The global dissemination of audio-visual products such as films and educational videos has resulted in widespread use of subtitling as a tool to minimize language barriers and enhance media accessibility (Kruger & Doherty, Reference Kruger and Doherty2016; Liao et al., Reference Liao, Kruger and Doherty2020). Although subtitle reading has been a topic of growing interest over the past decades, our understanding of the mental processes engaged during the reading of subtitles, and how that differs from the reading of static text, is still limited (Kruger, Reference Kruger2016). Our limited understanding likely reflects the inherent complexity involved in subtitle reading—that is, reading subtitles needs to be coordinated with other more or less demanding tasks, such as identifying objects from the background video and/or comprehending the linguistic content of the audio, all of which compete for limited attention and are subject to a variety of other perceptual (e.g., visual acuity) and cognitive (e.g., working memory) limitations.
The present study aims at contributing to our understanding of this complicated multimodal reading behavior involved in watching videos with subtitles, by providing more insights into the influence of audio on the reading and comprehension of subtitles. We first start with some relevant theoretical accounts and empirical evidence for text-picture integration, mainly focusing on the cognitive theory of multimedia learning by Mayer (Reference Mayer and Mayer2005, Reference Mayer2014) and the multimodal integrated-language framework by Liao et al. (Reference Liao, Yu, Reichle and Kruger2021). We then review what has been learned from previous empirical studies about the influence of audio on the reading of static text and subtitles. After that, we present an eye-tracking experiment that examined the interaction between the auditory and visual systems when watching videos with subtitles. Finally, we discuss how the multimodal integrated-language framework could be extended based on the empirical data from the present study to better understand reading in multimodal contexts, such as reading subtitles in educational videos.
Theoretical frameworks
The sheer complexity of the mental processes that support multimodal reading has motivated attempts to develop theories to explain what transpires in the mind of someone who is, for example, engaged in the watching of a subtitled film. Perhaps because of the complexity of what must be explained, however, these theories provide only high-level descriptions (rather than, e.g., being mathematical or computational models) that expand upon basic principles of cognitive psychology (e.g., Atkinson & Shiffrin, Reference Atkinson and Shiffrin1968, Reference Atkinson and Shiffrin1971) to explain the phenomena of interest. For example, the theories described how “streams” of information from two or more sensory modalities or formats (e.g., text vs. images) are encoded and processed to construct abstract representations of whatever content is being understood. As such, although the theories are limited in their utility, they nonetheless provide useful frameworks for both thinking about and making (qualitative) predictions about situations involving multimodal reading.
For example, Mayer’s (Reference Mayer and Mayer2005) cognitive theory of multimodal learning assumes that: (1) both linguistic and non-linguistic information can be extracted via the visual and/or auditory channels; (2) this information is actively processed in working memory; and (3) the rate of information processing is delimited by attention, working memory capacity, and the encoding/retrieval of information into/from long-term memory. These assumptions are consistent with what is generally known about cognition (Atkinson & Shiffrin, Reference Atkinson and Shiffrin1968, Reference Atkinson and Shiffrin1971) and thus allow the theory to, for example, explain why the processing of two information sources within one sensory modality is typically more difficult than processing across two modalities (e.g., visual acuity limitations cause image viewing to be more disruptive to reading than does listening to music).
Similarly, Schnotz’s (Reference Schnotz and Mayer2005) integrated text and picture comprehension theory describes in slightly more detail the subprocesses involved in multimodal reading (e.g., how the pronunciations of printed words are generated via grapheme-to-phoneme rules) and distinguishes between descriptive or symbolic media and representations (e.g., written and spoken language) versus depictive or analog media and representations (e.g., video images). The theory also distinguishes between an early surface or perceptual stage in which visual and auditory information is converted into linguistic and non-linguistic patterns, and a subsequent deep or semantic stage in which these patterns undergo descriptive or depictive processing to construct propositional representations of whatever is being conveyed by the media. Despite these additional assumptions, the theory is also largely limited to making qualitative predictions.
Although these two theories and others (e.g., see Cohn, Reference Cohn2016) have advanced our understanding of multimodal reading situations (e.g., see Mayer, Reference Mayer2014), we firmly believe that further progress will benefit from more formal theories (as exemplified in reading research; see Reichle, Reference Reichle2021), and for that reason, we have directed our efforts toward conducting eye-movement experiments that allow “traction” in the development of more computational accounts of multimodal reading. For example, in a previous attempt to examine how concurrent video content and subtitle presentation speed affect comprehension and various online indicators of language processing, Liao et al. (Reference Liao, Yu, Reichle and Kruger2021) found that simultaneous display of video and subtitle improved viewers’ comprehension even with a fast subtitle speed (e.g., 20 characters per second). Global eye-movement analyses revealed that increasing subtitle speed resulted in fewer, shorter fixations and longer saccades on the subtitles. Furthermore, their examination of the word-length effect, the word-frequency effect, and the wrap-up effect provided more detailed information about how the reading of subtitles was modulated by the global task demands due to the presence of video content and/or increasing subtitle speed. For example, the word-length effect—that longer words tend to be fixated more often and for longer (Pollatsek et al., Reference Pollatsek, Juhasz, Reichle, Machacek and Rayner2008; Rayner & McConkie, Reference Rayner and McConkie1976)—provides an index of visual and/or early lexical processing. Likewise, the word-frequency effect is another common indicator of lexical processing, which refers to the finding that words of low frequency tend to receive more and longer fixations than words of high frequency (Inhoff & Rayner, Reference Inhoff and Rayner1986; Rayner et al., Reference Rayner, Ashby, Pollatsek and Reichle2004), because it takes longer to retrieve information about uncommon words than common words from memory (Reichle, Reference Reichle2021). Finally, the wrap-up effect refers to the finding that, with word frequency and word length being equal, words at the end of a sentence or clause are likely to be recipients of longer fixations compared to words in other locations. Although the wrap-up process is also affected by factors unrelated to high-level integration (e.g., punctuation marks and intonation; see, e.g., Hirotani et al., Reference Hirotani, Frazier and Rayner2006; Stowe et al., Reference Stowe, Kann, Sabourin and Taylor2018), the wrap-up effect has been traditionally used as an indicator of post-lexical processing wherein readers are converting the linguistic representation of the sentence or clause into a propositional representation for the construction of the situational model of a text (see, e.g., Rayner et al., Reference Rayner, Kambe and Duffy2000; Tiffin-Richards & Schroeder, Reference Tiffin-Richards and Schroeder2018). Liao et al. (Reference Liao, Yu, Reichle and Kruger2021) found that increasing subtitle speed resulted in attenuated word-frequency effects (indicative of shallower lexical processing) and wrap-up effects (reflecting the incomplete post-lexical integration of the sentences). This suggests that, as subtitle speed increased, readers may have employed some type of text-skimming strategy to rapidly extract the gist of the text, and consequently, that lexical and post-lexical processing of the subtitles were attenuated.
Although Liao et al.’s result that presenting video content with subtitles yields better comprehension than presenting subtitles only is consistent with the prediction of the cognitive theory of multimedia learning, Mayer’s (Reference Mayer2014) theory does not specify or predict how the processing of one source of information (e.g., the video) might affect the processing of other sources of information (e.g., the subtitle). To provide a more detailed account of how the co-referencing across two visual sources (i.e., background video and subtitle) can facilitate comprehension, and how the presence of video content might influence the reading of subtitles, Liao et al. (Reference Liao, Yu, Reichle and Kruger2021) proposed a preliminary multimodal integrated-language framework. This theoretical framework extends E-Z Reader, a computational model that provides a high-level description of how the cognitive systems responsible for visual processing, attention, language, and oculomotor control are coordinated to support skilled reading (Reichle et al., Reference Reichle, Pollatsek and Rayner2006, Reference Reichle, Pollatsek and Rayner2012). It is also broadly compatible with the dual-coding theory proposed by Paivio (Reference Paivio1986, Reference Paivio2007).
An adapted schematic diagram of the framework is presented in Figure 1. (Note that components outside the dashed-line box represent the original framework by Liao et al., Reference Liao, Yu, Reichle and Kruger2021, while those inside the dashed-line box illustrate the new additions to the auditory channel in the initial framework. To facilitate our introduction of the framework here, we first focus on the original framework.) As shown, comprehension in multimodal reading is a process of constructing a situational model or mental representation for the integrated information coming from two different processing systems—the auditory system and the visual system. Different systems have sub-systems that are subject to different processing limitations, as indicated by the shading of the boxes. For example, the white boxes correspond to those processes that can only operate upon or actively maintain one representation at any given time (i.e., serial processing). Thus, according to this framework, only one printed word or visual object can be identified via the attention-binding mechanism at any given time because attention must be allocated in a strictly serial manner (Reichle et al., Reference Reichle, Liversedge, Pollatsek and Rayner2009). The gray boxes, however, correspond to those processes that can operate upon or concurrently maintain multiple representations (i.e., parallel processing). The locations of four or five visual objects, for example, can be simultaneously indexed via a pre-attentive stage of visual processing (Pylyshyn, Reference Pylyshyn2004; Pylyshyn & Storm, Reference Pylyshyn and Storm1988). This limited parallelism allows the viewer of a video to sidestep the “bottleneck” of attention that results from the serial allocation of attention, thereby allowing them to read the subtitles while, for example, simultaneously monitoring objects in the video in peripheral vision.
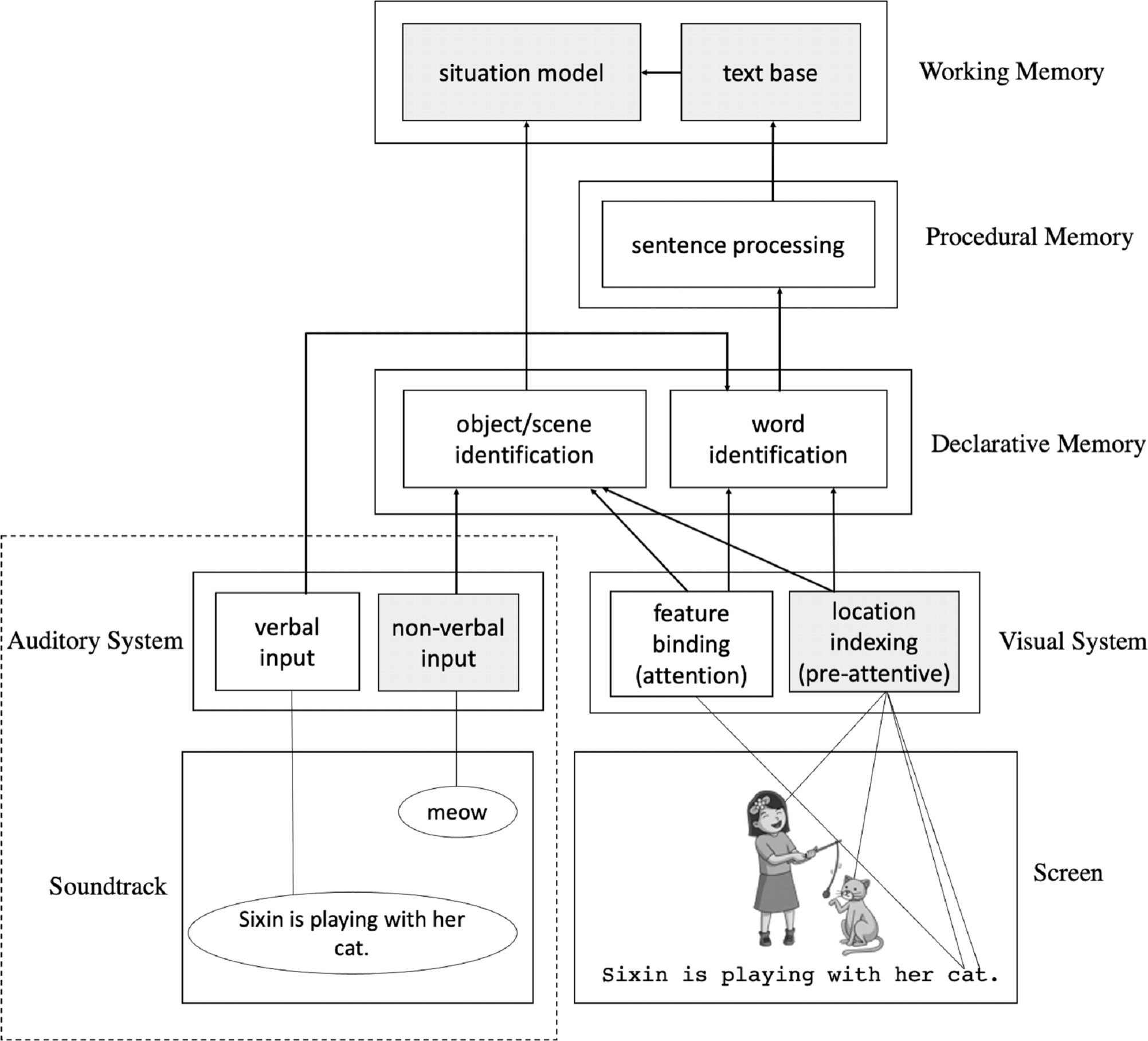
Figure 1. Schematic diagram of the new multimodal integrated-language framework. Components outside the dashed-line box are the same as those in the original framework by Liao et al., Reference Liao, Yu, Reichle and Kruger2021, while those inside the dashed-line box are new elements added to the auditory channel. The gray boxes correspond to processes that maintain/operate currently upon multiple representations (i.e., parallel processing), whereas the white boxes correspond to processes that maintain/operate upon only one representation at a time (i.e., serial processing).
Another critical characteristic of this framework is that, while each of the depicted processes performs a specific function, the processes also “communicate” in specific ways. This effectively means that, in multimodal reading situations, the non-textual sources of information that contain redundant (i.e., overlapping or similar) content with the written text can provide additional support for comprehension, thus modulating the reader’s need or propensity to read the text. For example, unlike the normal reading conditions wherein text comprehension is expected to be severely impaired when word identification (based on the written text only) is inaccurate or slow, the negative ramifications of poor word identification in multimodal reading situations could be compensated for—at least to some extent—by the information available from the other sources of information (e.g., the non-textual visual elements). This thus provides an explanation for Liao et al.’s (Reference Liao, Yu, Reichle and Kruger2021) finding that participants’ comprehension enhanced even when they spent less time reading the subtitles as subtitle speed increased.
Based on the multimodal integrated-language framework, Reichle et al. (Reference Reichle, Yu, Liao and Kruger2021) used the E-Z Reader model to simulate the possible strategies adopted by Liao et al.’s (Reference Liao, Yu, Reichle and Kruger2021) participants to compensate for the demands caused by faster subtitle speeds. Using sentences from the Schilling et al. (Reference Schilling, Rayner and Chumbley1998) corpus, they systematically manipulated the model’s parameters that control saccadic programming (e.g., fewer refixations, more accurate saccades, and longer preferred saccades) and lexical and/or more complex processing (e.g., imposition of lexical processing deadline and skipping of short words) to determine the processing strategy that would reproduce the qualitative patterns as observed in Liao et al.’s (Reference Liao, Yu, Reichle and Kruger2021) study—that is, fewer and shorter fixations, as well as longer saccades as subtitle speed increased from 12 to 28 cps. Simulation results showed that promising compensatory strategies include imposing a lexical-processing deadline, a simple word-targeting strategy of skipping short words, or using the video content to enhance the word predictability for difficult (low-frequency) words. These results indicate that, even in the demanding multimodal reading situation (i.e., very fast subtitle speed with video concurrently presented on the screen), readers could still employ some type of strategy to maintain a desirable level of comprehension.
However, it is important to note that, although the multimodal integrated-language framework by Liao et al. (Reference Liao, Yu, Reichle and Kruger2021) provides a feasible account of how non-text visual elements might support reading comprehension, and Reichle et al.’s (Reference Reichle, Yu, Liao and Kruger2021) simulations provided some preliminary evidence for its efficacy, it does not specify how verbal and non-verbal information from the auditory system might be integrated with information from the visual system (e.g., the video and subtitles) to support some overall level of video comprehension. Because empirical evidence in this regard is also lacking in Liao et al.’s (Reference Liao, Yu, Reichle and Kruger2021) study (because their experiment was done without audio), the present study thus provides an opportunity to extend and further evaluate the multimodal integrated-language framework.
Eye-tracking evidence from previous research
Despite the challenges in developing a full account of how perception and cognition are coordinated to support subtitle reading, a growing body of research has provided some clues by examining how background sounds (e.g., music, noise, and speech) affect the reading of static text. These studies generally report a negative effect of the sounds on reading comprehension, with background language being particularly disruptive (see Vasilev et al., Reference Vasilev, Kirkby and Angele2018, for a review). For example, reading with lyrical music or intelligible speech causes longer sentence-reading times and an increased number of fixations and regressions than reading in silence (Cauchard et al., Reference Cauchard, Cane and Weger2012; Vasilev et al., Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019; Yan et al., Reference Yan, Meng, Liu, He and Paterson2018; Zhang et al., Reference Zhang, Miller, Cleveland and Cortina2018). In addition, intelligible or meaningful speech generated more disruptions on various eye-movement measures compared with unintelligible speech (e.g., speech in an unknown language: Vasilev et al., Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019; scrambled speech, Yan et al., Reference Yan, Meng, Liu, He and Paterson2018), suggesting that semantic processing of the auditory content is the primary cause of the auditory disruption effect (Marsh et al., Reference Marsh, Hughes and Jones2008, Reference Marsh, Hughes and Jones2009; Martin et al., Reference Martin, Wogalter and Forlano1988).
The study by Hyönä and Ekholm (Reference Hyönä and Ekholm2016) is most relevant to the present study because in one of their experiments (Experiment 2), they manipulated the similarity of semantic content of the background speech. Specifically, participants were instructed to read texts in three background speech conditions: (1) silence; (2) scrambled speech of the to-be-read text (by randomizing the order of words of the to-be-read text so that the speech is semantically related to the written text); and (3) scrambled speech of an unrelated text (by randomizing the order of words of a text that is unrelated to the to-be-read text). It was found that scrambled speech yielded longer first-pass fixations times compared to the silent condition, but the two types of scrambled speech did not differ in the size of the disruption effect, indicating that the disruption of scrambled speech is not caused by the similarity of semantic content but rather by the fact that both sources of information (the written and spoken text) require the same resource for processing the meaning of words. However, because the speeches used by Hyönä and Ekholm (Reference Hyönä and Ekholm2016) were anomalous both syntactically and semantically, it remains unclear whether meaningful speech (i.e., semantically and syntactically accurate) with similar or identical semantic content (i.e., semantically relevant) to the written text would result in the disruption effect or not. Our experiment will provide an opportunity to address this question.
Furthermore, it is still inconclusive precisely how the reading process is disrupted by background speech. For example, Yan et al. (Reference Yan, Meng, Liu, He and Paterson2018) found that effects of the frequency of their manipulated target words were only observed in later fixation measures (i.e., gaze duration and total-reading time) but not in first-fixation duration in the presence of background speech (meaningful or meaningless), which was in contrast to silent reading, where the word-frequency effects were observed in both early and late fixation measures. This led Yan et al. to conclude that background noise disrupts the early processing of words during reading. However, Vasilev et al. (Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019) observed word-frequency effects in both first- and second-pass eye-movement measures regardless of whether the background sounds were intelligible, unintelligible, or absent. Critically, they found that intelligible speech produced more rereading fixations and regressions as compared to silent reading or reading with unintelligible speech. These findings collectively suggest that intelligible speech does not disrupt the early lexical stage of word identification, but instead interferes with the post-lexical stage of (linguistic) processing (e.g., the integration of words into their sentence contexts).
Although the above studies provide important insights into the influence of audio information on reading, it should be noted that the auditory stimuli used in these studies were mostly scrambled (i.e., meaningless) speeches or speeches that are meaningful but irrelevant to the text being read. As such, the semantic processing of the auditory information likely competes for the cognitive resources that are also involved in reading the text, thereby causing disruption to the reading process. Such situations differ from the normal situation of reading subtitles, where the auditory information is often highly relevant, if not identical, to the content of the text being read.
In contrast to what has been found in the reading of static text, studies on subtitle reading show that people actually spend less time reading subtitles when the audio is present than absent, or in a known than unknown language, indicating the text-relevant auditory information can support, instead of interfering with, subtitle reading. For example, Ross and Kowler (Reference Ross and Kowler2013) found that viewers spent less time reading subtitles when audio was present compared to the reading-only condition (without audio), due to the skipping of subtitles in the audio-present condition (see also, d’Ydewalle et al., Reference d’Ydewalle, Praet, Verfaillie and Van Rensbergen1991). Similar findings were also reported by Szarkowska and Gerber-Morón (Reference Szarkowska and Gerber-Morón2018) who examined eye movements in conditions with audio in a known versus unknown language. They found that participants spent less time reading subtitles when the audio was in their known (e.g., native or highly proficient second) language than an unknown language. Taken together, these studies provide evidence for the auditory support for subtitle reading—that is, for the hypothesis that viewers rely less on the reading of subtitles for comprehension when relevant verbal information is available from the auditory input.
However, it remains unclear how the auditory context would support subtitle reading. For example, does auditory processing support the lexical and/or post-lexical processing of subtitles? Our lack of understanding here is largely due to the fact that previous studies on subtitle reading have mostly reported only global eye-movement measures on the entire subtitle (see Table 1 for examples) and thus provide no indication of precisely how the presence versus absence of concurrent auditory information actually affects the processing of the subtitles. A global increase in sentence-reading times, for example, might reflect an overall slowing in lexical processing (e.g., increased fixation durations), more difficult post-lexical processing (e.g., more inter-word regressions), or both.
Table 1. Summary of major eye-tracking studies on the influence of audio on subtitle reading

Another limitation in the existing research on subtitle reading is that the studies reviewed above all presented subtitles in participants’ native language. For studies that used non-native language subtitles (see Table 1), subtitles were in a language that participants had no or little knowledge of (see, e.g., Bisson et al., Reference Bisson, van Heuven, Conklin and Tunney2014; d’Ydewalle & De Bruycker, Reference d’Ydewalle and De Bruycker2007). One exception is a recent study by Ragni (Reference Ragni2020), which examined second-language subtitles with native-language audio. However, as Ragni’s study did not provide a control condition (e.g., the no-audio condition), it is difficult to determine the influence of audio on the reading of second-language subtitles, although such experimental design serves its purpose of investigating the impact of translation strategies on the processing of second-language subtitles. Overall, there is limited empirical evidence for how the auditory input may influence subtitle reading when subtitles are in readers’ second language. Answers to this question will have significant practical implications for the application of subtitling in real-world activities given the widespread use of second-language subtitles in educational videos as a tool to assist learning for international students.
Given this brief overview of the work that has been done to examine the influence of auditory information on reading, our study aims at filling in the research gaps identified in two closely related disciplines—research on reading static text, where the influence of semantically relevant audio on reading is underexplored, and research on subtitle reading, where the influence of semantically relevant audio on reading has been impeded by methodological limitations. To this end, we made the first attempt to understand how semantically relevant auditory information will influence reading in the context of watching video with subtitles, using both global and local (i.e., word-based) eye-movement measures. We did this by manipulating three types of auditory information that were expected to modulate the necessity for reading (and understanding) English/L2 subtitles: (1) Chinese/L1 audio (i.e., interlingual subtitles with audio in a different language), which obviated the need to read the English subtitles; (2) English/L2 audio (i.e., intralingual subtitles with audio in the same language), which may facilitate the reading of the English subtitles; and (3) no audio, which necessitated subtitle reading if participants need to fully understand the video content. We also manipulated the presence versus absence of the concurrent video content to examine how the interaction between auditory processing and subtitle reading might be modulated by the overall visual-processing demands and/or a (partially) redundant source of information.
Based on the multimodal integrated-language framework (Liao et al., Reference Liao, Yu, Reichle and Kruger2021), which postulates that viewers can perform limited parallel processing (e.g., tracking a smaller number of objects in the background video using peripheral vision while reading subtitles) and can combine different sources of information in response to varying task demands to optimize comprehension, it is hypothesized that, on a global level, participants would rely less on subtitles when audio provides an additional source for identical or similar verbal information. Therefore, we expected fewer, shorter fixations, longer saccades as well as more skipping of subtitles with Chinese or English audio compared to without audio (Hypothesis 1). On a local level, as native-language audio presumably eliminated the need for subtitles, it is hypothesized that lexical and post-lexical processing of subtitles would be attenuated with Chinese audio than without audio (Hypothesis 2). However, participants might use the second-language audio to support the reading of second-language subtitles (or vice versa), thereby allowing them to engage in deeper lexical and post-lexical processing of subtitles with English audio than without audio (Hypothesis 3). Finally, the effects of audio on subtitle reading are likely to be more evident in the presence of concurrent video content (as opposed to the absence of video) which provides an additional source of overlapping information for comprehension (Hypothesis 4).
Method
Participants
Thirty-four Chinese native speakers who were also advanced speakers of English (scoring 6 or 7 in the Reading and Listening bands in the International English Language Testing System, or IELTS) were recruited as participants (26 females). Their average age was 25.8 years (SD = 3.98, range = 20–38). All participants reported normal or corrected-to-normal vision. Ethics approval was obtained from Macquarie University (Reference No: 5201830023375). Participants were awarded cash or course credit in accordance with ethical requirements.
Design
The experiment was a 3 (audio condition: Chinese/L1 audio, English/L2 audio, no audio) × 2 (video condition: present vs. absent) within-subject design, resulting in six experimental conditions. All conditions were counterbalanced via a Latin-square design to ensure that each participant watched each video in a given condition once. A Latin-square design was also used to assign each video to each of the six conditions equally often across participants. Videos were presented to participants in a random order.
Materials
Stimuli
Six video clips (each of 8–10 min) were selected from six episodes of the BBC documentary series Planet Earth (Fothergill, Reference Fothergill2006) as stimuli. The videos had no on-screen speakers, which makes it possible to change the language in the soundtrack without causing problems with lip synchronization. All video clips were self-contained and comparable in terms of the narrative structure, pace of spoken dialogue, and visual complexity. The linguistic complexity (i.e., reading ease) of the subtitles from the different videos was compared using Coh-Metrix (http://tool.cohmetrix.com/), a computational tool for readability testing (Graesser et al., Reference Graesser, McNamara, Cai, Conley, Li and Pennebaker2014) (see Table 2).
Table 2. Characteristics of video clips and subtitles

Note. Subtitle speed is measured by the number of characters presented per second (cps).
English subtitles for all video clips were generated as verbatim transcripts of the original English audio using the Aegisub subtitle-editing softwareFootnote 1 and guidelines listed in Table 3. Chinese audio, which was a direct translation of the original English audio, was extracted from the same documentary series broadcast by the Central Broadcasting Television (CCTV), the predominant state television broadcaster in Mainland China. Like the English audio, the Chinese audio was synchronized with the onset of the subtitle, and the semantic meaning of each subtitle was equivalent to the meaning of its corresponding Chinese audio for most subtitlesFootnote 2 (see Table 4 for examples of subtitles and auditory transcription). Subtitles that did not have the same semantic meanings with the Chinese audio were excluded in eye-movement analyses for all experimental conditions (13% data loss in global analyses and 11% in local analyses). In this way, the influence of the semantic discrepancy between the two information sources (i.e., the subtitle and the audio) was minimized. Apart from the languages being used (i.e., English vs. Chinese), the two audio conditions were exactly the same with respect to other non-verbal content (e.g., background noises).
Table 3. Guidelines for the generation of subtitles in the current study

Table 4. Examples of English subtitles and Chinese audio used in the study (back translation of the Chinese audio in square brackets)

Comprehension tests
Eight three-alternative-choice questions derived from the subtitles only were used to evaluate participants’ comprehension of each video. All questions were presented in bilingual scripts to preclude the confounding influence of language on comprehension results.
Apparatus and procedure
Participants’ eye movements during subtitle reading and video viewing were recorded using an EyeLink 1000+ (SR Research Ltd., Canada) eye tracker with a sampling rate of 2,000 Hz. Stimuli were displayed on a BenQZowie XL2540 screen with a refresh rate of 240 Hz and a screen resolution of 1,920 × 1,080 pixels. Videos were presented with a resolution of 1,280 × 720 pixels and a presentation rate of 30 frames per second at the center of the screen, and subtitles were presented below the video in mono-spaced Courier New font (30-point; RGB color: 255, 255, 102) (see Figure 2). Each subtitle was displayed on the screen one line at a time in synchrony with the audio, which was played with the volume level of 75–80 dBA via two external speakers that were placed on each side of the computer monitor in a sound-proof laboratory. A chin-and-forehead rest was used to minimize head movements. Participants were seated 95 cm away from the monitor, which produced a ∼0.4o visual angle for each letter on the screen. Viewing was binocular, but only the right eye was tracked.

Figure 2. Screenshots of stimuli in the video-present condition (at the top) and video-absent condition (at the bottom).
Participants were tested individually in a sound-proof and sufficiently illuminated laboratory. Prior to the eye-tracking experiment, participants were given a participant consent form and a brief verbal task instruction. Participants were not instructed to pay specific attention to subtitles. To ensure tracking accuracy, a nine-point calibration and validation procedure was performed prior to watching each video (the maximum allowance for the calibration error was 0.5°). Comprehension questions were presented at the center of the screen one by one after each video. Participants were given a 2-min break after watching each video to avoid fatigue. The whole experiment lasted approximately 2.5 hr.
Analyses
Three participants’ data were removed prior to the analyses due to tracking loss in some of the videos, resulting in 31 participants’ data being used for eye-movement analyses. Fixations shorter than 60 ms or longer than 800 ms were also excluded (8.68%) from the analyses.
Several global eye-movement measures of which the analyses were based on the entire subtitle region were reported: (1) average fixation durations, (2) total number of fixations, (3) progressive saccade length (i.e., average length of rightward saccades in degrees), and (4) percentage of skipped subtitles (i.e., percentage of entire subtitles that are not fixated). These global measures provide us with a general pattern of how the subtitle reading is modulated by participants’ needs for the subtitles in different audio conditions, and the potential strategy adapted by participants. For example, in Liao et al.’s (Reference Liao, Yu, Reichle and Kruger2021) study, the combination of shorter and fewer fixations, and longer saccade length is indicative of a skimming strategy.
In order to gain more insights into the lexical and post-lexical processing of subtitles, we also examined the word-frequency, word-length, and wrap-up effects using two word-based fixation measures that are commonly used in reading research: gaze durations (i.e., the sum of all fixations on a word prior to the eyes exiting the word) and total-reading times (i.e., the sum of all fixations on a word). Examination of these two measures allows us to probe into the influence of audio on different stages of linguistic processing, with gaze durations reflecting early stages and total-reading times reflecting relatively late stages of linguistic processing (including regressions back to words; Rayner, Reference Rayner1998, Reference Rayner2009).
Data were analyzed via generalized/linear mixed models (G/LMMs) using the lme4 package (version 1.1-23) in R (Version 3.6.3); p values were computed via the lmerTest package (Version 3.1-2, Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). Fixations were log-transformed in all analyses to meet the data assumption of the LMMs analyses. Main effects of experimental factors were extracted using sliding difference contrasts via the contr.sdif function, which compares consecutive factor levels of each variable (i.e., Chinese audio vs. English audio and English audio vs. no audio, for the audio condition comparison). The emmeans package (version 1.47) was used to compute and extract the estimated means between the Chinese-audio and no-audio conditions, and the simple effects.
When fitting a model, we first started with a maximal random-effect structure that included all experimental factors and their interactions as fixed effects, subject and subtitle item (or word item in the word-based analyses) as random intercepts, as well as random slopes for the fixed effects across subjects and subtitles/words (Barr et al., Reference Barr, Levy, Scheepers and Tily2013). Because all video clips were selected from the same documentary series and thus homogeneous (with linguistic complexity, video duration, and genre being comparable), a single random-effect variable was coded for each combination of video and subtitles in our global analyses, and for each combination of video, subtitle, and word in our word-based analyses. Insignificant random-effects components were progressively removed to generate a parsimonious model (Bates et al., Reference Bates, Kliegl, Vasishth and Baayen2015; see Appendix 1 for a summary of final models used in data analyses). Both word frequency and length were entered into the models as scaled and centered continuous variables; the word frequency is based on the Zipf scale, or log10 (frequency per billion words), from the SUBTLEX-UK word-frequency corpus (van Heuven et al., Reference van Heuven, Mandera, Keuleers and Brysbaert2014). For word-frequency/length effect analyses, the first and final words in each subtitle were excluded to avoid any potential confounds due to the sudden appearance or disappearance of the subtitle.
Because real-world (i.e., commercially available) videos were used as stimuli in the present study, the wrap-up effects were examined by comparing words in two locations: line ending versus non-ending, which includes all words from the second to the penultimate in the subtitles (cf., examine the wrap-up effect with experimental manipulation; Warren et al., Reference Warren, White and Reichle2009)Footnote 3 . The average zipf frequencies for the ending versus non-ending words were 4.5 versus 5.5, and their average lengths were 6.1 versus 4.9 letters, respectively.
Finally, to control for potential type I error associated with the use of multiple eye-tracking measures, Bonferroni correction was applied as a remedy by dividing the 0.05 alpha threshold by the number of dependent measures used to examine a given effect (von der Malsburg & Angele, Reference von der Malsburg and Angele2017). This yielded an alpha level of 0.013 for our global analyses (four measures used) and alpha of 0.025 for the two word-based analyses (two measures used).
Results
Comprehension
Mean comprehension accuracy across six conditions for each participant was above chance level (0.33), ranging from 0.60 to 0.85 (M = 0.72, SD = 0.45) across participants. Figure 3 shows that participants had higher comprehension accuracy with concurrent video content (z = 3.10, p < 0.05). No main effect of audio condition was observed (all |z|s < 1.57, ps > 0.05), which indicates that participants obtained similar levels of comprehension irrespective of whether or not there was semantically relevant audio.
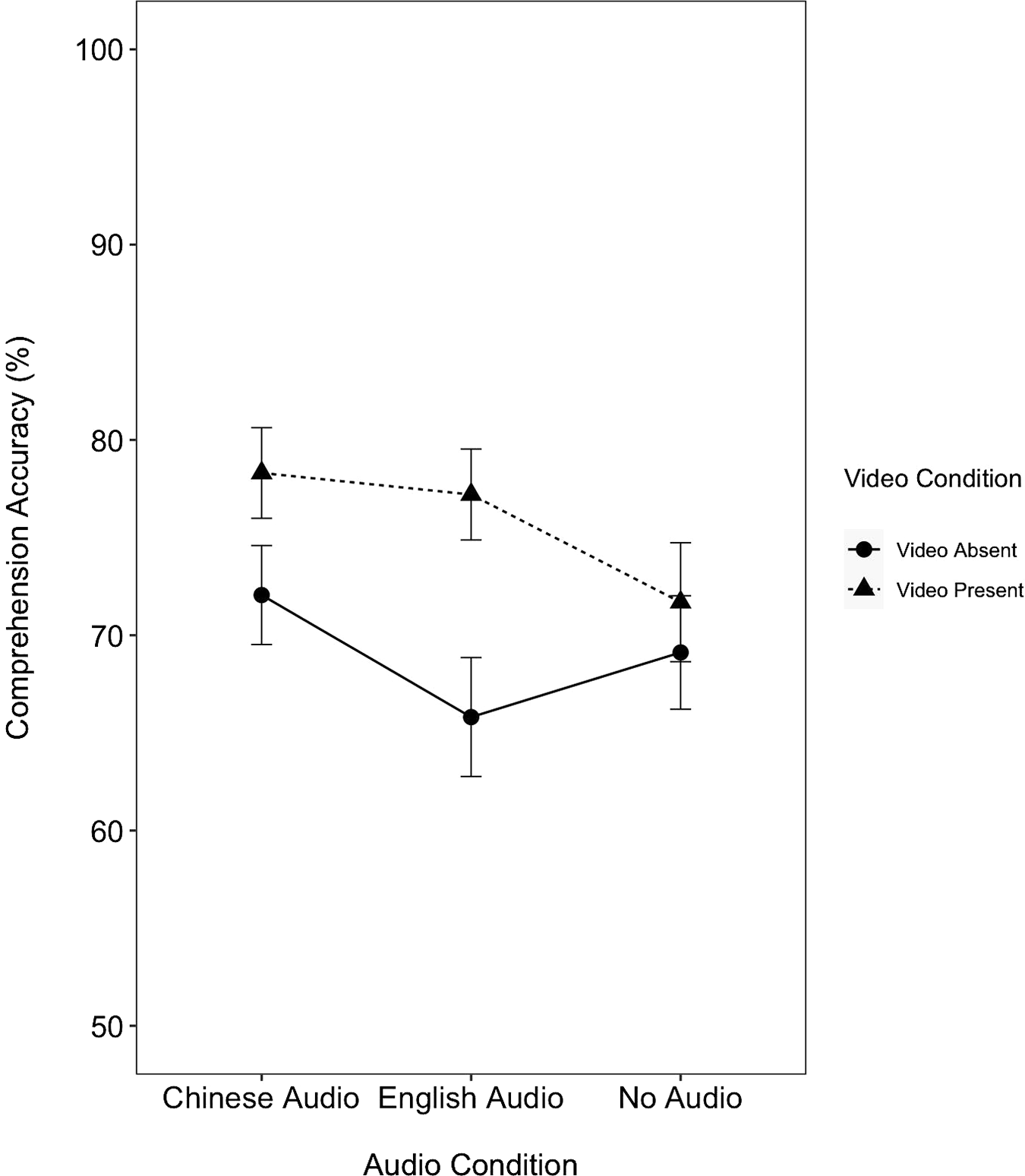
Figure 3. Comprehension accuracy as a function of video and audio conditions. Error bars represent the standard errors of the means.
Global analyses of eye movements
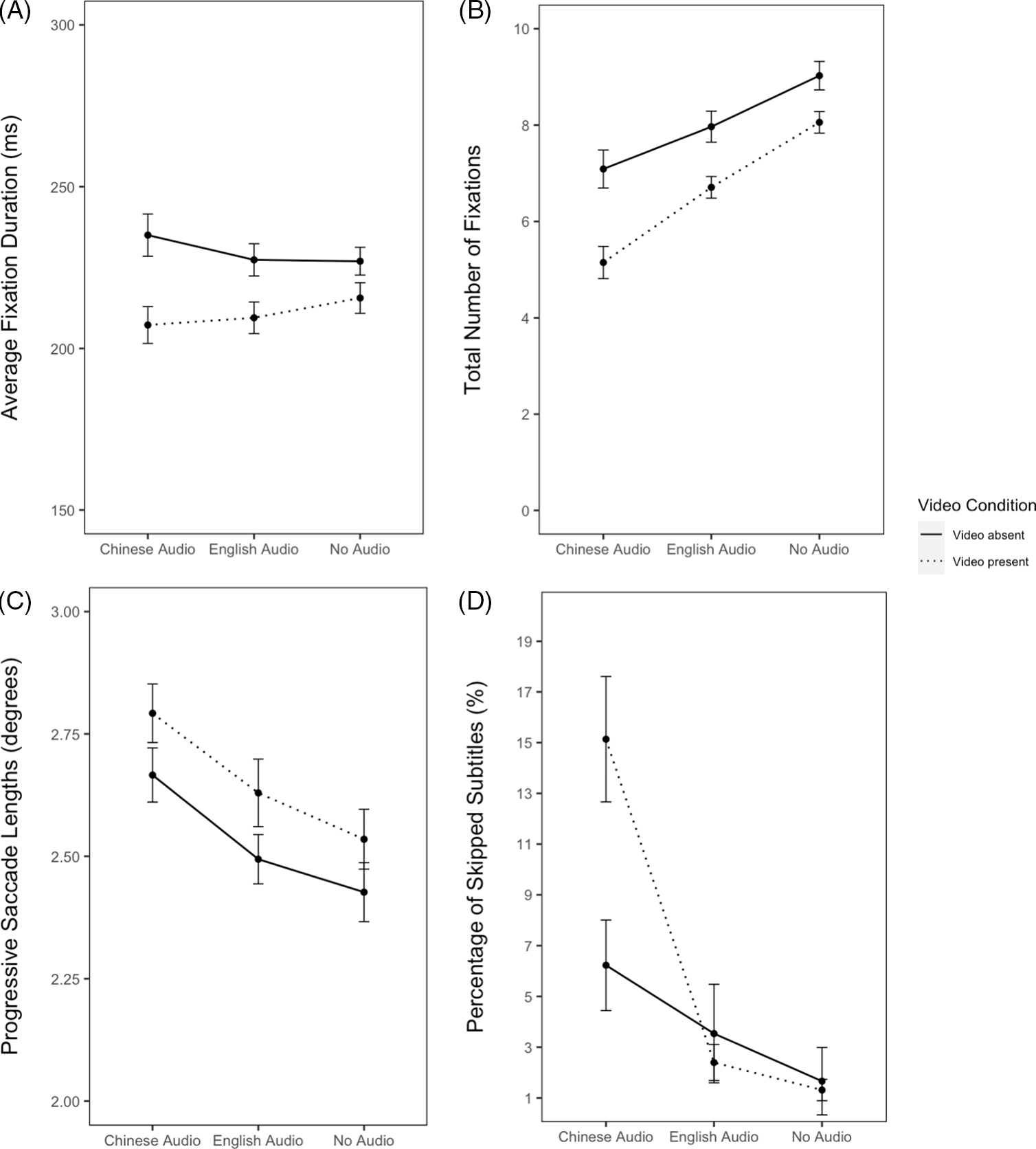
Mean fixation durations
As Tables 5 and 6 and Figure 4A show, participants made shorter fixations on subtitles when the video was present. There was no main effect of the audio condition, but interaction between video and audio (Chinese vs. no audio) was observed. Pairwise contrasts of the Video × Audio (Chinese vs. no audio) interaction revealed that fixations were shorter with Chinese audio than without audio, but only when video was present (video absent: t = 0.75, p = 0.45; video present: t = −3.35, p < 0.001). Finally, there was no significant difference between English audio and no audio.
Table 5. Mean and standard deviation of global eye-movement measures in the subtitle region.

Note. CA, Chinese audio; EA, English audio; NA, no audio.
Table 6. The LMMs results for the global analyses in the subtitle region

Note. Bold font indicates p < .013. CA, Chinese audio; EA, English audio; NA, no audio.

Figure 4. Mean descriptive statistics for global eye-movement measures in the subtitled region. Error bars represent the standard errors of the means.
Total number of fixations
As Tables 5 and 6 and Figure 4B show, there were fewer fixations in the subtitle region with video presentation than without. Participants also made fewer fixations on the subtitles as the need or propensity to read them decreased (i.e., moving from the no- to English- to Chinese-audio conditions). The difference between Chinese audio and no audio was more pronounced with video presentation, as revealed by the Video × Audio (Chinese vs. no audio) interaction (video absent: b = −1.88, t = −5.36, p < 0.0001; video present: b = −2.92, t = −10.36, p < 0.0001).
Progressive saccade length
As shown in Tables 5 and 6 and Figure 4C, participants made longer progressive saccades in the subtitle region when video was present than absent. Saccades were also longer with Chinese audio than with English audio or without audio.
Percentage of skipped subtitles
As shown in Tables 5 and 6 and Figure 4D, more subtitles were skipped when concurrent video was present than absent. Participants skipped more subtitles when the need or propensity to read them decreased (i.e., with Chinese audio compared to with English audio or without audio). But the difference between Chinese audio and English audio was only significant when video was present (video absent: t = 2.06, p = 0.04; video present: t = 7.76, p < 0.001), as revealed by the Video × Audio (Chinese vs. English) interaction. The contrast between English audio and no audio also interacted with video condition. Pairwise analyses of the Video × Audio (English vs. no audio) interaction showed that the difference between English audio and no audio was only numerical but did not reach significance in any video conditions (video absent: t = 2.40, p = 0.02; video present: t = −0.26, p = 0.79).
Local analyses of eye movements
Word-frequency and word-length effects
Gaze durations
As shown in Table 7 and Figures 5A and 6A, main effects of word frequency, word length, video condition, and audio condition (Chinese vs. English) were observed. Gaze durations on words decreased with increasing word frequency, decreasing word length, and concurrent video content. Participants also fixated words in the subtitles shorter when the audio was in Chinese than in English. The absence of Frequency × Audio and Length × Audio interactions indicated the word-frequency and word-length effects were similar across three audio conditions. Finally, the Frequency × Length × Video interaction indicated that the word-frequency effect increased with increasing word length, but only in the condition without video. Similarly, the word-length effect increased as words became infrequent, but only in the absence of video. The three-way interaction between word frequency, word length, and video condition produced patterns that are consistent with those observed in Liao et al. (Reference Liao, Yu, Reichle and Kruger2021).
Table 7. The LMMs results for the word-frequency and word-length effects

Note. Bold font indicates p < 0.025. CA, Chinese audio; EA, English audio; NA, no audio. Three-way and four-way interactions without significance were not reported for simplicity.
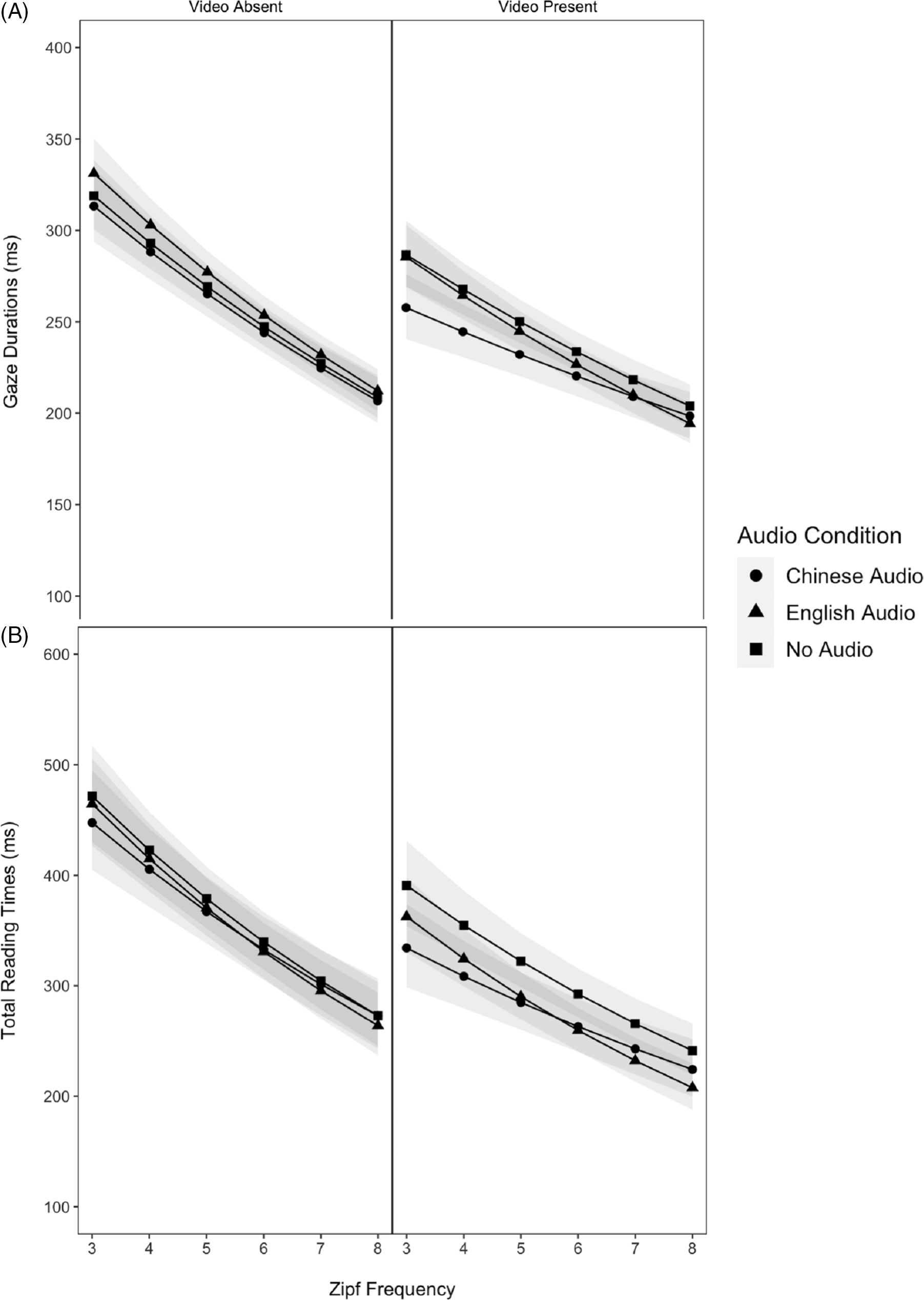
Figure 5. The LMMs-adjusted word-frequency effects as a function of video presence/absence and audio condition. Word frequency is based on the Zipf scale extracted from the SUBTLEX-UK word-frequency corpus. Ribbons represent the lower (5%) and upper limits (95%) of confidence intervals for the estimated marginal means.
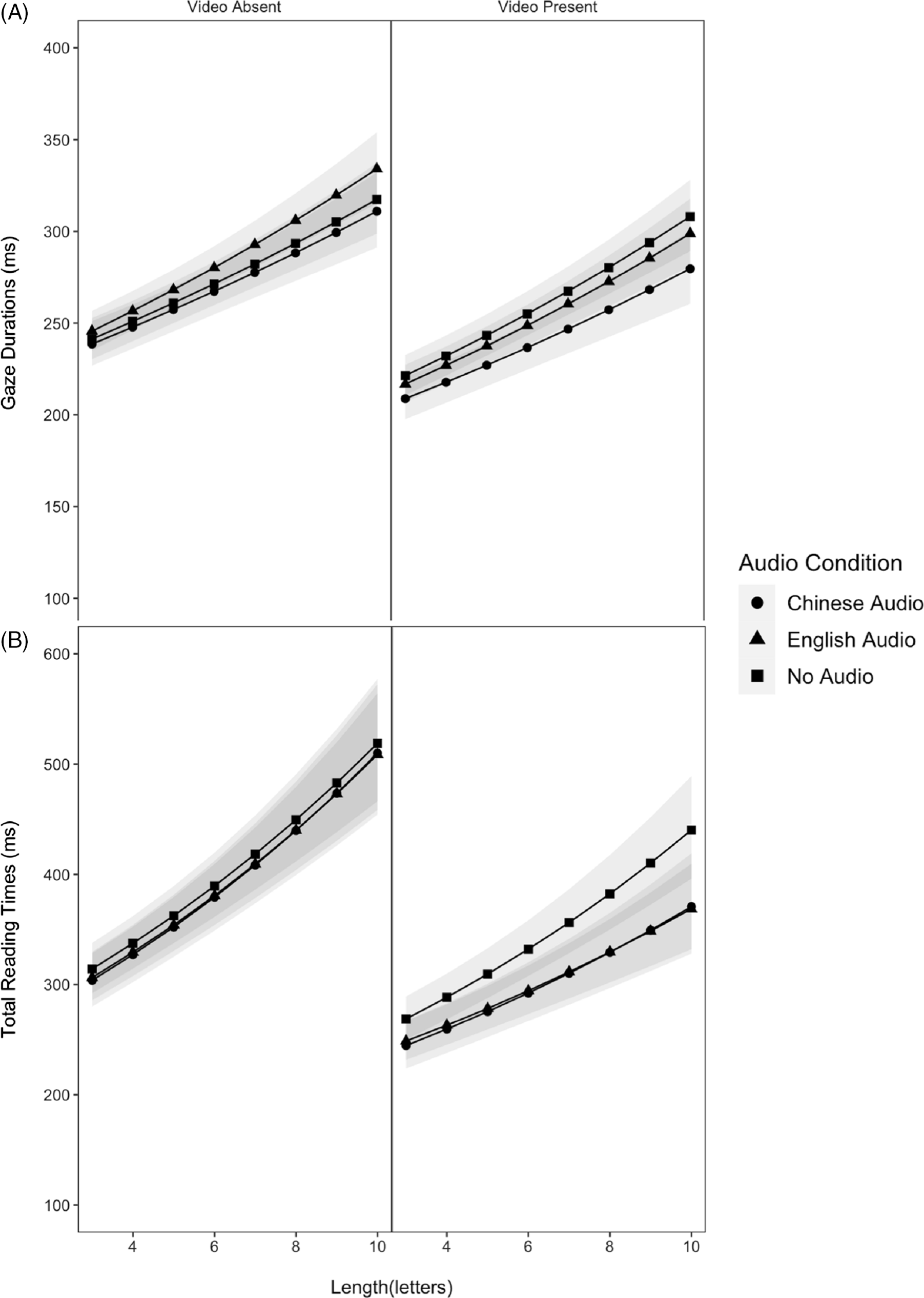
Figure 6. The LMMs-adjusted word-length effects as a function of video presence/absence and audio condition. Ribbons represent the lower (5%) and upper limits (95%) of confidence intervals for the estimated marginal means.
Total-reading times
Main effects of word frequency, word length, video, and audio conditions (Chinese vs. no audio; English vs. no audio) were found, as shown in Table 7 and Figures 5B and 6B. Total-reading times on words decreased with increasing word frequency, decreasing word length, concurrent video content, and low subtitle-reading need or propensity (i.e., when either the English or Chinese audio was available). The Length × Video interaction showed that the length effect was reduced with video presentation, which is again consistent with the results of Liao et al. (Reference Liao, Yu, Reichle and Kruger2021). Audio condition did not interact with word length or frequency, indicating that the word-length and word-frequency effects did not differ across three audio conditions.
Wrap-up effect
Gaze durations
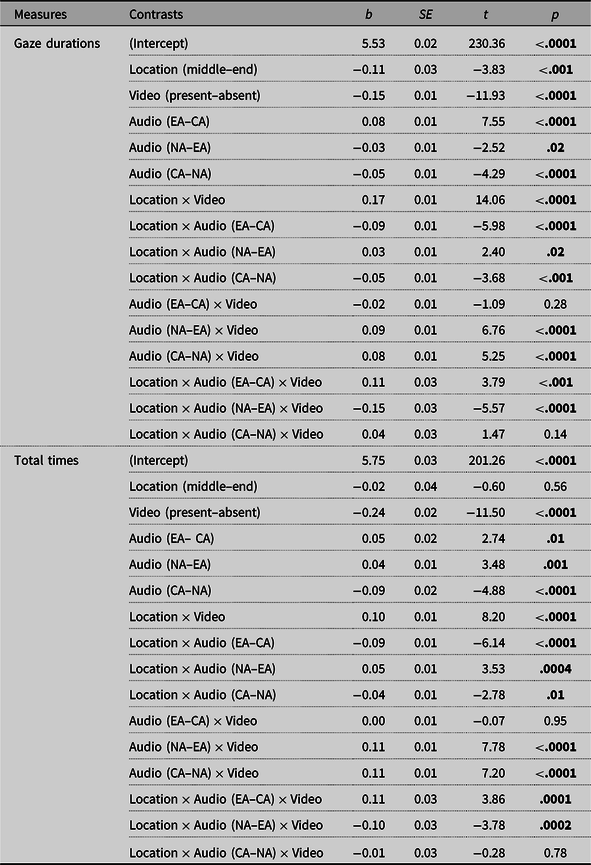
As shown in Table 8 and Figure 7A, main effects of word location (i.e., wrap up), video, and audio conditions were observed. The Location × Video interaction showed that the wrap-up effect was only visible when video was absent (video absent: t = 6.55, p < 0.0001; video present: t = 0.93, p = 0.35). The Location × Audio (Chinese vs. English) × Video interaction showed that the Location × Audio (Chinese vs. English) interaction was only significant when video was absent (video absent: t = −6.88, p < 0.0001; video present: t = −1.59, p = 0.11). Without video, the wrap-up effect was more pronounced with English audio compared to Chinese audio (Chinese audio: b = 0.14, t = 4.28, p < 0.0001; English audio: b = 0.28, t = 8.73, p < 0.001). The Location × Audio (English vs. no audio) × Video interaction revealed that the Location × Audio (English vs. no audio) interaction was significant in both video conditions but was more pronounced in the absence of video. When video was absent, the wrap-up effect was larger with English audio than without audio (English audio: b = 0.28, t = 8.73, p < 0.0001; no audio: b = 0.17, t = 5.35, p < 0.0001); however, when video was present, the wrap-up effect was only observed without audio but not with English audio (English audio: b = 0.02, t = 0.77, p = 0.44; no audio: b = 0.07, t = 2.11, p = 0.03). Finally, the wrap-up effect was attenuated with Chinese audio than without audio (Chinese audio: b = 0.07, t = 2.14, p = 0.03; no audio: b = 0.12, t = 3.93, p < 0.0001), as revealed by the Location × Audio (Chinese vs. no audio) interaction.
Table 8. The LMMs results for wrap-up effects
Note. Bold font indicates p < 0.025. CA, Chinese audio; EA, English audio; NA, no audio.

Figure 7. The LMMs-adjusted wrap-up effects as a function of video presence/absence and audio condition. Ribbons represent the lower (5%) and upper limits (95%) of confidence intervals for the estimated marginal means.
Total-reading times
Main effects of video and audio were observed, but no main effect of word location, as shown in Table 8 and Figure 7B. The Location × Video interaction showed that subtitle-ending words received numerically longer reading times than middle words (a normal wrap-up effect) when video was absent, whereas a reversed trend as observed when video was present, although none of these differences reached significance (video absent: t = 2.03, p = 0.04; video present: t = −0.89, p = 0.38). Likewise, the Location × Audio (Chinese vs. no audio) interaction revealed that subtitle-final words were fixated longer than middle words numerically (i.e., the normal wrap-up effect) without audio whereas a reversed pattern was observed for Chinese audio, although the effect of word location was not significant in these two audio conditions (Chinese audio: t = −0.63, p = 0.53; no audio: t = 0.51, p = 0.61). Similar to the patterns in gaze durations, Location × Audio (Chinese vs. English; English vs. no audio) × Video interactions were observed. Pairwise contrasts showed that the Location × Audio (Chinese vs. English; English vs. no audio) interactions were only significant when video was absent (video absent: |t|s > 5.02, ps < 0.0001; video present: |t|s < 1.67, ps > 0.10). Without video, the wrap-up effect was observed with English audio but not with Chinese audio or without audio (Chinese audio: t = 0.24, p = 0.81; English audio: t = 4.12, p < 0.0001; no audio: t = 1.44, p = 0.15).
General discussion
While some has been learned about how semantically irrelevant background speech affects reading, relatively little is known about how reading might be affected by speech that is semantically relevant to the text being read. The answer to this question will have significant practical implications because reading with semantically relevant audio is a common scenario in our daily life, such as reading subtitles when watching videos with soundtrack in a known language. The present study therefore aimed to understand how the reading process could be affected by semantically relevant auditory input in the context of reading English/L2 subtitles in video. A 2 (video condition: absence vs. presence) × 3 (audio condition: Chinese/L1 audio vs. English/L2 audio vs. no audio) eye-tracking experiment was conducted in which the manipulation of the audio and video conditions likely modulated the need or propensity to read the subtitles, with lowest propensity occurring with Chinese audio (because the participants were native Chinese speakers) and the highest propensity occurring without audio (because much of the video content could then only be extracted from the English subtitles).
Although there was no evidence from the present study that semantically relevant audio affects reading comprehension, our eye-movement data clearly show that readers adjusted the way they engaged in the reading of subtitles in response to the varying needs to read the subtitles in different audio conditions. Analyses of global eye-movement measures provided supportive evidence for Hypothesis 1—that is, as the reading propensity decreased from no audio to English audio or Chinese audio, participants tended to rely less on subtitles, yielding fewer, shorter fixations, longer saccades on the subtitles (similar to the “skimming” pattern as observed in Liao et al.’s, Reference Liao, Yu, Reichle and Kruger2021 study), as well as higher skipping rate of the subtitles.
While intelligible background speech has been generally found to disrupt the reading of static text by causing more fixations and longer reading times compared to reading in silence (see, e.g., Cauchard et al., Reference Cauchard, Cane and Weger2012; Vasilev et al., Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019; Yan et al., Reference Yan, Meng, Liu, He and Paterson2018), such auditory disruption effect was not observed in our study. Instead, our results are in line with previous findings from subtitling research that auditory input could facilitate the reading of subtitles by, for example, reducing the reading times (see, e.g., d’Ydewalle et al., Reference d’Ydewalle, Praet, Verfaillie and Van Rensbergen1991; Szarkowska & Gerber-Morón, Reference Szarkowska and Gerber-Morón2018) and skipping more subtitles (Ross & Kowler, Reference Ross and Kowler2013). However, it should be noted that the nature of the background speech used in our study is different from that of those used in reading research that caused the auditory disruption effect. Previous research on static text used speech that was unrelated to the text being read (Vasilev et al., Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019; Yan et al., Reference Yan, Meng, Liu, He and Paterson2018), or speech that was related to the written text but scrambled (e.g., Hyönä & Ekholm, Reference Hyönä and Ekholm2016), whereas our study used semantically accurate and relevant speech. Processing the semantically irrelevant or meaningless (scrambled) speech may compete for the same resources as required for reading (e.g., resources for semantic or sentence processing; cf., Hyönä & Ekholm, Reference Hyönä and Ekholm2016; Vasilev et al., Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019), thereby disrupting the reading process. On the contrary, because semantically relevant speech contains identical or similar meaning as in the subtitle, it therefore provides an additional source to establish a situational model that is the same or similar to the one developed by the reading of subtitles. This may explain why participants were still able to maintain some level of comprehension in the presence of Chinese or English audio even when subtitles were not processed as thoroughly as in the no-audio condition where reading subtitles was essential for the overall video comprehension.
It is worth noting that, although the “skimming”-like eye-movement patterns observed in the Chinese audio condition in the current study are similar to those observed in Liao et al.’s (Reference Liao, Yu, Reichle and Kruger2021) study when participants read the most rapidly displayed subtitles, the motivations for employing such strategy might be different. In Liao et al.’s (Reference Liao, Yu, Reichle and Kruger2021) study, skimming was probably motivated by increased task demands due to the limited availability of subtitles, whereas in the present study, skimming was probably adopted because thorough text processing becomes less compelling, or even unnecessary, with Chinese audio (i.e., the participants’ native language) because this auditory information allows easy access to the same linguistic information (contained in the English subtitles) required to understand the video. In other words, while superficial reading in the former study seems more likely to reflect global task constraints beyond the reader’s control, in the current study, it likely reflects a voluntary choice based on the reader’s monitoring of the inherent trade-offs among different sources of information (e.g., audio vs. subtitle vs. video content) and strategic decisions about the relative importance of each.
Local (word-based) eye-movement analyses provided more clues about the strategies employed by participants to both monitor their needs for the subtitles and for adapting their reading behavior (eye movements) to these needs so as to effectively maximize their comprehension. Although participants spent less time on individual words when reading subtitles with Chinese audio than without audio, lexical processing of subtitles was not attenuated with Chinese audio, indicating that participants showed an equal level of sensitivity to lexical variables such as word frequency and word length. One possible reason is that, because the video content of our stimuli was simple and the subtitles were presented at a relatively slow speed, participants might have sufficient time to watch the video content and process the individual words in the non-native subtitles for language learning even though the subtitles were not essential for comprehension. However, the wrap-up effect was attenuated in Chinese audio compared to no audio (in the absence of concurrent video presentation), which likely reflects the fact that readers engaged in less (or more superficial) post-lexical processing of the subtitles whereby they need to integrate word meanings into sentences for the construction of a situational model that is essential for comprehension. Taken together, our Hypothesis 2 that lexical and post-lexical processing of subtitles would be attenuated with Chinese audio than without audio was partially supported.
Similar to the Chinese-audio condition, participants with English audio also spent less time on individual words in the subtitle, but lexical processing was not attenuated. However, there was a more pronounced wrap-up effect with English audio compared to both the Chinese- and no-audio conditions, indicative of deeper post-lexical integration of word meanings within a clause/sentence representation in the former. This suggests that participants use English audio to support reading (or vice versa) to the extent that the audio permits the reader to engage more with the text and to process it more deeply—the type of processing that would otherwise be challenging when done alone (i.e., without audio) or unnecessary (i.e., with Chinese audio). These results partially supported Hypothesis 3, which predicted deeper lexical and post-lexical processing of the subtitles with English audio than without audio.
Finally, the consistent interaction between video condition and audio condition in the eye-movement measures demonstrated that the impact of audio was modulated by visual processing demands. In line with Hypothesis 4, while the overall pattern was one in which the presence of audio allowed viewers to rely less on the subtitles, the necessity or propensity to read the subtitles was further reduced with concurrent video content. Our separate manipulations of the video and audio conditions therefore show that, when situated in multimodal reading contexts containing multiple sources of information, readers can accurately gauge their needs for the subtitle and adjust their eye-movement routines to accommodate the task demands and maintain some desired level of comprehension.
It is also worth noting that, consistent with the findings reported by Liao et al. (Reference Liao, Yu, Reichle and Kruger2021), we observed an enhancing effect of video content—participants attained higher comprehension accuracy with concurrent video content than without, supporting the multimedia principle or notion that learning with text and picture is better than learning with text alone (Mayer, Reference Mayer2014). Moreover, the presence of video produced similar eye-movement patterns on subtitle reading as reported by Liao et al. (Reference Liao, Yu, Reichle and Kruger2021). Overall, with concurrent video content, participants made shorter, fewer fixations, and longer saccades on the subtitles. More subtitles were also skipped with video presentation than without. There could be two possible explanations for the fact that participants spent less time reading subtitles when video was present than absent. Participants might be attracted to the background video either because of the presence of dynamic visuals in the video (cf., exogenous influences on attentional selection during film viewing, Loschky et al., Reference Loschky, Larson, Smith and Magliano2020) or because they strategically used the video content to support the reading and comprehension of subtitles (cf., the bottom-up vs. top-down control of attention, Awh et al., Reference Awh, Belopolsky and Theeuwes2012).
Based on the finding that semantically relevant audio reduced the time spent on individual words of the subtitle but did not impair comprehension, we extended the multimodal integrated-language framework by adding more detailed assumptions about how auditory information (verbal and non-verbal) might influence overall comprehension and the reading of subtitles. New additions to the framework are presented inside the dashed-line box as shown in Figure 1. Like word or object identification, verbal input (e.g., spoken dialogue) in the audio can only be processed on a word-by-word basis because of its inherently serial nature. However, non-verbal input (e.g., background noise) can be processed in a parallel manner. Verbal input mainly contributes to word processing by, for example, facilitating the identification of words and/or integration of words into larger linguistic units (e.g., clauses or sentences). Non-verbal input, on the other hand, is largely beneficial to the processing of non-textual visuals, such as the identification of an object or a scene where the event described in the text takes place. The facilitation of object/scene identification will in turn be conducive to the processing and comprehension of written text by allowing readers to use multiple sources to establish a more elaborate situation model.
To make these ideas more concrete, consider a specific hypothetical example of someone watching a video about someone playing with a cat with the subtitle “Sixin is playing with her cat.” In this example (see Figure 1), the viewer receives visual inputs corresponding to the subtitles and other visual film elements (e.g., images of a girl and a cat), as well as the audio (e.g., the same sentence being spoken and other non-verbal sounds). Hearing the spoken word “cat” while simultaneously tracking the previously identified image of a cat on the screen would be expected to facilitate the identification of the referent’s corresponding written form (i.e., the printed word “cat”) in the subtitle, allowing its meaning to be retrieved from memory even under conditions where the printed form of the word may have been only superficial processed (e.g., fixated only briefly or identified from a distant viewing location). At the same time, other non-verbal auditory input (e.g., the “meow” sound of the cat) could also foster the identification of the cat in the scene, thereby contributing to the construction of a more elaborate situation model—one that is based on propositional representations generated by the processing of the subtitles, as well as propositional representation from other visual elements in the film.
In conclusion, by investigating the consequences of reading subtitles containing (partially) redundant auditory input and how this might modulate the high-level representations that people form from their video viewing experience, the current study provides important new information about multimodal reading. For example, our results provide clear evidence that eye movements in multimodal reading situations, such as reading subtitles in video, are not merely controlled by information from the visual modality. Instead, readers use inputs from both visual and auditory modalities in real time to make decisions about when and where (and even if) to move their eyes to read the subtitles. This complex decision making in turn indicates that the perceptual, cognitive, and oculomotor systems that are engaged during normal reading are both flexible and highly responsive to task demands. Moreover, eye-movement control during multimodal reading is much more complicated and nuanced than during “normal” reading (i.e., of statically displayed text), a complete understanding of which requires consideration of metacognitive strategies employed in evaluating the reader’s need for subtitles to maintain effective comprehension (Andrews & Veldre, Reference Andrews and Veldre2020). We admit that there are other factors that might modulate the effects of visual and auditory inputs (e.g., different strategies used in translating the audio into the subtitle might render different degrees of congruency in the semantic content between the two sources, thus affecting eye movements during subtitle reading, cf., Ghia, Reference Ghia and Perego2012; Ragni, Reference Ragni2020), but the study reported in this article brings us closer to understanding the mental processes underlying multimodal reading and the role of metacognition in these complicated visual-cognitive tasks.
Finally, despite its novel contributions, there are at least two limitations of the present study that need to be addressed in future research. First, comprehension performance was tested using relatively simple multiple-choice questions, and therefore provides only limited insight into the influence of auditory information on high-level comprehension of the text. Second, the auditory processing was not measured in the present study. Future research might address this second limitation by, for example, using secondary auditory tasks to determine the extent to which attention is allocated to the processing of auditory input. Despite these limitations, however, our study clearly documents how the redundancy of auditory input both modulates the propensity to read subtitles and the eye-movement routines deployed to do so. By proceeding in this incremental fashion, we hope to provide a better understanding of one of the most complex activities that humans can engage in—the reading of subtitles in multimodal video contexts.
Financial support
The first author was supported by a PhD scholarship from Macquarie University.
Conflict of interest
The authors declared no conflict of interest concerning the authorship or the publication of this article.
Appendix 1. Summary of final models in data analyses

Note. Number of subtitle items for all global analyses: 455; number of word items for word-frequency and word-length effects: 1919; number of word items for the wrap-up effect: 2428. Marginal R 2 evaluates the variance explained by the fixed effects, while conditional R 2 evaluates the variance explained by both fixed and random effects. Marginal R 2 and conditional R 2 were produced using sjPlot package (Lüdecke, Reference Lüdecke2020).