


Introduction
Treatment fidelity or integrity refers to the extent to which a psychological treatment is implemented as intended (Fairburn and Cooper, Reference Fairburn and Cooper2011), and consists of both adherence and competence. Adherence is the extent to which a therapist delivers a therapy in accordance with the therapy model or manual. Competence is the skill with which a therapist delivers the therapy. Adherence and competence have been shown to be highly correlated (Barber et al., Reference Barber, Liese and Abrams2003), with a complex hierarchical relationship. Adherence is necessary but not sufficient for therapist competence, and competence is not sufficient without adherence (Waltz et al., Reference Waltz, Addis, Koerner and Jacobson1993). Competence in therapy consists of adherence to the therapy, ability to engage a client and skilful use of treatment change strategies; as well as knowledge of when and when not to apply these strategies (Yeaton and Sechrest, Reference Yeaton and Sechrest1981).
Measuring fidelity or integrity in cognitive behavioural therapy (CBT) is necessary for outcomes research to be meaningful. CBT has become one of the most prominent psychological therapies worldwide (Hofmann et al., Reference Hofmann, Asnaani, Vonk, Sawyer and Fang2012) due to its strong performance in outcome studies. Clearly, it is important to know that the therapy offered in these studies is actually CBT. Reliable and valid measures of competence in CBT are needed to establish treatment fidelity (Shafran et al., Reference Shafran, Clark, Fairburn, Arntz, Barlow, Ehlers and Salkovskis2009) and these must be used with care: for example, a systematic review found that inter-rater reliability of the Cognitive Therapy Scale (CTS) or its revised version (CTS-R) is not often reported and when it is, the results are variable (Loades and Armstrong, Reference Loades and Armstrong2016).
As the demand for CBT increases, commissioners, services, trainers and researchers all need effective methods to ensure that CBT is delivered with fidelity to the evidence base. CBT is recommended in the UK for many psychological difficulties [National Institute for Clinical Excellence, 2004, 2007, 2011, 2014a, 2014b; Scottish Psychological Therapy Matrix (National Health Service Education for Scotland, 2015); Matrics Cymru: Delivering Evidence-Based Psychological Therapy in Wales (National Psychological Therapies Management Committee, 2017)]. In England there has been a firm commitment for services to deliver CBT through the roll-out of the Improving Access to Psychological Therapies (IAPT) initiative (Clark, Reference Clark2011). Commissioners and trainers responsible for disseminating CBT skills need effective methods to assess the impact of training on practitioner competence and to ensure the quality of CBT treatment in everyday practice (Kazantzis, Reference Kazantzis2003). Studies linking CBT competence to patient outcomes have not given consistent results (Branson et al., Reference Branson, Shafran and Myles2015; Dobson and Kazantzis, Reference Dobson and Kazantzis2003; Jacobson and Gortner, Reference Jacobson and Gortner2000). One explanation for this could be the poor reliability of tools used to assess competence (Crits-Christoph et al., Reference Crits-Christoph, Baranackie, Kurcias, Beck, Carroll, Perry and Gallagher1991).
The core competences needed to deliver effective CBT have been incorporated into a broad framework consisting of five domains: (1) generic therapeutic competences; (2) basic CBT competences; (3) specific behavioural and cognitive therapy competences; (4) problem specific competences; and (5) meta-competences (Roth and Pilling, Reference Roth and Pilling2007). This framework gives a comprehensive definition of CBT competence, but the authors acknowledge that it is not a measure of competence and advocate the use of competence measures that assess a subset of core competencies (Roth and Pilling, Reference Roth and Pilling2008).
A previous systematic review (Muse and McManus, Reference Muse and McManus2013) presented a helpful framework by which different levels of CBT competence can be demonstrated and assessed (see Fig. 1). The framework is based on Miller’s (Reference Miller1990) proposal that there are four levels of assessment of competence: (a) the clinician knows or has the knowledge; (b) the clinician knows how to use this knowledge; (c) the clinician can show how to do a skill; and (d) the clinician displays this skill in practice. Thus, in this hierarchical framework the highest level of competence is evidenced by the therapist using a skill in practice, which can be assessed by rating treatment sessions (assessor or self), supervisory assessments and patient surveys.
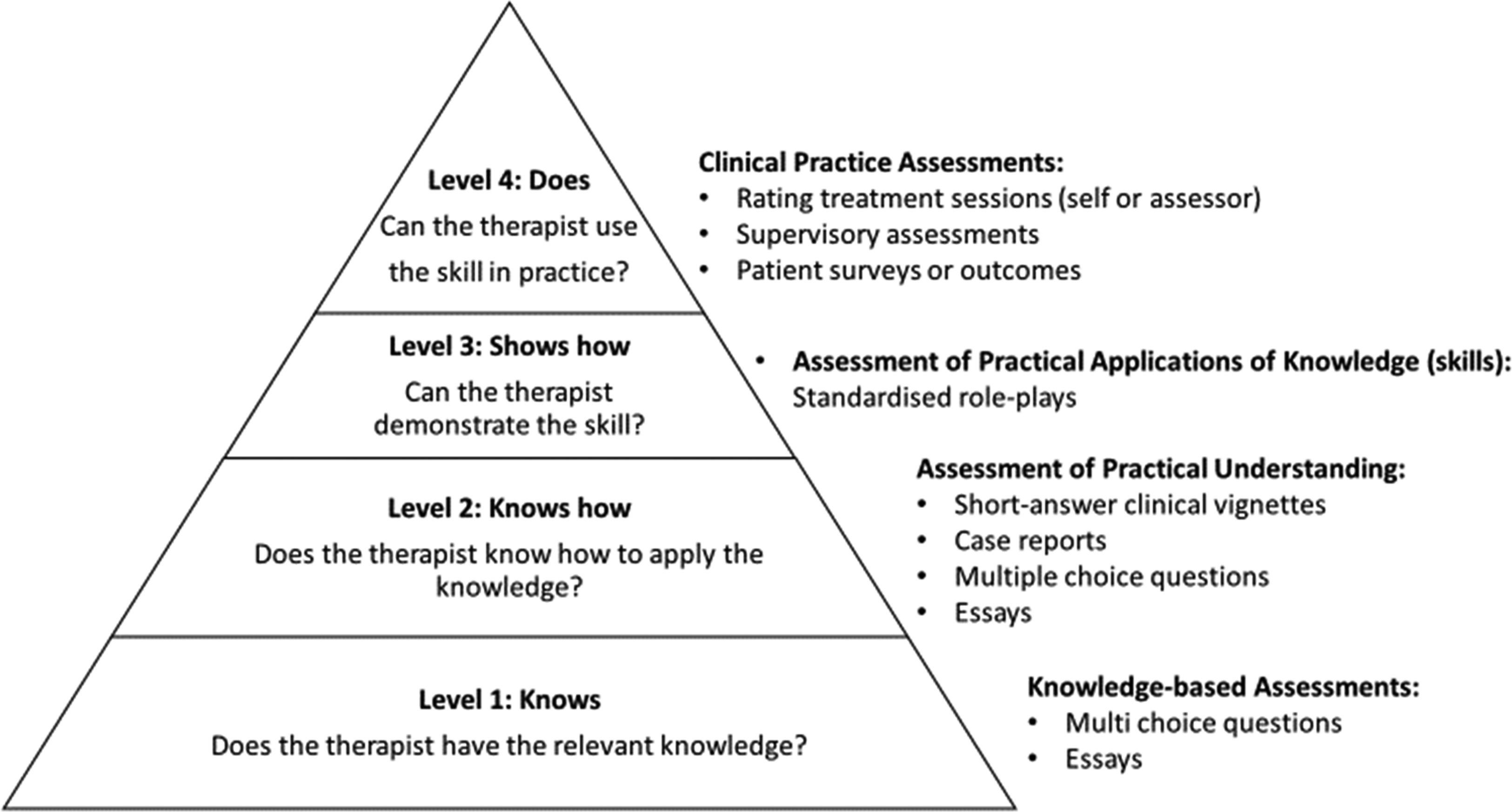
Figure 1. A framework for CBT therapist competence measures, based on Miller’s (Reference Miller1990) clinical skills hierarchy (Muse and McManus, Reference Muse and McManus2013).
The framework suggests that assessor ratings of therapist in-session performance are considered the ‘gold standard’ in assessing competency (Muse and McManus, Reference Muse and McManus2016). To carry out these ratings, assessors use CBT Competence Scales (CCSs) consisting of a list of domains in which the level of competence observed is rated on an analogue scale. Ratings from each domain can be combined to create an overall competence score and a cut-off point agreed at which a therapist has met a satisfactory level of competence. Crucially, CCSs can be used by independent assessors to avoid bias (Rozek et al., Reference Rozek, Serrano, Marriott, Scott, Hickman, Brothers and Simons2018).
One of the first CCSs developed was the Cognitive Therapy for Depression Checklist (CCCT: Beck et al., Reference Beck, Rush, Shaw and Emery1979); later developed into the Cognitive Therapy Scale (CTS: Dobson et al., Reference Dobson, Shaw and Vallis1985; Vallis et al., Reference Vallis, Shaw and Dobson1986). The CTS has been further revised (CTS-R: Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001), disorder-specific versions developed around the CTS/CTS-R framework (e.g. Competence Rating Scale for PTSD: Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017; CTS for Psychosis: Haddock et al., Reference Haddock, Devane, Bradshaw, McGovern, Tarrier, Kinderman and Harris2001; Cognitive Therapy Competence Scale for Social Phobia: von Consbruch et al., Reference von Consbruch, Clark and Stangier2012) and other global CCSs developed (e.g. Assessment of Core CBT Skills: Muse et al., Reference Muse, McManus, Rakovshik and Thwaites2017).
Due to the widespread use of CCSs in training, development and research, and the consensus that they are the ‘gold standard’ of competency assessment (Muse and McManus, Reference Muse and McManus2013, Reference Muse and McManus2016), it is essential that the measurement properties of these tools are assessed. A previous review of CBT competence found the reliability and validity of existing CCSs to be mixed (Kazantzis, Reference Kazantzis2003). A further systematic review examining the assessment of CBT competence found there was still a lack of empirically evaluated CCSs with adequate reliability and validity (Muse and McManus, Reference Muse and McManus2013). Further research is needed to either refine existing measures or develop new scales (Muse and McManus, Reference Muse and McManus2016), but to do so there must be a better understanding of the problems within the existing research.
In the field of psychometric research, it is important to distinguish between the study outcomes and the study design. As there are no published reviews that have assessed the quality of research examining the measurement properties of CCSs, the present review aims to fill this gap. Due to the complex relationship between adherence and competence, the present review will consider measures that assess either competence or a combination of adherence and competence. The specific research questions addressed within the review are:
-
(1) What is the quality of the research examining CCSs?
-
(2) How can research into the measurement properties of CCSs be improved?
-
(3) What are the implications for training and clinical practice in CBT?
Method
Search strategy
Studies were identified through an electronic search of relevant databases: MEDLINE, PsychINFO, Scopus and Web of Science, on 12 February 2018. The following general search strategy was used (see online Supplementary material for individual database search strategies):
-
(1) (‘therap* competen*’ OR ‘clinical competen*’ OR ‘therap* skill’ OR ‘assess* competen*’ OR ‘competen* assess*’ OR ‘therap* quality’ OR ‘intervention competen*’ OR ‘intervention quality’ OR ‘clinical expertise’) AND (‘cognitive therapy’ OR ‘behav* therapy’ OR ‘cognitive-behavio*’ OR ‘cognitive behavio*’ OR ‘CBT’)
OR
-
(2) (‘cognitive therapy scale’ OR ‘revised cognitive therapy scale’ OR ‘CTS-R’).
A further 10 studies were identified through snowballing methods by cross checking reference lists, key author searches and consultation with a CBT expert.
Inclusion/exclusion criteria
The following inclusion criteria was used to assess eligibility:
-
(1) Studies published in English from 1980 to the present day.
-
(2) Studies where the primary aim was the investigation of a CCS based on adult, individual, face-to-face CBT.
-
(3) Studies published in peer-reviewed journals.
-
(4) Studies that included competence or mixed adherence and competence scales.
Randomised control trials (RCTs) that use a CCS to assess treatment fidelity were excluded, because their primary focus is not investigating the validity, reliability or responsiveness of a CCS (Terwee et al., Reference Terwee, de Vet, Prinsen and Mokkink2011). Although the CCCT (Beck et al., Reference Beck, Rush, Shaw and Emery1979) was the first known attempt at a CCS, the psychometrics were not reported until its development into the CTS (Dobson et al., Reference Dobson, Shaw and Vallis1985; Vallis et al., Reference Vallis, Shaw and Dobson1986). Therefore, the date 1980 was used to ensure any scales reported before 1985 were identified. Article selection was conducted by the lead author (K.R.), in regular discussion with author L.W.
Quality assessment
A thorough literature search was conducted to identify a suitable tool to appraise the quality of the selected papers. As there are to date only a very few tools suitable for assessing the methodological quality of studies on measurement properties, an international Delphi study developed the COnsensus-based Standards for the selection of health Measurement INstruments checklist (COSMIN) (Mokkink et al., Reference Mokkink, Terwee, Patrick, Alonso, Stratford, Knol, Bouter and de Vet2010a, Reference Mokkink, Terwee, Knol, Stratford, Alonso, Patrick, Bouter and de Vet2010b). Although there is much overlap between the measurement properties of health status measurement instruments (HSMIs) and CCSs, there are some distinct differences. The COSMIN checklist was considered for use within the present review but was too broad in scope and lacked specificity in relation to studies reporting the measurement properties of CCSs. A new tool, The Checklist for the Appraisal of Therapy Competence Scale Studies (CATCS), was therefore developed for this purpose, based on the criteria in COMSIN, its accompanying definitions of measurement properties, scoring guidelines (when no other published information was available to inform the scoring) and information from a precursor to COSMIN proposing quality criteria (Terwee et al., Reference Terwee, Bot, de Boer, van der Windt, Knol, Dekker and de Vet2007): the CATCS checklist consists of 17 items relating to: (a) generalisability; (b) reliability: inter-rater reliability, test–re-test reliability, measurement error, internal consistency; (c) validity: structural validity, hypothesis testing, criterion validity, content validity; and (d) responsiveness (a copy of the CATCS can be found in the online Supplementary material). Each item is rated on a scale from 0 to 2 (0 = poor, 1 = fair and 2 = excellent) based on either the design and/or reporting. There is no assumption that these areas are equally weighted and therefore total scores for each paper were not calculated. Definitions of the measurement properties included can be found in Table 1. The results of the quality assessment were synthesised narratively due to the heterogeneity of the studies. Existing critical appraisal tools recognise the importance of generalisability but are unable to capture features that are important for CCSs. Poor reporting in this area undermines reporting of other properties (Terwee et al., Reference Terwee, Bot, de Boer, van der Windt, Knol, Dekker and de Vet2007): for example, excellent inter-rater reliability cannot be meaningfully generalised if a study does not provide adequate information about the patient population, therapists and raters. A total score for generalisability is reported, with ≥10 deemed to be acceptable.
Table 1. Definitions of measurement properties adapted from COSMIN (Mokkink et al., Reference Mokkink, Terwee, Patrick, Alonso, Stratford, Knol and de Vet2010c)

Results
Study selection
After 642 duplicates were removed, the remaining articles were assessed for inclusion by title or abstract and 925 excluded as clearly irrelevant. Full checks of the remaining 136 articles were then conducted, which led to 10 final papers that met inclusion criteria (see Fig. 2 for study flow diagram). Reference lists of the selected papers were also checked to identify any further potential studies.

Figure 2. Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA; Moher et al., Reference Moher, Liberati, Tetzlaff and Altman2009) study flow diagram.
Study characteristics
Three studies reported the measurement properties for the CTS (Dobson et al., Reference Dobson, Shaw and Vallis1985; Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017; Vallis et al., Reference Vallis, Shaw and Dobson1986) and two for the CTS-R (Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001; Gordon, Reference Gordon2006). Adapted disorder specific versions of the CTS/R were reported in four papers (Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017; Gordon, Reference Gordon2006; Haddock et al., Reference Haddock, Devane, Bradshaw, McGovern, Tarrier, Kinderman and Harris2001; von Consbruch et al., Reference von Consbruch, Clark and Stangier2012). Two studies reported a competence subscale within a scale that also examined adherence (Barber et al., Reference Barber, Liese and Abrams2003; Carroll et al., Reference Carroll, Nich, Sifry, Nuro, Frankforter, Ball and Rounsaville2000). One scale was a report of a newly developed global measure of CBT competence (Muse et al., Reference Muse, McManus, Rakovshik and Thwaites2017). See Table 2 for an overview of the studies.
Table 2. Overview of studies included in the review in chronological order

Findings of the quality assessment
The quality assessment of the studies in the current review was conducted by the lead author (K.R.) and a sample of 50% of the studies was assessed by a colleague independent from the review. Inter-rater reliability was assessed using a linear weighted kappa (Cohen, Reference Cohen1968) and was found to be good: κ = 0.76 (95% confidence interval, 0.70 to 0.88), p<0.0005 (Altman, Reference Altman1991). A small number of differences were identified and discussed between the two raters and resolved for the final ratings. Results of the quality assessment using the CATCS are reported in Table 3 for generalisability and Table 4 for quality of measurement property methodology and reporting.
Table 3. Critical appraisal results for generalisability using the CATCS

Scoring criteria for quality: 0, poor; 1, fair; 2, excellent. ACCS, Assessment of Core CBT Skills; CTS, Cognitive Therapy Scale: CTS; CTS-R, Cognitive Therapy Scale-Revised; CTACS, Cognitive Therapy Adherence and Competence Scale; YACS, Yale Adherence and Competence Scale; CRS-CPT, Competence Rating Scale for Cognitive Processing Therapy; CRS-PTSD, Competence Rating Scale for PTSD; CTCS-SP, Cognitive Therapy Competence Scale for Social Phobia; CTS-PSY, Cognitive Therapy Scale- Psychosis.
Table 4. Reliability and validity methodology ratings using the CATCS

Scoring criteria for quality: 0, poor; 1, fair; 2, excellent. Blank boxes indicate the domain was not reported on in the study. Items in brackets denote the sample size the analysis was performed on; ‘?’ indicates that the sample size was not clear. ACCS, Assessment of Core CBT Skills; CTS, Cognitive Therapy Scale: CTS; CTS-R, Cognitive Therapy Scale-Revised; CTACS, Cognitive Therapy Adherence and Competence Scale; YACS, Yale Adherence and Competence Scale; CRS-CPT, Competence Rating Scale for Cognitive Processing Therapy; CRS-PTSD, Competence Rating Scale for PTSD; CTCS-SP, Cognitive Therapy Competence Scale for Social Phobia; CTS-PSY, Cognitive Therapy Scale-Psychosis.
Generalisability
All but one study (Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017) had a total score ≥10 for generalisability. Therefore, most of the studies provided sufficient information that the results can be meaningfully interpreted within the specific contexts of each study. All the studies provided clear information about the purpose of the study, a protocol for the CCS and about the types of patients treated.
Three of the studies (Barber et al., Reference Barber, Liese and Abrams2003; Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001; Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017) received a poor rating for number of raters used or types of raters used. Risk of bias was increased in three studies that employed raters who were not independent of the study. The seven studies that received an excellent rating for ‘Raters’ employed at least one rater that was truly independent and provided a clear explanation of the training the raters underwent. Four studies were assessed as excellent both for the number of raters used and the characteristics of the raters (Gordon, Reference Gordon2006; Muse et al., Reference Muse, McManus, Rakovshik and Thwaites2017; Vallis et al., Reference Vallis, Shaw and Dobson1986; von Consbruch et al., Reference von Consbruch, Clark and Stangier2012).
All studies reported using an acceptable number of different therapists, with no studies receiving a poor rating in this domain. Similarly, most of studies provided an excellent description of therapists and their training, with only one study receiving a poor rating (YACS: Carroll et al., Reference Carroll, Nich, Sifry, Nuro, Frankforter, Ball and Rounsaville2000).
Reliability
Inter-rater reliability
Inter-rater reliability of competence scales can be measured for the total scales and individual items. Often the inter-rater reliability of total scales is found to be good but lower for individual items (e.g. Barber et al., Reference Barber, Liese and Abrams2003; Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001; Dobson et al., Reference Dobson, Shaw and Vallis1985; von Consbruch et al., 2011). All but one study (Vallis et al., Reference Vallis, Shaw and Dobson1986) reported both total scale and individual item correlations using appropriate statistical analysis.
Test–re-test reliability
Only one study (von Consbruch et al., Reference von Consbruch, Clark and Stangier2012) conducted a test–re-test reliability assessment for a CCS. Some researchers have suggested that the re-test method should not be used to estimate reliability and advocate the use of internal consistency (Nunnally and Bernstein, Reference Nunnally and Bernstein1994). Reasons cited include the stability of the attribute being measured and carry-over effects in the second rating (Polit, Reference Polit2015). Carry-over effects in relation to rating CCSs could include the rater recalling their previous ratings or wanting to appear consistent. von Consbruch and colleagues (Reference von Consbruch, Clark and Stangier2012) attempted to reduce the influence of carry-over effects by ensuring there was 18 to 24 months between each rating. Despite this, the sample size used for the analysis was only 15 tapes, so test–re-test reliability methodology received a ‘poor’ rating.
Measurement error
Measurement error was reported in only one study (Gordon, Reference Gordon2006). Although the analysis used was appropriate, the sample size was <30 and so received a poor rating.
Internal consistency
Internal consistency was reported in seven studies, with varying quality and sample sizes. Only one study received an excellent rating (ACCS: Muse et al., Reference Muse, McManus, Rakovshik and Thwaites2017). Studies that received a fair rating did so because they did not calculate factor analysis per dimension (Barber et al., Reference Barber, Liese and Abrams2003; von Consbruch et al., 2011) or they had small sample sizes. Caution should be exercised in interpreting the internal consistency results of the CRS-CPT and CRS-PTSD, as this domain received a ‘poor’ quality rating due to the small sample size in the study (Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017). There are no studies that have examined the internal consistency of the CTS-PSY (Gordon, Reference Gordon2006: Haddock et al., Reference Haddock, Devane, Bradshaw, McGovern, Tarrier, Kinderman and Harris2001) and YACS (Carroll et al., Reference Carroll, Nich, Sifry, Nuro, Frankforter, Ball and Rounsaville2000).
Validity
Criterion validity
Barber et al. (Reference Barber, Liese and Abrams2003) was the only study to report criterion validity but the description provided is more congruent with the definition of discriminant validity and so was considered as such. Criterion validity was included in the quality assessment tool as initially it appeared that some studies reported this construct, but an actual ‘gold standard’ for CCSs may not currently exist.
Content validity
Content validity is less relevant in studies of instruments that have been adapted from an original scale or if the scale has already demonstrated content validity reported elsewhere. Only two studies did not report content validity. It is not clear why it was not reported for the YACS (Carroll et al., Reference Carroll, Nich, Sifry, Nuro, Frankforter, Ball and Rounsaville2000), as this was a novel instrument. von Consbruch et al. (2011) may not have reported on this for the CTCS-SP as it was adapted from the CTS, but they should then have reported this for the new items. Overall, the quality of reporting of content validity was excellent in six studies; but two studies scored ‘fair’ as they did not cover the domain in sufficient detail (Haddock et al., Reference Haddock, Devane, Bradshaw, McGovern, Tarrier, Kinderman and Harris2001; Vallis et al., Reference Vallis, Shaw and Dobson1986).
Construct validity
Construct validity includes structural validity, hypothesis testing and cross-cultural validity. Cross-cultural validity refers to how well an instrument has been adapted for different cultures or languages but was not included in this review as the search strategy found no such studies published in English that met inclusion criteria.
Structural validity
Structural validity was reported in only three papers, with each achieving a ‘fair’ score. In two papers the method of analysis was good, but the sample size was not high enough to achieve an ‘excellent’ rating (Carroll et al., Reference Carroll, Nich, Sifry, Nuro, Frankforter, Ball and Rounsaville2000, n = 83; Vallis et al., Reference Vallis, Shaw and Dobson1986, n = 90), and the sample size was not clear in another (Barber et al., Reference Barber, Liese and Abrams2003).
Hypothesis testing
Hypothesis testing was included in seven of the papers. Five studies were rated ‘fair’ due to sample sizes of 30–99 or not making explicit hypotheses a priori. The two studies examining the CTS-PSY both received a ‘poor’ rating for hypothesis testing, again due to small sample sizes (Gordon, Reference Gordon2006, n = 20–26; Haddock et al., Reference Haddock, Devane, Bradshaw, McGovern, Tarrier, Kinderman and Harris2001, n = 24).
Responsiveness
For the purposes of clarity, this review adopted the COSMIN definition of responsiveness as ‘the ability of a scale to detect changes longitudinally’. In this case, it refers to a CCS detecting changes in competence over time, perhaps because of experience or training. If studies assessed the same therapists at different time points and calculated their change in scores, then this was considered a measure of responsiveness of the scale. If, however, this was done using a cross-sectional design, where change was not calculated for each individual therapist, then it was considered discriminant validity, as the aim was to assess if the scale can discriminate between different groups: e.g. expert versus novice.
Two studies (Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001; Muse et al., Reference Muse and McManus2013) reported discriminant validity, but the description they used fits the definition of responsiveness. Unfortunately, both studies received a ‘poor’ rating for the methodology due to small sample sizes.
Discussion
This study is the first attempt to assess the quality of research reporting the psychometric properties of CCSs. This study also sought to make recommendations for improving the quality of research examining CCSs and consider implications for training and clinical practice in CBT.
What is the quality of the research examining CCSs?
This review found that overall, the quality of the studies was very mixed, and no studies demonstrated ‘excellent’ quality throughout. The quality was significantly affected by small sample sizes. A sample size of n≤30 is defined as ‘poor’ based on the COSMIN guidelines for assessing the quality of patient HSMIs (Mokkink et al., Reference Mokkink, Terwee, Patrick, Alonso, Stratford, Knol, Bouter and de Vet2010a, Reference Mokkink, Terwee, Knol, Stratford, Alonso, Patrick, Bouter and de Vet2010b, Reference Mokkink, Terwee, Patrick, Alonso, Stratford, Knol and de Vet2012). The COSMIN benchmark was used due to a lack of any other guidelines, around sample sizes for measurement property research in competence scales, but using this benchmark requires caution. For example, the minimum sample size for performing confirmatory factor analysis is usually quoted as n = 200–300 (Polit, Reference Polit2015). This may be unachievable for studies examining the properties of CCSs and further guidance is required as to minimum sample sizes for assessing the structural validity of CCSs. There are high costs involved in rating CBT treatment sessions due to the need for expert raters (Weck et al., Reference Weck, Hilling, Schermelleh-Engel, Rudari and Stangier2011). Further consensus is needed to clarify the minimum number of recordings of rated sessions needed for each measurement property, as this may vary per dimension.
From this detailed analysis, some inferences about overall quality of the studies in the current review can be made. The methodologies of the studies examining the measurement properties of the CTS (Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017; Dobson et al., Reference Dobson, Shaw and Vallis1985; Vallis et al., Reference Vallis, Shaw and Dobson1986), CTS-R (Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001; Gordon, Reference Gordon2006) and CTS-PSY (Gordon, Reference Gordon2006; Haddock et al., Reference Haddock, Devane, Bradshaw, McGovern, Tarrier, Kinderman and Harris2001) were assessed as being of ‘poor’ to ‘fair’ quality. The exceptions to this were content validity reporting for most studies of the CTS and inter-rater reliability methodology in one CTS-R study (Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001), which were all rated as ‘excellent’. The findings of this review suggest the quality of these studies examining the CTS and CTS-R are not robust enough, and that conclusions about their reliability and validity need to be held tentatively.
The study examining the CTCS-SP (von Consbruch et al., 2011) had quality ratings between ‘fair’ and ‘excellent’. The ACCS (Muse et al., Reference Muse, McManus, Rakovshik and Thwaites2017) had quality ratings from ‘poor’ to ‘excellent’. ‘Fair’ and ‘poor’ scores were awarded due to small sample sizes, but methodology was appropriate otherwise. In some ways, these more recent studies have addressed some of the previous methodological problems in previous studies on the CTS and CTS-R but were still not of consistent high quality. For example, the study examining the CRS-CPT and CRS-PTSD (Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017) was the only study to not receive an acceptable score for generalisability and was awarded ‘poor’ for methodology in all domains, except the ‘content validity’ domain, which received an excellent rating.
Overall, the quality of the assessment of inter-rater reliability was affected by the variation in samples sizes and particular caution should be exercised when interpreting the inter-rater reliability results of the YACS (Carroll et al., Reference Carroll, Nich, Sifry, Nuro, Frankforter, Ball and Rounsaville2000), CRS-CPT (Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017) and CPT-PTSD (Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017) due to small sample sizes of n = 19 and n = 21, respectively. This is also true for the CTS, which was used with small sample sizes in three studies (Vallis et al., Reference Vallis, Shaw and Dobson1986, n = 10; Dittman et al., Reference Dittmann, Müller-Engelmann, Stangier, Priebe, Fydrich, Görg and Steil2017, n = 30; Dobson et al., Reference Dobson, Shaw and Vallis1985, n = 30).
Assessing measurement error appears to be a neglected area of CCS measurement property evaluation, despite its evident importance. For example, health measurements such as physiological markers of disease are reasonably stable characteristics but measuring competence could be influenced by other components that are not the subject of measurement (Rosenkoetter and Tate, Reference Rosenkoetter and Tate2018). This means that when measuring competence by a single assessor, a degree of error may exist between the true theoretical score and the actual given score. If a CCS has a cut-off score for competence (e.g. CTS-R), then calculating the measurement error can provide a confidence interval of the estimate of the score (Gordon, Reference Gordon2006).
How can research into the measurement properties of CCSs be improved?
Researchers need to identify a ‘gold standard’ in order to assess the ‘criterion validity’ of measures. Although the CTS-R (Blackburn et al., Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001) is used extensively in research and training to assess CBT competence, there is no empirical evidence that it is the ‘gold standard’ or that another exists. In future research examining the measurement properties of CCSs, ‘criterion validity’ should not be assessed unless the study presents good evidence that the comparative measure is a ‘gold standard’. This ‘gold standard’ is unlikely to be just one measure of competence, as multiple measures from different sources are more reliable (Muse and McManus, Reference Muse and McManus2013). Instead, ‘convergent validity’, which measures whether constructs on a scale that should be related are related, might be more appropriate.
Test–re-test reliability was a neglected area of measurement with only one study reporting it (von Consbruch et al., Reference von Consbruch, Clark and Stangier2012). Future research should consider examining test–re-test reliability as scoring the same treatment session, the same way on different occasions, should be an important feature of CCSs. It is, however, understandable that some studies are not able to run for sufficient time to provide conditions to assess test–re-test reliability, which would enable a reduction in carry-over effects. In these cases, calculating internal consistency only requires the rating of competence at one time point (Polit, Reference Polit2015), which might be preferable given the time and costs involved in rating the same session twice.
Finally, there is difficulty in interpreting responsiveness in CCS studies, due to the property it is measured against. The discrepancy found between the reporting of discriminant validity and responsiveness in Blackburn et al. (Reference Blackburn, James, Milne, Baker, Standart, Garland and Reichelt2001) and Muse et al. (Reference Muse and McManus2013) is perhaps understandable given some psychometricians have argued that responsiveness does not require its own label, describing it as longitudinal construct validity (Streiner et al., Reference Streiner, Norman and Cairney2015; Terwee et al., Reference Terwee, Dekker, Wiersinga, Prummel and Bossuyt2003). This may also be why no CCSs, in this review, have examined responsiveness explicitly. To know that a scale can detect change longitudinally you would need to have some way of ensuring that the competence level had in fact changed. There is research supporting the view that competence increases because of training (James et al., Reference James, Blackburn, Milne and Reichfelt2001; McManus et al., Reference McManus, Westbrook, Vazquez-Montes, Fennell and Kennerley2010), but these studies only measure competence using CCS scores, when multiple methods would strengthen their designs (Alberts and Edelstein, Reference Alberts and Edelstein1990). Although the COSMIN group reached consensus that responsiveness should be its own distinct domain for health measurement instruments, further clarity is needed to understand if and how this should be applied to CCS research. Regardless of whether responsiveness or discriminant validity is assessed, the research would benefit from including multiple measures of competence from which CCSs could be measured against.
The current review sought to define the properties clearly to assign quality scores, but there is difficulty in defining these constructs. As mentioned, some researchers assert that responsiveness is in fact a version of (longitudinal) construct validity (Streiner et al., Reference Streiner, Norman and Cairney2015). Similarly, criterion validity and convergent validity were often confused, as they may be evaluating the same construct. The COSMIN panel identified the similarity between responsiveness, construct validity and criterion validity (Mokkink et al., Reference Mokkink, Terwee, Patrick, Alonso, Stratford, Knol and de Vet2010c). Although the COSMIN team have attempted to define these properties for HSMIs, further consensus is again needed to specify these terms in relations to therapy competence scales.
What are the implications for training and clinical practice in CBT?
Overall, the quality of the studies means conclusions about the validity and reliability of all CCSs should be held tentatively particularly regarding criterion validity, measurement error, test–re-test reliability, responsiveness and criterion validity.
Researchers, trainers and supervisors should exercise caution if using single assessors to rate therapist’s competence based on a suggested cut-off score, as such a score may be subject to measurement error. Best practice would therefore be to ensure that a given session is rated by two different assessors, as is standard practice on British Association for Behavioural and Cognitive Psychotherapies accredited training programmes with all CTSs and CTS-Rs being marked and moderated by two assessors. Further examination of measurement error in research is need for CCSs that have a suggested cut-off score, especially if it is known that the CCSs are used by single assessors.
Limitations
As only the lead author conducted the paper selection, this increased the possibility of researcher bias. The lead author (K.R.) discussed the paper selection at every stage with author L.W., but the review would have been strengthened if paper selection was conducted fully by at least two authors.
The review developed a novel tool (CATCS) to assess the quality of studies examining the measurement properties of CCSs. The CATCS may also have utility for assessing the quality of other competence measures in psychotherapy. A recent systematic review found that 44 to 88% of papers that create novel measures do not report supporting information about the tool’s reliability and validity (Flake et al., Reference Flake, Pek and Hehman2017). The CATCS is the first published tool developed to assess the quality of competence measures research.
Although the inter-rater reliability of the CATCS was found to be good, the analysis was only conducted on half of the studies, which limits the reliability of the measure. Further assessment of the CATCS’s measurement properties is required to ascertain its reliability and validity. The CATCS could be further improved by more detailed instructions for scoring criteria to ensure results can be replicated between researchers: expert opinion from psychometrics, HSMI fields and psychotherapy may add further clarity to the construct definitions and adequate samples sizes.
The exclusion criteria were intentionally narrow to focus on research that specifically aims to examine the measurement properties of CCSs. Additional studies reporting some of the measurement properties of these tools were not included, e.g. RCTs using a CSS to assess fidelity. Furthermore, the present review did not have the resources to include non-English language studies which led to the review not examining cross-cultural validity, as it is only appropriate for translated instruments (Mokkink et al., Reference Mokkink, Terwee, Patrick, Alonso, Stratford, Knol and de Vet2010c). The CTS/R has been translated into other languages and further research could include a review of the measurement properties of these scales, including cross-cultural validity.
Conclusions
This systematic review presents the first attempt to assess the quality of the research examining measurement properties of CCSs. The review found only ten studies that met inclusion criteria and overall quality was assessed as ‘poor’ to ‘fair’, mostly due to sample sizes. Given the widespread use of CCS to assess competence in research, practice and training, it is important to note that the quality of the research reporting the properties of CCS was not better. The review makes recommendations to improve future research into the measurement properties of CCS, including clarity and consensus regarding definitions of measurement properties and adequate samples sizes.
Acknowledgements
None.
Financial support
This research received no specific grant from any funding agency, commercial or not-for-profit sectors and was undertaken as part of Kathryn Rayson’s DClinPsy training.
Conflicts of interest
Kathryn Rayson, Dougal Hare and Louise Waddington have no conflicts of interest with respect to this publication.
Ethical statement
No ethical approval was required as this is a review.
Data availability statement
The authors confirm that the data supporting the findings of this study are available with the article (and/or its supplementary material).
Supplementary material
To view supplementary material for this article, please visit: https://doi.org/10.1017/S1352465821000242









Comments
No Comments have been published for this article.