1. Introduction
Over the last decades, the study of bilingualism has grown into a prominent and independent research domain. Many phenomena unique to bilingualism have been identified and clarified by empirical studies using a variety of dedicated research techniques. By now, several verbal (pre-quantitative) and computational (quantitative) models have been proposed to account for specific aspects of bilingual processing, in particular with respect to word comprehension and production (Abutalebi & Green, Reference Abutalebi and Green2007; Bloem & La Heij, Reference Bloem and La Heij2003; Green, Reference Green1998; Lewy & Grosjean, Reference Lewy, Grosjean and Grosjean2008; Li & Farkas, Reference Li, Farkas, Heredia and Altarriba2002; Roelofs, Dijkstra & Gerakaki, Reference Roelofs, Dijkstra and Gerakaki2013; Roelofs, Piai, Garrido Rodriguez & Chwilla, Reference Roelofs, Piai, Garrido Rodriguez and Chwilla2016; Shook & Marian, Reference Shook and Marian2012; Zhao & Li, Reference Zhao and Li2010, Reference Zhao and Li2013). In the domain of bilingual visual word recognition, reference is often made to the implemented localist-connectionist Bilingual Interactive Activation model (BIA; Dijkstra & Van Heuven, Reference Dijkstra, Van Heuven, Grainger and Jacobs1998; Van Heuven, Dijkstra & Grainger, Reference Van Heuven, Dijkstra and Grainger1998) and its successor BIA+ (Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002). With respect to bilingual word production and word translation, the verbal Revised Hierarchical Model (RHM; Kroll & Stewart, Reference Kroll and Stewart1994) has frequently served as a reference framework for understanding empirical results.
As the next step forward towards a theoretical integration of bilingual research, Brysbaert, Verreyt, and Duijck (Reference Brysbaert and Duijck2010, p. 359) have proposed “to start from existing computational models of monolingual language processing and see how they can be adapted for bilingual input and output, as has been done in the Bilingual Interactive Activation model.” They also argue (p. 369) that it will be “a challenge [. . .] to see how [monolingual computational] models can be adapted so that they are able to recognize and translate words from more than one language, and how performance of these models alters as a function of the proficiency level”. In this paper, we attempt to rise up to this challenge and develop an implemented model of word retrieval that can simulate seminal aspects of bilingual visual word recognition, lexical-semantic processing, word naming and, especially, word translation. We will also take into account the point made by Kroll, Van Hell, Tokowicz, and Green (Reference Kroll, van Hell, Tokowicz and Green2010, p. 379) in their reply to Brysbaert et al., that “our goal is not only to test and specify models, but also to provide a synthesis of the available evidence that will enable the development of a more comprehensive account”. Following their adagium that “no model should be left behind” (p. 379), we will consider how insights gained with both the BIA/BIA+ models and the RHM can be integrated into a new model, called Multilink. In particular, we investigate how the BIA/BIA+ framework can be extended to account for the processing of cognates; and we implement the basic architecture of the RHM, consisting of input and output language systems, connected via shared meanings. We will consider the desired extension and implementation in the following sections.
The BIA/BIA+ model and cognate recognition
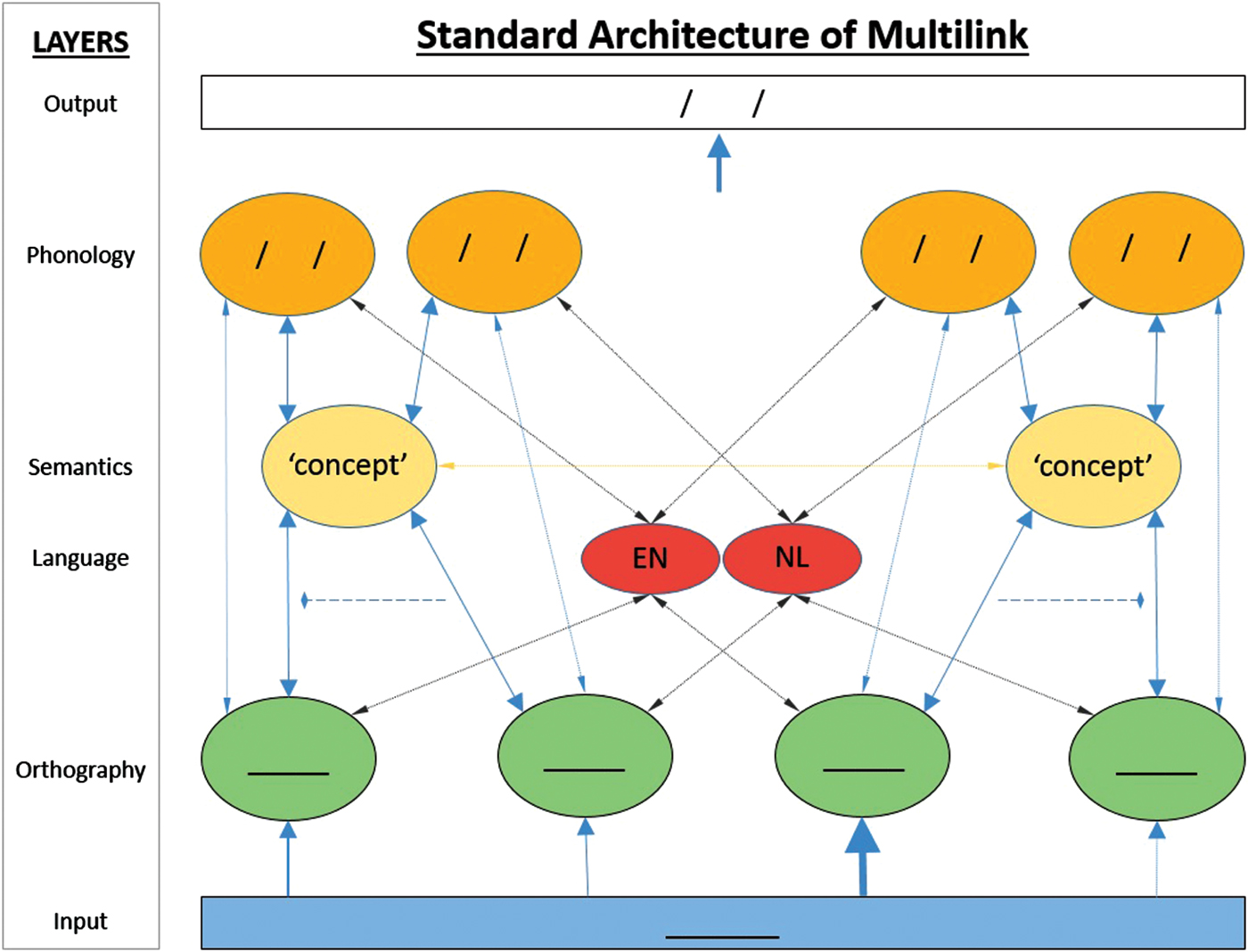
On the basis of a considerable body of empirical evidence, bilingual word recognition models such as BIA/BIA+ propose that the visual presentation of a word leads to co-activation of many word candidates from different languages that are similar to the input. This process is called ‘language non-selective lexical access’. For instance, in a Dutch–English bilingual, the activated competitor set (or neighborhood) of HOOD will include English words like FOOD, HOLD, and HOOT, and Dutch words like LOOD, HOND, and HOOS. All these orthographic representations will then begin to activate their meaning representations (e.g., Balota, Reference Balota and Gernsbacher1994; Grainger, Reference Grainger2008). Thus, the meaning of FOOD and HOND will be activated to some extent in parallel with the meaning of the input word HOOD. At the same time, active orthographic representations also directly activate their phonological counterparts (e.g., Coltheart, Rastle, Perry, Langdon & Ziegler, Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001), so HOOD activates /hu:d/, FOOD activates /fu:d/, and so on. Semantically active representations ‘spread’ their activation to other (associated or semantically related) units. For instance, HOOD may spread activation to the meanings ‘HAT’ or ‘CAR’, and FOOD to ‘HUNGRY’. Within this theoretical framework (depicted below in Figure 1 for Multilink), the processing of non-identical and identical cognates can be understood by assuming that both readings (orthographic representations) of a cognate become activated by the input and then send converging activation to a shared semantic representation (Dijkstra, Miwa, Brummelhuis, Sappelli & Baayen, Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Vanlangendonck, Peeters, Rueschemeyer & Dijkstra, in preparation; Voga & Grainger, Reference Voga and Grainger2007). For instance, the English input word ‘tomato’ may activate stored orthographic representations of both TOMATO and TOMAAT, its Dutch translation equivalent. Both may then co-activate the shared meaning of ‘tomato’. In the end, resonance between orthographic and semantic representations leads to the well-known cognate facilitation effect in recognition.
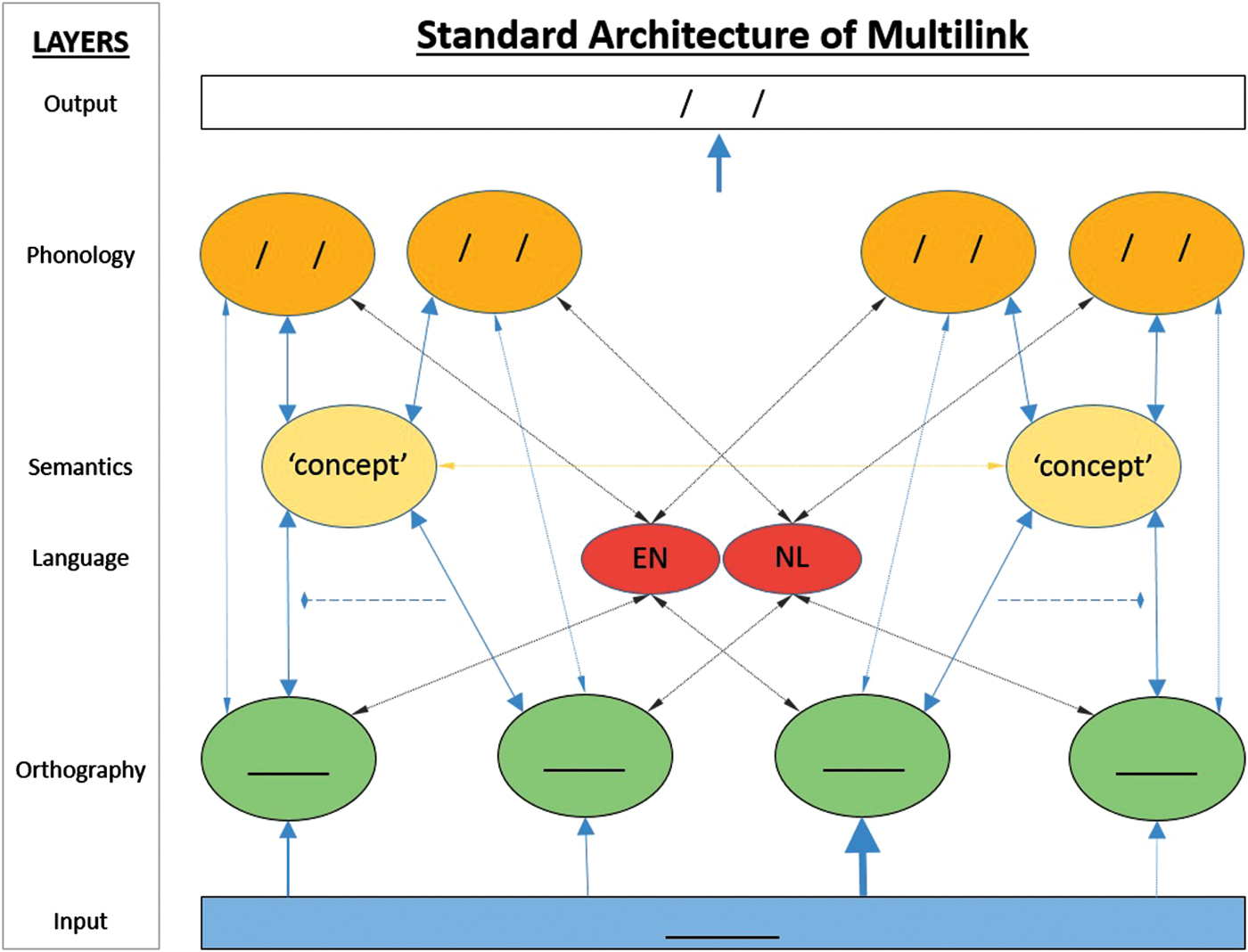
Figure 1. Standard network architecture of Multilink. Note: Input is indicated by blue underscore, orthographic (O) representations by green underscore, phonological (P) representations by slashes. EN = English, NL = Dutch. The dashed line between two connections from O to S (semantics) indicates that their activation is summed after taking half of the second node's activation input (see text). Output is task-dependent. Here slashes indicate a phonological output in the same or a different language (for word naming or translation).
Unfortunately, BIA and BIA+ only simulate the orthographic recognition of 4-letter (or 5-letter) words; lexical-semantic representations are not implemented. As a consequence, their cognate processing account is only verbal. One goal of Multilink is to go beyond this, simulating the recognition of 3–8 letter words including cognates of different lengths. Lexical decision times for these words are available in databases such as the Dutch Lexicon Project (Brysbaert, Stevens, Mandera & Keuleers, Reference Brysbaert, Stevens, Mandera and Keuleers2016) and the English Lexicon Project (Balota, Yap, Cortese, Hutchison, Kessler, Loftis, Neely, Nelson, Simpson & Treiman, Reference Balota, Yap, Cortese, Hutchison, Kessler, Loftis, Neely, Nelson, Simpson and Treiman2007). We will also simulate the lexical decision findings for cognates and non-cognates by Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) and Vanlangendonck et al. (Reference Vanlangendonck2012, in preparation) with Multilink.
The RHM and word translation production
While the BIA/BIA+ models consider word retrieval during language comprehension, the RHM addresses language production issues, in particular word translation (see Dijkstra & Rekké, Reference Dijkstra and Rekké2010, pp. 403–407). According to the RHM, in early stages of L2 learning, the meaning of presented L1 words is retrieved in a direct way, but retrieving that of L2 words requires mediation via the L1 translation equivalent. This indirect mediation proceeds via word association links between L2 and L1 word form representations.
To test the RHM, two variants of word translation tasks have been used: Translation production and translation recognition. When lay persons consider word translation, they usually think of it as a production task (cf. Kroll et al., Reference Kroll, van Hell, Tokowicz and Green2010, p. 374). A word in one language is presented, often in printed form, to a bilingual who then produces its translation in another language, usually in spoken form. This ‘translation production’ task encompasses both backward translation (L2 to L1) and forward translation (L1 to L2). In this task, participants must actively generate a response on the basis of their foreign language knowledge (De Groot, Reference De Groot2011, p. 91). In contrast, in the translation recognition task, participants decide as quickly as possible if the target is a correct translation of the prime or not (e.g., is FIETS the correct translation of BIKE?). According to De Groot (Reference De Groot2011), both tasks are generally sensitive to the same stimulus manipulations (e.g., word frequency and concreteness). In the present paper, we focus on word translation production, because we believe it is more straightforward and less strategy-sensitive than translation recognition, and because the RHM focuses more on the (faster) translation production process (Kroll et al., Reference Kroll, van Hell, Tokowicz and Green2010, p. 374).
In Multilink, orthographic representations activated on the basis of the input activate their associated semantic representations. In turn, semantic representations activate linked phonological representations in a language nonselective way (see Figure 1 below). For instance, the meaning ‘HOOD’ will activate its phonological representation /hʊd/ in English and /kap/ (for KAP) in Dutch. Other simultaneously active semantic representations will activate their translations; for instance, if the meaning of FOOD is active (because FOOD is a neighbor of HOOD), it will activate the Dutch phonological representation /vutsel/ for VOEDSEL, meaning food.
Because several lexical-phonological representations of both the input and output language are co-activated, there must be a task-dependent decision process that makes sure the correct translation in the correct language is produced. Suppose, for instance, that the input word HOOD must be translated. It is likely that for output the most active phonological word candidate will be /hʊd/, because it quickly becomes activated by its link to the orthographic input word. However, /hʊd/ cannot be produced, because it belongs to the wrong language (English) and is not a translation from the input word. In addition, apart from the Dutch word /kap/, other Dutch words may be active (like /vutsel/ or /hut/, which means ‘hat’), and therefore just selecting the most active Dutch word as a translation may not always succeed either. For instance, the English low-frequency input word HOOD co-activates its Dutch high-frequency neighbor HOOP, which directly activates its phonology /ho:p/. If a translation would be selected merely on the basis of language membership and an activation threshold based on a ‘first past the finish line’ criterion, /ho:p/ might be selected instead of the correct translation of HOOD.
Additional issues arise when we take into consideration cross-linguistic similarities and differences in vocabulary. For instance, we know that translation equivalents with form overlap (called ‘cognates’), like TOMATO (English) - TOMAAT (Dutch), lead to a facilitated translation process (e.g., Christoffels et al., Reference Christoffels, De Groot and Kroll2006). An open question is whether this effect arises on the recognition side or the production side of the translation process, or both.
A related issue that needs investigation is that of translation direction effects. As pointed out by Kroll et al. (Reference Kroll, van Hell, Tokowicz and Green2010, p. 373), several studies found that forward translation (from L1 to L2) led to longer translation latencies than backward translation (from L2 to L1) (Kroll & Stewart, Reference Kroll and Stewart1994; Sholl, Sankaranarayanan & Kroll, Reference Sholl, Sankaranarayanan and Kroll1995). The RHM originally explained this finding by the privileged access to meaning for L1 words, but a required mediation via the L1 translation equivalent for L2 words, at least in beginning L2 learners. However, as Kroll et al. (Reference Kroll, van Hell, Tokowicz and Green2010, p. 375) point out: “It became clear early on that the RHM's assumption of L1 translation mediation for comprehending the meaning of the L2 word was incorrect.” In contrast, the “evidence suggests that the asymmetry is more critical for lexicalization during production than for word recognition”. Said differently, differences between L1 and L2 should come out especially in word production and translation production.
Nevertheless, even in translation production studies, the findings with respect to translation direction effects are unclear. For instance, while Kroll, Michael, Tokowicz, and Dufour (Reference Kroll, Michael, Tokowicz and Dufour2002) found slower effects for forward translation than for backward translation, De Groot, Dannenburg, and Van Hell (Reference De Groot, Dannenburg and Van Hell1994) found that forward translation was slower or just as fast, and Christoffels, De Groot, and Kroll (Reference Christoffels, De Groot and Kroll2006) found that forward translation was actually faster than backward translation, with a larger effect for low proficiency bilinguals. Recently, the study by Christoffels et al. was replicated in our lab (Pruijn, Peacock & Dijkstra, in preparation; also see Christoffels, Ganushchak & Koester, Reference Christoffels, Ganuschchak and Koester2013). We will apply Multilink to simulate these studies of word translation in order to clarify potential underlying mechanisms.
2. The Multilink model for word recognition and word translation
Multilink has been implemented as a computational cognitive model, which can be defined as a precise, operationalized, and quantitative representation of reality in a restricted domain of human information processing. To simulate a particular cognitive process, a computational model specifies a series of computations, an ‘algorithm’, and applies it to certain theoretical constructs: for instance, symbolic representations for word forms and word meanings. Considering the large number of connections between representations required to model word retrieval from input to output, we have called our model ‘Multilink’. The basic architecture, representational units, parameter settings, and activation functions of Multilink follow those of a localist-connectionist paradigm, although some new features are added, such as the specification of orthographic differences between lexical items in terms of Levenshtein distance.
We believe that incorporating linguistic and psycholinguistic notions about word translation in a computational model results in several benefits relative to verbal models (like the RHM). First, verbal models are often underspecified and incomplete. Although this makes such models flexible and adaptable, it also leads to vagueness and interpretation problems with respect to model predictions. Furthermore, it is often difficult to test whether all assumptions made by the verbal model are critical for its processing or not. For example, in a verbal model it is difficult to specify the extent to which word association contributes to processing in situations that elicit conceptual mediation.
In contrast, a computational model like Multilink requires the formulation of explicit assumptions, which may be difficult but is necessary nonetheless for obtaining a working model. Because Multilink is actually implemented, the coherence and consistency of its underlying assumptions are guaranteed rather than assumed. Multilink helps us to understand the mechanisms underlying bilingual word retrieval both qualitatively and quantitatively. Even with respect to subcomponents such as word recognition and word production, Multilink clarifies how multiple underlying mechanisms interact and play out. For instance, particular assumptions on the input or output side can be added or left out to see if they are essential for generating particular Reaction Time (RT) patterns (e.g., asymmetry of translation effects). As such, a computational model like Multilink inspires the modeller to generate new hypotheses for empirical testing (i.e., it has heuristic value), because it allows simulations of complex interactions between many variables. It leads to fast and accurate quantitative and qualitative simulations for studies that otherwise take considerable time to complete, even including unknown and ‘unethical’ experimental conditions.
In the next section, we turn to a description of the basic assumptions underlying the Multilink model.
3. Assumptions underlying Multilink
Brysbaert and Duijck (Reference Brysbaert and Duijck2010, p. 368) mentioned five challenges to the RHM, to which Kroll et al. (Reference Kroll, van Hell, Tokowicz and Green2010) subsequently responded. Let us consider these challenges again from the perspective of both groups of researchers and explain the related assumptions made by Multilink.
(1) There is little evidence for separate lexicons
Are words from different languages stored separately or together? Brysbaert and Duijck (Reference Brysbaert and Duijck2010, p. 364) presented evidence of “L1 and L2 words acting very much as if they are words of the same language, interacting with each other as part of the word identification process”. In particular, strong evidence in favor of an integrated lexicon is that interlingual neighbors affect target word recognition (Van Heuven, Dijkstra & Grainger, Reference Van Heuven, Dijkstra and Grainger1998). In the years since the review by Brysbaert and Duijck, independent additional evidence has been collected: word candidates that are morphologically related to a target word (i.e., the target's morphological family) are activated even when they belong to another language – thus, reading the English word HOUSE may activate an English word like HOUSEKEEPER but also a Dutch word like WERKHUIS (‘work house’) (Mulder, Schreuder & Dijkstra, Reference Mulder, Schreuder and Dijkstra2013; Mulder, Dijkstra, Schreuder & Baayen, Reference Mulder, Dijkstra, Schreuder and Baayen2014).
However, Kroll et al. (p. 374) pointed out that: “It could very well be the case that the two lexicons are functionally separate but with parallel access and sublexical activation that creates resonance among shared lexical features.” In other words, as long as different languages use the same script, the sharing of letters and resonance with higher levels (i.e., lexical orthography) might result in language non-selective effects even when the lexicons are functionally separate.
Interestingly, in Interactive Activation (IA) models, languages can only be seen as separate (i.e., not integrated) to the extent that there is a difference in the size of lateral inhibition (between lexical orthographic or phonological nodes) within versus across languages. If lateral inhibition is assumed to be absent, the issue of separate versus integrated lexicons is no longer meaningful within this framework. Note that empirical evidence of interlingual interference could still be explained in terms of response competition. For Multilink, we decided to initially assume there are no lateral inhibitory effects between words, neither within nor between languages, as a sort of null hypothesis, just to see how far this would get us.
(2) There is little evidence for language selective access
Based on the current body of available evidence, Brysbaert et al. (Reference Brysbaert, Verreijt and Duijck2010) and Kroll et al. (Reference Kroll, van Hell, Tokowicz and Green2010) agreed that lexical access in comprehension is language non-selective; that is, when an input word is presented, lexical candidates from different languages compete for recognition. In line with this view, Multilink assumes language non-selective access and parallel activation of word form neighbors. With respect to production, Kroll et al. (p. 374) added that “what is hypothesized to be active when processing the L2 word for translation, is the L1 translation equivalent, not word form neighbors”. Multilink qualifies this statement in two respects. First, because co-activated orthographic neighbors of the input word are phonologically recoded, word form neighbors in the target language may compete with the correct translation (e.g., /tante/, meaning AUNT in Dutch, competes with the correct /mier/ as a translation of ANT). Second, word forms partially sharing their meaning with the target could also become active. This is not currently implemented in Multilink, but could be.
(3) Including excitatory connections between lexical translation equivalents risks impeding word recognition
In the RHM, word form representations are immediately linked to their translations via ‘word association’. Brysbaert and Duijck pointed out that such strong lexical connections between translations should result in strong cross-linguistic priming effects (e.g., the L2 word HORSE priming its L1 translation equivalent PAARD). However, there is not much evidence for such effects (e.g., in masked priming studies; Brysbaert & Duijck, Reference Brysbaert and Duijck2010, p. 365). Furthermore, if word forms directly activate their translation equivalents, they would introduce perturbations in the network due to the activation of irrelevant words (e.g., naming L2 HORSE might suffer interference from the co-activated L1 item PAARD). As the authors state (2010, p. 365), “if L1 and L2 words are part of the same lexicon. . . the conjecture of excitatory connections between them may result in quite harmful consequences for word recognition, in particular for low-frequency words.” In fact, there may be additional arguments (having to do with context sensitivity, multiple semantic mappings, and task criteria) for why following the word association route is not a reliable way to translate words. We will test the theoretical position that translation is not done via word association but only by conceptual mediation in Multilink by connecting word forms from different languages only via their semantics.
(4) The connections between L2 words and their meanings are stronger than proposed in RHM
In the last decades, more and more evidence has accrued that learners of a foreign language quickly link up new word forms to their meanings (see Meade & Dijkstra, in press, for a review). Nevertheless, as RHM suggests, beginning learners might pay relatively more attention to word forms than to meanings, because they obviously need the form to access the meaning. In Multilink, word forms are characterized by a frequency-dependent resting level activation. Because bilinguals with different L2-proficiency have used L2 words more or less frequently, this implies differences in the resting level activation for L2 words. In future simulations, we will consider to what extent the strength of links between meaning and word forms is dependent on L2-proficiency. For instance, the strength of links between semantics and output phonology could be made proficiency-dependent.
(5) It may be necessary to make a distinction between language-dependent and language-independent semantic features
Representations of word meaning may have features that are language-dependent or language-independent (Paradis, Reference Paradis and Copeland1981). For instance, there is a difference between the French words BALLE and BALLON in terms of the features ‘small’ and ‘hard’, whereas English does not make this distinction. Thus, full meaning equivalence does not hold for all translation pairs – and, in fact, might never hold (cf. De Groot, Reference De Groot2011; Pavlenko, Reference Pavlenko and Pavlenko2009). However, in this early implementation phase we are assuming holistic meaning representations that are fully shared or fully separate across languages (but see Mandera, Keuleers & Brysbaert, Reference Mandera, Keuleers and Brysbaert2017, for an alternative). Issues of multiple semantic mappings and spreading activation between semantic representations will be considered in a later stage of modelling after more basic assumptions of Multilink are tested.
4. A description of Multilink
Multilink was developed with the aim of providing a general implemented account of word form and meaning retrieval during word recognition and production (Dijkstra & Rekké, Reference Dijkstra and Rekké2010). Written in an object-oriented approach in the programming language Java, Multilink combines several characteristics of BIA/BIA+, RHM, and, for instance, WEAVER++ (Roelofs, Reference Roelofs2008). The localist-connectionist network that underlies Multilink accounts for a range of language processing activities concerning different types of words, tasks, and language users.
First, Multilink allows the simulation of monolingual and bilingual processing of words that vary in frequency of usage, length, and cross-linguistic similarity. An innovation relative to earlier models is the processing of words that are ‘special’, because they have form and meaning overlap across languages (i.e., cognates) or only meaning overlap (i.e., translation equivalents). At present, the simulations are restricted to Dutch (L1) and English (L2), but by incorporating other lexicons, bilingual processing in and translation across other language combinations can be simulated.
Second, because the model includes a task/decision system, it allows simulating word processing in psycholinguistic tasks such as lexical decision, orthographic and semantic priming, word naming, and word translation production. In addition, some other tasks can easily be implemented, for instance, progressive demasking, object naming, and semantic categorisation.
Third, because Multilink's lexicon and parameter settings can be fine-tuned to L2-proficiency, it can simulate performance of both high and low L2-proficiency bilinguals in these tasks. For instance, the model can simulate their word translation in forward and backward directions for cognates and non-cognates of different frequencies.
In the following sections, we describe the layered network architecture of Multilink, its integrated lexicon, its activation function, various parameter settings, and the current task/decision system. Next, we present several simulation studies in which we compare Multilink to IA and BIA/BIA+ (model-to-model comparison) and to empirical studies on the comprehension, production, and translation of words (model-to-data comparison).
Multilink's layered network architecture
The core representational structure of Multilink is the symbolic lexical network shown in Figure 1. A written input word activates various lexical-orthographic representations, which in turn activate their semantic and phonological counterparts, as well as associated language membership representations (English or Dutch). Multilink is an interactive model, so all activation flows are bidirectional. At present, semantic representations are simple holistic units, semantic spreading of activation between associated representations is left unconsidered, and onset differences in phonological representations are not taken into account. In future versions of Multilink, these aspects will be developed in more detail.
Multilink's integrated lexicon
Using the network just described, Multilink currently recognizes, produces, and translates English and Dutch words. These words are represented in an integrated English–Dutch lexicon. We first developed a base lexicon that was then used in two Simulation Series to assess Multilink's capacities for simulation using different Resting Level Activation functions and relative to other computational models. For three later Simulation Series, we used an enriched lexicon that extended the base lexicon with stimulus materials from four empirical studies, including various types of cognates and non-cognates of different lengths.
The base lexicon was built in a number of steps. First, we retrieved all English words of 3-to-8 letters present in two databases: the English Lexicon Project (ELP; Balota et al., Reference Balota, Yap, Cortese, Hutchison, Kessler, Loftis, Neely, Nelson, Simpson and Treiman2007) and the Free Association Database (Nelson, McEvoy & Schreiber, Reference Nelson, McEvoy and Schreiber1998). Next, each word was paired with the first Dutch translation in a word translation program (Euroglot Professional 5.0, 2008) available in the database of the Dutch Lexicon Project (DLP; Keuleers, Diependaele & Brysbaert, Reference Keuleers, Diependaele and Brysbaert2010). A word was kept if (a) its Dutch translation also had a length between 3 and 8 letters, (b) it did not share its orthographic form with its translation (i.e., identical cognates were removed), and (c) it had an RT in the ELP or DLP. Finally, we added each word's length in letters as well as its frequency per million in SUBTLEX-US (Brysbaert, New & Keuleers, Reference Brysbaert, New and Keuleers2012) and SUBTLEX-NL (Keuleers, Brysbaert & New, Reference Keuleers, Brysbaert and New2010). This resulted in a base lexicon for 892 Dutch–English word translation pairs (or 1784 words).
In Simulation Series 1, reported below, this complete base lexicon of 3–8 letter words was used as input to Multilink simulations to investigate how different activation functions affected the correlational fit between Multilink and empirical data.
In Simulation Series 2, Multilink simulation data for a subset of 441 words in this base lexicon were compared to IA and BIA/BIA+ simulations for shared 4-letter Dutch or English words in the models’ lexicons, using DLP and ELP RTs for model-to-data correlational analysis.
An enriched lexicon was developed next, given that the results of the two Simulation Series showed the potential of Multilink to capture empirical data. Translation pairs, including cognate pairs, were added for all stimulus words used in four empirical studies, to the extent that these did not introduce conflicts (e.g., Dutch ‘verhaal’ being translated in both English ‘tale’ and ‘story’). This resulted in a set of 1295 translation pairs. The enriched lexicon was used with minimal changes in Simulation Series 3–5. The empirical studies used for simulation purposes were two English lexical decision studies performed by Dutch–English bilinguals from Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) and Vanlangendonck et al. (Reference Vanlangendonck2012), two English word naming studies by Dutch–English bilinguals from De Groot (summary data file provided on 30 September 2016), and a word translation study (Pruijn et al., in preparation). While this latter study included Dutch and English words already paired as translations, the stimuli from the other three studies were merely lists of English words; thus, appropriate Dutch translations were selected by the authors. For the time being, complications in word translation were avoided by leaving out all interlingual homographs.
Multilink's resting level activation
The IA and BIA/BIA+ models allocate a resting level activation (RLA) to each word depending on its frequency, but only in an indirect way: RLA depends on the rank of each word after sorting all words in the lexicon from high to low frequency. However, this ranking system has undesirable aspects.
First, a ranking-based system does not properly handle the frequency difference between two words adjacent in rank, as the step size between such words in the list always remains the same across lexicons of the same size. For example, the differences in RLA for a lexicon containing three words with frequencies 1, 10, and 100 per million will be equal to those in a lexicon containing three words with frequencies 1, 2, and 3 per million. Second, because the size of the lexicon determines the step size between frequency ranks, adding a word to the lexicon results in a change in step size and thus a change in RLA for all words. This is problematic if we wish to compare model performance for monolinguals (having one lexicon) and low and high L2-proficiency bilinguals (having two integrated lexicons with different subjectively lower L2 frequencies). Finally, when there are many words with relatively similar (though not tied) frequencies, they may be assigned substantially different rank positions and will therefore differ considerably in RLA. Thus, assigning ranks to frequencies causes a dramatic change in the word frequency distribution as these frequencies are mapped to the RLA domain.
What is more, this rank-frequency distribution is, in fact, very different from RT distributions (which may, admittedly, also reflect decision level effects). Why does this matter? As we discuss below, an activation function defines how the activation of a model node grows and decays as a function of excitation from other nodes as well as time. This activation function can give rise to a sigmoid growth curve for a node's activation over time. For the task of word recognition, whereby a target word is recognized when its orthographic node crosses an activation threshold, this sigmoid growth curve effects a more or less linear mapping from RLA to recognition RTs. Thus, it is desirable that the RLA distribution mirrors the RT distribution for comprehension.
But since a rank-frequency distribution does not mirror the RT distribution, what might? One obvious contender is to apply a log transform to the word frequencies, given the standard practice of logging word frequencies in psycholinguistics. This transformation will cause the Zipfian distribution of the word frequencies, which is positively skewed (numerous low frequency words and few high frequency ones), to become less so, with the resulting log-frequency distribution appearing more Gaussian. Crucially, however, RT distributions for word recognition are negatively skewed (low frequency words are rather spread out along the RT domain on the slow side, while high frequency words are tightly clustered on the fast side). Thus, perhaps a better approach to achieve an RLA distribution that mirrors the RT distribution is to reverse the skew in the word frequencies rather than to eliminate it.
With this purpose in mind, we used Equations 1 and 2 below to map word frequencies to the RLA domain. These equations assume that each word representation has an RLA that depends on two factors only: the frequency of usage of the word itself (measured in occurrences per million or ‘opm’) and that of the highest and lowest frequencies in the lexicon, which are those of the words ‘the’ (in both English and Dutch) and an opm of 10, shared by numerous words. Equation 1 transforms the frequencies of the words so that their distribution approximates that of the RT distribution. Equation 2 rescales the transformed frequencies to an RLA domain ranging from -0.2 to 0, with “the” assigned an RLA of 0. (The range was established on the basis of preliminary exploratory simulations.)
Equation 1 for transformed frequency (TF) of word i:
 $$\begin{equation}
T{F_i} = {\rm{\ }}\frac{{ - 1}}{{\sqrt[7]{{op{m_i}}}}}
\end{equation}$$
$$\begin{equation}
T{F_i} = {\rm{\ }}\frac{{ - 1}}{{\sqrt[7]{{op{m_i}}}}}
\end{equation}$$
Equation 2 for rescaling to RLA domain TF of word i:
 $$\begin{equation}
{\it RLA}_{i} = {\rm{\ }}\frac{{0.2{\rm{*}}\left( {T{F_i} + {\rm{\ }}\left| {T{F_{\it max}}} \right|} \right)}}{{T{F_{\it max{\rm{\ }}}} - {\rm{\ }}T{F_{\it min}}}}
\end{equation}$$
$$\begin{equation}
{\it RLA}_{i} = {\rm{\ }}\frac{{0.2{\rm{*}}\left( {T{F_i} + {\rm{\ }}\left| {T{F_{\it max}}} \right|} \right)}}{{T{F_{\it max{\rm{\ }}}} - {\rm{\ }}T{F_{\it min}}}}
\end{equation}$$
Note that Equation 1 can be broken down into three separate transformations: taking a root, taking a reciprocal, and multiplying by -1:
1. The denominator represents a seventh-root transformation of the word frequencies, measured in occurrences per million. The root transformation reduces degree of skew. The value of 7 is a free parameter that was selected to reduce the skew from the Zipfian distribution to something more closely approximating that of the RT distribution.
2. The reciprocal transformation flips the ranking of the frequencies – high frequency words now have small values while low frequency words have high values. However, the distribution is still positively skewed, meaning that the mode is now over the high frequency words.
3. Multiplication by -1 flips the values over the y-axis into the negative domain, causing low frequency words to once again have lower values than high frequency words.
In Simulation Series 1 below, we compared the frequency conversion in Equation 2 to frequency logging in opm as a basis for the RLA, in simulations of the recognition data in ELP and DLP (the same rescaling Equation 2 was used for the case of simply taking the logarithm).
Using resting level activation to account for L2-proficiency differences
Because we wished to compare simulations for monolinguals and bilinguals at different L2-proficiency levels, RLAs were first determined for L1 Dutch on the basis of SUBTLEX-NL. Next, we assumed that for balanced Dutch–English bilinguals, the frequency of English words in opm as indicated by (monolingual) SUBTLEX reflects the actual frequency of these bilinguals’ usage. Dutch and English words of equal frequency in opm in SUBTLEX-US and SUBTLEX-NL then received the same RLA. Subjective English word frequency must be lower for unbalanced Dutch–English bilinguals than for native English speakers, but it is unknown to what extent and in what way. For present purposes, we assumed that English frequency in some unbalanced bilinguals can be approximated by dividing the native's frequency of a word by 4. Thus, an English word with an objective frequency of 100 opm was considered to have the same resting level as a Dutch word with a frequency of 25 opm (only English RLAs were adapted).
Multilink's core parameter settings
Representations in the lexical network are connected by links of varying strength. Furthermore, when activated representations receive no further input, their activation gradually decays towards their RLA. Appendix 1 summarizes the settings of different parameters regulating activation flow during word retrieval. Identical parameter settings were used during all simulations to be reported. There are a few points to be noted.
First, the parameter regulating lexical competition (lateral inhibition) in the model is currently set at 0. This implies that competition between lexical items does not arise within the word recognition system itself; competition could arise only due to response selection issues in the task at hand (i.e., response competition). Note that the presence or absence of lateral inhibition, a debated issue for considerable time, could be explicitly investigated by varying this parameter.
Second, in the case of cognates, activation from two orthographic nodes converges on one semantic node. When activation is simply summed, this leads to a substantial overestimation of the cognate effect. As a simplified solution, we decided to reduce the input activation from the least activated node by a factor 2. Alternatively, a proportion of the summed activation of both nodes could be taken. Further exploration here is necessary, but the proposed solution led to good results.
Multilink's activation function
For the activation of orthographic, semantic, and phonological representations, Multilink uses similar activation functions as IA (McClelland & Rumelhart, Reference McClelland and Rumelhart1981, Reference McClelland and Rumelhart1988) and BIA/BIA+ (Dijkstra & Van Heuven, Reference Dijkstra, Van Heuven, Grainger and Jacobs1998). The functions are given in Appendix 2. In Multilink, these activation functions are directly applied to the lexical level. Skipping sublexical levels and using the Levenshtein distance measure makes it possible to simultaneously activate words of different lengths (see Dijkstra & Rekké, Reference Dijkstra and Rekké2010, for a discussion) and diminishes the position-specific coding problem (i.e., letters mapping onto a specific position in the word only; Dijkstra, Reference Dijkstra, Cruse, Hundsnurscher, Job and Lutzeier2005).
The simulation of any word retrieval process takes place in a number of time steps or time cycles, during which activation for all nodes in the model is updated (see Equation A1 in Appendix 2). At each time step, the activation of each lexical (orthographic or phonological) representation in the bilingual lexicon is adapted by adding the damped effect of the current net input from all other connected nodes (Equation A2), including the presented word, to its activation at the previous time step, and then subtracting decay (Equation A3). Each stored orthographic representation receives activation from the input word to a proportion of its similarity strength (depending on the orthographic overlap of the stored representation and the presented word) (see Equation 3 below). Accordingly, an input word may activate a number of word candidates to varying extent. Each candidate's activation pattern changes over time depending on input from various sources (e.g., semantics), because resonance between different types of representations is assumed. Recognition in Multilink takes place when a word candidate's activation surpasses a threshold of 0.72.
Multilink's approach to word similarity
In Multilink simulations, input words of any length activate stored orthographic word representations, potentially from several languages. Words are activated depending on their orthographic similarity to the input word and their subjective frequency of usage. Levenshtein distance is used as the measure of orthographic similarity (see Schepens, Dijkstra & Grootjen, Reference Schepens, Dijkstra and Grootjen2012). It involves the computation of the minimal number of deletions, substitutions, and insertions needed to edit one expression into another. The formula for normalized Levenshtein scores for two expressions is given by Equation 3:
 $$\begin{eqnarray}
score = 1 - \left( {distance/length} \right)
\end{eqnarray}$$
$$\begin{eqnarray}
score = 1 - \left( {distance/length} \right)
\end{eqnarray}$$
where length = max(length of source expression, length of destination expression) and distance = min(number of insertions, deletions, and substitutions).
Levenshtein distance is in use by researchers with different backgrounds to explore the relation between orthographic, phonetic/phonological, and cross-linguistic similarity (e.g., Heeringa, Reference Heeringa2004; Kessler, Reference Kessler2005; Levenshtein, Reference Levenshtein1966). By normalizing the Levenshtein distance for word length, the activation of word candidates of different lengths is possible. The panels of Figure 2 illustrate this point by presenting a simulation for three input words of different length: PRICE, ICE, and RICE. As can be seen, although all three words are always activated upon presentation of each target, it is the target that is recognized (at a time that is co-dependent on its frequency of usage).

Figure 2 a-c. Activation of the words ICE, RICE, and PRICE after presentation of each of these to Multilink.
Thus, Levenshtein distance is a useful measure to simulate the activation of neighbors of a target word, even when they are of different lengths. Some recent studies suggest that Levenshtein distance captures effects of between-word similarity reasonably well. For instance, in the priming studies by Adelman, Johnson, McCormick, McKague, Kinoshita, Bowers, Perry, Lupker, Forster, Cortese, Scaltritti, Aschenbrenner, Coane, White, Yap, Davis, Kim & Davis (Reference Adelman, Johnson, McCormick, McKague, Kinoshita, Bowers, Perry, Lupker, Forster, Cortese, Scaltritti, Aschenbrenner, Coane, White, Yap, Davis, Kim and Davis2014), the addition to or removal of a letter from a word had about the same negative effect on target RTs as the substitution of a letter. In the bilingual domain, Levenshtein distance can be used to co-activate the two members of non-identical cognate pairs, such as CLOCK (English) and KLOK (Dutch).
Multilink's task / decision system
Figure 1 shows the lexical network through which activation flows. However, it does not represent the task/decision system that selects particular representations for output, sets parameters, and specifies responses depending on the task and stimulus list at hand (cf. Green, Reference Green1998). For instance, the task/decision system may check the language membership of input and output, and the degree of orthographic, phonological, or semantic activation, as requirements for the release of a response. At present, visual lexical decisions for words are assumed to take place based on an activation threshold of 0.72 of lexical-orthographic representations (cf. Grainger & Jacobs, Reference Grainger and Jacobs1996). Word naming and word translation start when phonological representations of the target language surpass the same threshold. The target language is the same as the input language for word naming, but different for word translation. We are currently specifying and extending the task/decision system to provide an account of interlingual homograph processing.
5. Simulation studies with Multilink
In this section, we apply Multilink in several simulation studies on word comprehension (Simulation Series 1–3), word naming (Simulation Series 4), and word translation (Simulation Series 5). Our general goal is to demonstrate the applicability of Multilink to word comprehension and production for a diversity of tasks and stimulus materials.
Simulation Series 1: Recognizing English or Dutch 3–8 letter words in two variants of Multilink
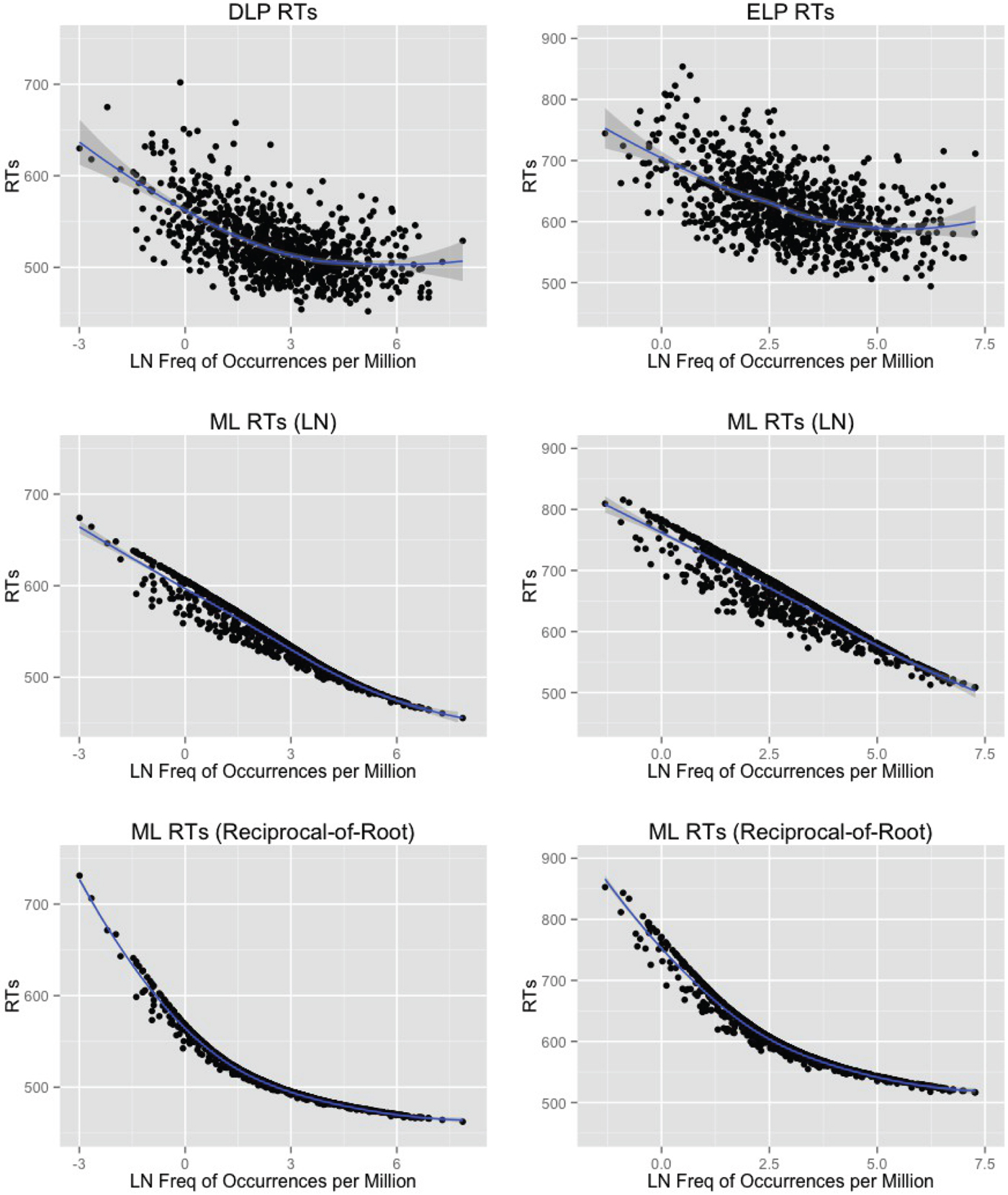
In this simulation series, we assessed Multilink's performance for two sets of RLA functions, making use of the base lexicon of 892 word pairs (specified above). Using the natural log function, the number of cycles produced by Multilink in the balanced bilingual simulations showed Pearson r correlations of 0.562 and 0.529 with the lexical decision data in DLP and in ELP, respectively. In the unbalanced simulations, the correlations were 0.565 for DLP and 0.506 for ELP. These and subsequently reported correlations are all significant at p<.001 unless otherwise noted.
Using the reciprocal-of-root function (see Equation 1), Multilink's simulations correlated 0.604 with DLP and 0.553 with ELP for balanced bilinguals, and 0.605 (DLP) and 0.554 (ELP) for unbalanced bilinguals. The greater correlations of the reciprocal-of-root simulations with RTs indicate that the transformed RLA distribution matches well with the RT distribution.
The panels of Figure 3 display scatterplots for simulation results with the two Multilink variants and the DLP and ELP data for Dutch and English lexical decision. For visualization and ease of comparison, we converted Multilink cycle times to RTs. We did this by equating the 1% and 99% quantiles of the cycle time distribution to the equivalent quantiles of the empirical RT distribution. We chose not to rescale by equating the full ranges of the two distributions due to possible distorting effects caused by outliers. Notice that for high frequency words in both Dutch and English simulations, the empirical RTs exhibited a pattern of nonlinear decrease, approaching an asymptotic baseline. This baseline represents a possible floor effect. In the case of the natural log-based simulations, there is no such asymptote; RTs continue to follow a generally linear negative trend. The reciprocal-of-root simulation data, on the other hand, indeed exhibit this asymptotic behavior as frequency increases. For this reason, and given the higher correlations achieved with the reciprocal-of-root function, we chose it for the remaining simulations in this paper.

Figure 3 a-c. Empirical response times for Dutch (left upper panel) and English (right upper panel) 3–8 letter words found in DLP and ELP as a function of log frequency, and simulated response times based on a logarithmic activation function (middle panels) or a reciprocal of root frequency activation function (lower panels).
As can be seen in these and later figures, Multilink underestimates the variance present in the empirical data. Its relatively small model variability may be ascribed to at least two sources. First, Multilink, IA and BIA/BIA+ do not take into account many relevant factors that systematically contribute to word retrieval (e.g., sublexical characteristics in the case of Multilink and semantics in the case of IA and BIA/BIA+). Second, there is unaccounted-for systematic or random variation within and across participants. To the extent that the models represent a kind of ‘supersubject’, they cannot be expected to account for subject-dependent sources of variance.
Simulation Series 2: Recognizing English or Dutch 4-letter words in IA, BIA/BIA+, and Multilink
In our second series of simulations, we used a subset of the base lexicon to compare performance on Dutch and English 4-letter words by Multilink, IA (McClelland & Rumelhart, Reference McClelland and Rumelhart1981), and BIA/BIA+ (Van Heuven et al., Reference Van Heuven, Dijkstra and Grainger1998). Simulated data were the lexical decision RTs for 4-letter words in DLP and ELP. We used jIAM by Van Heuven (Reference Van Heuven2015) as an on-line implementation of the IA and BIA/BIA+ models, setting the recognition threshold at 0.70. Furthermore, the integration rate / step size parameter in IA was reduced to 10% of its original value. This allows a higher resolution of cycle times and more accurate measurements (see Davis, Reference Davis, Kinoshita and Lupker2003; Davis & Lupker, Reference Davis and Lupker2006). Word frequencies for all items were taken from SUBTLEX-US and SUBTLEX-NL.
For the IA simulations, done separately in each language, we used the two lexicon files provided in the jIAM implementation of these models, consisting of, respectively, 983 Dutch words and 1323 English 4-letter words (dutch4.fpm and english4.fpm, see Van Heuven, http://www.psychology.nottingham.ac.uk/staff/wvh/jiam/). In BIA/BIA+ simulations, we used an integrated lexicon of 1852 words, in which cognates and false friends were avoided. We note that using smaller lexicons for IA and BIA/BIA+ would result in distorted simulations, because lexical neighborhood structure and its accompanying lateral inhibition effects would not be properly represented.
The Multilink simulations involved a subset of 441 4-letter words from the base lexicon, consisting of 214 Dutch and 227 English words. Out of these, the two IA input sets shared 210 Dutch words and 223 English words, and the BIA/BIA+ input set shared 185 Dutch words and 181 English words. Simulations were done for all these words, and correlations with DLP and ELP were computed for each set separately.
Lexical processing of balanced Dutch–English bilinguals by BIA and Multilink was simulated using word frequencies for natives found in the SUBTLEX databases. To simulate lexical processing of unbalanced bilinguals, we divided the English word frequencies by 4. We note that the participants in the Dutch Lexicon Project (DLP; Keuleers, Diependaele & Brysbaert, Reference Keuleers, Diependaele and Brysbaert2010) were, in fact, unbalanced Dutch–English bilinguals with Dutch as their native language (living in the Flemish-speaking part of Belgium). The correlational difference in simulation results for balanced and unbalanced bilinguals was limited. For Multilink, this is not so surprising, since effects of lateral inhibition were absent (in the present study, inhibition between words was set at 0).
Table 1 reports the correlations of Multilink, IA, and BIA/BIA+ simulations with empirical Dutch or English data for balanced and unbalanced bilinguals. Stimulus sets used for IA and BIA/BIA+ simulations were subsets of those for Multilink. As can be seen, correlations to the empirical data were generally lower for IA and BIA/BIA+ than for Multilink. An important reason for this lies in the indirect way RLA is computed in IA and BIA/BIA+, namely by converting rank order (correlated with frequency) (see McClelland & Rumelhart, Reference McClelland and Rumelhart1988, p. 213, 216).
Table 1. Correlations of Multilink, IA, and BIA/BIA+ with RTs in DLP and ELP for balanced and unbalanced variants of Multilink and BIA+.

Note: IO = Input to Orthography, OPB = Occurrences Per Billion.
In sum, Simulation Series 2 showed that Multilink performs well compared to IA and BIA/BIA+ even on 4-letter words, and is able to simulate performance of both balanced and unbalanced bilinguals. However, none of the models do account for all variance in the empirical data, and future research must determine to what extent the unexplained variance is systematic or random.
Simulation Series 3: Multilink and lexical decision studies in bilinguals
We are not aware of published bilingual (Dutch–English) databases with lexical decision times for large numbers of L2 (English) words that could be used for our simulation purposes. As an alternative, we performed a series of Multilink simulations using the lexical decision latencies for (non-)identical cognates from two comparatively large comprehension studies (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Vanlangendonck et al., Reference Vanlangendonck2012, in preparation). In these and later simulations, we used the enriched lexicon described above.
Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010)
In Experiment 1 of Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010), unbalanced Dutch–English bilinguals performed an English lexical decision experiment involving English words with varying Levenshtein distances to their Dutch translations. As input to Multilink, 175 out of 183 analyzed stimulus words of different categories were taken. These English items had perfect orthographic overlap with their Dutch translation equivalents (identical cognates), considerable overlap (non-identical cognates), or hardly any overlap (control words). An overall correlation of 0.539 was obtained between RTs and simulation cycles (based on English frequency divided by 4).
Figure 4 compares Multilink's simulation results and empirical data. For display purposes, cognates were defined as translation equivalents at a Levenshtein distance of 0 or 1, and non-cognates as translation equivalents at larger Levenshtein distances. For later simulations, we will display more specific categories dependent on Levenshtein distance. As can be seen, Multilink clearly distinguishes cognates and non-cognates, whereby the former have smaller RTs (converted from cycle times using the same quantile-based method discussed above). In the case of cognates, the input word activates two orthographically similar representations in both languages. These representations both send activation to their shared semantic node, causing it to gain activation more quickly than when a semantic node receives activation from a single orthographic node. Activation fed back from the semantic representation to the orthographic layer is thereby available earlier and more strongly for cognates than for non-cognates. The result is a larger activation of orthographic cognate representations than of non-cognates. Note that in the empirical data the separation between the two categories is less pronounced, although the direction of the effect remains the same.

Figure 4. Empirical (left panel) and Multilink simulation data (right panel) for the lexical decision study by Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010).
Vanlangendonck, Peeters, Rueschemeyer & Dijkstra (2012, in preparation)
The unbalanced Dutch–English participants of Vanlangendonck et al. also performed an English lexical decision experiment with identical cognates, non-identical cognates, and non-cognates (as well as false friends, not considered here). The correlation between the simulated and empirical latencies for 204 out of the 231 English items for which Vanlangendonck et al. (Experiment 1; in preparation) collected RTs, amounted to a Pearson r of 0.687. Figure 5 presents the observed patterns in RTs and cycle times per item category, with a more refined categorisation of cognates in terms of Levenshtein distance. Note that the empirical data show a gradual increase of mean RTs as Levenshtein distance increases, and this same pattern emerges in the Multilink simulation data (converted to RTs from cycle times). (For simulations of cognate processing during L2 learning with distributed connectionist models, see Dijkstra et al., 2012).

Figure 5. Empirical (left panel) and Multilink simulation data (right panel) for the lexical decision study by Vanlangendonck et al. (Reference Vanlangendonck2012).
Simulation Series 4: Multilink and bilingual word naming data
Multilink is not particularly well equipped to simulate word naming results, for instance, because it does not (yet) have any provision for simulating latency differences depending on word onset phoneme. Nevertheless, testing Multilink on word naming is of interest because it may demonstrate its general applicability across tasks and modalities.
Furthermore, the Dutch Lexicon Project does not contain word naming data. We therefore ran simulations using an English word naming dataset for Dutch–English bilinguals kindly provided to us by De Groot (30 September 2016). We initially used 419 out of 440 available stimulus items as input to Multilink; however, 5 words had to be excluded from our analysis because Multilink failed to properly name them. We then correlated the simulation latencies for the remaining 414 words with the naming RTs averaged for each word across the two naming experiments in the dataset.
The simulations were done with the same version of Multilink as before. No parameter settings were changed. A Pearson r value of 0.483 represents the relationship between empirical RTs and cycle times. Figures 6a and 6b show scatterplots for the empirical and simulation data, with frequency on the X-axis and naming latencies on the Y-axis (cycles times converted to RTs). The empirical data show considerable variability in latencies. A better model fit might be obtained if the production process would be made more dependent on the onset phoneme of the output word.

Figure 6. Empirical (left panel) and Multilink simulation data (right panel) for word naming data by De Groot (personal communication) averaged across two studies.
Multilink again clearly distinguishes RTs on the basis of not just word frequency but also cognate status, here with a fine-grained distinction between cognate pairs with a Levenshtein distance of 1, 2, or 3, as well as control words (having a distance greater than 3 to their translation). As before, this differentiation is less pronounced but in the right order in the empirical data. Confidence Intervals (CIs) were not presented for the smoothers in order to enhance plot readability. However, for the empirical data only the control condition's CI does not include a possible slope of zero (for the model data, none of the smoother's CIs included zero slopes). De Groot's data suggest that frequency had a limited effect on naming latencies for cognates, while non-cognates did exhibit reduced latencies as frequency increased. This could reflect a floor effect (faster naming not being possible), which is not accounted for in Multilink.
Simulation Series 6: Multilink and word translation data
Several studies have investigated the translation of cognates and non-cognates, both of high and low frequency, in the two directions of a bilingual's language pair (De Groot, Reference De Groot2011). Empirical studies generally agree that cognates are easier to translate than non-cognates, and that words of higher frequency are easier to translate than words of lower frequency.
However, studies have often yielded inconsistent results with respect to effects of translation direction. For instance, for translation production, Christoffels et al. (Reference Christoffels, De Groot and Kroll2006) found faster translations from L1 to L2 (forward) than vice versa (and a larger effect for low proficiency bilinguals). In contrast, De Groot et al. (Reference De Groot, Dannenburg and Van Hell1994) reported slower translations in the opposite direction, or no effect of direction. Kroll et al. (Reference Kroll, Michael, Tokowicz and Dufour2002) also found this (and with a larger effect for low proficiency bilinguals). These slower translation responses from L1 to L2 (forward) are in line with the RHM, because the L1-to-L2 route would be conceptually mediated and affected by semantic factors; in contrast, translation from L2 to L1 (backward) would be fast, using mainly word associations.
We decided to simulate the word translation study by Christoffels et al. (Reference Christoffels, De Groot and Kroll2006) to see if we would reproduce their forward (rather than backward) translation direction effect. Because the translation latencies per item were not available, we first replicated the translation production study with a number of changes to design and stimulus materials (see Pruijn et al., in preparation). First, we used the same set of word translation pairs for both translation directions. This set included cognates and non-cognates of high and low frequency. Second, we used a within-subject design, implying that participants translated the items twice, once in each translation direction (order counterbalanced across participants). Third, we replaced a few interlingual homographs in the original study, rematched word frequency, and balanced onset differences between output words from different categories. In total, eight different categories were formed, distinguishing cognates from non-cognates, high frequency words from low frequency words, and forward translation direction from backward translation direction. As each category contained 32 items, there were 256 items that were translated (128 from Dutch to English and 128 from English to Dutch).
Figure 7 shows the original empirical results from Christoffels et al. (Reference Christoffels, De Groot and Kroll2006), the new empirical results from Pruijn et al. (in preparation), and the simulation results by Multilink. No standard errors were provided in Christoffels et al. (Reference Christoffels, De Groot and Kroll2006). In the Dutch to English translation direction, 3 items (arend, boer, wolk) had to be excluded from simulations because they were incorrectly translated. In the English to Dutch direction, 1 item (curse) had to be excluded for the same reason. Christoffels et al. and Pruijn et al. report very similar patterns of forward translation direction effects, cognate facilitation, and frequency effects. Interestingly, Multilink was found to simulate the cognate effects and frequency effects observed in the two empirical studies, and also yielded a similar forward translation direction effect. We note that this forward translation direction effect was already available in raw cycle times and was not a consequence of rescaling (which was done on the data for both translation directions combined). Furthermore, the correlation between Multilink's cycle times and Pruijn et al.’s RTs was an impressive 0.674 for English to Dutch and 0.569 for Dutch to English.

Figure 7. Empirical data from Christoffels et al. (Reference Christoffels, De Groot and Kroll2006; left panel) and Pruijn et al. (in preparation; middle panel), and Multilink simulation data (right panel) for word translation. Note: Mean RTs across studies per translation direction and condition (CH=high frequency cognate, CL=low frequency cognate, NH=high frequency non-cognate, NL=low frequency non-cognate)
6. Discussion and evaluation
In this paper, we discussed Multilink, a computational model designed to provide a general account of monolingual and bilingual word retrieval in comprehension and production. In an earlier paper (Dijkstra & Rekké, Reference Dijkstra and Rekké2010), we provided the blueprint of our theoretical view in terms of a beta-version of Multilink, focusing on word translation. This earlier paper provided some sample simulations of both a qualitative and quantitative nature for a limited number of words. In the current paper, we presented a more mature version of Multilink, including the development and use of a sizeable lexicon. In line with Brysbaert et al. (Reference Brysbaert, Verreijt and Duijck2010), our simulations with Multilink show that domain-specific models using a symbolic, connectionist framework (like ML, but also IA, BIA/BIA+, and WEAVER++) can be integrated into a meaningful whole that captures essential underlying aspects and mechanisms of language processing.
Multilink can be seen as a variant of a localist connectionist model in which a number of simplifying assumptions are made. For instance, we assumed that Multilink's resting level activations for words are a direct logarithmic or reciprocal-of-root function of the frequency of usage of words. Furthermore, we assumed that the activation of competitors of different lengths from the same and another language directly depends on the orthographic overlap between the input word and stored lexical representations, as operationalized by their Levenshtein distance. We further made the simplifying assumption that word candidates compete only at a response choice level, but not in terms of lateral inhibition. We also assumed that orthographic lexical representations in one language are only indirectly (via semantics) linked to phonological (and orthographic) lexical representations in another language. Finally, the present model implementation incorporates a simple holistic representation of word meaning and a rudimentary task / decision system separate from the lexical activation network.
With these simplifying assumptions concerning architecture and process, Multilink already accounts for results from a range of different word comprehension and production studies in monolinguals and bilinguals. An evaluation of these simulations is given in the following sections. After this, we will evaluate the Multilink model more generally on the basis of criteria proposed by Jacobs and Grainger (Reference Jacobs and Grainger1994). Finally, we will discuss some current problems and future model developments.
Simulations on word comprehension
Two key aspects of comprehension that we simulated with Multilink were word frequency effects and word similarity effects, including length differences. We explored two ways to relate word frequency and Resting Level Activation (RLA). Both logarithmic and reciprocal-of-root RLA transformations worked relatively well in predicting RTs for 3-to-8 letter non-cognate words of different frequencies when they were linked up to a standard connectionist activation function. In order to simulate (1) neighborhood effects, (2) the recognition of control words of different lengths, and (3) the recognition of cognates with different degrees of orthographic overlap across languages, a measure of cross-linguistic similarity was required. Levenshtein distance provided a suitable and unifying measure, with both theoretical and practical applicability.
We positioned Multilink relative to the IA and BIA/BIA+ models in a series of simulations on 4-letter word recognition. In comparison, Multilink produced remarkably large correlations to empirical data in DLP and ELP, probably (also) because of the improved RLA function.
The strong performance of Multilink in simulating monolingual empirical effects provided a solid basis for the model's extension to bilingual processing. We therefore applied Multilink to four studies that applied lexical decision, word naming, or word translation to study how bilinguals process cognates and non-cognates of different lengths. In several series of simulations, our localist symbolic network model of the whole word retrieval process in bilinguals performed quite well. Correlations were all well above 0.40 (p<.001), which is quite high when one considers that the simulations often involved hundreds of words.
Simulations on word naming and word translation
Building on the findings in the comprehension domain, we next applied the model to word naming and word translation, tasks that have both comprehension and production aspects. Multilink simulations of word naming led to correlations with empirical data that were higher than anticipated (far above 0.40), given that sublexical and phonetic (onset) aspects of the process were not accounted for. This finding suggests that the basic triangular architecture of Multilink, connecting orthographic, phonetic/phonological, and semantic representations is useful.
However, we were especially interested in word translation, because, although every bilingual from a young child to a professional interpreter can to some extent perform this task, it is one of the most complex language activities that a human speaker can engage in.
One of the principle challenges in the word translation process is to ensure that the correct translation is selected from among a large set of co-activated representations. Problems that arise are concerned with (a) input activation of (higher frequency) form-similar competitors; (b) output activation of competitors via direct orthographic-to-phonological links; (c) activation of competitor semantics. (Other problems concern selecting one from multiple translations, context-dependence of translations, and polysemy.) An example word for which all three problems conspire is the low frequency English input word ANT, which must be translated into Dutch as /mi:r/ (MIER). The input word ANT co-activates both AUNT (English) and TANTE (Dutch) as competitors. However, TANTE happens to be the Dutch translation of AUNT, and both items map onto the same semantics. As a consequence, both orthographic and semantic representations boost the activation of the phonological output representation of TANTE. Because TANTE belongs to the correct output language in translation (Dutch) and is also semantically activated, it can easily be selected as the translation of ANT. Multilink was able to overcome this problem by reducing the summed activation in the case where multiple word candidates map onto the same semantic representation.
The same solution was applied to semantic convergence of activation in cognates. Due to the orthographic overlap of the two readings of a cognate, presentation of the cognate in one language results in co-activation of the cognate in the other language. Both of these map onto (largely) shared semantics. Co-activated orthography and shared semantics of the cognates directly and indirectly activate their linked phonological representations, boosting the cognate facilitation effect in word translation. Simulations showed that merely summing the co-activation of the two cognate readings on the shared semantic representation results in an overestimation of the cognate effect. Reducing the summed activation, however, solved the problem and led to improved simulation results. Indeed, Multilink simulated the processing time required for producing the translation in the case of cognates and non-cognates of different lengths quite well. In addition, it mimicked empirical data with respect to asymmetries in translation direction.
General theoretical consequences of the Multilink simulations
The application of Multilink to both comprehension and production issues (especially word translation) has been particularly revealing in showing the complexity of the interactions between lexical representations of different kinds. There are at least three insights that we can draw on the basis of the collection of simulations. They are concerned with the sources of cognate facilitation effects, word selection criteria in word translation, and the effectiveness of word association.
Cognate facilitation effects
The faster responses to cognates observed in a variety of experimental paradigms have been attributed to different sources. De Groot (Reference De Groot2011, p. 262) specifies three of them: cognates are co-activated due to overlap in input orthography; they share (part of) their (morpho-) semantics across languages; and their phonological representations are co-activated during word production via semantics. In the present study, we have identified an important fourth source for cognate facilitation in language production: lexical activation spreading from orthographic representations to their (same-language) phonological representations. Adaptation of the amount of activation converging on semantic representations was in part required to compensate for the boosting effect of orthographic to phonological activation spreading.
Target word selection
An important lesson to be learned from our findings is that the output word for translation is probably not selected on the basis of phonological activation only. In a model like WEAVER++, selection is not only based on phonological activation, but also on the language membership of an item. In other words, the output item must belong to the target language. This is an important addition to the phonological activation criterion, but our simulation work suggests that it is still not sufficient. One reason is that a low-frequency L2 input letter string may activate a high-frequency competitor from the L1 output language. Such a competitor would become phonologically activated and belongs to the right language for translation.
We propose therefore that an activated phonological output item that belongs to the right language will be accepted only as a correct translation if there is enough activation of the associated semantic representation as well. This implies that the link between phonology and semantics is checked before the word's translation is selected and produced.
However, on the basis of simulation work in progress, we suggest that even this solution is not sufficient to ensure a proper word translation in all cases. It fails in the case of the translation of interlingual homographs, like the Dutch–English word ROOM (meaning ‘cream’ in Dutch). When ROOM is presented as a Dutch word to be translated into English, the phonological representations of both the English word ROOM itself and the Dutch word ROOM's translation CREAM fulfil the criteria of having (a) activated phonology in the target language, and (b) activated semantics linked to the output representation. Thus, it seems that even the language membership of the input must be taken into account to allow correct word translation. We are currently investigating this issue and trying to solve it by adding an extended task account to the Multilink model (Goertz, Wahl & Dijkstra, in preparation).
Word association route in RHM
We believe that our simulation studies throw some doubt on the usefulness of word association as a translation route. First, use of this route further increases cognate facilitation, because the non-target cognate reading is not only coactivated together with the input, but is also activated directly by the form link to the input reading. Second, it must still be checked if a word that is activated via word association is indeed the correct translation of the target, because non-target translations could be activated via other types of word association as well (e.g., parcel in the fixed expression part and parcel). Third, although we currently restricted word translations to one-on-one word pairs, words can often be translated into several items from the other language (e.g., English BIKE can be translated into Dutch FIETS and RIJWIEL; Tokowicz & Kroll, Reference Tokowicz and Kroll2007). The consequence of this is that multiple translations of the input word are co-activated and simultaneously compete for selection. Without a disambiguating context, no selection is possible, except when additional criteria (like frequency of mapping) are used. In sentence translation, the specific meaning of translation that is appropriate to the context must be retrieved. To make the correct selection, the meaning of the sentence must be related to the specific shades of meaning of the lexical items under consideration. This argumentation suggests that the semantic link between input and output must standardly be checked to ensure selection of the optimal translation.
Evaluation of Multilink as presently implemented
Jacobs and Grainger (Reference Jacobs and Grainger1994) list several criteria to evaluate models in terms of their structural aspects, processing mechanisms, and similarity to empirical data. Below, we apply these criteria to Multilink (for an evaluation of BIA using these criteria, see Dijkstra & Van Heuven, Reference Dijkstra, Van Heuven, Grainger and Jacobs1998; for an evaluation of RHM, see Dijkstra & Rekké, Reference Dijkstra and Rekké2010).
Descriptive adequacy: Does Multilink retain essential properties of the human processing system and its representations?
The representational architecture underlying Multilink fits well with and extends monolingual computational models, such as the Dual Route Model (Coltheart et al., Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001) for reading and the WEAVER++ model (Roelofs, Reference Roelofs2008) for word production. The model simulates interactions between several codes (orthographic, phonological, and semantic) at an interval measurement level.
In the bilingual domain, Multilink, like BIA/BIA+ and RHM, assumes that word retrieval involves language non-selective processing. As discussed in the Introduction, there is abundant empirical evidence for this view, and most researchers in the domain of bilingualism adhere to it.
In addition, Multilink assumes that the bilingual lexicon is integrated, which essentially implies there is just one store for words from different languages. This parsimonious solution appears to be compatible with empirical data (cross-linguistic neighbors, see, e.g., Van Heuven et al., Reference Van Heuven, Dijkstra and Grainger1998; morphological family size effects, see Mulder et al., Reference Mulder, Schreuder and Dijkstra2013, Reference Mulder, Dijkstra, Schreuder and Baayen2014; and brain evidence, see Van Heuven & Dijkstra, Reference Van Heuven and Dijkstra2010).
Multilink further assumes that there is a link between translation equivalents only via semantics, which contrasts with the assumption of a word association route proposed by the RHM. Although such a route could easily be implemented in Multilink, simulation work and theoretical analysis (see above) suggest that one can do without it, at least in the case of the more proficient bilinguals whose data we simulated.
Finally, similar to BIA+, Multilink makes the far-reaching assumption that activation in the word retrieval system flows in the same way in different task situations. Differences in result patterns are considered to originate from differences in task demands, read-out codes (i.e., the specific representations used for responding in different tasks), parameter settings, and use of linguistic and non-linguistic context. The implication is that the present simulation results can probably be improved by including a task/decision component that is tuned to task differences, such as those that exist between lexical decision and word naming (De Groot, Borgwaldt, Bos & Van den Eijnden, Reference De Groot, Borgwaldt, Bos and Van den Eijnden2002).
Horizontal and vertical generality of ML: Can the model generalize across tasks and stimulus sets?
We have applied Multilink to data collected for different experimental tasks, such as lexical decision, word naming, and word translation. Although we believe that a task/decision system is required to do justice to the differences between techniques, these tasks apparently have a sufficient number of underlying processes in common to enable Multilink to account for various findings without any task-dependent parameter adjustment.
Multilink was able to handle different word types, including cognates and non-cognates of different lengths and frequency of usage in the two languages. The implementation of a cognate representation based on empirical studies (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Voga & Grainger, Reference Voga and Grainger2007) resulted in generally good fits between model and empirical data. At the same time, the lack of a sublexical representation was clearly problematic with respect to simulating details of word naming.
Thus, the Multilink model shows that a general connectionist framework for word retrieval can yield good simulation data for monolingual and bilingual studies, comprehension and production studies, and studies involving different tasks and stimulus materials. It is reassuring that all of this can be done within one theoretical paradigm, the localist connectionist approach. Missing here is the aspect of L2 word acquisition. We only briefly considered the performance of bilinguals with a high versus a low L2-proficiency in terms of Resting Level Activation differences. By varying RLAs, performance for different L2-proficiency groups could be simulated (as in Dijkstra, Haga, Bijsterveld & Sprinkhuizen-Kuyper, Reference Dijkstra, Haga, Bijsterveld, Sprinkhuizen-Kuyper, Altarriba and Isurin2011). An alternative solution is to incorporate a learning mechanism (as proposed by Grainger, Midgley & Holcomb, Reference Grainger, Midgley, Holcomb, Kail and Hickmann2010). Starting from scratch to build a completely new architecture in a new paradigm, using e.g., naive discrimination learning (Baayen, Milin, Filipovic Durdevic, Hendrix & Marelli, Reference Baayen, Milin, Filipovic Durdevic, Hendrix and Marelli2011; Mulder, Dijkstra & Baayen, Reference Mulder, Dijkstra and Baayen2015) or ‘deep learning’ (e.g., Young, Hazarika, Poria & Cambria, Reference Young, Hazarika, Poria and Cambria2017) could also be considered, but would ‘leave earlier models behind’ (cf. Kroll et al., Reference Kroll, van Hell, Tokowicz and Green2010) and run the risk of losing some laboriously obtained historical insights. Furthermore, theoretical analysis suggests that L2 word learning depends on complex mechanisms that are currently not well understood (see Meade & Dijkstra, Reference Meade, Dijkstra, Libben, Goral and Libben2017) and go far beyond differences in frequency of usage.
Falsifiability and modifiability
Verbal models are hard to falsify and easy to modify, for several reasons. First, in the case of data that seem to contradict the model's predictions, verbal solutions may be proposed (e.g., to fill in ‘theoretical holes’) that appear to solve the problems at hand (modifiability). However, often these solutions subsequently do not become a standard integrated part of the model, and/or are not tested for their feasibility and falsifiability. In contrast, in the case of computational models, the source of a particular empirical data fitting failure can be determined; next, the model can be improved or, in the case of contradictory evidence, rejected. Thus, implemented models are more vulnerable and more easily falsified than verbal models. At the same time, computational models are to some extent modifiable, because they have recognizable explicit components to which particular problems may be attributed. In the case of Multilink, for instance, the activation function can be easily replaced, or particular links between representations can be adapted, if their current implementation is determined to be problematic. However, there are limits to modifiability, because changing (several) fundamental assumptions with respect to model architecture implies, in fact, that the model at hand is rejected.
Goodness of fit and research generativity
A major criterion for model evaluation is goodness of fit. One way to determine the goodness of fit in early stages of model building is by computing correlations between simulation and empirical data. This was the measure applied in the present paper, and it led to promising results. However, more detailed analyses are possible. For instance, it can be determined if ANOVAs or regression models for the simulation data result in similar result patterns as those in the empirical data. In future research, such analyses might be applied to Multilink.
Another criterion for model evaluation is research generativity (which is one of the very strong points of the RHM). Multilink has already generated several predictions to be tested in future experimental studies. For example, Multilink indicates that due to feedback from semantics to orthography, cognates reactively obtain a higher orthographic activation than matched control words. Multilink also generates several interesting predictions with respect to interlingual homograph translation that are currently being tested in our lab. Just as for RHM and BIA/BIA+, the presence of a theoretical account of the target phenomena in Multilink gives researchers a handle for experimental work.
Future simulation work
Having formulated the structural and processing framework for Multilink, the next two major steps are clear. First, the task/decision account in the model must be extended to fully consider task-dependence in lexical processing. Second, the model must be tested in dedicated empirical studies (cf. Jacobs & Grainger, Reference Jacobs and Grainger1994). Both aspects are currently being considered by investigating the translation process of interlingual homographs. Apart from extending and testing the model, future investigations should again address the core issues of Resting Level Activation and within- and cross-linguistic word similarity. In addition, other issues to be examined concern the implementation of word association (from PAARD to /horse/), semantic priming effects (e.g., due to relations between category coordinates that are not associatively related, like LION and DOG), and the link to picture (object) naming (cf. Zhao & Li, Reference Zhao and Li2010, Reference Zhao and Li2013).
7. Conclusion
In word recognition and production, multiple factors interact in a complex fashion. Only a computational model can take into account all of these at the same time. Computational modelling of word retrieval requires making hard choices: about the general theoretical framework, lexical representations, and underlying processing mechanisms. Making these choices to specify a model clarifies one's thinking about general and specific theoretical issues. It also allows us to make both qualitative and quantitative predictions with respect to the time course of word retrieval and translation by various groups of bilinguals and in all sorts of task situations.
The validation and first testing of Multilink suggest that its structural and processing framework is capable of handling the retrieval of words of different lengths, frequency, language membership, and cognate status, in several comprehension and production tasks, and for monolingual and bilingual participant groups. As such, Multilink provides a promising basis for the development of a more general computational model of word retrieval.
Appendix 1. Model settings for resting level activation, connection strength, and other parameters. All unmentioned connections were set at 0.0. Parameter settings were the same across all simulations in the paper.
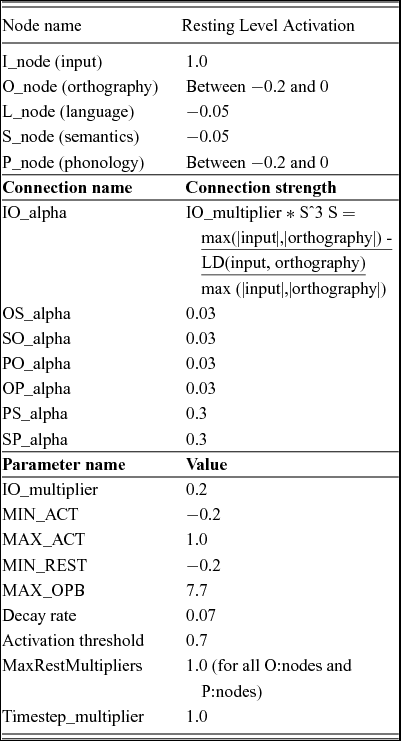
Appendix 2. Activation functions used in Multilink simulations
At each time step, all activations to a node, excitatory or inhibitory, are summed. This is the net input to a node at a certain time step, indicated in the following Equation A1:
 $$\begin{equation}
{n_i}\left( t \right) = {\rm{\ }}\mathop \sum \limits_j {k_{ij}}{e_j}\left( t \right)
\end{equation}$$
$$\begin{equation}
{n_i}\left( t \right) = {\rm{\ }}\mathop \sum \limits_j {k_{ij}}{e_j}\left( t \right)
\end{equation}$$
where ej can be positive (excitation) and negative (inhibition).
The value with which the node changes is given in Equation A2:
 $$\begin{equation}
{\epsilon _i}\left( t \right) = \left\{ {\begin{array}{@{}*{1}{c}@{}} {{n_i}\left( t \right)*\left( {M - {a_i}\left( t \right)} \right);\ if\ {n_i}\left( t \right) > 0\ }\\ {{n_i}\left( t \right)*\left( {{a_i}\left( t \right) - m} \right);\ if\ {n_i}\left( t \right) \le 0} \end{array}} \right.
\end{equation}$$
$$\begin{equation}
{\epsilon _i}\left( t \right) = \left\{ {\begin{array}{@{}*{1}{c}@{}} {{n_i}\left( t \right)*\left( {M - {a_i}\left( t \right)} \right);\ if\ {n_i}\left( t \right) > 0\ }\\ {{n_i}\left( t \right)*\left( {{a_i}\left( t \right) - m} \right);\ if\ {n_i}\left( t \right) \le 0} \end{array}} \right.
\end{equation}$$
As a result, the new activation of node i is computed as in Equation A3:
 $$\begin{equation}
{a_i}\left( {t + {\rm{\ \Delta }}t} \right) = {\rm{\ }}{a_i}\left( t \right) - {\rm{\ }}{{\rm{\Theta }}_i}{\rm{*}}\left( {{a_i}\left( t \right) - {\rm{\ }}rl{a_i}} \right) + {\rm{\ }}{\epsilon _i}\left( t \right)
\end{equation}$$
$$\begin{equation}
{a_i}\left( {t + {\rm{\ \Delta }}t} \right) = {\rm{\ }}{a_i}\left( t \right) - {\rm{\ }}{{\rm{\Theta }}_i}{\rm{*}}\left( {{a_i}\left( t \right) - {\rm{\ }}rl{a_i}} \right) + {\rm{\ }}{\epsilon _i}\left( t \right)
\end{equation}$$
The parameters in these functions are the following: