



Introduction
During language comprehension, previous information across various timescales can be used to predict upcoming words (Van Petten & Luka, Reference Thornhill and Van Petten2012). How comprehenders generate predictions during language comprehension has been a heated topic in recent yearsFootnote 1 (Ito et al., Reference Ito, Corley, Pickering, Martin and Nieuwland2016; Nieuwland et al., Reference Nieuwland, Politzer-Ahles, Heyselaar, Segaert, Darley, Kazanina and Huettig2018; Nieuwland et al., Reference Nieuwland, Barr, Bartolozzi, Busch-Moreno, Darley, Donaldson and Von Grebmer Zu Wolfsthurn2019). However, it remains unclear whether and how prediction differs when the contextual information used to generate the prediction is from immediately preceding sentence context (e.g., Xiaoyu came to the living room. She made a cup of lemon tea. Then she sat down in a chair. She opened a box/an album to look at the pictures.) or from earlier discourse context (e.g., Xiaoyu took out a box/an album. She made a cup of lemon tea. Then she sat down in a chair. She leisurely looked at the pictures.). This issue was addressed in the present study.
Prediction effects in language comprehension has been widely examined (Federmeier, Reference Federmeier2007; Kuperberg & Jaeger, Reference Kuperberg and Jaeger2016). It has been demonstrated that prediction of upcoming words can be generated not only based on local sentence context (Delong et al., Reference Delong, Urbach and Kutas2005; Federmeier et al., Reference Federmeier2007) but also on global discourse context (Otten & Van Berkum, Reference Otten and Van Berkum2007, Reference Otten and Van Berkum2008; Van Berkum et al., Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005). Highly constraining contexts (e.g., “in order to see the cells he used a…”) or mildly constraining contexts (e.g., “in order to see the objects he used a…”) have usually been designed to make an upcoming word (e.g., “microscope”) predictable or less predictable. In electroencephalogram (EEG) studies, predictable words were more associated with reduced N400 (an ERP component) amplitudes in comparison to less predictable or unpredictable words (Laszlo & Federmeier, Reference Laszlo and Federmeier2009; Li et al., Reference Li, Zhang, Xia and Swaab2017). The N400 component is a negative-going wave that reaches its peak at about 400 ms after the onset of the stimulus (Kutas & Hillyard, Reference Kutas and Hillyard1980, Reference Kutas and Hillyard1984). In prediction research, a reduced N400 amplitude for predictable words has been considered to reflect the benefits of confirmed prediction for semantic processing (Van Petten & Luka, Reference Thornhill and Van Petten2012). However, it is worth noting that N400 effects of prediction may not solely reflect predictive processing but could reflect a combination of processes that include both prediction and integration (Nieuwland et al., Reference Nieuwland, Barr, Bartolozzi, Busch-Moreno, Darley, Donaldson and Von Grebmer Zu Wolfsthurn2019).
Although the N400 effect was consistently observed to be sensitive to the prediction of upcoming words in both sentence and discourse contexts, a frontal post-N400 positivity has been reported to be sensitive to prediction processing mainly in sentence context (Delong et al., Reference Delong, Urbach, Groppe and Kutas2011; Federmeier et al., Reference Federmeier2007; Freunberger & Roehm, Reference Freunberger and Roehm2016; Thornhill & Van Petten, Reference Thornhill and Van Petten2012; Van Petten & Luka, Reference Thornhill and Van Petten2012). For instance, Thornhill and Van Petten (Reference Thornhill and Van Petten2012) found that a larger post-N400 positivity was elicited by unpredictable words than predictable words in sentence context, indicating the sensitivity of the anterior positivity to prediction of upcoming words. Despite these findings, the exact function of this anterior post-N400 positivity remains debated. One perspective is that this frontal positivity might be related to the costs of the inhibition of predicted words (Federmeier et al., Reference Federmeier2007; Thornhill & Van Petten, Reference Thornhill and Van Petten2012). An alternative perspective is that this late positivity might be linked to the revision of message- and/or discourse-level information following unpredictable information (Brothers et al., Reference Brothers, Swaab and Traxler2015; Freunberger & Roehm, Reference Freunberger and Roehm2016). It is worth noting that a more broadly distributed post-N400 positivity effect has been consistently observed for semantically incongruent words than for semantically congruent words during language processing and that this post-N400 positivity effect has been considered to reflect integration cost (Brouwer et al., Reference Brouwer, Fitz and Hoeks2012; Burkhardt, Reference Burkhardt2007). Moreover, many other researchers have considered that the post-N400 positivity associated with semantic incongruence might be related to domain-general processes (e.g., Sassenhagen & Bornkessel-Schlesewsky, Reference Sassenhagen and Bornkessel-Schlesewsky2015; Sassenhagen et al., Reference Sassenhagen, Schlesewsky and Bornkessel-Schlesewsky2014).
While frontal late positivity associated with prediction has been frequently reported in sentence-level studies, it has been seen in only a few discourse-level studies (e.g., Brothers et al., Reference Brothers, Swaab and Traxler2015; Delong et al., Reference Delong, Quante and Kutas2014). In light of these findings, it seems that sentence- and discourse-level contexts may affect prediction of upcoming words differently.
Language processing is incremental: predictions of upcoming words can be formed at various representational levels on the basis of the preceding context, which unfolds over time (Altmann & Mirković, Reference Altmann and Mirković2009). According to the memory-based view of language comprehension, contextual information does not indefinitely remain in a state of full activation in working memory but instead gradually decays as language unfolds (Albrecht & Myers, Reference Albrecht and Myers1998; Kintsch, Reference Kintsch1988; Van Den Broek et al., Reference Van Den Broek, Rapp and Kendeou2005). Based on this view, it is likely that (more recent) sentence-level information will have a stronger effect on linguistic prediction compared to (less recent) discourse-level information due to declining memory traces in working memory (Myers et al., Reference Myers, Cook, Kambe, Mason and O’Brien2000; O’Brien et al., Reference O’Brien, Plewes and Albrecht1990).
However, there have also been studies showing that global context led to a stronger effect than local context (Boudewyn et al., Reference Boudewyn, Gordon, Long, Polse and Swaab2012; Camblin et al., Reference Camblin, Gordon and Swaab2007). In light of this, it would be expected that discourse-level information could facilitate the prediction of upcoming words to a larger extent than sentence-level information. In fact, this has been observed in one prior study. In Boudewyn et al. (Reference Boudewyn, Long and Swaab2015), participants were presented with highly constraining discourses wherein the critical words were predictable or unpredictable based on the global discourse context and were semantically congruent or incongruent with the local sentence context (e.g., “Frank was throwing a birthday party, and he had made the dessert from scratch. After everyone sang, he sliced up some sweet/healthy and tasty cake/veggies that looked delicious”). A graded N400 was observed at the critical nouns; that is, the N400 was the smallest for the globally predictable and locally congruent words (“sweet and tasty cake”), followed by globally predictable but locally incongruent words (“healthy and tasty cake”), then by globally unpredictable but locally congruent words (“healthy and tasty veggies”), and finally by globally unpredictable and locally incongruent words (“sweet and tasty veggies”). Given that a smaller N400 was observed for globally predictable but locally incongruent words than for globally unpredictable but locally congruent words, the results indicated that global information can have a stronger influence than local information.
Boudewyn et al.’s study is valuable because it revealed the effects of the local sentence and global discourse contexts on the prediction of target words and indicated that global discourse context can have a stronger effect on online generated predictions of upcoming words than local context. However, in that study, sentence contexts provided a prototypical or atypical feature of the target noun, while discourse contexts presented both semantic-level information and a story scenario, which can be more important for discourse comprehension than semantic information (Boudewyn et al., Reference Boudewyn, Gordon, Long, Polse and Swaab2012; Boudewyn et al., Reference Boudewyn, Long and Swaab2013; Camblin et al., Reference Camblin, Gordon and Swaab2007). However, discourse contexts (in general) can provide many kinds of information, and some of them do not describe a story scenario, but detailed story information (Ledoux et al., Reference Ledoux, Camblin, Swaab and Gordon2006; Otten & Van Berkum, Reference Otten and Van Berkum2007). It is unclear whether this type of information has an influence on online predictive processing of upcoming words at all. Moreover, in Boudewyn et al.’s study, the predictability of the target words was mainly determined by the global discourse context rather than the local sentence context; more specifically, the global discourse context might not make a target word (e.g., “veggies”) very predictable even if the local sentence context contained a feature word (e.g., “healthy”) (see Nieuwland, Reference Nieuwland2019 for a discussion of this issue). Therefore, how sentence- and discourse-level contextual information influences the online prediction of upcoming words needs and deserves to be explored further.
Using ERPs, the present study aimed to examine the effects of sentence and discourse context on the prediction of upcoming words. Four-sentence discourses with the critical words located in the last sentence were used as materials (see Table 1).Footnote 2 For the sentence level, the crucial information that allows prediction of critical words was provided by the last sentence of the discourse, while for the discourse level it was provided by the first sentence. The level of constraint of the sentence and discourse conditions was manipulated so that the critical words were either predictable or unpredictable.Footnote 3 Also, these manipulated sentence and discourse contexts held similar, specific information. Thus, the only difference between the sentence and discourse conditions was the distance between the critical words and the preceding contexts, which were critical to predict the critical words. With the context and predictability of critical words orthogonally manipulated, four conditions were constructed: sentence/unpredictable (discourse/unpredictable), sentence/predictable (discourse/unpredictable), discourse/unpredictable (sentence/unpredictable), and discourse/predictable (sentence/unpredictable). The critical words, the two words preceding the critical words, and the second and third sentences were held constant in a set of discourses.
Table 1. Samples of the stimuli used in the experiment
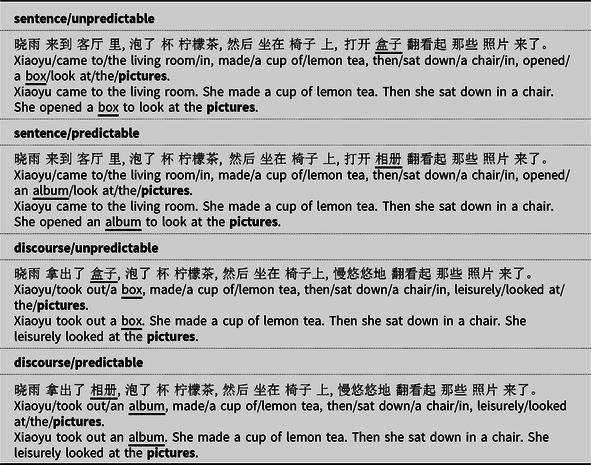
Note: The critical words are all bolded. The words that have been changed are underlined. The discourses were identical for the sentence and discourse conditions, and the second and third sentences were identical across the four conditions. Commas were used to separate the sentences of each discourse; this is often observed in short discourse in Chinese and would look more natural to Chinese readers. These commas, however, were changed into periods in the English translations to conform to the conventions of English.
We hypothesized that the neurocognitive process of predicting upcoming words would be associated with both benefits for confirmed prediction and costs for disconfirmed prediction, which would be reflected in a N400 and a frontal late positivity effect respectively (Van Petten & Luka, Reference Thornhill and Van Petten2012). Following previous studies (Delong et al., Reference Delong, Urbach and Kutas2005; Li et al., Reference Li, Zhang, Xia and Swaab2017; Otten & Van Berkum, Reference Otten and Van Berkum2007; Van Berkum et al., Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005), we hypothesized that both sentence-level and discourse-level supportive context could benefit semantic processing of predictable words, which could then lead to a smaller N400 for the predictable words than for the unpredictable words in both the sentence and discourse conditions. Moreover, the unpredictable words might give rise to the inhibition of predicted words (Federmeier et al., Reference Federmeier2007; Thornhill & Van Patten, Reference Thornhill and Van Petten2012) or the revision of message- and/or discourse-level information (Brothers et al., Reference Brothers, Swaab and Traxler2015; Freunberger & Roehm, Reference Freunberger and Roehm2016), which would be reflected in a frontal late positivity effect. If sentence context has a stronger effect on the prediction of target words than discourse context because of the decayed memory trace of the context (McKoon & Ratcliff, Reference McKoon and Ratcliff1998; Myers & O’Brien, Reference Myers and O’Brien1998), then a larger frontal late positivity effect would be observed in the sentence condition than in the discourse condition. Alternatively, if the discourse context has a stronger impact than sentence context (Boudewyn et al., Reference Boudewyn, Long and Swaab2015), then a larger frontal late positivity effect would be observed in the discourse condition than in the sentence condition.
Method
Participants
Twenty-four university students (12 males; mean age = 22.5 years; range = 18.0–30.0 years; SD = 3.1 years) participated in this study as paid volunteers. They were all native speakers of Mandarin Chinese, were right-handed, had normal or corrected-to-normal vision, and were without any reported neurological disorders. They all signed the informed written consent form required by the ethics committee of the Institute of Psychology, Chinese Academy of Sciences. The data of two female participants were excluded from the statistical analysis due to excessive artifacts.
Materials
We used 120 sets of discourses. Each discourse consisted of four sentences; the critical words were presented in the last sentence and were the same across all experimental conditions. The first sentence was manipulated as the discourse context, and the content before the critical word in the fourth sentence was manipulated as the sentence context. The critical word was either predictable or unpredictable based on the preceding sentence or discourse context; in other words, for the sentence condition, the contextual information in the fourth sentence was changed to make the critical word predictable or unpredictable, while for the discourse condition, the contextual information in the first sentence was changed to make the critical word predicable or unpredictable. The second and third sentences were the same in each set of discourses; thus, there were four conditions in total: sentence/unpredictable (discourse/unpredictable), sentence/predictable (discourse/unpredictable), discourse/unpredictable (sentence/unpredictable), and discourse/predictable (sentence/unpredictable). Following a Latin Squares design, the 120 sets of discourses were arranged into four lists, each containing 30 discourses per condition, to ensure that each discourse was presented only once. In addition, 90 incongruent discourses were added as fillers: 20 containing semantic violations in the last sentence, 20 containing semantic violations between the last sentence and the first sentence, and 50 containing semantic violations across various distances within the second and third sentences. Thus, the incongruent information was presented approximately equally among the four sentences. This violation paradigm was only used in the fillers, to draw our participants’ attention to each sentence equally, and the participants were not asked to detect the violations.
A group of 40 participants (20 males; mean age = 22.0 years; range = 18.0–34.0 years; SD = 3.6 years) who did not participate in the EEG experiment were recruited to complete a cloze probability pretest, in which the discourses were truncated before the critical words and the participants were asked to complete these discourses according to the preceding context. Each participant completed only one of the four lists. The cloze probabilities of the critical words were calculated as the proportion of participants who used the designated critical words to complete these discourses. A repeated-measures ANOVA was conducted with context (2 levels: sentence vs. discourse) and predictability of the critical words (2 levels: predictable vs. unpredictable) as independent variables and cloze probability as the dependent variable. The results revealed a significant main effect of predictability (F (1, 119) = 2563, p = .000, η 2 p = .96), indicating that the cloze probability of the predictable words was higher than that of the unpredictable words (see Table 2). The results did not indicate a significant main effect of context or a significant interaction between context and predictability.
Table 2. Pretest results for experimental materials

Using the cloze probability test, we computed the degree of constraint of the discourses; in this regard, we calculated the largest proportion of participants who were using the same words (critical words and noncritical words) to complete the discourses. Repeated-measures ANOVA revealed a significant main effect of predictability (F (1, 119) = 690.83, p = .000, η 2 p = .85), indicating that the constraint of the predictable conditions was higher than that of the unpredictable conditions (see Table 2). We did not find a significant main effect of context or a significant interaction between context and predictability.
An additional group of 24 university student participants (12 males; mean age = 21.2 years; range = 18.0–25.0 years; SD = 1.9 years) was recruited to rate the acceptability of the discourses on a seven-point scale (1 = extremely unacceptable, 7 = fully acceptable). All conditions were rated acceptable, although a repeated-measures ANOVA revealed a significant main effect of predictability (F (1, 119) = 17.21, p = .000, η 2 p = .13), indicating that predictable conditions were rated as more acceptable than unpredictable conditions (see Table 2). Again, the results showed that there was not a significant main effect of context. These results indicated that acceptability ratings were independent of context but not predictability. We also did not find a significant interaction between context and predictability.
Procedure
Participants were seated comfortably in front of a computer screen in an electrically shielded, sound-attenuating room. The 210 discourses (120 of which were critical materials) were presented in a pseudorandom order with white text on a black background. Each trial began with a fixation cross for 1000 ms in the center of the screen. This was followed by a presentation of the first three sentences of the discourse, sentence by sentence. Participants were asked to press the space bar when they finished reading the sentences. The last sentence was presented one word at a time, and each word appeared for 400 ms and was followed by an interstimulus interval of 300 ms. Participants were instructed not to move or blink during the presentation of individual words. To ensure that the participants read these discourses attentively, 80 out of 210 discourses were followed by a comprehension question related to the preceding discourse content; the participants were told to press “J” or “F” on the keyboard to answer true or false, respectively, and to press the space bar to continue to the trials. After a short practice session of 11 trials, all materials were presented in six blocks (35 trials per block) of about 10 minutes each, with brief rest periods separating the blocks. The entire experiment lasted about 2.5 hours, including preparation.
EEG recording and preprocessing
The EEG data were recorded using a NeuroScan system with an elastic cap containing 64 Ag/AgCl electrodes mounted according to the standard international 10–20 system. Recordings were completed with a sampling frequency of 500 Hz and an amplifier band pass of 0.05–100 Hz. The left mastoid served as the online reference, and the average of both mastoids served as the offline re-reference. The vertical electrooculogram (EOG) was monitored by electrodes placed above and below the participants’ left eyes, and the horizontal EOG was recorded by electrodes placed at the participants’ right and left outer canthi. All impedances were kept below 5 KΩ during the experiment.
The preprocessing of the EEG data was completed using NeuroScan 4.3 software (NeuroScan Labs, Houston, Texas). EOG artifacts were automatically corrected, using the ocular artifact algorithm of the NeuroScan 4.3 software package. The data were filtered off-line with a 0.1–30 Hz band-pass filter (24 dB/octave per slope). Critical epochs ranged from 200 ms before the onset of the critical words to 1000 ms after this onset, with baseline of –200 to 0 ms preceding this onset. An artifact rejection procedure was conducted, with a min/max-criterion of ± 75 µV. An average of 4.9% of all trials were rejected, with the remainder being equally distributed among the four conditions. There were, respectively, 28.73 ± 1.75, 28.41 ± 1.65, 28.50 ± 1.22, and 28.50 ± 2.37 artifact-free trials obtained for the sentence/unpredictable, sentence/predictable, discourse/unpredictable, and discourse/predictable conditions, respectively.
Data analysis
Based on visual inspection and previous research (Delong et al., Reference Delong, Quante and Kutas2014; Federmeier et al., Reference Federmeier2007; Freunberger & Roehm, Reference Freunberger and Roehm2016), the time windows of N400 and late positivity were determined to be 300–500 ms and 500–700 ms, respectively. The average amplitude of the ERPs within each of the selected time windows was computed across all trials per condition for each participant. A four-way repeated-measures ANOVA was conducted with context (2 levels: sentence, discourse), predictability (2 levels: predictable, unpredictable), hemisphere (3 levels: left, medial, right), and region (3 levels: frontal, central, parietal) as within-subject variables. Therefore, nine regions of interests were established, each containing five or six electrodes: left frontal (F3, F5, F7, FC3, FC5, FT7); left central (C3, C5, CP3, CP5, TP7); left parietal (P3, P5, P7, PO5, PO7, CB1); medial frontal (F1, FZ, F2, FC1, FCZ, FC2); medial central (C1, CZ, C2, CP1, CPZ, CP2); medial parietal (P1, PZ, P2, PO3, POZ, PO4); right frontal (F4, F6, F8, FC4, FC6, FT8); right central (C4, C6, CP4, CP6, TP8); and right parietal (P4, P6, P8, PO6, PO8, CB2).
We only reported the significant (including marginally significant, i.e., p < .06) effects involving the experimental conditions. All significant interactions were followed by simple effect tests. When Mauchly’s test of sphericity was significant, the Greenhouse–Geisser correction was applied to correct the reported p-values, but the degrees of freedom were uncorrected.
Results
Behavioral results
The average accuracy rate for the reading comprehension questions was 96.05% (SD = 2.48%), indicating that participants read the discourses carefully. Moreover, the average accuracy rates were comparable across the four conditions (mean ± SD: sentence/unpredictable, 97.77% ± 4.41%; sentence/predictable, 95.98% ± 5.80%; discourse/unpredictable, 93.30% ± 8.80%; discourse/predictable, 95.47% ± 7.78%).
ERP results
Figure 1 displays the grand average waveforms elicited by the critical words in all four conditions at nine representative electrodes (F3/FZ/F4, C3/CZ/C4, P3/PZ/P4). Figure 2 displays the topographies of the difference waves in the N400 (300–500 ms) and late positivity (500–700 ms) time windows. Results of the repeated-measures ANOVAs in the selected time windows are presented in Table 3.

Figure 1. Grand average waveforms evoked by the critical words in the four conditions at nine selected electrode sites. Waveforms are time-locked to the onset of the critical words and negative amplitude is plotted up.

Figure 2. Topographies of the difference waves formed by subtracting ERPs for the sentence/predictable from sentence/unpredictable (a) and discourse/predictable from discourse/unpredictable (b) respectively in the 300-500 ms (top) and 500-700 ms (bottom) time windows.
Table 3. ERP results of repeated-measures ANOVAs

Note: C, context; P, predictability; R, region; H, hemisphere. (Marginally) significant effects are marked in bold.
The results of the repeated-measures ANOVAs for the 300–500 ms time window show a significant main effect of predictability (see Table 3), indicating that predictable words reduced N400 amplitude relative to unpredictable words (mean ± SE: predictable, 1.93 ± 0.34 µV; unpredictable: 0.36 ± 0.42 µV; difference [predictable-unpredictable]: 1.57 ± 0.28 µV). There was a significant interaction between predictability and region (see Table 3). A simple effect analysis revealed that the effect of predictability was obtained over all three region levels but most prominently over the central and parietal areas (frontal: F (1, 21) = 6.47, p = .019, η 2 p = .24; central: F (1, 21) = 41.39, p = .000, η 2 p = .66; parietal: F (1, 21) = 86.13, p = .000, η 2 p = .80). There was also a significant interaction between predictability and hemisphere (see Table 3). A simple effect analysis for this interaction revealed that the effect of predictability was obtained over all three hemisphere levels (left: F (1, 21) = 18.25, p = .000, η 2 p = .47; medial: F (1, 21) = 31.85, p = .000, η 2 p = .60; right: F (1, 21) = 33.57, p = .000, η 2 p = .62). There was an interaction between context and region as well (see Table 3); the simple effect analysis for this interaction revealed that the effect of context was obtained only over the frontal area (F (1, 21) = 4.77, p = .041, η 2 p = .19), with the words in the discourse conditions showing reduced N400 amplitude compared to those in the sentence conditions (mean ± SE: discourse, 0.26 ± .48 µV; sentence, –0.24 ± 0.48 µV; difference [discourse-sentence], 0.50 ± 0.23 µV). Moreover, a significant interaction between context and hemisphere was found (see Table 3). The simple effect analysis for this interaction revealed that the effect of context was obtained only over the right hemisphere (F (1, 21) = 6.29, p = .020, η 2 p = .23), with the words in the discourse conditions showing reduced N400 amplitudes compared to those in the sentence conditions (mean ± SE: discourse, 1.32 ± 0.37 µV; sentence, 0.84 ± 0.35 µV; difference [discourse-sentence], 0.48 ± 0.19 µV). No significant interaction between context and predictability was found, indicating that there was no significant difference in the N400 effect between the sentence and discourse conditions.
In the 500–700 ms time window, a significant main effect of context was observed (see Table 3), indicating that the words in discourse conditions elicited more positive-going waves than the words in sentence conditions (mean ± SE: discourse, 2.13 ± 0.21 µV; sentence, 1.64 ± 0.23 µV; difference [discourse-sentence], 0.49 ± 0.17 µV). An interaction between context and region was obtained (see Table 3). A simple effect analysis revealed that the effect of context was obtained over the frontal and central areas (frontal: F (1, 21) = 10.99, p = .003, η 2 p = .34; central: F (1, 21) = 7.23, p = .014, η 2 p = .26). More importantly, the results revealed a significant interaction between context and predictability (see Table 3) and a three-way interaction of context × predictability × hemisphere (see Table 3). This three-way interaction was broken down by conducting separate analyses for each context level. For the sentence level, an ANOVA with predictability and hemisphere as the within-subject factors revealed a significant main effect of predictability (F (1, 21) = 4.76, p = .041, η 2 p = .19) and an interaction between predictability and hemisphere (F (2, 42) = 3.57, p = .051, η 2 p = .15), while the simple effect analysis revealed that unpredictable words elicited more positive-going waves than predictable words over left and medial areas (left: F (1, 21) = 8.69, p = .008, η 2 p = .29; mean ± SE: unpredictable, 2.17 ± 0.30 µV; predictable, 0.85 ± 0.36 µV; difference [unpredictable-predictable], 1.32 ± 0.45 µV; medial: F (1, 21) = 4.53, p = .045, η 2 p = .18; mean ± SE: unpredictable, 2.57 ± 0.42 µV; predictable, 1.53 ± 0.33 µV; difference [unpredictable-predictable], 1.04 ± 0.49 µV). For the discourse level, the ANOVA revealed neither a significant main effect of predictability nor any interaction between predictability and hemisphere (Fs < .37, ps > .695), suggesting that no late positivity effect was present for the discourse condition. Overall, a late positivity effect over the left and medial hemispheres was observed only for the sentence condition, not for the discourse condition.
Discussion
The goal of the present study was to investigate the effects of certain elements of sentence and discourse context on the prediction of target words. To this end, four-sentence discourses were presented in which the last sentence contained a critical word that was either predictable or unpredictable according to the preceding contextual information at sentence or discourse level. ERP results revealed that, relative to the unpredictable words, the predictable words were associated with lower N400 amplitude in both the sentence and discourse conditions. Also, we found larger late positivity for unpredictable words than for predictable words in the sentence condition but not in the discourse condition. These results indicate that the prediction effect does differ at sentence level from discourse level.
Effect of prediction
In the present study, the predictable words had a reduced N400 in comparison to the unpredictable ones in both the sentence and discourse conditions. This effect was widely distributed across the scalp, most prominently over central and parietal areas, paralleling the scalp distribution of the classic N400 effect (Kutas & Federmeier, Reference Kutas and Federmeier2011). The N400 is considered to reflect the ease or difficulty with which the meaning associated with words can be activated from semantic long-term memory, and a supportive semantic context can facilitate this process (Kutas & Federmeier, Reference Kutas and Federmeier2011). Here, the N400 effect was observed in both the sentence and discourse conditions, suggesting that both contexts can be used to generate a prediction as discourse unfolds, and was found to facilitate semantic processing of predictable words immediately when the prediction was confirmed. It is worth noting that a predictability-dependent N400 is not in itself strong evidence for actual prediction. Recent findings have suggested that predictability-dependent N400 is driven by a cascade of processes that activate and integrate words into contexts (Nieuwland et al., Reference Nieuwland, Barr, Bartolozzi, Busch-Moreno, Darley, Donaldson and Von Grebmer Zu Wolfsthurn2019); therefore, the N400 effect in the present study might reflect more than just the prediction of upcoming words.
Interestingly, a late positivity following the N400 also was observed. Unpredictable words elicited a larger late positivity compared to their predictable counterparts in the sentence condition; however, this effect disappeared completely in the discourse condition. This post-N400 positivity in the sentence condition was restrictively distributed over the left and medial electrodes. In previous studies (Delong et al., Reference Delong, Quante and Kutas2014; Van Petten & Luka, Reference Thornhill and Van Petten2012), two kinds of late positive components were observed. Compared to semantically congruent words, semantically incongruent words were associated with a larger positivity with a more posterior distribution (Diza & Swaab, Reference Diaz and Swaab2007; Pijnacker et al., Reference Pijnacker, Geurts, Van Lambalgen, Buitelaar and Hagoort2010). However, compared to predictable words, semantically congruent but unpredictable words were also associated with a larger positivity, and this effect was reported to be predominately distributed over more anterior region and was either left-lateralized (Coulson & Van Petten, Reference Coulson and Van Petten2007; Kutas, Reference Kutas1993) or not (Delong et al., Reference Delong, Urbach, Groppe and Kutas2011; Federmeier et al., Reference Federmeier2007). Given that the unpredictable words used in the present study were semantically congruent and a larger late positivity was elicited by the unpredictable words than the predictable words, this late positivity effect might be similar to the anterior positivity found in previous studies (Coulson & Van Petten, Reference Coulson and Van Petten2007; Delong et al., Reference Delong, Urbach, Groppe and Kutas2011; Federmeier et al., Reference Federmeier2007; Kutas, Reference Kutas1993). However, given that our statistical analyses of the late positivity did not show clear anterior distribution, an alternative interpretation is that this late positivity could be the more broadly distributed late positivity, which might reflect a more common integration process between the target words and their preceding context (Brouwer et al., Reference Brouwer, Fitz and Hoeks2012).
Effect of context
The manipulation of context did not show a modulation on the N400 effect in the current study. Based on the N400 results, at least a semantic prediction can be generated in both sentence and discourse contexts, and when the presented information matches the semantic prediction, semantic processing is facilitated comparably in both sentence and discourse conditions. In the sentence condition, the contextual information relevant for predicting the target words is located within the last sentence, which contains the critical word; in the discourse condition, the first sentence of each discourse provided important information for the prediction of the target word, which means that two sentences intervened between the critical word and the contextual information relevant to predict it. Here, the undifferentiated N400 effect between the sentence and discourse conditions may indicate that both contexts could equally facilitate semantic processing of the predictable words.
In the present study, we have carefully constructed our materials so that the cloze probability and acceptability of the critical words were well matched between the sentence and discourse conditions. These two factors have been shown to strongly influence N400 amplitude (Kutas & Federmeier, Reference Kutas and Federmeier2011). The nonsignificant N400 effect between sentence and discourse conditions indicates that these two kinds of contexts have similar impact on semantic processing when the cloze probability and acceptability of words are well matched. Our result is inconsistent with that of Boudewyn and colleagues (Reference Boudewyn, Long and Swaab2015), who found that the broader discourse context is superior to sentence context for word processing. The discrepancy between the results might be attributed to three factors. First, the sentence context manipulated in Boudewyn et al.’s study provided a prototypical or atypical semantic feature, while the discourse context provided a story scenario, which could have a stronger influence on prediction than lexical semantic information (Boudewyn et al., Reference Boudewyn, Gordon, Long, Polse and Swaab2012; Boudewyn et al., Reference Boudewyn, Long and Swaab2013; Camblin et al., Reference Camblin, Gordon and Swaab2007). In the present study, however, the manipulated contexts for the sentence and discourse conditions contained similar specific lexical information (e.g., box – pictures; album – pictures). Second, in Boudewyn et al. (Reference Boudewyn, Long and Swaab2015), the cloze probability of the critical words was not matched between the sentence and discourse conditions, whereas it was matched in the present study. Third, spoken stimuli were used as materials in Boudewyn et al. (Reference Boudewyn, Long and Swaab2015), while written stimuli were used in the present study. Modality could be a significant factor influencing semantic processing (Kutas et al., Reference Kutas, Neville and Holcomb1987; Van Petten et al., Reference Van Petten, Coulson, Rubin, Plante and Parks1999), which in turn might influence incremental predictive processing (Freunberger & Nieuwland, Reference Freunberger and Nieuwland2016).
We followed previous studies in using an stimulus onset asynchrony (SOA) of 700 ms to investigate the prediction of upcoming target words (Ito et al., Reference Ito, Corley, Pickering, Martin and Nieuwland2016; Li et al., Reference Li, Zhang, Xia and Swaab2017). However, the presentation rate has a significant impact on generation of predictions at different representational levels (e.g., Ito et al., Reference Ito, Corley, Pickering, Martin and Nieuwland2016; but see also Delong et al., Reference Delong, Chan and Kutas2019). The 700 ms SOA might allow more time to generate predictions than in experiments with shorter SOAs, benefiting predictions at more specific representational levels (Ito et al., Reference Ito, Corley, Pickering, Martin and Nieuwland2016). In light of this, it is possible that the presentation rate we use may allow our readers to predict more specific information such as lexical items or specific orthographic forms (Pickering & Garrod, Reference Pickering and Garrod2007, Reference Pickering and Garrod2013). However, given that the present study was not designed to explore the prediction of different representational levels, we could not draw a conclusion about whether the lexical items and their specific orthographic form were preactivated. Whether and how presentation rate influences prediction in sentence and discourse context deserves to be explored further in the future.
Interestingly, our results showed that context modulated the late positivity effect. Like the N400, the late positivity was smaller for predictable words than for unpredictable words. However, in contrast to the N400, the late positivity was only found in the sentence condition, not in the discourse condition. This dissociation indicates that the late positivity reflects a different cognitive process than the N400, one that is more sensitive to contextual information.
According to the inhibition view, when the input does not match readers’ predictions, the predicted information needs to be inhibited, and the cost associated with this inhibition is reflected in larger frontal late positivity (Kutas, Reference Kutas1993; Van Petten & Luka, Reference Van Petten and Luka2012). In light of this view, it seems that the larger post-N400 positivity for the unpredictable words than for the predictable words in the sentence condition might reflect the inhibition of predicted words. However, the inhibition account might be untenable given that a larger post-N400 positivity was also observed in the discourse/predictable condition, in which no predictable word needed to be inhibited.
In addition, our results seem to be incompatible with the revision view. According to the revision account, the late positivity is associated with a postlexical, discourse revision mechanism (Brothers et al., Reference Brothers, Swaab and Traxler2015; Freunberger & Roehm, Reference Freunberger and Roehm2016). When the encountered input disconfirms the predicted words, the language comprehension system revises the current discourse representation, which leads to an enhanced late positivity in the sentence condition. In light of this, it seems that the observed post-N400 positivity in our study could be related to the revision process.
However, it should be noted that in our results, the “outlier” is the sentence/predictable condition. All but the sentence/predictable condition led to enhanced late positivity—including the discourse/predictable condition, in which no unpredictable word initiates the revision process. Therefore, our results seem incompatible with the revision account.
Given that our statistical analysis of the late positivity reveals it to be broadly distributed rather than the frontal post-N400 positivity and also the important result that all but the sentence/predictable condition led to an enhanced late positivity, we consider that the late positivity might reflect the more common integration of upcoming words into preceding context (Brouwer et al., Reference Brouwer, Fitz and Hoeks2012), which might be modulated by context. In the sentence condition, it was more difficult to integrate the unpredictable words into preceding context as compared to the predictable words, which led to a larger late positivity for the unpredictable words than the predictable words. In the discourse condition, however, the relevant context was presented much earlier, and interpreting the target words with respect to this relevant background information have been more cognitively costly, leading to an enhanced late positivity for both the predictable and unpredictable words. In other words, while integrating upcoming words could benefit from detailed semantic information presented late, in the sentence context, this benefit could also be much reduced if the relevant information were presented much earlier, in the discourse context. The reason might be that the memory trace of the discourse context is lower than that of the sentence context, compatible with the memory-based view (Albrecht & Myers, Reference Albrecht and Myers1998; Kintsch, Reference Kintsch1988; Van Den Broek et al., Reference Van Den Broek, Rapp and Kendeou2005).
Recently, based on a large-scale (N = 334) study, Nieuwland and colleagues (Reference Nieuwland, Barr, Bartolozzi, Busch-Moreno, Darley, Donaldson and Von Grebmer Zu Wolfsthurn2019) found that part of the late positivity effect of predictability may be explained in terms of semantic similarity. In addition, there is the possibility that semantic similarity effects are more likely to occur for words that appear close together (here, sentence context, album-pictures) than for distant relationships (discourse context, given that memory trace decreases with longer distance) (Guerra & Knoeferle, Reference Guerra and Knoeferle2014). Therefore, we should not exclude the possibility that the positivity effect of predictability that we observed in the sentence condition is at least in part due to a semantic similarity effect. This issue highlights the need to develop a better way to manipulate prediction of target words at sentence and discourse levels in future studies.
There is also an alternative possibility that our results might reflect a priming effect between the critical words and the preceding information in the sentence and discourse context. However, given that a priming effect would not lead to any difference in late positivity in the two sentence conditions (Otten & Van Berkum, Reference Otten and Van Berkum2008), it could be inferred that our results reflect more than a priming effect, that is, also the difference between the prediction of target words at sentence and discourse levels.
In the field of psycholinguistics, difference between sentence and discourse processing has been a central topic for years (Boudewyn et al., Reference Boudewyn, Long and Swaab2015; Hasson et al., Reference Hasson, Chen and Honey2015). Our result adds to the literature by indicating that prediction of upcoming words benefits more from sentence context than from discourse context. This finding is compatible with the findings in previous studies (Myers et al., Reference Myers, Cook, Kambe, Mason and O’Brien2000; Yang et al., Reference Yang, Chen, Chen and Yang2015; Yang et al., Reference Yang, Zhang, Yang and Lin2018). While those studies did not directly investigate the cognitive process of prediction during language comprehension, they did show that readers need more cognitive effort to integrate long-distance information than short-distance information in discourse context (Myers et al., Reference Myers, Cook, Kambe, Mason and O’Brien2000; Yang et al., Reference Yang, Chen, Chen and Yang2015; Yang et al., Reference Yang, Zhang, Yang and Lin2018).
Moreover, similarly detailed semantic information was manipulated in the sentence and discourse contexts in the present study to eliminate confounds of contextual priming. It is worth noting that discourse context can provide many kinds of information, including story scenario and detailed semantic information (Ledoux et al., Reference Ledoux, Camblin, Swaab and Gordon2006; Otten & Van Berkum, Reference Otten and Van Berkum2007). Our findings add to the literature on prediction in discourse comprehension by indicating that the effect of detailed semantic information might differ from that of a story scenario (e.g., Boudewyn et al., Reference Boudewyn, Long and Swaab2015). More importantly, we should be aware that the effect of detailed semantic information might be modulated by the memory trace of contextual information.
In conclusion, the results of this study suggest that both sentence and discourse context allow readers to predict upcoming words and that a supportive sentence and discourse context can facilitate semantic processing of predictable words. More importantly, predictions based on sentence context have a more facilitating effect on processing than predictions based on discourse context. The results indicate that the position of the crucial contextual information that allows the prediction of upcoming words should be taken into consideration when considering prediction during discourse processing.
Acknowledgments
This research was supported by the State Key Program of the National Natural Science Foundation of China (Grant Nos. 61433018 and 31871108) and the Fundamental Research Funds for the Central Universities, Beijing Sport University (Grant No. 2019QD017).





