


The best thing to do with your data will be thought of by someone else.
—Rufus Pollock
In 1995, Brian Fagan drew attention to what he called “archaeology's dirty secret” (Reference Fagan1995:16)—the failure of archaeologists to publish definitive reports on their fieldwork, pointing to problems in scholarly culture including a focus on funding field research rather than analysis or publication. He identified the digital as a catalyst for change: “The demands of the electronic forum will make it harder to duck the responsibility of preparing one's data for scholarly use and scrutiny. In many cases, ‘publication’ will consist of meticulously organized databases, including graphics” (Reference Fagan1995:17). In the intervening years there has been a significant development of digital repositories in the United Kingdom, the United States, and elsewhere, facilitating this vision by providing for the preservation and distribution of archaeological data. However, rather than resolving archaeology's “dirty secret,” they have in fact unwittingly extended it. Consequently, referencing Fagan's “dirty secret,” Cherry has observed that archaeology “remains stubbornly intransigent in the face of digital technologies” (Reference Cherry2011:12).
In the meantime the preservation of archaeological data within digital repositories has become normative practice (Kansa, Kansa, and Arbuckle Reference Kansa, Kansa and Arbuckle2014:58), underlined by the current range of professional archaeology codes of practice. However, evidence of actual reuse of these data remains rare (Huvila Reference Huvila2016; Kansa, Kansa, and Arbuckle Reference Kansa, Kansa and Arbuckle2014:58), and reminiscent of Fagan's earlier criticism, much archaeological research remains focused on the generation and collection of new data. This is despite a number of studies demonstrating archaeological commitment to and support for digital preservation and data reuse (e.g., Faniel, Kansa, et al. Reference Faniel, Kansa, Whitcher Kansa, Barrera-Gomez and Yakel2013; Frank, Yakel, and Faniel Reference Frank, Yakel and Faniel2015). There is therefore a paradox: archaeologists deposit and share their data but make comparatively little use of data shared by others.
This situation has implications for the sustainability of the digital repositories that manage the data and for the wider discipline. Justifications for the considerable investment of time, money, expertise, and energy to create and manage archaeological data archives and to make data available for sharing might be open to question if they are seen solely as places for storage, even if those data are among the primary surviving evidence of fieldwork encounters with the past. Data resilience through reuse is seen to support data preservation into the future and at the same time to meet the ethical principle that research results should be capable of being reviewed and refined. As the Archaeology Data Service (ADS) emphasizes, “Reuse of data is the single surest way of maintaining the integrity of data and tracking errors and problems with it” (2014). However, the presumption of digital reuse contrasts with the evidence from nondigital archives, which traditionally show low levels of use of their resources (Merriman and Swain Reference Merriman and Swain1999:259–260). Why should we expect digital reuse to be any different?
ABSENCE OF EVIDENCE AND EVIDENCE OF ABSENCE
Digital archaeologists, digital archivists, and digital curators have recently begun to express anxiety about the difficulty of demonstrating reuse of digital resources, although the lack of evidence for data reuse in archaeology is often anecdotal. A survey of the literature reinforces the impression of a lack of reuse, since much of it focuses on the mechanics of making the data reusable in the first place—not unreasonable during an era that has seen the case made for the creation of digital repositories and their subsequent development and growth toward a tipping point at which they become genuinely useful resources. Numerous studies report on creating the means to support data sharing: for example, the FAIR principles (Findability, Accessibility, Interoperability, Reusability [Wilkinson et al. Reference Wilkinson, Dumontier, Jan Aalbersberg, Appleton, Axton, Baak, Blomberg, Boiten, da Silva Santos, Bourne, Bouwman, Brookes, Clark, Crosas, Dillo, Dumon, Edmunds, Evelo, Finkers, Gonzalez-Beltran, Gray, Groth, Goble, Grethe, Heringa, ’t Hoen, Hooft, Kuhn, Kok, Kok, Lusher, Martone, Mons, Packer, Persson, Rocca-Serra, Roos, van Schaik, Sansone, Schultes, Sengstag, Slater, Strawn, Swertz, Thompson, van der Lei, van Mulligen, Velterop, Waagmeester, Wittenburg, Wolstencroft, Zhao and Mons2016]) have reuse at their core but stop at the point of ensuring that it is feasible. Unless steps are taken to encourage researchers to take up and reuse such data, the data cycle easily stalls in the absence of motivation or incentive to reuse. Making data shareable and accessible is not the same as actual reuse, but evidencing this gap in the cycle has proved problematic.
Reassuringly this is not just an issue for archaeology. For example, a survey of digital archives across Europe identified reuse of data as a key aspect of sustainability and at the same time pointed to a lack of means to evaluate levels of reuse (Sasse et al. Reference Sasse, Smith, Broad, Tennison, Wells and Atz2017:67–68). Standard web metrics such as page impressions, click rates, and downloads are often used as indicative of reuse (for instance, Green Reference Green, Curdt and Willmes2016:21; Richards Reference Richards2002:359, Reference Richards2017:5–6), although they have a very ambiguous relationship with it; indeed, such metrics primarily capture supply rather than reuse (Figure 1). Even data downloads are a poor proxy for reuse since the purpose behind the download does not necessarily lead to reuse. For instance, in Figure 2 the Wharram Percy archive at the ADS saw 1,614 downloads resulting in 13 citations (including self-citations) according to the Thomson Reuters Data Citation Index (DCI). In comparison, 671 downloads of the Cleatham archive resulted in zero citations in the DCI, although a Google search revealed at least three citations (one PhD and two academic journal articles). Consequently, downloads demonstrate potential reuse at best and an equivocal relationship with subsequent citations.
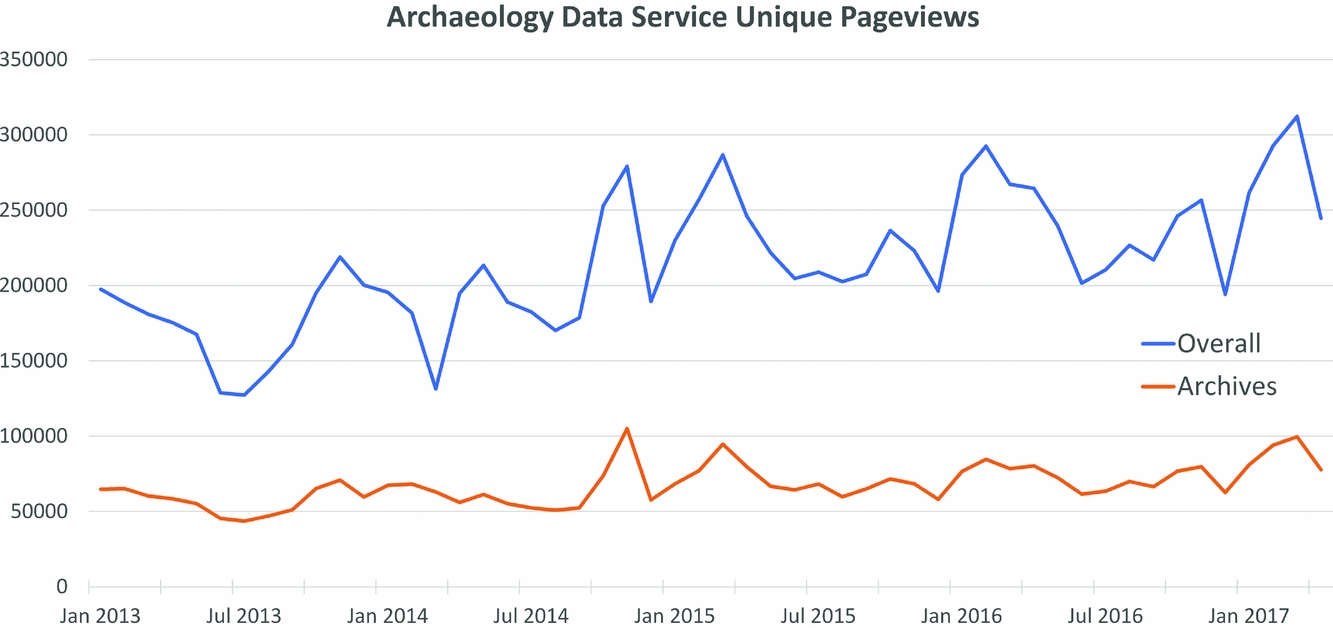
FIGURE 1. Archaeology Data Service unique page views, comparing overall views with archive views. (Data provided by the Archaeology Data Service.)
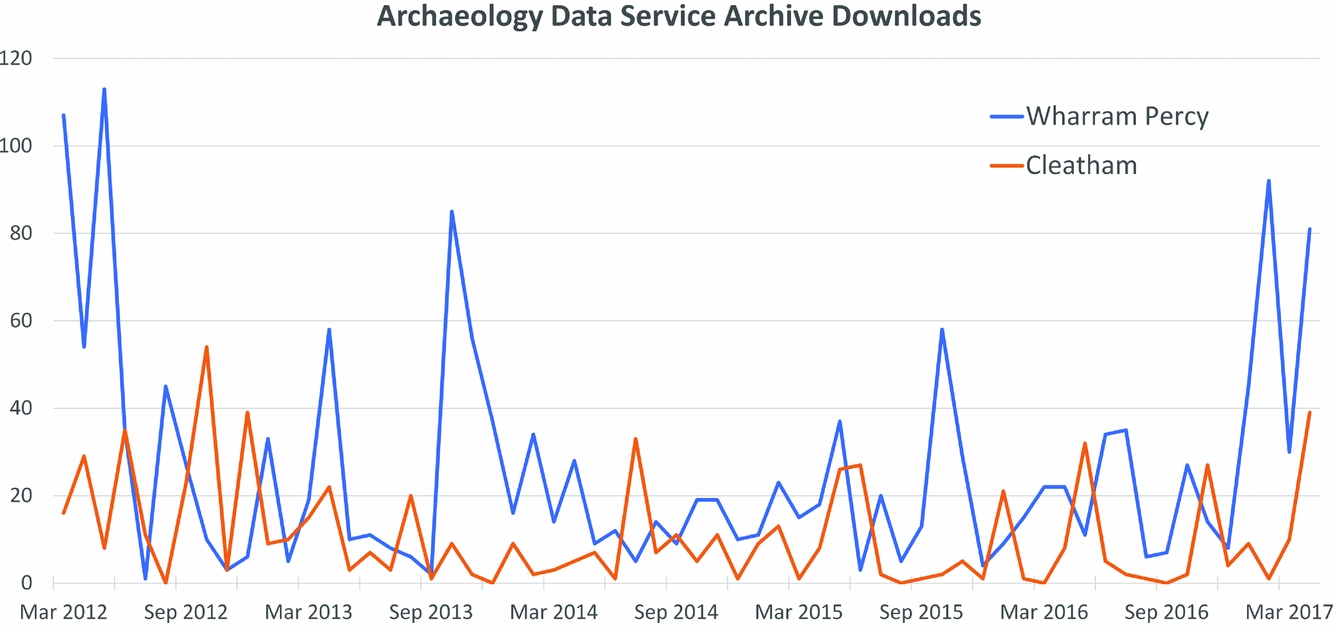
FIGURE 2. Comparison of data archive downloads from the Archaeology Data Service. (Data downloaded from individual Archaeology Data Service archive pages.)
Nevertheless, data citations are frequently seen as a more robust means of demonstrating reuse (for example, Piwowar and Vision Reference Piwowar and Vision2013), and the use of persistent Digital Object Identifiers (DOIs) enables datasets to be uniquely identified and reliably located. However, analyses of data citation demonstrate that their use is as yet limited: research data commonly go uncited (Peters et al. Reference Peters, Kraker, Lex, Gumpenberger and Gorraiz2016:740), explicit data citations in the reference sections of publications are rare, and where reference is made at all, it is to the title of the dataset in the body of the essay (Mooney and Newton Reference Mooney and Newton2012:7) or in the acknowledgments or supplementary materials. The lack or informality of data citation makes the identification and documentation of reuse difficult (Park and Wolfram Reference Park and Wolfram2017:457), and a brief overview of archaeological data citation suggests that the situation is much the same. For instance, a survey of Archaeology Data Service datasets indexed in the DCI indicates that 56 of 476 datasets (as of August 2017) had been cited, although only 12 had been cited more than once. In most cases these citations were by the original authors of the datasets themselves, often within the published reports that the data belong to, and such self-citation makes the evaluation of actual data reuse more complex still (Park and Wolfram Reference Park and Wolfram2017:457). Citation indexes such as the DCI currently lack the contextual nuance capable of distinguishing between the different kinds of formal and informal citation, original use, and actual reuse. Despite the problems surrounding data citation, it is considered to be a primary means of recognizing and validating the contribution of the original authors through increasing peer visibility and reputation (e.g., Dallmeier-Tiessen et al. Reference Dallmeier-Tiessen, Darby, Gitmans, Lambert, Matthews, Mele, Suhonen and Wilson2014:25). That this is poorly practiced and evidence for reuse is inadequately captured remains a significant problem.
Even if data citation capture were more comprehensive, its reliance on a traditional academic publication model restricts its value since there are modes of reuse that are not captured or warranted by academic-style citations, such as data used for teaching purposes, student projects, experimentation unrelated to the origins of the data, and so on (Piwowar and Vision Reference Piwowar and Vision2013:21). Altmetrics may provide an alternative mechanism for gauging levels of a wider range of reuse practices through capturing mentions on social media, social bookmarking, social recommending, and blogging and micro-blogging sites, for instance. However, altmetrics tools bring their own set of problems (e.g., Haustein Reference Haustein2016). Most rely on the use of DOIs, which assumes that these are widely used, but this does not yet appear to be the case in archaeology: for instance, Google searches for the DOIs of random ADS archives led back to the original archive rather than to references to the archive, even in cases where the archives were known to have been reused and cited. Event services such as those being developed by DataCite and Crossref are intended to capture the broader range of reuses but are dependent on the use of persistent identifiers (Dappert et al. Reference Dappert, Farquhar, Kotarski and Hewlett2017; Robinson-Garcia et al. Reference Robinson-Garcia, Mongeon, Jeng and Costas2017). Until archaeologists consistently use DOIs or other such persistent identifiers for their data, the capture of altmetrics for archaeological data citation seems equally problematic and equally unreliable as standard data citations, as indeed is the experience elsewhere (Peters et al. Reference Peters, Kraker, Lex, Gumpenberger and Gorraiz2016).
WHAT IS REUSE?
What this situation highlights is that reuse is in itself not straightforward and can mean different things in different circumstances; indeed, definitions can frequently seem contradictory. A useful distinction to start with is between “use” and “reuse,” where use is essentially related to the purposes of the originator of the data. Hence,
in the simplest situation, data are collected by one individual, for a specific research project, and the first “use” is by that individual to ask a specific research question. If that same individual returns to that same dataset later, whether for the same or a later project, that usually would be considered a “use” [Pasquetto, Randles, and Borgman Reference Pasquetto, Randles and Borgman2017:3].
By this definition, therefore, the level of data self-citations highlighted above is actually a measure of “use” rather than “reuse.” Use occurs after data collection and storage, although some definitions might suggest that all data processing subsequent to initial collection technically constitutes reuse rather than use (Custers and Uršič Reference Custers and Uršič2016:7–8). However, since data collection is a prerequisite for any kind of subsequent use, it seems more reasonable to see data use in terms of the actions of the primary authors up to and including any of their analyses employing the data. Whether or not the primary authors returning to the data subsequent to the data's deposition in a repository and retrieving them for further analysis constitutes use or reuse remains an open question (Pasquetto, Randles, and Borgman Reference Pasquetto, Randles and Borgman2017:3), although one might imagine in most cases the original investigators would work with copies that they retained prior to deposition, which would logically imply use rather than reuse by this definition.
A common characterization of “reuse” is as secondary use for purposes other than that for which the data were originally collected (e.g., Faniel, Kriesberg, and Yakel Reference Faniel, Kriesberg and Yakel2016:1404; Zimmerman Reference Zimmerman2008:634). On the face of it, this would mean that reproducibility, one of the most common reasons lying behind data sharing (Pasquetto, Randles, and Borgman Reference Pasquetto, Randles and Borgman2017:4), cannot be seen as reuse, since it entails the reanalysis of a prior study using the same data and methods as the original investigator in order to confirm or deny previous research (e.g., Marwick Reference Marwick2017:427). Other investigators, separated in time and space, might use the data for the purpose for which they were originally collected, and to deny that this constitutes reuse would seem perverse. The simplest approach to this use/reuse dichotomy is to see the key distinction between use and reuse as being less to do with the purpose of data (re)usage and more closely linked to the authorship of the data themselves: hence, “use” is associated with actions of the primary data producer(s), whereas “reuse” is any secondary use by those other than the primary producer(s). This aligns with Borgman's (Reference Borgman2015:64–65) characterization of “sources” and “resources,” where sources are data originating with the investigator and resources are existing data reused for a project.
Beyond these general definitions of “use” and “reuse,” it is also clear that reuse itself can entail a variety of different practices. Reuse may go beyond simply reusing data over again: for example, it may involve taking the data and combining them with other data to create a new dataset for a different and/or extended analysis (a “remix”), or it may reprocess (“recycle”) the data to create something new through altering the focus and/or discarding some data. An alternative characterization would be to see data as being reused within their original purpose (as in reproducibility) or reused for a different purpose altogether (a different research focus, such as a cemetery excavation dataset used in a pottery study); equally data may be reused in the same context (the cemetery dataset used in a comparative study with other contemporary datasets, for example) or reused in an entirely different context (the cemetery dataset contributing to a regional identity study, for instance). In this sense, reuse may entail repurposing or recontextualizing the data (see also Custers and Uršič Reference Custers and Uršič2016:9). In the process, reuse may result in new derived data products that themselves may be used and reused in subsequent analyses, creating a network of interdependencies and authorships. “Reuse” is therefore a more slippery concept than it might at first seem, but whether data are reused, remixed, recycled, repurposed, or recontextualized, two key questions lie behind potential reuse: What are the motivations behind reuse? and How reusable are the data themselves?
WHY REUSE IT?
Reasons behind reuse are rarely discussed; more common are reasons why data should be shared. For example, Borgman (Reference Borgman2012:1067) suggests four rationales for sharing data: reproducibility/verification, ensuring that publicly funded research is widely available, enabling new questions to be asked of the data, and advancing research and innovation. The first and third of these are equally appropriate as motivations for reuse, and the fourth might reasonably be hoped to be a consequence of them. At the same time, however, they reinforce an association between reuse and research that may be overemphasized. For example, a recent study of social scientists’ use of data archives shows that the proportion of teaching (15%) and learning (64%) significantly outweighed research-related downloads of data from the UK Data Service, with similar results from the Finnish Data Service (Bishop and Kuula-Luumi Reference Bishop and Kuula-Luumi2017:4–7). Conversely, an analysis of the ADS registered user demographic indicated that academic research was the most common reported reason for using the ADS (Green Reference Green, Curdt and Willmes2016:21–22), although this is not limited to downloads.
The reproducibility or verification of research is most commonly cited as the motivation for sharing data (Borgman Reference Borgman2012:1067; Pasquetto, Randles, and Borgman Reference Pasquetto, Randles and Borgman2017:4). Reproducibility is a key aspect of the scientific method, but an inability to reproduce results across a wide range of disciplines in the sciences and social sciences has led to claims of a reproducibility “crisis.” For example, a survey by Nature found that more than 70% of researchers had tried and failed to reproduce the results of others, while more than 50% had failed to reproduce their own experiments; overall, 52% believed that there was a significant reproducibility crisis (Baker Reference Baker2016:452). While data reuse can contribute to the ability to test archaeological arguments and explanations (e.g., Smith Reference Smith2015), such applications are relatively rare. In part, this issue is due to limited provisions made for reproducibility, linked to issues with the availability of the data and associated processing methods (Marwick Reference Marwick2017), but it can also be related to an approach to reproducibility that employs comparative data rather than in-depth reevaluation of the original data. In this respect, little seems to have changed since Barrett's (Reference Barrett1987:410) nondigital reanalysis of the Iron Age Glastonbury Lake Village, which entailed a deep reading of the original excavation report rather than a reliance on evidence from analogous sites and archives. Such practice remains rare and suggests that simply making data digitally available for reuse will not address reproducibility: there remains a strong tradition within archaeology of conducting new research by collecting new data rather than reusing old data collected by others (Huvila Reference Huvila2016).
Nor is it necessarily the case that data are reused as a means of driving forward new research. For example, in a study of researchers at the Center for Embedded Network Sensing it was found that the purpose behind data reuse was typically to establish a baseline or context to provide a background for research, rather than the external data being foregrounded as a primary means of research (Wallis, Rolando, and Borgman Reference Wallis, Rolando and Borgman2013:14).
A study of data reuse behaviors and the factors associated with data reuse practice among social scientists (Curty Reference Curty2016; Curty and Qin Reference Curty and Qin2014) helps clarify potential motivations behind reuse or reasons for non-reuse within archaeology. Six core factors influencing reuse were identified (Figure 3), with each subdivided into additional factors that to varying degrees affect attitudes toward and the feasibility of data reuse (Curty Reference Curty2016:100; Curty and Qin Reference Curty and Qin2014:2).

FIGURE 3. Data reuse behavioral model (adapted from Curty and Qin Reference Curty and Qin2014:Figure 1).
Perceived benefits are associated with the extent to which new knowledge might result from reuse, a cost/benefit analysis of using secondary data rather than collecting new primary data, and the extent to which the data available are seen as reliable (Curty Reference Curty2016:100–101). A balance of positive outcomes across these factors would support data reuse.
Perceived risks include the perception that reuse is less valued than original data in research, that there may be ethical issues associated with secondary data (for instance, copyright and confidentiality), that reuse might be seen as misuse or misinterpretation, and that there might be hidden errors within the secondary data that were not picked up (Curty Reference Curty2016:101–103). A balance of negative outcomes—high risk—across these factors would limit the likelihood of data reuse.
Perceived effort relates to the work entailed in handling secondary data that were not created by the researcher. Issues include the accessibility of the data, the ease of discovery, the extent to which the data are adaptable to the current research objectives, the extent to which the data have to be reworked for reuse in the new context, and an understanding and appreciation of the complexities of the original research that created the data in the first place (Curty Reference Curty2016:103–105). A balance of negative outcomes across these factors, suggesting high friction, would limit the likelihood of data reuse.
Perceived reusability covers the extent and quality of data documentation, the fitness of purpose, the trustworthiness and credibility of the data creator(s), the quality of the data in terms of their consistency (accuracy and reliability) and completeness (minimal missing data), and the rigor (methods, procedures, etc.) of the original research that created the data (Curty Reference Curty2016:105–107). A balance of positive outcomes across these factors, indicating confidence in the data, would support subsequent reuse.
Enabling factors facilitate reuse and relate to the availability of documentation associated with previous applications and contexts of use rather than data reusability (see above), the availability of data repositories, the potential accessibility of the data creators themselves, the level of training in data analysis and reuse, and the availability of support and assistance for reuse (Curty Reference Curty2016:107–109). A balance of positive outcomes across these factors would support reuse.
Social factors concern the attitudes of peers and the wider discipline: the extent to which data reuse is accepted as legitimate research and the levels of encouragement and incentivization for reuse (Curty Reference Curty2016:109–110). A balance of positive outcomes across these factors would support reuse.
The data reuse behavioral model in Figure 3 highlights a range of factors that contribute to a determination of the feasibility of reuse in a complex web of interrelated decisions. Some factors (such as data accessibility and data quality) are likely to be more significant than others (for example, the availability of the primary investigators) in terms of archaeological reuse, emphasizing that the balance of factors will vary between different potential reuse applications.
HOW REUSABLE IS IT?
If reuse is a slippery concept, so too are data. What constitute data is a matter of negotiation among the potentially conflicting perspectives of data producers, data curators, and data users, changing through time and through (re)use so that what was not considered to be data at one time may be of interest at a later stage and, conversely, what was once understood to be data may no longer be seen to have value. Consequently, we are dependent on the tacit knowledge and research agendas of those who precede us, just as those who follow us will be limited by ours (e.g., Wylie Reference Wylie2017:207). This notion has implications for the collection, curation, and subsequent reuse of data. For instance, recognizing that the future use of data cannot be fully anticipated reinforces the tension between the concept of “analytical destiny” (Carver Reference Carver, Cooper and Richards1985:50), in which materials/data have a known value and are collected where there is an identified purpose, and data that might conceivably have a future, as-yet-unforeseen, value that would otherwise be lost, yet there is a cost to its capture and retention. The FAIR Guiding Principles define a series of characteristics required for data to be reusable—rich description, detailed provenance, use of domain standards, and clear licensing arrangements (Wilkinson et al. Reference Wilkinson, Dumontier, Jan Aalbersberg, Appleton, Axton, Baak, Blomberg, Boiten, da Silva Santos, Bourne, Bouwman, Brookes, Clark, Crosas, Dillo, Dumon, Edmunds, Evelo, Finkers, Gonzalez-Beltran, Gray, Groth, Goble, Grethe, Heringa, ’t Hoen, Hooft, Kuhn, Kok, Kok, Lusher, Martone, Mons, Packer, Persson, Rocca-Serra, Roos, van Schaik, Sansone, Schultes, Sengstag, Slater, Strawn, Swertz, Thompson, van der Lei, van Mulligen, Velterop, Waagmeester, Wittenburg, Wolstencroft, Zhao and Mons2016:4)—but meeting even these basic requirements is not straightforward.
Data Wrangling
A considerable challenge to reuse is the need to rework data in terms of managing different recording conventions, data formats, and data models (e.g., Kandel et al. Reference Kandel, Heer, Plaisant, Kennedy, van Ham, Henry Riche, Weaver, Lee, Brodbeck and Buono2011). Numerous types of errors can occur within the data themselves: for instance, syntactic data anomalies (irregularities in format or value), semantic anomalies (inconsistencies within or across data such as duplicates, contradictory data), and coverage anomalies (missing or incomplete data; Müller and Freytag Reference Müller and Freytag2003:6–7). Such issues only escalate as datasets are increasingly aggregated into meta-analyses (Kansa Reference Kansa2015:225) and incorporated into “big data”–style analyses (Gattiglia Reference Gattiglia2015). Recognizing and dealing with such anomalies can be extremely time-consuming, assuming they are spotted in the first place, although it can be argued that this is outweighed by the cost savings in not having to collect the data again (e.g., Heidorn Reference Heidorn2008:290). Of course, in archaeology the data collection process is frequently unrepeatable, and instead new analogous data may be collected as an alternative to reuse.
Digital tools make it relatively easy to manipulate single datasets, to aggregate datasets that are notionally similar, or to integrate datasets that are seemingly unrelated and in the process create “new” data from old. This is assumed to be beneficial, but equally such consolidated datasets may be little more than what Clarke characterizes as a “melange” (Reference Clarke2016:83): collections of mixed or uncertain quality, with uncertain associations, combined and modified in ways that are not transparent. Clarity regarding the means by which reused datasets are arrived at prior to analysis can be variable, complicated by the range of possible issues that may be encountered beyond technical issues with the data. Commonplace are contextual discrepancies, methodological biases, and problems with associated documentation. Again, these are just as much a feature of nondigital data but are compounded by technical issues linked to the comparability, compatibility, and standardization of digital data. Where little or no information is provided about any data cleansing and manipulation in advance of analysis, confidence in the derived data and their subsequent use must be limited at best, especially when data “cleaning” may more often be concerned with the ease with which analytic tools can be applied to the data rather than the cleanliness of the data themselves (Clarke Reference Clarke2016:83).
Data Contexts
A key factor that a number of authors have identified is that archaeological data require associated contextual information in order to be considered for reuse (e.g., Atici et al. Reference Atici, Kansa, Lev-Tov and Kansa2013:667; Faniel, Barrera-Gomez, et al. Reference Faniel, Barrera-Gomez, Kriesberg and Yakel2013:798; Faniel, Kansa, et al. Reference Faniel, Kansa, Whitcher Kansa, Barrera-Gomez and Yakel2013:297; Frank, Yakel, and Faniel Reference Frank, Yakel and Faniel2015:144; Kansa, Kansa, and Arbuckle Reference Kansa, Kansa and Arbuckle2014:59). This problem is typically addressed through the provision of metadata—data about the data in question—although the levels of detail and coverage can vary widely. The most common metadata focus primarily on the needs of discovery (authorship, rights, sources, etc.) rather than reuse of the data, which requires paradata—data about provenance, process, and derivation (e.g., Baker Reference Baker, Bentkowska-Kafel, Denard and Baker2012; Mudge Reference Mudge, Bentkowska-Kafel, Denard and Baker2012). Indeed, depending on the kind of reuse, even paradata may not be sufficient, as they do not include computer codes or scripts used in the original analysis and manipulation of the data or even the computer environment itself (Marwick Reference Marwick2017). Consequently different kinds of reuse may require different levels of supporting contextual detail (e.g., Bechhofer et al. Reference Bechhofer, Buchan, De Roure, Missier, Ainsworth, Bhagat, Couch, Cruickshank, Delderfield, Dunlop, Gamble, Michaelides, Owen, Newman, Sufi and Goble2012:603), and by implication, the levels of contextual information available will place limits on the kinds of reuse that are possible for a specific dataset.
Despite this, meta/paradata associated with data are most commonly of value to the computational tools used to locate and manage the data rather than to the human agents seeking to make use of them. Indeed, although a lack of contextual information is frequently cited as a shortcoming of archaeological data, data are nevertheless reused as ways are found of circumventing it (Atici et al. Reference Atici, Kansa, Lev-Tov and Kansa2013:667; Faniel, Kansa, et al. Reference Faniel, Kansa, Whitcher Kansa, Barrera-Gomez and Yakel2013:298). As Borgman observes, “The effort required to explain one's research records adequately increases as a function of the distance between data originators and users” (Reference Borgman2007:167), and contextual information accompanying data is seen as a means of overcoming the “knowledge distance” between those reusing data and the original data producers (Markus Reference Markus2001:88). Consequently, its absence should be a significant barrier to reuse.
However, the significance of absent or limited contextual information is difficult to assess given a relative lack of studies explicitly examining the reuse of archaeological data. An investigation of the reuse of faunal data that lacked background contextual and methodological information (provenance, relationships, standards, etc.) demonstrated that, as expected, different analysts arrive at different conclusions from the same data (Atici et al. Reference Atici, Kansa, Lev-Tov and Kansa2013:670ff.). Individual analysts responded differently to the lack of contextual information in relation to issues of aggregation of data categories and assessment of data reliability, consistency, and comparability, for instance (Atici et al. Reference Atici, Kansa, Lev-Tov and Kansa2013:667). However, whether the absence of contextual information primarily governed some of these differences is debatable: for example, while the lack of information regarding sampling bias is clearly a limiting issue, choosing to lump (or split) data categories is an analytic decision likely to be equally associated with the personal experience and preferences of the analyst as with a lack of contextual information.
This suggests that different kinds of data and different kinds of reuse require different levels of contextual information. Qualitative data may be more sensitive to these requirements than quantitative data, and this might explain why common reuse applications tend to employ primarily quantitative (for example, zoological [e.g., Arbuckle et al. Reference Arbuckle, Kansa, Kansa, Orton, Çakırlar, Gourichon, Atici, Galik, Marciniak, Mulville, Buitenhuis, Carruthers, Cupere, Demirergi, Frame, Helmer, Martin, Peters, Pöllath, Pawłowska, Russell, Twiss and Würtenberger2014; Conolly et al. Reference Conolly, Colledge, Dobney, Vigne, Peters, Stopp, Manning and Shennan2011; Jones and Gabe Reference Jones and Gabe2015]), dating (e.g., Armit, Swindles, and Becker Reference Armit, Swindles and Becker2013), burial (e.g., Bradbury et al. Reference Bradbury, Davies, Jay, Philip, Roberts and Scarre2016), or locational data from large-scale regional databases (e.g., Bevan Reference Bevan2012; Cooper and Green Reference Cooper and Green2016; Richards, Naylor, and Holas-Clark Reference Richards, Naylor and Holas-Clark2009). Large-scale artifact and monument datasets in particular are widely used primarily because their focus on type and location enables their use as a backdrop to original research (see also Wallis, Rolando, and Borgman Reference Wallis, Rolando and Borgman2013:11), often with little or no contextual knowledge required. The greater frequency of reuse of quantitative as opposed to qualitative datasets is also noted in other disciplines (Park and Wolfram Reference Park and Wolfram2017:459), suggested in part to be simply due to the greater amount of quantitative data available and the relative ease of reuse of such data compared with more narrative forms. Indeed, textual data are frequently converted into quantitative data via coding to make them more “computable.”
Data Epistemologies
How we conceive of data clearly has implications for the practice of reuse; at the same time data analytics frequently operate within different epistemological frameworks, which can easily be set aside or go unrecognized in the pursuit of reuse. A traditional view of data as empirical “facts” implies a straightforward approach to data reuse and contrasts with a perspective on data as observations about attributes perceived as having some contemporary value in understanding the past, which suggests a more complex, ambiguous approach to data reuse. One outcome of this may again be a preference for collecting new data rather than reusing existing data, not only to avoid data wrangling and contextual issues but also as a means of sidestepping theoretical or philosophical tensions such as these.
Many examples of data reuse fall into the category of “meta-analysis” or data mining, an approach that only becomes feasible with the availability of large quantities of data held in open repositories. Incorporating data collected by others, frequently unknown to the reuser, with the data being used for very different purposes from its original intent, can be seen as an extreme form of reuse in which contextual information is useful but frequently absent (Markus Reference Markus2001:71–72). This practice aligns with an increasing interest in “Big Data,” an approach to data analysis where quantity of data is often seen to overcome limitations in quality or sampling (e.g., Gattiglia Reference Gattiglia2015:114, following Mayer-Shönberger and Cukier Reference Mayer-Shönberger and Cukier2013:33). Such approaches tend to adopt (or implicitly assume) a traditional view of data, one in which data are conceived as raw, unprocessed, and unworked, typically acquired using rigorous scientific methods and distinct from subjective interpretation or other contextual matters (Costa et al. Reference Costa, Beck, Bevan, Ogden, Earl, Sly, Crystanthi, Murietta-Flores, Papadopoulos, Romanowska and Wheatley2013:450; Huggett Reference Huggett, Wilson and Edwards2015:14ff.). This idea is often characterized as a data-information-knowledge pyramid (Figure 4)—a view of data at the bottom of a hierarchy that moves through information to knowledge and, ultimately, wisdom. In this data-information-knowledge-wisdom model, knowledge is created from a hierarchy of building blocks—data are transformed into information, information is processed into knowledge, and we travel up this hierarchy to arrive at wisdom (e.g., Kitchin Reference Kitchin2014:9–12; see also Gattiglia Reference Gattiglia2015:115). This notion has some attraction as an apparently commonsense perspective, mapping conveniently onto archaeological perceptions such as the image of a data mountain that is waiting to be transformed into archaeological knowledge. However, it is a perspective that is embedded in an essentially positivist approach to archaeology, in which data are seen as “separate from the subjectivities that generate them, and independent of the relational and intersubjective contexts that give rise to them” (Mauthner and Parry Reference Mauthner and Parry2009:292; see also Huggett Reference Huggett, Wilson and Edwards2015:15–17). In contrast, data are a consequence of cultural processes, and hence are theory-laden, process-laden, and purpose-laden (Huggett Reference Huggett, Mills, Pidd and Ward2014:5), and not raw in any sense; they emerge as the outcome of the application of knowledge and information in a reversal of the data-information-knowledge-wisdom model (e.g., Tuomi Reference Tuomi1999; Figure 5). Hence, based on their experience, research objectives, and so on, data creators articulate their knowledge to identify and categorize information, and that information, in order to be represented in a digital environment, is atomized to create data. Essentially, the data-information-knowledge of the reuser only emerges through an understanding of the knowledge-information-data disarticulation of the original creator (Huggett Reference Huggett, Wilson and Edwards2015:18). In the process, explicit, representable knowledge is prioritized, and what tends to be lost is the tacit, contextual knowledge.

FIGURE 4. Archaeological variant of the data-information-knowledge-wisdom pyramid (adapted from Kitchin Reference Kitchin2014:Figure 1.1).
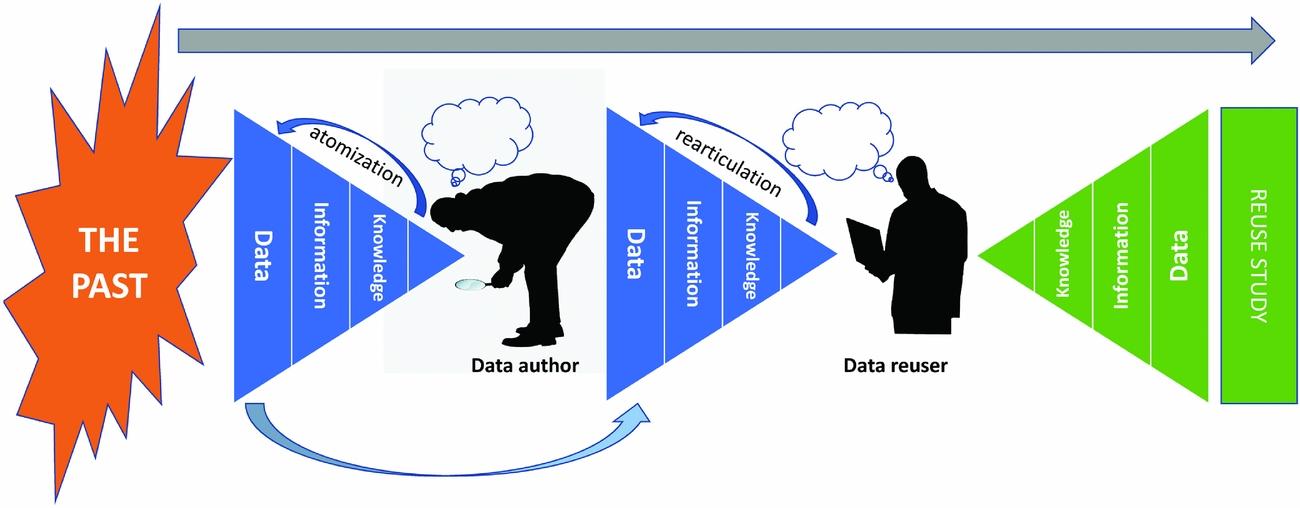
FIGURE 5. Modified data-information-knowledge model of archaeological data reuse, emphasizing the relationship between the reuser and the creator.
While most archaeological data do not conform to the characteristics of “big” data, nevertheless big data analytic approaches are increasingly being applied to “small” data, aided by the growth of archaeological data repositories and the access they provide to a wider range of data and the aggregation and integration of datasets that become possible as a result. “Big” or “small,” these analytic approaches come with new epistemologies attached (see Kitchin Reference Kitchin2014:133ff.). For example, data analytics are (in)famously associated with an “end of theory” (Anderson Reference Anderson2008) in which the quantity of data enables them to be analyzed without hypotheses, allowing algorithms to find patterns and identify correlations. Associated with this is the idea that data can speak for themselves free from theory: that data trump theory in a truly objective neutral fashion, stripped of context and bias. Related to this is the concept that data can be context-free—that they do not require contextual or domain-specific knowledge to carry meaning. Alternatively, the quantities of data available facilitate data-driven approaches in which information emerges from the data, replacing traditional knowledge-based approaches based on hypothesis. Such approaches to reuse present a challenge to traditional ways of doing archaeology, and their consequences are as yet not understood.
CHALLENGES FOR REUSE
We are not yet at the stage where archaeologists are increasingly expected to reuse existing data and need to justify primary data collection (Naylor and Richards Reference Naylor and Richards2005:90) or where the orthodoxy of excavation is challenged by access to reusable archaeological data (Beck and Neylon Reference Beck and Neylon2012:494), although obligations to funders may cause this to change in future. There is broad agreement with the view that digital archives should not be seen as the final resting places for digital data (Green Reference Green, Curdt and Willmes2016:17) or as the residue of research (Kansa and Kansa Reference Kansa and Kansa2014:223) but are instead part of a larger data life cycle. However, while this data cycle is reasonably well established in terms of capturing, documenting, and packaging the data for reuse, the missing element in the cycle is all too often the actual reuse of data. At the same time, most discussions concerning digital data focus on these established areas of the life cycle and pay significantly less attention to issues surrounding reuse (e.g., Borgman Reference Borgman2007, Reference Borgman2015), which is itself a rich and complex cycle of interconnections, interactions, and interrelationships (Figure 6). As a consequence, we can develop an appreciation of why we can benefit from reusing data, but the actual approaches and methods of reuse and their limitations are less well understood. This then makes evaluating the documentation and data that are available for sharing in terms of their worth and robusticity a primarily theoretical exercise, presenting a significant risk to the sustainability of digital data archiving in archaeology. The purpose of digital curation is ultimately to ensure future access and reuse, but until reuse becomes part of mainstream practice alongside archiving and sharing, this cannot be reliably confirmed.
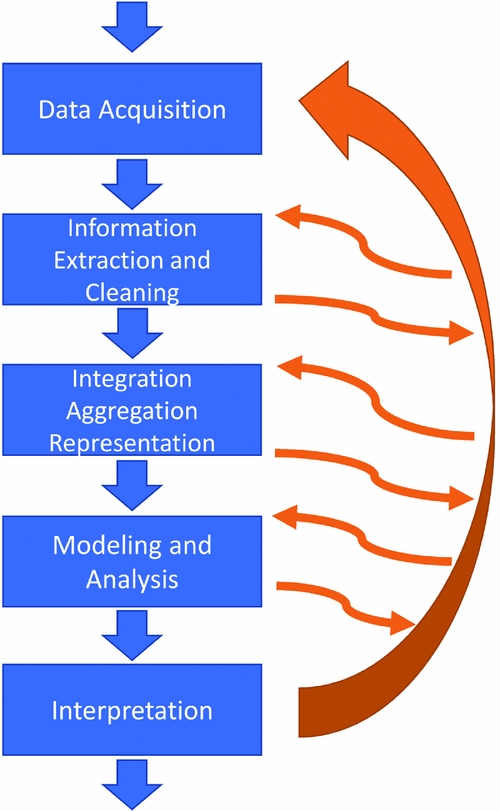
FIGURE 6. Data reuse cycles and feedbacks (adapted from Jagadish Reference Jagadish2015:Figure 1).
The primary challenges for digital data reuse therefore are not related so much to questions of suitable means of storage and the migration of data, or the provision of adequate documentation to facilitate reuse, or issues of trust and the credibility of the data, or the appropriate recognition or citation of reuse, or even the need for training and reward structures to support reuse, important though these are. Instead—or in addition—what is needed is a deeper understanding and appreciation of reuse in terms of what it entails: issues associated with the re-presentation and interpretation of old data, the nature and purpose of reuse, and the opportunities and risks presented by reuse. Such questions are not specific to digital data and have seen some debate over the years; however, digital data change the terms of engagement with their near-instant access, volume, and flexibility and their potentially transformative effects on the practice of archaeology now and in the future.
Relevant questions include the following:
• Recognizing that archaeological data do not create themselves but are performative in nature, how are they created and subsequently used, and how can this be represented for future reuse? How can the presumptions and “preunderstandings” (Wylie Reference Wylie2017:204) be incorporated in data past and present?
• Given that data have potential that we cannot anticipate, how should data be defined, captured, recorded, and curated in order that limits on future reuse are minimized?
• Since archaeological data are by their nature incomplete and imperfectly captured, how can this incompleteness and inconsistency best be represented and handled during their reuse? What are the implications of data being made to speak for data that are not captured and hence not available?
• What are the effects of reusing, repurposing, remixing, recycling, and recontextualizing data on archaeological knowledge? For instance, what are the implications of applying alternative frames of analysis, different research agendas, and so on to data collected under different theoretical regimes?
• What reprocessing and extraction procedures are required to extract and operationalize data from underlying sources? What are the consequences of methods such as standardizing, reducing, and mapping data into schemas as part of a preanalysis cleansing process?
• What are the implications of the different epistemologies associated with data analytics applied to archaeological data?
• How are steps in the data reuse cycle (Figure 6) shaping archaeological practice? What is being privileged, and what is being left behind?
• What mechanisms need to be put in place to support appropriate reuse of archaeological data?
Dealing with these questions in the context of digital data reuse will not only address the immediate concerns and technical issues associated with data reuse but also have implications for a deeper understanding of the nature of archaeology's digital turn. Borrowing from Ash, Kitchen, and Leszczynski (Reference Ash, Kitchen and Leszczynski2016), we are increasingly witness to archaeologies through the digital, archaeologies produced by the digital, and archaeologies of the digital, but it is as yet unclear how these are reshaping archaeological practice. A more refined appreciation of how we work with our digital data is a fundamental part of this and key to addressing archaeology's “dirty secret.”
Acknowledgments
This essay has its origins in the Society for American Archaeology 2017 forum “Beyond Data Management: A Conversation about ‘Digital Data Realities’” organized by Sarah Whitcher Kansa and Eric Kansa, and I am grateful to them for the invitation to contribute. Katie Green (Archaeology Data Service) kindly provided the data used in Figure 1, and Patricia Martin-Rodilla generously supplied the Spanish translation of the abstract. The editors and the two anonymous reviewers suggested several helpful improvements. No permits were required for this work.
Data Availability Statement
The data used in Figures 1 and 2 are available via the Archaeology Data Service website: http://archaeologydataservice.ac.uk/.






