problems arise only when morphosyntax is involved, perhaps because of difficulty applying morphosyntactic agreement rules online quickly enough. An interesting question for future research would be whether increased processing speed (e.g., increased speech rate) would lead to difficulty using semantic information to generate predictions in L2 as well.
Speaker accent can affect speech processing (Adank, Evans, Stuart-Smith & Scott, Reference Adank, Evans, Stuart-Smith and Scott2009; Lagrou et al., Reference Lagrou, Hartsuiker and Duyck2013b; Weber, Betta & McQueen, Reference Weber, Betta and McQueen2014). Dutch–English bilinguals in Belgium are frequently exposed to non-native speakers in school and work settings, and in the media. Therefore, they are familiar with Dutch-accented English like the accent of the speaker in the experiment. A previous study from our lab (Lagrou et al., Reference Lagrou, Hartsuiker and Duyck2013b) showed that, in a lexical decision task, Dutch–English bilinguals responded faster to English stimuli pronounced by a native speaker than to English stimuli pronounced by a non-native speaker. If words are recognized more slowly by L2 listeners when pronounced by an L2 speaker than by an L1 speaker (Lagrou et al., Reference Lagrou, Hartsuiker and Duyck2013b), then an interaction effect of language (L1 or L2) with prediction of upcoming information is likely to be more pronounced when the speaker of the experimental stimuli is a non-native speaker. No such interaction was found in the present experiment. Whether various strengths of non-native accents affect the prediction process differently in L1 and L2 listeners remains an open issueFootnote 11 .
English proficiency as measured with LexTALE (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012) did not affect the magnitude of the prediction effect in bilinguals and monolinguals. This may be due to the high level of proficiency of our participants, although these were still clearly unbalanced bilinguals who only use L2 during a small proportion of their time. Alternatively, there may not have been sufficient variance (bilinguals M = 78.5, SD = 10.49) to detect an interaction effect of proficiency with prediction skill. Conversely, production skill and not recognition skill may be an indicator of prediction skill (Mani & Huettig, Reference Mani and Huettig2012), and the LexTALE does not tap into production skill directly. In any case, the present data show that the proficiency level of these unbalanced bilinguals suffices for predictive language processing similar to that in the native language.
The time course analyses showed that prediction effects reached significance 100 ms later for bilinguals (in both languages) than for monolinguals. One theoretically interesting interpretation would be that activation and prediction develops slower for bilinguals. However, this may also merely be due to lack of power in the bilingual data sets. The monolinguals were exposed to both stimuli lists in English whereas the bilinguals were exposed to one list in each language. Therefore, the monolingual data set is twice the size of the bilingual data sets of each language, which increases power to detect effects. However, the delay of one time bin also exists in the full bilingual data set (English and Dutch combined), which is equal in size to the monolingual data set. This supports that there may not just be a power issue, but that in fact bilinguals predicted upcoming information slightly less rapidly than monolinguals. This would be consistent with the weaker links hypothesis of bilingual language processing, which states that division of use between a bilingual's two languages results in weaker links between lexical items’ semantics and phonology (Gollan et al., Reference Gollan, Montoya, Cera and Sandoval2008). This should result in slower lexical access and could possibly lead to slower predictions during language comprehension.
This study shows that L2 listeners use semantic information provided by sentences to restrict the expected subsequent domain of reference to the same extent as in L1 processing by bilinguals and monolinguals. This finding suggests that, when no grammatical rules need to be processed online in order for participants to generate a prediction, the basic principles of recent theories of prediction in language comprehension (cf. Altmann & Mirković, Reference Altmann and Mirković2009; Federmeier, Reference Federmeier2007; Kutas et al., Reference Kutas, DeLong, Smith and Bar2011; Pickering & Garrod, Reference Pickering and Garrod2013) also apply to L2 processing in highly proficient bilinguals. Future studies will have to point out more precisely in what circumstances predictive language processing is retained in L2 processing, and when it is not.
Appendix A. Stimuli sets in English and Dutch.