


Sentence repetition is a simple task with the instruction for a verbatim repetition of a just-heard sentence. Because repeating sentences requires their recall from memory, sentence repetition has often been used as a working-memory task (e.g., Delcenserie, Genesee, & Gauthier, Reference Delcenserie, Genesee and Gauthier2012). The task, however, involves more than just retrieving an episodic, form-based representation of the sentence. Performance on sentence repetition shows a stable and significant relationship with language and literacy measures over time (English: Hulme, Nash, Gooch, Lervag, & Snowling, Reference Hulme, Nash, Gooch, Lervåg and Snowling2015; Norwegian: Klem et al., Reference Klem, Melby-Lervåg, Hagtvet, Lyster, Gustafsson and Hulme2014), and it reliably reflects properties of early morphology and syntax in typically developing children (e.g., Devescovi & Caselli, Reference Devescovi and Caselli2007; Gábor & Lukács, Reference Gábor and Lukács2012; Polišenská, Chiat, & Roy, Reference Polišenská, Chiat and Roy2015). Furthermore, the difficulty in repeating sentences with more complex syntactic structures is not fully accounted for by differences in the length of the sentences, assumed to tax working memory (e.g., Moll, Hulme, Nag, & Snowling, Reference Moll, Hulme, Nag and Snowling2013). These lines of evidence provide support for the view that language processing systems and working memory are both engaged in sentence repetition. Here we take the discussion about the underpinnings of the task further by focusing on the contribution of language production mechanisms involved in grammatical and phonological encoding to performance on this task.
Language production studies using the nonword repetition task shed light on possible underlying mechanisms in tasks drawing on both linguistic representations and working memory (for a review, see Acheson & MacDonald, Reference Acheson and MacDonald2009a). For example, in a study by Acheson and MacDonald (Reference Acheson and MacDonald2009b), participants were required to recall nonword tongue twisters (e.g., shif seev sif sheev). In addition to providing standard measures of memory such as recall accuracy, Acheson and MacDonald also analyzed speech errors produced while recalling the tongue twisters. The speech errors were found to better reflect phonological encoding processes within the language production system than short-term memory constraints. For example, phoneme substitution errors followed positional constraints (e.g., onsets were exchanged with onsets), reflecting long-term knowledge of the phonological structure of the language and the constraints of phonological encoding processes in speech production.
In a similar vein, errors in sentence repetition can be expected to reflect long-term knowledge of language and the workings of sentence production mechanisms. Detailed analyses of the properties of speech errors have been an invaluable tool for understanding sentence production mechanisms in adults, and these analyses have served as the basis of all major models of the language production system (e.g., Bock, Reference Bock1996; Bock & Levelt, Reference Bock, Levelt and Gernsbacher1994; Dell, Reference Dell1986; Dell & O'Seaghdha, Reference Dell and O'Seaghdha1992; Goldrick, Baer, Murphy, & Beese-Berk, Reference Goldrick, Baker, Murphy and Baese-Berk2011). In such models, semantic substitution errors (e.g., saying cat when dog was intended), typically semantically related to the intended word, are considered to reflect lexical–semantic processing (Bock, Reference Bock1996); exchange errors such as producing He called her yesterday when She called him yesterday was intended, reflect grammatical encoding and specifically function assignment, because this type of error reflects exchanges in thematic roles (e.g., subject and object; Bock, Reference Bock1996); and morpheme exchange errors such as producing discharge replace when recharge displace was required reflect morphological processing (e.g., Melinger, Reference Melinger2003). Thus, whereas nonword repetition performance reflects language production mechanisms at the lexical and sublexical levels (e.g., Coady & Evans, Reference Coady and Evans2008; Dollaghan & Campbell, Reference Dollaghan and Campbell1998), sentence repetition may reflect conceptual processing and grammatical encoding, including the mechanisms of assembling lexical items into meaningful and grammatically correct sentences.
The investigation of the role of sentence production mechanisms in sentence repetition is particularly pertinent given the wide use of the task as a diagnostic tool in developmental disorders such as specific language impairment (Archibald & Joanisse, Reference Archibald and Joanisse2009; Conti-Ramsden, Botting, & Faragher, Reference Conti-Ramsden, Botting and Faragher2001; Redmond, Thompson, & Goldstein, Reference Redmond, Thompson and Goldstein2011). Children at family risk for dyslexia (Hulme et al., Reference Hulme, Nash, Gooch, Lervåg and Snowling2015; Moll et al., Reference Moll, Hulme, Nag and Snowling2013) and bilingual and multilingual children with possible language impairment (Chiat et al., Reference Chiat, Armon-Lotem, Marinis, Polišenská, Roy, Seeff-Gabriel and Gathercole2013; Nag & Snowling, Reference Nag and Snowling2011) also do poorly on this task. The task is also sensitive to the language acquisition history of the child (Delcenserie et al., Reference Delcenserie, Genesee and Gauthier2012; Gauthier & Genesee, Reference Gauthier and Genesee2011), and the levels of proficiency attained by learners of an additional language when compared to native monolingual speakers (Chiat et al., Reference Chiat, Armon-Lotem, Marinis, Polišenská, Roy, Seeff-Gabriel and Gathercole2013; Paradis, Reference Paradis2010). However, the key psycholinguistic mechanisms accounting for individual differences in sentence repetition are still poorly understood. The majority of the studies in the literature using sentence repetition have limited the analysis to gross accuracy measures at the level of the whole sentence or of words as categorical units (e.g., Klem et al., Reference Klem, Melby-Lervåg, Hagtvet, Lyster, Gustafsson and Hulme2014; Riches, Reference Riches2012; Stokes, Wong, Fletcher, & Leonard, Reference Stokes, Wong, Fletcher and Leonard2006). In the current study, we used speech errors to examine the contribution of specific language production mechanisms to task performance.
We used the standard model of language production (e.g., Bock & Levelt, Reference Bock, Levelt and Gernsbacher1994) as the theoretical framework to guide these analyses. According to this model, sentence production starts with the activation of the message (conceptual representation) of the utterance to be produced, and then engages sentence processing mechanisms in different language production subsystems (see Table 1, second column). Within this view, sentence repetition would involve the activation of the conceptual representations of the comprehended sentence (“message” in Table 1), and the individual lexical items of the heard sentence (Potter & Lombardi, Reference Potter and Lombardi1990). The lexical items of the sentence to be repeated would be assigned the appropriate thematic roles within the functional processing subsystem. Further assembly of the constituent words into syntactic structures, and the morphological units (particularly the inflections) into words, would occur during positional processing. During phonological encoding, the phonological structure of the utterance would be specified. These three broad subsystems of language production are generally agreed on across various theoretical models of production (Bock & Levelt, Reference Bock, Levelt and Gernsbacher1994; Dell, Reference Dell1986; Vigliocco & Hartsuiker, Reference Vigliocco and Hartsuiker2002). The key issues where the models differ are the amount of information flowing from one subsystem to the next, and the level of interactivity between the subsystems (e.g., Goldrick et al., Reference Goldrick, Baker, Murphy and Baese-Berk2011; Heisler, Goffman, & Younger, Reference Heisler, Goffman and Younger2010; Mirković & MacDonald, Reference Mirković and MacDonald2013; Vigliocco & Hartsuiker, Reference Vigliocco and Hartsuiker2002).
Table 1. The language subsystems in sentence repetition
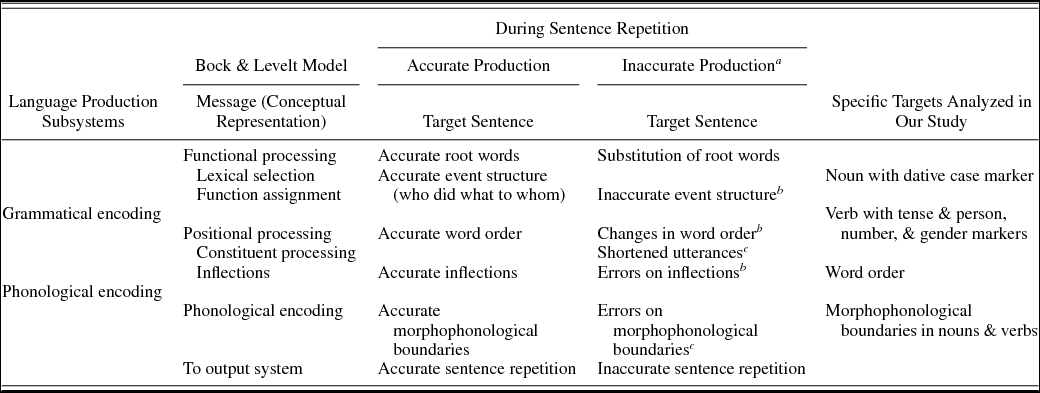
Note: The table illustrates Bock and Levelt's (Reference Bock, Levelt and Gernsbacher1994) model, performance on specific linguistic units during accurate and inaccurate sentence repetition, and the areas of analysis in the current study.
a Errors may be in one or more aspects of processing.
b Typically changes core event meaning.
c Typically preserves core event meaning.
The main aim of the current study was to investigate the contribution of sentence production mechanisms to sentence repetition in 5- to 8-year-old native speakers of Kannada. Kannada is a highly inflected and morphophonologically complex language of Southern India enabling a focus on grammatical and phonological encoding subsystems known to be vulnerable in children with developmental disorders (e.g., English: Botting & Conti-Ramsden, Reference Botting and Conti-Ramsden2003; Redmond et al., Reference Redmond, Thompson and Goldstein2011; Rice, Warren, & Betz, Reference Rice, Warren and Betz2005; Dutch: Wilsenach, Reference Wilsenach2006; Kannada: Sengottuvel & Rao, Reference Sengottuvel and Rao2013; for a review, see Leonard, Reference Leonard2014). We manipulated sentence type in the materials, and we included active, passive, and embedded sentences (see below). In a subset of the analyses, we specifically focused on active and passive sentences, two sentence types known to show different developmental trajectories (Demuth, Moloi, & Machobane, Reference Demuth, Moloi and Machobane2010; Gordon & Chafetz, Reference Gordon and Chafetz1990). Before outlining the specific aims of the current study, we describe the properties of Kannada that make it particularly suitable for this investigation of sentence repetition.
THE KANNADA LANGUAGE
Kannada is a southern Dravidian language spoken by approximately 70 million people. Events are communicated by the grammatical suffixes in content words (Sridhar, Reference Sridhar1990). Examples (1), (2), and (3) illustrate grammatical suffixes in nouns and verbs in three ditransitive structures:
-
(1)

-
(2)
-
(3)



Two properties make Kannada a particularly interesting language to use in sentence repetition. First, Kannada is inflectionally very rich, with inflections used to mark properties such as tense and number as in English, but also grammatical gender and case markings denoting sentential roles (e.g., recipient = dative, direct object = accusative). The morphological realization of specific inflections is influenced by semantic, syntactic, and phonological factors (Amritavalli, Reference Amritavalli2008; Sridhar, Reference Sridhar1990). For example, similar to English, in Kannada the verb form must agree with the subject in grammatical number. However, Kannada is a pro-drop language, and in sentences where the subject is missing, it is possible to use inflectional information to infer the agent from the person–number–gender markings on the verb; these are produced regardless of whether the subject is overt or covert (e.g., she dressed: “haak-id-aLu,” root word-past-3rd person feminine singular). Prominent in the language as well are phonological change processes at the word boundaries, referred to as sandhi. In English, morphophonological processes are seen, for example, in the change from /f/ to /v/ in noun plurals (e.g., elf–el v es, thief–thie v es). We see similar but more complex phenomena in Kannada. For instance, for the genitive marker –a, phonemic changes at the boundary may be with “y” and “v” (daari- y a, “of the path”; guru- v a, “teacher's”), while for the accusative –annu, the phonetic value at the boundary is often “v” (pustaka- v annu, “book”) but can change to “y” elsewhere (mane- y annu, “house”). The morphophonological complexity of Kannada makes it an ideal testing ground for the engagement of grammatical and phonological encoding mechanisms.
The second relevant property of Kannada (a predominantly subject–object–verb language) is that word order and word count can be kept constant across different syntactic structures (see Examples (1) and (2) above). This is different from languages where structure changes often involve word order changes and changes in sentence length (cf. the English translations for Examples (1) and (2) above), thus potentially confounding structural changes with memory load.
These properties of the Kannada language allowed us to perform a more thorough analysis of the contribution of different language production subsystems to performance on the sentence repetition task. Thus, in addition to general accuracy measures, we also analyzed children's speech errors. For sentence-level analyses, the errors were categorized as either preserving or changing the core event meaning of the target sentence. For word-level analyses, we examined morphophonological encoding. The highly inflected nature of Kannada allowed us to analyze separately performance on word roots, inflections, and root-inflection boundaries. As argued above, these errors can be revealing about the processing in the conceptual, grammatical, and morphophonological encoding subsystems, respectively. Moreover, these analyses allow examination of the relationship between the language production subsystems and other linguistic areas such as vocabulary and phonological processing as assessed in nonword repetition. Table 1 (last column) gives the specific linguistic units that were analyzed, with the middle columns showing examples of accurate and inaccurate repetition.
The two specific aims of the current study were the following:
-
1. To establish the extent to which the profile of performance on the task is sensitive to the linguistic properties of the material. For this aim, we analyzed both accurate performance and different types of speech errors.
-
2. To examine the extent to which performance on the sentence repetition task can be explained by individual variation in other linguistic skills and child-level factors. For this aim, we included measures of general ability, vocabulary, and nonword repetition.
METHOD
Participants
Native Kannada-speaking children were drawn from five schools in the Bangalore-Tumkur region of the southern state of Karnataka, India (N = 135). All children were considered typically developing based on their performance on cognitive and language tests (see below for details), but for the lowest performing children, language impairment cannot be ruled out. Our study therefore sampled a wide range of individual differences in language attainment.
The socioeconomic status (SES) of participating children was computed based on each parent's educational level, family spending on printed materials, and possessions at home. Details were available for 65.9% of the sample. Of these, 3.4%, 66.3%, and 30.3% belonged to the lower middle, middle, and upper middle SES groups, respectively. This proportion in each SES band may be considered representative of the SES level of children enrolled in similar schools in the region. The remaining children for whom SES data are not available attended all the same school activities, and did not receive any special financial concessions or tutorial support either in school or outside school, suggesting they were drawn from the same SES bands.
The children were participants in a larger longitudinal study and were assessed on general ability, vocabulary, nonword repetition, and sentence repetition. The battery also included other tests of oral language, cognitive, literacy, and numeracy skills not reported here. At the time of the current study, the children were between 5 and 8 years of age (M age = 79.79 months, SD = 8.45 months) and in the final term in school; 61 children were in the last year of preschool and 74 were in Grade 1. The first language of all children was Kannada. All were receiving literacy instruction in both Kannada and English with the proportion of time given for Kannada lessons equivalent across participating schools. To obtain an estimate of the children's experience with spoken language, we asked parents to list activities at home that were focused on oral narratives. Activities ranged from narrating of the epic stories and folktales of the region to sharing folksongs, film songs, community prayers, chants, and rhymes, and reading aloud from religious books and contemporary publications for children. The frequency of such activities was rated separately for Kannada and English on a 5-point scale (0 = never, 5 = several times a day). Table 2 gives a descriptive summary of the sample characteristics. The frequency of Kannada oral narratives was rated as significantly higher than that of English, t (88) = 7.713, p < .001, confirming that in this sample of children language experiences at home tended to be in Kannada. Age of onset of English exposure was between 1 and 6.5 years, but experience with English at home was remarkably similar across the group (Table 2, oral narratives in English) and rated as very low, suggesting that English was introduced mainly in school and that Kannada was the children's main language.
Table 2. Descriptive summary of the sample characteristics, language experiences, and cognitive–linguistic variables (N = 135)

Note: Raw scores (max.): general abilities (36), oral narratives in Kannada (5) and in English (5), vocabulary (42), and nonword repetition (25). Age and age of onset for English are in months.
a Data are available for 67% of the sample.
Materials
General ability
Raven's Coloured Progressive Matrices (Raven, Court, & Raven, Reference Raven, Court and Raven1995) was used to test nonverbal ability. The test requires the child to complete visual patterns by pointing to the correct from six alternatives.
Vocabulary
This 14-item test was constructed by taking every odd item from a longer vocabulary test (Nag, Reference Nag2008). The correlation between the abridged test and the full test was high (N = 106, r = .937, p < .001). The child had to explain the meaning of words representing actions, qualities, states, time, place, and result. Accurate definitions, synonyms, and translated equivalents received a score of 3, sentential use of the word and descriptions scored 2, and repeating of the word with an inflection or using idiomatic phrases was given 1 (Cronbach α = 0.76).
A native Kannada-speaking research assistant trained in coding the different levels of production scored the protocols. The first author independently coded 30% of the protocols randomly selected from within each participating school. Interrater agreement was calculated as the total agreed codes divided by total agreements and disagreements. Interrater agreement was 100% for responses coded as 3, and 95% each for responses coded as 2 and 1; all disagreements were around whether word descriptions were idiomatic phrases or the reverse.
Nonword repetition
This 25-item test was styled after the phonology of Kannada but with a set of constraints to derive less wordlike items. No nonword contained any Kannada word. The endings of final syllables were always long vowels, and more consonants were aspirated because these occur mainly in loan words. For ease of articulation and transcription, consonant clusters were not used, and all vowels were long because these are less prone to length reduction. An aspect of Kannada phonology retained in item construction was closed syllables in initial or middle positions with the syllable-final consonant either the legal consonant /l/ or /r/ (e.g., khaashii r taa, chhaakhoorii l pee). Five items each of one- to five-syllable length were presented one at a time in a fixed order. Accuracy on the complete syllable string was given a score of 1. The analyses presented here are based on z scores derived from the proportion correct (Cronbach α = 0.77).
Sentence repetition
The 25-item task comprised sentences constructed with early acquired, high-frequency words. We included three sentence types: actives, passives, and embedded sentences (see Examples (1)–(3) and Appendix A for the full set of items). The three sentence types differ in syntactic complexity, but they are also likely to differ in frequency (e.g., Demuth et al., Reference Demuth, Moloi and Machobane2010). Thus, we measured sentence structure frequency through 11 teachers’ ratings of the frequency with which the sentences were considered present in the input (“How often do people say this sentence like this?”) on a 4-point scale (1 = never, 4 = often). We also measured event plausibility denoted by each sentence using teacher ratings: the same teachers rated each sentence on a 5-point scale for “How possible is it for this event to happen?” (1 = not at all possible, 5 = very possible). Both of these measures reflect long-term linguistic and conceptual knowledge. The descriptive statistics for all measures are provided in Appendix A.
In sentence repetition studies, memory load is often manipulated by increasing word count (e.g., Moll et al., Reference Moll, Hulme, Nag and Snowling2013; Polišenská et al., Reference Polišenská, Chiat and Roy2015). Following this approach, we manipulated memory load for the active and passive sentences by increasing word count: the sentences in the long condition were similar to the sentences in the short condition in terms of event semantics (who does what to whom), but contained additional adjectives (Appendix A). Thus, in a subset of the analyses, we compared performance on the two sentence types (actives and passives) with two different sentence lengths (short and long). The four conditions were equated in the average age of acquisition of the words comprising the sentences. As expected, active sentences were rated as more frequent than passive sentences (the active-short condition was most frequent: Sentence Type × Length interaction), F (1, 16) = 6.28, p = .023. Longer sentences were rated as less frequent than shorter sentences: main effect of length, F (1, 16) = 22.82, p < .001. Event plausibility was equated across the two sentence types, but the addition of adjectives reduced event plausibility for the long sentences: main effect of length, F (1, 16) = 6.75, p = .019.
Procedure
Children were tested in a quiet room in their school over four 45-min sessions, two of which were for the tests reported here. The first session covered the general abilities test, nonword repetition, and one half of the sentence repetition task; the second covered the vocabulary task and the other half of the sentence repetition task. The sentences were presented in a pseudorandomized order, divided between the two sessions and counterbalanced across participants. The items were presented in a clear voice by a trained research assistant who was a native speaker of Kannada. The child's responses were directly transcribed for offline error scoring by research assistants blind to the conditions of the study. The sentence repetition task was always presented at the beginning of the session.
Data coding
Table 1 (middle columns) illustrates performance when sentence repetition is accurate and when there are errors, within the framework of Bock and Levelt's (Reference Bock, Levelt and Gernsbacher1994) model. Performance was analyzed at the sentence, word, and affix levels. Participants’ errors were scored offline from transcriptions by a trained Kannada-speaking research assistant. Thirty percent of responses from each school were independently coded by the first author. Interrater reliability ranged between 0.76 and 0.98. The lowest reliability was for nouns coded as nonwords rather than as dialect words, with greater ambiguity on some nouns because they attracted greater dialectal variations.
Sentence level coding
We measured word-order accuracy and the length of the produced utterance. Word order was scored as correct when the exact order of the sentence elements was preserved and length was unchanged. When the repetition was a phrase or a shorter syntactically complete sentence that preserved event semantics, we coded it as shortened utterance (see online-only supplementary material for examples). When the word order in the produced utterance diverged from the target, we coded word-order changes for interchange of the agent and recipient, which produced a significant change in the core event meaning (who did what to whom). A small proportion of errors was due to a shift in the position of the object or the verb where all linguistic components of the message were intact but the serial order had changed. These errors were very rare (~1%) and not analyzed further.
Word- and affix-level coding
Content words (nouns, verbs) with specific grammatical suffixes were scored for accuracy on the root, inflection, and the boundary (see online-only supplementary material for examples). We accepted dialect variations for roots of words (e.g., dropping of the glottal fricative /h/ in word initial position; thus aakidaLu for haakidaLu) and coded all other substitutions as a semantic change. Because inflections on the semantic substitutions and the boundary could be accurate for the new root–inflection pairing, we included semantic substitutions in the analyses of accuracy on boundaries and inflections. This is a lenient scoring scheme for assessing verbatim memory, but given the overall low error rate, this scoring scheme allows a wider assessment of the child's morphophonological and morphosyntactic skills.
For nouns, we focused on dative markers that were available in all sentences (25 tokens). The errors in case markings reflect grammatical encoding processes, both for thematic role assignment and at the positional levels of processing. Among verbs, categorization of errors becomes highly ambiguous in passive and embedded sentences because here the verbs carry several inflectional markers, which can interact with each other (e.g., koDisalaayitu: koDu-is-al-aay-it-u, root-causative-infinitive-passive-tense-person-number-gender marker). Thus, the focus of the verb analysis was on active sentences (10 tokens), where the verbs contain only tense and person–number–gender (PNG) markers (e.g., koTTaLu, root–tense–PNG markers), reflecting positional processing and subject–verb agreement (e.g., Bock & Miller, Reference Bock and Miller1991; Eberhard, Cutting, & Bock, Reference Eberhard, Cutting and Bock2005). Finally, for both noun and verb items, we analyzed morphophonological encoding processes (e.g., Levelt, Roelofs, & Meyer, Reference Levelt, Roelofs and Meyer1999), specifically on the boundary between the root and the inflection when it required a morphologically conditioned change (e.g., amma + -ige = amma-nige, mother dat.sg.). The numbers of unique boundary changes were seven and two across nouns and verbs, respectively. A small proportion of all responses (~1%) were omissions, nonproductions, and nonwords; and these were not included when computing the word-level measures.Footnote 2
RESULTS
The analyses are reported separately for sentence- and word-level measures. For both sets of measures, we start with a summary of the overall performance, followed by the analyses examining the relationship between linguistic properties of the materials and performance on the task. Here we used the analysis of variance on arcsine transformed proportions of different types of responses (arcsine transformation was used to correct distributional issues when using proportional data), and correlational analyses. The final analyses examined individual variation using mixed-effects modeling of sentence properties and child-level factors, and correlational analyses of word-level linguistic properties and child-level variables.
Sentence-level measures
Performance on sentence-level measures is summarized in Table 3. Overall, the children's mean sentence repetition accuracy was 69%. The majority of incorrectly produced sentences were a shortened utterance, and a smaller proportion were a change in word order (agent–recipient); the change in word order reflected a greater disruption in event meaning when compared to shortened utterances. Sixty percent of shortened sentences were thematically close to the target sentence, with a large proportion of productions being an omitted noun phrase in an otherwise grammatically accurate sentence. Thus, instead of saying “the girl dressed the child,” a shorter sentence response would be “dressed + PNG markers the child,” indicating that the event semantics was preserved because the verb was correctly marked for agent properties (see online-only supplementary material). These findings suggest that the sentence recall encompassed the conceptual representation of the message rather than only an episodic, form-based representation (e.g., Potter & Lombardi, Reference Potter and Lombardi1990).
Table 3. Descriptive summaries of proportion scores for accurate and error responses during sentence repetition

a Five sentences per condition.
b Typically preserves core event meaning.
c Typically changes core event meaning.
Sentence type influenced the accuracy of sentence repetition, with the highest accuracy for actives and the lowest accuracy for embedded sentences. We next examined the influence of sentence type and length on task performance by focusing on active and passive sentences. Actives were produced with higher accuracy than passives, F (1, 134) = 230.23, p < .001. Across both sentence types, shorter sentences were produced with higher accuracy than longer sentences, F (1, 134) = 170.21, p < .001, with no Sentence Type × Length interaction, F (1, 134) = 2.70, ns.
Passive sentences showed significantly more word order changes, F (1, 134) = 116.77, p < .001, and shortened utterances, F (1, 134) = 62.50, p < .001, than active sentences; and longer sentences had more shortened utterances, F (1, 134) = 53.50, p < .001, and word-order changes, F (1, 134) = 70.67, p < .001. However, with increasing length, passives “suffer” greater disruption in event meaning than actives, with more agent–recipient interchanges (Sentence Type × Length interaction), F (1, 134) = 25.30, p < .001.
Rated structure frequency positively correlated with word-order accuracy (r = .58, p < .001), and less frequent sentence structures showed more shortened utterances (r = –.55, p < .01). Frequency did not correlate with word-order changes (r = –.28, ns). Event plausibility did not correlate with performance on the task (accuracy: r = .20, ns; shortened utterances: r = .02, ns; word-order changes: r = –.20, ns). This pattern of correlations suggests that the sentence repetition task is tapping linguistic representations in long-term memory as reflected in the estimated frequency of the sentence structures.
Individual differences and sentence-level measures
We next examined correlations between the sentence-level measures and cognitive–linguistic measures of vocabulary and nonword repetition after controlling for both age and general abilities, which were significant correlates (Table 4). Both vocabulary and nonword repetition showed a moderate positive correlation with word-order accuracy, and a negative moderate association with shortened utterances. Associations with word-order changes were statistically nonsignificant.
Table 4. Associations between cognitive–linguistic and sentence repetition measures with age and general abilities partialled out (above diagonal) and their zero order correlations (below diagonal)

a Performance on Raven's Progressive Matrices.
†p > .05. *p < .05. **p < .01. ***p < .001.
To assess the predictors of individual differences in the ability to repeat the word order of sentences accurately, we examined several child-level measures as well as the contribution of structure frequency. A mixed-effects logistic regression model (xtmelogit in Stata 12) was used with participants and items treated as crossed random effects. We first assessed the effects of each predictor in a series of univariate regression models. At the child level, these included vocabulary, nonword repetition, age, and general abilities, and at the sentence level, rated structure frequency (word count and event plausibility were not correlates). All five measures were significant predictors of variation in word-order accuracy. Each measure was next considered in a more complex simultaneous regression model. From the complex model, effects that were nonsignificant were dropped until a parsimonious final model in which all predictors were significant was obtained iteratively. The parsimonious final model showed that frequency of sentences, and vocabulary scores, nonword repetition scores, and child's age are the predictors of word-order accuracy (Table 5).
Table 5. Effects of item level variable of frequency and child level variables of vocabulary, nonword repetition and age on accuracy of word order during sentence repetition

In summary, sentence repetition performance analyzed at the global sentence level revealed that sentence type, frequency, and length affect performance, and this in turn is predicted by the child-level variables of age, vocabulary, and phonological skill as measured by nonword repetition.
Word- and affix-level measures
Nouns with the dative case marker –ige and verbs with the tense + PNG markers (– idaLu, –id-anu) were scored for accuracy on the roots, inflections, and the morphophonological changes at the boundary between the root and inflection (e.g., for ammaniga error on amma root – n boundary – ige inflecion). We hypothesized that the three measures reflect different aspects of processing within the language production system (Table 1): the production of roots reflects encoding at the message-lexical level, inflections reflect grammatical encoding, and the boundary between the inflection and root, the interface between grammatical and phonological encoding. The descriptive summaries for these measures for the nouns and verbs of interest are given in Table 6.
Table 6. Means (standard deviations) of proportion scores on word level accuracy and errors responses during sentence repetition

a Inclusive of dialect variations.
b These are computed ignoring semantics, that is, both correct and substitutions on roots included.
Among roots, 84% of substitutions on noun roots and 79% on verb roots were semantically related to the target word, suggestive of conceptual representation of the message playing a greater role in word-level recall than form-based representation. Among nouns, there were more errors on roots than inflections; among verbs, inflections were more vulnerable. One possible reason for this difference between the two word types is that each sentence contained two or more nouns that were conceptually similar (e.g., boy–girl, mother–child, brother–sister), and conceptual similarity is a well-known factor that produces interference in processing at the message level (e.g., Ferreira & Firato, Reference Ferreira and Firato2002; Gennari, Mirković, & MacDonald, Reference Gennari, Mirković and MacDonald2012). Thus, an increased rate of noun root errors may reflect interference processes at the conceptual level of the language production system. The relatively greater frequency of inflection errors on verbs may reflect the additional complexity of verb inflections relative to noun inflections: the nouns in the sentences were only marked for case (denoting their agent/object/recipient role), whereas the verbs conveyed several pieces of grammatical information: tense, person, number, and gender, including agreement with the subject. Errors on the boundary between the root and the inflection were more common in nouns than in verbs perhaps because of the greater variety of boundary changes sampled across nouns than across verbs.
Individual differences and word- and affix-level measures
We next examined the errors on roots and inflections, for which we individually summed the noun and verb scores and derived a z score, which we named as the root error score and the inflection error score. Similarly for the errors on boundaries, we derived a z score and named this the boundary error score. After controlling for age, the associations between inflection and boundary error scores with vocabulary and nonword repetition were in the moderate range while for root error scores, the association with nonword repetition but not vocabulary was statistically significant (Table 7).
Table 7. Correlations among vocabulary, nonword repetition, and error scores on roots, inflections, and boundaries

a Association between vocabulary and nonword repetition with age controlled (r = .246*).
†p > .05. *p < .05. **p < .01. ***p < .001.
The strength of associations across the linguistic units was also of interest. We expected that phonological encoding would have a stronger association with the morphophonological units (word boundaries) than the morphology units (inflections), reflecting relatively more contribution from processing at the phonological encoding subsystem of language production (Levelt et al., Reference Levelt, Roelofs and Meyer1999). When controlling for vocabulary (Table 7), the association of nonword repetition with inflection errors was no longer significant, suggesting that inflectional errors may be more indicative of processing errors at the conceptual–grammatical than the phonological encoding level (Bock & Levelt, Reference Bock, Levelt and Gernsbacher1994; Vigliocco & Hartsuiker, Reference Vigliocco and Hartsuiker2002). In contrast, the association between nonword repetition and morphophonological boundary errors remained significant, which may be taken as evidence for the role of phonological encoding over and above the contributions of conceptual–lexical knowledge and grammatical encoding. In addition, when we controlled for age and nonword repetition scores (Table 7), the association of vocabulary with both inflection errors and boundary errors remained significant. This finding provides evidence of the involvement of lexical knowledge in both morphosyntactic and morphophonological encoding within the language production system. An unexpected finding was that the root error score was not associated with either vocabulary (when nonword repetition was controlled) or nonword repetition (when vocabulary was controlled; Table 7).
DISCUSSION
The two main aims of the current study were first, to explore the extent to which performance on the sentence repetition task is sensitive to linguistic properties of the materials, and second, to explore what factors influence the performance of individual children. To this end, we analyzed accuracy and error profiles on the task with children aged 5 to 8 years in Kannada, an inflectionally rich language.
We found that children's performance was influenced by linguistic properties of the materials. First, at the sentence level, accuracy was higher with active than passive sentences, and the error analyses demonstrated that an increase in length caused more disruption in thematic role assignment in passives, as evidenced by agent-recipient errors. The difference between actives and passives was at least partly driven by the difference in structure frequency, which was a strong and unique predictor of sentence repetition accuracy. Second, we found a different profile of errors for verbs and nouns. The complexity of verb inflection, which included information about tense, person, number, and gender, made them more vulnerable to inflection errors, whereas nouns had more root and root-inflection boundary errors. We argue that semantic competition ensuing from the presence of similar nouns in the same sentence may have contributed to the errors on the root, whereas boundary errors are due to morphophonological changes being more common in nouns than in verbs.
We also found that different factors contributed to individual variation in performance on the task. First, both lexical–conceptual knowledge and phonological processing, measured as vocabulary and nonword repetition scores, showed moderate positive correlations with word-order accuracy in sentence recall and negative moderate associations with a syntactically acceptable but shortened sentence recall (shortened utterances). Second, frequently encountered syntactic structures were repeated more accurately than less frequently encountered structures, and older children, arguably with more language experience, performed better than younger children. Furthermore, structure frequency was a unique predictor of accuracy with word order in sentences, and this was over and above child-level predictors of age, vocabulary knowledge, and accuracy on nonword repetition. Third, in word-level analyses, morphological (inflection) errors and errors on units that demand greater phonological encoding (boundary errors) showed a different pattern of association with cognitive–linguistic variables. Among morphological errors, accuracy with case markers on nouns and tense and person–number–gender markers on verbs was associated with better performance on a vocabulary task. Moreover, even though there were associations with phonological encoding as assessed by nonword repetition, these associations disappeared when vocabulary knowledge was controlled. In contrast, for boundary units that required greater phonological encoding because of phonological change processes, the associations between error rate and nonword repetition performance remained even after vocabulary knowledge had been controlled. Together, these analyses demonstrate that individual differences in performance on sentence repetition are related to individual differences in lexical–conceptual knowledge and phonological processing.
In parallel, we found sentence length to affect verbatim memory for the sentences, with lower accuracy, and more shortened utterances and word-order changes seen on longer sentences. While increased sentence length has typically been interpreted as increasing memory load (e.g., Moll et al., Reference Moll, Hulme, Nag and Snowling2013; Polišenská et al., Reference Polišenská, Chiat and Roy2015), in our materials longer sentences were also rated as denoting less plausible events. Thus, the sentence-length effect cannot be attributed purely to an increase in memory load. Further evidence of the interaction between sentence length and linguistic properties of the materials was found in word-order errors, and specifically an increase in agent–recipient errors in long passives relative to long actives.
Together, our findings provide converging evidence with other studies demonstrating the role of psycholinguistic mechanisms and long-term linguistic knowledge in sentence repetition performance (e.g., Devescovi & Caselli, Reference Devescovi and Caselli2007; Gábor & Lukács, Reference Gábor and Lukács2012; Riches, Reference Riches2012; Polišenská et al., Reference Polišenská, Chiat and Roy2015). A unique contribution of our study is that with an inflectionally complex language such as Kannada, we were able to assess and demonstrate the engagement of several language production subsystems within a single task. Beyond the involvement of processing at the conceptual level, we examined processing at the morphological and phonological levels. Bringing attention to phonology and morphophonology in sentence repetition is in line with proposals of the specific role of phonological encoding in the maintenance of verbal serial order (MacDonald, Reference MacDonald2013). Moreover, the finding that lexical knowledge plays a role in both morphosyntactic and morphophonological processing provides additional evidence in support of more interactive models of language production (e.g., Vigliocco & Hartsuiker, Reference Vigliocco and Hartsuiker2002). Our study thus provides an example of how cross-linguistic research in language production can potentially drive theory development about performance during sentence repetition (Jaeger & Norcliffe, Reference Jaeger and Norcliffe2009).
An implication of a fine-grained evaluation such as the one we conducted is that tasks may be designed to target specific language subsystems (e.g., sentence structures to target positional encoding, or inflections for morphophonological encoding). Such tasks may better capture individual differences and offer a tool for investigating developmental trajectories of language production mechanisms. This is particularly relevant because the task of sentence repetition has become a critical tool in the assessment of children in clinical settings (e.g., Conti-Ramsden et al., Reference Conti-Ramsden, Botting and Faragher2001).
Implications for assessment
Information about performance patterns across different linguistic units is of theoretical interest because in almost all assessments of language in childhood disorders, a pattern of strengths and weaknesses has been found (cf. Rice et al., Reference Rice, Warren and Betz2005). Moreover, sentence repetition accuracy has been a useful marker of specific language impairment (e.g., Conti-Ramsden et al., Reference Conti-Ramsden, Botting and Faragher2001). We found children's performance with sentence repetition reflected processing across the message, grammatical encoding, and phonological encoding subsystems. This task thus shares the engagement of phonological processing with the nonword repetition task, but it provides additional insights into the language production mechanisms. We also found that certain manipulations in the sentence condition were more demanding (e.g., introduction of adjectives). These findings indicate that the sentence repetition task can be used to develop a performance profile across several language production mechanisms, shedding more light on the reasons why this deceptively simple task has been an exceptionally useful clinical tool. Furthermore, the sentence repetition task offers itself as a quick assessment in educational settings.
A further implication is that the language subsystems framework provides a common model that can accommodate the varieties of complexity found across languages. As such, it can inform the development of badly needed clinical instruments suitable for cross-linguistic research and practice (e.g., Leonard, Reference Leonard2014; Rice et al., Reference Rice, Warren and Betz2005). Tests developed within the language subsystems framework would also allow for interesting comparisons with other language tasks including nonword repetition, which would shed additional light on any possible interactions between different language production representations and mechanisms.
To our knowledge, this is the first study to examine both grammatical and phonological encoding in sentence repetition and the pattern of associations between these and cognitive–linguistic measures such as vocabulary knowledge and nonword repetition within a model of the language production system. The findings provide support for growing evidence that the entire language system is recruited during sentence repetition while being sensitive to language-specific characteristics (e.g., inflections in Kannada: Nag & Snowling, Reference Nag and Snowling2011; prepositions in English: Moll et al., Reference Moll, Hulme, Nag and Snowling2013). Other studies have shown that the task has been sensitive to subtle individual differences, particularly to variations at the lower end of the distribution (e.g., English: Conti-Ramsden et al., Reference Conti-Ramsden, Botting and Faragher2001; Redmond et al., Reference Redmond, Thompson and Goldstein2011; Rice et al., Reference Rice, Warren and Betz2005; Dutch: Wilsenach Reference Wilsenach2006). It would therefore seem that a language subsystems approach to understanding individual differences during sentence repetition is a promising one and can provide a window into the nature of language production mechanisms and language development.
APPENDIX A
Table A.1. Sentence repetition items

Table A.2. Item properties in different conditions in the sentence repetition task (means)

ACKNOWLEDGMENTS
This work was funded by a research grant (to S.N.) under the Newton International Fellowship. We thank the children who participated in the study; Emma Hayiou-Thomas and R. Amritavalli for input during the construction of the sentence repetition task; the teachers who helped with item ratings; N. M. Arpana, Laxmi Sutar, Sudharshana, B. Kala, Mini Krishna, and Riona Lall for data collection and coding; and Maryellen MacDonald and an anonymous reviewer for their comments.
SUPPLEMENTARY MATERIAL
To view the supplementary material for this article, please visit https://doi.org/10.1017/S0142716417000200











