


Coming up with the name of a picture requires automatic and simultaneous access to both semantic and phonological representations associated with the picture’s visual features. Semantic representations reflect the meaning of the word whereas phonological representations are the mental representations for the sounds of words stored in long-term memory (Goswami, Reference Goswami2002). Previous studies have utilized the variable rime neighborhood density (RND) to index phonological representations in a number of language production tasks (e.g., De Cara & Goswami, Reference De Cara and Goswami2002; Storkel, Reference Storkel2002; Thomson, Richardson, & Goswami, Reference Thomson, Richardson and Goswami2005), but this methodology has not been applied to complex picture-naming tasks. The purpose of this study was to test whether RND affects rapid automatized naming (RAN) speed. This question is of interest because while the RAN task is ubiquitous in educational assessments of reading, the construct underlying the task has been widely debated (Georgiou & Parrila, Reference Georgiou and Parrila2013).
RAN
The RAN task measures the time it takes to name a succession of related items repeatedly pictured on a single page. Four types of familiar stimuli are typically used: letters, digits, colors, and pictures. Regardless of the type of stimuli presented, poor readers are slower on RAN tasks than good readers. This finding has been substantiated in hundreds of studies conducted in at least 10 different languages (see Kirby, Georgiou, Martinussen, & Parrila, Reference Kirby, Georgiou, Martinussen and Parrila2010; Norton & Wolf, Reference Norton and Wolf2012, for reviews), and along with phonological awareness, RAN is considered one of the strongest predictors of reading (Hulme & Snowling, Reference Hulme and Snowling2014; Song, Georgiou, Su, & Hua, Reference Song, Georgiou, Su and Hua2016). Accordingly, the RAN task has become a requisite component of literacy assessment across educational, clinical, and research settings (Lombardino & Gauger, Reference Lombardino and Gauger2014). Despite its utility and widespread use, the theoretical basis of RAN remains a matter of ongoing debate (Decker, Roberts, & Englund, Reference Decker, Roberts and Englund2013; Georgiou & Parrila, Reference Georgiou and Parrila2013; Logan, Schatsneider, & Wagner, Reference de Jong2011; Wagner, Torgesen, Rashotte, & Pearson, Reference Wagner, Torgesen, Rashotte and Pearson2013).
To understand why some individuals are slower at RAN than others, researchers have tried to identify the precise cognitive and linguistic components of RAN that are crucial contributors to RAN speed. For example, retrieving the name for “cat” requires visual uptake of the semantic features of the picture and lexical retrieval of phonological codes /kæt/ from long-term memory that are mapped to those combined semantic features. Response latencies are measured from the time a picture is presented to the onset of the verbal response. This pause time is thought to capture lexical retrieval processes, whereas articulation speed measures the duration of the verbal response. As naming speed for a typical RAN task captures the total time it takes to name all of the pictures in an array, RAN speed includes both lexical retrieval time and articulation time. A number of studies have documented that RAN speed is not fully accounted for by individual differences in global processing speed (Georgiou, Parilla, & Kirby, Reference Georgiou, Parrila and Kirby2009; Powell, Stainthorp, Stuart, Garwood, & Quinlan, Reference Powell, Stainthorp, Stuart, Garwood and Quinlan2007). There is also evidence that variability on the task is due to pause time between naming each item rather than to articulation time (Clarke, Hulme, & Snowling, Reference Clarke, Hulme and Snowling2005; Georgiou et al., Reference Georgiou, Parrila and Kirby2009; though see Georgiou, Parrila, & Papadopoulos, Reference Georgiou, Parrila and Papadopoulos2016). Thus, it is commonly thought that most of the individual variability in RAN speed comes from processes involved in lexical access, that is, in accessing, not producing, the names of the stimulus items (Clarke et al., Reference Clarke, Hulme and Snowling2005, de Jong, Reference de Jong2011). An open question in the literature and the focus of the present study is whether RAN-specific task demands influence access to phonological codes stored in long-term memory.
THE PHONOLOGICAL ACCESS THEORY OF RAN
RAN has been classified alongside phonological awareness as one of the most important phonological processing tasks related to the development of skilled reading for several decades (see Wagner & Torgesen, Reference Wagner and Torgesen1987; Wagner et al., Reference Wagner, Torgesen, Rashotte and Pearson2013). However, as the phonological underpinnings of RAN are not well understood, a number of competing explanations for RAN’s relationship to reading have been forwarded. Georgiou and Parrila (Reference Georgiou and Parrila2013) provide a summary of 17 different theories presented in the literature, many of which highlight important nonphonological components of the task. For example, the multicomponents theory suggests that RAN is related to reading because the two tasks tap the same complex set of cognitive and linguistic processes, including lexical access, but also visual uptake, visual scanning, and preparing for upcoming items (Wolf & Bowers, Reference Wolf and Bowers1999). This theory suggests that RAN is a proxy for reading. Other theories posit that RAN is particularly sensitive to cognitive sources of difficulty that commonly co-occur in poor readers such as working memory (Berninger et al., Reference Berninger, Abbott, Thomson, Wagner, Swanson, Wijsman and Raskind2006; Ramus & Szenkovits, Reference Ramus and Szenkovits2008) and poor inhibition (Denckla & Cutting, Reference Denckla and Cutting1999; Stringer, Toplak, & Stanovich, Reference Stringer, Toplak and Stanovich2004).
The phonological account of RAN holds that speed on the task measures the efficiency with which phonological representations of words are accessed from long-term memory (de Jong & van der Leij, Reference de Jong and van der Leij2002; Elbro, Borstrøm, & Petersen, Reference Elbro, Borstrøm and Petersen1998; Manis, Seidenberg, & Doi, Reference Manis, Seidenberg and Doi1999; Wagner & Torgesen, Reference Wagner and Torgesen1987; Wolf, Bowers, & Biddle, Reference Wolf, Bowers and Biddle2000). According to this view, RAN is related to reading because both naming and reading require rapid access to phonological representations. The phonological access theory is appealing because RAN is such a strong predictor of dyslexia, and there is now wide agreement that the primary deficit in dyslexia is processing, and perhaps specifically accessing, phonological representations (Boada & Pennington, Reference Boada and Pennington2006; Ramus & Szenkovits, Reference Ramus and Szenkovits2008). However, confirmatory experimental evidence supporting an implicit relationship between phonological representations and RAN speed is lacking. Because of this, the phonological theory of RAN has been widely scrutinized. One issue that remains unresolved is the extent to which (or if) RAN speed is critically influenced by phonological representational strength (Elbro & Jensen, Reference Elbro and Jensen2005; Goswami, Reference Goswami2002; Moll et al., Reference Moll, Ramus, Bartling, Bruder, Kunze, Neuhoff and … Tóth2014; Ramus & Szenkovits, Reference Ramus and Szenkovits2008).
Because phonological representations are psychological constructs, they can only be tested indirectly (Boada & Pennington, Reference Boada and Pennington2006; Elbro & Jensen, Reference Elbro and Jensen2005). Thus, a critical challenge to empirically investigating the phonological access account of RAN is finding a valid and reliable way to operationalize phonological representations in the task. The purpose of the present study was to test whether the phonological variable RND could be used as an index of phonological representational strength and to determine whether RND exerts a similar effect on naming latencies for RAN and isolated picture naming. The theoretical motivation for testing the effects of RND on naming speed is described in the following section.
PHONOLOGICAL NEIGHBORHOOD DENSITY EFFECTS
Words in the mental lexicon are thought to be organized on the basis of phonological similarities (Luce & Pisoni, Reference Luce and Pisoni1998). Similar sounding words that differ by only one phoneme (Ph), either through deletion (cat/at), addition (cat/scat), or substitution (cat/cab), are referred to as phonological neighbors. This calculation (Ph+/–1) derives the total number of phonological neighbors for each word in a language and describes in objective terms the word’s phonological neighborhood density (PhND). In more relative terms, words with many similar-sounding words are said to reside in dense neighborhoods, whereas those with few similar-sounding words reside in sparse neighborhoods.
Both facilitation and inhibitory effects of phonological neighborhood density have been documented for picture naming (see Sadat, Martin, Costa, & Alario, Reference Sadat, Martin, Costa and Alario2014, for extensive review). One hypothesis that predicts a facilitation effect is that words from dense neighborhoods have strong phonological representations and these words are more easily accessed than words from sparse neighborhoods, which are postulated to have relatively weaker phonological representations. In this case, higher density leads to faster naming. Theoretically, then, PhND should facilitate naming speed. A developmental explanation of this proposed benefit is also captured in the lexical restructuring theory (Metsala & Walley, Reference Metsala and Walley1998), which posits that as the number of similar sounding words in the mental lexicon increases with age, similar-sounding words are forced to compete during retrieval processes. Representations of holistic word units in the developing lexicon become increasingly more segmental at the sublexical (phonological) level in response to the increased pressure of a growing vocabulary. Over time, the mental lexicon is gradually restructured in terms of smaller phonological granularity, which, in turn, aids in rapid retrieval of lexical selection. An opposing hypothesis, which predicts an inhibitory effect, is that words from dense neighborhoods compete with many phonologically similar words in the same neighborhood, which results in interference during lexical access or poor monitoring during lexical selection (see Sadat et al., Reference Sadat, Martin, Costa and Alario2014, for discussion). In either of these scenarios, higher density should lead to slower naming.
Empirical evidence showing effects of phonological neighborhood density on naming has been inconsistent, both within and across languages (Sadat et al., 2007). In English, facilitative effects have been shown in at least one study of adults (Vitevitch, Reference Vitevitch2002), while other studies report inhibitory effects (Arnold, Conture, & Ohde, Reference Arnold, Conture and Ohde2005, in children; Gordon & Kurczek, Reference Gordon and Kurczek2014, in older adults) or null effects (Gordon & Kurczek, Reference Gordon and Kurczek2014, in adults; Ratner, Newman, & Strekas, Reference Ratner, Newman and Strekas2009). Only one study to our knowledge has tested the effects of phonological neighborhood density on RAN in Spanish-speaking children (Guardia & Goswami, Reference Guardia and Goswami2008). Consistent with the theory that lexical restructuring leads to stronger, more detailed phonological representations of words from dense phonological neighborhoods (Metsala & Walley, Reference Metsala and Walley1998; Storkel, Reference Storkel2002), and strong phonological representations should aid in phonological access, Guardia and Goswami (Reference Guardia and Goswami2008) predicted a facilitation effect of PhND on RAN speed; however, they found a significant inhibitory effect. That is, children named pictures from dense neighborhoods slower than those from sparse neighborhoods.
The present study is a partial replication of Guardia and Goswami (Reference Guardia and Goswami2008) using an alternative phonological similarity metric, RND. RND is a part-word iteration of the full-word PhND metric. It is defined as the number of phonological neighbors that share the rime of a target word. For example, cat shares the rime unit [-æt] with 24 other monosyllabic words, so cat has a RND of 24 (De Cara & Goswami, Reference De Cara and Goswami2002) and resides in a dense neighborhood compared to foot, which resides in a relatively sparse neighborhood with a RND of 2.
In English, rime neighbors make up the majority of phonological neighbors. De Cara and Goswami (Reference De Cara and Goswami2002) calculated phonological similarity metrics for 4,086 monosyllabic English words and found that the mean number of rime neighbors in the database (29.6) was higher than the mean number of phonological neighbors (17.9). Rime neighbors also predominate monosyllabic lexicons of French and German (see Goswami, Reference Goswami2002, for discussion), presumably as a function of the complex syllable structure. For example, the De Cara and Goswami (Reference De Cara and Goswami2002) database shows that the word stray has 47 neighbors with shared rimes (e.g., say, tray, may, hay, play, etc.), yet only 3 words can be formed by adding or deleting one phoneme following the Ph+/–1 metric (tray, straight, and strain). Because syllable complexity and phonotactic properties of a particular language impact the types of phonological neighbors that are likely to be represented in the lexicon, we reasoned that different types of phonological similarity metrics might also exert different effects on naming speed across languages. In addition, even though adults are thought to have fully specified fine-grained phonemic representations of words (De Cara & Goswami, Reference De Cara and Goswami2002), rime units are thought to be the natural units of spoken language (Kirtley, Bryant, MacLean, & Bradley, Reference Kirtley, Bryant, MacLean and Bradley1989). Models of language production have also theorized that syllables that occur frequently in a language are retrieved from the mental lexicon in holistic units rather than assembled phoneme by phoneme (Levelt & Wheeldon, Reference Levelt and Wheeldon1994).
PREVIOUS RAN MANIPULATION STUDIES
Previous RAN studies in English have attempted to experimentally manipulate the various components of the RAN task. The basic premise of these studies was to ascertain which components of RAN were important to reading. With regard to phonology, researchers approached the experiment on the premise that if reading and RAN are related via phonology, then increasing the demands of phonology in the RAN task should strengthen the relationship between RAN and reading (Scarborough, Reference Scarborough1998). Several studies attempted to tap the construct of “phonological demands” in RAN by manipulating letter stimuli (see Compton, Reference Compton2003; Jones, Obregón, & Kelly, & Branigan, Reference Jones, Obregón, Kelly and Branigan2008; McBride-Cheng & Manis, Reference McBride-Chang and Manis1996). The goal in these studies was to create an effect of phonological confusion by replacing one of the letters in the task with one that rhymes with other letters in the task. For example, Compton (Reference Compton2003) replaced the letter o with the letter v, which rhymes with the letters d and p already in the control stimulus set. In a similar paradigm, Jones et al. (Reference Jones, Obregón, Kelly and Branigan2008) measured response times and eye-tracking patterns when rhyming letters b and v or letters that shared onsets g and j were and were not adjacent in the task. While some of the altered RAN tasks turned out to be better predictors of reading (Compton, Reference Compton2003), neither dyslexic nor control groups were consistently or significantly affected by the manipulation of phonological confusability. That is, there were no significant effects of these manipulations on RAN speed. This null finding suggests that the manipulation did not achieve the intended goal of increasing the phonological demands of the task and, therefore, calls the construct validity of the manipulation into question. Without validation, it remains unclear whether the relationship between the experimental RAN task and reading was due to the theorized phonological manipulation itself or to an extraneous variable.
Another methodology designed to tap the phonological demands of RAN has been to manipulate stimulus set size. For example, Georgiou, Parrila, Cui, and Papadopoulos (Reference Georgiou, Parrila, Cui and Papadopoulos2013) posited that increasing the number of unique stimulus items repeated in the RAN task would place increased demands on phonological encoding because different phonological codes would have to be accessed more often. Results from a study with Greek children showed significant differences in naming speed in the predicted direction: they found that multiple repetitions of small sets of objects (2 items repeated 10 times; 5 items repeated 10 times) were more difficult for children than multiple repetitions from a large set of objects (10 items repeated 5 times). These findings, however, conflict with those from an earlier set-size manipulation study of Italian children reported by DiFilippo, Zoccolotti, and Ziegler (Reference Di Filippo, Zoccolotti and Ziegler2008), who found that both dyslexic and control groups were slower to name a large set of nonrepeating stimuli (50 items repeated 1 time) than a small set (5 items repeated 10 times) of repeating stimuli. As effect sizes of the manipulations were comparable across all tasks and stimulus types (d=1.34–1.78), the researchers concluded that the manipulation of set size (which also manipulated the variable “repeating,” in this case) could not account for large group differences in naming speed.
These studies are pertinent to the present study because they also attempted to test a direct relationship between phonological access and RAN using experimental manipulations. However, due to either nonsignificant or conflicting findings, the internal validity of the manipulations used in previous studies is called into question. Previous studies have carried out these manipulations in order to investigate a common phonological relationship between RAN and reading development, so many of the previous manipulation studies have been conducted with school-aged children at various stages of reading development (Georgiou et al., Reference Georgiou, Parrila and Kirby2009, is an exception). To control for age-related changes and the inherent heterogeneity of a developing reading system, a more conservative approach would be to first validate the effects of the phonological manipulation in skilled adult readers.
PRESENT STUDY
Our aim in the present study was to determine the effect of RND on both confrontation naming (i.e., naming one picture at a time) and RAN. Due to the theorized relationship between phonological representations and PhND, we reasoned that manipulating the RND of words used in each task would also be manipulating the relative strength of activation of each word’s phonological representations. Thus, finding a significant effect of RND on naming speed, regardless of the direction of that effect, would offer a theoretically sound methodology for indexing the impact of phonological representational strength in the RAN task.
We tested the effects of RND on four picture-naming tasks that were orthogonalized for item composition (repeating vs. nonrepeating) and presentation format (discrete vs. serial). The first task investigates the effects of RND using a repeating, serial format because this is the standard RAN paradigm used clinically and also because it has been shown to be a better predictor of reading. In a meta-analysis, for example, Logan and Schatschneider (Reference Logan and Schatschneider2014) reported that reading correlates moderately with serial RAN (.62) and weakly with discrete RAN (.29). Nevertheless, our second task employed RAN using a repeating, discrete format, which is frequently used in RAN research (de Jong, Reference de Jong2011; Georgiou et al., Reference Georgiou, Parrila, Cui and Papadopoulos2013; Jones, Ashby, & Branigan, Reference Jones, Ashby and Branigan2013; Logan et al., Reference Logan, Schatschneider and Wagner2011; Perfetti, Finger, & Hogaboam, Reference Perfetti, Finger and Hogaboam1978). This single-item-presentation approach is experimentally advantageous in that it provides a more precise mechanism for recording response times than serial RAN and is influenced by fewer confounding variables (Logan et al., Reference Logan, Schatschneider and Wagner2011). It is also believed to tap mechanisms involved in lexical access (de Jong, Reference de Jong2011; Jones et al., Reference Jones, Obregón, Kelly and Branigan2008; Logan et al., Reference Logan, Schatschneider and Wagner2011), which we were specifically interested in. In addition, because it does not require continuous visual scanning or articulation time, discrete naming provides a more accurate measure of the subprocesses involved in accessing lexical items from memory (de Jong, Reference de Jong2011; Logan et al., Reference Logan, Schatschneider and Wagner2011).
Considering the mixed findings of previous PhND manipulations for confrontation naming (see Sadat et al., Reference Sadat, Martin, Costa and Alario2014, for review), our third task tested the effects of RND on confrontation naming using discrete, nonrepeating stimuli. A fourth “hybrid” task comprised serial, nonrepeated stimuli. By including these four picture-naming tasks, we were able to observe interactions between hypothesized phonological demands of the RND manipulation and the unique task demands of the traditional RAN format, which employs repeating stimuli in serial presentation. Experimental questions and predictions follow:
1. Does RND exert a significant effect on naming speed, and if so, is the effect facilitatory or inhibitory? On the basis of the lexical restructuring theory (Metsala & Walley, Reference Metsala and Walley1998), which posits that (a) words from dense neighborhoods have stronger phonological representations than words from sparse neighborhoods and (b) stronger phonological representations are retrieved faster than weak ones, we predicted that RND would facilitate picture-naming speed. Alternatively, on the basis of interference, simultaneous activation of many words from dense neighborhoods could interfere with lexical selection processes and produce an inhibitory effect (Luce & Pisoni, Reference Luce and Pisoni1998). This is consistent with previous findings reported for Spanish-speaking children for RAN (Guardia & Goswami, Reference Guardia and Goswami2008). A third possibility would be to find null effects of this manipulation. This would indicate that phonological representational strength does not affect naming speed more than other lexical variables.
2. Does RND exert differential effects on naming speed as a function of naming task demands? In comparison to lexical retrieval processes for a single item (i.e., in a confrontation naming paradigm), a unique component of the RAN task is that all items to be named are presented simultaneously in a matrix. Previous studies have shown a processing advantage for repeated naming (RAN) over confrontation naming, which is attributed to the serial component of the RAN task. Specifically, as one scans left to right in the serial naming paradigm, items yet to be named become available in parafoveal preview. Theoretically, this preview allows visual features to be gleaned and phonological information to be primed for upcoming items. Research on serial naming has shown parafoveal preview facilitates RAN speed for typically developing readers, but impairs RAN speed for readers with dyslexia (Jones, Branigan, & Kelly, Reference Jones, Branigan and Kelly2009). However, the extent to which this benefit taps phonological representational strength has not yet been determined. If the parafoveal preview effect taps phonological representations, then a valid manipulation of phonological representational strength should produce larger effects on serial naming compared to discrete naming. Another unique aspect of the RAN task is that items to be named are repeated. Some researchers have suggested that repeated naming differs from single-item, discrete naming in that repeated naming requires lexical access from long-term memory only the first time the word is encountered, and for subsequent repeated occurrences, phonological codes are retrieved directly from the buffer of the working memory system (see, e.g., Berninger et al., Reference Berninger, Abbott, Thomson, Wagner, Swanson, Wijsman and Raskind2006). A number of studies have also shown that words from dense PhND are held in working memory longer than words from sparse neighborhoods (Guardia & Goswami, 2006). If the repeating component of RAN taps phonological representations stored in long-term memory, and words from dense neighborhoods are held in short-term memory longer than words from sparse neighborhoods, then the effects of a valid manipulation of phonological representational strength should be larger in a repeated paradigm compared to a nonrepeated paradigm. Taken together, we predicted a larger effect size of RND in (a) serial compared to discrete naming and (b) repeated compared to nonrepeated naming.
METHODS
Participants
Thirty participants ages 18 to 45 (M AGE 24.54; SD=7.9; 17 male) were recruited from a large American university and surrounding area. Each participant completed an extensive questionnaire regarding developmental and academic history. Inclusion criteria included a negative history for language, learning, reading, and generalized academic problems. Normal language and phonological processing abilities were confirmed using the Comprehensive Test of Phonological Processing (Wagner, Torgesen, & Rashotte, 1999) and the Shipley Vocabulary test (Shipley, Reference Shipley1940). These scores are shown in Table 1. Validity of self-report for normal reading ability is supported by previous research (Felton, Naylor, & Wood, Reference Felton, Naylor and Wood1990). All participants were monolingual, native speakers of English and were either enrolled in postsecondary institutions or had attained college degrees.
Table 1 Descriptive statistics

Note: PA, phonological awareness composite from elision and blending words subtests. RAN, rapid naming composite from the letter and digit naming subtests from the Comprehensive Test of Phonological Awareness (CTOPP; Wagner, Torgeson, & Rashotte, Reference Wagner, Torgeson and Rashotte1999). As the test is not normed for the age of many of our participants, we used standard scores derived from normative data available from the oldest group (18–21) to estimate phonological processing ability.
Procedures
Testing was conducted in a quiet room by either the first author or a trained research assistant. All participants signed an informed consent before proceeding with the experiment, which was approved by the university’s institutional review board for ethics. Experimental picture-naming tasks were created and used to examine the effects of RND on naming speed in four conditions including a RAN task, a confrontation naming task, and two hybrid tasks. Experimental tasks are described in detail later in this section. All tasks were presented in a fixed order and arranged so that no more than two naming tasks were administered in succession. Testing took approximately 60 min to administer and was completed in one session.
Experimental design
Table 2 shows an overview of the design. To explore the effects of RND across task constraints, we created four tasks orthogonalized for item composition (repeating vs. nonrepeating) and presentation format (discrete vs. serial). The standard serial RAN task presented repeated stimuli in a matrix format. The standard confrontation naming task presented nonrepeated stimuli one at a time on a computer screen. Two hybrid tasks combined elements of RAN and confrontation naming. One hybrid task used repeated stimuli in a discrete format, thus isolating the repeating aspect of RAN. The other hybrid task used nonrepeated stimuli in a matrix format, thus isolating the serial aspect of RAN. Each task was presented in two dichotomous conditions of RND (dense vs. sparse).
Table 2 Overview of the experimental tasks

To control for spurious effects of stimulus-specific lexical variables, alternate stimulus forms were created and counterbalanced across presentation formats. Half of the participants saw stimulus Set A in the discrete format and stimulus Set B in the matrix format, while the other half saw Set B in the discrete format and Set A in the matrix format. These alternate forms (Set A vs. Set B) were also used to check for internal consistency, which is the most appropriate measure of reliability for speeded tests (Anatasi & Urbina, Reference Anastasi and Urbina1997).
Experimental stimuli
A total of 120 words were selected for the experiment. Words were selected from the De Cara and Goswami (Reference De Cara and Goswami2002) database, which comprises 4,086 monosyllabic words originally derived from the CELEX lexical database (Baayen, Peipenbrock, & Van Rijn, Reference Baayen, Piepenbrock and Van Rijn1995). Phonological neighbors are traditionally calculated using the Ph+/–1 metric, which we discussed above. This method can also be used to calculate rime neighbors. However, we used the RND counts derived from the onset–vowel–coda (OVC) calculation as published in De Cara and Goswami (Reference De Cara and Goswami2002). The OVC metric includes the total number of monosyllabic words that share the rime of a target word. This measure produces a larger number of rime neighbors than the Ph+/–1 metric because it permits neighbors with initial consonant clusters to be included in the rime neighborhood. For example, using the strict Ph+/–1 metric, sat would be calculated as a neighbor of cat, but slat (Ph+2) and splat (Ph+3) would not. Unlike many languages (e.g., Spanish and Korean), which have words composed primarily of consonant–vowel (CV) or CVC combinations, English has a complex syllable structure allowing multiple consonant clusters in monosyllabic words (e.g., CCVC, CCVCC, and CCCVC). Using the OVC metric to calculate neighborhood density captures this specific psycholinguistic feature of the English language and allows for a more valid measure of RND of the language.
Black line drawings corresponding to the words were scanned and used to create picture-naming stimuli. The majority of the pictures were from the standardized Snodgrass and Vanderwort (Reference Snodgrass and Vanderwart1980) database. Name agreement was established for all experimental stimulus sets prior to the experiment and agreement on discrete and serial tasks was 93% and 94%, respectively. The serial tasks included a total of 25 pictures arranged in 5 rows of 5 items, printed on white 8.5-inch×11-inch cards. The discrete tasks were administered using DirectRT (Jarvis, Reference Jarvis2006), and pictures were individually randomized and presented by computer. For the nonrepeated naming tasks, we created two pair of word lists (Sets A and B), with each list comprising 25 picturable concrete nouns (Appendices A and B). For the repeated naming tasks, we created two pairs of dichotomous word lists (Sets A and B), each comprising 5 picturable, concrete nouns (see Appendix C and D). There was no overlap between the repeated and nonrepeated stimuli. Word lists were contrasted for the variable of interest, RND, and balanced for age of acquisition, word frequency, and word length (number of phonemes) as shown in Table 3, below. These three lexical variables are known to have a significant impact on picture-naming speed (Gordon & Kurczek, Reference Gordon and Kurczek2014; Pérez, Reference Pérez2007; Sadat et al., Reference Sadat, Martin, Costa and Alario2014).
Table 3 Lexical characteristics of experimental stimuli

Note: Each set is contrasted for RND and matched for other lexical variables. RND, rime neighborhood density, as reported by De Cara and Goswami (Reference De Cara and Goswami2002). AoA, age of acquisition, as reported by Kuperman, Stadthagen-Gonzalez, & Brysbaert (Reference Kuperman, Stadthagen-Gonzalez and Brysbaert2012). Log frequency is defined as the log 10 frequency of a word as reported by the HAL study. Length is the number of phonemes in a word. Metrics for frequency and length were taken from the English Lexicon Project (Balota et al., Reference Balota, Yap, Hutchison, Cortese, Kessler, Loftis and … Treiman2007).
Experimental procedure
Serial presentation
Participants were instructed to name all items on the card as quickly and accurately as possible following a left-to-right and row-by-row progression. Consistent with standardized administration procedures reported in test manuals and elsewhere (see, e.g., Wagner et al., Reference Wagner, Torgesen, Rashotte and Pearson2013), response times for naming each set of pictures were recorded in seconds (s). Administration procedures included a practice set prior to timing. Responses for the tasks were audio-recorded and later checked for accuracy. The dependent measure was the total time to name all pictures in the task.
Discrete presentation
A total of 50 pictures (25 sparse and 25 dense) of either Set A or Set B were presented one-by-one in the middle of a computer screen. Participants were instructed to name the pictures by providing a single-word response as quickly and as accurately possible. Response times were measured in milliseconds (ms) from the appearance of the picture to the onset of the participant’s vocal response using DirectRT software. In the serial presentation (described above), it was necessary to block low-density and high-density words in order to isolate the RND variable. To be consistent with this methodology, stimulus sets in the discrete presentation format were also blocked for dense and sparse RND. Internal validity was bolstered by randomizing presentation order within each block and using alternate forms, which were counterbalanced across participants. Prior to timing, participants were given five practice items to acclimate to the microphone that recorded verbal responses.
Data analysis
To address our first experimental question, we examined the effects of RND across picture naming formats using a 2 (neighborhood density: dense vs. sparse)×2 (stimulus composition: repeating vs. nonrepeating) analysis of variance (ANOVA). We ran separate ANOVAs for the serial and discrete formats because serial naming speed includes articulation time but the discrete measure does not. Our second question asked whether the effects of RND differ across the four picture-naming formats. To address this question, we calculated effect sizes of the RND manipulation in each of the four tasks using Cohen’s d statistic.
RESULTS
Data preparation
For the discrete naming tasks, we removed inaccurate responses from the trial level data. Response times (RTs)<250 ms were considered invalid or attributed to machine error and thus were also excluded from analysis. In the discrete repeated naming task, 0.3% of the 2,280 trial-level data points were inaccurate and 17.8% of the data (10.1% in the high-density and 7.7% in the low-density condition) were invalid. The effect of density on the number of trial-level data points removed was not significant using chi-square (p=.889). In the discrete nonrepeated naming task, 7.5% of the 1,550 trial-level data points were inaccurate (4.4% in the high-density condition and 3.1% in the low-density condition) and 5.9% of the data (3.4% in the high-density and 2.5% in the low-density condition) were invalid. The effect of density on the total number of trial-level data points removed was not significant using chi-square (p=.883). Name agreement, total number of trials, and percentage of data removed for inaccuracy are consistent with previous neighborhood density picture-naming experiments (e.g., Marian, Blumenfeld, & Boukrina, Reference Marian, Blumenfeld and Boukrina2008).
Alternate form reliability (Set A×Set B) was calculated using Cronbach’s α. reliability for the final data set used in the analyses was 0.73 and 0.77, respectively, for repeated and nonrepeated naming in the serial format and 0.70 and 0.96, respectively, for repeated and nonrepeated naming in the discrete format, all of which are within an acceptable range (George & Mallery, Reference George and Mallery2016). As alternate forms (Sets A and B) were counterbalanced across participants, paired samples t tests were conducted to examine order effects. These results were nonsignificant (all p≥.411). Parameters for skewness and kurtosis were within an acceptable range (all absolute values for skewness <0.88; kurtosis <1.04).
RND effects on picture naming
Serial presentation
Our first analysis examined the effects of RND on picture-naming speed in the serial (matrix) format. We compared naming speed on a typical RAN task to naming speed on a hybrid task that included nonrepeating pictures presented in a matrix format. Results are shown in Figure 1. Consistent with our predictions, the ANOVA revealed a significant main effect of RND, F (1, 28)=46.22, p<.0001, η2 p=.614, and a main effect of repeating, F (1, 28)=46.93, p<.0001, η2 p=.618. There was also a significant interaction, F (1, 28)=5.43, p<.027, η2 p=.158. Pairwise comparisons showed that on the traditional RAN task, naming was significantly faster for dense words (M=23.30 s, SD=3.80) than for sparse words (M=27.97 s, SD=5.77), t (29)=–2.33, p=.027. On the nonrepeated hybrid task, naming words from dense neighborhoods (M=19.27 s, SD=3.86) was also significantly faster than naming words from sparse neighborhoods (M=21.05 s, SD=3.80), t (29)=–2.89, p=.007.
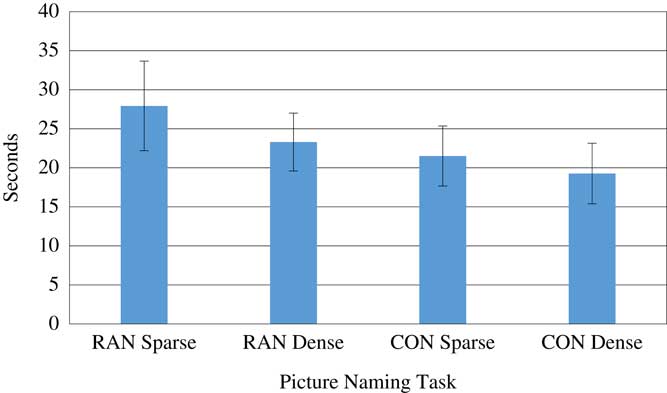
Figure 1 Serial naming speed for rapid naming (RAN) and confrontation (CON) naming. Error bars represent standard deviation of the mean.
Discrete presentation
A separate ANOVA was conducted for naming tasks presented in the discrete format. For the purposes of analyses, mean RTs were transformed to log10 but are reported in milliseconds, as shown in Figure 2. Results were consistent with those from the serial format in that there was a significant main effect of RND, F (1, 29)=4.82, p=.036, η2 p=.143, a significant main effect of repeating, F (1, 29)=65.17, p<.001, η2 p=.692, and a significant interaction effect, F (2, 58)=8.21, p=.008, η2 p=.221. Pairwise comparisons showed that on the repeated discrete task, contrary to our predictions, naming was slightly slower for dense words (M=945.04 ms, SD=261.27) compared to sparse words (M=916.64 ms, SD=181.86), but this difference was not significant, t (28)=–0.489, p=.626. For repeated naming, RTs were significantly faster in the dense condition (M=546.13 ms, SD=169.09) compared to the sparse condition (M=611.86 ms, SD=167.19), t (28)=–5.91, p<.001
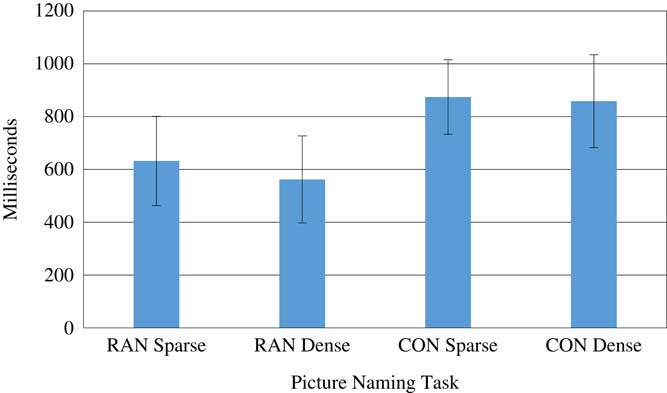
Figure 2 Discrete naming speed for rapid naming (RAN) and confrontation (CON) naming. Error bars represent standard deviation of the mean.
To summarize, the results from both ANOVAs showed significant facilitatory effects of RND on naming speed in three of the four tasks in which pictures were presented in either repeated or serial formats. There was no effect of RND on nonrepeated, discrete naming.
Effect sizes of RND across experimental naming tasks
Our second question asked whether the effects of RND were consistent across picture-naming formats that incorporate different components of RAN (i.e., serial vs. repeat). To determine effect sizes, we first determined the two means plus the correlation between the two means (i.e., naming speed in dense and sparse conditions), and the mean of the 2 SDs (Wiseheart, Reference Wiseheart2008). This method controls for dependence between the means and allows for effect sizes reported in this within-subjects design to be compared to between-subjects for future studies (Wiseheart, Reference Wiseheart2008). Results showed a large effect of RND on both repeated naming tasks (Cohen’s d=1.010 and 1.009 for serial and discrete RAN, respectively), a medium effect size for the serial nonrepeated naming task (d=0.530), and a small effect in the discrete nonrepeated naming (i.e., confrontation naming; d=0.136). As predicted, this trend shows the magnitude of the RND effect was influenced by RAN-specific components of naming. As the strongest effects were found in both serial and discrete RAN tasks, the impact of RND on naming speed appears to be most impacted by the repeating component of RAN.
DISCUSSION
This investigation tested the effects of RND on four experimental versions of rapid picture naming. As theories of RAN have implicated access to phonological representations as being causally related to RAN speed, our primary aim was to determine whether RND could be used as a valid index of phonological representational strength in the RAN task. We found the observed facilitation effect of RND was statistically significant in three of the tasks (ps<.001). The direction of the effect was also in line with theoretical predictions of the lexical restructuring theory (Metsala & Walley, Reference Metsala and Walley1998), which holds that words from dense neighborhoods have stronger phonological representations compared to words from sparse neighborhoods and therefore should be easier to access. However, there was no effect of facilitation in the discrete nonrepeated (confrontation naming) task. This finding is consistent with some previous studies of English-speaking adults, which reported null effects of PhND on discrete picture naming (Gordon & Kurczek, Reference Gordon and Kurczek2014; Ratner et al., Reference Ratner, Newman and Strekas2009). To the extent that the lexical restructuring account is accurate, we can conclude that manipulating RND of picture-naming stimuli provides a theoretically valid index of phonological representations under certain operational demands. This is the first study, to our knowledge, to test the effects of RND on rapid picture naming. Because RND is thought to reflect either activation strength or representational strength of the phonological forms of words (Storkel, Reference Storkel2002), this study provides experimental evidence to support the phonological access account of RAN. The claim that RAN relies on access to phonological representations of words stored in long-term memory has been proposed for decades, but frequently scrutinized as “underdeveloped and criticized on theoretical grounds” (Kirby et al., Reference Kirby, Georgiou, Martinussen and Parrila2010, p. 343).
The strongest effect size was found in the two RAN tasks, indicating that the operational demands of both serial and discrete RAN are sensitive to phonological variability. We also point out that the magnitude of the RND effect was consistent across the serial RAN task, which included articulation time, and the discrete RAN task, which did not include articulation time. This finding is in line with the characterization of RAN as being a measure of lexical retrieval speed rather than articulation speed (Clarke et al., Reference Clarke, Hulme and Snowling2005; de Jong, Reference de Jong2011).
The trend of the effect sizes (from small on the confrontation naming task to medium on serial, single item naming task to large effects on both repeated naming RAN tasks) also suggests that the task component of RAN that is most sensitive to the phonological characteristics of words is the use of repeated stimuli. A possible explanation for this comes from eye-tracking reports showing that good readers are able to take advantage of a parafoveal preview of adjacent or upcoming items in serial naming paradigms, whereas poor readers tend to view visual symbols in a one-at-a-time fashion, even when they are presented in a serial format (see, e.g., Yan, Pan, Laubrock, Kliegl, & Shu, Reference Yan, Pan, Laubrock, Kliegl and Shu2013). The implication is that serial naming paradigms (RAN) differentiate good and poor readers because good readers access phonological representations of upcoming stimuli in serial presentations, whereas poor readers do not. Our findings suggest, however, that in terms of exploiting phonological representations, the serial component of RAN is not as important as the fact that the items are repeated. Recall that the effect sizes for both discrete and serial RAN tasks were almost identical. Some researchers have suggested that repeated naming differs from single-item, discrete naming in that repeated naming requires lexical access only the first time the word is encountered and, on each subsequent occurrence, words are retrieved directly from the buffer of the working memory system (see, e.g., Berninger et al., Reference Berninger, Abbott, Thomson, Wagner, Swanson, Wijsman and Raskind2006). This explanation makes sense, especially in light of previous findings that words from dense neighborhoods are held in working memory longer than words from sparse neighborhoods (Guardia & Goswami, Reference Guardia and Goswami2008).
An alternative interpretation is that differences in the magnitude of the RND effect reflect differences in either set size or total items to be named, which differed between the RAN tasks (5 items repeated 8 times) and the single item tasks (25 items repeated 1 time) due to item selection constraints. As reviewed earlier, research findings regarding the effects of manipulating set size on naming speed have been mixed (Di Filippo et al., Reference Di Filippo, Zoccolotti and Ziegler2008; Georgiou et al., Reference Georgiou, Parrila, Cui and Papadopoulos2013). Because the effect sizes were so similar across the two RAN tasks, yet dissimilar across the two single-item naming tasks, we attribute the difference in effect size magnitude to the “repeating” variable rather than to differences in set size or total items.
Implications for understanding the effects of phonological neighborhood density
Our findings of a RND facilitation effect contrast with the PhND interference effects reported previously in a large-scale naming study by Sadat et al. (Reference Sadat, Martin, Costa and Alario2014) and in a similar RAN study by Guardia and Goswami (Reference Guardia and Goswami2008), both of which were conducted in Spanish. Our study differs from the aforementioned designs in that we used the RND metric rather than the PhND metric. A broad assumption is that different measures of phonological neighborhood density could exert different effects on naming at different developmental stages and in different languages, as suggested by previous researchers (Gordon & Kurscek, 2014; Ziegler & Goswami, Reference Ziegler and Goswami2005). Previous studies have varied methodologically in age and language of participants, and this may account for some of the inconsistencies in studies examining the effects of PhND on naming (Baus, Costa, & Carreiras, Reference Baus, Costa and Carreiras2008; Vitevitch & Stamer, Reference Vitevitch and Stamer2006). Because English emphasizes large speech sound units, or grain sizes (Ziegler & Goswami, Reference Ziegler and Goswami2005), such as rimes and syllables, it is possible that the effects of RND on RAN may be specific to languages like English in which the rime unit is particularly salient. The strength of the phonological neighborhood density effect may be attributed to the relatively complex syllable structure of English, which produces a lexical network densely populated with rime neighbors. Unlike many languages (e.g., Spanish and Korean), which have words composed primarily of CV or CVC combinations, English has a complex syllable structure allowing multiple consonant clusters in monosyllabic words (e.g., CCVC, CCVCC, and CCCVC). The OVC metric used to calculate neighborhood density captured this specific phonotactic feature of English, allowing for a more valid measure of RND of the language.
Another explanation for the conflicting findings is that the discrepancy between means of RND items dichotomized into artificial categories of sparse (5.2) and dense (34.5) words was quite large. However, facilitation effects of small PhND differences in previous naming studies have been reported (sparse=1.2 and dense=5.8; Marian et al., Reference Marian, Blumenfeld and Boukrina2008). An item-level analysis using regression methods would provide much-needed additional information regarding these effects. (Addressing these questions further, a analysis is available as part of the online-only Supplemental Materials.)
Implications for understanding RAN
As a final point of discussion, we offer some speculation as to how these findings might contribute to our understanding of RAN’s relationship to reading. It is well established that nonalphanumeric RAN (rapid naming of pictures and colors) predicts reading in young children; however, once children learn to read, alphanumeric RAN (rapid naming of letters and digits) is the stronger predictor of reading (Kirby et al., Reference Kirby, Georgiou, Martinussen and Parrila2010). One explanation for this phenomenon is that there is a shift in the mediators between RAN and early reading and RAN and late reading (Georgiou et al., Reference Georgiou, Parrila and Papadopoulos2016). Because early reading is more dependent on phonological representations, and skilled reading is dependent on orthographic representations, we speculate that picture RAN is related to early reading, but not skilled reading, because picture RAN, as we have shown, is uniquely sensitive to phonological representations. Likewise, alphanumeric RAN may be related to skilled reading because performance on the two tasks is more dependent on orthographic representations than phonological representations. Showing in the present study that picture RAN is sensitive to phonological representations in adults, we predict that this would also be the case for children. That is, we would expect to see a facilitative effect of RND in children. We also predict that the effect sizes of RND on a picture RAN task, such as the one used here, would predict reading in early readers, but not in skilled readers. We have begun conducting these studies in English. In addition to picture naming, these investigations include rapid naming experiments using single syllable digit names, which serendipitously, can be equally divided by RND into significantly different sparse and dense sets, allowing for dichotomous comparisons similar to those made in the present study.
Limitations and future directions
A few limitations should be noted. Finding enough items for this type of tightly controlled dichotomous comparison is extremely challenging (Storkel, Reference Storkel2002) and small sets of tightly controlled stimuli may exaggerate the extraneous effects of other lexical variables (Gordon & Kurczek, Reference Gordon and Kurczek2014). We attempted to mitigate some of this by counterbalancing two sets of stimuli across tasks. Future studies will need to be conducted to see if this effect generalizes to other populations and with other stimulus types, especially given that rapid naming of digits and letters is more predictive of reading in older children than rapid naming of pictures. Replications or extensions of this research should attempt to carefully control for frequency as well as other lexical characteristics, including onset density and orthographic neighborhood. It will be important in future investigations to establish whether there is a minimum difference at which point the facilitation effect is attenuated or perhaps reversed (see Sadat et al., Reference Sadat, Martin, Costa and Alario2014). Another important issue regarding the influence of lexical factors is that phonological effects are more likely to show up in low-frequency words (Andrews, Reference Andrews1992; Marian et al., Reference Marian, Blumenfeld and Boukrina2008). This may be important to future RAN studies as typical stimuli used in the task are chosen specifically on the basis of familiarity, which is typically highly correlated with frequency. Given the small sample size, this study will need to be replicated in larger samples of individuals to compare results across different ages and different languages. It would be interesting, for example, to replicate this study in a group similar to the one in Guardia and Goswami’s study.
To conclude, efforts to unravel the relationship between phonological representations and RAN speed require theory-driven means for operationalizing tacit phonological representations. We have provided preliminary evidence that selecting RAN stimuli on the basis of RND provides such a measure. This methodology has the potential to aid in understanding the relationship between the developing lexicon and the developmental relationship between RAN and reading, which is not yet fully understood.
APPENDIX A
STIMULUS ITEMS USED IN THE NONREPEATED NAMING TASKS, SET A
Table A1 Rime neighborhood density of stimuli in sparse and dense conditions

APPENDIX B
STIMULUS ITEMS USED IN THE NONREPEATED NAMING TASKS, SET B
Table A2 Rime neighborhood density of stimuli in sparse and dense conditions

APPENDIX C
STIMULUS ITEMS USED FOR REPEATED NAMING TASKS, SET A
Table A3 Rime neighborhood density of stimuli in sparse and dense conditions











