



Being able to recognize written words rapidly and accurately in alphabetic languages is a long process that implies being aware of letter identities/positions and internalizing frequently encountered letter combinations in long-term memory. The achievement of these two challenges results in an efficient cognitive system capable of recognizing a word automatically if all the letters in a certain order fit a stored lexical representation. Since the ability to extract regularities from the visual input is an important requirement to attain this information (Gibson, Reference Gibson1965; Pacton, Perruchet, Fayol, & Cleeremans, Reference Pacton, Perruchet, Fayol and Cleeremans2001), these representations may convey specific information about consonant–vowel (CV) letter combinations that constitute their idiosyncratic skeletal structure (e.g., the CV skeletal structure of the word casino would be CVCVCV).
The results from same–different experiments suggest that the perceptual processes involved in written-word identification are sensitive to the CV skeletal structure of words. Using French stimuli, Chetail and Drabs (Reference Chetail and Drabs2014) found that response times for “different” trials were slower when the two stimuli shared the CV skeletal structure (e.g., piorver–poivrer; piovrer–poivrer [CVVCCVC in both pairs]) than when the two stimuli did not share the CV skeletal structure (e.g., povirer–poivrer [CVCVCVC–CVVCCVC]). Chetail et al. (2014) concluded that “readers are sensitive to the organization of letter strings as determined by the alternation of consonant and vowel letters” (p. 949; see Chetail, Treiman, & Content, Reference Chetail, Treiman and Content2016, for converging evidence with a syllable counting task). Additional evidence comes from experiments that involve nonconscious use of orthographic representations. In a series of Stroop experiments in English, Berent and Marom (Reference Berent and Marom2005) reported that colors were named faster when the CV skeletal structure of the letter string was the same as the color name (e.g., dult [CVCC] when the color was pink [CVCC]) than when it was different (e.g., dut [CVC] or drult [CCVCC]). Their suggestion that “readers automatically assemble the skeletal structure of printed words” (p. 328) supports the claim that orthographic representations include abstract representations of CV combinations and that these are, to some extent, implicit to the internal lexicon. (Note, however, that this was a production experiment in which the levels of processing can be different from those involved in word recognition.) CV skeletal structure also plays a role during sentence reading. Blythe, Johnson, Liversedge, and Rayner (Reference Blythe, Johnson, Liversedge and Rayner2014) found that the word's CV skeletal structure makes some lexical items more accessible than others. In an eye movement experiment, they observed that consonant–consonant jumbled words (e.g., ssytem) and vowel–vowel jumbled words (e.g., faeture) were less disruptive during sentence reading than consonant–vowel jumbled words (e.g., fromat) and concluded: “the skeletal structure of a word is processed during lexical identification” (p. 2438). Another source of evidence supporting this view comes from neuropsychological studies, in which the spelling errors committed by dysgraphic and aphasic patients tend to preserve the CV skeletal structure of lexical representations (see Buchwald & Rapp, Reference Buchwald and Rapp2006; Caramazza & Micelli, Reference Caramazza and Miceli1990; Cotelli, Abutalebi, Zorzi, & Cappa, Reference Cotelli, Abutalebi, Zorzi and Cappa2003).
From a theoretical perspective, information on how letter combinations are encoded should aid computational models of written-word recognition and reading to incorporate this evidence into their coding mechanisms and construct a realistic front end of the reading system. Clearly, if the CV skeletal structure of a word is rapidly assembled during visual-word identification, most leading computational models of visual-word identification and reading should be amended. Keep in mind that the majority of the current models of written-word recognition and reading do not assign a differential role to vowels and consonants. In these models, the coding scheme is determined by the position of each letter across the string, and letters are coded independently of their consonant or vowel status (e.g., dual route cascaded model: Coltheart, Rastle, Perry, Langdon, & Ziegler, Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001; multiple read-out model: Grainger & Jacobs, Reference Grainger and Jacobs1996; spatial coding model: Davis, Reference Davis2010; interactive activation model: McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Bayesian reader model: Norris, Reference Norris2006; SERIOL model: Reference WhitneyWhitney, 2001). An exception is the CDP+ model (Perry, Ziegler, & Zorzi, Reference Perry, Ziegler and Zorzi2007), which assumes a level of letter group representations based on onset–vowel–coda structures. Thus, to our knowledge, the CDP+ is the only computational model of written-word recognition that can potentially capture consonant and vowel differences, at least in reading aloud tasks. This is the procedure for which simulations on this model have been conducted. Finally, it is important to indicate that other, nonimplemented models of written-word recognition also assign a different role for vowels and consonants. For instance, in the two-cycle model proposed by Berent and Perfetti (Reference Berent and Perfetti1995), consonants are quickly processed in an initial cycle, whereas vowels are processed more slowly in a second cycle. Similarly, the subsyllabic processing account proposed by Taft, Xu, and Li (Reference Taft, Xu and Li2017) assumes that “vowels are immediately differentiated from consonants” and that “the orthographic system comprises a hierarchical set of units representing onsets, vowels, and codas” (pp. 19–20).
Thus, an important and unanswered question is whether the assembling of the CV skeletal structure occurs in the very early stages of word processing. None of the above-cited experiments was designed to answer that question. An excellent technique to tap the early stages of written-word recognition while minimizing postaccess processes is the masked priming technique (Forster & Davis, Reference Forster and Davis1984; see Grainger, Reference Grainger2008). In this technique, an uppercase target word is preceded for a very short period of time (33–50 ms) by a masked lowercase prime (e.g., #####–beech–BEACH vs. #####–bench–BEACH when examining early phonological effects). There is empirical evidence that strongly suggests that consonants and vowels are not processed in the same way even in the early stages of word processing. In a masked priming lexical decision experiment, New, Araújo, and Nazzi (Reference New, Araújo and Nazzi2008) found that a consonant-preserving prime was more effective at activating a target word than a vowel-preserving prime (e.g., duvo–DIVA faster than rifa–DIVA; apis–OPUS faster than onub–OPUS; see New & Nazzi, Reference New and Nazzi2014; Soares, Perea, & Comesaña, Reference Soares, Perea and Comesaña2014, for converging evidence in French and Portuguese, respectively). New et al. (Reference New, Araújo and Nazzi2008) concluded that “lexical representations are accessed more reliably through consonantal than vocalic information” (p. 1226). Similarly, Duñabeitia, and Carreiras (Reference Duñabeitia and Carreiras2011) found a sizable masked form priming effect for subset primes that kept the consonants (e.g., frl–FAROL [lantern] faster than tsb–FAROL), but not for subset primes that kept the vowels (e.g., aeo–ACERO [steel] produced similar word identification times as iui–ACERO; see Carreiras, Duñabeitia, & Molinaro, Reference Carreiras, Dunabeitia and Molinaro2009, for electrophysiological correlates of this effect; see also Carreiras, Gillon-Dowens, Vergara, & Perea, Reference Carreiras, Gillon-Dowens, Vergara and Perea2009, for converging evidence with a letter-delay paradigm). Duñabeitia and Carreiras (Reference Duñabeitia and Carreiras2011) pointed out that consonants are the first elements being coded in the initial stages of visual word recognition and indicated: “An extreme position within this view would be to assume that when a masked prime is presented, only consonants and their information are deeply processed, whereas vowels are somehow ignored” (p. 1157). In the “lexical constraint” account proposed by Duñabeitia and Carreiras (Reference Duñabeitia and Carreiras2011), the orthographic input code is constrained by letter identities and their specific consonant–vowel status, which provides structural information to construct whole-word level representations and delimit possible lexical candidates. As consonants are more numerous and less variable in terms of position and combinability, a consonantal structure will typically be more stable than a vowel structure to provide orthographic input regularities (e.g., the consonant skeleton “csn” [as in the Spanish word casino] is much more constraining for lexical access than the vowel skeleton “aio”).
While the findings from the New et al. (Reference New, Araújo and Nazzi2008) and Duñabeitia and Carreiras (Reference Duñabeitia and Carreiras2011) experiments strongly suggest that consonants are processed faster than vowels in the early stages of word processing, these experiments were not specifically designed to examine whether the CV skeletal structure of printed words is rapidly assembled during written-word recognition. For instance, New et al. (Reference New, Araújo and Nazzi2008) kept the CV skeletal structure constant across priming conditions (duvo vs. rifa–DIVA, respectively) and Duñabeitia and Carreiras (Reference Duñabeitia and Carreiras2011) only employed consonants or vowels in their subset priming experiments (frl–FAROL vs. aeo–ACERO). Nonetheless, these experiments can be taken to suggest that it is the consonant skeleton rather than the CV skeleton that is the factor that plays a pivotal role in the early moments of lexical processing.
With these issues in mind, the main goal of the present experiments was to examine whether the word's CV skeletal structure plays a role at the very early stages of lexical processing or rather whether the key underlying factor is the word's consonant skeleton. To that end, we conducted two masked priming lexical decision experiments in which a target word could be preceded by a one-letter different prime that kept the same CV skeletal information or not. A consonant was replaced from the target word in Experiment 1, whereas a vowel was replaced from the target word in Experiment 2. Specifically, in Experiment 1, a target word such as PAISAJE (CVVCVCV; the phonological transcription is /pa
![]() .sa.xe/ [landscape]) could be preceded by a one-letter different prime, via replacing an internal vowel, that preserved the CV skeletal structure (congruent CV skeletal structure; e.g., paesaje; /pa.e.sa.xe/) or not (incongruent CV skeletal structure; parsaje; /par.sa.xe/). Experiment 2 paralleled Experiment 1 except that the primes were created by replacing an internal consonant letter of the target word so that it preserved the CV skeletal structure (i.e., another consonant, as in a.lus.no–ALUMNO [student]) or not (i.e., a vowel, as in a.lue.no–ALUMNO). To make sure that nonword primes were pronounceable, target words in Experiment 1 had an internal VV sequence (e.g., PAISAJE) while target words in Experiment 2 had an internal CC sequence (e.g., ALUMNO). The experiments were conducted in Spanish. Note that, unlike English or French, each vowel in Spanish is unequivocally endorsed to only one sound (e.g., paisaje; /pa
.sa.xe/ [landscape]) could be preceded by a one-letter different prime, via replacing an internal vowel, that preserved the CV skeletal structure (congruent CV skeletal structure; e.g., paesaje; /pa.e.sa.xe/) or not (incongruent CV skeletal structure; parsaje; /par.sa.xe/). Experiment 2 paralleled Experiment 1 except that the primes were created by replacing an internal consonant letter of the target word so that it preserved the CV skeletal structure (i.e., another consonant, as in a.lus.no–ALUMNO [student]) or not (i.e., a vowel, as in a.lue.no–ALUMNO). To make sure that nonword primes were pronounceable, target words in Experiment 1 had an internal VV sequence (e.g., PAISAJE) while target words in Experiment 2 had an internal CC sequence (e.g., ALUMNO). The experiments were conducted in Spanish. Note that, unlike English or French, each vowel in Spanish is unequivocally endorsed to only one sound (e.g., paisaje; /pa
![]() .sa.xe/). We also included an identity prime condition because without this latter condition, a null difference between the one-letter different priming conditions would be inconclusive (i.e., one could argue that perhaps participants were not processing the primes); furthermore, the identity condition may serve as a criterion to examine the effectiveness of the congruent CV priming condition.
.sa.xe/). We also included an identity prime condition because without this latter condition, a null difference between the one-letter different priming conditions would be inconclusive (i.e., one could argue that perhaps participants were not processing the primes); furthermore, the identity condition may serve as a criterion to examine the effectiveness of the congruent CV priming condition.
These experiments can be used to separate the predictions from an account that assumes an early activation of an abstract CV skeletal structure (Chetail & Drabs, Reference Chetail and Drabs2014; Chetain, Balota, Treiman, & Content, Reference Chetail, Balota, Treiman and Content2015; Chetail et al., Reference Chetail, Treiman and Content2016) and from an account based on the early activation of the word's consonant skeleton (Duñabeitia & Carreiras, Reference Duñabeitia and Carreiras2011; New et al., Reference New, Araújo and Nazzi2008). If the CV skeletal structure of a written word plays a role in the early stages of lexical processing, then word identification times would be faster for those prime–target pairs that share the CV skeletal structure than for those pairs that do not share the CV skeletal structure. As Chetail et al. (Reference Chetail, Balota, Treiman and Content2015) indicated, the CV skeletal structure of a word “conveys robust invariant cues that guide initial parsing” (p. 35). It is critical that these CV congruency effects should occur to a similar degree when a consonant is replaced from the target and when it is a vowel: paesaje–PAISAJE (congruent CV skeletal structure: CVVCVCV–CVVCVCV) should produce faster word identification times than parsaje–PAISAJE (incongruent CV skeletal structure: CVCCVCV–CVVCVCV), and alusno–ALUMNO (congruent CV skeletal structure: VCVCCV–VCVCCV) should produce faster identification times than alueno–ALUMNO (incongruent CV skeletal structure: VCVVCV–VCVCCV; Experiment 2).
In contrast, if the key factor at the early stages of lexical processing is not the CV skeletal structure of a printed word, but rather the consonant skeleton activated by the letter string (Duñabeitia & Carreiras, Reference Duñabeitia and Carreiras2011), then one would predict that primes composed of the same consonants as the target word would enjoy some processing advantage over those that do not. Thus, in Experiment 1, this account would predict an advantage of paesaje–PAISAJE (psj–psj) over parsaje–PAISAJE (prsj–psj). This prediction is the same as that of an activation of the CV skeletal structure. More important, in Experiment 2, neither the letter substitution with another consonant (e.g., alusno–ALUMNO [lsn–lmn]) nor the substitution with a vowel (e.g., alueno–ALUMNO [ln–lmn]) keeps the same consonantal information of the target word (i.e., lmn), and hence, one would expect a similar effectiveness of these two priming conditions.
Finally, as indicated earlier, the majority of current computational models of written-word recognition assume that consonants/vowels do not play a role at the early stages of lexical processing: these models would predict similar word response times for congruent and incongruent one-letter different priming conditions; that is, there would only be an advantage of the identity prime condition over the two one-letter different prime conditions. To illustrate this statement, we conducted simulations on a leading computational model of written-word recognition, namely, Davis's (Reference Davis2010) spatial coding model. Using the model's default parameters for our prime–target pairs, the model predicted an advantage of the identity condition (60.5 processing cycles) over both congruent and incongruent CV conditions (81.6 and 81.3 processing, cycles, respectively, congruent vs. incongruent conditions: p > .50) in Experiment 1. The pattern of data was remarkably similar in Experiment 2 (an average of 53.5, 74.7, and 74.0 processing cycles in the identity, congruent CV, and incongruent CV conditions, respectively).
EXPERIMENT 1
Method
Participants
Twenty-seven students from the Universitat de València, all of them native speakers of Spanish with no history of reading disorders, took part voluntarily in the experiment. In this and the subsequent experiment, all participants signed an informed consent form before the experiment and had normal (or corrected-to-normal) vision.
Materials
We selected 129 words between 5 and 9 letters (mean = 6.5) from the Spanish subtitle database EsPal (Duchon, Perea, Sebastián-Gallés, Martí, & Carreiras, Reference Duchon, Perea, Sebastián-Gallés, Martí and Carreiras2013). The average word-frequency count per million was 37.6 (range: 0.3–585.0), and the average orthographic Levenshtein distance to the 20 closest neighbors was 1.9 (range: 1.0–2.8). For each target word, we created three lowercase primes: (a) an identity prime (e.g., paisaje–PAISAJE); (b) a one-letter different nonword prime in which a vowel letter was replaced by another vowel (congruent CV skeletal structure prime; paesaje–PAISAJE); and (c) a one-letter different nonword prime in which a vowel letter, the same as in condition (b), was replaced by a consonant (always a neutral letter; e.g., ascending/descending letters such as “t” or “p” were not used; incongruent CV skeletal structure prime; parsaje–PAISAJE). All one-letter different primes were orthographically legal and easily pronounceable in Spanish. The number of orthographic neighbors and the mean log bigram frequency was matched across the congruent and incongruent primes (number of neighbors: M = 1.5, range = 1–6, vs. 1.6, range = 1–9, respectively, p > .27; mean log bigram frequency: 2.31, range = 1.60–3.05, vs. 2.35, range = 1.22–3.15, p > .14; Davis & Perea, Reference Davis and Perea2005). For the purposes of the lexical decision task, we also generated 129 orthographically legal nonwords with Wuggy (Keeulers & Brysbaert, Reference Keuleers and Brysbaert2010). The manipulation for the nonword targets was the same as that for word targets (i.e., an identity prime, a congruent CV skeletal structure prime, and an incongruent CV skeletal structure prime). To rotate the three priming conditions across all target words, we created three counterbalanced lists in a Latin square manner. Seven participants were randomly assigned to each list. The complete list of stimuli is available in Appendix A.
Procedure
Each participant was tested individually in a silent room. DMDX software (Forster & Forster, Reference Forster and Forster2003) was used to display the sequence of stimuli and to register the timing/accuracy of the participants’ responses. In each trial, a pattern mask (i.e., a series of #’s) was displayed for 500 ms in the center of a cathode ray tube screen. The mask was replaced by a lowercase prime stimulus for 50 ms, and then the prime was replaced by an uppercase target stimulus. The target stimulus was displayed on the screen until the participant responded or 2 s had passed. All stimuli were presented in black (Courier New 14-point font) on a white background. The length of the pattern mask corresponded to the length of the prime (target) stimulus. Participants were instructed to decide whether the target stimulus was a Spanish word or not by pressing the “sí” (yes) or the “no” key on the keyboard. Both speed and precision were stressed in the instructions. Sixteen practice trials preceded the 258 experimental trials. The session lasted for around 15 min.
Results and discussion
Both error responses and very short response times (RTs; <250 ms: 1 data point) were excluded from the latency analyses. RTs longer than 2 s were considered errors. The mean RTs and the accuracy data in each experimental condition are presented in Table 1.
Table 1. Mean correct response times (ms) and accuracy (standard errors by participants) for words and nonwords in Experiment 1

Rather than conducting an unfocused comparison of the three experimental conditions, we created two contrasts to test the critical effects using linear mixed-effects (LME) models (see Baayen, Davidson, & Bates, Reference Baayen, Davidson and Bates2008, for a description of the benefits of using LME models relative to by-subjects and by-items analyses of variance) in R (Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2015; Kuznetsova, Brockhoff, & Christensen, Reference Kuznetsova, Brockhoff and Christensen2015; R Core Team, 2016): (a) the congruency effect: CV congruent prime versus CV incongruent prime; and (b) the difference between the identity condition and the CV congruent condition (i.e., whether there is an advantage due to letter identity for those pairs that share the CV skeletal structure). Because of the normality assumption underlying LME analyses, raw RT was transformed as −1000/RT. There were 3,290 observations. The LME model included a fixed factor (prime type: identity, incongruent CV substituted-letter condition, congruent CV substituted-letter condition) that tested the two contrasts of interest (CV congruent vs. CV incongruent; identity vs. CV congruent) using the maximal random effects structure, that is, CV_WordRTs_LME = lmer(inv_RT ~ prime_type + (prime_type + 1|item) + (prime_type + 1|subject), data = CV_WordRTs. (For the interested reader, using untransformed RTs or using by-subjects and by-items analysis of variance would produce exactly the same pattern of results as that reported here.) For the accuracy analyses, the responses were coded as binary values (1 = correct response, 0 = error response), and we used the glmer function in the lme4 package. The maximal random effects structure model did not converge, and the presented results are from the model with by-subjects and by-items intercepts. The analyses for the nonword targets were analogous to those for the word targets.
Word data
Lexical decision times on the target words were, on average, 14 ms faster when the one-letter different prime kept the CV skeletal structure of the target word (e.g., paesaje–PAISAJE) than when the one-letter different prime did not keep the CV structure as the target word (parsaje–PAISAJE; 578 vs. 592 ms, respectively; t = 2.38, p = .023). In addition, we found a 12-ms advantage of the identity condition over the congruent CV priming condition (566 vs. 578 ms, respectively; t = –3.54, p = .001). The statistical analyses on the accuracy data for words did not show any significant effects (both ps > .18).
Nonword data
The analyses of the nonword targets did not show any significant effects in the latency/accuracy data (all ps > .26).
The main finding of this experiment is that target words were responded more rapidly when preceded by a congruent CV substituted-letter prime than when preceded by an incongruent CV substituted-letter prime (e.g., paesaje–PAISAJE faster than parsaje–PAISAJE).Footnote 1
While this finding cannot be accommodated by those models of visual word recognition that assume a similar processing for consonants and vowels, this pattern can be readily captured by an account based on the early activation of an abstract CV skeleton and by an account based on the activation of the consonant skeleton. To disentangle the predictions from these two accounts, it is necessary to examine whether this pattern holds when the replaced letter from the target word is a consonant. As indicated above, these two accounts predict a different outcome with this manipulation. Thus, Experiment 2 was parallel to Experiment 1 except that the replaced letter was a consonant instead of a vowel (i.e., alusno–ALUMNO vs. alueno–ALUMNO). Because it was difficult to obtain a large number of relatively common words in this experiment (the set was composed of 93 words), we increased sample size to 36 participants.
EXPERIMENT 2
Method
Participants
The participants were 36 students from the same population as in Experiment 1. None of them had taken part in the previous experiment.
Materials
Ninety-three Spanish target words between 5 and 9 letters (M = 6.8) were selected from the subtitle database EsPal (Duchon et al., Reference Duchon, Perea, Sebastián-Gallés, Martí and Carreiras2013). The average frequency per million was 42.7 (range = 1.0–324.8) and the average orthographic Levenshtein distance to the 20 closest neighbors was 2.12 (range = 1.50–3.15). For each target word, we created three primes: (a) an identity prime (e.g., alumno–ALUMNO); (b) a one-letter different nonword prime in which a consonant letter was replaced by another consonant (congruent CV skeletal structure prime; alusno–ALUMNO); and (c) a one-letter different nonword prime in which a consonant letter, the same as in condition (b), was replaced by a vowel (incongruent CV skeletal structure prime; alueno–ALUMNO). The nonword primes in conditions (b) and (c) were orthographically legal and easily pronounceable in Spanish. The number of orthographic neighbors and the mean log bigram frequency was similar for the congruent and incongruent primes (number of neighbors: M = 1.3, range = 1–4, vs. 1.1, range = 1–2, respectively, p > .13; mean log bigram frequency: 2.29, range = 1.30–2.94, vs. 2.28, range = 1.16–3.05, p > .66; Davis & Perea, Reference Davis and Perea2005). The number of syllables was the same in the one-letter different primes (e.g., a.lus.no vs. a.lue.no). As in Experiment 1, we also generated 93 orthographically legal nonword targets with Wuggy (Keeulers & Brysbaert, Reference Keuleers and Brysbaert2010). The manipulation for nonword targets was identical to that for word targets. Three lists were created to counterbalance the primes across target words. Twelve participants were randomly assigned to each list. The list of stimuli is available in Appendix A.
Procedure
The procedures were the same as in Experiment 1.
Results and discussion
As in Experiment 1, error responses and RTs shorter than 250 ms (5 data points [3 word trials and 2 word trials], i.e., 0.07% of the data points) were excluded from the latency analyses. The mean correct RTs and the accuracy data in each condition are presented in Table 2. The statistical analyses were the same as in Experiment 1.
Table 2. Mean correct response times (ms) and accuracy (standard errors by participants) for words and nonwords in Experiment 2
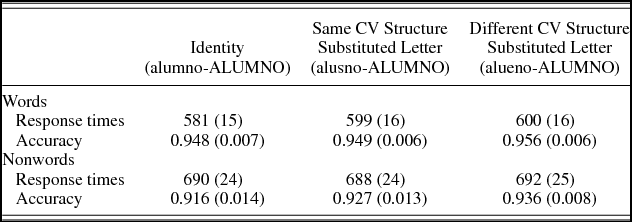
Word data
Lexical decision times on the target words were virtually the same when the one-letter different prime kept the CV skeletal structure of the target word (e.g., alusno–ALUMNO) and when the one-letter different prime did not keep the CV structure as the target word (alueno–ALUMNO; 599 vs. 600 ms, respectively; t < 1). In addition, we found an 18-ms advantage of the identity condition over the CV congruent condition (t = –0.278, p = .006). The statistical analyses on the accuracy data did not show any significant effects (both zs < 1).
Nonword data
The analyses of the nonword targets did not show any significant effects in the latency/accuracy data (all ps >.24).
Unlike Experiment 1, there were no signs of an advantage of the congruent over the incongruent CV priming conditions (i.e., alusno–ALUMNO = alueno–ALUMNO; the mean RTs were 599 and 600 ms). This null effect was not due to the participants’ lack of processing the primes, as we found a sizable advantage of the identity condition (581 ms) over the CV congruent condition.
GENERAL DISCUSSION
We designed two masked priming lexical decision experiments to examine whether the word's CV skeletal structure is assembled in the early stages of lexical processing or, instead, whether the critical factor is the word's consonant skeleton. If the specific organization of vowels and consonants emerges early during written-word processing in alphabetic languages, a congruent CV structure should facilitate the recognition of the target word with respect to an incongruent one, as it maps onto the same abstract CV pattern. Furthermore, this pattern should occur both when a vowel is replaced from the target word and when a consonant is replaced from the target word. In Experiment 1, we found a CV congruency effect: when a vowel was replaced from the target word, word identification times were faster in the CV congruent condition (e.g., paesaje–PAISAJE [CVVCVCV–CVVCVCV] than in the CV incongruent condition (e.g., parsaje–PAISAJE [CVCCVCV–CVVCVCV]). However, we found no signs of a parallel difference in Experiment 2: when a consonant was replaced from the target word, congruent CV skeletal structure pairs (e.g., alusno–ALUMNO [VCVCCV–VCVCCV]) produced very similar word identification times as the incongruent CV skeletal structure pairs (e.g., alueno–ALUMNO [VCVVCV–VCVCCV]). This experiment only showed an advantage of the identity condition.
Taken together, these findings pose problems to the idea that a word's CV skeletal structure is assembled and used in the early stages of lexical processing. This hypothesis was inspired by a series of studies that found detrimental effects of incongruent word structures (peginé–PEIGNE) over congruent ones (peingé–PEIGNÉ, piegné–PEIGNÉ) in same–different decisions (Chetail & Drabs, Reference Chetail and Drabs2014), and a tendency to preserve CV skeletal structure in spelling errors in nonclinical (Chetail et al., Reference Chetail, Treiman and Content2016) and clinical samples (Buchwald & Rapp, Reference Buchwald and Rapp2006). However, none of these studies directly examined the early orthographic processes involved in lexical activation. Thus, the effects of the CV skeletal structure during word processing may arise later in processing, possibly at a phonological stage (see Comesaña, Soares, Marcet, & Perea, Reference Comesaña, Soares, Marcet and Perea2016; Perea & Lupker, Reference Perea and Lupker2004, for a similar argument concerning consonant/vowel differences in letter position coding).
Instead, the present set of data favors an account based on the activation of the consonant skeleton at the early stages of lexical processing, as posited by the lexical constraint hypothesis (Duñabeitia & Carreiras, Reference Duñabeitia and Carreiras2011; see Carreiras, Duñabeitia, et al., Reference Carreiras, Dunabeitia and Molinaro2009; Massol, Carreiras, & Duñabeitia, Reference Massol, Carreiras and Duñabeitia2016; New et al., Reference New, Araújo and Nazzi2008; Perea & Lupker, Reference Perea and Lupker2004, for a similar view). In Experiment 1, the CV congruent pairs (e.g., paesaje–PAISAJE) shared the consonant skeleton (psj) with the target word, whereas the CV incongruent pairs (e.g., parsaje–PAISAJE) included an additional consonant (prsj–psj). The results showed an advantage of those pairs that shared the consonant skeleton (paesaje–PAISAJE [psj–psj] faster than parsaje–PAISAJE [prsj–psj]). In Experiment 2, neither the CV congruent pairs (e.g., alusno–alumno; lsn–lmn) nor the CV incongruent pairs (e.g., alueno–alumno; ln–lmn) kept the consonantal information of the target word, and we found similar word identification times for these two conditions. Further research using the masked priming technique should examine whether these effects are modulated by the consonants’ relative position in the letter string. In a recent perceptual matching experiment that used event-related potential recordings, Massol et al. (Reference Massol, Carreiras and Duñabeitia2016) found a relatedness effect in three time windows (120–200, 200–300, and 350–600 ms) for reference–target word pairs sharing the consonantal information in the same position (e.g., ducha–dicho vs. ducha–vello), but not when the position was relative (e.g., nogal–ingle vs. nogal–mitra). The behavioral data showed a relatedness effect that was greater in magnitude for absolute than for relative consonantal overlap. Massol et al. (Reference Massol, Carreiras and Duñabeitia2016) suggested that lexical entries that share the consonants at the same position (e.g., ducha–dicho) are perceptually closer than when they share the consonants at different positions (e.g., nogal–ingle).
The current findings have important theoretical implications. Most computational models of written-word recognition cannot account for the present findings, as they assign the same role to vowels and consonants. To accommodate the present data, the front-end orthographic scheme of leading models of written-word identification and reading should assign a stronger role to consonant than to vowel letters from the earliest stages of processing (see Duñabeitia & Carreiras, Reference Duñabeitia and Carreiras2011; Taft et al., Reference Taft, Xu and Li2017, for discussion). This consonant/vowel dissociation should apply not only to the encoding of letter identities but also to the encoding of letter positions (see Carreiras, Vergara, & Perea, Reference Carreiras, Vergara and Perea2009; Comesaña et al., Reference Comesaña, Soares, Marcet and Perea2016; Lupker, Perea, & Davis, Reference Lupker, Perea and Davis2008; Perea & Lupker, Reference Perea and Lupker2004, for evidence of consonant/vowel differences in letter position coding).
At a methodological level, the present findings suggest that researchers should be very careful at choosing the control conditions in their preview/priming experiments. Given that consonants and vowels are processed in a different manner, the orthographic distance between the target word beach and its homophonic prime word beech will be closer than that with the orthographic control bench (e.g., Lesch & Pollatsek, Reference Lesch and Pollatsek1993). As Pollatsek, Perea, and Carreiras (Reference Pollatsek, Perea and Carreiras2005) indicated, “this procedure clearly rests on the assumption that the homophone and the control are equally orthographically similar to the target” (p. 557). Clearly, a processing advantage of beech–BEACH over bench–BEACH could be due to homophony, but it could just be due to shared consonantal information. Therefore, researchers should control for consonant/vowel status when creating the orthographic controls in their preview/priming experiments.
To conclude, we have shown that the word's consonant skeleton plays an important role, over and above CV skeletal structure, at the early stages of written-word recognition. This finding favors those accounts that assume that the consonant/vowel status of the words’ constituent letters is quickly attained during the course of lexical processing (e.g., Duñabeitia & Carreiras, Reference Duñabeitia and Carreiras2011; New et al., Reference New, Araújo and Nazzi2008). Implementing a front-end letter scheme that takes into account consonant/vowel status is one of the most crucial challenges for the next generation of computational models of written-word recognition.
APPENDIX A
Experiment 1
The stimuli are presented in quadruplets: identity prime, CV congruent prime, CV incongruent prime, target stimulus.
Word trials: pañuelo, pañualo, pañuslo, PAÑUELO; nervioso, nerviaso, nervinso, NERVIOSO; fraile, fraule, frarle, FRAILE; prueba, pruiba, prumba, PRUEBA; viejo, viujo, vinjo, VIEJO; persiana, persiona, persisna, PERSIANA; patriota, patriata, patrinta, PATRIOTA; nuevo, nuivo, nusvo, NUEVO; nieto, niato, nisto, NIETO; sociedad, sociadad, socindad, SOCIEDAD; sueco, suico, susco, SUECO; niebla, niobla, nimbla, NIEBLA; nacional, nacienal, nacisnal, NACIONAL; deuda, deida, denda, DEUDA; grueso, gruiso, grunso, GRUESO; cuero, cuaro, cusro, CUERO; hielo, hialo, hislo, HIELO; sauna, saona, sasna, SAUNA; cielo, cialo, cirlo, CIELO; hueco, huaco, husco, HUECO; suelo, sualo, sunlo, SUELO; huevo, huivo, hunvo, HUEVO; idioma, idiama, idirma, IDIOMA; neumonía, neamonía, nenmonía, NEUMONÍA; trueno, truino, trurno, TRUENO; vuelo, vuilo, vunlo, VUELO; gladiador, gladiedor, gladindor, GLADIADOR; aduana, aduena, adusna, ADUANA; usuario, usuerio, ususrio, USUARIO; viaje, vioje, visje, VIAJE; duelo, dualo, durlo, DUELO; traidor, traodor, trasdor, TRAIDOR; variedad, variodad, varindad, VARIEDAD; diosa, diesa, dirsa, DIOSA; curioso, curieso, curinso, CURIOSO; pausa, paesa, pansa, PAUSA; acuario, acuerio, acusrio, ACUARIO; creación, creoción, cresción, CREACIÓN; ciudad, ciodad, cindad, CIUDAD; nuera, nuira, nusra, NUERA; secuela, secuila, securla, SECUELA; baile, baule, banle, BAILE; nieve, niuve, nirve, NIEVE; gaseosa, gaseisa, gasersa, GASEOSA; gaviota, gaviuta, gavinta, GAVIOTA; lenguaje, lenguije, lengusje, LENGUAJE; escuela, escuila, escurla, ESCUELA; vestuario, vestuerio, vestunrio, VESTUARIO; ingeniero, ingeniaro, ingenisro, INGENIERO; italiano, italiono, italisno, ITALIANO; realista, reolista, renlista, REALISTA; diario, dierio, disrio, DIARIO; criatura, crietura, crintura, CRIATURA; ciego, ciogo, cisgo, CIEGO; fuego, fuago, fusgo, FUEGO; violencia, vialencia, vinlencia, VIOLENCIA; poesía, poasía, ponsía, POESÍA; juicio, juacio, juscio, JUICIO; anuario, anuerio, anusrio, ANUARIO; causa, caesa, carsa, CAUSA; limpieza, limpiuza, limpisza, LIMPIEZA; androide, androade, androsde, ANDROIDE; silueta, siluota, silunta, SILUETA; hueso, huiso, hurso, HUESO; dieta, diuta, dinta, DIETA; ruido, ruado, rusdo, RUIDO; reina, reana, resna, REINA; piano, pieno, pisno, PIANO; propiedad, propiadad, propisdad, PROPIEDAD; anciano, ancieno, ancisno, ANCIANO; violín, vialín, vislín, VIOLÍN; paisaje, paesaje, parsaje, PAISAJE; circuito, circueto, cincueto, CIRCUITO; ansiedad, ansiudad, ansindad, ANSIEDAD; océano, océino, océsno, OCÉANO; leopardo, leipardo, lempardo, LEOPARDO; higiene, higiane, higirne, HIGIENE; suero, suoro, sunro, SUERO; paraíso, paraéso, paranso, PARAÍSO; suavidad, suevidad, survidad, SUAVIDAD; viuda, vieda, vinda, VIUDA; jaula, jaela, jasla, JAULA; guapo, guopo, gumpo, GUAPO; rueda, ruada, runda, RUEDA; prioridad, prieridad, prisridad, PRIORIDAD; tatuaje, tatuije, taturje, TATUAJE; aliado, aliudo, alindo, ALIADO; aplauso, aplaiso, aplarso, APLAUSO; fraude, fraode, frande, FRAUDE; peinado, peonado, pernado, PEINADO; diabetes, diubetes, dimbetes, DIABETES; piedad, piodad, pirdad, PIEDAD; periódico, periádico, perirdico, PERIÓDICO; balneario, balneurio, balnesrio, BALNEARIO; trauma, traema, trasma, TRAUMA; miedo, miado, mirdo, MIEDO; bautizo, baetizo, bantizo, BAUTIZO; peine, peune, pesne, PEINE; neurona, neirona, nesrona, NEURONA; ruina, ruena, rusna, RUINA; realidad, reolidad, reslidad, REALIDAD; racional, raciunal, racisnal, RACIONAL; abuela, abuila, abusla, ABUELA; flauta, flaita, flanta, FLAUTA; fauna, faona, fasna, FAUNA; aceite, aceote, acente, ACEITE; suave, sueve, surve, SUAVE; cuaderno, cuiderno, cunderno, CUADERNO; empleado, empleido, emplesdo, EMPLEADO; suciedad, suciodad, sucirdad, SUCIEDAD; grieta, griota, grinta, GRIETA; aguacate, aguicate, agurcate, AGUACATE; suizo, suezo, surzo, SUIZO; iguana, iguena, igusna, IGUANA; marciano, marcieno, marcisno, MARCIANO; violeta, viuleta, virleta, VIOLETA; cueva, cuiva, cusva, CUEVA; coalición, coilición, coslición, COALICIÓN; pieza, piaza, pirza, PIEZA; griego, griago, grisgo, GRIEGO; caimán, caomán, casmán, CAIMÁN; diamante, diemante, dirmante, DIAMANTE; caudal, caidal, cardal, CAUDAL; mafioso, mafieso, mafinso, MAFIOSO; religioso, religiuso, religirso, RELIGIOSO; período, períedo, perísdo, PERÍODO; teoría, tearía, tenría, TEORÍA; cuidador, cuadador, curdador, CUIDADOR; juego, juigo, jurgo, JUEGO
Nonword trials: diriota, diriata, dirinta, DIRIOTA; tageonico, tageanico, tagernic, TAGEONICO; cliecura, cliocura, clincura, CLIECURA; majuilo, majualo, majunlo, MAJUILO; vestoeria, vestouria, vestonri, VESTOERIA; aviore, aviare, avisre, AVIORE; aduisa, aduesa, adunsa, ADUISA; ipaeza, ipaoza, ipanza, IPAEZA; laciodad, laciedad, lacisdad, LACIODAD; hanienal, haniunal, hanisnal, HANIENAL; jaunio, jaonio, jasnio, JAUNIO; infituiro, infituaro, infitusr, INFITUIRO; asuonio, asuanio, asurnio, ASUONIO; cucieco, cuciaco, cucisco, CUCIECO; riasa, riesa, rinsa, RIASA; vioda, vieda, vinda, VIODA; cuifa, cuafa, cunfa, CUIFA; puenoria, puanoria, pusnoria, PUENORIA; criale, criole, crisle, CRIALE; pauday, paiday, pasday, PAUDAY; tuero, tuaro, tunro, TUERO; crueja, cruoja, crusja, CRUEJA; braita, braota, branta, BRAITA; afrieco, afrioco, afrisco, AFRIECO; cauro, cairo, casro, CAURO; tiezo, tiozo, tiszo, TIEZO; pajuiso, pajuaso, pajuaso, PAJUISO; guobo, guibo, gurbo, GUOBO; alfriede, alfriode, alfrinde, ALFRIEDE; gaubla, gaobla, gambla, GAUBLA; mueco, muico, murco, MUECO; rauca, raica, ranca, RAUCA; fampioza, fampieza, fampisza, FAMPIOZA; mepeoda, mepeida, meperda, MEPEODA; cuasarno, cuisarno, cunsarno, CUASARNO; acoeria, acoaria, aconria, ACOERIA; pearidon, peoridon, penridon, PEARIDON; triesa, triusa, trinsa, TRIESA; fivione, fiviane, fivisne, FIVIONE; mafrieta, mafriuta, mafrista, MAFRIETA; prueno, pruino, prusno, PRUENO; nuejo, nuijo, nunjo, NUEJO; seivetes, seovetes, servetes, SEIVETES; cilmioto, cilmiato, cirmiato, CILMIOTO; fialancia, fiulancia, firlanci, FIALANCIA; gauto, gaeto, ganto, GAUTO; ivaena, ivauna, ivarna, IVAENA; jaubo, jaebo, jasbo, JAUBO; fagieta, fagiota, fagista, FAGIETA; almiodad, almiudad, almirdad, ALMIODAD; eltriada, eltrioda, eltrisda, ELTRIADA; veisa, veusa, vensa, VEISA; acioda, aciuda, acisda, ACIODA; huicona, huacona, huncona, HUICONA; veirin, vearin, venrin, VEIRIN; priede, priade, prisde, PRIEDE; suinadad, suonadad, surnadad, SUINADAD; ceusan, ceosan, cersan, CEUSAN; viero, vioro, vinro, VIERO; reuco, reaco, resco, REUCO; vaibe, vaobe, vasbe, VAIBE; roniodad, roniedad, ronisdad, RONIODAD; sucuidot, sucuedot, sucurdot, SUCUIDOT; vairio, vaorio, vanrio, VAIRIO; suine, suane, surne, SUINE; toecotion, toicotion, torcotio, TOECOTION; paiso, paeso, parso, PAISO; beobundo, beabundo, berbundo, BEOBUNDO; biare, biore, binre, BIARE; rauco, raico, ranco, RAUCO; estuisa, estuesa, estunsa, ESTUISA; caibo, caubo, cambo, CAIBO; vuero, vuaro, vunro, VUERO; piase, piose, pinse, PIASE; huena, huina, husna, HUENA; siosante, siusante, sirsante, SIOSANTE; teureta, teireta, tenreta, TEURETA; plieta, pliuta, plinta, PLIETA; cuenal, cuinal, cusnal, CUENAL; avoalate, avoilate, avoilate, AVOALATE; paisido, paesido, parsido, PAISIDO; semiosa, semiesa, seminsa, SEMIOSA; pasviana, pasviona, pasvirna, PASVIANA; nasmioso, nasmieso, nasmirso, NASMIOSO; artiono, artieno, artisno, ARTIONO; fraugo, fraigo, frasgo, FRAUGO; teutijo, teatijo, tentijo, TEUTIJO; nuedo, nuodo, nurdo, NUEDO; tuelo, tuilo, tuslo, TUELO; gaive, gauve, gasve, GAIVE; imacueco, imacuico, imacurco, IMACUECO; chuelo, chualo, chuslo, CHUELO; huejo, huijo, husjo, HUEJO; miaza, mioza, minza, MIAZA; macaiva, macaova, macasva, MACAIVA; tacuore, tacuere, tacusre, TACUORE; preaniad, preoniad, presniad, PREANIAD; gauta, gaeta, garta, GAUTA; dievo, diuvo, dinvo, DIEVO; sanuinal, sanuenal, sanusnal, SANUINAL; umoerio, umourio, umosrio, UMOERIO; clapiodor, clapiador, clapindo, CLAPIODOR; triacor, triecor, triscor, TRIACOR; cieba, ciuba, cirba, CIEBA; rausa, raesa, ransa, RAUSA; bainia, baonia, basnia, BAINIA; piomije, piamije, pismije, PIOMIJE; horniario, hornierio, hornisri, HORNIARIO; gaulo, gaelo, ganlo, GAULO; traicidad, traocidad, trancida, TRAICIDAD; abeana, abeona, abesna, ABEANA; roimio, roamio, rosmio, ROIMIO; peadarta, peodarta, pendarta, PEADARTA; piena, piona, pirna, PIENA; omiaca, omieca, omirca, OMIACA; juira, juara, jusra, JUIRA; fiuca, fieca, fisca, FIUCA; bamiova, bamieva, bamirva, BAMIOVA; fiesa, fiosa, finsa, FIESA; ciucay, ciecay, ciscay, CIUCAY; ciapidor, ciopidor, cispidor, CIAPIDOR; tausa, taisa, tarsa, TAUSA; fensuane, fensuone, fensusne, FENSUANE; caulo, caelo, canlo, CAULO; vuebo, vuibo, vumbo, VUEBO; proviodaz, proviadaz, provisda, PROVIODAZ; pemibieso, pemibiaso, pemibirs, PEMIBIESO; malmiono, malmieno, malmisno, MALMIONO; nuemo, nuamo, nusmo, NUEMO
Experiment 2
The stimuli are presented in quadruplets: identity prime, CV congruent prime, CV incongruent prime, target stimulus.
Word trials: cerebro, cerecro, cerearo, CEREBRO; permiso, pelmiso, peimiso, PERMISO; aplauso, aglauso, aelauso, APLAUSO; nobleza, notleza, noaleza, NOBLEZA; tambor, tasbor, taubor, TAMBOR; rencor, rescor, reicor, RENCOR; patria, pabria, paeria, PATRIA; doblar, doclar, doalar, DOBLAR; pintor, pistor, pietor, PINTOR; costumbre, contumbre, coitumbre, COSTUMBRE; rector, restor, reitor, RECTOR; margen, masgen, maugen, MARGEN; maldad, mardad, maudad, MALDAD; dimensión, dimelsión, dimeusión, DIMENSIÓN; sector, sextor, seutor, SECTOR; jersey, jensey, jeisey, JERSEY; neblina, neclina, nealina, NEBLINA; mercurio, mencurio, meicurio, MERCURIO; autopsia, autojsia, autoesia, AUTOPSIA; bolso, bopso, boiso, BOLSO; turismo, turilmo, turiemo, TURISMO; patrón, pabrón, paerón, PATRÓN; fiesta, fiexta, fieuta, FIESTA; ritmo, rilmo, riemo, RITMO; bondad, bosdad, boedad, BONDAD; cumbre, cusbre, cuabre, CUMBRE; marfil, masfil, maufil, MARFIL; princesa, prilcesa, priocesa, PRINCESA; nublado, nurlado, nualado, NUBLADO; pobreza, pocreza, poareza, POBREZA; virtud, vintud, vietud, VIRTUD; bronce, brosce, broice, BRONCE; niebla, niefla, nieala, NIEBLA; hospital, horpital, houpital, HOSPITAL; silvestre, sinvestre, siovestre, SILVESTRE; olimpo, olixpo, oliupo, OLIMPO; mensaje, mersaje, meusaje, MENSAJE; población, poflación, poelación, POBLACIÓN; antena, artena, autena, ANTENA; esplendor, esclendor, esalendor, ESPLENDOR; factor, fastor, faitor, FACTOR; avance, avarce, avaice, AVANCE; festival, fentival, feutival, FESTIVAL; distrito, disbrito, diserito, DISTRITO; riesgo, riengo, rieugo, RIESGO; cisne, cirne, ciane, CISNE; congreso, combreso, conareso, CONGRESO; negro, nepro, nearo, NEGRO; artista, artinta, artiota, ARTISTA; puente, puelte, pueite, PUENTE; fábrica, fátrica, fáerica, FÁBRICA; núcleo, núpleo, núaleo, NÚCLEO; consenso, copsenso, coisenso, CONSENSO; tablero, taclero, taelero, TABLERO; problema, proclema, proelema, PROBLEMA; nirvana, nizvana, niuvana, NIRVANA; fiscal, fincal, fiucal, FISCAL; juzgado, jurgado, juegado, JUZGADO; doctor, dostor, doitor, DOCTOR; ejército, ejélcito, ejéucito, EJÉRCITO; dormir, dosmir, doumir, DORMIR; pancarta, pascarta, paucarta, PANCARTA; alumno, alusno, alueno, ALUMNO; indio, irdio, iadio, INDIO; vitrina, vifrina, vierina, VITRINA; amargura, amasgura, amaigura, AMARGURA; piedra, piefra, pieora, PIEDRA; nuclear, nuslear, nuilear, NUCLEAR; vidrio, vinrio, viurio, VIDRIO; discusión, dircusión, diecusión, DISCUSIÓN; germen, gesmen, geimen, GERMEN; infancia, infarcia, infaucia, INFANCIA; lectura, leztura, leitura, LECTURA; polvo, ponvo, poivo, POLVO; cofradía, cotradía, coaradía, COFRADÍA; concepto, corcepto, coicepto, CONCEPTO; recurso, recunso, recuoso, RECURSO; césped, cénped, céiped, CÉSPED; pastel, paltel, pautel, PASTEL; ciclista, ciclirta, cicliata, CICLISTA; declive, deslive, deulive, DECLIVE; obsesivo, orsesivo, ousesivo, OBSESIVO; juventud, juvertud, juveatud, JUVENTUD; amistad, amirtad, amietad, AMISTAD; compás, corpás, coipás, COMPÁS; símbolo, sírbolo, siebolo, SÍMBOLO; petróleo, pefróleo, pearóleo, PETRÓLEO; evento, evexto, eveito, EVENTO; rostro, roltro, roitro, ROSTRO; jardín, jasdín, jaudín, JARDÍN; círculo, cínculo, cíaculo, CÍRCULO; nutrición, nusrición, nuarición, NUTRICIÓN; lector, lestor, leitor, LECTOR
Nonword trials: motruve, mobruve, moaruve, MOTRUVE; otruiba, obruiba, oaruiba, OTRUIBA; nitaclo, nitablo, nitaulo, NITACLO; teplor, teglor, tealor, TEPLOR; misfora, minfora, miafora, MISFORA; lismurfla, linmurfla, liemurfla, LISMURFLA; tébrina, téfrina, téarina, TÉBRINA; sulfor, sunfor, suafor, SULFOR; pacleo, pableo, paoleo, PACLEO; dalcro, datcro, daucro, DALCRO; facrio, fatrio, faerio, FACRIO; murpal, muspal, muipal, MURPAL; upinfo, upisfo, upiafo, UPINFO; armélico, asmélico, aumélico, ARMÉLICO; filsor, finsor, fiesor, FILSOR; orlunfa, orlunfa, oilunfa, ORLUNFA; isfico, irfico, iafico, ISFICO; firpreno, finpreno, fiapreno, FIRPRENO; ipormico, iponmico, ipoumico, IPORMICO; poncrumo, poscrumo, poicrumo, PONCRUMO; mepríseo, megríseo, mearíseo, MEPRÍSEO; maolca, maofca, maouca, MAOLCA; ipanco, ipasco, ipauco, IPANCO; eljonfia, eljosfia, eljoefia, ELJONFIA; pelta, perta, peita, PELTA; vicleo, visleo, viuleo, VICLEO; tamisco, tamirco, tamieco, TAMISCO; tuclezo, tublezo, tuolezo, TUCLEZO; tuacro, tuanro, tuairo, TUACRO; helfumal, henfumal, heifumal, HELFUMAL; ponfel, posfel, poifel, PONFEL; burtena, bustena, buatena, BURTENA; ricla, rinla, riola, RICLA; onfus, orfus, oifus, ONFUS; fuaspe, fuarpe, fuaipe, FUASPE; lecrón, lesrón, leirón, LECRÓN; finpascle, firpascle, fiupascle, FINPASCLE; patrecual, pabrecual, paorecual, PATRECUAL; cilpen, cifpen, ciapen, CILPEN; retrico, refrico, rearico, RETRICO; oiralfua, oiranfua, oiraifua, OIRALFUA; tisnoda, tirnoda, tianoda, TISNODA; flircona, fliscona, fliucona, FLIRCONA; mestín, mertín, meitín, MESTÍN; irolca, irofca, irouca, IROLCA; sipleón, sisleón, sioleón, SIPLEÓN; fismal, firmal, fiemal, FISMAL; lanfor, lasfor, laufor, LANFOR; glatrico, glabrico, glaerico, GLATRICO; mensil, mersil, meusil, MENSIL; bonlor, boslor, boulor, BONLOR; bispal, binpal, biupal, BISPAL; nirtal, nintal, nietal, NIRTAL; buacro, buanro, buairo, BUACRO; pilten, piften, piuten, PILTEN; fespinta, fenpinta, feupinta, FESPINTA; pecrulo, petrulo, pearulo, PECRULO; jemarso, jemanso, jemauso, JEMARSO; danlora, daslora, dailora, DANLORA; fensutio, fersutio, feisutio, FENSUTIO; neblucia, neclucia, nealucia, NEBLUCIA; satrea, safrea, saorea, SATREA; jurpe, juspe, juope, JURPE; felco, fenco, feuco, FELCO; etusca, etunca, etueca, ETUSCA; rinfor, risfor, riefor, RINFOR; poflinca, poclinca, poelinca, POFLINCA; merlabión, meslabión, meilabión, MERLABIÓN; riucra, riudra, riuera, RIUCRA; felensior, felersior, feleisior, FELENSIOR; veprosa, vecrosa, vearosa, VEPROSA; maspón, marpón, maipón, MASPÓN; etunco, etusco, etuico, ETUNCO; duclarión, duslarión, duelarión, DUCLARIÓN; tospán, torpán, toipan, TOSPÁN; erulcán, eruncán, eruecán, ERULCÁN; rusalfud, rusanfud, rusaufud, RUSALFUD; sulpamo, surpamo, suepamo, SULPAMO; latmor, lasmor, laumor, LATMOR; lusdén, lurdén, luadén, LUSDÉN; pacriso, pabriso, paeriso, PACRISO; rencal, rescal, reical, RENCAL; mespor, menpor, meipor, MESPOR; olinseno, olirseno, oliaseno, OLINSENO; nismato, ninmato, niomato, NISMATO; guscal, guncal, guical, GUSCAL; pilfajo, pitfajo, piefajo, PILFAJO; vurpisco, vunpisco, vuapisco, VURPISCO; tiflano, tirlano, tielano, TIFLANO; clusta, clunta, clueta, CLUSTA; iscrelbán, iscrefbán, iscreubán, ISCRELBÁN; gunticol, gusticol, guaticol, GUNTICOL; fusmelco, furmelco, fuamelco, FUSMELCO
ACKNOWLEDGMENTS
The research reported in this article was partially supported by Grants PSI2014-53444-P and BES-2015-07414 from the Spanish Ministry of Economy and Competitiveness. We thank Jon Andoni Duñabeitia and two anonymous reviewers for their very helpful feedback on a previous version of this paper.


