


Introduction
Linguists of different theoretical persuasions sometimes emphasize that theories of language should not only rely on traditional methods of descriptive linguistics but also be tested against psycholinguistic evidence. Chomsky (Reference Chomsky1981, p. 9) noted, for example, that findings from acquisition, processing, and disorders of language are relevant to determining the properties of both Universal Grammar and particular grammars. Coming from a different theoretical perspective, Klein (Reference Klein, Huebner and Ferguson1991, p. 184) stated that fully developed languages should only be seen as a borderline case and that the study of developing systems may contribute to a better understanding of how language in general is structured. Yet, despite encouraging statements of this kind, linguistic studies of language typically rely on language-internal considerations without much reference to results and findings from psycholinguistic studies. Against this background, this study presents an unusual case in which experimental results from (non-native) language learners proved to be more instructive for a general theoretical controversy than familiar data from native speakers.
The present study compares derivational and inflectional phenomena with specific reference to Turkish. The question of whether derivation and inflection differ in any substantial way is controversial among morphologists. Distributed Morphology, for example, does not explicitly distinguish between derivational and inflectional processes; see Harley and Noyer (Reference Harley and Noyer1999) for review. Realization-based theories of morphology, by contrast, assume distinct morpholexical representations for derived words that distinguish them from the products of inflectional or paradigmatic processes. In Anderson's (Reference Anderson1992) theory of morphology, for example, derivational processes “constitute sources for lexical stems”, whereas inflectional processes “introduce inflectional material into the surface forms of words” (Anderson, Reference Anderson1992, pp. 184–185, emphasis added). Other realization‑based approaches, such as Matthews (Reference Matthews1991) and Stump (Reference Stump2001), establish a similar split between processes that define derivational stem entries and those that define inflected forms. Hence, the outputs of derivational processes are words, i.e. entries stored in the lexicon, whereas the output of an inflectional rule is a feature–form pairing, not an entry.
The psycholinguistic study of morphology investigates the representation of morphologically complex words in the mental lexicon and in accessing these representations during recognition and production. Most previous experimental studies have examined the role of lexical storage versus morphological (de)composition in recognizing derived and inflected words and how frequency, length, and transparency of a morphologically complex word as a whole and its component parts influence processing. Yet, the insight from realization-based morphology that derived word forms may have morpholexical representations distinct from those of inflected forms has had little impact on previous psycholinguistic research. Recently, experimental psycholinguistic research on morphological processing has been extended to non-native L2 learners, but the number of studies is small and the interpretation of experimental findings is still controversial. While some researchers have argued that L2 morphological processing is native-like, at least for advanced L2 learners (e.g., Diependaele, Duñabeitia, Morris & Keuleers, Reference Diependaele, Duñabeitia, Morris and Keuleers2011; Feldman, Kostić, Basnight-Brown, Filipović Durdević & Pastizzo, Reference Feldman, Kostić, Basnight-Brown, Filipović Durdević and Pastizzo2010), others proposed native/non-native differences in this domain; see Clahsen, Felser, Neubauer, Sato and Silva (Reference Clahsen and Neubauer2010) for review.
The present study investigates morphological processing in Turkish, a non-Indo-European language with largely agglutinating morphology. We report results from masked priming experiments comparing inflectional and derivational processes in both native and non-native speakers of Turkish. The phenomena under study, regular (Aorist) inflection and deadjectival -lIk nominalization, have similar form-level properties and are highly frequent, productive, and transparent; see section ‘Linguistic background: Turkish inflection and derivation’ below for further descriptive details. Yet, different priming patterns were found for inflection and derivation, specifically in L2 Turkish. These results provide support for the proposal that derived and inflected words have different morpholexical representations and that these affect online processing.
Inflection and derivation in L1 processing
There is a rich literature on morphological processing in native speakers, a detailed review of which is beyond the scope of the present study. Instead, our focus here is on priming experiments comparing inflected and derived word forms.
In priming tasks, participants are presented a prime word before a target word on which they are asked to perform a lexical (word/non-word) decision or which they have to name. The researcher manipulates the semantic, phonological, orthographic, or morphological relation between prime and target words to examine the potential influence of these variables on the participants’ responses. Prime words can be presented overtly or for a very short period of time (usually 30–80 ms) within a forward and/or backward mask, which unlike overt priming designs does normally not permit conscious recognition of the prime word.
Several studies using overt priming designs have compared inflectional and derivational processes in different languages. The results are, however, not entirely conclusive. On the one hand, differences between inflection and derivation were reported in some studies, for instance, stronger morphological priming effects for (regularly) inflected than for derived word forms (e.g., Feldman, Reference Feldman1994; Stanners, Neiser, Hernon & Hall, Reference Stanners, Neiser, Hernon and Hall1979), priming effects for different inflected words of the same adjective but not for different derived word forms (Schriefers, Friederici & Graetz, Reference Schriefers, Friederici and Graetz1992), and inhibition effects for inflected forms that contain stem homographs, i.e. different verb stems that have the same spelling, e.g., Italian spar-ivano “(they) disappeared” vs. spar-are “to shoot”, but not for corresponding derived forms, e.g., spar-izion-e “disappearance” vs. spar-are (Laudanna, Badecker & Caramazza, Reference Laudanna, Badecker and Caramazza1992). These contrasts suggest morphologically decomposed representations for inflected but not for derived word forms. Other overt priming studies, however, reported the same efficient priming effects for regular inflection and derivation, suggesting that they are both represented in a morphologically structured format; see Clahsen, Sonnenstuhl and Blevins (Reference Clahsen, Sonnenstuhl, Blevins, Baayen and Schreuder2003) and Marslen-Wilson (Reference Marslen-Wilson and Gaskel2007) for reviews.
Masked priming studies have focused on showing that priming effects obtained for inflected or derived word forms are morphological in nature and dissociable from any facilitation due to the orthographic and/or semantic overlap between primes and targets (e.g., Boudelaa & Marslen-Wilson, Reference Boudelaa and Marslen-Wilson2005; Drews & Zwitserlood, Reference Drews and Zwitserlood1995; Frost, Forster & Deutsch, Reference Frost, Forster and Deutsch1997; Grainger, Colé & Segui, Reference Grainger, Colé and Segui1991; Rastle, Davis, Marslen-Wilson & Tyler, Reference Rastle, Davis, Marslen-Wilson and Tyler2000). In addition, several studies found that semantically unrelated prime–target pairs, such as the English corner–corn, in which the prime contained a pseudo-affix (-er), produce facilitation effects in the masked priming task similar to those of truly related prime–target pairs, such as driver–drive (Boudelaa & Marslen-Wilson, Reference Boudelaa and Marslen-Wilson2005; Domínguez, Segui & Cuetos, Reference Domínguez, Segui and Cuetos2002; Marslen-Wilson, Bozic & Randall, Reference Marslen-Wilson, Bozic and Randall2008; Rastle, Davis & New, Reference Rastle, Davis and New2004; Rastle et al., Reference Rastle, Davis, Marslen-Wilson and Tyler2000). These results have been taken to indicate that masked priming taps morphological decomposition processes during early visual word recognition independently of the activation of semantic information and beyond pure orthographic priming.Footnote 1 Thus, a priming effect for a morphologically related prime–target pair such as bitterness–bitter relative to an unrelated control condition has been explained in terms of repeated activation of the corresponding stem bitter resulting from bitterness being decomposed into stem and affix. In addition, masked priming effects for word pairs with pseudo-affixed prime words (e.g., corner) suggest that the presence of a potential affix in a prime word is sufficient to trigger morphological decomposition, irrespective of the word's meaning or function (Rastle et al., Reference Rastle, Davis, Marslen-Wilson and Tyler2000; Rastle et al., Reference Rastle, Davis and New2004). Yet, due to a lack of direct comparisons of inflection and derivation, the question remains of whether this account of masked morphological priming effects holds in the same way for inflectional and derivational processes. Another caveat to the idea that masked priming is directly tapping morphological decomposition comes from studies showing masked priming effects for irregular inflection (Crepaldi, Rastle, Coltheart & Nickels, Reference Crepaldi, Rastle, Coltheart and Nickels2010; Neubauer & Clahsen, Reference Neubauer and Clahsen2009) including non-affixed prime words (e.g., fell) that cannot be readily decomposed into stem and affix. Consequently, Crepaldi et al. (Reference Crepaldi, Rastle, Coltheart and Nickels2010) proposed that masked priming effects may arise in two ways, firstly through the familiar morphological decomposition route, and secondly through shared lexical entries, as for example, in the case of fell–fall.
L2 processing of inflected and derived word forms
Although morphological processing of a non-native language has recently received much attention, the question of how it differs from L1 morphological processing is still controversial. Broadly speaking, two main views are currently discussed. One view holds that the same mechanisms are employed in both L1 and L2 processing and that observed L1/L2 differences in experimental results are due to influence from the L2 learners’ L1(s) and/or from L2 processing being generally slower and cognitively more demanding (e.g., McDonald, Reference McDonald2006). The alternative view – while not discarding the role of L1 transfer, reduced processing speed, higher working demands and the like – maintains that these factors are insufficient to explain L1/L2 processing differences and that parts of L2 grammatical processing are not native-like; see Clahsen et al. (Reference Clahsen, Felser, Neubauer, Sato and Silva2010) for review. It has been proposed, for example, that L2 processing is more dependent on lexical memory and less on the procedural system than L1 processing (Ullman, Reference Ullman and Sanz2005) and that adult L2 learners’ ability to make use of grammatically-based parsing is reduced relative to their sensitivity to lexical-semantic and other non-structural information cues, even for L2 learners at higher levels of L2 proficiency (Clahsen & Felser, Reference Clahsen and Felser2006).
Studies investigating the processing of L2 morphology have not yet resolved this controversy. Some studies reported largely similar native-like performance patterns for adult L2 learners, others reported differences. Consider, for example, results of masked priming studies. For regular inflectional morphology in L2 English and L2 German, Neubauer and Clahsen (Reference Neubauer and Clahsen2009) and Silva and Clahsen (Reference Silva and Clahsen2008) revealed non-native-like masked priming patterns, significant repetition paired with no morphological priming effects. Likewise, Clahsen and Neubauer (Reference Clahsen and Neubauer2010) testing highly proficient Polish L2 learners of German obtained the same non-native-like priming pattern for German -ung nominalizations as for regularly inflected words, namely repetition priming without morphological priming. On the other hand, for L2 English Feldman et al. (Reference Feldman, Kostić, Basnight-Brown, Filipović Durdević and Pastizzo2010) reported a significant masked priming effect for regularly inflected primes in L2 English (albeit only for a subgroup of their L2 participants), and Diependaele et al. (Reference Diependaele, Duñabeitia, Morris and Keuleers2011) found facilitation effects for derivationally related prime–target pairs in L2 English, similarly to what has been reported in previous L1 studies of English (Rastle et al., Reference Rastle, Davis and New2004). The question of how to explain L1/L2 differences and similarities in morphological processing is still unresolved. A serious limitation of previous research in this domain is that most studies have examined English and German, which raises the question of whether the reported findings generalize to typologically different target languages. Furthermore, there is to our knowledge only one study that directly compared inflectional and derivational processes in L2 learners, Silva and Clahsen (Reference Silva and Clahsen2008), investigating German and Chinese L2 learners of English using a series of masked priming experiments. This study found priming effects for derived nominals with -ness or -ity in L2 English, but (unlike in L1 English) no priming for regularly inflected -ed forms, suggesting differences between inflection and derivation in L2 processing. It is not clear, however, whether Silva and Clahsen's (Reference Silva and Clahsen2008) findings generalize to other inflectional and derivational phenomena, other target languages, and other groups of L2 learners. Clearly, more research is needed to better understand the similarities and differences between inflection and derivation in L2 processing.
Linguistic background: Turkish inflection and derivation
As the present study examines inflectional and derivational processes in Turkish, specifically Aorist verb inflection and nominal derivation processes, this section presents a brief descriptive overview of these phenomena and related properties of Turkish that are relevant for the design of the experiments.
Unlike many Indo-European languages, Turkish has rich and productive morphology, largely of the agglutinating type. Morphologically complex word forms in Turkish are formed through affixation – mainly suffixation – of inflectional and derivational morphemes to roots and stems. Like in other agglutinating languages, affixation to already derived stems is extremely productive and, as illustrated in (1) below, an already complex stem may serve as the basis for even more complex word forms (Hankamer, Reference Hankamer, Dalrymple, Goldberg, Hanson, Inman, Piñon and Wechsler1986). Yet, allomorphy, i.e. unpredictable phonological changes to the stem or root, is extremely rare, and in most cases the stem/root remains unaltered after suffixation (Aksu-Koç, Ketrez, Laalo & Pfeiler, Reference Aksu-Koç, Ketrez, Laalo, Pfeiler, Laaha and Gillis2007).
- (1)

Another characteristic of Turkish morphology is that some suffixes allow for iteration, a further source of morphological productivity (Durgunoğlu, Reference Durgunoğlu2006). One such suffix that permits iterative loops is the derivational -lIk suffix, which was tested in the present study. The -lIk suffix predominantly derives nouns from nouns, adjectives and adverbs.Footnote 2 As illustrated in (2), this suffix (here surfacing as -lik due to the rules of vowel harmony) can also be used repeatedly to form new lexical items. Note that the last two forms, temizlikçilikçi and temizlikçilikçilik, are indeed possible word forms (albeit normally not used).
- (2)
Due to these properties of Turkish morphology, the number of possible word forms associated with a given root is extremely high in this language. Hankamer (Reference Hankamer and Marslen-Wilson1989) estimated 1.8 million possible word forms for verbal and over 9 million for nominal roots, without including any iterative or recursive processes. It has been speculated that the properties of Turkish morphology should promote combinatorial processing, for example, decomposition of complex forms into their morphological component parts during word recognition (Frauenfelder & Schreuder, Reference Frauenfelder, Schreuder, Booij and van Marle1992; Hankamer, Reference Hankamer and Marslen-Wilson1989). Yet, experimental evidence from previous studies on morphological processing is highly limited for L1 Turkish and, to our knowledge, nonexistent for L2 Turkish. Gürel (Reference Gürel1999) reported word-form frequency effects for morphologically complex word forms in an unprimed lexical decision experiment with adult native speakers of Turkish suggesting that high-frequency forms may have (additional?) whole-word access representations. However, combinatorial processing, e.g., morphological decomposition during word recognition, has not yet been examined for Turkish word forms, in either the L1 or the L2.
Two specific morphological phenomena were examined for the present study, regular Aorist verb inflection with the morpheme -(V)r and nominal derivation with -lIk. The Turkish Aorist has been described as habitual aspect or “general present tense” marker (Kornfilt, Reference Kornfilt1997; Menges, Reference Menges1968) as illustrated in (3).
- (3)

The suffix is spelled out differently depending on whether it is attached to a monosyllabic or multisyllabic verbal root in line with the rules of vowel harmony. If the Aorist suffix is attached to a multisyllabic consonant-final verbal root, it surfaces as a variant of -Ir (-ir, -ır, ‑ur, -ür); see (4) below. The Aorist surfaces as -r if it is attached to a vowel-final verbal root; see (5). Finally, most consonant-final monosyllabic verbal roots take a variant of the -Ar suffix (‑ar or -er); see (6a). An exception to this are 13 monosyllabic forms that take a variant of the -Ir suffix instead (-ır, -ir, -ur, ‑ür) as shown in (6b); see Nakipoğlu and Ketrez (Reference Nakipoğlu, Ketrez, Bamman, Magnitskaia and Zaller2006).
- (4)
(5)
(6)



The function of the -lIk nominalization suffix in Turkish is equivalent to the -ness suffix in English. It typically derives nouns from nouns, adjectives, and adverbs, and is highly productive and phonologically transparent. The -lIk suffix surfaces in four different forms, ‑lık, -lik, -luk, and -lük as illustrated in (7), again in line with the rules of Turkish vowel harmony. Furthermore, -lIk suffixation does not yield any root changes.
- (7)

The present study
The aim of the experiments reported below was to compare early automatic processes involved in the recognition of inflected and derived word forms in L1 and L2 Turkish using the masked visual priming technique. In a masked priming experiment, a prime word is briefly presented immediately followed by a target word or non-word, and participants have to decide whether the target is an existing word or a non-word. The short prime presentation times do not usually allow participants to consciously recognize the prime. For native speakers, several studies using this technique found morphological priming effects for inflected and derived word forms in different languages that could be dissociated from any facilitation due to the orthographic and/or semantic overlap between primes and targets (Rastle, et al., Reference Rastle, Davis, Marslen-Wilson and Tyler2000; Rastle & Davis, Reference Rastle, Davis, Kinoshita and Lupker2003). Given these findings and the transparency of Aorist inflected verb forms and -lIk nominalizations, we expect masked morphological priming effects for both of these morphological processes in native speakers of Turkish. As mentioned above, previous findings from masked priming experiments with non-native speakers are less conclusive. If L2 processing employs the same mechanisms as L1 processing, we would expect to find masked morphological priming effects in the L2 data similar to those in the L1 data. If, on the other hand, adult L2 learners rely less on grammatically-based parsing, then their ability to make use of morphological decomposition during word recognition should be reduced. Consequently, masked morphological priming effects will be less robust than in native speakers of Turkish. To test these predictions, we examined groups of both L1 and advanced L2 speakers of Turkish in two masked priming experiments. The main experiment examined morphologically related prime–targets pairs relative to unrelated control conditions. In a follow-up experiment, potential priming effects resulting from orthographic relatedness between primes and targets were tested.
Participants
The main experiment (Experiment 1) had 32 native speakers of Turkish (15 females, mean age: 26.4; SD: 6.1) and 32 L2 learners of Turkish with a variety of L1 backgrounds (11 females, mean age: 21.0; SD: 2.8).Footnote 3 The follow-up experiment (Experiment 2) tested 56 (28 L1 and 28 L2) participants taken from the participant pool of Experiment 1. All L2 participants were current university students in Turkey, receiving extensive Turkish tutoring at the Gazi University Turkish Learning and Research Center (Gazi TÖMER) in Ankara. All L1 participants were also current or former university students. The L2 participants had first been exposed to Turkish in a classroom setting in their respective native countries and none of them had learned Turkish before the age of 10 years or considered themselves bilingual. The L2 participants’ mean age of first exposure to Turkish was 16.8 years (SD: .77; range: 16–19 years). They had all been living in Turkey at the time of testing, with a mean of 8.5 months (SD: 3.3, range: 3–24 months). At the time of testing, all L2 participants took a Gazi TÖMER Turkish proficiency test and achieved a mean proficiency score of 83.0 (SD: 9.2) out of a maximum score of 100, as a result of which they had been placed in the highest possible proficiency groups at the institution. The L2 participants were further asked to self-rate their L2 Turkish skills in speaking, listening comprehension, reading comprehension and writing in every-day situations on a four-point scale (1–4), where 1 stood for “insufficient” and 4 for “very good”. They rated their L2 Turkish speaking, listening comprehension, reading comprehension and writing skills as 2.8 (SD: 0.5), 3.3 (SD: 0.5), 3.3 (SD: 0.6) and 2.9 (SD: 0.7), respectively. All participants had normal or corrected-to-normal vision, were never diagnosed with any learning or other behavioral disorders, and were naïve with respect to the purpose of the experiments. They were paid a small fee for their participation.
Materials
The critical materials for Experiment 1 consisted of 30 pairs of morphologically related primes and targets, 15 with deadjectival -lIk derivations and 15 with -(V)r Aorist inflections as critical primes, and 30 unrelated prime–target pairs in which there was no morphological, orthographic, or semantic relation between the prime and target word; see Appendix A. An example stimulus set is shown in (8).
- (8)

To properly test for stem-priming effects, it is important that the target word does not introduce any new material that is not available from the (related) prime, because any unprimed material might reduce potential priming effects (e.g., Clahsen, Eisenbeiss, Hadler & Sonnenstuhl, Reference Clahsen, Eisenbeiss, Hadler and Sonnenstuhl2001). In languages such as English this is easy to achieve as bare stems constitute legal word forms, hence the preference for prime–target pairs such as walked–walk over walked–walks in masked priming studies (e.g., Silva & Clahsen, Reference Silva and Clahsen2008). Constructing comparable materials for the present study was more challenging, as bare forms are much less common in Turkish than in English. Yet, the materials illustrated in (8) meet the required criteria. The targets for the Aorist condition were bare verbal stems (which function as imperatives in Turkish) and for the -lIk derivation condition bare adjectival stems. Furthermore, the targets in both conditions were fully contained in the (related) prime words. To minimize visual overlap between primes and targets, target words in both conditions were presented in upper case, and prime words in lower case letters.
These materials allow for direct comparisons of stem-priming effects for inflection and derivation without any interference from unprimed affixes, in the same way as in previous masked priming studies of English. Although matching along these criteria was given priority, the frequency and length of the stimuli were also kept as similar as possible. Stem and word frequencies were measured as occurrences per Million, and their length was measured in terms of number of letters. All verb targets were between two and four letters long (mean: 3.0) and had a mean stem frequency of 15.84 in the Middle East Technical University (METU) Turkish corpus (Say, Zeyrek, Oflazer & Özge, Reference Say, Zeyrek, Oflazer, Özge, İmer and Doğan2002).Footnote 4 The adjective targets were between three and six letters long (mean: 4.93), and had a mean stem frequency of 48.56 in the METU corpus. The inflectionally related prime words were third person singular Aorist forms, which are formed through the addition of a variant of the -Ar suffix (-ar or -er) to consonant-final monosyllabic verbal roots. As mentioned above, the -Ar suffix represents the most regular subset of Aorist inflection. Furthermore, these Aorist forms do not contain any overt person or number affix, which might have produced additional unwanted effects. The Aorist prime words were on average 5.0 letters long, and had a mean word-form frequency of 63.2. The derivationally related prime words were deadjectival nominalizations with the suffix -lIk, consisting of 7.9 letters on average, and had a mean word-form frequency of 18.04.
To assess the additional matching criteria statistically, two one-way ANOVAs for the factor “stimulus type” (prime: Aorist, target: Aorist, prime: -lIk, target: -lIk) were performed, the first one with the dependent measure “frequency” (per Million) and the second with “length” (in letters). While the analysis for “frequency” revealed no significant effect of stimulus type (F(3,56) = 2.01, p = .12), the one for “length” yielded a significant main effect of stimulus type (F(3,56) = 116.45, p < .001). Subsequent planned comparisons showed that the -lIk items were significantly longer than the Aorist ones, both the primes (7.9 vs. 5.0, t(14) = 10.22, p < .001) and the targets (4.93 vs. 3.0, t(14) = 6.44, p < .001). Thus, the prime–target pairs in the -lIk condition consisted of longer stimuli than those in the Aorist condition. The question of whether this difference affects the priming results will be discussed below.
The purpose of the follow-up Experiment 2 was to examine whether any facilitatory effects in Experiment 1 could be attributed to the orthographic overlap between prime and target words. To this end, the related prime–target pairs in Experiment 2 were semantically and morphologically unrelated but had a similar degree of orthographic overlap as the morphologically related prime–target pairs in Experiment 1. Orthographic overlap was measured by the proportion of the number of letters in the prime that also appeared in the target. For the prime–target pair yorgunluk–yorgun, for example, the overlap ratio is 0.67, since six of the nine letters in the prime word also appear in the target. The mean overlap ratios were parallel across conditions and for both experiments (Aorist: .60, -lIk: .62, orthographic overlap: .60). The critical materials for Experiment 2 consisted of 15 related and 15 unrelated prime–target pairs; see Appendix B. An example stimulus set is shown in (9).
- (9)

Note that devre and dev are both semantically and morphologically unrelated, as -re does not exist as a suffix in Turkish. The critical targets were monosyllabic unaffixed word forms, which were between two and three letters long (mean: 2.9) and had a mean frequency of 40.95 in the METU Corpus. The orthographically related test primes were disyllabic unaffixed word forms which were between four and six letters long (mean: 4.93) and had a mean frequency of 39.95. The unrelated primes were between three and seven letters long (mean: 5.13) and had a mean frequency of 39.64.
In both experiments, the prime target pairs were distributed over two experimental versions each to ensure that no participant saw the same target more than once. In each of the two versions of Experiment 1, a set of 420 filler pairs was added to the 30 critical prime–target pairs. Likewise, a set of 225 filler pairs was added to the 15 critical prime–target pairs of each of the two versions of Experiment 2. For both versions of both experiments, half of the targets were existing words and half were pseudowords, while all primes were existing word forms. The pseudowords were constructed by changing one or two letters of existing Turkish words, yielding phonotactically legal forms in Turkish. The proportion of targets preceded by a related prime constituted 25% of the stimuli encountered by each participant. The prime–target pairs in each list were pseudo-randomized so that no semantic association existed between consecutive items and not more than three consecutive items were of the same prime–target pair type in order to eliminate undesired priming effects across items.
Procedure, data scoring, analysis
The masked visual priming technique (Forster & Davis, Reference Forster and Davis1984) was used for both experiments. Each trial started with an asterisk in the middle of the screen for 500 ms, followed by a blank screen for 500 ms and a forward mask consisting of 11 hashes (#s) for 500 ms, which also served as a fixation point. This was immediately followed by the prime (displayed for 50 ms), which was then immediately followed by the target item for 750 ms. After the target disappeared, participants were allowed a further 1200 ms to respond. The stimuli were presented on a 15-inch monitor in white letters (font: Courier New, size: 20) on a black background. The presentation of the stimuli and the measurement of response times were controlled by E-Prime (Schneider, Eschman & Zuccolotto, Reference Schneider, Eschman and Zuccolotto2002). Each experiment began with a short practice session of 15–20 trials. Participants were tested individually and were instructed to decide whether a given letter string was a real Turkish word or not and to press as quickly as possible the appropriate button on a gamepad. The participants were provided with written and oral instructions in Turkish and/or English prior to each experiment, and the experiments were started only after the participants had fully understood the task. Each participant took the two experiments in two separate sessions on the same day, with at least three hours between the two sessions. The experiments did not last longer than approximately 20 minutes each. Both the L1 and the L2 participants were offered one break during each experiment. At the end of each experiment, participants were asked to provide a description of the task and of what they had seen. None of the participants reported to have seen any of the prime words. For the L2 participants we also determined at the end of each experiment whether they knew the experimental items they had to respond to. To this end, the L2 participants were asked to provide English translations, Turkish synonyms or descriptions in Turkish or English for all target words. All target words were correctly described or named by the L2 participants.
Incorrect responses, i.e. non-word responses to existing words, were not included in the analysis of reaction times. Outliers, i.e. extreme reaction times exceeding two SDs from a participant's mean per condition, were also excluded from any further analysis; this led to the exclusion of 4.4% of the data points from the L1 and 4.2% from the L2 data sets in Experiment 1, 7.1% from the L1 and 13.2% from the L2 data sets in Experiment 2. The reaction time (RT) and error data were submitted to analyses of variance (ANOVA) followed by planned comparisons if appropriate. The p-values of all analyses were Greenhouse-Geisser corrected for non-sphericity whenever applicable.
Results
Experiment 1 directly compares an inflectional and a derivational process of Turkish, regular Aorist verb inflection and productive deadjectival nominalizations with -lIk in L1 and advanced L2 speakers of Turkish. Table 1 displays mean RTs to the targets (as well as standard deviations and error rates) for the morphologically related and the unrelated control conditions. Planned comparisons are shown in Table 2.
Table 1. Mean RTs (in ms), SDs (in parentheses), and error rates (in %) in Experiment 1.

Table 2. Planned comparisons of the mean RTs in Experiment 1.
Table 1 shows that overall the L2 groups had higher error rates (particularly in the derivation condition) and longer RTs across conditions than the L1 group. More importantly, with respect to the inflection and derivation conditions, the L1 group had similarly reduced mean RTs for related (relative to unrelated) items for both Aorist verb inflection and -lIk derivation, whereas the L2 groups had reduced RTs in the derivationally related condition (like the L1 group), but not in the inflectionally related condition.
ANOVAs with the factors Group (L1, L2), Prime Type (Related, Unrelated), and Condition (Aorist, -lIk) on the error data revealed significant main effects of Group (F1(1,62) = 50.85, p < .0001; F2(1,56) = 25.77, p < .0001) and Condition (F1(1,62) = 28.99, p < .0001; F2(1,56) = 5.45, p < .05), and an interaction of Group and Condition (F1(1,62) = 15.91, p < .0001; F2(1,56) = 6.71, p < .05). These results are a reflection of the considerably higher error rates for derivation than for inflection, particularly in the L2 group, which are probably due to the fact that the adjectives used as target words in the derived condition were less familiar to participants than the verbal stems used as targets in the inflected condition.
The RT data revealed a significant three-way interaction of Prime Type, Group and Condition in the participant analysis (F1(1,62) = 4.06, p < .05; F2(1,56) = 1.07, p = .31) as well as a significant interaction of Condition and Prime Type, again in the participant analysis only (F1(1,62) = 6.07, p < .05; F2(1,56) = 1.67, p = .20). There were also main effects for Group (F1(1,62) = 9.32, p < .005; F2(1,56) = 80.11, p < .0001), Condition (F1(1,62) = 1.00, p = .320; F2(1,56) = 4.80, p < .05), the latter significant for items only, and Prime Type (F1(1,62) = 12.08, p < .005; F2(1,56) = 3.06, p = .09). There were no further significant main effects or interactions in the RT data. Planned comparisons (Table 2 above) showed a significant priming effect for (Aorist) inflection in the L1 in the participant analysis (marginally significant for items) and no priming in the L2 group. For -lIk derivation, on the other hand, significant priming effects were found in the participant analyses for both the L1 and the L2 group.
Recall that prime and target words for the derived condition were longer (in terms of number of letters) than those for the inflected condition, by a factor of 1.6 (7.9 vs. 5.0; 4.93 vs. 3.0). If the priming results were attributable to this contrast, we would have expected a corresponding difference in the size of the priming effects for derivation and inflection. This was not the case, however. In the L1 group, the size of the priming effects (in terms of Cohen's d) were parallel in both conditions (Aorist: d = .28; ‑lIk: d = .34), and the L2 group showed efficient priming for derivation, with an effect size similar to the L1 group (d = .32), but no priming at all for inflection. Thus, the size of the priming effects did not vary as a function of the length of the stimuli, in either the L1 or the L2 group.
The results from the L1 group are familiar from previous masked priming studies with native speakers of different languages; see, for example, Marslen-Wilson (Reference Marslen-Wilson and Gaskel2007). These priming effects have been taken to result from early automatic morphological decomposition processes during visual word recognition. The pattern of results we found for the L2 group is clearly different from what is known about L1 processing in that priming for derivation paired with no priming for regular inflection has not been reported in any previous L1 masked priming study. These results indicate that L2 processing does not employ early automatic morphological parsing mechanisms in the same way as L1 processing because otherwise we should have found the same priming effects for the L2 group as for the L1 group. Yet, L2 participants do not seem to store morphologically complex word forms as unanalyzed wholes because if that was the case we should not have found the same priming effects for derivational forms in the L2 group as in the L1 group. We propose an account for the reported similarities and differences between L1 and L2 morphological priming in the next section. The question that needs to be addressed before is whether the priming effects obtained in Experiment 1 are indeed morphological in nature. This was the purpose of Experiment 2.
Experiment 2 employed the same procedures and tested subgroups from the same participant pool as Experiment 1. The critical related condition in Experiment 2 consisted of prime–target pairs that had the same degree of orthographic overlap as the prime–target pairs of Experiment 1 but were otherwise unrelated. If the priming effects in Experiment 1 were due to the orthographic overlap between primes and targets rather than to their morphological relatedness, we should find parallel priming effects in Experiment 2. The results are shown in Table 3.
Table 3. Mean RTs (in ms), SDs (in parentheses), and error rates (in %) in Experiment 2.
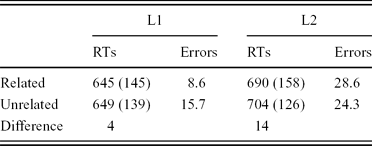
The results again show overall higher error rates and longer RTs for the L2 than the L1 group. More importantly, however, within each group the RTs between the (orthographically) related and the unrelated control prime–target pairs were similar. Correspondingly, the ANOVAs yielded a main effect of Group for both the error (F1(1,54) = 17.31, p < .0001; F2(1,28) = 11.16, p < .005) and the RT data, the latter in the by-items analysis only (F1(1,54) = 1.94, p = .17; F2(1,28) = 8.84, p < .05) without any other main effects or interactions. These results confirm that orthographic overlap between primes and targets does not yield masked priming effects at short stimulus onset asynchronies (SOAs).
Discussion
In this section, we discuss the results obtained from the experiments on L1 and L2 Turkish along with findings from other languages to identify the linguistic representations and processing mechanisms for inflected and derived words that are shared and those that are different in the L1 and the L2.
Comparison with previous masked priming studies
The present set of results demonstrates both similarities and differences between inflection and derivation and between L1 and L2 processing. The two masked-priming experiments revealed similar priming patterns for inflection and derivation in native L1 speakers of Turkish and different ones in non-native L2 learners. Experiment 1 showed that inflected words were efficient primes in the L1, but not in the L2, whereas derived words yielded significant priming effects in both the L1 and the L2. Experiment 2 indicated that the priming effects obtained in Experiment 1 cannot be attributed to orthographic (prime–target) overlap, in either the L1 or the L2.
To evaluate our findings on Turkish in relation to studies on other languages, consider Table 4, which summarizes the results of previous masked priming studies comparing morphological processing in native and non-native speakers.
Table 4. Masked priming studies on L1 vs. L2 morphology.
For native speakers, our results on L1 Turkish are parallel to what has been found for regular inflectional and transparent derivational processes in L1 English and German. In addition, Neubauer and Clahsen (Reference Neubauer and Clahsen2009) reported masked priming effects for irregular inflection in L1 German, similarly to Crepaldi et al.'s (Reference Crepaldi, Rastle, Coltheart and Nickels2010) findings for irregular past tense forms in L1 English. For non-native speakers, masked priming studies on morphology also begin to produce a consistent picture. Firstly, masked priming experiments testing regularly inflected word forms yielded significant priming effects in the L1, and no priming in the L2. This holds for all available studies summarized in Table 4 except for Feldman et al. (Reference Feldman, Kostić, Basnight-Brown, Filipović Durdević and Pastizzo2010), who reported a priming effect for -ed forms in English for a subgroup of their L2 learners.Footnote 5 Secondly, masked priming experiments testing derived word forms yielded significant priming effects in both the L1 and the L2. This holds for all available studies summarized in Table 4 except for Clahsen and Neubauer (Reference Clahsen and Neubauer2010), who found a masked priming effect for derived words in L1 but not in L2 German. Thirdly, the two studies that allow for direct comparisons of masked priming effects for derivational and inflectional processes (Silva & Clahsen, Reference Silva and Clahsen2008) on L2 English and the present study on L2 Turkish yielded similar results, significant priming for derivational and no priming for regular inflection. Fourthly, for irregular inflection, there is only one masked priming study to date (Neubauer & Clahsen, Reference Neubauer and Clahsen2009), which obtained the same significant priming effect for advanced L2 learners of German as in native speakers. Taken together, the L2 masked priming patterns seem to be fairly robust across studies.
Inflection and derivation in the L1
Recall that masked priming at short SOAs is believed to tap an early stage of word recognition at which word structure information including morphological constituency is accessible, but not yet a prime word's semantic properties (Davis & Rastle, Reference Davis and Rastle2010). In psycholinguistic research, the distinction between word-structure and conceptual/semantic levels of representation is familiar from models of language production (e.g., Levelt, Reference Levelt, Brown and Hagoort1999). In Levelt's model, for example, the lemma entry contains a word's meaning and syntactic properties, and the lexeme entry a word's internal structure and morphological properties. Using this terminology, we may say that masked priming is sensitive to relatedness at the lexeme or word-structure level and not, or less so, at the lemma level. Furthermore, lexemes may have complex, internally structured representations consisting, for example, of slots for stems and affixes, or of different subentries representing the different stem forms of a verb (Clahsen et al., Reference Clahsen, Eisenbeiss, Hadler and Sonnenstuhl2001; Jackendoff, Reference Jackendoff1997; Wunderlich, Reference Wunderlich, Booij and van Marle1996). In this framework, masked morphological priming effects for L1 processing can be attributed to two sources, (i) decomposition of prime words into stems and affixes, (ii) activation of shared lexeme entries. This is illustrated in Figure 1 using examples from English.
Figure 1. Word-form representations for inflected and derived words.
Priming via the decomposition route is essentially due to stem reactivation. By decomposing words such as walked and bitterness into their morphological constituents, the base stem is isolated during the recognition of the prime word, which subsequently facilitates the recognition of the target word through repeated stem activation. Priming via the lexeme route is due to shared lexeme entries and applies to prime–target pairs such as fell–fall in which the irregular word form constitutes a subentry of the main lexeme entry. Thus, fell activates fall through a shared lexeme entry, which subsequently facilitates the recognition of the corresponding target word, and hence the priming effect. If this account is correct and there are indeed two sources for masked priming effects from inflected word forms in L1 processing, the question arises as to how priming effects for derived word forms are to be explained. One possibility is that priming for derived words such as bitterness is due to morphological decomposition and subsequent stem reactivation, in the same way as for regularly inflected word forms such as walked. An additional possibility is lexically mediated priming, resulting from lexeme-level entries for derived words (Anderson, Reference Anderson1992). If, as illustrated in Figure 1, a derived word form such as bitterness has its own lexeme entry ([[bitter]-ness]N) which is partially shared with the lexeme entry of its corresponding base ([bitter]Adj), then priming for bitterness–bitter may arise via the lexical route, in the same way as for fell–fall. Since L1 speakers show masked priming effects for both irregular and regular inflection, testifying both decompositionally and lexically mediated priming, this also means that the source of the observed priming effects for derived words in the L1 is difficult to determine.
Masked morphological priming in the L2
With respect to the L2 results, some commonly mentioned accounts of non-native language processing do not seem to apply in the present case. It has been proposed, for example, that L1/L2 processing differences can be attributed to L1 transfer from an L2 learners’ native language (compare e.g., Chen, Shu, Liu, Zhao & Li, Reference Chen, Shu, Liu, Zhao and Li2007; Sabourin & Haverkort, Reference Sabourin, Haverkort, Van Hout, Hulk, Kuiken and Towell2003). This account clearly fails to explain the masked priming results summarized in Table 4. Masked priming experiments with non-native speakers yielded an unusual pattern of results compared to what is known about masked morphological priming effects in the L1 in that priming for irregular inflection and for derived word forms paired with no priming for regular inflection has not been reported in any study of L1 processing. The L2 masked priming pattern was found to be parallel across a heterogeneous set of L1 backgrounds and different target languages. Despite typological differences between their L1s, Arabic, Chinese, Japanese, and German learners showed the same priming patterns in L2 English. This was even the case for German L2 learners of English who have direct translation equivalents of the inflected and derived English word forms in their L1 (Silva & Clahsen, Reference Silva and Clahsen2008). Furthermore, the results of the present study show that the L2 masked priming patterns previously obtained for English and German generalize to a typological different target language, Turkish. The contrast we found in L2 Turkish between efficient priming for derivation and no priming for regular inflection is particularly striking for an agglutinating language such as Turkish which one would have thought promotes decomposition for all kinds of morphologically complex word forms.
Another proposal from the L2 processing literature claims that native and non-native language processing are parallel to each other except that L2 processing requires extra time and is generally slower than L1 processing (e.g., McDonald, Reference McDonald2006). This account also fails to explain the masked priming results. Firstly, Silva and Clahsen (Reference Silva and Clahsen2008) found that the Chinese L2 learners’ target response times across all conditions were on average more than 100 ms longer than those of the German L2 learners. While the two L2 groups were matched on their general English language proficiency, the different overall response times are likely to be due to differences in familiarity with the Latin script. Importantly, however, the masked priming patterns were parallel in the two L2 groups for both inflection and derivation. Secondly, Clahsen, Balkhair, Cunnings and Schutter (Reference Clahsen, Balkhair, Cunnings and Schutter2012) performed a masked priming experiment with a group of Arabic-speaking L2 learners of English to specifically address the possibility that reduced priming effects in the L2 may be due to slowed processing. The modified design included a blank screen shown for 200 ms after the (masked) prime, to provide extra time to process the prime word. Yet, the results for this delayed design were parallel to those of a control experiment using the standard masked priming design in which target words immediately followed the primes. In both designs, the L2 learners showed repetition priming but no morphological priming effects for regular inflection. Thirdly, our finding that the same L2 learners of Turkish demonstrated efficient priming for derivation without any priming for inflection cannot be explained in terms of speed of processing differences. Taken together, we conclude that factors such as L1 transfer or reduced speed of processing are insufficient to explain the L2 results.
An alternative source for the observed L1/L2 differences in masked priming might be that parts of L2 grammatical processing are not functioning native-like; see Ullman (Reference Ullman and Sanz2005) and Clahsen and Felser (Reference Clahsen and Felser2006) for specific proposals. Here we suggest that morphological decomposition is not operative during early L2 word recognition and that this causes the unusual morphological priming patterns reported for L2 learners. Consider Figure 1 again and suppose that while L2 learners’ lexical representations of morphologically complex words are identical to those of L1 speakers, the prime words are not morphologically decomposed during early stages of L2 word recognition. If this is correct, masked priming effects should only be found for prime–target pairs that have lexically linked lexeme entries. As indicated by the dotted lines in the figure, this is the case for irregularly inflected and derived, but not for regularly inflected word forms. Since regularly inflected word forms do not have their own lexeme entries, morphological decomposition is the only source of masked priming effects for regular inflection. This means that during early visual word recognition in an L2, a lexeme such as [walk] is not activated by the prime /walked/ because walked is not morphologically decomposed, and hence there is no priming in such cases. The two word forms walk and walked are of course semantically and orthographically related, but as has been demonstrated in previous studies, masked priming at short SOAs is not particularly sensitive to semantic or orthographic relatedness, either in the L1 or in the L2. In this way, shared lexeme entries can account for the L2 masked priming patterns.
An apparent challenge for the account of masked priming effects proposed here comes from the results of a recent study (Diependaele et al., Reference Diependaele, Duñabeitia, Morris and Keuleers2011) which reported masked priming effects in groups of L2 learners for word pairs with pseudo-affixed prime words, for example, corner as a prime for corn, which were taken to indicate that L2 learners morphologically decompose potentially complex words irrespective of a word's meaning or function. Closer inspection of Diependaele et al.'s (Reference Diependaele, Duñabeitia, Morris and Keuleers2011) results reveals, however, that this interpretation is unwarranted. According to their Tables 4 and 5, there were no significant differences in the magnitudes of priming either in the L1 Spanish or in the L1 Dutch group between so-called “opaque” and “form” prime types, which means that prime–target pairs with pseudo-affixed primes (corner–corn) and orthographically related prime–target pairs (yellow–yell) produced the same results. Thus, in contrast to what Diependaele et al. argued, the priming effect for corner–corn cannot be taken to signal decomposition triggered by apparent morphological structure, but may instead simply be due to the surface-form overlap between prime and target, in the same way as for yellow–yell. Furthermore, Baayen, Milin, Filipović Durdević, Hendrix and Marelli (Reference Baayen, Milin, Filipović Durdević, Hendrix and Marelli2011) questioned the corner–corn effect at a more general level observing that many of the items that are commonly treated as “pseudo-affixed” or opaque are indeed to a certain degree transparent. Consider, for example, the supposedly pseudo-affixed adjectives fruitless and cryptic (Rastle et al., Reference Rastle, Davis and New2004) which both contain segmentable affixes, -less/-ic (as in Semit-ic or rhythm-ic), plus a stem or bound root respectively (fruit-, crypt-) that both contribute to the meanings of the adjectives. Baayen et al. (Reference Baayen, Milin, Filipović Durdević, Hendrix and Marelli2011) noted that these cases are clearly different from the familiar corner–corn example, and yet in Rastle et al. (Reference Rastle, Davis and New2004) they formed part of the same supposedly pseudo-affixed prime condition. The same applies to Diependaele et al. (Reference Diependaele, Duñabeitia, Morris and Keuleers2011) who put together items such as fruitless, tactic, and hearty (which contain suffixes that clearly function as adjectival or adverbial markers) with non-transparent items such as corner and number into one so-called opaque condition, calling into question conclusions drawn from this experimental condition.
Conclusion
The present study compared the processing of inflected and derived word forms in L1 and L2 Turkish using the masked priming paradigm. Our findings on regular (Aorist) inflection in Turkish together with the results of previous studies indicate clear L1/L2 contrasts for inflectional processes across different target languages. While adult native speakers of English, German and Turkish demonstrated efficient morphological priming effects for regularly inflected word forms, this was not the case for L2 learners of these languages. For derivational processes, on the other hand, advanced L2 learners performed more native-like. Again, L1 speakers showed the same significant morphological priming effects for productive derivational processes as for regular inflection across different languages. Unlike for regular inflection, however, derived word forms also yielded significant masked priming effects for L2 learners, e.g., for deadjectival nominalizations with -ness in English and with ‑lIk in Turkish.
We conclude with the following final observations. The present findings indicate that L1 and L2 processing of morphologically complex words differ in subtle rather than in superficial or obvious ways. It is not the case that L1 and L2 processing are alike except for L2 processing being slower and affected by L1 transfer, or that morphology is generally difficult for L2 learners. Instead, more complex explanations are required to account for the reported differences between inflectional and derivational processes in the L2. We proposed that advanced L2 learners’ lexical representations of morphologically complex words are identical to those of L1 speakers, but that (unlike in the L1) L2 processing does not make use of morphological decomposition. Consequently, masked priming effects in the L2 can only arise in cases in which prime and target words share lexical entries. Although this proposal accounts for the masked priming patterns in the L2, we acknowledge that future research is necessary to determine whether these results reflect an isolated gap in the L2 system affecting early stages of visual word recognition only, or whether the pattern of results generalizes to later stages of visual word recognition, to auditory word recognition, or to production. Finally, with respect to linguistic theories of morphology, we note that the present set of findings is unusual in that data from non-native speakers were found to be more informative for a matter of general controversy than familiar data from native speakers. In our case, the L2 data provided clear psycholinguistic evidence for a contrast between inflection and derivation, which was not visible from the L1 data. This contrast is consistent with realization-based models of morphology that posit precisely the kind of split observed in the L2 data.
Appendix A. Morphologically related and unrelated prime–target pairs for Experiment 1
Appendix B. Critical items for Experiment 2







