



Formulaic sequences (FSs) are prefabricated word bundles that are recurrent in language and possess highly conventional meanings. As mounting evidence has shown that the acquisition of FSs is closely related to overall language proficiency (Boers et al., Reference Boers, Eyckmans, Kappel, Stengers and Demecheleer2006; Dai & Ding, Reference Dai, Ding and Wood2010; Lindstromberg & Boers, Reference Lindstromberg and Boers2008; Nattinger & DeCarrico, Reference Nattinger and DeCarrico1992; Pawley & Syder, Reference Pawley and Syder1983; Weinert, Reference Weinert1995), increasing attention has been given to how native speakers (NSs) and nonnative speakers (NNSs) process FSs. However, as Myles and Cordier (Reference Myles and Cordier2017) pointed out, many studies gauging the processing of FS are unclear in defining what type of FS they are investigating and often generalize the processing advantage found for a single type of FS to all formulaic language, claiming that FSs are holistically stored in long-term memory. Nevertheless, the fact that FSs are processed faster does not necessarily indicate that they are represented as a whole in the mental lexicon (Siyanova-Chanturia, Reference Siyanova-Chanturia2015). In addition, the great diversity in types of FSs makes it untenable to treat all FSs as if they were psychologically the same (Boers & Lindstromberg, Reference Boers and Lindstromberg2012). Recent research (Carrol & Conklin, Reference Carrol and Conklin2020) has found that NSs’ processing of different types of FSs is regulated by different linguistic properties (i.e., idioms by frequency, familiarity, and decomposability; binominals by predictability and semantic association; collocations by mutual information). This complication in turn poses difficulties for the integration of findings about FS processing into FS acquisition because NSs and NNSs do not perceive and use all FSs in the same way (Nekrasova, Reference Nekrasova2009). The present study set out to address the issue by comparing the online processing of two subtypes of FSs and investigating the extent to which processing speed by NSs and NNSs is related to how well they understand FSs.
In the FS literature, a sizable number of studies have employed online instruments, such as reaction/reading times or eye-tracking paradigms, to investigate NSs and/or NNSs’ processing patterns (e.g., Carrol & Conklin, Reference Carrol and Conklin2020; Conklin & Schmitt, Reference Conklin and Schmitt2008; Gyllstad & Wolter, Reference Gyllstad and Wolter2016; Jiang & Nekrasova, Reference Jiang and Nekrasova2007; Jiang et al., Reference Jiang, Jiang and Siyanova-Chanturia2020; Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin and Schmitt2011; Tabossi et al., Reference Tabossi, Fanari and Wolf2009; Tremblay et al., Reference Tremblay, Derwing, Libben and Westbury2011; Underwood et al., Reference Underwood, Schmitt, Galpin and Schmitt2004; Vilkaitė & Schmitt, Reference Vilkaitė and Schmitt2019; Wolter & Yamashita, Reference Wolter and Yamashita2014, Reference Wolter and Yamashita2018; Yamashita & Jiang, Reference Yamashita and Jiang2010). Many studies have utilized offline measures, such as metalinguistic ratings, controlled production, or verbal reports, to assess the status of speakers’ FS knowledge (e.g., Bardovi-Harlig & Stringer, Reference Bardovi-Harlig and Stringer2017; Cieślicka, Reference Cieślicka2006; Cooper, Reference Cooper1999; Irujo, Reference Irujo1986; Kim, Reference Kim2016; Martinez & Murphy, Reference Martinez and Murphy2011; Nekrasova, Reference Nekrasova2009; Siyanova-Chanturia & Janssen, Reference Siyanova-Chanturia and Janssen2018; Spöttl & McCarthy, Reference Spöttl, McCarthy and Schmitt2004; Van Lancker Sidtis, Reference Vanlancker-Sidtis2003). The present study goes one step further by triangulating two concurrent measures, reaction time (RT) and think-aloud (TA) protocols, to examine how NSs and NNSs process two different types of FSs, namely idioms and matched nonidiom FSs, to determine if there is a relationship between how fast speakers respond to and how well they understand the two types of FSs.
Literature review
There are two main strands of FS research: processing-based research and comprehension-based research. The former focuses on the holistic nature and representation of FSs in the mental lexicon, while the latter examines how well language users know FSs and what strategies they employ to comprehend FSs. Most studies test only NSs, or only NNSs. Only a few have juxtaposed NSs and NNSs, comparing the psychological status and/or acquired knowledge about FSs in the first and second languages (L1 and L2). These studies are reviewed in detail below.
Underwood et al. (Reference Underwood, Schmitt, Galpin and Schmitt2004) investigated how NSs and NNSs processed a mixed class of FSs using eye-tracking paradigms. Each FS (met the deadline by the skin of his teeth) and a matched non-FS with the same final word (met the dentist who looked at his teeth) were embedded in short stories. Both NSs and NNSs fixated on the FS final words fewer times than non-FS final words, while NSs’ fixation durations on FS final words were shorter than non-FS final words. The authors claimed that both NSs and NNSs retrieved FSs holistically, but that reading time could only be lessened with the full acquisition of FSs. The authors also pointed out that one possible cause of these conflicting results between fixations and reading times was that NNSs did not process all types of FSs holistically and that a subset of FSs may be processed analytically, thereby increasing overall fixation durations. To avoid the potential issue caused by the heterogeneity of FSs, Conklin and Schmitt (Reference Conklin and Schmitt2008) used a similar experimental design but only focused on idioms. In contrast to the previous findings, reading times collected in a self-paced reading task showed that both NSs and NNSs processed idioms significantly faster than control phrases, regardless of whether the context favored a figurative or a literal reading. Siyanova-Chanturia et al. (Reference Siyanova-Chanturia, Conklin and Schmitt2011) adopted Conklin and Schmitt’s (Reference Conklin and Schmitt2008) design, using eye tracking to investigate NSs and NNSs processing of idioms in literal contexts versus figurative contexts. Their findings for NSs replicated the previous study although NNSs processed idioms and novel phrases at a comparable speed. Moreover, figurative readings of idioms were processed more slowly than their literal readings by NNSs. Analysis of fixation time spent before and after the idiom key (the word that determines when an idiom can be recognized as an idiom; Cacciari & Tabossi, Reference Cacciari and Tabossi1988) revealed that NNSs spent a longer time on figurative reading before reaching the idiom key, which was the cause of their slowed processing. Similarly, Cieślicka (Reference Cieślicka2006) and Cieślicka and Heredia (Reference Cieślicka and Heredia2011) found that NSs showed processing advantages for the figurative meanings of idioms, while NNSs showed processing advantages for their literal meanings of idioms. Based on this pattern, Cieślicka (Reference Cieślicka2006) proposed the literal salience hypothesis, that is, the literal meaning of an idiom is more salient to NNSs. However, in a more recent study, Van Ginkel and Dijkstra (Reference Van Ginkel and Dijkstra2020) used primed lexical decision paradigms to investigate similar questions and found that both NSs and NNSs responded faster to words either figuratively or literally related to primed idioms than unrelated words. Among all these studies, only Siyanova-Chanturia et al. (Reference Siyanova-Chanturia, Conklin and Schmitt2011) used NNSs’ familiarity ratings to ensure that NNSs knew the target idioms and did not find any advantages for NNSs’ processing of FSs.
Studies investigating isolated FSs also generated conflicting findings. Jiang and Nekrasova (Reference Jiang and Nekrasova2007) conducted grammaticality judgment tasks to investigate the online processing of nonidiomatic FSs (to tell the truth) and their matched nonformulaic phrases (to tell the price) by English NSs and NNSs. Both NSs and NNSs responded to the FSs faster and with fewer errors than to the nonformulaic controls. Based on these findings, the authors claimed that FSs are holistically represented in both NSs’ and NNSs’ lexicons. However, focusing on a different type of FS, Gyllstad and Wolter (Reference Gyllstad and Wolter2016) found the opposite patterns for lexical collocations. Both NSs and NNSs judged collocations more slowly than free combinations, which might be due to the semi-transparent nature of collocations according to the authors. The processing speed was found to be sensitive to the phrasal frequency.
Additionally, addressing the issue of formulaic advantages but with attention given to the fixedness of FSs, different studies have found different patterns for NNSs. Siyanova-Chanturia et al. (Reference Siyanova-Chanturia, Conklin and van Heuven2011) used eye tracking to compare the processing of binominal collocations (bride and groom) and their reversed forms (groom and bride). They found that both NSs and advanced NNSs showed processing advantages for binominals over their reversed controls and attributed the pattern to the high phrasal frequency effect. Vilkaitė (Reference Vilkaitė2016) and Vilkaitė and Schmitt (Reference Vilkaitė and Schmitt2019) compared NSs and NNSs processing of adjacent collocations (provided information) and nonadjacent collocations (provide some of the information) also using eye tracking. However, their results showed that unlike NSs, who demonstrated processing advantages for both types of collocations over their novel controls, NNSs only demonstrated advantages for adjacent collocations. In addition, the authors found that NNSs’ processing speed was correlated with their pre-existing vocabulary knowledge.
The aforementioned studies mainly concentrated on the comparison between FSs and their nonformulaic controls. Another line of research has focused on internal differences between subcategories of a single type of FS and has mainly concerned the formulaic transfer from L1 to L2 by examining NNS processing of L1-L2 congruent versus incongruent collocations (Wolter & Gyllstad, Reference Wolter and Gyllstad2011, Reference Wolter and Gyllstad2013; Wolter & Yamashita, Reference Wolter and Yamashita2018; Yamashita & Jiang, Reference Yamashita and Jiang2010) or idioms (Carrol & Conklin, Reference Carrol and Conklin2014, Reference Carrol and Conklin2017; Carrol et al., Reference Carrol, Conklin and Gyllstad2016). Their major contribution is the finding that congruent FSs have a processing advantage over incongruent FSs, and that this congruency effect may be attributed to the cross-language lexical activation combined with the frequency and compositionality of the FSs. In addition to the consistent finding of the congruency effect, some studies have also found that NNSs’ knowledge about FSs might be another influential factor. For example, Wolter and Gyllstad (Reference Wolter and Gyllstad2011) found that NNSs’ online processing patterns paralleled their quality of knowledge patterns. Carrol et al. (Reference Carrol, Conklin and Gyllstad2016) found that when L1 knowledge was not available, how fast L2 FSs were processed was significantly related to how familiar they were to the NNS participants. Carrol and Conklin (Reference Carrol and Conklin2017) also reported an emerging familiarity effect in L2 idiom processing. Those studies have demonstrated that NNSs’ online processing of FSs was regulated to different extents by how well they knew the FSs. This raises the question of whether the inconsistent processing patterns found for NNSs in previous studies are because some research assumed that NNSs knew the tested FSs but did not test this knowledge.
Indeed, only a handful of studies have examined how well NSs and NNSs know FSs. In a rating study, Carrol et al. (Reference Carrol, Littlemore and Dowens2018) asked English NSs and NNSs to rate idioms’ familiarity, transparency, compositionality, and meaning (selecting the correct figurative meaning for an idiom). They found that familiarity had a significant effect on perceptions of transparency and that meaning was strongly affected by compositionality. Based on the NS–NNS differences, the authors concluded that NNSs are more inclined to undertake analytical processing, allowing them to see possible connections between constituent words and whole phrases that NSs tended to overlook. Bardovi-Harlig (Reference Bardovi-Harlig2009) used an aural recognition task and an oral production task to investigate the relationship between the recognition and production of FSs by NSs and NNSs, finding that recognition of FSs is a necessary but not sufficient condition for NNSs to correctly produce them. Other factors, such as the degree of familiarity and overuse of some high-frequency expressions, may also cause NNSs to use FSs less frequently than NSs. Nekrasova (Reference Nekrasova2009) conducted a gap-filling task and a dictation task to compare NSs’ and NNSs’ knowledge of two types of FSs, discourse-organizing bundles (what do you think) and referential bundles (one of the most). In the gap-filling task, intermediate NNSs’ knowledge of FSs was significantly poorer than that of NSs and advanced NNSs. In the dictation task, advanced NNSs outperformed both intermediate NNSs and NSs. In both tasks, discourse-organizing bundles were found to be better acquired than referential bundles by all three groups. The results indicated that speakers’ knowledge about FSs was more affected by linguistic registers and discourse functions than by frequency. Based on these findings, the author also suggested that not all types of FSs have the same psycholinguistic status. Carrol and Conklin (Reference Carrol and Conklin2020), who found that the processing of FSs is type sensitive for NS, made the same claim. However, to our knowledge, no study has directly compared NSs’ and NNSs’ processing of different types of FSs.
The present study
This study set out to compare two subtypes of Chinese FSs, idioms and nonidiom FSs. Idioms (e.g., kick the bucket) are fixed phrases whose conventional meanings are not always derivable from the literal meanings of the constituent words. Chinese idioms also include elements of ancient Chinese grammar and lexis (e.g., 一目了然 one-eye-clear-understand be apprehended at a glance; a noun “eye” can serve as a verb “look” in ancient Chinese) that can set them apart from nonidiom phrases that conform to modern Chinese grammar, such as lexical bundles (e.g., 一看就懂 yí-kàn-jiù-dǒng one-look-then-understand be apprehended at a glance) or collocations (e.g., 重要手段 zhòngyào-shǒuduàn important-method important method), even if every constituent word of an idiom identifiably contributes to the overall meaning. Nonidiom FSs (e.g., to begin with) in this study refer to fully transparent multiword expressions that “occur as phrases and as coherent semantic units at a relatively high frequency” (Jiang & Nekrasova, Reference Jiang and Nekrasova2007, p. 433). On the one hand, the meaning of nonidiom FSs can be derived from the combination of each constituent word’s literal meaning, setting them apart from idioms. On the other hand, despite being fully compositional in semantics, nonidiom FSs are different from novel phrases (e.g., to dance with) because they enjoy a higher frequency of reoccurrence in texts. Although both idioms and nonidiom FSs are recurrent in language and found to have processing superiority (Wray, Reference Wray2002), they differ in many linguistic dimensions, such as degree of fixedness and figurative meaning, making idioms intuitively more likely to be processed as holistic units than nonidiom FSs like corpus-derived lexical bundles (Boers & Lindstromberg, Reference Boers and Lindstromberg2012). Based on these differences, researchers have adopted the theoretical view that FSs are on a continuum (Coulmas, Reference Coulmas and Asher1994; N. Ellis, Reference Ellis2012; Wray & Perkins, Reference Wray and Perkins2000) that includes “at the one extreme, idiomatic and immutable strings, …, and, at the other, transparent and flexible ones containing slots for open class items” (Wray & Perkins, Reference Wray and Perkins2000, p. 1). The targets of the present study, idioms and nonidiom FSs, are far apart on the FS continuum, differing mainly in the dimension of idiomaticity. We want to examine whether this difference in the speaker-external (linguistic) dimension also appears in any speaker-internal (processing) dimension for NSs and NNSs.
To achieve this goal, two concurrent data sources, RT and TA verbalizations, are triangulated. RTs, often used to investigate online processing (Jiang, Reference Jiang2011), are an indicator of how much cognitive effort individuals make to process language. TAs, as a window into the minds of speakers, can be used to probe speakers’ depth of processing and understanding (Adrada-Rafael, Reference Adrada-Rafael2017; Bowles, Reference Bowles2010). Leow et al. (Reference Leow, Grey, Marijuan and Moorman2014) suggested that RT and TA can complement one another in providing a fuller picture of L2 processing. In this study, both are used to answer the following research questions (RQs).
RQ1. Are the two types of FSs processed differently by NSs and NNSs?
RQ2. Do NSs and NNSs display the same quality of understanding (QOU) about the two types of FSs?
RQ3. Are NSs’ and NNSs’ processing affected by their QOU about the two types of FSs?
Method
Participants
The twenty NSs were Chinese undergraduate and graduate students (12 females; 8 males; Meanage = 27.5). The NNS participants were 22 Chinese degree learners (12 females; 10 males; Meanage = 22.5) recruited from four Chinese universities. They came from nine countries: Egypt, Japan, Kazakhstan, Korea, Mongolia, Nepal, Thailand, Russia, and Vietnam. All NNS participants had passed Hanyu Shuiping Kaoshi (Chinese Proficiency Test) level 6Footnote 1 within the last 2 years.
Materials
The FSs used in this study consisted of 48 idioms and 48 nonidiom FSs in Chinese, chosen using the following criteria. First, 76 three-character (3-C) and four-character (4-C) idioms were selected from The Contemporary Chinese Dictionary (6th edition) based on their corpus frequency. Second, 33 experienced Chinese second language (CSL) teachers were invited to rate how many HSK-6 learners would know these idioms using a 5-point scale (5 = all HSK-6 learners should know; 1 = no HSK-6 learners should know). Idioms that received an average rating lower than 4 were excluded. Finally, an equal number (n = 24) of 3-C idioms and 4-C idioms were selected for the test list. Every idiom was matched with a nonidiom FS (see Table 1 for examples). Because Chinese idioms contain ancient syntactic structures, it was unlikely to find a grammatical nonidiom FS by just changing one word in the idiom, as some previous studies have done. However, the nonidiom FSs and their idiomatic counterparts were matched in the following aspectsFootnote 2 : 1) they had an equal number of characters and similar structures, 2) they shared at least one identical keyword, and 3) they had similar total stroke numbers and whole-phrase frequency. Because some of the nonidiom FSs were absent from the existing Chinese frequency corpora, we followed Libben and Titone’s (Reference Libben and Titone2008) practice, using the log-transformed page counts of a Chinese website search engine (www.baidu.com) to represent the whole-phrase frequency. Independent samples t-tests (α = .0125) showed that frequency and stroke numbers were matched for idiom and nonidiom FSs. Specifically, there were no significant differences in the frequency (t = −0.57, df = 46, p = .57) or stroke number (t = 0.36, df = 46, p = .72) between 3-C idioms and 3-C nonidioms or in the frequency (t = 0.09, df = 46, p = .93) or stroke number (t = 0.08, df = 46, p = .94) between 4-C idioms and 4-C nonidioms.
Table 1. Examples of test stimuli

In summary, the test stimuli consisted of four classes of FSs: 3-C idioms, 4-C idioms, 3-C nonidioms, and 4-C nonidioms. Each class had 24 items (full list in Supplementary Materials). Another 96 ungrammatical phrases were included as filler items. All test items were evenly divided into two counterbalanced blocks (A and B). The block that contained an idiom did not contain its matched nonidiom FS. All NNS participants were given a character list to study at home and then completed a character quiz before the main test began. This procedure was performed to confirm that all characters in the test stimuli were known to NNSs. Two NNSs who did not get 100% correct were removed.
Test instruments
The instruments used to assess the processing and comprehension of FSs are phrase acceptability judgment tasks (AJTs), with one conducted silently (to gather RT) and another conducted with TAs (to collect TA data). Although silent AJTs have been widely used to measure L2 acquisition, researchers have found that NNSs can be inconsistent in making dichotomous judgments (R. Ellis, Reference Ellis1991) and have suggested that the cognitive recourse that L2 learners use for immediate recognition “does not necessarily imply language acquisition” (Leow, Reference Leow1993, p. 334). Thus, while the silent AJT taps into participants’ speeded recognition, TA AJT is a complementary measure that allows us to gather qualitative data about how learners process the FSs. All participants performed the two AJTs in a counterbalanced order with a 1-week interval between the two. In each AJT session, participants saw both blocks of test material with a 5-min break in between. Figure 1 presents the experimental procedure.

Figure 1. Experimental Procedure.
Silent acceptability judgment task
In the silent AJT, participants had a brief instruction session followed by a 10-trial training session. First, a fixation cross appeared in the center of the screen for 800 ms and disappeared. A phrase was then exposed in the same position. Participants were asked to judge whether the FS was likely to be used in Chinese by pressing A for “YES” and L for “NO.” No time limit was set for each trial, so the FS remained on the screen until a response was entered. However, the test was speeded because participants were instructed to make a judgment as quickly as possible. The experiment was run in Paradigm (Perception Research Systems, 2007) on a Lenovo laptop.
Think-aloud–acceptability judgment task
The TA-AJT session was similar to the silent session except that instead of pressing a button to respond participants were instructed to verbalize their Yes or No judgment and report what they were thinking when they made the judgment. Before the experiment, written instructions were given to participants to ensure that they understood they should verbalize whatever thoughts went through their minds when performing the AJT. Participants were also given spoken instructions regarding how to think aloud. First, they were informed that one of the research goals was to obtain a realistic representation of how they understood language. Therefore, they were asked first to read aloud the FS they saw and then judge whether the FS was likely to be read or heard in Chinese. The instructions emphasized that it was important to “speak whatever can help you make a judgment for a stimulus” without worrying about giving explanations, using examples or using incomplete sentences. Both NSs and NNSs were asked to think aloud in the target language, Chinese, since Adrada-Rafael and Filgueras-Gómez (Reference Adrada-Rafael, Filgueras-Gómez and Leow2019) found no qualitative difference between TAs that intermediate NNSs completed in their L1 versus in their L2. As in Kim and Bowles (Reference Kim and Bowles2019), this was also practical for the researchers given that the NNSs came from nine different L1 backgrounds. Throughout the experiment, an assistant sat beside the participant and prompted them when they fell silent (Bowles, Reference Bowles2010). The whole TA-AJT session was audio-recorded using Audacity and transcribed. A full transcription of an NNS participant is provided (Supplementary Materials).
Coding
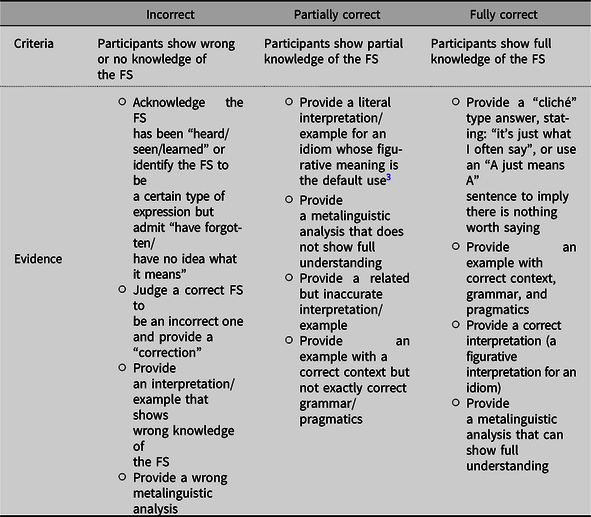
The Yes/No judgments about the FSs were first coded for accuracy (correct vs. incorrect) and then for QOU. Previous research (Cooper, Reference Cooper1999) has shown that participants can utilize a variety of strategies in the process of understanding an FS. Because the TA procedure in this study only intended to probe participants’ success in understanding FSs rather than the strategies they used, we coded three levels of QOU based on previous research (Boers & Demecheleer, Reference Boers and Demecheleer2001; Schmitt et al., Reference Schmitt, Schmitt and Clapham2001): incorrect, partially correct, and fully correct. Table 2 presents the operationalization of the coding procedure, adapted from previous coding procedures for depth of processing (Adrada-Rafael, Reference Adrada-Rafael2017; Leow & Mercer, Reference Leow and Mercer2015).
Table 2. Operationalization of QOU
The first author and a research assistant coded 25% of the data independently. The interrater agreement was 100% for judgment accuracy and 94.6% for QOU. After discussing some controversial cases, the two raters coded another 5% of the data for QOU, and the interrater agreement reached 98.4% (Cohen’s kappa = 0.85). The results were considered high enough for the first author to code the remaining data alone.
Results
Test order effect
To examine whether there was a test order effect (silent-TA vs. TA-silent), judgments and RTs from the silent AJT sessions (time point 1 for Group 1 and time point 2 for Group 2) were compared using independent samples t-tests (α = .0125). No significant differences in judgment accuracy were found between the two orders for either NSs (p = .75) or NNSs (p = .29). There were no significant differences in mean RTs based on test order for either NSs (p = .49) or NNSs (p = .21). Therefore, the two order conditions were merged, with (non)-nativeness being the only between-group condition in the following analyses.
Preliminary analysis
The two AJTs resulted in 1920 datasets (20 participants × 96 target items) from each group. Each dataset includes four data points: a silent Yes/No judgment and its RT and a verbalized Yes/No judgment and its TA report. Data were trimmed by removing whole datasets instead of single data points. First, only consistently correctly judged items in the two AJT sessions were included in the analyses. This procedure removed 2% of the NS datasets and 17% of the NNS datasets (Table 3). To further trim outliers, a participant’s RT data that were 3 standard deviations from their mean were eliminated. This procedure removed another 2.7% of the NS datasets and 1.6% of the NNS datasets. After removing these data, 1830 sets of NS data (95%) and 1564 sets of NNS data (81%) were retained for analysis. RT data were then Log10-transformed to reduce skewing. Log10RT data were analyzed using linear mixed-effects models (LMMs), and QOU coding was analyzed using generalized linear mixed-effects models (GLMMs) in R (version 4.1.0; R Development Core Team, 2021) using the lmerTest package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). When fitting the models, Group, Type, and Length (or a subset of these three factors) were included as fixed effects, and subjects and items were entered as random effects (Baayen et al., Reference Baayen, Davidson and Bates2008). The maximal random effects structure was first included and then reduced when the model failed to converge, following Bates et al.’s (Reference Bates, Kliegl, Vasishth and Baayen2015) advice. Pairwise comparisons were computed using the emmeans package (Lenth et al., Reference Lenth, Buerkner, Herve, Love, Riebl and Singmann2021). In all analyses, we report the model structure and the significance of the fixed effects, including the coefficient (β), standard error (SE), and t value (z value for QOU). The full model outputs are provided in the Supplementary Materials (Tables C1-E2).
Table 3. Judgment error rate and consistently correct rate in two AJTs

RQ1. Online processing
RQ1 asked whether NSs’ and NNSs’ online processing patterns were different. Raw RT data were first analyzed descriptively (Table 4). For NSs, the mean RTs of both 3-C and 4-C idioms were shorter than those of their nonidiom counterparts. For NNSs, the mean RTs of both 3-C idioms and nonidioms were shorter than their 4-C counterparts; the mean difference between 3-C and 4-C FSs was greater for idioms (357 ms) than nonidioms (114 ms). The mean RT of 4-C idioms was the shortest in the NS group but the longest in the NNS group.
Table 4. Descriptive statistics of RTs (ms)

The LMM analysis was then conducted for Log10RTs with Group, Type, and Length entered as fixed effects and subjects and items entered as random effects including random intercepts for subjects and items and by-subject and by-item random slopes for Group, Type, and Length. The analysis returned a significant effect for Group (β = 0.23, SE = 0.04, t = 6.36, p < .00), Type (β = 0.03, SE = 0.01, t = 2.20, p = .03), and the Group × Length interaction (β = 0.08, SE = 0.02, t = 4.04, p < .00) but not for Length (β = −0.01, SE = 0.01, t = −0.83, p = .41), the Group × Type interaction (β = −0.01, SE = 0.02, t = −0.32, p = .75), the Type × Length interaction (β = 0.00, SE = 0.02, t = −0.10, p = .92), or the three-way interaction (β = −0.04, SE = 0.02, t = −1.62, p = .11). To determine whether a significant Type and Length effect existed for each group, the LMM analysis was conducted separately for NSs and NNSs. For NSs, the Type effect was significant (β = 0.03, SE = 0.01, t = 2.60, p = .01), with both 3-C and 4-C idioms processed faster than their nonidiom counterparts (ps < .05), but the Length effect was nonsignificant (β = −0.01, SE = 0.01, t = −0.82, p = .42). In contrast, for NNSs, the Type effect was nonsignificant (β = 0.03, SE = 0.02, t = 1.27, p = .21), but the Length effect was significant (β = 0.07, SE = 0.01, t = 4.75, p < .001), with 3-C idioms and nonidioms both processed faster than their 4-C counterparts (ps < .05). The overall pattern demonstrated that NSs’ processing was more likely to be affected by the type of FS, whereas NNSs’ processing was more likely to be affected by the length of FSs.
RQ2. Quality of understanding
RQ2 asked whether there was a difference in NSs’ and NNSs’ QOU with different types/lengths of FSs. To answer this question, the QOU coding was analyzed. As Table 5 illustrates, NSs’ incorrect TAs were observed less than 1% of the time under different FS conditions, and partially correct TAs were less than 3%. However, the frequencies of NNSs’ incorrect TAs varied greatly under different FS conditions, ranging from 1.0% (3-C nonidioms) to 10.6% (4-C idioms), as did the frequencies of partially correct TAs, ranging from 13.2% (3-C nonidioms) to 20.8% (4-C nonidioms). The most successful FSs in the NS group were 4-C idioms with the highest fully correct ratio (99.4%), which were the most unsuccessful FSs in the NNS group with the lowest fully correct ratio (70.2%).
Table 5. Frequency of QOU

The GLMM analysis was first conducted on QOU with Group, Type, and Length being entered as fixed effects and subjects and items added as random effects including a maximal random effects structure. After a series of model fitting following a backwards elimination algorithm, the model with minimal random effects structure still failed to reach convergenceFootnote 4 . The fixed-effect-only generalized linear model finally converged and returned a significant effect only for Group (β = −0.12, SE = 0.05, z = −2.42, p = .02). All the other effects including Type (β = 0.01, SE = 0.05, z = 0.19, p = .85), Length (β = −0.01, SE = 0.05, z = 0.22, p = .83), and the interaction of Group × Type (β = 0.05, SE = 0.07, z = 0.72, p = .47), Group × Length (β = −0.01, SE = 0.07, z = −1.33, p = .19), Type × Length (β = −0.01, SE = 0.07, z = −0.21, p = .84), and Group × Type × Length (β = 0.03, SE = 0.10, z = 0.32, p = .75) were all nonsignificant. To explore whether Type and Length had an effect on QOU within each group, separate analyses were conducted with the same model fitting procedure. The analysis for NSs yielded no significant effect for Type (β = 0.00, SE = 0.05, z = 0.19, p = .85), Length (β = 0.01, SE = 0.05, z = 0.22, p = .83), or their interaction (β = −0.01, SE = 0.07, z = −0.21, p = .84); pairwise comparisons also returned no statistical significance (ps > .05). For NNSs, although the main analysis did not show a clear effect for Type (β = 0.06, SE = 0.05, z = 1.12, p = .26), Length (β = −0.09, SE = 0.06, z = −1.54, p = .12), or their interaction (β = 0.02, SE = 0.08, z = 0.24, p = .81), pairwise comparisons showed that the difference between two lengths was significant (p = .04) with 3-C FSs understood better than 4-C FSs, and the difference between two types was marginally significant (p = .07) with nonidioms better understood than idioms. The overall results show that NSs’ understanding of FSs with different types and lengths did not vary much. However, NNSs’ understanding of different types and lengths of FSs varied to different extents. Longer FSs were understood more poorly than shorter FSs; the QOU of idioms was lower than that of nonidioms. Although inferential statistics showed only a marginal difference in NNSs’ understanding of idioms versus nonidioms, the frequency distribution demonstrated that both 3-C and 4-C idioms elicited more incorrect TAs and fewer fully correct TAs than their nonidiom counterparts. Additionally, NNSs’ relatively high frequencies of incorrect TAs (4.5%) and partially correct TAs (18.2%) indicated that although NNSs’ judgments of the FSs were repeatedly correct, their FS knowledge might be partial or completely wrong.
RQ3. Effect of the QOU on online processing
To determine whether the QOU has an effect on the online processing of FSs, the LMM used in RQ1 was conducted again on Log10RT with QOU added as the covariate. The results (Table 6) generally replicated the findings of RQ1. However, no statistical effect of QOU was obtained. To examine if there was any interaction between QOU and Type and Length variables, separate LMM analyses were run for NSs and NNSs. Type and Length were combined into Category (4 levels: 3-C idiom, 4-C idiom, 3-C nonidiom, and 4-C nonidiom) to remedy the multicollinearity issue. Results (Table 7) show that QOU was not a significant predictor of either NSs or NNSs online processing. Pairwise comparisons (Table 8) only yielded a marginal difference in NNSs’ processing speed of fully correct versus partially correct 3-C nonidioms, but no reliable effect of QOU on the processing speed was found for any other Category condition in either group. This pattern of results suggests that NSs and NNSs’ online processing of a specific category of FSs was not directly affected by how well they understood the FSs.
Table 6. Results of fixed effects of the LMM analysis with QOU as the covariate

*p < .05; ***p < .001; + p = .05–.10.
Table 7. Results of fixed effects of LMM analyses for NS and NNS group
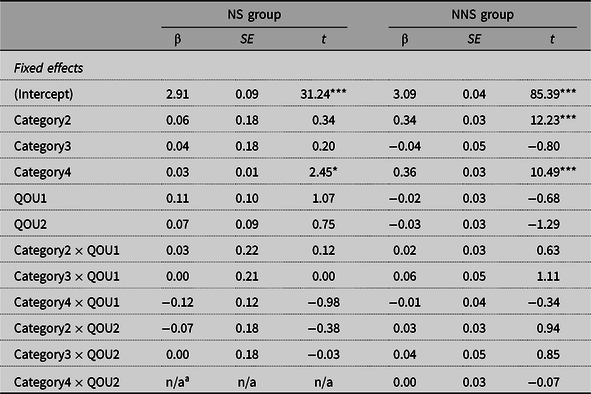
Table 8. Pairwise comparisons for QOU × Category

+ p = .05–.10.
Discussion
Research question 1
The first question asked whether NSs and NNSs’ FS processing patterns were different. The RT data show that NSs’ processing was more likely to be modulated by the type of FS, with idioms being processed faster than nonidiom FSs regardless of length. In contrast, NNSs’ processing was more likely to be modulated by length of FS, with 3-character FSs being processed faster than 4-character FSs regardless of type.
The finding that NSs and NNSs demonstrated different processing patterns when reading idioms versus literal phrases replicates some past resultsFootnote 5 (Carrol & Conklin, Reference Carrol and Conklin2014, Reference Carrol and Conklin2017; Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin and Schmitt2011). The NS processing pattern may indicate that idioms and nonidiom FSs have different psychological statuses in NSs’ mental lexicons. In this study, phrasal frequencies were matched for idioms and nonidiom FSs; therefore, this pattern could also suggest that idiomaticity rather than phrasal frequency plays a more significant role in modulating NSs online processing of FSs, a phenomenon known as the idiom superiority effect (Tabossi et al., Reference Tabossi, Fanari and Wolf2009). Regarding how idiomaticity could modulate processing speed, we speculate two possibilities. The first reason might involve compositionality. Idioms are less compositional than nonidioms, and some parts of an idiom’s constituents may not identifiably contribute to its meaning. For Chinese idioms, lower compositionality could also mean that contemporary Chinese speakers have trouble parsing an idiom’s ancient syntactic configuration even if all the constituent words are to some extent related to the whole idiom’s meaning. Thus, the acquisition of idioms may involve an item-based mechanism, requiring storing each form-meaning association in the lexicon. Therefore, once a target FS was recognized as an idiom, its meaning would be directly retrieved just as with long complex words (Gibbs & O’Brien, Reference Gibbs and O’Brien1990; Swinney & Cutler, Reference Swinney and Cutler1979), hence the processing advantage. The second reason concerns how fast an idiom can be recognized as an idiom, which might have to do with its formal fixedness (Fraser, Reference Fraser1970; Swinney & Cutler, Reference Swinney and Cutler1979). This was evidenced by the internal processing difference between 4-character and 3-character idioms, with 4-character idioms processed faster than 3-character idioms (but not significantly so). Chinese 4-character idioms, also referred to as chéng-yǔ (proverbs; literally translated as “fixed language”), are mostly obtained from classical Chinese and have absolutely frozen forms that are not subject to any lexical substitution or syntactic operation. Because of their fixed nature, we suspect that NSs were able to recognize a 4-character idiom as an idiom at a superior speed. However, we could not rule out the possibility that the 4-character idioms were also less compositional than 3-character idioms and thus more likely to be prestored and retrieved directly. To distinguish between these possibilities, a post hoc analysis was conducted using NSs’ ratings on Chinese idioms’ decomposability in a large-scale norming study (Zheng, Reference Zheng2019). The analysis showed that the target 4-character idioms were rated more decomposable than the 3-character idioms (t=−4.58, p < .00, ratings listed in Test Stimuli in Supplementary Materials). This result suggests that the faster processing speed of 4-character idioms was more likely due to the form fixedness. Even though 4-character idioms were longer and more decomposable than 3-character ones, NSs can quickly predict the whole sequence without having to finish reading every word. The absence of the length effect in the NS group could be explained by the perceptual span of Chinese NSs. Since 3- and 4-character phrases fall in the average perceptual span of native Chinese readers (Inhoff & Liu, Reference Inhoff, Liu and Chen1997), the one-character difference may have been too subtle to be reflected in the RT data, especially given the ceiling effect.
No idiomaticity advantage was observed for NNSs. This result indicates that idiom and nonidiom FSs appear to be processed in a similar fashion by NNSs. Furthermore, the length effect might suggest that it is very likely that NNSs processed both idiom and nonidiom FSs in a word-by-word manner. This verbatim processing of idioms by NNSs suggests that NNSs and NSs handle idioms differently. Such a difference can more clearly be seen through the processing of 4-character idioms, the fastest type for NSs to grasp but the slowest type for NNSs to grasp. These results reinforce the claim (Abel, Reference Abel2003; Myles & Cordier, Reference Myles and Cordier2017) that just because an FS is stored holistically in NSs’ lexicons does not mean that it is also stored holistically in NNSs’ lexicons. For nonidiom FSs, the presence of a length effect showed that they may also be processed in a verbatim fashion by NNSs. In contrast, in Jiang and Nekrasova’s (Reference Jiang and Nekrasova2007) study where nonidiom FSs (mostly lexical bundles, e.g., to start with) were found to be processed faster than nonformulaic controls (e.g., to bring with) by NNSs, the authors claimed that NNSs processed nonidiom FSs holistically as single units. Because the current study did not have nonformulaic controls, the two studies may not be directly comparable. Nevertheless, the unconformity prompts us to reconsider whether the speed advantage can be directly taken as an account for the “holistic” nature, the question previously raised by Siyanova-Chanturia (Reference Siyanova-Chanturia2015) and Siyanova-Chanturia and Martinez (Reference Siyanova-Chanturia and Martinez2015). This study showed that this was not the case, at least for NNSs. As cautioned by Siyanova-Chanturia (Reference Siyanova-Chanturia2015), the speed of whole phrase processing can tell little about whether or not individual constituents are processed and thus cannot be used as evidence to ascertain analytical or holistic processing.
It is also worth mentioning that although the length effect implied that NNSs may approach both types of FSs in a word-by-word manner, the silent AJT was simply a visual recognition task. What can be inferred from the RT data may be more pertinent to how an FS’s form was recognized than how its meaning was processed.
Research question 2
The second question inquired whether there is any difference in speakers’ QOU about different types of FSs and was addressed using TA data. The results show that NSs were at or near the ceiling for every subtype of FS. This is highly predictable given that the selected FSs are all frequently used in written or spoken Chinese and hence very familiar to adult NSs. The high familiarity was also evidenced by the fact that approximately half of NSs’ TAs (54.5% of idioms, 49% of nonidioms) were “cliché” type responses, such as “It’s just what I often say.” Clearly, NSs tend to use their intuition to make judgments, which is often considered a shallow form of processing that involves little cognitive effort (Leow & Mercer, Reference Leow and Mercer2015). The small proportion of incorrect TAs (0.3%) from NSs occurred not because of incorrect understanding but because they questioned whether a lexical bundle (e.g., 不是所有 not-copula-all-all not all of) could be used in isolation.
For NNSs, their understanding of both types of FSs was to some extent limited, especially for the idioms. The different QOU between idioms and nonidioms might be explained by the different contexts in which they commonly occur. Nonidiom FSs are commonly used in daily communications. Thus, NNSs who study Chinese in China not only have adequate exposure to nonidiom FSs but also abundant opportunities to use them. The usage-based model predicts that maximal and interactive exposure can enhance learners’ sensitivity to language (Abbot-Smith & Tomasello, Reference Abbot-Smith and Tomasello2006; Bannard & Lieven, Reference Bannard, Lieven, Corrigan, Moravcsik, Ouali and Wheatley2009). Therefore, nonidiom FSs were better acquired by NNSs. One may argue that since the phrasal frequency of idioms and nonidioms was matched in this study, learners should have an equal chance of being exposed to idioms as they are to nonidioms. As pointed out by Carrol and Conklin (Reference Carrol and Conklin2020), corpus frequency is different from subjective familiarity although the two are often highly correlated. The fact is that idioms are highly frequent in formal written texts, such as newspaper articles and literary works, a register and genre that NNSs seldom encounter, unlike NSs. Thus, despite the matched corpus frequency, NNSs’ subjective familiarity with idioms may be lower than with nonidioms.
Another explanation for the better understanding of nonidiom FSs may have to do with compositionality. Nonidiom FSs are fully transparent items whose meaning is the combination of each individual word. Thus, learners can make sense of an unfamiliar nonidiom FS simply by analyzing its vocabulary items (Libben, Reference Libben1998; Sandra, Reference Sandra1990), as exemplified in the excerpts below.
Excerpt 1
Participant 6 (Korean L1)
Target (4-C nonidiom): 轻松自在/light-slack-self-exist/relaxed and unrestrained
TA: “我没见过这个, 但是能明白, 意思就是很轻松, 很自由.”
“I have never seen this one but can understand; it just means very relaxed, very free.”
The target FS in Excerpt 1 is a nonidiomatic collocation composed of two disyllabic adjectives 轻松 “relaxed” and 自在 “unrestrained.” Although the participant claimed that she never used the phrase before, she successfully put together a correct meaning ostensibly by interpreting the two disyllabic words that she knew. However, when learners applied the same strategy to idioms, comprehension errors occurred. Excerpt 2 and 3 demonstrated this process.
Excerpt 2
Participant 9 (Japanese L1)
Target (3-C idiom): 出人命/happen-human-life/death causing
TA: “对的, 就是出生了一个人.”
“Correct, meaning ‘to give birth to a person’.”
Excerpt 3
Participant 11 (Thai L1)
Target (4-C idiom): 谈天说地/talk-sky-speak-earth/talk of everything under the sun
TA: “对的, 就是谈论天气.”
“Correct, meaning ‘to talk about the weather’.”
In Excerpts 2 and 3, participants were not familiar with the target idioms, but they attempted to make sense of them by analyzing the literal meanings of the constituent words. Nevertheless, the figurative meaning of an idiom is not always derivable from constituent words (Titone & Connine, Reference Titone and Connine1994), so the strategy led to an incorrect understanding. The processing strategies exhibited in the two excerpts were consistent with what the literal salience hypothesis proposed, that “understanding L2 idioms entails an obligatory computation of the literal meanings of idiom constituent words” (Cieślicka, Reference Cieślicka2006, p. 115). Therefore, NNSs’ lower QOU about idioms might also be caused by the decomposing strategy they used to process idioms.
Regarding NNSs’ poorer understanding of longer FSs, NNSs’ TAs showed that they often understood the basic meanings of the longer FSs but provided example sentences with grammar or pragmatic errors. This is why 4-character FSs had more partially correct TAs than 3-character FSs. These instances suggest that longer FSs might be more difficult to fully acquire not because they are semantically more complex but because they are contextually more constrained. What the TA data further tell us is that there are some FSs that “learners think they know but they do not” (Laufer, Reference Laufer1989, p. 11). With judgment data alone, one might be tempted to conclude that a learner knows the correct meaning of any FS that s/he consistently judged correctly; however, TA data show when this is and is not the case.
Research question 3
The third question investigated the role that QOU plays in the online processing of FSs. The results suggest that both NSs and NNSs processing speed was not directly related to their understanding of FSs. The finding about NSs is not surprising given the ceiling effect for NSs’ FS knowledge (RQ2). The disassociation between NNSs’ understanding and processing speed seems counterintuitive, as previous research has shown that the better understood FSs were also processed faster (Liontas, Reference Liontas2003; Vilkaitė & Schmitt, Reference Vilkaitė and Schmitt2019; Wolter & Gyllstad, Reference Wolter and Gyllstad2011). However, previous research either did not directly test the understanding of FSs or did not strictly measure online processing. The dissociated relationship may indicate that NNSs employed different sources of knowledge to complete the two tasks. Although processing speed elicited in the silent AJT probes the immediate recognition of the forms of FSs, the QOU elicited in the TA-AJT probes the understanding of the meanings of FSs. Our findings suggest that NNSs need not fully acquire an FS to perform speedy and successful recognition. NNSs’ reports show that they can recognize an FS using surface-level knowledge, such as just having “seen/heard it before.” It was also observed that NNSs utilized a variety of strategies to compensate for limited knowledge and make a correct judgment. Consider the following three “partially correct” excerpts.
Excerpt 4
Participant 3 (Japanese L1)
Target (4-C idiom): 谈天说地/talk-sky-speak-earth/talk of everything under the sun
TA: “对的, 不确定是什么意思, 但汉语里有 ‘什么天什么地’这样的结构.”
“Correct, not sure about its meaning, but Chinese has the structure like something Sky something Earth.”
Excerpt 4 shows that the learner did not know the idiom but was aware that Chinese idioms can have a prototypical structure “something A, something B.” This instance illustrates that advanced learners who have developed good idiom awareness were able to use metalinguistic knowledge to make a correct acceptability judgment, even though they did not know the idiom’s figurative meaning.
Excerpt 5
Participant 16 (Mongolian L1)
Target (3-C idiom): 开夜车/drive-night-car/burn midnight oil
TA: “对的. 蒙语也有这个说法. 就是晚上开车.”
“Correct. Mongolian has this saying, too, just meaning ‘to drive at night’.”
Excerpt 5 presents a case of L1-to-L2 transfer, which has been found to facilitate L2 FS processingFootnote 6 (Carrol et al., Reference Carrol, Conklin and Gyllstad2016; Irujo, Reference Irujo1986; Yamashita & Jiang, Reference Yamashita and Jiang2010). However, this excerpt shows us that L1 transfer can also be detrimental to L2 idiom comprehension. In this case, idioms in the two languages share the same literal meaning but not the same metaphorical extension.
Excerpt 6
Participant 9 (Korean L1)
Target (4-C idiom): 一帆风顺/one-sail-wind-smooth/everything is going on smoothly
TA: “‘一路顺风’的话听过, ‘一帆风顺’应该差不多的意思.”
“I only heard ‘one-road-smooth-wind’ (another idiom, meaning wish you a happy voyage); ‘one-sail-wind-smooth’ should have a similar meaning.”
Excerpt 6 demonstrates the role that pre-existing knowledge plays in idiom processing. The learner judged an unseen idiom based on a known idiom that has a similar form to the target. This shows that advanced learners have stored some L2 idioms in their repertoires and that this knowledge network can provide some clues for NNSs to make a well-formed conjecture about an idiom’s figurative meaning (Liontas, Reference Liontas2003).
The above excerpts demonstrate that advanced NNSs were able to employ strategies to make a correct judgment, although these strategies were not sufficient to enable learners to achieve fully accurate comprehension. Conversely, as Underwood et al. (Reference Underwood, Schmitt, Galpin and Schmitt2004) suggested, although it is only with full mastery of FSs that the processing time can be shortened, partial mastery is still rewarded in some way. We speculate that the processing strategies used by NNSs had an offsetting effect, causing partially understood idioms to be recognized as quickly as well-understood nonidioms. However, we caution that this finding was based on a limited number of observations. The issue of how specific L2 processing strategies may contribute to processing speed (see van Gelderen et al., Reference van Gelderen, Schoonen, de Glopper, Hulstijn, Simis, Snellings and Stevenson2004) needs to be accounted for by larger-scale studies.
Conclusions, implications, and future research
Through analyzing RT data and TA protocols, this study investigated NSs and NNSs’ processing of idiom and nonidiom FSs, comparing whether the two were processed in the same way. Given the relatively small sample size, we consider that the findings constitute tentative rather than conclusive answers to our research questions. For NSs, the RT data indicate that idioms were processed significantly more rapidly than matched nonidiom FSs. This result may serve as evidence that the processing advantage found for individual types of FSs may not imply that all FSs are created equal. Moreover, it provides psycholinguistic evidence for the continuum view of FSs. Because both idiom and nonidiom FSs enjoy some degree of formulaicity, the processing difference found between the two cannot be categorically interpreted as one being prestored and the other not. Rather, it would be better to consider the difference between the two as a gradient, which may have something to do with the extent to which an overall meaning needs to be prestored due to the noncompositionality and the extent of the formal fixedness. For NNSs, what the RT data tell us is that NNSs might very well be utilizing a words-and-rules approach to unraveling both idioms and nonidioms because longer FSs were processed significantly more slowly than shorter ones regardless of type. Underwood et al. (Reference Underwood, Schmitt, Galpin and Schmitt2004) suggested that the processing difference between NSs and NNSs is a product of lifetime exposure to FSs. Boers and Lindstromberg (Reference Boers and Lindstromberg2012) claimed that even when NNSs encounter FSs a sufficient number of times, they are also less likely to process FSs in a way that resembles NSs. The findings of this study provide support for these claims because the processing patterns of NNSs and NSs were fundamentally different. However, it is worth noting that the RT difference between NSs and NNSs might not be directly used as evidence of holistic versus analytical processing because the whole form recognition task did not tap into how the internal words are processed.
TA data showed that NSs’ understanding of FSs reached ceiling while NNSs’ understanding of idioms was significantly poorer than that of nonidioms despite the comparable processing speed. What the TA data further reveal is that NNSs demonstrated some explicit idiom awareness, which may have facilitated their recognition of the idioms that they did not fully understand. Kim (Reference Kim2016) argued that the awareness of idioms is a stepping stone to the more effective learning of idioms. We argue that awareness is also a step in the direction of automatic idiom processing. From a methodological perspective, our findings demonstrate that learners’ cognitive processes, as revealed by TA data, can be a useful source to investigate learners’ awareness (Leow, Reference Leow2000).
Another methodological issue raised by the comparison of RT and TA data that may merit reconsideration is whether the psycholinguistic account of NNSs’ FS processing should be established on the finding of speedy and successful recognition of the target FSs or established on the finding of speedy and successful understanding of the target FSs. Note that NSs have solid knowledge of FSs, and under this premise, the difference in RTs was translated into a different status in the mental lexicon. However, the premise did not hold for NNSs even at advanced proficiency levels. Thus, it might be premature to make claims about how FSs are represented by NNSs without knowing whether they actually knew the FSs or not. As Boers and Lindstromberg (Reference Boers and Lindstromberg2012) claimed, “one can argue that it is only when a sequence is deeply entrenched in a language user’s long-term memory that it qualifies as truly formulaic for that user” (p. 85).
Although the present research did find new evidence that the two subtypes of FSs are qualitatively different, there are some limitations in the research that must be mentioned. First, the chosen idioms are heterogeneous in many ways, such as degree of literality (whether an idiom’s literal interpretation can be used in any real-world context). Because the focus of the study is to see whether NNSs and NSs process the same sets of FSs in a similar way, we did not investigate the impact of these linguistic variables. However, these variables may play a different role for NSs than for NNSs (Hubers et al., Reference Hubers, Cucchiarini and Strik2020). Future research efforts on how these variables modulate the ease and difficulty of FS processing can certainly provide insights into the differences observed between NSs and NNs. The same issue also existed in nonidiom materials. The nonidiom FSs used in the study included lexical bundles and collocations. Lexical bundles are “frequently recurring strings of words that often span traditional syntactic boundaries” (Tremblay et al., Reference Tremblay, Derwing, Libben and Westbury2011, p. 569), and collocations that are fully decomposable co-occurrences whose meanings are transparent and unlikely to “cause trouble for L2 learners from a comprehension perspective” (Wolter & Yamashita, Reference Wolter and Yamashita2018, p. 396). Previous research (Carrol & Conklin, Reference Carrol and Conklin2020) found that different subtypes of nonidiom FSs are processed differently by NSs. Our TA data also revealed that NSs might have more trouble judging lexical bundles than collocations because lexical bundles sound like incomplete sentence fragments. Therefore, to fully account for why different subtypes of FSs are processed differently, the subdivision of nonidiomatic formulae is also needed. Another issue regarding the test material is that the current study did not have a baseline condition, and thus, strictly speaking, any processing advantage found in this study may not be claimed to be the formulaic advantage over the nonformulaic phrases. In addition, although the test materials were selected based on the familiarity ratings of experienced CSL teachers, the selection cutoff (4 out of 5) may have been too lenient because not all the selected idioms were equally familiar to NNS participants. Future research may consider adopting a stricter cutoff to make more conclusive claims about whether FSs have mental representations in the L2 lexicon. Alternatively, Hubers et al. (Reference Hubers, Cucchiarini and Strik2020) suggested that the selection of idiom material could be based on L2 speakers’ intuition ratings, which have been proven to be reliable and better reflect L2 knowledge than L1 speakers’ intuitions.
Although the TA data in this study revealed novel findings that were not reflected in the RT data, the controversial issue of this method, namely its reactivity, is still worth mentioning. In the preliminary analysis, we found that the NNSs’ error rate in the TA-AJT session (10.3%) was lower than that in the silent AJT session (13.1%). Closer scrutiny showed that the difference was only due to nonidiom FSs. That is, nonidiom FSs were judged more accurately in the TA session than in the silent session, while the error rates of idioms were similar in the two sessions. Based on this pattern, we speculate that the difference in error rates may be attributable to the read-aloud effect. In the TA session, participants read aloud the stimulus that they saw. This performance helped NNSs avoid some reading errors that could happen in the silent session. Because idioms were not judged more accurately by NNSs in the TA session and neither type of FS was judged more accurately by NSs in the TA session, we concluded that TA protocols did not significantly influence speakers’ cognitive processes of reading FSs, which is generally consistent with previous findings (Bowles, Reference Bowles2008, Reference Bowles2010; Bowles & Leow, Reference Bowles and Leow2005; Leow & Morgan-Short, Reference Leow and Morgan-Short2004). Furthermore, the study demonstrates that TA protocols and RT data can complement each other and provide a fuller picture of L2 processing (Leow et al., Reference Leow, Grey, Marijuan and Moorman2014). We believe that this methodology may be useful for future research efforts. However, more comprehensive and reliable findings will require larger-scale studies.
In conclusion, the present study compares the processing of two different types of FSs to gain insights into FS processing by NSs and NNSs. The findings demonstrate the importance of tapping into NNSs’ thought processes to provide evidence rather than just speculating as to why NNSs’ processing or behavioral patterns are different from those of NSs.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0142716421000552
Acknowledgments
We would like to thank Professor Chilin Shih and Misumi Sadler for their feedback on an earlier version of this article as well as Dr. Gareth Carrol and the anonymous AP reviewers for their insightful comments. This research is supported by a Chinese Lexicography Research Center Grant (CSZX-PY-202009).










