First language (L1) knowledge and L1 processing routines can heavily influence second language (L2) online processing (Ellis, Reference Ellis2006; Ellis et al., Reference Ellis, Hafeez, Martin, Chen, Boland and Sagarra2014; Hopp & Lemmerth, Reference Hopp and Lemmerth2018; Roberts & Liszka, Reference Roberts and Liszka2013) and offline interpretation and production (Ellis & Sagarra, Reference Ellis and Sagarra2011; Huensch & Tracy-Ventura, Reference Huensch and Tracy-Ventura2017; Murakami & Alexopoulou, Reference Murakami and Alexopoulou2016). Several theories of L2 input processing additionally foreground a critical role for L1, such as L1-entrenched attention allocation and blocking (Cintrón-Valentín & Ellis, Reference Cintrón-Valentín and Ellis2016; Ellis, Reference Ellis2006) and L2 processing routines that can be influenced by the L1 (MacWhinney, Reference MacWhinney2005, Reference MacWhinney2012; O’Grady, Reference O’Grady2013; VanPatten, Reference VanPatten2002). Very little research, however, has examined the extent to which this research evidence base about L1 influence in L2 acquisition can be used to enhance the effectiveness of L2 grammar learning, including theorizing about how explicit information (EI) about the L1 might influence L2 performance, online or offline. Research to date in this area has shown that EI about L1 and L2 form–meaning mappings for crosslinguistically different target features immediately benefitted written, untimed L2 production (Ammar, Lightbown, & Spada, Reference Ammar, Lightbown and Spada2010; Horst, White, & Bell, Reference Horst, White and Bell2010; Kupferberg, Reference Kupferberg1999), whereas EI about the L2 only (but not about the L1) for crosslinguistically different features did not benefit performance on grammaticality judgment tests (Tolentino & Tokowicz, Reference Tolentino and Tokowicz2014).
Building on this agenda, McManus and Marsden (Reference McManus and Marsden2017, Reference McManus and Marsden2018) provided EI about the L1 (unlike Tolentino & Tokowicz, Reference Tolentino and Tokowicz2014) and interpretation practice of both French (L2) and English (L1) sentences (unlike any of the aforementioned studies) to investigate their instructional effectiveness for aspect in L2 French, a well-documented area of difficulty due to crosslinguistic differences (Howard, Reference Howard2005; Izquierdo & Collins, Reference Izquierdo and Collins2008; McManus, Reference McManus2013, Reference McManus2015). McManus and Marsden’s explicit instruction lasted 3.5 hrs and was delivered over 4 weeks. EI about L1 and L2 processing routines followed by interpretation practice of English (L1) and French (L2) sentences improved learners’ speed (online) and accuracy (offline) of aspectual interpretation (imparfait, passé composé, présent) 4 days after instruction (immediate posttest) and 6 weeks later (delayed posttest). While that post-instruction evidence suggested that L1 EI benefited L2 online and offline performance, we understand very little about the nature of the actual learning trajectory during the practice, including the extent to which learning during the practice was affected by receiving prepractice EI about the L1. The current study addressed this gap by examining learners’ item-by-item interpretation of French sentences while undertaking practice, to better understand how performance during the practice contributed to the learning gains at immediate posttest and delayed posttest as previously reported by McManus and Marsden (Reference McManus and Marsden2017, Reference McManus and Marsden2018). To our knowledge, no previous research has investigated the extent to which EI about L1 and L2 processing routines can affect the accuracy, speed, and automaticity of learners’ responses during practice.
In addition, the current study addressed a potential methodological limitation of McManus and Marsden’s (Reference McManus and Marsden2017, Reference McManus and Marsden2018) study, in which the two crosslinguistic outcome tests (where items provided an L1 context followed by L2 stimulus) may have advantaged the L2+L1 group. The current study removes this possible confound by examining performance during L2 practice in which no L1 context was given in the practice sentences. Thus, benefits for L1 explicit instruction on activities that did not coerce crosslinguistic processing would suggest that McManus and Marsden’s previous findings were unlikely to have been an artifact of the nature of the tests themselves.
PRACTICE, AUTOMATIZATION, AND ITS SIGNATURES
Research examining the effectiveness of EI and practice have mostly assessed learning using offline outcome measures, often immediately after instruction without delayed posttesting (for review, see Shintani, Reference Shintani2015), with very few analyses of performance during practice. These lines of research cannot (and have not sought to) address theoretical questions about learning subprocesses during practice. Skill acquisition theory (Anderson, Reference Anderson1983) proposes sequenced subprocesses that assign practice a key role in development (see DeKeyser, Reference DeKeyser2015). First, establishing reliable and accurate declarative knowledge is argued to be essential (Cornillie, Van Den Noorgate, Van den Branden, & Desmet, 2017; DeKeyser, Reference DeKeyser1997), although no research to date has examined whether providing information about the L1 may affect subsequent stages of skill acquisition. Procedural knowledge is thought to underpin the conscious rule-governed behavior that rehearses this declarative knowledge and has been characterized by decreasing error rates and faster reaction times. Over time, such practice can lead to automatization, “a fast, parallel, fairly effortless process that is not limited by short-term memory capacity, is not under direct subject control, and is responsible for the performance of well-developed skilled behaviors” (Schneider, Dumais, & Shiffrin, Reference Schneider, Dumais and Schiffrin1984, p.1). Although the accuracy and reliability of declarative knowledge representations prior to practice are argued to play a key role (Anderson, Reference Anderson1983), little research exists into longitudinal behavioral signatures that may follow this new declarative knowledge about language (i.e., during practice). Such data are critical for determining the validity of skill acquisition theory in accounting for aspects of L2 learning.
To our knowledge, only two studies have examined fine-grained signatures of learning in longitudinal designs. Both studies found that accuracy improved and reaction times (RTs) decreased as a function of practice. These curves of development showed large changes early on in the practice with smaller changes later on, indicative of qualitative improvements in the stability and efficiency of processing rather than processing speed-up only. In DeKeyser (Reference DeKeyser1997), all participants received the same EI about morphosyntax of a novel language and were assigned to one of three practice conditions: comprehension, written production, or equal proportions of both. Practice lasted 8 weeks, distributed over 15 sessions (24 practice items per session, with feedback for incorrect responses). Longitudinal analyses across all practice sessions showed that performance was strongly influenced by practice type: “performance in comprehension or production is severely reduced if only the opposite skill was practiced” (p. 213, see also Li & DeKeyser, Reference Li and DeKeyser2017). Furthermore, independent of practice type, DeKeyser found that RTs decreased and accuracy improved as a function of the practice, most noticeably between the first two sessions, with smaller changes between latter sessions. Similar findings were reported by Cornillie et al. (Reference Cornillie, Van Den Noortgate, Van den Branden and Desmet2017), who documented signatures of learning English morphosyntax during online gaming. All participants received the same prepractice EI about the L2 (as in DeKeyser, Reference DeKeyser1997), completed the same comprehension practice, but received different types of corrective feedback during the practice: correct/incorrect feedback or correct/incorrect feedback with EI about the L2. Practice was game-based grammaticality judgments over 31 sessions (192 practice items per session) in 2 practice sessions (with 2 weeks between them), with two short reading comprehensions before and after gaming. Two target features were investigated: English quantifiers and dative alternation. Results showed similar accuracy scores for both target features in the first practice session. In the second practice session, however, quantifier accuracy scores were higher than those for the dative alternation. In terms of feedback type, additional EI appeared to provide few benefits for dative alternation. Like DeKeyser (Reference DeKeyser1997), within-group analyses showed that increasing amounts of practice led to faster and more accurate performance. The largest improvements were also found in the earlier practice sessions, with fewer improvements later on. While both studies considered RT decreases and accuracy increases to reflect processing improvement, the stability of the RT curves of development were considered evidence of automatization leading the authors to conclude that practice led to qualitative improvements in the stability and efficiency of processing behavior rather than leading only to faster processing.
Because faster RTs could index both automatization (a mechanism within skill acquisition) and, more simply, “speed-up” (Segalowitz, Reference Segalowitz2010; Segalowitz & Segalowtiz, 1993), more accurate and faster performance do not necessarily reflect automatic/unconscious processing. Automaticity is the restructuring of underlying processing routines that enhances processing efficiency and stability, but speed-up corresponds to accelerated performance without necessarily indicating qualitative restructuring (Paradis, Reference Paradis2009; Segalowitz, Reference Segalowitz2010). Segalowitz and Segalowitz (Reference Segalowitz and Segalowitz1993) proposed that processing stability combined with faster performance may be signatures of greater processing efficiency. To tease apart automatization from processing that speeds up but in the absence of change in the nature of the knowledge, as would be required for proceduralization and automatization, researchers have used the coefficient of variation (CV), a measure of processing stability (mean standard deviation [SD] divided by mean RT). CV distinguishes between a general speed-up (where SD and RTs decrease at the same rate) and automatization (where the rate of decrease in SD exceeds the rate of decrease in RTs). This is because automatization is understood to entail elimination or reduction of inefficient subprocesses/components that are the cause of processing variability. Thus, processing stability is reflected by SD of RTs getting narrower over time at a faster rate than the decrease in RTs over time, resulting in a trajectory of decreasing CVs.
CV interpretation in L2 research is mixed. Cross-sectional designs have shown CV reductions as instruction/proficiency level increases (Hulstijn, van Gelderen, & Schoonen, Reference Hulstijn, van Gelderen and Schoonen2009; Lim & Godfroid, Reference Lim and Godfroid2015), but longitudinal designs have shown that CV trajectories can be more variable with no clear direction of change (Solovyeva & DeKeyser, Reference Solovyeva and DeKeyser2017; Suzuki, Reference Suzuki2017). Time is one potential explanation for these findings: longitudinal analyses examined change over hours and days, whereas cross-sectional designs examined change over years. The latter offers more opportunities for practice, understood to be a key driver for automatization, whereas shorter term yet longitudinal (within-subject) data may reflect earlier stages in skill acquisition: knowledge creation and/or restructuring, as in proceduralization.
To our knowledge, no previous research has used CV signatures following different types of prepractice EI about morphosyntax to interpret the effects of L2 instruction during practice. One advantage of this design is that we can explore the extent to which CV variability might index creation and/or restructuring of knowledge that is indicative of proceduralization, as suggested by Solovyeva and DeKeyser (Reference Solovyeva and DeKeyser2017). Solovyeva and DeKeyser’s proposal, however, is based on evidence about lexical processing in a novel language (using lexical decision data of novel words and reanalysis of similar data from Brown and Gaskell, Reference Brown and Gaskell2014, and Bartolotti and Marian, Reference Bartolotti and Marian2014). Lim and Godfroid (Reference Lim and Godfroid2015) suggest that CV might better explain lexical processing efficiency because lexical processing tends to rely more heavily on lower level processes (e.g., lexical access), whereas sentence-level/(morpho)syntactic processing tends to require higher level and multilayered processes, including, for example, lexical access, inferencing, using background information, and building a text model (see also Grabe & Stoller, Reference Grabe and Stoller2013). It is possible that CV changes might be more detectable when processing involves fewer component processes (as in lexical processing, for example). Although it has been argued that CV changes (with no clear trajectory) might represent signatures of change in the nature of lexical knowledge, the extent to which such CV changes might explain morphosyntactic processing remains an empirical question.
In sum, the current study addresses the following gaps. First, unlike both Cornillie et al. (Reference Cornillie, Van Den Noortgate, Van den Branden and Desmet2017) and DeKeyser (Reference DeKeyser1997), whose learners all received the same prepractice EI about the L2, we compared different types of prepractice EI: EI about L2 only versus EI about L2 and L1. Second, participants were authentic classroom learners of L2 French, thus contrasting with previous investigations of longitudinal development during practice with (semi-)artificial languages in lab-based settings (but see Cornillie et al.). Third, our instruction focused on the meaning(s) of the grammatical feature under investigation (in contrast to Cornillie et al.). Fourth, we provided extensive practice with many opportunities for proceduralization. Fifth, we examined learners’ item-by-item, longitudinal performance during each practice session, thus offering a detailed picture of accuracy and RT trajectories. In these ways, we extend the agenda on using CV as an index of knowledge restructuring and automatization involving morphosyntax.
RESEARCH QUESTIONS
This study examined whether the type of EI (L2-only or L2+L1) provided before practice moderated the accuracy and speed of responses during practice. Faster response speeds, as evidenced by decreasing RTs, were further examined using CV to distinguish between speeded-up and automatic performance. We sought to address the following research questions:
∙ To what extent do the accuracy, speed, and automaticity (as measured by CV) of responses change over time with increasing amounts of L2 interpretation practice?
∙ Compared to L2-only EI+interpretation practice, to what extent do the accuracy, speed, and automaticity (as measured by CV) of responses change when undertaking additional L1 interpretation practice with and without L1 EI?
METHOD
Participants
Participants were 53 university learners of French as a foreign language in semester two of a 4-year bachelor of arts honors degree in French. All participants were L1 English speakers, aged 18–21, had completed A2-level French (English high school leaving qualification, equivalent to 700 to 800 hr of instruction), and had not spent more than 6 weeks abroad in a French-speaking country. Mean years of learning French was 10.3 (SD=2.7) and the mean time spent abroad in a French-speaking country was 3.3 weeks (SD=6.07). Advanced-level learners were recruited because our target feature, French imparfait, is acquired late, typically not taught in beginning language classes, and is absent among beginners (Bartning & Schlyter, Reference Bartning and Schlyter2004). Furthermore, in order to examine the extent to which different types of EI plus practice can improve learners’ knowledge of imparfait’s form–meaning mappings, our design required previous knowledge of imparfait’s inflectional forms, but not its full set of form–meaning mappings (as was confirmed by pretest performanceFootnote 1 ).
Target feature: French imparfait (IMP)
The target feature was French IMP verbal morphology, a past tense form used to express past habituality and ongoingness (e.g., il jouait au foot – “he used to play/was playing football”). This feature was selected because second language acquisition research has repeatedly shown its full set of functions are late-acquired due to functional complexity, including complex L1-L2 form–meaning mapping differences (see Bartning & Schlyter, Reference Bartning and Schlyter2004; Howard, Reference Howard2005; McManus, Reference McManus2013, Reference McManus2015). All exemplars of IMP were third-person singular forms: 25 regular (e.g., jouait “play”) and 23 irregular (e.g., finissait “finish”) verb types balanced across 48 lexical verb types: 12 states (e.g., be happy), 12 activities (e.g., run in the park), 12 accomplishments (e.g., walk to the shop), and 12 achievements (e.g., arrive home). For stimuli examples, see Appendix B and IRIS (www.iris-database.org).
Study design
Three instructional treatments were implemented: L2 EI+L2 practice (L2-only, hereafter); L2 EI+L2 practice+L1 EI+L1 practice (L2+L1, hereafter); L2 EI+L2 practice+L1 practice (L2+L1prac, hereafter). Participants were randomly assigned to one of these treatments, which were administered one-to-one with laptops using E-Prime 2.0 and delivered in four 45-min sessions over 3 weeks, totalling 3.5 hrs. The first author collected all of the data.
Sessions 1 and 2 were delivered in Week 2, Session 3 in Week 3, and Session 4 in Week 4. There were approximately 3 days between each session, and spacing was the same for each treatment group. In addition, spacing between the final treatment session and the posttest and delayed posttests were almost identical across all treatment groups. (See Suzuki, Reference Suzuki2017, for a discussion of the potential effects of different distributions of practice and of different ratios of interpractice and practice–test spacing. As our treatment groups experienced similar spacing, we attempted to control for such effects).
Each session had a different instructional focus on morphemic contrasts expressed by IMP: Session 1, ongoingness in the past (IMP) versus present (present tense); Session 2, habituality in the past (IMP) versus present (present tense); Session 3, past ongoingness (IMP) versus past habituality (IMP); Session 4, past ongoingness (IMP) versus past habituality (IMP) versus past perfectivity (passé composé). Sessions 1 and 2 presented information that was new (i.e., within the experiment), Session 3 combined information that had already been experienced in Sessions 1 and 2, and Session 4 included information that had been experienced in all three previous sessions. All materials are available on IRIS.
Instructional treatments
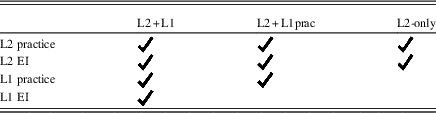
For all three groups (L2-only, L2+L1, and L2+L1prac), treatments included an identical core of EI about French IMP and practice interpreting it. We first describe this common core, before describing the additional L1 treatments. Table 1 summarizes the different instructional components received by each treatment group.
Table 1 Summary of instructional differences between the treatment groups
EI about L2
Prepractice EI was first provided for approximately 5 min at the start of each session and depicted conceptual–semantic information using a short video, image, or sound file of events. Ongoingness in present versus past was the instructional focus in Session 1, for example. Ongoingness was depicted using a 10 second video of a man eating an apple, in which the apple was never fully eaten. Learners were then asked to think about how they would describe what they just saw in the video (e.g., he is eating an apple). Then the appropriate L2 aural and written forms were presented, and information given about how to interpret their meaning. For example, French verb endings can be used to distinguish between past ongoingness and present ongoingness (e.g., il jouait – past IMP, il joue – present tense), and so watching/listening out for verb endings can be helpful to distinguish ongoingness in the past versus present in French. See Appendix C for description of EI used in Session 1.
Practice in L2
Prepractice EI was immediately followed by practice in listening and reading that forced learners to attend to form–meaning mappings expressed by IMP, passé composé or présent (see VanPatten, Reference VanPatten2002, for referential activities in processing instruction, and Marsden, Reference Marsden2006, on using inflections to interpret tense). Learners selected the stimulus’s meaning from two options in Sessions 1 to 3 and three options in Session 4. The L2 practice contained 552 exemplars (96 in each of Sessions 1 and 2; 144 in Session 3; and 216 in Session 4) that were randomly ordered within each session for different participants; each verb type occurred eight times with IMP (n=384), counterbalanced across listening/reading and ongoing/habitual.Footnote 2 All learners completed the same amounts of L2 practice across all treatments, though the items within each practice session were presented randomly by E-Prime. See Appendix A for frequencies of French stimuli and examples. Stimuli were single clause in Sessions 1 and 2 (e.g., Il court dans la rue “he is running in the street”). To practice interpreting IMP’s habituality or ongoingness by relying, critically, on the inflectional morphemes in the broader discourse context, two clause stimuli were necessary in Sessions 3 and 4 (e.g., Elle mangeait un sandwich quand la cloche a sonné “She was eating a sandwich when the bell rang”). An image (e.g., sandwich) plus a bracketed infinitive (e.g., manger “eat”) appeared alongside two clause stimuli so that learners knew which verb to interpret. The stimulus appeared first (e.g., jouait au foot quand sa petite amie est arrivee “was playing football when his girlfriend arrived”), then after 2500 ms (for two-clause stimuli) and 500 ms (for single-clause stimuli) the response options appeared and stayed on screen until a response was pressed. For aural stimuli, the response options did not appear until after the full stimuli had played. Thus, for all practice items, responses were not time pressured. Responses could not be changed after initial selection.
Correct/incorrect feedback was shown immediately after each response. Additional EI was provided during the practice following incorrect responses only, which, as Appendix A, Table A.2, shows, was infrequent and occurred in very (statistically) similar amounts in all treatments.
L2+L1 treatment
In addition to EI about L2 and practice in L2, the L2+L1 treatment included prepractice EI about the L1 (how English expresses the meanings taught in each session; e.g., ongoingness in Session 1) as well as practice interpreting L1 forms expressing those same meanings (e.g., present vs. past progressive in Session 1). The design of the L1 EI and L1 practice followed the exact same design principles as outlined above for L2 EI and L2 practice. See Appendix C for description of L1 EI used in Session 1, and Table A.3, for frequencies of English stimuli.Footnote 3 Correct/incorrect feedback was shown after each response. Additional EI was given following incorrect responses only.Footnote 4
L2+L1prac treatment
The L2+L1prac treatment included L2 EI and L2 practice (as in L2-only and L2+L1 treatments) plus L1 practice. No EI about the L1 was provided, either prepractice or during the practice.
Data analysis
E-Prime collected accuracy and RT data for every response. For accuracy, responses were coded as correct (1) or incorrect (0). Reliability coefficients for accuracy, calculated using the Kuder–Richardson Formula 20, were as follows: Session 1 (.91), Session 2 (.87), Session 3 (.73), and Session 4 (.79).Footnote 5 RTs were calculated in milliseconds from the onset of response options to response selection. We analyzed raw RT data, trimmed in line with Keating and Jegerski’s (Reference Keating and Jegerski2015) recommendations, removing RTs less than 150 ms and greater than 2000 ms. Verbs were coded verbs as irregular or regular.
Accuracy and RT were analysed separately in R (R Core Team 2018). In addition, separate analyses were conducted for each session because each had a different instructional focus (as previously described) and not all sessions included the same number of practice items. For accuracy, we conducted logit mixed-effects analyses (Jaeger, Reference Jaeger2008) using the lme4 package (Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2015). For RT, we conducted mixed-effects linear regression analyses (Baayen, Davidson, & Bates Reference Baayen, Davidson and Bates2008) using nlme (Pinheiro, Bates, DebRoy, Sarkar, & R Core Team, 2018). For both accuracy and RT analyses, explanatory variables were as follows: group (L2+L1, coded as –1; L2+L1prac, coded as 1; L2-only, coded as 0); item (i.e., ranked practice item number); and verb (regular, coded as 1; irregular, coded as 0). These were entered into the models as fixed effects. Subject and items were added as cross-random factors.
In contrast to analyses of variance, mixed-effects analyses avoid violating the assumption of independence because they model relationships between observations, an important consideration for our longitudinal analyses (Field, Miles, & Field, Reference Field, Miles and Field2012; Murakami, Reference Murakami2016). Mixed-effects models additionally offer many other advantages over analyses of variance, including greater flexibility of data distribution (e.g., binomial variables) and robustness against violations of homoscedasticity and sphericity. This makes mixed-effects models particularly useful for longitudinal research and more desirable for our analyses (Cunnings & Finlayson, Reference Cunnings and Finlayson2015; Linck & Cunnings, Reference Linck and Cunnings2015).
For each session, multiple models were constructed and the most plausible model was found through comparison. We started with the simplest model, with new parameters added to the model one at time (Field et al., Reference Field, Miles and Field2012; Murakami, Reference Murakami2016). We compared models as they were built using maximum-likelihood estimation (Field et al., Reference Field, Miles and Field2012).
We fitted a baseline model in which we included only the intercept, then we fitted a model that allowed the intercept to vary over subjects. Finally, to verify whether allowing the intercepts to vary improved the model fit significantly, we compared the models using the Akaike information criterion and the anova function. The final models were then built by adding group, item, and verb as fixed-effect factors, followed by a random slope added for the effect of item (thus allowing the effect of item to vary across subjects, because items were randomly ordered within each session for each participant), and then a Group×Item fixed-effect interaction. After adding each new parameter to the model, we verified whether its addition significantly improved the fit of the model (using AIC and anova, see Table 2 for accuracy and Table 3 for RT). A parameter was only retained in the optimal model if its addition significantly decreased the AIC value (see Cunnings & Finlayson, Reference Cunnings and Finlayson2015; Field et al., Reference Field, Miles and Field2012). For example, the verb parameter in Sessions 1–3 for RT did not significantly improve the final model, but its removal did. As a result, our optimal models in Sessions 1–3 for RT excluded the verb parameter.
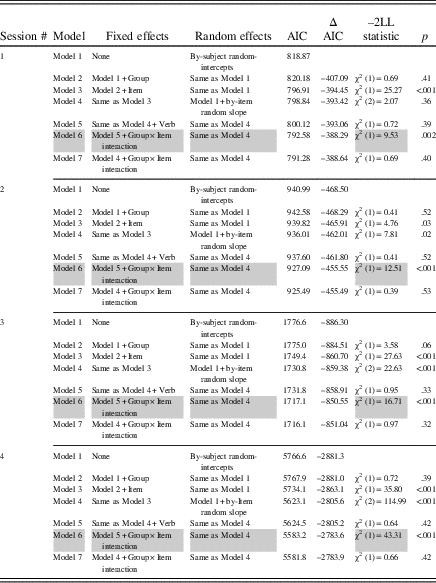
Table 2 Summary of logit mixed-effects model comparisons for accuracy
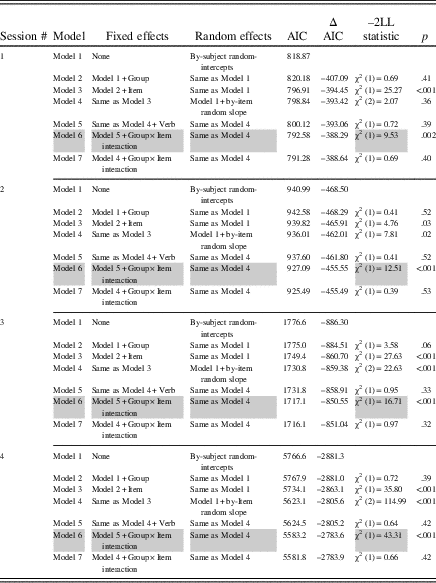
Note: Gray shading indicates optimal model.
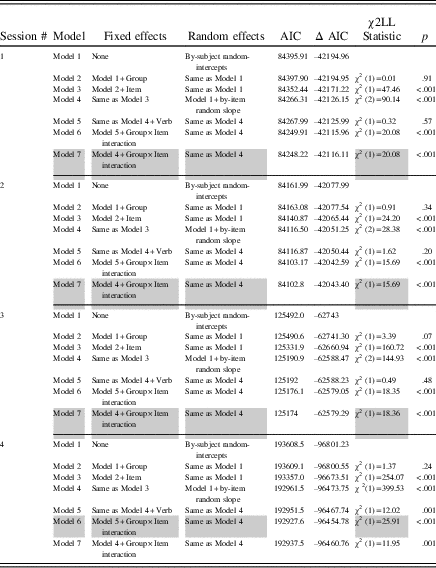
Table 3 Summary of mixed-effects linear model comparisons for RT
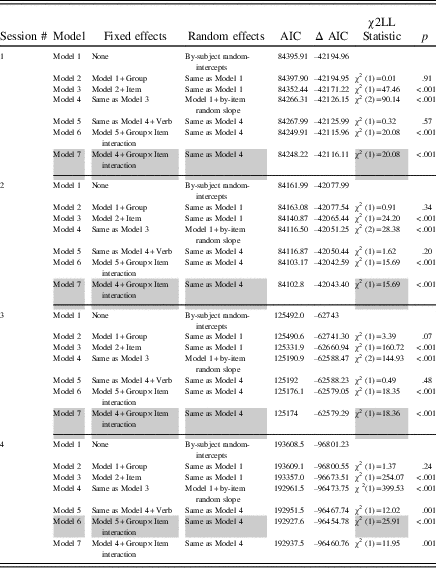
Note: Gray shading indicates optimal model.
Because each optimal model contained three treatment groups, Group×Item interactions were further explored using lme4 (for accuracy) and nlme (for RT) for each group (equivalent to post hoc testing; see Field et al., Reference Field, Miles and Field2012), thus allowing further examination of treatment effects on performance over time.
For RTs that significantly quickened over time in each session, we calculated the CV. As done by Hulstijn et al. (Reference Hulstijn, van Gelderen and Schoonen2009), Lim and Godfroid (Reference Lim and Godfroid2015), and Suzuki and Sunada (Reference Suzuki and Sunada2016), data for our CV analyses included RTs for correct responses only, and excluded (a) incorrect responses, to reduce potential confounds between processing speed and accuracy of linguistic knowledge, and (b) extremely slow RTs of more than 3 SD above the mean, to exclude potentially invalid data. This procedure removed 3,272 data points (11.3% of the data). Simple linear regression analyses were used to model the nature and size of the relationship between CV (outcome variable) and ranked item number (predictor variable). Linearity was examined using scatterplots, which showed linear distribution of the data.
For all analyses, the α was set at .05. To interpret effect estimates and magnitudes of change, we present 95% confidence intervals (CIs) and R 2 effect sizes. CIs that do not pass through zero can be considered reliable indicators of change. Like other standardized effect size statistics, R 2 can be used as a summary index for statistical models to evaluate model fit, compare magnitudes of effect across studies, and can be used for meta-analysis (Nakagawa & Schielzeth, Reference Nakagawa and Schielzeth2013). R 2 values range from 0 to 1 and are used to estimate how much of the variance in performance (accuracy, RT, and CV) can be accounted for by group, item (ranked item number), and verb (ir/regularity), individually and collectively (see Plonsky & Oswald, Reference Plonsky and Oswald2017). We report R 2 values for all fixed effects (marginal R 2), computed using the MuMIn package (Bartoñ, Reference Bartoñ2018) in R (R Core Team, 2018). R 2 values around .18, .32, and .51 are interpreted as small, medium, and large, respectively, in terms of the explained variance they represent (Plonsky & Ghanbar, Reference Plonsky and Ghanbar2018).
RESULTS
Results are presented separately for accuracy and RT. CV analyses are used to interpret RTs that reduced over time.
Accuracy
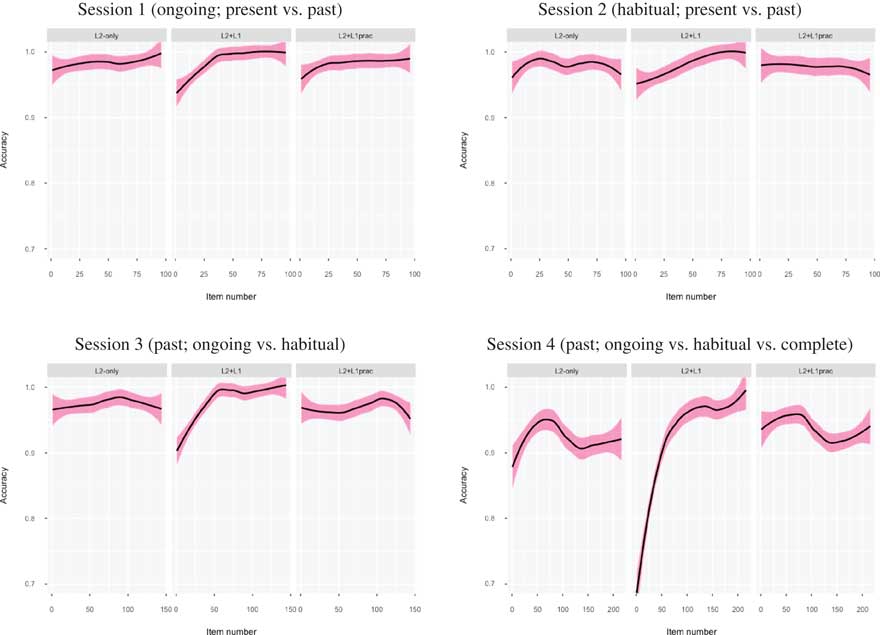
Table 4 shows the effects of the fixed factors and the interaction between treatment group and ranked item number for accuracy in all practice sessions (see Figure 1 for corresponding plots with 95% CI shading).
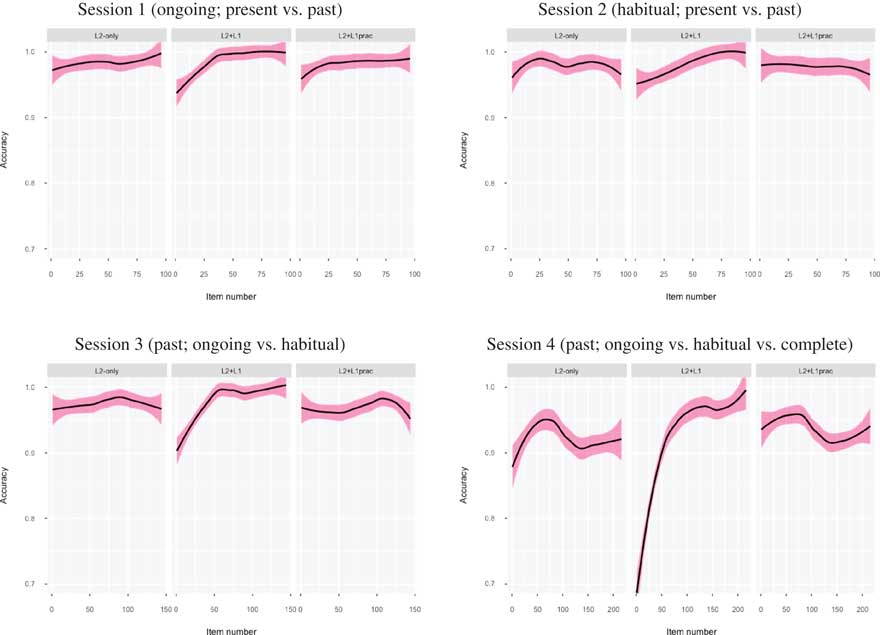
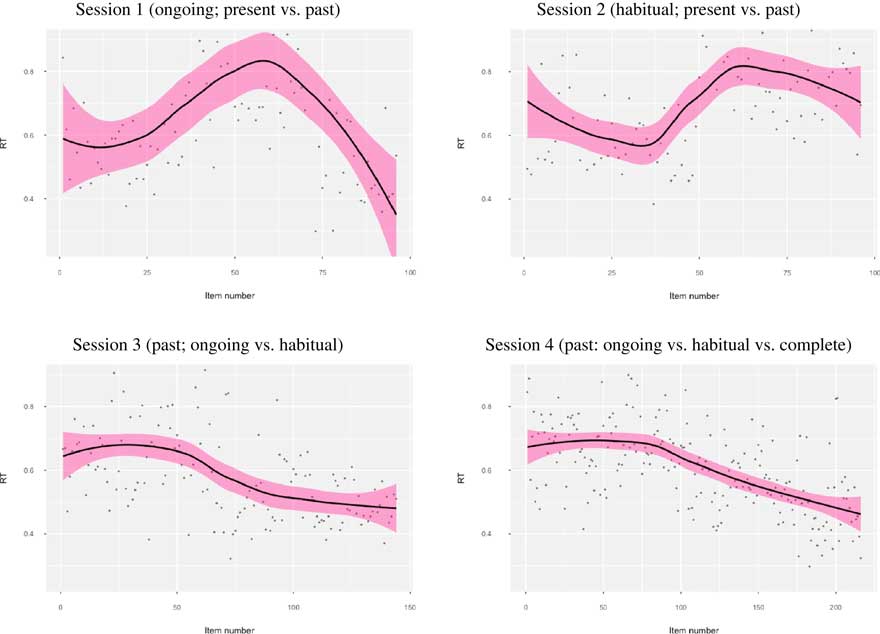
Figure 1 Accuracy scores over time in each training session (black line=regression line, pink shading=95% confidence intervals).6
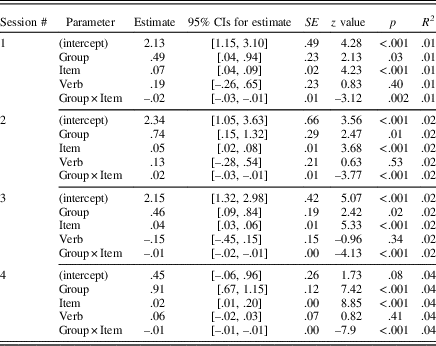
Table 4 Summary of fixed effects for accuracy
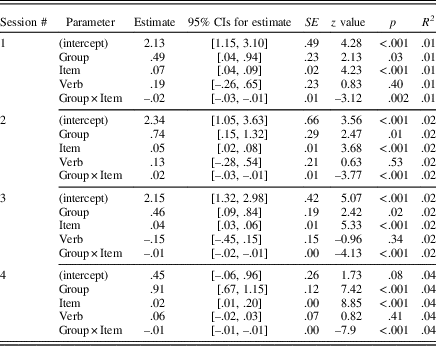
Verb regularity did not significantly influence the accuracy of learners’ performance in any practice session (p>. 05, all CIs passed through zero). Group, item number, and the interaction between group and item number, however, were all statistically significant (with CIs that did not pass through zero), indicating that group and item number both individually and together significantly influenced the accuracy of learners’ performance over time.
Post hoc tests examining each group’s performance over time indicated that the L2+L1group’s accuracy improved significantly over time in all four practice sessions: Session 1, b=.07, 95% CI [.03, .09], z=4.54, p<.001, R 2=.03; Session 2, b=.05, 95% CI [.02, .08], z=3.24, p=.001, R 2=.04; Session 3, b=.04, 95% CI [.03, .05], z=5.85, p<.001, R 2=.04; Session 4, b=.02, 95% CI [.01, .02], z=7.48, p<.001, R 2=.08. Although R 2 values over the four practice sessions were very small overall, practice explained more of the variance in performance in Session 4 than any of the previous sessions.
In contrast, we found that accuracy did not significantly improve over time for the L2+L1prac and L2-only groups. For L2+L1prac, accuracy worsened slightly but significantly over time in Session 4, b=.00, 95% CI [–.01, .00], z=–2.32, p=.02, R 2=.01, but not in the other practice sessions: Session 1, b=–.01, 95% CI [–.01, .03], z=–1.68, p=.09, R 2=.00; Session 2, b=–.01, 95% CI [–.03, .01], z=–1.15, p=.25, R 2=.01; Session 3, b=.00, 95% CI [.00, .01], z=.77, p=.44, R 2=.01. Results for the L2-only group showed no change over time for accuracy in any of the sessions: Session 1, b=.01, 95% CI [–.01, .04], z=1.09, p=.27, R 2=.01; Session 2, b=–.01, 95% CI [–.03, .02], z=–0.54, p=.59, R 2=.01; Session 3, b=.00, 95% CI [–.01, .01], z=0.82, p=.41, R 2=.01; Session 4, b=.00, 95% CI [–.01, .00], z=0.06, p=.95, R 2=.02. All CIs for L2+L1prac and L2-only either passed through zero and/or included zero. There were also few changes in R 2 values over time, which were even smaller than those found for the L2+L1 treatment, indicating that increasing amounts of practice contributed little to explaining performance, thus contrasting with the patterning of results found for the L2+L1 treatment.
Taken together, these results indicate that only the L2+L1 group’s accuracy over time significantly improved with increasing amounts of practice. We found no such evidence for the L2+L1prac and L2-only groups. These learning trajectories are visualized in Figure 1.
RTs
Table 5 shows the effects of the fixed factors and the interaction between treatment group and ranked item number for RT in all practice sessions (see Figure 2 for corresponding plots with 95% CI shading).
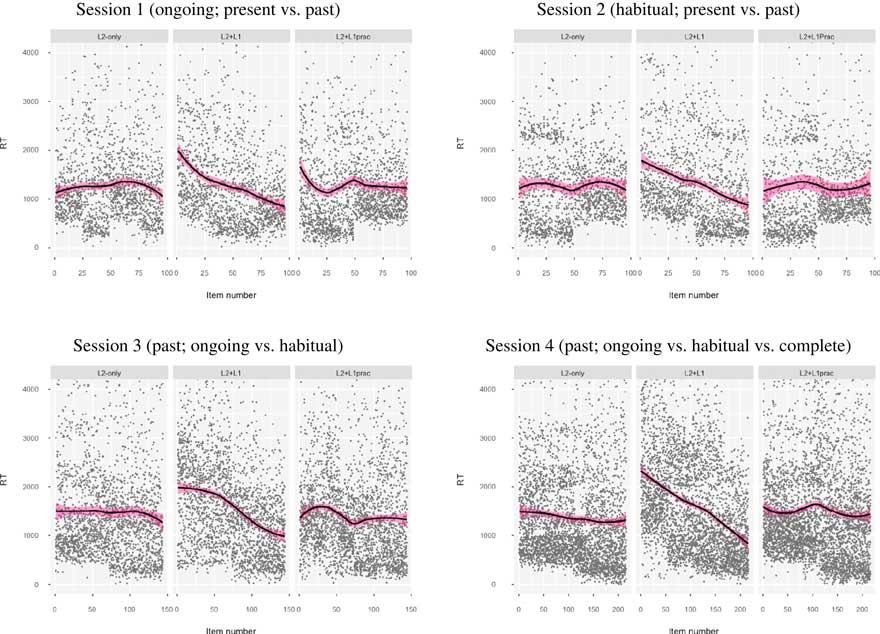
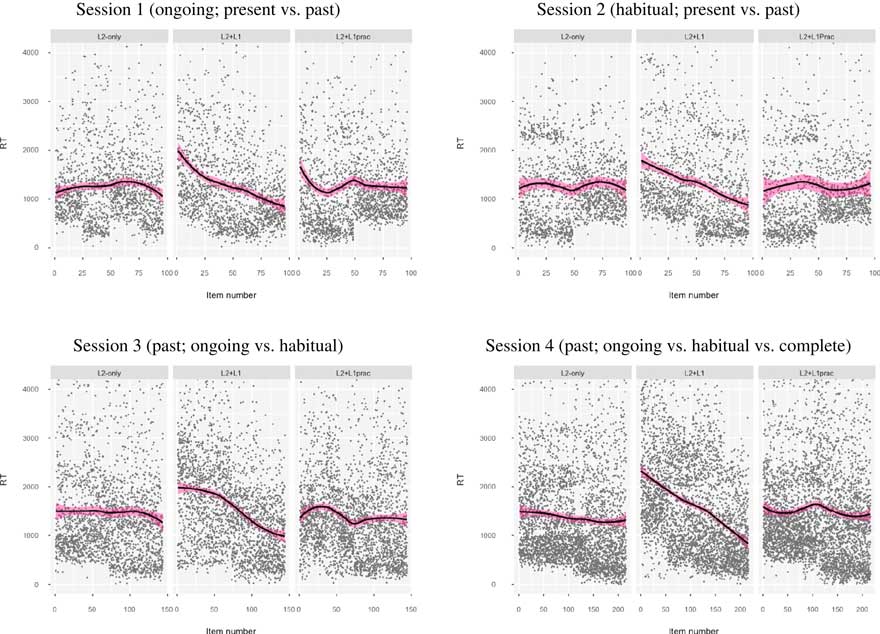
Figure 2 Reaction times over time in each training session (black line=regression line, pink shading=95% confidence intervals, gray dots=individual data points).
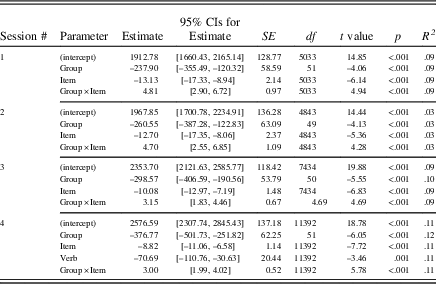
Table 5 Summary of fixed effects for RT
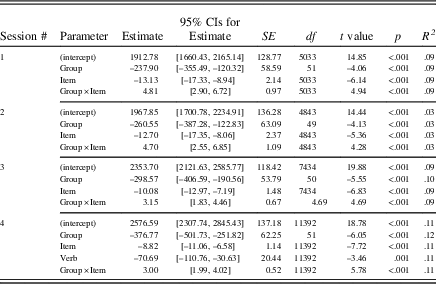
The addition of a fixed main effect for verb in Sessions 1, 2, and 3 did not lead to an improvement of model fit (see Table 3), indicating that verb regularity did not significantly influence the speed of learners’ performance in these sessions. In Session 4, however, verb regularity significantly influenced the speed of learners’ performance (p<.05, CIs did not pass through zero). Although post hoc tests showed significantly slower performance on irregular than regular verbs for L2+L1prac, b=–113.81, 95% CI [–184.62, –43.00], t (4083)=–3.15, p=.002, R 2=.09, and L2-only, b=–75.97, 95% CI [–151.53, –0.41], t (3653)=–1.97, p=.05, R 2=.04, verb regularity only explained a very small proportion of the variance. In the L2+L1 group, however, we found no differences between irregular and regular verbs, b=–14.89, 95% CI [–75.06, 45.28], t (3653)=–0.49, p=.63, R 2=.04.
Group, item number, and the interaction between group and item number, however, were all statistically significant (with CIs that did not pass through zero), indicating that group and item number both individually and together significantly influenced the speed of learners’ performance over time.
Post hoc tests examining each group’s performance over time indicated that the L2+L1group’s speed of performance got significantly faster over time in all four practice sessions: Session 1, b=–10.27, 95% CI [–12.12, –8.27], t (1614)=–10.96, p<.001, R 2=.13; Session 2, b=–9.61, 95% CI [–12.09, –7.13], t (1614)=–7.58, p<.001, R 2=.12; Session 3, b=–8.37, 95% CI [–9.56, –7.18], t (2430)=–13.74, p<.001, R 2=.20; Session 4, b=–6.59, 95% CI [–7,73 –5.47], t (3653)=–11.48, p<.001, R 2=.32. R 2 values over the four practice sessions additionally indicated that practice explained more of the variance in performance in Session 4 than any of the previous sessions, similar to our findings for accuracy, albeit with larger R 2 values (e.g., Session 4 R 2 values were .08 for accuracy, but .32 for RT).
In contrast, we found that L2+L1prac’s speed of processing tended not to change significantly over time, except in Session 3 when RTs got significantly faster over time, b=–1.92, 95% CI [–3.05, –0.80], t (2716)=–3.36, p<.001, R 2=.02, but we found no significant change in the other sessions: Session 1, b=–0.44, 95% CI [–2.61, 1.73], t (1804)=–0.39, p=.69, R 2=.06; Session 2, b=–0.20, 95% CI [–3.04, 2.63], t (94)=–0.14, p=.89, R 2=.01; Session 4, b=–0.51, 95% CI [–2.02, 0.99], t (4083)=–0.66, p=.51, R 2=.09. Except in Session 3, CIs passed through zero. Similarly, L2-only’s speed of performance did not change significantly over time: Session 1, b=0.38, 95%CI [–2.75, 3.50], t (1614)=.24, p=.81, R 2=.09; Session 2, b=–0.08, 95% CI –3.50, 3.34], t (1614)=–0.05, p=.96, R 2=.02; Session 3, b=–75, 95% CI [–3.19, 1.70], t (2287)= –0.59, p=.55, R 2=.07; Session 4, b=–1.23, 95% CI [–2.62, 0.15], t (3653)= –1.75, p=.08, R 2=.04. CIs in all sessions passed through zero, and there was no clear trajectory of R 2 values.
Consistent with our results for accuracy, fixed main effects for group, item number, and the interaction between group and item number were all statistically significant in all four Sessions (p<.05, CIs did not pass through zero), suggesting that group and item number, both individually and together, significantly influenced the speed of learners’ performance over time. Exclusively in Session 4, verb regularity significantly influenced L2+L1prac’s and L2-only’s reaction times, in that they were slower at giving responses to irregular than regular verbs. Verb regularity did not influence L2+L1’s performance. In sum, therefore, the L2+L1 group’s performance over time significantly improved as a function of the practice. We found no such evidence for the L2-only group. L2+L1prac’s RT got faster over time in Session 3, but there were no changes in Sessions 1, 2, and 4. Practice explained a medium-sized proportion of the variance in Session 4 for the L2+L1group. These learning trajectories are visualized in Figure 2.
Automaticity as measured by coefficient of variation of reaction times
Because only L2+L1’s RTs decreased significantly over time, we present CV analyses to interpret the faster RTs in this treatment group (for summary, see Figure 2). Recall, CVs scores that increase, remain broadly constant, or have no clear direction have traditionally been argued to indicate speed-up or they may indicate, as argued more recently by Solovyeva and DeKeyser (Reference Solovyeva and DeKeyser2017) in relation to novel word learning, the creation and/or restructuring of knowledge. CVs that gradually decrease over time are thought to indicate qualitative changes in processing efficiency and stability, indicative of automatization, a process driven by practice.
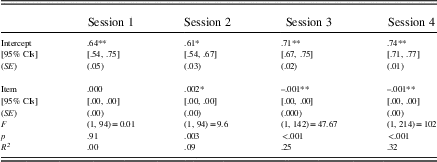
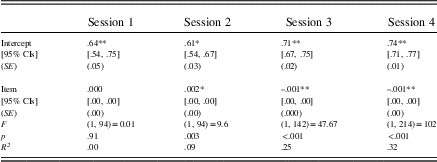
In order to ascertain the extent to which CVs significantly reduced over time, linear regressions were calculated to predict CVs based on item number (see Table 6). Results showed that CVs in Sessions 1 and 2 were variable with no clear direction over time: CV trajectories over time were broadly bell shaped (Session 1) or “S” shaped (Session 2). Ranked item number was not a significant predictor of CVs in Session 1 (R 2=.00). In Session 2, however, ranked item number was a significant predictor of increasing CVs (R 2=.09).
Table 6 Linear regression results for CV scores in each practice session for the L2+L1 group
Note: *p<.01. **p<.001.
In Sessions 3 and 4, reductions in CV appear more visible (see Figure 3). Linear regression results in these sessions showed that ranked item number significantly predicted decreasing CVs (Session 3, R 2=.25; Session 4, R 2=.32). In other words, CVs reduced with increasing amounts of practice. Increasing R 2 values indicate that item number explained more of the variance in Session 4 than in Session 3, and in both sessions, practice explained a small to medium proportion of the variance.
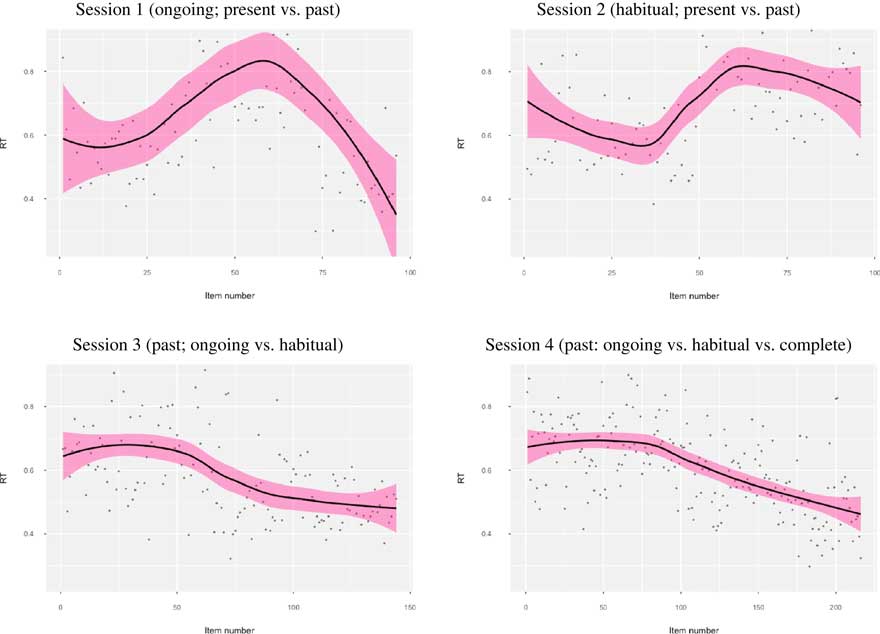
Figure 3 Coefficients of variation over time for L2+L1 group in all sessions (black line=regression line, pink shading=95% confidence intervals, gray dots=individual data points).
In sum, CV trajectories in Sessions 1 and 2 had no clear direction or changed little over time (small R 2 value in Session 2), and then appeared to visibly and reliably decrease over time in Sessions 3 and 4 (medium R 2 values). These results suggest that processing efficiency and stability, indicative of automatization, was not evident in the earlier sessions and was only observable in the last two practice sessions.
DISCUSSION
We examined whether EI about the L1 and/or practice in interpreting the L1 affected the accuracy and speed of learners’ responses during L2 practice, in comparison to receiving only instruction about the L2 (EI and practice). All groups received the same L2 instruction. We examined fine-grained item-by-item performance over time for accuracy and RT over the course of four practice sessions. Results showed that increasing amounts of practice led to more accurate and faster performance in the group that received L1 EI (L2+L1), but not in the groups that did not (L2+L1prac, L2-only).
As all groups received the same L2 EI and practice, these results indicate that L2 practice alone did not lead to the differences observed. This contrasts with the findings of Cornillie et al. (Reference Cornillie, Van Den Noortgate, Van den Branden and Desmet2017) and DeKeyser (Reference DeKeyser1997), where automatization effects were detected after L2 explicit instruction. However, different study designs may explain the difference in our results compared with those from previous research. First, Cornillie et al. provided larger amounts of corrective feedback (yes/no plus EI). Second, DeKeyser’s practice was distributed over a longer period of time (his 15 weeks vs. our 3 weeks). Third, the L1 EI and practice may have been necessary in our study. That is, as neither Cornillie et al. nor DeKeyser focused on crosslinguistically complex form–meaning mappings, additional L1 EI may have been necessary for our target feature (IMP) due to its crosslinguistic complexity. In particular, it may have been necessary to elicit subtle changes among these upper intermediate-advanced learners who were already relatively accurate, at least in terms of the target form (but not its form–meaning mappings).
Although our plots showing performance over time showed initially lower accuracy and slower RTs for L2+L1 than the other groups in each session, L2+L1’s performance significantly improved with practice. These trajectories indicate that L1 EI (received only by the L2+L1 group) created a delayed advantage: performance was initially less accurate and slower, but increasing amounts of practice led to more accurate and faster performance than in the groups without L1 EI.
We used CVs to interpret L2+L1’s faster RTs over time. CV trajectories had no clear direction during Sessions 1 and 2 and decreased during Sessions 3 and 4. Recall also that Sessions 1 and 2 presented and practiced information that was new for the participants (within the context of this experiment), and Sessions 3 and 4 revisited this information through different configurations of practice. Solovyeva and DeKeyser (Reference Solovyeva and DeKeyser2017) proposed two interpretations for CV change. First, knowledge creation and/or restructuring is reflected in CV trajectories that vary but with no clear direction because new (sub)processes are added to existing processing routines (see Suzuki, Reference Suzuki2017). Second, automatization of established/existing knowledge results in decreasing CVs due to the elimination and/or restructuring of inefficient processing routines (see Hulstijn et al., Reference Hulstijn, van Gelderen and Schoonen2009; Lim & Godfroid, 2014). Solovyeva and DeKeyser’s (Reference Solovyeva and DeKeyser2017) proposals repurposed CV, when observed in different patterns, as an indicator of learning in the earlier stages in skill acquisition (where declarative knowledge is established and incorporated into existing knowledge, as it is proceduralized), as well as of the later stages of automatization. Although, to our knowledge, no previous research has used CVs to examine the effects of different types of prepractice EI on L2 performance during practice, Solovyeva and DeKeyser’s (Reference Solovyeva and DeKeyser2017) hypothesis helps explain our observed trajectories.
First, CV trajectories that vary with no clear direction, as found in Sessions 1 and 2, in particular, suggest the restructuring of existing L2 knowledge through the addition of new processes and/or representations (Solovyeva & DeKeyser, Reference Solovyeva and DeKeyser2017). In our case, prepractice EI about the L1 provided new information about form–meaning mappings and processing routines for ongoingness and habituality. We suggest that CV trajectories with no clear direction were underpinned by the integration of new knowledge (EI about the L1) with existing L2 knowledge, thereby changing the nature of the L2 knowledge and its processing, and introducing temporary instabilities into the L2 knowledge system (see Figure 3).
Second, CV decreases in Sessions 3 and 4 appear compatible with automatization of knowledge, due to the elimination of slower, less efficient processing procedures. Our results indicate that reducing CVs only emerged after opportunities to undertake considerable practice (approximately 1.5 hr over two prior sessions, which introduced and rehearsed the same information though in different types of practice items). Session 4 contained the most practice items, and rehearsed information that had already been presented and practiced in three prior sessions, which could explain why we see clearer CV decreases because there were more opportunities for automatization to occur, both within the session and prior to it.
These accuracy, RT, and CV results for performance during practice are consistent with McManus and Marsden’s (Reference McManus and Marsden2017, Reference McManus and Marsden2018) previously discussed post-instruction findings at posttest and delayed posttest, which showed that providing L1 EI with L1 practice alongside a core of L2 EI with L2 practice (i.e., the L2+L1 treatment) improved the speed (on a self-paced reading task) and accuracy (on a sentence judgment task in reading and listening) of L2 processing, immediately after instruction and with gains retained 6 weeks later. There were few reliable learning benefits for groups that did not receive L1 EI as part of their instruction.
Taken together, two trends emerge from the current study’s findings and those for post-instruction performance as reported by McManus and Marsden (Reference McManus and Marsden2017, Reference McManus and Marsden2018). First, performance during the practice was consistent with performance at both posttest and delayed posttest: learners whose performance improved during practice also showed improvement in the outcome measures. Second, our findings indicate that improvement in the accuracy, speed, and stability of L2 performance, both during the practice and post-instruction at the posttests, was found only for learners whose treatment included EI about the L1 (i.e., the L2+L1 group). In other words, L2 practice by itself (without EI about the L1, and even if accompanied by practice in the L1), did not improve the accuracy, speed, and stability of L2 performance, either during the practice or post-instruction at the posttests.
Learning processes during practice
Our results suggest that the L2+L1 treatment (additional L1 EI+L1 practice) played an important role in improving the accuracy, speed, and stability of learners’ responses during practice. L2+L1 EI was more effective than L2-only EI arguably because it addressed the nature of the crosslinguistic learning problem.
Our CV results indicated qualitative changes in learners’ processing, suggesting reduction/elimination of inefficient subprocesses/components that are understood to be a cause of processing variability (Segalowitz, Reference Segalowitz2010). Over time, systematic practice appeared to lead to more efficient/stable processing, in line with our pedagogical aims. We speculate that CV trajectories that vary with no clear direction in Sessions 1 and 2 followed by CV reductions over time in Sessions 3 and 4 reflected adjustment of prior processing routines. We further speculate that this constituted moving away from routines that interpreted IMP via L1 processing routines, such as via a constrained mapping of IMP to meanings expressed by L1 forms, like “BE(past)+ing” (for ongoing meaning) or “used to+verb” (for habitual meaning) or via lexical cues (e.g., adverbials), toward routines that more speedily and reliably interpreted IMP by using inflectional morphology that is used elsewhere in the sentence as a reliable cue for extracting the habitual and ongoing meanings of IMP. This would be consistent with some interpretations that decreases in CV indicate greater processing stability and efficiency brought about by extensive opportunities for practice (e.g., Solovyeva & DeKeyser, Reference Solovyeva and DeKeyser2017; Suzuki, Reference Suzuki2017).
Limitations and future research
Given our small sample sizes, we emphasize that our accounts are tentative. In addition, our interpretations that CV trajectories that vary with no clear direction index knowledge creation and/or restructuring rest on a small body of evidence, and more research is needed to corroborate these interpretations. Nonetheless, this constitutes an important research agenda if we wish to understand the mechanisms underpinning learning effects during practice and seek empirical support for skill acquisition accounts of learning L2s.
We leave to future research the task of investigating how these signatures of automaticity relate to comprehension and production performance after instruction. According to the post-instruction performance results in McManus and Marsden (Reference McManus and Marsden2017, Reference McManus and Marsden2018), it seems that performance on a controlled, interpretation outcome measure (self-paced reading test), even 6 weeks postinstruction, was in line with the during-practice trends observed in the current analysis. That is, both the postinstruction and during instruction measures showed the most benefits for the group that received additional L1 EI plus practice.
The current study provides evidence of benefits of L1 EI (combined with L1 practice, L2 EI, and L2 practice) on L2 inflectional verb morphology with, specifically, crosslinguistically different form–meaning mappings. We saw that a CV signature of automatization was observable most clearly and reliably during a fourth training session (after 2.25 hrs of training). Perhaps critically, this fourth session facilitated repetitive interpretation practice of the material introduced in the previous three sessions. During those first three sessions, and particularly the first two, we observed evidence indicative of knowledge creation and/or restructuring. It remains to be determined how much practice is required for evidence of automatization to emerge, beyond a general speeding-up, for other features and L2 proficiencies.
Our finding that additional L1 EI benefitted the learning of a crosslinguistically complex L2 feature provides some evidence of the usefulness of explicit L1 grammar teaching. For this target feature, L1 grammar teaching led to evidence of change in the nature of L2 knowledge and the speed of access to it. Future research should investigate the extent to which L1 EI may benefit the L2 learning of other linguistic features. Based on these data and our previous research (see McManus & Marsden, Reference McManus and Marsden2017, Reference McManus and Marsden2018), however, L1 EI might be most beneficial for L2 features that are sensitive to crosslinguistic influence at the level of form–meaning mapping (as determined by second language acquisition research), especially for target features that exhibit L1-L2 form–meaning mapping differences like IMP for English speakers. Other target features could include learning of (a) the ser-estar distinction in L2 Spanish and (b) zai in L2 Chinese by L1 English speakers. Similar to IMP, ser-estar and zai exhibit complex L1-L2 form–meaning mapping differences: (a) the meaning expressed by a single form in English (be) is expressed by multiple forms in Spanish (ser and estar; see Silva-Corvalán, Reference Silva-Corvalán2014), and the distinction between “permanent” and “temporary” characteristics (which ser and estar convey) can be expressed by multiple adjectival forms in English (bored and boring) and one form in Spanish (aburrido) or (b) the meaning expressed by a single form in Chinese (zai) is expressed by multiple forms in English (progressive V+ing and prepositional “in”; see Xiao & McEnery, Reference Xiao and McEnery2004). Future research should also investigate the extent to which the usefulness of L1 EI for L2 learning is moderated by age and L2 proficiency. These avenues would help tailor L2 instruction to the nature of the learning problem in different contexts.
APPENDIX A
Table A.1 Frequencies of French stimuli used all treatments
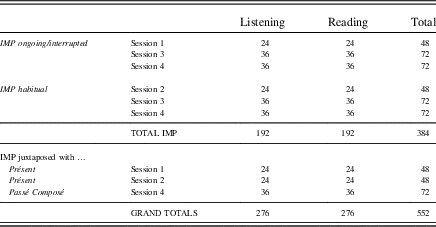
Table A.2 Frequencies of EI received during training when selecting incorrect answers, by group

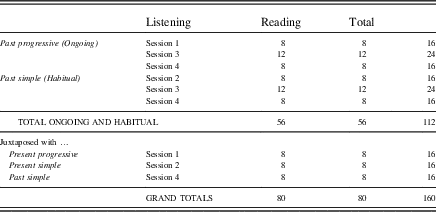
Table A.3 Frequencies of English stimuli used in L2+L1 and L2+L1prac treatments
APPENDIX B
EXAMPLES OF FRENCH STIMULI
Session 1. Ongoing: Participants choose between past versus present

Note: IMP, imparfait. PRES, présent.
Session 2. Habitual: Participants had to choose between past versus present

Note: IMP, imparfait. PRES, présent.
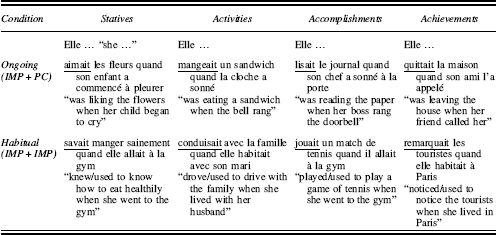
Session 3. Past: Participants had to choose between ongoing versus habitual (“regularly repeated”)
Session 4. Past: Participants had to choose between ongoing versus habitual (regularly repeated) versus complete.
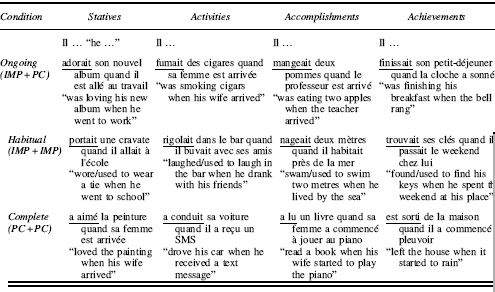
Note: IMP, imparfait, PC, passé composé. Words are underlined for illustrative purposes only, to indicate which verb the participants had to respond to. Only main->subordinate clause ordering is illustrated here
EXAMPLES OF ENGLISH STIMULI
Session 1. Ongoing: Participants had to choose between past versus present

Session 2. Habitual: Participants had to choose between past versus present

Session 3. Past: Participants had to choose between ongoing versus habitual

Note: Words are underlined for illustrative purposes only, to indicate which verb the participants had to respond to. Only main->subordinate clause ordering is illustrated here.
Session 4. Past: Participants had to choose between ongoing versus habitual versus complete

Note: Words are underlined for illustrative purposes only, to indicate which verb the participants had to respond to.
APPENDIX C
Session 1. Ongoingness (present vs. past)

ACKNOWLEDGMENTS
This research was supported by British Academy Postdoctoral Fellowship PF130001 (awarded to K.M., with E.M. as Mentor). Many thanks to the learners who participated in this study, and to Laurence Richard, Angela O’Flaherty, and Nigel Armstrong for help with recruitment. We would also like to thank the editors and three anonymous reviewers for their valuable comments.