


Introduction
Words do not typically occur in isolation. Rather, we encounter them in spoken or written discourse where surrounding words provide us with a rich context within which we interpret words. This surrounding context not only facilitates our processing of upcoming words but also is important when we interpret the meaning of rare or unknown words. Indeed, the results of a number of earlier studies suggest that native speakers (L1) as well as bilinguals using their second language (L2) process words easier when they are presented in the context of a coherent discourse, i.e., when the context provides semantic cues to the occurrence and the meaning of these words (e.g., Camblin, Gordon & Swaab, Reference Camblin, Gordon and Swaab2007; Federmeier & Kutas, Reference Federmeier and Kutas1999; Hahne, Reference Hahne2001; Moreno & Kutas, Reference Moreno and Kutas2005; Van Berkum, Brown, Zwitserlood, Kooijman & Hagoort, Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005). Against this background, the current study examines whether first and second language speakers of a language can use the given contextual information to predict upcoming words in the input and use their predictions to interpret the meanings of unknown words in a discourse.
As words are encountered in spoken language discourse, they are rapidly integrated into not just the local sentence-level context but also into the global discourse context. It comes as no surprise, then, that words that are coherent within both sentence and discourse level context are comprehended with greater ease than words that are coherent at just one of these levels. Van Berkum and Hagoort (Reference Van Berkum, Hagoort and Brown1999), for instance, examined monolingual participants’ event-related potentials (ERPs) to words like quick which were coherent with the local sentence-level context, e.g., in Jane told the brother that he was exceptionally quick, but not with the global discourse context, e.g., against the background of a scenario in which Jane's brother was still not ready when Jane picked him up at a pre-arranged time. The authors found that words coherent with the sentence-context alone elicit a strong negativity in comparison to words coherent with both sentence- and global context, e.g., slow. This negativity is interpreted as an index of difficulties in further semantic processing of globally incoherent words, i.e., that such words are perceived as incoherent in terms of the preceding wide-range discourse context. They conclude, therefore, that successful comprehension requires coherence of a word within both local and global context (cf. Federmeier & Kutas, Reference Federmeier and Kutas1999; Kutas & Hillyard, Reference Kutas and Hillyard1984).
Indeed, a number of recent studies (e.g., Boudewyn, Gordon, Long, Polse & Swaab, Reference Boudewyn, Gordon, Long, Polse and Swaab2012; Kutas & Van Petten, Reference Kutas, Van Petten and Gernsbacher1994; Salmon & Pratt, Reference Salmon and Pratt2002; Van Petten & Kutas, Reference Van Petten and Kutas1990) demonstrate that the provision of a global discourse context facilitates listeners’ comprehension of the meanings of upcoming words. For instance, Salmon and Pratt (Reference Salmon and Pratt2002) suggest that listeners find it is easier to recognise words embedded in stories relative to words embedded in isolated sentences: words embedded in global discourse context elicited reduced negativity relative to words embedded in local sentence-level contexts. They suggest that information available in an isolated sentence may be insufficient for the readers or listeners to build a mental representation of the described situation. In contrast, listeners provided with a global discourse context can gradually expand their mental representation of a given situation by adding meaningful information from the discourse context, and may also be able to use this richer context to better anticipate and more easily recognise upcoming input in the discourse.
Studies investigating the predictive potential of discourse context on both sentence and message levels (Altmann & Kamide, Reference Altmann and Kamide1999; DeLong, Urbach & Kutas, Reference DeLong, Urbach and Kutas2005; Federmeier & Kutas, Reference Federmeier and Kutas1999; Otten & Van Berkum, Reference Otten and Van Berkum2008; Wicha, Moreno & Kutas, Reference Wicha, Moreno and Kutas2004) suggest that unfolding context helps listeners to anticipate upcoming words. In a series of seminal studies, Altmann and colleagues (Altmann & Kamide, Reference Altmann and Kamide1999; Kamide, Altmann & Haywood, Reference Kamide, Altmann and Haywood2003) examined listeners’ prediction of upcoming input in spoken language processing using the visual world paradigm (VWP, Tanenhaus, Spivey-Knowlton, Eberhard & Sedivy, Reference Tanenhaus, Spivey-Knowlton, Eberhard and Sedivy1995). For instance, Kamide et al. (Reference Kamide, Altmann and Haywood2003) presented participants with a picture of a man, a girl, a motorbike, a carousel among other objects and sentences such as The man will ride the motorbike or The girl will ride the carousel. They report that participants fixated the image of a motorbike more upon hearing The man will ride. . . relative to The girl will ride. . . and that, critically, participants fixated the motorbike even before hearing the word motorbike. Similarly, participants fixated the image of the carousel more upon hearing The girl will ride. . .even before hearing the word carousel. Early eye movements towards the object yet to be named are explained as a result of participants’ anticipation of the target word based on the information presented in the input thus far. Thus, participants’ processing of the initial part of the sentence leads to them building expectations of how they think the sentence will conclude based on the semantic information presented in the context. This context is updated rapidly, with semantic assimilation of the grammatical subject man or girl with the meaning of the verbal predicate ride accounting for the preference for the intended target even before this target is explicitly named. Similarly, analysis of the brain reaction to the anomalous words in highly predictive scenarios compared to non-predictive scenarios reported in Otten and Van Berkum (Reference Otten and Van Berkum2008) suggests that readers are able to anticipate upcoming words on the basis of the contextual information provided by the preceding discourse context (cf. DeLong et al., Reference DeLong, Urbach and Kutas2005; Nieuwland & Van Berkum, Reference Nieuwland and Van Berkum2006; Van Berkum et al., Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005 (Experiment 1)).
Metusalem and colleagues in their recent study also provide evidence for the predictive power of discourse context in reading scenarios such as A huge blizzard ripped through town last night. My kids ended up getting the day off from school. They spent the whole day outside building a big snowman in the front yard. As expected, scenario context helped listeners to predict the upcoming word snowman in the discourse, as indexed by reduced N400 to discourse congruent words like snowman relative to unrelated words like towel. Replacing the word snowman in the same discourse with the word jacket – which is incompatible with the sentence-level context but is compatible, in general, with the discourse context – revealed a similarly reduced N400 to discourse-compatible words like jacket, relative to unrelated words like towel. Interestingly, in the absence of the preceding discourse context, jacket and towel elicit a similarly increased negativity relative to snowman. These results suggest that, during discourse processing, the activated scenario-related knowledge integrates the information provided at the discourse level (e.g., winter, cold, snow), thereby facilitating processing of the upcoming concept. Supporting this idea, the authors conclude that readers construct a mental representation of the depicted situation on the basis of activated scenario-related knowledge which has a rapid impact on subsequent comprehension processes and accounts for our ability to rapidly process upcoming input (Metusalem, Kutas, Urbach, Hare, McRae & Elman, Reference Metusalem, Kutas, Urbach, Hare, McRae and Elman2012).
While the studies reported above focus on monolingual language processing, the conclusions of these studies can be extended to bilingual language processing, at least with regard to the beneficial effects of local sentence-level context. For instance, Hahne and Friederici (Reference Hahne and Friederici2001) found that sentences with semantically incorrect endings, e.g., The volcano was eaten, elicited a similar increased negativity (relative to sentences with semantically appropriate ending) in both Japanese L2 speakers of German and native German speakers (for similar results on sentence-bound word processing in bilinguals see, e.g., Hahne, Reference Hahne2001; Moreno & Kutas, Reference Moreno and Kutas2005; Weber-Fox & Neville, Reference Weber-Fox and Neville1996). This suggests that second language speakers and native speakers of a language face similar difficulties integrating a semantically incoherent word in the local-level context set by a sentence. Indeed, several studies on L2 processing report that restrictive sentence-level contexts facilitate L2 speakers’ retrieval of word's meaning (e.g., Libben & Titone, Reference Libben and Titone2009; Schwartz & Kroll, Reference Schwartz and Kroll2006, Trenkic, Mirkovic & Altmann, Reference Trenkic, Mirkovic and Altmann2013) as well as enhance their ability to predict lexical information consistent with the context provided by the input thus far (e.g., Bradlow & Alexander, Reference Bradlow and Alexander2007).
Nevertheless, from other studies examining this issue, it appears that bilinguals’ ability to predict upcoming language input – at least in reading – may be reduced relative to native speakers. For instance, Martin, Thierry, Kuipers, Boutonnet, Foucart & Costa (Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) presented English native speakers and advanced L2 learners of English with visually presented sentences containing either a predictable or an unpredictable noun at the end. ERPs were time locked to articles preceding the sentence-final nouns, which were either consistent or inconsistent with the sentence-final nouns. For instance, participants read the sentence Since it is raining, it is better to go out with a/an. . . where umbrella, the expected continuation of the sentence, would be consistent with the article an and inconsistent with the article a. L2 speakers showed a reduced N400 to unexpected articles relative to native speakers, which the authors interpret as a reduced ability to predict upcoming words in language input in L2 speakers relative to native speakers. In other words, L2 speakers may find it more difficult to use contextual cues to anticipate upcoming language input relative to native speakers and may also, by extension, find it more difficult to use contextual cues to infer the meanings of unknown words in sentences. Indeed, this conclusion is supported by findings which suggest that language processing in L2 is generally slower than and not as precise as in L1 (e.g., Favreau & Segalowitz, Reference Favreau and Segalowitz1983; Harrington & Sawyer, Reference Harrington and Sawyer1992; Magiste, Reference Magiste1986; Segalowitz, Reference Segalowitz1986). Unlike the studies discussed earlier, Martin et al.’s (Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) study includes the prediction of the upcoming word form on the basis of the preceding context (the indefinite article a signals an upcoming word form starting with a consonant, e.g., raincoat, while the indefinite article an prompts a word form starting with a vowel, e.g., umbrella).
Thus, there appears to be a discrepancy in the bilingual literature between studies finding no differences between L1 and L2 speakers’ ability to detect the incongruence of words in a given sentence context (e.g., Hahne & Friederici, Reference Hahne and Friederici2001; Trenkic et al., Reference Trenkic, Mirkovic and Altmann2013, although these effects may be delayed in L2 speakers) and other studies finding differences in L1 and L2 speakers’ ability to predict upcoming input on the basis of the semantic context provided thus far (e.g., Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013). Thus, although L2 speakers may be less able to use contextual information to predict upcoming words in a discourse, they are able to discriminate contextually congruent words from incongruent words once they have heard them. Against this background, the current study examines the influence of increasing discourse context on L1 and L2 listeners’ ability to anticipate or predict contextually appropriate words in auditory discourse.
Another prominent focus of the current study is to examine listeners’ ability to use the increasing discourse context to disambiguate the meanings of unknown words (pseudo-words) via conceptual anticipation of an existing lexical entry. This is especially pertinent in the context of bilingual processing since L2-learners are regularly confronted with a similar disambiguation task in everyday life, when they come across an unknown word within ordinary discourse and have to infer its meaning on the basis of the information provided by the word environment.
Earlier research has reported that the presentation of unknown words in a meaningful, supportive context not only helps comprehenders to infer the meaning of the unknown words but also leads to effective learning and retention of the word's meaning (e.g., Batterink & Neville, Reference Batterink and Neville2011; Frishkoff, Perfetti & Collins-Thompson, Reference Frishkoff, Perfetti and Collins-Thompson2010; Nagy, Herman & Anderson, Reference Nagy, Herman and Anderson1985). For instance, Batterink and Neville (Reference Batterink and Neville2011) examined the learning of unknown words embedded in meaningful and non-meaningful scenarios and found that words embedded in meaningful contexts elicited a smaller N400 than words in non-meaningful contexts, both while participants read the scenarios and also in later explicit recall and recognition tasks (see Nagy et al., Reference Nagy, Herman and Anderson1985, for similar results with school-aged children).
L2 learners appear to similarly resort to inferring the unknown word's meaning from contextual cues. Indeed, some researchers go so far as to suggest that this is considered the most frequently used word learning strategy for L2 learners (Fraser, Reference Fraser1999; Paribakht & Wesche, Reference Paribakht and Wesche1999). For instance, Webb (Reference Webb2008) reports that L2 learners scored higher in meaning recognition and recall tasks after reading short discourse passages in L2 containing pseudo words if the passages provided strong semantic cues to the intended meaning of the embedded pseudo words. These results suggest that the high semantic informational quality of the surrounding context is decisive for the effectiveness of word meaning deduction and retention even in L2 learners (see also Paribakht & Wesche, Reference Paribakht and Wesche1999)
On the other hand, some research suggests that L2 learners often disregard inferring from context: either if the surrounding context is too difficult to comprehend or poor in semantic cues, or if L2 learners are not able to identify the supportive quality of the provided contextual information. Under such circumstances inferring on the basis of context is neither effective for comprehending the word's meaning, nor for word learning. Indeed, in a reading study with adult L2 speakers of English, Nassaji (Reference Nassaji2003) demonstrated that L2 readers may experience difficulties in retrieving the unknown words’ meaning on the basis of their context even though the surrounding text is otherwise easy to understand (see also, e.g., Bensoussan & Laufer, Reference Bensoussan and Laufer1984; Haastrup, Reference Haastrup1991). However, most research on word learning has focussed on meaning inference during reading, since learning from written texts is regarded as a more efficient way of vocabulary enhancement (e.g., de Leeuw, Segers & Verhoeven, Reference de Leeuw, Segers and Verhoeven2014; Frishkoff et al., Reference Frishkoff, Perfetti and Collins-Thompson2010; Nagy et al., Reference Nagy, Herman and Anderson1985).
In the current study, we extend this to examining meaning inference during listening, which may be considered an equally important source for vocabulary acquisition in both L1 and L2 (see Borovsky, Elman & Kutas, Reference Borovsky, Elman and Kutas2012; Borovsky, Kutas & Elman, Reference Borovsky, Kutas and Elman2010, Reference Borovsky, Kutas and Elman2013 for similar studies where subjects are given only a single exposure to a novel word in biasing and neutral contexts). In particular, participants listened to seven-sentence long passages whilst viewing four static images on a screen. Two of the images were related to the textual content, i.e., a target object and a competitor object both of which were associatively related to a prime word which reoccurred throughout the passage, and two were unrelated distractors.
We created passages containing familiar word primes followed subsequently in the discourse by either familiar word target images (pictured on the screen) or pseudo-word targets (intended referent of pseudo-word pictured on screen). Each passage contained six critical sentences and one final sentence to wrap up the topic. The first occurrence of the prime was towards the end of the first sentence of the passage where relatively few contextual details were available to guide the listeners’ anticipation of the intended target. The visual input to the participants allowed us to examine how participants used the given discourse context, since we presented participants with an image of the intended target as well as an image of a semantically related competitor. Of interest here, however, is whether participants fixate the intended target more in biasing contexts compared to neutral targets, especially since the competitor is also a candidate for fixations at this point in the text. Here, we predict that while native speakers may fixate the intended target even early in the discourse, L2 learners may have difficulties using this reduced context provided early in the discourse to fixate the intended target (see Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013 for similar results).
The second occurrence of the prime that we were especially interested in was closer to the end of the text, i.e., towards the end of the fifth sentence, where more contextual information had been provided to the participant, which they could use to infer the intended target, i.e., the meaning of the unknown word in the passage. At this point in the discourse, given more information biased towards the intended target, listeners may preferentially fixate the target image upon hearing preceding information containing biasing primes, demonstrating their ability to use discourse context to correctly anticipate only the intended target, and not the competitor.
Of interest here is performance in passages containing pseudo-word targets, since only these passages can tell us whether participants use discourse information to anticipate an intended target, and use this anticipated content to simultaneously infer the meaning of the unknown word. In other words, when the targets are themselves embedded into the passages – as in passages containing the real word targets – it is likely that both L1 and L2 speakers will fixate the target in preference to the competitor once they have heard the target labels. We were interested, however, whether participants will use the information provided by the discourse to infer the intended target and fixate this image upon hearing the prime in passages containing pseudo-words where the target is never explicitly mentioned. Here it is of interest, to see whether L1 and L2 speakers are similarly able to use discourse context online to anticipate information in a discourse and use this to infer the meanings of unknown words in spoken discourse. Anticipatory looks to the target picture on hearing the first occurrence of prime word and this later occurrence of prime word are interpreted as indices of participants’ prediction of upcoming input based on increasing discourse-bound information, i.e., conceptual activation of target or the target concept prior to its naming in the unfolding discourse context (cf. Altmann & Kamide, Reference Altmann and Kamide1999, Reference Altmann and Kamide2007). Therefore, our analysis will focus on the time windows immediately following the first occurrence of the prime, and this later occurrence of the prime, examining participants’ fixation of the intended target (in preference to the competitor and other distractor objects) upon hearing passages containing familiar word primes and familiar real word and pseudo-word targets.
Note that we employ the terminology of priming literature to discuss the influence of discourse context on processing of the first and second occurrence of the target merely to maintain consistency in our description of the lexical tokens used in the discourse. It is important to note, however, that there are considerable differences in the kind of context the first and second occurrences of the target are presented in. While the first occurrence is likely to be primed merely by the semantic association between the target and prime lexical items, the second occurrence is embedded in a deeper discourse context, including but not restricted to the second occurrence of the prime. Nevertheless, in order to highlight this semantic-associative connectedness between both critical concepts discussed in the study, we will refer to them as prime and (intended) target, both in the early and late time windows. We choose this notation since it reflects the basis on which we have selected the prime-target pairs, as described in the Stimuli section.
Method
Participants
A total of 80 adults, 40 native speakers of German (Mean age: 24.5 years; Range: 19 to 43 years, 25 female) and 40 advanced learners of German (Mean age: 26.9 years; Range: 19 to 41 years, 26 female) took part in the experiment after giving their informed consent. All participants responded to an advertisement placed at different University campus sites. All native speakers of German learnt German from birth as their first language, although they reported having intermediate to high fluency in English as well as basic to intermediate level of proficiency in another foreign language. All the L2 learners participating in the study had achieved at least B2 level of proficiency in German (vantage, or upper intermediateFootnote 1 ), according to the Common European Framework of Reference for Languages (CEFR, Council of Europe, 2011). To provide an index of their current language proficiency, L2 participants took an on-line diagnostic placement test of the Goethe Institute (Testen Sie Ihr Deutsch, 2013) and scored on average 22.5 out of 30 possible points consistent with their self-reported proficiency level. All of the L2 participants began learning German at school or as adults. When the study was conducted all the L2 participants lived in Germany and used German as well as their native language in everyday life.
We excluded the data from four native speakers and three L2 learners from the statistical analysis due to their providing less than 60 per cent of screen-directed looks throughout the experiment. Thus, we analysed the data of 36 native speakers and 37 L2 learners. Their native languages were distributed as follows: Azerbaijani (1), Chinese (6), English (4), French (3), Italian (1), Japanese (1), Kurdish (1), Lithuanian (1), Polish (1), Russian (8), Spanish (4), Turkish (2), Hungarian (1). To rule out the influence of the factor native language on the results of the L2 group, the languages were combined into 4 groups: Romance (French, Italian, Spanish), Slavic (Belarusian, Polish, Russian, Ukrainian), West GermanicFootnote 2 (English), and other (Azerbaijani, Chinese, Japanese, Kurdish, Lithuanian, Turkish, Hungarian) and were analysed as factor native language with 4 levels (see Results section). All participants had normal or corrected-to-normal vision and normal hearing. Each person was paid 5 euros for the participation in the experiment.
Stimuli
The auditory stimulus set consisted of 160 coherent German passages, 80 of which provided participants with increasing discourse information biased towards a particular target (biasing context). The other 80 passages, while structured similarly to the biasing context passages, provided participants with information that was neutral with regard to the target, i.e., applied equally to a semantically related competitor (neutral context). All passages described a commonplace scene using grammatical structures and vocabulary conforming to foreign language proficiency level B2 according to CEFR.
All passages had a similar structure, consisting of exactly seven sentences each presenting participants with repetitions of a prime and a target word/pseudo-word. Eighty passages presented participants with our critical condition containing familiar word primes and pseudo-word targets (40 in biasing context and 40 in neutral context) while 80 passages presented participants with familiar word primes and real word targets (40 in biasing context and 40 in neutral context). The structure of the passages was as follows. The first sentence ended with the presentation of the prime word (Prime1). The second sentence presented participants with the first presentation of the target word (Target1), either a real word or a pseudo-word. Three subsequent sentences built up the scenario further, such that more information biased towards the target was provided in the biasing contexts while sentences in the neutral context were consistent with both the target as well as a semantically related competitor (also pictured on screen). The fifth sentence concluded with a further repetition of the prime word (Prime2), while the sixth sentence presented the second repetition of the target (Target2). The seventh sentence merely concluded the text. Text structure and the position of targets and primes within text stimuli are presented in Table 1. To select prime–target/competitor word triads for the study, we used the Noun Associations for German (NAG) database by Melinger and Weber (Reference Melinger and Weber2006) consisting of 409 German nouns with their semantic associates. Out of all possible associations for a given word, e.g., Opa ‘grandpa’ listed in the database output, we selected two for each input word (subsequently used in the study as target–competitor pairs) on the basis of several strict pre-defined criteria: first, target and competitor had to be of the same grammatical gender (masculine, feminine or neuter); second, their maximal overall difference in frequency could not exceed 5 counts, and their minimal frequency could not be lower than 2 counts on the NAG scaleFootnote 3 ; third, they had to be imageable for a visual world paradigm experiment design; and fourth, target and competitor belonged to the same semantic category, like e.g., Gehstock ‘cane’ – Hut ‘hat’, such that both words could be considered as plausible continuations of the sentences provided in the passage – at least early on in the passage, in the case of the biasing context passages.
Table 1. Examples of text stimuli used in the current study showing the distribution of semantically associated and neutral primes preceding real and pseudo-word targets in biasing and neutral contexts.
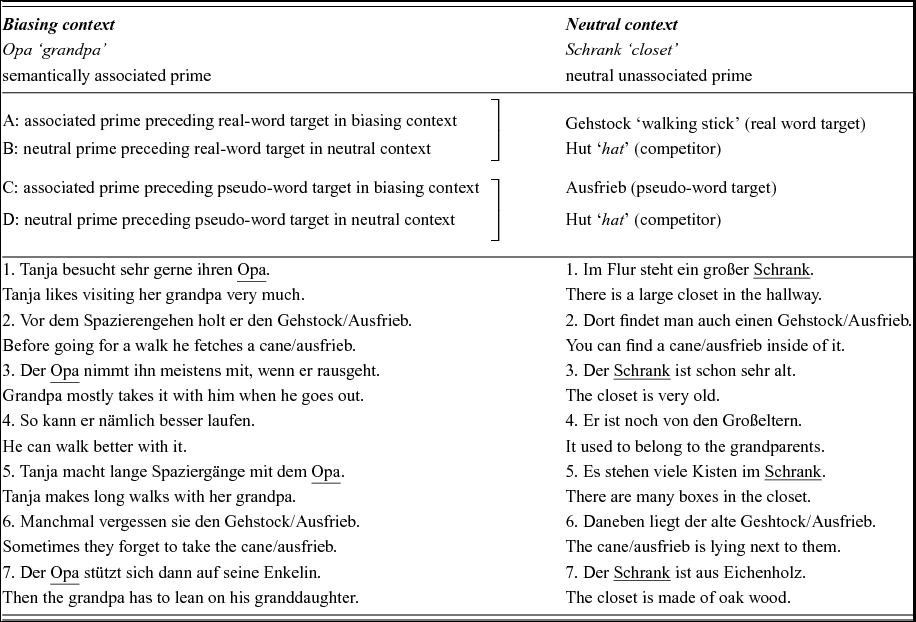
On the basis of these restrictions, we selected 40 prime–target/competitor triads. Thus, the NAG-input word (e.g., Opa ‘grandpa) functioned for the purpose of our experimental stimuli as a prime and its two associations (Gehstock ‘cane’ and Hut ‘hat’) as target and competitor respectively. These 40 prime–target/competitor triads formed the basis of 40 passages providing participants with discourse information biased, initially, towards anticipation of both the target and the competitor, and later on in the passage towards the target alone.
Primes and targets were unambiguously related to one another such that the presentation of the prime ought to automatically induce looks towards the target. The inclusion of the competitor allowed us to examine how increasing discourse information provided participants with additional cues as to the identity of the intended target. This is especially relevant for our focus on meaning inference of the pseudo-words. Thus, upon the first presentation of the prime, both target and competitor images are equally consistent with the given context and could be equally good candidates for the intended meaning of the pseudo-word target presented in the next sentence. It is only upon presentation of additional discourse information (in sentences three to five) that the intended meaning of the pseudo-word is unambiguously restricted to the target. Thus, the inclusion of the competitor allows us to examine how increasing discourse information helps participants narrow their hypotheses regarding the intended meaning of the pseudo-words.
We also constructed another 40 passages for the neutral context condition where we presented participants with primes that were not associatively related to either the targets or the competitors, henceforth referred to as neutral primes, e.g., Schrank ‘closet’ and included different sentences into which we embedded the same target – competitor pairs, Gehstock ‘cane’ – Hut ‘hat’.
In a final step, we created a further 80 passages, where we replaced the real word targets by pseudo words in all 80 passages (biasing plus neutral context), creating our critical pseudo word condition. Note that the pseudo-words were well-formed pronounceable German words which were created for the purpose of the current study.
Our stimulus set comprised, therefore, a total of 160 passages distributed across 4 conditions described lower in the Procedure section (condition A-D are presented in Table 1). Finally, 160 stimuli were divided into 4 lists, each list consisting of 40 critical trials, 10 from each of the 4 conditions; each participant was assigned to a list. We controlled for the frequency of the prime, target and competitor triads (e.g., Brysbaert, Buchmeier, Conrad, Bölte & Böhl, Reference Brysbaert, Buchmeier, Conrad, Jacobs, Bölte and Böhl2011) ensuring that there were no systematic differences in the lexical frequency of the strong and neutral primes as well as between real target words and competitors, ps>.2, according to the SUBTLEX lexical frequency database for German (cf. van Heuven, Mandera, Keuleers & Brysbaert, Reference van Heuven, Mandera, Keuleers and Brysbaert2014).
All the passages used in the study were judged by 5 independent native speakers of German as coherent and grammatically valid. The passages were spoken by a female native speaker of German with standard German pronunciation. The digital recording of the texts was done in a quiet room using Adobe Audition software with a sampling rate of 44.100 Hz. After recording, auditory stimulus onset and volume were matched using GoldWave v5.70.
Finally, we chose coloured images representing targets and competitors as well as two unrelated yoked distractors for each target-competitor pair. The four coloured images appeared on a black display (1280×1024 pixels) in four rectangular fields against a grey background, counterbalancing for the side of presentation of the targets, competitors and unrelated distractors. The two distractors did not overlap with targets, primes and competitors on phonological, shape and semantic parameters. The groups of four static images were then combined with auditory stimuli to create 160 videos presenting participants with the different conditions (40 videos per condition), using flash animation software. The images remained static throughout the trial.
Procedure
Participants were seated in a dimly lit, quiet experimental booth, facing a 92 cm wide and 50 cm high TV screen at a distance of approximately 65 cm from the screen. A remote eye tracker (Tobii X 120, Tobii Technology AB) was mounted on a platform underneath the TV screen and set to record gaze data at 60 Hz with an average accuracy of 0.5° visual angle. The Tobii Studio package was used to present the videos to the participant during the experiment. All instructions given to participants, including the written instructions provided previously on an instruction sheet, were in German. Participants were told that they would be simultaneously presented with short stories and see pictures on the screen in front of them. They were asked to look at the display as they listened to the passages.
Prior to testing, we calibrated the gaze of each participant using a 9-point calibration procedure, in which an attention-getter appeared in every position of a 3-by-3 grid of calibration points. The experiment started if eight or more points were successfully calibrated for at least one of the eyes.
Each trial started with a centrally located white fixation cross which appeared against a black background for 500 ms, followed by the presentation of the four images on a grey background. The images remained on screen for 2000 ms in silence, followed by the onset of the spoken passages. Primes and targets occurred, naturally, at different times within the trial but, on average, participants heard the first occurrence of the prime at 3724 ms, the first occurrence of the real/pseudo-word target 6383 ms, the last occurrence of the prime 15247 ms and the second occurrence of the real/pseudo-word target 18124 ms following onset of the visual stimuli. Order of trials presenting participants with the different conditions was randomised with inter-mingling of the four different conditions.
Of the 160 passages, each participant was presented with one of the four lists of 40 passages, with 10 critical trials per condition (biasing context – real word target; biasing context – pseudo-word target; neutral context – real word target, neutral context – pseudo-word target). Across participants, we counterbalanced the stimuli such that participants heard each prime and saw each target-competitor pair in each of the different conditions. Across all four conditions, the same combination of images depicting the target word, its semantic competitor and two unrelated objects was used. Within subjects, however, each participant saw each combination of yoked four images (targets, competitors, unrelated distractors) in only one of the four experimental conditions, i.e., participants never saw the same image twice in different conditions. The position of target, competitor and distractors on the screen was randomized across all trials to exclude bias towards the position of the target or competitor on the screen (left/right vs. top/bottom). Stimuli were counterbalanced across participants, such that real and pseudo-word targets appeared equally often in the biasing and neutral context. Similarly, for each subject, target-competitor pairs appeared equally often in the real vs. pseudo-word condition. An example of experimental texts illustrating the combination of all four experimental conditions is provided in Table 1. The visual stimulus stayed on the screen throughout the trial, which lasted about 20s (see Figure 1 for the schematic presentation of a trial). The entire experiment lasted about 20 minutes.

Figure 1. Schematic presentation of the trial structure with early and late prime phases. Sentences 3 to 5 in biasing context provide further semantic cues related to the target concept. In neutral context, no specific cues are provided which would bias the comprehender towards the target concept. Note that we used coloured pictures in the experiment.
After the experiment, L2 learners were presented with a list of real-word targets used in the experiment and asked to mark those words which were not familiar to them. They were also asked to take part in a diagnostic placement test for German as a foreign language (Testen Sie Ihr Deutsch, 2013) which consisted of thirty tasks and was to be filled out on-line. These tasks took L2 participants about 10 minutes to complete.
Data analysis
Areas of interest were defined according to the size of the individual images (480 × 340 pixels) and their location on screen. The eye-tracker provides an estimate of where participants were looking at for each time-stamp during the trial, with one data-point approximately every 8 ms. Data from time-stamps were only included when the eye-tracker reliably acquired data from one or both eyes of the participant (validity less than 2 on Tobii scale). Gaze data from the eye-tracker was aggregated into 40 ms bins such that each 40 ms bin was coded for whether participants were looking at the target (T), competitor (C) and two distractors (D1+2). We then calculated the proportion of looks to the target or to the competitor during each trial across three windows. The first window analysed all eye movements that took place between 200 ms and 1000 ms after the onset of the first occurrence of the prime word, i.e., before hearing the target word. The second window analysed all eye movements that took place between 200 ms and 1000 ms after the onset of the later occurrence of the prime word at the end of the passage, i.e., after participants have been provided with sufficient biasing context to allow them to differentiate between the intended target and the competitor object. We have restricted our analysis to the above time windows for the following reasons. It is standard to allow at least 200 ms for adults to initiate a saccade in response to the auditory stimulus as fixations prior to this time cannot be reliably interpreted as a response to the given auditory stimulus. We then consider all fixations until 1000 ms post-onset of the critical word to cover the entire gaze response range to a given stimulus (cf. Huettig & Altmann, 2005; Huettig & McQueen, 2007). Finally, the baseline window analysed all eye-movements that took place before the onset of the auditory stimulus, to provide us with a measure of participants’ baseline preference for the images presented on-screen, uninfluenced by any auditorily presented information.
Across each window, we calculated the proportion of looks to the target [(PTL =T/(T+C+D1+2)]. We then subtracted the proportion of target looking in the baseline window from the proportion of target looking in the two critical windows, to obtain a baseline-corrected proportion of participants’ target fixations following the first and last occurrence of the prime. This way, we could ensure that any change in participants’ eye-movements following the two instances of the prime were unlikely to be driven by participants’ visual preference for any of the images on-screen. For statistical analysis, we aggregated each participant's proportion of target looks by condition separately for native speakers and L2 learners.
Results
Figures 2a and 2b plot the time course of the proportion of looks to the intended target and competitorFootnote 4 images in both early (2a) and late (2b) time windows, i.e., 200–1000 ms upon hearing the prime, for real and pseudo-word targets. We report all analyses by subjects and by items and will restrict our conclusions purely to stable results across both analyses.

Figure 2. (a) Early prime phase. (b) Late prime phase.
A repeated measures 2×2×2×2 ANOVA with the within-subject factors Context (biasing, neutral), Word (real, pseudo), Repetition (early vs. late occurrence of the prime within a trial) and the between-subject factor Group (native speakers vs. L2 learners) revealed a main effect of Context F1 (1,71)=43.48, p<.001, ƞp 2 =.38, F2 (1,36)=21.85, p<.001, ƞp 2 =.378, a main effect of Repetition F1 (1,71)=102.74, p<.001, ƞp 2 =.591, F2 (1,36)=212.91, p<.001, ƞp 2 =.855, and an interaction between Word*Context*Repetition F1 (1,71)=15.50, p<.001, ƞp 2 =.179, F2 (1,36)=8.86, p=.005, ƞp 2 =.197. There was also a significant interaction between Word*Group F1 (1,71)=10.35, p=.002, ƞp 2 =.127, F2 (1,36)=13.46, p=.001, ƞp 2 =.272, a significant interaction between Repetition*Group F1 (1,71)=4.38, p=.04, ƞp 2 =.058, F2 (1,36)=8.82, p=.005, ƞp 2 =.197, and a significant interaction between Word*Repetition*Group F1 (1,71)=4.47, p=.038, ƞp 2 =.059, F2 (1,36)=13.85, p=.001, ƞp 2 =.278. No other main effects or interactions were significant across both analyses. To further break down the three-way interaction between Word*Context*Repetition we ran two separate 2×2 ANOVAs pivoting on the factor Word, with the factors Context (biasing, neutral) and Repetition (early, late) separately for the real word and the pseudo-word condition. Furthermore, given the significant Word*Repetition*Group interaction, we also ran two separate 2×2 ANOVAs with the factors Repetition (early, late) and Group (native, L2) separately for the real word condition and for the pseudo-word condition. In what follows, we first report all analyses for the real word condition.
In the real-word condition
an ANOVA with the factors Context and Repetition revealed a main effect of Context F1 (1,72)=4.89, p=.038, ƞp 2 =.059, F2 (1,38)=6.72, p=.013, ƞp 2 =.152, a main effect of Repetition F1 (1,72)=85.52, p<.001, ƞp 2 =.543, F2 (1,38)=228.70, p<.001, ƞp 2 =.858, and no interaction between Context*Repetition. This suggests that participants looked more at the target in the primed condition relative to the neutral condition and more at the target in the late time window relative to the early time window.
The ANOVA with the factors Repetition and Group showed a main effect of Repetition F1 (1,71)=91.18, p<.001, ƞp 2 =.562, F2 (1,39)=204.73, p<.001, ƞp 2 =.840, and a significant interaction between Repetition and Group F1 (1,71)=6.94, p=.014, ƞp 2 =.082, F2 (1,39)=24.81, p<.001, ƞp 2 =.389. Breaking this interaction down further we found that both L1 and L2 speakers showed increased proportion of looks to the target in the late window relative to the early window, ps < .001. Furthermore, independent-samples t-tests found that L2 speakers looked more at the target in the late time window relative to L1 speakers, t1 (71)=−3.18, p=.002, d=.074, t2 (39)=−6.55, p<.001, d=.067.
Given the focus of the current research, planned comparisons (e.g., Roberts & Russo, Reference Roberts and Russo2014) investigated the effect of context within both groups for each repetition of the prime word analysed by subject (t1) and by item (t2). In the real word condition, analysis of eye-movements following the first occurrence of the prime revealed, for the native speakers’ group, a significantly greater proportion of looks to the target in biasing context than in neutral contexts t1 (35)=2.08, p=.045, d=.51, t 2(38)=2.42, p=.021, d=.38. This comparison failed to reach significance for the L2 learners’ group, t1 (36)=.77, p>.44, d=.19, t 2(38)=.67, p>.50, d=.016. The analyses of eye-movements following the later occurrence of the prime revealed a trend towards between-group differences in their reaction to biasing as compared to neutral context. Native speakers tended to direct greater proportion of looks to the target in biasing context as compared to neutral context, t1 (35)=1.74, p=.091, d=.28, t 2(38)=2.50, p=.017, d=.038. However, given that this test failed to reach significance across subjects and items, we will interpret this finding cautiously. L2 learners showed no differences in their reaction in this comparison, t1 (36)=.40, p>.69, d=.08, t 2(38)=.67, p>.50, d=.012.
Figure 3 plots the proportion of looks to target in each of the two critical windows, i.e., following the early and late occurrence of the prime in passages containing real words in biasing and neutral contexts in both groups of participants.

Figure 3. Mean PTL in both post-prime phases in the real word condition in biasing context (dotted bars) as compared to neutral context (grey bars). Asterisks mark significant differences between conditions (***p < .001; **p < .01; *p < .05).
In the pseudo-word condition
the 2×2 ANOVAs with the factors Context and Repetition revealed a main effect of Context F1 (1,72)=52.69, p<.001, ƞp 2 =.423, F2 (1,37)=30.29, p<.001, ƞp 2 =.450, a main effect of Repetition F1 (1,72)=43.79, p<.001, ƞp 2 =.378, F2 (1,37)=37.43, p<.001, ƞp 2 =.503, and a significant interaction between Context*Repetition F1 (1,71)=24.70, p<.001, ƞp 2 =.225, F2 (1,37)=11.49, p=.002, ƞp 2 =.237. The ANOVAs with the factors Repetition and Group found a main effect of Repetition F1 (1,71)=43.26, p<.001, ƞp 2 =.379, F2 (1,39)=41.37, p<.001, ƞp 2 =.515, but no interaction between Repetition*Group. Thus, L1 and L2 speakers alike showed increased looks to the target in the late time window relative to the early time window.
Similar to the analyses reported for the real word condition in the pseudo-word condition, planned t-tests (e.g., Roberts & Russo, Reference Roberts and Russo2014) of fixations following the first occurrence of the prime revealed, for the native speakers’ group, a significantly greater proportion of looks to the target in biasing context than in neutral contexts t1 (35)=2.54, p=.016, d=.27, t 2(37)=1.89, p=.066, d=.036. Again, this comparison failed to reach significance for the L2 learners’ group, t1 (36)=1.32, p>.19, d=.28, t 2(37)=1.19, p>.24, d=.023.
In contrast to passages containing real word targets, however, analysis of eye-movements following the last occurrence of the prime revealed significantly different proportion of looks to the intended target across biasing and neutral contexts in both groups of participants, native speakers, t1 (35)=5.07, p<.001, d=1,4, t 2(37)=4.91, p<.001, d=.91; L2 learners, t1 (36)=7.31, p<.001, d=1.45, t 2(37)=4.46, p<.001, d=.77, suggesting successful disambiguation of the pseudo-word by showing preference to the image of the intended pseudo word referent in L1 and L2. Figure 4 plots the proportion of looks to target in each of the two critical windows, i.e., following the early and late occurrence of the prime in passages containing pseudo-words in biasing and neutral contexts in both groups of participants.

Figure 4. Mean PTL in both post-prime phases in the pseudo-word condition in biasing context (dotted bars) as compared to neutral context (grey bars).
An additional repeated-measures ANOVA for the L2 learners’ group with the within-subjects factors context (biasing, neutral), word (real, pseudo), repetition (1st vs. last occurrence of the prime within a passage) and the between-subjects factor native language (4 levels) revealed no main effect of native language or any interaction with native language within the L2 group of participants, ps>.1, suggesting no impact of the L2 learners’ native language on their auditory text processing.
General discussion
The goal of the study was to examine whether native speakers and advanced L2 learners of German can use semantic cues provided by the preceding biasing context to predict upcoming input and fixate images related to this input, as well as infer the meaning of unknown words in the discourse on the basis of their predictions. In particular, we were interested in how participants’ fixations vary as a result of increasing discourse-bound information being provided about the intended target. In our discussion of the results we focus on comparing the native speakers’ and L2 learners’ proportion of anticipatory language-induced eye movements to the target objects as an index of their prediction of the target concept on the basis of the preceding discourse.
Anticipatory looks to target in reduced discourse context
Some differences between native speakers and L2 learners were revealed in our analysis of fixations to the target upon hearing the first occurrence of prime, i.e., when the discourse does not as yet provide them with too much information as to the intended target. We found that native speakers direct significantly more looks to target following a related prime compared to a neutral prime. These results suggest, first, that native speakers are sensitive to the semantic cues provided by even this early biasing context and, second, that they use the semantic information provided by the associated prime ‘grandpa’ to anticipate upcoming input consistent with the thematic constraints of the provided semantic information, prompting their looks towards related targets, e.g., ‘cane’. This finding not only suggests native speakers’ sensitivity to a biasing context at an early phase in speech processing but also provides evidence that, in line with our experiment design, biasing and neutral contexts do, in fact, differentially impact visual fixations of the target objects. However, L2 learners on their own did not show any difference in their fixations to the target upon hearing biasing or neutral primes. This might be taken to suggest that L2 learners show a weaker ability to anticipate the upcoming target upon hearing semantically constraining prime words or may be relatively weaker at using their anticipation of the upcoming target to fixate a potential target objectFootnote 5 .
However, while the difference in the results of native speakers and L2 learners are in line with Martin et al.’s (Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) conclusion on differential predictive abilities in L1 and L2 listeners, we also note that there were no significant differences between groups in the effect of context on fixations to the target. Thus, although the effect of context did not independently modulate L2 learners’ responses the way it did native speakers’ responses, overall there appeared to be no significant differences in the effect of context on native speakers’ and L2 learners’ performance.
Nevertheless, we examine potential reasons for the finding of a significant effect of context on native speakers’ responses and the absence of such a significant effect on L2 learners’ responses. One possibility would be to suggest that there are differences in the strength of activation of the target upon hearing the prime across native speakers and L2 learners. Indeed, studies on L1 processing suggest that such spreading of activation from related primes to target is a fairly automatic process in L1 (Camblin et al., Reference Camblin, Gordon and Swaab2007; Sereno & Rayner, Reference Sereno and Rayner1992) but may be less automated in L2 processing (cf. Ardal, Donald, Meuter, Muldrew & Luce, Reference Ardal, Donald, Meuter, Muldrew and Luce1990; Segalowitz, Reference Segalowitz1986).
However, given that other studies find robust semantic priming effects in proficient L2 participants when, for instance, participants are presented with pairs of related words (e.g., Phillips, Segalowitz, O'Brien & Yamasaki, Reference Phillips, Segalowitz, O'Brien and Yamasaki2004; Kotz & Elston-Güttler, Reference Kotz and Elston-Güttler2004), it seems unlikely that the absence of an early priming effect in our L2 group is solely due to their lack of sensitivity to the associative relationship between the auditory prime and the label for the pictured target. An alternative source of the differences between L1 and L2 speakers might lie in their differential abilities to construct situation models of discourse. According to memory-based situation models, also known as mental representations of discourse (Gernsbacher, Reference Gernsbacher1996; Kintsch, Reference Kintsch1988; McKoon & Ratcliff, Reference McKoon and Ratcliff1998; Sanford & Garrod, Reference Sanford and Garrod1998; for a review on situation models see Zwaan & Radvansky, Reference Zwaan and Radvansky1998), incremental processing of incoming words depends on two crucial information sources: processing of the semantic information provided by discourse context and the activation of the situation-related world knowledge stored in long term memory. The construction of a situation model of a discourse starts early by integration of incoming words into the immediately preceding contextual information and gradually increases by adding subsequent message-level information. In order to anticipate an incoming word in a speech stream, listeners must exploit the information provided by the context, activate the situation-induced world knowledge and construct a mental representation of the described situation, or its situation model (cf. Federmeier & Kutas, Reference Federmeier and Kutas1999; Metusalem et al., Reference Metusalem, Kutas, Urbach, Hare, McRae and Elman2012). Indeed, the possibility of constructing a cohesive situation model on the basis of contextual information in a discourse may be one reason for the differences between comprehension of sentences in discourse context and the processing of context-free isolated sentences (van Dijk & Kintsch, Reference Van Dijk and Kintsch1983). Thus, even though the biasing context provided early in the discourse is rather limited and may not carry enough information to build up a fully-specified situation model, it is nonetheless sufficient to trigger listeners’ pre-activation of semantic information related to upcoming concept (cf. Federmeier, Reference Federmeier2007).
According to this model, the prediction effect observed in the L1 group could arise from their construction of situation model on the basis of the semantic cues provided in the early discourse context. Since context-embedded cues are known to trigger rapid access to the comprehenders’ event knowledge and, when combined, to narrow down the range of the expectations as far as the incoming concept is concerned (cf. McRae & Matsuki, Reference McRae and Matsuki2009), the differing findings in native speakers and L2 learners’ target fixations upon hearing the first occurrence of the prime could reflect differences in the processing of contextual cues by the two groups of participants. Thus, native speakers effectively use the semantic cues of the biasing reduced context to anticipate the upcoming target (cf. DeLong et al., Reference DeLong, Urbach and Kutas2005), whereas this ability appears to be less pronounced in the L2 learners. We conclude that L2 speakers may demonstrate lower predictive ability of the upcoming concept on the basis of reduced coherent discourse context (cf. Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013). In particular, we suggest that the contrast between earlier results showing simple associative priming in L2 learners (Phillips et al., Reference Phillips, Segalowitz, O'Brien and Yamasaki2004; Kotz & Elston-Güttler, Reference Kotz and Elston-Güttler2004) and the current findings (see also Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013) speaks to the notion of differences in native speakers’ and L2 learners’ predictive abilities. This, in turn, could be attributed to poorer vocabulary knowledge in L2 which leads to higher cognitive effort during the retrieval of the word meaning from the LTM and results in slower processing and integration of the prior semantic cues for building up a local-level situation model (cf. Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013; Hahne & Friederici, Reference Hahne and Friederici2001; Moreno & Kutas, Reference Moreno and Kutas2005).
Anticipatory looks to target given increased discourse context
Next, we focus our attention on participants’ target fixations upon hearing the later occurrence of the prime, when additional discourse context has been provided to bias participants towards the intended target. Here, we need to differentiate between passages containing real word targets and pseudo-word targets. In other words, by the time participants hear this later occurrence of the prime, they would have already heard either the intended real word target (in real word passages) or a pseudo-word target (in pseudo-word passages). In passages containing real word targets, once the listener has identified the target word as a real known word (e.g., Gehstock ‘cane’), and noted the match between this heard word and one of the images on-screen, this lexical entry can easily be retrieved from long term memory and integrated into the mental representation of the text, such that the forthcoming information can be processed incrementally with reference to this target word.
The results from analyses of the second occurrence of the prime in the real word condition are quite similar to the analyses of the first occurrence of the prime in the same condition. In particular, native speakers tend to fixate the target similarly in a biasing context and in a neutral context. Similarly, L2 speakers do not differentiate between fixations to the target in biasing and neutral contexts.
Since there was no significant difference in the effect of context on native speakers and L2 learners, it appears that when L1 and L2 listeners are presented with an unambiguous referent, i.e., having heard the target word, they continue to fixate the target image similarly across biasing and neutral contexts. While we could explain these results in a similar manner to the results from the analysis following the first occurrence of the prime above, we note that this explanation is somewhat complicated given the results with pseudo-words, which we discuss next. For the real word condition, at the very least, it appears that there was no modulation of the effect of context by repetition of the prime word, i.e., by increasing discourse context (as also indicated by the absence of a Context*Repetition interaction in these data).
In passages containing pseudo-word targets, the heard pseudo-word contradicts with the label of the target image on-screen and is unfamiliar to the listener. Thus, were participants to pre-activate the label for the target image on-screen (Meyer, Belke, Telling & Humphreys, Reference Meyer, Belke, Telling and Humphreys2007; Mani & Plunkett, Reference Mani and Plunkett2010), this pre-activated label would conflict with the pseudo-word target presented in the discourse, thereby disrupting the construction of a situation model. In order to restore this discourse-based situation model, then, the listener needs to deduce the meaning of the unknown pseudo-word target based on information provided in the discourse, potentially by inferring that the meaning of the unknown word is related to the concept activated not just from the information provided in the discourse but also from the visual images presented on-screen.
In passages containing pseudo-word targets, fixations towards the intended target upon hearing this later occurrence of the prime in passages containing pseudo-word targets appear to be quite similar in native speakers and L2 learners. Here, the results show that both native speakers and L2 learners fixate the target object more in biasing contexts as compared to neutral contexts upon hearing the later occurrence of the prime.
Again, we suggest here that fixations do not merely reflect the associative relationship between the prime word and the label of the intended target image, since this associative relationship was also present early on in the discourse and is unlikely to, of itself, impact target processing differentially early and later in the discourse (Camblin et al., Reference Camblin, Gordon and Swaab2007). In our opinion, this finding suggests that listeners rely strongly on the preceding context as a whole to infer the meaning of the pseudo-word target. Indeed, by the time they hear the later occurrence of the prime word, the information provided in the biasing context is sufficient to allow them to infer the meaning of the pseudo-word target and relate this to the target image on-screen. Thus, the increased context provided by the intervening sentences in the discourse makes it possible for listeners to construct a mental representation of the pseudo-word concept which would fit into the incrementally developing situation model. To this end, the repeated instances of the prime word may be interpreted as merely additional semantic cues contributing to listeners’ disambiguation of the pseudo-word target meaning.
On the other hand, the discourse information provided in the neutral context passages appears insufficient for listeners to disambiguate the meaning of the unknown pseudo-word target. Thus, by the time listeners hear the later occurrence of the neutral prime word, they have not yet been able to distinctly identify the intended target since the intervening sentences have not provided them with adequate information to do so.
It is of some interest that L2 learners appear to be able to use surrounding context to infer the meaning of an unknown word, but do not appear to be influenced by this surrounding context in their anticipation of an upcoming word in the discourse, especially when they have heard this word previously in the discourse (as in the case of the second occurrence of the prime). In this regard, we note, first, it is not the case that L2 learners are unable to use surrounding context to predict upcoming words in the discourse (since there was no difference in the effect of context on native speakers and L2 learners). Rather it appears to be the case that L2 learners may be less robustly influenced by surrounding context in their prediction of upcoming words in the discourse. This finding is consistent with other studies reporting similar difficulties in L2 learners’ anticipating of upcoming discourse (Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013). Second, we explain the differences in the responses of L2 learners to the second occurrence of the prime in the real and pseudo-word condition as follows. We have suggested earlier that there might be some (quantitative but not qualitative) differences between L1 and L2 speakers in their ability to construct situation models of discourse. Therefore, it might be possible that, when presented with an unknown word in the discourse, L2 learners are forced to enhance their models of the discourse in order to infer the meaning of this new word, leading to an effect of context in their processing of pseudo-words. Thus, the additional requirements imposed by the presentation of the pseudo-word trigger increased contextual processing in order for participants to infer the meaning of the pseudo-word. We note, however, that this suggestion must remain tentative since there were no significant differences in the effect of context in the real word condition between groups, suggesting, at the most, that L2 learners are merely less robustly able to use surrounding context to anticipate upcoming spoken language input.
In conclusion, our studies, therefore, extend the findings of previous work on the use of context in L1 and L2 speakers’ prediction of upcoming input in spoken language discourse. We replicate previous findings that, early in the discourse given reduced discourse context, L2 learners may show reduced prediction of upcoming language input in spoken discourse. In contrast, native speakers robustly anticipate an upcoming word even in reduced biasing context. Later on in the discourse, however, given more information, both L2 speakers and native speakers alike have no difficulties using the additional information provided by the context to infer the intended target of a discourse and fixate this intended target preferentially. Thus, with increasing discourse context, L2 speakers and native speakers alike, have little difficulties anticipating intended targets in discourse or inferring the referent of unknown words in a strongly biasing discourse context.
Supplementary material
For supplementary material accompanying this paper, visit http://dx.doi.org/10.1017/S1366728916001139






